
Abstract
Background
Aneurysm is a severe and fatal disease. This study aims to comprehensively identify the highly conservative co-expression modules and hub genes in the abdominal aortic aneurysm (AAA), thoracic aortic aneurysm (TAA) and intracranial aneurysm (ICA) and facilitate the discovery of pathogenesis for aneurysm.
Methods
GSE57691, GSE122897, and GSE5180 microarray datasets were downloaded from the Gene Expression Omnibus database. We selected highly conservative modules using weighted gene co‑expression network analysis before performing the Gene Ontology, Kyoto Encyclopedia of Genes and Genomes pathway and Reactome enrichment analysis. The protein–protein interaction (PPI) network and the miRNA-hub genes network were constructed. Furtherly, we validated the preservation of hub genes in three other datasets.
Results
Two modules with 193 genes and 159 genes were identified as well preserved in AAA, TAA, and ICA. The enrichment analysis identified that these genes were involved in several biological processes such as positive regulation of cytosolic calcium ion concentration, hemostasis, and regulation of secretion by cells. Ten highly connected PPI networks were constructed, and 55 hub genes were identified. In the miRNA-hub genes network, CCR7 was the most connected gene, followed by TNF and CXCR4. The most connected miRNAs were hsa-mir-26b-5p and hsa-mir-335-5p. The hub gene module was proved to be preserved in all three datasets.
Conclusions
Our study highlighted and validated two highly conservative co-expression modules and miRNA-hub genes network in three kinds of aneurysms, which may promote understanding of the aneurysm and provide potential therapeutic targets and biomarkers of aneurysm.
Similar content being viewed by others

Background
Aneurysms are permanent dilation of the arteries, secondary to pathologic changes of arterial walls. They can occur at any site of arteries and may lead to serious outcomes such as rupture and dissection [1, 2], which are related to high mortality. Abdominal aortic aneurysm (AAA), thoracic aortic aneurysm (TAA) and intracranial aneurysm (ICA) are three common kinds of aneurysms [3,4,5]. Intriguingly, previous studies have shown the co-occurrences of any two of them [6,7,8,9,10] at different levels. Furthermore, Kim et al. noted the familial association of aortic aneurysm and ICA [11], indicating the possible common genetic predisposition underlying the aortic and cerebral aneurysm.
Recently, whole-genome linkage studies have identified some genomic loci serving as common genetic risk factors. For example, 4q32-34 and 19q for AAAs and IAs, 3p24-25 and 5q for TAAs and IAs, and 18q11 and 15q21 for all three kinds of aneurysm [12, 13]. Besides, an increasing number of gene-expression regulators and key genes were identified in different aneurysms [14,15,16]. With the development of gene sequencing techniques, there are an increasing number of studies focusing on the expression profile of artery aneurysm [17,18,19]. However, there are no studies focusing on identifying how gene expression profile preserved in these three kinds of aneurysms.
Therefore, three gene expression microarray datasets in the Gene Expression Omnibus (GEO) were included in the present study. Weighted gene co‑expression network analysis (WGCNA) was used to construct a co-expression network, and the highly preserved expression modules with genes were selected. Subsequently, we performed a comprehensive functional enrichment analysis of the selected modules. The protein–protein interaction (PPI) was conducted with the identification of highly connected genes and their targeted miRNAs. In the present study, the in‑depth analysis may increase the knowledge into the pathogenesis of aneurysm, along with key genes and therapeutic targets for the human aneurysm.
