
Abstract
The attentional blink (AB) refers to a deficit in reporting the second of two targets (T2) in a rapid serial visual presentation (RSVP) stream when this target is presented less than 500 ms after the onset of the first target (T1). It is under debate whether the AB originates from a limitation of cognitive resources or from an attentional suppression process triggered by a distractor or by target discontinuity. In this study, we placed a distractor (Dinter) or an extra target (Tinter) between T1 and T2 while at the same time manipulating the time interval between Dinter (or Tinter) and T2 (0, 200, or 500 ms). The level of attentional enhancement induced by the detection of T1 was also manipulated by adding external noise to T1. The results showed that, as compared to the dual-target condition, T2 performance was better in the consecutive-target condition, when T2 was close in time to Tinter (i.e., the spread of sparing), but was worse with a longer interval between T2 and the preceding item. Adding external noise to T1 improved T2 performance when T2 was close in time to the preceding item, irrespective of whether this item was Dinter or Tinter. These findings present difficulties for the existing models of the AB, although the overall pattern observed is generally more consistent with the episodic simultaneous-type, serial-token (eSTST) model than with conventional resource accounts or distractor-based attentional selection accounts of the AB.
Similar content being viewed by others

When observers search for two targets in a rapid serial visual presentation (RSVP) stream, they usually have no difficulty reporting the first target (T1). But if the second target (T2) appears after T1 onset with a stimulus onset asynchrony (SOA) of 200 to 500 ms, the T2 report accuracy drops dramatically relative to the performance at longer SOAs (e.g., longer than 500 ms). This phenomenon is known as the attentional blink (AB; Broadbent & Broadbent, 1987; Raymond, Shapiro, & Arnell, 1992).
Aimed at understanding the underlying mechanism of AB, several theorists have postulated that the AB originates from a capacity limitation of central processing resources, such as those for working memory consolidation (Jolicœur & Dell’Acqua, 1998; Jolicœur, Tombu, Oriet, & Stevanovski, 2002). According to these resource accounts, mental resources that are limited in capacity are required for working memory. The detection of a potential target triggers the opening of an attentional gate, allowing the perceptual representation of the target to enter the memory-encoding stage and initiate consolidation. The closing of this gate is sluggish, allowing the directly succeeding item to also enter the memory-encoding stage due to its temporal proximity to the target. Thus, if this T1 + 1 item is a distractor (i.e., distractor at lag 1), the processing of this distractor interferes with T1 consolidation, resulting in an extension of the time course of memory encoding for T1. Given the limitation of central processing resources, the transfer of all subsequently presented items to the memory-encoding stage may fail, due to depletion of the central resource by T1 processing, rendering the representations of these items vulnerable to decay or interruption. If this loss of representation occurs on T2, an effect of AB (i.e., a deficit of T2 report) is observed.
Resource accounts of the AB are supported by several lines of research. For example, an unreported T2 is nonetheless processed at a relatively high level—for example, the semantic level—indicating that the bottleneck of identifying a second target during the AB is not located at the perceptual processing stage (Chua, Goh, & Hon, 2001; Luck, Vogel, & Shapiro, 1996; Maki, Frigen, & Paulson, 1997; Shapiro, Driver, Ward, & Sorensen, 1997). Increasing the difficulty of encoding T1 into working memory by increasing memory load leads to more severe AB on T2, indicating that T2 performance varies as a function of the resource requirement of T1 processing (Akyürek, Hommel, & Jolicœur, 2007; Akyürek, Leszczyński, & Schubö, 2010; Jolicœur & Dell’Acqua, 1998; Ouimet & Jolicœur, 2007; Scalf, Dux, & Marois, 2011). On the other hand, if the distractor directly following T1, which provides backward masking to T1 and prolongs T1 processing, is replaced by a brief blank, the report of T2 shows no (Chun & Potter, 1995; Raymond et al., 1992; Seiffert & Di Lollo, 1997) or little (Nieuwenstein, Potter, & Theeuwes, 2009; Nieuwenstein, Van der Burg, Theeuwes, Wyble, & Potter, 2009) performance deficit.
A well-known phenomenon in the study of the AB, lag 1 sparing, can also be interpreted in the framework of resource accounts. If T2 is presented immediately after T1, the report of T2 does not suffer from a performance deficit (Potter, Chun, Banks, & Muckenhoupt, 1998). According to the resource accounts, T2 is either included in the attentional gate opened by T1 and can experience consolidation together with T1, or T1’s perceptual representation enters into working memory without competition for resources from a distractor, and hence does not delay T2 processing.
However, a new finding, called the spread of sparing, provides difficulties for the resource account. No AB effect is observed on T2 if the distractors between T1 and T2 in the RSVP stream are replaced with other targets. That is, the sparing effect on T2 in the lag 1 sparing phenomenon also spreads to later lags if more targets are presented continuously (Di Lollo, Kawahara, Ghorashi, & Enns, 2005; Kawahara, Kumada, & Di Lollo, 2006; Nieuwenstein & Potter, 2006; Olivers, van der Stigchel, & Hulleman, 2007). It is difficult for the resource account to interpret this spread of sparing, since the resource account predicts that the depletion of resources would become more severe as the number of targets increases, and a more severe report deficit should be observed on the targets presented after lag 1.
Aimed at interpreting both the AB effect and the spread-of-sparing phenomenon, another group of accounts of the AB focuses on attentional selection processes, rather than resource limitation (Di Lollo, Kawahara, Ghorashi, & Enns, 2005; Olivers & Meeter, 2008; Taatgen, Juvina, Schipper, Borst, & Martens, 2009; Wyble, Bowman, & Nieuwenstein, 2009). An early version of the selection accounts, called the interference theory, postulates that the distractor at the T1 + 1 position, due to its temporal proximity to T1 and the sluggish attentional window opened by T1, elicits an attentional inhibition process that interferes with T1 identification and, more importantly, suppresses the processing of subsequent inputs (Raymond et al., 1992). If T2 is presented during this suppression period, it would be difficult for T2 to be processed at the conscious level, resulting in the AB effect.
Another version of the selection accounts, called the boost-and-bounce theory (Olivers & Meeter, 2008), further details the distractor interference mechanism. According to this theory, the detection of target-like features opens an attentional gate, allowing the target representation to enter into working memory. The onset of a target will trigger a top-down attentional enhancement effect (a boost) and benefit the processing of subsequent items presented within several hundreds of milliseconds (Nakayama & Mackeben, 1989). In contrast, detection of distractor features would close this attentional gate and trigger an inhibitory process, impairing the processing of subsequent items. Importantly, given that the T1 + 1 distractor is processed along with T1 because of its temporal proximity to T1, it initially receives a boost of attentional enhancement; this boost, however, would then induce a stronger inhibitory process that lasts for an extended period of time (a bounce).
