
Abstract
Background and objective
In recent years, the complex interplay between systemic health and oral well-being has emerged as a focal point for researchers and healthcare practitioners. Among the several important connections, the convergence of Type 2 Diabetes Mellitus (T2DM), dyslipidemia, chronic periodontitis, and peripheral blood mononuclear cells (PBMCs) is a remarkable example. These components collectively contribute to a network of interactions that extends beyond their domains, underscoring the intricate nature of human health. In the current study, bioinformatics analysis was utilized to predict the interactomic hub genes involved in type 2 diabetes mellitus (T2DM), dyslipidemia, and periodontitis and their relationships to peripheral blood mononuclear cells (PBMC) by machine learning algorithms.
Materials and Methods
Gene Expression Omnibus datasets were utilized to identify the genes linked to type 2 diabetes mellitus(T2DM), dyslipidemia, and Periodontitis (GSE156993).Gene Ontology (G.O.) Enrichr, Genemania, and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathways were used for analysis for identification and functionalities of hub genes. The expression of hub D.E.G.s was confirmed, and an orange machine learning tool was used to predict the hub genes.
Result
The decision tree, AdaBoost, and Random Forest had an A.U.C. of 0.982, 1.000, and 0.991 in the R.O.C. curve. The AdaBoost model showed an accuracy of (1.000). The findings imply that the AdaBoost model showed a good predictive value and may support the clinical evaluation and assist in accurately detecting periodontitis associated with T2DM and dyslipidemia. Moreover, the genes with p-value < 0.05 and A.U.C.>0.90, which showed excellent predictive value, were thus considered hub genes.
Conclusion
The hub genes and the D.E.G.s identified in the present study contribute immensely to the fundamentals of the molecular mechanisms occurring in the PBMC associated with the progression of periodontitis in the presence of T2DM and dyslipidemia. They may be considered potential biomarkers and offer novel therapeutic strategies for chronic inflammatory diseases.
Similar content being viewed by others
Introduction
In recent years, the intricate connections between systemic health and oral well-being have garnered significant attention among researchers and healthcare practitioners. One such multifaceted interrelation exists at the crossroads of Type 2 Diabetes Mellitus (T2DM), dyslipidemia, and chronic periodontitis [1]. Each condition substantially impacts health, with consequences extending beyond their respective domains.
Type 2 Diabetes Mellitus(T2DM), a metabolic disorder characterized by hyperglycemia resulting from insulin resistance and inadequate insulin secretion, has become a global epidemic [2]. Beyond its immediate effects on glucose metabolism, T2DM has been implicated as a systemic inflammatory state, influencing various organs and systems throughout the body [2]. One of the less explored yet critical aspects of this relationship is the potential bidirectional link between T2DM and chronic periodontitis, a chronic inflammatory condition affecting the supporting structures of teeth. This connection may create a cyclical worsening of both conditions, complicating disease management [3,4,5,6,7,8,9,10,11].
Dyslipidemia, characterized by abnormal lipid profiles in the bloodstream, is another prevalent condition with systemic implications. The disrupted lipid balance often seen in dyslipidemia can contribute to atherosclerosis and cardiovascular diseases [12]. The intricate interplay between dyslipidemia and T2DM and chronic periodontitis can further amplify the systemic inflammatory burden, potentially exacerbating disease progression.
Periodontitis, a prevalent oral inflammatory disease, involves a dysbiotic microbial community interacting with the host immune response, destroying periodontal tissues. Beyond its local consequences, chronic periodontitis has been linked to systemic inflammation and various systemic diseases, including diabetes and cardiovascular diseases [13]. This bidirectional relationship underscores the importance of considering oral health as an integral component of overall health [14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34].
