
Abstract
Background
Low back pain is a common and costly health complaint for which there are several moderately effective treatments. In some fields there is evidence that funder and financial conflicts are associated with trial outcomes. It is not clear whether effect sizes in back pain trials relate to journal impact factor, reporting conflicts of interest, or reporting funding.
Methods
We performed a systematic review of English-language papers reporting randomised controlled trials of treatments for non-specific low back pain, published between 2006-2012. We modelled the relationship using 5-year journal impact factor, and categories of reported of conflicts of interest, and categories of reported funding (reported none and reported some, compared to not reporting these) using meta-regression, adjusting for sample size, and publication year. We also considered whether impact factor could be predicted by the direction of outcome, or trial sample size.
Results
We could abstract data to calculate effect size in 99 of 146 trials that met our inclusion criteria. Effect size is not associated with impact factor, reporting of funding source, or reporting of conflicts of interest. However, explicitly reporting ‘no trial funding’ is strongly associated with larger absolute values of effect size (adjusted β=1.02 (95 % CI 0.44 to 1.59), P=0.001). Impact factor increases by 0.008 (0.004 to 0.012) per unit increase in trial sample size (P<0.001), but does not differ by reported direction of the LBP trial outcome (P=0.270).
Conclusions
The absence of associations between effect size and impact factor, reporting sources of funding, and conflicts of interest reflects positively on research and publisher conduct in the field. Strong evidence of a large association between absolute magnitude of effect size and explicit reporting of ‘no funding’ suggests authors of unfunded trials are likely to report larger effect sizes, notwithstanding direction. This could relate in part to quality, resources, and/or how pragmatic a trial is.
Similar content being viewed by others

Background
Low back pain (LBP) is a common and costly health complaint for which the life-time prevalence may be as high as 84 % [1]. Each year approximately 4 % of the UK population take time off work because of LBP; this equates to around 90 million working days lost and between eight and 12 million GP consultations per year [2, 3]. Globally, LBP ranks number one for contributions to Years Lived with Disability (YLDs) [4]. Several therapist-delivered interventions have been identified as useful for the early management of persistent non-specific LBP [5]. It can be difficult to choose which interventions will suit which patients, so guidelines recommend taking account of patient preference [5]. This is in part due to the different reporting methods used, the variance of reported effect sizes and a paradox that in the largest trials effect sizes tend to be quite similar irrespective of intervention and small to medium in magnitude [6, 7]. We are currently unable to determine for whom a particular treatment will be effective, as outcome has not often been shown to be dependent on participant characteristics [8]. Notwithstanding these challenges, a great deal of trust is placed in authors’ work and their estimates of treatment effect sizes, which inform decision-making and policy [9].
Readers of LBP trial reports often look first at the abstract and conclusion [9]. Some go on to look at potential known sources of bias such as lack of allocation concealment or lack of outcome assessment blinding [9]. Fewer examine funding source or conflicts of interest, possibly because it is generally assumed that, except in exceptional circumstances, these are unlikely to materially affect results. However, in 2010, an additional item recommending the reporting of trial funding was added to the CONSORT statement following the emergence of evidence that studies sponsored by pharmaceutical companies were more likely to have outcomes favouring the sponsor than studies with other sponsors, with an odds ratio of 4.05, (95 % CI 2.98 to 5.51) [10, 11]. While CONSORT does not specifically recommend reporting conflicts of interest, this is a requirement for submission to most journals. Bekelman et al found, in a review of reviews, that those with financial conflicts of interest were more likely to report a result in favour of pro-industry conclusions, with an odds ratio of 3.60 (95 % CI 2.63 to 4.91) [12]. Given the challenges to choosing between treatments for LBP, it is important to explore whether such an association is present in the field of LBP research. This will help to inform consumers’ interpretations of LBP trial results in the case a similarly large association exists.
Journal impact factors (IFs) quantify the average number of citations per article published in a particular journal over a specific time period; usually, the past two, or the past five-years. The Thomson Reuters Institute for Scientific Information (ISI), tracks both publications and citations of articles across journals. While use of IFs have been criticised,[13] they are widely regarded as a proxy of output quality and journal esteem, and are commonly used for advertising and self-promotion by journals on the home pages of their websites [13, 14]. Consequently, many authors select a target journal publication in-part based on that journal’s IF [15]. Effect sizes are known to become smaller as the quality of the study improves and we wanted to determine if a similar phenomenon occurred with IF, an established proxy for journal quality [16, 17]. It is not known whether the IF of a journal is associated with reported outcomes in LBP research. Submission and acceptance patterns could be influenced by several factors including perceived interest factor; perceived quality; how newsworthy a report is, especially if it is particularly novel, or goes against accepted practice in showing a null or negative result for a commonly used treatment; or how topical it is. We hypothesised that the direction or magnitude of treatment effect size is associated with journal IF.
We systematically reviewed trials of treatments for non-specific LBP to explore methodological factors as part of a larger project. In this paper, we test the null hypotheses that reported effect sizes in non-specific LBP trials are independent of (1) five-year journal IF, (2) reporting of conflicts of interest, and (3) reporting of funding sources. We also explored whether direction of outcome and trial sample size is associated with IF to find the extent to which these two factors are related to IF.
Methods
Our focus was on trials comparing any interventions for treating non-specific LBP, measuring any patient-reported continuous (or quasi-continuous) outcome, and published over a five-year period. We included all reports of trials for interventions for non-specific LBP unless they met one or more of the following exclusion criteria: reports that self-identified as pilot/feasibility studies; trials including mixed samples of back pain (e.g. including neck or thoracic pain in addition to LBP); LBP due to known pathology (e.g cancer, ankylosing spondylitis, or disc herniation); LBP associated with pregnancy; non-English language publications; samples that included participants with radiating leg pain, or referred pain extending past the knee; and because of limited utility: non-inferiority designs (i.e. trials of interventions that are hypothesised to be non-different with respect to a given delta); cross-over designs; secondary reports; trials using solely objective or psychological outcome measures; and multiple publications. In the case of multiple publications, we included the first published article and excluded subsequent publications.
We searched PubMed, EMBASE, and The Cochrane Register of Controlled Trials for non-specific LBP trials published between January 1, 2006 and January 1, 2012 using the non-specific LBP string from a Cochrane Back Pain Review group search strategy [18]. Two reviewers (either TB, PB, or DR) working independently, identified all randomised controlled trial (RCT) reports for inclusion by combining all database hits in an Endnote (Version 14; Thomson Reuters, Philadelphia) library, removing duplicates, and short-listing by title and abstract. Full-texts were obtained if the titles and abstract alone contained insufficient information.
Data abstraction
Using Microsoft Visual Basic 6.3 (Microsoft, Washington) and Microsoft Office Excel 2003 (Microsoft, Washington), we developed a front-end program to assist the data abstraction process and transfer abstracted data to a spread sheet. The program ensured consistency of data abstraction and comprehensive form completion as it insisted on correct completion of each field, producing error messages alerting reviewers to missed fields.
Two reviewers (either TB, PB, DR) independently abstracted all data. Disagreements were resolved through discussion and, if necessary, with arbitration and a fourth reviewer (RF). First the primary outcome was identified. An outcome measure was identified as ‘primary’ if (1) the outcome was nominated as the primary outcome by the authors; if no outcome was nominated, or multiple outcomes were nominated, we used (2) the outcome measure on which the sample size calculation was based; if this was not reported, we referred to (3) the first outcome measure referred to in the abstract; and if this was not identified in the abstract, we used (4) the first outcome mentioned in the paper. This approach has been used in other methodological reviews [19]. We identified the primary end-point, or used the first follow-up time point in cases when this was not clear. We then abstracted data on standardised effect size according to a set protocol.
First, we identified whether the paper reported a between-group difference in the primary outcome, or change scores or baseline and follow-up scores for each group from which we could calculate the between-group difference. The difference was recorded as positive if it favoured the intervention and negative if it favoured the control or comparison intervention. If there were more than two groups (and therefore more than two comparisons) we included the comparison with the largest effect size. To obtain the standardised effect size, if it was not directly reported, we extracted a pooled baseline SD, if available, otherwise we extracted SDs from baseline or change scores from single arms and calculated a pooled SD. We then divided the between-group difference by the SD to obtain the standardised effect size (i.e the standardised mean difference (SMD)) [20].
Second, we identified if the paper reported a standard error (SE) for the between-group difference. As the SE relates to the standard deviation of a specific outcome measure, and since we were looking at different outcome measures, we needed to re-standardise the SE across all outcome measures. We divided the SE by the SD extracted or calculated in the previous step to produce a re-standardised SE (SSE α ). If SE for between-group difference was not reported, we identified whether a 95 % CI was reported for the between-group difference, and under the assumption of normality, we calculated the standardised SE according to Eq. 1 (SSE β ). We prioritised these first two methods respectively where they were available, as these represent the adjusted errors in cases where authors included covariates within modelling. If neither the SE nor CI for a between-group difference was reported, then we estimated the crude standardised SE for the between-group difference (SSE Δ ). As the outcomes in these LBP trials are patient reported and quasi-continuous in nature, the SE is calculated as \(\frac {\sigma }{\sqrt {n}}\) in each arm. On standardising this by the SD the expression simplifies to that shown in Eq. 2.
where Upp=the upper limit of the 95% CI, and Lwr= the lower limit of the 95% CI; n=sample size, t=treatment group, c=control/comparator group, σ b =the pooled baseline SD.
If, during any of these steps, the required information could not be ascertained, we recorded the reason and did not analyse data from that paper. For consistency in this process we developed a flow chart for reviewers’ use (Additional file 1).
In addition, we abstracted data on the number of participants on whom data were analysed, COIs, classifying these as either ‘not reported’, ‘none reported’, or ‘some reported’; and funding status, which we classified in the same way. We used 2011 five-year IF for the corresponding journals, which we obtained from Thompson Reuters ISI Web of Knowledge (Thompson Reuters, Philadelphia).
Analysis
We tested the null hypotheses that effect size is independent of (1) 5-year journal IF; (2) COI reporting category; and (3) funding reporting category. As high-magnitude departures from the null value regardless of direction of effect size might be equally attractive to some journals, we also explored relationships to the absolute value of effect size. We explored sample size by COI and funding reporting category compared to not reporting any details, whether sample size was independent of journal IF, and whether there was any difference in journal IF in journals publishing positive and negative trial reports.
We fitted random effects meta-regression models of effect size on IF, COI category, and funding status, using within-study SSEs (vide supra) to weight observations. We used a restricted maximum likelihood (REML) estimator for between-study variance [21–23]. Within the REML algorithm used, coefficients as well as between-study variance was estimated with weighted least squares, so error terms were unbiased by heteroschedasticity [24, 25]. In the case that a journal did not have an official IF, we imputed an IF value of zero. We performed sensitivity analyses, using log-transformed IF (involving small non-zero imputations for journals with no official impact factor) and sample size, to allay concerns that readers more familiar with transformations than REML estimation to overcome heteroschedasticity might have in relation to the heteroschedasticity.
We first fitted crude models, i.e. with only the outcome and predictor variable for each hypothesis, and subsequently fitted adjusted models including the other predictor variables; i.e IF, COI category, and funding category, as well as trial sample size, and publication year, in case relationships changed over time. If predictors appeared non-linear we explored fitting polynomial terms to the model.
Model fits were assessed by graphical examination of standardised predicted random effects. We did not dismiss models on the basis of a high proportion of residual error explained by heterogeneity (i.e. I2), since our focus was on the associations between effect size and characteristics across a number of different interventions and not on estimation of any one intervention effect in particular. All analyses were performed using Stata, version 12.1 for Unix (Statacorp, Texas) and we used the package metareg v2.6.1 to fit the meta-regression models [24, 26].
Results
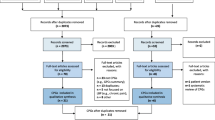
Figure 1 details hits obtained from the databases searched, exclusions made at the title and abstract phase, and 165 rejections at full-text level [27–191].

Flow chart of excluded and included trials. The figure shows the path and number of excluded and included trials
We could abstract the required effect size data on 99 trials [192–290] from the 146 articles that met inclusion criteria [192–337]. We could not abstract data on SD for the remaining 47 cases (Additional file 1). (Additional file 2: Table S1) shows the characteristics of included studies and (Additional file 3: Table S2) shows the characteristics of excluded studies.
Within our sample, the mean standardised effect size was 0.374, the mean total sample size was 149.3 (SD=217.4), ranging from 12 to 1,261, and the mean IF was 3.14 (4.33), ranging from less than 1 to 33.79. We were able to abstract the SE of the between-group difference directly in two trials (2 %), we calculated the SE from the 95 % CI of the between-group difference (Eq. 1) in 27 trials (27 %), and we calculated a the SE using Eq. 2 for the remaining 70 trials (71 %). Authors explicitly identified their primary outcome in 53 (54 %) trials. Table 1 shows that no comment on funding was made in 35 (35 %) trials, whereas authors specifically reported that there was no funding in 11 (11 %) trials, and acknowledged a funder in 53 (54 %) trials. No comments were made about COIs in the reports of 70 trials (71 %), authors explicitly stated there were no COIs in 22 trials (22 %), and reported at least one COI in 7 trials (7 %). We imputed zeros for IFs for 16 cases in which 13 unique journals did not have an official ISI IF. Table 1 also shows mean sample size, effect size, absolute effect size, and IF by each of the funding and COI categories. Compared to not reporting any funding details, sample size in trials reporting some funding was larger; absolute effect size in trials reporting no funding was larger; and IF in trials reporting some funding was higher.
Adjusted for trial sample size, there was no evidence of a difference in journal IF between positive or negative trials (P=0.270). Adjusted for direction of effect, there was very strong evidence of a linear association between IF and sample size, suggesting that the IF of the publishing journal increases by 0.008 (95 % CI 0.004 to 0.012) per unit increase in total sample size (P<0.0005).
