
Abstract
Vision and audition have complementary affinities, with vision excelling in spatial resolution and audition excelling in temporal resolution. Here, we investigated the relationships among the visual and auditory modalities and spatial and temporal short-term memory (STM) using change detection tasks. We created short sequences of visual or auditory items, such that each item within a sequence arose at a unique spatial location at a unique time. On each trial, two successive sequences were presented; subjects attended to either space (the sequence of locations) or time (the sequence of inter item intervals) and reported whether the patterns of locations or intervals were identical. Each subject completed blocks of unimodal trials (both sequences presented in the same modality) and crossmodal trials (Sequence 1 visual, Sequence 2 auditory, or vice versa) for both spatial and temporal tasks. We found a strong interaction between modality and task: Spatial performance was best on unimodal visual trials, whereas temporal performance was best on unimodal auditory trials. The order of modalities on crossmodal trials also mattered, suggesting that perceptual fidelity at encoding is critical to STM. Critically, no cost was attributable to crossmodal comparison: In both tasks, performance on crossmodal trials was as good as or better than on the weaker unimodal trials. STM representations of space and time can guide change detection in either the visual or the auditory modality, suggesting that the temporal or spatial organization of STM may supersede sensory-specific organization.
Similar content being viewed by others

Introduction
Short-term (or working) memory is the remarkable ability to observe and encode information from the surrounding environment, maintain an internal representation of that information, and then draw on that memory representation to make judgments about future events (Voytek & Knight, 2010). An extensive previous literature has described the capacity and precision of visual short-term memory (STM; for reviews, see Brady, Konkle, & Alvarez, 2011; Luck & Vogel, 2013; Ma, Husain, & Bays, 2014), verbal span (reviewed in Hurlstone, Hitch, & Baddeley, 2014), and nonverbal auditory memory (e.g., Parmentier & Jones, 2000; Visscher, Kaplan, Kahana, & Sekuler, 2007). Several groups have compared perceptual and memory effects in the visual and auditory modalities (e.g., Balch & Muscatelli, 1986; Guttman, Gilroy, & Blake, 2005; McAuley & Henry, 2010; Shih, Kuo, Yeh, Tzeng, & Hsieh, 2009; Tremblay, Parmentier, Guérard, Nicholls, & Jones, 2006), but only a few researchers have investigated how easy it is to use the information encoded in one sensory modality to make judgments about information presented in another modality (Collier & Logan, 2000; Harrington, Castillo, Fong, & Reed, 2011). Descriptions of crossmodal judgments are valuable because they shed light on the processes by which sensory-specific episodic information is transformed into more abstract representations, accessible to multiple perceptual streams. Here we investigated STM performance on spatial and temporal tasks for information presented in the visual and auditory sensory modalities, and explored whether there are costs to STM performance when comparisons are made across modalities.
Specialization of sensory modalities
Sensory modalities are specialized for different information domains, as well as for different forms of environmental energy. Visual input is intrinsically spatial, comprising a two-dimensional array of luminances across the retina, and vision has a corresponding affinity for spatial information. Spatial characteristics define the features to which the visual system is most sensitive, such as edges and texture (Hubel & Wiesel, 1959). Spatiotopic cortical maps are found throughout the visual processing pathway (Silver & Kastner, 2009; Swisher, Halko, Merabet, McMains, & Somers, 2007). Auditory perception of space, on the other hand, is relatively poor (Jackson, 1953), and spatiotopic maps have not been identified at any stage of the mammalian cortical auditory pathway (Barrett & Hall, 2006).
Auditory sensory inputs comprise a series of fluctuating pressure oscillations; the frequency of these oscillations and how the energy at each frequency changes through time are what convey information to the auditory sense. Audition has an affinity for temporal information, with exquisite sensitivity to temporal features such as onset and frequency, and primary auditory cortex displays a tonotopic organization (Da Costa et al., 2011; Merzenich & Brugge, 1973; Wessinger, Buonocore, Kussmaul, & Mangun, 1997). The auditory system is able to make very fine discriminations in the judgment of time intervals (Creelman, 1962; Ivry & Hazeltine, 1995; Lhamon & Goldstone, 1974), with precision at least an order of magnitude better than in the visual modality (Lhamon & Goldstone, 1974).
These complementary sensory affinities have perceptual consequences, often described as modality appropriateness (Welch & Warren, 1980). Vision tends to dominate when the cognitive task at hand is spatial. For instance, when reporting the location of an auditory stimulus source, observers are biased toward the spatial location of a visual stimulus presented at a similar time, a phenomenon known as the ventriloquism effect (Bertelson & Aschersleben, 1998; I. P. Howard & Templeton, 1966). Conversely, audition tends to dominate when the cognitive task is temporal, resulting in a temporal ventriloquism effect: When reporting the time at which a visual event occurred, participants are biased toward the time (temporal location) of a nearby auditory stimulus (Bizley, Shinn-Cunningham, & Lee, 2012; Burr, Banks, & Morrone, 2009; Fendrich & Corballis, 2001; Morein-Zamir, Soto-Faraco, & Kingstone, 2003; Shams, Kamitani, & Shimojo, 2000). Welch and Warren (1980) hypothesized that these effects arise from the innate correspondence between sensory modalities and information domains. More recently, these effects have been attributed to each modality’s reliability in the information domain at hand. If the reliability of input in one sensory modality is reduced, that modality’s contribution to the final percept is also reduced; analyzed on the basis of the reliability of information, the brain comes remarkably close to optimally combining information across sensory modalities (Alais & Burr, 2004).
Similar effects of modality occur in STM. Memory for spatial locations is superior when those locations are presented visually rather than through sound (Lehnert & Zimmer, 2008), and the abstraction of the up–down contour of a sequence of sensory events is more efficient from visuospatial than from melodic stimuli (Balch & Muscatelli, 1986). On the other hand, memory for rhythms and time intervals is superior when stimuli are presented to the ears rather than the eyes (Collier & Logan, 2000). Indeed, auditory distractors interfere with memory for visual rhythms, hinting that both may be held in a common store (Guttman et al., 2005). The perceptual reliability of visual and auditory inputs may shape STM for spatial and temporal information.