Type 2 Diabetes Mellitus (T2DM), which affects roughly 90% of D.M. patients, is linked to obesity and insulin resistance. D.M. sometimes arises with other systemic abnormalities, such as dyslipidemia, a metabolic inefficiency caused by high blood lipoprotein levels. Dyslipidemia (DL) may contribute to DM-induced immune cell changes. People with diabetes have higher LDL/triglycerides even when blood glucose is effectively managed. Cytokine levels accelerate lipid mobilization from the liver and adipose tissue, which elevates LDL binding to the endothelium and smooth muscles and LDL-receptor gene transcription.T2DM, dyslipidemia, and periodontitis [35, 36] are often found together due to the nonlinear aspect of periodontal disease and diabetes mellitus and the link between periodontitis and reduced lipid metabolism. Identifying hub genes in different diseases is crucial for understanding the underlying molecular mechanisms and pathways. This helps in disease understanding, biomarker discovery, therapeutic target identification, personalized medicine, and network analysis. Hub genes are involved in crucial biological functions and pathways, providing insights into disease biology and potential therapeutic targets. They can also be disease diagnosis, prognosis, and treatment response biomarkers. Hub genes enable targeted treatment approaches by stratifying patients based on molecular profiles.
Machine learning can be used to predict interactomic hub genes, which play a central role in protein interaction networks. Machine learning algorithms can identify and prioritize hub genes based on their potential importance in biological pathways by leveraging network analysis, feature selection, and predictive modeling.
Given the intricate web of interactions between Type 2 Diabetes Mellitus, dyslipidemia, and chronic periodontitis, a comprehensive understanding of their interplay is essential for clinicians and researchers aiming to provide holistic patient care. This study aims at shared pathways to predict hub genes using machine learning in periodontitis and diabetes with dyslipidemia.
Methods
Gene expression database
The NCBI GEO dataset [37] GSE156993 was located and downloaded using the keywords periodontitis, peripheral blood mononuclear cells, dyslipidemia, and type 2 diabetes mellitus. The expression patterns of the identified genes were then examined in periodontitis, peripheral blood mononuclear cells, dyslipidemia, and type 2 diabetes mellitus. These databases contained information about gene expression, including which genes were differentially expressed.
Analyzing differential expression
Differential expression analysis was conducted using appropriate statistical tools to identify the genes that had altered expression. This investigation examines the gene expression levels in T2DM, dyslipidemia, and periodontitis to spot the genes that show substantially significant effects.
Network analysis
Cytoscape GENEMANIA [38] and the appropriate bioinformatics tools created a gene co-expression network. Network analysis methods were employed to determine the hub genes based on the interactions between the genes and their connectivity within the network.
Network topology analysis
Genes with high connectivity and central roles were identified using network topology metrics such as node degree, betweenness centrality, and closeness centrality. Hub genes have been found to have substantial effects on network structure and interconnectivity.
Analysis of genes with differentially expressed functions
Functional Identification of hub genes was done by enrichr for Gene Ontology (G.O.) [39]. The enriched gene sets’ false discovery rate (F.D.R.) was 0.05. A Gene was considered significant if it had at least three genes and a p-value of 0.05 based on t-test analysis between disease and healthy samples. Gene Ontology (G.O.) is a standardized functional annotation system that categorizes genes based on their biological functions, molecular activities, and cellular locations.
Orange machine learning for predictive hub genes
An open-source toolkit for data visualization and machine learning is called Orange. Orange is a handy tool for data analysis and predictive modeling since it integrates easily with all other well-known machine learning frameworks. Outliers were removed from the top 250 DEGs’ statistical data before subjecting them to machine learning algorithms [40].
The data was divided into training and testing segments using a decision tree, AdaBoost, and random forest widgets, and it was cross-validated to achieve the desired results.
The processes make use of multi-dimensional scaling, model scoring, and cross-validation. Orange integrates Python libraries like NumPy, scipy, and sci-kit-learn into workflow blocks for data manipulation, machine learning method parameters modification, browsing results, and inferred model visualization.
Decision tree
One non-parametric supervised learning method for classification and regression is decision trees. It has a hierarchical tree structure with internal and leaf nodes, roots, and branches.
Adaptive boosting
Machine learning ensemble approaches use the AdaBoost algorithm, commonly called adaptive boosting. Adaptive boosting [41] refers to assigning weights to each instance, with heavier weights going to incorrectly identified instances.
Random forest
This algorithm for supervised machine learning is well-known. It can be used for ML problems involving both regression and classification. The system learns and determines the output based on the majority decisions of the several decision trees (Fig. 1). The method most frequently used to classify patients based on biomarkers [41].

Orange Workflow of the current study
Results
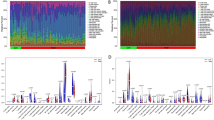
Gene expression datasets for Periodontitis GSE156993 were chosen from the GEO database. Five hundred differentially expressed genes (D.E.G.s)(Fig. 2) were found using GEO2R from periodontitis. The cut-off criteria used to define D.E.G. were |log2 fold change (F.C.)| >0 and P-value 0.05.