There was no evidence of an association (either linear or non-linear) between effect size and IF (P=0.527) but journals with low IFs tended to report trials with a wider range of effect sizes than high If journals (Fig. 2). Compared to nothing being reported about COIs, there was no evidence of an effect of reporting no COIs (P=0.624) or some COIs (P=0.950). Compared to nothing being reported about funding, there was no evidence of an effect of reporting no funding (P=0.481) or some funding (P=0.847). Table 2 shows full results, including both crude and adjusted beta estimates, and covariates.

Effect size by 2011 5-year journal impact factor. The figure shows the effect size and the variance of effect size by journal impact factor
Table 3 shows the results of the meta-regression of absolute magnitudes of effect size on COI categories and funding categories, including covariates. There was no evidence of an effect of IF on absolute effect size (P=0.806). Compared to nothing being reported about COIs, there was no evidence of an effect of reporting no COIs (P=0.512) or some COIs (P=0.464). There was very strong evidence of a large effect of reporting no funding compared to reporting no details about funding (β=1.02,P=0.001), and no evidence of an effect of reporting some funding compared to reporting no details about funding (P=0.506).
As anticipated, residual variance due to heterogeneity was high (91.06 % >I2>85.76 %) across all models. Quadratic terms in IF and sample size were not significant in either unadjusted or adjusted models. Graphical inspection of standardised predicted random effects showed adequate model fits. Sensitivity analyses (not reported) showed near identical results.
Discussion
Main findings, implications and comparisons to existing research
While no associations were found between effect size and IF, reporting sources of funding, or conflicts of interest, there was strong evidence of a large association between absolute magnitude of effect size and the explicit reporting of ‘no funding’. We first discuss IF and then COIs and funding.
Impact factor
The results show no evidence that IF is associated with effect size reported in LBP trials. Effect size is much more variable in journals with low IFs and since journals with higher IFs tend to publish larger trials this likely explains the relationship between effect size variance and journal IF. Journal IF was not associated with direction of result, although there was some evidence that trials reporting a funder had a higher IF than those who did not report funding status.
Suñé et al reviewed clinical trials evaluating drug therapy published between 1997 and 2004 and classified the outcomes of these trials as positive, negative, or descriptive (non-controlled) [338]. They found no difference in IF based on trial direction, but they found the IF was significantly lower in trials classified as descriptive. Littner et al found that over a five-year period in the field of neonatology, articles with negative results were more likely than articles with positive results to be published in journals with lower IFs [339]. Penel and Adenis found the same pattern of association in phase II trials investigating anticancer therapies [340]. Outside of the medical fields, Murtaugh has explored the relationship between standardised effects and IFs in published meta-analyses of terrestrial plant competition, predation in streams, woody plant growth under elevated CO2, and marine nutrient enrichment experiments. Using raw data, he similarly applied weighted least squares regression analysis of study-specific means of the absolute values of the log response ratios on log of journal IFs and found some evidence that in two of the four areas studied (Nutrient enrichment experiments and predation in streams) that journal IF was associated with reported effects [341].
The presence or absence of associations differs across different research areas. It may be that there is less competition in high-impact journals in terms of newsworthiness of LBP trial results relative to other fields. As it is rare for individual treatments for LBP to stand out dramatically from others in terms of effect size, effect sizes in LBP trials may not be a big driver of an acceptance decision in higher-impact journals.
COI and funding status
We found no evidence that COI category or reported funding status is associated with effect size reported in LBP trials. However, we observed that absolute magnitudes of effect sizes tended to be about one SD larger for trials that declared no funding compared with trials that did not report funding status. The observed association is not due to confounding by sample size. Jacob Cohen, who originally defined standardised effect sizes, considered effect sizes of 0.2 or less to be small, 0.5 to be medium, and 0.8 and above to be large [20]. Using Cohen’s categorisation, the effect size in the larger trials of interventions for LBP tend to be only small-to-medium in magnitude [7].
This relationship is in marked contrast to that observed in other fields, where evidence suggests industry-funded, industry-linked studies, or studies with an industry-funded author, report greater effect sizes than independently funded studies [11, 12, 342, 343]. In the authors’ experiences, LBP research trials tend to be more commonly funded by government and charitable organisations rather than by industry. It may be that, in the case of LBP trials, reporting larger effect sizes, may be higher amongst studies with fewer resources.
Our a priori approach was to compare categories of explicitly reporting no funding/COIs, and explicitly reporting funding/COIs with not reporting anything about funding/COIs, and it is these results that are reported. As a post hoc comparison to explore reporting of funding further, we compared trials that explicitly reported having funding with trials that explicitly reported not having funding, and found strong evidence of a large effect (β=−0.89 (95 % CI −1.46 to −0.33), P = 0.002), suggesting that those reporting receiving funding, report considerably smaller effect sizes than those reporting their trials were not funded.
Trial quality may partially explain the results. It has been previously shown that larger trials in non-specific LBP tend to be higher quality [17, 344]. We did not explore trial quality in our study. Another consideration may be that pragmatic trials tend to be done more often in LBP research, since many interventions under assessment are complex in nature and pharmacological interventions (which are usually of efficacy rather than effectiveness) [345] are comparatively rare. It may be that trials more toward the pragmatic end of the spectrum, which may be more difficult to do in the absence of funding given their typical requirement to be large in scale, may be associated with smaller effect sizes simply because the comparator is often another active intervention. Conversely, efficacy trials may have higher effect sizes in part due to more commonly utilising placebo/sham comparisons. We did not explicitly set out to explore this. However, as another post hoc comparison we looked at the intervention comparisons in our included trials, and those that were compared to sham/placebo had an effect size of 0.74 (large), in contrast with those compared to a non-sham/placebo interventions, which had an effect size of 0.29 (P = 0.077; i.e weak evidence of a small-to-moderate difference).
Strengths and limitations
Meta-regression modelling is most useful in this case as a tool to assess the role of chance in the observed results. We caution against use for prediction, since epistemologically this may not be entirely sensible: prediction may involve a reversal of the direction of causality; authors likely choose journals on the basis of publishing work they believe to be newsworthy, high-quality, or of interest to a particular journal’s readership. More robust and simpler solutions to establishing the role of chance, and whether relationships between effect size and IF are monotonic could be used (such as non-parametric correlation) but, as Murtaugh points out, such approaches are less able to incorporate study-specific weights and are ultimately less powerful [341]. Also, such approaches are not as conducive to the inclusion of covariates. In this study we had sufficient power to detect a medium-to-large effect size in terms of funding category, but not in terms of COI, which were only reported in 7 % of trials.
COIs disclosure may or may not be insisted upon by a journal, or COI forms may have been completed but not reported with the article. Additionally, disclosed COIs may or may not be relevant to the trial. We explored only the presence or absence of such statements reported with the article and did not judge the relevance of disclosed COIs to the trial, nor whether the publishing journal required disclosure, and this as a limitation of our study.
The large I2 values for the models suggests that the residual variance explained by heterogeneity is very high. This is to be expected since the included trials featured many different interventions. In our analysis, other than having a detrimental effect on power, the high I2 is inconsequential to interpretation and does not present a limitation as it would in a meta-analysis of a specific treatment effect. We were not focused on estimating the effect of a specific intervention, but the association between effect size and IF, COIs, and funding across many different interventions for nsLBP, some of which will naturally have larger effects than others.
We imputed zero values for IF in the case of journals without an official IF. Many journals use unofficial IFs and including these could have been used to introduce more information into our models. We reasoned that the majority of journals without official IFs would likely have unofficial IFs of less than 1.00 and preferred to use only official values. We note that if IFs had been associated with effect size then our estimates may have been exaggerated. As we did not find any association with effect size, imputing values where there was no official IF was of limited consequence and does not affect conclusions.
In attempting to explain our results, we have hypothesised that there may be a link to study quality, which we did not explore. While there is some evidence of a small effect of poor quality on effect size in LBP trials from other work, we would welcome future investigations using the Cochrane Risk of Bias tool, since the judgement criteria in this tool can be applied to either pragmatic or efficacy trials without prejudice. Lower quality trials may have been associated with both absence of definition of primary outcome measure, where we would have used outcome measure selection method 3 or 4 (see Methods section), as well as with larger study effects. While we recorded and reported authors explicitly identifying an outcome as primary, for the trials in which this was not explicitly identified, we did not record how often primary outcome identification method 2, 3, or 4 needed to be used. So we caution that there may have been an unmeasured confounding factor.
We rejected trials from which we could not abstract population-specific SD data required for the meta-analysis. This resulted in 47 rejections and opens a possibility for bias, in the case that not reporting these data is also associated with reported effect size. While not specifically an item in the CONSORT statement, this is something one might reasonably expect to be discussed within a sample size calculation. For this reason, we suggest the absence of its reporting, is more likely to be associated with lower quality. Assuming this, and the premise that lower quality trials report larger effect sizes notwithstanding direction, are both correct, then our results will tend toward being conservative.
Finally, we restricted our systematic review to three large databases, reasoning that these index the majority of nsLBP RCTs. We acknowledge however, that the review of the period is unlikely to be exhaustive and that there may be further associations between trials indexed in other databases alone, and quality; and thus with the potential to alter results. However, our results cover most of the field and therefore provide a useful account of behaviour.
Recommendations
Based on our results we recommend that journal editors consider giving increased scrutiny at peer-review stage to unfunded LBP trials. Researchers need to carefully consider whether the trial in question can be adequately and appropriately conducted in the absence of funding, and whether the protocol should be subject to peer review. Consumers of LBP trial reports should note this relationship in the case trials are unfunded.
The causal pathway for the relationship between funding and effect size needs further exploration. If larger effect sizes yielded by unfunded trials are incorrect, these may add noise to data consumed by review work decreasing the precision of meta-analyses. If internal validity is a factor, one might raise the question of whether it is ethically justified to undertake unfunded trials of interventions for LBP. If the extent of the pragmatism of a trial is a driving factor, then absorption of the higher absolute effect sizes into specific review work is less of a concern, but a scale of pragmatism might aid interpretation of effect size from individual trials and be useful to reviewers.
Research into the relationship between funding status and effect size, and IF and effect size, appears to be dependent of the field of research and the nature of interventions under investigation. For this reason we suggest that investigations are conducted across different fields and interventions so that the relationships between COIs and funding and effect size can be better understood and consumers can take this into consideration, as appropriate.
Authors of LBP trials should explicitly report whether or not funding was attained, as only around two-thirds of all authors are currently doing this. Moreover, more authors need to be explicit about whether or not there were COIs as in our dataset only 29 % of authors are doing this. Journals and editors could consider taking steps to ensuring this information is reported.
Conclusions
While there is no evidence that reported funding status and reported conflicts of interest influence effect size, there is very strong evidence that authors who explicitly report that their LBP trial was unfunded tend to report larger absolute magnitudes of effect size. Journal editors, researchers, and consumers may have need to be cautious of large effect sizes in unfunded trials, possibly giving additional scrutiny to internal validity. Our results contrast with findings in pharmacological research and suggests relationships may vary by field. Further discipline-specific investigations would inform interpretation of trial reports and help identify causal pathways of associations between effect sizes and trial/report characteristics.
Abbreviations
- CI:
-
Confidence interval
- CONSORT:
-
Consolidated standards of reporting trials
- COI:
-
Conflict of interest
- IF:
-
Impact factor
- ISI:
-
(Thomson Reuters) Institute for scientific information
- LBP:
-
Low back pain
- RCT:
-
Randomised controlled trial
- REML:
-
Restricted maximum likelihood
- SD:
-
Standard deviation
- SE:
-
Standard error
- SMD:
-
Standardised mean difference
- SSE:
-
Re-standardised standard error
- YLD:
-
Years lived with disability
References
Walker BF. The prevalence of low back pain: a systematic review of the literature from 1966 to 1998. J Spinal Disord. 2000; 13(3):205–17.
Maniadakis N, Gray A. The economic burden of back pain in the UK. Pain. 2000; 84:95–103.
Dunn KM, Croft PR. Epidemiology and natural history of low back pain. Europa Medicophysica. 2004; 40(1):9–13.
Vos T, Flaxman AD, Naghavi M, Lozano R, Michaud C, Ezzati M, et al.Years lived with disability (YLDs) for 1160 sequelae of 289 diseases and injuries 1990-2010: a systematic analysis for the global burden of disease study 2010. Lancet. 2012; 380(9859):2163–96. doi:10.1016/S0140-6736(12)61729-2.
Savigny P, Watson P, Underwood M, Group GD. Early management of persistent non-specific low back pain: summary of nice guidance. BMJ. 2009; 338:1805.
Froud R, Eldridge S, Lall R, Underwood M. Estimating number needed to treat from continuous outcomes in randomised controlled trials: Methodological challenges and worked example using data from the UK back pain exercise and manipulation (BEAM) trial. BMC Med Res Meth. 2009; 9:35.
Froud R. Improving interpretation of patient-reported outcomes in low back pain trials. PhD Thesis. London: Queen Mary University of London : 2010.
Underwood MR, Morton V, Farrin A. Do baseline characteristics predict response to treatment for low back pain? Secondary analysis of the UK BEAM dataset [ISRCTN32683578]. Rheumatology (Oxford). 2007; 46(8):1297–302.
Froud R, Underwood M, Carnes D, Eldridge S. Clinicians’ perceptions of reporting methods for back pain trials: a qualitative study. Br J Gen Pract. 2012; 62(596):151–9. doi:10.3399/bjgp12X630034.
Schulz KF, Altman DG, Moher D, CONSORT. Consort 2010 statement: updated guidelines for reporting parallel group randomised trials. BMJ. 2010; 340:32.
Lexchin J, Bero LA, Djulbegovic B, Clark O. Pharmaceutical industry sponsorship and research outcome and quality: systematic review. BMJ. 2003; 326(7400):1167–70. doi:10.1136/bmj.326.7400.1167.
