
Abstract
Background
Research has long found ‘J-shaped’ relationships between alcohol consumption and certain health outcomes, indicating a protective effect of moderate consumption. However, methodological limitations in most studies hinder causal inference. This review aimed to identify all observational studies employing improved approaches to mitigate confounding in characterizing alcohol–long-term health relationships, and to qualitatively synthesize their findings.
Methods
Eligible studies met the above description, were longitudinal (with pre-defined exceptions), discretized alcohol consumption, and were conducted with human populations. MEDLINE, PsycINFO, Embase and SCOPUS were searched in May 2020, yielding 16 published manuscripts reporting on cancer, diabetes, dementia, mental health, cardiovascular health, mortality, HIV seroconversion, and musculoskeletal health. Risk of bias of cohort studies was evaluated using the Newcastle-Ottawa Scale, and a recently developed tool was used for Mendelian Randomization studies.
Results
A variety of functional forms were found, including reverse J/J-shaped relationships for prostate cancer and related mortality, dementia risk, mental health, and certain lipids. However, most outcomes were only evaluated by a single study, and few studies provided information on the role of alcohol consumption pattern.
Conclusions
More research employing enhanced causal inference methods is urgently required to accurately characterize alcohol–long-term health relationships. Those studies that have been conducted find a variety of linear and non-linear functional forms, with results tending to be discrepant even within specific health outcomes.
Trial registration
PROSPERO registration number CRD42020185861.
Similar content being viewed by others


Background
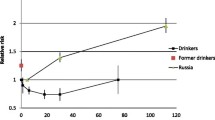
While the contribution of heavy alcohol consumption to the burden of disease is well-known [1], findings that moderate alcohol consumption is associated with health benefits for a wide range of outcomes persist. This relationship is often characterized as ‘J-shaped’, where low-to-moderate consumption coincides with the lowest risk, compared to a slightly higher risk for alcohol abstainers and much greater risk for heavy consumers. However, findings are inconsistent, and many functional forms have been reported for alcohol–long-term health relationships (see Fig. 1 for exemplar forms). Much recent research supports positive linear/monotonically increasing relationships for many outcomes, including most cancers [1, 2]. However, methodologically rigorous individual studies continue to find exceptions, e.g., for mortality [3], and indeed for dementia, diabetes, and particular cardiovascular conditions, evidence remains largely consistent with a J/U-shape [1, 2]. Which of the myriad reported functional forms reflect true causal relationships, and which are merely methodological artefacts, remains unclear.

Exemplar functional forms between alcohol consumption and health outcomes. Legend: A = J-shaped; B=U-shaped; C = reverse J-shaped; D = positive linear; E = negative linear; F = monotonically increasing; G = monotonically decreasing
In addition to these inconsistent findings, J-shaped relationships are sometimes found for certain outcomes (e.g., cirrhosis of the liver) which lack plausible biological mechanisms [4]. More generally, that studies across a broad array of health outcomes (with different underlying biological pathways) arrive at similar functional forms has prompted scrutiny of biases in observational studies – specifically confounding, reverse causality, selection bias and measurement error [5,6,7]. Confounding may constitute the biggest threat to causal inference, i.e., confidence that a relationship’s observed functional form/strength reflects the actual causal effect of exposure on outcome. Indeed, several confounders (e.g., socioeconomic disadvantage [8, 9] and limited health care access [9]) may be driving the relationship between alcohol abstention and poor health outcomes.
Standard approaches to counter confounding include control for covariates via multivariable regression adjustment, stratification or (exact) matching [10]. These methods are limited; regression with adjustment requires correct specification of the functional form (i.e., algebraic form in regression equations) of covariate–outcome relationships [11, 12], and relies on extreme extrapolation when there are insufficient observations for all combinations of exposure, covariates and outcomes [12,13,14]. Similarly, the ‘curse of dimensionality’ – that the number of groups to compare increases exponentially with the inclusion of additional covariates, resulting in too few observations per group – is a limitation for matching and stratification [14]. It is also difficult to know if all (and only) relevant covariates have been identified, and whether they may be imperfectly measured, leading to residual confounding. Indeed, some propose that certain relevant confounders are not even measurable [10]. While confounding is generally obviated by the randomization mechanism in randomized controlled trials (RCTs), no long-term RCTs have been performed evaluating the relationships between alcohol use and long-term health outcomes because of ethical and compliance concerns.
To investigate alcohol–long-term health relationships, the field is therefore limited to observational studies. As such, efforts to improve causal inference have centered on mitigating bias. There is increased acknowledgement that data collection and analysis decisions can substantially affect conclusions about relationship strength and form [15, 16], so should be made in a considered, literature-informed manner. A particularly hazardous decision here is treating lifetime abstainers and former drinkers (whose abstinence is often precipitated by illness) as a homogenous group, thereby inducing a ‘sick quitter bias’ which effectively shifts poor health outcomes that have accrued to former drinkers to the abstaining group [7]. Certain tools and strategies can assist with limiting bias, such as creating directed acyclic graphs (DAGs) at study outset, and, following primary analysis, assessing robustness to methodological decisions (‘sensitivity analysis’), bias (‘bias analysis’), sample-specific confounding (‘cross-cohort comparison’) or research type (‘triangulation’) [17]. Indeed, the impact of analytical decisions such as how exposures are categorized and compared has been the focus of recent reviews/meta-analyses of alcohol–health research [15, 16].
Particularly promising, however, for addressing the identified limitations of existing research, are modern methods for data analysis and alternative observational designs. Conventional designs (e.g., prospective cohort studies) can be enhanced with modern analysis methods, such as propensity scores used for matching or weighting, and ‘G-methods’ such as marginal structural models (MSMs; which can account for time-varying variables that act as both confounders and mediators). Regarding alternative designs, twin studies and other family-based designs control automatically for shared confounders, as do negative controls [18]. Natural experiments are another alternative, mimicking the random allocation of RCTs and thus guarding against confounding and reverse causation. These include instrumental variables (IV) designs, where as-if/randomly allocated proxies for exposures are used in place of exposures themselves. Mendelian Randomization (MR), a kind of IV design, offers particular promise given the potential of genetic proxies for alcohol consumption.