Interactome and Analysis of Differentially Expressed Genes’ Functional Enrichment.
Interactome of periodontitis identified hub genes, and centrality was measured using genemania. (Fig. 3), Gene enrichment analysis was done using Enrichr. According to the G.O. analysis, D.E.G.s are more prevalent in biological processes connected to immunity, including “pattern recognition receptor signaling and “keratinocyte proliferation.” Most of the signaling pathways in D.E.G.s are involved in the immune system, such as the “T.G.F.- beta signaling pathway.” Enrichr was used to do the enrichment analysis. (Fig. 4A to D .)

shows a volcano plot of D.E.G.s of PBMCs in periodontitis and diabetes

An integrated network of periodontitis, T2DM, and dyslipidemia

A shows the biological function of D.E.G.s in biotic stimulus and keratinocyte proliferation. B shows the cellular component cation and calcium channel complex of D.E.G.s. C shows the molecular component DNA-directed polymerase activity of D.E.G.s. D shows the T.G.F. beta signaling pathway of D.E.G.s
We recalculated hub gene and non-hub gene similarities in cross-validation steps to assess the effectiveness of predicting interactome hub gene and non-hub gene in periodontitis, diabetes, dyslipidemia, and PBMC associations.
The testing samples’ association likelihood scores are used to organize them. Favorable samples with higher rankings have node connections. Positive samples have a hub gene-disease node pair relationship and an association score above a threshold. To create a receiver operating characteristic (R.O.C.) curve, T.P.R.s and F.P.R.s are calculated. TP/ TP + FN and FP/ FP + TN define TPR and FPR.
The sign F.N. denotes the number of hub genes that were mistakenly identified, and the letter T.P. denotes positively identified samples that were successfully recognized. The TN/FP measures the proportion of incorrectly identified positive to properly identified negative samples. A helpful metric for evaluating a method’s overall prediction performance is the area under the R.O.C. curve (A.U.C.). (Figures 5 and 6)

shows the R.O.C. curve for HUB GENE, indicating a good prediction accuracy model

shows the R.O.C. curve Shows a good predictive model for non-hub genes
Positive associations between hub gene and non-hub gene disorders are out of proportion with negative correlations. This is when the precision-recall (P.R.) curve and its area (AUPR) are utilized to evaluate a prediction approach. The definitions of recall and precision are as follows:
A good classifier should have one precision (high). Precision only occurs when the numerator and denominator match or when T.P. = T.P. + F.P. F.P. is 0. Thus, this implies. Precision = TP ÷ TP + F.P.
A good classifier must have 1 or 1 recall. T.P. = T.P. + F.N., where F.N. is zero, and recall becomes one if the denominator and numerator are identical. The denominator becomes more important than the numerators as F.N. grows, decreasing recall. Recall = (TP ÷ TP + FN).
Because F.P. and F.N. are zero, a competent classifier has one precision and recall. Therefore, we need a statistic that considers recall and precision. The F1-score, which accounts for precision and recall, is [(Precision x Recall)/(Precision + Recall)] x 2.
AUC-ROC curves can be assessed using a confusion matrix, recall, precision, specificity, and accuracy. The test’s target characteristic is the hub and non-hub gene predictions. The study used stratified sampling with multiple Folds 20 and cross-validation. The matrix indicates how many true positives, true negatives, false positives, and false negatives the model generated from test data.
Results of various models with A.U.C. of 98% for Decision tree, 100% for AdaBoost, and 99% for Random Forest (Table 1).
