
Abstract
Performance in working memory (WM) tasks depends on the capacity for storing objects and on the allocation of attention to these objects. Here, we explored how capacity models need to be augmented to account for the benefit of focusing attention on the target of recall. Participants encoded six colored disks (Experiment 1) or a set of one to eight colored disks (Experiment 2) and were cued to recall the color of a target on a color wheel. In the no-delay condition, the recall-cue was presented after a 1,000-ms retention interval, and participants could report the retrieved color immediately. In the delay condition, the recall-cue was presented at the same time as in the no-delay condition, but the opportunity to report the color was delayed. During this delay, participants could focus attention exclusively on the target. Responses deviated less from the target’s color in the delay than in the no-delay condition. Mixture modeling assigned this benefit to a reduction in guessing (Experiments 1 and 2) and transposition errors (Experiment 2). We tested several computational models implementing flexible or discrete capacity allocation, aiming to explain both the effect of set size, reflecting the limited capacity of WM, and the effect of delay, reflecting the role of attention to WM representations. Both models fit the data better when a spatially graded source of transposition error is added to its assumptions. The benefits of focusing attention could be explained by allocating to this object a higher proportion of the capacity to represent color.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Our ability to hold in mind information about our visual environment is constrained by the capacity of a system known as visual working memory (WM). Visual WM enables us to form a representation of our surroundings, to maintain it after the visual input has disappeared, and to manipulate in mind representations of previously seen objects. This is the reason why considerable research has been devoted to understand how representations are encoded, maintained, and retrieved from visual WM.
Research on visual WM has shown, on the one hand, that people can retain only a handful of the information presented on a visual display. These studies have put forward that both the quantity and quality of the representations that are stored in WM are limited (e.g., Bays & Husain, 2008; Zhang & Luck, 2008). On the other hand, studies examining the interplay of attention and WM have shown that performance is improved when attention is focused on a subset of the information held in WM (e.g., Griffin & Nobre, 2003; Landman, Spekreijse, & Lamme, 2003). These two lines of research have highlighted complementary aspects of WM: its capacity limitations and the flexibility with which its limited capacity can be allocated.
The main aim of the present article is to put the findings of these two fields in relation to each other. To achieve this goal, we combined the experimental paradigms of both fields to empirically examine how focused attention affects the quantity and the quality of the representations held in visual WM. Despite the ample literature showing that focused attention improves WM, it is still unclear whether focused attention impacts the quantity, the quality, or both of these mnemonic parameters. Next, we used computational modeling to instantiate versions of two popular models of WM capacity—namely, the flexible-resource model and the discrete-capacity model. Our goal was to explore how these models could be expanded to accommodate the effect of focusing attention on some of WM's contents.
The structure of the present article is the following. First, we briefly introduce the two mainstream models of capacity limits in visual WM and summarize some of the findings that have fueled the debate over what is the source of capacity limits in WM. Next, we present the main findings of studies concerned with the role of attention to WM contents. We then present two experiments testing how focused attention improves performance in WM tasks. Finally, we present our modeling approach to WM capacity and to the role of focused attention to WM contents.
Capacity limits on quantity and quality of representations in visual WM
The question of what limits the capacity of visual WM has been a matter of a vivid debate in the literature. According to the flexible-resource model, WM capacity consists of a continuous resource divided among the objects to be represented: the larger the number of objects, the lower the quality (precision) of each object representation in memory (Bays, Catalao, & Husain, 2009; Bays & Husain, 2008; Wilken & Ma, 2004). Consequently, the flexible-resource model predicts a trade-off between the quantity and quality of representations in WM.
Alternatively, one can think of WM capacity as a limited number of discrete units or slots. Within a slot, an object is represented with good, although not perfect, quality (Cowan, 2001; Luck & Vogel, 1997; Vogel, Woodman, & Luck, 2001; Zhang & Luck, 2008, 2009, 2011). According to this discrete-capacity model, one cannot trade-off quantity with quality: Either an object receives a whole slot, thereby being represented with good precision, or no information is stored about it at all. There is, however, some room for flexibility: According to one implementation of the discrete-capacity model (the slot+averaging model proposed by Zhang & Luck, 2008), multiple slots can be assigned to a single object to achieve higher precision for that object. By averaging across slots, the noise associated with a representation is reduced, and quality improves.
To test the predictions of WM capacity models, researchers have developed tasks to assess not only the number, but also the precision of WM representations. One of these tasks is the continuous recall task (Prinzmetal, Amiri, Allen, & Edwards, 1998; Wilken & Ma, 2004). In a prototypical task, participants are asked to retain the feature values of an array of objects (e.g., the colors of solid disks; the orientations of tilted bars). At the end of a brief interval, the participant is prompted to reproduce the relevant feature of a target object in a continuous feature space (e.g., select the color of the target in a color wheel; reproduce the target’s orientation using a dial). The dependent measure in this task is the deviation between the reported feature value and the target's true feature value. A set of mixture models has been proposed to analyze the distribution of response deviations (cf. Bays et al., 2009; Zhang & Luck, 2008). These models allow the extraction of several memory parameters, such as (1) the precision with which the target is recalled, given that it is recalled, and (2) failures in recalling the target object’s feature (in which case, the participant either guesses or wrongly reports another object from the memory array).
By using these mixture models, it has been established that the estimated precision of representations decreases as the number of objects in the memory set increases, producing the so-called set size effect (Anderson & Awh, 2012; Anderson, Vogel, & Awh, 2011; Bays et al., 2009; Bays, Gorgoraptis, Wee, Marshall, & Husain, 2011; Bays & Husain, 2008; Fougnie, Asplund, & Marois, 2010; Fougnie, Suchow, & Alvarez, 2012; Gorgoraptis, Catalao, Bays, & Husain, 2011; Zhang & Luck, 2008, 2009). However, there is still dispute over whether precision can decrease infinitely as the number of objects increases, as implied by the flexible-resource model; or whether precision plateaus when the set size reaches the maximum number of objects that can be maintained in WM, as predicted by the discrete-capacity model. Some studies have failed to find a plateau in mnemonic resolution (Bays et al., 2009; Bays, Gorgoraptis, et al., 2011; Bays & Husain, 2008; Gorgoraptis et al., 2011), whereas others have reported that precision does not decrease any further after the memory set size exceeds the individual's estimated capacity limit (Anderson & Awh, 2012; Anderson et al., 2011; Gorgoraptis et al., 2011, Experiment 3; Zhang & Luck, 2008).
To date, adjudicating between flexible-resource and discrete-capacity models has proven to be a difficult enterprise, mainly because the behavioral predictions of these models considerably overlap. In most cases, mixture modeling has been applied to the data, and the pattern of findings has been interpreted on the basis of the predictions of either flexible-resource or discrete-capacity models. The mixture models, however, make no assumptions regarding the effects of memory set size on performance. As a consequence, they are neutral regarding the nature of capacity limitations. Later, we will present models that implement flexible-resource and discrete-capacity assumptions and that, therefore, could be potentially used to inform the debate of capacity limits in WM. Our goal, however, was mainly to probe how these models could potentially explain the benefit of focusing attention on some WM contents.
Attention to objects in WM
Performance in WM tasks depends not only on the capacity for encoding and maintaining a set of objects, as implied by capacity models, but also on the allocation of attention to objects within the memory set. Any successful model of WM capacity should also explain how people efficiently use their capacity by selectively attending to the objects in WM that are likely to be most relevant.
We define attention as the prioritization of information matching the individual’s task goals (Nobre & Stokes, 2011). This prioritization can occur for perceptually present stimuli, sometimes referred to as external attention, or for a set of mental representations, referred to as internal attention (Chun, Golomb, & Turk-Browne, 2011) or as the focus of attention in WM (Cowan, 2011; Oberauer & Hein, 2012). In the present article, we will mainly focus on the effects of attention to information that is already maintained in WM and, therefore, is regarded as prioritized by internal attention.
In WM tasks, internal attention can be directed to a WM object by presenting a cue during the retention interval (known as a retro-cue). The effect of retro-cues is well established in change detection tasks (Astle, Summerfield, Griffin, & Nobre, 2012; Berryhill, Richmond, Shay, & Olson, 2012; Griffin & Nobre, 2003; Kuo, Stokes, & Nobre, 2012; Landman et al., 2003; Lepsien, Griffin, Devlin, & Nobre, 2005; Lepsien, Thornton, & Nobre, 2011; Matsukura, Cosman, Ropper, Vatterott, & Vecera, 2014; Matsukura & Hollingworth, 2011; Matsukura, Luck, & Vecera, 2007; Maxcey-Richard & Hollingworth, 2013; Nobre, Griffin, & Rao, 2008; Rerko & Oberauer, 2013; Rerko, Souza, & Oberauer, 2014a; Schmidt, Vogel, Woodman, & Luck, 2002; Souza, Rerko, & Oberauer, 2014; Tanoue & Berryhill, 2012; Williams & Woodman, 2012). In these tasks, participants are asked to decide whether a probe stimulus is the same or changed, as compared with the object presented in the same location in the memory array. When an objects is retro-cued before being probed, responses are faster and more accurate, as compared with baseline trials without cues (or with noninformative cues) or as compared with responses to probes presented in one of the noncued locations (Griffin & Nobre, 2003). This finding is known as the retro-cue benefit. However, because supra-threshold changes are often used in change detection tasks, it is not possible to determine what kind of memory error is reduced by cuing.
By combining the retro-cue paradigm with precision tasks, one can assess which source of memory errors is reduced by attention—that is, whether focusing attention on the target of recall improves its probability of being recalled, its precision, or both. This information can advance the explanations of the retro-cue benefit, and it can help to establish a link between capacity limitations and control mechanisms that determine how capacity is allocated to retrieve relevant information from WM.
