
Abstract
Background
This study aimed to screen multiple genes biomarkers based on gene expression data for predicting the survival of ovarian cancer patients.
Methods
Two microarray data of ovarian cancer samples were collected from The Cancer Genome Atlas (TCGA) database. The data in the training set were used to construct Reactome functional interactions network, which then underwent Markov clustering, supervised principal components, Cox proportional hazard model to screen significantly prognosis related modules. The distinguishing ability of each module for survival was further evaluated by the testing set. Gene Ontology (GO) functional and pathway annotations were performed to identify the roles of genes in each module for ovarian cancer.
Results
The network based approach identified two 7-gene functional interaction modules (31: DCLRE1A, EXO1, KIAA0101, KIN, PCNA, POLD3, POLD2; 35: DKK3, FABP3, IRF1, AIM2, GBP1, GBP2, IRF2) that are associated with prognosis of ovarian cancer patients. These network modules are related to DNA repair, replication, immune and cytokine mediated signaling pathways.
Conclusions
The two 7-gene expression signatures may be accurate predictors of clinical outcome in patients with ovarian cancer and has the potential to develop new therapeutic strategies for ovarian cancer patients.
Similar content being viewed by others


Background
Ovarian cancer is the most common lethal gynecologic malignancy in women worldwide, with an estimated 22,280 newly diagnosed cases and approximately 14,240 deaths in 2016 in the United States [1]. Due to the lack of specific symptoms and effective screening tests, approximately 70 % of ovarian cancer patients have been in advanced-stage (stage III or IV) when they are firstly diagnosed, leading to the 5-year survival rate of less than 30 % [2]. By contrast, patients who are diagnosed with early-stage (stage I or II) have a 5-year survival rate of up to 70–90 % [2]. These data indicate the importance to identify the sensitive biomarkers to early distinguish the patients with different prognosis, aiming to determine optimal treatment strategies.
In the past years, remarkable achievements have been obtained in the investigation of prognostic markers for ovarian cancer. For instance, a 10-gene signature (AEBP1, COL11A1, COL5A1, COL6A2, LOX, POSTN, SNAI2, THBS2, TIMP3, and VCAN) has been validated to be associated with poor overall survival in patients with high-grade serous ovarian cancer [3]. The presence of a BRCA1 or BRCA2 mutation is associated with a better prognosis in patients with invasive ovarian cancer [4]. A recent study has found that suppression of ABHD2 in OVCA420 cells increased phosphorylated p38 and ERK, platinum resistance, and side population cells, promoting a malignant phenotype and poor prognosis in serous ovarian cancer [5]. Furthermore, CD73 enhances ovarian tumor cell growth and expression of antiapoptotic BCL-2 family members, indicating a role of CD73 as a prognostic marker of patient survival in high-grade serous ovarian cancer [6]. Although the aforementioned genes have been shown to be correlated with the prognosis in ovarian cancer, their prognostic accuracy may be limited because the development of disease usually involves several genes and the interaction between them to form a complex pathway. Therefore, it is necessary to identify gene networks and pathways including multiple genes and their interactions, which can be achieved by Reactome functional interaction (FI) network construction as described previously [7, 8].
In the present study, we aimed to construct the Reactome FIs network to analyze the gene signatures that was significantly related to ovarian cancer patient survival based on gene expression profiling data extracted from The Cancer Genome Atlas (TCGA) database.
Methods
As the paper did not involve any human or animal, the ethical approval was not required.
Gene expression data
Two gene expression datasets with their corresponding clinical data (including survival status and time) for ovarian cancer samples were downloaded from TCGA database (https://tcga-data.nci.nih.gov/tcga). Data of one gene expression dataset were produced from the BI-HT-HG-U133A platform, in which 536 samples were included and 12042 genes were expressed in each sample (defined as BI). The other gene expression profiling from 559 ovarian cancer patients was produced from the UNC-AgilentG4502A-07-3 microarray platform, in which 17814 genes were included (defined as U3). These two datasets were randomly divided into training (BI) or testing sets (U3).
