
Abstract
The recent years have seen a proliferation of Internet of Things (IoT) devices and an associated security risk from an increasing volume of malicious traffic worldwide. For this reason, datasets such as Bot-IoT were created to train machine learning classifiers to identify attack traffic in IoT networks. In this study, we build predictive models with Bot-IoT to detect attacks represented by dataset instances from the Information Theft category, as well as dataset instances from the data exfiltration and keylogging subcategories. Our contribution is centered on the evaluation of ensemble feature selection techniques (FSTs) on classification performance for these specific attack instances. A group or ensemble of FSTs will often perform better than the best individual technique. The classifiers that we use are a diverse set of four ensemble learners (Light GBM, CatBoost, XGBoost, and random forest (RF)) and four non-ensemble learners (logistic regression (LR), decision tree (DT), Naive Bayes (NB), and a multi-layer perceptron (MLP)). The metrics used for evaluating classification performance are area under the receiver operating characteristic curve (AUC) and Area Under the precision-recall curve (AUPRC). For the most part, we determined that our ensemble FSTs do not affect classification performance but are beneficial because feature reduction eases computational burden and provides insight through improved data visualization.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Introduction
The IoT is a network of physical objects with limited computing capability [1]. In recent years, there has been rapid growth in the use of these smart devices, as well as an increasing security risk from malicious network traffic. Several datasets have been created for the purpose of training machine learning classifiers to identify attack traffic. One of the more recent datasets for network intrusion detection is Bot-IoT [2].
The Bot-IoT dataset contains instances of various attack categories: denial-of-service (DoS), distributed denial-of-service (DDoS), reconnaissance, and information theft. The processed full dataset was generated by the Argus network security tool [3] and is available from an online repository of several comma-separated values (CSV) files. Bot-IoT has 29 features and 73,370,443 instances. Table 1 shows the categories and subcategories of IoT network traffic for the full dataset.
In this work, we identify normal and attack type classes of Bot-IoT. The attack types we identify are from the information theft category and from its data exfiltration and keylogging subcategories. Hence, we evaluate three datasets, one composed of normal and information theft attack instances, another composed of normal and data exfiltration attack instances, and a third composed of normal and keylogging attack instances. The keylogging [4] subcategory refers to the interception of information sent from input devices, while the data exfiltration [5] subcategory broadly refers to the unauthorized transfer of data from a computer.
Each of the three datasets has 9543 instances labeled as Normal traffic. In addition, the Information Theft dataset has 1587 instances labeled as the information theft attack type, the data exfiltration dataset has 118 instances labeled as the data exfiltration attack type, and the keylogging dataset has 1469 instances labeled as the keylogging attack type. Based on the minority-to-majority class ratios (i.e., ratios of attack-to-normal instances), all three datasets have a class imbalance. To address the class imbalance, we use the random undersampling (RUS) [6] technique.
In all experiments, we employ the following eight learners: CatBoost [7], Light GBM [8], XGBoost [9], RF [10], DT [11], LR [12], NB [13], and a MLP [14]. To gauge the performance of these classifiers, the AUC and AUPRC metrics are used. Also, during training for some experiments, we apply hyperparameter tuning.
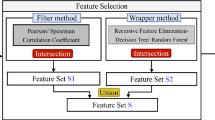
The crux of this study involves the comparison of results from experimentation with and without ensemble feature selection for the information theft, data exfiltration, and keylogging attack types. Feature selection reduces computational burden (i.e., speeds up training time) and provides data clarity (i.e., facilitates visual detection of patterns). In some cases, feature selection can improve classification performance and mitigate the effects of class imbalance [6]. Ensemble FSTs incorporate multiple feature ranking techniques to produce a combined method that is more efficient than its individual components [15]. Our ensemble FSTs are derived from both supervised and filter-based feature ranking techniques [16].
As far as we are aware, this is the first paper that exclusively evaluates the effect of ensemble feature selection on the Bot-IoT information theft category and subcategories. Furthermore, our use of eight different classifiers boosts the validity of our results.
The remainder of this paper is organized as follows: "Bot-Iot developmental environment" section describes the developmental environment and tools used to create Bot-IoT; "Related works" section discusses related Bot-IoT literature; "Methodology" section discusses preprocessing and classification tasks; "Results and discussion" section presents and analyzes our results; and "Conclusion" section concludes with the main points of this paper. In addition, Appendix A provides a list of features and their definitions, Appendix B contains tables of selected features, and Appendix C contains tables of tuned parameter values.
Bot-Iot developmental environment
Created in 2018 by the University of New South Wales (UNSW), Bot-IoT was designed to be a realistic representation of botnet attacks on IoT devices. The dataset was developed in a virtualized environment, with ten virtual machines hosted by an ESXi [17] hypervisor that accessed the Internet through a packet-filtering firewall. Fig 1 shows a schematic of the network within which Bot-IoT was created.

Network diagram
The virtual machines were divided into three groups: IoT, Bots, and Supporting. Normal network traffic was generated by the Ostinato [18] tool, and IoT traffic was generated by the Node-Red [19] tool, along with several scripts run on a group of the virtual machines. Node-Red was used to simulate five IoT scenarios: a weather station, a smart refrigerator, motion activated lights, a smart garage door, and a smart thermostat. Attack traffic was generated using a variety of tools from the Kali Linux [20] suite, an open-source Linux distribution popular with penetration testers and others in the information security industry.
The IoT group of virtual machines comprised four machines running different operating systems. An Ubuntu server [21], which hosted some basic network services as well as the Message Queuing Telemetry Transport (MQTT) [22] protocol broker, was one of the most essential IoT virtual machines. In IoT networks, the MQTT protocol is used to share data between IoT devices and other clients using a publish/subscribe approach. It is utilized in a range of industries and provides a lightweight communications solution that uses less bandwidth. Mosquito MQTT [23] is the MQTT broker used in this testbed. Fig 2 provides an illustrative example of the MQTT broker involved in a data sharing task.

MQTT example
The other three IoT virtual machines ran Ubuntu Mobile [24], Windows 7, and Metasploitable [25], among other operating systems. Ubuntu Mobile is a Linux-based mobile phone operating system that is based on the Ubuntu desktop operating system. Windows 7 is a deprecated version of the Microsoft Windows operating system. Rapid7 created and published Metasploitable, a Linux-based virtual machine with many built-in vulnerabilities. The flaws were purposely built into Metasploitable to allow it to be utilized in penetration testing laboratories. These three virtual machines used Node-Red to act as IoT clients and devices, communicating with the Ubuntu server using the MQTT protocol. These four machines combined served as the attack surface for the Bots group of virtual machines.