While these methods are still limited in their approach to inferring causal relationships from observational data, they represent significant improvements over conventional analyses (see Table 1 for a full list of methods of interest, their advantages, and their limitations). Some of these approaches are gaining popularity [19], but they are not routinely applied to alcohol–long-term health research [20]. Importantly, reviews in this area rarely focus on improved analytical methods to counter confounding and tend to exclude novel study designs. This review therefore aims to identify all observational studies employing such approaches, and to synthesize their findings on the functional form and strength of alcohol–long-term health relationships.
Methods
Search strategy and study selection
This review’s methods are reported in detail in the study protocol, which was registered with PROSPERO (CRD42020185861) and published [38]. Briefly, searches for peer-reviewed, English-language journal articles and grey literature on MEDLINE, PsycINFO, Embase and Scopus were performed in May 2020 with no limits on publication date. Choice of causal inference methods of interest incorporated expert feedback. Search terms were generated by adapting those from recent reviews and searching keywords/index terms of key eligible papers known to the authors, with iterative refinement. These included controlled vocabulary terms and free text words, and related to: 1) alcohol; 2) levels/patterns of drinking 3) observational, longitudinal studies; 4) analytical approaches to improve causal inference that are used in conjunction with conventional study designs; and 5) design-based approaches to improve causal inference. Groups of terms were combined as follows: 1 and 2 and ((3 and 4) or 5). MEDLINE search terms are provided in Table S1. Additionally, reference lists of eligible, retrieved studies were manually searched.
Only human research was eligible. The exposure of interest was level of alcohol consumption (volume over a given period), or level and pattern of consumption (incorporating frequency/heavy episodic drinking). While studies were eligible regardless of their findings on functional form, their methods must have been capable of detecting non-linearity – were it to be present. For this reason, studies were only eligible if they categorized alcohol consumption, and subsequently performed comparisons between a chosen reference category and the other levels of consumption. This approach does not require assuming a functional form (unlike a single regression using a continuous predictor). Specifically, a non-drinking/light drinking reference was required in addition to at least two other levels of consumption (alternative methods of comparison allowing for the detection of non-linearity were permitted for IV/MR designs). Any long-term health outcome was eligible; studies only reporting on acute/short-term conditions (e.g., injury) were excluded. Eligible studies needed to employ one of the pre-specified approaches to improving causal inference (see Table 1). Studies needed to be longitudinal cohort or case-control designs (excepting IV/MR designs). IV/MR studies must have performed formal IV analysis or otherwise provided estimates in terms of predicted alcohol consumption. Reviews and interventional studies were excluded.
Retrieved titles and abstracts were screened by one reviewer (RV), with a second reviewer (JW) additionally screening a random 25%. Full-text articles were independently assessed by two reviewers (RV and JW). A third reviewer (LM) was consulted regarding unresolved discrepancies.
Data extraction
Extraction was performed independently by two reviewers (RV and JW) using pre-piloted forms. Extracted data included publication details (author/s, year), participant characteristics (sample size, setting, mean age, eligibility criteria, cohort name), exposure details (number and spread of measurement occasions, nature of discretized categories), study design and analysis methods, health outcome/s (how assessed, whether binary/continuous, interval to measurement), and results (relationship strength and form). Study authors were contacted if further information was required (see Table S2).
Quality assessment
Given the range of designs targeted by this review, two risk of bias assessment tools were used. Cohort studies were assessed using the relevant Newcastle-Ottawa Scale (NOS) [39], and a recently developed tool specific to MR [40] was employed. One reviewer (RV) applied the tools to all studies, with a second reviewer (JW) additionally assessing a random 25%. In line with other similar reviews, formal assessment of evidence quality was limited to risk of bias [40, 41].
Synthesis and reporting
Data synthesis was limited to narrative description given the heterogeneity in health outcomes and methods employed by included studies. Reporting of this review complies with the Preferred Reporting Items for Systematic Review and Meta-Analysis (PRISMA) [42], the checklist for which can be found in Table S3.
Results
Characteristics of included studies
Sixteen articles met inclusion criteria (see Fig. 2), comprising four MR studies, nine twin designs, and three prospective cohort studies employing MSMs, reporting on health outcomes broadly related to cancer, diabetes, dementia, mental health, cardiovascular health, mortality, HIV, and musculoskeletal health. Two cohorts provided all twin study data, with all but one non-MR study conducted with Swedish or Finnish populations. Study characteristics are summarized in Table 2, and exclusion reasons for key ineligible papers are provided in Table S4. The two reviewers were in agreement on title and abstract screening for 93.13% of cases, and all discrepancies at full-text screening were resolved by discussion between reviewers.

PRISMA flow chart
Cancer
One twin study reported on two prostate cancer outcomes, prostate cancer and prostate cancer mortality, and results were consistent with reverse J- and J-shaped relationships, respectively, with light drinking at the nadir [43]. Hazard ratios (HRs) for abstainers ranged from 2.85–2.98 (monozygotic (MZ) and combined twin analyses) compared to light drinkers, and for heavy drinkers compared to light drinkers ranged from 1.63–2.00. With the maximum sample (all twin analyses), the confidence interval (CI) for the abstainer comparison was large. Results were similar when restricting analyses to twins discordant for prostate cancer outcome.
Diabetes
Two studies reported on diabetes, including one twin study, and one MR study. Carlsson et al.’s twin-based findings on the risk for type 2 diabetes (T2D) resemble a J-shape [44], but were critically underpowered, preventing interpretation. In Peng et al.’s MR study, local average treatment effects (LATEs) were employed to detect non-linearity – indicated by a LATE slope (effect of genetically-predicted alcohol consumption plotted against discretized observed alcohol consumption) significantly different to zero [45]. Results did not support non-linearity for diabetes-related biomarkers. Substantive effects were only interpreted for men, with women used as a negative control due to their lack of alcohol consumption (effect of genetic instrument on diabetic markers should be observed in men but not women if alcohol consumption is the only causal pathway). In linear IV analyses, small positive linear relationships with narrow CIs were found for fasting blood glucose (FBG), 2-h post-load plasma glucose (P2hBG) and insulin resistance (HOMA-IR), while there were no relationships for haemoglobin A1c (HbA1c) or beta-cell function (HOMA-beta).
