
Abstract
The accurate prediction of in-hospital mortality in Asian women after ST-Elevation Myocardial Infarction (STEMI) remains a crucial issue in medical research. Existing models frequently neglect this demographic's particular attributes, resulting in poor treatment outcomes. This study aims to improve the prediction of in-hospital mortality in multi-ethnic Asian women with STEMI by employing both base and ensemble machine learning (ML) models. We centred on the development of demographic-specific models using data from the Malaysian National Cardiovascular Disease Database spanning 2006 to 2016. Through a careful iterative feature selection approach that included feature importance and sequential backward elimination, significant variables such as systolic blood pressure, Killip class, fasting blood glucose, beta-blockers, angiotensin-converting enzyme inhibitors (ACE), and oral hypoglycemic medications were identified. The findings of our study revealed that ML models with selected features outperformed the conventional Thrombolysis in Myocardial Infarction (TIMI) Risk score, with area under the curve (AUC) ranging from 0.60 to 0.93 versus TIMI's AUC of 0.81. Remarkably, our best-performing ensemble ML model was surpassed by the base ML model, support vector machine (SVM) Linear with SVM selected features (AUC: 0.93, CI: 0.89–0.98 versus AUC: 0.91, CI: 0.87–0.96). Furthermore, the women-specific model outperformed a non-gender-specific STEMI model (AUC: 0.92, CI: 0.87–0.97). Our findings demonstrate the value of women-specific ML models over standard approaches, emphasizing the importance of continued testing and validation to improve clinical care for women with STEMI.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
Premenopausal women typically exhibit a lower risk of ST-elevation myocardial infarction (STEMI), but this risk escalates with age and the emergence of cardiovascular disease (CVD) risk factors, leading to more severe outcomes compared to men1,2,3. Studies indicate a higher in-hospital mortality rate for women with STEMI, as well as a higher prevalence of comorbidities such as hypertension, diabetes, and obesity. However, most randomized clinical trials have limited female representation, which raises concerns about the relevance of their findings4,5,6,7.
Risk scoring systems such as Thrombolysis in Myocardial Infarction (TIMI) and the Global Registry of Acute Coronary Events (GRACE) are vital for predicting STEMI mortality. However, they are largely based on the Western population from the 1990s and early 2000s, inadequately representing the diverse Asian population8,9,10. Furthermore, discrepancies in risk factors, such as differing smoking rates among Western and Asian females with acute myocardial infarction (AMI), and atypical AMI symptoms in women, limit their global applicability11. Additionally, their reliance on logistic regression (LR) presents limitations like rigid data assumptions. These issues underscore the need for new methods tailored to predict mortality in Asian female STEMI patients12,13,14.
Machine learning (ML), with its diverse statistical techniques and algorithms, presents a powerful alternative to traditional risk-scoring systems, enabling computers to learn from data and enhance decision-making and performance without explicit programming in healthcare 15,16,17,18. These include ML algorithms such as LR, support vector machine (SVM), k-nearest neighbours (KNN), decision tree (DT), random forest (RF), extreme gradient boosting (XGBoost), and adaptive boosting (AdaBoost)19,20,21,22. These algorithms have been especially beneficial for patient subgroups defined by specific characteristics such as age and comorbid diabetes, giving superior area under the curve (AUC) metrics than traditional methods9,23,24,25,26,27.
Despite ML's growing presence in cardiology, research focused on STEMI in Asian women remains limited. Studies have been reported on risk factors in multi-ethnic cohorts and age-related CVD patterns using ML algorithms; however, gender-specific ML-based models are scarce28,29. This gap highlights the urgent need for gender-specific ML models in cardiology tailored to Asian women with STEMI.