Methods
Microarray data download and preprocessing
We downloaded GSE57691, GSE122897, and GSE5180 microarray data from NCBI GEO (http://www.ncbi.nlm.nih.gov/geo/). After excluding the control datasets, there are 49 datasets from samples obtained from patients with AAA in GSE57691, 44 intracranial aneurysm datasets from the intracranial cortical artery samples in GSE122897, and 12 thoracic ascending aortic aneurysm datasets from the patients with tricuspid aortic valve. The platforms for GSE57691, GSE122897, and GSE5180 are Illumina HumanHT-12 V4.0 expression beadchip, Illumina HiSeq 2500 (Homo sapiens), and Affymetrix Human Genome U133A Array, respectively. Raw data of these datasets were preprocessed using R software (version 4.0.3, https://www.R-project.org/). Specifically, we implemented the preprocessing pipeline in limma [20] package for GSE57691. For GSE122897, the transcript abundance was filtered at a CPM of 0.5 and the trimmed mean of M values (TMM) was implemented to normalize the raw data with the help of the edgeR [21] Bioconductor package. The uploaded GSE5180 data has normalized already. The annotation for the probes and clinical traits information were downloaded using GEOquery [22] package. After excluding the probes that are unable to be annotated, we combined the probes annotated with the same genes using the median method.
WGCNA construction and module selection process
WGCNA [23] package was required for the co-expression network construction. Firstly, we selected common genes in the three datasets and chose the forty percent genes with the most variance in the GSE57691. After evaluating the correlations between the three datasets using the verbose Scatterplot function, we calculated the soft threshold value based on a scale-free topology criterion in GSE57691 (scale-free R2 = 0.9). The weighted adjacency matrix was constructed using the soft-thresholding power. Relationships between one gene and all the other genes in the analysis were incorporated, and the adjacency matrix was transformed into the topological matrix (TOM). Subsequently, a hierarchical clustering analysis [24] of genes was performed using 1‑TOM as the distance measure. To acquire a small number of large modules, modules were detected using a dynamic tree cut algorithm with a minimum module size of 50 and a minimum cut height of 0.99. Furthermore, module preservation between the two datasets was measured using the specific function of the WGCNA [23] software package. In general, the higher the value of "Zsummary.pres" the more preserved the module is between data sets: 5 < Z < 10 indicates moderate preservation, while Z > 10 indicates high preservation. We selected the modules with high preservation in both GSE122897 and GSE5180.
Gene Ontology (GO), Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway and Reactome enrichment analysis
GO [25] analysis was a popular method to elucidate potential biological processes (BP), molecular functions (MF), and cellular components (CC) associated with the genes. KEGG pathway database contains information about the mechanism of networking between molecules or genes. It complements the majority of the existing molecular biology databases with further information, including information on the individual gene [26]. Biological pathways enriched in the selected modules were also interrogated with the Reactome pathway database. We performed the enrichment analysis in Metascape (http://metascape.org/), a gene annotation, and analysis resource [27]. The threshold for P-value was set at 0.01 and the minimum enrichment score was 1.5. The heatmap of enriched terms was plotted and the genes that belong to the same enriched ontology term were shown in a Circos plot [28].
PPI network and hub gene identification and validation
PPI enrichment analysis was carried out using the following databases: BioGRID [29], InWeb_IM [30], and OmniPath [31] in Metascape (http://metascape.org/). Molecular Complex Detection (MCODE) [32] was used to screen the densely connected network with the default parameters in the whole PPI network. For each MCODE component, pathway and process enrichment analysis has been applied. The three functional description terms with best-scoring p-value have been retained. The genes within each component were selected as hub genes.
The construction of the miRNA-hub genes network
The interactions of miRNA-hub genes were predicted using the miRNet [33] web-based platform. By uploading the list of gens IDs of interest, users can map genes to their microRNAs (miRNAs) according to the miRTarBase [34] v8.0, TarBase [35] v8.0 and miRecords [36]. The results were presented as each row representing the interaction between one miRNA and its target and visualized in Cytoscape [37]. 3.7.2 software. The interactions between two genes were acquired from the STRING [38] database. We implemented the yFiles Layout Algorithms app (“https://www.yworks.com/products/yfiles-layout-algorithms-for-cytoscape)” to construct a circular layout. In the network, a node represents a gene or a miRNA; the undirected link between two nodes is an edge.