Nature of STM stores
The dominant model of STM is Baddeley and Hitch’s (1974) working memory description, in which discrete visuospatial and verbal stores are both linked to a central executive component. Early evidence for this separation of two stores came from studies that crossed visuospatial or verbal STM tasks with concurrent visuospatial or verbal secondary tasks. These studies consistently identified modality-specific interference effects. For example, STM for visual imagery, but not for verbal lists, is disrupted by a simultaneous visual pursuit task (Baddeley, Grant, Wight, & Thomson, 1975) or a spatial manipulation task (Alloway, Kerr, & Langheinrich, 2010; Guérard & Tremblay, 2008; Logie, Zucco, & Baddeley, 1990). Conversely, the maintenance of auditory STM is impaired by simultaneous verbal articulation, but visual STM is not (Alloway et al., 2010; Guérard & Tremblay, 2008; Kroll, Parks, Parkinson, Bieber, & Johnson, 1970), and verbal, but not visuospatial, STM is disrupted by a simultaneous arithmetic task (Logie et al., 1990). Further evidence for two discrete stores has come from distraction effects. Unexpected, task-irrelevant events in the spatial or verbal information domain impair, respectively, spatial or verbal memory performance and reasoning (Farmer, Berman, & Fletcher, 1986; Lange, 2005). Syncopated tapping also disrupts verbal STM, suggesting that rhythm draws on the verbal STM store (Larsen & Baddeley, 2003). Additional support for the separate-stores account has come from lesion patients with impaired digit span but normal spatial span, and other patients with the converse pattern of impairment (Hanley, Young, & Pearson, 1991; Vallar & Baddeley, 1984).
Previous work on nonverbal auditory information and STM has been sparser. Verbal STM is disrupted by vocal and nonvocal music, but not by auditory noise, implying that some nonverbal auditory information shares an STM store with verbal information (Salamé & Baddeley, 1989). Memory for pitch is disrupted by intervening tones or words of similar pitch (Deutsch, 1972; Semal, Demany, Ueda, & Hallé, 1996), but not by visual patterns (Pechmann & Mohr, 1992). Memory for timbre is also disrupted by similar intervening items (Starr & Pitt, 1997). Nonverbal auditory information is thus believed to share an STM store with verbal information, separate from that for visuospatial information (Baddeley, 2012). Intriguingly, visual and auditory rhythms seem to share an STM store, although performance when judging auditory rhythms is superior (Collier & Logan, 2000).
A few studies have pointed to a shared memory process that is recruited by both visual and auditory or verbal STM. Verbal STM is impaired for words that are visually and phonologically similar, as compared to words that are phonologically similar but visually different (Logie, Della Sala, Wynn, & Baddeley, 2000). Visual and auditory STM are influenced by many of the same factors, such as serial position, retention interval, and load (Visscher et al., 2007). STM capacity for mixed auditory and visual arrays is larger than capacity for either visual or auditory information, but smaller than their sum, suggesting that some portion of STM capacity is shared between modalities (Fougnie, Zughni, Godwin, & Marois, 2014; Saults & Cowan, 2007).
Crossmodal memory-guided cognition
In daily life, humans frequently work with information in multiple sensory modalities; we use visual information to predict forthcoming auditory input, and vice versa. For example, a person standing at the kitchen sink might hear a noise behind him and, on turning around, expect to see a family member at the kitchen door. A different person or a different location would be quite unexpected. Only a few studies have investigated memory performance when using visual stimuli to probe auditory encoding, or vice versa (crossmodal memory). Both examples that we know of have been investigations in the temporal domain, one into the representation of single intervals (Harrington et al., 2011), the other into the representation of rhythms (Collier & Logan, 2000). Both studies showed that subjects’ performance in unimodal auditory conditions was superior to their performance in unimodal visual conditions. Crossmodal comparison of single intervals is better than either auditory or visual unimodal comparison when the auditory interval is presented first, but worst than both auditory and visual unimodal comparison when the visual interval is presented first (Harrington et al., 2011), while crossmodal comparison of rhythms is better than visual but worse than auditory comparison (Collier & Logan, 2000).
The present work
Here, we measured STM for visual or auditory stimuli using a sequence change detection task that required storage of either spatial locations or temporal intervals. Subjects performed both unimodal change detection (comparing either two visual sequences or two auditory sequences) and crossmodal change detection (comparing a visual to an auditory sequence, or vice versa). We tested four hypotheses:
H1: STM modality appropriateness
The visual and auditory modalities differ in their abilities to extract and represent spatial and temporal information. Unimodal change detection performance for spatial tasks will be superior for visual relative to auditory trials, whereas performance on temporal tasks will show the opposite effect.
H2: Shared domain-specific memory stores
If STM representations are stored according to task demands (i.e., information domain, rather than input modality) and these task-based STM stores can be accessed by both modalities, then performance on crossmodal change detection will be as good as or better than performance in the weaker unimodal case. That is, the costs of crossmodal STM come only from modality-specific limitations, rather than from any additional cost of translating between modalities.
H3: Dependence on STM encoding
Observers likely minimize STM load by encoding only the first sequence into STM; they then perform an online comparison between the memory representation and the incoming second sequence to determine whether each sequence element matches the memory representation. If so, the fidelity of the STM representation of the first sequence is crucial, dominating performance. In crossmodal tasks, performance on spatial tasks will be better on visual-first trials than on auditory-first trials; performance on temporal tasks will be better on auditory-first than on visual-first trials.
H4: Interference from task-irrelevant changes
If the spatial and temporal information domains interact, it may be easy to detect that a change has occurred, but difficult to discriminate changes in timing from changes in spatial location. Some authors have hypothesized that either the location (e.g., Johnston & Pashler, 1990; Treisman & Gelade, 1980) or the time of occurrence (e.g., Dixon & Spitz, 1980; M.W. Howard & Kahana, 2002) is an essential cue for binding features in different modalities or different information domains into a coherent percept and a shared memory representation. Therefore, if there are task-irrelevant changes between the first and second sequences (i.e., while subjects are performing the spatial task, sequence timing changes), it will disrupt the ability to detect change in the task-relevant information domain.
Our results supported H1, H2, and H3, but not H4.
Method
All protocols were approved by the Institutional Review Board of Boston University.
Subjects
Twenty-five young adults enrolled in the Introduction to Psychology course at Boston University participated in this study for partial course credit (ages 18–22, 16 women, nine men). We computed mean change detection sensitivity, which we used to screen out participants with very low performance. We selected, a priori, an arbitrary threshold of d′ = 0.5, and five subjects whose performance was below this threshold were excluded. All results presented here are from the remaining 20 subjects. Our sample size (20 subjects passing a minimum performance criterion) was selected a priori using effect size estimates from pilot data.
