
Abstract
Background
Despite advances in the care of women and their babies in the past century, an estimated 1.7 million babies are born still each year throughout the world. A robust method to estimate a pregnant woman’s individualized risk of late-pregnancy stillbirth is needed to inform decision-making around the timing of birth to reduce the risk of stillbirth from 35 weeks of gestation in Australia, a high-resource setting.
Methods
This is a protocol for a cross-sectional study of all late-pregnancy births in Australia (2005–2015) from 35 weeks of gestation including 5188 stillbirths among 3.1 million births at an estimated rate of 1.7 stillbirths per 1000 births. A multivariable logistic regression model will be developed in line with current Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) guidelines to estimate the gestation-specific probability of stillbirth with prediction intervals. Candidate predictors were identified from systematic reviews and clinical consultation and will be described through univariable regression analysis. To generate a final model, elimination by backward stepwise multivariable logistic regression will be performed. The model will be internally validated using bootstrapping with 1000 repetitions and externally validated using a temporally unique dataset. Overall model performance will be assessed with R2, calibration, and discrimination. Calibration will be reported using a calibration plot with 95% confidence intervals (α = 0.05). Discrimination will be measured by the C-statistic and area underneath the receiver-operator curves. Clinical usefulness will be reported as positive and negative predictive values, and a decision curve analysis will be considered.
Discussion
A robust method to predict a pregnant woman’s individualized risk of late-pregnancy stillbirth is needed to inform timely, appropriate care to reduce stillbirth. Among existing prediction models designed for obstetric use, few have been subject to internal and external validation and many fail to meet recommended reporting standards. In developing a risk prediction model for late-gestation stillbirth with both providers and pregnant women in mind, we endeavor to develop a validated model for clinical use in Australia that meets current reporting standards.
Similar content being viewed by others
Background
Prevention of stillbirth remains one of the greatest challenges in modern maternity care. Globally, one in every 137 pregnancies that reach 20 weeks’ gestation will result in a stillborn child [1, 2]. Despite advances in the care of women and their babies in the past century, an estimated 1.7 million babies die before birth each year throughout the world [3]. The 2016 Lancet Ending Preventable Stillbirths series highlighted differences in rates of late stillbirth (≥ 28 weeks) between high-income countries ranging from 1.7 per 1000 to 8.8 per 1000 births [4]. Australia is a high-income country where over 2000 families each year—six families each day—have a stillbirth, and there has been no improvement in stillbirth rates among late pregnancy stillbirths for over 20 years [5, 6]. Among women who were born elsewhere [7, 8], women with lower socioeconomic status [9], and women who identify as Aboriginal and Torres Strait Islander [10], the risk of stillbirth is higher [4, 11]. Failure to identify and appropriately care for women with risk factors for stillbirth contributes to 20–50% of preventable stillbirths, which has the potential to avoid 400 stillbirths each year for Australian families [12,13,14].
Detecting women at risk for stillbirth is challenging. In the absence of a tool to assess a pregnant woman’s individualized risk of late-pregnancy stillbirth, we rely on generalized, population-level information. Awareness of risk factors that increase the risk of stillbirth at or near term is a necessary first step in improving care and to ultimately reduce the number of stillbirths. Despite a high proportion of unexplained stillbirths between 39 and 41 weeks of gestation, many women who have a stillbirth have one or more risk factors that are often unrecognized [15].
Around 38 weeks of gestation, the risk of stillbirth increases overall and varies by maternal and clinical characteristics while the decision on whether to intervene becomes more challenging [5, 10, 16, 17]. The balance between benefit and harm is complicated by potentially avoiding a stillbirth at the risk of neonatal morbidity [18]. A robust prediction model to assess a woman’s individualized risk of late-pregnancy stillbirth has the potential to alleviate some interventional uncertainty by informing antenatal care and decision-making around the timing of birth.
