
Abstract
Binocular rivalry is a phenomenon of visual competition in which perception alternates between two monocular images. When two eye’s images only differ in luminance, observers may perceive shininess, a form of rivalry called binocular luster. Does dichoptic information guide attention in visual search? Wolfe and Franzel (Perception & Psychophysics, 44(1), 81–93, 1988) reported that rivalry could guide attention only weakly, but that luster (shininess) “popped out,” producing very shallow Reaction Time (RT) × Set Size functions. In this study, we have revisited the topic with new and improved stimuli. By using a checkerboard pattern in rivalry experiments, we found that search for rivalry can be more efficient (16 ms/item) than standard, rivalrous grating (30 ms/item). The checkerboard may reduce distracting orientation signals that masked the salience of rivalry between simple orthogonal gratings. Lustrous stimuli did not pop out when potential contrast and luminance artifacts were reduced. However, search efficiency was substantially improved when luster was added to the search target. Both rivalry and luster tasks can produce search asymmetries, as is characteristic of guiding features in search. These results suggest that interocular differences that produce rivalry or luster can guide attention, but these effects are relatively weak and can be hidden by other features like luminance and orientation in visual search tasks.
Similar content being viewed by others

Each of our two eyes captures a slightly different view of the world, and the brain typically combines the two retinal projections into a single, stable, 3-D view. Binocular stability falls apart when the input to the two eyes becomes too different. Faced with unreconcilable differences between the eyes, perception will alternate between two different monocular inputs (R. Blake & Camisa, 1978). This phenomenon is called binocular rivalry (see Brascamp, Klink, & Levelt, 2015, for a recent review). A special case of binocular rivalry is binocular luster, luster is specifically associated with luminance differences between monocular inputs: “In a stereogram intended to represent some object, suppose that a certain area in one of the pictures is shown in white, and in the other picture in black, or suppose that the particular place is colored differently in the two pictures…then, when the two views are combined stereoscopically, this area will shine with a certain lustre Footnote 1” (Von Helmholtz, 1924, p. 512). Wolfe and Franzel (1988) asked whether rivalry and luster could guide attention using a visual search paradigm (Wolfe & Franzel, 1988). In a visual search task, observers search for a target among a number of distractors. All else being equal, each additional distractor will make the search more difficult (Egeth, 1977). However, if a target is defined a feature (e.g., color, orientation) not present in the distractors, search performance will be more efficient. If the guiding feature is salient enough, RT will be independent of the number of distractors, and the target is said to “pop-out” (the slope of RT × Set Size will be near zero; Egeth, 1972). More generally, the strength of guidance can be quantified by the degree to which the presence of a feature can reduce RT × Set Size slopes. For example, suppose you are looking for a T among Ls—a classic “unguided” search. The slope might be 30 ms/item for target-present items. If the search is for a red T and the Ls are equally divided between red and green items, the slope will be near 15 ms/item because the guidance will be nearly perfect, and half of the items can be ignored. If the red L is presented among red and reddish-orange Ls, the guidance will be less perfect, and the slope will lie somewhere between 15 and 30 ms/item. A limited set of attributes can guide attention in this way (reviewed in Wolfe & Horowitz, 2004; Wolfe, 2014). The purpose of this study is to revisit the status of binocular rivalry and luster on the list of guiding attributes.
An important characteristic of guiding features is that search for the presence of a feature tends to be more efficient than search for its absence. This is known as a “search asymmetry” (Treisman, 1985; Wolfe, 2001). For example, it is easier to detect a moving stimulus among stationary distractors than a stationary stimulus among moving distractors (Dick, Ullman, & Sagi, 1987). Researchers have taken such asymmetries as evidence for the existence in the visual system of a basic feature detector that responds to a particular feature—motion, in this example (Treisman, 1988). Search asymmetries are widely used as an important tool in the study of visual attention, though Rosenholtz (2001) points out some important limitation of the use of asymmetries to identify features.
In 1988, Wolfe and Franzel (1988) argued that targets defined by binocular rivalry did not “pop out” but that targets defined by binocular luster did. At that time, analysis of visual search data was dominated by Treisman’s division of search tasks into serial and parallel (Treisman & Gelade, 1980) on the basis of the slopes of RT × Set Size functions and other metrics. Subsequently, it became clear that the efficiency of search tasks formed a continuum (Wolfe, 1998a, p. 21). For instance, Treisman had argued that serial search was required for conjunction tasks in which the target was defined by a combination of two features (e.g., a red vertical target among RED horizontal and green VERTICAL distractors; Treisman & Gelade, 1980). It has since become clear that conjunction searches can be more efficient than Treisman proposed (e.g., Nakayama & Silverman, 1986; Quinlan & Humphreys, 1987; Zohary & Hochstein, 1989). Features that produced pop-out in homogeneous displays (e.g., red among green) could “guide” attention in conjunction tasks (Wolfe, Cave, & Franzel, 1989). Moreover, weak features might guide attention only weakly even in search for a target among homogeneous distractors. Thus, while a red target will pop out among green distractors, producing an RT × Set Size slope near zero ms/item, the same red target will not be found so efficiently among reddish-orange distractors. As the difference between target and distractors decreases, the slope of the RT × Set Size function increases (Nagy & Sanchez, 1990). Slopes will also increase if the distractors differ among themselves. Red among green will be more efficient than red among green, blue, and yellow; though both of those searches will be easy (Duncan & Humphreys, 1989).