Predicted
The decision tree model’s evaluation of the expected outcomes using the confusion matrix produced classification results for the hub gene that were 91.2% for True Positive and 20% for True Negative. (Table 2)
Predicted
When the Adaboost model’s projected results were evaluated, the hub gene’s True Positive prediction was 100%, while the non-hub gene’s True Negative prediction was 0%. (Table 3)
Predicted
The classification results for the hub gene True positive were evaluated using the Confusion Matrix on the Random Forest Model. They were 93.9%, whereas the True negative predicted result for the non-hub gene was 32%. (Table 4)
Discussion
Interactome hub genes offer insights into biological system complexity, disease mechanisms, and therapeutic targets. They can serve as biomarkers for disease diagnosis, prognosis, and treatment response, enabling personalized medicine and drug development by identifying specific disease conditions. In T2DM, PBMCs may exhibit pro-inflammatory characteristics. There is evidence of increased production of pro-inflammatory cytokines such as interleukin-6 (IL-6) and tumor necrosis factor-alpha (TNF-α) by PBMCs in individuals with T2DM. This inflammatory activation may contribute to chronic low-grade inflammation seen in T2DM [42]. T2DM can lead to impaired immune function, affecting the ability of PBMCs to respond effectively to infections. This can increase susceptibility to various illnesses [43, 44]. In periodontitis, PBMCs may migrate to the periodontal tissues as part of the immune response to the oral infection. This migration can accumulate immune cells in the gingival tissues, contributing to local inflammation.
PBMCs within the periodontal tissues may exhibit an activated pro-inflammatory state, producing cytokines contributing to tissue destruction in chronic periodontitis [14, 45, 46]. Dyslipidemia can affect PBMCs by altering their lipid metabolism. Bloodstream white blood cells are lipid-laden peripheral blood mononuclear cells (PBMCs). They are heavy in fat molecules or lipids. Elevated levels of circulating lipids, particularly low-density lipoprotein cholesterol (LDL-C), can lead to lipid accumulation in PBMCs. This lipid loading can increase oxidative stress and inflammation within these cells [47].
Lipid-laden PBMCs may produce inflammatory mediators, further contributing to systemic inflammation associated with dyslipidemia and increasing the risk of atherosclerosis [48]. Hence, PBMCs in these individuals can produce inflammatory molecules and altered immune responses, which may contribute to chronic inflammation and immune dysfunction, impacting overall health. Both periodontitis and diabetes and dyslipidemia are multifactorial diseases marked by persistent inflammation that results in the deterioration of tissue and bone around the teeth or joints, as appropriate. IGLJ3, DNASE1L3, ABCG1, DPEP2, and KIF19 are highly differentiated genes associated with diabetes and periodontitis. IgLJ3 (Immunoglobulin Lambda Joining 3 [49] is present in higher levels in people with type 1 diabetes than in people without diabetes. This suggests that IgLJ3 may play a role in developing the diseases. DNASE1L3 [50] (Deoxyribonuclease 1-like 3) is an enzyme involved in D.N.A. degradation. It belongs to the deoxyribonuclease I family. Single nucleotide polymorphism can alter protein expression and non-synonymous SNPs, resulting in single amino acid changes affecting protein function and potentially causing disease. Studies have shown that DNASE1L3 levels are elevated in people with diabetes, possibly contributing to diabetic complications.
DNASE1L3- deoxyribonuclease 1 like 3 [51] may contribute to the inflammatory response that destroys periodontal tissue and can cause vascular occlusion in periodontitis. The immune cells secrete the enzyme in response to bacterial infection and break down D.N.A. from bacteria and host cells. This can release inflammatory molecules that injure tissues. Periodontal pathogens have identified changes in cholesterol efflux-related enzymes ( ABCG1- ATP binding cassette subfamily G member one and CYP46A1), contributing to foam cell formation and enhanced Ca2 + signaling and R.O.S. production as critical events in lipid homeostasis disruption. Excess cholesterol ester production via ACAT1 and decreased cellular cholesterol efflux via ABCG1 are two pathways that may contribute to atherosclerosis caused by Pg-LPS [52]. Type 2 diabetics have lower ABCG1 expression and cholesterol efflux. This decreased ABCG1-mediated cholesterol export dramatically increases intracellular cholesterol [53]. ABCA1 dysfunction impairs insulin secretion by disrupting cholesterol transport [54]. Deficit of both ABCA1 and ABCG1 leads to more significant β-cell function abnormalities than either transporter alone, leading to dyslipidemia and diabetes. DPEP2, KIF19 induced diabetes associated with obesity and showing strong interactions with periodontal disease [55].
The present study showed fewer false positives and negatives in the estimated hub genes with ROC. Curve, demonstrating a good predictive model. We need further research with larger sample sizes and improved algorithms to prove that machine learning models are more effective. In this study, adaboost exhibited an AUC of 1 with overfitting, a binary classification model performance metric. Strategies to avoid overfitting include collecting more data, selecting relevant features, regularization techniques, cross-validation, early stopping, ensemble methods, and regular evaluation.
