
Abstract
We evaluate the uncertainties due to nuclear effects in global fits of proton parton distribution functions (PDFs) that utilise deep-inelastic scattering and Drell–Yan data on deuterium targets. To do this we use an iterative procedure to determine proton and deuteron PDFs simultaneously, each including the uncertainties in the other. We apply this procedure to determine the nuclear uncertainties in the SLAC, BCDMS, NMC and DYE866/NuSea fixed target deuteron data included in the NNPDF3.1 global fit. We show that the effect of the nuclear uncertainty on the proton PDFs is small, and that the increase in overall uncertainties is insignificant once we correct for nuclear effects.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Parton distribution functions (PDFs) are an essential ingredient in the theoretical predictions of hadronic observables at the LHC [1,2,3]. PDFs for the proton are determined via global QCD fits to a range of experimental data, including those where the proton is not in a free state. In particular, these include deep-inelastic scattering (DIS) and Drell–Yan (DY) fixed target collisions involving deuterium and heavy nuclear targets. In these processes the interaction of the proton is altered due to nuclear effects, and this difference propagates through to the fitted PDFs. Measurements involving deuterium targets still play a significant role in the determination of proton PDFs, in particular to separate the up and down flavours for large momentum fraction x, a region which is especially important for searches for physics beyond the Standard Model. Because of this, deuteron corrections have been extensively studied and have been included in PDF analyses via parametrizations of a nuclear smearing function [4,5,6,7,8], inspired by various deuteron wavefunction models [9,10,11,12,13]. This approach relies on model assumptions, which can ultimately bias the determination of the PDFs in a way which is difficult to quantify. Because the precision of the PDFs is now constrained by the data to a few percent for most quark flavours in a wide kinematic range [14], a faithful estimate [15] of the theoretical uncertainty associated with nuclear effects (potentially of comparable size) is becoming necessary.
In a previous study [16] we showed how theoretical uncertainties due to heavy nuclear targets in DIS and DY measurements can be incorporated into global fits of proton PDFs. Specifically, in the framework of the NNPDF methodology (see [17] and references therein for a comprehensive description), we added to the experimental covariance matrix a theoretical covariance matrix, accounting for the additional uncertainties due to nuclear effects. Two distinct procedures were adopted: in the first, the contribution of the nuclear data to the PDF fit is deweighted by an uncertainty that encompasses both the difference between proton and nuclear PDFs and the uncertainty in the nuclear PDFs; in the second, the difference between proton and nuclear PDFs is used to correct the theoretical predictions, while the deweighting only takes the nuclear PDF uncertainty into account, and is therefore correspondingly smaller. If the uncertainty in the nuclear PDFs is correctly estimated, and smaller than the shift, the second procedure should give more precise results. The nuclear PDFs were determined as an equally weighted replica average of the DSSZ [18], nCTEQ15 [19], and EPPS16 [20] PDF sets for the relevant heavy nuclei (Cu, Fe and Pb). Despite the fact that these are obtained from a global analysis of experimental data taken in a wide variety of processes, there are sizeable differences between them. This suggests that these three sets might not be sufficiently consistent to determine a precise nuclear correction, but can be used to estimate the uncertainty due to nuclear effects, and indeed the second procedure led to a worse global fit than the first.
Nuclear corrections to deuterium are rather smaller than those for heavy nuclei. In the framework of the NNPDF methodology, these corrections have been studied in a dedicated work [5], based on the NNPDF2.3 release [21], and again in the context of the NNPDF3.0 and NNPDF3.1 determinations (see, respectively, Sect. 5.1.4 in [17] and Sect. 4.11 in [14]). Variants of the NNPDF2.3, NNPDF3.0 and NNPDF3.1 fits were performed by correcting all deuterium data according to Eq. (8) of [6], with parameter values determined in [22]. In all cases results were consistent. Specifically, for NNPDF3.1, it turned out that the central value of the up and down quark PDFs were moderately affected at large x (less than half a sigma), and that the corresponding uncertainty was somewhat increased. Other PDFs were hardly affected. A slight increase in the global \(\chi ^2\) was observed, a fact that suggested that the theoretical uncertainty associated with the nuclear correction was not optimally quantified. For these reasons, nuclear corrections were not included in the baseline NNPDF3.1 set.
In this paper, we revisit the impact of nuclear corrections in deuterium data by extending the approach developed for heavy nuclei in [16]. We focus on the dataset included in the NNPDF3.1 PDF determination [23], which is made up of 3978 data points (see [14] for details). Out of these, 418 data points (about 10% of the whole dataset) come from experiments using deuterium targets, specifically SLAC [24], BCDMS [25], NMC [26], and DYE866/NuSea [27]. The DIS data are in the form of deuteron to proton structure function ratios, \(F_2^d/F_2^p\), for NMC, and of deuteron structure functions, \(F_2^d\), for SLAC and BCDMS; the DY data is in the form of ratios of cross sections for a proton beam on a deuteron target to a proton beam on a proton target, \(\sigma ^{\mathrm{DY}}_{pd}/ \sigma ^{\mathrm{DY}}_{pp}\), for DYE866/NuSea.
