
Abstract
Socioeconomic status (SES) has been linked to mortality rates, with family income being a quantifiable marker of SES. However, the precise association between the family income-to-poverty ratio (PIR) and all-cause mortality in adults aged 40 and older remains unclear. A cross-sectional study was conducted using data from NHANES III, including 20,497 individuals. The PIR was used to assess financial status, and various demographic, lifestyle, and clinical factors were considered. Mortality data were collected from the NHANES III linked mortality file. The study revealed a non-linear association between PIR and all-cause mortality. The piecewise Cox proportional hazards regression model showed an inflection point at PIR 3.5. Below this threshold, the hazard ratio (HR) for all-cause mortality was 0.85 (95% CI 0.79–0.91), while above 3.5, the HR decreased to 0.66 (95% CI 0.57–0.76). Participants with lower income had a higher probability of all-cause mortality, with middle-income and high-income groups showing lower multivariate-adjusted HRs compared to the low-income group. This study provides evidence of a non-linear association between PIR and all-cause mortality in adults aged 40 and older, with an inflection point at PIR 3.5. These findings emphasize the importance of considering the non-linear relationship between family income and mortality when addressing socioeconomic health disparities.
Similar content being viewed by others


Introduction
Addressing socioeconomic health inequities has received a lot of attention in the field of public health1,2. Several epidemiological studies have demonstrated, across various populations, that socioeconomic status (SES) is significantly associated with mortality range3,4,5. Income, education, job, and neighbourhood features are all markers of SES and are correlated with mortality rates6,7. Additionally, these factors could affect mortality independently. Thus, analyzing the impact of each SES indicator on mortality is crucial to comprehending the precise purpose of socioeconomic status differences in mortality rates.
Some previous studies have investigated the relationship between each SES indicator (education, job) and mortality8,9. Nevertheless, disease studies find limited utility in employing educational and occupational stratifications as these models overly prioritize schooling and job placements while disregarding individuals' health-acquiring and purchasing capabilities10,11. Indexes of education and work are particularly challenging since they only specify aspects of these fields both within and across peers10,11. Family income is one of the most easily quantifiable of these factors, which can be adjusted according to the family income-to-poverty ratio (PIR)12. The PIR index of socioeconomic standing is potentially a more reliable indicator of socioeconomic status compared to education and occupation.
Insufficient data exists regarding the relationship between PIR (a validated measure of income inequality) and the overall impact on mortality rates. Nevertheless, research does suggest that individuals with a lower PIR have a higher vulnerability to all-cause mortality13,14,15. A cross-sectional study was conducted to establish an association between the PIR and the total mortality rate among individuals aged 40 and above. In order to ensure precision, we considered factors such as demographics, lifestyle, and clinical indications.
Methods
Study design and population
This study utilized a prospective cohort design and employed data obtained from the US National Health and Nutrition Examination Survey (NHANES). The NHANES is a survey undertaken by the National Centre for Health Statistics (NCHS) of the United States. Centre for Disease Control and Prevention (CDC) is a large-scale, multistage, ongoing, and nationally representative health survey of noninstitutionalized US civilians in 2-year cycles since 1999–2000. The research study collects data on demographics, socioeconomic status, nutrition, physiology, and laboratory tests through a combination of interviews and medical exams. All participants provided written informed consent. In the current study, we used publically available data (https://www.cdc.gov/nchs/nhanes/index.htm) from two cycles of NHANES from 2005 to 2008 (2005–2006 and 2007–2008). The participants who did not meet the inclusion criteria were excluded from the analysis. This study initially included 20497 people. However, 6058 people were enrolled in the final analysis after the adoption of exclusion criteria. Figure 1 presents the study flow chart.

Flow chart of participants selection. NHANES, National Health and Nutrition Examination Survey; PIR, the ratio of family income to poverty.