Experimental task
We adapted the change detection paradigm (Phillips, 1974; Vogel et al. 2001) to require subjects to compare two short sequences. Subjects first observed a sequence in one modality (visual or auditory), followed by a brief delay (0.5 s). After the delay, subjects observed a second sequence and were asked to report whether it was identical to or different from the first in either its sequence of spatial locations (space task) or its sequence of temporal intervals (time task). Note that the properties of the stimuli were identical in both tasks; only the instructions given to the subjects differed.
Each subject performed both the space and the time tasks in both unimodal and crossmodal forms. On each trial of unimodal change detection, subjects encountered either two visual sequences or two auditory sequences, and decided whether the sequences were identical in the task-relevant information domain (either space or time). We will denote these unimodal trials as VV and AA, respectively. On each trial of crossmodal change detection, subjects encountered two sequences in different modalities, either visual first and auditory second or vice versa, and compared across modalities to determine whether the two sequences matched in the task-relevant information domain. We will denote these types of trials as VA and AV, respectively.
A third factor was the presence or absence of changes in the task-irrelevant information domain, allowing us to test whether such changes affected performance. That is, while performing the space task, were subjects impaired by irrelevant changes in the time domain? To investigate this, we constructed blocks of trials in which the task-irrelevant information domain was always fixed between the first and second sequences of each trial, and blocks of trials in which the task-irrelevant information domain had a 50% probability of containing a change. The order of blocks within the space and time tasks was randomized for each subject.
Stimuli
The visual and auditory stimuli were constructed to contain both spatial and temporal information. Each item in a sequence had a unique spatial location; each pair of items was separated by a unique temporal interval. Figure 1 shows schematics of the visual and auditory stimuli used in this experiment.

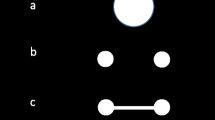
Visual and auditory stimuli for the sequence change detection task. (A) The visual stimuli comprised an array of mostly static images. Across the ensuing sequence, four of these images were replaced by their mirror-flipped counterparts (one at a time). When performing the space task, subjects were to remember the sequence of locations of these four replacements; when performing the time task, they were to remember the sequence of intervals between successive replacements. (B) The auditory stimuli comprised a series of 50-ms complex tones, lateralized by interaural time difference. When performing the space task, subjects were to remember the sequence of lateral locations; when performing the time task, they were to remember the sequence of intervals between successive tones.
For visual sequences (Fig. 1A), subjects observed a semicircular array of five images presented on a CRT monitor. Each sequence item consisted of the instantaneous left–right mirror flip of one image. Each item thus had a spatial location within the array, and a temporal interval separating it from the previous flip. The images were drawn from a collection of animal images (e.g., drawings, photographs) against white backgrounds, retrieved from a Web search and scaled so that the images were clearly visible and approximately the same size. On each trial, five copies of a single image were used. Whether each copy was in the original orientation or was mirror-flipped at initial onset was randomly assigned, so that the instantaneous orientations of the images provided no information about whether or not that item had already flipped. This stimulus paradigm was originally designed for a long-term memory experiment and was adapted for the present STM purposes; here, the identity of the animals was irrelevant, but the animal images may have increased subject interest and vigilance in the task.
These stimuli are not perfectly parallel to their auditory equivalents (described below). All five images were visible on the screen throughout the entire sequence, whereas the auditory items were presented one at a time. We had three reasons for this decision. First, sudden, discrete onsets and offsets of visual stimuli are unusual among natural visual inputs, whereas changes in state of an already-present item are more common. Second, in piloting, we found that onsetting and offsetting visual stimuli drove a strong subjective experience of an internal auditory representation, regardless of the task. Finally, the persistent images acted as visual masks, making the visual tasks more attentionally demanding.
For the auditory sequences (Fig. 1B), subjects listened to a stream of complex tones. The tones were presented via stereo headphones at a subject-adjusted, comfortable, clearly audible listening level (between 65 and 85 dB SPL). A sequence item consisted of a single tone, lateralized by interaural time difference. Each item thus had a spatial location in azimuth, and a temporal interval separating it from the previous tone. We generated complex tones by first selecting one of ten base frequencies (logarithmically spaced between 200 Hz and 400 Hz). Two other frequencies were then selected at 1.33 and 1.59 times the base frequency. The tones included these three fundamental frequencies and their first three harmonics at equal intensities, and were windowed with a 16-ms cosine-squared ramp at onset and offset. This process generated a set of tones with similar timbres and varying pitches. All tones within a trial were composed of the same frequencies. Each tone had an interaural time difference drawn from the set of −1,000, −350, 0, 350, and 1,000 μs (selected randomly, as noted below), producing tones whose lateral angle corresponded roughly to the five spatial locations in the visual display.
The stimulus sequences in both modalities comprised four sequence items with three inter item intervals. At the start of each trial, a sequence of locations was drawn without replacement from the set of far-left, left, center, right, and far-right locations. Similarly, a sequence of inter item intervals was drawn from the set of 250.0-ms, 404.5-ms, 654.5-ms, and 1,059.0-ms intervals. This order of locations and intervals specified that trial’s first sequence.
This family of intervals was selected to comply with three constraints. We selected intervals that were not integer multiples of each other, to reduce the rhythmicity of the stimuli. Then we selected intervals that were approximately 1 s in duration and below, because longer interval timing disrupts performance (Collier & Logan, 2000). Finally, pilot testing showed that intervals shorter than 250 ms are nearly impossible to track in the visual modality.
During blocks of trials in which the task-irrelevant information domain was fixed, the second sequence was either identical to the first or, with 50% probability, contained a change in the task-relevant information domain, with two locations or two intervals swapping serial positions (with the stipulation that the first item’s location never changed, in an attempt to equate the memory loads between the space and time tasks). During blocks of trials that included task-irrelevant changes, such changes occurred with 50% probability and were independent of the presence or absence of a change in the task-relevant information domain. The second sequence could thus contain changes in locations, intervals, both, or neither, each with 25% probability.
