
Abstract
Background
The mutant allele (*2) of aldehyde dehydrogenase type 2 (ALDH2) caused by a single nucleotide variant (rs671) inhibits enzymatic activity and is associated with multiple diseases. In recent years, an explosive number of original studies and meta-analyses have been conducted to examine the associations of ALDH2 rs671 polymorphism with diseases. Due to conflicting results, the overall associations of ALDH2 rs671 polymorphism and multiple diseases remain unclear.
Methods
A quantitative umbrella review will be conducted on meta-analyses of genetic association studies to examine the pleiotropic effects of ALDH2 rs671, mainly including cardio-cerebral vascular disease, diabetes mellitus, cancer, neurodegenerative disease, and alcohol-induced medical disease. A search of relevant literature according to comprehensive search strategies will be performed on studies published before July 1st, 2022 in PubMed, MEDLINE Ovid, Embase, Cochrane Database of Systematic Reviews, and Web of Science. Study selection, data extraction, methodology quality assessment, and strength of evidence assessment will be conducted by two reviewers independently and in duplicate. Included meta-analyses will be grouped by outcomes. Data conflicts and overlap between meta-analyses will be managed through updated standardized and customized methods including the calculation of CCA for study selection reference, application of Doi plots to assess small-study effects and others. Evidence from included meta-analyses will be quantitatively synthesized by overlap-corrected analyses and meta-analysis using primary studies.
Discussion
This umbrella review is expected to generate systematic evidence on the association between ALDH2 rs671 and diseases. Specific approaches were developed to address key challenges in conducting an umbrella review, including assessment tools of methodology and evidence quality of meta-analyses, methods to manage overlap between meta-analyses, a “stop-light” plot to summarize key findings. These approaches provide applicable methods for future umbrella reviews of meta-analyses on genetic association studies.
Trial registration
CRD42021223812
Similar content being viewed by others

Background
Mitochondrial aldehyde dehydrogenase (aldehyde dehydrogenase type 2, ALDH2) belongs to the aldehyde dehydrogenase superfamily of proteins, which shows the highest affinity for acetaldehyde among enzymes oxidizing aldehydes [1, 2]. In the alcohol metabolism pathway, alcohol dehydrogenase oxidizes ethanol to acetaldehyde, and then ALDH2 catalyzed the oxidation of acetaldehyde to acetate, which is excreted to the blood and finally converted to CO2 [3]. Besides ethanol metabolism, ALDH2 is a key enzyme involved in the degradation of toxic reactive acetaldehydes, such as 4-hydroxy-2-nonenal (4-HNE) and malondialdehyde (MDA), into nontoxic acetic acid [4]. Apart from liver, ALDH2 is also expressed in multiple tissues that require high mitochondrial content, such as the heart, kidney, lung, and brain [5].
A common ALDH2 deficient allele (ALDH2*2, Glu504Lys) is caused by a single nucleotide polymorphism (SNP), which is a G to A mutation at codon 504 in exon 12 of ALDH2 gene located on chromosome 12q24 (rs671 G>A), resulting in the substitution of glutamate (Glu) with lysine (Lys) in subsequent translation process. Both heterozygous and homozygous ALDH2*2 carriers (ALDH2*1/*2 or ALDH2*2/*2) have enzymatically inactive ALDH2 [1, 6]. ALDH2*2 is largely limited to East Asian populations, affecting approximately 40% of East Asian populations (560 million) and 8% of global populations [7].
ALDH2 deficiency is a double-edged “sword”. Lacking functional ALDH2 enzyme causes rapid accumulation of acetaldehyde, resulting in facial flushing reactions in many east Asians [7]. On the one hand, flushing and dysphoria urge the carriers to drink less, reducing the risks of initiation and progression of alcohol-related diseases. On the other hand, local culture and social norms in certain regions still promote drinking despite this reaction, resulting in adverse health effects.
ALDH2 is activated by protein kinase C isotype–ε, and functions as a protector against oxidative stress and apoptosis [8]. Enzymatically inactivated ALDH2 causes accumulation of reactive aldehydes, generating reactive oxygen species, upregulating downstream enzymes involved in stress-response pathways activation, such as P38 mitogen-activated protein kinase [9] and AMP-dependent protein kinase [10], resulting in ischemic cardiomyopathy [10, 11], aberrant adipogenesis [12], and damage on nervous system [13, 14]. End products of non-oxidized acetaldehyde, such as 4-HNE and MDA, can easily diffuse through cell membranes, and may indirectly impact the nuclear genome via the formation of DNA and protein adducts, activating apoptosis pathways and driving oxidative stress-induced cell apoptosis [15, 16]. These mechanisms lead to pleiotropic associations of ALDH2 loss of function mutation with multiple disorders, including cardiovascular diseases, diabetes mellitus, neurodegenerative diseases, alcohol-induced pathophysiology, upper aerodigestive tract cancer, and pain, etc [17].
An explosive number of meta-analyses have been conducted on the associations of ALDH2 rs671 polymorphism with diseases, with increasing publication frequencies over the years and conflicting results [18,19,20,21,22,23,24,25,26,27,28,29]. Typically, these meta-analyses focused on single disease outcome such as hypertension, cardiovascular disease, or cancer, and showed both deleterious and protective associations of ALDH2 rs671 polymorphism with these diseases. These studies warrant synthesis of evidence to explore reasons for conflicts between results and to provide clarity to healthcare decision-makers and people affected by the deficiency of ALDH2.
