
Abstract
The memory effects of semantic attributes (e.g., concreteness, familiarity, valence) have long been studied by manipulating their average perceived intensities, as quantified in word rating norms. The semantic ambiguity hypothesis specifies that the uncertainty as well as the intensity of semantic attributes is processed when words are encoded. Testing that hypothesis requires a normed measure of ambiguity, so that ambiguity and intensity can be manipulated independently. The standard deviation (SD) of intensity ratings has been used for that purpose, which has produced three characteristic ambiguity effects. Owing to the recency of such research, fundamental questions remain about the validity of this method of measuring ambiguity and about its process-level effects on memory. In a validity experiment, we found that the rating SDs of six semantic attributes (arousal, concreteness, familiarity, meaningfulness, negative valence, positive valence) passed tests of concurrent and predictive validity. In three memory experiments, we found that manipulating rating SDs had a specific effect on retrieval: It influenced subjects’ ability to use reconstructive retrieval to recall words. That pattern was predicted by the current theoretical explanation of how ambiguity benefits memory.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The semantic ambiguity hypothesis is the proposal that (a) uncertainty in the perceived intensity of common semantic attributes (e.g., concreteness, familiarity, valence) affects how they are processed as words are encoded, and (b) those processing differences have downstream effects on episodic memory. To study this hypothesis, a standardized method of measuring and manipulating attribute ambiguity is needed. Normed variability in the perceived intensity of semantic attributes has been used for that purpose in recent experimentation. The primary objective of the research that we report here was to resolve two unanswered questions about this method. First, is it valid – that is, is there any independent evidence that it taps the uncertainty of those perceptions? Second, if ambiguity-driven differences in encoding have downstream memory effects, which specific retrieval processes capture those effects?
The semantic ambiguity hypothesis
Published word norms for semantic attributes have been used to study the semantic ambiguity hypothesis. Such norms are widely used tools in the larger memory and cognition literature. That literature contains several such norms, in which thousands of words have been judged for the perceived intensity of specific attributes – with judgments usually being made on unimodal (lower → higher) numerical scales. Published rating norms provide the means (Ms) and standard deviations (SDs) of intensity ratings of individual words. Sixteen examples are displayed in Table 1, along with an illustrative norming project for each attribute.
It has often been found that varying the M intensity ratings of semantic attributes affects the content that people process when they encode words (e.g., Einstein & McDaniel, 1990; Gomes et al., 2013; Henriques & Davidson, 2000; Kounios & Holcomb, 1994), as well as the accuracy of subsequent memory for those words (for reviews, see Bookbinder & Brainerd, 2016; Juhasz, 2005; Kensinger, 2009; Marschark et al., 1987). The semantic ambiguity hypothesis posits that varying the SDs of those same ratings also affects the content that people process when they encode words and the accuracy of subsequent memory (Brainerd, 2018; Brainerd et al., 2021a).
Empirically, we know that not only does an attribute’s perceived intensity differ for different words [e.g., mother has a stronger positive valence than father, Ms = 8.38 and 7.08, respectively, in the Bradley & Lang, 1999 norms], but so does the degree of uncertainty that attaches to those perceptions – even among words whose perceived intensities are the same on average. For instance, the M valence ratings of freedom and talent are the same (7.6 in the Bradley-Lang norms), but people disagree far more in their valence perceptions of freedom than their perceptions of talent (SDs = 2.0 and 1.3, respectively). The hypothesis that such differences affect how people process semantic attributes during encoding is counterintuitive from the perspective of the traditional idea (e.g., Toglia & Battig, 1978) that rating SDs are merely indexes of measurement error (unreliability in the measurement of perceived intensity).
Nevertheless, some early support for this hypothesis can be found in research by Mattek et al. (2017) on perceived valence. Mattek et al. evaluated the prediction that if ambiguity affects how valence is encoded, correlations between M intensity ratings of valence and arousal, which are expected to be high on theoretical grounds (see Kuppens et al., 2013), will be low when valence ambiguity is high. They found that, indeed, such correlations varied dramatically for items whose valence was uncertain versus items that were clearly positive or negative. Brainerd (2018) then used valence rating SDs to measure graded changes in the ambiguity of perceived valence. In emotional word and picture norms, he found that the strength of such valence-arousal correlations declined linearly as rating SDs increased.
The ambiguity hypothesis has been extended by generating further predictions about valence ambiguity and showing that those same predictions hold for other semantic attributes. Two such predictions about valence ambiguity were discussed by Brainerd, et al., (2021a) and then extended to other attributes by Brainerd et al. (2021b). The predictions were that (a) words’ rating SDs should be inverted-U functions of their M intensity ratings for an attribute, and (b) words with higher rating SDs should be easier to remember in recall experiments. Both predictions follow from fuzzy-trace theory’s (FTT) account of how subjects perceive the intensity of semantic attributes (e.g., Brainerd et al., 2017). Concerning the first, FTT posits that ambiguity is low when a word retrieves few attribute features (low intensity) or many features (high intensity) but is high when it retrieves a moderate number (intermediate intensity). Concerning the other prediction, FTT posits that when manipulations make semantic attributes more ambiguous, controlled processing increases, which yields richer and more detailed representations that redound to the benefit of later recall (see also, Bugg, 2014).
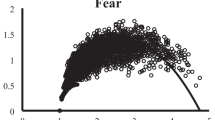
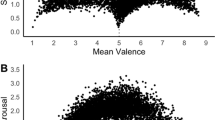
Brainerd et al. (2021a) confirmed both predictions for valence, and Brainerd et al. (2021a) confirmed them for some other semantic attributes. In the latter research, it was found that all 16 attributes in Table 1 exhibited inverted-U relations between M intensity ratings and rating SDs. Those results included various controls that ruled out the possibility that the inverted Us could be artifacts of scale boundary effects (i.e., that variance at the low and high endpoints can only go in one direction, back toward the mean, and hence must be lower than for other scale numbers). Three examples appear in Fig. 1. It was also found that words with higher SDs yielded better recall than words with lower SDs when the M intensity ratings and rating SDs of selected attributes were manipulated factorially.

The present experiments
The current situation with respect to the ambiguity hypothesis is this. On the one hand, rating SDs are known to be psychometrically reliable indexes and three predicted patterns have been detected with them – namely, that inter-attribute correlations of M intensity ratings vary inversely with the size of rating SDs, that rating SDs for individual attributes are inverted-U functions of M intensity ratings, and that recall is more accurate after encoding words with higher rating SDs. On the other hand, two fundamental questions remain about rating SDs as indexes of attribute ambiguity. The first is validity – whether attribute ambiguity is actually what rating SDs measure. That question is the focus of Experiment 1. The other question is exactly how, at the level of specific retrieval processes, higher-SD items improve recall. That question is the focus of Experiments 2–4.
The validity question
The current validity situation is that rating SDs have high face validity as an ambiguity index, but no data have been reported that establish either concurrent validity or predictive validity. Concerning face validity, if the perceived intensity of an attribute (say, valence) is more ambiguous for one word than another (say, for freedom than for talent), people should disagree more in their intensity ratings of the first word than the second (Brainerd, 2018). Psychologically, the attribute features that are retrieved by the first word are less determinative than those that are retrieved by the second, leading to more variability in perceived intensity.