In light of the subsequent development of the field, Wolfe and Franzel’s (W&F; 1988) conclusions about rivalry and luster deserve a new look. Search for vertical versus horizontal rivalry among vertical or horizontal fused distractors was inefficient (W&F Exp. 1: 26 ms/item for target present, 36 ms/item for target absent—comparable for what one might get for a classic inefficient search for a T among Ls or a 2 among 5s; Wolfe, 1998b). Chromatic rivalry (red–green rivalry among red and green fused distractors) produced target-present slopes averaging 16 ms/item (Exp. 3) and target-present slopes were just 9.5 ms/item for left versus right oblique grating rivalry among left and right oblique distractors. Experiment 3 used larger set sizes than Exp. 1 as well. W&F declared this result to be “consistent with the predictions of serial, self-terminating search.” However, having moved away from a strict serial/parallel dichotomy in the analysis of search results, slopes around 10 ms/item are in the range produced by guided conjunction searches (Wolfe, 1998a, p. 22) and would be considered reasonably efficient. They suggest that something is guiding the search, making it worth revisiting the original W&F claim.
There has been some work on the role of monocular information in visual search since the original W&F paper. Some evidence suggests that eye-of-origin information can modulate the deployment of attention (Shneor & Hochstein, 2006; Zhaoping, 2012). Solomon et al. argued that a form of proto-rivalry can support texture segmentation, at least if the texture elements are fairly closely packed (Solomon, John, & Morgan, 2006). The most extensive work on search for interocular conflict has been done by Paffen et al. (Paffen, Hessels, & Stigchel, 2012; Paffen, Hooge, Benjamins, & Hogendoorn, 2011). They found efficient search for a target that was vertical in one eye and horizontal in the other among distractors that were vertical or horizontal in both eyes. Because this was in apparently conflict with the Wolfe and Franzel (1988) results, they embarked on a series of experiments to uncover the source of the difference. When they directly replicated W&F’s conditions, they obtained essentially the same results that W&F reported. Interestingly, when they reduced the contrast of their vertical and horizontal gratings, search for the interocular conflict target became much more efficient. This might seem surprising because reducing the salience of stimuli usually makes search less efficient (e.g., for conjunction search; Wolfe et al., 1989). However, in binocular phenomenology, reducing contrast makes dichoptic stimuli more likely to appear fused (Liu, Tyler, & Schor, 1992). Paffen et al. (2011) hypothesize that the “abnormal fusion” (Wolfe, 1983) of vertical and horizontal gratings created a dichoptic plaid-like stimulus that was easily found amidst simple gratings. It is not simply that Paffen’s observers were looking for a plaid. They could still search for their binocular conflict stimuli when the distractors were plaids. As Wolfe (1983) also noted, abnormally fused gratings do not look like “real” plaids, but neither do they appear rivalrous. When Paffen et al. optimized the conditions for abnormal fusion, search became even more efficient. They tie their results to the proto-rivalry phenomena of Solomon et al. (2006).
Whatever the exact phenomenology, the Paffen et al. (2011) results show that interocular conflict can support efficient search under conditions that may give rise to abnormal fusion. In the following experiments, we extend this result to show that, under the right circumstances, rivalry seems to guide attention under conditions that did not produce an impression of abnormal fusion. In Experiment 1, we test the hypothesis that search for a rivalrous target can be disrupted by the orientation contrast between vertical and horizontal distractors. To reduce that contrast, we use checkerboards of vertical and horizontal patches as the stimuli. When a rivalrous checkerboard is presented among fused checkerboards, we find that search becomes reasonably efficient. We also revisit the question of guidance by binocular luster. Luster has not received much attention as an attention-guiding attribute since the original W&F report. Computer graphics displays were somewhat cruder in 1988. With better control over some potential artifacts, Experiments 2 and 3 indicate that luster is a fairly weak guiding feature. Finally, Experiment 4 shows that adding luster to a target can make it easier to find.
Experiment 1: Search for rivalry-checkerboard pattern can be quite efficient
Method
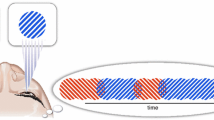
In the rivalry search experiment of W&F, observers searched for a target that was a vertical grating in one eye and a horizontal grating in the other (rivalry) among distractors that were vertical in both eyes or horizontal in both eyes (fused). Grating displays produce strong orientation contrasts between vertical and horizontal patches. As a result, the display was filled with strong orientation contrasts that might have added bottom-up noise to the display and reduced any guidance by the interocular conflict. For instance, a vertical grating, flanked by two horizontal gratings, would produce a bigger bottom-up orientation signal than a vertical grating, flanked by two verticals. Such signals would be uninformative and might hide any putative rivalry signal when bottom-up and top-down signals are summed into an attention guiding salience map (Rangelov, Müller, & Zehetleitner, 2012). We hypothesized that we might see more guidance by rivalry if we used a checkerboard pattern of vertical and horizontal gratings (see Fig. 1a) rather than simple grating stimuli (Fig. 1b). This hypothesis is based on the observation that bottom-up orientation contrasts appear to be stronger with gratings than with checkerboard stimuli. This is demonstrated in Fig. 1, where it is much easier to find two targets with the simple grating stimuli (Fig. 1b), because those grating generate stronger, bottom-up orientation signals than do the checkerboard stimuli. In rivalry experiments, these orientation contrasts may mask the signal from a rivalry target, making it easier to search for rivalry when using the checkerboard stimuli of Fig. 1a.