A key limitation of developing a late-gestation stillbirth risk prediction model for clinical use is the lack of high-quality data from a complete population. With recent quality improvements for population-level data in Australia, it is now possible to leverage population-based data to develop, internally validate, and externally validate a model to predict potentially preventable and rare pregnancy outcomes [19]. Therefore, the objective of this study is to develop and validate a prognostic model for late-pregnancy stillbirth risk that is designed to inform decision-making around the timing of birth.
Methods
Aim
We endeavor to develop multivariable logistic regression prediction models to estimate the risk of late-pregnancy stillbirth from 35 weeks of gestation using a national dataset of all births in Australia (2005–2015) to ultimately inform decision-making around the timing of birth for women who reside in Australia.
Study design
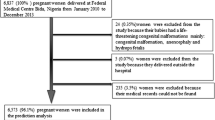
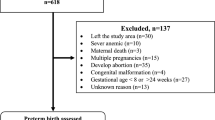
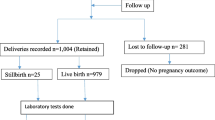
This is a protocol for a cross-sectional study using the total population of singleton term gestation births in Australia (2005–2015) derived from the National Perinatal Data Collection (NPDC) (1998–2015) [11, 20]. The dataset includes 5188 stillbirths among 3.1 million births at an estimated rate of 1.7 stillbirths per 1000 births [11]. Multiple pregnancies, congenital abnormalities, and babies missing gestational age information will be excluded. A congenital abnormality is defined as a stillbirth classified as code 0100 “Congenital Abnormality” using the Perinatal Society of Australia and New Zealand (PSANZ) Perinatal Death Classification System [21]. A completed Compliance with Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) checklist is available in supplementary materials (Supplementary Table 1).
Sample size
To ensure the development of a robust prediction model for each week gestation from 35 weeks, sample size calculations recommended by Riley et al. are provided for stillbirth as a binary outcome to (B1) estimate overall outcome proportion with precision, (B2) target a small mean absolute prediction error, (B3) target a shrinkage factor of 0.9, and (B4) target small optimism of 0.05 in the apparent R2 [22]. Based on these criteria, the population derived from the NPDC is expected to be sufficient and is detailed below.
Stata 16.0 procedure pmsampsize was used for criteria B1, B3, and B4 where anticipated R2 value is 0.003 with a maximum of 25 parameters (candidate risk factors), and the overall proportion of stillbirth is 0.0017 and derived from the estimated stillbirth rate of 1.7 stillbirths per 1000 births in our study population [22, 23]:
This indicates that at least 74,875 births are required, corresponding to 128 events (where the prevalence of stillbirth is 0.0017) and events per candidate predictor parameter of 5.09.
For criteria B2, we applied the mean absolute prediction error (MAPE) formula at a value of 0.050 for the anticipated outcome proportion (0.0017) and 25 candidate predictor parameters. This indicated a required total of 92 participants in the development dataset at a MAPE of 0.05 or 494 participants at a MAPE of 0.02.
Data source
All births with gestational age information from 35 weeks of gestation in Australia (2005–2015) will be included. Data will be made available via the AIHW Maternal and Perinatal Health Unit. Further information on available data items and reporting can be found in the supplementary materials (Supplementary Table 2). The NPDC is a national population-based cross-sectional collection of data for all pregnancies and births established in 1991 [24]. All births from the 6 states and 2 territories of Australia are reported as part of the NPDC and include Queensland (QLD), New South Wales (NSW), Australian Capital Territory (ACT), Victoria (VIC), South Australia (SA), Tasmania (TAS), Western Australia (WA), and Northern Territory (NT) (Table 1). Perinatal data are collected for each birth in each state and territory, usually by midwives and other birth attendants [11]. The data is collated by the relevant state or territory health department and a standard de-identified extract is provided to the AIHW on an annual basis to form the NPDC [11]. Stillbirths in Australia are defined by the PSANZ as fetal deaths from gestational age of at least 20 weeks or birthweight of at least 400 g, except in Victoria and Western Australia, where births are included if gestational age is at least 20 weeks or, if gestation is unknown, birthweight is at least 400 g [11, 21].