Construction of Reactome FI network
The annotated FIs were extracted from five pathway databases, including Reactome [9], kyoto encyclopedia of genes and genomes (KEGG) [10], protein annotation through evolutionary relationship (Panther) [11], The Cancer Cell Map (http://cancer.cellmap.org/), and NCI Pathway Interaction Database (NCI-PID) [12]. The protein FIs were predicted by physical protein-protein interactions (PPIs) in human organisms (catalogued in the Biological General Repository for Interaction Datasets (BioGrid) [13], the Human Protein Reference Database (HPRD) [14] and IntACT [15]), model organisms (from IntAct [15] based on Ensembl Compara [16]), and protein domain–domain interactions (from PFam [17]). The naive Bayes classifier, a simple machine learning method [18], was used to score the probability that a protein pair-wise relationship reflects a functional pathway event, during which the annotated FIs were selected as positive training sets, whereas the predicted FIs were defined as negative training sets. Subsequently, the gene expression data of BI from the TCGA were mapped into the constructed Reactome FIs via co-expression relationships (calculated by Pearson correlation) to distribute the weight of each edge.
Markov clustering (MCL)
The gene/protein correlations in the Reactome FI network were input into the Reactome FI Cytoscape plugin (MCL) [7] to generate a sub-network for a list of selected network modules based on module size (≥7) and average correlation (Pearson correlation coefficient ≥0.25). To control the size of network modules generated from the MCL clustering, the inflation coefficient was set as 5.0.
Analysis of prognosis-related modules
The prognosis-related modules were further predicted based on the supervised principal components (superpc) [19] using the Superpc V1.05 software package under the programming environment R (http://statweb.stanford.edu/~tibs/superpc/). A module-based gene expression matrix was generated by using mean expression level of genes in each module across 536 ovarian cancer samples, and then underwent the superpc analysis. A 10-fold cross-validation curve was performed for estimating the best threshold. In addition, Cox proportional hazard (PH) model was also performed to correlate each module with survival data (p < 0.05), followed by Kaplan-Meier analysis to demonstrate the distinguishing ability of each module for survival.
Gene Ontology (GO) functional and pathway annotations
The genes in prognosis-related modules were subjected to the GO and pathway enrichment analyses to identify their roles in ovarian cancer. GO and pathway functional annotations were conducted for the survival-associated genes using the Reactome FI plug-in of Cytoscape [20]. False discovery rate (FDR) < 0.05 was used for a threshold to assess the statistical significance.
Results
Data information
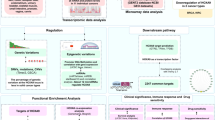
Two datasets [BI-HT-HG-U133A (BI), and UNC-AgilentG4502A-07-3(U2)] were obtained from TCGA. The BI dataset contained 536 samples, and expression data of 12042 genes were included in each sample. The U2 dataset contained 559 samples, and expression data of 17814 genes were included in each sample. In this study, BI was used as the training dataset, and U2 was used as the test dataset (Fig. 1).

The flow chart of the whole analysis in this study
Analysis of the FI network and modules
Based on the BI dataset, a weighted FI network including 710 proteins and 9516 interactions were constructed. Subsequently, using MCL network clustering, a total of 41 modules were obtained, and the number of genes in each module ranged from 7 to 118. Furthermore, using the Superpc package with a threshold value of 0.73, 14 prognosis-related modules were identified from the 41 modules (Table 1). Afterwards, 6 significant modules (modules 6, 8, 20, 26, 31 and 35) with the p-value < 0.05 were identified from the 14 modules based on the Cox PH analysis (Table 2). These 6 modules were validated by the U2 dataset, and two modules (modules 31 and 35) were also significant in the U2 dataset. Thus, modules 31 and 35 were further analyzed.