Dementia
One twin study reported on dementia [46]. Analyses were consistent with a J-shape, with HRs for abstainers compared to light drinkers between 1.37–1.39, and for moderate-to-very-heavy drinkers compared to light drinkers between 1.57–3.07. Analyses of dementia-concordant twins demonstrated that only very heavy alcohol consumers had a much earlier age of onset than their light-drinking co-twins (10.67-year discrepancy in diagnosis compared to 6.79 years when both twins were light drinkers).
Mental health
Two articles reported on mental health outcomes: a prospective cohort study of depression employing MSMs, and a twin study assessing disability pension due to mental health diagnoses (MHD). Gemes et al. employed DAG-informed MSMs incorporating inverse probability of exposure and attrition weights [47]. Results support a U-shaped relationship (although there were few excessive consumers), with relative risks (RR) of 1.60 and 1.77 for abstainers and excessive drinkers respectively compared to light drinkers. Excluding those with baseline depression increased risk for excessive consumers such that the form approximated a J-shape, with RRs of 1.46 and 2.83 for abstainers and excessive drinkers respectively. Stratifying by gender, only abstainers were at increased risk for men, while both abstainers and excessive consumers remained at increased risk for women.
Samuelsson et al. discretized alcohol consumption into categories based on both volume and frequency [48]. In analyses of outcome-discordant twins, abstainers were at increased risk for pension due to MHD compared to light frequent consumers (HRs of 1.93–2.17 for MZ and combined twin analyses), as were heavy infrequent consumers with an HR of 2.10 (disappeared in MZ-only analyses; HR of 1.09), and light infrequent consumers (HRs of 2.80 and 3.67 for MZ and combined twin analyses respectively). Heavy frequent consumers were at decreased risk, although there were too few pairs to conduct MZ-specific analyses.
Cardiovascular events/diagnoses
Four studies reported on cardiovascular events/diagnoses, including two twin studies, one MSM and one MR study. Ilomaki et al. reported on myocardial infarction (MI), comparing various crude, adjusted and MSM models [49]. The DAG-informed MSM incorporated time-varying consumption and both time-varying and invariant covariates. Results were consistent with a J-shape, with RRs of 1.27 for the lowest group and 1.59 for the highest group respectively, both with fairly narrow CIs (although they included the null). Models 2, 3 and 4 (non-MSM but with assorted incorporation of time-varying exposures/confounders) were consistent with monotonically increasing, reverse-J/U, and J-shaped relationships respectively.
Kadlecova et al. examined the relationship between midlife alcohol consumption and later stroke/transient ischaemic attack (TIA) using MZ twins [50]. In co-twin analyses, all groups had higher odds ratios (ORs) for stroke/TIA than very light consumers, with the highest estimate for abstainers (OR of 2.22; consistent with a reverse J-shape). In twins concordant for stroke/TIA, heavy consumers had shorter time to event (5.68 years), while all other groups had slightly longer time to event than the very light drinking group.
Milwood et al. also reported on stroke (ischaemic, intracerebral haemorrhage, total stroke), in addition to acute myocardial infarction (AMI), and total coronary heart disease (CHD) [51]. As for Peng et al., women were negative controls. Comparing categories of genetically-predicted alcohol consumption, MR results were consistent with monotonically increasing relationships for stroke and subtypes, and with no causal relationships for AMI/CHD. Log RRs for those relationships with evidence of linearity ranged from 1.27–1.58 per 280 g of alcohol per week consumed.
Finally, Ropponen et al. reported on disability pension due to circulatory system diagnoses using a twin design [52]. For same-sex twins discordant for outcome, there appeared to be little clear relationship in MZ-only analyses, while the dizygotic (DZ)-only analyses were consistent with a reverse J-shape (both moderate and heavy consumers had HRs < 1 compared to abstainers).
Continuous cardiovascular measures
Three MR studies reported on lipids, with two of these also reporting on blood pressure and obesity anthropometrics. Peng et al., using the same methods as for diabetes outcomes, found no evidence of non-linear relationships for any lipids, blood pressure measures or obesity anthropometrics, but did find positive linear relationships for BMI, waist circumference, hip circumference, non-HDL-C, triglycerides (TG), total cholesterol (TC), systolic blood pressure (SBP) and diastolic blood pressure (DBP).
Silverwood et al. applied the LATE method to pooled data from 22 studies to examine cardiovascular and inflammatory measures, finding non-linearity (J-shapes) for SBP, non-HDL-C, BMI, WC and C-reactive protein (CRP) [53]. Nadirs for these relationships corresponded to small volumes of alcohol, ranging from 1 to 3.5 units of alcohol/week, and the differences in biomarker outcomes at the nadir compared with abstinence were also small. For those outcomes with no evidence of non-linearity, standard IV analysis revealed a positive linear relationship between alcohol consumption and IL-6 (an inflammatory marker), but a lack of relationship with HDL-C and triglycerides.
Finally, Vu et al. discretized genetically-predicted alcohol consumption into quartiles, comparing lipids in each with the lowest quartile [54]. Results provide evidence of non-linearity for TG, TC, HDL2-C, LDL-C, sdLDL-C and apoB. For these outcomes, all quartiles had more favorable levels than quartile 1. Benefits peaked at quartile 3, equivalent to .5–.1 genetically-predicted units per week. Results do not support causal relationships between alcohol and HDL-C overall, HDL3-C or Lp(a).
Mortality
One twin study assessed all-cause mortality, finding the three heaviest alcohol consuming groups had greater mortality risk compared to their lighter consuming reference, with HRs ranging from 1.60–2.99 [55]. This pattern replicated in the MZ-only sample, but with less precision and with CIs crossing the null. Abstainers were at decreased risk (HR of .43) in the MZ-only sample, but the CI included the null.