That is merely a conceptual argument, however, which must have empirical consequences if it is true – specifically, evidence of concurrent and predictive validity. With respect to concurrent validity, rating SDs ought to correlate with other variables that have high face validity as measures of attribute ambiguity. With respect to predictive validity, rating SDs ought to correlate with other variables that, according to theory, should be affected by ambiguity. Data on both forms of validity are reported in Experiment 1.
Concurrent and predictive validity tests were conducted at the level of individual words, with data that were averaged across the performance of individual subjects. Concurrent validity was evaluated by having subjects (a) make conventional intensity ratings of six of the attributes in Table 1 and (b) also make numerical ratings of their certainty that these intensity ratings were accurate. The concurrent validity tests evaluated whether the SDs of individual words’ attribute intensity ratings correlated with the M certainty of the words’ intensity ratings. Turning to predictive validity, we measured the latencies of subjects’ attribute intensity ratings of words, as well as the numerical values of the ratings. Because theory posits that increased ambiguity triggers more controlled processing of attribute features, intensity ratings should slow as uncertainty increases. Therefore, the predictive validity tests evaluated whether the SDs of individual words’ attribute intensity ratings correlated with the M latencies of the words’ intensity ratings.
The retrieval process question
Of the three predictions that have been tested for rating SDs, the most counterintuitive one is that recall is more accurate when rating SDs are higher than when they are lower. That is because SDs should have the opposite effect under the traditional assumption that measurement error increases as SDs increase, that intensity perceptions with higher SDs are inherently noisier than perceptions with lower SDs. For instance, Pollock (2018) and Neath and Surprenant (2020) tested the hypothesis that data showing that words with higher M concreteness intensity ratings yield better recall than words with lower M intensity ratings were SD artifacts – specifically, were due to high-concreteness words having lower rating SDs than low-concreteness words. Neither study confirmed that hypothesis. In other experiments in which M intensity and rating SDs were factorially manipulated for categorization, concreteness, meaningfulness, negative valence, and positive valence, recall was better when SDs were higher (Brainerd et al. 2021a, b).
The working explanation of the beneficial effects of higher SDs on recall is that the encoding of a word’s semantic content becomes more controlled and thorough as an attribute’s perceived intensity becomes more ambiguous. Brainerd et al. (2021b) noted that this hypothesis makes an obvious prediction that follows from prior research in which controlled processing has been encouraged by various manipulations (e.g., increased encoding time; Smith & Kimball, 2012). A well-known finding is that such manipulations enhance later recall, which means that they must enhance some of the retrieval operations that support recall. Which ones?
Here, we note, first, that a variety of evidence suggests that recall is supported by two distinct retrieval operations, direct verbatim access and reconstruction, plus a slave familiarity process (for a review, see Brainerd et al., 2009). To elaborate, subjects recall words by either (a) using direct access to recover literal verbatim traces of their presentation or (b) reconstructing them from gist traces of their semantic content. In the latter case, items that are recovered via reconstruction are subjected to familiarity checks before they are read out on recall tests. If higher rating SDs trigger more thorough encoding of semantic attributes, they ought to enhance recall by improving reconstructive retrieval because reconstruction is focused on semantic content. This prediction was evaluated in Experiments 2–4.
Experiment 1
This was a norming experiment that was focused on the validity question. We used published norms for arousal, concreteness, familiarity, meaningfulness, negative valence, and positive valence to sample pools of words for these attributes. Half the words in each pool had received high M ratings on the target attribute and half had received low M ratings. Half the words in the high and low M rating groups had high-rating SDs and half had low-rating SDs. Within individual experimental conditions, subjects rated all the words in three of the six pools for the intensity of their respective attributes on a lower → higher numerical scale.
To test concurrent validity, our subjects also judged the certainty that their intensity ratings of each of the six attributes were accurate on a lower → higher numerical scale. Words’ M certainty ratings should be inversely related to the SDs of the words’ intensity ratings, if the latter are valid measures of attribute ambiguity. To evaluate predictive validity, we measured the latencies of our subjects’ attribute intensity ratings and certainty ratings. The M latency of words’ intensity ratings and of words’ certainty ratings should both be positively related to the SDs of words’ intensity ratings, if the latter are valid measures of attribute ambiguity.
Method
Subjects
This experiment was conducted over two academic semesters. The subjects were 85 undergraduates who participated to fulfill a course requirement. They received course credits for participation. Individual subjects were randomly assigned to 19 experimental conditions, in which they rated three randomly selected word pools that had been sampled from a larger set of six word pools. The individual words in each word pool were rated by an average of 43 subjects, which is comparable to the numbers of subjects who rated individual words in the Toglia and Battig (1978) norms and 30% larger than the numbers of subjects who rated individual words in the Scott et al. (2019) norms. The complete norming data for all attributes and measures appear in the Appendix.
Materials
The materials consisted of six pools of 120 words, each of which was rated for the perceived intensity of a target attribute. The words in the first pool were selected from the Scott et al. (2019) arousal norms, and they represented a broad range of intensities (Ms ranged from 2.5 to 7.1) and ambiguities (SDs ranged from 1.6 to 3.2). The words in the second pool were selected from the Scott et al. (2019) concreteness norms, and they represented a broad range of intensities (Ms ranged from 2.2 to 6.8) and ambiguities (SDs ranged from 0.7 to 2.3). The words in the third pool were selected from the Scott et al. (2019) familiarity norms, and they represented a broad range of intensities (Ms ranged from 2.5 to 6.7) and ambiguities (SDs ranged from 0.8 to 2.4). The words in the fourth pool were selected from the Toglia and Battig (1978) meaningfulness norms, and they represented a broad range of intensities (Ms ranged from 1.4 to 5.1) and ambiguities (SDs ranged from 1.5 to 2.3). The words in the fifth pool were selected from the Scott et al. (2019) valence norms, and they represented a broad range of negative intensities (Ms ranged from 1.4 to 5) and ambiguities (SDs ranged from 0.8 to 2.2). The words in the sixth pool were selected from the Scott et al. (2019) valence norms, and they represented a broad range of positive intensities (Ms ranged from 5 to 8.4) and ambiguities (SDs ranged from .9 to 2.4).
Procedure
Except for the specific rated attributes, the procedure was the same for all 19 conditions. First, the subject received instructions about the nature of the experiment – that he or she would be rating three pools of words and that each pool would be rated for one of three semantic attributes. Next, the subject received instructions about how to make ratings for one of six attributes (arousal, concreteness, familiarity, meaningfulness, negative valence, or positive valence). The rating instructions for meaningfulness were drawn from the Toglia and Battig (1978) norms, and the rating instructions for the other five attributes were drawn from the Scott et al. (2019) norms.
Following the first set of instructions, the items in the first pool were rated for the target attribute. Each word was centered on the computer screen and printed in 36-pt black font. The subject then rated the words for one of the six attributes. All ratings were self-paced. Two ratings were made for each word. First, the strength of the target attribute was rated (e.g., how arousing the word was, how concrete it was) by clicking a number between 1 and 7 on a scale that appeared below the word (from 1 = extremely low to 7 = extremely high). After the subject chose a number, the strength rating was cleared from the screen. Second, the subject rated his or her certainty that the word’s strength rating was accurate by checking a number between 1 and 7 on a lower ⟶ higher rating scale (from 1 = not at all certain to 7 = extremely certain). Following the certainty judgment, the screen cleared, and the next word was presented for strength and certainty ratings. The latencies as well as the numerical responses were recorded for both judgments.