Ensemble ML, an advanced ML method, combines multiple models to improve predictive accuracy and adaptability, which is very useful in healthcare's complex environment16. Its application is evident in CVD studies, where studies using ensemble ML show better illness prediction accuracy and patient outcomes30,31,32. Ensemble ML is reported to outperform single ML algorithms, which is crucial in medical fields where precision impacts patient survival33. Feature selection techniques further optimize ML models in healthcare, essential for identifying mortality risk factors in high-risk STEMI patients34,35. However limited studies have been reported on ensemble ML and feature selection methods of women in STEMI.
Addressing the underrepresentation of Asian women in STEMI-related ML models, our study explores both base and ensemble ML models, employing six established algorithms like SVM, KNN, DT, RF, XGBoost, and AdaBoost as base learners. We also focus on identifying key factors associated with in-hospital mortality among multi-ethnic Asian women, a demographic often neglected in existing models, using ML feature selection methods. We aim to compare traditional risk scores with both base ML and advanced ensemble ML models, employing feature selection techniques rooted in RF and SVM algorithms. This also involves analysing our models against diverse registry data and evaluating a model specifically tailored for women against a more general model encompassing all STEMI patients. Ultimately, our goal is to improve prediction accuracy, fostering more personalized and effective clinical decision-making for Asian women with STEMI.
Materials and methods
Study design and setting
We conducted a retrospective cohort analysis using anonymised data from the National Cardiovascular Disease Database (NCVD-ACS) from 2006 to 2016. The NCVD, which is supported by the Ministry of Health Malaysia (MOH) and the National Heart Association of Malaysia (NHAM), collects detailed information on patients diagnosed with Acute Coronary Syndrome (ACS), which includes conditions like STEMI and non-ST segment elevation myocardial infarction (NSTEMI). It includes a wide range of patient information from 24 collaborating Malaysian hospitals, including demographics, treatments, and medications 36.
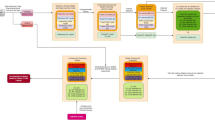
The study focused on female STEMI patients, to address a research gap in this demographic, particularly in Malaysia. The data gathered from a network of healthcare facilities in both urban and rural areas, represents an extensive and robust sample for research. The study proposes the application of advanced ML techniques to construct predictive models tailored to the unique epidemiological profiles of Asian women with STEMI, hence improving the personalization and effectiveness of their clinical care. The study's workflow and methods are shown in Fig. 1.

Research workflow and methodology applied in this study.
Participants
The cohort for this study was collected from the NCVD-ACS registry and spanned the years 2006 to 2016. Our primary analysis included primarily female STEMI patients’ complete data records for clinical outcome analysis. For our secondary analysis, we increased the scope by incorporating three distinct datasets to enhance the robustness and generalizability of our findings:
-
Women complete dataset: consisting of female patients with complete data, allowing a focused analysis on the intended demographic with no missing values in predictor variables.
-
Women imputed dataset: including a larger dataset with missing values addressed through multivariable imputation, increasing female patient records to represent a broader range of clinical circumstances.
-
General complete dataset: including complete data for both male and female STEMI patients, which provides a comparative perspective across genders and allows us to examine the model's performance in a broader context.
Data Source
Our study utilized anonymized patient data from the NCVD-ACS registry spanning from 2006 to 2016. Consecutive in-hospital STEMI cases comprised a total of 15,407 with 6299 complete cases identified (with no missing values on predictors). This study utilised 871 cases of female patients for primary analysis using complete cases from a total of 6299 datasets.
In 2007, the Medical Review & Ethics Committee (MREC) of the MOH of Malaysia approved the NCVD registry study (Approval Code: NMRR-07-20-250). The MREC waived patient informed consent for NCVD37,38. This study also has been authorized by the UiTM ethics committee (Reference number: 600-TNCPI (5/1/6)) and NHAM. The data used in this study were made anonymous before use, as in our research data are interested only in the values and features without having access to patient personal information.
The dataset used in this study includes each patient's information at the time of STEMI hospitalization. Based on the data available at the time, predictions for in-hospital mortality were developed, with the model being utilized once per patient. During the hospital stay, no more predictions were made, aligning the prediction frequency with the crucial decision-making period at the time of patient admission.