Umbrella review (also known as overview of systematic reviews), is a publication type, emerging as the result of explosive growth of systematic reviews. It allows findings of separate reviews to be compared and contrasted, formulating a comprehensive but concise conclusion, providing decision-makers with the evidence they need [30]. In terms of the hierarchy of evidence synthesis methods, some consider umbrella reviews to be in the highest evidence level, superseding meta-analysis, systematic reviews, and individual studies [31]. The objective of this paper is to examine the pleiotropic associations between ALDH2 rs671 polymorphism with multiple disease outcomes, by conducting an umbrella review to quantitatively synthesize evidence from published meta-analyses of genetic association studies.
Methods
Our umbrella review will adhere to the PRISMA 2020 statement: an updated guideline for reporting systematic reviews [32]. Preferred Reporting Items for Systematic Reviews and Meta-analysis Protocols (PRISMA-P) checklist [33] was adopted to guide the development of this protocol. Our review protocol was registered with the International Prospective Register of Systematic Reviews (PROSPERO) (registration number CRD42021223812). Results of this umbrella review will be published in a peer-reviewed journal. Potential changes to the protocol will be described in the final umbrella review report.
In the following sections, we will refer to an umbrella review following Overviews of Reviews guidelines in the Cochrane Handbook for Systematic Reviews of Interventions [34] as a “Cochrane overview” [34]. Searches, study selection, data extraction, methodology quality assessment, and strength of evidence assessment will be conducted by two reviewers independently and in duplicate, with disagreements solved through discussion with a third reviewer.
Study selection
Study designs
A systematic review is defined as a review with clearly stated objectives, reported search strategy and sources searched, eligibility criteria, study selection process, and reproducible methods to identify, extract, and synthesize the findings of included primary studies.
Systematic reviews utilizing quantitative synthesis methods or mixed synthesis methods (both qualitative and quantitative methods) on evidence are eligible for inclusion. If a systematic review evaluated multiple genetic variants, it is eligible for inclusion if at least part of the data synthesis was performed on the association of ALDH2 rs671 polymorphism and disease. To be eligible for inclusion, the types of primary studies included in the review should be cohort, nested case-control, or case-control studies.
Population
Meta-analyses with case and control groups will be included. Cases are defined as patients with cardio-cerebral vascular disease, diabetes mellitus, cancer, neurodegenerative disease, or alcohol-induced medical disease, diagnosed by symptoms, physical examinations, or radiological examinations by qualified physicians, according to criteria suggested by clinical guidelines. Patients with self-reported diseases will be excluded. Controls are defined as healthy individuals, whose sources can be population-based or hospital-based.
Exposure
Meta-analyses examining ALDH2 rs671 polymorphism, genotyped by polymerase chain reaction, DNA microarrays, DNA sequencing, or other molecular biological techniques, will be included.
Comparator
The comparator is ALDH2 major allele, detected by methods above.
Outcomes
Outcomes of interest are susceptibility to the following diseases, which were formed through consultation of published narrative reviews [17] and preliminary searches.
-
1.
Cardio-cerebral vascular disease:
-
(1).
Essential hypertension
-
(2).
Coronary artery disease and myocardial infarction
-
(3).
Ischemic stroke
-
(1).
-
2.
Diabetic mellitus and diabetic retinopathy
-
3.
Cancer:
-
(1).
Esophageal cancer
-
(2).
Gastric cancer
-
(3).
Hepatocellular carcinoma
-
(4).
Pancreatic cancer
-
(5).
Colorectal cancer
-
(6).
Head and neck cancer
-
(7).
Breast cancer
-
(1).
-
4.
Neurodegenerative disease:
-
(1).
Alzheimer’s disease
-
(2).
Parkinson’s disease
-
(1).
-
5.
Alcohol-induced medical disease:
-
(1).
Alcoholic liver cirrhosis
-
(2).
Alcoholic pancreatitis
-
(1).
Language and publication status
Studies reported in English and published in peer-review journals are eligible for inclusion.
Through preliminary searches, we noticed discrepancies in the inclusion criteria regarding Hardy-Weinberg Equilibrium (HWE). Some meta-analyses excluded primary studies whose control groups departed from HWE [28], while others included these studies with or without sensitivity analysis in further statistical calculations [27, 29]. Currently, there are three procedures to address studies that depart from HWE in meta-analysis: (i) perform a sensitivity analysis by excluding studies that depart from HWE and studies without sufficient information to test for HWE; (ii) exclude studies with significant (P < 0.05, adjusting for multiple testing) deviation from HWE completely from meta-analysis; (iii) correct pooled OR and its variance to account for departure from HWE; of them, none of the procedures is clearly superior but procedure (i) is routinely adopted [35]. Thus, we will include meta-analysis that did not exclude primary studies whose control groups departed from HWE in the study selection stage, flag these studies and conduct sensitivity analyses.
A summary of the main study inclusion criteria is provided in Table 1.
Data source
The search strategy was developed based on reference to several meta-analyses on ALDH2 polymorphism and diseases found during preliminary searches [18,19,20,21,22,23,24,25,26,27,28,29]. Three groups of keywords were used to conduct the search: “ALDH2” group, “polymorphism” group, and “systematic review” group. Boolean rule “AND” was used between each group, while Boolean rule “OR” was used within each group. The “ALDH2” group included: ALDH2, ALDH-2, “ALDH 2”, “aldehyde dehydrogenase type 2”, “aldehyde dehydrogenase 2”, “aldehyde dehydrogenase-2”, “aldehyde dehydrogenase II”, “mitochondrial aldehyde dehydrogenase”, ALDM, “alcohol metabolism”. The “polymorphism” group included: polymorphism*, variation*, variant*, mutation*, genotype*, allele*, “single nucleotide polymorphism”, SNP, rs671, G487A, 487Lys, 504Lys, “ALDH2*2”. The “systematic review” group adopted the “Literature reviews and meta-analyses search filter for Ovid Medline” developed by the Quebec chapter of Canadian Health Libraries Association (ASTED 3S) [36], and was modified to fit with searching on each database. (Detailed search strategy in each database is outlined in Additional file 1.)