Assessment of PIR
PIR is a predetermined continuous variable in NHANES. We utilized the PIR, which is an indicator of income relative to the economic needs of a household. This was achieved by calculating annual fluctuations in household size and cost of living and monitoring the consumer price index in relation to household income and federally established poverty limitations16. However, it is not applicable if respondents reported incomes below or above $20,000. Furthermore, values over 5.00 were coded as 5.00 or greater for confidentiality reasons. PIR levels were defined as low income (PIR<1), middle income (1≤PIR<4), and high income (PIR ≥ 4)17.
Measurement of covariates
Covariates, such as age, sex, race/ethnicity, education, smoking status, alcohol intake, physical activity, sleep quality, self-reported diseases, health insurance and Body mass index (BMI) were required to account for spurious relationships between PRI and death. These data were obtained directly from the family questionnaire and medical conditions sections of the NHANES questionnaires. Non-Hispanic Whites, Blacks, Mexican Americans, and other racial groups were established18. The classification of marital status included married or cohabiting, widowed, divorced, separated, and never married19. There were three categories for educational level: less than high school, high school, and some college or higher20. We classified smokers in this study as either current smokers, former smokers (defined as 100 cigarettes or more smoked but no longer smoked), or never smokers (defined as less than 100 cigarettes smoked but no longer smoked)18,21. Participants were categorized into four alcohol consumption groups: never-drinkers, ex-drinkers, low-to-moderate drinkers (women consuming ⩽ 7 drinks/week or men consuming ⩽ 14 drinks/week), and heavy drinkers (women consuming > 7 drinks/week or men consuming > 14 drinks/week) according to standard guidelines22,23. Physical activity was classified into three groups: inactive (< 1 h/ week of moderate or vigorous activity), moderately active (neither inactive nor active), and vigorous (> 2.5 h/ week or > 1 h/ week)24. When a household survey question was asked, "Are you covered by health insurance or any other type of health care plan?" and the response was affirmative, it was assumed that the individual had health insurance or some other type of healthcare coverage. The Pittsburgh Sleep Quality Index (PSQI) was developed to assess the quality and patterns of sleeping in adolescents or adults25,26. During NHANES 20052008, eight self-reported questions were used to determine PSQI27. Examining the PSQI score in sleep latency, sleep disturbance, and daytime dysfunction, sleep quality could be categorized as “poor” or “good”. The cumulative scores of the three components latency, disturbances, and daytime dysfunction—were utilized to derive the PSQI total score (0–23). A sleep quality score of five or higher indicated inadequate sleep, while a score below five was favorable27. The official NHANES website (https://www.cdc.gov/nchs/nhanes/) provides the interpretation, measurement, and calculation details for eight self-reported measures used to evaluate PSQI. BMI was determined by dividing the weight in kilograms by the square of the height in meters kg/m2. The World Health Organization (WHO) expert consultation used a BMI of 30 kg/m2 as the threshold to identify obesity28,29. The self-reported diseases were categorized as follows: diabetes, hypertension, hypercholesterolemia, cardiovascular disease, and other diseases. Diabetes diagnosis criteria include self-reported diabetes, medication or insulin use, HbAl > 6.5, and fasting glucose ⩾ 7.030. If these people self-reported using antihypertensive drugs, they were diagnosed with hypertension; if they had a total cholesterol level of 6.2 mmol/L or more and were taking medication for it, they were diagnosed with hypercholesterolemia29. A self-reported medical history of coronary heart disease, myocardial infarction, angina, or stroke was considered cardiovascular disease (CVD)31,32. Additional ailments encompass self-reported conditions such as lung disease, arthritis, gout, thyroid disease, digestive system disease, and cancer.
Ascertainment of mortality
This study investigated both identified and unidentified causes of mortality in order to determine the total death rate. Data on mortality were collected using the NHANES III linked mortality file, which was made available by the NCHS and the mortality assessment period lasted from December 31, 2015, to the baseline interview, which was carried out between 1988 and 199433. From the survey date through December 31, 2015, we used data from the NHANES public-use linked mortality file (https://www.cdc.gov/nchs/data/datalinkage/LMF2015_Methodology_Analytic_Considerations.pdf), which was linked to the National Death Index using a probabilistic matching algorithm by the NCHS34,35.