In the same vein, the threaded cognition model (Taatgen et al., 2009) assumes that the detection of a distractor that immediately follows a target will activate a control rule that prevents the processing of further input and protects the consolidation of the current target. This control process lasts until target consolidation is finished. Thus, the T2 that appears after a distractor and during the T1 consolidation period will be blocked from high-level processing, leading to an AB effect.
The interference theory, the boost-and-bounce theory, and the threaded cognition model all focus on the interference process elicited by distractors immediately following the target; thus, these accounts can be labeled distractor-based selection accounts (Lagroix, Spalek, Wyble, Jannati, & Di Lollo, 2012). The distractor-based selection accounts can conveniently interpret the spread of sparing, given the absence of interference on T2 processing from distractors. Similarly, these accounts can also accommodate the finding that the AB seems to be removed when the distractors between T1 and T2 are replaced by a blank time interval (Raymond et al., 1992). However, other studies have shown that, with a more sensitive T2 task, an AB is still observable when no intertarget distractor is presented (Lagroix et al. 2012; Nieuwenstein, Potter, & Theeuwes, 2009; Nieuwenstein, Van der Burg, et al., 2009). The latter finding could still be accommodated by distractor-based selection accounts, if these accounts assume that a blank interval preceding T2 would cause a weak interruption to attentional engagement and a deficit in T2 report (e.g., in the boost-and-bounce theory; Olivers & Meeter, 2008; see also Lagroix et al., 2012).
Another model, called the episodic simultaneous-type, serial-token model (i.e., eSTST), attempts to interpret the spread of sparing, the basic AB effects, and the AB effects in the condition when an intertarget distractor is absent (Wyble et al., 2009). The eSTST model assumes that some mechanisms parse visual input into temporal packets (episodes) as they are encoded into memory. In searching through a sequence of stimuli, a target will initiate an attentional episode that lasts for about 200 ms. The encoding of this target would activate a competition to regulate attention: an excitatory process that is induced by the visual input and sustains attention during the encoding of the target, and an inhibitory process that is caused by ongoing memory encoding of the target. For the target, the excitatory process dominates the competition and enhances attention, lasting for about 200 ms (Nakayama & Mackeben, 1989). If the following (lag 1) item is a distractor or a blank, it would provide sufficient time for attention to be suppressed, assuming that each item is presented for 100 ms. This would produce an AB for a subsequent target (T2). However, if the lag 1 item is a target (T2), the suppression elicited from T1 is counteracted by the amplified excitation from T2, and the attentional gate is held open, leading to lag 1 sparing. The same procedure can be applied to all succeeding targets, and the spread of sparing is then observed.
Although the eSTST model postulates a form of resource limitation by assuming that targets may interfere with each other in perceptual processing and/or in memory encoding, this interference is assumed to be weak and only to function within an episode: It is not the dominant factor in the attentional dynamics that results in the AB, and thus does not cause a major portion of the attentional blink (Wyble, Potter, Bowman, & Nieuwenstein, 2011). However, this interference could be more severe when the number of targets within a single episode increases (i.e., when T1’s memory load is elevated), leading to prolonged T1 memory encoding, which produces stronger suppression of attention for a longer duration. This may explain why the AB is more severe in the high than in the low T1-memory-load situation (Akyürek et al., 2007; Akyürek et al., 2010; Jolicœur & Dell’Acqua, 1998; Ouimet & Jolicœur, 2007; Scalf et al., 2011).
Note that the interference between targets may also occur at the semantic level. Taylor and Hamm (1997) found that the T2 report deficit is more severe when T1 and T2 belong to the same category (e.g., both targets are letters) than when T1 and T2 belong to different categories (e.g., T1 is a number when T2 is a letter). The authors therefore put forward a semantic interference account to interpret the findings. This idea of semantic interference could help to understand the asymmetry of the AB effect between the left and right visual fields, in which the T2 report deficit during the AB is more severe when both targets are presented in the right visual field than when they are in the left visual field (Holländer, Corballis, & Hamm, 2005; Holländer, Hausmann, Hamm, & Corballis, 2005; Verleger, Śmigasiewicz, & Möller, 2011). Since the left hemisphere is superior in language processing, targets presented to the left hemisphere through the right visual field may cause more semantic interference than targets presented to the right hemisphere (Holländer, Corballis, & Hamm, 2005).
In summary, although the AB has been investigated for a relatively long time, we still do not have a unified understanding of its underlying mechanisms. By revisiting the spread of sparing, in the present study we aimed to provide new evidence for discriminating different accounts of the AB. To this end, we employed RSVP tasks with two kinds of target continuity. One was the spread-of-sparing condition, in which three targets were presented continuously without intertarget distractors (the TTT condition). The performance levels for the first and third targets in this condition were defined as T 1 and T 2 , to enable comparison with the corresponding targets in the conventional dual-target AB task. The target between T1 and T2 in the TTT condition was called T inter . Another condition was the conventional AB condition, in which two targets, T1 and T2, were presented in the stream with an intertarget distractor, called D inter , which was presented immediately after T1 (the TDT condition). Importantly, we manipulated the time interval between T2 and the preceding Tinter or Dinter, such that this interval could be either 0 ms (i.e., no interval, referred to as TT 0 T or TD 0 T), short (200 ms: TT 200 T or TD 200 T), or long (500 ms: TT 500 T or TD 500 T). This time interval was filled with a blank screen. Note that this manipulation is different from the apparently similar manipulations in previous studies that have compared conditions in which either a distractor or a blank time window was presented immediately after T1 (before T2). The AB effect on T2 was observable in some of these studies for the blank condition (Chun & Potter, 1995; Lagroix et al., 2012; Nieuwenstein, Potter, & Theeuwes, 2009; Nieuwenstein, Van der Burg, et al., 2009; Seiffert & Di Lollo, 1997), but this effect was completely absent in other studies (e.g., Raymond et al., 1992).