Bekelman JE, Li Y, Gross CP. Scope and impact of financial conflicts of interest in biomedical research: a systematic review. JAMA. 2003; 289(4):454–65.
Seglen P. Why the impact factor of journals should not be used for evaluating research. BMJ. 1997; 314:497.
Saha S, Saint S, Christakis DA. Impact factor: a valid measure of journal quality?J Med Libr Assoc. 2003; 91(1):42–6.
Gasparyan A. Choosing the target journal: Do authors need a comprehensive approach?J Korean Med Sci. 2013; 28(8):1117–1119.
Hempel S, Booth M, Miles J, Wang Z, Maglione M, Morton S, et al.Empirical evidence of associations between trial quality and effect size. Technical report, Agency for Healthcare Research and Quality. 2011.
van Tulder MW, Suttorp M, Morton S, Bouter LM, Shekelle P. Empirical evidence of an association between internal validity and effect size in randomized controlled trials of low-back pain. Spine (Phila Pa 1976). 2009; 34(16):1685–92.
Heymans MW, van Tulder MW, Esmail R, Bombardier C, Koes BW. Back schools for non-specific low-back pain. Cochrane Database Syst Rev. 2004; 30(19):2153–63.
Diaz-Ordaz K, Froud R, Sheehan B, Eldridge S. A systematic review of cluster randomised trials in residential facilities for older people suggests how to improve quality. BMC Med Res Methodol. 2013; 13:127. doi:10.1186/1471-2288-13-127.
Cohen JW. A power primer. Psychol Bull. 1992; 112(1):155–9.
Higgins JPT, Thompson SG. Controlling the risk of spurious findings from meta-regression. Stat Med. 2004; 23(11):1663–82. doi:10.1002/sim.1752.
Knapp G, Hartung J. Improved tests for a random-effects meta-regression with a single covariate. Stat Med. 2003; 22:2693–710.
Thompson SG, Sharp SJ. Explaining heterogeneity in meta-analysis: a comparison of methods. Stat Med. 1999; 18:2693–708.
Harbord R, Higgins J. Meta-regression in stata. Stata J. 2008; 8(4):493–519.
Stanley T, Doucouliagos H. Better than random: Weighted least squares meta-regression analysis. Technical report: Deakin University; 2013.
Sharp S. Meta-analysis regression. Stata Tech Bull. 1998; 42:16–22.
Adamczyk A, Kiebzak W, Wilk-Franczuk M, Sliwinski Z. Effectiveness of holistic physiotherapy for low back pain. Ortop Traumatol Rehabil. 2009; 11(6):562–76.
Anon. Erratum: Efficacy and safety of tapentadol extended release for the management of chronic low back pain: results of a prospective, randomized, double-blind, placebo- and active-controlled phase iii study. Expert Opin Pharmacother. 2010; 11(16):2773.
Ansari NN, Ebadi S, Talebian S, Naghdi S, Mazaheri H, Olyaei G, et al.A randomized, single blind placebo controlled clinical trial on the effect of continuous ultrasound on low back pain. Electromyogr Clin Neurophysiol. 2006; 46(6):329–36.
Barker KL, Elliott CJ, Sackley CM, Fairbank JC. Treatment of chronic back pain by sensory discrimination training. a phase i rct of a novel device (fairmed) vs. tens. BMC Musculoskelet Disord. 2008; 9:97.
Basler HD, Bertalanffy H, Quint S, Wilke A, Wolf U. Ttm-based counselling in physiotherapy does not contribute to an increase of adherence to activity recommendations in older adults with chronic low back pain–a randomised controlled trial. Eur J Pain. 2007; 11(1):31–7.
Belavy DL, Armbrecht G, Gast U, Richardson CA, Hides JA, Felsenberg D. Countermeasures against lumbar spine deconditioning in prolonged bed rest: resistive exercise with and without whole body vibration. J Appl Physiol. 2010; 109(6):1801–11.
Bergholdt K, Fabricius RN, Bendix T. Better backs by better beds?Spine (Phila Pa 1976). 2008; 33(7):703–8.
Bogefeldt J, Grunnesjo MI, Svardsudd K, Blomberg S. Sick leave reductions from a comprehensive manual therapy programme for low back pain: the gotland low back pain study. Clin Rehabil. 2008; 22(6):529–41.
Bronfort G, Maiers MJ, Evans RL, Schulz CA, Bracha Y, Svendsen KH, et al.Supervised exercise, spinal manipulation, and home exercise for chronic low back pain: A randomized clinical trial. Spine J. 2011; 11(7):585–98.
Browder DA, Childs JD, Cleland JA, Fritz JM. Effectiveness of an extension-oriented treatment approach in a subgroup of subjects with low back pain: a randomized clinical trial. Phys Ther. 2007; 87(12):1608–18.
Bruehl S, Burns JW, Chung OY, Quartana P. Anger management style and emotional reactivity to noxious stimuli among chronic pain patients and healthy controls: the role of endogenous opioids. Health Psychol. 2008; 27(2):204–14.
Bruehl S, Chung OY, Burns JW, Diedrich L. Trait anger expressiveness and pain-induced beta-endorphin release: support for the opioid dysfunction hypothesis. Pain. 2007; 130(3):208–15.
Buttagat V, Eungpinichpong W, Chatchawan U, Kharmwan S. The immediate effects of traditional Thai massage on heart rate variability and stress-related parameters in patients with back pain associated with myofascial trigger points. J Bodyw Mov Ther. 2011; 15(1):15–23.
Buynak R, Etropolski M, Lange B, Shapiro DY, Okamoto A, Steup A, et al.Dose stability of tapentadol er for the relief of chronic low back pain: Results of a randomized, active- and placebo-controlled study. Arthritis Rheum. 2009; 60:1494.
Cabitza P, Randelli P. Efficacy and safety of eperisone in patients with low back pain: a double blind randomized study. Eur Rev Med Pharmacol Sci. 2008; 12(4):229–35.
Casserley-Feeney SN, Bury G, Daly L, Hurley DA. The ACCESS trial - randomised controlled trial of public hospital-based versus private clinic-based physiotherapy for low back pain: clinical outcomes. J Bone Joint Surg Br. 2008; 90(SUPP III):492.
Cevik R, Bilici A, Gur A, Sarac AJ, Yildiz H, Nas K, et al.Effect of new traction technique of prone position on distraction of lumbar vertebrae and its relation with different application of heating therapy in low back pain. Journal of Back and Musculoskeletal Rehabilitation. 2007; 20(2-3):71–77.
Christiansen S, Oettingen G, Dahme B, Klinger R. A short goal-pursuit intervention to improve physical capacity: A randomized clinical trial in chronic back pain patients. Pain. 2010; 149(3):444–52.
Clark D, Chu L. Tolerance and opioid-induced hyperalgesia in clinical populations. Eur J Pain Suppl. 2010; 4(1):29.
Cleland J, Fritz J, Kulig K, Davenport TE, Eberhart S, Magel JS, et al.Comparison of the effectiveness of 3 manual physical therapy techniques in a subgroup of patients with low back pain who satisfy a clinical prediction rule: a randomized clinical trial. Spine. 2009; 34(25):2720–9.
Codding C, Levinsky D, Hale ME, Thomas JW, Lockhart E, Best A, et al.Efficacy and safety evaluation of 12 weeks extended-release hydrocodone/acetaminophen treatment in patients with chronic low back pain (clbp) by prior opioid use. Pain Med. 2009; 10(1):260.
Cohen SP, Stojanovic MP, Crooks M, Kim P, Schmidt RK, Shields CH, et al.Lumbar zygapophysial (facet) joint radiofrequency denervation success as a function of pain relief during diagnostic medial branch blocks: a multicenter analysis. Spine J. 2008; 8(3):498–504.
Costantino C, Marangio E, Coruzzi G. Mesotherapy versus systemic therapy in the treatment of acute low back pain: A randomized trial. Evid Based Complement Alternat Med. 2011; 2011:317183.
Cox JM. A randomized controlled trial comparing 2 types of spinal manipulation and minimal conservative medical care for adults 55 years and older with subacute or chronic low back pain. J Manipulative Physiol Ther. 2009; 32(7):601.
Critchley DJ, Ratcliffe J, Noonan S, Jones RH, Hurley MV. Effectiveness and cost-effectiveness of three types of physiotherapy used to reduce chronic low back pain disability: a pragmatic randomized trial with economic evaluation. Spine (Phila Pa 1976). 2007; 32(14):1474–81.
Curnow D, Cobbin D, Wyndham J, Boris Choy ST. Altered motor control, posture and the pilates method of exercise prescription. J Bodyw Mov Ther. 2009; 13(1):104–11.
Yelland MJ, Mar C, Pirozzo S, Schoene ML, Vercoe P. Prolotherapy injections for chronic low-back pain. Cochrane Database Syst Rev. 2007; (2):CD004059. http://www.ncbi.nlm.nih.gov/pubmed/18254037.
Day IJ, Kent CF, Burnham RS. Can topical anesthetic reduce the pain associated with diagnostic blocks of the lumbosacral spine?Pain Med. 2008; 9(6):675–9.
del Pozo-Cruz B, Hernandez Mocholi MA, Adsuar JC, Parraca JA, Muro I, Gusi N. Effects of whole body vibration therapy on main outcome measures for chronic non-specific low back pain: a single-blind randomized controlled trial. J Rehabil Med. 2011; 43(8):689–94.
Demoulin C, Maquet D, Tomasella M, Croisier J, Crielaard J, Vanderthommen M. Benefits of a physical training program after back school for chronic low back pain patients. Journal of Musculoskeletal Pain. 2006; 14(2):21–31.
Deshpande A, Furlan A, Mailis-Gagnon A, Atlas S, Turk D. Opioids for chronic low-back pain. Cochrane Database Syst Rev. 2007; (3):CD004959. http://www.ncbi.nlm.nih.gov/pubmed/18254037.
Desmoulin GT, Yasin NI, Chen DW. Initial results using khan kinetic treatment(trademark) as a low back pain treatment option. J Musculoskelet Pain. 2007; 15(3):91–102.
Dianne Liddle S, Gracey JH, David Baxter G. Advice for the management of low back pain: A systematic review of randomised controlled trials. Manual Therapy. 2007; 12(4):310–27.
Eisenberg DM, Post DE, Davis RB, Connelly MT, Legedza AT, Hrbek AL, et al.Addition of choice of complementary therapies to usual care for acute low back pain: a randomized controlled trial. Spine (Phila Pa 1976). 2007; 32(2):151–8.
Engers A, Jellema P, Wensing M, van der Windt DA, Grol R, van Tulder MW. Individual patient education for low back pain. Cochrane Database Syst Rev. 2008; (1):CD004057. http://www.ncbi.nlm.nih.gov/pubmed/18254037.
Etropolski M, Rauschkolb-Loffler C, Shapiro D, Okamoto A, Lange C. A randomized, double-blind, placebo- and active-controlled phase iii study of tapentadol er for chronic low back pain: Analysis of efficacy endpoint sensitivity. J Pain. 2009; 10(4):51.
Etropolski MS, Okamoto A, Shapiro DY, Rauschkolb C. Dose conversion between tapentadol immediate and extended release for low back pain. Pain Physician. 2010; 13(1):61–70.
Evans DD, Carter M, Panico R, Kimble L, Morlock JT, Spears MJ. Characteristics and predictors of short-term outcomes in individuals self-selecting yoga or physical therapy for treatment of chronic low back pain. PM R. 2010; 2(11):1006–15.
Facci LM, Nowotny JP, Tormem F, Trevisani VF. Effects of transcutaneous electrical nerve stimulation (tens) and interferential currents (ifc) in patients with nonspecific chronic low back pain: randomized clinical trial. Sao Paulo Med J. 2011; 129(4):206–16.
Fritz JM, Lindsay W, Matheson JW, Brennan GP, Hunter SJ, Moffit SD, et al.Is there a subgroup of patients with low back pain likely to benefit from mechanical traction? results of a randomized clinical trial and subgrouping analysis. Spine (Phila Pa 1976). 2007; 32(26):793–800.
Gatti R, Faccendini S, Tettamanti A, Barbero M, Balestri A, Calori G. Efficacy of trunk balance exercises for individuals with chronic low back pain: a randomized clinical trial. J Orthop Sports Phys Ther. 2011; 41(8):542–2.
George SZ, Childs JD, Teyhen DS, Wu SS, Wright AC, Dugan JL, et al.Brief psychosocial education, not core stabilization, reduced incidence of low back pain: results from the prevention of low back pain in the military (polm) cluster randomized trial. BMC Med. 2011; 9:128.
George SZ, Teyhen DS, Wu SS, Wright AC, Dugan JL, Yang G, et al.Psychosocial education improves low back pain beliefs: results from a cluster randomized clinical trial (nct00373009) in a primary prevention setting. Eur Spine J. 2009; 18(7):1050–8.
George SZ, Wittmer VT, Fillingim RB, Robinson ME. Comparison of graded exercise and graded exposure clinical outcomes for patients with chronic low back pain. J Orthop Sports Phys Ther. 2010; 40(11):694–704.
George SZ, Zeppieri JG, Cere AL, Cere MR, Borut MS, Hodges MJ, et al.A randomized trial of behavioral physical therapy interventions for acute and sub-acute low back pain (nct00373867). Pain. 2008; 140(1):145–57.
Gould EM, Jensen MP, Victor TW, Gammaitoni AR, White RE, Galer BS. The pain quality response profile of oxymorphone extended release in the treatment of low back pain. Clin J Pain. 2009; 25(2):116–22.
Guthrie RJ, Grindstaff TL, Croy T, Ingersoll CD, Saliba SA. The effect of traditional bridging or suspension exercise bridging on lateral abdominal thickness in individuals with low back pain. J Sport Rehabil. 2012; 21(2):151–60.