Conclusion
Predicting interactomic hub genes and deciphering the intricate molecular networks underlying periodontitis and systemic diseases. Novel algorithms can uncover new therapeutic targets and reveal details about the underlying mechanisms of various diseases by integrating large genomic and protein datasets. More experimental research still needs to validate the anticipated hub genes and their functional roles in personalized medicine. We can improve our comprehension of and ability to treat periodontitis with systemic diseases by using machine learning to predict interactomic hub genes in peripheral blood mononuclear cells.
Data availability
https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE156993.
References
Sanz M, Ceriello A, Buysschaert M, Chapple I, Demmer RT, Graziani F, et al. Scientific evidence on the links between periodontal diseases and diabetes: Consensus report and guidelines of the joint workshop on periodontal diseases and diabetes by the International Diabetes Federation and the European Federation of Periodontology. J Clin Periodontol. 2018;45(2):138–49.
Ayoobi F, Salari Sedigh S, Khalili P, Sharifi Z, Hakimi H, Sardari F, et al. Dyslipidemia, diabetes and periodontal disease, a cross-sectional study in Rafsanjan, a region in southeast Iran. BMC Oral Health. 2023;23(1):549.
Mealey BL, Oates TW. Diabetes Mellitus and Periodontal diseases. J Periodontol. 2006;77(8):1289–303.
Sangwan A, Tewari S, Singh H, Sharma RK, Narula SC. Periodontal Status and Hyperlipidemia: statin users Versus non-users. J Periodontol. 2013;84(1):3–12.
De Nordenflycht D, Tesch RS. Advantages of ultrasound guidance for TMJ arthrocentesis and intra-articular injection: A narrative review. Dent Med Probl [Internet]. 2022;59(4):647–56. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85145105679&doi=10.17219%2fdmp%2f146820&partnerID=40&md5=ab82e6408610bfdb0c46e70d3b99a6fa.
Mazur M, Ndokaj A, Bietolini S, Nissi V, Duś-Ilnicka I, Ottolenghi L. Green dentistry: Organic toothpaste formulations. A literature review. Dent Med Probl [Internet]. 2022;59(3):461–74. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85139513538&doi=10.17219%2fdmp%2f146133&partnerID=40&md5=f9666d944290aca0d04b942a09cd2cce.
Di Stasio D, Lauritano D, Romano A, Salerno C, Minervini G, Minervini G, Gentile E, Serpico R, Lucchese A. In vivo characterization of oral pemphigus vulgaris by optical coherence tomography. J Biol Regul Homeost Agents. 2015;29:39–41.
d’Apuzzo F, Nucci L, Delfino I, Portaccio M, Minervini G, Isola G, Serino I, Camerlingo C, Lepore M. Application of vibrational spectroscopies in the qualitative analysis of gingival crevicular fluid and periodontal ligament during orthodontic tooth movement. J Clin Med. 2021;10:1405. https://doi.org/10.3390/jcm10071405.
Marrelli M, Tatullo M, Dipalma G, Inchingolo F. Oral infection by Staphylococcus Aureus in patients affected by White Sponge Nevus: a description of two cases occurred in the same family. Int J Med Sci. 2012;9(1):47–50.
Adina S, Dipalma G, Bordea IR, Lucaciu O, Feurdean C, Inchingolo AD, et al. Orthopedic joint stability influences growth and maxillary development: clinical aspects. J Biol Regul Homeost Agents. 2020;34(3):747–56.
Lo Russo L, Guida L, Mariani P, Ronsivalle V, Gallo C, Cicciù M, et al. Effect of Fabrication Technology on the Accuracy of Surgical guides for Dental-Implant surgery. Bioengineering. 2023;10(7):875.
Zhang D, Zhao C, Liu Z, Ding Y, Li W, Yang H, et al. Relationship between periodontal status and dyslipidemia in patients with type 2 diabetic nephropathy and chronic periodontitis: a cross-sectional study. J Periodontal Res. 2022;57(5):969–76.
Aizenbud I, Wilensky A, Almoznino G. Periodontal Disease and Its Association with metabolic Syndrome-A Comprehensive Review. Int J Mol Sci. 2023;24(16).