To the best of our knowledge, only three studies have used retro-cues on tasks assessing the quality of WM representations. In the study by Pertzov, Bays, Joseph, and Husain (2013), participants were shown tilted bars and, at the end of a variable retention interval, were asked to adjust the orientation of a probe-bar to match the orientation of the target in the memory display. Pertzov et al. compared performance on baseline (no-cue) trials with performance on retro-cue trials on which a retro-cue indicated one of the memory objects as likely to be tested. As compared with the baseline trials, deviations between the reported orientation and the target orientation were smaller when the tested object was the retro-cued one but larger when the tested object was one of the noncued ones. Furthermore, deviations in reporting the target orientation increased over the retention interval, with the exception of the retro-cued object, which was reported with low error after all retention interval durations. These findings were interpreted as evidence that focusing attention on a memory object protects it from degradation over time. However, in this study, mixture modeling was not applied to the distributions of errors, and therefore it is difficult to estimate whether the retro-cue benefit was due to an effect on precision, on the probability of having the object in memory, or both.
In the study by Murray, Nobre, Clark, Cravo, and Stokes (2013), participants discriminated whether a probe-arrow was rotated clockwise or counterclockwise, as compared with the orientation of a memory object. The precision of the memory representation was assessed by varying the degree of change between the probe and the target orientation: Larger changes can be discriminated even with a coarse memory representation, whereas smaller changes require fine resolution. Retro-cuing an object significantly increased the estimated probability of having that object in memory but did not affect the precision with which it was remembered. This retro-cue benefit was obtained even in comparison with baseline trials whose retention interval was matched to the time between memory encoding and presentation of the cue on retro-cue trials. This result rules out protection from degradation over time as the cause of the retro-cue benefit, suggesting instead that the retro-cue can be used to access a representation that would be otherwise unavailable when the test display is shown at the same point in time. However, because a probe with a random orientation was displayed in the location of the memory object, it is possible that the retro-cue benefit arose because attention protected the cued object from interference from the probe (Makovski & Jiang, 2007; Makovski, Sussman, & Jiang, 2008). If this were the case, the retro-cue benefit would not be observed in tasks not using a probe, including the cued-recall paradigm typically used to assess the quantity and quality of representations in WM.
Williams, Hong, Kang, Carlisle, and Woodman (2013) used a cued-recall task: Participants encoded the color of one or two disks and, after a brief delay, selected the color of a target from a color wheel. On half of the two-object trials, a retro-cue (an arrow) was shown in the middle of the retention interval. The cue pointed to one of the locations of a memory object, thereby indicating that this object was not going to be tested and could be forgotten. Recall improved on retro-cue trials, as compared with no-cue trials. Unlike the study of Murray et al. (2013), however, both the probability of correctly recalling the target and the precision with which it was reported improved on retro-cue trials.
To sum up, these studies show that retro-cues improve performance in tasks assessing the quality of memory representations in a continuous feature space. The results, however, are mixed regarding whether retro-cues improve only the probability of recall (Murray et al., 2013) or both the probability of having the prioritized object in memory and its precision (Williams et al., 2013). There are several methodological differences between these studies that could possibly explain their discrepant findings: the set size examined (four and eight objects in Murray et al., 2013, vs. two objects in Williams et al., 2013), the information conveyed by the retro-cue (a cue that pointed to the object to be retained vs. a cue that pointed to the object to be forgotten), and also regarding how the retention interval on retro-cue and no-cue trials was matched (ruling out protection from time-based degradation vs. not ruling out the contribution of this variable).
The present study
Here, we further explored the effects of directing attention to an object held in WM using a continuous cued-recall task. In our experiments, an array of colored disks was presented to be memorized over a brief retention interval. At the end of this interval, a recall cue identified one memory object as the target, and participants had to recall its color using a color wheel. To assess the benefit of focusing attention in this task, we created two conditions that differed in how long participants could use the recall cue before reporting the color of the target. In the no-delay condition, participants could immediately report the color of the target after presentation of the recall cue. This condition is similar to what is usually done in experiments testing the capacity of visual WM (cf. Zhang & Luck, 2008). We considered this condition to be equivalent to a simultaneous-cue condition in the traditional recognition or change detection paradigm—that is, a condition in which a cue is shown together with the probe stimulus and participants can immediately compare the probe with the object in memory and report whether they match or mismatch. The presentation of a simultaneous cue (or simu-cue for short) does not enhance performance, as compared with a no-cue condition, in recognition tests, and retro-cue benefits have been observed when retro-cue trials are compared with both baselines (cf. Makovski et al., 2008). In the delay condition, the recall cue is displayed at the same point in time as in the no-delay condition, but the opportunity to report the target color is delayed by a full second. We assume that during this delay, the only thing participants can do is to focus attention on the target of recall. This is equivalent to what a retro-cue affords in the traditional cuing paradigm: Participants cannot respond after a retro-cue; they can only focus attention on the cued object.
The choice of this design has two advantages that help to constrain explanations of the retro-cue benefit. First, we equated the time for which representations could undergo degradation (by decay or some other process) across our no-delay and delay conditions. If anything, our focused attention condition (aka delay condition) has a longer overall retention interval, thereby ruling out protection from time-based degradation as an explanation of our focusing benefit. Second, by presenting a recall cue in both conditions, we avoided the interference that could be produced by presenting a probe stimulus in the location of the memory object. Consequently, in our design, the focusing benefit cannot be explained as protection from probe interference. Ruling out these explanations is an important first step to consider what the focusing benefit reveals about the structure of WM. If performance in the cued-recall paradigm reflects something about an individual's capacity, what changes when attention is focused on one object?
We conducted two experiments. In Experiment 1, the memory array contained six objects, and trials were equally split into no-delay and delay conditions. In Experiment 2, in addition to manipulating delay, we varied the number of objects participants had to memorize (one to eight objects). The manipulation of set size allows the examination of how focused attention impacts performance when WM is taxed at different levels. We applied two kinds of models to our data. First, to assess which source of error is affected by focusing attention on the target representation during the delay, we fitted a three-parameter mixture model (Bays et al., 2009) to the data of both experiments. This model estimates (1) the precision with which the target color is retrieved, given that it is available; (2) the probability that the participant confuses memory objects with each other and, therefore, reports one of the nontarget objects (making a transposition error); and (3) the probability that no object was available to be retrieved and the participant guessed.
To foreshadow our results, the delay condition reduced the mean deviation in reporting the target color, relative to the no-delay condition. The mixture modeling assigned this benefit to a reduced probability of memory failures (reduction in guessing in Experiments 1 and 2 and, to a lesser extent, in transposition errors in Experiment 2), but not in the precision with which the target was recalled.
In a second step, we tested two families of computational models of WM capacity: flexible-resource models (Bays et al., 2009), on the one hand, and fixed-capacity or slot models, on the other hand, the latter building on the slot+averaging model (Zhang & Luck, 2008). Because none of the published models of WM capacity provides a mechanism for adequately explaining the focusing benefit we observed, we explored a set of plausible models in each family to find out how such a benefit could arise. The main goal of this modeling work is to determine which features are necessary for a flexible-resource model or for a discrete-capacity model to explain both the effect of memory set size, reflecting the limited capacity of WM, and the effect of delaying recall after a retro-cue, reflecting the role of attention to representations in WM.
General method
Participants
Sixteen students (11 women; mean age = 23.8 years) at the University of Zurich participated in a 1-h session in Experiment 1, and 22 students (15 women; mean age = 23.7 years) participated in two 1-h sessions in Experiment 2. There was no overlap between the two samples. Participation was compensated with course credit or 15 Swiss francs per session. One participant completed only one experimental session in Experiment 2, due to experimenter error, and was excluded from subsequent analyses. Participants read and signed an informed consent form prior to the study and were debriefed regarding the purpose of the experiment at the end.
Materials and procedure
The experimental task was programmed in MATLAB using the Psychophysics Toolbox extension (Brainard, 1997; Pelli, 1997). Participants were tested in individual booths where they sat approximately 50 cm from the computer screen (viewing distance was unconstrained).
The task required the memorization of a set of colored disks for a subsequent memory recall test. In Experiment 1, six disks were presented in the memory display, whereas in Experiment 2, memory set size was varied from one to eight. The disks (radius of 1.1 cm) appeared evenly spaced around an imaginary circle (radius of 5.5 cm) centered in the middle of the screen. In Experiment 1, the memoranda were presented evenly at fixed positions (starting with an angle of 60º). In Experiment 2, the exact positions of the disks varied on a trial-by-trial basis: The position (angle) of the first object was selected at random, and the positions of the other objects were distributed at even angular distances from this point. The edge-to-edge distance between two objects varied between 9 cm (set size 2) and 2.1 cm (set size 8).
Each disk color in a memory array was sampled from a color wheel consisting of 360 values evenly distributed on the hue dimension in the cylindrical HSL (hue, saturation, and lightness) color model, with the values for saturation fixed to 1 and lightness to .5. Color values were selected randomly, with the constraint that all objects’ colors on a given trial were at a minimum distance of 20° on the color wheel from each other. At the end of the trial, participants were cued to recall the color of a single object, selected at random. The target of recall was indicated by presenting a white outlined circle at the target’s location in the memory array. Participants had to report the color of the target object by clicking on a point on the color wheel. The color wheel was rotated randomly on each trial. The instructions emphasized accuracy but not speed.