After the strength and certainty judgments for the words in the first randomly selected pool, the instructions about how to make ratings for the second attribute were presented. The subject then made strength and certainty ratings of the 120 words in the second pool. After the subject had completed all the words in the second pool, the instructions about how to make ratings for the final attribute were presented, followed by strength and certainty ratings of the 120 words in the third pool.
The complete norms for each word in each of the six pools that were generated by this procedure appear in the Appendix. The norms for the words in the arousal and concreteness pools appear in Appendix Table 8. The norms for the words in the familiarity and meaningfulness pools appear in Appendix Table 9. The norms for the words in the positive and negative valence pools appear in Appendix Table 10.
Results
In the first subsection below, as a manipulation check, we consider whether the rating SDs for these six attributes behaved in the manner that rating SDs in published norms are known to behave. The results that bear on the concurrent and predictive validity of attribute rating SDs are reported in the second subsection.
Quadratic relations between M ratings and rating SDs
We saw that rating SDs in published norms are inverted-U functions of M intensities; that is, functions of the form SD = aM2 + bM + c, whose first derivatives are negative when they are maximized (which occurs when a < 0 and b > 0). The results in Table 2 reveal this same pattern in the present experiment. First, note that a < 0 and b > 0 for all six attributes, so that all the functions are inverted Us. Second, note the values of the fit statistics in the r2Q, r2L, and r2C columns. When rating SDs are regressed on M ratings, these are the proportions of variance accounted for by the general quadratic equation (r2Q), by the model that is one step simpler (r2L for the general linear equation), and by the model that is one step more complex (r2C for the general cubic equation). To conclude that SD = f(M) is quadratic, it must be found that r2Q is significantly larger than r2L, but that r2Q does not differ significantly from r2C. This is exactly the pattern for the six attributes in Table 2. Over the six attributes, the mean values of r2Q, r2L, and r2C were .53, .25, and .54, respectively.
As in our prior studies of M-SD functions, we conducted three supplementary analyses to ensure that the results in Table 2 were not artifacts of certain boundary effects (see Brainerd et al. 2021a) that are possible with numerical rating scales – namely, situations in which the bulk of the ratings pile up at the high and low endpoints (ceiling and floor effects), where variance is lower because it can only move in one direction (back toward the mean). First, we generated the frequency distributions for the intensity ratings of the six attributes. Those distributions produced no evidence of either ceiling or floor effects for any of the attributes. Second, we refit all the linear, quadratic, and cubic functions in Table 2 using a data transformation of the raw Ms and SDs that eliminates boundary effects (arcsine). The refits of the transformed data produced the same patterns as before – for each attribute, the quadratic fit still accounted for significantly more variance than the corresponding linear fit, and the cubic fit still did not account for significantly more variance than the quadratic fit. Finally, we refit the functions in Table 2 using only the data of words whose M intensities were well above the low boundary (Ms ≥ 3) and well below the upper boundary (Ms < 6). Those refits also produced the same patterns as in Table 2.
Validity
First, we report descriptive statistics for three variables that figured in the validity analyses: the SDs of the intensity ratings of the six attributes, the mean latencies of the intensity ratings, and the means of the certainty ratings of the intensity ratings. Those results appear in Table 3. Visual inspection reveals differences among the six attributes on each of the three variables, and one-way analyses of variance (ANOVAs) established that the differences were significant for each variable. For rating SDs, F(5, 595) = 23.25, MSE = .07, ηp2 = .16, p < .001, for M intensity rating latency, F(5, 595) = 132.27, MSE = .09, ηp2 = .53, p < .001, and for M certainty rating, F(5, 595) = 135.71, MSE = .137, ηp2 = .53, p < .001. Post hoc tests indicated that the magnitude orderings were: (a) concreteness < familiarity = positive valence = meaningfulness < negative valence = arousal for rating SDs; (b) familiarity < arousal = positive valence < negative valence < meaningfulness = concreteness for M rating latencies; and (c) meaningfulness < negative valence = positive valence < arousal = concreteness < familiarity for M certainty ratings. It must be remembered that subjects rated different word pools for each attribute. Hence, the differences among the attributes in rating SDs, M intensity rating latencies, and M certainty ratings cannot be interpreted as inherent attribute differences in any of the three variables. Rather, the data in Table 3 should be viewed as descriptive results for each attribute that may suggest psychometric explanations of some of the validity findings.
We report two sets of validity results, one for concurrent validity and the other for predictive validity. The concurrent validity question asks whether the SDs of attribute intensity ratings of individual words are correlated with a direct, intuitive measure of the ambiguities of those ratings: the M certainty that subjects express about their intensity ratings of each word. The relevant attenuation-corrected validity coefficients appear in the first column of Table 4 for arousal, concreteness, familiarity, meaningfulness, negative valence, and positive valence. To begin, consider the coefficients for concreteness and familiarity. For these attributes, both concurrent validity coefficients are virtually perfect, and thus, there was extremely strong support for the hypothesis that the subjective certainty that their intensity ratings are correct declines as those ratings become more variable. For the six attributes as a group, all the concurrent validity coefficients were statistically reliable. The mean value of the six coefficients was .66, which is a moderately strong relation in the language of correlations. Thus, the SDs of intensity ratings passed concurrent validity tests because rating SDs increased reliably as the judged uncertainty of intensity ratings increased.
Turning to predictive validity, the question is whether the intensity rating SDs of individual words forecasts the words’ M values for other variables that theory expects that they should predict. Here, theory makes a pair of predictions (Brainerd et al., 2021b). The first falls out of the working explanation of why recall is better for words with higher rating SDs, which is that such words trigger more thorough and detailed encoding. On the hypothesis that thorough encoding requires more time than superficial encoding, rating SDs ought to predict the M latencies of intensity ratings. The other prediction is concerned with the certainty judgments that subjects made about their intensity ratings. If rating SDs and M certainty ratings are both measuring ambiguity, M certainty ratings should also predict the M latencies of intensity ratings. The results for the two forms of predictive validity appear in the second and third columns of Table 4.
Taking SD-latency first, consider the validity coefficients for concreteness and familiarity –two attributes for which concurrent validity was especially high. Strong positive correlations would be expected, and they were observed, with the average value being .94. For the other four attributes, all the validity coefficients were reliable and positive, with a mean value of .48.
Continuing to M certainty ratings, consider the validity coefficients for concreteness and familiarity first, as before. Strong negative correlations would be expected (greater certainty = shorter latencies), and they were observed, with both being nearly perfect. For the other four attributes, the general picture was one of stronger predictive validity correlations for M certainty than for rating SDs. In fact, all the predictive validity coefficients in the third column are larger than the corresponding ones in the second column, except for familiarity.
A cautionary comment about the predictive validity results is in order. As the coefficients in the third column of Table 4 are larger than those in the second column, it is tempting to entertain theoretical interpretations of that difference, such as positing that certainty judgments somehow tap attribute ambiguity more directly than rating SDs. Any such hypothesis would be speculative, however, because our experiments did not include procedures to measure the relative sensitivity of different indexes of attribute ambiguity.
Experiments 2–4
In prior experimentation, increases in attribute rating SDs have produced improvements in recall for multiple attributes when their rating SDs and M intensity ratings were manipulated factorially. The exact reason is unclear. The working explanation is that increases in ambiguity trigger more thorough, detailed encoding of attribute features (Brainerd, et al., 2021a), which receives direct support from the finding (Table 4) that intensity rating latencies are longer when intensity levels are more uncertain (higher rating SDs). To improve recall, however, that encoding effect must translate into downstream effects on specific retrieval processes. Our aim in Experiments 2–4 was to identify those retrieval processes.