Design and procedures
As we described above, this study had a 2 (Task: space, time) × 4 (Modality Permutation: VV, VA, AV, AA) × 2 (Task-Irrelevant Changes: yes, no) within-subjects design. Pilot data suggested that intermixed conditions dramatically impaired subjects’ ability to discriminate changed from unchanged trials, possibly due to the demands of shifting cognitive sets. We therefore used a blocked design in our experiment. Each subject completed one block (48 trials) of each condition. Response identities and reaction times were recorded; because subjects were not prompted to answer until after the second sequence was complete, the reaction times are minimally informative, and only the response identities (i.e., “same” or “different”) are analyzed here.
After giving informed consent and completing a basic demographic questionnaire, subjects received instructions on either the space task or the time task. They then completed all eight blocks of trials in that task. After a brief break, subjects received instructions on the remaining task, and again they completed eight blocks of trials in that task. The order of tasks was counterbalanced across subjects; the order of conditions within each task was randomized for each subject.
Performance was operationalized as change detection sensitivity, measured by d′. We chose to measure sensitivity rather than accuracy because d′ is not affected by subjects’ criteria for reporting “different,” and we suspected that those criteria might differ between conditions.
Results
Subjects were able to discriminate changed from unchanged sequences (overall mean d′ = 1.02, SD = 0.26). A two-way repeated measures analysis of variance (ANOVA) with the factors Modality Permutation (VV, VA, AV, and AA) and Task (space and time) identified a significant main effect of modality [F(3, 57) = 13.47, p < .0001], a significant main effect of task [F(1, 19) = 7.76, p = .012], and a significant interaction between them [F(3, 217) = 69.34, p < .0001].
Figure 2 shows performance on the space and time tasks for each modality permutation, collapsed across blocks in which the task-irrelevant information domain was fixed and blocks in which it could change. As we predicted, there was a substantial STM modality appropriateness effect, with performance being higher on VV than on AA for the space task [t(19) = 12.30, p < .0001, Cohen’s d = 2.78], but lower on VV for the time task [t(19) = 7.64, p < .0001, Cohen’s d = 1.71].

Change detection sensitivity on the space task (left) and the time task (right) for all four modality permutations. Performance was best in the task-appropriate modality, and showed no cost of crossmodal change detection beyond that attributable to the perceptual weakness of the task-inappropriate modality. * p < .05; ** p < .01; *** p < .001.
The two crossmodal conditions were consistently as good as or better than the weaker unimodal condition. In the space task, performance was better on VA than on AA [t(19) = 3.32, p = .004, Cohen’s d = 0.76], and we found no significant difference between performance on AV and on AA [t(19) = –0.45, p = .66, Cohen’s d = 0.10]. Similarly, in the time task, performance was better on AV than on VV [t(19) = 2.90, p = .009, Cohen’s d = 0.66], and we found no significant difference between performance on VA and on VV [t(19) = 0.20, p = .84, Cohen’s d = 0.05]. This is consistent with an STM store that can be freely accessed by both modalities, with no additional cost of switching between them.
Finally, in the crossmodal conditions, the order of modalities mattered. In the space task, there was a substantial advantage to encountering the visual sequence first [VA > AV, t(19) = 4.02, p = .0007, Cohen’s d = 0.93); in the time task, there was a moderate advantage to encountering the auditory sequence first [AV > VA, t(19) = 2.41, p = .03, Cohen’s d = 0.54]. This highlights the importance of STM encoding of the initial sequence in this paradigm.
Using multiple linear regression, we quantified the influences of task, modality, and task-appropriateness on change detection performance. To reduce the effects of individual differences in memory capacity and motivation, we first standardized each subject’s d′ scores over the 16 blocks of trials. Then we fit a linear model using five binary predictors: the task-appropriateness of the modalities in which the first and second sequences were presented (β1 and β2); the task (β3; time > space); and the modalities of the first and second sequences (β4 and β5; V > A). (Note that all predictors were binary, with mean 0.5.) The model also included a constant term.
Figure 3 shows the resulting beta weights. The single strongest predictor is whether the modality of the first sequence was appropriate to the task the subject was performing (i.e., visual for the space task and auditory for the time task; β1 = 1.00, SE = 0.09). This factor alone accounted for .26 of the variance in standardized scores. The task-appropriateness of the second sequence’s modality was the next-strongest factor (β2 = 0.48, SE = 0.09), followed by task (with a benefit for time; β3 = 0.37, SE = 0.09). The effects of modality alone were modest. This analysis confirmed and quantified the striking degree to which the task-appropriateness of the first sequence affects change detection performance.

Factor weights from a multiple linear regression comparing the effects of modality, task appropriateness, and task. The alignment between the task and the first sequence’s modality is by far the strongest predictor, accounting for a full standard deviation in performance.
We also assessed whether task-irrelevant changes between the encoding sequence and the probe sequence had any effect on behavior. Figure 4 shows performance on the blocks of trials when the event values in the unattended information dimension were always the same in the two sequences (fixed within a block; top panel), as well as in the mixed blocks, broken down by whether the task-irrelevant information was fixed or changed (bottom panel). A three-way ANOVA with the factors Modality Permutation, Task, and Task-Irrelevant Information (always fixed, fixed trials in mixed blocks, and changed trials in mixed blocks) revealed no significant effect of task-irrelevant information [F(2, 38) = 0.96, p = .391], no interaction between task-irrelevant information and either modality permutation [F(2, 38) = 0.55, p = .584] or task [F(6, 114) = 0.97, p = .447], and no three-way interaction [F(6, 114) = 1.29, p = .269]. In short, we found no evidence for any effect of the stability or changeability of the task-irrelevant information domain. A multiple regression similar to the one above that included whether each block’s task-irrelevant dimension was fixed or mixed resulted in very similar beta weights on all regressors, confirming this result.

Change detection sensitivity on the space task (left) and the time task (right) for all four modality permutations, broken down by the presence or absence of task-irrelevant changes. There was no effect of task-irrelevant changes.
Discussion
We developed a sequence change detection task that allowed us to probe unimodal and crossmodal STM use of spatial and temporal information. In both spatial and temporal tasks, change detection substantially improved when stimulus sequences were presented in the modality that was most appropriate for the task demands: Spatial task performance was best in the unimodal visual condition, and temporal task performance was best in the unimodal auditory condition. We also showed that crossmodal change detection has no performance costs beyond those associated with the poorer perceptual representation in the weaker modality, suggesting that the STM stores for spatial and temporal information are accessible to both sensory modalities. Furthermore, in crossmodal change detection, performance depended on the order of the modalities. Spatial change detection was better when the first sequence was visual and the second auditory than in the opposite order, and temporal change detection showed the converse effect.