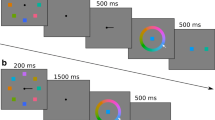
Across two experimental conditions, we varied the time between presentation of the prompt to recall an object and the presentation of the color wheel (opportunity to recall): 0 ms (no-delay condition) or 1,000 ms (delay condition). Figure 1 illustrates the flow of events on these trials. Each trial started with the presentation of a white fixation cross against a gray background. In the no-delay condition, we presented the color wheel together with the fixation cross, and the color wheel remained on-screen throughtout the trial. After 500 ms, the memory array was displayed for 1,000 ms. The offset of the memory array was followed by a 1,000-ms retention interval, after which the cue to recall (circle outline) was displayed in both conditions. In the no-delay condition, the color wheel was already available when the cue to recall was shownFootnote 1; in the delay condition, the color wheel was presented only after an additional 1,000-ms delay had elapsed. In both conditions, the recall cue remained on the screen until participants clicked on a color on the color wheel. No performance feedback was provided. After response, a blank intertrial interval of 1,000 ms followed. To prevent articulatory rehearsal, participants were asked to repeat the sequence der–die–das throughout the trial (articulatory suppression).

Sequence of events in the no-delay and delay conditions, showing memory arrays with set sizes 6 and 8, respectively. At the beginning of a trial, a fixation cross was shown for 500 ms, after which a memory array consisting of six colored disks (Experiment 1) or one to eight colored disks (Experiment 2) was presented for 1,000 ms. Participants were instructed to remember the colors of the disks and their locations. The offset of the memory array was followed by a 1,000-ms retention interval, at the end of which one object from the memory array was cued (white circle outline) as the target of recall. Participants had to indicate the color of the target object by clicking on a color wheel. In the no-delay condition, the color wheel was available throughout the trial, and participants could respond immediately to the recall cue; in the delay condition, the color wheel was shown 1,000 ms after the the presentation of the recall cue, delaying the opportunity to select the retrieved color. During this delay, participants could only focus their attention on retrieving the target color
In Experiment 1, participants completed a total of 500 trials in one 1-h session. Trials were equally split into the two delay conditions (i.e., 250 trials per conditon). In Experiment 2, participants completed a total of 992 trials across two 1-h sessions. In this experiment, the delay (no-delay or delay) and set size (one to eight objects) variables were orthogonally manipulated, producing a total of 16 conditions (62 trials per condition). Trials in all conditions were randomly intermixed. Trials in each session were divided among 10 blocks, and between blocks, short breaks were allowed. Participants were reminded to continue with the articulatory suppression task at the beginning of each block. At the beginning of each session, participants completed an additional set of 10 (Experiment 1) or 16 (Experiment 2) practice trials that were discarded from subsequent analyses.
Data analysis
We performed two set of analyses. First, we computed response deviations on each trial by calculating the angular distance in color space between the color reported by the participant and the target object’s true color. Deviations could fall between 0° (perfect recall) and ±180° (color opposite to the correct color). We then used the absolute deviation to compute the mean deviation in each experimental condition. This measure provides a raw indication of performance differences across experimental conditions.
In a second step, we fitted the three-parameter mixture model to the distributions of response deviations in each condition. The mixture model served as a measurement model to decompose the distributions into several sources of memory errors.
Mixture modeling
If the target object is in memory, the distribution of responses should be centered on the target’s color (0º), with the frequency of responses falling off with increasing distance between the target's color and a response on the color dimension. The standard deviation (SD) of this distribution reflects the precision of the target object in memory: the larger the SD, the lower the precision. We will refer to SD and precision as interchangeable terms hereafter. If the target is not retrieved, there are two possible alternatives: (1) Participants can guess at random, thereby selecting any color from the color wheel with equal probability; or (2) participants can erroneously report the color of another object from the memory array, thereby making a transposition error, in which case the distribution of errors will be centered on the color of a nontarget object. The three-parameter modelFootnote 2 estimates these three mnemonic parameters (namely, SD, guessing, and transpositions) from the distributions of response deviations. The distribution of responses centered on the color of the target object (and on the color of nontargets) is described by a normal distribution for circular data, the so-called von Mises distribution, and guessing is modeled as a uniform distribution (see Bays et al., 2009). The probability of retrieving the target color was defined as 1 − (Guessing + Transpositions). The mean of the von Mises distribution was set to 0 under the assumption that there was no response bias, which is the usual finding in the literature (e.g., Anderson & Awh, 2012; Anderson et al., 2011; Bays et al., 2009; Fougnie et al., 2010; Zhang & Luck, 2008, 2011). Maximum-likelihood estimation procedures were used to fit the mixture model (using the simplex algorithm in MATLAB). The estimation procedure was repeated a minimum of five times with different initial parameters.
Results
Experiment 1
On average, the reported target color deviated less from the true target color in the delay condition (M = 38.3, SD = 11.1) than in the no-delay condition (M = 48.7, SD = 11.0), t(15) = 5.42, p < .001. To examine which mnemonic parameter is improved by focusing attention in the target during the retention interval, we fitted a series of mixture models to the data. First, we fitted the traditional three-parameter mixture model in which SD, guessing rate, and transposition rate were estimated separately and independently for each delay condition. Next, we fitted a series of reduced models in which some parameters were fixed to be equal across delay conditions. Table 1 presents the estimated parameters from the fitted models and model fit.
As is shown in Table 1, when the traditional mixture model was applied to the data, the average estimated SD and transposition rate were similar and nonsignificantly different across delay conditions [precision, t(15) = −0.645, p = .529; transposition, t(15) = 0.909, p = .378]. The difference between the conditions was limited to the guessing rate, which was significantly lower in the delay condition, t(15) = 2.735, p = .015. To examine whether this difference was related to possible trade-offs between the estimation of the parameters in the mixture model (Suchow, Brady, Fougnie, & Alvarez, 2013), we fitted several mixture models in which we constrained some of the parameters to be equal across delay conditions, whereas we let the other parameters vary freely while fitting the mixture model to both conditions simultaneously. These models are shown in Table 1 as versions 1–6. Parameters that were fixed to equal values across conditions are printed in bold. We ranked the model versions in relation to their fit, as compared with the traditional model. Fixing the precision and transposition rate to be equal across conditions substantially improved the fit, leading to the best fitting model (i.e., version 6). In contrast, forcing the model to assign the differences between delay conditions to the precision parameter substantially impaired the fit, leading to the worst model (i.e., version 4). Moreover, in all model versions in which the guessing rate was fixed to be equal between delay conditions, model fit was worsened, as compared with models without this constraint. These results strengthen our conclusion that focused attention increases the probability of retrieving the target object, but not the precision with which it is reported.
Experiment 2
In Experiment 2, in addition to varying the delay before reporting the target color, we also varied set size from one to eight. To test the effect of both delay and set size on recall performance, we used repeated measures analyses of variance (ANOVAs). For these analyses, whenever the sphericity assumption was violated, corrected Greenhouse–Geisser degrees of freedom (recognizable by noninteger values) were reported. The results of the ANOVAs are shown in Table 2. Furthermore, we followed up on the significant main effects of set size and set size × delay interactions by running repeated contrast tests, which compare each variable level with the following one. The results of these analyses are presented in Table 3.
Figure 2a shows the mean absolute angular deviation between the response selected by the participant and the target’s true color in each set size and delay condition. Deviations increased as set size increased, as indicated by the significant effect of set size in the ANOVA (Table 2), and this effect was significant between each set size and the next (Table 3). Furthermore, the main effect of delay condition was significant, showing that focusing attention on the target object reduced the deviation in reporting its color. The interaction of set size and delay was also significant. Repeated contrast tests indicated that the interaction was significant up to set size 4. This analysis shows that the magnitude of the improvement produced by the delay increased from set sizes 1 to 4 and remained stable thereafter.

a Deviation in reporting the color of the target object. b Predicted deviation by the three-parameter mixture model. The deviation from the data is presented in gray for comparison. Panels c to e show the estimated parameters from the mixture model, c Standard deviation (SD): the larger the SD, the less precise the representation of the reported object. d Probability of guessing a random color. e Probability of a transposition error—that is, reporting one of the nontarget colors from the memory array. f Capacity, K. Error bars represent within-subjects 95 % confidence intervals (Cousineau, 2005)
In the following, we describe the results of the three-parameter model. Figure 2b shows the average recall error predicted by this model using the best-fitting parameters. On average, the predictions of the model closely resemble the data (shown in gray for comparison). Panels c–e present the estimated model parameters (SD, guessing, and transpositions), and panel f shows a capacity estimate, known as K.
Figure 2c shows the SD in each set size and delay condition. The ANOVA results in Table 2 confirm the visual impression that set size, but not delay, significantly affected SD. Repeated contrast tests (Table 3) showed that SD significantly increased until set size 5; the increase in SD from set sizes 6 to 8 was not significant. In sum, the precision of representations in memory declined with the number of objects to be retained up to set size 5, but it was not modulated by our delay manipulation, replicating the results of Experiment 1.
Figure 2d shows the probability of guessing estimated from the three-parameter mixture model. As is confirmed by the ANOVA results in Table 2, guessing rate increased over set size and was significantly reduced in the delay condition, as compared with the no-delay condition. Set size and delay did not interact. We also conducted repeated contrast tests to follow up on the main effect of set size (see Table 3), which revealed a significant increase on guessing only until set size 4.
Figure 2e shows the probability of making a transposition error. For this measure, we excluded set size 1 from the analysis (because a nontarget recall could not occur at this set size). As is shown in Table 2, transposition errors increased over set size and were reduced in the delay condition. Repeated contrast tests (Table 3) indicated that transpositions increased up to set size 6, after which the values were not statistically different. The set size × delay interaction was not significant.