We mentioned earlier that because attribute ambiguity is concerned with semantic features, retrieval operations that process semantic content, reconstruction in particular, should be affected by ambiguity-driven enhancements in encoding. To evaluate that possibility, it is necessary to separate reconstructive retrieval from retrieval operations that process literal verbatim content. Modeling techniques that accomplish this are available for both recognition (see Abadie et al., 2013; Abadie & Camos, 2019; Greene et al., in press; Greene & Naveh-Benjamin, 2020, 2021; Lampinen et al., 2005; Lampinen & Odegard, 2006; Niedzialkowska & Nieznański, in press; Nieznański & Obidzinski, 2019; Singer & Remillard, 2008; Singer & Spear, 2015) and recall (see Barnhardt et al., 2006; Bouwmeester & Verkoeijen, 2011; Bruer & Pozzulo, 2014; Marche et al., 2016; Palmer & Dodson, 2009; Storbeck & Clore, 2005; Tractenberg et al., 2015).
Returning to the working explanation of ambiguity-driven improvements in recall, the explanation obviously predicts that these improvements should be tied to enhanced reconstructive retrieval. This prediction is easily tested with the dual-retrieval model (Gomes et al., 2014; Tractenberg et al., 2015), which was developed to secure separate estimates of reconstruction, direct verbatim access, and familiarity judgment for recall. It supplies maximum likelihood estimates of the six retrieval parameters in Table 5 for free, cued, and serial recall data.
Two parameters measure successful reconstruction (R1 and R2), two measure successful verbatim access (D1 and D2), and two measure successful familiarity judgment (J1 and J2). In prior experiments with this model, classic semantic manipulations (e.g., deep vs. shallow encoding instructions, large vs. small numbers of category exemplars, subjects with normal vs. impaired meaning comprehension) have affected the reconstruction parameters, whereas classic item distinctiveness manipulations (e.g., full vs. divided attention, shorter vs. longer lists, familiar vs. unusual fonts) have affected the direct access parameters (for a review, see Gomes et al., 2014). Consequently, if semantic content is encoded more thoroughly as attribute ambiguity increases, the values of one or both reconstruction parameters ought to be larger for words with higher rating SDs than for words with lower SDs. This effect might spill over to the direct access or familiarity judgment parameters, too, but the key prediction is that one or both reconstruction parameters ought to be affected if the working explanation is correct.
We evaluated this prediction in three experiments in which attribute ambiguity and attribute intensity were manipulated factorially. They followed the multi-trial methodology that has been previously used to identify memory effects of attribute ambiguity. This multi-trial procedure is required to implement the dual-retrieval model. As the model contains six parameters, experiments with three separate trials are the minimum designs that generate sufficient degrees of freedom to estimate all the parameters and compute goodness-of-fit tests (see Brainerd et al., 2009).
In Experiment 2, the target attribute was meaningfulness. Subjects learned to recall lists of words on which the items were high or low in normed values of SDs for meaningfulness intensity ratings and were high or low in normed values of the Ms of those ratings. We located two previously reported experiments of the same type that had produced robust ambiguity effects for two other attributes (categorization and concreteness) but had not been analyzed with the dual-retrieval model. We conducted a retrospective modeling analysis of those studies (Experiments 3 and 4) so that any conclusions about the retrieval effects of attribute ambiguity would cut across multiple attributes and be grounded in a large amount of data.
Our focus in Experiments 2–4 was squarely on using the dual-retrieval model to explain how ambiguity enhances recall by pinpointing its retrieval locus. A secondary objective was to determine whether that locus was the same as the corresponding one for the effects of attribute intensity. It is sensible that it should be, for two reasons. First, as noted, it has been previously reported for attributes such as concreteness and imagery that variations in attribute intensity affect reconstructive retrieval. Second, for any specific attribute, variations in intensity and ambiguity involve variations in the same semantic features.
Method
Subjects
The subjects in Experiment 2 were a sample of 72 undergraduates, the subjects in Experiment 3 were an independent sample of 68 undergraduates, and the subjects in Experiment 4 were an independent sample of 83 undergraduates. The experiments were conducted during four semesters over two academic years. The subjects in all experiments participated to fulfill course requirements. Power analyses that relied on data from past experiments with this paradigm (Brainerd, et al., 2021a) indicated that a sample size of 65 would provide a > .80 probability of detecting all main effects and interactions at the .05 level. However, we tested all additional subjects who volunteered for individual experiments – hence, the somewhat different sample sizes.
Materials
In Experiment 2, the materials were word lists sampled from a pool of words that had been derived from the Toglia and Battig (1978) semantic word norms, in which meaningfulness was rated on a 1–7 scale for 2,852 words. The pool of words from which the items on the lists that were administered to individual subjects were sampled was constructed in such a way that their meaningfulness ambiguities varied from high to low and their meaningfulness intensities varied from high to low. Each subject studied and recalled two lists of 36 words (nine high ambiguity/high intensity, nine high ambiguity/low intensity, nine low ambiguity/high intensity, and nine low ambiguity/low intensity). Thus, each list that was administered to individual subjects had a 2 (meaningfulness ambiguity: high vs. low) × 2 (meaningfulness intensity: high vs. low) factorial structure. Over lists, items’ mean intensities were MI = 8.8 (high) and 4.6 (low), and their mean ambiguities were MA = 4.1 (high) and 2.7 (low). Each list was composed of 36 words, and the differences between the high and low MAs and the high and low MIs over the lists were highly reliable (all ps < .0001 by t tests). The differences in MAs and MIs were uncorrelated; that is, the high and low MA conditions did not differ reliably in MIs, and conversely.
In Experiment 3, the word lists that were administered to individual subjects were constructed in the same way, using the Toglia and Battig (1978) norms, except that the word pool from which they were sampled was derived from subjects’ ratings of concreteness. Thus, each subject studied and recalled two lists of 36 words, for which the list design was 2 (concreteness ambiguity: high vs. low) × 2 (concreteness intensity: high vs. low). Over lists, the mean intensities were MI = 5.3 (high) and 3.1 (low), and the mean ambiguities were MA = 2.2 (high) and 1.6 (low) on the 1–7 concreteness scale. The intensity and ambiguity differences were highly reliable (all ps < .001 by t tests), and the differences were uncorrelated.
In Experiment 4, the word lists that were administered to individual subjects were constructed in the same way, using the Toglia and Battig (1978) norms, except the word pool from which they were sampled was based on subjects’ ratings of categorization. Thus, each subject studied and recalled two lists of 36 words, for which the list design was 2 (categorization ambiguity: high vs. low) × 2 (categorization intensity: high vs. low). Over lists, the mean intensities were MI = 5.5 (high) and 3.1 (low), and the mean ambiguities were MA = 2.0 (high) and 1.6 (low) on the 1–7 categorization SD scale. The intensity and ambiguity differences were highly reliable (all ps < .0001 by t tests), and the differences were uncorrelated.
