
Abstract
Evaluating portfolio performance under different stress scenarios is an important risk management tool. Designing stress scenarios for portfolios can be complex as it involves determining potential market changes in different asset classes and risk factors in a coherent manner that are extreme but plausible. This paper describes an approach to design such stress scenarios where the portfolio performance depends on market changes in many risk factors and asset classes. The scenario design is customized for the portfolio and helps describe plausible market changes that would have the most adverse impact on the portfolio performance. The approach relies on historical data and derives the scenario based on market changes during historical periods that would have been the most stressful for the given portfolio. The proposed approach also allows one to adjust the level of severity and if desired incorporate any specific market conditions of concern (such as scenario design for increasing interest rate environment and/or certain level of unemployment rate, etc.). The main advantages of the proposed approach are (a) flexibility in scenario design with and without constraints on market conditions with adjustable levels of severities, (b) computational simplicity, (c) scalability to any number of market risk factors, (d) no need of prior assumptions on joint distribution of market risk factors, and (e) transparency of the results as they are developed from market changes during actual stressful historical periods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Apart from value at risk (VaR), stress tests are commonly used in portfolio management to quantify the downside risk of portfolios. The goal of stress tests is to evaluate losses in extreme but plausible market conditions. For financial institutions stress tests also play an important role in Federal Reserve’s capital adequacy tests (Comprehensive Capital Analysis and Review 2016). Stress scenarios are often static and used to quantify economic impact to the portfolio under a specific market condition such as 2008 financial crisis. Such static scenarios that do not take into consideration the portfolio risk profile are not useful in answering questions such as “what are the worst market conditions for the given portfolio?” Reverse stress testing, an approach encouraged by regulators (such as FSA (FSA)), aims to address this question by focusing scenario design on the specific vulnerabilities of the portfolio. In reverse stress testing one starts with a question such as “what market condition would result in financial failure of the institution” and work backward from there to identify the sequence of events that would result in market conditions reaching the point that result in failure of the institution. Since such an exercise helps identify events that would cause the institution to fail, it is also very useful in business planning so that the firm takes measures to protect itself from such catastrophic events. Because of its focus on possible events that could cause firm’s failure, apart from market risk, reverse stress testing could also include liquidity and funding risk, etc., as well as idiosyncratic events that are critical to the firm’s survival. Given the starting point of failure of firm’s business model, these approaches are less useful for portfolio management where failure is hard to define.
The objective of this paper is to propose an approach for creating plausible market stress scenarios while also incorporating portfolio vulnerabilities and risk profile as is the case in reverse stress testing. Here we propose algorithms to addresses questions such as “what would be the expected market changes such that the resulting portfolio losses are unlikely to occur more than once in N years”? In some instances one is interested in stress scenario design when certain types of market conditions are specified—for example, quantifying potential downside in an increasing interest rate and/or increasing crude oil price environment. The proposed approach can also be used to answer such questions as “what would be the expected market changes in an environment of increasing rates so that the resulting portfolio losses are unlikely to occur more than once in N years”?
There have been numerous approaches proposed in recent years for scenario design such as Breuer et al. (2009), Flood and Korenko (2012), Glasserman et al. (2015), and Rebonato (2010). Scenario design approaches can be broadly classified into three categories—(a) expert judgment, (b) historical data based, and (c) analytical/quantitative approaches based on some assumptions on distribution of the underlying risk factors. In the first approach, one relies on expert judgment such as views of economists for potential market changes for the scenario of concern. Apart from being fairly subjective, the approach may be difficult to implement for portfolios whose value depends on thousands of market risk factors as it may be difficult to provide coherent market changes for thousands of risk factors using expert judgment. Historical data-based portfolio stress designs are commonly used and are typically based on the market changes during a specified period that would have been quite stressful for the portfolio. This approach of choosing market changes over a specified historical period provides transparency and is easy to implement but has certain drawbacks such as inability to adjust the level of severity of market shocks since choosing a particular stressful period uniquely determines the scenario. Additionally, stress scenarios based on specific historical periods may not be particularly meaningful if those dates do not correspond to period of extreme stress for the given portfolio.
In analytical approaches such as Breuer et al. (2009), Flood and Korenko (2012), Glasserman et al. (2015), and Rebonato (2010), stress scenarios are designed based on certain assumptions on the distributions of the market risk factors (for example, elliptic distribution) or assumptions about conditional probabilities of events. Assumptions on the statistical distributions of the market risk factors allow the authors to quantify plausibility and capture the tradeoff between scenario severity and plausibility. Distributional assumptions also allow one to address the inverse problem (for example, as in Flood and Korenko (2012))—“what market changes are most likely to produce portfolio losses above a certain level?” The proposed approach in the paper differs from these references in one fundamental way—instead of starting with some distributional assumptions on the market risk factors, here the statistical properties of the market risk factors are derived from their changes during the most stressful historical periods for the given portfolio. Thus instead of a priori assumptions on the statistical properties of the market risk factors, they are determined after the identification of the most stressful historical periods for the given portfolio. Since the most stressful historical periods for two portfolios with different risk profiles are likely to be different, the statistical properties and correlations of the underlying risk factors used for scenario design would be different for two different portfolios. The proposed approach also does not suffer from artificial “dimensional dependence” of the scenario design that arises in some analytical approaches. For example Breuer et al. (2009) have shown that without any adjustments, adding market risk factors that are irrelevant to the portfolio performance may impact the plausibility results or result in different shifts for the same risk factors. The proposed approach does not suffer from such dimensional dependence. Indeed if the portfolio depends on N market risk factors, the final scenario design for the specified level of plausibility has the same market changes for the N relevant risk factors regardless of the number of additional irrelevant risk factors that are included in the scenario design.