HIV seroconversion
One study employing MSMs reported on HIV seroconversion in men, incorporating both inverse probability of exposure and censoring weights [56]. Results were consistent with a monotonically increasing risk function, with an RR of 1.61 for heavy drinkers compared with abstainers.
Musculoskeletal health (MSD)
Three twin studies reported on MSD – all using receipt of disability pension due to MSD conditions as the outcome. Pietikainen et al. found a roughly monotonically increasing relationship for pension due to lower back disorders, with lower risk for abstainers the clearest effect (HR of .79), although all CIs included the null [57]. When stratified by sex, the protective effect of abstinence was more pronounced in men (HR .45; CI .13,1.48), while the functional form in women changed such that there was also reduced risk for moderate consumers (HR .76; CI .45,2.32).
Using the same cohort, Ropponen et al. (2011) examined disability pension due to osteoarthritis and due to MSD more generally [58]. Results were not consistent with a clear functional form but do support abstainers having the lowest risk for both outcomes.
Finally, in a different cohort, Ropponen et al. (2014) evaluated risk for disability pension due to MSD [52]. Again, outcome-discordant twin analyses did not reveal a clear functional form, with discrepant results between MZ and DZ samples.
Risk of bias
Cohort studies ranged in scores from 7 to 9 out of 9 on the NOS tool (see Table S5), with most losing marks for self-reported ascertainment of exposure. MR studies all had a combination of low and moderate risk across the five domains (see Table S6).
Discussion
This review found that improved causal inference methods have been applied minimally to research on alcohol–long-term health relationships. Non-linearity was apparent for several outcomes: prostate cancer and related mortality (reverse J-shaped and J-shaped respectively), dementia risk (J-shaped; although age of onset better characterized by monotonically increasing relationship), mental health (U/J-shaped for depression; increased risk for abstainers for disability pension due to MHD), and certain lipids (LDL-C; reverse J-shaped, sdLDL-C and apoB; monotonically decreasing, and HDL-2C; inverted reverse J-shaped). However, many of the individual comparisons from which these overall forms were of small effect size or were imprecise. While the level of consumption coinciding with lowest risk varied between outcomes, it tended to fall in the light range – as little as .5–.1 units/week [54]. Positive linear/monotonically increasing relationships were found for DBP, hip circumference, IL-6, all-cause mortality, and HIV seroconversion (although it is not possible to partition short-term pathways via risky sexual behavior and longer-term effects on immune function). No relationships were found between alcohol and HDL-3C, Lp(a), or waist-to-hip ratio.
Where multiple studies reported on an outcome, findings were inconsistent. For diabetes-related biomarkers, there was a positive linear relationship, but the one study reporting on T2D itself lacked power to support a clear functional form. For cardiovascular events/diagnoses, one twin study found preliminary evidence for a J-shaped relationship with myocardial infarction, while MR failed to find any relationship. For stroke, one twin study found a reverse J-shape (monotonically increasing for time to stroke), while MR found monotonically increasing relationships. For cardiovascular disease more generally, no clear causal relationship emerged. The results of Millwood et al. imply that broad outcomes (in this case total CHD) mask various discrepant sub-functional forms (as is likely for all-cause mortality) [59]. For cardiovascular biomarkers, all three studies evaluating HDL-C were consistent with a lack of causal relationship. There was little consistency across other cardiovascular biomarkers, lipids and obesity anthropometric measures, with conflicting functional forms found for non-HDL-C, triglycerides, total cholesterol, SBP, BMI and waist circumference. This was the case even when the same MR method was used, which may reflect the impact of using different ethnic populations and genetic instruments. Finally, for musculoskeletal health, results varied between a monotonically increasing form, no clear functional form, and no clear functional form with nadir at abstinence.
Some of these findings are roughly consistent with the conclusions on functional form made by recent reviews of the broader observational literature, but there were also outcomes where the present findings do not concord with the broader literature; evidence has been triangulated in Table 3. Triangulation with the broader observational research is key, as evidence for most health outcomes was only available from one or two studies in the present review, and thus not definitive.
Importantly though, where included studies performed conventional analyses for comparison with modern methods to address confounding, results were often discrepant. Most starkly, Millwood et al. found typical J/U/reverse-J-shaped relationships via conventional analyses, but monotonically increasing (or no) relationships when using MR. Even when functional forms roughly replicated across methods, the strength of individual comparisons differed. With pooled cohort analysis, Dickerman et al. found abstainers had slightly increased risk for prostate cancer, compared to much greater risk when utilising discordant twins. The application of improved causal inference methods is therefore essential to accurately characterize alcohol–health relationships.
Also of note, there were several methods of interest for which no eligible studies were identified. It may be that certain methods are ill-suited to address this research question – for example, it may be difficult to find a non-genetic IV to proxy for multiple levels of alcohol consumption, while others, such as G-estimation, may not yet have gained traction in research more generally [21]. Negative controls, while not identified as a primary design approach, were incorporated into two of the MR studies. Of the methods that were represented, there were fewer eligible studies than expected – particularly for MR, where many articles were excluded for only performing linear IV analyses, or for providing estimates in terms of the effects of genetic variants (e.g., ADH1B A-allele carriers vs non-carriers) rather than genetically-predicted alcohol consumption. Consistent with other reviews of the literature [10], covariates controlled for across studies varied considerably (see Table S7).
Strengths
This review applied a novel framework to examining alcohol–health relationships, identifying and synthesizing information from those observational studies that best mitigate confounding and thus promote causal inference. The search strategy included terms for a broad range of analytical and design-based approaches informed by the literature and consultation with experts. As many included studies performed both conventional analyses and causal inference approaches, this review was able to highlight the difference that such methods make. A further strength was that all long-term health outcomes were eligible, providing a comprehensive picture of the state of the evidence base, and importantly, on the large gaps in the literature where the aforementioned methods require application.