A significant weakness in our treatment of nuclear effects in heavy nuclei was its dependence on externally determined nuclear PDFs. To avoid this when treating deuterium, we fit our own deuterium PDFs directly from the deuteron data by means of a procedure which is iterated to consistency with the global proton fit. In this way we account simultaneously for the nuclear uncertainties in the deuteron when determining global proton PDFs, and the uncertainties in the proton PDF when determining the deuteron PDF (and thus the nuclear correction). The advantage of the new approach is that the deuteron and proton fits are all performed using a consistent theoretical and methodological fitting framework, and the resulting nuclear corrections and their uncertainties are thus equally reliable and unbiased. It is very similar to the self consistent procedure set out in [15] for the simultaneous determination of PDFs and fragmentation functions using experimental data from semi-inclusive DIS.

A schematic representation of the iterative procedure adopted to determine the uncertainty due to deuteron corrections in proton PDF fits, see text for details. The global dataset is the union of the proton and deuteron datasets
The logical structure of the procedure is depicted in Fig. 1. The NNPDF3.1 global dataset is split into two disjoint subsets: ‘deuteron data’, including the aforementioned datasets (SLAC, BCDMS, NMC and DYE866/NuSea); and ‘proton data’ including all the other datasets. The global dataset is the union of deuteron and proton datasets. Note that the proton data also includes CHORUS [28], NuTeV [29], and DYE605 [30] data taken in experiments on heavy nuclei. The effect of nuclear corrections on these measurements was studied in [16] and is not considered here as we want to focus exclusively on the nuclear effects in deuterium.
The deuteron data themselves may be split into two sets: ‘pure’ deuteron data, from DIS on a deuteron target (the SLAC and BCDMS data for \(F_2^d\)), and ‘mixed’ deuteron data, which also involve protons (the NMC data for the ratio \(F_2^d/F_2^p\), and the DYE866/NuSea DY data for the ratio \(\sigma ^{DY}_{pd}/\sigma ^{DY}_{pp}\)). We denote the theoretical predictions for the pure deuteron data by \(T_i^d[f_d]\), where \(f_d\) is the deuteron PDF, and the theoretical predictions for the mixed deuteron data by \(T_i^d[f_d,f_p]\), where \(f_p\) is the proton PDF. In each case the index i runs over the individual data points. In a conventional global proton fit, without deuteron nuclear corrections, the deuteron observables \(T_i^d[f_d]\) and \(T_i^d[f_d,f_p]\) are included in the fit by replacing \(f_d\) by the isoscalar PDF
Here \(f_n\) is the neutron PDF, determined from the proton PDF by assuming exact isospin invariance (and thus in practice by swapping the up and down PDFs).
The proton data are used to determine a first set of pure proton PDFs \(\{f_p^{(k)}: k=1\cdots N_{\mathrm{rep}}\}\), using the usual NNPDF methodology. The central prediction is \(f_p^{(0)} = \langle f_p^{(k)}\rangle \), where the angled brackets denote a simple average over the \(N_{\mathrm{rep}}\) Monte Carlo replicas. If the deuteron data were all pure deuteron data, in practice only the SLAC and BCDMS datasets, we could simply produce a similar set of pure deuteron PDFs \(\{f_d^{(k)}: k=1\cdots N_{\mathrm{rep}}\}\). These by construction will include the nuclear effects and the size of the nuclear correction would be \(T_i^d[f_d^{(0)}]-T_i^d[f_s^{(0)}]\), with \(f_s^{(0)}\) determined from the proton PDFs using Eq. (1) averaged over proton PDF replicas. To include the mixed deuteron data, in particular the data from NMC and DYE866/NuSea, we have to be more careful since to evaluate the theoretical predictions for a given deuteron PDF we also need a proton PDF. For this we can use the central value of the pure proton fit \(f_p^{(0)}\) (i.e. replica zero, the average of all the other replicas) and the size of the deuteron nuclear correction is then \(T_i^d[f_d^{(0)},f_p^{(0)}]-T_i^d[f_s^{(0)},f_p^{(0)}]\). However we must also include the uncertainty in the proton fit, as part of the theoretical (proton) uncertainty in determining the deuteron PDF from these data: this can be done by computing the theory covariance matrix
where i, j run over the data points in the mixed deuteron datasets only. Note that this covariance matrix incorporates correlations between the mixed datasets due to their common dependence on the proton PDF. This theoretical covariance matrix is added to the experimental covariance matrix of the mixed deuteron data when performing the deuteron fit, to take account of the uncertainty of the proton PDF in the determination of the deuteron PDFs.