Searches will be conducted using MeSH terms combining with title/abstract keywords for studies published prior to July 1st, 2022 on five databases: PubMed, MEDLINE (Ovid interface), Embase, Cochrane Database of Systematic Reviews, and Web of Science. The literature search will be limited to English. Citation abstracts and full text of search results will be imported to EndNote software. After excluding duplicates, they will be screened based on study selection criteria. Systematic searches in the databases will be supplemented by the “snowballing” strategy, i.e., reference lists of retrieved full-text papers will be screened to avoid potential omissions. Prior to quantitative evidence synthesis, searches will be updated to the latest availability.
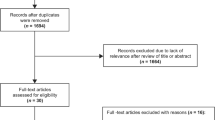
Titles and abstracts of search records will be scanned against criteria 1 to 5 in Table 1. Full texts of studies meeting these criteria will be further scanned against criteria 6 to 7 in Table 1. A flow diagram of the study selection process is outlined in Fig. 1.

Flow diagram of the study selection process
Data extraction
The following information at meta-analyses level (2-1 in Additional file 2) will be extracted: name of the first author, year of publication, exposure of interest, comparison, outcome of interest, total number of participants, number of primary studies, study design of primary studies, length of follow-up of primary studies (if applicable), quality assessment method for primary studies, pooled effect size (ES), confidence interval (CI) or standard error (SE), measurement of ES, meta-analyses method, p value of pooled ES, genetic model, and heterogeneity (Cochrane Q or I2 statistics). The following information at primary studies level (2-2 in Additional file 2) will be extracted in each meta-analysis: name of the first author, year of publication, ethnicity, study design, source of control, alcohol consumption status, sex, exposure of interest, comparison, precalculated ES, CI or SE, measurement of ES, genetic model, p value for HWE χ2 test.
Methodological quality assessment
The measurement tool to Assess the Methodological Quality of Systematic Reviews (AMSTAR) [37] is widely used by umbrella reviewers of quantitative systematic reviews. However, there are challenges for applying AMSTAR to rate. For instance, questions within the AMSTAR checklist are often multi-faceted, which complicates the rating process and implicates more subjective factors in the assessment [38]. In 2017, original developers of AMSTAR developed an updated measurement approach called a critical appraisal tool for systematic reviews that include randomized or non-randomized studies of healthcare interventions, or both (AMSTAR2), adapting to a more detailed assessment of systematic reviews with moves to extend AMSTAR to incorporate systematic reviews of observational studies [39]. Good reliability for most items on sample systematic reviews was reported [39]. Currently, no consensus has been made on which approach is clearly superior, but an ongoing study is being performed to assess these approaches [40].
AMSTAR2 is a 16-item checklist with 7 critical items, mainly for quality assessment of systematic reviews of health interventions [39]. It comprehensively evaluates the potential bias in search, study selection, data extraction, data presentation, risk assessment, statistical methods, and funding sources. For each item, the answer will be given as “yes”, “partial yes”, “no”, or “inapplicable”. It is not appropriate to generate a quality score when using AMSTAR/AMSTAR2 [38, 39]. Instead, rating overall confidence of each review will be graded as “high”, “moderate”, “low”, or “critically low” according to the number of critical flaws or non-critical weaknesses in these items [39]. To fit AMSTAR2 with meta-analyses of observational studies, we modified several items in AMSTAR2 checklist with the reference of AMSTAR [37], ROBIS [41], and quality assessment approaches for observational studies, such as Newcastle-Ottawa Scale (NOS) [42] and Strengthening the Reporting of Genetic Association studies (STREGA) [43]. (Modified AMSTAR2 and quality assessment table are in Additional file 3.)
No re-assessment on primary studies will be conducted. We will adopt the quality assessment approach and results performed by included meta-analyses’ authors.
Strength of evidence assessment
Grading of Recommendations Assessment, Development and Evaluation (GRADE) [44] is mainly adopted by umbrella review authors for assessing systematic reviews using quantitative synthesis methods. However, gaps remain in application of GRADE in systematic reviews [45]. For instance, the subjectivity associated with the application of each criterion of GRADE has been reported [38, 46]. Even among most experienced reviewers, reaching agreements on the overall strength of evidence can be difficult [46]. Efforts have been made to address these gaps, including proposal of a more algorithmic approach to judge quality of evidence based on GRADE [38, 47], clarification of factors considered in applying each criterion of GRADE [48], and development of Evaluating Strength of the Quantitative Evidence at the Level of an Umbrella Review [49].
Since the exposure evaluated is a SNP, nearly all included meta-analyses are based on evidence from observational studies. Consequently, applying GRADE will inherently start with a level of “low quality” [50]. This may result in a poor reflection of the evidence quality variations between reviews, since the quality of evidence of most reviews will be limited to “low” or “very low”. Meanwhile, since all included studies are meta-analyses, which are methodologically unified, utilizing statistical results, such as p value of pooled ES or range of CI, may result in a clear appraisal. Therefore, we decided to adopt the method for grading evidence of meta-analyses in several recent published umbrella reviews [51,52,53,54], which use the p value of Z-test on pooled ES as the main criterion for grading evidence (Additional file 4).