Variables and data preprocessing
Variables
STEMI was defined as persistent ST-segment elevation ≥ 1 mm in two contiguous electrocardiographic leads, or the presence of a new left bundle branch block in the setting of positive cardiac markers39. Input variables are features that are used as input in the development of a model to predict the outcome (in-hospital mortality). 48 variables (9 continuous, 39 categorical) from a complete set of data were used in this study (Supplementary Table 1). The categories of variables used were sociodemographic characteristics, CVD diagnosis and severity, CVD risk factors, CVD comorbidities, non-CVD comorbidities, clinical presentation, baseline investigation, electrocardiography (ECG), treatments, and pharmacological therapy. Variables used for model development are variables in the emergency department as first contact as well as variables in the hospital. Our study adopts the following method to address the dynamic nature of patient data during hospitalization:
-
Clinical history, examination, and investigation findings: based on information obtained at the time of admission, these provide a baseline understanding of each patient's initial status.
-
Treatment: we include the initial medical responses and interventions, as well as the primary treatment administered during hospitalization.
-
Medication: recognizing that medication regimens can change, our models consider the final pharmaceutical regimen recommended before discharge, capturing any substantial changes in treatment.
-
Outcome variable (in-hospital mortality): determined based on the patient's condition at the time of discharge, providing a specific endpoint for each case.
The mortality period begins on the day of hospital admission. For in-hospital mortality, the calculation period began with the first hospital admission. Through record links with the Malaysian National Registration Department, the death was confirmed. The registry does not collect information on short-term complications, such as heart failure. Planned follow-up data points were intended to collect this information, but we omitted them from this study due to the high rate of missing values. To increase the significance of this study, we centred our algorithm on policy-altering endpoints such as death. This was accomplished in similar publications9,40,41. The missing rates for each variable utilised in this study are presented in Supplementary Table 1.
Data splitting
We used the stratified random sampling to separate the dataset for model development (70%) and validation (30%) based on Kuhn and Johnson study42 to avoid data leakage43. In circumstances of multiple admissions, a unique patient identification ensured that each patient's data was consistently labelled as the training or testing set, preserving anonymity44.
Data pre-processing methods such as imputation (on missing cases) and balancing (both complete and missing cases) were performed on training data only. Meanwhile, normalization methods were done separately on both training and testing data. We accessed the performance of the developed model and TIMI using a validation set that accounts for 30% of data that is not used for model development.
Data balancing
Our dataset had a significant class imbalance, with non-survival cases (n = 73) accounting for approximately 8.38% of the total dataset (n = 871) and survival cases (n = 798) accounting for 91.62%. To mitigate the imbalance issue and improve the robustness of our model, we used the ROSE package to combine up-sampling and down-sampling techniques on the training data45. The class distribution was adjusted to better reflect a balanced scenario, improving the reliability of subsequent analyses and the predictive performance of the developed models. To preserve the integrity and representativeness of real-world clinical scenarios, this treatment was not applied to the validation dataset.
Data imputation
Since our dataset is prospective, the proportion of missing values across all variables was arbitrary and out of our hands. The definition of an incomplete dataset is up to 30% of variables missing. The probability of missing data in our dataset is independent of both observed values and unseen data components. Our dataset is classified as missing completely at random, indicating that the distribution of missing values is random and independent of any variable that may or may not be included in the analysis. We performed multivariable imputation using chained equations and predicted mean matching from the MICE R package to deal with missing cases for the secondary analysis 46. This method imputes missing values using actual values from other cases in which predicted values are the closest.
Data normalization
Data normalization was used to reduce the bias of features that contribute more numerically to pattern class discrimination42. We employed standardization or z-score normalization, for continuous variables (age, heart rate, systolic and diastolic blood pressure, total cholesterol, high-density lipoproteins (HDL), low-density lipoproteins (LDL), triglyceride, fasting blood glucose) in this study.
