
Abstract
Independent lines of evidence suggest that the representation of emotional evaluation recruits both vertical and horizontal spatial mappings. These two spatial mappings differ in their experiential origins and their productivity, and available data suggest that they differ in their saliency. Yet, no study has so far compared their relative strength in an attentional orienting reaction time task that affords the simultaneous manifestation of both types of mapping. Here, we investigated this question using a visual search task with emotional faces. We presented angry and happy face targets and neutral distracter faces in top, bottom, left, and right locations on the computer screen. Conceptual congruency effects were observed along the vertical dimension supporting the ‘up = good’ metaphor, but not along the horizontal dimension. This asymmetrical processing pattern was observed when faces were presented in a cropped (Experiment 1) and whole (Experiment 2) format. These findings suggest that the ‘up = good’ metaphor is more salient and readily activated than the ‘right = good’ metaphor, and that the former outcompetes the latter when the task context affords the simultaneous activation of both mappings.
Similar content being viewed by others


Introduction
We can readily understand someone’s emotional state if they tell us that they are “feeling down” or that “things are looking up”. Such metaphors feature pervasively in the English language, occurring at a rate of about six metaphors per minute (Geary, 2011), and also pervade the symbolism observed in a wide range of cultural manifestations such as movies (Winter, 2014). They are an interesting linguistic phenomenon in their own right, but when we go about describing one thing in terms of another in this way, is it just to make communication easier or do we actually think in metaphors too?
Recent empirical investigations suggest that spatial representations take a constitutive role in thought processes (Schnall, 2014). Regarding the representation of affective states in vertical spatial terms (the ‘up = good’ / ‘bad = down’ metaphor), it has been shown that the processing of positive and negative stimuli is facilitated in metaphor congruent locations. For instance, participants are faster to categorize a positive word such as ‘candy’ if it appears in the top location of the computer screen than if it appears in the bottom location, whilst negative words such as ‘cancer’ are categorized faster when they appear in the bottom rather than the top location (Meier & Robinson, 2004). Results consistent with the ‘up = good’ metaphor have also been observed with sentences (Marmolejo-Ramos, Montoro, Elosúa, Contreras & Jiménez-Jiménez, 2014), pictures and faces (Crawford, Margolies, Drake & Murphy, 2006), and even auditory tones (Weger, Meier, Robinson & Inhoff, 2007). They also occur in a variety of different tasks, including online processing tasks (Meier & Robinson, 2004; Santiago, Ouellet, Román & Valenzuela, 2012), memory tasks (Brunyé, Gardony, Mahoney & Taylor, 2012; Casasanto & Dijkstra, 2010; Crawford et al., 2006), and tasks requiring vertical movements (Casasanto & Dijkstra, 2010; Dudschig, de la Vega & Kaup, 2014; Freddi, Cretenet & Dru, 2013; Koch, Glawe & Holt, 2011). People from different ages and cultures show this mapping, which led Tversky, Kugelmass and Winter (1991) to suggest that it is a universal character.
The ‘up = good’ metaphor is consistent with a wide experiential basis. Upright (erect) postures have been linked to positive mood and slumped postures to negative mood (Oosterwijk, Rotteveel, Fischer & Hess, 2009; Riskind, 1984). ‘Up = good’ metaphors also abound in linguistic experience, as in expressions like “We hit a peak last year, but it's been downhill since then” (Lakoff & Johnson, 1980). These linguistic metaphors are highly productive, allowing innovations that can be understood readily (“we sky-rocketed”; Casasanto, 2009). Finally, many cultural conventions place good things in upper locations and bad things in lower locations, as the relative locations of heaven and hell exemplify. Therefore, the ‘up = good’ metaphor can be learnt from any of these many consistent experiences. Moreover, the vertical spatial dimension is highly salient and vertical spatial locations are discriminated and produced more easily than either sagital or lateral locations (Franklin & Tversky, 1990; van Sommers, 1984).
Recent studies have shown that emotional evaluation can also be mapped onto the lateral axis (the ‘right = good’ / ‘left = bad’ metaphor). In right-handers, good is mapped onto the right side and bad onto the left side in a number of tasks, including diagram tasks (Casasanto, 2009; Komisky & Casasanto, 2013), lateral choices (Casasanto, 2009; Casasanto & Henetz, 2012), reaching and grasping (Ping, Dillon & Beilock, 2009), online processing (de la Vega, de Filippis, Lachmair, Dudschig & Kaup, 2012; de la Vega, Dudschig, de Filippis, Lachmair & Kaup, 2013), memory tasks (Brunyé et al., 2012), gesture (Casasanto & Jasmin, 2010), and political party evaluations (Dijkstra, Eerland, Zijlmans & Post, 2012). Like the vertical mapping of evaluation, the lateral mapping is consistent with several different experiential sources: perceptuo-motor experiences of fluency in right-handers, linguistic expressions (“he is my right hand”, “he has two left feet”) and cultural conventions, such as those establishing that shaking hands, saluting or blessing must be done with the right hand.
However, the two mappings differ in some essential ways. Firstly, the linguistic expressions that manifest the ‘right = good’ metaphor are scarcely productive, that is, they are a fixed set of idioms that cannot be flexibly modified without losing their figurative meaning. For example, a person cannot be “my right foot”, or have “two left eyes” (Casasanto, 2009). Secondly, the lateral axis is the most difficult to process, produce and discriminate of the three spatial axes (e.g., Franklin & Tversky, 1990; Rossi-Arnaud, Pieroni, Spataro & Baddeley, 2012; van Sommers, 1984). The natural axes of the human body in the upright observer are grounded in the common, embodied experience of gravity, exerting an asymmetric force on our perceptual world. The resulting experience is one where vertical relations among objects generally remains constant under navigation, whilst horizontal relations depend largely on the bilateral perspectives of the mobile individual (e.g., Crawford et al., 2006). Likewise, short, left-to-right horizontal lines are often drawn by participants with a slightly shaky, tremulous line, whereas vertical downward movements are made more confidently, thus indicating greater fluency of localized movement along the vertical than horizontal plane (van Sommers, 1984). These complex interactions with objects and organisms in the real world have a lasting effect: even when prompted to imagine a series of objects, participants access the vertical dimension of space more readily than the horizontal one, as indicated by faster response times to locate imagined objects placed above or below the observer than to their left or right (e.g., Franklin & Tversky, 1990). The activation of the vertical dimension of space is often considered to operate in an automatic manner, such that patterns presented in a vertical arrangement are recalled with more accuracy than horizontal or diagonal arrangements—a finding that occurs even under increased working memory demands (e.g., Rossi-Arnaud et al., 2012). Finally, available evidence on the ‘right = good’ mapping suggests that only the first set of causes, the embodied experience of fluency, contributes to the experiential basis of the ‘right = good’ mapping. The association between right and good is present only in right-handers, whereas left-handers associate good with left, crucially, to a greater extent than right-handers associate good with right (Casasanto, 2009; Casasanto & Henetz, 2012). If language and culture (which are shared by right- and left-handers) contribute to the learning of this conceptual mapping, their influence should add to that of embodied experiences (which differ in right- and left-handers), leading to a stronger bias in right-handers than in left-handers. Even when the right-handers came from a Muslim culture (Morocco) with very strong beliefs against the left and in favour of the right, the strength of their ‘right = good’ association did not differ from Western participants (de la Fuente, Casasanto, Román & Santiago, 2014). Further evidence demonstrating the experiential basis of the ‘right = good’ mapping is found in experimental manipulations that promote greater motor fluency in participants’ non-dominant hand. Temporarily engaging natural right-handers to use their left hand in a more fluent and flexible manner, even for as little as 12 min, is sufficient to induce right-handers to associate “good” with “left,” as natural left-handers do (Casasanto & Chrysikou, 2011; see also Milhau, Brouillet & Brouillet, 2013; Milhau, Brouillet & Brouillet, 2014). Although there is no evidence as to the relative strength and efficacy of different kinds of causes (perceptuo-motor, linguistic, cultural) on the vertical mapping (‘up = good’), it is possible that it does not share the exclusive reliance on perceptuo-motor fluency of the lateral mapping (‘right = good’).