No re-assessment on primary studies will be conducted.
Data preparation
Before data synthesis, included meta-analyses will be grouped based on outcomes of interest. Meta-analyses reporting multiple outcomes will be categorized in the respective outcome group, deconstructed and evaluated separately, only on the outcomes of interest in the respective group.
For each meta-analysis, if precalculated ES for primary studies were not fully presented, or if the ES of primary studies for some of the genetic models were not calculated while there is sufficient individual participant data (number of cases and controls under each genotype) to conduct the calculation, individual participant data will be used to supplement the calculation. For each primary study without reporting whether the control group followed HWE, χ2 test (significant level alpha will be set at 0.05 level) will be used to measure whether the control group followed HWE. The results will be filled in the data extraction form (2-2 in Additional file 2).
Through preliminary searches, we discovered a substantial number of conflicts between the precalculated ES and CI on the same primary studies included in multiple meta-analyses. This may originate from errors in calculation or data extraction of included meta-analyses. Conflicts will be resolved according to the following pre-specified procedure: (i) first, ES will be recalculated using individual participant data to prevent calculation errors in each meta-analysis. (ii) If the error is caused by data extraction, or if there is no sufficient individual participant data presented in the meta-analyses, the primary study will be reviewed and data will be extracted. (2-3 in Additional file 2) The finalized individual participant data will be decided by comparison with the data extracted by each meta-analysis, and further discussions between reviewers. ES and CI will subsequently be calculated based on the finalized individual participant data. (iii) If there is no sufficient data presented in the primary study to calculate ES, the precalculated ES in the meta-analyses with the highest methodology quality will be adopted.
Managing overlap
Managing overlap between systematic reviews is significant in conducting umbrella reviews. Pieper et al.’s review of 60 umbrella reviews showed a substantial amount of duplicate primary studies in included reviews; however, only half of the authors addressed the overlap, while the rest disregarded this issue [55]. This may lead to underestimation of the overlap, since primary studies included in multiple reviews are calculated multiple times, resulting in disproportionate statistical power [55]. On the other hand, researchers need to be cautious of overestimation of overlap, when multiple reviews include the same primary study, but non-overlapping data is extracted from this study [55].
Based on Pieper et al.’s method, a citation matrix will first be presented, and the covered area (CA) and corrected covered area (CCA) will be calculated as measures of degree of overlap for each health outcome with multiple reviews included [55]. (Format of citation matrix and formula for CA and CCA are in Additional file 5)
In dealing with duplicate primary studies in quantitative umbrella reviews, early published studies chose to decrease the degree of overlap by removing part of the included meta-analyses based on completeness, recency, and methodological quality, which introduces bias of its own [56, 57]. In 2013, Munder et al. [58] reported a statistical method to deal with duplicate primary studies in their meta-meta-analysis and was further adopted by two other meta-meta-analyses [59, 60], which requires transforming ES to Fisher’s Z and calculating overlap-adjusted weight for each meta-analysis. (Detailed formulas and explanations are in Additional file 6) Preliminary searches indicated that most included meta-analyses used odds ratio as the measurement of the ES. Moreover, the method above did not consider the sample size of each primary study, which is highly related to the standard error of odds ratio, which determines the overlap-adjusted weight, of each meta-analysis. Thus, transforming the ES to Fisher’s Z and adopting the method above is not meaningful. To achieve a smaller overlap without removing too many primary studies, the corrected covered area (CCA) will be calculated for each disease after dropping one or more meta-analyses; the combination with the smallest CCA will be selected for further analyses if it drops the least number of primary studies compared with other combinations with similar CCA. When two meta-analyses include identical primary studies or one’s is completely a subset of another for certain outcomes, only the latest meta-analyses would be included. If the overlap management methods lead to only one meta-analysis for certain outcomes, the results of that meta-analysis would be directly used for those outcomes. For meta-analyses that include similar primary studies but focus on different features/aspects/subgroup analyses and others, we would still include them to ensure there is a sufficient number of meta-analyses to conduct the umbrella review on each of those different features/aspects/subgroup analyses [61].
According to Cochrane Handbook for Overviews, when it is possible for reviewers to avoid double-counting outcome data from overlapping reviews by ensuring that each primary study’s data is extracted only once, reviewers should include all relevant reviews and follow this approach, though it is time-intensive and methodologically complex [34]. We define the criteria for correcting overlap in quantitative synthesis as ensuring all primary studies in all relevant meta-analyses are included, and ensuring data from each primary study is extracted only once.
Quantitative synthesis
Calculations will be conducted based on available data assuming the following genetic models: allelic (A vs. G), dominant (AG + AA vs. GG), heterozygous (AG vs. GG), homozygous (AA vs. GG), and recessive (AA vs. GG + AG).