Different accounts of the AB lead to different predictions concerning our manipulation (see Table 1). The resource accounts predict that, as compared to the long-interval conditions (i.e., outside the AB), an AB should occur in both the TTT and TDT conditions when T2 is presented during the AB period. Moreover, a more severe AB effect would be expected for T2 in the TTT condition than in the TDT condition, due to the larger memory load in the TTT condition (three targets) than in the TDT condition (two targets). In contrast, the distractor-based selection accounts predict a larger AB effect in the TDT condition than in the TTT condition, due to the existence of an intertarget distractor in the former case. For the eSTST model, a spread of sparing would be expected in the TT0T condition only. When a short time interval is inserted between T2 and the preceding targets (i.e., in the TT200T condition), the inhibitory process of attention, initiated by the memory encoding of the preceding targets, would cause an AB effect on T2. A similar phenomenon would be predicted by the eSTST model in the TD0T or TD200T condition, due to the discontinuity of target input caused by Dinter. This implies that the inhibitory effect of attention should occur earlier in the TD200T condition (where it is initiated by the presence of Dinter) than in the TT200T condition (where it is initiated by the presence of the blank screen after Tinter). This is because Tinter provides an additional source of excitation to attention, which delays the peak of the inhibitory process (i.e., when this inhibition would reach maximum). In addition, according to the eSTST model, Tinter in the TTT condition could induce interference to the consolidation of T1, and therefore prolong memory encoding of T1 (and Tinter) in the TTT condition as compared to the TDT condition. This interference could produce stronger and/or sustained suppression on the subsequent T2, leading to a more severe AB in the TT200T condition than the TD200T condition when T2 and the preceding items are interrupted by a short blank interval.
In addition, since the resource limitation accounts assume that the T2 performance is modulated by the load imposed on mechanisms engaged to consolidate pre-T2 targets, they predict that the central processing mechanism is more likely to have spare resources to process T2 when Tinter is missed, as compared to the situation in which Tinter is correctly reported. This assumption can be investigated by applying a principle called within-trial contingency in the data analysis (Dell’Acqua, Jolicœur, Luria, & Pluchino, 2009). That is, T2 performance should be lower when the report accuracy is analyzed only in the condition in which Tinter is correctly reported than when it is analyzed irrespective of the accuracy of Tinter report. The eSTST model has a similar prediction; it predicts that the load of memory consolidation would be reduced when Tinter was not successfully processed, leading to less suppression on T2 processing. In contrast, the distractor-based selection accounts would not expect to find an influence of Tinter performance on the AB, since they do not assume any form of memory-encoding-related limitation or suppression.
The boost-and-bounce theory assumes that the more attentional engagement is on T1, the greater the suppression (i.e., the bounce) on the subsequent T2 elicited by the distractor(s) between T1 and T2. To directly investigate this assumption, we manipulated the magnitude of the T1-induced attentional enhancement effect by varying the difficulty of T1 perceptual processing. We set up a “difficult” and an “easy” condition of T1 perceptual processing by presenting T1 with or without external noise. Table 2 lists the predictions concerning the T1 noise manipulation by different accounts of the AB.
The underlying assumption of this noise manipulation is that the difficulty of target (T1) perceptual processing forces the visual system to deploy more attentional resources to increase the signal-to-noise ratio of the target. This idea is consistent with the argument that a critical function of attention in perceptual processing is to exclude external noise in the target region (Dosher & Lu, 2000a, 2000b; Lu & Dosher, 2000; Lu, Lesmes, & Dosher, 2002). Empirical work has also demonstrated that the impact of attention upon perceptual processing can be enhanced by the perceptual difficulty of target processing. For example, the attention effect was larger in a conjunction feature discrimination task than in a simple feature detection task (Briand, 1998; Briand & Klein, 1987). According to Nakayama and Mackeben (1989), the impact of increased attention induced by a target would peak about 100–150 ms after target onset and last for several hundred milliseconds. The attention spared from processing a noise-added T1 could, for a short time window, enhance the processing of subsequent items in the RSVP task. The boost-and-bounce theory’s boost procedure is based on Nakayama and Mackeben’s attentional account. Therefore, this theory predicts that a stronger boost would be induced by T1 in the noise condition than in the no-noise condition in a continuously presented target stream. This enhanced boost effect would benefit the processing of subsequent targets, leading to increased T2 performance in the TTT condition.
Alternatively, however, if the boost-and-bounce theory assumes a weaker T1 representation in the noise condition, relative to the no-noise condition, it would predict an opposite pattern for the T1 noise manipulation, relative to the prediction listed above. That is, T1 in the noise condition would induce a weaker boost as well as a weaker bounce when compared to the no-noise condition. Therefore, T2 performance should be lower in the T1 noise condition than in the no-noise condition for the TTT situation. This pattern would be reverse in the TDT situation.
For the resource accounts, it is generally assumed that increasing the difficulty of T1 processing leads to more severe central-resource depletion for T2 encoding. However, the noise manipulation in the present study would increase the processing difficulty of T1 at the perceptual rather than the central level—that is, at working memory encoding. In addition, this noise manipulation might increase the attentional enhancement effect induced by T1, which might facilitate the processing of T2 presented within the T1-induced attentional window. Therefore, the resource accounts predict higher T2 performances in the T1 noise than in the no-noise condition when T2 is presented shortly after T1 onset. The eSTST model assumes that targets that are presented in a brief attentional window compete with each other at the perceptual processing level to enter central processing (Wyble et al., 2011). When noise reduced the trace of the T1 representation, a T2 presented shortly after T1 would have an increased opportunity of winning the competition with T1, as compared to the no-noise condition. Therefore, the eSTST model predicts better T2 performance in the T1 noise condition than in the no-noise condition, but only when T2 is presented shortly after T1. Table 2 summarizes the main predictions for the noise manipulation provided by the different accounts.
Method
Participants
Eighteen participants were tested in the present study. Two of them were excluded from the analysis due to their low T1 report accuracy (less than 30%) in at least one experimental condition. Therefore, 16 participants were included in the final data analysis (13 female, three male; ranging from 18 to 24 years old, overall T1 performance ranging from 72% to 95%). All of the participants were university students and were paid for taking part in the study. All reported normal or corrected-to-normal vision and were naive to the aims of the study. Informed consent was obtained from each participant. This study was carried out in accordance with the Declaration of Helsinki and was approved by the Ethics Committee of the Department of Psychology, Peking University.
Design and stimuli
The experiment had a 2 (noise manipulation: T1 noise vs. no noise) × 2 (target type: TTT vs. TDT) × 3 (blank interval preceding T2: 0 vs. 200 vs. 500 ms) within-participants factorial design. We used a skeletal RSVP paradigm (Duncan, Ward, & Shapiro, 1994; McLaughlin, Shore, & Klein, 2001) in which a total of four items—T1, Tinter or Dinter, T2, and a distractor as a T2 mask—were included in each trial. The duration of each item was set to 50 ms. Three levels of blank interval were employed: (1) The blank interval between Tinter or Dinter and T2 was 0 ms, leading to a T1–T2 SOA of 100 ms; (2) a brief blank screen of 200 ms was inserted, leading to a T1–T2 SOA of 300 ms; (3) a blank screen of 500 ms was inserted after Tinter or Dinter, leading to an outside-AB SOA of 600 ms.