If emotional evaluation can be mapped onto the vertical and the horizontal axes, on which axis will it be mapped when the task affords both mappings simultaneously? Will both axes be used? In such case, will they be used to the same extent? Or instead, will only one axis be recruited for the mapping, and the other be left unused? Only a handful of very recent studies are relevant to these questions, and none has used an attentional orienting reaction time task. Crawford et al. (2006) presented positive and negative affective pictures at different screen positions, and asked participants to remember the location at which the stimulus had appeared. Positive pictures were biased upwards and negative pictures downward, but none of them showed any lateral bias. In an analogous paradigm, Brunyé et al. (2012) described positive or negative events (e.g., “six kittens are rescued from a tree”) while showing their location on a city map, and asked their participants at the test phase to remember the location where a given event had appeared. As in the prior study, positive events were biased upwards and negative events downwards, but they also found a lateral bias that depended on handedness: right-handers displaced positive events to the right and negative events to the left, and left-handers showed the opposite bias. However, when Marmolejo-Ramos, Elosúa, Yamada, Hamm and Noguchi 2013, (Experiment 2) asked right-handed participants to allocate words denoting positive and negative personality traits on a square, they observed only a vertical, but not a lateral bias.
Developing independently from metaphor-congruency effects, but still yielding results that could potentially be interpreted in terms of a ‘right = good’ bias, some studies involve participants to identify a facial expressions of emotion from a pair of faces presented side by side along the horizontal axis. In such tasks, participants make ‘left’ or ‘right’ verbal or manual responses often under specific experimenter prompts on each trial (e.g., “which of these two faces looks more afraid?”). Participants demonstrate greater levels of accuracy in identifying a positive facial expression when it appeared to the right of the neutral face, but greater levels of accuracy for a negative facial expression when it appeared on the left of the neutral face. However, these lateral mappings are not always consistently found across studies, even when the same experimental stimuli are used. Other factors, such as the participant’s sex and the explicit nature of the task’s instructions appear to play a more crucial role in determining the effectiveness of the lateral mappings to the task at hand (e.g., Jansari, Tranel & Radolphs, 2000; Rodway, Wright & Hardie, 2003). All in all, this set of studies suggest that the vertical ‘up = good’ metaphor is highly salient and universal, whereas the manifestation of the lateral ‘right = good’ metaphor is less consistent and its effect is often difficult to replicate.
The observed pattern could, nonetheless, be due just to the fact that the vertical axis is easily discriminable, whereas the lateral axis is the hardest spatial axis to process and produce (Franklin & Tversky, 1990; van Sommers, 1984). Overcoming this problem, Marmolejo-Ramos et al. (2013, Experiment 1) asked speakers of 21 languages to assess the emotional valence of the words “up”, “down”, “left”, and “right” on independent scales. Universally, the word “up” was considered positive, and the word “down” negative. The word “right” was considered positive by right-handed speakers of all languages and, with only a couple of exceptions, also by left-handers. The word “left” was considered negative or neutral by right-handers, whereas left-handers considered it to be more positive than the word “right”. This study thus suggests universal agreement on the vertical mapping of valence, as well as on the valence of the right, whereas left- and right-handers disagree on the valence of the left. Effect sizes also suggested higher discriminability between the vertical than the lateral words. No reaction time evidence from an online attentional task is available to bear directly on the question of the simultaneous activation of the vertical and lateral mappings of emotional valence. However, two studies have simultaneously assessed vertical and horizontal attentional effects related to the processing of two concepts closely related to emotional valence: the religious concepts of God and Evil (Chasteen, Burdzy & Pratt, 2010; Xie & Zhang, 2014). Both of them observed that processing words related to God favours subsequent perceptual discrimination at upper and right locations, and words related to Evil favours down and left locations. This evidence suggests a simultaneous activation of both the vertical and lateral spatial dimensions when processing religious concepts. It is unclear, though, how well these findings can be extended to emotional (non-religious) evaluation.
Therefore, the question of the simultaneous activation of the vertical and lateral mappings of emotional evaluation remains to be elucidated. Clearly response time measures are essential to establish the extent to which attentional resources prioritize metaphor congruent locations along the vertical axis over the horizontal one (e.g., Moeller, Robinson & Zabelina, 2008). Online measures made available through the analysis of reaction times are needed to provide greater theoretical insight into the more immediate cognitive processes involved in the spatial representation of affect which may otherwise be masked by strategic factors in designs that focus on the end product of metaphor-based cognition (e.g., Wang, Taylor & Brunyé, 2012). Studies using response time measures have provided supporting evidence for both the 'up = good' and 'right = good' metaphors when examined in isolation (e.g., de la Vega et al., 2012, 2013; Meier & Robinson, 2004; see review above), which suggests that this type of measure will allow us to compare the relative strength of each metaphor when the task affords their simultaneous deployment.