Hale M, Khan A, Kutch M, Li S. Once-daily oros hydromorphone er compared with placebo in opioid-tolerant patients with chronic low back pain. Curr Med Res Opin. 2010; 26(6):1505–18.
Hale ME, Ahdieh H, Ma T, Rauck R. Efficacy and safety of opana er (oxymorphone extended release) for relief of moderate to severe chronic low back pain in opioid-experienced patients: a 12-week, randomized, double-blind, placebo-controlled study. J Pain. 2007; 8(2):175–84.
Hancock MJ, Maher CG. Letter to editor re: Cleland JA, Fritz JM, Kulig K, et al. Comparison of the effectiveness of three manual physical therapy techniques in a subgroup of patients with low back pain who satisfy a clinical prediction rule. A randomized clinical trial. Spine. 2010; 35:839.
Hasegawa TM, Baptista AS, De Souza MC, Yoshizumi AM, Natour J. Acupuncture for acute non-specific low back pain: A randomized, controlled, placebo trial. Arthritis Rheum. 2009; 60:1497.
Helmhout PH, Harts CC, Viechtbauer W, Staal JB, de Bie RA. Isolated lumbar extensor strengthening versus regular physical therapy in an army working population with nonacute low back pain: a randomized controlled trial. Arch Phys Med Rehabil. 2008; 89(9):1675–85.
Helmhout PH, Staal JB, Heymans MW, Harts CC, Hendriks EJ, de Bie RA. Prognostic factors for perceived recovery or functional improvement in non-specific low back pain: secondary analyses of three randomized clinical trials. Eur Spine J. 2010; 19(4):650–9.
Henchoz Y, Pinget C, Wasserfallen JB, Paillex R, de Goumoens P, Norberg M, et al.Cost-utility analysis of a three-month exercise programme vs usual care following multidisciplinary rehabilitation for chronic low back pain. J Rehabil Med. 2010; 42(9):846–52.
Heymans MW, Anema JR, Vet HC, Mechelen W. Does flexion-distraction help treat chronic low back pain?Nat Clin Pract Rheumatol. 2006; 2(7):360–1.
Hides JA, Stanton WR, Mendis MD, Gildea J, Sexton MJ. Effect of motor control training on muscle size and football games missed from injury. Med Sci Sports Exerc. 2012; 44(6):1141–9.
Hlobil H, Uegaki K, Staal JB, de Bruyne MC, Smid T, van Mechelen W. Substantial sick-leave costs savings due to a graded activity intervention for workers with non-specific sub-acute low back pain. Eur Spine J. 2007; 16(7):919–24.
Hollinghurst S, Sharp D, Ballard K, Barnett J, Beattie A, Evans M, et al.Randomised controlled trial of alexander technique lessons, exercise, and massage (ateam) for chronic and recurrent back pain: economic evaluation. BMJ. 2008; 337:2656.
Hurley DA, O’Donoghue G, Tully MA, Moffett JK, van Mechelen W, Daly L, et al.A walking programme and a supervised exercise class versus usual physiotherapy for chronic low back pain: a single-blinded randomised controlled trial. (the supervised walking in comparison to fitness training for back pain (swift) trial). BMC Musculoskelet Disord. 2009; 10:79.
Hush J. Tens of unknown value in the treatment of chronic low back pain. Aust J Physiother. 2006; 52(1):64.
Ijzelenberg H, Meerding WJ, Burdorf A. Effectiveness of a back pain prevention program: A cluster randomized controlled trial in an occupational setting. Spine. 2007; 32(7):711–9.
Ikegami S, Kamimura M, Uchiyama S, Nakagawa H, Hashidate H, Takahara K, et al.Anti-nociceptive effects of elcatonin injection for postmenopausal women with back pain: A randomized controlled trial. Osteoporos Int. 2010; 21:197–8.
Inoue M, Hojo T, Nakajima M, Kitakoji H, Itoi M. Comparison of the effectiveness of acupuncture treatment and local anaesthetic injection for low back pain: a randomised controlled clinical trial. Acupunct Med. 2009; 27(4):174–7.
Jans MP, Korte d EM, Heinrich J, Hildebrandt VH. Intermittent follow-up treatment with Cesar exercise therapy in patients with subacute or chronic aspecific low back pain: results of a randomized, controlled trial with a 1.5-year follow-up. / Intermitterende vervolgbehandeling oefentherapie Cesar bij subacute of chronische aspecifieke lage-rugklachten: een RCT Cochrane Register of Controlled Trials. 2006: CN-00592636. 2006. http://www.ncbi.nlm.nih.gov/pubmed/15106234.
Kasis AG, Marshman LAG, Krishna M, Bhatia CK. Significantly improved outcomes with a less invasive posterior lumbar interbody fusion incorporating total facetectomy. Spine (Phila Pa 1976). 2009; 34(6):572–7.
Katz N, Borenstein D, Birbara C, Bramson C, Nemeth M, Smith M, et al.Tanezumab, an anti-nerve growth factor (ngf) antibody, for the treatment of chronic low back pain (clbp) - a randomized, controlled, double-blind, phase 2 trial. J Pain. 2009; 10(4):42.
Katz N, Rauck R, Ahdieh H, Ma T, Van Der Hoop RG, Kerwin R, et al.A 12-week, randomized, placebo-controlled trial assessing the safety and efficacy of oxymorphone extended release for opioid-naive patients with chronic low back pain. Curr Med Res Opin. 2007; 23(1):117–28.
Kavanagh S, Lange B, Ashworth J, Etropolski MS, McNeill M, Rauschkolb C. Tapentadol extended release (er) for chronic low back pain: Results of euroqol-5 dimension (eq-5d) and short form-36 (sf-36) health status questionnaires. Value Health. 2009; 12(7):376.
Kettenmann B, Wille C, Lurie-Luke E, Walter D, Kobal G. Impact of continuous low level heatwrap therapy in acute low back pain patients: subjective and objective measurements. Clin J Pain. 2007; 23(8):663–8.
Kool J, Bachmann S, Oesch P, Knuesel O, Ambergen T, de Bie R, et al.Function-centered rehabilitation increases work days in patients with nonacute nonspecific low back pain: 1-year results from a randomized controlled trial. Arch Phys Med Rehabil. 2007; 88(9):1089–94.
Kovacs F, Abraira V, Santos S, Diaz E, Gestoso M, Muriel A, et al.A comparison of two short education programs for improving low back pain-related disability in the elderly: a cluster randomized controlled trial. Spine (Phila Pa 1976). 2007; 32(10):1053–9.
Kullich W, Schwann H, Machreich K, Ausserwinkler M. Additional outcome improvement in the rehabilitation of chronic low back pain after nuclear resonance therapy. Rheumatologia. 2006; 20(1):7–12.
Kullich W, Schwann H, Walcher J, Machreich K. The effect of MBST-NuclearResonanceTherapy with a complex 3-dimensional electromagnetic nuclear resonance field on patients with low back pain 23. Journal of Back and Musculoskeletal Rehabilitation. 2006; 19:79–87.
Lamb SE, Lall R, Hansen Z, Castelnuovo E, Withers EJ, Nichols V, et al.A multicentred randomised controlled trial of a primary care-based cognitive behavioural programme for low back pain. the back skills training (best) trial. Health Technol Assess. 2010; 14(41):1–253.
Lee JW, Shin HI, Park SY, Lee GY, Kang HS. Therapeutic trial of fluoroscopic interlaminar epidural steroid injection for axial low back pain: effectiveness and outcome predictors. AJNR Am J Neuroradiol. 2010; 31(10):1817–23.
Lee TJ. Pharmacologic treatment for low back pain: one component of pain care. Phys Med Rehabil Clin N Am. 2010; 21(4):793–800.
Leeuw M, Goossens ME, van Breukelen GJ, de Jong JR, Heuts PH, Smeets RJ, et al.Exposure in vivo versus operant graded activity in chronic low back pain patients: results of a randomized controlled trial. Pain. 2008; 138(1):192–207.
Leichtfried V, Kantner-Rumplmair W, Raggautz M, Bartenbach C, Aigner M, Winkler D, et al.Can bright light therapy ameliorate symptoms associated with low back pain (LBP)? A randomized controlled trial. J Psychosom Res. 2010; 68(6):642.
Lewis C, Khan A, Souvlis T, Sterling M. A randomised controlled study examining the short-term effects of strain-counterstrain treatment on quantitative sensory measures at digitally tender points in the low back. Man Ther. 2010; 15(6):536–41.
Li C, Ni J, Wang Z, Li M, Gasparic M, Terhaag B, et al.Analgesic efficacy and tolerability of flupirtine vs. tramadol in patients with subacute low back pain: a double-blind multicentre trial. Curr Med Res Opin. 2008; 24(12):3523–0.
Limke JC, Rainville J, Pena E, Childs L. Randomized trial comparing the effects of one set vs two sets of resistance exercises for outpatients with chronic low back pain and leg pain. Eur J Phys Rehabil Med. 2008; 44(4):399–405.
Lin ML, Lin MH, Fen JJ, Lin WT, Lin CW, Chen PQ. A comparison between pulsed radiofrequency and electro-acupuncture for relieving pain in patients with chronic low back pain. Acupunct Electrother Res. 2010; 35(3-4):133–46.
Long A, May S, Fung T. The comparative prognostic value of directional preference and centralization: A useful tool for front-line clinicians?J Manual Manip Therapy. 2008; 16(4):248–54.
Macfarlane GJ. Changing patient perceptions of their illness: Can they contribute to an improved outcome for episodes of musculoskeletal pain?Pain. 2008; 136(1-2):1–2.
Magnusson ML, Chow DH, Diamandopoulos Z, Pope MH. Motor control learning in chronic low back pain. Spine (Phila Pa 1976). 2008; 33(16):532–8.
Mandara A, Fusaro A, Musicco M, Bado F. A randomised controlled trial on the effectiveness of osteopathic manipulative treatment of chronic low back pain. Int J Ost Med. 2008; 11(4):156.
Mattila R, Malmivaara A, Kastarinen M, Kivela SL, Nissinen A. The effects of lifestyle intervention for hypertension on low back pain: a randomized controlled trial. Spine (Phila Pa 1976). 2007; 32(26):2943–7.
Mehling WE. Breath therapy for chronic low back pain. J Bodyw Mov Ther. 2006; 10(2):96–8.
Mehta S, Chopra A, Goregaonkar A, Chandanwale A, Medhi B, Shah V, et al.Evaluation of efficacy and safety of eperisone hydrochloride in treatment of acute musculoskeletal spasm associated with low back pain: A randomized, doubleblind, placebo-controlled trial. Pain Pract. 2009; 9:123.
Meng K, Seekatz B, Roband H, Worringen U, Vogel H, Faller H. Intermediate and long-term effects of a standardized back school for inpatient orthopedic rehabilitation on illness knowledge and self-management behaviors: a randomized controlled trial. Clin J Pain. 2011; 27(3):248–57.
Mirovsky Y, Grober A, Blankstein A, Stabholz L. The effect of ambulatory lumbar traction combined with treadmill on patients with chronic low back pain. J Back Musculoskeletal Rehabil. 2006; 19(2-3):73–8.
Miyazaki S, Hagihara A, Kanda R, Mukaino Y, Nobutomo K. Applicability of press needles to a double-blind trial: a randomized, double-blind, placebo-controlled trial. Clin J Pain. 2009; 25(5):438–4.
Murtezani A, Hundozi H, Orovcanec N, Sllamniku S, Osmani T. A comparison of high intensity aerobic exercise and passive modalities for the treatment of workers with chronic low back pain: a randomized, controlled trial. Eur J Phys Rehabil Med. 2011; 47(3):359–66.
Najm WI. German acupuncture trials (gerac) for chronic low back pain. Med Acupunct. 2008; 20(2):131–2.
Nath S, Nath CA, Pettersson K. Percutaneous lumbar zygapophysial (facet) joint neurotomy using radiofrequency current, in the management of chronic low back pain: a randomized double-blind trial. Spine (Phila Pa 1976). 2008; 33(12):1291–71298.
Nelson-Wong E, Callaghan JP. Changes in muscle activation patterns and subjective low back pain ratings during prolonged standing in response to an exercise intervention. J Electromyogr Kinesiol. 2010; 20(6):1125–33.
North RB, Kidd DH, Olin J, Sieracki JM, Boulay M. Spinal cord stimulation with interleaved pulses: A randomized, controlled trial. Neuromodulation. 2007; 10(4):349–57.
O’Brien N, Hanlon M, Meldrum D. Randomised, controlled trial comparing physiotherapy and Pilates in the treatment of ordinary low back pain. Concrans Register of Controlled Trials. 2006; 452:3165. http://pesquisa.bvsalud.org/evidences/resource/en/CN-00592705.
O’Donnell JB, Ekman EF, Spalding WM, Bhadra P, McCabe D, Berger MF. The effectiveness of a weak opioid medication versus a cyclo-oxygenase-2 (cox-2) selective non-steroidal anti-inflammatory drug in treating flare-up of chronic low-back pain: results from two randomized, double-blind, 6-week studies. J Int Med Res. 2009; 37(6):1789–802.
Paatelma M, Kilpikoski S, Simonen R, Heinonen A, Alen M, Videman T. Orthopaedic manual therapy, mckenzie method or advice only for low back pain in working adults: a randomized controlled trial with one year follow-up. J Rehabil Med. 2008; 40(10):858–63.
Padua R, Bondi R, Ceccarelli E, Alviti F. Re: A randomized study of back school in women with chronic low back pain. quality of life at three, six, and twelve months follow-up. Spine (Phila Pa 1976). 2009; 34(12):1336.
Pareek A, Chandurkar N, Chandanwale AS, Ambade R, Gupta A, Bartakke G. Aceclofenac-tizanidine in the treatment of acute low back pain: a double-blind, double-dummy, randomized, multicentric, comparative study against aceclofenac alone. Eur Spine J. 2009; 18(12):1836–42.