The proposed approach can be viewed as a combination of historical and analytical approaches. Unlike typical historical stress scenario design where market shifts are obtained from changes in a particular historical period, the proposed approach is based on the synthesis of multiple historical periods that would have been stressful for the portfolio. Reliance on historical data adds transparency to the scenario design and also provides deeper understanding of market conditions that could result in such a stress scenario. The proposed approach relies on the answers to the following two fundamental questions:
If one had held the portfolio for the entire duration of historical data,
-
(a)
what would have been the frequency of stressful periods (how many times would the portfolio have suffered losses above a certain threshold level)?
-
(b)
what would have been portfolio losses in each of those stress periods identified in step (a)?
By incorporating both the frequency of occurrence of stressful periods as well as portfolio loss severities in those periods, one can adjust plausibility and severity in a coherent manner that is consistent with the historical data. The plausibility of the designed scenario is characterized in terms of “one in N year event” and increasing N allows one to increase the severity of the stress scenario. Suitably adjusting the possible frequency/likelihood of the scenario, allows one to scale the scenario to the desired level of severity while maintaining the relative changes of market risk factors (correlations) consistent with those in stressful historical periods.
The main advantages of the proposed approach are:
-
1.
Transparency about the scenario risk factor changes due to reliance on historical data. Knowledge of the events and economic conditions in the historical stressful periods that are used for scenario design, provide deeper insights about market conditions that could result in such a stress scenario.
-
2.
Customization of scenario design based on the portfolio risk profile. Since the scenario design is based on worst historical periods identified for the given portfolio, the scenario is specifically designed for the given portfolio. Thus the risk factor statistical properties assumed in the scenario construction depend on the portfolio risk profile.
-
3.
The approach provides a consistent framework to compare the downside risk of different portfolios. By comparing 1 in N year losses of two different portfolios derived from the same historical data, one can compare the downside risk for the two different portfolios even though the stress scenarios for the two portfolios could be quite different.
-
4.
Ability to customize the level of severity and plausibility while maintaining the relative market changes and correlations observed during the stressful periods. The scenarios are described as 1 in N year events and by increasing N, one increases the level of severity.
-
5.
Stability of results as additional risk factors are introduced or risk profile is changed by a small amount.
-
6.
Ability to incorporate some desired market conditions for the scenario (for example, design a scenario with combinations of some conditions such as rates increase/decrease, USD strengthens/weakens, and/or unemployment rate above x).
-
7.
Computationally simple algorithm that does not involve any complex stochastic models for risk factors or Monte Carlo simulations.
The main disadvantage of the proposed approach as with any other historical data-based scenario design is that the scenario shifts and correlations are informed by the historical data and thus may not be very useful in scenario design for events that have no historical precedence. As observed by Alfaro and Drehmann (2009), unless the prevailing macro conditions are already weak, stress scenarios designed based on historical data are often not sufficiently severe. At the same time if the stress scenarios deviate materially from any historical precedence, they may lack credibility and be hard to justify. For scenario designs to be sufficiently stressed using the proposed approach, it is thus preferable to have sufficiently long historical data so that it includes some periods that would have been sufficiently stressful for the given portfolio.
The sections that follow will provide an algorithm and an example for:
-
Unconstrained scenario design Determine the changes in all risk factors that impact the portfolio value such that the level of loss could occur only once in N years for the given portfolio;
-
Constrained scenario design The same objective as above under some constraints on market changes (e.g., interest rates increase and/or oil prices fall).
Scenario design inputs
In this section, we describe all the inputs and design choices that are used in the scenario design.
Quantifying portfolio value change from risk factor changes
Portfolio risk profile is a key input in the proposed scenario design methodology. This provides a link between changes in markets (the risk factors such as equity prices, rates for different maturities, exchange rates, implied volatilities) and the NPV for the portfolio. In cases where the underlying portfolio NPV depends on numerous risk factors (for example, greater than thousand) and computational time is a constraint, it may be preferable to use a simpler proxy portfolio for scenario design with sensitivities to fewer market parameters. Since the objective in scenario design is to determine market changes and not estimate the precise portfolio losses in a particular scenario, it is not necessary that the NPV of the proxy portfolio match exactly that of the given portfolio as long as the portfolio losses of the proxy portfolio have strong correlation to the losses in the given portfolio. This could, for example, be tested by historical correlation of NPV changes of the actual and the proxy portfolio. If a simpler proxy portfolio is used for the scenario design with fewer risk factors than required for the actual portfolio, we will describe later how one can determine shifts for all the market risk factors (regardless of the number) in a coherent manner that is consistent to the observed correlations between all the risk factors in stressful periods.