Statistical analysis
The differentiation between PIR classes was analyzed using one-way ANOVA and the χ2 test. The Cox proportional hazard regression model was utilized to determine the hazard ratios (HRs) for all-cause mortality in relation to PIR, along with a 95% confidence interval (CI). Personal time was measured based on the NHANES interview until death or the end of the follow-up period, whichever came first. Covariates and confounding factors were selected for their correlations with outcomes or effect estimates greater than 10%36,37. To address missing data in the covariates (all of which were categorical variables), we introduced a category specifically for missing data. This approach aimed to minimize the drop in sample size caused by missing covariate data38. Three models based on Cox regression analysis were used to determine the correlation between PIR and the risk of all-cause mortality. Model 1 did not consider any potential covariates. Demographics were considered when adjusting Model 2. All covariates were considered while adjusting Model 3. The test of Cochran-Armitage trend was used to test for a linear trend across various PIR levels. We used the likelihood ratio test to check for nonlinearity. The threshold effect of the PIR on all-cause mortality was examined using a smoothing function in a linear regression model. Furthermore, the one-line linear regression model was compared with the two-piecewise linear model using loglikelihood ratios. The analyses used Empower software (X&Y Solutions, Inc.; www.empowerstats.com) and statistical software R language (version 4.0.3), with statistically significant results when P < 0.05.
Results
Participant characteristics
The present analysis comprised 6058 participants (3057 men and 3001 females) aged 40–85 years from NHANES 2005 to 2008 (Fig. 1). In the low-income, middle-income, and high-income groups, there were 931, 3337, and 1790 participants, respectively. Table 1 shows the individuals in each of the three categories whose various demographic data differed considerably. The percentages of male participants (957 and 53.5%), non-Hispanic (Black or White) participants (1491 and 83.3%), and participants aged less than 65 years (1406 and 78.5%), married or living with a partner non-Hispanic (1378 and 77.0%), graduated from some college or more (1308 and 73.1%), smoking never or ever (935 and 52.2%; 608 and 34.0%), with low to moderate alcohol consumption (1135 and 69.5%), vigorous physical activity (667 and 43.6%), health insurance (1711 and 95.6%), hypercholesterolemia (2704 and 83.1%) were markedly higher in high-income level than other income levels. In comparison to other income levels, there were considerably more participants with diabetes (252 and 28.8%), cardiovascular disease (144 and 15.5%), and self-reported other conditions (739 and 79.4%) in low-income levels. In addition, a significantly higher proportion of individuals in the medium-income group (1583 and 47.5%) had hypertension than those in the lower-income group. In contrast, the average BMIs and percentages of good sleep were comparable across all three income levels.
Association between PIR and all-cause mortality
A total of 1445 patients experienced mortality from any cause, resulting in an incidence rate of 23.9%. The Cox regression analyses of all-cause mortality about PIR are presented in Table 2. We employed three models to assess the correlation between PIR and overall mortality. No covariates were considered in Model 1, whereas when revising Model 2, age, gender, and race/ethnicity were considered. Model 3 was adjusted all covariates presented in Table 1. In Model 3, after adjusting for various factors, the hazard ratios (HRs) for all-cause mortality were calculated for different income groups. Compared to the low-income group, the middle-income group had an HR of 0.80(95%CI 0.70–0.92), while the high-income group had an HR of 0.38 (95% CI 0.31–0.47). Model 3 shows that the middle-income and high-income groups had higher multivariateadjusted HRs (95% CIs) for all-cause mortality relative to the low-income group: 0.80 (95% CI 0.70 0.92) and 0.38(95% CI 0.31 0.47), respectively. when PIR considered as a categorical variable, and the results were similar. The trend test showed that, as the PIR value increases, the P value for PIR and all-cause mortality becomes increasingly more significant. These findings suggest that the PIR and all-cause mortality may not be linear when all factors are included.