Analysis of modules 31 and 35
A set of 7 genes (DCLRE1A, EXO1, KIAA0101, KIN, PCNA, POLD3, POLD2) were included in the module 31 (Fig. 2a), and 7 genes (DKK3, FABP3, IRF1, AIM2, GBP1, GBP2, IRF2) were included in the module 35 (Fig. 2b). Kaplan-Meier plot demonstrated that the gene expression in these two modules can significantly distinguish the patients with longer and shorter survivals (Fig. 3).

Kaplan-Meier survival plot for the module 31 (a) and 35 (b). All samples were divided into two groups based on the median value of gene expression in modules. The green curve is for samples having lower expression, while the red curve for samples having higher expression

Genes and interaction relationship in the module 31 (a) and 35 (b). The arrow indicates the co-expression relationship and known pathway regulatory relationship; the dotted line indicates the newly predicted interaction; the full line indicates the common complex
To further investigate the biological functions of the genes in modules 31 and 35, GO and pathway annotations were performed. The genes in module 31 were mainly related to the functions of DNA repair, DNA replication and cell cycle (Fig. 4). The genes in module 35 were significantly associated with functions about immune and cytokine or interferon mediated signaling pathways (Fig. 5).

GO functional and KEGG pathway enrichment analyses of the genes in the module 31. MF, CC and BP are the three categories of the GO functional enrichment analysis. GO Gene Ontology, KEGG Kyoto Encyclopedia Of Genes And Genomes, BP biological process, CC cellular component, MF molecular function

GO functional and KEGG pathway enrichment analyses of the genes in the module 35. MF, CC and BP are the three categories of the GO functional enrichment analysis. GO Gene Ontology, KEGG Kyoto Encyclopedia Of Genes And Genomes, BP biological process, CC cellular component, MF molecular function
Discussion
In this study, a total of 41 modules were obtained from the FI network based on the expression data in the BI dataset. Using MCL network clustering, superpc modeling and Cox PH analysis, two modules, modules 31 and 35, were identified to be significantly associated with prognosis of ovarian cancer patients. Seven genes were included in the two modules (31: DCLRE1A, EXO1, KIAA0101, KIN, PCNA, POLD3, POLD2; 35: DKK3, FABP3, IRF1, AIM2, GBP1, GBP2, IRF2). Furthermore, the genes in module 31 were related to DNA repair or replication, whereas the genes in module 35 were associated with immune and cytokine interferon mediated signaling pathways.
DCLRE1, also known as SNM1A, belongs to a member of a small gene family that is characterized by a metallo-β-lactamase fold and an appended β-CASP domain that together are proposed to function as a DNA endonuclease to participate in DNA inter-strand cross-link repair [21]. DNA cross-link repair is beneficial to maintain genomic stability and enables cells to survive DNA damage, contributing to less risk of tumorigenesis [22]. However, recent studies indicate that the high efficiency of DNA cross-link repair may also promote the excessive proliferation of cells, driving tumor initiation and progression [23–25]. Thus, down-regulation of DNA repair genes may be a promising target for anticancer therapy [26], which has been demonstrated by the study of Wu et al. [27]. Wu et al. have found that DCLRE1A is significantly decreased by bufalin, which promotes lung cancer apoptosis [27]. In addition, inhibition of DNA cross-link repair was also proved to reverse treatment resistance and improve the therapeutic efficacy [28].
EXO1 encodes exonuclease and plays important roles in mismatch repair by resecting the damaged strand. Similar to DCLRE1A, Exo1 is also shown to be higher expressed in tumor tissues than that in the normal tissues [29, 30]. A previous study has demonstrated that FOXM1 facilitates DNA repair through regulating direct transcriptional target EXO1 to protect ovarian cancer cells from cisplatin-mediated apoptosis, and attenuating EXO1 expression by small interfering RNA augments the cisplatin sensitivity of ovarian cancer cells [31]. POLD2 or POLD3 are both the subunits of DNA polymerase delta that possesses both polymerase and 3′ to 5′ exonuclease activity and plays a critical role in DNA replication and repair [32]. POLD2 was found to be increased in average 2.5- to almost 20-fold in moderately and poorly differentiated serous carcinomas of epithelial ovarian cancer, eventually leading to poor prognosis [33].