A final consideration about the materials is a point that Pollock (2018) raised in connection with word lists that have been used to manipulate M intensity in prior studies of the concreteness attribute. Pollock listed five linguistic variables that tended to be correlated with M intensity differences in those experiments and, hence, might have produced the observed memory effects: word frequency, age of acquisition, number of phonemes, word length, and number of syllables. Neath and Surprenant (2020 , Experiment 1) controlled all these variables in a recall study in which concreteness rating SDs and M concreteness ratings were manipulated factorially. Recall was not affected by either rating SDs or M ratings. Consequently, we analyze the word pools for our three experiments for each of the above linguistic variables, using WordMine2 (Durda & Buchanan, 2006). We found that these five variables were not reliable predictors of differences in words ambiguity or intensity ratings. In each experiment, we tested the null hypotheses that this set of variables did not differ reliably for words with high versus low attribute ambiguity scores and did not differ reliably for words with high versus low attribute intensity scores. In each case, the core analysis was a 2 (attribute ambiguity: high vs. low ambiguity words) × 2 (attribute intensity: high vs. low intensity words) × 5 (linguistic variables: age of acquisition, frequency, length, number of phonemes, number of syllables) mixed ANOVA. The main effect for attribute ambiguity tested the first null hypothesis, and the main effect for attribute intensity tested the second. Neither of those main effects was significant in any of the three experiments. The statistical details of these analyses can be found in Appendix Tables 11 and 12.
Procedure
The free-recall procedure was the same for all three experiments. The subject first read instructions on the computer screen, which explained the multi-trial procedure. The instructions stated that the subject would participate in a series of trials in which a word list would be studied and recalled, and would then participate in a second series of trials in which a second word list would be studied and recalled. Next, the subject participated in the first phase of the experiment, which consisted of three study-buffer-test trials on List 1. This was followed by a second phase in which three study-buffer-test trials on List 2 were administered. During the first phase, the study cycle of each trial consisted of presenting the 36 words individually on the screen, with the subject being instructed to read the words silently as they were presented. Individual words were presented in random order at a 3-s rate, centered in 36-pt black font. After the last word had been presented, the subject performed a 45-s buffer task, which consisted of typing answers to simple arithmetic problems that appeared on the screen. The buffer task was followed by a 1-min free-recall test. The subject was instructed to type as many words as could be remembered from the list in any order. The subject was also told that accurate spelling was not required for responses to be counted as correct. Misspellings were rare, and when they occurred, it was obvious that they referred to one of the words on this list. After the first recall test was completed, the second trial of study-buffer-test began. The procedure for the second trial was identical to the procedure for the first trial. After the second recall test was completed, the third trial of study-buffer-test began, and it followed the same procedure as the first two trials.
Following the third recall test, there was a 1-min rest period before the second phase of the experiment. The second phase began with instructions that explained the upcoming procedure. The subject then participated in three trials of study-buffer-test on List 2. The procedure for these three trials was identical to the procedure for the three trials of the first phase.
Results
Principal interest attaches to the dual-retrieval analyses, rather than the usual descriptive findings. However, we begin with a brief synopsis of such findings, simply to determine whether the effects of ambiguity and intensity on raw recall were robust across attributes. In all the results reported below, the dependent variable was correct free recall.
Descriptive results
Figure 2 provides an overall picture of the recall effects of ambiguity and intensity on Trials 1–3 for meaningfulness, concreteness, and categorization. The plotted points are for the pooled data of List 1 and List 2, as performance on the two lists did not differ appreciably. Panels A, C, and E on the left side of Fig. 2 depict the ambiguity effects for meaningfulness, concreteness, and categorization, respectively. It is obvious at a glance that recall was better when attribute ambiguity was high than when it was low, on all three trials and regardless of attribute. Panels B, D, and F on the right side depict the corresponding intensity effects for these attributes. Except for Trial 1 in Panel B, it can be seen that recall was better when attribute intensity was high than when it was low, on all trials for all attributes.

Memory effects of meaningfulness ambiguity (Panel A), meaningfulness intensity (Panel B), concreteness ambiguity (Panel C), concreteness intensity (Panel D), categorization ambiguity (Panel E), and categorization intensity (Panel F)
Turning to statistical tests of these patterns, we computed a 2 (attribute ambiguity: high vs. low) × 2 (attribute intensity: high vs. low) × 3 (trial: 1, 2, 3) ANOVA of the proportions of correct recall in each experiment, for the pooled data of Lists 1 and 2. The results were consistent with the patterns in Fig. 2. In Experiment 2, there were main effects for meaningfulness ambiguity, F(1, 71) = 24.21, MSE = .03, ηp2 = .25, p < .001, meaningfulness intensity, F(1, 71) = 8.98, MSE = .03, ηp2 = .11, p < .004, and trial, F(2, 142) = 188.67, MSE = .02, ηp2 = .73, p < .001. The ambiguity and intensity factors did not interact, but there was a small Intensity × Trial interaction, F(2, 142) = 4.23, MSE = .01, ηp2 = .06, p < .01. Post hoc analysis revealed what is obvious in Fig. 2: The meaningfulness intensity effect was larger on Trials 2 and 3 than on Trial 1, and indeed, the intensity effect was not reliable on Trial 1. Turning to Experiment 3, there were main effects for concreteness ambiguity, F(1, 67) = 93.64, MSE = .02, ηp2 = .58, p < .001, concreteness intensity, F(1, 67) = 83.39, MSE = .03, ηp2 = .55, p < .0001, and trial, F(2, 134) = 575.39, MSE = .01, ηp2 = .90, p < .001. There was no Ambiguity × Intensity interaction, and neither attribute factor interacted with the trial factor. Last, for Experiment 4, there was a main effect for categorization ambiguity, F(1, 82) = 44.15, MSE = .02, ηp2 = .35, p < .001, a main effect for categorization intensity, F(1, 82) = 66.66, MSE = .02, ηp2 = .45, p < .001, and a main effect for trial, F(2, 156) = 216.33, MSE = .03, ηp2 = .73, p < .001. There was also an Ambiguity × Intensity interaction, F(1, 82) = 18.82, MSE = .02, ηp2 = .19, p < .001. Post hoc tests indicated that the ambiguity effect was larger when intensity was low than when it was high, but it was reliable at both intensity levels.
Dual-retrieval model
The results of principal interest involved fitting the dual-retrieval model to the data of these experiments and estimating its parameters for the various conditions. Statistical procedures for this model are provided in Gomes et al. (2014). Briefly, the following steps are involved in fitting the model in Table 5 to the data of all the conditions of an experiment. The individual words on each list that the subjects learned to recall generate a data space with eight distinct patterns of errors and successes: C1C2C3, C1C2E3, …, E1E2E3, where Ci denotes a correct recall on the ith test,, and Ei denotes an error. When probabilities are attached to these patterns, there are seven independent probabilities for each of the four conditions of each experiment (2 levels of attribute ambiguity × 2 of attribute intensity). This means that the model in Table 5 is fit to the data of each condition with one degree of freedom: There are seven free probabilities in the data space versus six probabilities (parameters) in the model.
The fit test runs as follows. The likelihood of the data is estimated with all probabilities free to vary, and then it is re-estimated with only the model’s parameters free to vary. Twice the negative natural log of the ratio of these likelihoods is a G2(1) statistic with a critical value of 3.84 to reject the null hypothesis that the model fits the target data. If this null hypothesis cannot be rejected for the conditions of an experiment, the model’s parameters are then estimated and can be compared to determine if they differ reliably between conditions. These between-condition significance tests for parameters also involve computing a pair of likelihoods – one in which all the model’s parameters are completely free to vary in both target conditions and a second in which one of the model’s parameters is constrained to be equal in the two conditions. The likelihood ratio statistics is G2(1), with a 3.84 critical value to reject the null hypothesis that the parameter has the same value in the two conditions.