Since the scenario design goal is to create stressful conditions that are very infrequent, it is important that the historical data for risk drivers are sufficiently long to cover periods of extreme market changes and correlations that would have been quite stressful for the portfolio. In most cases, data spanning at least one economic cycle or about 10 years are adequate for scenario design. We will also assume that historical data include daily values of all risk drivers—either obtained directly from the market (such as stock values, interest and exchange rates) or inferred indirectly from some market observables.
For determining the most stressful periods for the portfolio, one has to estimate the portfolio value change (assuming no change to the portfolio) for risk factor changes between any two specified dates. It is assumed that one has all the required inputs to estimate portfolio value change based on risk factor changes between any two dates. Let t be the as of date for scenario design (for example current date) and let X t be the set of all risk factor values needed to evaluate the portfolio value on date t. It is assumed that for any past dates T 1 and T 2 within historical data range with T 2 > T 1, we have all the risk factor values to compute change in portfolio value at time t based on risk factor changes from time T 1 to T 2:
Change in time t portfolio value based on risk factor changes from T 1 to T 2
= Portfolio value (risk factor values at time t plus changes in risk factor values from T 1 to T 2)
− Portfolio value (risk factor values at time t)
The above computation may be based on full revaluation of the portfolio or estimated approximately using portfolio Greeks (Delta and Gamma) if computationally time is an issue.
Incorporating scenario attributes
In some instances we may be interested in stress scenario design with either (a) certain type of market changes (such as rates increase and/or cruder oil prices fall) or (b) certain type of macro-economic conditions (such as unemployment rate greater than x %). For such scenario designs, we will assume that daily data are available of the scenario attribute factors that allow us to identify whether any given start and end date in the historical data satisfies the scenario attributes. The only purpose of scenario attributes is to eliminate from historical data any start and end dates that are inconsistent with the required scenario characteristics. For example if the objective is to design a stress scenario where 10-year treasury yields increase, in analysis of historical data to identify stressful periods we will ignore any start and end date where the 10-year treasury yields did not increase.
Maximum time horizon for the stress scenario
This input describes that maximum period to be considered for change in market conditions. In stress scenario analysis, the typical assumption is that the market changes immediately by the specified amounts without any ability to hedge or change the risk profile of the portfolio. From a practical perspective, it is thus not very useful to have a stress period design based on shifts that would occur over a long period (such as a year) for portfolios that are actively managed. This design input should thus be based on the liquidity of the portfolio and the ability to actively adjust the portfolio positions. As the maximum time horizon for stress scenario increases, the severity of the stress scenario increases as the potential market changes can be greater over a longer period.
Scenario severity
The level of severity is quantified using the likelihood of encountering market risk scenario of such level of severity. When the input for this field is N years, it implies that we are interested in market changes so that we are likely to see that level of loss no more than once in N years. Increasing N produces more severe scenario for the portfolio.
The scenario design algorithm
In the scenario design the first step is to identify historical periods which would have been stressful for the portfolio. In that regard, it would be helpful to have a precise definition of what is implied by stressful period.
Definition
Stress period for loss threshold level L The time period between date A and date B is said to be a stress period for loss threshold level L if (a) the number of days between A and B is less than the maximum time horizon for the scenario design (input in "Maximum time horizon for the stress scenario" and one quarter for example), (b) based on the changes in the risk factors between these two dates, the portfolio loss would have exceeded amount L, and (c) market changes from dates A to B meet the required scenario constraints if any (as described in “Incorporating scenario attributes”).
The algorithm is divided into five main steps:
-
(a)
Identification of all non-overlapping stress periods for loss threshold level L For a specified loss level L, find all non-overlapping stress periods for loss threshold level L in the historical data range (the risk factor changes over those non-overlapping periods would result in portfolio loss greater than L).
-
(b)
Obtain frequency of stress periods for loss threshold level L Estimate the frequency of occurrence of stress periods for loss threshold level L from the number of such periods in historical data.
-
(c)
Obtain a calibration of loss distribution for portfolio losses in stress periods for loss threshold level L Using a suitably chosen parametric form or extreme value theory (EVT), obtain a calibration of portfolio loss distribution for portfolio losses from all identified stress periods for threshold level L.
-
(d)
Obtain the portfolio loss for the one in N year scenario from the calibrated loss distribution From the calibrated loss distribution and the percentile of the distribution for a one in N year stress event, obtain the target portfolio loss for a one in N year stress event.
-
(e)
Estimate the scenario shifts for the risk factors for the scenario portfolio loss Obtain the expected scenario shifts that would result in the desired portfolio loss in the stress scenario. The conditional estimate of risk driver shifts for the specified scenario loss is obtained based on the correlation between portfolio losses and risk factors in the identified historical stress periods for loss threshold level L.
We now describe each of the steps in more detail. In the proposed approach loss threshold level L, a design parameter, is used to identify historical stress periods used in scenario design. At the end of the next section, we will comment on how this parameter is chosen but for now let us assume that we have chosen a portfolio loss threshold level L to identify stressful periods.