The Bots group was made up of four virtual machines intended to simulate a botnet, which is a collection of machines controlled and used by a criminal actor. The Kali Linux operating system was installed on each of the four machines. They were equipped with a large toolkit that was used to conduct various assaults against the IoT group. The Theft attacks were carried out with the help of exploits and tools from the Metasploit penetration testing framework [26].
The Supporting group assisted in the generation and collection of data within the testbed. These machines consisted of an Ubuntu tap and a pfSense [27] firewall. The Ubuntu tap virtual machine sat on the same virtual network as the IoT and Bots groups. It utilized a conventional Ubuntu operating system, but was configured with a promiscuous network interface controller (NIC) to operate in promiscuous mode. The automatic filtering of network traffic not intended for the host is disabled when the NIC is set to promiscuous mode. This allows packet analyzers like tcpdump [28] to record all traffic passing through the NIC. All communication to and from any of the IoT or Bots group of virtual machines was captured by the Ubuntu tap virtual machine. The pfSense firewall, which is the other virtual machine in the Supporting group, had both a local area network (LAN) interface and a wide area network (WAN) interface. The pfSense device served as the primary gateway out of the virtual network.
Related works
In this section, we highlight works associated with detecting malicious traffic in Bot-IoT. To the best of our knowledge, none of the related works have exclusively focused on detecting instances of information theft with ensemble FSTs.
Koroniotis et al. [29] proposed a network forensics model that authenticates network data flows and uses a deep neural network (DNN) [30] based on particle swarm optimization (PSO) [31] to identify traffic anomalies. The authors used the 5% Bot-IoT dataset, which they split in an 80:20 ratio for training and testing. The logistic cost function [32] was utilized, as it has been shown to be efficient at separating normal from attack traffic. The cost function is defined by the following equation [29]:
To treat class imbalance, weights for normal traffic \(w_0\) and attack traffic \(w_1\) were incorporated into this cost function. This modified equation is defined as follows: equation [29]:
The best scores obtained by the model for accuracy, precision, recall, and F-measure were 99.90%, 100%, 99.90%, and 99.90%, respectively. Model performance was evaluated against the reported performance of models from other studies. The authors state that their model outperformed these other models (NB, MLP, association rule mining (ARM) [33], DT, support vector machine (SVM) [34], recurrent neural network (RNN) [35], and long short-term memory (LSTM) [36]). Evaluating model performance from one study against reported model performance from a non-identical study is problematic, since there may be too many factors of variation in the external study to account for.
Using a convolutional neural network (CNN) [37] and CUDA deep neural network LSTM (cuDNNLSTM)Footnote 1 hybrid, Liaqat et al. [38] set out to prove that their proposed model could outperform a Deep Neural Network-Gated Recurrent Unit (DNN-GRU) [39] hybrid, as well as a long short-term memory-gated re-current unit (LSTM-GRU) [39] hybrid. The dataset sample contained 477 normal instances and 668,522 attack instances from Bot-IoT. During data preprocessing, the data was normalized, feature extraction was performed, and to address class imbalance, the number of normal instances was up-sampled to 2,400. The hybrid CNN-cuDNNLSTM model was shown to be the best performer with top scores of 99.99%, 99.83%, 99.33%, and 99.33% for accuracy, precision, recall and F-measure, respectively. We point out that the use of up-sampling techniques can sometimes result in overfitted models [40]. For this study, the authors have not provided adequate information on their up-sampling technique and the model-building process in order for us to rule out the occurrence of overfitting. Therefore, we believe that their proposed model should also be evaluated on out-of-sample data to reaffirm their results.
Mulyanto et al. [41] proposed a cost-sensitive neural network based on focal loss [42]. The cross-entropy loss function [43], which is widely used in neural network classification models, is integrated with focal loss to reduce the influence of the majority class(es) for binary and multi-class classification. A CNN and a DNN served as the neural network classifiers for this approach. The networks were trained on the NSL-KDD [44], UNSW-NB15, and Bot-IoT datasets. The Bot-IoT dataset sample contained about 3,000,000 instances. For binary classification, the cost-sensitive neural networks based on focal loss outperformed neural networks where the synthetic minority oversampling technique (SMOTE) [45] technique was applied and also outperformed plain neural networks. For Bot-IoT, top scores were obtained for the DNN cost-sensitive, focal-loss model: 99.83% (accuracy), 99.93% (precision), 96.89% (recall), and 98.30 (F-measure). We note that there is an inadequate amount of information provided on the preprocessing stage for Bot-IoT.
Ge et al. [46] trained a feedforward neural network [47] and an SVM on Bot-IoT to evaluate performance for binary and multi-class classification. About 11,175,000 Bot-IoT instances were selected. After feature extraction and data preprocessing, the dataset was split in a 64:16:20 ratio for training, validation, and testing, respectively. To address class imbalance, higher weights were assigned to underrepresented classes. Class weights for the training data were obtained by dividing the packet count for each class by the total packet count and then inverting the quotient. Classification results show that the neural network outperformed the SVM. For binary classification with the neural network, the best score for accuracy was 100%, while the best scores for precision, recall, and F-measure were all 99.90%. While multi-class classification scores were provided for the SVM classifier, binary classification scores were not. Hence, the binary classification scores for the neural network cannot be compared with classification scores for the SVM. This detracts from the authors’ conclusion that the feedforward neural network is the better classifier.
Finally, to detect DDoS attacks, Soe et al. [48] trained a feedforward neural network on 477 normal instances and about 1,900,000 DDoS instances from Bot-IoT. The dataset was split in a ratio of 66:34 for training and testing, and the SMOTE algorithm was utilized to address class imbalance. After the application of SMOTE during data preprocessing, the training dataset contained about 1,300,000 instances for each class, while the test dataset contained 655,809 normal instances and 654,285 DDoS instances. The data was then normalized. Precision, Recall, and F-measure scores were all 100%. We point out that there is a lack of information on data cleaning in the study. In addition, it is unclear why the authors believe that balancing the classes (positive to negative class ratio of 50:50) is the optimal solution. Also, in their paper, only the DT classifier is used, i.e., reliance on only one classifier.
We again note that after reviewing these five works, none were found to be solely based on Bot-IoT information theft detection. In addition, we use ensemble feature selection for building our predictive models.
Methodology
Data cleaning
As discussed in the next three paragraphs, there are six features in Bot-IoT that do not provide generalizable information [49].