First, we computed the model fit tests for the conditions of these experiments, using the 2 (attribute ambiguity) × 2 (attribute intensity) factorial structure pooled over the three trials as the four conditions of each experiment. The mean values of the four G2(1) fit tests for each experiment were 2.02 (Experiment 2, meaningfulness), 3.38 (Experiment 3, concreteness), and .56 (Experiment 4, categorization). As a value of 3.84 is required to reject the null hypothesis of fit, this hypothesis could not be rejected in any of the experiments, and hence, we estimated the retrieval parameters for the four list conditions for each of the experiments. The results are shown in Table 6. There, the parameter values are organized by retrieval process, with the values for direct verbatim access blocked in columns 1 and 2, the values for reconstruction blocked in columns 3 and 4, and the values for familiarity judgment blocked in columns 5 and 6.
The focal question is where, at the level of retrieval processes, the effects of attribute ambiguity are localized – reconstruction, direct verbatim access, or familiarity judgment. Recall that our working explanation predicts that it will be a reconstruction effect; that it will be easier to learn how to reconstruct list items from their semantic content when rating SDs are high than when they are low because attribute features are more thoroughly processed for high-SD items. Scanning down the paired columns in Table 6, a consistent finding was that ambiguity affected reconstructive retrieval – specifically, the R1 parameter, which measures the proportion of items that can be reconstructed after the first study cycle. Over the three attributes, that proportion was .37 when rating SDs were high and .27 when they were low, a highly reliable difference. Attribute ambiguity did not have a reliable effect on R2, which measures the proportion of items that can be reconstructed after two or more study cycles.
These results yield a simple account of how attribute ambiguity enhances recall. Prior research on the dual-retrieval model indicates that words differ substantially in how easy it is to learn to reconstruct them from their semantic features on recall tests. For some, a single study trial is all that is needed to learn a search algorithm that will reconstruct them, whereas others require multiple trials. The two reconstruction parameters are sensitive to this difference: R1 can be interpreted as the proportion of list items that are easier to learn how to reconstruct, and R2 can be interpreted as the proportion that are harder to learn to reconstruct (Brainerd et al., 2014). (Some items can never be reconstructed, and that proportion is 1 – R1 - (1- R1)R2 - (1- R1)(1-R2)R2 in these experiments.) Thus, the primary effect of the ambiguity manipulation in all these experiments was to enlarge the subset of easier-to-reconstruct items, while not affecting the subset of harder-to-reconstruct items. Based on the grand means of R1 for these experiments, the easier-to-reconstruct subset was more than one-third larger when rating SDs were high, relative to when they were low.
Attribute ambiguity also produced some reliable effects on other retrieval processes, but they were not consistent across experiments. With respect to direct verbatim access, ambiguity affected one of the two D parameters for both concreteness and categorization but not the same one, and it did not affect either D parameter for meaningfulness. With respect to familiarity judgment, ambiguity affected one of the two J parameters for concreteness, but it did not affect either of them for meaningfulness or categorization.
Turning to attribute intensity, because differences in M intensity ratings are concerned with the same semantic features as differences in rating SDs, the theoretical expectation is that the retrieval loci of their effects should be similar. That assumption proved to be correct. Intensity consistently affected reconstructive retrieval – in particular, high intensity increased R1 but not R2, relative to low intensity, for all three attributes. Theoretically, then, attribute intensity also increases the subset of easier-to-reconstruct items without affecting the subset of harder-to-reconstruct items. This similar retrieval effect for intensity could not have been due to correlations between the M intensity and rating SD manipulations because, as mentioned, they were uncorrelated in the lists that were administered in these experiments. Also similar to ambiguity, intensity did not produce consistent effects for direct verbatim access or familiarity judgment. With respect to the D parameters, D2 was significantly larger for high-intensity items in two of the experiments but not in the third. With respect to the J parameters, intensity had a reliable effect on J1 in Experiment 2 and a reliable effect on J2 in Experiment 3, but the effects ran in opposite directions.
Summing up, the dual-retrieval analyses converge on the conclusion that the ambiguity of these three semantic attributes affects reconstructive retrieval, and it does so in a specific way.
When one increases normed values of the ambiguity of attributes’ perceived intensity, the total number of items that can be reconstructed increases. Moreover, this increase occurs because the size of the subset of easier-to-reconstruct items expands while the size of the subset of harder-to-reconstruct items remains invariant.
By way of qualification, it should be noted that all the ambiguity and intensity effects that were observed in Experiments 2–4 were detected in mixed-list designs. In the literature, there is an established pattern in which various list manipulations are more likely to produce memory effects with mixed-list designs than with pure-list designs (see Gomes et al., 2013, for a discussion of this point in connection with valence). Therefore, it remains to be seen whether the ambiguity and intensity effects that we reported will also be detected in pure-list experiments.
General discussion
Rating norms for words’ semantic attributes have been used to manipulate the types of meaning that subjects encode in a wide range of memory paradigms. Those manipulations have centered on varying attributes’ average perceived intensities, as indexed by words’ M intensity ratings (e.g., Citron et al., 2014; Mikels et al. 2005a; Mikels et al. 2005b). It is well established that such intensity manipulations produce robust memory effects for attributes such as arousal, concreteness, familiarity, and valence. Recently, evidence has accumulated that a second property, the level of ambiguity that attaches to attributes’ perceived intensity, produces separate memory effects. However, some fundamental questions remain about the normed quantity that is used to manipulate ambiguity (rating SDs). We investigated two of them: Is this quantity a valid measure of ambiguity? Which retrieval processes are affected when this quantity is varied?
The validity question was investigated for six attributes that have long histories in the memory literature (arousal, concreteness, familiarity, meaningfulness, negative valence, and positive valence). We normed separate word pools for these attributes in the traditional way, using lower → higher intensity rating scales, and subjects also rated their degree of certainty that words’ intensity ratings were accurate. In addition, we normed these word pools for the latencies of words’ intensity ratings. Those norms are provided in the Appendix.
We computed concurrent validity correlations between words’ rating SDs and the M certainty of words’ intensity ratings. To provide further evidence of validity, we computed predictive validity correlations between words’ rating SDs and the M latencies of words’ intensity ratings. We also computed predictive validity correlations between the M certainty of words’ intensity ratings and the M latencies of words’ intensity ratings. All those results converged on the conclusion that attribute rating SDs measure the ambiguity of attributes’ perceived intensities.
Next, we investigated the retrieval question in recall experiments with three different semantic attributes. We used the data of experiments in which the rating SDs and M ratings of those attributes were manipulated factorially to pinpoint the retrieval loci of ambiguity’s effects on recall and compare them to the retrieval loci of intensity’s effects. The high-low SD manipulation had a specific retrieval effect across all attributes: The pool of items that subjects learned to reconstruct was roughly one-third larger when their rating SDs were high rather than low. That pattern was predicted by the working explanation of why ambiguity enhances recall, which posits that uncertainty about attribute intensity triggers more thorough encoding of words’ semantic features. Importantly, the retrieval locus of the effects of the high-low intensity manipulation was the same as that of the high-low ambiguity manipulation, which also was anticipated on theoretical grounds. However, the two manipulations did not interact in two of the three experiments.