Overlap-corrected analysis
For each outcome, if more than one meta-analysis is included, overlap between meta-analyses will be corrected based on a formed procedure. If a certain meta-analysis which included all primary studies that were included in other meta-analyses existed, and if these meta-analyses extracted identical data from these primary studies, which is considered as a “complete overlapping” meta-analysis, pooled ES and CI of this meta-analysis will be adopted as overlap-corrected results. Otherwise, precalculated ES and CI of all primary studies being included in all meta-analyses will be used to conduct a meta-analysis under each genetic model, ensuring that each primary study is counted only once. As described in the previous section, similar studies with different features/aspects/subgroup analyses and others will be kept if previous overlap managing steps leave too few studies for meta-analyses. Precalculated ES and CI will be converted to Log Odds Ratio (Log_OR) and SE of Log_OR (formula is in Additional file 7). Heterogeneity and inconsistency across meta-analyses will be investigated and measured using Cochran’s Q test [62] and I2 test [63] respectively. A random effects model (Hartung-Knapp-Sidik-Jonkman adjustment method) [64] will be adopted for all outcomes to account for heterogeneity between studies and allow the effect estimates generalizing to target populations. Sensitivity analysis will be performed on primary studies whose control group deviate from HWE, or information of whether the control group followed HWE or not is unavailable. Funnel plots [65], Egger’s tests [66], Doi Plot [67], and LFK index [67] will be performed to assess the small-study effects of included primary studies. To assess the possible presence of small-study effects, sensitivity analysis will be performed by sequentially dropping one inter-study at a time to detect the impact of each inter-study on pooled ES. Subgroup analysis will be performed to explore possible sources of heterogeneity, and will be conducted based on available subgroup individual participant data or precalculated ES of primary studies on meta-analyses level. Primary studies will be stratified by ethnicity, gender, alcohol consumption, and source of control under each genetic model. Strength of each finding will be graded based on the “Strength of evidence assessment” procedure. A cumulative meta-analysis, ranked by year, will be performed to detect small-study effects.
Meta-analysis using primary studies
Subsequently, primary studies included by the eligible meta-analyses will be identified and used as a unit of analysis to perform an extensive meta-analysis and provide estimates on ALDH2’s ALDH2*2 allele’s effect towards multiple diseases. All primary studies will be included only once to prevent overlap.
Assessment of risk of bias will also be applied. Funnel plots [65], Egger’s tests [66], Doi plot and LFK index [67] will be performed to assess the small-study effects of included primary studies.
For each outcome, pooled ES and CI of included primary studies will be transformed to Log Odds Ratio (Log_OR) and SE of Log_OR. Heterogeneity across primary studies will be investigated and measured using Cochran’s Q test [62] and I2 test [63]. A random effects model (Hartung-Knapp-Sidik-Jonkman adjustment) [64] will be adopted for all outcomes.
Data presentation
Under each genetic model, to briefly summarize and present the results of included meta-analyses, pooled ES and CI will be presented as a “stop-light” plot [30] on the overall effects of ALDH2 rs671 polymorphism and diseases risks. Pooled ES and CI of all outcomes of interest calculated during the overlap-corrected analysis will be presented as a “stop-light” plot [30]. In the plot, outcomes which ALDH2 polymorphism has a higher disease risk will be filled with “red”, while the corresponding colors for a lower risk of disease and no effect (statistically insignificance) are “green” and “yellow”.
All statistical calculations will be conducted with R (R Foundation for Statistical Computing, Vienna, Austria, version 4.1.2), and R package “metafor” [68].
Methodology summary
As a relatively new and emerging method for synthesizing evidence, gold standard guidance for conducting umbrella reviews is currently lacking, and challenges have been reported on umbrella review methods [45, 69]. We identified several challenges that have not been fully addressed in previous umbrella reviews, developed and refined several approaches, and will apply them in our umbrella review:
-
(i)
Quality assessment: to fit quality assessment approaches for meta-analyses including observational studies, we specified and modified AMSTAR2 [39], and selected a checklist (Additional file 3), to assess methodological quality and grade strength of evidence.
-
(ii)
Missing data and data conflicts: to supplement potential missing or not fully presented results in a certain meta-analysis, when there is sufficient individual participant data in the meta-analysis for us to conduct the calculation, we will supplement the calculation, which results will subsequently be adopted in quantitative synthesis. To solve data conflicts on a primary study between multiple meta-analyses, a sequential procedure was developed by recalculating odds ratio and CI using individual participant data, re-extracting data on primary study level, and deciding by quality assessment results.
-
(iii)
Managing overlap: to report the degree of overlap between included meta-analyses, we will conduct citation matrices of primary studies and report CA, CCA [55]. For each disease, the combination with the smallest CCA will be selected for further analyses unless too few studies are left; under such condition, similar studies with different features will be included to ensure the feasibility of meta-analyses. To deal with overlap between meta-analyses and reduce bias of pooled ES, precalculated ES and CI of all primary studies included in all meta-analyses will be used to reconduct a meta-analysis as the overlap-corrected results, and data of each primary study will be ensured to be counted only once.
-
(iv)
Summarizing key findings in a brief assessable format: “stop-light” plots [30] will be presented on results of all included meta-analyses, and on findings calculated during overlap-corrected analysis.
Discussion
This umbrella review will systematically review the pleiotropic associations between ALDH2 rs671 polymorphism and multiple diseases. Understanding the associations between ALDH2 polymorphism and diseases will help decision-makers in frontline healthcare pay special attention and propose targeted prevention plans for populations with ALDH2 deficiency, constituting approximately 560 million populations. Synthesizing evidence from existing meta-analyses helps to resolve controversial results benefiting from a larger statistical power, providing a comprehensive and concise conclusion. Several challenges in conducting umbrella reviews have been addressed in our protocol, which will at least provide an applicable approach for future umbrella reviews of meta-analyses of genetic association studies for pertinent gene-disease associations.