Note that the theory covariance matrix Eq. (2) itself depends on the deuteron PDF, which is what we are trying to determine. However the dependence of the fitted deuteron PDF on the uncertainty in the proton PDF is relatively weak, since it only affects the weight of the mixed data in the fit. Thus to a good approximation we can replace \(f_d^{(0)}\) in Eq. (2) with \(f_s^{(0)}\), determined from the pure proton fit. For a more accurate determination of the deuteron PDFs, we could then iterate to consistency, performing a second fit to the deuteron data where \(f_d^{(0)}\) in Eq. (2) is determined from the first fit. It is clear that this iterative process would converge very rapidly.
However our aim here is not so much to determine the deuteron PDF, but rather to use it to determine a theoretical covariance matrix that takes into account the nuclear effects in the deuteron data (both pure and mixed) when using these data in a global fit of the proton PDF. Since the size of the nuclear correction is given by the difference between predictions with deuteron and isosinglet PDFs, this theoretical (deuteron) covariance matrix is
Again this covariance matrix incorporates correlations between all the nuclear corrections in the various deuteron datasets, due to their common dependence on the deuteron PDF. To perform a global fit of the proton PDF including nuclear uncertainties in the deuteron data, we can simply add the theory covariance matrix to the experimental covariance matrix of the deuteron datasets and perform the proton fit in the usual way; this yields a set of replicas of proton PDFs \(\{f_p^{(k)}\}\).
Since the global proton PDFs will be more precise than the pure proton PDFs we started with, it makes sense once again to iterate; we use our global proton PDFs to determine an improved theoretical proton covariance matrix Eq. (2), repeat the deuteron fit, use this to determine an improved theoretical deuteron covariance matrix Eq. (3), and then use this to perform a new global fit of the proton PDF. This is the iterative procedure shown schematically in Fig. 1. Note that through this procedure the deuteron PDF is also iterated concurrently. We expect the iterations to converge very rapidly to a self consistent set of deuteron and (global) proton PDFs for several reasons: firstly, a small change in the proton PDF makes a small difference to the deuteron correction; secondly, we expect the effect of the deuteron correction on the weight of these data in the global fit to be small; thirdly, the influence of the deuteron data in the global fit is already relatively small (just as the influence of the proton PDF on the deuteron fit is small). Note that the deuteron data are not double counted in this procedure; in the deuteron fit they are used to determine (empirically) the nuclear uncertainty, while in the global fit they influence the central value of the proton PDF directly, but taking into account this nuclear uncertainty. Indeed, the nuclear uncertainty reduces the weight of the deuteron data in the global fit, so they actually count less. As a byproduct, we also determine a set of deuteron PDFs.
This realises the first of the two procedures described in [16], whereby the deuteron datasets are deweighted by the nuclear uncertainty but theoretical predictions are not shifted by a nuclear correction. As in [16], we also implement the second procedure: in this case, the theoretical (deuteron) covariance matrix is defined as
while the corrections applied to the theoretical predictions \(T_i^d[f_s^{(0)}]\) and \(T_i^d[f_s^{(0)},f_p^{(0)}]\) for the deuteron datasets are
This procedure is implemented in the same way as the first, with the theoretical predictions for the deuteron data corrected before performing each iteration of the global proton fit. Since, unlike in [16], the corrections are determined empirically and self consistently, we expect the second method to be more precise than the first method; the central values of the theoretical predictions should be a little more accurate, and the uncertainty due to nuclear effects in the deuteron correspondingly a little smaller.

The ratio between the SLAC, BCDMS, NMC and DYE866/NuSea deuteron observables computed either with the central prediction with deuteron PDFs, \(T_i^d[f^0_d]\), or the central prediction with proton PDFs, \(T_i^d[f^0_s]\). Data points are ordered in bins of increasing values of momentum fraction x and energy Q

The square root of the diagonal elements of the covariance matrices normalised to the experimental data, \(\sqrt{\mathrm{cov}_{ii}}/D_i\), for the deuteron measurements from SLAC, BCDMS, NMC and DYE866/NuSea. We show results for the experimental covariance matrix (C), for the deuteron covariance matrix (S), computed from Eq. (3), and for their sum \((C+S)\)
The set of fits which we performed, all using NNPDF methodology, are summarised in Table 1. They are all accurate to next-to-next-to-leading order (NNLO) in perturbative QCD, heavy quarks are treated in the FONLL scheme and the charm PDF is parametrised in the same way as the lighter quark PDFs. All PDF sets are made of \(N_{\mathrm{rep}}=100\) Monte Carlo replicas. The baseline fit, ‘global-base’, is a fit equivalent to the base fit performed in [31]. It is a minor variant of the fit presented in [23]: a bug affecting the computation of theoretical predictions for charged-current DIS cross sections has been corrected; positivity of the \(F_2^c\) structure function has been enforced; and NNLO massive corrections [32, 33] have been included in the computation of neutrino-DIS structure functions. ‘proton-ite0’ is the corresponding fit based on the proton data alone. We then perform two iterations of the procedure described above (denoted as iteration 1 and 2), after which we determine a fit of deuteron PDFs (based only on the deuteron data, and supplemented with a proton covariance matrix), and a global fit of proton PDFs (based on the proton and deuteron data, and supplemented with a deuteron covariance matrix). The deuteron fits ‘deuteron-ite1’ and ‘deuteron-ite2’, are performed using exactly the same theoretical and methodological settings as the proton fits, except that the isotriplet PDFs are set to zero since the deuteron is isoscalar. After the first iteration we produce a single global fit of proton PDFs, ‘global-ite1-dw’, in which the deuteron covariance matrix is evaluated according to Eq. (3). After the second iteration we produce instead two global fits of proton PDFs: ‘global-ite2-dw’ in which the deuteron covariance matrix is evaluated with Eq. (3), and ‘global-ite2-sh’, in which the deuteron covariance matrix is evaluated with Eq. (4), and the theoretical predictions are first corrected according to Eq. (5).