Data analysis
Primary analysis
A total of 6299 in-hospital STEMI complete cases were identified (with no missing values on predictors). 871 cases of woman patients were extracted from the data and used as the final dataset for primary analysis. This rendered a full predictor set of 48 variables (9 continuous, 39 categorical) for the study as shown in Table 1.
Secondary analysis
Secondary analyses on the best-performing algorithm were carried out;
(i) For the 15,407 STEMI cases with missing data, we employed multivariable imputation using chained equations to estimate missing values, creating a comprehensive dataset for modelling. This allowed us to include a total of 2197 additional female patients in our analysis, broadening the scope and applicability of our results.
(ii) A total of 4369 patients out of 6299 in-hospital STEMI patients with complete cases, including both male and female patients, were used to train the algorithm with the best performance. Both a women-specific model and a population-specific model were tested and compared using identical testing datasets (262 cases) from the primary analysis of all cases.
Additional statistics
This study presents the mean and standard deviation (SD) of continuous variables as well as the frequencies of categorical variables. Correlation analysis revealed variable associations. Univariate analysis used a Chi-Square test to find significant variables and a two-sided independent student t-test (p < 0.05) to compare them. Pair-wise corrected resampled t-tests were used to compare the base and ensemble ML model performance 49,67. A p-value less than 0.001 indicated statistical significance.
Feature selection
RF and SVM algorithms have produced better results than other base learners in this study. Hence, ranked features from RF and SVM algorithms were used for feature selection. The sequential backward elimination (SBE) algorithm removes irrelevant features in ascending order using model significance value47. Iteratively, SBE was applied to RF and SVM-ranked variables in ascending order48. The prediction models were trained and evaluated for each iteration using the 30% validation dataset that was not used for model development. The models' predictive performance was calculated, and the models with the highest performance and fewest variables were chosen. Then, the base and ensemble ML models were constructed using the selected features from RF and SVM.
Model development
Base ML algorithms
ML algorithms such as SVM52, KNN53, DT54, RF54, XGBoost55, and AdaBoost56 were used to develop prediction models for women with STEMI in R (Version 4.1.2).
SVM is a robust learning algorithm that was used in this study in conjunction with both a linear and a radial basis function (RBF) kernel. KNN is a simple supervised machine learning algorithm that has seen widespread use in the healthcare industry for classification and regression problems (Bansal et al., 2018). DT is a non-parametric supervised learning technique used for classification and regression. To generate multiple small decision trees, RF employs bagging with DT as the primary classifier. The models use the class with the most votes predicted by RF trees. XGB is an implementation of gradient boosting. Gradient Boosting with XGB is more regularised, which improves model generalisation and prevents overfitting, resulting in a more precise result. AdaBoost is an adaptive learning algorithm because it transforms weak learners into strong learners through multiple iterations. These algorithms were chosen based on previous CVD mortality-related research22,24,27,28,57,58. All the hyper-parameters utilised in the development of base and ensemble ML models were tuned using a combination of random search and manual tuning (refer to Supplementary Table 2).
Ensemble ML algorithms
Stacking, a type of ensemble ML algorithm, is a meta-learning strategy that uses the predictions of multiple base learners as input for training a new meta-learner, which makes the final prediction. It is more effective than any individual algorithm in classification and regression problems. In this study, six commonly used ML algorithms, including SVM, KNN, DT, RF, XGBoost, and AdaBoost, are used as base learners, followed by three commonly used meta learners, including RF, generalised logistic model (GLM), and generalized boosted models (GBM)59,60,61. 10-fold cross-validation was used to avoid overfitting for model development on the training set49.