From the historical data determine all non-overlapping stress periods for threshold level L
In this step, one sorts through all the possible start and end dates in the historical data and determines the stressful historical periods for the portfolio that are (a) shorter than maximum scenario horizon, (b) meet the requirements of the scenario attributes if any, and (c) risk factor changes between the start and end dates result in portfolio losses in excess of threshold amount L. We will discuss later how one should choose the loss threshold level L. Let us assume the available historical data for scenario design spans T years. If in a particular time period there are multiple ways to choose the start date and end dates where loss level exceeds L, to be conservative the pair of start and end dates are chosen that produce the maximum loss for the portfolio.
Since the objective is to determine distinct historical periods with losses in excess of amount L, any date that lies within one stressful period cannot be within another stressful period. In other words, there should be no overlap between distinct historical stress periods. To illustrate how the search algorithm for identification of stressful periods works, let T_start and T_end be the start and end dates of the most stressful period identified from the given historical data among all possible combinations of start and end dates for which portfolio losses exceed amount L. Let A be the set of all dates from the historical data that end just before T_start and let B be the set of all dates from the historical data that begin just after T_end. Thus neither A nor B contain any dates from T_start to T_end. When searching for the next stressful period, the start and end dates are chosen from sets A and B with the constraint that both start and end dates are in the same set—in other words one identifies the worst period from sets A and B with portfolio losses above amount L and then takes the worse one. The reason end date in set B is not considered for start dates in set A is because such a period would cover the period between T_start and T_end which in turn would result in period from T_start to T_end being included in multiple historical stress periods. The search process continues in this manner where the search takes place within several sets with the constraint that both start and end dates are in the same set of dates where each set corresponds to one continuous period. Whenever the worst time period is identified from the remaining dates, the set that includes the worst period is split in two as described above. This process continues until we have obtained all the historical stress periods with losses in excess of L.
The following example illustrates the approach to determine the worst historical periods. Let the historical data be the daily market data from Jan 1, 2006 to Dec 31, 2015. Then the algorithm will proceed as follows
-
(a)
Determine all the possible start and end dates in the range from Jan 1, 2006 to Dec 31, 2015 for which (a) the end date is within the scenario horizon window of the start date (for example, end date within one quarter of the start date), (b) if specified, the scenario design attributes are satisfied for the period covered by start and end dates and (c) portfolio losses based on risk factor change between those dates exceeding L. From all possible pairs of start and end dates, determine the one where the portfolio losses are the maximum. If the historical data cover 2500 days (roughly 10 years) and on average each possible start date has 40 eligible end dates, the determination of the worst possible start and end date pair would require about 100,000 P&L computations for the portfolio. For illustration, let us assume that the worst period for the portfolio was September 25, 2008–Dec 10, 2008.
-
(b)
Divide the historical data into two distinct periods (a) Jan 1, 2006–Sept 24, 2008 (data before the worst period), and (b) from Dec 11, 2008 to Dec 31, 2015 (data after the worst period). For each of the two time periods, determine the worst start and end dates that lie within the same contiguous time period with portfolio losses above L. Let the worst periods for the portfolio for the two sets be Jan 3, 2007–March 14, 2007 and Feb 3, 2009–March 22, 2009. Then the second worst period for the portfolio is the one of these two periods which results in greater portfolio losses. Let us assume that second worst historical period is Feb 3, 2009–March 22, 2009.
-
(c)
We now describe how one determines the third worst historical period having identified the worst two periods. Let us divide the original data into three contiguous time periods that are separated by the most stressful periods identified so far. Thus the three separate periods are (i) Jan 1, 2006–Sep 24, 2008, (ii) Dec 11, 2008–Feb 2, 2009, and (iii) March 23, 2009–Dec 31, 2015. For each of these three sets, we determine the worst start and end dates within these sets with losses above L and the third worst period is the one with the maximum portfolio losses amongst these three periods.
This process continues until there are no more periods with losses exceeding the loss threshold level L. Please note that regardless of the number of stress periods for losses above threshold level L, the portfolio value change for risk factor changes has to be determined only once. In other words, if the historical data of risk factors contain 2500 possible start dates and 40 possible end dates (based on maximum gap between start and end dates), portfolio value changes have to be computed once for 2500*40 = 100,000 combinations of risk factor changes. The determination of all stress periods for threshold level L proceeds as described above and is simply an exercise in sorting and eliminating a set of start and end dates at each step. This step of determining the most stressful historical periods is computationally the most time-consuming part of the algorithm.
Typically, loss threshold level L is chosen so that there are between ten and thirty distinct stress periods for threshold level L in the available historical data (not too many so as to focus on the worst periods but also enough to make meaningful observations about their frequency and market correlations in stressful periods for the portfolio). The final scenario design is based on the observed market changes during the identified stress periods for threshold level L and thus this choice of loss level L does impact the scenario shifts of risk factors. There are two competing issues that partially offset each other to decrease the overall sensitivity of scenario design to the choice of loss threshold level L. If L is lower there are more stress periods for threshold level L in the same historical period and thus the frequency of their occurrence is higher; but if L is lower, the average magnitude of risk factor changes and the corresponding portfolio losses are also less severe. On the other hand, while higher level of loss threshold level L results in fewer but more severe stress periods being considered, it also results in lower frequency of occurrence of stress periods. This issue is discussed further in the “Example” which presents an illustrative example of the proposed approach and discusses the sensitivity of scenario design to the chosen loss threshold level L.