Model development
Established characteristics and conditions associated with an increased risk of stillbirth will be considered as candidate predictors [16, 25,26,27]. The predictor selection process is illustrated in Fig. 1. Reference group coding will be informed by literature and existing reporting recommendations. Frequencies (%) will be presented for categorical variables and for all missing data (further information on the handling of missing data described below). For normally distributed continuous variables, the mean and standard deviation will be reported. For continuous variables demonstrating skewed distributions, median and IQR will be reported. For all continuous variables, minimum and maximum will be presented. If clinically appropriate and statistically justifiable, independent continuous variables will be converted to groups according to published guidelines and recommendations [11, 28].

Selection of predictors in a study developing a multivariable logistic regression model for stillbirth
Univariable logistic regression models will be developed first for all gestations to explore individual prognostic factors where the outcome (stillbirth) is binary and the prognostic factors are either continuous or categorical. Univariable models will only be used to provide context to the final multivariable logistic regression model. Variance inflation factor (VIF) will be performed prior to fitting the final multivariable regression model to identify collinearity where VIF < 4 indicates a low correlation, VIF between 5 and 10 indicates a high correlation, and VIF above 10 indicates multicollinearity [29]. Candidate predictors demonstrating multi- or collinearity with VIF ≥ 5 will be reviewed through clinical consultation to ultimately select candidate predictor for inclusion in the final model. Backward stepwise elimination in a multivariable logistic regression model will be applied to remove non-significant factors with p values greater than 0.100 in line with Akaike’s information criterion [30]. Finally, the risk prediction model will be applied and fully validated for each week’s gestation from 35 weeks (six total models: 35, 36, 37, 38, 40, and 41+ weeks).
Missing data
Missing data for predictors is most likely to result from failed reporting for all births in specific years by jurisdictions (see Supplementary Table 2 for comments on missing data). Data-years where reporting of candidature predictors may be excluded if missing data exceeds 5% for the total population [31, 32].
If clinically appropriate, a “hot deck” formula for multiple imputations will be considered for predictors with greater than 5% missing values where a substitute value will be imputed from another dataset [32,33,34]. For candidate predictors with fewer or equal to 5% missing values, missing values for categorical predictors will be treated as null or “no” and continuous predictors will be recorded as a mean value. No births will be excluded due to missing candidate predictor data except for those missing gestational age information.
Validation
Final gestation-specific models will be subject to temporal internal and external validation. Population characteristics and performance measures will be reported for all individual models [35]. Internal validation will be performed using bootstrapping with 1000 repetitions [36]. Summary stillbirth rates will be reported for the bootstrapped sample. Final models will be externally validated using data derived from study years not used for model development [37].
Model performance
The performance of development and validation datasets will be assessed via overall performance (R2), calibration, discrimination, and clinical performance will be assessed through positive predictive value (PPV) and negative predictive value (NPV). A fixed false-positive cutoff of 10% will be used for PPV and NPV [38].
Calibration characterizes model performance in terms of agreement between predicted (expected) risk and observed risk and is reported using a calibration plot [39]. An intercept of zero and ratio of observed and expected equal to one (O/E = 1) is defined as the best possible calibration [40]. Calibration plots will contain 95% confidence intervals to infer the degree of calibration between observed outcomes and predictions.
Discrimination is defined as the model’s ability to distinguish stillbirths and non-stillbirths and will be measured via calculation of the C statistic and receiver operator characteristic (ROC) curve. A ROC curve is used to assess the performance of a categorical classifier and is a plot of sensitivity (true positive rate) versus 1-specificity (false positive rate) where different points on the curve correspond to different cutoff points used to designate positive identification/classification [41].. Using the ROC curve, the performance of the predictors will be further quantified by calculating the area under the curve or AUC. The AUC score range is 0.0–1.0, where a score of 0.5 can be equated to a “coin flip”, 0.0 is perfectly inaccurate, and 1.0 is perfectly accurate [42]. A non-parametric comparison of AUC will be performed using the Mann-Whitney U statistic for individual gestational age models [26].