Nonlinearity and the threshold effect between PIR and all-cause mortality
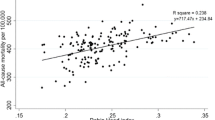
Even after accounting for all significant factors in Table 2, smooth curve fitting revealed a non-linear connection between PIR and all-cause mortality (Fig. 2). Two Cox proportional hazards regression models were used to fit the PIR-all-cause mortality relationship. The log-likelihood ratio test returned a P-value of <0.010. This suggests that the piecewise Cox proportional hazards regression model provides a more accurate explanation for PIR and all-cause mortality. The inflection point was determined to be at 3.5 using a combination of recursive and two-piecewise Cox proportional hazards regression. At PIR < 3.5, HR and 95% CI were 0.85 and 0.79−0.91, respectively. Table 3 shows that HR and 95% CI values for PIR ≥ 3.5 were 0.66 and 0.57−0.76, respectively.

The smooth curve fitting showed that the non-linear association between PIR and all-cause mortality. All covariates were adjusted.
Discussion
This study demonstrates the initial discovery of a non-linear correlation between PIR and mortality from any cause. This study indicates that the piecewise Cox proportional hazards regression model provides a more effective analysis of PIR and all-cause mortality. The P-value of the log-likelihood ratio test is < 0.010, which provides strong evidence to support this conclusion. We used a two-piecewise Cox proportional hazards regression and recursive technique to calculate the inflection point as 3.5. At PIR < 3.5, HR and 95% CI were 0.85 and 0.79 0.91, respectively. The HR and 95% CI for PIR 3.5 were 0.66 and 0.57 0.76, respectively.
Furthermore, this study found that individuals with a lower income had a higher likelihood of experiencing death from any cause, which aligns with the findings of subsequent analyses. Recent studies conducted in developed countries, such as the United States, have shown that there are lower odds ratios (ORs) for cardiovascular disease (CVD) risk among individuals with low and moderate incomes compared to those with high incomes. In contrast, lower SES was associated with greater mortality risk across all causes39. Zhang and colleagues investigated 1988–1994 (NHANES III) and 1999–2014 (continuous cycles) NHANES participants39. After determining SES by latent class analysis of PIR, employment, education, and health insurance, these researchers discovered that those with low SES were twice as likely to pass away from CVD-related causes and all causes combined. Gender differences have been observed in CHD death rates by Odutayo et al. Both genders had about double the CHD incidence in the low-income group as compared to the high-SES group14.
Possible mechanisms encompass a diverse array of resources, including knowledge, wealth, power, status, and supportive social networks. Additionally, protective factors such as access to health care services and a healthy lifestyle play a role. Other influential factors include education, medical compliance, stress levels, dietary habits, safety of neighbourhoods, physical activity, smoking and drug use, and air pollution40,41,42,43,44. For example, one study found that lifestyle variables explained 12.3% of the correlation between socioeconomic status and mortality39. People from poorer socioeconomic backgrounds are more likely to die from any cause due to a combination of biological, behavioural, and psychological risk factors44. The previously mentioned data clarifies the reason why individuals who have a low income are more prone to mortality from any cause.
There are various limitations in this study. Firstly, it is crucial to acknowledge that although the well-established PIR serves as the primary measure for income inequality in our research, it does not entirely consider the impact of SES on mortality from any cause. Secondly, it is critical to acknowledge the possibility of residual confounding because of the observational nature of this study. Lastly, we are unable to ascertain the direction or causation of the PIR-all-cause mortality connection due to the current cross-sectional study methodology.
Conclusion
This study found a non-linear association between PIR and all-cause death among persons aged 40 and older. The PIR inflection point, where the link switches direction, was 3.5.