Frequency of stress periods with loss threshold level L
Once a loss threshold level L has been chosen and all stress periods with losses above L are identified, frequency of occurrence of stress events for threshold level L is estimated as follows:
Frequency of occurrence of stress periods for threshold level L
Thus, for example, if the twenty distinct periods were identified from 10 years of historical data with portfolio losses in excess of amount L, then the frequency of occurrence of such stress events would be 20 events/10 years = 2 per year.
Loss distribution calibration for portfolio losses in stress periods for threshold level L
The next step is to fit a loss distribution for portfolio losses in stress periods for threshold level L which are obtained as described in “From the historical data determine all non-overlapping stress periods for threshold level L. ” The choice of loss distribution calibration should take into account the following desirable attributes:
-
(a)
loss distribution is one-sided (zero probability of losses below zero or loss threshold level L as we are interested in modeling portfolio losses that exceed loss threshold L)
-
(b)
low severity losses are more likely than high severity losses (see for example Fig. 1 related to the Example)
Fig. 1 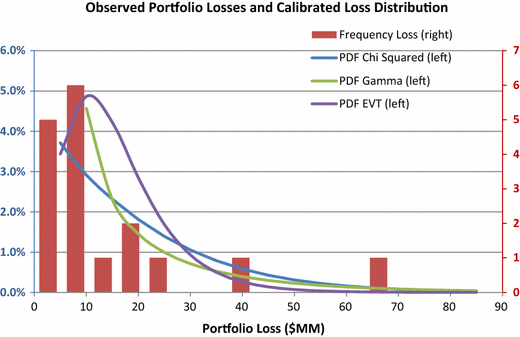
Comparison of historical stress event losses and PDF of the calibrated loss distribution for the case when 10-year treasury yields increase by at least 10 bp. For χ 2 and Gamma distributions, loss distributions are calibrated to match the mean and the standard deviation of losses in the stress periods (last column of Table 3) while EVT/Gumbel distribution parameters are the maximum likelihood estimates
-
(c)
fat tail of the loss distribution (rare occurrences of very large losses)

For calibrating loss distributions, we will consider parametric forms as well as EVT. For parametric calibration, we chose two parameterizations that are analytically tractable and have the desired attributes described above. EVT relates to limiting distributions for the minimum or the maximum of a large collection of independent random variables. For example, let L 1, L 2, L N be maximum daily losses within years 1, 2, …, N. Let L N_max = maximum {L 1, …,L N } be the maximum daily loss from the N peak yearly loss levels. EVT is useful in modeling L N_max for large values of N.
The choice of loss distribution calibration is a design input which influences the final scenario design. In the illustrative example we will compare results obtained using two parametric forms as well as EVT. For parametric forms, the calibration is based on matching only the first two moments (mean and standard deviation) of the portfolio losses in stress periods for threshold level L but one could easily extend this approach to more complex parameterizations and also match other higher order moments such as kurtosis. Below we describe the three different loss distribution calibration methods considered here.
Parametric distribution 1: non-central χ 2 distribution
We first describe non-central χ 2 distribution with one degree of freedom parametrization for calibrating loss distribution for stress events of threshold level L. Recall that non-central χ 2 distribution with one degree of freedom and non-centrality parameter λ is the distribution of \(X^{2}\) where \(X\) is normally distributed with mean of \(\sqrt \lambda\) and standard deviation of 1:
where X ~ N(0,1) (normal random variable with mean 0 and standard deviation of 1)
The mean and variance of non-central χ 2 distribution with one degree of freedom and non-centrality parameter λ are as follows:
Mean non-central χ 2 random variable \(= E\left\{ {\left( {X + \sqrt \lambda } \right)^{2} } \right\} = 1 + \lambda\)
The above implies that for this distribution
or that there is only one degree of freedom in the distribution—one can fix either mean or standard deviation but not both. The cumulative density function for this distribution can be easily obtained from that of normal distribution as
For the loss distribution calibration we will assume that a portfolio loss is a multiple of non-central χ 2 random variable:
The two positive parameters K and λ are obtained so that the mean and the variance of the above distribution match the mean and variance of the observed losses from all stress events of threshold level L. This parametrization has support for loss Є [0,∞) and not loss Є [L,∞) but is chosen for tractability and the fact that it produces reasonable results. Let
M L = mean of portfolio loss in historical stress events of threshold level L
StDev L = standard deviation of portfolio loss for historical stress events of threshold level L
Define
Since Y has non-central χ 2 distribution, from Eq. 2B the scaling parameter K must be the positive solution of the following quadratic equation:
And the parameter λ is determined from Eq. 2A from either the mean or the standard deviation of the scaled loss Y:
The above equations highlight the fact that to calibrate the distribution to the required mean and standard deviation, the standard deviation cannot be too large relative to the mean. If this is the case, higher degrees of freedom non-central χ 2 distribution or other parametric forms should be chosen.