In addition to calibration and discrimination, PPV and NPV will be reported to characterize clinical usefulness. A decision curve analysis will be considered to characterize potential decision thresholds [43].
Discussion
Prediction models designed for obstetrics hold enormous promise. However, unlike other clinical prediction models, we do not yet understand whether their application improves birth outcomes [44]. With many models for adverse pregnancy outcomes being developed through various approaches, it is inevitable that only a minority have been subject to full internal and external validation and many fail to meet recommended reporting standards. By utilizing a population-based, individual-level dataset, our study is expected to provide a sufficient sample size of singleton stillbirths and births to develop and validate gestation-specific prediction models that can be translated into clinical tools or decision aids.
There have been attempts to develop risk prediction models for stillbirth, yet none are designed to predict stillbirth risk at- or near-term or use a population-level data source for singleton pregnancies in a high-income setting [45]. Among existing prediction models designed for obstetrics, logistic regression models are widely utilized [45]. Yerlikaya et al. reported a prediction model for stillbirth with low predictive accuracy beyond the early term period [46]. Trudell et al. reported a clinical prediction tool for antenatal testing with the modest discrimination for stillbirth at or beyond 32 weeks’ gestation that included risk factors such as maternal age, African-American/Black race, nulliparity, body mass index, smoking, chronic hypertension, and pre-gestational diabetes [36]. Although there is a growing interest in algorithmic methods such as machine learning, evidence suggests that performance is highly comparative to statistical modeling [47, 48]. Regarding approaches to validation, the most commonly used methods include split-sample, bootstrap, and cross-validation. Bootstrapping tends to demonstrate increased variability and split-sampling often results in unreliable assessments of model performance. A cross-validation is an effective approach for validating a prediction model for low-prevalence obstetric outcomes like stillbirth due to stability and ability to use a larger part of the study sample for model development [42, 49]. Cross-validation is an extension of split-sample validation that uses a larger part of the sample for model development (> 80% vs. 50%) [39]. While not the most computationally efficient approach, the bootstrap repeated procedure is ideal and expected to produce stable results while conserving the complete study population for validation [22, 36, 50]. In our proposed validation design, a temporal approach to externally validate the model will be explored. While this is not considered a “fully independent external validation,” it is expected to provide an additional layer of assessment not yet reported for any existing stillbirth prediction model.
While there are numerous benefits to utilizing large observational datasets for the development of prediction models—particularly for rare pregnancy outcomes and multiple pregnancies, there are certain limitations [51]. Completeness of routinely reported variables and potentially relevant risk factors not captured by the NPDC, such as maternal ethnicity, will have an impact on the final model. Missing data for risk factors used in a prediction model will be vulnerable to misclassification due to reporting evolution over time. While clinical definitions have largely remained consistent from 1998 to 2015, some data items for certain years have changed from voluntary to required. The impact of these changes over time on classification is not yet documented and will be assessed through a supplementary sensitivity analysis. Certain variables collected by NPDC that are not available for release due to quality issues include maternal asthma, type of assisted reproductive therapy, fetal growth restriction, and other pregnancy-specific medical conditions. Environmental exposures are not currently captured by the NPDC, and other spatial risk factors cannot be explored due to sensitivity restrictions. However, most key risk factors identified in literature and informed by background clinical knowledge will be considered and are expected to produce a full prediction model for stillbirth using routinely collected data without attempting to identify new predictors or using biomarkers. Future studies should consider exploring the care pathway and risk management of multiple pregnancies and unique risk factors (including maternal pregnancy conditions).
Lastly, subsequent pregnancy outcomes depend heavily on the outcome of previous pregnancies where each birth is not independent of births [52,53,54]. An anticipated complication of our analysis that will impact on the interpretation of results is the absence of a unique identifier for mothers to account for potential clustering. Parity will be assessed to distinguish first versus subsequent births [55], but the lack of independence of births in our models will be limited. There are recommendations for the generalized estimating equation approach, but will not be possible due to an inability to appropriately cluster pregnancies according to unique mothers [55, 56].