Model evaluation
Model calibration was evaluated using standardized measures on untouched raw validation dataset62. The primary evaluation metric, the AUC, was chosen based on research establishing its effectiveness in a wide range of class distributions, including imbalanced datasets 63,64. While AUC-PR provides more granularity for minority class predictive performance, AUC is still a widely accepted measure for overall diagnostic accuracy. Additional metrics included accuracy, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV), which provide a comprehensive view of model performance across both classes. To compare the predictive performance of ML models, a paired resampled t-test was used65. In addition, the net reclassification index (NRI) was calculated to determine the percentage improvement in identifying both positive and negative cases with the best model compared to the TIMI risk score66.
Results interpretation
Due to their black-box nature, it is difficult to implement ML models in clinical medicine. Since ML models are agnostic, perturbing input and observing predictions can reveal the behaviour of the underlying model50. Modifying components that are understandable by humans enables us to interpret the input. Thus, we interpret the best ML model in this study using local interpretable model-agnostic explanations (LIME)51. LIME employs a simple linear model to approximate a black-box model locally, as opposed to globally.
Comparative analysis
The computed TIMI scores obtained from the NCVD registry were utilized for validating the performance of the data. Using the 30% validation set data, the TIMI score was compared to the developed base and ensemble ML models using AUC. A performance breakdown graph was also created to evaluate the performance of the TIMI score based on clinical practice and literature cut-off points.
Validation of data was NCVD registry calculated TIMI scores were used for validation data performance. Using a validation set that was not used for model development, the AUC of TIMI score performance was compared to the developed base and ensemble ML models. A graph was also created to compare performance with the TIMI score based on clinical practice and literature cut-off points. The ML high-risk population for this study is defined by a mortality probability of greater than 50%, which is equivalent to a TIMI score of greater than 5.
Ethical declaration
This study was authorized by the UiTM Research Ethics Committee (Reference: 600-TNCPI (5/1/6)), with the approval code REC/673/19. The UiTM Ethics Committee conducts following the ICH Good Clinical Practice Guidelines, Malaysia Good Clinical Practice Guidelines and Declaration of Helsinki.
Results
Patient characteristics
The characteristics of patients utilised in this study are detailed in Table 1. In the complete cases dataset, the mean age of in-hospital female STEMI survivors is 61.8 (SD 11.5) years, while the mean age of non-survivors is 67 (SD 9.8) years. Nearly 90% of the patients were non-smokers. 73% of the patients have a hypertension history, and 57% have diabetes. 32% of patients received percutaneous coronary intervention (PCI) treatment. The reported overall hospital mortality rate for women was 8.4%.
Table 1 also displays the summary statistics for the imputed dataset. The overall mortality rate for women was 12.8 %. There were significant differences in systolic blood pressure, Killip class, fasting blood glucose, beta-blocker, ACE inhibitor, and oral hypoglycemic agent between survivors and non-survivors in both complete cases and imputed datasets (p < 0.001 for all).
Feature selection
SBE feature selection methods were combined with ML algorithms SVM and RF to construct predictive models with optimal performance (refer to methods). The comparison between features selected by ML feature selection with TIMI risk score is illustrated in Table 2. Killip class, fasting blood glucose, age and systolic blood pressure, beta blocker and percutaneous coronary intervention were observed as common predictors in both ML feature selection models in this study. The best SVM Linear model was built using twelve features selected using SVM algorithm feature selection methods. Age, Killip class, and systolic blood pressure are common characteristics shared by the TIMI risk score for STEMI and the best model. The ranking of the selected features by variable importance is presented in Supplementary Table 3.
Algorithm performance on complete cases
On the 30% validation dataset, the models constructed using complete sets (48 variables) and a reduced set of variables compared to the TIMI risk score demonstrated the highest predictive performance (Table 3). Except for base DT and ensemble GBM, most ML models outperformed TIMI risk scores for the prediction of STEMI in women. The model with the best performance was base SVM (SVM selected var; p < 0.001). Table 4 provides a detailed performance evaluation of ML models relative to the TIMI risk score.