The pkSeqID and seq features were removed because they are row or sequence identifiers and only provide information regarding order. Removing pkSeqID was obvious based on the definition provided by Koroniotis et al. [2]. However, removing seq was less so, as seq has been highly utilized in many studies [49]. Based on our consultation with the developers of the Argus network security tool and on our own investigation, we discovered that seq is a monotonically increasing sequence number pertaining to the records processed by the tool. With this clarification, we determined that it did not provide any additional relevant or generalizable information for our models.
The features stime and ltime are timestamps corresponding to the start packet time and last packet time for each instance. While they are useful for determining key features like duration or rate, this information is already provided by the features dur, rate, srate, and drate. With that information already present, we believe that both stime and ltime are unlikely to provide any additional information and may contribute to the overfitting of data by our models.
The saddr and daddr features pertain to the source and destination Internet Protocol (IP) addresses for each of the instances. While this information can provide highly relevant contextual information for security analysts, we chose to exclude it because private IP addresses can vary from network to network. Should a model learn to attribute a behavior based entirely or partially on the source or destination IP, it would be ineffective if tested against a dataset generated with different IP addresses.
We also discovered that many instances using Internet Control Message Protocol (c) have a hexadecimal value for the sport and dport features or are missing values for these features. Because of this, we changed all missing and hexadecimal ICMP values for sport and dport to -1 to indicate an invalid port value.
Data transformations
The flgs_number, fproto_number, sport, dport, and state_number categorical features were one-hot encoded. The one-hot encoding process, which was implemented by CatBoost’s Ordered Target StatisticsFootnote 2, transforms categorical features into dummy variables. We also performed feature scaling to provide a [0,1] normalized range for all numerical features.
Data sampling
RUS is a technique to deal with class imbalance where we discard members of the majority class until the ratio of instances of majority and minority class members reaches a desired level. If the experiment involved RUS, we applied it to the training data only. The desired minority-to-majority class ratios we used RUS to obtain are those from [50], where the authors report yield strong results. These ratios are 1:1, 1:3, and 1:9. However, given the initial ratios of minority-to-majority class in the Information Theft dataset (1587:9543), it was only possible to do RUS for the 1:1 and 1:3 ratios.
Ensemble feature selection
A further preprocessing step we employed for some experiments is our ensemble FST. The FST is a two-step process. For the first step, we employed three filter-based feature ranking techniques. They are the information gain [51], information gain ratio [52], and Chi squared (Chi 2) [53] feature ranking techniques. We also ranked features according to four supervised learning-based feature ranking techniques. Feature importance lists from RF, CatBoost, XGBoost, and LightGBM served as the basis for the supervised feature ranking techniques.
We then took the 20 highest ranked attributes. We decided to use 20 features based on results of previous studies [54]. Therefore, we searched for features occurring in a set number of 7 rankings, where that number ranges from 4 to 7. Put another way, since we have 7 rankings, we require a majority of rankings to agree that a feature is among the 20 most important features in order to select it. This yielded 4 datasets sets of selected features, which we called the 4 Agree, 5 Agree, 6 Agree, and 7 Agree datasets. The tables in Appendix A show the features selected for the supervised-based feature ranking techniques, the filter-based feature ranking techniques, and the 4, 5, 6 and 7 Agree datasets.
Classifiers and performance metrics
This study involves four ensemble classifiers (CatBoost, Light GBM, XGBoost, and RF) and four non-ensemble classifiers (DT, LR, NB, and an MLP). These classifiers belong to various machine learning families of algorithms and are widely considered to be reliable [55]. CatBoost, Light GBM, and XGBoost were implemented with their respective self-named Python libraries, while the other classifiers were implemented with Scikit-learn.Footnote 3
CatBoost, Light GBM, and XGBoost are gradient-boosted decision trees (GBDTs) [56], which are ensembles of sequentially trained trees. An ensemble classifier combines weak algorithms, or instances of an algorithm, into a strong learner. CatBoost relies on ordered boosting to order the instances used for fitting DTs. Light GBM is characterized by gradient-based one-side sampling and exclusive feature bundling. One-side sampling disregards a significant fraction of instances with small gradients, and exclusive feature bundling categorizes mutually exclusive features to reduce variable count. XGBoost utilizes a sparsity-aware algorithm and a weighted quantile sketch. Sparsity is defined by zero or missing values, and a weighted quantile sketch benefits from approximate tree learning [57] to support pruning and merging tasks. RF is also an ensemble of DTs, but unlike the GBDTs, it uses a bagging technique [58].
DT is a non-parametric approach that offers a simplistic tree-like representation of observed data. Each internal node represents a test on a specified feature, and each branch represents the outcome of a particular test. Each leaf node represents a class label. LR uses a sigmoidal function to generate probability values. Predictions for class membership are centered on a specified probability threshold. NB uses conditional probability to determine class membership. This classifier is considered “naive” because it operates on the assumption that features are independent of each other. An MLP is a type of artificial neural network with fully connected nodes. It utilizes a non-linear activation function and contains an input layer, one or more hidden layers and an output layer.
In our work, we used more than one performance metric (AUC and AUPRC) to better assess the challenge of evaluating classifiers. AUC is the area under the receiver operating characteristic (ROC) curve, which is a plot of true positive rate (TPR) versus false positive rate (FPR). This metric incorporates all classification thresholds represented by the curve [59] and is essentially a summary of overall model performance. AUPRC is the area under the Precision-Recall curve. This metric shows the trade-off between precision and recall for specific classification thresholds [60].
Parameters and cross validation
Before we trained our classifiers, we used default hyperparameters and/or tuned hyperparameters to help control the learning process. Hyperparameter tuning was effected by RandomizedSearchCVFootnote 4, a module of Scikit-learn. We list these tuned parameters in Appendix B.
During training, we implemented ten iterations of stratified five-fold cross-validation, which means there are 50 performance scores obtained per classifier for each metric. For k-fold cross-validation, every instance is placed in a validation set once and placed in a training set k-1 times. This means that for five-fold cross-validation, every instance gets to be in a validation set once and in a training set four times. The stratified component of cross-validation aims to ensure that each class is equally represented across each fold [61]. Because we randomly shuffled instances before cross-validation, certain algorithms such as LR may yield different results when the order of instances is changed [62]. One way of addressing the undesirable effect of this randomness is by performing several iterations, as we have done [63]. Note that each AUC or AUPRC value shown in the classification performance tables is an average of the 50 performance scores.
High-level methodology overview
For each of the attack types (information theft, data exfiltration, and keylogging), we divided our experiments into those that did not use ensemble FSTs and those that used them. For the tasks that did not involve ensemble FSTs, we first performed experimentation where we did not use hyperparameter tuning or data sampling. Second, we performed experimentation where we applied data sampling. Third, we performed experimentation where we applied both data sampling and hyperparameter tuning. For the tasks that involved ensemble FSTs, feature selection was a necessary component for all three experimentation steps.