STM modality appropriateness
Demonstrating that audition and vision are uneven in their abilities to represent spatial and temporal information is consistent with an extensive body of prior work and confirms the validity of our task, providing confidence that we were probing spatial and temporal representations in STM. Temporal information is perceived more accurately and precisely through the auditory than through the visual modality (Lhamon & Goldstone, 1974), and this advantage extends into STM (Collier & Logan, 2000; Guttman et al., 2005). Conversely, spatial information is perceived more accurately and precisely through the visual than through the auditory modality (Jackson, 1953), and this advantage also holds in STM (Lehnert & Zimmer, 2008). These results, along with this prior work, confirm that the modality appropriateness hypothesis (Welch & Warren, 1980) can be generalized to describe properties of STM.
Our results do not separate perceptual limitations in the weaker modality from STM limitations. We think it very likely that the impaired spatial change detection we observed in the unimodal auditory condition and the impaired temporal change detection we observed in the unimodal visual condition reflect, at least in part, those modalities’ reduced abilities to detect and extract the relevant stimulus features. However, our further study of crossmodal change detection (e.g., AV and VA conditions) equalized perceptual limitations and isolated STM processes, particularly retrieval and comparison.
Shared domain-specific memory stores
It was unclear how modalities and task demands would interact if the first and second sequences were presented to different modalities. If STM were stored strictly according to sensory modality (as in a naïve implementation of the Baddeley & Hitch, 1974, model), crossmodal change detection would require an extra step of translation from one modality-specific representation to another, which should result in additional costs to performance. If this were the case, crossmodal change detection would be even more difficult than change detection in the weaker unimodal condition. Conversely, if STM were stored according to the informational requirements of the task, although a task-appropriate modality might still have a perceptual advantage, there should be no costs of crossmodal comparison that were not attributable to limitations from the representation in the less accurate modality for that information domain. Our results support the latter interpretation, with both crossmodal conditions resulting in change detection that was as good as or better than in the weaker unimodal condition (although still below the level in the stronger unimodal condition). Our pattern of results matches that previously observed in STM for temporal sequences (Collier & Logan, 2000); here, we’ve shown that it holds for the spatial information domain, as well.
One alternative interpretation of these data is that STM stores are strictly segregated according to sensory modality, but the brain can translate between sensory-specific representations with perfect fluency. Memory capacity measures in unimodal and crossmodal STM tasks may provide an avenue for distinguishing between these interpretations (Fougnie & Marois, 2011; Saults & Cowan, 2007). Nonetheless, we argue that memory stores that are fluently accessible to guide judgments in any modality are not meaningfully separated by modality in the classic sense. Information domain appears to supersede sensory modality as an organizational principle for STM stores.
We suspect that crossmodal change detection involves a process of encoding sensory input into a representation that is appropriate for the task demands. A number of studies have suggested that visual temporal processing relies on auditory mechanisms (e.g., Guttman et al., 2005; Keller & Sekuler, 2015; Van der Burg, Olivers, Bronkhorst, & Theeuwes, 2008), although others have disputed this (McAuley & Henry, 2010). Similarly, auditory spatial representations seem to rely on the visuospatial processing pathway (Martinkauppi, Rämä, Aronen, Korvenoja, & Carlson, 2000). A recent project investigating the brain networks engaged during unimodal change detection for spatial and temporal information identified visual-biased and auditory-biased areas in posterior lateral frontal cortex (Michalka, Kong, Rosen, Shinn-Cunningham, & Somers, 2015a). A similar task-specific recruitment occurs within parietal lobe regions that contain visual maps (Michalka, Rosen, Kong, Shinn-Cunningham, & Somers, 2015b). Activity in the visual-biased areas was stronger in an auditory spatial task than in an auditory temporal task, suggesting that these areas may be recruited to support processing in an information domain that is better-suited to vision than audition. Auditory-biased areas, conversely, were more strongly activated in a visual temporal task than in a visual spatial task, again suggesting recruitment to support processing in the temporal information domain. Given this evidence for domain recruitment, it is likely that similar processes support crossmodal change detection.
Dependence on STM encoding
In crossmodal change detection, the modality of the first sequence had a strong impact. Subjects performed substantially better when the first sequence was presented in the task-appropriate modality than when the first sequence was task-inappropriate. In change detection tasks, subjects encode the first stimulus into STM, and then use the memory representation to drive a comparison process as they observe the second stimulus (Collier & Logan, 2000). In a sequential task such as ours, this comparison likely involves the sequential allocation of attention to particular locations at particular times (those locations and times that match the stored memory representation of the initial sequence). The stronger the memory representation (and thus, the expectations about forthcoming sequence items), the better the discrimination between same and different trials (Summerfield & Egner, 2009). If subjects were, instead, encoding the entirety of both sequences into memory and performing comparisons on the memory representations, we would not expect to see a large asymmetry between performance for the visual-first and auditory-first crossmodal conditions.
Several possible mechanisms could give rise to the strong effect of task modality appropriateness at the first stimulus sequence. One mechanism is the perceptual limitations of each sensory modality in its weaker information domain. That is, vision is relatively poor at extracting timing information from sensory input (Lhamon & Goldstone, 1974), and audition is relatively poor at extracting spatial information (Jackson, 1953). The change detection impairment that we observed when the first sequence was presented in the weaker modality may be attributable to confusions between locations (auditory space task) or intervals (visual time task). Another possible source is differences in modality-specific access to STM. It may be that, whereas both modalities can freely access STM stores, one has an advantage. This privileged access may result in stronger or more-precise memory representations when information is presented in the privileged modality (auditory for temporal information and visual for spatial information). Our experiment does not allow us to separate these two possible explanations; further work will be needed to test these effects.
A third possible explanation is that memory representations decay more quickly when the modality and the task are poorly aligned (Collier & Logan, 2000; Donkin et al., 2014). When the first sequence is presented in a task-inappropriate modality, its memory representation may have deteriorated (via either sudden death or gradual decay; Zhang & Luck, 2009) by the time that subjects are assessing whether the two sequences are the same. Likewise, when the first sequence is presented in the task-appropriate modality, its memory representation may remain more intact and more effectively comparable to the second sequence. We find this account less convincing than the perceptual-limitations or privileged memory access explanations, because the time scales in our experiment were shorter than those generally identified to increase memory decay over time, but the study reported here is not sufficient to disprove this hypothesis. Further work measuring performance changes at longer or shorter time scales may be able to tease these two effects apart.