Illustrating the hypothetical effect of orientation contrast signals on the detection of targets. Search for targets that are orthogonal to the distractors will be easier with grating stimuli (b) than with checkerboard stimuli (a). The larger bottom-up orientations signals in b may masking a rivalry signal when grating stimuli are used in rivalry search
Thus, in Experiment 1, participants searched for rivalrous targets among fused distractors or for fused targets among rivalrous distractors. There were two versions of each of these searches: A grating condition and a checkerboard condition.
Participants
Thirteen participants (mean age = 26.6 years, SD = 5.4, six females) gave informed consent and were paid $10/hr to participate in this experiment. Stereoacuity was measured using the Titmus Stereo test (Stereo Optical Co., Chicago, IL). All had normal or corrected-to-normal vision and were unaware of the research goal of the experiments. The data of participants whose average error rate more than 20% were excluded from further analysis, leaving a total number of eleven participants.
Apparatus and stimuli
Stimuli consisted of left eye images and right eye images were drawn and scripted using PsychoPy (Peirce, 2007) and presented on two 20-in. Planar PL2010M LCD (Planar Systems Inc.) monitors respectively with a resolution of 1,600 × 1,200 pixels, and a 60Hz refresh rate, and participants were seated approximately 70 cm from the screen. The two monitors were mounted one above the other with a polarized mirror set in between. Dichoptic presentation was achieved when observers wore polarized glasses. Each display consisted of a variable number of items that were presented on an imaginary circle with a diameter of 12.1° around a fixation point. The circle contained 12 possible positions for items evenly spaced every 30 degrees around the circle. On each trial, the items were randomly assigned to these positions. Set sizes were 4, 8, and 12. The items consisted of checkerboard or square-wave grating patterns. Figure 2 shows an example of checkerboard stimuli with a set size of 12. The visual angle of each item was around 1.5 degree at a 70-cm viewing distance. Spatial frequency of the gratings was ~5 cycles/deg. The fixation cross was visible throughout the whole experiment to aid the fusion of binocular images. No chin rest was used during the experiment. The luminance of the gray background of the monitor was 61 cd/m2. Gratings were high contrast with white bars of 241 cd/m2 and black bars of 1.9 cd/m2.

Stimuli used in Experiment 1 (checkerboard condition). The rivalry target was highlighted by red rectangle, not shown to the observer(Color figure online)
Procedure and design
The task was to detect whether a target was present or absent among distractors by pressing a corresponding key. Participants were instructed to respond as quickly and accurately as they could. Without binocular information, participants were unable to find the target using only one eye. There were two versions of both experiment and control conditions: (1) search for a rivalrous target among fused distractors and (2) search for a fused target among rivalrous distractors. Each configuration consisted of 180 trials that were evenly distributed between the three set sizes. These trials were preceded by 18 practice trials. A target was present on half of trials. Target presence or absence was randomized across trials. Target location was also randomized for target-present trials. The search task was displayed until a response was made or for 10 seconds, whichever occurred earlier. Accuracy feedback was provided after each trial.
Results
In checkerboard and grating experiments, the error rate in search for rivalry among fused distractors was larger than that in search for a fused target among rivalry. The accuracy for gratings was better than for checkerboards. All error trials were removed from the analysis of reaction times. A two (rivalry or fused) by two (grating or checkerboard) repeated-measures ANOVA on arcsine transformed error rates shows that the difference between rivalry (M = 5.25%) and fused (M = 14.0%) was significant, F(1, 10) = 29.39, p < .001, and the difference between checkerboard (M = 7.98%) and grating (M = 11.3%) was also significant, F(1, 10) = 8.60, p = .015, as well as the interaction between these factors, F(1, 10) = 17.73, p = .002. To further assess the interaction, paired-sample t tests showed that all comparisons were significant (all ps < .01) except for the difference between rivalry gratings and rivalry checkerboards, t(10) = 0.44, p = .67.
Graphs of RT as a function of set size are shown in Fig. 3. It can be seen that search for the rivalrous target is more efficient in the checkerboard case. Search for the fused condition is markedly less efficient in than search for rivalry (a classic search asymmetry; Treisman, 1985). Search for a fused target is easier in the grating condition. These observations are borne out by statistical analysis.

Results of Experiment 1: average reaction time (y-axis) as a function of set size (x-axis). a Search for checkerboard targets. b Search for grating targets. Rivalrous target data are presented in purple and fused target data are in blue. Solid lines show linear regression fits for present trials, dashed lines show absent trials. Error bars indicate ±1 SEM
A three-way, repeated-measures ANOVA conducted on target-present RTs revealed main effects of set size, F(2, 20) = 24.69, p < .001, target pattern (checkerboard or grating), (F(1, 10) = 7.07, p = .024), target type (rivalry or fused), F(1, 10) = 34.83, p < .001, and significant interactions between set size and target type, F(2, 20) = 13.77, p < .001, target pattern and target type, F(1, 10) = 24.45, p < .001, as well as a marginally significant interaction between set size and target pattern, F(2, 20) = 3.07, p = .069. The three-way interaction between set size, target pattern, and target type was also significant, F(2, 20) = 10.28, p < .001. A similar pattern was seen in the absent trials. The interaction between target type and target pattern was examined with a paired-sample t test. RTs were generally faster with fused grating versus fused checkerboard, t(10) = 3.69, p = .004, and this effect was not observed for rivalrous stimuli, t(10) = 0.40, p = .70. The faster search seen when the grating stimuli were used may simply reflect the relative simplicity of those stimuli (Foster & Westland, 1995).