Parametric distribution 2: Gamma distribution
Another parametrization for loss distribution calibration that has the desirable properties is the following probability density function for loss
where L is the loss threshold level used in the identification of historical stressful periods and Gamma_pdf is the density function for the Gamma distribution. Parameters α and β are the shape and the rate parameters of the distribution. This distribution has the advantage of support in the desired range of loss Є [L,∞). The parameters α and β can be easily obtained from the mean and the variance of estimated losses of the historical data-based stress events of threshold level L since for the distribution described by Eq. 3,
EVT distribution: Gumbel distribution
The probability density function for the extreme value distribution (Type 1 or Gumbel distribution) is the limiting distribution of minimum of large number of unbounded identically distributed random variables (see for example Lawless (1982)):
where μ is the location parameter and σ is the scale parameter. The above density function is suitable for modeling the minimum value but can be used for modeling the maximum value by switching sign of the random variables.
The two parameters μ and σ are typically chosen to be the maximum likelihood estimates for the given data (portfolio losses in stress periods for loss threshold L).
Obtaining the portfolio loss under the given scenario
Let us assume we have to design 1 in N year scenario. Let freq denote the frequency of occurrence of stress events of threshold level L as obtained from Eq. 1. Then the worst 1 in N year event would be the worst of 1 of N*freq random draws from the calibrated loss distribution. This is equivalent to determining the loss amount such that probability of loss exceeding this amount is only 1/(N*freq). As an example, consider a situation where stress events of threshold level L occur at the rate of 2 per year (freq = 2/year). If we are interested in one in 10-year scenario design, we are interested in the loss amount that is the worst in 10*2 = 20 loss amounts drawn from the distribution. In other words we are interested in the loss amount so that the probability of exceeding it is only 1/20 = 5%. For the calibrated distributions described above, it is easy to determine the inverse of the cumulative distribution and obtain the portfolio loss for the desired percentile of the loss distribution.
Estimating the shift of risk factors for the scenario from the target portfolio loss
In the previous step, the scenario loss is determined for the given portfolio. In this step we describe an approach to obtain the expected shifts that would result in the desired level of scenario portfolio loss. This problem is equivalent to finding conditional estimate of shifts for the given loss amount where the relationships between risk factors and portfolio losses are based on that observed in the stress periods for threshold level L. This problem is generally quite complex as (a) the portfolio loss is often a non-linear function of changes in key risk factors (for example, when Gamma terms are not zero) and (b) the joint distribution of key risk factors and portfolio loss can be quite complex and depends on the choice of parametrization.
We will for simplicity use the following result which provides the linear unbiased estimate that minimizes the error variance of the conditional estimate.
Lemma
(Linear unbiased minimum variance estimator)
Let X and Y be random variables (each possibly a vector) with the following first and second-order statistics:
Then the linear estimate of Y given X that is unbiased (unbiased means \(E\left\{ {\widehat{Y}} \right\} = E\left\{ Y \right\}\)) and minimizes the error variance (regardless of the distribution of X and Y) is
With the above estimate, the error variance is
Moreover if X and Y are normally distributed then the estimate given by \(\widehat{Y}\) given above is also the conditional estimate
where the conditional estimate error variance is the same as that above in (6):
For completeness, the proof is provided in the Appendix. The above Lemma can be applied to obtain conditional estimate of a risk driver shifts (\(\hat{Y})\) in the stress scenario for a given a given scenario loss amount (X) where the first and second-order moments used in Eq. (5) (\(\bar{X}\), \(\bar{Y}, \varSigma_{XX} , \varSigma_{YY}\, {\text{and}}\, \varSigma_{XY}\)) are obtained from the identified historical periods with portfolio losses above L (as described in “From the historical data determine all non-overlapping stress periods for threshold level L”).
Remark 1
The form of Eq. (5) is intuitively appealing. The first term is the expected value or the average value of Y (the average value of shift of risk factor over all the historical stress events with threshold level L). The second term modifies the risk factor shift based on how far X (the target portfolio loss in the stress scenario) deviates from its average value (average portfolio loss in the historical stress periods for threshold level L). The proportionality constant (\(\varSigma_{YX} \varSigma_{XX}^{ - 1} )\) can be viewed as the “beta” of risk driver change relative to the portfolio loss.
Remark 2
In case the scenario design is based on a simplified portfolio with fewer risk factors, Eq. 5 can still be used to obtain shifts for all the risk factors (even if they are not part of the scenario design) as long as historical data of their changes are available for the identified stress periods for threshold level L. This is because from portfolio losses and market change of any risk driver over the identified stress periods with portfolio losses above L, one can obtain the required first- and second-order moments needed to estimate (Eq. 5) the risk factor shift for a given target portfolio loss.
Example
For the scenario design we will consider the following simplified portfolio where we will assume that the NPV changes can be adequately approximated by first- and second-order portfolio Greeks:
The first column in Table 1 describes the asset type (the actual portfolio would likely have more granular description), the second column the observable market risk factor used to quantify the change in the portfolio value, the third column describes whether market changes for that risk factor are computed based on relative changes or additive changes, and the last two columns provide Greeks with respect to the risk factors. The portfolio above has long position in equities (with positive convexity), investment grade and non-investment grade corporates, crude oil, USD (DXY). The portfolio benefits from rally in short maturity rates but benefits from increase in 10 year rates. The above table corresponds to scenario design inputs described in “Quantifying portfolio value change from risk factor changes.”