Limitations
While the included studies mitigate confounding, other methodological limitations (not necessarily captured by the NOS) may be present. For example, the prospective cohort studies likely suffered from sick quitter bias in failing to separate ex-drinkers from lifelong abstainers – exacerbated in those studies where baseline mean age was over 50. Misclassification was likely in many of the twin studies as most based classification on a single measurement, and most of these focused on shared confounding, without additionally controlling for measured covariates. While MSMs can account for consumption and covariates at multiple timepoints, these studies were still vulnerable to residual confounding, with Gemes et al. noting that unmeasured social confounders may partially underpin their findings. As approaches to minimize these biases consist largely of literature-informed, considered researcher decisions and sensitivity analyses, they are not suited to systematic database searching, and were not the focus of this review. While MR is largely immune to both misclassification and confounding, it suffers from its own idiosyncratic limitations, with controversy over its application to alcohol–health research specifically [71,72,73]. For example, two of the included MR studies discretized genetically-predicted alcohol consumption, resulting in the lowest categories aligning with occasional consumption – not strictly comparable with abstinence.
Additionally, despite evidence of the importance of accounting for pattern of consumption [74], MR studies are limited in their ability to do so [73], and only one cohort study [48] used drinking pattern as the exposure, rather than volume alone (or volume and frequency separately). Finally, several of the included studies evaluated alcohol’s relationship with condition-specific disability pension, rather than the condition itself. This is an imperfect proxy, with receipt of pension also reflecting the interference of the disease with one’s ability to work, as well as incentive to apply [57]. Given that all included studies evaluating musculoskeletal health used disability pension as a proxy, findings with respect to these outcomes should be interpreted with caution.
Future directions
This review has identified clear gaps in alcohol–long-term health research, demonstrating great potential for further application of enhanced causal inference methods. Analysis methods such as MSMs are particularly promising as they do not require the establishment of twin registries or large genetic datasets, but are able to mitigate confounding, differential censoring and misclassification. And as evidenced by studies included in this review, they are suitable for examining alcohol–long-term health relationships.
Analysis and design approaches that mitigate confounding should be combined with sensitivity analyses such as multiverse analyses (to quantify robustness to data processing/analysis decisions) [75], as well as bias analyses such as e-value generation (to quantify robustness to unmeasured confounding) [76]. Given the unique advantages and limitations of each analytical and design-based approach, triangulation of findings across observational evidence is crucial. Combining data across studies through data harmonization techniques should also be considered to mitigate power issues, which were evident in several included studies with rare exposure–outcome combinations. Finally, while acknowledging the limitations of the included studies, the identification of some evidence consistent with causal protective effects of light-to-moderate alcohol consumption for several health outcomes justifies further exploration of the biological mechanisms that could underpin these (potential) effects. This is particularly true of those outcomes for which findings were concordant with the broader observational literature (see Table 3).
Conclusions
This novel review found that, when enhanced causal inference approaches are applied, a variety of functional forms – including linear, J-shaped, and no relationship – are found between alcohol consumption and various long-term health outcomes. However, few studies have employed these methods, with covariate-adjusted, conventional cohort analyses remaining dominant, preventing a conclusive picture of the nature of these relationships from emerging. Given that associations found between moderate alcohol consumption and good health impact safe drinking guidelines and public health policy [77, 78], further research employing methods to mitigate confounding and other biases is urgently required to establish whether such findings are truly causal.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- RCT:
-
Randomised controlled trial
- DAG:
-
Directed acyclic graph
- MSM:
-
Marginal structural model
- IV:
-
Instrumental variables
- MR:
-
Mendelian randomisation
- NOS:
-
Newcastle-Ottawa Scale
- PRISMA:
-
Preferred Reporting Items for Systematic Review and Meta-Analysis
- T2D:
-
Type 2 diabetes
- LATE:
-
Local average treatment effects
- FBG:
-
Fasting blood glucose
- P2hBG:
-
2-h post-load plasma glucose
- HOMA-IR:
-
insulin resistance
- HbA1c:
-
Haemoglobin A1c
- HOMA-beta:
-
beta-cell function
- MHD:
-
Mental health diagnoses
- MZ:
-
Monozygotic
- MI:
-
Myocardial infarction
- TIA:
-
Transient ischaemic attack
- AMI:
-
Acute myocardial infarction
- CHD:
-
Coronary heart disease
- DZ:
-
Dizygotic
- TG:
-
Triglycerides
- TC:
-
Total cholesterol
- SBP:
-
Systolic blood pressure
- DBP:
-
Diastolic blood pressure
- CRP:
-
C-reactive protein
References
Griswold MG, Fullman N, Hawley C, et al. Alcohol use and burden for 195 countries and territories, 1990–2016: a systematic analysis for the global burden of disease study 2016. Lancet. 2018;392(10152):1015–35.
Rehm J, Gmel GE Sr, Gmel G, et al. The relationship between different dimensions of alcohol use and the burden of disease—an update. Addiction. 2017;112(6):968–1001.
Keyes KM, Calvo E, Ornstein KA, et al. Alcohol consumption in later life and mortality in the United States: results from 9 waves of the health and retirement study. Alcohol Clin Exp Res. 2019;43(8):1734–46.
Andreasson S, Chikritzhs T, Dangardt FHH, Naimi T, Stockwell T. Evidence about health effects of “moderate” alcohol consumption: reasons for scepticism and public health implilcations. Alcohol Soc. 2014;6.
Naimi TS, Stockwell T, Zhao J, et al. Selection biases in observational studies affect associations between ‘moderate’ alcohol consumption and mortality. Addiction. 2017;112(2):207–14. https://doi.org/10.1111/add.13451.
Callinan S, Chikritzhs T, Livingston M. Consistency of drinker status over time: Drinking patterns of ex-drinkers who describe themselves as lifetime abstainers. J Stud Alcohol Drugs. 2019;80(5):552–6. https://doi.org/10.15288/jsad.2019.80.552.