Data availability
Publicly available datasets were analyzed in this study. Tese data can be found at: www.cdc.gov/nchs/nhanes/.
References
Schaap, R. et al. Improving the health of workers with a low socioeconomic position: Intervention mapping as a useful method for adaptation of the participatory approach. BMC Public Heal. 20, 1–13. https://doi.org/10.1186/s12889-020-09028-2 (2020).
Demakakos, P., Nazroo, J., Breeze, E. & Marmot, M. Socioeconomic status and health: The role of subjective social status. Soc. Sci. Med. 67, 330–340. https://doi.org/10.1016/j.socscimed.2008.03.038 (2008).
Steenland, K., Henley, J., Calle, E. & Thun, M. Individual-and area-level socioeconomic status variables as predictors of mortality in a cohort of 179,383 persons. Am. J. Epidemiol. 159, 1047–1056. https://doi.org/10.1093/aje/kwh129 (2004).
Khang, Y.-H. & Kim, H. R. Explaining socioeconomic inequality in mortality among South Koreans: An examination of multiple pathways in a nationally representative longitudinal study. Int. J. Epidemiol. 34, 630–637. https://doi.org/10.1093/ije/dyi043 (2005).
Stringhini, S. et al. Association of socioeconomic position with health behaviors and mortality. Jama 303, 1159–1166. https://doi.org/10.1001/jama.2010.297 (2010).
Karlsson, O., Kim, R., Joe, W. & Subramanian, S. The relationship of household assets and amenities with child health outcomes: An exploratory cross-sectional study in India 2015–2016. SSM-Popul. Heal. 10, 100513. https://doi.org/10.1016/j.ssmph.2019.100513 (2020).
Galobardes, B., Lynch, J. & Smith, G. D. Measuring socioeconomic position in health research. Br. Med. Bull. https://doi.org/10.1093/bmb/ldm001 (2007).
Stringhini, S. et al. Socioeconomic status and the 25 × 25 risk factors as determinants of premature mortality: A multicohort study and meta-analysis of 1.7 million men and women. LANCET 389, 1229–1237 (2017).
Puka, K. et al. Educational attainment and lifestyle risk factors associated with all-cause mortality in the us. JAMA Health Forum. 3, e220401 (2022).
Salonen, M. K. et al. Role of socioeconomic indicators on development of obesity from a life course perspective. J. Environ. Public Health 2009, 625168 (2009).
Braveman, P. A. et al. Socioeconomic status in health research: One size does not fit all. JAMA-J. Am. Med. Assoc. 294, 2879–2888 (2005).
Kanjilal, S. et al. Socioeconomic status and trends in disparities in 4 major risk factors for cardiovascular disease among us adults, 1971–2002. Arch. Intern. Med. 166, 2348–2355. https://doi.org/10.1001/archinte.166.21.2348 (2006).
Beckman, A. L., Herrin, J., Nasir, K., Desai, N. R. & Spatz, E. S. Trends in cardiovascular health of us adults by income, 2005–2014. JAMA Cardiol. 2, 814–816. https://doi.org/10.1001/jamacardio.2017.1654 (2017).
Odutayo, A. et al. Income disparities in absolute cardiovascular risk and cardiovascular risk factors in the United States, 1999–2014. JAMA Cardiol. 2, 782–790. https://doi.org/10.1001/jamacardio.2017.1658 (2017).
He, J. et al. Trends in cardiovascular risk factors in us adults by race and ethnicity and socioeconomic status, 1999–2018. Jama 326, 1286–1298. https://doi.org/10.1001/jama.2021.15187 (2021).
Minhas, A. M. K. et al. Family income and cardiovascular disease risk in american adults. Sci. Rep. 13, 279. https://doi.org/10.1038/s41598-023-27474-x (2023).