Results and discussion
In this section, we present results for classification performance, with and without the application of FSTs, and also present statistical analyses. Results are compartmentalized by attack type (information theft, data exfiltration, and keylogging).
Experiment names indicate the classifier used, whether we apply RUS (and in what ratio), and whether we apply hyperparameter tuning. For example, the experiment name “MLP Tuned RUS 1:3 6 Agree” indicates we use the MLP classifier, with hyperparameters tuned by RandomizedSearchCV, with RUS to a 1:3 ratio, and the 6 Agree FST. If there is no mention of RUS or a ratio in the experiment name this means we did not apply RUS.
Information theft
Information theft without ensemble feature selection
Table 2 contains results for experiments with default hyperparameters and no RUS. For AUC, the highest score of 0.99703 was obtained by CatBoost. For AUPRC, the highest score of 0.99984 was obtained by CatBoost.
Table 3 contains results for experiments with default hyperparameters after RUS is applied. For AUC, the highest score of 0.99842 was obtained by CatBoost with a balanced class ratio of 1:1. For AUPRC, the highest score of 0.99983 was obtained by CatBoost with a balanced class ratio of 1:1.
Table 4 contains results for experiments after RUS and hyperparameter tuning are applied. For AUC, CatBoost with a balanced class ratio of 1:1 obtained the highest score of 0.99803. For AUPRC, CatBoost with a minority-to-majority class ratio of 1:3 obtained the highest score of 0.99980.
Information theft with ensemble feature selection
Due to the number of experiments performed, Tables 5 and 6 only report the best performance by classifier, over all combinations of RUS, hyperparameter tuning, and ensemble FSTs. Table 5 shows AUC scores obtained. CatBoost, with a class ratio of 1:3 and 5 Agree FST, yielded the highest score in this table of 0.99838. Table 6 shows AUPRC scores obtained. CatBoost with a 7 Agree FST and no RUS produced the highest score in this table of 0.99986.
Information theft statistical analysis
To understand the statistical significance of the classification performance scores, we run analysis of variance (ANOVA) tests. ANOVA establishes whether there is a significant difference between group means [64]. A 99% (\(\alpha\) = 0.01) confidence level is used for our ANOVA tests. The results are shown in Tables 7 and 8, where Df is the degrees of freedom, Sum Sq is the sum of squares, Mean Sq is the mean sum of squares, F value is the F-statistic, and Pr(>F) is the p-value.
The first ANOVA test we run for Information Theft evaluates the impact of factors on performance in terms of AUC. As shown in Table 7, the p-value associated with every factor is practically 0. Therefore, we conclude all factors have a significant impact on performance in terms of AUC.
The second ANOVA test we run for information theft evaluates the impact of factors on performance in terms of AUPRC. As shown in Table 8, the p-value associated with every factor is practically 0. Therefore, we conclude all factors have a significant impact on performance in terms of AUPRC
Since all factors significantly impact performance for both AUC and AUPRC, Tukey’s Honestly Significant Difference (HSD) tests [65] are performed to determine which groups are significantly different from each other. Letter groups assigned via the Tukey method indicate similarity or significant differences in performance results within a factor.
With regard to AUC, we first apply the HSD test to the group classifier factor, with the results shown in Table 9. In this table, the highest ranked classifiers are the GBDT classifiers, followed by RF. Next, we cover the HSD test for the RUS factor. The results of this test, as shown in Table 10, reveal that undersampling, either to the 1:1 or 1:3 minority-to majority-class ratios yield similar performance, which is better than not using undersampling. For the hyperparameter tuning factor, the results of the HSD test provided in Table 11 indicate that hyperparameter tuning is generally better than the default hyperparameter values. Table 12 shows the HSD test results for the FST factor. Here, we find the only FST that has significantly worse performance than the others is the 7 Agree. Otherwise, using all features or any other FST yields similar results. Since the 6 Agree FST yields the smallest number of features in group ‘a’, we recommend using the features that the 6 Agree FST selects. Classifiers usually train faster on datasets with comparatively fewer features.
In terms of AUPRC, the HSD test results for the group classifier factor, as shown in Table 13, indicate that the GBDT classifiers yield the best performance. However, unlike the case for performance in terms of AUC, the performance of RF, which is not a GBDT classifier, is not significantly less than that of the GBDT classifiers. The HSD test results for the RUS factor are provided in Table 14. It turns out that not doing RUS is the best choice. As shown in Table 15, the HSD test results for the hyperparameter tuning factor indicate that default hyperparameter values are the better choice. Finally, Table 16 provides HSD test results for the FST factor. These results are similar to those we see for performance in terms of AUC. Only the 7 agree FST yields a lower performance than other levels of FST. Therefore, the 6 Agree FST is preferred, since it has fewer features than the 4 Agree and 5 Agree FSTs.
Information theft conclusion
The GBDT classifiers, and in some cases RF, yield similar performance. HSD test results indicate their performance is better than that of the other classifiers. While the ANOVA tests reveal that hyperparameter tuning is a significant factor, we see that hyperparameter tuning yields better performance in terms of AUC, but worse performance in terms of AUPRC. Therefore, we conclude that hyperparameter tuning is only necessary for optimizing performance in terms of AUC. For the case of performance in terms of AUC, undersampling has a positive impact on performance. However, for performance in terms of AUPRC, we see that the best strategy for RUS is to not use it. We find there is no impact on performance in terms of AUC or AUPRC when we apply the 4, 5, or 6 Agree FSTs, since the HSD test ranks these in the best performing group, along with the technique where we use all features. Furthermore, these techniques all outperform the 7 Agree FST. Since using fewer features yields performance equivalent to using all features, we conclude that we should use the 6 Agree FST in future work. The 6 Agree FST yields the smallest number of features, and model training is usually faster with fewer features.
Data exfiltration
Data exfiltration without ensemble feature selection
Table 17 contains results for experiments with default hyperparameters and no RUS. For AUC, the highest score of 0.98126 was obtained by CatBoost. For AUPRC, the highest score of 0.99446 was obtained by CatBoost.
Table 18 contains results for experiments with default hyperparameters after RUS is applied. For AUC, the highest score of 0.99011 was obtained by RF with a balanced class ratio of 1:1. For AUPRC, the highest score of 0.99148 was obtained by CatBoost with a minority-to-majority class ratio of 1:9.