In the present study, we addressed this issue by employing an emotion perception task in which happy or angry faces appeared on screen in four different spatial locations together with three neutral faces, and in which response times and error rates were recorded in participants’ detection of the discrepant target face, a visual search task designed by Damjanovic, Roberson, Athanasopoulos, Kasai and Dyson (2010). Only one published study has so far used emotional facial expressions to study conceptual mappings (Lynott & Coventry, 2014). This study focused only on the vertical ‘up = good’ metaphor, presenting faces only at upper and lower locations on the screen, and explicitly mapped a valence judgment onto left and right response keys (e.g., “press the right key when the face is happy”). Extending this procedure to allow for the simultaneous activation of both the ‘up = good’ and ‘right = good’ metaphors requires the presentation of emotional faces at upper, lower, left, and right locations of the screen. Although response mappings were switched half way through Lynott and Coventry’s (2014) emotion perception task, explicitly mapping left and right keypresses to the dimension of emotional valence could nevertheless artifactually boost the activation of the lateral (‘right = good’) mapping at the expense of the vertical (‘up = good’) mapping (Santiago, Ouellet, Román & Valenzuela, 2012; Torralbo, Santiago & Lupiáñez, 2006). The same-different judgment used in the task devised by Damjanovic and colleagues (2010) solves this problem to a great extent. It secures the processing of the relevant dimension of emotion, as this is the dimension which discriminates target from distractors, but divorces it from left and right keypresses, which are now used to provide same-different responses. The task relevance of the left-right axis is thus much decreased by not being linked explicitly to the emotional valence dimension, and the same responses can be used for detecting the effects of both the vertical and the lateral mappings. It should be noted that, under these conditions, the lateral axis is not yet completely task irrelevant. Although this may make it difficult to interpret any metaphoric congruency effect on the lateral axis, it will actually make more convincing the absence of an effect of the ‘right = good’ metaphor—a possibility suggested by prior research (see above).
To summarize, Experiment 1 aims to assess whether each or both metaphorical mappings (‘up = good’ and ‘right = good’) are activated in an attentional orienting reaction time task that affords their simultaneous use. Prior evidence leads us to predict a conceptual congruency effect of the ‘up = good’ metaphor. Given that Damjanovic and colleagues’ (2010) visual search task resulted in a processing bias favouring happy face targets over angry ones (i.e., a happiness bias), we expected conceptual congruency of the ‘up = good’ metaphor to facilitate the speeded detection of happy faces when they appeared in the top relative to the bottom location. Regarding the ‘right = good’ metaphor, prior evidence is less consistent, but it mostly suggests that this mapping will fail to generate a detectable congruency effect. We therefore predicted its absence. In Experiment 2, we sought to replicate the robustness of the findings by using the same experimental design, but with stimuli of improved ecological validity.
Experiment 1
Method
Participants
Eighteen right-handed (Oldfield, 1971) participants were recruited from the student population of a Higher Education institution in the North West region of the United Kingdom. These participants ranged in age from 20 to 24 years (Mdn age: 20.5 years, MAD = 0.74), and 13 were female. Participants were of White-British ethnic origin and with English as their first language and took part in the experiment as part of a course requirement. All participants self-reported to possess normal or corrected-to-normal vision. This study was approved by the Department of Psychology Ethics Committee at the University of Chester, United Kingdom. Consenting participants gave written informed consent. The number of participants was deemed satisfactory in terms of statistical power based on our own previous studies using similar sample sizes in the same task (e.g., Damjanovic et al., 2010) and previous emotional visual search studies (e.g., Williams, Moss, Bradshaw & Mattingley 2005).
Stimuli and apparatus
The visual search task and data collection were conducted with an Intel Core PC desktop computer with a 2.93-GHz processor and 19-inch monitor. A refresh rate of 60 Hz and a resolution of 1280 x 1024 were used. SuperLab version 4.0 delivered stimuli and recorded responses and reaction times (RT). Manual responses to the visual search display were collected from the ‘x’ and ‘.’ keys on the computer’s keyboard, which recorded participants’ RT and error rates for each trial. Damjanovic et al.’s (2010) visual search task (Experiment 2) was used in the present study, and involved facial stimuli modified from the Matsumoto and Ekman (1988) database of facial affect.
Four different Caucasian individuals (two male and two female) provided normed facial expressions depicting anger and happiness, along with their neutral face counterpart. Each colour image was converted to grayscale and sized to fill a 126 pixels wide by 168 pixel high oval template applied in Adobe Photoshop in order to remove external facial features such as hair, ears and neckline. Adobe Photoshop was used to equate the mean luminance and contrast across faces and expressions. Each visual search trial consisted of four faces belonging to the same individual arranged in an imaginary circle, occupying top, right, bottom and left locations on the computer screen, with a fixation cross at the centre viewed at a distance of 60 cm. The picture settings function within SuperLab positioned each picture such that it measured 250 pixels from the centre of the screen to the centre of each picture (see Fig. 1).

Example stimulus display from the visual search task showing a schematic representation of a happy target (top location) among neutral faces
Procedure
The visual search task consisted of 5 practice trials and 112 experimental trials. For the ‘different’ display trials, participants were always presented with four faces belonging to the same individual, where they were required to search for an angry or a happy target against three neutral distractor faces. Each target face (angry or happy) appeared eight times in each of the four possible locations in a randomly determined order. The ‘same’ display trials consisted of four faces belonging to the same individual displaying the same emotional expression (i.e., all angry, all happy or all neutral). There were 64 ‘different’ trials (32 in each condition) and 48 same display trials (16 angry, 16 happy, 16 neutral expressions). The same and different trials were randomized within the experiment and presented in a different random order to each participant.
Each trial began with a fixation cross in the centre of the screen for 500 ms followed by a display of four faces surrounding the central fixation point for 800 ms. The inter-trial interval was set to 2000 ms. Participants were provided with the following instructions: “Your task is to decide whether all of these pictures show the SAME emotion or whether one shows a DIFFERENT emotion”. Participants were instructed to respond with their index fingers as quickly and as accurately as possible by using the ‘x’ and ‘.’ keys, which were covered with green and orange stickers, respectively. Response keys were counterbalanced across participants, with feedback in the form of a 1,000 ms beep being provided on incorrect trials.
Design and analysis
Target detection performance was measured using RT recorded from the onset of each trial to participant response and percentage errors on ‘different’ trials (Damjanovic et al., 2010). Given that the main hypotheses of interest predicted interactions along the vertical and horizontal dimensions, we investigated the effects of location on emotion detection performance separately for the two dimensions using two 2 (target: angry or happy) × 2 (location: top or bottom/left or right) repeated measures ANOVAs for each dependent variable (see also Chasteen et al., 2010; Crawford et al., 2006, for separate analyses for vertical and horizontal locations).
Significant interactions between target and location were followed up with paired samples t-tests planned comparisons to test for metaphor-congruency effects as indicated by faster and less error prone detection performance to happy faces in the top location than the bottom location, but faster and less error prone detection performance to angry targets presented in the bottom than the top location. The alpha level for the pairwise planned comparisons was set at 0.05. Along the horizontal axis, metaphor-congruency effects would emerge when detection performance to happy faces is faster and less error prone in the right than the left location, but performance is faster and less error prone detection to angry targets presented in the left than the right location. Partial eta squared (η p) effect sizes are reported for main effects and interactions of interest and correlation effect size (r) was used for pairwise planned comparisons. Partial eta squared (η p 2) can be interpreted as follows: 0.01 = small, 0.06 = medium and 0.14 = large (see Cohen, 1988). Correlation effect size (r) can be interpreted as follows: .10 small, .30 medium and .50 large (see Cohen, 1992). However, these benchmarks should be taken with caution (Lakens, 2013) and interpreted in the context of the effect sizes reported in other studies in the relevant literature.