Pengel LH, Refshauge KM, Maher CG, Nicholas MK, Herbert RD, McNair P. Physiotherapist-directed exercise, advice, or both for subacute low back pain: a randomized trial. Ann Intern Med. 2007; 146(11):787–96.
Peniston JH, Gould E. Oxymorphone extended release for the treatment of chronic low back pain: a retrospective pooled analysis of enriched-enrollment clinical trial data stratified according to age, sex, and prior opioid use. Clin Ther. 2009; 31(2):347–59.
Perrot S, Krause D, Crozes P, Naim C. Efficacy and tolerability of paracetamol/tramadol (325 mg/37.5 mg) combination treatment compared with tramadol (50 mg) monotherapy in patients with subacute low back pain: a multicenter, randomized, double-blind, parallel-group, 10-day treatment study. Clin Ther. 2006; 28(10):1592–606.
Petersen T, Larsen K, Jacobsen S. One-year follow-up comparison of the effectiveness of mckenzie treatment and strengthening training for patients with chronic low back pain: outcome and prognostic factors. Spine (Phila Pa 1976). 2007; 32(26):2948–56.
Petersen T, Larsen K, Nordsteen J, Olsen S, Fournier G, et al.The mckenzie method compared with manipulation when used adjunctive to information and advice in low back pain patients presenting with centralization or peripheralization: a randomized controlled trial. Spine (Phila Pa 1976). 2011; 36(24):1999–2010.
Petrofsky JS, Batt J, Brown J, Stacey L, Bartelink T, Le Moine M, et al.Improving the outcomes after back injury by a core muscle strengthening program. J Appl Res. 2008; 8(1):62–75.
Podichetty VK, Varley ES, Oleske dm, lavender sa, andersson gb, et al.are back supports plus education more effective than education alone in promoting recovery from low back pain? results from a randomized clinical trial. spine 2007; 32:2050-7. Spine (Phila Pa 1976). 2008; 33(3):349–50.
Popovic DB, Bijelic G, Miler V, Dosen S, Popovic MB, Schwirtlich L. Lumbar stimulation belt for therapy of low-back pain. Artif Organs. 2009; 33(1):54–60.
Portenoy RK, Messina J, Xie F, Peppin J. Fentanyl buccal tablet (fbt) for relief of breakthrough pain in opioid-treated patients with chronic low back pain: a randomized, placebo-controlled study. Curr Med Res Opin. 2007; 23(1):223–33.
Pushpika Attanayake AM, Somarathna KI, Vyas GH, Dash SC. Clinical evaluation of selected yogic procedures in individuals with low back pain. Ayu. 2010; 31(2):245–50.
Quartana PJ, Burns JW, Lofland KR. Attentional strategy moderates effects of pain catastrophizing on symptom-specific physiological responses in chronic low back pain patients. J Behav Med. 2007; 30(3):221–31.
Ralph L, Look M, Wheeler W, Sacks H. Double-blind, placebo-controlled trial of carisoprodol 250-mg tablets in the treatment of acute lower-back spasm. Curr Med Res Opin. 2008; 24(2):551–8.
Ralph L, Wheeler B, Sacks H. Improvement in functional status with carisoprodol 250-mg tablets in patients with acute lower back spasm: A randomized, double-blind, placebo-controlled trial. Pain Med. 2009; 10(1):258.
Rauck RL, Bookbinder SA, Bunker TR, Alftine CD, Ghalie R, Negro-Vilar A, et al.The action study: a randomized, open-label, multicenter trial comparing once-a-day extended-release morphine sulfate capsules (avinza) to twice-a-day controlled-release oxycodone hydrochloride tablets (oxycontin) for the treatment of chronic, moderate to severe low back pain. J Opioid Manag. 2006; 2(3):155–66.
Rauck RL, Bookbinder SA, Bunker TR, Alftine CD, Ghalie R, Negro-Vilar A, et al.A randomized, open-label study of once-a-day avinza (morphine sulfate extended-release capsules) versus twice-a-day oxycontin (oxycodone hydrochloride controlled-release tablets) for chronic low back pain: the extension phase of the action trial. J Opioid Manag. 2006; 2(6):325–83313.
Rivero Arias O, Gray A, Frost H, Lamb SE, Stewart Brown S. Cost-utility analysis of physiotherapy treatment compared with physiotherapy advice in low back pain. Spine. 2006; 31(12):1381–7.
Romano CL, Romano D, Bonora C, Mineo G. Pregabalin, celecoxib, and their combination for treatment of chronic low-back pain. J Orthop Traumatol. 2009; 10(4):185–91.
Rusinyol FC, Perice RV, Boronat ER, Bosch FF. Effects of two different doses of eperisone in the treatment of acute low back pain. J Appl Res. 2009; 9(1-2):23–9.
Ruth M, Weber M, Zenz M. Laser acupuncture for chronic back pain. a double-blind clinical study. Schmerz. 2010; 24(5):485–93.
Schimmel JJ, de Kleuver M, Horsting PP, Spruit M, Jacobs WC, van Limbeek J. No effect of traction in patients with low back pain: a single centre, single blind, randomized controlled trial of intervertebral differential dynamics therapy. Eur Spine J. 2009; 18(12):1843–50.
Schmidt-Wilcke T. Affective components and intensity of pain correlate with structural differences in gray matter in chronic back pain patients. Pain. 2006; 125(1-2):89–97.
Schwarz I, Lawrence DJ. Relative responsiveness of 3 different types of clinical outcome measures on chiropractic patients with low back pain. J Manip Physiol Ther. 2007; 30(1):77–8.
Serfer GT, Wheeler WJ, Sacks HJ. Randomized, double-blind trial of carisoprodol 250 mg compared with placebo and carisoprodol 350 mg for the treatment of low back spasm. Curr Med Res Opin. 2010; 26(1):91–9.
Sertpoyraz F, Eyigor S, Karapolat H, Capaci K, Kirazli Y. Comparison of isokinetic exercise versus standard exercise training in patients with chronic low back pain: a randomized controlled study. Clin Rehabil. 2009; 23(3):238–47.
Shakoor MA, Salek AKM, Islam MT, Moyeenuzzaman M. Evaluation of the effects of selective rehabilitation on the patients with chronic low back pain. Int J Rheum Dis. 2010; 13:221.
Sherman KJ, Cherkin DC, Ichikawa L, Avins AL, Barlow WE, Khalsa PS, et al.Characteristics of patients with chronic back pain who benefit from acupuncture. BMC Musculoskelet Disord. 2009; 10:114.
Sherman KJ, Cherkin DC, Ichikawa L, Avins AL, Delaney K, Barlow WE, et al.Treatment expectations and preferences as predictors of outcome of acupuncture for chronic back pain. Spine (Phila Pa 1976). 2010; 35(15):1471–7.
Shimoji K, Takahashi N, Nishio Y, Koyanagi M, Aida S. Pain relief by transcutaneous electric nerve stimulation with bidirectional modulated sine waves in patients with chronic back pain: a randomized, double-blind, sham-controlled study. Neuromodulation. 2007; 10(1):42–51.
Shum G. Movement coordination of the lumbar spine and hip during a picking up activity in low back pain subjects. Eur Spine J. 2006; 16(6):749–58.
Skljarevski V, Zhang S, Desaiah D, Palacios S, Miazgowski T, Patrick K. Efficacy and safety of duloxetine 60 mg once-daily in patients with chronic low back pain. J Pain. 2010; 11(4):38.
Skljarevski V, Zhang S, Desaiah D, Palacios S, Miazgowski T, Patrickm K. Effect of duloxetine 60 mg once daily versus placebo in patients with chronic low back pain: A 12-week, randomized, double-blind trial. Pain Med. 2010; 11(2):322.
Slater MA, Weickgenant AL, Greenberg MA, Wahlgren DR, Williams RA, Carter C, et al.Preventing progression to chronicity in first onset, subacute low back pain: an exploratory study. Arch Phys Med Rehabil. 2009; 90(4):545–2.
Smeets RJ. Do lumbar stabilising exercises reduce pain and disability in patients with recurrent low back pain?Aust J Physiother. 2009; 55(2):138.
Smeets RJ, Vlaeyen JW, Hidding A, Kester AD, van der Heijden GJ, Knottnerus JA. Chronic low back pain: physical training, graded activity with problem solving training, or both? the one-year post-treatment results of a randomized controlled trial. Pain. 2008; 134(3):263–76.
Smeets RJEM, Beelen S, Goossens MEJB, Schouten EGW, Knottnerus JA, Vlaeyen JWS. Treatment expectancy and credibility are associated with the outcome of both physical and cognitive-behavioral treatment in chronic low back pain. Clin J Pain. 2008; 24(4):305–15.
Smeets RJEM, Vlaeyen JWS, Hidding A, Kester ADM, Van Der Heijden GJMG, Van Geel ACM, et al.Active rehabilitation for chronic low back pain: Cognitive-behavioral, physical, or both? first direct post-treatment results from a randomized controlled trial [ISRCTN22714229]. BMC Musculoskelet Disord. 2006; 7:5.
Smeets RJEM, Vlaeyen JWS, Kester ADM, Knottnerus JA. Reduction of pain catastrophizing mediates the outcome of both physical and cognitive-behavioral treatment in chronic low back pain. J Pain. 2006; 7(4):261–71.
Smith AL, Kolt GS, McConville JC. The effect of the felenkrais method on pain and anxiety in people experiencing chronic low back pain 3136. N Z J Physiother. 2007; 29(1):6–14.
Sokunbi O, Watt P, Moore A. Changes in plasma concentration of serotonin in response to spinal stabilisation exercises in chronic low back pain patient. Nig Q J Hosp Med. 2007; 17(3):108–11.
Soonawalla DF, Joshi N. Efficacy of thiocolchicoside in indian patients suffering from low back pain associated with muscle spasm. J Indian Med Assoc. 2008; 106(5):331–5.
Steenstra IA, Anema JR, Bongers PM, de Vet HC, Knol DL, van Mechelen W. The effectiveness of graded activity for low back pain in occupational healthcare. Occup Environ Med. 2006; 63(11):718–25.
Steiner D, Munera C, Hale M, Ripa S, Landau C. The efficacy and safety of buprenorphine transdermal system (BTDS) in subjects with moderate to severe low back pain: A double-blind study. J Pain. 2009; 10(4):51.
Steiner D, Munera C, Hale M, Ripa S, Landau C. Efficacy and safety of buprenorphine transdermal system (BTDS) for chronic moderate to severe low back pain: a randomized, double-blind study. J Pain. 2011; 12(11):1163–73.
Steiner DJ, Sitar S, Wen W, Sawyerr G, Munera C, Ripa SR, et al.Efficacy and safety of the seven-day buprenorphine transdermal system in opioid-naive patients with moderate to severe chronic low back pain: an enriched, randomized, double-blind, placebo-controlled study. J Pain Symptom Manag. 2011; 42(6):903–17.
Sutlive TG, Mabry LM, Easterling EJ, Durbin JD, Hanson SL, Wainner RS, et al.Comparison of short-term response to two spinal manipulation techniques for patients with low back pain in a military beneficiary population. Mil Med. 2009; 174(7):750–6.
Tavafian SS, Jamshidi A, Mohammad K, Montazeri A. Low back pain education and short term quality of life: a randomized trial. BMC Musculoskelet Disord. 2007; 8:21.
Tavafian SS, Jamshidi AR, Mohammad K. Treatment of chronic low back pain: a randomized clinical trial comparing multidisciplinary group-based rehabilitation program and oral drug treatment with oral drug treatment alone. Clin J Pain. 2011; 27(9):811–8.
Tavafian SS, Jamshidi AR, Montazeri A. A randomized study of back school in women with chronic low back pain: quality of life at three, six, and twelve months follow-up. Spine (Phila Pa 1976). 2008; 33(15):1617–21.
Tekur P, Chametcha S, Hongasandra RN, Raghuram N. Effect of yoga on quality of life of clbp patients: A randomized control study. Int J Yoga. 2010; 3(1):10–7.
Tekur P, Singphow C, Nagendra HR, Raghuram N. Effect of short-term intensive yoga program on pain, functional disability and spinal flexibility in chronic low back pain: a randomized control study. J Altern Complement Med. 2008; 14(6):637–44.
Tilbrook HE, Cox H, Hewitt CE, Kang’ombe AR, Chuang LH, Jayakody S, et al.Yoga for chronic low back pain: a randomized trial. Ann Intern Med. 2011; 155(9):569–78.
Tsao H, Hodges PW. Immediate changes in feedforward postural adjustments following voluntary motor training. Exp Brain Res. 2007; 181(4):537–46.
Underwood M, Mistry D, Lall R, Lamb S. Predicting response to a cognitive-behavioral approach to treating low back pain: Secondary analysis of the best data set. Arthritis Care Res (Hoboken). 2011; 63(9):1271–9.
Vasseljen O, Fladmark AM. Abdominal muscle contraction thickness and function after specific and general exercises: a randomized controlled trial in chronic low back pain patients. Man Ther. 2010; 15(5):482–9.
Warming S, Ebbehoj NE, Wiese N, Larsen LH, Duckert J, Tonnesen H. Little effect of transfer technique instruction and physical fitness training in reducing low back pain among nurses: a cluster randomised intervention study. Ergonomics. 2008; 51(10):1530–48.
Westrom KK, Maiers MJ, Evans RL, Bronfort G. Individualized chiropractic and integrative care for low back pain: the design of a randomized clinical trial using a mixed-methods approach. Trials. 2010; 11:24.
Wheeler WJ, Gever LN. Functional status of patients with acute low back pain following treatment with carisoprodol 250-mg tablets assessed by the roland-morris disability questionnaire (rmdq). Pain Med. 2010; 11(2):305.