The validation of the hub gene module
Taking the GSE57691 as the reference dataset and the hub genes as a module, we validated the hub gene module by examining the reproductivity (or preservation) in three independent test datasets (GSE13353:ICA, GSE7084:AAA, GSE98278:AA) with the method illustrated in Langfelder et al.’s work [39]. The download and normalization methods for the validation datasets were as previously stated. The module preservation measurements can be influenced by several factors such as the size of the network and the modules etc. Hence, 200 permutation tests were applied to assess the significance of the preservation statistics. Taking advantage of aggregating multiple preservation statistics into summary preservation statistics, all of the density and connectivity based preservation measures were summarized using three composite Z statistics Zdensity, Zconnectivity and Zsummary [40, 41]. In case that modules are defined as clusters, the in group proportion (IGP) statistic, a benchmark statistic for module preservation assessment [42], was also calculated.
Results
Identification of highly preserved WGCNA modules
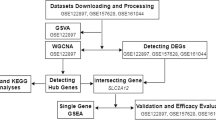
As illustrated in Fig. 1, our study attempted to identify co‑expression modules with high preservation of artery aneurysm from different locations: abdominal (GSE57691), intracranial (GSE122897) and thoracic (GSE5180) using WGCNA. We selected 4306 genes with the aforementioned method and the weighted adjacency matrix was constructed using six as the soft-thresholding power (Additional file 1). Then, we assessed the correlation of average gene expression between the three datasets (Fig. 2). The correlation coefficients of any of the two datasets were all statistically significant which suggests that these datasets were suitable for further analysis. Then, we set the parameter “deepSplit” = 0 to achieve a small number of large modules (Additional file 2). In the GSE57691 dataset, 14 modules are identified as the training set and were reconstructed as a validation set in the GSE122897 and GSE122897 datasets (Fig. 3). These modules are illustrated in the branches of the dendrogram with unique colors. In 2 of the 14 modules, only the black and magenta modules were well preserved, with Z‑scores > 10 in both validation datasets (Table 1). Thus, the black (193 genes) and magenta (159 genes) modules were selected for further analysis.

Flow chart diagram for analysis process. WGCNA: weighted gene co‑expression network analysis; PPI: protein–protein interaction

Expression correlation analysis of genes in three datasets. Cor correlation coefficient

Dendrogram and clustering for identification of gene co‑expression modules between a GSE57691, b GSE122897, and c GSE5180
Enrichment analysis of the genes in the highly conserved modules
To improve our understanding of the biological information of the two modules in artery aneurysm, we performed comprehensive functional enrichment analysis in various databases (Fig. 4a). Up to 100 enriched terms can be accessed in Additional file 3. Terms such as positive regulation of cytosolic calcium ion concentration, hemostasis, and regulation of secretion by cells were enriched in both datasets. Meanwhile, the results for black module were the immune-related terms mostly such as lymphocyte activation and immune response-activating signal transduction and for magenta module, actin filament-based process and muscle system process were enriched. As shown in Fig. 4b, there were considerable genes that belong to the same enriched ontology term in magenta and black modules.

a Function enrichment analysis for genes in magenta and black modules. The top 20 enriched terms were illustrated and color by p values. b Overlap of enriched terms between the genes in magenta and black modules. Blue curves link genes that belong to the same enriched ontology term. The inner circle represents gene lists, where hits are arranged along the arc
Construction of PPI network and hub gene identification
We downloaded the resultant network from the Metascape and processed it with Cytoscape [37]. 3.7.2 software. The MCODE analysis indicated 10 highly connected networks, in which 35 genes were from black module and 20 genes were from magenta module (Fig. 5). The top three enriched functional description terms with best-scoring p-value were tabulated in Table 2. The analysis did not yield any results for MCODE 3. Taken all the identified networks together, positive regulation of cytosolic calcium ion concentration, lymphocyte activation, and regulation of cytosolic calcium ion concentration were identified. All 55 genes were treated as hub genes.