The targets in each trial were Arabic numbers ranging from 2 to 9, and different numbers were used for T1 and T2. The distractors were selected from 16 English letters (A, E, F, G, H, K, L, M, N, R, T, U, V, W, X, and Y). All of these characters subtended 0.9° horizontally and 0.6° vertically (26 × 17 pixels) and were displayed in Courier New font. Each of the characters was presented in light gray (RGB: 192, 192, 192) at the center of a dark gray (RGB: 64, 64, 64) background.
The T1 with external noise used in the T1 noise condition was created by increasing or decreasing the luminance of each of the 26 × 17 pixels, with the added values being consistent with a Gaussian distribution that had a mean value of 0 (i.e., the T1s had equal overall luminances with or without noise). The standard deviation for the distribution of luminance for the noise added to T1 ranged from 5% to 10%, which was to ensure that different number targets had similar signal-to-noise ratios (3:1). Targets with and without noise are illustrated in Fig. 1.

Target numbers. Top: Targets without noise. Bottom: Targets with external noise
Participants were tested individually in a soundproof and dimly lit room. They were seated in front of a Dell 19-in. CRT monitor (1,024 × 768 resolution, 100-Hz refresh) with their heads mounted on a chinrest. The eye-to-monitor distance was 70 cm. Presentation of the stimuli and recording of participants’ responses were controlled by a program written in MATLAB with the Psychophysics Toolbox extension (Brainard, 1997).
Procedure
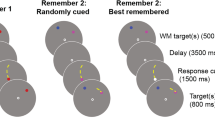
As is depicted in Fig. 2, each trial consisted of a sequence of four items: T1 was followed by a distractor (Dinter) in the TDT condition or by an extra target (Tinter) in the TTT condition, and T2 was always followed by a distractor. The trial began with the presentation of a fixation cross at the center of the screen for 500 ms, followed by a blank screen with a randomly selected duration of 400, 500, or 600 ms. T1 and Tinter (or Dinter) were then each presented for 50 ms at the same position. Depending on the SOA between T1 and T2, T2 either was presented immediately after Tinter (or Dinter; i.e., SOA = 100 ms) or was delayed for 200 or 500 ms (i.e., SOA = 300 or 600 ms). That is, a blank screen was inserted between Tinter (or Dinter) and T2. A final distractor was presented immediately after T2. The durations of T2 and the final distractor were also 50 ms. Responses were collected by asking participants to select each of the target numbers sequentially—that is, T1 and T2 in the TDT condition, and T1, Tinter, and T2 in the TTT condition—from a set of the numbers from 2 to 9 presented on screen. However, in the data analysis, report accuracy was computed irrespective of the order of report.

Experimental conditions and the procedure. Visual displays were at the center of the screen, illustrated from the left to the right in the figure. Each frame in the RSVP stream was presented for 50 ms
The target type (TTT vs. TDT) was blocked to make sure that (1) participants knew explicitly how many targets to report for the current trial and (2) participants in the TTT condition processed Tinter at the same level as T1 and T2; in other words, if the two conditions were mixed, this would prevent participants from applying the strategy of processing Dinter for the TDT condition during the processing of Tinter for the TTT condition. Given that the TTT block and the TDT block each lasted about 45 min, each participant was tested in two separate sessions, at the same time of day on adjacent days. Half of the participants were tested with TTT stimuli first and the other half with TDT stimuli first. Trials with different SOAs and T1 manipulations (T1 noise and no noise) were randomly mixed within each block.
Each condition had 48 trials. Thus, the TTT block had 288 (2 × 3 × 48) trials. In addition to the 288 critical trials, the TDT block also included 96 filler trials in which T1 and T2 were presented as the first and second items in a sequence. This was done to make sure that, overall, participants paid attention to all of the first three positions in the test sequences, as in the TTT block.
Results
T1 report accuracy
An analysis of variance (ANOVA) was conducted on T1 report accuracy with Noise Manipulation (T1 noise vs. no noise), Target Type (TDT vs. TTT), and Blank Interval (0 vs. 200 vs. 500 ms) as three within-participants factors. These (and all later) results can be found in Table 3. As is shown in Fig. 3 (left panel), T1 report was not affected by target type (82.5% in the TDT condition and 83.6% in the TTT condition), F(1, 15) < 1, but it decreased severely when T1 was presented with external noise (70.2%) versus when it was not (95.9%), F(1, 15) = 88.29, p < .001, η2 p = .85. This noise effect interacted with target type, F(1, 15) = 8.50, p < .01, η2 p = .36. Since no blank-interval-related main effect or interaction was significant, ps > .1, we collapsed T1 report accuracy over blank intervals to further analyze the interaction between the noise manipulation and target type. When no noise was added to T1, T1 accuracy was higher in the TDT condition (97.4%) than in the TTT condition (94.3%), p < .05, η2 p = .37, indicating that T1 competed less with other items in the TDT condition than in the TTT condition (Potter, Staub, & O’Connor, 2002). This effect of intertarget competition (i.e., T1 vs. Tinter, as compared with T1 vs. Dinter) could be accounted for by a mechanism of resource limitation (Jolicœur & Dell’Acqua, 1998; Wyble et al., 2011) or semantic interference (Taylor & Hamm, 1997). This difference disappeared when T1 was presented with noise, p > .1. No other effects reached significance.

Mean accuracies of T1 (left panel) and T2 | T1 (right panel), reported as a function of blank interval. Error bars represent one standard error of the mean
T2 report accuracy
T2 reports conditionalized on correct report of T1 (T2 | T1) were entered into the ANOVA with the three within-participants factors. The main effect of target type was significant, F(1, 15) = 10.69, p < .01, η2 p = .42. As is shown in Fig. 3 (right panel), overall, T2 | T1 performance was higher in the TDT conditions (76.5%) than in the TTT conditions (71.1%). The main effect of noise manipulation was also significant, F(1, 15) = 6.78, p < .05, η2 p = .31, suggesting that T2 | T1 report accuracy was higher when external noise was added to T1 (75.4%) than when T1 had no noise (72.3%). The main effect of the blank interval was also significant, F(2, 30) = 34.58, p < .001, η2 p = .69. Pairwise comparisons showed that the T2 | T1 report accuracy was lower when the duration of the blank interval was 0 ms (63.9%) than when the duration was 200 ms (71.5%), p < .05, η2 p = .79. T2 | T1 report accuracy in the 0-ms blank interval condition and the 200-ms interval condition were both lower than when the blank interval lasted for 500 ms (86.0%), ps < .001, η2 p = .79.