The probability of reporting the target object can be derived from the estimated parameters by computing target recall = 1 − (guessing + transpositions). We used this measure to calculate the number of objects participants can access from memory. This measure, computed as target recall × set size, is often referred to as an estimate of capacity, called K, in the context of discrete-capacity models (Anderson et al., 2011; Cowan, 2001; Zhang & Luck, 2008). The K estimates produced by this calculation are presented in Fig. 2f, and the ANOVA results are presented in Table 2. When considering all conditions, the ANOVA yielded significant effects of set size and delay condition and a significant interaction between these variables. This result is not surprising given that K increased from set sizes 1–5 (see repeated contrast tests in Table 3), consistent with the fact that for set sizes below capacity, the formula underestimates the true capacity of the person. For larger set sizes, the estimated K plateaued at a constant value, as would be expected from a discrete-capacity theory. We reran the ANOVA entering only set sizes 6–8, values for which the K estimate was approximately flat. This analysis yielded only a main effect of delay condition (see Table 2), showing that increasing the time to use the recall cue increased K by roughly 1 unit (no-delay, K = 3.06; delay, K = 3.94).
Discussion of experiments 1 and 2
In Experiments 1 and 2, we assessed the benefits of focusing attention on one of the objects currently held in WM. Our main empirical goal was to examine whether attention improves performance in tasks assessing both the quantity and quality of WM representations. We manipulated focused attention in a cued recall task by delaying the opportunity to recall the cued object’s feature: During the delay, participants could focus attention exclusively on the target color but not compare or select it from the color wheel. The recall error in this delay condition was smaller than in a no-delay condition. In addition to the delay, we also manipulated set size in Experiment 2. Increasing set size impaired performance: The deviation in reporting the color of the target was a function of the number of objects in the memory set. Focusing attention during the delay, however, reduced the error in reporting the target as soon as more than one representation was being held in WM (i.e., from set size 2 on).
These results show that focused attention does improve performance in cued-recall tasks. But which memory parameter is improved by attention? To answer this question, we submitted our data to mixture modeling to estimate target precision, guessing rate, and transposition errors. This modeling showed that the probability of recalling the target object increased in the delay condition, as compared with the no-delay condition, at the expense of random guessing (Experiments 1 and 2) and, to a lesser extent, of transposition errors (Experiment 2). The precision in reporting the target's color, however, was unaffected by our delay manipulation. These findings converge with the results of Murray et al. (2013) and with other experiments conducted in our own lab (Rerko, Souza, & Oberauer, 2014b) but are in contrast with the results of Williams et al. (2013). As was mentioned in the introduction, there are several methodological differences between the present study and the one by Williams et al. that could possibly explain this discrepant result. At present, it is unclear which of these methodological differences could explain the discrepant results between our study (and the one by Murray et al., 2013) and the study of Williams et al. However, so far, there are more studies pointing to selective effects on guessing rate than studies showing an effect of focused attention on precision.
One concern that might arise with our task relates to differences in the presentation of the color wheel across conditions: in the no-delay condition, the color wheel was displayed at the very beginning of the trial (together with the fixation cross), whereas in the delay condition, the color wheel was shown at the very end. This means that the color wheel was on-screen when the memory objects were displayed on no-delay trials, but not on delay trials. Could the presence of the color wheel during encoding and maintenance explain the difference in performance between the no-delay and delay conditions? We think this is very unlikely. First, we were not the first to display the memory objects together with the color wheel. In Experiment 4b of Zhang and Luck (2011), the color wheel was on-screen when the memory objects were shown, and the estimated capacity in this experiment was not different from that in the other experiments in that series (Experiments 1, 2, and 3). Second, in other experiments in our lab, we have either (1) presented the color wheel together with the recall cue on both delay and no-delay trials or (2) displayed the color wheel throughout the trial in both delay and no-delay conditions (Rerko et al., 2014b). In both cases, performance was better in the delay than in the no-delay condition, replicating the findings reported in the present experiments. Therefore, we are confident that the performance differences between the delay and no-delay conditions do reflect the benefit of focusing attention in the cued representation during the delay.
Our results have implications for explanations of the retro-cue benefit. First, unlike in Pertzov et al. (2013) and Williams et al. (2013), our focusing benefits cannot be explained by protection from time-based forgetting: In our delay condition, the interval between memory array offset and test was longer than in the no-delay condition. If time-based forgetting was the explanation of this benefit, performance should have been better in the no-delay than in delay condition (see also Murray et al., 2013, for a similar control of time-based degradation). Therefore, our results are inconsistent with an explanation of the retro-cue benefit as protection from degradation (cf. Matsukura et al., 2007).
Second, unlike in Murray et al. (2013), we did not show a probe stimulus to be compared with a target object in memory, thereby ruling out an explanation of the retro-cue benefit in terms of protection from interference from a probe stimulus presented at the same location as the memory object (cf. Makovski et al., 2008).
Our results are consistent with other explanations of the retro-cue benefit that have been proposed in the literature. One such explanation is that by focusing attention on the target, noncued objects are removed from WM, thereby freeing capacity (e.g., Souza et al., 2014; Williams et al., 2013). Another hypothesis is that the binding between an object and its retrieval cue (namely, its position in the memory array) is strengthened by focused attention without changing the status of the noncued objects in memory. This is the binding-strengthening hypothesis (e.g., Rerko & Oberauer, 2013). Yet a third possibility is that by focusing attention on the retro-cued object, a labile representation of the memory object can be stabilized and, therefore, survive the retrieval process or the comparison with the test display. Unlike the more specific probe interference hypothesis (Makovski & Jiang, 2007; Makovski et al., 2008), this hypothesis states that memory representations are susceptible to interference from the test situation itself (Landman et al., 2003; Sligte, Scholte, & Lamme, 2008).
All of these hypotheses are not necessarily inconsistent with the structure of visual WM put forward by the two mainstream capacity models. At the same time, capacity models do not offer a ready explanation for the delay effect. In the next section, we will examine how a focusing benefit could emerge when one considers the assumptions of flexible-resource and discrete-capacity models. To attain this aim, we implemented several computational models of capacity limits in WM in which we explored the role of focused attention.
Computational models of WM capacity
We will describe two families of models, one implementing the assumptions of a resource model and the other implementing the notion of discrete capacity, building on the slot+averaging model by Zhang and Luck (2008). Our goal was to create models that, akin to the three-parameter mixture model, separate the distribution of response deviations in terms of the precision of reporting the target, guessing rate, and transposition rate but, unlike the pure mixture model, explain the effects of memory set size on performance on the basis of the theoretical assumptions of continuous and discrete capacity.
We fitted each of these models to the data of Experiment 2. We used a similar fitting routine as described for the mixture model, and we examined the fit and the plausibility of the parameter estimates from the model. The main purpose of this work is to examine the mechanisms these models could conceivably incorporate to account for the focusing benefit.
Flexible resource model
Bays and Husain (2008) have proposed a simple resource model that relates the distribution of the resource over N objects to the precision of these representations in memory. This function follows a power law of the form, precision = R α, where R is the resource share of an object and α is a free parameter. In this context, Bays and colleagues (Bays et al., 2009; Bays & Husain, 2008) defined precision as the variability in the observed response distribution. Because this variability is not separated into different components, as in the mixture model, this rudimentary model cannot explain how the flexible allocation of resources translates into the probability of reporting the target, the probability of a transposition error, and the SD (which we refer to here as precision) in reporting the target color.
To be able to derive predictions of a flexible resource model to the level of detail achieved in the mixture model, we implemented several computational versions of a resource model. We attempted to be faithful to what we consider to be the core assumptions of this model (Bays et al., 2009; Bays & Husain, 2008): (1) A constant amount of a WM resource is distributed flexibly among the objects to be represented; (2) the precision of an object is a function of its share of the resource; and (3) attention modulates the resource distribution.
In implementing the assumptions listed above, we were confronted with two major challenges. First, we had to specify how the resource distribution translates into the probability of recalling the target, the probability of recalling a nontarget, and the precision of recall by defining resource performance functions for these three performance measures. Second, we had to specify the number of separate resources determining performance in our WM task. The resource model discussed by Bays and Husain (2008) assumes a single resource determining the precision with which the to-be-recalled feature is represented. Accurate recall, however, also depends on retrieving the target object, and as we have seen in the results of the mixture model in Experiments 1 and 2, people occasionally commit a transposition error, or they fail to recall any object at all. In verbal WM, transposition errors tend to be confusions of objects with close neighbors in the memory list: The probability of recalling a nontarget decreases monotonically as the ordinal distance between the position of a nontarget and the position of the target in the memory list increases. Some of us have recently shown that the same is true for transposition errors in visual WM: The probability of recalling a given nontarget declines monotonically with increasing spatial distance of the nontarget from the target location in the array (Rerko, Oberauer, & Lin, 2014). This fact raises the possibility that transposition errors arise from limits in the precision of representing the spatial positions of memory objects. This idea has also been featured in the resource literature. For example, Bays et al. (2009) suggested that memory for the relevant feature and memory for the location of an object in the memory array might both be imprecise and draw on separate resources. Therefore, we considered model versions with one resource determining the precision of the to-be-recalled feature (here, color); and versions with two resources, one for the relevant color feature and one determining the precision of the object’s spatial location.
Table 4 summarizes the structure of the resource models we implemented. First, we implemented a model version (version 1) in which, at encoding, a single resource is evenly distributed between the N objects in the memory set, so that the resource share of each object (R i ) equals 1/N. At the moment of cuing, however, the resource is flexibly redistributed: An extra share of the resource is given to the target of recall and taken away from the nontargets.Footnote 3 This extra share, which we refer to here as resource boost, is a proportion (set by the free parameter B) of the total resource share assigned to all nontargets (Equation 2; Table 4).