Protein–protein interaction network and MCODE components identified in the gene lists. MCODE: Molecular Complex Detection. The edge of node represents the module they belong, i.e., red for the magenta module and black for black module
Construction of miRNA-hub genes network
We uploaded the hub gene lists in the black and magenta modules to the miRNet website, and filtered the results so that only miRNA-gene interactions verified in at least two databases would be shown. The interactions are illustrated in Fig. 6. The genes in the black and magenta module and miRNAs were in black, red and yellow respectively. Notably, the CCR7 was the most connected gene (21 degrees) while TNF and CXCR4 interacted with 19 other nodes. The most connected miRNAs were hsa-mir-26b-5p and hsa-mir-335-5p with 9 and 8 degrees.

miRNAs and hub genes interactions illustration. The genes in the black module and magenta module are colored in black and red, respectively. The size of each nodes represents the number of interactions with other nodes. All the miRNAs were in yellow
Validation of the hub genes module
Another 3 gene expression datasets: GSE13353, GSE7084, GSE98278 were downloaded from the GEO database. The detailed information and normalization methods for each dataset used in this study were shown in Additional file 4. For all three datasets, the hub gene module showed consistent conservation as proved by the four main statistics we focused (Fig. 7). GSE98278 achieved the highest value in Zsummary preservation (12.13) while the GSE7084 showed a moderate but still a good Zsummary preservation score (6.97). The full analyse results for all module preservation statistics were attached in Additional file 5. Moreover, we plotted the hub gene module network in these three validation datasets (Fig. 8). Note the similarity between the three validation datasets and the reference dataset. CCR7 is consistently highlighted in all datasets.

Quantitative evaluation of the similarities among the networks. a the composite preservation statistic Zsummary. The hub gene module in the reference dataset is highly preserved in the GSE98278 (Zsummary > 10) and moderately preserved in the other two datasets. b, c the density and connectivity statistics, respectively. d Results of the in group proportion (IGP) analysis shows that the hub gene module is equally preserved in all network

Network plot of the hub gene module in three validation datasets. Positive correlations are represented by red lines, while negative correlations are represented by blue lines. Correlation strength is represented by thickness and color saturation of the line. Intramodular hub genes are represented by larger points and their names
Discussion
One of the key features of pathological changes in aneurysm is inflammatory infiltration and enzymatic destruction of the elastic lamellae and extracellular matrix (ECM) proteins [43]. Plasma Membrane Calcium ATPase 4 (PMCA4) plays a role in transporting calcium from the cytosol to the extracellular and it is also known to be expressed in aortic tissue [44]. Kinza et al. [45] have demonstrated that the expression of PMCA4 could be reduced in human primary aortic endothelial cells during inflammation which enhanced the proteins related to ECM remodeling. Especially, another study conducted by Alexander et al. [46] reported that mitochondrial calcium uptake 2 (Micu2) is an intermitochondrial membrane protein functioning to reduce the amount of calcium coming into the mitochondrial matrix [47]. They showed that naive Micu2−/− mice could develop abdominal aortic aneurysms with spontaneous rupture with modest blood pressure elevation and concluded Micu2 is crucial in protecting the abdominal aorta. In our analysis, the term “positive regulation of cytosolic calcium ion concentration” is underlined in our enrichment analysis for the highly conserved modules and also the hub genes. More thorough knowledge of how the potential regulators including PCMA4 and Micu2 take part in the cytosol calcium concentration regulation during artery aneurysm progression will support the development of therapeutic strategies.
Interestingly, the hub genes in MCODE 6 were predicted to participate in the NF-kappa B pathway with tumor necrosis factor (TNF) as a key player. The other three genes are Lymphotoxin-α and -β (LTA and LTB), and TNF receptor-associated factor 3 (TRAF3). LTA, also called TNF-β, is produced by lymphocytes and is involved in various cellular activities such as promoting lymphoid tissue development and inflammatory and immune responses [48]. In an earlier study conducted by Magne et al. in the human myeloma cell line OH-2., TNF mediates NF-kappa B activation via both TNF receptors, whereas LTA does so only via TNF-R1. Similarly, LTB, together with its receptor, is also a critical role in the immune system development, response and activation of the pro-inflammatory NF-kappa B pathway [49]. In vascular smooth muscle cells (VSMCs), the LTB receptor has been demonstrated to participate in atherosclerosis protection via artery tertiary lymphoid organs [50]. A better understanding of the role of lymphotoxin may help to guide the development of a new therapeutic strategy to treat aneurysm.