There was also a significant interaction between target type and blank interval, F(2, 30) = 38.71, p < .001, η2 p = .72. Since target type did not interact with noise manipulation and the three-way interaction between target type, noise manipulation, and blank interval was not significant, ps > .1, we collapsed T2 | T1 report accuracy over the noise manipulation to further analyze the interaction between the target type and blank interval. Bonferroni-corrected pairwise comparisons showed that T2 | T1 report accuracy was higher in the TT0T condition (70.9%) than in the TD0T condition (57.0%), when the duration of the blank interval was 0 ms (i.e., a spread-of-sparing effect), p < .001, η2 p = .61. This pattern was reversed when the duration of the blank interval was 200 ms, with higher T2 | T1 report accuracy in the TD200T condition (81.9%) than in the TT200T condition (61.1%), p < .001, η2 p = .69. The reversed pattern was also observed when the blank interval was 500 ms (90.7% vs. 81.3%), p < .001, η2 p = .65. We also conducted a test to specifically investigate whether the target type showed different patterns of AB deficit in T2 | T1 report accuracy when the blank interval was 200 ms, as compared to the conditions in which the blank interval was 500 ms (i.e., T1–T2 SOAs of 300 vs. 600 ms). We found not only a significant main effect of blank interval (the AB effect), F(1, 15) = 41.57, p < .001, η2 p = .73, but also an interaction between target type and blank interval, F(1, 15) = 11.73, p < .01, η2 p = .44. The T2 | T1 report deficit for the 200-ms versus the 500-ms blank interval was more severe in the TT200T condition (with a differential effect of 20.2%) than in the TD200T condition (with a differential effect of 8.8%), indicating that the AB effect in the 200-ms blank interval condition (i.e., a T1–T2 SOA of 300 ms) was larger in the TTT condition than in the TDT condition.
The interaction between noise manipulation and blank interval was significant, F(2, 30) = 14.97, p < .001, η2 p = .50. The 0-ms blank condition was the only condition in which the T2 | T1 report accuracy was higher for T1 with noise (68.5%) than for T1 without noise (59.4%), p < .001, η2 p = .63. No effects were found of noise manipulation when the blank interval was 200 or 500 ms.
There was no interaction between target type and noise manipulation, F(1, 15) < 1, indicating that changing the T1 signal-to-noise ratio had the same effect on T2 | T1 report accuracy irrespective of whether T1 was followed by Dinter or Tinter.
The same pattern of effects was observed when the above statistical analyses were conducted for the T2 report accuracy conditionalized on correct report of both T1 and Tinter (T2 | T1 & Tinter). Moreover, the same pattern of effects was observed when T2 report accuracies were corrected by taking into account the difference in the chance level for guessing T2 in the TTT and TDT conditions (i.e., there were three opportunities to guess T2 in the TTT condition, as opposed to only two in the TDT condition, given that the order of reporting targets was discounted when the report accuracies were computed).
Tinter report accuracy
Tinter reports conditionalized on the correct report of T1 (Tinter | T1) were entered into the ANOVA with Noise Manipulation and Blank Interval as two within-participants factors. The main effect of noise manipulation was marginally significant, F(1, 15) = 3.76, p = .07, η2 p = .20, indicating that Tinter | T1 report accuracy was slightly higher when external noise was added to T1 (95.4%) than when T1 had no noise (93.5%). The main effect of the blank interval was highly significant, F(2, 30) = 61.81, p < .001, η2 p = .80. Pairwise comparisons showed that Tinter | T1 report accuracy was lower when the blank interval after Tinter was 0 ms (85.2%) than when it was 200 ms (99.4%), p < .05, η2 p = .79, or 500 ms (99.4%), ps < .001, η2 p = .79. The Tinter performance was extremely high due to the lack of a backward mask in the 200-ms and 500-ms blank interval conditions. The interaction between noise manipulation and blank interval was significant, F(2, 30) = 4.55, p < .05, η2 p = .23. The 0-ms blank interval was the only condition in which the Tinter | T1 report accuracy was higher for T1 with noise (87.5%) than for T1 without noise (83.0%), p < .05, η2 p = .23; this pattern was similar to that found for T2 performance. No effects were found for the noise manipulation when the blank interval after Tinter was 200 or 500 ms.
The within-trial contingency effect
Since Tinter report was almost 100% correct when the blank interval was 200 or 500 ms, we only included the 0-ms blank interval when analyzing the within-trial contingency effect on T2 performance in the TTT condition. Following Dell’Acqua et al. (2009), we compared T2 report accuracy conditionalized on correct T1 report (T2 | T1) with the accuracy conditionalized on correct report of both T1 and Tinter (T2 | T1 & Tinter), with T1 noise as another within-participants factor. The main effect of Tinter consideration was significant, F(1, 15) = 30.40, p < .001, η2 p = .67, with T2 | T1 & Tinter report accuracy (68.3%) being lower than T2 | T1 report accuracy (70.9%). This effect indicated that the T2 report accuracy was higher when the accuracy of Tinter report was not taken into consideration (i.e., when the trials with incorrect Tinter reports were included and the load on pre-T2 target consolidation was relatively low). This within-trial contingency effect interacted with the noise manipulation, F(1, 15) = 8.34, p < .05, η2 p = .36, with a slightly less pronounced within-trial contingency effect in the T1 noise condition (a difference of 1.3%, p < .05, η2 p = .31) than in the no-noise condition (a difference of 3.8%, p < .001, η2 p = .62). The main effect of noise manipulation was significant, F(1, 15) = 12.88, p < .001, η2 p = .46, consistent with the previous analyses.
Discussion
The main findings of the present study can be summarized in Tables 1 and 2. T2 report accuracy was higher in the TT0T condition than in the TD0T condition, when all items were presented consecutively. However, when there was a blank time interval (200 or 500 ms) between Tinter (or Dinter) and T2, T2 report accuracy was higher in the TDT condition than in the TTT condition. Adding external noise to T1 did not affect this pattern of effects. However, adding external noise to T1 did improve T2 report accuracy, irrespective of whether the intermediate item was Tinter or Dinter. In the following paragraphs, we compare these findings with the predictions made by the different theoretical accounts depicted in Table 1 and discuss the implications of these findings for the debate between the previous AB accounts.