Results and discussion
We applied identical truncation parameters as used in our earlier work (Damjanovic et al., 2010) to calculate mean RT for correct responses for each cell of the design, excluding RTs less than 100 ms or greater than 2000 ms (3.82 %).Footnote 1
The vertical representation of affect
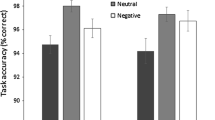
A 2 × 2 ANOVA on RT revealed a significant main effect of target, yielding response times that were consistent with a happiness bias (angry target: M = 1125.68, SD = 178.62 vs happy target: M = 1084.79, SD = 198.17) and indicating that, when combining across locations, participants responded more quickly when detecting a happy target than when detecting an angry target [F (1, 17) = 4.99, MSE = 6031.29, p = .039, η p 2 = .23]. Participants were also significantly faster to respond to targets, irrespective of their emotionality, when they appeared in the top rather than the bottom location [F (1, 17) = 12.71, MSE = 10,763.98, P = .002, η p 2 = .43; top location: M = 1061.64, SD = 187.14 vs bottom location: M = 1148.83, SD = 196.27]. However, more importantly, and as predicted, these two main effects were qualified by a significant target × location interaction [F (1, 17) = 7.36, MSE = 8941.92, p = .015, η p 2 = .30]. As shown in Fig. 2, whilst participants were significantly faster to detect happy face targets when they appeared in the top versus the bottom location [t (17) = 5.00, P < .001, r = .77], response times to detect the angry target were unaffected by vertical location [t (17) = 0.74, P = .472, r = .18].

Individual cell means for the target by location interaction for Experiment 1 with cropped faces. Upper panels Mean reaction times for angry and happy face targets along the vertical (left panel) and horizontal (right panel) dimension. Lower panels Mean percentage of errors for angry and happy targets along the vertical (left panel) and horizontal (right panel) dimension. Error bars ±1 SEM. **P < .001
A 2 × 2 ANOVA on percentage errors did not produce any significant main effects for either target [angry: M = 15.97, SD = 9.82 vs. happy: M = 12.15, SD = 10.16, F (1, 17) = 1.93, MSE = 135.96, P = .182, η p 2 = .10), or location [top location: M = 10.07, SD = 7.60 vs. bottom location: M = 18.06, SD = 15.14, F (1, 17) = 3.70, MSE = 310.58, P = .298, η p 2 = .18]. The target × location interaction was not significant [F (1, 17) = 1.15, MSE = 227.87, P = .298, η p 2 = .06].
The horizontal representation of affect
When combining across lateral locations, participants again responded more quickly when detecting a happy target than when detecting an angry target [angry target: M = 1113.63, SD = 208.86 vs. happy target: M = 1052.52, SD = 192.14, F (1, 17) = 11.96, MSE = 5620.07, P = .003, η p 2 = .41]. There was no significant main effect of location, [F (1, 17) = 0.89, MSE = 13648.62, P = .358, η p 2 = .05], right location: M = 1070.08, SD = 210.58 vs. left location: M = 1096.08, SD = 200.74) and it did not interact significantly with the emotionality of the target face [F (1, 17) = 0.63, MSE = 9851.42, P = .437, η p 2 = .04 , see Fig. 2].
A 2 × 2 ANOVA on percentage errors produced a significant main effect for target (angry: M = 22.22, SD = 14.42 vs. happy: M = 10.96, SD = 10.61), with significantly fewer errors made to happy than angry targets [F (1, 17) = 10.98, MSE = 207.94, P = .004, η p 2 = .39]. The main effect of location (right location: M = 13.74, SD = 12.31 vs. left location: M = 19.44, SD = 11.91) approached significance [F (1, 17) = 3.80, MSE = 154.11, P = .068, η p 2 = .18], but did not interact significantly with the emotionality of the target face [F (1, 17) = 0.56, MSE = 49.06, P = .463, η p 2 = .03].
These findings demonstrate that the processing bias for happy faces reported previously in Damjanovic and colleagues’ (2010) visual search task can be facilitated in metaphor-congruent locations, but only for faces appearing along the vertical dimension (i.e., ‘up = good’ metaphor). We also replicate the work of Lynott and Coventry (2014) by demonstrating processing asymmetries along the vertical axis that extend to the perception of angry and happy facial expressions in a task where stimulus-response mappings are made less procedurally salient. Thus, whilst the detection of happy faces was facilitated in locations compatible with the ‘up = good’ metaphor, angry faces presented in the bottom location were processed just as quickly as angry faces appearing in the top location.
The lateral dimension did not show a corresponding conceptual congruency effect, as demonstrated statistically by the absence of a target by location interaction. It therefore appears that, under complex processing demands when both vertical and lateral metaphors can guide attentional resources equally to the task at hand, the vertical one is activated more readily for facilitating the detection of facial expressions of emotion, whereas the lateral is not activated to the necessary extent to affect performance.
We know of no other study examining emotion–space interactions that has used facial stimuli to represent bipolar oppositions in stimulus dimensions within the same task. Given the novelty of these results and their theoretical relevance to contemporary models of representational thought, we sought to replicate the prioritisation of the vertical metaphor for happy faces in a procedurally identical study, by using more realistic facial stimuli (Song, Vonasch, Meier & Bargh, 2012). Applying cropping templates to remove extraneous facial characteristics (e.g., hairline, neck, ears, etc), whilst common in visual search studies of this kind (e.g., Calvo & Nummenmaa, 2008; Damjanovic et al., 2010; Williams et al., 2005), may limit the overall ecological validity of the facial stimulus (Burton, 2013). In order to address this particular concern, Experiment 2 utilized the same experimental design, but presented participants with facial stimuli that were intact and in full colour. Thus, Experiment 2 was identical to Experiment 1 in all ways except as noted below.
Experiment 2
Method
Participants
A separate group of 18 right-handed (Oldfield, 1971) participants from the same population and matched for male-female split as those participants in Experiment 1 took part in the study as part of a course requirement. These participants ranged in age from 18 to 43 years (Mdn age: 21.5 years, MAD = 2.22). Participants were of White-British ethnic origin and with English as their first language and took part in the experiment as part of a course requirement. All participants self-reported to possess normal or corrected-to-normal vision. This study was approved by the Department of Psychology Ethics Committee at the University of Chester, United Kingdom. Consenting participants gave written informed consent.