Shaper AG, Wannamethee G, Walker M. Alcohol and mortality in British men: explaining the U-shaped curve. Lancet. 1988;332(8623):1267–73. https://doi.org/10.1016/S0140-6736(88)92890-5.
Kerr WC, Lui CK, Williams E, Ye Y, Greenfield TK, Lown EA. Health risk factors associated with lifetime abstinence from alcohol in the 1979 National Longitudinal Survey of youth cohort. Alcohol Clin Exp Res. 2017;41(2):388–98.
Naimi TS, Brown DW, Brewer RD, et al. Cardiovascular risk factors and confounders among nondrinking and moderate-drinking U.S. adults. Am J Prev Med. 2005;28(4):369–73. https://doi.org/10.1016/j.amepre.2005.01.011.
Wallach JD, Serghiou S, Chu L, et al. Evaluation of confounding in epidemiologic studies assessing alcohol consumption on the risk of ischemic heart disease. BMC Med Res Methodol. 2020;20(1):1–10. https://doi.org/10.1186/s12874-020-0914-6.
Brookhart MA, Wyss R, Layton JB, Stürmer T. Propensity score methods for confounding control in nonexperimental research. Circ Cardiovasc Qual Outcomes. 2013;6(5):604–11. https://doi.org/10.1161/CIRCOUTCOMES.113.000359.
Thoemmes F, Ong AD. A primer on inverse probability of treatment weighting and marginal structural models. Emerg Adulthood. 2016;4(1):40–59. https://doi.org/10.1177/2167696815621645.
Greenland S, Mansournia MA, Altman DG. Sparse data bias: a problem hiding in plain sight. BMJ. 2016;353:1–6. https://doi.org/10.1136/bmj.i1981.
Melberg HO. Does Moderate Alcohol Intake Reduce Mortality? (Jon Elster OG, Moene AH and K, eds.). Oslo Academic Press; 2006.
Chu L, Ioannidis JPA, Egilman AC, Vasiliou V, Ross JS, Wallach JD. Vibration of effects in epidemiologic studies of alcohol consumption and breast cancer risk. Int J Epidemiol. 2020;49(2):608–18. https://doi.org/10.1093/ije/dyz271.
Stockwell T, Zhao J, Panwar S, Roemer A, Naimi T, Chikritzhs T. Do “moderate” drinkers have reduced mortality risk? A systematic review and meta-analysis of alcohol consumption and all-cause mortality. J Stud Alcohol Drugs. 2016;77(2):185–98.
Richmond RC, Al-amin A, Smith GD, Relton CL. Approaches for drawing causal inferences from epidemiological birth cohorts: a review. Early Hum Dev. 2014;90:769–80. https://doi.org/10.1016/j.earlhumdev.2014.08.023.
Lipsitch M, Tchetgen ET, Cohen T. Negative controls: a tool for detecting confounding and bias in observational studies. Epidemiology. 2010;21(3):383.
Benedetto U, Head SJ, Angelini GD, Blackstone EH. Statistical primer: propensity score matching and its alternatives. Eur J Cardio-thoracic Surg. 2018;53(6):1112–7. https://doi.org/10.1093/ejcts/ezy167.
McQuire C, de Vocht F. Methodological advances to mitigate some of the challenges of research on alcohol and all-cause mortality: commentary on Rehm. Drug Alcohol Rev. 2019;38(1):7–8. https://doi.org/10.1111/dar.12898.
Watkins TR. Understanding uncertainty and bias to improve causal inference in health intervention research. [PhD thesis]. Sydney, Australia: The University of New South Wales; Published online 2019.
Naimi AI, Cole SR, Kennedy EH. An introduction to g methods. Int J Epidemiol. 2017;46(2):756–62. https://doi.org/10.1093/ije/dyw323.
Mansournia MA, Etminan M, Danaei G, Kaufman JS, Collins G. Handling time varying confounding in observational research. BMJ. 2017;359(October). https://doi.org/10.1136/bmj.j4587.
Hernán MA. Robins JM. What If. Chapman & Hill/CRC: Causal Inference; 2020.
Williamson T, Ravani P. Marginal structural models in clinical research: When and how to use them? Nephrol Dial Transplant. 2017;32(February):ii84-ii90. doi:https://doi.org/10.1093/ndt/gfw341
Schuler MS, Rose S. Targeted maximum likelihood estimation for causal inference in observational studies. Am J Epidemiol. 2017;185(1):65–73. https://doi.org/10.1093/aje/kww165.
Gunasekara FI, Richardson K, Carter K, Blakely T. Fixed effects analysis of repeated measures data. Int J Epidemiol. 2014;43(December 2013):264–9. https://doi.org/10.1093/ije/dyt221.
Fergusson DM, Boden JM, Horwood LJ. Psychosocial sequelae of cannabis use and implications for policy : findings from the Christchurch health and development study. Soc Psychiatry Psychiatr Epidemiol. 2015;50(9):1317–26. https://doi.org/10.1007/s00127-015-1070-x.
Fergusson DM, Boden JM, Horwood LJ. Tests of causal links between alcohol abuse or dependence and major depression. Arch Gen Psychiatry. 2009;66(3):260–6.
Fergusson DM, Boden JM, Horwood LJ. Unemployment and suicidal behavior in a New Zealand birth cohort: a fixed effects regression analysis. Crisis. 2007;28(2):95–101.
Allison PD. Fixed effects regression methods for longitudinal data using SAS. SAS Institute Inc; 2005.
Richiardi L, Bellocco R, Zugna D. Mediation analysis in epidemiology: methods, interpretation and bias. Int J Epidemiol. 2013;42(5):1511–9. https://doi.org/10.1093/ije/dyt127.
Pearce N, Lawlor DA. Causal inference — so much more than statistics. Int J Epidemiol. 2017;45(6):1895–903. https://doi.org/10.1093/ije/dyw328.
Vanderweele TJ. Mediation Analysis: A Practitioner ’ s Guide. Annu Rev Public Health. 2016;37(17–32). doi:https://doi.org/10.1146/annurev-publhealth-032315-021402
Dunning T. Natural experiments in the social sciences: a design-based approach: Cambridge University Press; 2012.