The attenuated T2 report deficit in the TT0T condition, as compared to the TD0T condition, replicated the typical spread of lag 1 sparing (Di Lollo et al., 2005; Kawahara, Kumada, & Di Lollo, 2006; Nieuwenstein & Potter, 2006; Olivers et al., 2007). As we indicated in the introduction, this effect creates a difficulty for the resource accounts. The resource accounts argue that increasing the memory load of target processing by increasing the number of targets should lead to more severe mental resource deficits. Therefore, a more severe AB, rather than spread of sparing, would be expected by the resource accounts in the TTT versus the TDT condition, irrespective of the level of time interval between the intermediate item and T2. Similarly, the semantic interference account, which assumes more severe intertarget interference in the TTT condition than in the TDT condition, also has difficulty interpreting the spread of sparing.
On the contrary, the distractor-based selection accounts can easily accommodate this spread of sparing. These accounts assume that the AB occurs only when an intertarget distractor exists: The distractor preceding T2 would directly elicit an inhibitory process that suppresses processing of the subsequent target, leading to deteriorated T2 performance in this condition (Olivers & Meeter, 2008; Raymond et al., 1992; Taatgen et al., 2009). Therefore, a spread of sparing would be expected when no distractor interference exists in the TTT condition. The eSTST model can also accommodate this spread of sparing. As we mentioned above, the eSTST model postulates that the AB is caused by a top-down attentional suppression elicited by T1 memory encoding. However, continuous visual input of a target stream (e.g., the target stream of the TT0T condition) might, at the same time, keep the attentional window open by providing a strong activation for attention, overcoming the top-down suppressive effect. Therefore, a spread of sparing instead of an AB would be expected by the eSTST model in the TT0T condition.
A crucial finding in the present study was that T2 performance deteriorated in the TT200T condition, as compared to the TD200T condition, when a short blank time interval was inserted between Tinter (or Dinter) and T2. This finding was consistent with the prediction of resource accounts and the semantic interference account of the AB, because consolidation of T1 and Tinter in the TT200T condition would deplete more resources and/or induce more severe semantic interference than consolidation of T1 in the TD200T condition, thus leading to more severely impaired T2 performance in the former than in the latter situation.
In contrast, the distractor-based selection accounts have difficulties accommodating this finding. According to the boost-and-bounce theory (and the threaded cognition model), Dinter, which was presented immediately after T1, would exert strong inhibition on the processing of the subsequent target. This inhibitory process, lasting for several hundred milliseconds, would impair the processing of a T2 presented 200 ms after Dinter. Thus T2 performance should be worse in the TD200T condition than in the TT200T condition. Clearly, the present results contradict this prediction. It is worth noting that the boost-and-bounce theory could still postulate that a blank interval preceding T2 would cause a weak interruption to attentional engagement, due to its “unpredictability,” and might lead to a T2 deficit in the TTT condition (Olivers & Meeter, 2008; see also Lagroix et al., 2012). However, this putative disruption effect is much weaker than a real distractor (Lagroix et al., 2012; Nieuwenstein, Potter, & Theeuwes, 2009). Thus, a more severe T2 report deficit in the TD200T condition than in the TT200T condition would still be expected.
The eSTST model postulates that the suppressive effect induced by the memory encoding of targets would succeed in suppressing attention when no new target input appeared. When a blank interval of 200 ms was inserted preceding T2, the memory encoding of T1 (and Tinter, in the TTT condition) would close the attentional episode initiated by T1, and the inhibitory process initiated by this encoding would then have the upper hand, preventing the processing of a subsequent T2. Therefore, the eSTST model can successfully explain the AB effects in both the TT200T and TD200T conditions. Furthermore, as we argued in the introduction, since the eSTST model assumes interference between targets in a single episode, target encoding would be prolonged in the TTT condition, thus resulting in stronger suppression of attention for a longer duration. This predicts a more severe AB in the TT200T condition than in the TD200T condition.
However, although the overarching theory inherent in the eSTST model predicts a larger AB for TT200T, the implementation of the model has difficulty simulating the effect. The reason for this difficulty is that the unmasked Tinter is simulated as a persisting trace in iconic memory that provides a continuous excitation of attention. Thus, in the model, an unmasked target keeps the attentional gate open, whereas the data collected here suggest that an unmasked Tinter is not capable of prolonging the duration of attention. We suggest that the model should be modified such that only the onset of a new target produces an attentional effect; the continued duration of a target, either on the screen or in an unmasked, iconic store, is not sufficient to excite attention. This modification of the model is also supported by the data from Experiment 2 of Nieuwenstein, Van der Burg, et al. (2009), which showed that presenting T1 continuously on the screen was insufficient to prevent the onset of the AB.
Another crucial modification of the implementation of the eSTST model that is suggested by our data is that the suppression of attention elicited by the memory encoding of pre-T2 targets may be too strong. With its current parameters, the eSTST model predicts that when the time interval between T2 and Tinter was 0 ms, T2 | T1 performance during the blink should be below 5%, whereas participants here evidenced a far less severe AB. We argue that these modifications are both consistent with the overarching theory of the eSTST model, and our simulations indicate that they allow the model to replicate the deeper AB of the TTT condition.
An important point to observe from the data is that performance remains worse for very long lags in the TT500T relative to the TD500T condition. This finding may suggest that the duration of the AB produced by two targets is much longer than the AB produced by a single target, due to the interference between target-related perceptual representations (Wyble et al., 2011) and/or semantic representations (Taylor & Hamm, 1997), although it may also be the case that some participants have difficulty remembering all three items on some fraction of the trials.
A within-trial contingency effect was also observed in our data, replicating previous studies (e.g., Dell’Acqua et al., 2009). That is, T2 performance was higher when the data were analyzed irrespective of whether or not Tinter report was correct than when only the trials with a correct Tinter report were considered. This effect could be interpreted by resource accounts, which assume that when Tinter was missed, the central processing mechanism should have more spread resources available for processing T2. The eSTST model could also account for this effect by assuming that the failure of Tinter processing leads to reduced memory load and further alleviates the suppression effect induced by memory encoding. However, the within-trial contingency effect provides a difficulty for distractor-based selection accounts, since they do not assume any form of memory-encoding-related limitation or suppression in the mechanism of the AB.