Various miRNAs have been identified as key regulators that modulate the pathogenesis of aneurysm [51, 52]. In our results, miR-26b-5p and miR-335-5p were highlighted. Studies have revealed that miR-26b-5p plays a negative regulatory role in the angiogenesis process of hepatocellular carcinoma. Recently, Changwu et al. reported miR‑26b‑5p regulated the transforming growth factor β (TGFβ)/Smad4 signaling pathway to modulate hypoxia‑induced phenotypic switching of VSMCs. On the other hand, harnessing the results of a prior study [53], Bei et al. [54] designed a novel device that would determination of the severity of AAA by detecting miRNA-335-5p. However, little is known about the specific regulation network of these two miRNAs in the aneurysm. Our study provides novel insights for future studies that focus on researching how miRNAs take part in aneurysms.
There are some limitations in the present study. Firstly, our results are based on pure public data with unavoidable biases, such as age and gender differences. Additionally, further in-vivo and in-vitro experimental exploration and validation for the identified genes and modules are required.
Conclusions
To conclude, the present study comprehensively identified the highly conservative co-expression modules and hub genes in three kinds of aneurysms. The potential biological function of the modules, hub genes and the miRNA-hub gene interactions may possess important clinical implications for the treatment and diagnosis of aneurysm.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- TGFβ:
-
Transforming growth factor β
- VSMCs:
-
Vascular smooth muscle cells
- TNF:
-
Tumor necrosis factor
- LTA and LTB:
-
Lymphotoxin-α and -β
- TRAF3:
-
TNF receptor-associated factor 3
- Micu2:
-
Mitochondrial calcium uptake 2
- ECM:
-
Extracellular matrix
- PMCA4:
-
Plasma membrane calcium ATPase 4
- PPI:
-
Protein–protein interaction
- miRNAs:
-
MicroRNAs
- MCODE:
-
Molecular complex detection
- BP:
-
Biological processes
- MF:
-
Molecular functions
- CC:
-
Cellular components
- GO:
-
Gene ontology
- KEGG:
-
Kyoto encyclopedia of genes and genomes
- TOM:
-
Topological matrix
- TMM:
-
Trimmed mean of M values
- GEO:
-
Gene expression omnibus
- WGCNA:
-
Weighted gene co‑expression network analysis
- AAA:
-
Abdominal aortic aneurysm
- TAA:
-
Thoracic aortic aneurysm
- ICA:
-
Intracranial aneurysm
References
Calero A, Illig KA. Overview of aortic aneurysm management in the endovascular era. Semin Vasc Surg. 2016;29(1–2):3–17.
Guo MH, Appoo JJ, Saczkowski R, Smith HN, Ouzounian M, Gregory AJ, et al. Association of mortality and acute aortic events with ascending aortic aneurysm: a systematic review and meta-analysis. JAMA Netw Open. 2018;1(4):e181281.
Sakalihasan N, Limet R, Defawe OD. Abdominal aortic aneurysm. Lancet (London, England). 2005;365(9470):1577–89.
Kuzmik GA, Sang AX, Elefteriades JA. Natural history of thoracic aortic aneurysms. J Vasc Surg. 2012;56(2):565–71.
Brown RD Jr, Broderick JP. Unruptured intracranial aneurysms: epidemiology, natural history, management options, and familial screening. Lancet Neurol. 2014;13(4):393–404.
Rouchaud A, Brandt MD, Rydberg AM, Kadirvel R, Flemming K, Kallmes DF, et al. Prevalence of Intracranial Aneurysms in Patients with Aortic Aneurysms. AJNR Am J Neuroradiol. 2016;37(9):1664–8.