Wang, M. et al. Association between cancer prevalence and different socioeconomic strata in the us: The national health and nutrition examination survey, 1999–2018. Front. Public Heal. 10, 873805. https://doi.org/10.3389/fpubh.2022.873805 (2022).
Fang, M., Wang, D., Coresh, J. & Selvin, E. Trends in diabetes treatment and control in us adults, 1999–2018. N. Engl. J. Med. 384, 2219–2228. https://doi.org/10.1056/NEJMsa2032271 (2021).
You, Y. et al. Associations between health indicators and sleep duration of American adults: NHANES 2011–2016. Eur. J. Public Health. 31, 1204–1210. https://doi.org/10.1093/eurpub/ckab172 (2021).
Ikonte, C. J., Mun, J. G., Reider, C. A., Grant, R. W. & Mitmesser, S. H. Micronutrient inadequacy in short sleep: Analysis of the NHANES 2005–2016. Nutrients 11, 2335. https://doi.org/10.3390/nu11102335 (2019).
Strozyk, D., Gress, T. M. & Breitling, L. P. Smoking and bone mineral density: Comprehensive analyses of the third national health and nutrition examination survey (NHANES III). Arch. Osteoporos. 13, 1–7. https://doi.org/10.1007/s11657-018-0426-8 (2018).
Liang, L., Hua, R., Tang, S., Li, C. & Xie, W. Low-to-moderate alcohol intake associated with lower risk of incidental depressive symptoms: A pooled analysis of three intercontinental cohort studies. J. Affect. Disord. 286, 49–57. https://doi.org/10.1016/j.jad.2021.02.050 (2021).
Phillips, J. A. Dietary guidelines for americans, 2020–2025. Work. Health Saf. 69, 395–395. https://doi.org/10.1177/21650799211026980 (2021).
Akbaraly, T. N., Sabia, S., Shipley, M. J., Batty, G. D. & Kivimaki, M. Adherence to healthy dietary guidelines and future depressive symptoms: Evidence for sex differentials in the Whitehall II study. Am. J. Clin. Nutr. 97, 419–427. https://doi.org/10.3945/ajcn.112.041582 (2013).
Vézina-Im, L.-A., Nicklas, T. A. & Baranowski, T. Associations among sleep, body mass index, waist circumference, and risk of type 2 diabetes among us childbearing-age women: National health and nutrition examination survey. J. Women’s Heal. 27, 1400–1407. https://doi.org/10.1089/jwh.2017.6534 (2018).
Buysse, D. J., Reynolds, C. F. III., Monk, T. H., Berman, S. R. & Kupfer, D. J. The pittsburgh sleep quality index: A new instrument for psychiatric practice and research. Psychiatry Res. 28, 193–213. https://doi.org/10.1016/0165-1781(89)90047-4 (1989).
Wang, L. et al. The role of dietary inflammatory index on the association between sleep quality and long-term cardiovascular risk: A mediation analysis based on NHANES (2005–2008). Nat. Sci. Sleep 14, 483–492. https://doi.org/10.2147/nss.S357848 (2022).
Tan, K. et al. Appropriate body-mass index for Asian populations and its implications for policy and intervention strategies. The Lancet https://doi.org/10.1016/s0140-6736(03)15268-3 (2004).
Chen, Y. et al. Low-or high-dose preventive aspirin use and risk of death from all-cause, cardiovascular disease, and cancer: A nationally representative cohort study. Front. Pharmacol. 14, 347. https://doi.org/10.3389/fphar.2023.1099810 (2023).
Zhang, Y. et al. Non-linear associations between visceral adiposity index and cardiovascular and cerebrovascular diseases: Results from the NHANES (1999–2018). Front. Cardiovasc. Med. 9, 908020. https://doi.org/10.3389/fcvm.2022.908020 (2022).
Suresh, S., Sabanayagam, C. & Shankar, A. Socioeconomic status, self-rated health, and mortality in a multiethnic sample of us adults. J. Epidemiol. 21, 337–345. https://doi.org/10.2188/jea.JE20100142 (2011).