The experimental (left) and total (right) correlation matrices for the SLAC, BCDMS, NMC and DYE866/NuSea deuteron experiments. The deuteron covariance matrix, added to the experimental covariance matrix to obtain the total covariance matrix, is computed according to Eq. (3)
Before discussing the results of our fits, we look more closely at the pattern of deuteron corrections, and at the deuteron covariance matrix defined in Eq. (3). As representative examples, results are obtained from proton and deuteron PDFs determined after the first iteration. We explicitly checked that they remain stable after an additional iteration.
In Fig. 2 we display the nuclear correction for the deuteron data obtained from our procedure. Specifically, for each data point i (after kinematic cuts), we show the observables computed with the central deuteron PDF, normalised to the expectation value computed with the central proton PDF, \(T_i^d[f^0_d]/ T_i^d[f^0_s]\). Data points are ordered in bins of increasing values of momentum fraction x and energy Q. The deuteron correction generally amounts to a few percent for all of the experiments considered. Uncertainties are rather large and the ratio is mostly compatible with one, except for data points at higher values of momentum fraction x and energy Q, where the correction is negative, as expected from models of nuclear shadowing.
To gain a further idea of the effects to be expected from nuclear corrections in deuteron, in Fig. 3 we show the square root of the diagonal elements of the experimental (C) and theoretical (S) covariance matrices, and their sum \((C+S)\), each normalised to the central value of the experimental data: \(\sqrt{\mathrm{cov}_{ii}}/D_i\). The theoretical covariance matrix accounts for the nuclear uncertainties, and is computed with Eq. (3). The general pattern of the results does not change qualitatively if Eqs. (4) and (5) are used instead. The pattern observed in Fig. 2 is paralleled in Fig. 3, in particular concerning the dependence of the size of the nuclear uncertainties on the bin kinematics for each experiment. Moreover we can now see that the deuteron uncertainties are smaller than the data uncertainties for SLAC and BCDMS, while they are comparable for NMC and DYE866/NuSea. This is largely because the pure deuteron measurements from SLAC and BCDMS are of cross-sections, whereas the more precise mixed measurements from NMC and DYE866/NuSea are of cross-section ratios, for which systematic uncertainties largely cancel.
Finally, we show the experimental correlation matrix, \(\rho _{ij}^C=C_{ij}/\sqrt{C_{ii}C_{jj}}\), and the sum of the experimental and deuteron correlation matrices, \(\rho _{ij}^{C+S} =(C_{ij}+S_{ij})/\sqrt{(C_{ii}+S_{ii})(C_{jj}+S_{jj})}\), as heat plots in Fig. 4. Note that, whenever the proton and deuteron data are both included in the global proton fit, there are small normalisation uncertainties correlated between \(F_2^p\) and \(F_2^d\) measurements within the SLAC and BCDMS experiments. These correlations, not shown in Fig. 4, are taken into account by default in all NNPDF analyses, including this one (for details, see Sect. 2.1 in [34]). The theoretical covariance matrix is computed according to Eq. (3), though the qualitative behaviour of the total correlation matrix is unaltered if Eqs. (4) and (5) are used instead. Our procedure captures the sizeable correlations of the deuteron corrections between different bins of momentum and energy, systematically enhancing bin-by-bin (positive and negative) correlations in the data. As we might expect, nuclear uncertainties are also strongly correlated across the different experiments.
We now turn to discuss the results of the fits collected in Table 1. In Tables 2 and 3 we display the values of the experimental \(\chi ^2\) per data point (as defined in Eq. (4) of [16]) for the fits of the deuteron PDFs (based on the deuteron data) and of the proton PDFs (based on the global dataset including both deuteron and proton data), respectively. In Table 3 values are displayed both for separate datasets, and for groups of datasets corresponding to measurements of similar observables in the same experiment. Indented datasets are subsets of the preceding non-indented dataset.