Gage SH, Munafo MR, Smith GD. Causal inference in developmental origins of health and disease ( DOHaD ) research. Annu Rev Psychol. 2016;67:567–85. https://doi.org/10.1146/annurev-psych-122414-033352.
Davies NM, Holmes M V, Smith GD. Reading Mendelian randomisation studies: A guide, glossary, and checklist for clinicians. BMJ. 2018;362. doi:https://doi.org/10.1136/bmj.k601
Visontay R, Sunderland M, Slade T, Wilson J, Mewton L. Are there non-linear relationships between alcohol consumption and long-term health? Protocol for a systematic review of observational studies employing approaches to improve causal inference. BMJ Open. 2021;11(3):e043985.
Wells G, Shea B, O’Connell D, et al. The Newcastle-Ottawa Scale (NOS) for assessing the quality of nonrandomised studies in meta-analyses Available from: http://www.ohri.ca/programs/clinical_epidemiology/oxford.htm.
Mamluk L, Jones T, Ijaz S, et al. Evidence of detrimental effects of prenatal alcohol exposure on offspring birthweight and neurodevelopment from a systematic review of quasi-experimental studies. Int J ofEpidemiology, Published online. 2020:1–24. https://doi.org/10.1093/ije/dyz272.
Mamluk L, Edwards HB, Savovi J, et al. Low alcohol consumption and pregnancy and childhood outcomes: time to change guidelines indicating apparently ‘ safe ’ levels of alcohol during pregnancy ? A systematic review and meta-analyses. BMJ Open. 2017;7:e015410. https://doi.org/10.1136/bmjopen-2016-015410.
Moher D, Liberati A, Tetzlaff J, et al. Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. PLoS Med. 2009;6(7):e1000097. https://doi.org/10.1371/journal.pmed.1000097.
Dickerman BA, Coseo S, Markku M, Pukkala E, Mucci LA, Kaprio J. Alcohol intake, drinking patterns, and prostate cancer risk and mortality : a 30-year prospective cohort study of Finnish twins. Cancer Causes Control. 2016;27(9):1049–58. https://doi.org/10.1007/s10552-016-0778-6.
Carlsson S, Hammar N, Grill V, Kaprio J. Alcohol consumption and the incidence of type 2 diabetes a 20-year follow-up of the Finnish twin cohort study. Diabetes Care. 2003;26(10):2–7.
Peng M, Zhang J, Zeng T, et al. Alcohol consumption and diabetes risk in a Chinese population: a Mendelian randomization analysis. Addiction. 2019;114(3):436–49.
Handing EP, Andel R, Kadlecova P, Gatz M, Pedersen NL. Midlife alcohol consumption and risk of dementia over 43 years of follow-Up : a population-based study from the Swedish twin registry. J Gerontol Ser A Biomed Sci Med Sci. 2015;70(10):1248–54. https://doi.org/10.1093/gerona/glv038.
Gémes K, Forsell Y, Janszky I, et al. Moderate alcohol consumption and depression-a longitudinal population-based study in Sweden. Acta Psychiatr Scand. Published online 2019.
Samuelsson Å, Ropponen A, Alexanderson K, Svedberg P. A prospective cohort study of disability pension due to mental diagnoses : the importance of health factors and behaviors. BMC Public Health. 2013;13(1):1. https://doi.org/10.1186/1471-2458-13-621.
Ilomäki J, Hajat A, Kauhanen J, et al. Relationship between alcohol consumption and myocardial infarction among ageing men using a marginal structural model. Eur J Pub Health. 2012;22(6):825–30. https://doi.org/10.1093/eurpub/ckr013.
Kadlecová P, Andel R, Mikulík R, Handing EP, Pedersen NL. Alcohol consumption at midlife and risk of stroke during 43 years of follow-up: cohort and twin analyses. Stroke. 2015;46(3):627–33. https://doi.org/10.1161/STROKEAHA.114.006724.
Millwood IY, Walters RG, Mei XW, et al. Conventional and genetic evidence on alcohol and vascular disease aetiology: a prospective study of 500 000 men and women in China. Lancet. 2019;393(10183):1831–42.
Ropponen A, Svedberg P. Single and additive effects of health behaviours on the risk for disability pensions among Swedish twins. Eur J Pub Health. 2013;24(4):643–8. https://doi.org/10.1093/eurpub/ckt168.
Silverwood RJ, Holmes MV, Dale CE, et al. Testing for non-linear causal effects using a binary genotype in a Mendelian randomization study: application to alcohol and cardiovascular traits. Int J Epidemiol. 2014;43(6):1781–90. https://doi.org/10.1093/ije/dyu187.
Vu KN, Ballantyne CM, Hoogeveen RC, Nambi V. Causal role of alcohol consumption in an improved lipid Profile : the atherosclerosis risk in communities ( ARIC ) study. PLoS One. 2016;11(2):e0148765. https://doi.org/10.1371/journal.pone.0148765.
Sipilä P, Rose RJ, Kaprio J. Drinking and mortality : long-term follow-up of drinking- discordant twin pairs. Addiction. 2016;111(2):245–54. https://doi.org/10.1111/add.13152.
Sander PM, Cole SR, Stall RD, et al. Joint effects of alcohol consumption and high-risk sexual behavior on HIV seroconversion among men who have sex with men. AIDS. 2013;27(5):815–23. https://doi.org/10.1097/QAD.0b013e32835cff4b.
Pietikäinen S, Silventoinen K, Svedberg P, et al. Health-related and Sociodemographic risk factors for disability pension due to low Back disorders: a 30-year prospective Finnish twin cohort study. J Occup Environ Med. 2011;53(5):488–96. https://doi.org/10.1097/JOM.0b013e31821576dd.
Ropponen A, Silventoinen K, Svedberg P, et al. Health-related risk factors for disability pensions due to musculoskeletal diagnoses : a 30-year Finnish twin cohort study. Scand J Public Health. 2011;39(8):839–48. https://doi.org/10.1177/1403494811418283.