Using known predictors from routine population-level data, we endeavor to develop a validated risk prediction model for late-gestation stillbirth for clinical use in Australia with both providers and pregnant women in mind that meets all TRIPOD standards and recommendations [57]. Such a prediction model could be used in a narrow or broad impact analysis that explores decision rules to reduce stillbirth by improving decision-making around the timing of birth [43, 49].
Availability of data and materials
Study outputs including full model details will be published in a peer-reviewed journal; however, the dataset is not publicly available due to sensitivity and individual privacy protection restrictions as stipulated by human research ethics. Study data can be accessed through a formal request from the AIHW (https://www.aihw.gov.au/our-services/data-on-request).
Abbreviations
- TRIPOD:
-
Transparent Reporting of a multivariable logistic regression model for Individual Prognosis or Diagnosis
- AIHW:
-
Australian Institute of Health and Welfare
- NPDC:
-
National Perinatal Data Collection
- ROC:
-
Area under the receiver-operator curve
- HREC:
-
Human research ethics committee(s)
- PSANZ:
-
Perinatal Society of Australia and New Zealand
- NHMRC:
-
National Health and Medical Research Council
- ASGS:
-
Remoteness Area as per the Australian Statistical Geography Standard
- ASGC:
-
Australian Standard Geographical Classification (ASGC)
- SEIFA:
-
Socio-Economic Indexes for Areas
- IRSD:
-
Index of Relative Socio-Economic Disadvantage
- VIF:
-
Variance inflation factor
- NT:
-
Northern Territory
- QLD:
-
Queensland
- NSW:
-
New South Wales
- VIC:
-
Victoria
- ACT:
-
Australian Capital Territory
- TAS:
-
Tasmania
- SA:
-
South Australia
- WA:
-
Western Australia
References
Blencowe H, Cousens S, Jassir FB, Say L, Chou D, Mathers C, et al. National, regional, and worldwide estimates of stillbirth rates in 2015, with trends from 2000: a systematic analysis. Lancet Global Health. 2016;4(2):e98–e108.
Li Z ZR, Hilder L, Sullivan EA. Australia’s mothers and babies 2011. Perinatal statistics series no 28 Cat no PER 59. 2013(Cat. no. PER 50).
GBD 2016 Mortality Collaborators. Global, regional, and national under-5 mortality, adult mortality, age-specific mortality, and life expectancy, 1970-2016: a systematic analysis for the Global Burden of Disease Study 2016. Lancet (London, England). 2017;390(10100):1084-150.
Flenady V, Wojcieszek AM, Middleton P, Ellwood D, Erwich JJ, Coory M, et al. Stillbirths: recall to action in high-income countries. Lancet (London, England). 2016;387(10019):691-702.
Hilder L, Flenady V, Ellwood D, Donnolley N, Chambers GM. Improving, but could do better: Trends in gestation-specific stillbirth in Australia, 1994-2015. Paediatric and perinatal epidemiology. 2018;32(6):487–94.
United Nations Statistics Division. Standard country or area codes for statistical use (M49) New York: United Nations Department of Economic and Social Affairs 2020 [Available from: https://unstats.un.org/unsd/methodology/m49/.
Choi SKY, Henry A, Hilder L, Gordon A, Jorm L, Chambers GM. Adverse perinatal outcomes in immigrants: a ten-year population-based observational study and assessment of growth charts. Paediatric and perinatal epidemiology. 2019;33(6):421–32.
Mozooni M, Preen DB, Pennell CE. Stillbirth in Western Australia, 2005-2013: the influence of maternal migration and ethnic origin. The Medical journal of Australia. 2018.
de Graaff EC, Wijs LA, Leemaqz S, Dekker GA. Risk factors for stillbirth in a socio-economically disadvantaged urban Australian population. J Maternal-Fetal Neonatal. 2017;30(1):17–22.