For equities since the shifts are computed in terms of relative changes, 3% fall in equities will have the following impact based on the Delta and Gamma described in the first row of Table 1:
P&L from 3% drop in S&P = −0.7*3 + 0.5*0.03*3*3 = −$1.965MM
If 10-year Treasury yields were to go up by 10 bp, the P&L would be $0.2MM/bp*10 bp = $2MM. On the other hand, if 2 year Treasury yields were to go up by 10 bp, the P&L would be −$0.1MM/bp*10 bp = −$1MM.
For the above two portfolio we will consider two stress scenario designs:
-
(1)
Stress Scenario 1 no constraints on market changes. This scenario tries to capture the worst possible market changes for the given portfolio.
-
(2)
Stress Scenario 2 if increase in longer term rates is a concern, one maybe interested in a scenario with increase in 10-year rates. To design such a scenario, one may wish to impose a constraint that 10-year treasury yields increase by at least 10 bp (an illustrative scenario design constraint discussed in "Incorporating scenario attributes”).
Let us assume that we are interested in market changes that could occur over a period no longer than a quarter in which case the input corresponding to “Maximum time horizon for the stress scenario” will be 91 calendar days. Thus for determination of historical stressful periods in which portfolio losses would have exceeded loss threshold L, we would consider only those combinations where the end date is no later than 91 calendar days from the start date.
For the scenario design we will also consider sensitivity with two key design inputs: (a) the choice of parametrization for loss distribution and (b) the loss threshold level L in identification of stressful periods for the portfolio.
Choosing one quarter as the maximum gap from start date to end date and using daily data from April 11, 2007 to August 27, 2016, the following Tables 2 and 3 provide the historical periods with and without constraints as well as portfolio losses in those stressful historical periods where the portfolio loss threshold loss level is $12MM for the unconstrained case and $6MM for the rate increasing case.
As one might expect, the most stressful historical periods for the portfolio as well as losses are different when there are constraints in the scenario (here ten treasury yield increase in the constrained case). For the unconstrained case, there were nineteen distinct periods between April 11, 2007 and August 26, 2016 for which portfolio losses exceeded $12MM. Similarly for the constrained case 10-year treasury yields increase at least 10 bp, there were only seventeen periods when portfolio losses exceeded $6MM.
As described in “Loss distribution calibration for portfolio losses in stress periods for threshold level L ,” we now obtain parametrization of the loss distributions. For parametric representations, the parameters are obtained to match the mean and standard deviation of the portfolio losses in the stressful historical periods identified in Tables 2 and 3 (last column). Tables 4 and 5 below provide parametrization of loss distribution based on the two parametric distributions considered.
The maximum likelihood estimates for the EVT distribution parameters described in Eq. (4) are provided in Table 6.
The above parameterizations are illustrated in the plot below which shows the histogram of observed losses in historical stress events in the increasing rate environment (Table 3) and the probability density function of the calibrated loss distributions.
Next we describe the determination of portfolio losses for the desired scenarios. There were nineteen stress periods with portfolio loss greater than $12MM for the unconstrained case (Table 2) and seventeen stress periods with loss greater than $6MM in the 10-year rate increasing scenario (Table 3). The historical data span 9.38 years (from April 11, 2007 to August 26, 2016). Thus stress events with portfolio losses of at least $12MM for the unconstrained case occur at the rate of 19/9.38 = 2.03 per year. This implies that over 10 years, one would expect 2.03*10 = 20.3 such scenarios. Thus one in 10-year scenario will be the worst scenario out of every 20.3 scenarios drawn from the calibrated loss distribution. Thus the probability of losses exceeding one in 10-year stress event is 1/20.3 = 4.94% (or loss percentile is 95.06% of the loss distribution). The Tables 7 and 8 below describe the loss percentile for several scenarios ranging from one in 5 year to one in 25-year stress events together with loss amount corresponding to the desired loss percentile from the loss distribution calibrations described above.
As one would expect, portfolio losses for the same severity scenario (for example, one in 10-year scenario) are greater when there are constraints on the scenario. For example using the non-central χ 2 distribution, portfolio loss for one in 5-year scenario without constraints is $44MM, while under the increasing 10-year rate constraint it is $37MM.
For stress scenarios of the same severity (the same percentile of loss distribution), portfolio losses are usually highest for Gamma distribution. The “fatter tail” of Gamma distribution is in part due to the fact that the probability density function is zero for losses below threshold level L, while for other distributions there is a non-zero probability of losses being lower than threshold level L. EVT/Gumbel distribution produces less severe portfolio losses for the same level of severity than the two parametric calibrations. Since EVT describes limiting distribution (maximum or minimum of a very large set of random variables), it may be more accurate if there are many stress events of threshold level L in the historical data or very extreme scenarios needs to be designed. For most practical applications we find that Gamma distribution provides quite reasonable and expected results.
In the final step of the algorithm, one uses the Lemma describing the conditional unbiased estimate to obtain shifts of risk drivers given the loss amount in the scenario. These estimates, described in Tables 9 and 10, are obtained using Eq. (5) which involves the first and second moments obtained from the observed market changes and portfolio losses described in Tables 2 and 3. Please note that in Table 10, 10-year treasury yield increases as desired in the constrained scenario design.