Furthermore, proliferating cell nuclear antigen (PCNA) is a ring-shaped homo-triomeric protein that functions as a necessary clamping platform to recruit numerous enzymes involved in DNA replication and repair, such as DNA polymerases, endonuclease, and DNA ligase, ultimately responsible for cell proliferation [34]. Therefore, PCNA is widely considered as a biomarker for cancer progression and prognosis. A recent study has found that PCNA was expressed in 52.2 % of gastric cancer patients, and positive expression of PCNA was significantly associated with poor 3-year disease-free survival (p = 0.035) [35]. KIAA0101 is a 15-kDa protein that has a conserved motif to bind to PCNA via a yeast two-hybrid system and thus involved in the regulation of DNA repair and cell proliferation [36]. Similar to PCNA, overexpression of KIAA0101 can promote growth and invasion of cancer cells [37] and predict poor prognosis in cancer patients [38, 39]. Collectively, these genes in the module 31 may play critical roles in the prognosis of ovarian cancer via regulation of DNA repair and cell proliferation.
In the module 35, 7 genes were included. Interferon regulatory factor 1 (IRF1) is a member of the interferon regulatory transcription factor (IRF) family, which can cause the inhibition of cell proliferation and stimulation of apoptosis [40]. IRF2 is a functional antagonist of IRF1 and may act as an oncogene, promoting the formation and progression of cancer [41]. A previous study has demonstrated that increased level of IRF1 is associated with both increased progression-free and overall survival of patients with ovarian carcinoma, and IRF1 is an independent predictor of platinum resistance and survival in high-grade serous ovarian carcinoma [42]. Furthermore, IRF1 directly mediates the interferon-γ (IFN-γ)-induced apoptosis via the activation of caspase-1 gene expression in IFN-γ-sensitive ovarian cancer cells [43]. However, in a recent study of ovarian cancer, IRF-1 was identified to be up-regulated in ovarian cancer samples compared with healthy ovarian tissue although strong expression of IRF-1 predicted improved disease-free survival and overall survival [44]. This finding may be attributed to a compensation or adaptation mechanism. Further study indicated the IRF1 seemed to play a key role in the transcriptional activation of interferon-inducible guanylate binding proteins (GBP1 and GBP2) [45], which subsequently induces T-lymphocyte immune response against the cancer cell spreading and proliferation [46]. Therefore, GBP1 and GBP2 may be also tumor suppressor genes and associated with better prognosis [47].
AIM2 is another human IFN-inducible protein, which forms the AIM2 inflammasome with an adaptor protein ASC upon sensing foreign cytoplasmic double-stranded DNA [48]. The activated AIM2 inflammasome in macrophages promotes the proteolytic cleavage and secretion of pro-inflammatory cytokines (IL-1β and IL-18) through the activation of caspase-1, leading to cell senescence, apoptosis and preventing cancer progression [49]. Thereby, AMI2 may be also correlated with excellent prognosis [50, 51].
Conclusion
Based on gene expression profiling data, two 7-gene functional interaction modules were identified to be likely associated with prognosis of ovarian cancer patients. These network modules were related to DNA repair, replication, immune and cytokine mediated signaling pathways. However, further experimental studies are required to confirm these genes in the modules.
References
Siegel RL, Miller KD, Jemal A. Cancer statistics, 2016. CA Cancer J Clin. 2016;66(1):10–29.
Baldwin LA, Huang B, Miller RW, Tucker T, Goodrich ST, Podzielinski I, et al. Ten-year relative survival for epithelial ovarian cancer. Obstet Gynecol. 2012;120(3):612–8.
Cheon DJ, Tong Y, Sim MS, Dering J, Berel D, Cui X, et al. A collagen-remodeling gene signature regulated by TGFβ signaling is associated with metastasis and poor survival in serous ovarian cancer. Clin Cancer Res. 2014;20(3):711–23.