Ibiebele I, Coory M, Smith GC, Boyle FM, Vlack S, Middleton P, et al. Gestational age specific stillbirth risk among Indigenous and non-Indigenous women in Queensland, Australia: a population based study. BMC pregnancy and childbirth. 2016;16(1):159.
Australian Institute of Health Welfare (AIHW). Stillbirths and neonatal deaths in Australia 2015 and 2016. Canberra: AIHW; 2019.
Page JM, Thorsten V, Reddy UM, Dudley DJ, Hogue CJR, Saade GR, et al. Potentially preventable stillbirth in a diverse U.S. cohort. Obstetrics and gynecology. 2018;131(2):336–43.
Queensland Maternal and Perinatal Quality Council. Queensland mothers and babies 2014 and 2015. Brisbane: State of Queensland. p. 2018.
The Consultative Council on Obstetric and Paediatric Mortality and Morbidity. Victoria’s Mothers, Babies, and Children: 2014 and 2015. Melbourne; 2017.
Australian Institute of Health and Welfare. Perinatal deaths in Australia 2013-2014. Canberra: Australian Government; 2018.
Flenady V, Koopmans L, Middleton P, Froen JF, Smith GC, Gibbons K, et al. Major risk factors for stillbirth in high-income countries: a systematic review and meta-analysis. Lancet (London, England). 2011;377(9774):1331–40.
Gordon A, Raynes-Greenow C, McGeechan K, Morris J, Jeffery H. Risk factors for antepartum stillbirth and the influence of maternal age in New South Wales Australia: a population based study. BMC pregnancy and childbirth. 2013;13:12.
Page JM, Silver RM. Interventions to prevent stillbirth. Seminars in fetal & neonatal medicine. 2017;22(3):135–45.
Riley RD, Ensor J, Snell KIE, Debray TPA, Altman DG, Moons KGM, et al. External validation of clinical prediction models using big datasets from e-health records or IPD meta-analysis: opportunities and challenges. BMJ (Clinical research ed). 2016;353:i3140.
Australian Government Bureau of Meteorology (BOM). Climate data online 2018 [Available from: http://www.bom.gov.au/climate/data/.
Perinatal Society of Australia and New Zealand (PSANZ). Perinatal Society of Australia and New Zealand Clinical Practice Guideline for Perinatal Mortality. 2009.
Riley RD, Ensor J, Snell KIE, Harrell FE, Martin GP, Reitsma JB, et al. Calculating the sample size required for developing a clinical prediction model. BMJ (Clinical research ed). 2020;368:m441.
@joie_ensor (Joie Ensor). New @Stata package: ‘pmsampsize’ to calculate minimum sample size required for developing a prediction model Based on work by @Richard_D_Riley, @GSCollins, @f2harrell, @Kym_Snell, @CarlMoons, @DanielleBurke88 Type ‘ssc install pmsampsize’. #rstats version coming soon .... Twitter2018.
Australian Institute of Health and Welfare. National Perinatal Data Collection (NPDC) Canberra: Australian Government; 2019 [Available from: https://www.aihw.gov.au/about-our-data/our-data-collections/national-perinatal-data-collection.
Getahun D, Ananth CV, Kinzler WL. Risk factors for antepartum and intrapartum stillbirth: a population-based study. American journal of obstetrics and gynecology. 2007;196(6):499–507.
Ananth CV, Goldenberg RL, Friedman AM, Vintzileos AM. Association of temporal changes in gestational age with perinatal mortality in the United States, 2007-2015. JAMA pediatrics. 2018;172(7):627–34.
Smith LK, Hindori-Mohangoo AD, Delnord M, Durox M, Szamotulska K, Macfarlane A, et al. Quantifying the burden of stillbirths before 28 weeks of completed gestational age in high-income countries: a population-based study of 19 European countries. Lancet (London, England). 2018.