In order to examine the convergence of our procedure, we must quantify the statistical equivalence between pairs of PDFs obtained from the various fits. To this purpose we display in Fig. 5 the distance (as defined in Eq. (63) of [35]) between the central values of the two iterations of fits based on the deuteron data (deuteron-ite1 and deuteron-ite2), and the corresponding two iterations on the global data (global-ite1-dw and global-ite2-dw). For two PDF sets made of \(N_{\mathrm{rep}}=100\) replicas, a distance of \(d\simeq 1\) corresponds to statistically equivalent sets, while a distance of \(d\simeq 10\) corresponds to sets that differ by one sigma in units of the corresponding standard deviation. Note that in the left panel of Fig. 5u and \(\bar{u}\) actually denote the combinations \((u+d)/2\) and \((\bar{u}+\bar{d})/2\), where \(u=d\) and \(\bar{u}=\bar{d}\) by definition. These are the isosinglet combinations determined in the fits to deuteron data.

Distances between the central values of the deuteron-ite1 and deuteron-ite2 fits (left) and of the global-ite1-dw and global-ite2-dw fits (right), see Table 1 for details. For the deuteron fits, u and \(\bar{u}\) actually denote the combinations \((u+d)/2\) and \((\bar{u}+\bar{d})/2\), where \(u=d\) and \(\bar{u}=\bar{d}\) by definition. Results are displayed as a function of x at a representative scale of the deuteron dataset, \(Q=10\) GeV. The ReportEngine software [36] was used to generate this figure
From the results displayed in Tables 2 and 3 and in Fig. 5, we can conclude that one iteration is sufficient to achieve stability. The variation of the global \(\chi ^2\) per data point for fits obtained in subsequent iterations is smaller than statistical fluctuations. This is true both in the case of fits of deuteron PDFs (the global \(\chi ^2\) per data point is 0.97 and 0.98 for the deuteron-ite1 and deuteron-ite2 fits, respectively), and in the case of global fits of proton PDFs (the global \(\chi ^2\) per data point is 1.16 in both the global-ite1-dw and global-ite2-dw fits), see Tables 2 and 3. Variations of the \(\chi ^2\) per data point for single experiments are likewise smaller than statistical fluctuations. Furthermore, distances between the central values of the corresponding PDFs are at most of the order of two or three, for both deuteron and proton fits. The PDF flavours that change the most upon iteration are u, \(\bar{u}\), d, \(\bar{d}\) in the valence region of the deuteron fit, as might be expected.
Next, in Fig. 6 we compare the deuteron PDFs obtained from each iteration (deuteron-ite1 and deuteron-ite2). Specifically we show the average of up and down quark, the average of up and down antiquark, the strange quark, and the gluon distributions: because the deuteron is isoscalar, \(d=u\) and \(\bar{d}=\bar{u}\) by construction. Again we see that the PDFs hardly change from one iteration to the next, so the procedure has converged. In addition in this plot we compare our NNLO deuteron PDFs with a recent NLO determination of nuclear PDFs based on the NNPDF methodology, nNNPDF2.0 [37]. These were obtained by fitting a range of nuclear and proton data, and assuming a smooth dependence on the mass and atomic numbers A and Z. Due to this assumption, which in effect constrains the deuteron as an interpolation between proton and heavy nuclei, their uncertainties are smaller than our own. Our determination of the deuteron PDFs is thus very conservative.
Note that the central values of the deuteron PDFs in nNNPDF2.0 are mostly consistent with ours within uncertainties. A discrepancy of about one sigma, in units of the uncertainty of the deuteron-ite2 fit, is observed for the average of up and down quarks around \(x\sim 0.1\). Whether this discrepancy might be explained in light of the fact that the two determinations are at different orders in perturbation theory remains unclear. Available nuclear PDF sets accurate to NNLO [38, 39] currently include only inclusive DIS measurements, and thus have larger PDF uncertainties than nNNPDF2.0. This obscures the phenomenological impact of higher order corrections.

Comparison between the deuteron-ite1, deuteron-ite2 and nNNPDF2.0 [37] deuteron PDFs. The average of up and down, the average of antiup and antidown, strange and gluon PDFs are shown at \(Q=10\) GeV. Dashed lines denote one sigma uncertainties, while plain bands 68% confidence level intervals. The ReportEngine software [36] was used to generate this figure
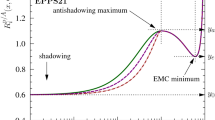
To explore the nuclear corrections further, in Fig. 7 we show the ratio \(F_2^d/F_2^p\) computed with our deuteron PDFs, at \(Q=10\) GeV. We see that the correction for nuclear effects in deuteron is only a few per cent over the full range of x, and is negative in the valence region, as expected from nuclear shadowing. However the uncertainty in our determination is as large as the correction. For comparison, we also show the same quantity computed using the nNNPDF2.0 deuteron PDFs [37]: these are NLO, but have a smaller uncertainty since, as explained above, in these fits continuity in A/Z is implicitly assumed, which adds a significant constraint. However the reduction in uncertainty due to this constraint is considerably less in the structure function ratio than it was in the PDFs. We also show the parametric correction used in the MMHT14 fits [6], which has four fitted parameters. Again this has a yet smaller uncertainty, particularly at large x, due to the assumed theoretical constraints of the model. However we note that all three of these estimates are mutually consistent, within uncertainties. The estimate obtained here is clearly the most conservative, particularly outside the valence region, as expected since it is free from any model dependence.