Davis, J. S. et al. Use of non-steroidal anti-inflammatory drugs in us adults: Changes over time and by demographic. Open Heart 4, e000550. https://doi.org/10.1136/openhrt-2016-000550 (2017).
Qiu, Z. et al. Associations of serum carotenoids with risk of cardiovascular mortality among individuals with type 2 diabetes: Results from NHANES. Diabetes Care 45, 1453–1461. https://doi.org/10.2337/dc21-2371 (2022).
Bao, W. et al. Association between bisphenol a exposure and risk of all-cause and cause-specific mortality in us adults. JAMA Netw Open. 3, e2011620 (2020).
Pande, R. L., Perlstein, T. S., Beckman, J. A. & Creager, M. A. Secondary prevention and mortality in peripheral artery disease: National health and nutrition examination study, 1999 to 2004. Circulation. 124, 17–23 (2011).
Jaddoe, V. W. et al. First trimester fetal growth restriction and cardiovascular risk factors in school age children: Population based cohort study. Bmj 348, g14. https://doi.org/10.1136/bmj.g14 (2014).
Kernan, W. N. et al. Phenylpropanolamine and the risk of hemorrhagic stroke. N. Engl. J. Med. 343, 1826–1832. https://doi.org/10.1056/nejm200012213432501 (2000).
Sun, Y. et al. Association of normal-weight central obesity with all-cause and cause-specific mortality among post-menopausal women. JAMA Netw. Open 2, e197337–e197337. https://doi.org/10.1001/jamanetworkopen.2019.7337 (2019).
Zhang, Y.-B. et al. Associations of healthy lifestyle and socioeconomic status with mortality and incident cardiovascular disease: Two prospective cohort studies. Bmj https://doi.org/10.1136/bmj.n604 (2021).
Bhatnagar, A. Environmental determinants of cardiovascular disease. Circ. Res. 121, 162–180. https://doi.org/10.1161/circresaha.117.306458 (2017).
Schilbach, F., Schofield, H. & Mullainathan, S. The psychological lives of the poor. Am. Econ. Rev. 106, 435–440. https://doi.org/10.1257/aer.p20161101 (2016).
White, J. S. et al. Long-term effects of neighbourhood deprivation on diabetes risk: Quasi-experimental evidence from a refugee dispersal policy in Sweden. Lancet Diabetes Endocrinol. 4, 517–524. https://doi.org/10.1016/s2213-8587(16)30009-2 (2016).
Hicken, M. T., Lee, H., Morenoff, J., House, J. S. & Williams, D. R. Racial/ethnic disparities in hypertension prevalence: Reconsidering the role of chronic stress. Am. J. Public Health 104, 117–123. https://doi.org/10.2105/ajph.2013.301395 (2014).
Lynch, J. W., Kaplan, G. A., Cohen, R. D., Tuomilehto, J. & Salonen, J. T. Do cardiovascular risk factors explain the relation between socioeconomic status, risk of all-cause mortality, cardiovascular mortality, and acute myocardial infarction?. Am. J. Epidemiol. 144, 934–942. https://doi.org/10.1093/oxfordjournals.aje.a008863 (1996).
Funding
This study was supported by the key research project of Jiangxi Education Department (No. GJJ2200105), the Key Research and Development Program of Jiangxi Provience (No. 20223BBG71010), and National Natural Science Foundation of China (No. 82260067).
Author information
Authors and Affiliations
Contributions
HY, ML, and ZZ wrote the main manuscript text. ZG, LH, YD, XL, YT, ZX, ZX, and YX prepared figures and tables in the text. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yi, H., Li, M., Dong, Y. et al. Nonlinear associations between the ratio of family income to poverty and all-cause mortality among adults in NHANES study. Sci Rep 14, 12018 (2024). https://doi.org/10.1038/s41598-024-63058-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-63058-z
- Springer Nature Limited