Perinatal Society of Australia and New Zealand (PSANZ). Clinical practice guideline for care around stillbirth and neonatal death. 2018.
Andegiorgish AK, Andemariam M, Temesghen S, Ogbai L, Ogbe Z, Zeng L. Neonatal mortality and associated factors in the specialized neonatal care unit Asmara, Eritrea. BMC public health. 2020;20(1):10.
Sauerbrei W. The use of resampling methods to simplify regression models in medical statistics. Journal of the Royal Statistical Society: Series C (Applied Statistics). 1999;48(3):313–29.
Batra P, Higgins C, Chao SM. Previous adverse infant outcomes as predictors of preconception care use: an analysis of the 2010 and 2012 Los Angeles Mommy and Baby (LAMB) Surveys. Maternal and child health journal. 2016;20(6):1170–7.
Kayode GA, Grobbee DE, Amoakoh-Coleman M, Adeleke IT, Ansah E, de Groot JA, et al. Predicting stillbirth in a low resource setting. BMC pregnancy and childbirth. 2016;16:274.
Sterne JAC, White IR, Carlin JB, Spratt M, Royston P, Kenward MG, et al. Multiple imputation for missing data in epidemiological and clinical research: potential and pitfalls. BMJ (Clinical research ed). 2009;338:b2393.
Hawthorne G, Elliott P. Imputing cross-sectional missing data: comparison of common techniques. Australian and New Zealand J Psychiatry. 2005;39(7):583–90.
DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44(3):837–45.
Trudell AS, Tuuli MG, Colditz GA, Macones GA, Odibo AO. A stillbirth calculator: development and internal validation of a clinical prediction model to quantify stillbirth risk. (Research Article). PloS one. 2017;12(3):e0173461.
Collins GS, de Groot JA, Dutton S, Omar O, Shanyinde M, Tajar A, et al. External validation of multivariable prediction models: a systematic review of methodological conduct and reporting. BMC medical research methodology. 2014;14:40.
Flatley C, Gibbons K, Hurst C, Flenady V, Kumar S. Cross-validated prediction model for severe adverse neonatal outcomes in a term, non-anomalous, singleton cohort. BMJ paediatrics open. 2019;3(1):e000424.
Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology (Cambridge, Mass). 2010;21(1):128–38.
Ahmed I, Debray TP, Moons KG, Riley RD. Developing and validating risk prediction models in an individual participant data meta-analysis. BMC Med Res Methodology. 2014;14:3.
Carter JV, Pan J, Rai SN, Galandiuk S. ROC-ing along: evaluation and interpretation of receiver operating characteristic curves. Surgery. 2016;159(6):1638–45.
Steyerberg EW, Eijkemans MJ, Harrell FE Jr, Habbema JD. Prognostic modeling with logistic regression analysis: in search of a sensible strategy in small data sets. Medical Decision Making. 2001;21(1):45–56.
Vickers AJ, Elkin EB. Decision curve analysis: a novel method for evaluating prediction models. Medical Decision Making. 2006;26(6):565–74.
Vickers AJ. Prediction models: revolutionary in principle, but do they do more good than harm? J Clin Oncology. 2011;29(22):2951–2.
Kleinrouweler CE, Cheong-See FM, Collins GS, Kwee A, Thangaratinam S, Khan KS, et al. Prognostic models in obstetrics: available, but far from applicable. Am J Obstetr Gynecol. 2016;214(1):79–90 e36.
Yerlikaya G, Akolekar R, McPherson K, Syngelaki A, Nicolaides KH. Prediction of stillbirth from maternal demographic and pregnancy characteristics. Ultrasound in obstetrics & gynecology : the official journal of the International Society of Ultrasound in Obstetrics and Gynecology. 2016;48(5):607–12.
Christodoulou E, Ma J, Collins GS, Steyerberg EW, Verbakel JY, Van Calster B. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. Journal of clinical epidemiology. 2019;110:12–22.