Mclaughlin JR, Rosen B, Moody J, Pal T, Fan I, Shaw PA, et al. Long-term ovarian cancer survival associated with mutation in BRCA1 or BRCA2. J Natl Cancer Inst. 2013;105(2):141–8.
Yamanoi K, Matsumura N, Murphy SK, Baba T, Abiko K, Hamanishi J, et al. Suppression of ABHD2, identified through a functional genomics screen, causes anoikis resistance, chemoresistance and poor prognosis in ovarian cancer. Oncotarget. 2016
Turcotte M, Spring K, Pommey S, Chouinard G, Cousineau I, George J, et al. CD73 is associated with poor prognosis in high-grade serous ovarian cancer. Cancer Res. 2015;75(21):4494–503.
Wu G, Stein L. A network module-based method for identifying cancer prognostic signatures. Genome Biol. 2012;13(12):R112.
Wu G, Feng X, Stein L. A human functional protein interaction network and its application to cancer data analysis. Genome Biol. 2010;11(5):R53.
Vastrik I, D'Eustachio P, Schmidt E, Joshi-Tope G, Gopinath G, Croft D, et al. Reactome: a knowledge base of biologic pathways and processes. Genome Biol. 2007;8(3):R39.
Kanehisa M, Goto S, Kawashima S, Okuno Y, Hattori M. The KEGG resource for deciphering the genome. Nucleic Acids Res. 2004;32 suppl 1:D277–80.
Mi H, Dong Q, Muruganujan A, Gaudet P, Lewis S, Thomas PD. PANTHER version 7: improved phylogenetic trees, orthologs and collaboration with the Gene Ontology Consortium. Nucleic Acids Res. 2010;38 suppl 1:D204–10.
Schaefer CF, Anthony K, Krupa S, Buchoff J, Day M, Hannay T, et al. PID: the pathway interaction database. Nucleic Acids Res. 2009;37 suppl 1:D674–9.
Chatr-Aryamontri A, Breitkreutz B-J, Heinicke S, Boucher L, Winter A, Stark C, et al. The BioGRID interaction database: 2013 update. Nucleic Acids Res. 2013;41(D1):D816–23.
Prasad TK, Goel R, Kandasamy K, Keerthikumar S, Kumar S, Mathivanan S, et al. Human protein reference database—2009 update. Nucleic Acids Res. 2009;37 suppl 1:D767–72.
Kerrien S, Alam-Faruque Y, Aranda B, Bancarz I, Bridge A, Derow C, et al. IntAct—open source resource for molecular interaction data. Nucleic Acids Res. 2007;35 suppl 1:D561–5.
Flicek P, Aken BL, Ballester B, Beal K, Bragin E, Brent S, et al. Ensembl’s 10th year. Nucleic Acids Res. 2010;38 suppl 1:D557–62.
Finn RD, Mistry J, Schuster-Böckler B, Griffiths-Jones S, Hollich V, Lassmann T, et al. Pfam: clans, web tools and services. Nucleic Acids Res. 2006;34 suppl 1:D247–51.
Murakami Y, Mizuguchi K. Applying the Naïve Bayes classifier with kernel density estimation to the prediction of protein–protein interaction sites. Bioinformatics. 2010;26(15):1841–8.
Bair E, Tibshirani R. Semi-supervised methods to predict patient survival from gene expression data. PLoS Biol. 2004;2(4):E108.
Smoot ME, Ono K, Ruscheinski J, Wang P-L, Ideker T. Cytoscape 2.8: new features for data integration and network visualization. Bioinformatics. 2011;27(3):431–2.
Yan Y, Akhter S, Zhang X, Legerski R. The multifunctional SNM1 gene family: not just nucleases. Future Oncol. 2010;6(6):1015–29.
Ahkter S, Richie CT, Zhang N, Behringer RR, Zhu C, Legerski RJ. Snm1-deficient mice exhibit accelerated tumorigenesis and susceptibility to infection. Mol Cell Biol. 2005;25(22):10071–8.