Stimuli and apparatus
The software and hardware configurations for the visual search task were identical to those of Experiment 1. The same stimuli set as selected from the Matsumoto and Ekman (1988) database for Experiment 1were used in this study. Each colour image was cropped to fill a rectangular template measuring 126 pixels wide by 168 pixels high using Adobe Photoshop, displaying only the full head and neck of each individual against a uniform background. Adobe Photoshop was used to equate the mean luminance and contrast across faces and expressions. Four full face images of the same individual were arranged in an imaginary circle using the same position settings as delivered by SuperLab in Experiment 1, occupying top, right, bottom and left positions, with a fixation cross at centre viewed at distance of 60 cm. The picture settings function within SuperLab positioned each picture such that it measured 250 pixels from the centre of the screen to the centre of each picture.
Results and discussion
As in Experiment 1, mean RTs for correct responses were calculated for each cell of the design, excluding RTs less than 100 ms or greater than 2000 ms (3.02 %).
The vertical representation of affect
A 2 × 2 ANOVA on RT revealed a significant main effect for target, with faster responses to happy than angry face targets [angry target: M = 1157.07, SD = 145.38 vs. happy target: M = 1104.80, SD = 129.90, F (1, 17) = 7.37, MSE = 6671.54, P = .015, η p 2 = .30], but not for location [F (1, 17) = 1.20, MSE = 11366.58, P = .288, η p 2 = .07, top location: M = 1117.15, SD = 151.44 vs. bottom location: M = 1144.71, SD = 132.00]. However, as hypothesized, these two main effects were qualified by a significant target × location interaction [F (1, 17) = 7.23, MSE = 9393.84, P = .016, η p 2 = .30]. As shown in Fig. 3, participants were significantly faster to detect happy face targets when they appeared in the top versus the bottom location [t (17) = 3.53, P = .003, r = .65]. However, participants’ response times to detect the angry target did not differ by vertical location [t (17) = 0.83, P = .829, r = .20].

Individual cell means for the target by location interaction for Experiment 2 with whole faces. Upper panels Mean reaction times for angry and happy face targets along the vertical (left panel) and horizontal (right panel) dimension. Lower panels Mean percentage of errors for angry and happy targets along the vertical (left panel) and horizontal (right panel) dimension. Error bars ±1 SEM. *P < .01
A 2 × 2 ANOVA on percentage errors produced a significant main effect for target, with more errors associated with angry than happy targets [angry: M = 18.40, SD = 13.54 vs happy: M = 12.15, SD = 14.62, F (1, 17) = 5.79, MSE = 121.53, P = .028, η p 2 = .25], but not for location [Top: M = 14.93, SD = 14.68 vs Bottom: M = 15.63, SD = 16.64, F (1, 17) = 0.03, MSE = 312.51, P = .870, η p 2 = .00]. The target × location interaction was not significant, [F (1, 17) = 0.70, MSE = 197.61, P = .413, η p 2 = .04].
The horizontal representation of affect
A 2 × 2 ANOVA on RT revealed a significant main effect of target, yielding response times that were consistent with a happiness bias (angry target: M = 1145.11, SD = 137.92 vs. happy target: M = 1096.50, SD = 122.15) and indicating that when combining across locations, participants responded more quickly when detecting a happy target than when detecting an angry target [F (1, 17) = 10.30, MSE = 4129.12, P = .005, η p 2 = .38]. There was no significant main effect of location [F (1, 17) = 0.17, MSE = 16913.80, p = .688, η p 2 = .01, right location: M = 1127.06, SD = 131.20 vs left location: M = 1114.55, SD = 152.06] and it did not interact significantly with the emotionality of the target face [F (1, 17) = 0.58, MSE = 6289.91, P = .457, η p 2 = .03, see Fig. 3].
A 2 × 2 ANOVA on percentage errors revealed no significant differences between the two types of targets [angry: M = 19.79, SD = 15.49 vs. happy: M = 14.63, SD = 14.24, F (1, 17) = 2.14, MSE = 223.83, P = .162, η p 2 = .11] or locations [right location: M = 14.63, SD = 13.02 vs. left location: M = 19.79, SD = 18.72, F (1, 17) = 1.27, MSE = 479.03, P = .276, η p 2 = .07]. The target x emotion interaction was not significant [F (1, 17) = 0.03, MSE = 64.15, P = .877, η p 2 = .00].
Once again, the vertical dimension exerted a stronger effect in facilitating the processing of happy faces in metaphor-congruent locations than the horizontal dimension. Even with stimuli of improved ecological validity, we continued to find no interaction between target and location along the horizontal dimension, thus lending further support to the view that the vertical, rather than the horizontal dimension, is more salient in activating spatial representations of affect under complex attentional tasks.
General discussion
The current study sought to fulfill one specific aim: to determine whether vertical and horizontal representations of affect are activated, and to what degree, in an attentional task requiring the processing of emotional facial expressions. In Experiment 1, we showed that spatial representations of affect influence visual search processing speed, but not accuracy, for facial expressions of emotion indicating that response time measures may provide a more sensitive index of metaphor-based cognition (e.g., Schubert, 2005; Wang et al., 2012). Extending the happiness bias reported by Damjanovic et al. (2010), we found a conceptual congruency effect consistent with the ‘up = good’ metaphor. In contrast, there were no congruency effects on performance between emotional valence and the horizontal dimension. This pattern of results was replicated in Experiment 2 using faces of improved ecological validity in the visual search task. The null effect of the ‘right = good’ metaphor occurred in the context of a procedure where the left-right spatial axis enjoys some degree of task relevance: although it is not linked explicitly to emotional evaluation, its activation was needed in order to program the keypresses that provided “same” and “different” responses. In contrast, the vertical axis was completely irrelevant to the task. This reinforces the conclusion of the differential saliency of the ‘up = good’ and ‘right = good’ metaphorical mappings, and it is consistent with the greater linguistic saliency of the ‘up = good’ metaphor (e.g., Casasanto, 2009; Marmolejo-Ramos et al., 2013).
The origins of this asymmetry in the conceptual representation of affect are varied and remain speculative, and range from the grounding of verticality in the common, embodied experience of gravity, to the associations we form between nurturance and spatial orientation in our early interactions with our caregivers (Spitz, 1965). It appears that the perceptual contrast between up/down and the corresponding experiences of reward/deprivation as acquired in the preverbal infant are reinforced more readily than associations created by the contrasts between left/right and reward/deprivation. These early socialisation experiences between reward and nourishment (Spitz, 1965) go on to to set the stage for a linguistic expression of verticality in abstract thought as cognitive development matures (e.g., Piaget & Inhelder, 1969; Schwartz, 1981), leading adults to use the vertical dimension to express and represent their emotional states (Tolaas, 1991) with greater saliency and frequency than the horizontal dimension (e.g., Casasanto, 2009; Marmolejo-Ramos et al., 2013).