Van Calster B, Verbakel JY, Christodoulou E, Steyerberg EW, Collins GS. Statistics versus machine learning: definitions are interesting (but understanding, methodology, and reporting are more important). Journal of clinical epidemiology. 2019;116:137–8.
Steyerberg EW. Clinical prediction models: a practical approach to development, validation, and updating. Second edition.. ed. Cham, Switzerland: Springer; 2019.
Steyerberg EW, Vergouwe Y. Towards better clinical prediction models: seven steps for development and an ABCD for validation. European heart journal. 2014;35(29):1925–31.
Goodin A, Delcher C, Valenzuela C, Wang X, Zhu Y, Roussos-Ross D, et al. The power and pitfalls of big data research in obstetrics and gynecology: a consumer’s guide. Obstetrical Gynecological Survey. 2017;72(11):669–82.
Gordon A, Raynes-Greenow C, McGeechan K, Morris J, Jeffery H. Stillbirth risk in a second pregnancy. Obstetrics and gynecology. 2012;119(3):509–17.
Lamont K, Scott NW, Jones GT, Bhattacharya S. Risk of recurrent stillbirth: systematic review and meta-analysis. BMJ (Clinical research ed). 2015;350:h3080.
Hernández-Díaz S, Toh S, Cnattingius S. Risk of pre-eclampsia in first and subsequent pregnancies: prospective cohort study. BMJ (Clinical research ed). 2009;338:b2255.
Vinet E, Chakravarty EF, Simard JF, Clowse M. Use of administrative databases to assess reproductive health issues in rheumatic diseases. Rheumatic diseases clinics of North America. 2018;44(2):327–36.
Ziegler A. Generalized estimating Equations. 1st ed. 2011. New York: Springer New York : Imprint: Springer; 2011.
TRIPOD Group. Transparent reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) Checklist: Prediction Model Development and Validation 2019 [Available from: https://www.tripod-statement.org/Downloads.
National Health and Medical Research Council, Australian Research Council, Universities Australia. National statement on ethical conduct in human research. Canberra: Commonwealth of Australia; 2018.
Acknowledgements
We thank the Maternal and Perinatal Health Unit of the Australian Institute of Health and Welfare for their ongoing support and role in procuring the dataset for this project. We also thank our peer reviewers whose comments and suggestions helped improve and clarify this manuscript.
Funding and competing interests
This study is being undertaken as part of the existing strategic work under the National Health and Medical Research Council (“NHMRC”) Centre of Research Excellence in Stillbirth (“Stillbirth CRE”) at the University of Queensland – Mater Research Institute. The project has received funding from the National Health and Medical Research Council through the Centre for Research Excellence (GNT1116640). The authors declare no competing interests or conflicts of interest.
Author information
Authors and Affiliations
Contributions
VF conceived and JS developed the methods and wrote the protocol in consultation with MC, SK, and SL. All authors provided intellectual contributions to and approved the final version of this protocol manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This study was jointly approved with a waiver of consent by the AIHW Ethics Committee (EO2018/2/451 “Stillbirths in Australia: An epidemiological study to identify and quantify stillbirth risk”) and Mater Research Human Research Ethics Committee (HREC) (HREC/15/MHS/36). Bilateral approvals were received from the following jurisdictions: Australian Capital Territory (2019/LRE/00011), Aboriginal Health Council (04-19-825), Northern Territory (2019-3306), Queensland Department of Health (EO2018/2/451), South Australia (HREC/19/SAH/28), and New South Wales Ministry of Health (H20/12350).
Consent for publication
A waiver of consent is justified and has been approved under all HREC jurisdictions involved in this study. In Australia, only a HREC may grant waiver of consent for research using personal information in medical research or personal health information [58].
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sexton, J.K., Coory, M., Kumar, S. et al. Protocol for the development and validation of a risk prediction model for stillbirths from 35 weeks gestation in Australia. Diagn Progn Res 4, 21 (2020). https://doi.org/10.1186/s41512-020-00089-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s41512-020-00089-w