The share of resource of each object determines its probability of being selected for recall. We assumed that the object with the highest resource amount at the moment of recall is selected for retrieval. This winner-takes-all selection process is noisy; that is, the resource share assigned to each object fluctuates randomly. The probability of each object having the highest amount of the resource under conditions of noise is expressed by the Boltzmann equation (Equation 5; Table 4). In this equation, the probability of recalling an object over all other objects in memory is a function of the object's share of resource and a free temperature parameter (φ) that captures the random fluctuation of resource amounts assigned to objects. We also assumed that if none of the memory object’s resource share exceeds a threshold (free parameter τ), then no object is retrieved, and the person guesses at random. The probability of guessing equals the probability that τ is larger than the resource amount of any of the objects. We can therefore simply include τ in the equation as if it were the resource amount of an additional object (for a similar use of the Boltzmann equation in the context of an interference model, see Oberauer & Kliegl, 2006).
The object selected for retrievalFootnote 4 (target or nontarget) is reported with a certain precision, which is also a function of that object’s share of the resource. We chose the sample-size function (Palmer, 1990; Equation 6; Table 4) to relate the share of resource to the precision of each object in memory. The rationale of the sample-size function is to assume a limited number of neurons available for coding for an object’s attribute such as color; these neurons are the limited resource that has to be shared among all objects in WM. The representation of that attribute by each neuron is noisy. The SD in representing the object’s attribute jointly by all neurons in a sample will be inversely proportional to the square-root of the number n of neurons coding it. Because the total number of neurons can be considered as a constant resource, we can replace n by the proportional share of that resource, R i , assigned to each object i. Therefore, the SD is proportional to the square-root of 1/R i . Finally, the SD at set size 1 (i.e., when the entire resource is assigned to a single object) was used as the scaling parameter.
In order to capture differences between delay conditions, we assumed that with more time, more of the resource is reallocated to the target and away from the nontargets (which lose in precision). This is reflected in separate boost parameters for the no-delay and the delay conditions.
In sum, as is shown in Table 4, version 1 has five free parameters: two color boosts (B No-Delay and B Delay); the temperature (φ) parameter that modulates the distinctiveness of objects in memory; a threshold to retrieve objects, which determines the probability of guessing (τ); and precision at set size 1 (σ Min), which serves as a scaling parameter in the sample-size function.
Table 4 also shows another set of models (versions 2 and 3), in which each object is represented with a share of two resources: one for its color and one for its spatial position. This allowed us to model variations in positional distinctiveness between objects on the basis of spatial proximity. We assumed that for both color and position, resources are evenly distributed during encoding but, again, are reallocated at the moment of cuing, such that the target of recall receives boosts of both resources, expressed by two free parameters (color boost, cB; position boost, pB; Equations 2 and 8 in Table 4). As for version 1, we defined precision of color (and also of position) as a function of the resource share (following the sample-size function; Equations 6 and 9; see Table 4).
The probability of retrieving each object was modeled as follows. Because objects were arranged on a virtual circle in the memory array (and their position varied on a trial-by-trial basis), we assumed that precision of spatial position (akin to color precision) reflects the SD of a von Mises probability distribution centered on the object’s true location (L i ). The von Mises density of object i at the spatial location of the cue and the target, LT, expresses the likelihoodFootnote 5 that object i has been in LT in the memory display as a function of the distance between the true location of object i (L i ) and the target location (LT).
We evaluate the likelihood, p(i|LT), of each object i being in the target location (Equation 10, Table 4). We defined the probability of an object being selected for retrieval as its likelihood of being in location LT over the sum of likelihoods of all objects being in that location (Equation 11). Finally, the color of the object selected for retrieval was reported with the SD determined by its share of color resource as for version 1.
We considered two options to capture the benefits of focusing attention during the delay condition. In version 2, during the delay, an additional share of color resource is shifted away from the nontargets to the target of recall. In version 3, an additional share of position resource is shifted away from the nontargets to the target. In versions 2 and 3, we constrained the boost in the delay condition to be larger than the boost in the no-delay condition to maximize the chance of the model parameters converging on meaningful values.
In sum, models version 2 and 3 have five free parameters: color boost (which in the case of version 2 is separated into cBNo-Delay and cBDelay); position boost (which in the case of version 3 is separated into pBNo-Delay and pBDelay); color precision at set size 1 (σ Min); and position precision at set size 1 (ω Min).
Model results and comparison
Table 5 shows the best-fitting parameters of each resource model version and the model fit. Figure 3 presents the average predicted performance for each set size and delay condition obtained with the best-fitting parameters and estimates for precision, guessing rate, and transposition errors derived from these parameters. In Table 5, we highlighted the variable in which the focusing benefit is assumed to arise below the version’s number. The parameter allowed to vary between delay conditions in each version showed the assumed difference in the expected direction (higher values for the delay than for the no-delay condition). For version 1, guessing probability was estimated to be close to zero for most participants because the retrieval threshold τ was estimated to be close to zero.

Estimated variables from the resource models. Each column displays one model version. In version 1, a single resource is shared between objects, and the target receives an extra boost that varies between delay conditions. In versions 2 and 3, each object is represented with two resources: one for its color and one for its position. The target receives extra boosts of each resource. Delay conditions are allowed to differ only in the color boost provided to the target in version 2 or in the position boost in version 3. a Predicted mean error in reporting the target color obtained with the best-fitting parameters of each model. Data from Experiment 2 are shown for comparison (in gray). b Estimated color precision. c Estimated position precision. d Estimated probability of transposition errors
Figure 3a shows the mean deviation in reporting the target color predicted by each model’s version and the data of Experiment 2 for comparison (in gray). All model versions predicted an increase in deviation as set size increased. For version 1, the models' predictions captured well the performance difference between the no-delay and delay conditions but considerably overestimated the true response deviations obtained in Experiment 2 in small set sizes and underestimated it for larger set sizes. For versions 2 and 3, the predicted deviation was close to the data in the no-delay condition; however, the focusing benefits predicted were quite small (version 2; focusing effect on the color boost) or absent (version 3; focusing effect on the position boost).
Figure 3b shows the estimated color precision. For all model versions, SD increased over set size, showing that the model correctly predicts a reduction in precision as more objects are retained in memory. Delay condition, by contrast, had a modest effect on SD in version 1, a large effect in version 2, and no effect in version 3. A difference in precision between the no-delay and delay conditions is expected to arise in versions 1 and 2 because, in these models, we allowed the color resource boost to vary between delay conditions. In version 3, however, differences between delay conditions were constrained to other parameters not impacting color precision. The magnitude of the color precision difference was nevertheless small in version 1, probably because the model estimated small boost values for both conditions (see Table 5). For versions 2 and 3, one can also examine the estimated position precision (shown in Fig. 3c). Position SD also increased over set size, but this effect was reduced in the delay condition in version 3 because different position boosts were allowed between delay conditions.
Figure 3d presents the rate of transposition errors. In all models, transpositions increased over set size. In version 1, transpositions were lower in the delay condition than in the no-delay condition. Given that the guessing rate was negligible across all set sizes in this model (data not shown), the differences in transposition errors between conditions directly reflect the difference in the probability of recalling the target object. In versions 2 and 3, however, delay conditions did not differ in transposition errors, and this is the reason why hardly any performance differences were predicted between delay conditions in these models.
Regarding model fit (BIC; see Table 5), version 2 had a better fit than version 1. The difference between these models was 1'124, which in terms of Bayes-factor represents 1.4 × 10244. This result provides overwhelming support for the models with two resources over a single-resource model. When we compare the models with two resources with each other, allowing the focusing benefit to arise in the color boost (version 2) produced a better fit than allowing it to arise in the position boost (version 3), ΔBIC = 160; Bayes-factor = 5.5 × 1034. This results shows that in the case of representing the objects with two resources, the color boosting should be strongly favored as a mechanism of focused attention, in comparison with position boosting.
In sum, our flexible-resource models relate the distribution of a limited commodity (a single resource or two resources) to the probability of retrieving objects from WM and the precision with which they are recalled. Our modeling showed that the assumption of two independent resource performance functions determining precision and probability of recall (version 1) could capture the qualitative differences between delay conditions in terms of mean deviation, and the delay effect was mostly in the estimates of probability of recall of the target over the nontargets. This model, however, had a lower fit than the models assuming two resources (versions 2 and 3). This second class of models assumed a direct relation between the distribution of resources and the probability of selecting a given color feature (belonging either to the target or a nontarget). These models better captured the observed average deviation in reporting the target color, especially in the no-delay condition. Nevertheless, predicted performance differences between the two delay conditions hardly emerged. A hint of a benefit was observed when we allowed the conditions to differ in the color boost. However, the model attributed the delay benefit to differences in the precision, contrary to what was found in the mixture model. Differences in the probability of recall did not emerge in versions 2 and 3. This is understandable for version 2, in which the delay affected only the distribution of the color resource, but it requires some explanation for version 3, in which delay was assumed to affect the distribution of the spatial position resource. The reason why this did not translate into a sizable delay effect on the probability of retrieving the target is that increasing the precision of the position of one object implies reducing the precision of all other objects: Therefore, increases in precision of the target position increase the likelihood that the target was in that location but also increase the likelihood that the nontargets were at the position of the target because their location information becomes less precise, thereby abolishing any benefit that could be obtained from boosting the representation of the target location.