Another interesting finding in the present study was that adding external noise to T1 impaired T1 report but improved T2 report. Since the analyzed T2 report accuracy was conditionalized on correct T1 responses, this improvement of T2 report cannot simply be attributed to a possible compensation mechanism driven by resources saved from T1 processing. This finding was in accordance with our assumption that the increased perceptual difficulty of T1 processing recruits more attention to T1 and benefits the processing of a subsequent T2 presented at the same location. It also clearly demonstrates that the effect of the T1 noise manipulation on T2 processing employed an underlying mechanism different from those in most of the previous studies, which have examined the effect of T1 difficulty on T2 performance by manipulating the memory load (Akyürek et al., 2010; Jolicœur & Dell’Acqua, 1998; Ouimet & Jolicœur, 2007; Scalf et al., 2011; Taatgen et al., 2009; Zhang, Zhou, & Martens, 2011), mental rotation (Taatgen et al., 2009; Zhang et al., 2011), or response selection (Giesbrecht, Sy, & Elliott, 2007) associated with T1 processing. In those studies, more resources were needed to process T1 in working memory—according to the resource accounts, for example—leaving fewer resources for T2 processing. In the present study, however, T1 with external noise would not incur more demand for central memory processing. Because a critical function of attention during perceptual processing is to exclude external noise in the target region (Dosher & Lu, 2000a, 2000b; Lu & Dosher, 2000; Lu et al., 2002), increasing the external noise level of a target might require the visual system to recruit more attentional resources to solve the increased perceptual difficulty. This attentional effect peaks around 100 to 150 ms after T1 onset and benefits subsequent stimulus processing (Nakayama & Mackeben, 1989)—for example, T2 encoding shortly after T1 onset.
The intriguing point was that the beneficial effect of T1 perceptual difficulty on T2 performance was essentially the same for T2 in both the TDT and TTT conditions. The resource accounts can accommodate this finding because T2 processing in both conditions would benefit from the increased attention associated with T1 noise. However, the boost-and-bounce theory predicts an interaction between the T1 noise manipulation and target type: On the one hand, the boost-and-bounce theory may assume that the T1-triggered attentional enhancement enhances the processing of Tinter and T2 in the TTT condition, but leads to a stronger bounce process for Dinter in the TDT condition, impairing further T2 performance. On the other hand, the boost-and-bounce theory may assume that the decrease of the signal-to-noise ratio of T1 impairs T1-triggered attentional enhancement in the TTT condition, but also impairs the bounce in the TDT condition. Clearly, our findings do not fit either of these predictions.
For the eSTST model, the weakened T1 representation in the noise condition, as compared with the no-noise condition, would induce less interference for the processing of subsequent targets that were presented in a brief time window after T1. This reduction of interference in the noise condition would lead to increased performance for Tinter and for T2 when T2 was presented shortly after T1 (i.e., in the no-blank-interval condition). Our data fit well with this prediction. In addition, if the weakened T1 representation led to an impaired T1 semantic trace, the semantic interference account would have the same prediction as the eSTST model regarding our noise effect finding.
To conclude, by manipulating the time interval between Tinter (or Dinter) and T2, and by adding external noise to T1, in the present study we demonstrated that the spread of lag 1 sparing in the TTT condition, as compared with the TDT condition, can be either positive (i.e., better T2 performance in the former than in the latter condition) or negative (i.e., worse T2 performance in the former than in the latter condition), depending on whether a blank time interval is interposed between Tinter (or Dinter) and T2. This finding is accommodated better by the eSTST model than by conventional resource accounts or distractor-based attentional selection accounts of the attentional blink.
References
Akyürek, E. G., Hommel, B., & Jolicœur, P. (2007). Direct evidence for a role of working memory in the attentional blink. Memory & Cognition, 35, 621–627. doi:10.3758/BF03193300
Akyürek, E. G., Leszczyński, M., & Schubö, A. (2010). The temporal locus of the interaction between working memory consolidation and the attentional blink. Psychophysiology, 47, 1134–1141.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Briand, K. A. (1998). Feature integration and spatial attention: More evidence of a dissociation between endogenous and exogenous orienting. Journal of Experimental Psychology: Human Perception and Performance, 24, 1243–1256. doi:10.1037/0096-1523.24.4.1243
Briand, K. A., & Klein, R. M. (1987). Is Posner’s “beam” the same as Treisman’s “glue?” On the relation between visual orienting and feature integration theory. Journal of Experimental Psychology: Human Perception and Performance, 13, 228–241. doi:10.1037/0096-1523.13.2.228
Broadbent, D. E., & Broadbent, M. H. P. (1987). From detection to identification: Response to multiple targets in rapid serial visual presentation. Perception & Psychophysics, 42, 105–113. doi:10.3758/BF03210498
Chua, F. K., Goh, J., & Hon, N. (2001). Nature of codes extracted during the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 27, 1229–1242. doi:10.1037/0096-1523.27.5.1229
Chun, M. M., & Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. Journal of Experimental Psychology: Human Perception and Performance, 21, 109–127. doi:10.1037/0096-1523.21.1.109
Dell’Acqua, R., Jolicœur, P., Luria, R., & Pluchino, P. (2009). Reevaluating encoding-capacity limitations as a cause of the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 35, 338–351. doi:10.1037/a0013555
Di Lollo, V., Kawahara, J., Ghorashi, S. M. S., & Enns, J. T. (2005). The attentional blink: Resource depletion or temporary loss of control? Psychological Research, 69, 191–200. doi:10.1007/s00426-004-0173-x
Dosher, B. A., & Lu, Z.-L. (2000a). Mechanisms of perceptual attention in precuing of location. Vision Research, 40, 1269–1292. doi:10.1016/S0042-6989(00)00019-5
Dosher, B. A., & Lu, Z.-L. (2000b). Noise exclusion in spatial attention. Psychological Science, 11, 139–146. doi:10.1111/1467-9280.00229
Duncan, J., Ward, R., & Shapiro, K. (1994). Direct measurement of attentional dwell time in human vision. Nature, 369, 313–315. doi:10.1038/369313a0
Giesbrecht, B., Sy, J. L., & Elliott, J. C. (2007). Electrophysiological evidence for both perceptual and postperceptual selection during the attentional blink. Journal of Cognitive Neuroscience, 19, 2005–2018. doi:10.1162/jocn.2007.19.12.2005
Holländer, A., Corballis, M. C., & Hamm, J. P. (2005a). Visual-field asymmetry in dual-stream RSVP. Neuropsychologia, 43, 35–40. doi:10.1016/j.neuropsychologia.2004.06.006
Holländer, A., Hausmann, M., Hamm, J. P., & Corballis, M. C. (2005b). Sex hormonal modulation of hemispheric asymmetries in the attentional blink. Journal of the International Neuropsychological Society, 11, 263–272.
Jolicœur, P., & Dell’Acqua, R. (1998). The demonstration of short-term consolidation. Cognitive Psychology, 36, 138–202. doi:10.1006/cogp.1998.0684
Jolicœur, P., Tombu, M., Oriet, C., & Stevanovski, B. (2002). From perception to action: Making the connection. In W. Prinz & B. Hommel (Eds.), Common mechanisms in perception and action: Attention and performance XIX (pp. 558–586). Oxford, UK: Oxford University Press.