Whitehurst DG, Lewis M, Yao GL, Bryan S, Raftery JP, Mullis R, Hay EM. A brief pain management program compared with physical therapy for low back pain: results from an economic analysis alongside a randomized clinical trial. Arthritis Rheum. 2007; 57(3):466–73.
Wilkey A, Gregory M, Byfield D, McCarthy PW. A comparison between chiropractic management and pain clinic management for chronic low-back pain in a national health service outpatient clinic. J Altern Complement Med. 2008; 14(5):465–73.
Wilson-MacDonald J, Fairbank J, Frost H, Yu LM, Barker K, Collins R, et al.The mrc spine stabilization trial: surgical methods, outcomes, costs, and complications of surgical stabilization. Spine (Phila Pa 1976). 2008; 33(21):2334–40.
Worth SGA, Henry SM, Bunn JY. Real-time ultrasound feedback and abdominal hollowing exercises for people with low back pain. NZ J Physiother. 2007; 35(1):4–11.
Yakhno N, Guekht A, Skoromets A, Spirin N, Strachunskaya E, Ternavsky A, et al.Analgesic efficacy and safety of lornoxicam quick-release formulation compared with diclofenac potassium: randomised, double-blind trial in acute low back pain. Clin Drug Investig. 2006; 26(5):267–77.
Zaina F, Vismara L, Menegoni F, Galli M, Negrini S, Villa V. Clinical and kinematic evaluation of osteopathy vs specific exercises in obese non-specific chronic low back pain females patients: A randomized controlled trial. Spine. 2010; 2010:244.
Ackerman WE, Ahmad M. Pain relief with intraarticular or medial branch nerve blocks in patients with positive lumbar facet joint spect imaging: A 12-week outcome study. South Med J. 2008; 101(9):931–4.
Ahmed MS, Shakoor MA, Khan AA. Evaluation of the effects of shortwave diathermy in patients with chronic low back pain. Bangladesh Med Res Counc Bull. 2009; 35(1):18–20.
Akbari A, Khorashadizadeh S, Abdi G. The effect of motor control exercise versus general exercise on lumbar local stabilizing muscles thickness: Randomized controlled trial of patients with chronic low back pain. J Back Musculoskelet Rehabil. 2008; 21(2):105–12.
Becker A, Leonhardt C, Kochen MM, Keller S, Wegscheider K, Baum E, et al.Effects of two guideline implementation strategies on patient outcomes in primary care: a cluster randomized controlled trial. Spine (Phila Pa 1976). 2008; 33(5):473–80.
Bello AI, Kalu NH, Adegoke BOA, Agyepong-Badu S. Hydrotherapy versus land-based exercises in the management of chronic low back pain: A comparative study. J Musculoskelet Res. 2010; 13(4):159–65.
Ben Salah Frih Z, Fendri Y, Jellad A, Boudoukhane S, Rejeb N. Efficacy and treatment compliance of a home-based rehabilitation programme for chronic low back pain: a randomized, controlled study. Ann Phys Rehabil Med. 2009; 52(6):485–96.
Bialosky JE, Bishop MD, Robinson ME, Zeppieri JG, George SZ. Spinal manipulative therapy has an immediate effect on thermal pain sensitivity in people with low back pain: a randomized controlled trial. Phys Ther. 2009; 89(12):1292–303.
Bicalho E, Palma Setti JA, Macagnan J, Rivas Cano JL, Manffra EF. Immediate effects of a high-velocity spine manipulation in paraspinal muscles activity of nonspecific chronic low-back pain subjects. Man Ther. 2010; 15(5):469–75.
Brennan GP, Fritz JM, Hunter SJ, Thackeray A, Delitto A, Erhard RE. Identifying subgroups of patients with acute/subacute “nonspecific” low back pain: results of a randomized clinical trial. Spine. 2006; 31(6):623–31.
Calmels P, Queneau P, Hamonet C, Le Pen C, Maurel F, Lerouvreur C, et al.Effectiveness of a lumbar belt in subacute low back pain: an open, multicentric, and randomized clinical study. Spine (Phila Pa 1976). 2009; 34(3):215–0.
Cecchi F, Molino-Lova R, Chiti M, Pasquini G, Paperini A, Conti AA, et al.Spinal manipulation compared with back school and with individually delivered physiotherapy for the treatment of chronic low back pain: a randomized trial with one-year follow-up. Clin Rehabil. 2010; 24(1):26–36.
Chan CW, Mok NW, Yeung EW. Aerobic exercise training in addition to conventional physiotherapy for chronic low back pain: a randomized controlled trial. Arch Phys Med Rehabil. 2011; 92(10):1681–5.
Chang ST, Chen LC, Chang CC, Chu HY, Tsai KC. Effects of piroxicam-beta-cyclodextrin sachets on abnormal postural sway in patients with chronic low back pain. J Clin Pharm Ther. 2008; 33(5):495–506.
Chatzitheodorou D, Mavromoustakos S, Milioti S. The effect of exercise on adrenocortical responsiveness of patients with chronic low back pain, controlled for psychological strain. Clin Rehabil. 2008; 22(4):319–28.
Cherkin DC, Sherman KJ, Avins AL, Erro JH, Ichikawa L, Barlow WE, et al.A randomized trial comparing acupuncture, simulated acupuncture, and usual care for chronic low back pain. Arch Intern Med. 2009; 169(9):858–66.
Cherkin DC, Sherman KJ, Kahn J, Wellman R, Cook AJ, Johnson E, et al.A comparison of the effects of 2 types of massage and usual care on chronic low back pain: a randomized, controlled trial. Ann Intern Med. 2011; 155(1):1–9.
Chiu CK, Low TH, Tey YS, Singh VA, Shong HK. The efficacy and safety of intramuscular injections of methylcobalamin in patients with chronic nonspecific low back pain: a randomised controlled trial. Singapore Med J. 2011; 52(12):868–73.
Chown M, Whittamore L, Rush M, Allan S, Stott D, Archer M. A prospective study of patients with chronic back pain randomised to group exercise, physiotherapy or osteopathy. Physiotherapy. 2008; 94(1):21–8.
Costa LO, Maher CG, Latimer J, Hodges PW, Herbert RD, Refshauge KM, et al.Motor control exercise for chronic low back pain: a randomized placebo-controlled trial. Phys Ther. 2009; 89(12):1275–86.
Cuesta-Vargas AI, Garcia-Romero JC, Arroyo-Morales M, Diego-Acosta AM, Daly DJ. Exercise, manual therapy, and education with or without high-intensity deep-water running for nonspecific chronic low back pain: a pragmatic randomized controlled trial. Am J Phys Med Rehabil. 2011; 90(7):526–345358.
Demirel R, Ucok K, Kavuncu V, Gecici O, Evcik D, Dundar U, et al.Effects of balneotherapy with exercise in patients with low back pain. J Back Musculoskelet Rehabil. 2008; 21(4):263–72.
Di Cesare A, Giombini A, Di Cesare M, Ripani M, Vulpiani MC, Saraceni VM. Comparison between the effects of trigger point mesotherapy versus acupuncture points mesotherapy in the treatment of chronic low back pain: a short term randomized controlled trial. Complement Ther Med. 2011; 19(1):19–26.
Diaz Arribas MJ, Ramos Sanchez M, Pardo Hervas P, Lopez Chicharro J, Angulo Carrere T, Ortega Molina P, et al.Effectiveness of the physical therapy godelive denys-struyf method for nonspecific low back pain: primary care randomized control trial. Spine (Phila Pa 1976). 2009; 34(15):1529–38.
Dufour N, Thamsborg G, Oefeldt A, Lundsgaard C, Stender S. Treatment of chronic low back pain: a randomized, clinical trial comparing group-based multidisciplinary biopsychosocial rehabilitation and intensive individual therapist-assisted back muscle strengthening exercises. Spine (Phila Pa 1976). 2010; 35(5):469–76.
Dundar U, Solak O, Yigit I, Evcik D, Kavuncu V. Clinical effectiveness of aquatic exercise to treat chronic low back pain: a randomized controlled trial. Spine (Phila Pa 1976). 2009; 34(14):1436–40.
Durmus D, Akyol Y, Alayli G, Tander B, Zahiroglu Y, Canturk F. Effects of electrical stimulation program on trunk muscle strength, functional capacity, quality of life, and depression in the patients with low back pain: a randomized controlled trial. Rheumatol Int. 2009; 29(8):947–54.
Durmus D, Durmaz Y, Canturk F. Effects of therapeutic ultrasound and electrical stimulation program on pain, trunk muscle strength, disability, walking performance, quality of life, and depression in patients with low back pain: a randomized-controlled trial. Rheumatol Int. 2010; 30(7):901–10.
Engbert K, Weber M. The effects of therapeutic climbing in patients with chronic low back pain: a randomized controlled study. Spine (Phila Pa 1976). 2011; 36(11):842–9.
Ewert T, Limm H, Wessels T, Rackwitz B, von Garnier K, Freumuth R, et al.The comparative effectiveness of a multimodal program versus exercise alone for the secondary prevention of chronic low back pain and disability. PM R. 2009; 1(9):798–808.
Farhadi K, Schwebel DC, Saeb M, Choubsaz M, Mohammadi R, Ahmadi A. The effectiveness of wet-cupping for nonspecific low back pain in iran: a randomized controlled trial. Complement Ther Med. 2009; 17(1):9–15.
Ferreira ML, Ferreira PH, Latimer J, Herbert RD, Hodges PW, Jennings MD, et al.Comparison of general exercise, motor control exercise and spinal manipulative therapy for chronic low back pain: A randomized trial. Pain. 2007; 131(1-2):31–7.
Ferreira ML, Ferreira PH, Latimer J, Herbert RD, Maher C, Refshauge K. Relationship between spinal stiffness and outcome in patients with chronic low back pain. Man Ther. 2009; 14(1):61–7.
Field T, Hernandez-Reif M, Diego M, Fraser M. Lower back pain and sleep disturbance are reduced following massage therapy. J Bodyw Mov Ther. 2007; 11(2):141–5.
da Fonseca JL, Magini M, de Freitas TH. Laboratory gait analysis in patients with low back pain before and after a pilates intervention. J Sport Rehabil. 2009; 18(2):269–82.
Franca FR, Burke TN, Hanada ES, Marques AP. Segmental stabilization and muscular strengthening in chronic low back pain: a comparative study. Clinics (Sao Paulo). 2010; 65(10):1013–7.
Gladwell V, Head S, Haggar M, Beneke R. Does a program of pilates improve chronic non-specific low back pain?J Sport Rehabil. 2006; 15(4):338–50.
Goldby LJ, Moore AP, Doust J, Trew ME. A randomized controlled trial investigating the efficiency of musculoskeletal physiotherapy on chronic low back disorder. Spine. 2006; 31(10):1083–93.
Göhner W, Schlicht W. Preventing chronic back pain: evaluation of a theory-based cognitive-behavioural training programme for patients with subacute back pain. Patient Educ Couns. 2006; 64(1-3):87–95.
Haake M, Muller HH, Schade-Brittinger C, Basler HD, Schafer H, Maier C, et al.German acupuncture trials (gerac) for chronic low back pain: randomized, multicenter, blinded, parallel-group trial with 3 groups. Arch Intern Med. 2007; 167(17):1892–8.
Hall AM, Maher CG, Lam P, Ferreira M, Latimer J. Tai chi exercise for treatment of pain and disability in people with persistent low back pain: a randomized controlled trial. Arthritis Care Res (Hoboken). 2011; 63(11):1576–83.
Harts CC, Helmhout PH, de Bie RA, Staal JB. A high-intensity lumbar extensor strengthening program is little better than a low-intensity program or a waiting list control group for chronic low back pain: a randomised clinical trial. Aust J Physiother. 2008; 54(1):23–31.
Hartvigsen J, Morso L, Bendix T, Manniche C. Supervised and non-supervised nordic walking in the treatment of chronic low back pain: a single blind randomized clinical trial. BMC Musculoskelet Disord. 2010; 11:30.
Henchoz Y, de Goumoens P, Norberg M, Paillex R, So AK. Role of physical exercise in low back pain rehabilitation: a randomized controlled trial of a three-month exercise program in patients who have completed multidisciplinary rehabilitation. Spine (Phila Pa 1976). 2010; 35(12):1192–9.
Henchoz Y, de Goumoens P, So AK, Paillex R. Functional multidisciplinary rehabilitation versus outpatient physiotherapy for non specific low back pain: randomized controlled trial. Swiss Med Wkly.2010;140. doi:10.4414/smw.2010.13133.
Heymans MW, Vet HC, Bongers PM, Knol DL, Koes BW, Mechelen W. The effectiveness of high-intensity versus low-intensity back schools in an occupational setting: a pragmatic randomized controlled trial. Spine. 2006; 31(10):1075–82.
Hsieh LL, Kuo CH, Lee LH, Yen AM, Chien KL, Chen TH. Treatment of low back pain by acupressure and physical therapy: randomised controlled trial. BMJ (Clin Res ed.) 2006; 332(7543):696–700.
Iles R, Taylor NF, Davidson M, O’Halloran P. Telephone coaching can increase activity levels for people with non-chronic low back pain: a randomised trial. J Physiother. 2011; 57(4):231–8.
Inoue M, Kitakoji H, Ishizaki N, Tawa M, Yano T, Katsumi Y, et al.Relief of low back pain immediately after acupuncture treatment–a randomised, placebo controlled trial. Acupunct Med. 2006; 24(3):103–8.
Johnson RE, Jones GT, Wiles NJ, Chaddock C, Potter RG, Roberts C, et al.Active exercise, education, and cognitive behavioral therapy for persistent disabling low back pain: a randomized controlled trial. Spine (Phila Pa 1976). 2007; 32(15):1578–85.
Kapitza KP, Passie T, Bernateck M, Karst M. First non-contingent respiratory biofeedback placebo versus contingent biofeedback in patients with chronic low back pain: a randomized, controlled, double-blind trial. Appl Psychophysiol Biofeedback. 2010; 35(3):207–17.