We acknowledge several limitations in our study. Populations of primary studies stemming from a same dataset may have some extent of overlap. For instance, two primary studies included in different meta-analysis might be case-control studies utilizing the same case group. Since we will not extract data on primary studies level, it may not be possible to detect the overlapping populations in primary studies. But we anticipate these circumstances are relatively rare and the impact of which can be degraded by a large statistical power of all primary studies included. Population stratification cannot be addressed with single variant data; however, based on pilot studies, majority of the studies were conducted in east and south Asian populations; thus, we anticipate the effects of population stratification are small. Other limitations are that language of included studies is limited to English, which might lead to language bias, no updates on primary studies not included in published meta-analyses are planned, and that potential small-study effects due to inclusion of only peer-reviewed journal.
Availability of data and materials
Not applicable.
Abbreviations
- ALDH2:
-
Aldehyde dehydrogenase type 2
- 4-HNE:
-
4-hydroxy-2-nonenal
- MDA:
-
Malondialdehyde
- ALDH2*2:
-
Aldehyde dehydrogenase type 2 deficient allele
- Glu504Lys:
-
Aldehyde dehydrogenase type 2 deficient allele
- SNP:
-
Single nucleotide polymorphism
- rs671 G>A:
-
a G to a mutation at codon 504 in exon 12 of aldehyde dehydrogenase type 2 gene located on chromosome 12q24
- Glu:
-
Glutamate
- Lys:
-
Lysine
- PRISMA:
-
Preferred Reporting Items for Systematic Review and Meta-analysis
- PRISMA-P:
-
Preferred Reporting Items for Systematic Reviews and Meta-analysis Protocols
- PROSPERO:
-
International Prospective Register of Systematic Reviews
- HWE:
-
Hardy-Weinberg Equilibrium
- ES:
-
Effect size
- CI:
-
Confidence interval
- SE:
-
Standard error
- AMSTAR:
-
The Measurement Tool to Assess the Methodological Quality of Systematic Reviews
- AMSTAR2:
-
a Critical Appraisal Tool for Systematic Reviews that Include Randomized or Non-randomized Studies of Healthcare Interventions, or Both
- NOS:
-
Newcastle-Ottawa Scale
- STREGA:
-
STrengthening the REporting of Genetic Association studies
- GRADE:
-
Grading of Recommendations Assessment, Development and Evaluation
- CA:
-
Covered area
- CCA:
-
Corrected covered area
- Log_OR:
-
Log odds ratio
References
Yoshida A, Hsu LC, Yasunami M. In: Cohn WE, Moldave K, editors. Genetics of human alcohol-metabolizing enzymes, in progress in nucleic acid research and molecular biology: Academic Press; 1991. p. 255–87.
Marchitti SA, et al. Non-P450 aldehyde oxidizing enzymes: the aldehyde dehydrogenase superfamily. Expert Opin Drug Metab Toxicol. 2008;4(6):697–720.
Zakhari S. Overview: how is alcohol metabolized by the body? Alcohol Res Health. 2006;29(4):245–54.
O'Brien PJ, Siraki AG, Shangari N. Aldehyde sources, metabolism, molecular toxicity mechanisms, and possible effects on human health. Crit Rev Toxicol. 2005;35(7):609–62.
Stewart MJ, Malek K, Crabb DW. Distribution of messenger RNAs for aldehyde dehydrogenase 1, aldehyde dehydrogenase 2, and aldehyde dehydrogenase 5 in human tissues. J Invest Med. 1996;44(2):42–6.
Lai C-L, et al. Dominance of the inactive asian variant over activity and protein contents of mitochondrial aldehyde dehydrogenase 2 in human liver. Alcoholism. 2014;38(1):44–50.
Li H, et al. Refined geographic distribution of the oriental ALDH2*504Lys (nee 487Lys) variant. Ann Human Genet. 2009;73(3):335–45.
Ohta S, Ohsawa I, Kamino K, Ando F, Shimokata H. Mitochondrial ALDH2 deficiency as an oxidative stress. Mitochondrial Pathogenesis: Springer; 2004. p. 36–44.
Xu D, et al. Mitochondrial aldehyde dehydrogenase attenuates hyperoxia-induced cell death through activation of ERK/MAPK and PI3K-Akt pathways in lung epithelial cells. Am J Physiol Lung Cell Mole Physiol. 2006;291(5):L966–75.
Ma H, et al. Aldehyde dehydrogenase 2 (ALDH2) rescues myocardial ischaemia/reperfusion injury: role of autophagy paradox and toxic aldehyde. Eur Heart J. 2011;32(8):1025–38.
Chen C-H, et al. Activation of aldehyde dehydrogenase-2 reduces ischemic damage to the heart. Science. 2008;321(5895):1493.
Yu Y-H, et al. PKC-ALDH2 pathway plays a novel role in adipocyte differentiation. PLoS One. 2016;11(8):e0161993.
Guo J-M, et al. ALDH2 protects against stroke by clearing 4-HNE. Cell Res. 2013;23(7):915–30.
Zuo G, et al. Activation of TGR5 with INT-777 attenuates oxidative stress and neuronal apoptosis via cAMP/PKCε/ALDH2 pathway after subarachnoid hemorrhage in rats. Free Radical Biol Med. 2019;143:441–53.
Brooks PJ, Zakhari S. Acetaldehyde and the genome: Beyond nuclear DNA adducts and carcinogenesis. Environ Mole Mutagenesis. 2014;55(2):77–91.
Song B-J, et al. Post-translational modifications of mitochondrial aldehyde dehydrogenase and biomedical implications. J Proteomics. 2011;74(12):2691–702.