Irrespective of the many experiential causes that may underpin the greater saliency attached to the vertical dimension, the present study provides novel evidence in an attentional orienting reaction time task that complements existing research findings, indicating that the vertical dimension does appear to have a special role in processing affective information, in contrast to a much smaller relevance of the lateral dimension. Finally, the present results contrast with those reported for the processing of religious concepts of God and Evil (Chasteen, Burdzy & Pratt, 2010; Xie & Zhang, 2014), which have been shown to activate both up-down and left-right mappings. Therefore, conceptual mappings of religious concepts cannot be reduced to the representation of their emotional evaluation.
The present findings extend these conclusions to socially relevant pictorial stimuli and highlight an early encoding mechanism that may subsequently underpin the systematic biases found in spatial recall tasks with emotionally salient cues and events (i.e., Brunyé et al., 2012; Crawford et al., 2006). Visual search tasks may prove to be a particularly fruitful methodology for evaluating the effect of multiple metaphor mappings on cognition such as those observed for affect and location. Indeed, visual search tasks provide a robust cognitive tool with strong ecological appeal to study how attentional resources are captured by emotionally salient social stimuli (e.g., Damjanovic, Pinkham, Phillips & Clarke, 2014). The present study may facilitate future research endeavors to explore the attentional constraints of representational thought with different facial expressions of emotion and to establish how individual differences may alter the attentional relationship between affect and location (e.g., Brunyé, Mahoney, Augustyn & Taylor, 2009; Frischen, Eastwood & Smilek, 2008; Gollan, Norris, Hoxha, Irick, Hawkley, Cacioppo, 2014; Moeller et al., 2008). The current findings indicate that when several distractors are embedded in a visual search display for happy faces targets, preferential attentional processing is achieved along the vertical rather than along the horizontal axis. Further research is required to establish whether the horizontal dimension is reinstated as an effective source of metaphorical representation when attentional competition is reduced, as in the case with experimental tasks where only two pictures are presented on the left and right. As far as accuracy is concerned, there is some evidence to indicate that participants are better at discriminating positive facial expressions when they are located on the right side of the computer screen, and negative facial expressions when they are presented on the left (e.g., Jansari et al., 2000). However, the magnitude of such emotion by location interactions tends to be constrained by working memory demands and may even be conflated by a response bias caused by the emotion-specific linguistic labels participants are instructed to use over the course of the task (e.g., Kinsbourne, 1970; Rodway et al., 2003). Thus, the horizontal dimension does not appear to enjoy the same degree of automaticity as the vertical dimension in the processing of facial expressions of emotion even in tasks that completely exclude any attentional competition from the vertical dimension (e.g., Rossi-Arnaud et al., 2012). Additional investigation using reaction time measures is needed to determine whether an emotion by location interaction for the horizontal dimension emerges when greater efforts are made to reduce the effects of response bias on emotion perception.
Before closing, a final point remains to be discussed. The pattern of interaction that we observed between vertical space and emotional evaluation replicates prior findings by Lynott and Coventry (2014): happy faces were responded to faster in the upper than the lower location, while angry faces were not affected by vertical location. Lynott and Coventry (2014), following Lakens (2012), interpreted this funnel interaction as evidence for a polarity correspondence view of conceptual congruency effects, which is a theoretical contender of the conceptual metaphor view. Basically, polarity correspondence suggests that congruency effects arise as a result of a purely structural matching between the bipolar dimensions that are processed in the task. Each dimension (vertical space and emotional evaluation) has an unmarked or + pole and a marked or – pole. The + pole enjoys a processing advantage over the – pole, and when poles of the same sign coincide in a trial (e.g., a positive word presented at an upper location), there is an extra processing advantage. Because the polarity correspondence view predicts both main effects as well as their interaction, the interaction is predicted to be a funnel interaction. In contrast, conceptual metaphor theory suggests that congruency effects arise because the internal representation of an abstract concept such as emotional evaluation resorts to concrete concepts such as space (Boroditsky, 2000; Casasanto & Boroditsky, 2008; Lakoff & Johnson, 1999). Therefore, conceptual metaphor predicts an interaction, but says nothing about main effects.
Lakens (2012) and Lynott and Coventry (2014) interpreted the silence of conceptual metaphor theory about main effects as its inability to predict a funnel interaction. However, conceptual metaphor theory is compatible with main effects along each of the dimensions in the task, which may arise for other reasons. For example, it is a frequent finding that upper locations are processed faster than lower locations (e.g., Santiago et al., 2012)—a bias that might be due to well-practiced scanning patterns linked to reading skills (e.g., Schubert, 2005). In the present study, we observed main effects of vertical location, with faster processing of faces presented above than below, as well as a main effect of emotional evaluation, with happy- processed faster than angry-faces. Both main effects can be caused by factors that are unrelated to the potential causes of the interaction between the two dimensions. Thus, in contexts where there are likely alternative causes for the main effects, the finding of a funnel interaction has a limited diagnostic value regarding the theoretical controversy between conceptual metaphor theory and polarity correspondence (see Santiago & Lakens, 2015, for an extended discussion of this issue).
In conclusion, the present study provides novel information with respect to the attentional mechanisms involved in the spatial representation of affect. Our results replicate those of Lynott and Coventry (2014) and extend the phenomenon of the vertical activation of affect using a more automatic and linguistically neutral, in terms of the instructions, experimental context. In contrast, the horizontal dimension is not salient enough to attract attentional resources towards emotional stimuli. These findings are generally in keeping with the view of stronger emotion-space mappings for the vertical than the horizontal dimension (e.g., Brunyé et al., 2012; Casasanto, 2009; Crawford et al., 2006, Marmolejo-Ramos et al., 2013). We propose that the visual search task offers a unique resource to combine bipolar oppositions in stimulus dimensions within the same task and is worthy of further empirical investigation in establishing the attentional mechanisms that underlie representational thought.
Notes
Side-by-side analyses consisting of ANOVAs where the mean was calculated from the median RT per participant per condition were performed on the RT data reported in Experiments 1 and 2. Since the results of this additional analysis left the interaction, that is central to our hypotheses, unchanged, we report only the results on the filtered mean RT.
References
Boroditsky, L. (2000). Metaphoric structuring: Understanding time through spatial metaphors. Cognition, 75, 1–28.