Rehm J. Why the relationship between level of alcohol-use and all-cause mortality cannot be addressed with meta-analyses of cohort studies. Drug Alcohol Rev. 2019;38(1):3–4. https://doi.org/10.1111/dar.12866.
Zhao J, Stockwell T, Roemer A, Chikritzhs T. Is alcohol consumption a risk factor for prostate cancer ? A systematic review and meta – analysis. BMC Cancer. 2016;16(1):1–13. https://doi.org/10.1186/s12885-016-2891-z.
Taghdiri S. Association of Alcohol Consumption with Glucose Homeostasis : A Systematic Review and Meta-Analysis. [PhD thesis]. Toronto, Canada: University of Toronto; Published online 2017.
Roerecke M, Tobe SW, Kaczorowski J, et al. Sex-specific associations between alcohol consumption and incidence of hypertension: a systematic review and meta-analysis of cohort studies. J Am Heart Assoc. 2018;7(13):e008202.
Sayon-Orea C, Martinez-gonzalez MA, Bes-rastrollo M. Alcohol consumption and body weight : a systematic review. Nutr Rev. 2011;69(8):419–31. https://doi.org/10.1111/j.1753-4887.2011.00403.x.
Minzer S, Losno RA, Casas R. The effect of alcohol on cardiovascular risk factors: is there new Information ? Nutrients. 2020;12(4):1–22.
Larsson SC, Wallin A, Wolk A, Markus HS. Differing association of alcohol consumption with different stroke types : a systematic review and meta-analysis. BMC Med. 2016;14(1). doi:https://doi.org/10.1186/s12916-016-0721-4
Yang Y, Liu D-C, Wang Q-M, et al. Alcohol consumption and risk of coronary artery disease : a dose-response meta-analysis of prospective studies. Nutrition. 2016;32(6):637–44. https://doi.org/10.1016/j.nut.2015.11.013.
Visontay R, Rao RT, Mewton L. Alcohol use and dementia: new research directions. Curr Opin Psychiatry. 2021;34(2):165–70. https://doi.org/10.1097/yco.0000000000000679.
Li J, Wang H, Li M, et al. Effect of alcohol use disorders and alcohol intake on the risk of subsequent depressive symptoms: a systematic review and meta-analysis of cohort studies. Addiction. 2020;115(7):1224–43. https://doi.org/10.1111/add.14935.
Rehm J, Probst C, Shield KD, Shuper PA. Does alcohol use have a causal effect on HIV incidence and disease progression ? A review of the literature and a modeling strategy for quantifying the effect. Popul Health Metrics. 2017;15(1):1–7. https://doi.org/10.1186/s12963-017-0121-9.
Shuper PA, Neuman M, Kanteres F, Baliunas D, Joharchi N, Rehm J. Causal considerations on alcohol and HIV / AIDS — a systematic review. Alcohol Alcohol. 2010;45(2):159–66. https://doi.org/10.1093/alcalc/agp091.
Mukamal KJ, Stampfer MJ, Rimm EB. Genetic instrumental variable analysis : time to call mendelian randomization what it is . The example of alcohol and cardiovascular disease. Eur J Epidemiol. 2020;35(2):93–7.
Davey G, Michael S, Davies NM, Ebrahim S. Mendel ’ s laws , Mendelian randomization and causal inference in observational data : substantive and nomenclatural issues. Eur J Epidemiol. 2020;35(2):99.
Ellison RC, Grønbæk M, Skovenborg E. Using Mendelian randomization to evaluate the effects of alcohol consumption on the risk of coronary heart disease. Drugs and Alcohol Today. Published online 2021.
Roerecke M, Rehm J. Alcohol consumption, drinking patterns, and ischemic heart disease: a narrative review of meta-analyses and a systematic review and meta-analysis of the impact of heavy drinking occasions on risk for moderate drinkers. BMC Med. 2014;12(1):182.
Steegen S, Tuerlinckx F, Gelman A, Vanpaemel W. Increasing transparency through a multiverse analysis. Perspect Psychol Sci. 2016;11(5):702–12. https://doi.org/10.1177/1745691616658637.
Vanderweele TJ, Ding P. Sensitivity analysis in observational Research : introducing the E-value. Ann Intern Med. 2017;167(4):268–74. https://doi.org/10.7326/M16-2607.
Sherk A, Gilmore W, Churchill S, Lensvelt E, Stockwell T, Chikritzhs T. Implications of cardioprotective assumptions for national drinking guidelines and alcohol harm monitoring systems. Int J Environ Res Public Health. 2019;16(24):1–17. https://doi.org/10.3390/ijerph16244956.
Stockwell T, Room R. Constructing and responding to low-risk drinking guidelines: conceptualisation, evidence and reception. Drug Alcohol Rev. 2012;31(2):121–5. https://doi.org/10.1111/j.1465-3362.2011.00416.x.
Acknowledgments
The authors would like to thank Jessica Hughes, librarian at the University of Sydney, for assisting with the literature search, Dr. Cheryl McQuire (University of Bristol) and Dr. Tim Watkins (University of New South Wales) who were consulted on the causal inference methods included in our search, as well as the authors of included studies who were generous with their time in assisting with queries.
Funding
Rachel Visontay is funded by the National Health and Medical Research Council (GNT1190255), as well as the University of Sydney. Publication fees were supported by the National Health and Medical Research Council Centre of Research in Prevention and Early Intervention in Mental Illness and Substance Use (PREMISE; APP11349009). None of these bodies played a role in the design of the study, collection, analysis and interpretation of data, or manuscript preparation.
Author information
Authors and Affiliations
Contributions
RV, MS, TS and LM conceptualised the study. RV and JW undertook data extraction and curation. All authors contributed to, read, revised, and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Visontay, R., Sunderland, M., Slade, T. et al. Are there non-linear relationships between alcohol consumption and long-term health?: a systematic review of observational studies employing approaches to improve causal inference. BMC Med Res Methodol 22, 16 (2022). https://doi.org/10.1186/s12874-021-01486-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-021-01486-5