In closing, an important remaining question is concerned with conceptual differences between attribute ambiguity and more traditional notions of ambiguity. Customarily, we say that a word is ambiguous when (a) its meaning is unfamiliar, or (b) we know that it has multiple salient meanings. For example, most people are not aware that insouciant means indifferent and moiety means half, but most people know that toast has two salient meanings (bread, speech) and so does bank (money, river). Both these forms of uncertainty are concerned with a word’s semantic content as a whole, whereas attribute ambiguity is a componential form of uncertainty that targets a specific property (intensity) of a specific semantic attribute (e.g., concreteness, valence). Attribute ambiguity can be present at high levels notwithstanding that a word is familiar and that it does not have multiple salient meanings. For instance, angel, gravity, unicorn, and vampire are all familiar and none has multiple salient meanings, but the uncertainty of their perceived concreteness levels is very high (all rating SDs > 2 on a 7-point rating scale).
Although attribute ambiguity is conceptually distinct from these traditional forms of ambiguity, it might be strongly correlated with them. Indeed, a plausible hypothesis is that uncertainty about a word’s meaning, either because it is unfamiliar or it has multiple meanings, would drive up uncertainty about the intensity of specific semantic attributes and, thus, produce strong correlations between their respective measures. This hypothesis leads to two obvious predictions that can be used to test it. The first is that words’ overall familiarity levels will be well correlated with words’ rating SDs for individual semantic attributes. The second is that relative to words that do not have multiple meanings, words that do (toast, bank) should display elevated rating SDs for individual semantic attributes. We tested both these predictions, and neither proved to be accurate.
The first prediction was evaluated by correlating attribute rating SDs with word familiarity measures, using published attribute rating norms. Two intuitive measures of word familiarity are available to conduct such tests: (a) familiarity ratings of words on lower → higher scales and (b) word frequencies in printed text and spoken language. The most extensive sources of evidence on both measures are the Toglia and Battig (1978) and Scott et al. (2019) norms, in which subjects rated familiarity and several other attributes for thousands of words. We added word frequencies to both norms, using the Wordmine2 database (Durda & Buchanan, 2006). We computed the predictive validity correlations between each of the familiarity measures and the rating SDs of six attributes in the Toglia-Battig norms and the rating SDs of eight other attributes in the Scott et al norms. The results appear in Table 7.
These validity correlations do not provide support for the notion that attribute ambiguity increases as words’ meanings become more unfamiliar. If that were true, the coefficients would be large and negative; instead, they are mostly very small, accounting for an average of 1% of the variance. Further, one-third of them are positive, with the two strongest ones (for the SDs of meaningfulness and number of features in the Toglia-Battig norms) being positive. In short, the relations between words’ judged familiarity and their frequency in the lexicon, on the one hand, and the rating SDs of several semantic attributes, on the other, are weak and inconsistent.
We conducted a similar validity analysis for the prediction that attribute ambiguity will be greater for words with multiple salient meanings using data from the Scott et al. (2019) norms. The 5,553 words in those norms includes a subsample of 379 words that each have two salient meanings (e.g., bank, figure, live, medium, toast). We computed the rating SDs of the nine rated attributes separately for these multiple-meaning words versus the remaining 5,174 words. The prediction, of course, is that for all nine attributes, the mean rating SDs of the multiple-meaning words will be higher than the mean rating SDs of other words. To test that prediction, using rating SDs as the dependent variable, we computed a 2 (word ambiguity: multiple-meaning words vs. other words) × 9 (rated attribute) ANOVA. The key result is the main effect for word ambiguity, which should be significant if multiple meanings increase attribute ambiguity. It was not significant, however; the rating SDs of multiple-meaning words did not differ reliably from the rating SDs of other words.
To conclude, beyond the results in Experiments 1–4, it seems that the normed quantitative measure of attribute ambiguity is empirically distinct from more traditional conceptions of semantic ambiguity. The data that were just reported reveal that attribute ambiguity is unrelated to either the familiarity or multiple-meanings conception of ambiguity: There was no evidence of strong negative correlations between rating SDs and words’ rated familiarity or words’ objective frequency in linguistic usage, and there was no evidence that rating SDs are higher for words with multiple salient meanings.
References
Abadie, M., & Camos, V. (2019). False memory at short and long term. Journal of Experimental Psychology: General, 148(8), 1312–1334.
Abadie, M., Waroquier, L., & Terrier, P. (2013). Gist memory and the unconscious thought effect. Psychological Science, 24(7), 1253–1259.
Barnhardt, T. M., Choi, H., Gerkens, D. R., & Smith, S. M. (2006). Output position and word relatedness effects in a DRM paradigm: Support for a dual-retrieval process theory of free recall and false memories. Journal of Memory and Language, 55(2), 213–231.
Bookbinder, S. H., & Brainerd, C. J. (2016). Emotion and false memory: The context-content paradox. Psychological Bulletin, 142(12), 315–351.
Bouwmeester, S., & Verkoeijen, P. P. J. L. (2011). Why do some children benefit more from testing than others? Gist trace processing to explain the testing effect. Journal of Memory and Language, 65(1), 32–41.
Bradley, M. M., & Lang, P. J. (1999). Affective norms for English words (ANEW): Stimuli, instruction manual and affective ratings (tech. Rep. No. C-1). Gainesville, FL: The Center for Research in psychophysiology, University of Florida.
Brainerd, C. J. (2018). The emotional ambiguity hypothesis: A large-scale test. Psychological Science, 25(10), 1706–1715.
Brainerd, C. J., Chang, M., & Bialer, D. M. (2021a). Emotional ambiguity and memory. Journal of Experimental Psychology: General, 150(8), 1476–1499.
Brainerd, C. J., Chang, M., Bialer, D. M., & Toglia, M. P. (2021b). Semantic ambiguity and memory. Journal of Memory and Language. Article Number, 104286.
Brainerd, C. J., Nakamura, K., & Reyna, V. F. (2017). Overdistribution: Categorical judgments produce them, confidence ratings reduce them. Journal of Experimental Psychology: General, 146(1), 20–40.
Brainerd, C. J., Reyna, V. F., Gomes, C. F. A., Kenney, A. E., Gross, C. J., Taub, E. S., & Spreng, R. N. (2014). Dual-retrieval models and neurocognitive impairment. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(1), 41–65.
Brainerd, C. J., Reyna, V. F., & Howe, M. L. (2009). Trichotomous processes in early memory development, aging, and neurocognitive impairment: A unified theory. Psychological Review., 116(4), 783–832.
Bruer, K. C., & Pozzulo, J. D. (2014). Familiarity and recall memory for environments: A comparison of children and adults. Journal of Applied Developmental Psychology, 35(4), 318–325.
Bugg, J. M. (2014). Conflict-triggered top-down control: Default mode, last resort, or no such thing? Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(2), 567–587.
Citron, F. M., Weekes, B. S., & Ferstl, E. C. (2014). How are affective word ratings related to lexicosemantic properties? Evidence from the Sussex affective word list. Applied PsychoLinguistics, 35(2), 313–331.
Durda, K., & Buchanan, L. (2006). WordMine2 [online] Available from: http://web2.uwindsor.ca/wordmine
Einstein, G. O., & McDaniel, M. A. (1990). Normal aging and prospective memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16(4), 717–726.
Engelthaler, T., & Hills, T. T. (2018). Humor norms for 4,997 English words. Behavior Research Methods, 50(3), 1116–1124.
Ferré, P., Guasch, M., Martínez-García, N., Fraga, I., & Hinojosa, J. A. (2017). Moved by words: Affective ratings for a set of 2,266 Spanish words in five discrete emotion categories. Behavior Research Methods, 49(3), 1082–1094.