Because we are particularly interested in whether that the set size effect differs in checkerboard and grating conditions, we followed up those interactions by performing paired-sample t tests on the target-present slopes of the RT × Set Size functions. The results revealed that the average slope for the rivalry checkerboard was significantly shallower than that for the rivalry grating, t(10) = 2.58, p = .027, while the slope for fused checkerboard was significantly steeper than that for fused grating, (t(1,10) = 5.25, p < .001. In the checkerboard condition, the rivalrous target slope was significantly shallower than the fused target slope, t(10)=5.91, p < .001, but this difference was not significant in the grating condition, t(10)=1.71, p = .12.
Discussion
The results of Experiment 1 replicate the findings of Wolfe and Franzel’s (1988). Even with the checkerboard stimuli, rivalry does not “pop out” (slope = 16 ms/item), though, consistent with our hypothesis, the search for rivalrous among fused was markedly more efficient with checkerboard stimuli than with grating stimuli. This more efficient search is not due to a speed–accuracy trade-off with rivalry checkerboard stimuli, because there is no obvious difference in error rate between these two conditions. If there is a weak rivalry signal that can guide attention, use of the checkerboard stimuli made it easier to see that signal in action. Search asymmetry is another diagnostic sign of a guiding signal. The presence of a feature guides attention more effectively than the absence. Paffen et al. (2011) reported an asymmetry with their with low-contrast, dichoptic stimuli. In Experiment 1, the checkerboard results reveal a clearer search asymmetry than do the grating results. Because the asymmetry favors the search for the rivalrous target, we would conclude that rivalry, not fusion, generates the guiding signal. In this view, interocular fusion is the absence of rivalry rather than being a guiding feature in its own right. In this, it may be comparable to motion. Finding one moving stimulus among stationary distractors is much easier than funding one stationary target among moving distractors (Dick et al., 1987; Royden, Wolfe, & Klempen, 2001). Based on these results, we suggest that, contrary to Wolfe and Franzel’s (1988) original claim, interocular conflict can be a guiding feature. It may provide only fairly weak guidance, but, as others have suggested (Paffen et al., 2011; Zhaoping, 2012), it does appear to guide attention. Wolfe and Franzel may have failed to see evidence of this weak signal because it was masked by irrelevant orientation contrasts between items.
Experiment 2: Search for luster doesn’t always pop out
Method
The other major conclusion of Wolfe and Franzel’s (1988) paper was that luster, created by interocular luminance mismatch, did guide attention. Experiments 2 and 3 revisit this claim. Luster/shininess is an important feature of visible surface (Beck & Prazdny, 1981; A. Blake & Bülthoff, 1990; Fleming, Dror, & Adelson, 2003; Motoyoshi, Nishida, Sharan, & Adelson, 2007). The aim of Experiment 2 is to investigate whether search for luster is still efficient when potentially artifactual contrast and luminance cues are reduced. Wolfe and Franzel showed that binocular luster behaves like a basic feature (RT independent of the number of distractors). In the original W&F paper, Experiment 6 found very efficient search for a dark/black disk in one eye and a white disk in the other eye amidst distractors that were white in both eyes or dark in both eyes. Introspectively, the task is search for the shiny/lustrous target, but it could be that it was simply easy to find a target of intermediate average luminance among distractors that were lighter or darker. In Experiment 2, distractor disks with variable gray levels were used to reduce this luminance cue. Luster was produced by presenting darker disks to one eye and lighter disks to the other eye (Formankiewicz & Mollon, 2009), but the simple arithmetic mean of the two disks was no longer a reliable guide to the target.
Participants
Nine subjects (mean age = 26.7 years, SD = 5.2, three females) participated this experiment. Stereoacuity was measured using the Titmus Stereo test (Stereo Optical Co., Chicago, IL), and all had normal or corrected-to-normal vision.
Stimuli, apparatus, and procedure
The apparatus and viewing conditions were the same as in Experiment 1. Stimuli were generated by MATLAB with the Psychophysics Toolbox (Brainard, 1997). A set of 4, 8 or 16 disks appeared within a 21.2° diameter ring in each trial. Even spacing was maintained for all set sizes. For example, if set size was 4, the four items were constrained to four positions with even distance between them. The outline of the ring, the outlines of all possible disks, and the fixation cross were visible throughout the whole experiment in order to maintain accurate vergence on the plane of the monitor. An example of the Experiment 2 conditions is shown in Fig. 4. All disks were centered at a distance of 8.5° from the fixation cross. The size of each element was 1.3°.

Stimuli used in Experiment 2. Luster is produced by presenting a brighter disk to one eye and darker disk to the other eye. (Highlighted by red rectangle, not shown to the observer). Importantly, neither monocular nor binocular luminance is a reliable cue to target location (Color figure online)
The task was to detect whether there was a shiny/luster target. However, targets could be defined by different combinations of bright and dark disks and distractors could also have various grey levels, as shown in Fig. 4. The parameters of target and distractor disks are described in Table 1. Participants completed 360 trials in total. Three types of targets were pseudorandomized (120 trials each target). A break was allowed every 180 trials. Participants resumed the experiment when they felt ready.
Results and discussion
As shown in Fig. 5, with these stimuli, search for targets defined by interocular luminance difference/luster was markedly less efficient than W&F finding of a 4.9 ms/item slope of the RT × Set Size function. Here the slope averaged 16 ms/item. Overall error rate is 2.8% in this experiment, and all error trials were removed from the analysis of reaction times. A two (target type: rivalry, fused) by three (set size: 4,8,16) repeated-measures ANOVA on the target-present data revealed a main effect of set size, F(2, 16) = 15.20, p < .001, no significant effect of target type, F(2, 16) = 0.95, p= .41, and no significant interaction between set size and target type, F(4, 32) = 0.64, p = .64. A paired-sample t tests show no significant differences between any of two targets.