Hajishengallis G. Immunomicrobial pathogenesis of periodontitis: keystones, pathobionts, and host response. Trends Immunol. 2014;35(1):3–11.
Tanaka T, Hara S, Hendawy H, El-Husseiny HM, Tanaka R, Asakura T. Development of Small-Diameter Artificial Vascular Grafts Using Transgenic Silk Fibroin. Prosthesis [Internet]. 2023;5(3):763–73. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85172099037&doi=10.3390%2fprosthesis5030054&partnerID=40&md5=b55fcbc686f29d2e16c6fb9737004193.
Choi S, Kang YS, Yeo ISL. Influence of Implant–Abutment Connection Biomechanics on Biological Response: A Literature Review on Interfaces between Implants and Abutments of Titanium and Zirconia. Prosthesis [Internet]. 2023;5(2):527–38. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85163744250&doi=10.3390%2fprosthesis5020036&partnerID=40&md5=aefc7b44f87fbad41c2c5d9ee7c9ca89.
Hernández-Ortega MF, Torres-SanMiguel CR, Alcántara-Arreola EA, Paredes-Rojas JC, Cabrera-Rodríguez O, Urriolagoitia-Calderón GM. Numerical Assessment of Interspinous Spacers for Lumbar Spine. Prosthesis [Internet]. 2023;5(3):939–51. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85172092372&doi=10.3390%2fprosthesis5030065&partnerID=40&md5=fd371d0b9ff58b6406be7211aeb5f021.
Romanos GE, Schesni A, Nentwig GH, Winter A, Sader R, Brandt S. Impact of Implant Diameter on Success and Survival of Dental Implants: An Observational Cohort Study. Prosthesis [Internet]. 2023;5(3):888–97. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85172150194&doi=10.3390%2fprosthesis5030062&partnerID=40&md5=f1c0d14025f819aab4c8ce3ced089ce3.
Lanzetti J, Michienzi PD, Collura J, Sabatini S, Vilardi S, Deregibus A. Comparison of two electric toothbrushes: evaluation on orthodontic patients. Minerva Dental and Oral Science [Internet]. 2023;72(3):125–30. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85163417080&doi=10.23736%2fS2724-6329.22.04711-8&partnerID=40&md5=9303ddc4412faf90dcd3093b981f7ecf.
Chandan C, Shetty SK, Shetty SK, Shah AK. Quality of life assessment in patients with long-term neurosensory dysfunction after mandibular fractures. Minerva Dental and Oral Science [Internet]. 2023;72(2):118–23. Available from: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85152312536&doi=10.23736%2fS2724-6329.21.04462-9&partnerID=40&md5=a3217c3b938e69cac0dbf5ad3a9dad69.
Minervini G, Franco R, Marrapodi MM, Fiorillo L, Cervino G, Cicciù M. The association between parent education level, oral health, and oral-related sleep disturbance. An observational crosssectional study. Eur J Paediatr Dent. 2023;24(3):218–23.
Minervini G, Marrapodi MM, Cicciù M. Online Bruxism‐related information: can people Understand what they read? A cross‐sectional study. J Oral Rehabil. 2023;50:1211–1216. https://doi.org/10.1111/joor.13519.
Minervini G, Franco R, Marrapodi MM, Di Blasio M, Ronsivalle V, Cicciù M. Children oral health and parents education status: a cross sectional study. BMC Oral Health. 2023;23(1):787.
Minervini G, Franco R, Marrapodi MM, Almeida LE, Ronsivalle V, Cicciù M. Prevalence of temporomandibular disorders (TMD) in obesity patients: a systematic review and meta-analysis. J Oral Rehabil. 2023;50(12):1544–53.
Contaldo M, della Vella F, Raimondo E, Minervini G, Buljubasic M, Ogodescu A, Sinescu C, Serpico R. Early childhood oral health impact scale (ECOHIS): literature review and Italian validation. Int J Dent Hyg. 2020;18:396–402. https://doi.org/10.1111/idh.12451.
Franco R, Barlattani A, Perrone MA, Basili M, Miranda M, Costacurta M, Gualtieri P, Pujia A, Merra G, Bollero P. Obesity, bariatric surgery and periodontal disease: a literature update. Eur Rev Med Pharmacol Sci. 2020;24:5036–5045. https://doi.org/10.26355/eurrev_202005_21196.