Kell RT, Asmundson GJ. A comparison of two forms of periodized exercise rehabilitation programs in the management of chronic nonspecific low-back pain. J Strength Cond Res. 2009; 23(2):513–23.
Kell RT, Risi AD, Barden JM. The response of persons with chronic nonspecific low back pain to three different volumes of periodized musculoskeletal rehabilitation. J Strength Cond Res. 2011; 25(4):1052–64.
Kofotolis N, Kellis E. Effects of two 4-week proprioceptive neuromuscular facilitation programs on muscle endurance, flexibility, and functional performance in women with chronic low back pain. Phys Ther. 2006; 86(7):1001–12.
Koldaş Doǧan S, Sonel Tur B, Kurtaiş Y, Atay MB. Comparison of three different approaches in the treatment of chronic low back pain. Clin Rheumatol. 2008; 27(7):873–81.
Kroll HR, Kim D, Danic MJ, Sankey SS, Gariwala M, Brown M. A randomized, double-blind, prospective study comparing the efficacy of continuous versus pulsed radiofrequency in the treatment of lumbar facet syndrome. J Clin Anesth. 2008; 20(7):534–7.
Kumar S, Negi MP, Sharma VP, Shukla R, Dev R, Mishra UK. Efficacy of two multimodal treatments on physical strength of occupationally subgrouped male with low back pain. J Back Musculoskelet Rehabil. 2009; 22(3):179–88.
Kumar S, Sharma VP, Negi MP. Efficacy of dynamic muscular stabilization techniques (dmst) over conventional techniques in rehabilitation of chronic low back pain. J Strength Cond Res. 2009; 23(9):2651–9.
Lalanne K, Lafond D, Descarreaux M. Modulation of the flexion-relaxation response by spinal manipulative therapy: a control group study. J Manipulative Physiol Ther. 2009; 32(3):203–9.
Lamb SE, Hansen Z, Lall R, Castelnuovo E, Withers EJ, Nichols V, et al.Group cognitive behavioural treatment for low-back pain in primary care: a randomised controlled trial and cost-effectiveness analysis. Lancet. 2010; 375(9718):916–23.
Lau PM, Chow DH, Pope MH. Early physiotherapy intervention in an accident and emergency department reduces pain and improves satisfaction for patients with acute low back pain: a randomised trial. Aust J Physiother. 2008; 54(4):243–9.
Lengsfeld M, Konig IR, Schmelter J, Ziegler A. Passive rotary dynamic sitting at the workplace by office-workers with lumbar pain: a randomized multicenter study. Spine J. 2007; 7(5):531–40.
Leonardt C, Keller S, Chenot J, Luckmann J, Basler H, Wegscheider B, et al.Ttm-based motivational counselling does not increase physical activity of low back pain patients in a primary care setting-a cluster-randomized controlled trial. Patient Educ Couns. 2008; 70:50–60.
Lewis C, Souvlis T, Sterling M. Strain-counterstrain therapy combined with exercise is not more effective than exercise alone on pain and disability in people with acute low back pain: a randomised trial. J Physiother. 2011; 57(2):91–8.
Machado LA, Maher CG, Herbert RD, Clare H, McAuley JH. The effectiveness of the mckenzie method in addition to first-line care for acute low back pain: a randomized controlled trial. BMC Med. 2010; 8:10.
Mackawan S, Eungpinichpong W, Pantumethakul R, Chatchawan U, Hunsawong T, Arayawichanon P. Effects of traditional thai massage versus joint mobilization on substance p and pain perception in patients with non-specific low back pain. J Bodyw Mov Ther. 2007; 11(1):9–16.
Marshall P, Murphy B. Self-report measures best explain changes in disability compared with physical measures after exercise rehabilitation for chronic low back pain. Spine (Phila Pa 1976). 2008; 33(3):326–8.
Mibielli MA, Geller M, Cohen JC, Goldberg SG, Cohen MT, Nunes CP, et al.Diclofenac plus b vitamins versus diclofenac monotherapy in lumbago: the dolor study. Curr Med Res Opin. 2009; 25(11):2589–99.
Mohseni-Bandpei MA, Rahmani N, Behtash H, Karimloo M. The effect of pelvic floor muscle exercise on women with chronic non-specific low back pain. J Bodyw Mov Ther. 2011; 15(1):75–81.
Morone G, Paolucci T, Alcuri MR, Vulpiani MC, Matano A, Bureca I, et al.Quality of life improved by multidisciplinary back school program in patients with chronic non-specific low back pain: a single blind randomized controlled trial. Eur J Phys Rehabil Med. 2011; 47(4):533–41.
Muehlbacher M, Nickel MK, Kettler C, Tritt K, Lahmann C, Leiberich PK, et al.Topiramate in treatment of patients with chronic low back pain: a randomized, double-blind, placebo-controlled study. Clin J Pain. 2006; 22(6):526–31.
Muller-Schwefe GHH, Uberall MA. Dysport(registered trademark) for the treatment of myofascial back pain: Results from an open-label, phase ii, randomized, multicenter, dose-ranging study. Scand J Pain. 2011; 2(1):25–33.
Nassif H, Brosset N, Guillaume M, Delore-Milles E, Tafflet M, Buchholz F, et al.Evaluation of a randomized controlled trial in the management of chronic lower back pain in a french automotive industry: An observational study. Arch Phys Med Rehabil. 2011; 92(12):1927–364.
Nordeman L, Nilsson B, Moller M, Gunnarsson R. Early access to physical therapy treatment for subacute low back pain in primary health care: a prospective randomized clinical trial. Clin J Pain. 2006; 22(6):505–11.
Norris C, Matthews M. The role of an integrated back stability program in patients with chronic low back pain. Complement Ther Clin Pract. 2008; 14(4):255–63.
Pach D, Brinkhaus B, Roll S, Wegscheider K, Icke K, Willich SN, et al.Efficacy of injections with disci/rhus toxicodendron compositum for chronic low back pain - a randomized placebo-controlled trial. PLoS ONE. 2011; 6(11):e26166.
Paoloni M, Bernetti A, Fratocchi G, Mangone M, Parrinello L, Del Pilar Cooper M, et al.Kinesio taping applied to lumbar muscles influences clinical and electromyographic characteristics in chronic low back pain patients. Eur J Phys Rehabil Med. 2011; 47(2):237–44.
Powers CM, Beneck GJ, Kulig K, Landel RF, Fredericson M. Effects of a single session of posterior-to-anterior spinal mobilization and press-up exercise on pain response and lumbar spine extension in people with nonspecific low back pain. Phys Ther. 2008; 88(4):485–93.
Ritvanen T, Zaproudina N, Nissen M, Leinonen V, Hanninen O. Dynamic surface electromyographic responses in chronic low back pain treated by traditional bone setting and conventional physical therapy. J Manipulative Physiol Ther. 2007; 30(1):31–7.
Roche-Leboucher G, Petit-Lemanac’h A, Bontoux L, Dubus-Bausiere V, Parot-Shinkel E, Fanello S, et al.Multidisciplinary intensive functional restoration versus outpatient active physiotherapy in chronic low back pain: a randomized controlled trial. Spine (Phila Pa 1976). 2011; 36(26):2235–42.
Sahin N, Albayrak I, Durmus B, Ugurlu H. Effectiveness of back school for treatment of pain and functional disability in patients with chronic low back pain: a randomized controlled trial. J Rehabil Med. 2011; 43(3):224–9.
Santaella Da Fonseca Lopes De Sousa K, Garcia Orfale A, Mara Meireles S, Roberto Leite J, Natour J. Assessment of a biofeedback program to treat chronic low back pain. J Musculoskelet Pain. 2009; 17(4):369–77.
Schiltenwolf M, Buchner M, Heindl B, Reumont J, Müller A, Eich W. Comparison of a biopsychosocial therapy (BT) with a conventional biomedical therapy (mt) of subacute low back pain in the first episode of sick leave: a randomized controlled trial. Eur Spine J. 2006; 15(7):1083–92.
Senna MK, Machaly SA. Does maintained spinal manipulation therapy for chronic nonspecific low back pain result in better long-term outcome?Spine (Phila Pa 1976). 2011; 36(18):1427–37.
Shankar N, Thakur M, Tandon OP, Saxena AK, Arora S, Bhattacharya N. Autonomic status and pain profile in patients of chronic low back pain and following electro acupuncture therapy: a randomized control trial. Indian J Physiol Pharmacol. 2011; 55(1):25–36.
Sherman KJ, Cherkin DC, Wellman RD, Cook AJ, Hawkes RJ, Delaney K, et al.A randomized trial comparing yoga, stretching, and a self-care book for chronic low back pain. Arch Intern Med. 2011; 171(22):2019–6.
Skljarevski V, Zhang S, Chappell AS, Detke MJ, Murray I, Backonja M. Maintenance of effect of duloxetine in patients with chronic low back pain. European J Pain. 2009; 13:195.
Skljarevski V, Zhang S, Desaiah D, Alaka KJ, Palacios S, Miazgowski T, et al.Duloxetine versus placebo in patients with chronic low back pain: a 12-week, fixed-dose, randomized, double-blind trial. J Pain. 2010; 11(12):1282–90.
Sorensen PH, Bendix T, Manniche C, Korsholm L, Lemvigh D, Indahl A. An educational approach based on a non-injury model compared with individual symptom-based physical training in chronic lbp. a pragmatic, randomised trial with a one-year follow-up. BMC Musculoskelet Disord. 2010; 11:212.
Suen LK, Wong TK, Chung JW, Yip VY. Auriculotherapy on low back pain in the elderly. Complement Ther Clin Pract. 2007; 13(1):63–9.
Tefner IK, Nemeth A, Laszlofi A, Kis T, Gyetvai G, Bender T. The effect of spa therapy in chronic low back pain: a randomized controlled, single-blind, follow-up study. Rheumatol Int. 2011; 32(10):3163–9.
Thomas KJ, MacPherson H, Thorpe L, Brazier J, Fitter M, Campbell MJ, et al.Randomised controlled trial of a short course of traditional acupuncture compared with usual care for persistent non-specific low back pain. BMJ: Br Med J. 2006; 333(7569):1–6.
Unsgaard-Tondel M, Fladmark AM, Salvesen O, Vasseljen O. Motor control exercises, sling exercises, and general exercises for patients with chronic low back pain: a randomized controlled trial with 1-year follow-up. Phys Ther. 2010; 90(10):1426–40.
Vasseljen O, Unsgaard-Tondel M, Westad C, Mork PJ. Effect of core stability exercises on feedforward activation of deep abdominal muscles in chronic low back pain: A randomized controlled trial. Spine (Phila Pa 1976). 2011; 37(13):1101–8.
Vong SK, Cheing GL, Chan F, So EM, Chan CC. Motivational enhancement therapy in addition to physical therapy improves motivational factors and treatment outcomes in people with low back pain: a randomized controlled trial. Arch Phys Med Rehabil. 2011; 92(2):176–83.
Weiner DK, Perera S, Rudy TE, Glick RM, Shenoy S, Delitto A. Efficacy of percutaneous electrical nerve stimulation and therapeutic exercise for older adults with chronic low back pain: a randomized controlled trial. Pain. 2008; 140(2):344–57.
Wetherell JL, Afari N, Rutledge T, Sorrell JT, Stoddard JA, Petkus AJ, et al.A randomized, controlled trial of acceptance and commitment therapy and cognitive-behavioral therapy for chronic pain. Pain. 2011; 152(9):2098–107.
Whitfill T, Haggard R, Bierner SM, Pransky G, Hassett RG, Gatchel RJ. Early intervention options for acute low back pain patients: a randomized clinical trial with one-year follow-up outcomes. J Occup Rehabil. 2010; 20(2):256–63.
Williams K, Abildso C, Steinberg L, Doyle E, Epstein B, Smith D, et al.Evaluation of the effectiveness and efficacy of iyengar yoga therapy on chronic low back pain. Spine (Phila Pa 1976). 2009; 34(19):2066–76.
Zaringhalam J, Manaheji H, Rastqar A, Zaringhalam M. Reduction of chronic non-specific low back pain: a randomised controlled clinical trial on acupuncture and baclofen. Chin Med. 2010; 5:15.
Albaladejo C, Kovacs FM, Royuela A, del Pino R, Zamora J. The efficacy of a short education program and a short physiotherapy program for treating low back pain in primary care: a cluster randomized trial. Spine (Phila Pa 1976). 2010; 35(5):483–96.
Anema JR, Steenstra IA, Bongers PM, de Vet HC, Knol DL, Loisel P, et al.Multidisciplinary rehabilitation for subacute low back pain: graded activity or workplace intervention or both? a randomized controlled trial. Spine (Phila Pa 1976). 2007; 32(3):291–8.
Attanayake AMP, Somarathna K, Vyas GH, Dash SC. Clinical evaluation of selected yogic procedures in individuals with low back pain. Ayu. 2010; 31(2):245–50.
Birkenmaier C, Veihelmann A, Trouillier HH, Hausdorf J, von Schulze Pellengahr C. Medial branch blocks versus pericapsular blocks in selecting patients for percutaneous cryodenervation of lumbar facet joints. Reg Anesth Pain Med. 2007; 32(1):27–33.
Bishop PB, Quon JA, Fisher CG, Dvorak MF. The chiropractic hospital-based interventions research outcomes (chiro) study: a randomized controlled trial on the effectiveness of clinical practice guidelines in the medical and chiropractic management of patients with acute mechanical low back pain. Spine J. 2010; 10(12):1055–64.
Brinkhaus B, Witt CM, Jena S, Linde K, Streng A, Wagenpfeil S, et al.Acupuncture in patients with chronic low back pain: a randomized controlled trial. Arch Intern Med. 2006; 166(4):450–7.