Kuzmik GA, Feldman M, Tranquilli M, Rizzo JA, Johnson M, Elefteriades JA. Concurrent intracranial and thoracic aortic aneurysms. Am J Cardiol. 2010;105(3):417–20.
Larsson E, Vishnevskaya L, Kalin B, Granath F, Swedenborg J, Hultgren R. High frequency of thoracic aneurysms in patients with abdominal aortic aneurysms. Ann Surg. 2011;253(1):180–4.
DeFreitas MR, Quint LE, Watcharotone K, Nan B, Ranella MJ, Hider JR, et al. Evaluation for abdominal aortic aneurysms is justified in patients with thoracic aortic aneurysms. Int J Cardiovasc Imaging. 2016;32(4):647–53.
Norrgård O, Angqvist KA, Fodstad H, Forssell A, Lindberg M. Co-existence of abdominal aortic aneurysms and intracranial aneurysms. Acta Neurochir. 1987;87(1–2):34–9.
Kim DH, Van Ginhoven G, Milewicz DM. Familial aggregation of both aortic and cerebral aneurysms: evidence for a common genetic basis in a subset of families. Neurosurgery. 2005;56(4):655–61; discussion -61.
Ruigrok YM, Elias R, Wijmenga C, Rinkel GJ. A comparison of genetic chromosomal loci for intracranial, thoracic aortic, and abdominal aortic aneurysms in search of common genetic risk factors. Cardiovasc Pathol. 2008;17(1):40–7.
van’t Hof FN, Ruigrok YM, Lee CH, Ripke S, Anderson G, de Andrade M, et al. Shared genetic risk factors of intracranial, abdominal, and thoracic aneurysms. J Am Heart Assoc. 2016;5(7):e002603.
Venkatesh P, Phillippi J, Chukkapalli S, Rivera-Kweh M, Velsko I, Gleason T, et al. Aneurysm-specific miR-221 and miR-146a participates in human thoracic and abdominal aortic aneurysms. Int J Mol Sci. 2017;18(4):875.
Li T, Jiang B, Li X, Sun HY, Li XT, Jing JJ, et al. Serum matrix metalloproteinase-9 is a valuable biomarker for identification of abdominal and thoracic aortic aneurysm: a case-control study. BMC Cardiovasc Disord. 2018;18(1):202.
Wang XL, Liu O, Qin YW, Zhang HJ, Lv Y. Association of the polymorphisms of MMP-9 and TIMP-3 genes with thoracic aortic dissection in Chinese Han population. Acta Pharmacol Sin. 2014;35(3):351–5.
Kleinloog R, Verweij BH, van der Vlies P, Deelen P, Swertz MA, de Muynck L, et al. RNA sequencing analysis of intracranial aneurysm walls reveals involvement of lysosomes and immunoglobulins in rupture. Stroke. 2016;47(5):1286–93.
Majumdar R, Miller DV, Ballman KV, Unnikrishnan G, McKellar SH, Sarkar G, et al. Elevated expressions of osteopontin and tenascin C in ascending aortic aneurysms are associated with trileaflet aortic valves as compared with bicuspid aortic valves. Cardiovasc Pathol. 2007;16(3):144–50.
Biros E, Gäbel G, Moran CS, Schreurs C, Lindeman JH, Walker PJ, et al. Differential gene expression in human abdominal aortic aneurysm and aortic occlusive disease. Oncotarget. 2015;6(15):12984–96.
Ritchie ME, Phipson B, Wu D, Hu Y, Law CW, Shi W, et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015;43(7):e47.
McCarthy DJ, Chen Y, Smyth GK. Differential expression analysis of multifactor RNA-Seq experiments with respect to biological variation. Nucleic Acids Res. 2012;40(10):4288–97.
Davis S, Meltzer PS. GEOquery: a bridge between the Gene Expression Omnibus (GEO) and BioConductor. Bioinformatics (Oxford, England). 2007;23(14):1846–7.