The predictive performance of ML models constructed with SVM-selected features (AUC ranging from 0.70 to 0.93) was better compared to that of models constructed with RF-selected features (AUC ranging from 0.60 to 0.90). There was a significant difference between the base SVM-Linear (SVM selected var) algorithm and the base SVM-Linear (RF selected var) algorithm (p < 0.001). Models constructed with the ensemble RF model (AUC: 0.91, CI: 0.87–0.96) perform the best among ensemble ML models (Table 2). However, the base SVM with the linear kernel (SVM selected var) algorithm demonstrated the highest predictive performance with a reduced number of predictors (12 predictors) for in-hospital prediction of STEMI patients (AUC = 0.93, 95% CI = 0.89 to 0.97) compared to other base and ensemble ML models.
Secondary analysis on best performing model
The best performing ML models, base SVM (SVM selected var), were also trained on an imputed dataset and a general dataset (data with complete cases that are not gender-specific). Then, both types of models were evaluated utilizing the complete cases validation dataset. This enables a valid comparison between models constructed with imputed, general, and complete cases models (Table 5).
SVM (SVM selected var), trained on imputed datasets performed comparably to models trained on the complete dataset using a similar validation dataset of complete cases: SVM (SVM selected var) (AUC = 0.89, CI: 0.81–0.96 vs AUC = 0.93, CI: 0.89–0.98) (p = 0.540). There is no statistically significant difference between the SVM model (SVM selected var) using complete cases with the imputed model.
Using the complete cases validation dataset, the model trained with women's complete cases performed better compared to the models trained with complete cases data that are not gender specific: SVM (SVM selected var) (AUC = 0.93, CI: 0.89–0.98 vs AUC = 0.92, CI: 0.87–0.97) (p < 0.001).
Model interpretation
LIME provides explanations for any individual patient, and the contribution of a given variable may change depending on other features of the patient. The contributions of the variables used for prediction by LIME analysis are illustrated for dead (Fig. 2) and alive (Fig. 3) cases respectively using the best performing model, base SVM Linear (SVM selected var) model.

LIME model plots explaining individual predictions for dead cases.

LIME model plots explaining individual predictions for alive cases.
Each graph illustrates the ten variables that best characterise the prediction in the local region. The blue bars represent variables that increase the predicted probability (supports), while the red bars represent variables that decrease the predicted probability (reduces) (contradicts). For instance, for the dead cases, a high Killip class > 3 and no PCI intervention with high systolic blood pressure (patient #1) or an older age > 74 years old (patient #68) are variables that strongly indicate non-survival. In the meantime, did not receive PCI intervention with high fasting blood sugar > 14.3 (patient #2) and older age > 74 with higher blood pressure (patient #3) were also strong indicators of non-survival. Pharmacological interventions are noted as variables that contradict and lower the predicted probability of non-survival in (patients #3 and #2). For patients who are alive (Fig. 3), a younger age of 58 years, the absence of chronic renal disease, a lower Killip class < 2, and a lower fasting blood glucose < 6.7 are all supportive of the survival outcome.
Comparison with TIMI conventional risk score
Using a similar validation set, TIMI achieved a lower AUC of 0.81 (0.72–0.89) compared to most of the ML models except for the base DT and ensemble GBM model. Figures 4 and 5 illustrate the graph plotted from the TIMI risk score and the best-performing model, base SVM Linear (SVM selected var) in predicting the mortality risk of the women STEMI patients respectively. For the women patients, the ML score categorized patients as low risk with the probability of < 50% and high-risk stratum as ≥ 50%. This is equivalent to a TIMI low-risk of score ≤ 5 and a high-risk score of > 568.

Mortality rate distribution on the validation set of TIMI risk scores.

Mortality rate distribution on the validation set of base SVM (using SVM variables) model.