Herrera M, Dominguez G, Garcia JM, Peña C, Jimenez C, Silva J, et al. Differences in repair of DNA cross-links between lymphocytes and epithelial tumor cells from colon cancer patients measured in vitro with the comet assay. Clin Cancer Res. 2009;15(17):5466–72.
Kauffmann A, Rosselli F, Lazar V, Winnepenninckx V, Mansuet-Lupo A, Dessen P, et al. High expression of DNA repair pathways is associated with metastasis in melanoma patients. Oncogene. 2008;27(5):565–73.
van Gent DC, Kanaar R. Exploiting DNA repair defects for novel cancer therapies. Mol Biol Cell. 2016;27(14):2145–8.
Abbotts R, Thompson N, Madhusudan S. DNA repair in cancer: emerging targets for personalized therapy. Cancer Manag Res. 2014;6:77.
Wu S-H, Hsiao Y-T, Chen J-C, Lin J-H, Hsu S-C, Hsia T-C, et al. Bufalin alters gene expressions associated DNA damage, cell cycle, and apoptosis in human lung cancer NCI-H460 cells in vitro. Molecules. 2014;19(5):6047–57.
Ledermann JA, Gabra H, Jayson GC, Spanswick VJ, Rustin GJ, Jitlal M, et al. Inhibition of carboplatin-induced DNA interstrand cross-link repair by gemcitabine in patients receiving these drugs for platinum-resistant ovarian cancer. Clin Cancer Res. 2010;16(19):4899–905.
Ioana M, Angelescu C, Burada F, Mixich F, Riza A, Dumitrescu T, et al. MMR gene expression pattern in sporadic colorectal cancer. J Gastrointestin Liver Dis. 2010;19(2):155–9.
Kretschmer C, Sterner-Kock A, Siedentopf F, Schoenegg W, Schlag PM, Kemmner W. Identification of early molecular markers for breast cancer. Mol Cancer. 2011;10(1):15.
Zhou J, Wang Y, Yin X, He Y, Chen L, Wang W, et al. FOXM1 modulates cisplatin sensitivity by regulating EXO1 in ovarian cancer. PLoS One. 2014;9(5):e96989–9.
Tian X, Swenberg J, Nakamura J. POLD3 is required for DNA damage response to endogenous and exogenous DNA damage in human cells. Cancer Res. 2013;73(8 Supplement):1281–1.
Elgaaen BV, Haug KBF, Wang J, Olstad OK, Fortunati D, Onsrud M, et al. POLD2 and KSP37 (FGFBP2) correlate strongly with histology, stage and outcome in ovarian carcinomas. 2010.
Essers J, Theil AF, Baldeyron C, van Cappellen WA, Houtsmuller AB, Kanaar R, et al. Nuclear dynamics of PCNA in DNA replication and repair. Mol Cell Biol. 2005;25(21):9350–9.
Li N, Deng W, Ma J, Wei B, Guo K, Shen W, et al. Prognostic evaluation of Nanog, Oct4, Sox2, PCNA, Ki67 and E-cadherin expression in gastric cancer. Med Oncol. 2015;32(1):1–9.
Yu P, Huang B, Shen M, Lau C, Chan E, Michel J, et al. p15^ P^ A^ F, a novel PCNA associated factor with increased expression in tumor tissues. Oncogene. 2001;20(4):484–9.
Jain M, Zhang L, Patterson EE, Kebebew E. KIAA0101 is overexpressed, and promotes growth and invasion in adrenal cancer. PLoS One. 2011;6(11):e26866.
Kato T, Daigo Y, Aragaki M, Ishikawa K, Sato M, Kaji M. Overexpression of KIAA0101 predicts poor prognosis in primary lung cancer patients. Lung Cancer. 2012;75(1):110–8.
Su X, Zhang T, Cheng P, Zhu Y, Li H, Li D, et al. KIAA0101 mRNA overexpression in peripheral blood mononuclear cells acts as predictive marker for hepatic cancer. Tumor Biol. 2014;35(3):2681–6.