Discrete-capacity model
The assumptions of the discrete-capacity account are formalized in a computational model known as the slot+averaging (SA) model (Zhang & Luck, 2008). According to this model, each individual has a limited number K of slots available to represent objects in WM. Each slot represents the object’s feature with a fixed precision, expressed as the SD σ Slot. An object represented in a slot is recalled with probability, p = 1, and an object not in a slot is recalled with p = 0. If an object is probed that is not available in a slot, the person has to guess. Therefore, the probability (p) of having the probed object in memory is set by the individual’s number of slots (K) and the N of objects to be stored. When the number of objects is lower than the number of slots, multiple slots can be assigned to a single object. This leads to an advantage, because the precision in reporting an object’s feature depends on the n of slots (n ranging from 1 to K) assigned to represent that object’s feature: σ target = σ Slot/sqrt(n).Footnote 6
The traditional implementation of the SA model does not account for transposition errors. Recently, it has been shown that the simple addition of a free parameter to account for the probability of nontarget recalls to the SA model improves its fit, as compared with a version without this parameter (van den Berg, Awh, & Ma, 2014). In this modeling, there was no theoretical explanation of why transposition errors occur. In contrast, in our modeling approach, we explored how transposition errors could arise in a more theoretically driven fashion. As for the resource model, our main goal was to explore how the beneficial effects of focused attention could emerge when the theoretical assumptions of fixed capacity are considered.
Table 6 presents the structure of the SA models we implemented. First, it presents a version in which we added to the SA model a mechanism similar to that implemented in the resource model to account for the focusing benefit: Namely, at retrieval, the target is prioritized by allocating more of WM's capacity to it. The difference between the implementation in the resource model and the one in the discrete-capacity model is regarding the granularity with which capacity is shifted to the target: In the SA model, the target receives an additional slot (which is moved from another object to the target), whereas in the resource model, it receives a continuously varying extra share of the resource. As is shown in Equations 2 and 3 (Table 6), we implemented this shifting by assuming that if the target has initially n slots (from 0 to K−1), it will receive an additional slot with a probability set by the free parameter S. Shifting an extra slot to the target means that either (1) the target will be represented with more precision (for any n > 0), or (2) in case n = 0, the target that was not in WM will be brought to WM. Akin to the resource model, we assumed that prioritization of the target happens both in the no-delay and the delay conditions, but it might become more effective with more time, resulting in a larger parameter S.
In sum, version 1 has four free parameters: K slots to represent objects, the precision (σ Slot) with which each slot represents the object's color, and the probabilities of success in shifting a slot to the target in the no-delay and delay conditions (S No-Delay and S Delay).
Next, we explored how this model could be extended to include the possibility of transposition errors. Following the suggestion of Rerko, Oberauer, and Lin (2014), we assumed that not only the representation of an object's color is stored with limited precision, but also the object’s location in space. Table 6 shows two models (versions 2 and 3) in which capacity to represent the object's color and position was limited by two free K parameters: one for color (cK) and one for position (pK).Footnote 7 Within each slot, color and position were stored with a fixed precision (color, σ Slot; position, ω Slot). These assumptions are parallel to the ones added to the resource model with two independent resources to represent an object’s color and position (i.e., resource model versions 2 and 3).
At retrieval, the target is prioritized by shifting to it an extra color and an extra position slot (see Equations 2 and 3, Table 6); these slots are removed from one of the nontargets. The probabilities of success in shifting a color slot (cS) and of shifting a position slot (pS) were estimated independently. Again similar to the resource model, we tested two alternatives to account for the focusing benefit: The delay conditions differed either in the probability of shifting color slots (version 2) or in the probability of shifting position slots (version 3).
In versions 2 and 3, recall proceeded in three steps. First, we determined the probability that the probed position was in memory on the basis of the proportion of position slots assigned to each object. Second, because the position information stored in each slot is imprecise (and dependent on the n slots representing it; see Equation 7 in Table 6), we weighted the probability of having the target object position in a slot by the probability that the position of this object would be confused with the position of other objects held in memory. As in the resource model, we took the von Mises density of object i at the probed location (Equation 8 in Table 6) as its subjective likelihood of being at the target location. Its probability of being retrieved was computed as its likelihood of being at the target location over the sum of the likelihoods of all objects represented in position slots being at that location (Equation 9; Table 6). Finally, the color of the object selected for retrieval (target or nontarget) was reported with the precision set by the number of color slots assigned to it.
In sum, model versions 2 and 3 have seven free parameters: the number of color slots (cK) and position slots (pK) available to represent objects, the color (σ Slot) and position (ω Slot) precision of each type of slot, the probability of shifting a color slot to the target of retrieval (cS; which, in version 2, was further split into cS No-Delay and cS Delay), and the probability of shifting a position slot to the target (pS; which, in version 3, was further split into pS No-Delay and pS Delay).
Model results and comparison
Table 7 shows the values of the best-fitting parameters and the fit of each SA model. In Table 7, we indicated the parameter in which the focusing benefit was allowed to arise below each version’s number. Figure 4 presents the average predicted performance for each set size and delay condition obtained with the best-fitting parameters of SA models and estimates for precision, guessing rate, and transposition rate.

Estimated variables from the slot+averaging models. Each column displays one model version. In version 1, only capacity to maintain colors in memory is limited. In versions 2 and 3, storage of the color and the position of objects are limited by different capacities (i.e., separate slots for colors and positions). In all models, the target of recall is prioritized by shifting to it an extra slot. In versions 1 and 2, delay conditions are allowed to differ in the probability of shifting color slots; in version 3, delay conditions differ in the probability of shifting position slots. a Mean error in reporting the target color predicted with the best-fitting parameters of each model. Data from Experiment 2 are presented for comparison (in gray). b Estimated color precision. c Estimated position precision. d Estimated probability of transposition errors. e Estimated probability of guessing
As can be seen in Table 7, when delay conditions were allowed to differ in the probability of success in shifting a color slot (cS; versions 1 and 2), cS was higher in the delay condition than in the no-delay condition; similarly, when delay conditions were allowed to differ in the probability of shifting position slots (pS; version 3), pS was higher in the delay than in the no-delay condition. Moreover, in the models assuming two capacities, pK was estimated to be much higher than cK; however, positions were stored with less precision than color.
Figure 4a presents the mean deviation in reporting the target color predicted in each model version. In all versions, the predicted mean deviation increased over set size, closely resembling the data of Experiment 2. Versions 1 and 2 also predicted a focusing benefit: Smaller deviations were predicted for the delay than for the no-delay condition. These models differ, however, in how well they predicted performance in Experiment 2. In version 1, the mean deviation was overestimated between set sizes 2–5 and underestimated in set sizes 7 and 8. Version 2, on the other hand, predicted deviations that closely resemble the data. Finally, version 3 was not able to predict any differences between delay conditions, despite the fact that higher probabilities of shifting a position slot were obtained for the delay than for the no-delay condition (see Table 7).
Figure 4b shows the precision-by-set-size function estimated for the color feature. The difference in the probabilities of shifting a color slot between delay conditions (versions 1 and 2) was reflected in a small reduction in SD for the delay condition, as compared with the no-delay condition. For versions 2 and 3, we also estimated the precision of the spatial position (shown in Fig. 4c), which, in turn, affected the probability of transposition errors (Fig. 4d). As is shown in Fig. 4c, position SD increased more sharply over set size than did color SD, probably because the estimated capacity for pK was larger than that for cK for most participants. The difference in the probabilities of shifting position slots between delay conditions (version 3) yielded lower position SDs in the delay condition, as compared with the no-delay condition. As is shown in Fig. 4d, transposition errors also increased over set size but were similar across delay conditions for version 2 and only slightly smaller in the delay condition in version 3. Finally, Fig. 4e shows the probability of guessing. Guessing increased over set size and was reduced in the delay condition, as compared with the no-delay condition, in versions 1 and 2, but not in version 3.
Regarding model fit, the models assuming two independent capacities to store color and position (versions 2 and 3) had a much better fit than the model assuming a single capacity (version 1): ΔBIC = 1151.7, Bayes-factor = 1.2 × 10250 for the comparison of versions 1 and 2; and ΔBIC = 861.7, Bayes-factor = 1.3 × 10187 for the comparison of versions 1 and 3. When one compares versions 2 and 3, allowing delay conditions to differ in the probability of shifting color slots yielded a better fit than did allowing them to differ in the probability of shifting position slots: ΔBIC = 290, Bayes factor = 9.46 × 1062.
In sum, we explored how the SA model could be expanded to predict transposition errors and the focusing benefit. Similarly to the resource models, we implemented a spatially graded source of transposition errors that depended on a separate capacity for storing the position of memory objects. The inclusion of this source of errors overwhelmingly improved the fit of the model to the data of Experiment 2, as compared with the model without this assumption. Regarding the focusing benefit, we also included an equivalent mechanism to the one explored in the resource models: prioritization of the target by shifting to it an extra share of WM’s capacity. In the case of the SA model, this share was a fixed quanta or slot. Our results showed that an increase in the probability of shifting a color slot to the target in the delay condition can make the model predict a delay benefit (see version 1). The focusing benefit, however, only quantitatively resembled the one observed in Experiment 2 when we also allowed the model to store the positions with limited precision, such that transposition errors could also occur (version 2). Similar to what we observed for the resource model, boosting the target by allocating more of the capacity to store positions (version 3) did not lead to the prediction of a focusing benefit, and the reason is the same as in the resource model: Boosting the target increases its positional precision but decreases the precision of the nontargets; these effects go on opposite directions, thereby cancelling each other.
General discussion
In the present study, we showed that focusing attention on one of the objects currently held in WM improves the probability of retrieving this object, but not the precision with which its feature was recalled, suggesting independence between these measures. We also implemented several computational versions of the flexible-resource and the discrete-capacity models. The main goal of the this modeling work was to explore plausible mechanisms giving rise to the dissociation between recall probability and recall precision and to explore how these mechanisms are affected by focused attention.