Kawahara, J.-I., Kumada, T., & Di Lollo, V. (2006). The attentional blink is governed by a temporary loss of control. Psychonomic Bulletin & Review, 13, 886–890. doi:10.3758/BF03194014
Lagroix, H. E. P., Spalek, T. M., Wyble, B., Jannati, A., & Di Lollo, V. (2012). The root cause of the attentional blink: First-target processing or disruption of input control? Attention, Perception, & Psychophysics, 74, 1606–1622. doi:10.3758/s13414-012-0361-5
Lu, Z.-L., & Dosher, B. A. (2000). Spatial attention: Different mechanisms for central and peripheral temporal precues? Journal of Experimental Psychology: Human Perception and Performance, 26, 1534–1548. doi:10.1037/0096-1523.26.5.1534
Lu, Z.-L., Lesmes, L. A., & Dosher, B. A. (2002). Spatial attention excludes external noise at the target location. Journal of Vision, 2(4), 312–323.
Luck, S. J., Vogel, E. K., & Shapiro, K. L. (1996). Word meanings can be accessed but not reported during the attentional blink. Nature, 383, 616–618. doi:10.1038/383616a0
Maki, W. S., Frigen, K., & Paulson, K. (1997). Associative priming by targets and distractors during rapid serial visual presentation: Does word meaning survive the attentional blink? Journal of Experimental Psychology: Human Perception and Performance, 23, 1014–1034. doi:10.1037/0096-1523.23.4.1014
McLaughlin, E. N., Shore, D. I., & Klein, R. M. (2001). The attentional blink is immune to masking-induced data limits. Quarterly Journal of Experimental Psychology, 54A, 169–196. doi:10.1080/02724980042000075
Nakayama, K., & Mackeben, M. (1989). Sustained and transient components of focal visual attention. Vision Research, 29, 1631–1647. doi:10.1016/0042-6989(89)90144-2
Nieuwenstein, M. R., & Potter, M. C. (2006). Temporal limits of selection and memory encoding: A comparison of whole versus partial report in rapid serial visual presentation. Psychological Science, 17, 471–475. doi:10.1111/j.1467-9280.2006.01730.x
Nieuwenstein, M. R., Potter, M. C., & Theeuwes, J. (2009). Unmasking the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 35, 159–169. doi:10.1037/0096-1523.35.1.159
Nieuwenstein, M., Van der Burg, E., Theeuwes, J., Wyble, B., & Potter, M. (2009). Temporal constraints on conscious vision: On the ubiquitous nature of the attentional blink. Journal of Vision, 9(9), 18. doi:10.1167/9.9.18. 1–14.
Olivers, C. N. L., & Meeter, M. (2008). A boost and bounce theory of temporal attention. Psychological Review, 115, 836–863. doi:10.1037/a0013395
Olivers, C. N. L., van der Stigchel, S., & Hulleman, J. (2007). Spreading the sparing: Against a limited-capacity account of the attentional blink. Psychological Research, 71, 126–139. doi:10.1007/s00426-005-0029-z
Ouimet, C., & Jolicœur, P. (2007). Beyond Task 1 difficulty: The duration of T1 encoding modulates the attentional blink. Visual Cognition, 15, 290–304.
Potter, M. C., Chun, M. M., Banks, B. S., & Muckenhoupt, M. (1998). Two attentional deficits in serial target search: The visual attentional blink and an amodal task-switch deficit. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24, 979–992. doi:10.1037/0278-7393.24.4.979
Potter, M. C., Staub, A., & O’Connor, D. H. (2002). The time course of competition for attention: Attention is initially labile. Journal of Experimental Psychology: Human Perception and Performance, 28, 1149–1162. doi:10.1037/0096-1523.28.5.1149
Raymond, J. E., Shapiro, K. L., & Arnell, K. M. (1992). Temporary suppression of visual processing in an RSVP task: An attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 18, 849–860. doi:10.1037/0096-1523.18.3.849
Scalf, P. E., Dux, P. E., & Marois, R. (2011). Working memory encoding delays top-down attention to visual cortex. Journal of Cognitive Neuroscience, 23, 2593–2604. doi:10.1162/jocn.2011.21621
Seiffert, A. E., & Di Lollo, V. (1997). Low-level masking in the attentional blink. Journal of Experimental Psychology: Human Perception and Performance, 23, 1061–1073. doi:10.1037/0096-1523.23.4.1061
Shapiro, K., Driver, J., Ward, R., & Sorensen, R. B. (1997). Priming from the attentional blink: A failure to extract visual tokens but not visual types. Psychological Science, 8, 95–100.
Taatgen, N. A., Juvina, I., Schipper, M., Borst, J. P., & Martens, S. (2009). Too much control can hurt: A threaded cognition model of the attentional blink. Cognitive Psychology, 59, 1–29. doi:10.1016/j.cogpsych.2008.12.002
Taylor, T. L., & Hamm, J. (1997). Category effects in temporal visual search. Canadian Journal of Experimental Psychology, 51, 36–46.
Verleger, R., Śmigasiewicz, K., & Möller, F. (2011). Mechanisms underlying the left visual-field advantage in the dual stream RSVP task: Evidence from N2pc, P3, and distractor-evoked VEPs. Psychophysiology, 48, 1096–1106. doi:10.1111/j.1469-8986.2011.01176.x
Wyble, B., Bowman, H., & Nieuwenstein, M. (2009). The attentional blink provides episodic distinctiveness: Sparing at a cost. Journal of Experimental Psychology: Human Perception and Performance, 35, 787–807. doi:10.1037/a0013902
Wyble, B., Potter, M. C., Bowman, H., & Nieuwenstein, M. (2011). Attentional episodes in visual perception. Journal of Experimental Psychology: General, 140, 488–505. doi:10.1037/a0023612
Zhang, D., Zhou, X., & Martens, S. (2011). Negative attentional set in the attentional blink: Control is not lost. Attention, Perception, & Psychophysics, 73, 2489–2501. doi:10.3758/s13414-011-0207-6
Author note
We are extremely grateful to Brad Wyble, Jeff Hamm, and an anonymous reviewer for their valuable comments and suggestions. We would also like to thank Philip Blue for help the preparation of the manuscript.This study was supported by the National Basic Research Program from the Ministry of Science and Technology of China (973 Program: 2010CB833904, 2015CB856400), and by grants from the National Natural Science Foundation of China (31170972, 91232708).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Chen, X., Zhou, X. Revisiting the spread of sparing in the attentional blink. Atten Percept Psychophys 77, 1596–1607 (2015). https://doi.org/10.3758/s13414-015-0886-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-015-0886-5