Gomes, C. F. A., Brainerd, C. J., Nakamura, K., & Reyna, V. F. (2014). Markovian interpretations of dual retrieval processes. Journal of Mathematical Psychology, 59, 50–64.
Gomes, C. F. A., Brainerd, C. J., & Stein, L. M. (2013). Effects of emotional valence and arousal on recollective and nonrecollective recall. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(3), 663–677.
Greene, N. R., Chism, S., & Naveh-Benjamin, M. (in press). Levels of specificity in episodic memory: Insights from response accuracy and subjective confidence ratings in older adults and in younger adults under full or divided attention. General.
Greene, N. R., & Naveh-Benjamin, M. (2020). A specificity principle of memory: Evidence from aging and associative memory. Psychological Science, 31(3), 316–331.
Greene, N. R., & Naveh-Benjamin, M. (2021). The effects of divided attention at encoding on specific and gist-based associative episodic memory. Advance online publication.
Henriques, J. B., & Davidson, R. J. (2000). Decreased responsiveness to reward in depression. Cognition and Emotion, 14(5), 711–724.
Hinojosa, J. A., Martínez-García, N., Villalba-García, C., Fernández-Folgueiras, U., Sánchez-Carmona, A., Pozo, M. A., & Montoro, P. R. (2016). Affective norms of 875 Spanish words for five discrete categories and two emotional dimensions. Behavior Research Methods, 48(1), 272–284.
Juhasz, B. J. (2005). Age-of-acquisition effects in word and picture identification. Psychological Bulletin, 131(5), 684–712.
Juhasz, B. J., Lai, Y.-H., & Woodcock, M. L. (2015). A database of 629 English compound words: Ratings of familiarity, lexeme meaning dominance, semantic transparency, age of acquisition, imageability, and sensory experience. Behavior Research Methods, 47(4), 1004–1019.
Kensinger, E. A. (2009). Remembering the details: Effects of emotion. Emotion Review, 1(2), 99–113.
Kounios, J., & Holcomb, P. J. (1994). Concreteness effects in semantic processing: ERP evidence supporting dual-coding theory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20(4), 804–823.
Kuppens, P., Tuerlinckx, F., Russell, J. A., & Barrett, L. F. (2013). The relation between valence and arousal in subjective experience. Psychological Bulletin, 139(4), 917–940.
Lampinen, J. M., & Odegard, T. N. (2006). Memory editing mechanisms. Memory, 14(6), 649–654.
Lampinen, J. M., Odegard, T. N., Blackshear, E., & Toglia, M. P. (2005). Phantom ROC. In D. T. Rosen (Ed.), Trends in experimental psychology research (pp. 235–267). NOVA Science Publishers.
Marche, T. A., Briere, J. L., & von Baeyer, C. L. (2016). Children's forgetting of pain-related memories. Journal of Pediatric Psychology, 41(2), 220–231.
Marschark, M., Richman, C. L., Yuille, J. C., & Hunt, R. R. (1987). The role of imagery in memory: On shared and distinctive information. Psychological Bulletin, 102(2), 28–41.
Mattek, A. M., Wolford, G. L., & Whalen, P. J. (2017). A mathematical model captures the structure of subjective affect. Perspectives on Psychological Science, 12(3), 508–526.
Mikels, J. A., Fredrickson, B. L., Larkin, G. R., Lindberg, C. M., Maglio, S. J., & Reuter-Lorenz, P. A. (2005a). Emotional category data on images from the international affective picture system. Behavioral Research Methods, 37(4), 626–630.
Mikels, J. A., Larkin, G. R., Reuter-Lorenz, P. A., & Carstensen, L. L. (2005b). Divergent trajectories in the aging mind: Changes in working memory for affective versus visual information with age. Psychology and Aging, 20(4), 542–553.
Neath, I., & Surprenant, A. M. (2020). Concreteness and disagreement: Comment on Pollock (2018). Memory & Cognition, 48(4), 683–690.
Niedzialkowska, D., & Nieznański, M. (in press). Recollection of "true" feedback is better than "false" feedback independently of a priori beliefs: An investigation from the perspective of dual-recollection theory. Memory.
Nieznański, M., & Obidzinski, M. (2019). Verbatim and gist memory and individual differences in inhibition, sustained attention, and working memory capacity. Journal of Cognitive Psychology, 31(1), 16–33.
Paivio, A., Yuille, J. C., & Madigan, S. A. (1968). Concreteness, imagery and meaningfulness values for 925 nouns. Journal of Experimental Psychology Monograph Supplement, 76(1, Pt.2), 1–25.
Palmer, J. E., & Dodson, C. S. (2009). Investigating the mechanisms fueling reduced false recall of emotional material. Cognition & Emotion, 23(2), 238–259.
Pexman, P. M., Muraki, E., Sidhu, D. M., Siakaluk, P. D., Siakaluk, P. D., & Yap, M. J. (2019). Quantifying sensorimotor experience: Body–object interaction ratings for more than 9,000 English words. Behavior Research Methods, 51(2), 453–466.
Pollock, L. (2018). Statistical and methodological problems with concreteness and other semantic variables: A list memory experiment case study. Behavior Research Methods, 50(3), 1198–1216.
Schock, J., Cortese, M. J., Khanna, M. M., & Toppi, S. (2012). Age of acquisition estimates for 3,000 disyllabic words. Behavior Research Methods, 44(4), 971–977.
Scott, G. G., Keitel, A., Becirspahic, M., Yao, B., & Sereno, S. C. (2019). The Glasgow norms: Ratings of 5,500 words on nine scales. Behavior Research Methods, 51(3), 1258–1270.
Singer, M., & Remillard, G. (2008). Veridical and false memory for text: A multiprocess analysis. Journal of Memory and Language, 59(1), 18–35.
Singer, M., & Spear, J. (2015). Phantom recollection of bridging and elaborative inferences. Discourse Processes, 52(5–6), 356–375.
Smith, T. A., & Kimball, D. R. (2012). Revisiting the rise and fall of false recall: Presentation rate effects depend on retention interval. Memory, 20(6), 535–553.
Stadthagen-González, H., Ferré, P., Pérez-Sánchez, P. A., Imbault, C., & Hinojosa, J. A. (2018). Norms for 10,491 Spanish words for five discrete emotions: Happiness, disgust, anger, fear, and sadness. Behavior Research Methods, 50(5), 1943–1952.
Stevenson, R. A., Mikels, J. A., & James, T. W. (2007). Characterization of the affective norms for English words by discrete emotional categories. Behavior Research Methods, 39(4), 1020–1024.
Storbeck, J,, & Clore, G. L. (2005). With sadness comes accuracy; with happiness, false memory: Mood and the false memory effect. Psychological Science, 16(10), 785-791.
Toglia, M. P., & Battig, W. F. (1978). Handbook of semantic word norms. Erlbaum.
Tractenberg, S. G., Viola, T. W., Gomes, C. F. A., Wearick-Silva, L. E., Kristensen, C. H., Stein, L. M., & Grassi-Oliveira, R. (2015). Dual-memory processes in crack cocaine dependents: The effects of childhood neglect on recall. Memory, 23(7), 955–971.
Underwood, B. J., & Schulz, R. W. (1960). Meaningfulness and verbal learning. Chicago: Lippincott.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Brainerd, C.J., Chang, M., Bialer, D.M. et al. How does attribute ambiguity improve memory?. Mem Cogn 51, 38–70 (2023). https://doi.org/10.3758/s13421-022-01343-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-022-01343-w