Interference from task-irrelevant changes
Contrary to our interference hypothesis, subjects were not noticeably affected by changes between Sequences 1 and 2 in the task-irrelevant information domain. That is, subjects were able to consistently separate temporal from spatial information in short visual and auditory sequences. Previous work has suggested that shared location may be an essential cue for binding multiple stimulus features into a single representation (e.g., Johnston & Pashler, 1990; Treisman & Gelade, 1980). Shared timing has similarly been proposed as a cue for binding, particularly across modalities (Dixon & Spitz, 1980), or as an organizing principle in memory (M. W. Howard & Kahana, 2002). Our results do not preclude location or timing playing an important role in perceptual and episodic binding; they merely highlight an ability to “unbind” and separate the domains. We do not have enough information to assess whether this separation occurs before memory encoding, so that only the relevant information domain is stored in memory, or whether it occurs at memory retrieval, with subjects selecting the relevant information from the memory representation in order to guide their comparisons. This appears to be a promising avenue for further investigation.
We should note that the classical tau effect (i.e., changes in the time intervals between successive stimuli bias the perceived spatial distance between them; Helson & King, 1931) and kappa effect (i.e., changes in the spatial distance between successive stimuli bias the perceived time intervals between them; Cohen, Hansel, & Sylvester, 1953) also predict interactions between task-relevant and task-irrelevant information domains. However, unlike those earlier studies, our task included a small number of discrete locations, which were explicitly identified to subjects, as well as a small number of discrete time intervals. This may have minimized the bias in location or interval judgments.
General discussion
Our task required subjects to make at least one explicit translation between reference frames. The spatial locations in the visual task comprised five equally spaced locations around the perimeter of a semicircle on the (vertical) screen in front of them; the spatial locations in the auditory task comprised five locations in the azimuth (horizontal) plane, with interaural differences selected to roughly match the angular separation of the visual locations (note that the mapping between interaural time differences and lateral angle is compressive, rather than linear, explaining our choice of binaural cues). No subjects reported confusion about this remapping; modern humans perform such tasks on a regular basis, such as when mapping from a mouse or touchpad to a computer screen, and are quite fluent in them.
One key limitation of this study is that we only investigated a single family of intervals, both for the inter item intervals within sequences and for the interstimulus interval between the two sequences of a given trial. Crossmodal memory likely requires some time to be recoded from a modality-specific representation to a modality-general one, or from a task-inappropriate to a task-appropriate representation (see Collier & Logan, 2000, for an extensive investigation of the effects of rate and timing on a crossmodal rhythm task). We suspect that if we reduced the time between paired sequences, or shortened the sequence intervals, performance on the task would be decreased, especially in visual timing tasks. Conversely, it is likely that if the intervals were lengthened to suprasecond ranges, quite different results might occur. Collier and Logan found that at those longer intervals, rhythm change detection was generally impaired, and the advantage of auditory presentation was reduced.
To our knowledge, this is the first study simultaneously to investigate the effects of sensory modality and of task demands on change detection performance. Our results emphasize the importance of memory encoding and the likelihood that sensory inputs are recoded into a task-specific rather than a modality-specific representation, as well as reaffirming the strong links between sensory modalities and specific information domains.
References
Alais, D., & Burr, D. (2004). The ventriloquist effect results from near-optimal bimodal integration. Current Biology, 14, 257–262. doi:10.1016/j.cub.2004.01.029
Alloway, T. P., Kerr, I., & Langheinrich, T. (2010). The effect of articulatory suppression and manual tapping on serial recall. European Journal of Cognitive Psychology, 22, 297–305. doi:10.1080/09541440902793731
Baddeley, A. (2012). Working memory: Theories, models, and controversies. Annual Review of Psychology, 63, 1–29. doi:10.1146/annurev-psych-120710-100422
Baddeley, A. D., Grant, S., Wight, E., & Thomson, N. (1975). Imagery and visual working memory. In P. M. A. Rabbitt & S. Dornic (Eds.), Attention and performance V (pp. 205–217). Hillsdale, NJ: Erlbaum.
Baddeley, A. D., & Hitch, G. J. (1974). Working memory. In G. H. Bower (Ed.), The psychology of learning and motivation (Vol. 8, pp. 47–89). New York, NY: Academic Press.
Balch, W. R., & Muscatelli, D. L. (1986). The interaction of modality condition and presentation rate in short-term contour recognition. Perception & Psychophysics, 40, 351–358.
Barrett, D. J. K., & Hall, D. A. (2006). Response preferences for “what” and “where” in human non-primary auditory cortex. NeuroImage, 32, 968–977. doi:10.1016/j.neuroimage.2006.03.050
Bertelson, P., & Aschersleben, G. (1998). Automatic visual bias of perceived auditory location. Psychonomic Bulletin & Review, 5, 482–489. doi:10.3758/BF03208826
Bizley, J. K., Shinn-Cunningham, B. G., & Lee, A. K. C. (2012). Nothing is irrelevant in a noisy world: Sensory illusions reveal obligatory within- and across-modality integration. Journal of Neuroscience, 32, 13402–13410. doi:10.1523/JNEUROSCI.2495-12.2012
Brady, T. F., Konkle, T., & Alvarez, G. A. (2011). A review of visual memory capacity: Beyond individual items and toward structured representations. Journal of Vision, 11(5), 4:1–34. doi:10.1167/11.5.4
Burr, D., Banks, M. S., & Morrone, M. C. (2009). Auditory dominance over vision in the perception of interval duration. Experimental Brain Research, 198, 49–57. doi:10.1007/s00221-009-1933-z
Cohen, J., Hansel, C. E. M., & Sylvester, J. D. (1953). A new phenomenon in time judgment. Nature, 172, 901.
Collier, G. L., & Logan, G. (2000). Modality differences in short-term memory for rhythms. Memory & Cognition, 28, 529–538.
Creelman, C. D. (1962). Human discrimination of auditory duration. Journal of the Acoustical Society of America, 34, 582–593.