Results of Experiment 2: Average reaction time (y-axis) as a function of set size (x-axis). Three types of targets are shown in three different colors, but it is clear that target type is not an important modulator of the results. Error bars indicate ±1 SEM
Figure 5 shows that each of the three target types produced a similar RT × Set Size function. There is no reliable difference between the slopes for these three, ANOVA, F(2, 24) = 0.047, p = .95. The slopes differ from zero, all t(8) > 2.7, all ps < .025. If luster was guiding attention in Experiment 2, it was doing so in weak manner. Perhaps, as in the grating rivalry condition, the differences between targets on an irrelevant dimension, in this case luminance, acted to hide a weak luster signal. We will return to this topic in the general discussion.
Experiment 3: A search asymmetry for luster
Method
Wolfe and Franzel (1988) did not find a significant search asymmetry in luster search. Searching for matte among shiny was only slightly less efficient than search for shiny among matte. However, if we consider the possibility of using just the average luminance as the search signal, in the matte search condition, the target would be the only bright or dark item among items of a uniform middle gray. This might be expected to be easier than a search for the middle gray among a mix of bright and dark. The experimental design, itself, is asymmetric (Rosenholtz, 2001). In Experiment 3, in order to correct for this design flaw, we designed a symmetric task in which participants searched for bright shiny and dark shiny targets among bright and dark matte distractors and vice versa.
Participants
The same nine subjects in Experiment 2 participated this experiment.
Stimuli, apparatus, and procedure
Except as noted, the apparatus and stimuli were as described in Experiment 2. The parameter of targets and distractors were shown in Table 2. Many of the classical studies of binocular luster studied monocular stimuli that are not just of different luminance but are of reversed contrast polarity (Anstis, 2000), but some level of luster may also be perceived even if the contrast polarity of the dichoptic spots is the same as long as their contrasts or luminance differ (Anstis, 2000; Formankiewicz & Mollon, 2009). In this experiment, luster targets were produced with monocular spots of the same polarity but different luminance. Gray levels of targets and distractors were chosen in a manner intended to maximize the contrast differences of both bright shiny and black dark targets simultaneously. Observers reported the phenomenological experience of luster with these parameter settings.
As noted above, in Experiment 3, there were always two types of targets and two types of distractors. Of course, if the target were reliably brighter or dimmer than the distractors, search could be based on luminance rather than on luster or its absence. To avoid this, we used the method of adjustment to equate the apparent brightness of lustrous and matte targets. It is surprisingly hard to match the gray level of a shiny surface to that of a matte surface. Thus, to meet our goal of thwarting a brightness cue, a random amount [0%–10%] was added to or subtracted from each gray level for every stimulus. This 10% noise is sufficient to mask subjective brightness differences between the lustrous and matte items. The noise changed on every trial so that luminance would be an (almost) useless cue. Luster or its absence was the only reliable guiding feature here.
There were two blocks in this experiment: (1) search for a lustrous target and (2) search for a matte target. Set size and target presence were randomized within each block. Figure 6 shows an example of stimuli used in matte target block. Participants completed 480 trials in total. Accuracy feedback was given after each trial.

A sample of stimuli in matte target block of Experiment 3. When fused, all distractors would be lustrous. Only the target, highlighted by red rectangle (not shown to observers), would appear matte (Color figure online)
Results and discussion
Average RTs as a function of set size are shown in Fig. 7. It is clear that search for the matte target was a much harder task than search for a lustrous target. This is seen in both speed and accuracy. Starting with accuracy, average error rate was 7% for luster search versus 21% for matte search. A repeated-measures ANOVA on arcsine transformed error rates revealed a main effect of target type (luster or matte), F(1, 8) = 17.22, p = .003. All error trials were removed from the RT analysis as were all RTs > 6 seconds; a further 1.8% of the trials. A 2 (target type: luster, matte) × 3 (set size: 4,8,16) repeated-measures ANOVA conducted on the target-present data revealed a main effect of target type, F(1, 8) = 13.9, p = .006, and set size, F(2, 16) = 20.01, p < .001, as well as a significant interaction between set size and target type, F(2, 16) = 4.27, p = .033. A similar pattern was seen in absent trials. We calculated search slopes for each target condition, and examined the interaction with paired-sample t tests, finding that there was a marginally significant difference between the luster present (15 ms/item) and matte present (47 ms/item) slopes, t(8) = 2.2, p = .058. The marginal significance is due to large speed–accuracy trade-offs for the matte condition. Average d′ for the luster condition is 3.25. Average for the matte condition is only 2.0, reflecting the higher error rate for the matte condition. Moreover, 4 of 9 observers have d′ <= 1.0 for the matte condition. If we analyze the RT data with only the five reasonably accurate observers, the average target present slope rises from 47 to 71 ms/item. With only those five, matte search is significantly less efficient than luster search, t(4) = 4.6, p = .01. Thus, search for matte targets is either much slower or much less accurate than search for a luster target. This is consistent with a role for luster as a guiding feature, albeit a relatively weak one.