Franco R, Gianfreda F, Miranda M, Barlattani A, Bollero P. The hemostatic properties of chitosan in oral surgery. Biomed Biotechnol Res J. 2020;4:186. https://doi.org/10.4103/bbrj.bbrj_43_20.
Orzeszek SM, Piotr S, Waliszewska-Prosół M, Jenca A, Osiewicz M, Paradowska -Stolarz A, et al. Relationship between pain severity, satisfaction with life and the quality of sleep in Polish adults with temporomandibular disorders. Dent Med Probl. 2023;60(4):609–17.
Minervini G, Romano A, Petruzzi M, Maio C, Serpico R, Lucchese A, Candotto V, Di Stasio D. Telescopic overdenture on natural teeth: prosthetic rehabilitation on (OFD) syndromic patient and a review on available literature. J Biol Regul Homeost Agents. 2018;32:131–134.
Fama F, Cicciu M, Sindoni A, Nastro-Siniscalchi E, Falzea R, Cervino G, et al. Maxillofacial and concomitant serious injuries: an eight-year single center experience. Chin J Traumatol. 2017;20(1):4–8.
Cervino G, Fiorillo L, Spagnuolo G, Bramanti E, Laino L, Lauritano F, et al. Interface between MTA and dental bonding agents: scanning electron microscope evaluation. J Int Soc Prev Community Dent. 2017;7(1):64.
Di Paola A, Tortora C, Argenziano M, Marrapodi MM, Rossi F. Emerging roles of the Iron chelators in inflammation. Int J Mol Sci. 2022;23(14):7977.
Rossi F, Tortora C, Paoletta M, Marrapodi MM, Argenziano M, Di Paola A, et al. Osteoporosis in Childhood Cancer survivors: Physiopathology, Prevention, Therapy and Future perspectives. Cancers (Basel). 2022;14(18):4349.
Uzunçıbuk H, Marrapodi MM, Meto A, Ronsivalle V, Cicciù M, Minervini G. Prevalence of temporomandibular disorders in clear aligner patients using orthodontic intermaxillary elastics assessed with diagnostic criteria for temporomandibular disorders (DC/TMD) axis II evaluation: a cross-sectional study. J Oral Rehabil. 2024;51:500–509. https://doi.org/10.1111/joor.13614.
Bitencourt FV, Nascimento GG, Costa SA, Orrico SRP, Ribeiro CCC, Leite FRM. The role of Dyslipidemia in Periodontitis. Nutrients. 2023;15(2).
Lamster IB, Cheng B, Burkett S, Lalla E. Periodontal findings in individuals with newly identified pre-diabetes or diabetes mellitus. J Clin Periodontol. 2014;41(11):1055–60.
Barrett T, Wilhite SE, Ledoux P, Evangelista C, Kim IF, Tomashevsky M, et al. NCBI GEO: archive for functional genomics data sets–update. Nucleic Acids Res. 2013;41(Database issue):D991–5.
Montojo J, Zuberi K, Rodriguez H, Kazi F, Wright G, Donaldson SL et al. GeneMANIA Cytoscape plugin: fast gene function predictions on the desktop. Bioinformatics. 2010;26(22).
Kuleshov MV, Diaz JEL, Flamholz ZN, Keenan AB, Lachmann A, Wojciechowicz ML, et al. ModEnrichr: a suite of gene set enrichment analysis tools for model organisms. Nucleic Acids Res. 2019;47:W1.
Vaishnav D, Rao BR. Comparison of Machine Learning Algorithms and Fruit Classification using Orange Data Mining Tool. In: 2018 3rd International Conference on Inventive Computation Technologies (ICICT). 2018. p. 603–7.
Greener JG, Kandathil SM, Moffat L, Jones DT. A guide to machine learning for biologists. Nat Rev Mol Cell Biol. 2022;23(1):40–55.
Pickup JC, Crook MA. Is type II diabetes mellitus a disease of the innate immune system? Diabetologia. 1998;41(10):1241–8.
Geerlings SE, Hoepelman AI. Immune dysfunction in patients with diabetes mellitus (DM). FEMS Immunol Med Microbiol. 1999;26(3–4):259–65.