Next we discuss the sensitivity of scenario design to the loss threshold levels chosen in determination of stressful historical periods. Recall that the loss thresholds for choosing stress periods were $12MM for the unconstrained scenario and $6MM for the scenario with increasing 10-year treasury yields. If one had chosen loss threshold of $15MM and $8MM, respectively, for the two scenarios, only the first thirteen scenarios of Table 2 and the first twelve of Table 3 would exceed the threshold loss amount and thus be used in the scenario design. Changing loss threshold results in a different loss scenario parameterization and also results in different frequency of loss severity. For example, only thirteen stressful events were observed with portfolio losses in excess of $15MM. The frequency of occurrence of such events in 9.38 years is 13/9.38 = 1.39 per year. One in 10-year scenario would then be the worst among 1.39*10 = 13.9 such stress events and thus correspond to 1–1/13.9 = 92.78% of the loss distribution (as opposed to 95.06% in Table 7 which was based on the assumption of 2.03 stress events per year). Table 11 below shows the comparison of scenario design for the constrained case (increasing rates) for the two different choices of loss threshold—$6MM and $8MM, respectively, based on non-central χ 2 loss parametrization. The results are not very sensitive to the choice of loss threshold level. This is due to two factors that partially offset each other—increasing loss threshold results in lower frequency of occurrence of stress periods (fewer stress periods in the same time period with losses above the threshold level) but at the same time the average severity of stress events is also greater and thus the calibrated loss distribution has higher losses for the same percentile.
Summary
This paper presents an approach to create stress scenarios for portfolios involving several risk factors. Reliance on historical stressful periods provides transparency to resulting scenario design as the shifts and correlations can be benchmarked against actual changes observed in the markets during stressful periods. The scenario design is customized to the portfolio and thus designed to stress specific risk features of the portfolio. The approach also allows one to adjust the level of severity and analyze the tradeoff between plausibility and severity. The approach can also be easily adapted to scenario design with constraints on macro or market conditions (such as on unemployment rate or interest rates) by limiting the historical data to only those periods which are consistent with the required scenario constraints. The approach is computationally also very tractable even when there are large number of market risk factors.
References
Alfaro, R., and M. Drehmann. 2009. Macro Stress Tests and Crises: What Can We Learn? BIS Quarterly Review 12: 29–41.
Breuer, T., M. Jandacka, K. Rheinberger, and M. Summer. 2009. How to Find Plausible, Severe, and Useful Stress Scenarios. International Journal of Central Banking 5 (3): 205–224.
Comprehensive Capital Analysis and Review 2015 Summary Instructions and Guidance. Board of Governors of the Federal Reserve System. January, 2016.
Flood, M., and Korenko, G. 2012. Systematic Scenario Selection. Office of Financial Research, U.S. Department of Treasury.
Glasserman, P., C. Kang, and W. Kang. 2015. Stress Scenario Selection by Empirical Likelihood. Quantitative Finance 15: 25–41.
Lawless, J.F. 1982. Statistical Models and Methods for Lifetime Data. New York: Wiley.
Rebonato, R. 2010. Coherent Stress Testing: A Bayesian Approach. New York: Wiley.
Reverse Stress Testing, FSA. http://www.fsa.gov.uk.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Krishan Nagpal is a Managing Director in Corporate Market Risk at Wells Fargo & Co. The opinions expressed here are those of the author and do not represent those of his employer Wells Fargo & Co.
Appendix
Appendix
Proof of unbiased minimum variance estimate Lemma
Here we will prove the Lemma that describes the linear minimum variance unbiased estimator. Let the linear estimate of Y given X be
where matrix A and the vector b are to be determined so that (a) the above estimate is unbiased (unbiased means E{\(\widehat{Y}\)} = E{\(Y\)}) and (b) the variance of the estimation error is minimized. Taking expectation of both sides together with unbiased requirement implies
Let tr() represent the trace of a matrix. Then the error variance of the estimate that needs to be minimized is
where A′ is the transpose of matrix A. Differentiating the above with respect to A and setting that to zero results in (together with some trace derivative formulae)
Substitution the above expressions for A and b results in the optimal linear estimator form of (5).
Now we prove that under the Gaussian assumption, the estimate is the conditional estimate with the variance the same as the error variance (we will prove (7) and (8)). Let
Also note that the form of the variance of the combined vector \(\tilde{X}\) and \(\tilde{Y}\):
From the definition of Gaussian distribution, the density function of \(\tilde{X}\) and the combined vector \(\tilde{X}\) and \(\tilde{Y}\) are
where \(P^{ - 1}\) can be obtained by applying Matrix Inversion Lemma on the expression of P defined above
where F and G are as follows:
The conditional density function of \(\tilde{Y}\) given \(\tilde{X}\) can thus be expressed as
Note that the above probability density function of \(\tilde{Y}\) given \(\tilde{X}\) is a Gaussian distribution where the mean and variance of the distribution are
Since \(\tilde{X} = {\text{X}} - \bar{X},\;\tilde{Y} = {\text{Y}} - \bar{Y}\), the first equation above is equivalent to Eq. (7) while Eq. (8) follows from the second equation above.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Nagpal, K.M. Designing stress scenarios for portfolios. Risk Manag 19, 323–349 (2017). https://doi.org/10.1057/s41283-017-0024-x
Published:
Issue Date:
DOI: https://doi.org/10.1057/s41283-017-0024-x