Langfelder P, Horvath S. WGCNA: an R package for weighted correlation network analysis. BMC Bioinform. 2008;9:559.
Langfelder P, Horvath S. Fast R functions for robust correlations and hierarchical clustering. J Stat Softw. 2012;46(11).
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, et al. Gene ontology: tool for the unification of biology. Gene Ontol Consort Nat Genet. 2000;25(1):25–9.
Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28(1):27–30.
Zhou Y, Zhou B, Pache L, Chang M, Khodabakhshi AH, Tanaseichuk O, et al. Metascape provides a biologist-oriented resource for the analysis of systems-level datasets. Nat Commun. 2019;10(1):1523.
Krzywinski M, Schein J, Birol I, Connors J, Gascoyne R, Horsman D, et al. Circos: an information aesthetic for comparative genomics. Genome Res. 2009;19(9):1639–45.
Stark C, Breitkreutz BJ, Reguly T, Boucher L, Breitkreutz A, Tyers M. BioGRID: a general repository for interaction datasets. Nucleic Acids Res. 2006;34(Database issue):D535–9.
Li T, Wernersson R, Hansen RB, Horn H, Mercer J, Slodkowicz G, et al. A scored human protein-protein interaction network to catalyze genomic interpretation. Nat Methods. 2017;14(1):61–4.
Türei D, Korcsmáros T, Saez-Rodriguez J. OmniPath: guidelines and gateway for literature-curated signaling pathway resources. Nat Methods. 2016;13(12):966–7.
Bader GD, Hogue CW. An automated method for finding molecular complexes in large protein interaction networks. BMC Bioinform. 2003;4:2.
Fan Y, Siklenka K, Arora SK, Ribeiro P, Kimmins S, Xia J. miRNet—dissecting miRNA-target interactions and functional associations through network-based visual analysis. Nucleic Acids Res. 2016;44(W1):W135–41.
Huang HY, Lin YC, Li J, Huang KY, Shrestha S, Hong HC, et al. miRTarBase 2020: updates to the experimentally validated microRNA-target interaction database. Nucleic Acids Res. 2020;48(D1):D148–54.
Karagkouni D, Paraskevopoulou MD, Chatzopoulos S, Vlachos IS, Tastsoglou S, Kanellos I, et al. DIANA-TarBase v8: a decade-long collection of experimentally supported miRNA-gene interactions. Nucleic Acids Res. 2018;46(D1):D239–45.
Xiao F, Zuo Z, Cai G, Kang S, Gao X, Li T. miRecords: an integrated resource for microRNA-target interactions. Nucleic Acids Res. 2009;37(Database issue):D105–10.
Shannon P, Markiel A, Ozier O, Baliga NS, Wang JT, Ramage D, et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 2003;13(11):2498–504.
Szklarczyk D, Franceschini A, Wyder S, Forslund K, Heller D, Huerta-Cepas J, et al. STRING v10: protein-protein interaction networks, integrated over the tree of life. Nucleic Acids Res. 2015;43(Database issue):D447–52.
Langfelder P, Luo R, Oldham MC, Horvath SJPCB. Is my network module preserved and reproducible? PLoS Comput Biol. 2011;7(1):e1001057.
Ray S, Hossain SMM, Khatun L, Mukhopadhyay AJBB. A comprehensive analysis on preservation patterns of gene co-expression networks during Alzheimer’s disease progression. BMC Bioinform. 2017;18(1):579.
Li B, Zhang Y, Yu Y, Wang P, Wang Y, Wang Z, et al. Quantitative assessment of gene expression network module-validation methods. Sci Rep. 2015;5(1):1–14.
Kapp AV, Tibshirani RJB. Are clusters found in one dataset present in another dataset? Biostatistics. 2007;8(1):9–31.
Akutsu K. Etiology of aortic dissection. Gen Thorac Cardiovasc Surg. 2019;67(3):271–6.