Finally we consider the impact of the deuteron uncertainties in the global fit of proton PDFs. We compare the global fits (to the deuteron and proton data), made without the inclusion of the theoretical covariance matrix (global-base), and then with the inclusion of the theoretical covariance matrix after the second iteration, either with Eq. (3) (global-ite2-dw) or with Eq. (4) and the associated shifts, (5) (global-ite2-sh). From Table 3 we conclude that the nuclear corrections give a small improvement in the overall fit quality (the global \(\chi ^2\) per data point is reduced from 1.18 in the global-base fit to 1.16 in the global-ite2-dw and global-ite2-sh fits, which corresponds to one standard deviation of the \(\chi ^2\) distribution), and a significant improvement in the fit quality of the deuteron datasets.
Turning to the PDFs themselves, in Fig. 8 we compare the proton PDFs obtained from these three fits. Here we show only the up and down quark and antiquark PDFs, normalised to the global-base fit, and the corresponding relative uncertainties, since the other quark flavours and the gluon PDFs are only scarcely affected by the nuclear corrections in deuteron. We also show, in Fig. 9 the distances (defined as in Fig. 5) between the baseline fit (global-base) and each of the two global fits with deuteron uncertainties included after the second iteration (global-ite2-dw and global-ite2-sh). Again, a distance of \(d\simeq 10\) corresponds to sets that differ by one sigma in units of the corresponding standard deviation.
The effect of the nuclear corrections on the PDF central values is largest in the up antiquark in the valence region: it differs by about half a sigma (\(d\sim 5\) in Fig. 9) in both the global-ite2-dw and global-ite2-sh fits with respect to the global-base fit. As apparent from Fig. 8, the central value of the up antiquark PDFs is suppressed in the valence region, while that of the down antiquark is enhanced. The effect is seen irrespective of whether the theoretical predictions are shifted. The inclusion of the nuclear uncertainty in the global fits of proton PDFs results in a slight increase in the uncertainties in comparison to the global-base fit, but this increase is rather larger in the global-ite2-dw fit than in the global-ite2-sh fit, where it is scarcely visible. This result, combined with the fact that both these fits have comparable quality (see Table 3), leads us to conclude that the shifted fit is to be preferred. This is as expected, given that the uncertainty due to nuclear corrections has been determined self-consistently, and turns out to be a little smaller in the valence region than the nuclear correction itself (see Fig. 2). This in contrast to the result we found in the case of heavy nuclei [16], for which nuclear uncertainties were instead estimated from independent global determinations of nuclear PDFs. Clearly the self-consistency of our procedure is advantageous, and should therefore be preferred in the case of deuteron data (and for heavy nuclei whenever it is possible to perform a consistently reliable determination of the nuclear PDFs and their uncertainties).

The nuclear correction factor \(F_2^d/F_2^p\), calculated using our final deuteron fit deuteron-ite2, the deuteron PDF from nNNPDF2.0, and the model fit used for deuteron corrections in MMHT2014. Results are displayed as a function of x at the representative scale \(Q=10\) GeV

Comparison between the global-base, global-ite2-dw and global-ite2-sh global fits of proton PDFs. The up, antiup, down and antidown PDFs, normalised to the global-base fit (left) and the corresponding relative uncertainties (right) are shown at \(Q=10\) GeV. Dashed lines denote one sigma uncertainties, while plain bands 68% confidence level intervals. The ReportEngine software [36] was used to generate this figure

Distances between the central values of the global-base and global-ite2-dw fits (left) and of the global-base and global-ite2-sh fits (right), see Table 1 for details. Results are displayed as a function of x at a representative scale for the deuteron dataset, \(Q=10\) GeV. The ReportEngine software [36] was used to generate this figure
In summary, we have developed an iterative procedure to incorporate theoretical uncertainties due to nuclear effects self-consistently into global fits of proton PDFs that include DIS and DY data on deuterium targets, without any model dependent assumptions regarding the physics of the nuclear corrections. In the framework of the NNPDF3.1 global analysis we have shown that the effect of the additional uncertainty in the global determination of the proton PDFs is small, and can be reduced further by applying an empirical correction to the theoretical predictions of the deuteron data. Such a fit thus leads to slightly more precise PDFs. We therefore conclude that, in a fit of proton PDFs including deuteron data, the approach in which nuclear effects give a correction plus uncertainty is preferred to the more conservative one in which they give a (larger) uncertainty only. A similar procedure might be used to improve the determination of kaon fragmentation functions, and thus the strange and anti-strange proton PDFs, by means of semi-inclusive DIS measurements that are sensitive to both. The PDF sets discussed in this work are available in the LHAPDF format [40] from the authors upon request.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The data associated to this manuscript are not deposited as they are not intended for public use, however they are available from the authors upon request.]