Naveed M, Ahmed I, Khalid N, Mumtaz AS. Bioinformatics based structural characterization of glucose dehydrogenase (gdh) gene and growth promoting activity of Leclercia sp. QAU-66. Braz J Microbiol. 2014;45(2):603–11.
Naveed M, Mubeen S, Khan S, Ahmed I, Khalid N, Suleria HAR, et al. Identification and characterization of rhizospheric microbial diversity by 16S ribosomal RNA gene sequencing. Braz J Microbiol. 2014;45(3):985–93.
Naveed M, Tehreem S, Mubeen S, Nadeem F, Zafar F, Irshad M. No Title. Open Life Sci [Internet]. 2016;11(1):402–16. https://doi.org/10.1515/biol-2016-0054.
Bettman N, Avivi I, Rosenbaum H, Bisharat L, Katz T. Impaired migration capacity in monocytes derived from patients with gaucher disease. Blood Cells Mol Dis. 2015;55(2):180–6.
Duewell P, Kono H, Rayner KJ, Sirois CM, Vladimer G, Bauernfeind FG, et al. Erratum: {NLRP}3 inflammasomes are required for atherogenesis and activated by cholesterol crystals. Nature. 2010;466(7306):652.
Planas R, Carrillo J, Sanchez A, de Villa MCR, Nuñez F, Verdaguer J, et al. Gene expression profiles for the human pancreas and purified islets in type 1 diabetes: new findings at clinical onset and in long-standing diabetes. Clin Exp Immunol. 2009;159(1):23–44.
Li N, Zheng X, Chen M, Huang L, Chen L, Huo R et al. Deficient\ \{DNASE\}1L3\ facilitates\ neutrophil\ extracellular\ traps\-induced\ invasion\ via\ cyclic\ \{GMP\}\-\{AMP\}\ synthase\ and\ the\ non\-canonical\ \{NF\}\-\$\upkappa\$B\ pathway\ in\ diabetic\ hepatocellular\ carcinoma\.\ Clinical\ \{\\&\}amp\$\mathsemicolon\$\ Translational\ Immunol\.\ 2022;11\(4\)\.
Rho JH, Kim HJ, Joo JY, Lee JY, Lee JH, Park HR. Periodontal pathogens promote foam cell formation by blocking lipid Efflux. J Dent Res. 2021;100(12):1367–77.
Liu F, Wang Y, Xu J, Liu F, Hu R, Deng H. Effects of Porphyromonas gingivalis lipopolysaccharide on the expression of key genes involved in cholesterol metabolism in macrophages. Archives Med Sci. 2016;5:959–67.
Mauldin JP, Nagelin MH, Wojcik AJ, Srinivasan S, Skaflen MD, Ayers CR, et al. Reduced expression of {ATP}-Binding Cassette Transporter G1 increases cholesterol Accumulation in macrophages of patients with type 2 diabetes Mellitus. Circulation. 2008;117(21):2785–92.
Kruit JK, Wijesekara N, Westwell-Roper C, Vanmierlo T, de Haan W, Bhattacharjee A, et al. Loss of both {ABCA}1 and {ABCG}1 results in increased disturbances in islet sterol homeostasis, inflammation, and impaired $\upbeta$-Cell function. Diabetes. 2012;61(3):659–64.
Prashanth G, Vastrad B, Tengli A, Vastrad C, Kotturshetti I. Investigation of candidate genes and mechanisms underlying obesity associated type 2 diabetes mellitus using bioinformatics analysis and screening of small drug molecules. BMC Endocr Disord. 2021;21(1).
Acknowledgements
Not applicable.
Funding
This research received no external funding.
Author information
Authors and Affiliations
Contributions
Conceptualization PKY; DA; methodology; PKY; software, PKY; formal analysis, PKY .; investigation, DA; and PKY; data curation, PKY; and DA; writing—original draft preparation, MDB,VR; M.C.; G.M. ; writing—review and editing, VR; MC.; G.M.; supervision, GM; funding acquisition, MDB; administration: MDB. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
not applicable.
Consent for publication
Not Applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
yadalam, P.k., Arumuganainar, D., Ronsivalle, V. et al. Prediction of interactomic hub genes in PBMC cells in type 2 diabetes mellitus, dyslipidemia, and periodontitis. BMC Oral Health 24, 385 (2024). https://doi.org/10.1186/s12903-024-04041-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12903-024-04041-y