Results of Experiment 3: Average reaction time (y-axis) as a function of set size (x-axis). Luster-target data are presented in purple and matte-target data are in blue. Target-present data are fitted linearly fitted with solid lines and target-absent data are dashed lines. Error bars indicate ±1 SEM
Experiment 4: Adding luster to target can facilitate visual search
Method
Experiment 4 is a replication of the basic luster search with a different set of stimuli, shown in Fig. 8. Here it would be possible to search for the target that was black on the right among targets that were black on the left. Thus, luster was not necessary to the task. However, in the luster conditions it proves to be easier to find the target if it is the lustrous one. Twelve subjects (mean age = 29.4 years, SD = 11.1, eight females) participated in this experiment. Stereoacuity was measured using the Titmus Stereo test (Stereo Optical Co., Chicago, IL), and all had normal or corrected-to-normal vision.

Configuration of stimuli in Experiment 4 (Color figure online)
The apparatus were the same as described in other experiments. In this experiment, the target was the always the disk with a dark half on the right. There were three conditions in this experiment, shown in Fig. 8. In the luster condition, as shown in the top green rectangle, the dark half of the target would be perceived as lustrous. In the matte condition (middle, blue rectangle), the dark left halves of the distractors appeared lustrous, so the target was the only matte item. In the control condition highlighted with the purple rectangle, all items were matte. The target was the only item with its dark side on the right; a search task known to be inefficient (Kleffner & Ramachandran, 1992; Logan, 1995). All disks were centered on an imaginary circle with a diameter of 10° around a fixation point. The size of each element was 0.85°.
Set size and target presence were randomized within each condition. Participants completed 720 trials in total. Set sizes of 2, 4 or 8 were used in Experiment 4. The outline of the ring, the outlines of all possible disks and the fixation cross were visible throughout the whole experiment to allow the easy maintenance of vergence. Accuracy feedback was given after each trial.
Results and discussion
RT × Set Size functions are shown in Fig. 9. It is clear that search is much easier when the target item has luster added to it. Performance was good on this task. Participants had a mean error rate of 3%. All error trials were removed from analysis as well as all RTs greater than 4 seconds (0.3% of trials). A 3 (target type) × 3 (set size) repeated-measures ANOVA conducted on the target-present data revealed a main effect of set size, F(2, 22) = 154.13, p < .001, and target type, F(2, 22) = 76.27, p < .001, as well as a significant interaction between set size and target type, F(4, 44) = 59.25, p < .001. A similar pattern was seen in absent trials. We followed up the interaction with paired-sample t tests, finding that the slopes of three target types differ from each other, all t(11) > 3.84, all ps < .003.

Results of Experiment 4: Average reaction time (y-axis) as a function of set size (x-axis). Error bars indicate ±1 SEM
Experiment 4 shows that luster can be a useful piece of information in distinguishing targets and distractors. As noted, search for the target with black on the right among black-on-left distractors is known to be hard. It would, of course, be much easier if the target was colored red or made to move. Here we show that the search is made easier if the target is “colored” shiny. As in the previous experiments in this study, a uniquely shiny target does not pop-out of the display, producing a near zero RT × Set Size slope. Instead, it produces a reasonably efficient slope of 14 ms/item. Half of the observers have target present slopes of 9 ms or shallower in the luster condition. These results are consistent with weak guidance, as if the target had been colored, perhaps, a pale green. The matte condition is clearly better than the control condition, but worse than the luster condition, replicating the asymmetry, seen in Experiment 3. This, too, is consistent with the notion that luster is a weak feature, and that its absence is more difficult to detect than its presence. It is possible that observers were detecting a gray target in the luminance condition (black averaged with white). However, the search asymmetry would be somewhat surprising under that account because it would assume that a gray target among black distractors is easier to find than a black (matte) target among gray (luster) distractors.
General discussion
Wolfe and Franzel (1988) argued that binocular rivalry was not a preattentive feature. In light of our new data and in light of our changing ideas about guidance of attention, we would suggest that rivalry is, in fact, a guiding feature, though it appears to be fairly weak. Slopes of RT × Set Size functions this study and in the original W&F paper fall into the ambiguous realm of moderate efficiency, but many of our observers appear to be able to search quite efficiently for rivalry with group averages being pulled down by a few quite inefficient searchers. Moreover, the reliable rivalrous/fused search asymmetry is consistent with the idea that the presence of rivalry guides search while its absence does not. Paffen et al. (2011) also found efficient search for interocular difference. In their experiments, however, efficiency was improved (paradoxically), by reducing stimulus contrast in a way that may accentuate an abnormal fusion cue to the location of the target. In our Experiment 1, the critical move seems to have been to reduce the between-item orientation contrast by switching to plaids that form an essentially homogeneous set of distractors.
Turning to luster, Wolfe and Franzel (1988) had found luster to be a strong guiding feature. They found target present slopes of about 5 ms/item with similar slopes for target absent. Search for matte targets was somewhat more difficult, but not much more difficult. In these experiments, we do not produce such efficient slopes. Across three experiments, the target present slopes are around 15 ms/item. The mean RTs are slower in the new data than in the old data as well.Footnote 2 The presence of a clear search asymmetry in Experiment 3 and 4 is consistent with guidance by a luster feature but the evidence is clearly weaker than that put forward by W&F. There are at least two plausible accounts for the difference. It could be that luminance artifacts contaminated the W&F results. Alternatively, it could be that distractor heterogeneity or other factors weakened the luster signal in the presence experiments. These two accounts are not mutually exclusive. It is difficult to produce targets and distractors that differ from each other only in shininess. Using binocular luster to produce shininess, as we do here, raises the possibility of luminance confounds. There are other ways to make something look shiny. For instance, shiny objects typically have highlights on them from the specular reflection of the light source (Fleming et al., 2003; Muryy, Fleming, & Welchman, 2014). Removing a specular reflection can make a shiny sphere appear matte, but the search could then become a trivial search for the presence of a small white dot rather than a search for shininess. In unpublished work, we have tried to create convincing search for the shine of a specular reflection without notable success (Birnkrant, Wolfe, Kunar, & Sng, 2004). For the present, the results leave us with the conclusion that binocular luster is, at best, a fragile feature.