Cairns MC, Foster NE, Wright C. Randomized controlled trial of specific spinal stabilization exercises and conventional physiotherapy for recurrent low back pain. Spine. 2006; 31(19):670–81.
Cleland JA, Fritz JM, Kulig K, Davenport TE, Eberhart S, Magel J, et al.Comparison of the effectiveness of three manual physical therapy techniques in a subgroup of patients with low back pain who satisfy a clinical prediction rule: a randomized clinical trial. Spine (Phila Pa 1976). 2009; 34(25):2720–9.
Demoulin C, Grosdent S, Capron L, Tomasella M, Somville PR, Crielaard JM, et al.Effectiveness of a semi-intensive multidisciplinary outpatient rehabilitation program in chronic low back pain. Joint Bone Spine. 2010; 77(1):58–63.
Djavid GE, Mehrdad R, Ghasemi M, Hasan-Zadeh H, Sotoodeh-Manesh A, Pouryaghoub G. In chronic low back pain, low level laser therapy combined with exercise is more beneficial than exercise alone in the long term: a randomised trial. Aust J Physiother. 2007; 53(3):155–60.
Donzelli S, Domenica E, Cova AM, Galletti R, Giunta N. Two different techniques in the rehabilitation treatment of low back pain: a randomized controlled trial. Eura. 2006; 42(3):205–10.
Durmus D, Akyol Y, Cengiz K, Terzi T, Canturk F. Effects of therapeutic ultrasound on pain, disability, walking performance, quality of life, and depression in patients with chronic low back pain: A randomized, placebo controlled trial. Turkish J Rheumatol. 2010; 25(2):82–7.
Ergun H, Polat O, Demirkan NA, Gunalp M, Gurler S. The efficacy, safety, and pharmacokinetics of intramuscular and oral phenyramidol in patients with low back pain in an emergency department. Turkish J Med Sci. 2010; 40(1):71–6.
Fiore P, Panza F, Cassatella G, Russo A, Frisardi V, Solfrizzi V, et al.Short-term effects of high-intensity laser therapy versus ultrasound therapy in the treatment of low back pain: a randomized controlled trial. Eur J Phys Rehabil Med. 2011; 47(3):367–73.
Friedrich M, Gittler G. Long-term effects of a combined exercise and motivation program in patients with chronic low back pain: A five-year follow-up. Pain Pract. 2009; 9:121.
Glazov G, Schattner P, Lopez D, Shandley K. Laser acupuncture for chronic non-specific low back pain: a controlled clinical trial. Acupunct Med. 2009; 27(3):94–100.
Hagen EM, Odelien KH, Lie SA, Eriksen HR. Adding a physical exercise programme to brief intervention for low back pain patients did not increase return to work. Scand J Public Health. 2010; 38(7):731–8.
Hancock MJ, Maher CG, Latimer J, McLachlan AJ, Cooper CW, Day RO, et al.Assessment of diclofenac or spinal manipulative therapy, or both, in addition to recommended first-line treatment for acute low back pain: a randomised controlled trial. Lancet. 2007; 370(9599):1638–43.
Hondras MA, Long CR, Cao Y, Rowell RM, Meeker WC. A randomized controlled trial comparing 2 types of spinal manipulation and minimal conservative medical care for adults 55 years and older with subacute or chronic low back pain. J Manipulative Physiol Ther. 2009; 32(5):330–43.
Juni P, Battaglia M, Nuesch E, Hammerle G, Eser P, van Beers R, et al.A randomised controlled trial of spinal manipulative therapy in acute low back pain. Ann Rheum Dis. 2009; 68(9):1420–7.
Kulisch A, Bender T, Nemeth A, Szekeres L. Effect of thermal water and adjunctive electrotherapy on chronic low back pain: a double-blind, randomized, follow-up study. J Rehabil Med. 2009; 41(1):73–9.
Kumar S, Sharma VP, Shukla R, Dev R. Comparative efficacy of two multimodal treatments on male and female sub-groups with low back pain (part ii). J Back Musculoskelet Rehabil. 2010; 23(1):1–9.
Lambeek LC, van Mechelen W, Knol DL, Loisel P, Anema JR. Randomised controlled trial of integrated care to reduce disability from chronic low back pain in working and private life. BMJ. 2010; 340:1035.
Little P, Lewith G, Webley F, Evans M, Beattie A, Middleton K, et al.Randomised controlled trial of alexander technique lessons, exercise, and massage (ateam) for chronic and recurrent back pain. BMJ. 2008; 337:884.
Magnussen L, Strand LI, Skouen JS, Eriksen HR. Motivating disability pensioners with back pain to return to work - a randomized controlled trial. J Rehabil Med. 2007; 39(1):81–7.
Marshall P. Muscle activation changes after exercise rehabilitation for chronic low back pain. Arch Phys Med Rehabil. 2008; 89(7):1305–13.
Mazza M, Mazza O, Pazzaglia C, Padua L, Mazza S. Escitalopram 20 mg versus duloxetine 60 mg for the treatment of chronic low back pain. Expert Opin Pharmacother. 2010; 11(7):1049–52.
Mohseni-Bandpei MA, Critchley J, Staunton T, Richardson B. A prospective randomised controlled trial of spinal manipulation and ultrasound in the treatment of chronic low back pain. Physiotherapy. 2006; 92(1):34–42.
Muthukrishnan R, Shenoy SD, Jaspal SS, Nellikunja S, Fernandes S. The differential effects of core stabilization exercise regime and conventional physiotherapy regime on postural control parameters during perturbation in patients with movement and control impairment chronic low back pain. Sports Med Arthrosc Rehabil Ther Technol. 2010; 2:13.
Newcomer KL, Vickers Douglas KS, Shelerud RA, Long KH, Crawford B. Is a videotape to change beliefs and behaviors superior to a standard videotape in acute low back pain? a randomized controlled trial. Spine J. 2008; 8(6):940–7.
Nigg BM, Davis E, Lindsay D, Emery C. The effectiveness of an unstable sandal on low back pain and golf performance. Clin J Sport Med. 2009; 19(6):464–70.
Oleske DM, Lavender SA, Andersson GB, Kwasny MM. Are back supports plus education more effective than education alone in promoting recovery from low back pain?: Results from a randomized clinical trial. Spine (Phila Pa 1976). 2007; 32(19):2050–7.
Paolucci T, Morone G, Iosa M, Fusco A, Alcuri R, Matano A, et al.Psychological features and outcomes of the back school treatment in patients with chronic non-specific low back pain.a randomized controlled study. Eur J Phys Rehabil Med. 2011; 48(2):245–53.
Perez-Palomares S, Olivan-Blazquez B, Magallon-Botaya R, De-La-Torre-Beldarrain MML, Gaspar-Calvo E, Romo-Calvo L, et al.Percutaneous electrical nerve stimulation versus dry needling: Effectiveness in the treatment of chronic low back pain. J Musculoskelet Pain. 2010; 18(1):23–30.
Rasmussen J, Laetgaard J, Lindecrona AL, Qvistgaard E, Bliddal H. Manipulation does not add to the effect of extension exercises in chronic low-back pain (LBP). a randomized, controlled, double blind study. Joint Bone Spine. 2008; 75(6):708–13.
Rasmussen-Barr E, Ang B, Arvidsson I, Nilsson-Wikmar L. Graded exercise for recurrent low-back pain: a randomized, controlled trial with 6-, 12-, and 36-month follow-ups. Spine (Phila Pa 1976). 2009; 34(3):221–8.
Roche G, Ponthieux A, Parot-Shinkel E, Jousset N, Bontoux L, Dubus V, et al.Comparison of a functional restoration program with active individual physical therapy for patients with chronic low back pain: a randomized controlled trial. Arch Phys Med Rehabil. 2007; 88(10):1229–35.
van der Roer N, van Tulder M, Barendse J, Knol D, van Mechelen W, de Vet H. Intensive group training protocol versus guideline physiotherapy for patients with chronic low back pain: a randomised controlled trial. Eur Spine J. 2008; 17(9):1193–200.
Shirado O, Doi T, Akai M, Hoshino Y, Fujino K, Hayashi K, et al.Multicenter randomized controlled trial to evaluate the effect of home-based exercise on patients with chronic low back pain: the japan low back pain exercise therapy study. Spine (Phila Pa 1976). 2010; 35(17):811–9.
da Silva AG, de Sousa CP, Koehler J, Fontana J, Christo AG, Guedes-Bruni RR. Evaluation of an extract of brazilian arnica (solidago chilensis meyen, asteraceae) in treating lumbago. Phytother Res. 2010; 24(2):283–7.
Skljarevski V, Ossanna M, Liu-Seifert H, Zhang Q, Chappell A, Iyengar S, et al.A double-blind, randomized trial of duloxetine versus placebo in the management of chronic low back pain. Eur J Neurol. 2009; 16(9):1041–8.
Skljarevski V, Zhang S, Desaiah D, Palacios S, Miazgowski T, Patrick K. Efficacy and safety of duloxetine 60 mg once-daily in patients with chronic low back pain. J Pain. 2010; 11(4):38.
Steenstra IA, Anema JR, van Tulder MW, Bongers PM, de Vet HC, van Mechelen W. Economic evaluation of a multi-stage return to work program for workers on sick-leave due to low back pain. J Occup Rehabil. 2006; 16(4):557–78.
Suni J, Rinne M, Natri A, Statistisian MP, Parkkari J, Alaranta H. Control of the lumbar neutral zone decreases low back pain and improves self-evaluated work ability: a 12-month randomized controlled study. Spine. 2006; 31(18):611–20.
Szczurko O, Cooley K, Busse JW, Seely D, Bernhardt B, Guyatt GH, et al.Naturopathic care for chronic low back pain: a randomized trial. PLoS One. 2007; 2(9):919.
Witt CM, Jena S, Selim D, Brinkhaus B, Reinhold T, Wruck K, et al.Pragmatic randomized trial evaluating the clinical and economic effectiveness of acupuncture for chronic low back pain. Am J Epidemiol. 2006; 164(5):487–96.
Yildirim Y, Soyunov S. Relationship between learning strategies of patients and proper perception of the home exercise program with non-specific low back pain. J Back Musculoskelet Rehabil. 2010; 23(3):137–42.
Suñé P, Suñé JM, Montoro JB. Positive outcomes influence the rate and time to publication, but not the impact factor of publications of clinical trial results. PLoS One. 2013; 8(1):54583. doi:10.1371/journal.pone.0054583.
Littner Y, Mimouni F, Dollberg S, Mandel D. Negative results and impact factor a lesson from neonatology. 2005; (159):1036–7.
Penel N, Adenis A. Publication biases and phase ii trials investigating anticancer targeted therapies. Invest New Drug. 2009; 27(3):287–288.
Murtaugh P. Journal quality, effect size, and publication bias in meta-analysis. Ecology. 2002; 83(4):1162–1166.
Killin LOJ, Russ TC, Starr JM, Abrahams S, Della Sala S. The effect of funding sources on donepezil randomised controlled trial outcome: a meta-analysis. BMJ Open. 2014; 4(4):004083. doi:10.1136/bmjopen-2013-004083.
Tungaraza T, Poole R. Influence of drug company authorship and sponsorship on drug trial outcomes. Br J Psychiatry. 2007; 191:82–3. doi:10.1192/bjp.bp.106.024547.
Hempel S, Miles J, Suttorp M, Wang Z, Johnsen B, Morton S, et al.Detection of associations between trial quality and effect sizes. Technical report, Methods Research Report. Prepared by the Southern California Evidence-based Practice Center under Contract No. 290-2007-10062-I. AHRQ Publication No. 12-EHC010-EF. Rockville, MD: Agency for Healthcare Research and Quality January 2012.
Roland M, Torgerson D. Understanding controlled trials: What are pragmatic trials?BMJ. 1998; 316(7127):285.
Acknowledgements
We thank Campus Kristiania, University of Warwick, and Monash University for funding this study, and the European School of Osteopathy for contributing additional reviewer time. A full research proposal for the project was prepared for the principal funder, Campus Kristiania, which was internally assessed by people not involved in the research prior to a funding decision being made. Additional funding was provided to senior co-authors by University of Warwick and Monash University for additional reviewer time to abstract some of the data required for this study (approximately 35 % of total). Thanks are due to Simon Gates and Gary Abel for useful conversations and comments relating to our analysis. RB is funded in-part by an Australian National Health and Medical Research Council (NHMRC) Practitioner Fellowship.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
TB, PB, DR, DE, RB and SE declare that they have no competing interests. RF and MU are also directors and shareholders of a company that provides electronic measurement services to health services researchers; notwithstanding this, they declare that they have no conflicts of interest. MU is a co-author on one of the trials included in this review.
Authors’ contributions
RF, RB, DE, MU, and SE conceived the study. RF managed the study, trained the review group, arbitrated reviewers decisions, performed the analyses, and wrote the first draft of the manuscript. TB, PB, and DR performed the review and abstracted data. All authors commented on the results, discussed the implications, and commented on successive drafts of the manuscript. All authors read and approved the final manuscript. All authors meet the ICMJE guidelines for authorship.
Additional files
Additional file 1
Reviewers’ flowchart. A copy of the flowchart used by reviewers, guiding how to abstract standardised effect sizes and standardised SEs in PNG format. (PNG 198 kb)
Additional file 2
Characteristics of included studies. A table of characteristics of included studies in PDF format. (PDF 60 kb)
Additional file 3
Characteristics of excluded studies. A table of characteristics of excluded studies in PDF format. (PDF 69 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver(http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

{kind=link}
Cite this article
Froud, R., Bjørkli, T., Bright, P. et al. The effect of journal impact factor, reporting conflicts, and reporting funding sources, on standardized effect sizes in back pain trials: a systematic review and meta-regression. BMC Musculoskelet Disord 16, 370 (2015). https://doi.org/10.1186/s12891-015-0825-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12891-015-0825-6