Brunyé, T. T., Mahoney, C. R., Augustyn, J. S., & Taylor, H. A. (2009). Emotional state and local versus global spatial memory. Acta Psychologica, 130, 138–146. doi:10.1016/j.actpsy.2008.11.002
Brunyé, T. T., Gardony, A., Mahoney, C. R., & Taylor, H. A. (2012). Body-specific representations of spatial location. Cognition, 123, 229–239. doi:10.1016/j.cognition.2011.07.013
Burton, A. M. (2013). Why has research in face recognition progressed so slowly? The importance of variability. The Quarterly Journal of Experimental Psychology, 66, 1467–1485. doi:10.1080/17470218.2013.800125
Calvo, M. G., & Nummenmaa, L. (2008). Detection of emotional faces: Salient physical features guide effective visual search. Journal of Experimental Psychology: General, 137, 471–494. doi:10.1037/a0012771
Casasanto, D. (2009). Embodiment of abstract concepts: Good and bad in right- and left-handers. Journal of Experimental Psychology: General, 138, 351–367. doi:10.1037/a0015854
Casasanto, D., & Boroditsky, L. (2008). Time in the mind: Using space to think about time. Cognition, 106, 579–593. doi:10.1016/j.cognition.2007.03.004
Casasanto, D., & Chrysikou, E. G. (2011). When Left is "Right": Motor fluency shapes abstract concepts. Psychological Science, 22, 419–422. doi:10.1177/0956797611401755
Casasanto, D., & Dijkstra, K. (2010). Motor action and emotional memory. Cognition, 115, 179–185. doi:10.1016/j.cognition.2009.11.002
Casasanto, D., & Henetz, T. (2012). Handedness shapes children’s abstract concepts. Cognitive Science, 36, 359–372. doi:10.1111/j.1551-6709.2011.01199.x
Casasanto, D., & Jasmin, K. (2010). Good and bad in the hands of politicians: Spontaneous gestures during positive and negative speech. PLoS ONE, 5, e11805. doi:10.1371/journal.pone.0011805
Chasteen, A. L., Burdzy, D. C., & Pratt, J. (2010). Thinking of God moves attention. Neuropsychologia, 48, 627–630. doi:10.1016/j.neuropsychologia.2009.09.029
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). New Jersey: Erlbaum.
Cohen, J. (1992). A power primer. Psychological Bulletin, 112, 155–159.
Crawford, L. E., Margolies, S. M., Drake, J. T., & Murphy, M. E. (2006). Affect biases memory of location: Evidence for the spatial representation of affect. Cognition and Emotion, 20, 1153–1169. doi:10.1080/02699930500347794
Damjanovic, L., Roberson, D., Athanasopoulos, P., Kasai, C., & Dyson, M. (2010). Searching for happiness across cultures. Journal of Cognition and Culture, 10, 85–107. doi:10.1163/156853710X497185
Damjanovic, L., Pinkham, A. E., Clarke, P., & Phillips, J. (2014). Enhanced threat detection in experienced riot police officers: Cognitive evidence from the face-in-the-crowd effect. The Quarterly Journal of Experimental Psychology, 67, 1004–1018. doi:10.1080/17470218.2013.839724
de la Fuente, J., Casasanto, D., Román, A., & Santiago, J. (2014). Can culture influence body-specific associations between space and valence? Cognitive Science, 39, 821–832. doi:10.1111/cogs.12177
de la Vega, I., de Filippis, M., Lachmair, M., Dudschig, C., & Kaup, B. (2012). Emotional valence and physical space: Limits of interaction. Journal of Experimental Psychology: Human Perception and Performance, 38, 375–385. doi:10.1037/a0024979
de la Vega, I. D., La, D., Filippis, C., De, M., Lachmair, M., & Kaup, B. (2013). Keep your hands crossed: The valence-by-left/right interaction is related to hand, not side, in an incongruent hand–response key assignment. Acta Psychologica, 142, 273–277. doi:10.1016/j.actpsy.2012.12.011
Dijkstra, K., Eerland, A., Zijlmans, J., & Post, L. S. (2012). How body balance influences political party evaluations: A Wii balance board study. Frontiers in Psychology, 3(536), 1–8. doi:10.3389/fpsyg.2012.00536
Dudschig, C., de la Vega, I., & Kaup, B. (2014). Embodiment and second-language: Automatic activation of motor responses during processing spatially associated L2 words and emotion L2 words in a vertical Stroop paradigm. Brain & Language, 132, 14–21. doi:10.1016/j.bandl.2014.02.002
Franklin, N., & Tversky, B. (1990). Searching imagined environments. Journal of Experimental Psychology: General, 119, 63–76. doi:10.1037/0096-3445.119.1.63
Freddi, S., Cretenet, J., & Dru, V. (2013). Vertical metaphor with motion and judgment: A valenced congruency effect with fluency. Psychological Research, 78, 736–748. doi:10.1007/s00426-013-0516-6
Frischen, A., Eastwood, J. D., & Smilek, D. (2008). Visual search for faces with emotional expressions. Psychological Bulletin, 134, 662–676. doi:10.1037/0033-2909.134.5.662
Geary, J. (2011). I is an other: The secret life of metaphor and how it shapes the way we see the world. New York: Harper Collins.
Gollan, J. K., Norris, C. J., Hoxha, D., Irick, J. S., Hawkley, L. C., & Cacioppo, J. T. (2014). Spatial affect learning restricted in major depression relative to anxiety disorders and healthy controls. Cognition & Emotion, 28, 36–45. doi:10.1080/02699931.2013.794772
Jansari, A., Tranel, D., & Adolphs, R. (2000). A valence-specific lateral bias for discriminating emotional facial expressions in free field. Cognition and Emotion, 14, 341–353. doi:10.1080/026999300378860
Kinsbourne, M. (1970). The cerebral basis of lateral asymmetries in attention. Acta Psychologica, 33, 193–201. doi:10.1016/0001-6918(70)90132-0
Koch, S. C., Glawe, S., & Holt, D. V. (2011). Up and down, front and back: Movement and meaning in the vertical and sagittal axes. Social Psychology, 42, 214–224. doi:10.1027/1864-9335/a000065
Kominsky, J. F., & Casasanto, D. (2013). Specific to whose body? Perspective-taking and the spatial mapping of valence. Frontiers in Psychology, 4(266). doi:10.3389/fpsyg.2013.00266
Lakens, D. (2012). Polarity correspondence in metaphor congruency effects: Structural overlap predicts categorization times for bipolar concepts presented in vertical space. Journal of Experimental Psychology: Learning, Memory, & Cognition, 38, 726–736. doi:10.1037/a0024955
Lakens, D. (2013). Calculating and reporting effect sizes to facilitate cumulative science: a practical primer for t-tests and ANOVAs. Frontiers in Psychology, 4(863). doi:10.3389/fpsyg.2013.00863
Lakoff, G., & Johnson, M. (1980). Metaphors we live by. Chicago: University of Chicago Press.
Lakoff, G., & Johnson, M. (1999). Philosophy in the flesh: The embodied mind and its challenge to Western thought. New York: Basic Books.
Lynott, D., & Coventry, K. (2014). On the ups and downs of emotion: Testing between conceptual-metaphor and polarity accounts of emotional valence-spatial location interactions. Psychonomic Bulletin & Review, 21, 218–226. doi:10.3758/s13423-013-0481-5
Marmolejo-Ramos, F., Elosúa, M. R., Yamada, Y., Hamm, N., & Noguchi, K. (2013). Appraisal of space words and allocation of emotion words in bodily space. PLoS ONE, 8, e81688. doi:10.1371/journal.pone.0081688
Marmolejo-Ramos, F., Montoro, P. R., Elosúa, M. R., Contreras, M. J., & Jiménez-Jiménez, W. A. (2014). The activation of representative emotional verbal contexts interacts with vertical spatial axis. Cognitive Processing, 15, 253–267. doi:10.1007/s10339-014-0620-6
Matsumoto, D., & Ekman, P. (1988). Japanese and Caucasian facial expressions of emotion (JACFEE) and (JACNeuf). San Francisco State University.