Table 19 contains results for experiments after RUS and hyperparameter tuning are applied. For AUC, CatBoost with a minority-to-majority class ratio of 1:9 obtained the highest score of 0.99281. For AUPRC, CatBoost with a minority-to-majority class ratio of 1:9 obtained the highest score of 0.99292.
Data exfiltration with ensemble feature selection
Due to the number of experiments performed, Tables 20 and 21 only report the best performance by classifier, over all combinations of RUS, hyperparameter tuning, and ensemble FSTs. Table 20 shows AUC scores obtained. CatBoost, with a minority-to-majority class ratio of 1:9 and 4 Agree FST, yielded the highest score in this table of 0.99076. Table 21 shows AUPRC scores obtained. CatBoost with a 5 Agree FST and no RUS produced the highest score in this table of 0.99448.
Data exfiltration statistical analysis
As done previously for the Information Theft statistical analysis, we perform ANOVA tests for the Data Exfiltration dataset. The results are shown in Tables 22 and 23, where Df is the degrees of freedom, Sum Sq is the sum of squares, Mean Sq is the mean sum of squares, F value is the F-statistic, and Pr(>F) is the p-value.
The first ANOVA test we run for Data Exfiltration evaluates the impact of factors on performance in terms of AUC. As shown in Table 22, the p-value associated with every factor is practically 0. Therefore, we conclude all factors have a significant impact on performance in terms of AUC.
The second ANOVA test we run for data exfiltration evaluates the impact of factors on performance in terms of AUPRC. As shown in Table 23, the p-value associated with every factor is practically 0. Therefore, we conclude all factors have a significant impact on performance in terms of AUPRC
With regard to AUC, we begin with the HSD test applied to the group classifier factor, with the results shown in Table 24. In this table, the GBDT classifiers and RF show the best performance. However, CatBoost is ranked above all others. Next, we address the HSD test for the RUS factor. The results of this test, as shown in Table 25, indicate that the 1:1 or 1:3 class ratios yield the best performance. For the hyperparameter tuning factor, the results of the HSD test provided in Table 26 indicate that hyperparameter tuning is a better alternative than the default hyperparameter values. Table 27 shows the HSD test results for the FST factor. Here, we find the 7 Agree FST yields better performance than any other FST. This is an ideal result, since the less complex model with fewer features outperforms the models that have more features.
In terms of AUPRC, the HSD test results for the group classifier factor, as shown in Table 28, indicate that the GBDT classifiers and RF yield the best performance. The HSD test results for the RUS factor are provided in Table 29. It turns out that not doing RUS is the best choice. As shown in Table 30, the HSD test results for the hyperparameter tuning factor indicate that hyperparameter tuning is a better alternative than the default hyperparameter values. Finally, Table 31 provides HSD test results for the FST factor. Since the 6 Agree technique yields fewer features than the 4 Agree and 5 Agree techniques, we prefer the 6 Agree.
Data exfiltration conclusion
Similar to results for classifying the Information Theft attack type data, the GBDT classifiers yield the best performance, along with RF. For classifying the data exfiltration attack type, we find results for AUC and AUPRC with hyperparameter tuning are higher than those where we use default parameter tuning. As in the case with classifying the Information Theft dataset, there are mixed results for the application of RUS. For performance in terms of AUC, applying RUS to the data before training improves performance. However, for performance in terms of AUPRC, not using RUS yields better results. For classifying data exfiltration attack type data, if AUC is the more important metric, then the best FST for classification performance is the 7 Agree FST. However, if AUPRC is the more important metric, then the 6 Agree FST yields a dataset with the fewest features, but yields performance similar to using all features.
Keylogging
Keylogging without ensemble feature selection
Table 32 contains results for experiments with default hyperparameters and no RUS. For AUC, the highest score of 0.99643 was obtained by Light GBM. For AUPRC, the highest score of 0.99987 was obtained by CatBoost.
Table 33 contains results for experiments with default hyperparameters after RUS is applied. For AUC, the highest score of 0.99796 was obtained by CatBoost with a balanced class ratio of 1:1. For AUPRC, the highest score of 0.99981 was obtained by CatBoost with a balanced class ratio of 1:1.
Table 34 contains results for experiments after RUS and hyperparameter tuning are applied. For AUC, CatBoost with a balanced class ratio of 1:1 obtained the highest score of 0.99749. For AUPRC, CatBoost with a balanced class ratio of 1:1 also obtained the highest score of 0.99971.
Keylogging with ensemble feature selection
Due to the number of experiments performed, Tables 35 and 36 only report the best performance by classifier, over all combinations of RUS, hyperparameter tuning, and ensemble FSTs. Table 35 shows AUC scores obtained. CatBoost with a 6 Agree FST and a balanced class ratio of 1:1 yielded the highest score in this table of 0.99807. Table 36 shows AUPRC scores obtained. CatBoost with a 6 Agree FST and no RUS produced the highest score in this table of 0.99988.
Keylogging statistical analysis
As done previously for the Information Theft and data exfiltration datasets, we perform ANOVA tests for the Keylogging dataset. The results are shown in Tables 37 and 38, where Df is the degrees of freedom, Sum Sq is the sum of squares, Mean Sq is the mean sum of squares, F value is the F-statistic, and Pr(>F) is the p-value.
The first ANOVA test we run for keylogging evaluates the impact of factors on performance in terms of AUC. As shown in Table 37, the p-value associated with every factor is practically 0. Therefore, we conclude all factors have a significant impact on performance in terms of AUC.
The second ANOVA test we run for keylogging evaluates the impact of factors on performance in terms of AUPRC. As shown in Table 38, the p-value associated with all factors, except hyperparameter tuning (0.8137) is practically 0. Therefore, we conclude that only hyperparameter tuning does not have a significant impact on performance in terms of AUPRC.
With regard to AUC, we begin with the HSD test applied to the group classifier factor, with the results shown in Table 39. In this table, the GBDT classifiers and RF show the best performance. Next, we cover the HSD test for the RUS factor. The results of this test, as shown in Table 40, indicate that the 1:1 or 1:3 class ratios yield the best performance. For the hyperparameter tuning factor, the results of the HSD test provided in Table 41 indicate that hyperparameter tuning is a better alternative than the default hyperparameter values. Table 42 shows the HSD test results for the FST factor. Here, we see that using the dataset with a larger number of features yields the best result.
In terms of AUPRC, the HSD test results for the group classifier factor, as shown in Table 43, indicate that the GBDT classifiers and RF yield the best performance. The HSD test results for the RUS factor are provided in Table 44. It turns out that not doing RUS is the best choice. Finally, Table 45 provides HSD test results for the FST factor. We prefer the 6 Agree FST since it yields performance similar to using all features, and it has the fewest features.