Thus, compared the conclusions of Wolfe and Franzel (1988), we are more convinced that rivalry has an ability to guide attention and less convinced that luster pops out. Indeed, they seem to be about equally effective as guiding features. This is, perhaps, a bit of a surprise. Luster is a surface property. Some objects are shiny. Rivalry is not really a property of surfaces. It is an accident of their placement, relative to our two eyes. We think of guiding attributes as properties of objects in the world so one might expect shininess to guide and rivalry not to. However, a very recent study by Zou et al. showed that binocular rivalry can be induced from conflicting but invisible spatial patterns (Zou, He, & Zhang, 2016). The invisible gratings produced significant BOLD activities in the early visual cortex but not in frontoparietal cortical areas, suggesting that interocular competition is triggered by and resolved by local mechanisms in the early visual cortex. If rivalry information is available in early visual cortex, similar to reliable features like color and orientation, it is not unreasonable that rivalry could guide attention, as shown in our study. Even though at first glance binocular rivalry and binocular luster are quite different phenomena, it is possible that they share some part of the same mechanism. For the present, it appears that both of these forms of interocular differences can guide attention with modest effectiveness.
Conclusion
The findings of our study modify our understanding of the role of interocular difference in guiding attention. We have demonstrated that rivalry and luster have similar abilities to guide attention in visual search tasks. Both produce search asymmetries as is characteristic of guiding features. Moreover each can support fairly efficient search slopes that seems to be easily disrupted by other stronger guiding features like orientation and luminance.
Notes
Lustre and luster are both used as spellings for a word roughly synonymous with “shiny.” Henceforth, we will use “luster.”
Some of the difference in RT could be due to equipment. The original Wolfe and Franzel experiments were run on a modified SubRoc-3D video game machine from a 1980s video arcade. The “alien invasion” game would no longer impress but the response keys were better than a Mac keyboard for these purposes.
References
Anstis, S. M. (2000). Monocular lustre from flicker. Vision Research, 40(19), 2551–2556. doi:10.1016/S0042-6989(00)00131-0
Beck, J., & Prazdny, S. (1981). Highlights and the perception of glossiness. Perception & Psychophysics, 30(4), 407–410. doi:10.3758/BF03206160
Birnkrant, R. S., Wolfe, J. M., Kunar, M. A., & Sng, M. (2004). Is shininess a basic feature in visual search? doi:10.1167/2.7.551
Blake, A., & Bülthoff, H. (1990). Does the brain know the physics of specular reflection? Nature, 343(6254), 165–168. doi:10.1038/343165a0
Blake, R., & Camisa, J. (1978). Is binocular vision always monocular? Science, 200(4349), 1497–1499.
Brainard, H. D. (1997). The Psycholysics Toolbox. Spatial Vision, 10(4), 433–436.
Brascamp, J. W., Klink, P. C., & Levelt, W. J. M. (2015). The “laws” of binocular rivalry: 50 years of Levelt’s propositions. Vision Research, 109, 20–37. doi:10.1016/j.visres.2015.02.019
Dick, M., Ullman, S., & Sagi, D. (1987). Parallel and serial processes in motion detection. Science. Retrieved from http://science.sciencemag.org/content/237/4813/400.short
Duncan, J., & Humphreys, G. W. (1989). Visual search and stimulus similarity. Psychological Review, 96(3), 433–458. doi:10.1037/0033-295X.96.3.433
Egeth, H. (1972). Parallel processing of multielement displays. Cognitive Psychology, 3(4), 674–698. doi:10.1016/0010-0285(72)90026-6
Egeth, H. (1977). Attention and preattention. Psychology of Learning and Motivation, 11, 277–320. doi:10.1016/S0079-7421(08)60480-6
Fleming, R. W., Dror, R. O., & Adelson, E. H. (2003). Real-world illumination and the perception of surface reflectance properties. Journal of Vision, 3(5), 3. doi:10.1167/3.5.3
Formankiewicz, M. A., & Mollon, J. D. (2009). The psychophysics of detecting binocular discrepancies of luminance. Vision Research, 49(15), 1929–1938. doi:10.1016/j.visres.2009.05.001
Foster, D. H., & Westland, S. (1995). Orientation contrast vs orientation in line-target detection. Vision Research, 35(6), 733–738. doi:10.1016/0042-6989(94)00178-O
Kleffner, D. A., & Ramachandran, V. S. (1992). On the perception of shape from shading. Perception & Psychophysics, 52(1), 18–36. doi:10.3758/BF03206757
Liu, L., Tyler, C. W., & Schor, C. M. (1992). Failure of rivalry at low contrast: Evidence of a suprathreshold binocular summation process. Vision Research, 32(8), 1471–1479. doi:10.1016/0042-6989(92)90203-U
Logan, G. D. (1995). Linguistic and conceptual control of visual spatial attention. Cognitive Psychology, 28(2), 103–174. doi:10.1006/cogp.1995.1004
Motoyoshi, I., Nishida, S., Sharan, L., & Adelson, E. H. (2007). Image statistics and the perception of surface qualities. Nature, 447(7141), 206–209. doi:10.1038/nature05724