Chen C-H, et al. Targeting Aldehyde Dehydrogenase 2: New Therapeutic Opportunities. Physiol Rev. 2014;94(1):1–34.
Jia K, Wang H, Dong P. Aldehyde dehydrogenase 2 (ALDH2) Glu504Lys polymorphism is associated with hypertension risk in Asians: a meta-analysis. Int J Clin Exp Med. 2015;8(7):10767–72.
Wu Y, et al. Positive association between ALDH2 rs671 polymorphism and essential hypertension: A case-control study and meta-analysis. PLoS One. 2017;12(5):e0177023.
Zhang SY, et al. Meta-analysis of association between ALDH2 rs671 polymorphism and essential hypertension in Asian populations. Herz. 2015;40(Suppl 2):203–8.
Xu Y-L, et al. Aldehyde dehydrogenase 2 rs671G > A polymorphism and ischemic stroke risk in Chinese population: a meta-analysis. Neuropsychiatric Dis Treatment. 2019;15:1015–29.
Liu H, et al. Association between ALDH2 gene polymorphism and late-onset Alzheimer disease: an up-to-date meta-analysis. Curr Alzheimer Res. 2020;17(2):105–11.
Li D, Zhao H, Gelernter J. Strong protective effect of the aldehyde dehydrogenase gene (ALDH2) 504lys (*2) allele against alcoholism and alcohol-induced medical diseases in Asians. Hum Genet. 2012;131(5):725–37.
Li G-Y, Li Z-B, Li F, Dong L-P, Tang L, Xiang J, et al. Meta-analysis on the association of ALDH2 polymorphisms and type 2 diabetic mellitus, diabetic retinopathy. Int J Environ Res Public Health. 2017;14(2):165.
Zuo W, et al. Effect of ALDH2 polymorphism on cancer risk in Asians: A meta-analysis. Medicine (Baltimore). 2019;98(13):e14855.
Cai Q, et al. Association between Glu504Lys polymorphism of ALDH2 gene and cancer risk: a meta-analysis. PLoS One. 2015;10(2):e0117173.
Lan X, et al. Assessing the effects of the percentage of chronic disease in households on health payment-induced poverty in Shaanxi Province, China. BMC Health Serv Res. 2018;18(1):871.
Mei X-F, et al. ALDH2 Gene rs671 Polymorphism May Decrease the Risk of Essential Hypertension. Int Heart J. 2020;61(3):562–70.
Zheng Y, et al. Association Between ALDH-2 rs671 and Essential Hypertension Risk or Blood Pressure Levels: A Systematic Review and Meta-Analysis. Front Genet. 2020;11:685.
Aromataris E, et al. Summarizing systematic reviews: methodological development, conduct and reporting of an umbrella review approach. Int J Evid Based Healthc. 2015;13(3):132–40.
Fusar-Poli P, Radua J. Ten simple rules for conducting umbrella reviews. Evid Based Mental Health. 2018;21(3):95–100.
Page MJ, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372:n71.
Shamseer L, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015: elaboration and explanation. BMJ. 2015;349:g7647.
Pollock M, Fernandes RM, Becker LA, Pieper D, Hartling L. Chapter V: Overviews of Reviews. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. Cochrane Handbook for Systematic Reviews of Interventions version 6.3 (updated February 2022). Cochrane. 2022. Available from www.training.cochrane.org/handbook.
Zintzaras E, Lau J. Synthesis of genetic association studies for pertinent gene–disease associations requires appropriate methodological and statistical approaches. J Clin Epidemiol. 2008;61(7):634–45.
Mahée L. Literature reviews and meta-analyses search filter. 2018. https://extranet.santecom.qc.ca/wiki/!biblio3s/doku.php?id=concepts:revues-de-la-litterature-et-meta-analyses. Assessed 1 June 2022.
Shea BJ, et al. Development of AMSTAR: a measurement tool to assess the methodological quality of systematic reviews. BMC Med Res Methodol. 2007;7:10.
Pollock A, Farmer SE, Brady MC, Langhorne P, Mead GE, Mehrholz J, et al. Interventions for improving upper limb function after stroke. Cochrane Database Syst Rev. 2014(11).
Shea BJ, et al. AMSTAR 2: a critical appraisal tool for systematic reviews that include randomised or non-randomised studies of healthcare interventions, or both. BMJ. 2017;358:j4008.
Gates A, et al. Evaluation of the reliability, usability, and applicability of AMSTAR, AMSTAR 2, and ROBIS: protocol for a descriptive analytic study. Syst Rev. 2018;7(1):85.
Whiting P, et al. ROBIS: A new tool to assess risk of bias in systematic reviews was developed. J Clin Epidemiol. 2016;69:225–34.
Stang A. Critical evaluation of the Newcastle-Ottawa scale for the assessment of the quality of nonrandomized studies in meta-analyses. Eur J epidemiol. 2010;25(9):603–5.
Little J, et al. STrengthening the REporting of Genetic Association studies (STREGA)--an extension of the STROBE statement. Eur J Clin Invest. 2009;39(4):247–66.
Guyatt GH, et al. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ. 2008;336(7650):924.
Pollock A, et al. Selecting and implementing overview methods: implications from five exemplar overviews. Syst Rev. 2017;6(1):145.
Berkman ND, et al. Interrater reliability of grading strength of evidence varies with the complexity of the evidence in systematic reviews. J Clin Epidemiol. 2013;66(10):1105–1117.e1.
McClurg D, et al. Conservative interventions for urinary incontinence in women: an Overview of Cochrane systematic reviews. Cochrane Database Syst Rev. 2016;2016(9):CD012337.