Keylogging conclusion
As with other attack types, we see the GBDT classifiers yield the best performance. The HSD tests for the influence of hyperparameter tuning on results in terms of AUC show that hyperparameter tuning yields better performance. However, for performance in terms of AUPRC, hyperparameter tuning is not significant. Similar to what we observe with results for classifying data exfiltration attack types, we see that if performance in terms of AUC is most important, then data sampling yields better results. However, for results in terms of AUPRC, we find that not applying data sampling gives better results. For performance in terms of AUPRC, we obtain similar results when using the 4 Agree, 5 Agree, 6 Agree FSTs or using all features, since all are in the HSD group ‘a’. However, for performance in terms of AUC, the 4 Agree and 5 Agree FSTs are in category ‘ab’, while All Features is in category ‘a’. This indicates that for AUC, the ensemble FSTs slightly impact performance.
Conclusion
The Bot-IoT dataset is geared toward the training of classifiers for the identification of malicious traffic in IOT networks. In this study, we examine the effect of ensemble FSTs on classification performance for information theft attack types. An ensemble feature selection approach is usually more efficient than its individual FSTs.
To accomplish our research goal, we investigate three datasets, one composed of Normal and Information Theft attack instances, another composed of Normal and data exfiltration attack instances, and a third composed of normal and keylogging attack instances. In general, we observed that our ensemble FSTs do not affect classification performance scores. However, our technique is useful because feature reduction lessens computational burden and provides clarity.
Future work will assess other classifiers that are trained on the identical datasets used in our study. There is also an opportunity to evaluate classifier performance, with respect to information theft detection, on other IOT intrusion detection datasets.
Availability of data and materials
Not applicable.
Notes
Abbreviations
- ANOVA:
-
Analysis of variance
- ARM:
-
Association rule mining
- ARP:
-
Address resolution protocol
- AUC:
-
Area under the receiver operating characteristic curve
- AUPRC:
-
Area under the precision-recall curve
- CNN:
-
Convolutional neural network
- CSV:
-
Comma-separated values
- cuDNNLSTM:
-
CUDA deep neural network LSTM
- CV:
-
Cross-validation
- DDoS:
-
Distributed denial-of-service
- DNN:
-
Deep neural network
- DNN-GRU:
-
Deep neural network-gated recurrent unit
- DoS:
-
Denial-of-service
- DT:
-
Decision tree
- ENN:
-
Edited nearest neighbor
- FAU:
-
Florida Atlantic University
- FN:
-
False negative
- FNR:
-
False negative rate
- FP:
-
False positive
- FPR:
-
False positive rate
- FST:
-
Feature selection technique
- GBDT:
-
Gradient-boosted decision tree
- GM:
-
Geometric mean
- HSD:
-
Honestly significant difference
- HTTP:
-
Hypertext transfer protocol
- ICA:
-
Independent component analysis
- ICMP:
-
Internet control message protocol
- IP:
-
Internet protocol
- IoT:
-
Internet of Things
- k-NN:
-
k-Nearest neighbor
- LR:
-
Logistic regression
- LSTM:
-
Long short-term memory
- LSTM-GRU:
-
Long short-term memory-gated recurrent unit
- MLP:
-
Multi-layer perceptron
- MSE:
-
Mean square error
- NB:
-
Naive Bayes
- NL:
-
Noise level
- NSF:
-
National Science Foundation
- OS:
-
Operating system
- PC:
-
Principal component
- PCAP:
-
Packet capture
- PCA:
-
Principal component analysis
- PSO:
-
Particle swarm optimization
- RF:
-
Random forest
- RNN:
-
Recurrent neural network
- ROC:
-
Receiver operating characteristic
- RUS:
-
Random undersampling
- SMOTE:
-
Synthetic minority oversampling technique
- SVM:
-
Support vector machine
- TCP:
-
Transmission control protocol
- TN:
-
True negative
- TNR:
-
True negative rate
- TP:
-
True positive
- TPR:
-
True positive rate
- ULB:
-
Université Libre de Bruxelles
- UDP:
-
User datagram protocol
- UNSW:
-
University of New South Wales
- AUC:
-
Area under the receiver operating characteristic curve
- FNR:
-
False negative rate
- GM:
-
Geometric mean
- AUC:
-
Area under the receiver operating characteristic curve
- AUPRC:
-
Area under the precision-recall curve
- DT:
-
Decision tree
- FST:
-
Feature selection technique
- ICA:
-
Independent component analysis
- IoT:
-
Internet of Things
- LR:
-
Logistic regression
- MLP:
-
Multi-layer perceptron
- NB:
-
Naive Bayes
- PCA:
-
Principal component analysis
- RF:
-
Random forest
- DT:
-
Decision tree
- FST:
-
Feature selection technique
- LR:
-
Logistic regression
- MLP:
-
Multi-layer perceptron
- NB:
-
Naive Bayes
- RF:
-
Random forest
- RUS:
-
Random undersampling
- RF:
-
Random forest
References
Leevy JL, Khoshgoftaar TM, Peterson JM. Mitigating class imbalance for iot network intrusion detection: a survey. In: 2021 IEEE seventh international conference on big data computing service and applications (BigDataService). IEEE; 2021. 143–148.
Koroniotis N, Moustafa N, Sitnikova E, Turnbull B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-iot dataset. Future Gener Comput Syst. 2019;100:779–96.
Argus: Argus. https://openargus.org/.
Fu Y, Husain B, Brooks RR. Analysis of botnet counter-counter-measures. In: Proceedings of the 10th annual cyber and information security research conference, 2015;1–4.
Ullah F, Edwards M, Ramdhany R, Chitchyan R, Babar MA, Rashid A. Data exfiltration: A review of external attack vectors and countermeasures. Journal of Network and Computer Applications. 2018;101:18–54.
Leevy JL, Khoshgoftaar TM, Bauder RA, Seliya N. A survey on addressing high-class imbalance in big data. J Big Data. 2018;5(1):42.
Hancock JT, Khoshgoftaar TM. Catboost for big data: an interdisciplinary review. J Big Data. 2020;7(1):1–45.
Leevy JL, Hancock J, Khoshgoftaar TM, Seliya N. Iot reconnaissance attack classification with random undersampling and ensemble feature selection. In: 2021 IEEE 7th international conference on collaboration and internet computing (CIC). IEEE; 2021.
Hancock J, Khoshgoftaar TM. Medicare fraud detection using catboost. In: 2020 IEEE 21st international conference on information reuse and integration for data science (IRI). IEEE; 2020. 97–103.