References
J. Gao, L. Harland-Lang, J. Rojo, The structure of the proton in the LHC precision era. Phys. Rep. 742, 1–121 (2018)
J.J. Ethier, E.R. Nocera, Parton distributions in nucleons and nuclei. Ann. Rev. Nucl. Part. Sci. 70, 1–34 (2020). arXiv:2001.07722
S. Forte, S. Carrazza, Parton distribution functions Artif. Intell. Part. Phy. World Scientific Publishing. arXiv:2008.12305
J. Owens, A. Accardi, W. Melnitchouk, Global parton distributions with nuclear and finite-\(Q^2\) corrections. Phys. Rev. D 87(9), 094012 (2013). arXiv:1212.1702
NNPDF Collaboration, R.D. Ball, V. Bertone, L. Del Debbio, S. Forte, A. Guffanti, J. Rojo, M. Ubiali, Theoretical issues in PDF determination and associated uncertainties. Phys. Lett. B 723, 330–339 (2013). arXiv:1303.1189
L. Harland-Lang, A. Martin, P. Motylinski, R. Thorne, Parton distributions in the LHC era: MMHT 2014 PDFs. Eur. Phys. J. C 75(5), 204 (2015). arXiv:1412.3989
A. Accardi, L. Brady, W. Melnitchouk, J. Owens, N. Sato, Constraints on large-\(x\) parton distributions from new weak boson production and deep-inelastic scattering data. Phys. Rev. D 93(11), 114017 (2016). arXiv:1602.03154
S. Alekhin, S. Kulagin, R. Petti, Nuclear effects in the deuteron and constraints on the d/u ratio. Phys. Rev. D 96(5), 054005 (2017). arXiv:1704.00204
R.B. Wiringa, V. Stoks, R. Schiavilla, An accurate nucleon–nucleon potential with charge independence breaking. Phys. Rev. C 51, 38–51 (1995). arXiv:nucl-th/9408016
W. Melnitchouk, A.W. Schreiber, A.W. Thomas, Relativistic deuteron structure function. Phys. Lett. B 335, 11–16 (1994). arXiv:nucl-th/9407007
W. Melnitchouk, M. Sargsian, M. Strikman, Probing the origin of the EMC effect via tagged structure functions of the deuteron. Z. Phys. A 359, 99–109 (1997). arXiv:nucl-th/9609048
R. Machleidt, The high precision, charge dependent Bonn nucleon–nucleon potential (CD-Bonn). Phys. Rev. C 63, 024001 (2001). arXiv:nucl-th/0006014
F. Gross, Covariant spectator theory of np scattering: deuteron magnetic moment. Phys. Rev. C 89(6), 064002 (2014). arXiv:1404.1584 [Erratum: Phys. Rev. C 101, 029901 (2020)]
NNPDF Collaboration, R.D. Ball et al., Parton distributions from high-precision collider data. Eur. Phys. J. C 77(10), 663 (2017) arXiv:1706.00428
R.D. Ball, A. Deshpande, The proton spin, semi-inclusive processes, and measurements at a future Electron Ion Collider, in Contribution to the volume “From My Vast Repertoire...: Guido Altarelli’s Legacy”. World Scientific Publishing
NNPDF Collaboration, R.D. Ball, E.R. Nocera, R.L. Pearson, Nuclear uncertainties in the determination of proton PDFs. Eur. Phys. J. C 79(3), 282 (2019). arXiv:1812.09074
NNPDF Collaboration, R.D. Ball et al., Parton distributions for the LHC Run II, JHEP 04, 040 (2015). arXiv:1410.8849
D. de Florian, R. Sassot, P. Zurita, M. Stratmann, Global analysis of nuclear parton distributions. Phys. Rev. D 85, 074028 (2012). arXiv:1112.6324
K. Kovarik et al., nCTEQ15—global analysis of nuclear parton distributions with uncertainties in the CTEQ framework. Phys. Rev. D 93(8), 085037 (2016). arXiv:1509.00792
K.J. Eskola, P. Paakkinen, H. Paukkunen, C.A. Salgado, EPPS16: nuclear parton distributions with LHC data. Eur. Phys. J. C 77(3), 163 (2017). arXiv:1612.05741
R.D. Ball et al., Parton distributions with LHC data. Nucl. Phys. B 867, 244–289 (2013). arXiv:1207.1303
A. Martin, A. Mathijssen, W. Stirling, R. Thorne, B. Watt, G. Watt, Extended parameterisations for MSTW PDFs and their effect on lepton charge asymmetry from W decays. Eur. Phys. J. C 73(2), 2318 (2013). arXiv:1211.1215
NNPDF Collaboration, R.D. Ball, S. Carrazza, L. Del Debbio, S. Forte, Z. Kassabov, J. Rojo, E. Slade, M. Ubiali, Precision determination of the strong coupling constant within a global PDF analysis. Eur. Phys. J. C 78(5), 408 (2018). arXiv:1802.03398