Grgic J, et al. Wake up and smell the coffee: caffeine supplementation and exercise performance—an umbrella review of 21 published meta-analyses. Bri J Sports Med. 2020;54(11):681.
Antonio MG, P.O, Lau F. The state of evidence in patient portals: umbrella review. J Med Internet Res. 2020;22(11):e23851.
Guyatt G, et al. GRADE guidelines: 1. Introduction—GRADE evidence profiles and summary of findings tables. J Clin Epidemiol. 2011;64(4):383–94.
Bortolato B, et al. Systematic assessment of environmental risk factors for bipolar disorder: an umbrella review of systematic reviews and meta-analyses. Bipolar Disord. 2017;19(2):84–96.
Solmi M, et al. Environmental risk factors and nonpharmacological and nonsurgical interventions for obesity: an umbrella review of meta-analyses of cohort studies and randomized controlled trials. Eur J Clin Invest. 2018;48(12):e12982.
Solmi M, Radua J, Stubbs B, Ricca V, Moretti D, Busatta D, et al. Risk factors for eating disorders: an umbrella review of published meta-analyses. Braz J Psychiatry. 2020;43:314–23.
Veronese N, et al. Dietary fiber and health outcomes: an umbrella review of systematic reviews and meta-analyses. Am J Clin Nutr. 2018;107(3):436–44.
Pieper D, et al. Systematic review finds overlapping reviews were not mentioned in every other overview. J Clin Epidemiol. 2014;67(4):368–75.
Grissom RJ. The magical number. 7±. 2: Meta-meta-analysis of the probability of superior outcome in comparisons involving therapy, placebo, and control. J Consult Clin Psychol. 1996;64(5):973.
Cooper H, Koenka AC. The overview of reviews: unique challenges and opportunities when research syntheses are the principal elements of new integrative scholarship. Am Psychol. 2012;67(6):446.
Munder T, et al. Researcher allegiance in psychotherapy outcome research: an overview of reviews. Clin Psychol Rev. 2013;33(4):501–11.
Weber L, et al. Treatment of child externalizing behavior problems: A comprehensive review and meta–meta-analysis on effects of parent-based interventions on parental characteristics. Eur Child Adolesc Psychiatry. 2019;28(8):1025–36.
Mingebach T, et al. Meta-meta-analysis on the effectiveness of parent-based interventions for the treatment of child externalizing behavior problems. PloS One. 2018;13(9):e0202855.
Lunny C, et al. Managing overlap of primary study results across systematic reviews: practical considerations for authors of overviews of reviews. BMC Med Res Methodol. 2021;21(1):140.
Cochran WG. The comparison of percentages in matched samples. Biometrika. 1950;37(3/4):256–66.
Higgins JPT, Thompson SG. Quantifying heterogeneity in a meta-analysis. Stat Med. 2002;21(11):1539–58.
IntHout J, Ioannidis JPA, Borm GF. The Hartung-Knapp-Sidik-Jonkman method for random effects meta-analysis is straightforward and considerably outperforms the standard DerSimonian-Laird method. BMC Med Res Methodol. 2014;14(1):25.
Light RJ, Pillemer DB. Summing up; the science of reviewing research; 1984.
Egger M, et al. Bias in meta-analysis detected by a simple, graphical test. BMJ. 1997;315(7109):629–34.
Furuya-Kanamori L, Barendregt JJ, Doi SAR. A new improved graphical and quantitative method for detecting bias in meta-analysis Int J Evid Based Healthc. 2018;16(4):195–203.
Viechtbauer W. Conducting meta-analyses in R with the metafor Package. J Stat Software. 2010;36(3):1–48.
Hunt H, et al. An introduction to overviews of reviews: planning a relevant research question and objective for an overview. Syst Rev. 2018;7(1):39.
Acknowledgements
Not applicable.
Funding
The research results of this article (or publication) are sponsored by the Kunshan Municipal Government research funding. Grant number is not applicable. The financial provider will not be involved in any other aspect of the review, such as planning the design, data collection, analyses, or interpretation of the results.
Author information
Authors and Affiliations
Contributions
LY is the supervisor of this review. PT is a context expert and provided critical suggestions on refining the review design. ZH, XJ, and LY developed the idea for this review. All authors contributed to the development of the selection criteria. ZH and LY developed the search strategy. QG and YL validated the search strategy. ZH and QG conducted preliminary searches and scans. ZH developed the method for quality assessment and data extraction forms, which were validated by QG. ZH, XJ, and LY developed the method for managing overlap and data synthesis, which were validated by ZH and YL. CH provided crucial advice on revising the management of overlap and data synthesis. ZH drafted the manuscript. ZH and YL redrafted the manuscript based on reviewers’ feedback. YL and QG revised the manuscript based on reviewer's comments. All authors read, provided feedback, and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1.
Search strategy in each database.
Additional file 2.
Data extraction sheet.
Additional file 3.
Methodology quality assessment checklist.
Additional file 4.
Evidence strength assessment checklist.
Additional file 5.
Pieper’s method of reporting overlap between systematic reviews.
Additional file 6.
Munder’s method [1] for statistically managing overlap between meta-analyses.
Additional file 7.
Formula for effect size transformation.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
He, Z., Guo, Q., Ling, Y. et al. Aldehyde dehydrogenase 2 rs671 polymorphism and multiple diseases: protocol for a quantitative umbrella review of meta-analyses. Syst Rev 11, 185 (2022). https://doi.org/10.1186/s13643-022-02050-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13643-022-02050-y