Modeling recall probability and precision
First of all, in order to dissociate precision and recall probability in the resource model, we had to specify how the resource share of each object affects its probability of being recalled and the precision with which it is recalled. We took two approaches to deal with this problem: Either we used two resource performance functions, or we had the model represent position and color with separate and independent resources. In the latter case, the probability of recalling an object is a function of the precision with which an object is remembered to be in the probed location.
In contrast to the resource model, the dissociation between recall probability and precision is already part of the structure of the SA model: On the one hand, the probability of an object being assigned at least one slot is the probability that it will be recalled; the precision of recall, on the other hand, depends on the slot precision and the n of slots representing that object. However, this model could not predict transposition errors. To include this feature, we also assumed that color and position are represented separately, and akin to the resource model, we let the probability of confusing memory objects depend on the precision with which an object is remembered to be in the probed location.
Our modeling showed that in order to better reproduce the data from Experiment 2, both the flexible-resource and the discrete-capacity models had to incorporate assumptions regarding the precision in storing the color and the precision in storing the position of an object (two resource versions or two discrete capacity versions). This result echoes recent reports providing evidence for three characteristics of visual WM. First, when multiple features of a single WM object have to be reported, the errors in reporting each feature are uncorrelated (Bays, Wu, & Husain, 2011; Fougnie & Alvarez, 2011). Second, a large proportion of errors in visual WM tasks comprise nontarget recalls (Bays et al., 2009; Bays, Gorgoraptis, et al., 2011; Fougnie et al., 2010; Gorgoraptis et al., 2011), and the inclusion of transposition errors improves model fit no matter the nature of capacity limitations considered (van den Berg et al., 2014). Third, nontarget recalls tend to be confusions with objects spatially close to the target (Emrich & Ferber, 2012; Rerko, Oberauer, & Lin, 2014). Our results corroborate these findings and offer a way of incorporating them into extant models by showing that the storage of position information can be modeled in the same manner as the storage of the color feature of an object.
Modeling the focusing benefit
Our second goal was to explore ways in which a resource model or a slot model could explain the focusing benefit. These models can predict the beneficial effect of a delay between cue and test by assuming that relevant information (namely, the target of recall) is prioritized and that this process becomes more efficient over time. In both flexible-resource and discrete-capacity models, this was reflected in a larger or more probable reassignment of WM’s limited capacity to the target in the delay condition, as compared with the no-delay condition: In the case of the flexible-resource models, the target received a varying continuous extra share of resources, whereas in the discrete capacity model, the extra share was fixed to one slot, but the probability of receiving this slot increased over time.
We explored which type of target boosting would give rise to our focusing benefits: extra shares of capacity to maintain colors or positions. The answer seems to lie in a greater prioritization of the color feature. Shifting more of the color resource, or an additional color slot, to the target improved performance. Whereas version 2 of the resource model underestimated the difference between delay conditions, the SA model version 2 reproduced the delay benefit in Experiment 2, not just qualitatively, but also quantitatively.
Theoretical implications
The aim of our modeling work was to explore what mechanisms need to be added to flexible-resource models or to discrete-slot models to enable them to account for the detailed pattern of data from our experiments. In doing so, we did our best to incorporate theoretical ideas raised by proponents of these models, such as the notion of a separate resource for spatial precision (Bays et al., 2009) and the notion of shifting resources to a focused object (Bays et al., 2011). This endeavor was reasonably successful, but are the mechanisms needed to achieve this success theoretically plausible? There are reasons to question that they are, and these reasons point to fundamental limitations of both flexible-resource and discrete-slot models.
Both kinds of models explain the delay benefit by assuming that part of the limited capacity is shifted to the cued object during the retention interval. In the flexible-resource model, this is a continuously varying share of the resource, and in the discrete-slot model, this is a single slot. In the slot model, this could mean that an object that has not been represented in a slot before is now represented in a slot. According to the original SA model, an object not represented in a slot is forgotten for good. We need to wonder how an object not represented in WM before the cue can be represented after the cue. Where does the information about that object come from, given that it did not exist in WM before the cue? The same problem arises in both kinds of models, if the prioritized object was in WM and it received a resource boost or an extra slot. This would lead to an increase in the precision of its representation in memory. Increasing the precision means increasing the information retained about an object. Where does that information come from?
If the information in WM is the only information available to the cognitive system for recalling a tested object’s feature, the assumption that performance can be improved by shifting extra capacity to it during the retention interval is absurd. To escape theoretical absurdity, these models will have to be augmented by assumptions about additional sources of information that could be available to WM during the retention interval. One possibility is that focusing attention on a cued object before the test enables salvaging information from a fragile high-capacity memory system (Landman et al., 2003; Pinto, Sligte, Shapiro, & Lamme, 2013; Sligte et al., 2008) that is abolished by the test display. Another possibility is that focusing enables retrieval of information from long-term memory that, for some reason, is not available at the time of test (Brady, Konkle, & Alvarez, 2011). Either route implies that the models will have to become substantially more complex, adding a second memory store in addition to the resource-limited or slot-limited WM.
Notes
We did not present the color wheel simultaneously with the recall cue to avoid possible visual competition between the two events. We also have conducted experiments in our lab in which the color wheel was shown at the moment of test in the no-delay condition or was displayed during encoding and retention in both the no-delay and delay conditions, and in both cases, delay benefits were obtained.
We also fitted a two-parameter model to the data of both experiments, which estimates only precision and guessing rate. However, the fit of the three-parameter mixture model was better, as indexed by the Bayesian information criterion (BIC). The BIC = −2 * ln(L max) + k ln(n), in which L max refers to the likelihood of the best-fitting model given the data; k refers to the number of free parameters; and n refers to the number of trials. The difference in the BIC between the two models was of 199 points (Experiment 1) and of 251 points (Experiment 2). We used this difference to compute the Bayes factor for the comparison between two models (Raftery, 1995). The Bayes factor equals exp(ΔBIC/2), which was equal to 1.7 × 1043 (Experiment 1) and 3.82 × 1054 (Experiment 2), showing that our data are overwhelmingly more likely under the three-parameter model than under the two-parameter model.
One might question our choice to boost the target in both the no-delay and delay conditions. Our reasoning was that this resource boost allows the target representation to be selected over the competitors in memory. This selection boost might be needed in both conditions and simply be more effective in the delay condition, in which attention is focused on the target for a longer period before retrieval. We also tested whether removing this boost in the no-delay condition improves the model fit; however, fit was substantially reduced for all resource models under consideration.
The full model's probabilities are described as follows:
$$ p\left(\theta \right)={P}_{\theta}\phi \left(\theta -\theta, {\sigma}_{\theta}\right)+{\displaystyle \sum_{i=1}^m{P}_{\theta_i^{*}}\phi \left(\theta -{\theta}_i^{*},{\sigma}_{\theta_i^{*}}\right)+{P}_{\tau}\frac{1}{360}} $$in which \( \widehat{\theta} \) stands for the reported feature and θ and θ i * stand for the target and each of the nontarget's features, respectively. P is the probability of selecting each option—namely, target, nontarget (ranging from 1 to m number of nontargets), and guessing (represented by τ)—and φ stands for the von Mises, with its mean centered on the indicated object’s color, and standard deviation σ of the target and non-target features in memory.
The von Mises density can be interpreted as the probability that a given object was in each of an infinite number of locations, p(Lx|i).
This rule is the same as the sample size function assumed in the resource models we implemented. The only difference is regarding the granularity in the distribution of the samples over objects (Zhang & Luck, 2008).
We also tested a version in which capacity for holding the color and the location of an object was constrained by the same K. This model, however, had a worse fit than the model not assuming transposition errors.
References
Anderson, D. E., & Awh, E. (2012). The plateau in mnemonic resolution across large set sizes indicates discrete resource limits in visual working memory. Attention, Perception, & Psychophysics, 74, 891–910. doi:10.3758/s13414-012-0292-1
Anderson, D. E., Vogel, E. K., & Awh, E. (2011). Precision in visual working memory reaches a stable plateau when individual item limits are exceeded. The Journal of Neuroscience, 31, 1128–1138. doi:10.1523/JNEUROSCI.4125-10.2011
Astle, D. E., Summerfield, J., Griffin, I., & Nobre, A. C. (2012). Orienting attention to locations in mental representations. Attention, Perception, & Psychophysics, 74, 146–162. doi:10.3758/s13414-011-0218-3
Bays, P. M., Catalao, R. F. G., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9, 7. doi:10.1167/9.10.7
Bays, P. M., Gorgoraptis, N., Wee, N., Marshall, L., & Husain, M. (2011). Temporal dynamics of encoding, storage, and reallocation of visual working memory. Journal of Vision, 11, 6. doi:10.1167/11.10.6
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321, 851–854. doi:10.1126/science.1158023
Bays, P. M., Wu, E. Y., & Husain, M. (2011). Storage and binding of object features in visual working memory. Neuropsychologia, 49, 1622–1631. doi:10.1016/j.neuropsychologia.2010.12.023
Berryhill, M. E., Richmond, L. L., Shay, C. S., & Olson, I. R. (2012). Shifting attention among working memory representations: Testing cue type, awareness, and strategic control. The Quarterly Journal of Experimental Psychology, 65, 426–438. doi:10.1080/17470218.2011.604786
Brady, T. F., Konkle, T., & Alvarez, G. A. (2011). A review of visual memory capacity: Beyond individual items and toward structured representations. Journal of Vision, 11, 4. doi:10.1167/11.5.4
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Chun, M. M., Golomb, J. D., & Turk-Browne, N. B. (2011). A taxonomy of external and internal attention. Annual Review of Psychology, 62, 73–101. doi:10.1146/annurev.psych.093008.100427
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorial in Quantitative Methods for Psychology, 1, 42–45.