L.W. Whitlow, E.M. Riordan, S. Dasu, S. Rock, A. Bodek, Precise measurements of the proton and deuteron structure functions from a global analysis of the SLAC deep inelastic electron scattering cross-sections. Phys. Lett. B 282, 475–482 (1992)
BCDMS Collaboration, A. Benvenuti et al., A high statistics measurement of the deuteron structure functions F2 (X, \(Q^2\)) and R from deep inelastic muon scattering at high \(Q^2\). Phys. Lett. B 237, 592–598 (1990)
New Muon Collaboration, M. Arneodo et al., Accurate measurement of F2(d)/F2(p) and Rd-Rp. Nucl. Phys. B 487 (1997) 3–26. http://arxiv.org/abs/hep-ex/9611022
NuSea Collaboration, R. Towell et al., Improved measurement of the anti-d/anti-u asymmetry in the nucleon sea. Phys. Rev. D 64, 052002 (2001). arXiv:hep-ex/0103030
CHORUS Collaboration, G. Onengut et al., Measurement of nucleon structure functions in neutrino scattering. Phys. Lett. B 632, 65–75 (2006)
NuTeV Collaboration, M. Goncharov et al., Precise measurement of dimuon production cross-sections in \(\nu _{\mu }\) Fe and \(\bar{\nu }_{\mu }\) Fe deep inelastic scattering at the Tevatron. Phys. Rev. D 64, 112006 (2001). arXiv:hep-ex/0102049
G. Moreno et al., Dimuon production in proton–copper collisions at \(\sqrt{s} = 38.8\)-GeV. Phys. Rev. D 43, 2815–2836 (1991)
F. Faura, S. Iranipour, E.R. Nocera, J. Rojo, M. Ubiali, The strangest proton? Eur. Phys. J. C 80(12), 1168 (2020). arXiv:2009.00014
E.L. Berger, J. Gao, C.S. Li, Z.L. Liu, H.X. Zhu, Charm-quark production in deep-inelastic neutrino scattering at next-to-next-to-leading order in QCD. Phys. Rev. Lett. 116(21), 212002 (2016). arXiv:1601.05430
J. Gao, Massive charged-current coefficient functions in deep-inelastic scattering at NNLO and impact on strange-quark distributions. JHEP 02, 026 (2018). arXiv:1710.04258
S. Forte, L. Garrido, J.I. Latorre, A. Piccione, Neural network parametrization of deep inelastic structure functions. JHEP 05, 062 (2002). arXiv:hep-ph/0204232
R.D. Ball, L. Del Debbio, S. Forte, A. Guffanti, J.I. Latorre, J. Rojo, M. Ubiali, A first unbiased global NLO determination of parton distributions and their uncertainties. Nucl. Phys. B 838, 136–206 (2010). arXiv:1002.4407
Z. Kassabov, Reportengine: a framework for declarative data analysis (2019). https://doi.org/10.5281/zenodo.2571601
R. Abdul Khalek, J.J. Ethier, J. Rojo, G. van Weelden, nNNPDF2.0: quark flavor separation in nuclei from LHC data. JHEP 09, 183 (2020). arXiv:2006.14629
NNPDF Collaboration, R. Abdul Khalek, J.J. Ethier, J. Rojo, Nuclear parton distributions from lepton-nucleus scattering and the impact of an electron-ion collider. Eur. Phys. J. C 79(6), 471 (2019). arXiv:1904.00018
M. Walt, I. Helenius, W. Vogelsang, Open-source QCD analysis of nuclear parton distribution functions at NLO and NNLO. Phys. Rev. D 100(9), 096015 (2019). arXiv:1908.03355
A. Buckley, J. Ferrando, S. Lloyd, K. Nordström, B. Page, M. Rüfenacht, M. Schönherr, G. Watt, LHAPDF6: parton density access in the LHC precision era. Eur. Phys. J. C 75, 132 (2015). arXiv:1412.7420
Acknowledgements
We thank our colleagues in the NNPDF collaboration for comments on the manuscript, in particular Rabah Abdul Khalek, Stefano Forte, Zahari Kassabov and Juan Rojo. R.D.B. and E.R.N. are supported by the UK STFC Grants ST/P000630/1 and ST/T000600/1. E.R.N. was also supported by the European Commission through the Marie Skłodowska-Curie Action ParDHonSFFs.TMDs (Grant number 752748). R.L.P. is supported by the UK STFC Grant ST/R504737/1.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3
About this article

Cite this article
Ball, R.D., Nocera, E.R. & Pearson, R.L. Deuteron uncertainties in the determination of proton PDFs. Eur. Phys. J. C 81, 37 (2021). https://doi.org/10.1140/epjc/s10052-020-08826-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-020-08826-7