Bouker KB, Skaar TC, Riggins RB, Harburger DS, Fernandez DR, Zwart A, et al. Interferon regulatory factor-1 (IRF-1) exhibits tumor suppressor activities in breast cancer associated with caspase activation and induction of apoptosis. Carcinogenesis. 2005;26(9):1527–35.
Cui L, Deng Y, Rong Y, Lou W, Mao Z, Feng Y, et al. IRF-2 is over-expressed in pancreatic cancer and promotes the growth of pancreatic cancer cells. Tumor Biol. 2012;33(1):247–55.
Cohen S, Mosig R, Moshier E, Pereira E, Rahaman J, Prasad-Hayes M, et al. Interferon regulatory factor 1 is an independent predictor of platinum resistance and survival in high-grade serous ovarian carcinoma. Gynecol Oncol. 2014;134(3):591–8.
Kim EJ, Lee JM, Namkoong SE, Um SJ, Park JS. Interferon regulatory factor-1 mediates interferon-γ-induced apoptosis in ovarian carcinoma cells. J Cell Biochem. 2002;85(2):369–80.
Zeimet AG, Reimer D, Wolf D, Fiegl H, Concin N, Wiedemair A, et al. Intratumoral interferon regulatory factor (IRF)-1 but not IRF-2 is of relevance in predicting patient outcome in ovarian cancer. Int J Cancer. 2009;124(10):2353–60.
Ramsauer K, Farlik M, Zupkovitz G, Seiser C, Kröger A, Hauser H, et al. Distinct modes of action applied by transcription factors STAT1 and IRF1 to initiate transcription of the IFN-γ-inducible gbp2 gene. Proc Natl Acad Sci. 2007;104(8):2849–54.
Godoy P, Cadenas C, Hellwig B, Marchan R, Stewart J, Reif R, et al. Interferon-inducible guanylate binding protein (GBP2) is associated with better prognosis in breast cancer and indicates an efficient T cell response. Breast Cancer. 2014;21(4):491–9.
Britzen-Laurent N, Lipnik K, Ocker M, Naschberger E, Schellerer VS, Croner RS, et al. GBP-1 acts as a tumor suppressor in colorectal cancer cells. Carcinogenesis. 2013;34(1):153–62.
Fernandesalnemri T, Yu JW, Datta P, Wu J, Alnemri ES. AIM2 activates the inflammasome and cell death in response to cytoplasmic DNA. Nature. 2009;458(7237):509–13.
Ponomareva L, Liu H, Duan X, Dickerson E, Shen H, Panchanathan R, et al. AIM2, an IFN-inducible cytosolic DNA sensor, in the development of benign prostate hyperplasia and prostate cancer. Mol Cancer Res. 2013;11(10):1193–202.
Dihlmann S, Tao S, Echterdiek F, Herpel E, Jansen L, Chang-Claude J, et al. Lack of Absent in Melanoma 2 (AIM2) expression in tumor cells is closely associated with poor survival in colorectal cancer patients. Int J Cancer. 2014;135(10):2387–96.
Liu R, Truax AD, Chen L, Hu P, Li Z, Chen J, et al. Expression profile of innate immune receptors, NLRs and AIM2, in human colorectal cancer: correlation with cancer stages and inflammasome components. Oncotarget. 2015;6(32):33456–69.
Acknowledgements
None.
Funding
None.
Availability of data and material
The raw data were collected and analyzed by the Authors, and are not ready to share their data because the data have not been published.
Authors’ contributions
XW,SSW and LZ carried out all the operations,designed and applied the technique. And they had also critically reviewed the final draft of the manuscript. LY and LMZ collected the data,wrote the manuscript,conceived of the study,participated in its design and coordination and found and organized the literature. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Consent for publication
Not applicable.
Ethics approval and consent to participate
Not applicable.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Wang, X., Wang, Ss., Zhou, L. et al. A network-pathway based module identification for predicting the prognosis of ovarian cancer patients. J Ovarian Res 9, 73 (2016). https://doi.org/10.1186/s13048-016-0285-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13048-016-0285-0