Muryy, A. A., Fleming, R. W., & Welchman, A. E. (2014). Key characteristics of specular stereo. Journal of Vision, 14(2014), 1–26. doi:10.1167/14.14.14
Nagy, A. L., & Sanchez, R. R. (1990). Critical color differences determined with a visual search task. Journal of the Optical Society of America A, 7(7), 1209. doi:10.1364/JOSAA.7.001209
Nakayama, K., & Silverman, G. H. (1986). Serial and parallel processing of visual feature conjunctions. Nature, 320(6059), 264–265. doi:10.1038/320264a0
Paffen, C. L. E., Hessels, R. S., & Stigchel, S. (2012). Interocular conflict attracts attention. Attention, Perception, & Psychophysics, 74(5), 1073. doi:10.3758/s13414-012-0299-7
Paffen, C. L. E., Hooge, I. T. C., Benjamins, J. S., & Hogendoorn, H. (2011). A search asymmetry for interocular conflict. Attention, Perception & Psychophysics, 73(4), 1042–1053. doi:10.3758/s13414-011-0100-3
Peirce, J. W. (2007). PsychoPy-Psychophysics software in Python. Journal of Neuroscience Methods, 162(1/2), 8–13. doi:10.1016/j.jneumeth.2006.11.017
Quinlan, P. T., & Humphreys, G. W. (1987). Visual search for targets defined by combinations of color, shape, and size: An examination of the task constraints on feature and conjunction searches. Perception & Psychophysics, 41(5), 455–472. doi:10.3758/BF03203039
Rangelov, D., Müller, H. J., & Zehetleitner, M. (2012). The multiple-weighting-systems hypothesis: Theory and empirical support. Attention, Perception, & Psychophysics, 74(3), 540–552. doi:10.3758/s13414-011-0251-2
Rosenholtz, R. (2001). Search asymmetries? What search asymmetries? Perception & Psychophysics, 63(3), 476–489. doi:10.3758/BF03194414
Royden, C. S., Wolfe, J. M., & Klempen, N. (2001). Visual search asymmetries in motion and optic flow fields. Perception & Psychophysics, 63(3), 436–444. doi:10.3758/BF03194410
Shneor, E., & Hochstein, S. (2006). Eye dominance effects in feature search. Vision Research, 46(25), 4258–4269. doi:10.1016/j.visres.2006.08.006
Solomon, J. A., John, A., & Morgan, M. J. (2006). Monocular texture segmentation and proto-rivalry. Vision Research, 46(8/9), 1488–1492. doi:10.1016/j.visres.2005.07.002
Treisman, A. (1985). Preattentive processing in vision. Computer Vision, Graphics, and Image Processing, 31(2), 156–177. doi:10.1016/S0734-189X(85)80004-9
Treisman, A. (1988). Feature analysis in early vision—Evidence from search asymmetries. Psychological Review, 95(1), 15–48.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12(1), 97–136. doi:10.1016/0010-0285(80)90005-5
Von Helmholtz, H. (1924). Helmholtz’s treatise on physiological optics (Vol. 3). Retrieved from https://scholar.google.com/scholar?q=Helmholtz++vol+3+1924&btnG=&hl=en&as_sdt=0%2C22
Wolfe, J. M. (1983). Influence of spatial frequency, luminance, and duration on binocular rivalry and abnormal fusion of briefly presented dichoptic stimuli. Perception, 12(4), 447–456. doi:10.1068/P120447
Wolfe, J. M. (1998a). Visual search. Attention, 1, 13–73. doi:10.1016/j.tics.2010.12.001
Wolfe, J. M. (1998b). What can 1 million trials tell us about visual search? Psychological Science, 9(1), 33–39. doi:10.1111/1467-9280.00006
Wolfe, J. M. (2001). Asymmetries in visual search: An introduction. Perception & Psychophysics, 63(3), 381–389. doi:10.3758/BF03194406
Wolfe, J. M. (2014). Approaches to visual search: Feature integration theory and guided search. In E. C. Anna Nobre & S. Kastner (Eds.), The Oxford handbook of attention. doi:10.1093/oxfordhb/9780199675111.013.002
Wolfe, J. M., Cave, K. R., & Franzel, S. L. (1989). Guided search: An alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human Perception and Performance, 15(3), 419–433. doi:10.1037/0096-1523.15.3.419
Wolfe, J. M., & Franzel, S. L. (1988). Binocularity and visual search. Perception & Psychophysics, 44(1), 81–93. doi:10.3758/BF03207480
Wolfe, J. M., & Horowitz, T. S. (2004). What attributes guide the deployment of visual attention and how do they do it? Nature Reviews Neuroscience, 5(6), 495–501. doi:10.1038/nrn1411
Zhaoping, L. (2012). Gaze capture by eye-of-origin singletons: Interdependence with awareness. Journal of Vision, 12(2), 17. doi:10.1167/12.2.17
Zohary, E., & Hochstein, S. (1989). How serial is serial processing in vision? Perception, 18(2), 191–200. doi:10.1068/P180191
Zou, J., He, S., & Zhang, P. (2016). Binocular rivalry from invisible patterns. Proceedings of the National Academy of Sciences of the United States of America, 113(30), 8408–8413. doi:10.1073/pnas.1604816113
Acknowledgements
This research was supported in part by NIH (EY017001), National 973 Program of China (2013CB328805), and Program for Basic Research of National Research University Higher School of Economics (TZ-64, year 2016). B.Z. thanks China Scholarship Council for the financial support.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zou, B., Utochkin, I.S., Liu, Y. et al. Binocularity and visual search—Revisited. Atten Percept Psychophys 79, 473–483 (2017). https://doi.org/10.3758/s13414-016-1247-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1247-8