Breiman L. Random forests. Mach Learn. 2001;45(1):5–32.
Zuech R, Hancock J, Khoshgoftaar TM. Investigating rarity in web attacks with ensemble learners. J Big Data. 2021;8(1):1–27.
Rymarczyk T, Kozłowski E, Kłosowski G, Niderla K. Logistic regression for machine learning in process tomography. Sensors. 2019;19(15):3400.
Saritas MM, Yasar A. Performance analysis of ann and naive bayes classification algorithm for data classification. Int J Intell Syst Appl Eng. 2019;7(2):88–91.
Rynkiewicz J. Asymptotic statistics for multilayer perceptron with relu hidden units. Neurocomputing. 2019;342:16–23.
Wang H, Khoshgoftaar TM, Napolitano A. A comparative study of ensemble feature selection techniques for software defect prediction. In: 2010 Ninth international conference on machine learning and applications. IEEE; 2010. 135–140.
Najafabadi MM, Khoshgoftaar TM, Seliya N. Evaluating feature selection methods for network intrusion detection with kyoto data. Int J Reliabil Qual Saf Eng. 2016;23(01):1650001.
VMware: What is ESXi?: Bare Metal Hypervisor: Esx. https://www.vmware.com/products/esxi-and-esx.html.
Ostinato: Ostinato Traffic Generator for Network Engineers. https://ostinato.org/.
Foundation TO. Node-RED: Low-code programming for event-driven applications. https://nodered.org/.
OffSec: Kali Docs: Kali Linux documentation. https://www.kali.org/.
Canonical: enterprise open source and Linux. https://ubuntu.com/.
MQTT.org: MQTT—the standard for IoT messaging. https://mqtt.org/.
Foundation E. Eclipse mosquitto. https://mosquitto.org/.
Canonical: Ubuntu Phone Documentation. https://phone.docs.ubuntu.com/en/devices/.
Rapid7: Download metasploitable—intentionally vulnerable machine. https://information.rapid7.com/download-metasploitable-2017.html.
Metasploit R. Penetration testing, software, pen testing security. https://www.metasploit.com/.
pfSense: learn about the pfSense Project. https://www.pfsense.org/.
Tcpdump: TCPDUMP/LIBPCAP public repository. https://www.tcpdump.org/.
Koroniotis N, Moustafa N, Sitnikova E. A new network forensic framework based on deep learning for internet of things networks: a particle deep framework. Future Gener Comput Syst. 2020;110:91–106.
Amaizu GC, Nwakanma CI, Lee J-M, Kim D-S. Investigating network intrusion detection datasets using machine learning. In: 2020 International conference on information and communication technology convergence (ICTC). IEEE; 2020.1325–1328.
Malik AJ, Khan FA. A hybrid technique using binary particle swarm optimization and decision tree pruning for network intrusion detection. Cluster Comput. 2018;21(1):667–80.
De Cock M, Dowsley R, Nascimento AC, Railsback D, Shen J, Todoki A. High performance logistic regression for privacy-preserving genome analysis. BMC Med Genomics. 2021;14(1):1–18.
Ceddia G, Martino LN, Parodi A, Secchi P, Campaner S, Masseroli M. Association rule mining to identify transcription factor interactions in genomic regions. Bioinformatics. 2020;36(4):1007–13.
Ahmad I, Basheri M, Iqbal MJ, Rahim A. Performance comparison of support vector machine, random forest, and extreme learning machine for intrusion detection. IEEE Access. 2018;6:33789–95.
Ferrag MA, Maglaras L, Moschoyiannis S, Janicke H. Deep learning for cyber security intrusion detection: approaches, datasets, and comparative study. J Inf Secur Appl. 2020;50:102419.
Lin P, Ye K, Xu C-Z. Dynamic network anomaly detection system by using deep learning techniques. In: International conference on cloud computing. Springer; 2019. 161–176.
Kaur G, Lashkari AH, Rahali A. Intrusion traffic detection and characterization using deep image learning. In: 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech). IEEE; 2020. 55–62.
Liaqat S, Akhunzada A, Shaikh FS, Giannetsos A, Jan MA. Sdn orchestration to combat evolving cyber threats in internet of medical things (iomt). Comput Commun. 2020;160:697–705.
Nakayama S, Arai S. Dnn-lstm-crf model for automatic audio chord recognition. In: Proceedings of the international conference on pattern recognition and artificial intelligence; 2018. 82–88.
Santos MS, Soares JP, Abreu PH, Araujo H, Santos J. Cross-validation for imbalanced datasets: avoiding overoptimistic and overfitting approaches [research frontier]. IEEE Comput Intell Mag. 2018;13(4):59–76.
Mulyanto M, Faisal M, Prakosa SW, Leu J-S. Effectiveness of focal loss for minority classification in network intrusion detection systems. Symmetry. 2021;13(1):4.
Nemoto K, Hamaguchi R, Imaizumi T, Hikosaka S. Classification of rare building change using cnn with multi-class focal loss. In: IGARSS 2018-2018 IEEE international geoscience and remote sensing symposium. IEEE; 2018. 4663–4666.
Ho Y, Wookey S. The real-world-weight cross-entropy loss function: modeling the costs of mislabeling. IEEE Access. 2019;8:4806–13.
Dhanabal L, Shantharajah S. A study on nsl-kdd dataset for intrusion detection system based on classification algorithms. Int J Adv Res Comput Commun Eng. 2015;4(6):446–52.
Shamsudin H, Yusof UK, Jayalakshmi A, Khalid MNA. Combining oversampling and undersampling techniques for imbalanced classification: a comparative study using credit card fraudulent transaction dataset. In: 2020 IEEE 16th international conference on control & automation (ICCA). IEEE; 2020. 803–808.
Ge M, Fu X, Syed N, Baig Z, Teo G, Robles-Kelly A. Deep learning-based intrusion detection for iot networks. In: 2019 IEEE 24th Pacific rim international symposium on dependable computing (PRDC). IEEE; 2019. 256–25609.
Varsamopoulos S, Criger B, Bertels K. Decoding small surface codes with feedforward neural networks. Quant Sci Technol. 2017;3(1):015004.
Soe YN, Santosa PI, Hartanto R. Ddos attack detection based on simple ann with smote for iot environment. In: 2019 Fourth international conference on informatics and computing (ICIC). IEEE; 2019. 1–5.
Peterson JM, Leevy JL, Khoshgoftaar TM. A review and analysis of the bot-iot dataset. In: 2021 IEEE international conference on service-oriented system engineering. IEEE; 2021. 10–17.