Da Costa, S., van der Zwaag, W., Marques, J. P., Frackowiak, R. S., Clarke, S., & Saenz, M. (2011). Human primary auditory cortex follows the shape of Heschl’s gyrus. Journal of Neuroscience, 31, 14067–14075. doi:10.1523/JNEUROSCI.2000-11.2011
Deutsch, D. (1972). Mapping of interactions in the pitch memory store. Science, 175, 1020–1022. doi:10.1126/science.175.4025
Dixon, N. F., & Spitz, L. (1980). The detection of auditory visual desynchrony. Perception, 9, 719–721.
Donkin, C., Nosofsky, R., Gold, J., & Shiffrin, R. (2014). Verbal labeling, gradual decay, and sudden death in visual short-term memory. Psychonomic Bulletin & Review, 22, 170–178. doi:10.3758/s13423-014-0675-5
Farmer, E. W., Berman, J. V. F., & Fletcher, Y. L. (1986). Evidence for a visuo-spatial scratch-pad in working memory. Quarterly Journal of Experimental Psychology, 38A, 675–688. doi:10.1080/14640748608401620
Fendrich, R., & Corballis, P. M. (2001). The temporal cross-capture of audition and vision. Perception & Psychophysics, 63, 719–725.
Fougnie, D., & Marois, R. (2011). What limits working memory capacity? Evidence for modality-specific sources to the simultaneous storage of visual and auditory arrays. Journal of Experimental Psychology: Learning, Memory, and Cognition, 37, 1329–1341. doi:10.1037/a0024834
Fougnie, D., Zughni, S., Godwin, D., & Marois, R. (2014). Working memory storage is intrinsically domain specific. Journal of Experimental Psychology: General, 144, 30–47. doi:10.1037/a0038211
Guérard, K., & Tremblay, S. (2008). Revisiting evidence for modularity and functional equivalence across verbal and spatial domains in memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 556–569. doi:10.1037/0278-7393.34.3.556
Guttman, S. E., Gilroy, L. A., & Blake, R. (2005). Hearing what the eyes see: Auditory encoding of visual temporal sequences. Psychological Science, 16, 228–235. doi:10.1111/j.0956-7976.2005.00808.x
Hanley, J. R., Young, A. W., & Pearson, N. A. (1991). Impairment of the visuo-spatial sketch pad. Quarterly Journal of Experimental Psychology, 43A, 101–125. doi:10.1080/14640749108401001
Harrington, D. L., Castillo, G. N., Fong, C. H., & Reed, J. D. (2011). Neural underpinnings of distortions in the experience of time across senses. Frontiers in Integrative Neuroscience, 5, 32. doi:10.3389/fnint.2011.00032
Helson, H., & King, S. M. (1931). The tau effect: An example of psychological relativity. Journal of Experimental Psychology, 14, 202–217.
Howard, M. W., & Kahana, M. J. (2002). A distributed representation of temporal context. Journal of Mathematical Psychology, 46, 269–299. doi:10.1006/jmps.2001.1388
Howard, I. P., & Templeton, W. B. (1966). Human spatial orientation. London, UK: Wiley & Sons.
Hubel, D. H., & Wiesel, T. N. (1959). Receptive fields of single neurones in the cat’s striate cortex. Journal of Physiology, 148, 574–591.
Hurlstone, M. J., Hitch, G. J., & Baddeley, A. D. (2014). Memory for serial order across domains: An overview of the literature and directions for future research. Psychological Bulletin, 140, 339–373. doi:10.1037/a0034221
Ivry, R. B., & Hazeltine, R. E. (1995). Perception and production of temporal intervals across a range of durations: Evidence for a common timing mechanism. Journal of Experimental Psychology: Human Perception and Performance, 21, 3–18. doi:10.1037/0096-1523.21.1.3
Jackson, C. V. (1953). Visual factors in auditory localization. Quarterly Journal of Experimental Psychology, 5, 52–65.
Johnston, J. C., & Pashler, H. (1990). Close binding of identity and location in visual feature perception. Journal of Experimental Psychology: Human Perception and Performance, 16, 843–856. doi:10.1037/0096-1523.16.4.843
Keller, A. S., & Sekuler, R. (2015). Memory and learning with rapid audiovisual sequences. Journal of Vision, 15(15), 7. doi:10.1167/15.15.7
Kroll, N. E., Parks, T., Parkinson, S. R., Bieber, S. L., & Johnson, A. L. (1970). Short-term memory while shadowing: Recall of visually and of aurally presented letters. Journal of Experimental Psychology, 85, 220–224.
Lange, E. B. (2005). Disruption of attention by irrelevant stimuli in serial recall. Journal of Memory and Language, 53, 513–531. doi:10.1016/j.jml.2005.07.002
Larsen, J. D., & Baddeley, A. (2003). Disruption of verbal STM by irrelevant speech, articulatory suppression, and manual tapping: Do they have a common source? Quarterly Journal of Experimental Psychology, 56A, 1249–1268. doi:10.1080/02724980244000765
Lehnert, G., & Zimmer, H. D. (2008). Modality and domain specific components in auditory and visual working memory tasks. Cognitive Process, 9, 53–61. doi:10.1007/s10339-007-0187-6
Lhamon, W. T., & Goldstone, S. (1974). Studies of auditory–visual differences in human time judgment: 2. More transmitted information with sounds than lights. Perceptual and Motor Skills, 39, 295–307.
Logie, R. H., Della Sala, S., Wynn, V., & Baddeley, A. D. (2000). Visual similarity effects in immediate verbal serial recall. Quarterly Journal of Experimental Psychology, 53A, 626–646.
Logie, R. H., Zucco, G. M., & Baddeley, A. D. (1990). Interference with visual short-term memory. Acta Psychologica, 75, 55–74. doi:10.1016/0001-6918(90)90066-O
Luck, S. J., & Vogel, E. K. (2013). Visual working memory capacity: From psychophysics and neurobiology to individual differences. Trends in Cognitive Sciences, 17, 391–400. doi:10.1016/j.tics.2013.06.006
Ma, W. J., Husain, M., & Bays, P. M. (2014). Changing concepts of working memory. Nature Neuroscience, 17, 347–356. doi:10.1038/nn.3655
Martinkauppi, S., Rämä, P., Aronen, H. J., Korvenoja, A., & Carlson, S. (2000). Working memory of auditory localization. Cerebral Cortex, 10, 889–898.