Stafford N, Wilson C, Oceandy D, Neyses L, Cartwright EJ. The plasma membrane calcium ATPases and their role as major new players in human disease. Physiol Rev. 2017;97(3):1089–125.
Khan K, Campanero MR, Cotton J, Redondo JM, Armesilla AL. BS53 The role of plasma membrane calcium atpase 4 (PMCA4) in vascular remodelling during abdominal aortic aneurysm formation. Heart. 2019;105:A175.
Bick AG, Wakimoto H, Kamer KJ, Sancak Y, Goldberger O, Axelsson A, et al. Cardiovascular homeostasis dependence on MICU2, a regulatory subunit of the mitochondrial calcium uniporter. Proc Natl Acad Sci USA. 2017;114(43):E9096–104.
Bertolini MS, Chiurillo MA, Lander N, Vercesi AE, Docampo R. MICU1 and MICU2 play an essential role in mitochondrial Ca(2+) uptake, growth, and infectivity of the human pathogen Trypanosoma cruzi. mBio. 2019;10(3).
Upadhyay V, Fu YX. Lymphotoxin signalling in immune homeostasis and the control of microorganisms. Nat Rev Immunol. 2013;13(4):270–9.
Banach-Orłowska M, Wyszyńska R, Pyrzyńska B, Maksymowicz M, Gołąb J, Miączyńska M. Cholesterol restricts lymphotoxin β receptor-triggered NF-κB signaling. Cell Commun Signal: CCS. 2019;17(1):171.
Hu D, Mohanta SK, Yin C, Peng L, Ma Z, Srikakulapu P, et al. Artery tertiary lymphoid organs control aorta immunity and protect against atherosclerosis via vascular smooth muscle cell lymphotoxin β receptors. Immunity. 2015;42(6):1100–15.
Korostynski M, Morga R, Piechota M, Hoinkis D, Golda S, Dziedzic T, et al. Inflammatory responses induced by the rupture of intracranial aneurysms are modulated by miRNAs. Mol Neurobiol. 2020;57(2):988–96.
Boon RA, Dimmeler S. MicroRNAs and aneurysm formation. Trends Cardiovasc Med. 2011;21(6):172–7.
Wanhainen A, Mani K, Vorkapic E, De Basso R, Björck M, Länne T, et al. Screening of circulating microRNA biomarkers for prevalence of abdominal aortic aneurysm and aneurysm growth. Atherosclerosis. 2017;256:82–8.
Lu B, Liu L, Wang J, Chen Y, Li Z, Gopinath SCB, et al. Detection of microRNA-335-5p on an interdigitated electrode surface for determination of the severity of abdominal aortic aneurysms. Nanoscale Res Lett. 2020;15(1):105.
Acknowledgements
Not applicable.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 81700410), the Sichuan Science and Technology Program, China (Grant No. 2019YFS0344 2019YFS0251).
Author information
Authors and Affiliations
Contributions
Siwei Bi concepted the study, collected and analysed the data. Ruiqi Liu also helped to concept the study and collect the data. Jun Gu took part in the study conception and design. The assembly, analysis and interpretation of data were performed by Siwei Bi, Ruiqi Liu, Linfeng He, Jingyi Li. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Additional file 1.
Construction of weighted adjacency matrix. 4306 genes were included for the construction of the weighted adjacency matrix and the authors used six as the soft-thresholding power.
Additional file 2.
Gene clustering and different deepsplit method. The parameter “deepSplit” was set to 0 to achieve a small number of large modules.
Additional file 3.
The 100 enriched terms for the genes in magenta and black modules.
Additional file 4
.The datasets used in the project for module preservation identification.
Additional file 5
. Full analyse results for all module preservation statistics
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

{kind=link}
Cite this article
Bi, S., Liu, R., He, L. et al. Bioinformatics analysis of common key genes and pathways of intracranial, abdominal, and thoracic aneurysms. BMC Cardiovasc Disord 21, 14 (2021). https://doi.org/10.1186/s12872-020-01838-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12872-020-01838-x