Zuech R, Hancock J, Khoshgoftaar TM. Detecting web attacks using random undersampling and ensemble learners. J Big Data. 2021;8(1):1–20.
Naghiloo M, Alonso J, Romito A, Lutz E, Murch K. Information gain and loss for a quantum maxwell’s demon. Phys Rev Lett. 2018;121(3):030604.
Dong R-H, Yan H-H, Zhang Q-Y. An intrusion detection model for wireless sensor network based on information gain ratio and bagging algorithm. Int J Netw Secur. 2020;22(2):218–30.
Leevy JL, Khoshgoftaar TM. A survey and analysis of intrusion detection models based on cse-cic-ids2018 big data. J Big Data. 2020;7(1):1–19.
Leevy JL, Hancock J, Zuech R, Khoshgoftaar TM. Detecting cybersecurity attacks across different network features and learners. J Big Data. 2021;8(1):1–29.
Seiffert C, Khoshgoftaar TM, Van Hulse J, Napolitano A. Mining data with rare events: a case study. In: 19th IEEE international conference on tools with artificial intelligence (ICTAI 2007). IEEE; 2007;2, 132–139.
Hancock JT, Khoshgoftaar TM. Gradient boosted decision tree algorithms for medicare fraud detection. SN Comput Sci. 2021;2(4):1–12.
Gupta A, Nagarajan V, Ravi R. Approximation algorithms for optimal decision trees and adaptive tsp problems. Math Oper Res. 2017;42(3):876–96.
González S, García S, Del Ser J, Rokach L, Herrera F. A practical tutorial on bagging and boosting based ensembles for machine learning: algorithms, software tools, performance study, practical perspectives and opportunities. Inf Fusion. 2020;64:205–37.
Lobo JM, Jiménez-Valverde A, Real R. Auc: a misleading measure of the performance of predictive distribution models. Glob Ecol Biogeogr. 2008;17(2):145–51.
Saito T, Rehmsmeier M. The precision-recall plot is more informative than the roc plot when evaluating binary classifiers on imbalanced datasets. PloS One. 2015;10(3):0118432.
Kohavi R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In: Proceedings of the 14th international joint conference on artificial intelligence-Volume 2. Morgan Kaufmann Publishers Inc.; 1995. 1137–1143.
Suzuki S, Yamashita T, Sakama T, Arita T, Yagi N, Otsuka T, Semba H, Kano H, Matsuno S, Kato Y, et al. Comparison of risk models for mortality and cardiovascular events between machine learning and conventional logistic regression analysis. PLoS One. 2019;14(9):0221911.
Van Hulse J, Khoshgoftaar TM, Napolitano A. An empirical comparison of repetitive undersampling techniques. In: 2009 IEEE international conference on information reuse and integration. IEEE; 2009. 29–34.
Iversen GR, Wildt AR, Norpoth H, Norpoth HP. Analysis of variance. Sage, 1987.
Tukey JW. Comparing individual means in the analysis of variance. Biometrics.1949; 99–114.
Acknowledgements
We would like to thank the reviewers in the Data Mining and Machine Learning Laboratory at Florida Atlantic University.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
JLL searched for relevant papers and drafted the manuscript. All authors provided feedback to JLL and helped shape the work. JLL, JH, and JMP prepared the manuscript. TMK introduced this topic to JLL and helped to complete and finalize the work. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
In this section, we provide a list of features and their definitions for the full processed Bot-IoT dataset (Table 46).
Appendix B
Here, we report classification results where we use our ensemble FSTs. First, we report the 20 highest ranked features from each ranking technique in Tables 17 and 18. Throughout this case study the reader may notice a supervised feature ranking technique such as CatBoost or XGBoost may fail to yield 20 features. This is due to the fact that in some instances, classifiers do not assign importance to all features in a dataset. These rankings are followed by a report of which features are in each of the 4 Agree, 5 Agree, 6 Agree, and 7 Agree datasets (Tables 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58).
Feature selection for information theft
Feature selection for data exfiltration
Feature selection for keylogging
Appendix C
In this section, we report tuned hyperparameter values. Due to the number of experiments, we do not report hyperparameter values for every experiment. We report hyperparameter values for classifiers that yields best performance in terms of AUC or AUPRC over the possible levels of data sampling we employ. Since RandomizedSearchCV employs stochastic techniques for discovering hyperparameters, it may discover different settings for hyperparameter values over 10 iterations of 5-fold cross validation. Therefore, we report the mode (most frequently occurring) value of hyperparameters that RandomizedSearchCV discovers.
If RandomizedSearchCV does not discover hyperparameter values different from a classifier’s default values, we do not report a table of hyperparameters for that classifier. For default values of MLP, NB, DT, LR, and RF classifiers’ hyperparameters please see the Scikit-learn classifier documentation Footnote 5, for XGBoost’s default hyperparameter values we refer to XGBoost documentation Footnote 6, for CatBoost default hyperparameter values we refer the reader to the CatBoost documentation Footnote 7, and for Light GBM default hyperparameter values, please consult their documentation Footnote 8.
Information theft hyperparameters
Information theft without ensemble feature selection
Here, we report hyperparameter values for classifiers that yield results we report in Tables 2, 3 and 4 (Tables 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70).
Information theft with ensemble feature selection
Here, we report hyperparameter values for classifiers that yield results we report in Tables 5 and 6 , after the application of ensemble FSTs (Tables 71, 72, 73, 74, 75 ).
Data exfiltration hyperparameters
Data exfiltration without ensemble feature selection
Here, we report hyperparameter values for classifiers that yield results we report in Tables 17, 18 and 19 (Tables 76, 77, 78, 79, 80, 81, 8283, 84, 85, 86, 87, ).
Data exfiltration with ensemble feature selection
Here, we report hyperparameter values for classifiers that yield results we report in Tables 20 and 21 , after the application of ensemble FSTs (Tables 88, 89, 90, 91, 92).
Keylogging hyperparameters
Keylogging without ensemble feature selection
Here, we report hyperparameter values for classifiers that yield results we report in Tables 32, 33 and 34 (Tables 93, 94, 95, 96, 97, 98, 99, 100, 101102, 103, 104).
Keylogging with ensemble feature selection
Here, we report hyperparameter values for classifiers that yield results we report in Tables 35 and 36 , after the application of ensemble FSTs (Tables 105, 106, 107, 108, 109).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Leevy, J.L., Hancock, J., Khoshgoftaar, T.M. et al. IoT information theft prediction using ensemble feature selection. J Big Data 9, 6 (2022). https://doi.org/10.1186/s40537-021-00558-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40537-021-00558-z