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24, 87–114.
Cowan, N. (2011). The focus of attention as observed in visual working memory tasks: Making sense of competing claims. Neuropsychologia, 49, 1401–1406. doi:10.1016/j.neuropsychologia.2011.01.035
Emrich, S. M., & Ferber, S. (2012). Competition increases binding errors in visual working memory. Journal of Vision, 12, 12. doi:10.1167/12.4.12
Fougnie, D., & Alvarez, G. A. (2011). Object features fail independently in visual working memory: Evidence for a probabilistic feature-store model. Journal of Vision, 11, 3. doi:10.1167/11.12.3
Fougnie, D., Asplund, C. L., & Marois, R. (2010). What are the units of storage in visual working memory? Journal of Vision, 10, 27. doi:10.1167/10.12.27
Fougnie, D., Suchow, J. W., & Alvarez, G. A. (2012). Variability in the quality of visual working memory. Nature Communications, 3, 1229. doi:10.1038/ncomms2237
Gorgoraptis, N., Catalao, R. F. G., Bays, P. M., & Husain, M. (2011). Dynamic updating of working memory resources for visual objects. The Journal of Neuroscience, 31, 8502–8511. doi:10.1523/JNEUROSCI.0208-11.2011
Griffin, I. C., & Nobre, A. C. (2003). Orienting attention to locations in internal representations. Journal of Cognitive Neuroscience, 15, 1176–1194. doi:10.1162/089892903322598139
Kuo, B.-C., Stokes, M. G., & Nobre, A. C. (2012). Attention modulates maintenance of representations in visual short-term memory. Journal of Cognitive Neuroscience, 24, 51–60. doi:10.1162/jocn_a_00087
Landman, R., Spekreijse, H., & Lamme, V. A. F. (2003). Large capacity storage of integrated objects before change blindness. Vision Research, 43, 149–164. doi:10.1016/S0042-6989(02)00402-9
Lepsien, J., Griffin, I. C., Devlin, J. T., & Nobre, A. C. (2005). Directing spatial attention in mental representations: Interactions between attentional orienting and working-memory load. NeuroImage, 26, 733–743. doi:10.1016/j.neuroimage.2005.02.026
Lepsien, J., Thornton, I., & Nobre, A. (2011). Modulation of working-memory maintenance by directed attention. Neuropsychologia, 49, 1569–1577.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281.
Makovski, T., & Jiang, Y. V. (2007). Distributing versus focusing attention in visual short-term memory. Psychonomic Bulletin & Review, 14, 1072–1078. doi:10.3758/BF03193093
Makovski, T., Sussman, R., & Jiang, Y. V. (2008). Orienting attention in visual working memory reduces interference from memory probes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 369–380. doi:10.1037/0278-7393.34.2.369
Matsukura, M., Cosman, J. D., Ropper, Z. J. J., Vatterott, D. B., & Vecera, S. P. (2014). Location-specific effects of attention during visual short-term memory maintenance. Journal of Experimental Psychology: Human Perception and Performance. Advance online publication. doi:10.1037/a0035685
Matsukura, M., & Hollingworth, A. (2011). Does visual short-term memory have a high-capacity stage? Psychonomic Bulletin & Review, 18, 1098–1104. doi:10.3758/s13423-011-0153-2
Matsukura, M., Luck, S. J., & Vecera, S. P. (2007). Attention effects during visual short-term memory maintenance: Protection or prioritization? Perception & Psychophysics, 69, 1422–1434. doi:10.3758/BF03192957
Maxcey-Richard, A. M., & Hollingworth, A. (2013). The strategic retention of task-relevant objects in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 760–772. doi:10.1037/a0029496
Murray, A. M., Nobre, A. C., Clark, I. A., Cravo, A. M., & Stokes, M. G. (2013). Attention restores discrete items to visual short-term memory. Psychological Science, 24, 550–556. doi:10.1177/0956797612457782
Nobre, A. C., Griffin, I. C., & Rao, A. (2008). Spatial attention can bias search in visual short-term memory. Frontiers in Human Neuroscience, 1, 1–9. doi:10.3389/neuro.09.004.2007
Nobre, A. C., & Stokes, M. G. (2011). Attention and short-term memory: Crossroads. Neuropsychologia, 49, 1391–1392. doi:10.1016/j.neuropsychologia.2011.04.014
Oberauer, K., & Hein, L. (2012). Attention to information in working memory. Current Directions in Psychological Science, 21, 164–169. doi:10.1177/0963721412444727
Oberauer, K., & Kliegl, R. (2006). A formal model of capacity limits in working memory. Journal of Memory and Language, 55, 601–626. doi:10.1016/j.jml.2006.08.009
Palmer, J. (1990). Attentional limits on the perception and memory of visual information. Journal of Experimental Psychology: Human Perception and Performance, 16, 332–350.
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Pertzov, Y., Bays, P. M., Joseph, S., & Husain, M. (2013). Rapid forgetting prevented by retrospective attention cues. Journal of Experimental Psychology: Human Perception and Performance, 39, 1224–1231. doi:10.1037/a0030947
Pinto, Y., Sligte, I. G., Shapiro, K. L., & Lamme, V. A. F. (2013). Fragile visual short-term memory is an object-based and location-specific store. Psychonomic Bulletin & Review, 20, 732–739. doi:10.3758/s13423-013-0393-4
Prinzmetal, W., Amiri, H., Allen, K., & Edwards, T. (1998). Phenomenology of attention: I. Color, location, orientation, and spatial frequency. Journal of Experimental Psychology: Human Perception and Performance, 24, 261–282. doi:10.1037/0096-1523.24.1.261
Raftery, A. E. (1995). Bayesian model selection in social research. Sociological Methodology, 25, 111–163.
Rerko, L., & Oberauer, K. (2013). Focused, unfocused, and defocused information in working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 1075–1096. doi:10.1037/a0031172
Rerko, L., Oberauer, K., & Lin, H.-Y. (2014). Spatial transposition gradients in visual working memory. The Quarterly Journal of Experimental Psychology, 67, 3–15. doi:10.1080/17470218.2013.789543
Rerko, L., Souza, A. S., & Oberauer, K. (2014a). Retro-cue benefits in working memory without sustained focal attention. Memory & Cognition. doi:10.3758/s13421-013-0392-8
Rerko, L., Souza, A. S., & Oberauer, K. (2014b). Time to improve working memory: Accessing more information with longer retrieval time. Unpublished Manuscript.
Schmidt, B. K., Vogel, E. K., Woodman, G. F., & Luck, S. J. (2002). Voluntary and automatic attentional control of visual working memory. Perception & Psychophysics, 64, 754–763. doi:10.3758/BF03194742
Sligte, I. G., Scholte, H. S., & Lamme, V. A. F. (2008). Are there multiple visual short-term memory stores? PLoS ONE, 3, e1699. doi:10.1371/journal.pone.0001699
Souza, A. S., Rerko, L., & Oberauer, K. (2014). Unloading and reloading working memory: Attending to one item frees capacity. Journal of Experimental Psychology: Human Perception and Performance. Advance online publication. doi:10.1037/a0036331
Suchow, J. W., Brady, T. F., Fougnie, D., & Alvarez, G. A. (2013). Modeling visual working memory with the MemToolbox. Journal of Vision, 13, 9. doi:10.1167/13.10.9
Tanoue, R. T., & Berryhill, M. E. (2012). The mental wormhole: Internal attention shifts without regard for distance. Attention, Perception, & Psychophysics, 74, 1199–1215. doi:10.3758/s13414-012-0305-0
Van den Berg, R., Awh, E., & Ma, W. J. (2014). Factorial comparison of working memory models. Psychological Review, 121, 124–149. doi:10.1037/a0035234
Vogel, E. K., Woodman, G. F., & Luck, S. J. (2001). Storage of features, conjunctions, and objects in visual working memory. Journal of Experimental Psychology: Human Perception and Performance, 27, 92–114.
Wilken, P., & Ma, W. J. (2004). A detection theory account of change detection. Journal of Vision, 4, 11. doi:10.1167/4.12.11
Williams, M., Hong, S. W., Kang, M.-S., Carlisle, N. B., & Woodman, G. F. (2013). The benefit of forgetting. Psychonomic Bulletin & Review, 20, 348–355. doi:10.3758/s13423-012-0354-3
Williams, M., & Woodman, G. F. (2012). Directed forgetting and directed remembering in visual working memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38, 1206–1220. doi:10.1037/a0027389
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453, 233–235. doi:10.1038/nature06860
Zhang, W., & Luck, S. J. (2009). Sudden death and gradual decay in visual working memory. Psychological Science, 20, 423–428. doi:10.1111/j.1467-9280.2009.02322.x
Zhang, W., & Luck, S. J. (2011). The number and quality of representations in working memory. Psychological Science, 22, 1434–1441. doi:10.1177/0956797611417006
Acknowledgments
This research was supported by grants from the Forschungskredit of the University of Zurich (project FK-13-083) to Alessandra Souza and from the Swiss National Science Foundation (project 100014_126766/1) to Klaus Oberauer. We thank Stefanie Colaço and Iliana Karipidis for collecting the data.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Souza, A.S., Rerko, L., Lin, HY. et al. Focused attention improves working memory: implications for flexible-resource and discrete-capacity models. Atten Percept Psychophys 76, 2080–2102 (2014). https://doi.org/10.3758/s13414-014-0687-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0687-2