McAuley, J. D., & Henry, M. J. (2010). Modality effects in rhythm processing: Auditory encoding of visual rhythms is neither obligatory nor automatic. Attention, Perception, & Psychophysics, 72, 1377–1389. doi:10.3758/APP.72.5.1377
Merzenich, M. M., & Brugge, J. F. (1973). Representation of the cochlear partition on the superior temporal plane of the macaque monkey. Brain Research, 50, 275–296.
Michalka, S. W., Kong, L., Rosen, M. L., Shinn-Cunningham, B. G., & Somers, D. C. (2015a). Short-term memory for space and time flexibly recruit complementary memory-biased frontal lobe networks. Neuron, 87, 882–892. doi:10.1016/j.neuron.2015.07.028
Michalka, S. W., Rosen, M. L., Kong, L., Shinn-Cunningham, B. G., & Somers, D. C. (2015b). Auditory spatial coding flexibly recruits anterior, but not posterior, visuotopic parietal cortex. Cerebral Cortex. doi:10.1093/cercor/bhv303
Morein-Zamir, S., Soto-Faraco, S., & Kingstone, A. (2003). Auditory capture of vision: Examining temporal ventriloquism. Cognitive Brain Research, 17, 154–163.
Parmentier, F. B. R., & Jones, D. M. (2000). Functional characteristics of auditory temporal–spatial short-term memory: Evidence from serial order errors. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 222–238. doi:10.1037/0278-7393.26.1.222
Pechmann, T., & Mohr, G. (1992). Interference in memory for tonal pitch: Implications for a working-memory model. Memory & Cognition, 20, 314–320.
Phillips, W. A. (1974). On the distinction between sensory storage and short-term visual memory. Perception & Psychophysics, 16, 283–290. doi:10.3758/BF03203943
Salamé, P., & Baddeley, A. (1989). Effects of background music on phonological short-term memory. Quarterly Journal of Experimental Psychology, 41A, 107–122. doi:10.1080/14640748908402355
Saults, J. S., & Cowan, N. (2007). A central capacity limit to the simultaneous storage of visual and auditory arrays in working memory. Journal of Experimental Psychology: General, 136, 663–684. doi:10.1037/0096-3445.136.4.663
Semal, C., Demany, L., Ueda, K., & Hallé, P.-A. A. (1996). Speech versus nonspeech in pitch memory. Journal of the Acoustical Society of America, 100, 1132–1140.
Shams, L., Kamitani, Y., & Shimojo, S. (2000). Illusions: What you see is what you hear. Nature, 408, 788. doi:10.1038/35048669
Shih, L. Y. L., Kuo, W.-J. J., Yeh, T.-C. C., Tzeng, O. J. L., & Hsieh, J.-C. C. (2009). Common neural mechanisms for explicit timing in the sub-second range. NeuroReport, 20, 897–901. doi:10.1097/WNR.0b013e3283270b6e
Silver, M. A., & Kastner, S. (2009). Topographic maps in human frontal and parietal cortex. Trends in Cognitive Sciences, 13, 488–495. doi:10.1016/j.tics.2009.08.005
Starr, G. E., & Pitt, M. A. (1997). Interference effects in short-term memory for timbre. Journal of the Acoustical Society of America, 102, 486–494.
Summerfield, C., & Egner, T. (2009). Expectation (and attention) in visual cognition. Trends in Cognitive Sciences, 13, 403–409. doi:10.1016/j.tics.2009.06.003
Swisher, J. D., Halko, M. A., Merabet, L. B., McMains, S. A., & Somers, D. C. (2007). Visual topography of human intraparietal sulcus. Journal of Neuroscience, 27, 5326–5337. doi:10.1523/JNEUROSCI.0991-07.2007
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:10.1016/0010-0285(80)90005-5
Tremblay, S., Parmentier, F. B. R., Guérard, K., Nicholls, A. P., & Jones, D. M. (2006). A spatial modality effect in serial memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32, 1208–1215. doi:10.1037/0278-7393.32.5.1208
Vallar, G., & Baddeley, A. D. (1984). Fractionation of working memory: Neuropsychological evidence for a phonological short-term store. Journal of Verbal Learning and Verbal Behavior, 23, 151–161. doi:10.1016/S0022-5371(84)90104-X
Van der Burg, E., Olivers, C. N. L., Bronkhorst, A. W., & Theeuwes, J. (2008). Pip and pop: Non-spatial auditory signals improve spatial visual search. Journal of Experimental Psychology: Human Perception and Performance, 34, 1053–1065. doi:10.1037/0096-1523.34.5.1053
Visscher, K. M., Kaplan, E., Kahana, M. J., & Sekuler, R. (2007). Auditory short-term memory behaves like visual short-term memory. PLoS Biology, 5, e56. doi:10.1371/journal.pbio.0050056
Vogel, E. K., Woodman, G. F., & Luck, S. J. (2001). Storage of features, conjunctions, and objects in visual working memory . Journal of Experimental Psychology: Human Perception and Performance, 27, 92–114. doi:10.1037/0096-1523.27.1.92
Voytek, B., & Knight, R. T. (2010). Prefrontal cortex and basal ganglia contributions to visual working memory. Proceedings of the National Academy of Sciences, 107, 18167–18172. doi:10.1073/pnas.1007277107
Welch, R. B., & Warren, D. H. (1980). Immediate perceptual response to intersensory discrepancy. Psychological Bulletin, 88, 638–667. doi:10.1037/0033-2909.88.3.638
Wessinger, C. M., Buonocore, M. H., Kussmaul, C. L., & Mangun, G. R. (1997). Tonotopy in human auditory cortex examined with functional magnetic resonance imaging. Human Brain Mapping, 5, 18–25.
Zhang, W., & Luck, S. J. (2009). Sudden death and gradual decay in visual working memory. Psychological Science, 20, 423–428. doi:10.1111/j.1467-9280.2009.02322.x
Author note
This research was supported in part by NIH Grant No. R01-EY022229 and by CELEST, an NSF Science of Learning Center (Grant No. SMA-0835976).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Noyce, A.L., Cestero, N., Shinn-Cunningham, B.G. et al. Short-term memory stores organized by information domain. Atten Percept Psychophys 78, 960–970 (2016). https://doi.org/10.3758/s13414-015-1056-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-015-1056-5