Meier, B. P., & Robinson, M. D. (2004). Why the sunny side is up: Associations between affect and vertical position. Psychological Science, 15, 243–247. doi:10.1111/j.0956-7976.2004.00659.x
Milhau, A., Brouillet, T., & Brouillet, D. (2013). Biases in evaluation of neutral words due to motor compatibility effect. Acta Psychologica, 144, 243–249. doi:10.1016/j.actpsy.2013.06.008
Milhau, A., Brouillet, T., & Brouillet, D. (2014). Valence-space compatibility effects depend on situated motor fluency in both right- and left-handers. The Quarterly Journal of Experimental Psychology, 68, 887–899. doi:10.1080/17470218.2014.967256
Moeller, S. K., Robinson, M. D., & Zabelina, D. L. (2008). Personality dominance and preferential use of the vertical dimension of space: Evidence from spatial attention paradigms. Psychological Science, 19, 355–361. doi:10.1111/j.1467-9280.2008.02093.x
Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh Inventory. Neuropsychologia, 9, 97–113. doi:10.1016/0028-3932(71)90067-4
Oosterwijk, S., Rotteveel, M., Fischer, A. H., & Hess, U. (2009). Embodied emotion concepts: How generating words about pride and disappointment influences posture. European Journal of Social Psychology, 39, 457–466. doi:10.1002/ejsp.584
Piaget, J., & Inhelder, B. (1969). The psychology of the child. New York: Basic Books.
Ping, R. M., Dhillon, S., & Beilock, S. L. (2009). Reach for what you like: The body’s role in shaping preferences. Emotion Review, 1, 140–150. doi:10.1177/1754073908100439
Riskind, J. H. (1984). They stoop to conquer: Guiding and self-regulatory functions of physical posture after success and failure. Journal of Personality and Social Psychology, 47, 479–493. doi:10.1037//0022-3514.47.3.479
Rodway, P., Wright, L., & Hardie, S. (2003). The valence-specific laterality effect in free viewing conditions: The influence of sex, handedness, and response bias. Brain and Cognition, 53, 452–463. doi:10.1016/S0278-2626(03)00217-3
Rossi-Arnaud, C., Pieroni, L., Spataro, P., & Baddeley, A. (2012). Working memory and individual differences in the encoding of vertical, horizontal and diagonal symmetry. Acta Psychologica, 141, 122–132. doi:10.1016/j.actpsy.2012.06.007
Santiago, J., & Lakens, D. (2015). Can conceptual congruency effects between number, time, and space be accounted for by polarity correspondence? Acta Psychologica, 156, 179–191. doi:10.1016/j.actpsy.2014.09.016
Santiago, J., Ouellet, M., Román, A., & Valenzuela, J. (2012). Attentional factors in conceptual congruency. Cognitive Science, 36, 1051–1077. doi:10.1111/j.1551-6709.2012.01240.x
Schnall, S. (2014). Are there basic metaphors? In M. J. Landau, M. D. Robinson, & B. P. Meier (Eds.), The power of metaphor: Examining its influence on social life (pp. 225–247). Washington, DC: American Psychological Association. doi:10.1037/14278-010
Schubert, T. W. (2005). Your Highness: Vertical positions as perceptual symbols of power. Journal of Personality and Social Psychology, 89, 1–21. doi:10.1037/0022-3514.89.1.1
Schwartz, B. (1981). Vertical classification : A study in structuralism and the sociology of knowledge. Chicago: University of Chicago Press.
Song, H., Vonasch, A. J., Meier, B. P., & Bargh, J. A. (2012). Brighten up: Smiles facilitate perceptual judgment of facial lightness. Journal of Experimental social Psychology, 48, 450–452. doi:10.1016/j.jesp.2011.10.003
Spitz, R. A. (1965). The first year of life: A psychoanalytic study of normal and deviant development of object relations. Oxford: International Universities Press.
Tolaas, J. (1991). Notes on the origin of some spatialization metaphors. Metaphor and Symbolic Activity, 6, 203–218. doi:10.1207/s15327868ms0603_4
Torralbo, A., Santiago, J., & Lupiáñez, J. (2006). Flexible conceptual projection of time onto spatial frames of reference. Cognitive Science, 30, 745–757.
Tversky, B., Kugelmass, S., & Winter, A. (1991). Cross-cultural and developmental trends in graphic productions. Cognitive Psychology, 23, 515–557.
van Sommers, P. (1984). Drawing and cognition: Descriptive and experimental studies of graphic production processes. New York: Cambridge: Cambridge University Press.
Wang, Q., Taylor, H. A., & Brunyé, T. T. (2012). When going the right way is hard to do: Distinct phases of action compatibility in spatial knowledge development. Acta Psychologica, 139, 449–457. doi:10.1016/j.actpsy.2012.01.006
Weger, U. W., Meier, B. P., Robinson, M. D., & Inhoff, A. W. (2007). Things are sounding up: Affective influences on auditory tone perception. Psychonomic Bulletin & Review, 14, 517–521.
Williams, M. A., Moss, S. A., Bradshaw, J. L., & Mattingley, J. B. (2005). Look at me, I’m smiling: Visual search for threatening and nonthreatening facial expressions. Visual Cognition, 12, 29–50. doi:10.1080/13506280444000193
Winter, B. (2014). Horror movies and the cognitive ecology of primary metaphors. Metaphor and Symbol, 29, 151–170. doi:10.1080/10926488.2014.924280
Xie, W., & Zhang, W. (2014). Contributions of cognitive factors in conceptual metaphors. Metaphor and Symbol, 29, 171–184. doi:10.1080/10926488.2014.924282
Acknowledgments
The research of Ljubica Damjanovic was supported partly by a University of Chester International Research Excellence Award, funded under the Santander Universities scheme (SAFS10-SS-LD). Julio Santiago was funded by grants P09-SEJ-4772 (Consejería de Innovación, Ciencia y Empresa, Andalusian Government) and PSI2012-32464 (Spanish Ministry of Economy and Competitivity). Thanks to Elizabeth Dell, April Phillips and Nathan Tindsley who facilitated in collecting the experimental data. We thank Panos Athanasopoulos and Daniel Casasanto for providing helpful feedback on earlier drafts of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Damjanovic, L., Santiago, J. Contrasting vertical and horizontal representations of affect in emotional visual search. Psychon Bull Rev 23, 62–73 (2016). https://doi.org/10.3758/s13423-015-0884-6
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0884-6