Table 6 tabulates the percentage of mortality in the patients with predicted low risk (TIMI score: ≤ 5; ML probabilities < 0.5) and high risk (TIMI score: > 5; ML probabilities: ≥ 0.5). In the high-risk group, ML models predicted mortality better in comparison to TIMI for in-hospital death in women STEMI patients.
NRI analysis
NRI for the in-hospital model, the net reclassification of women STEMI patients using the base SVM (SVM selected var) produced a net reclassification improvement of 18.8% with p < 0.00001 over the original TIMI risk score.
Number of individuals | Reclassification | Net correctly reclassified (%) | ||||
|---|---|---|---|---|---|---|
Machine learning | Increased risk | Decreased risk | ||||
Low risk | High risk | |||||
TIMI score | ||||||
Individuals with events (died) (n = 22) | ||||||
Low risk | 0 | 5 | 5 | 1 | 18 | |
High risk | 1 | 16 | ||||
Individuals without events (alive) (n = 240) | ||||||
Low risk | 143 | 35 | 35 | 37 | 0.83 | |
High risk | 37 | 25 | ||||
Net reclassification index (NRI) | 18 + 0.83 = 18.83 | |||||
Z, p-value | Z= \(\frac{18.83}{\sqrt{\frac{5+1 }{{22}^{2}}+\frac{35+37}{{240}^{2}}}}\) = 161.19 225.13, p < 0.00001 | |||||
Conclusion | It was statistically significant. ML model has a better predictive ability compared with the TIMI risk scores model in predicting the mortality rate of Asian women with STEMI patients, and the proportion of correct classification increased by 18.8% | |||||
Discussion
This study developed and evaluated ML models to predict in-hospital mortality in Asian women with STEMI, comparing them with traditional risk scores like TIMI. Notably, it is the first study to apply ensemble ML models in this context, achieving higher accuracy than conventional risk scores. Key findings include: the crucial role of feature selection in enhancing model performance; identifying consistent predictors like systolic blood pressure, Killip class, fasting blood glucose, beta-blockers, ACE inhibitors, and oral hypoglycaemics medications; improved performance of ML models using selected features, the SVM linear model with SVM selected features showing the highest accuracy outperforming ensemble ML; most ML models, except DT and GBM, outperform TIMI score; and the use of LIME for model interpretability. These results underscore the value of advanced ML in specific clinical settings, enhancing predictive accuracy and decision-making in treating STEMI in Asian women.
Feature selection enhances ML model performance in our study, aligning with findings from Perez et al.69. Applications of feature selection algorithms increase ML model performance 70,71,72,73,74,75, as seen in this study with the RF (11 predictors) and SVM (12 predictors) models. However, this approach contrasts with other mortality post-STEMI studies where models using larger sets of predictors showed optimal performance 35,76. ML with significant predictors improves risk stratification in Asian STEMI women, providing clinicians with a prognostic tool for better emergency care management.
This study's findings also reveal that ensemble ML methods show promise in predicting in-hospital mortality for Asian female patients, though their performance did not consistently exceed that of base ML algorithms. Particularly, base learners like SVM (AUC: 0.93) and RF (AUC: 0.90) performed on par with ensemble ML models. In medical contexts, even small increases in predictive model performance are crucial77. However, it is notable that the ensemble ML method does not always outperform the base model78. This has been demonstrated in this study that the improvement of the ensemble ML model was not significantly greater than the best-performing base learners SVM, as demonstrated in the literature27,50.
The best-performed model, base SVM Linear managed to identify high-risk patients that reported higher mortality than those classified as high-risk in TIMI. Despite its widespread use in Asia, the TIMI risk score, originally developed from a predominantly Western Caucasian cohort, had limited Asian representation, and only included 25% female participants, indicating an underrepresentation of women. In our study, ML models validated against TIMI showed an AUC value of 0.81 in a non-restricted PCI eligible population, higher than the 0.78 AUC for the fibrinolytic eligible STEMI population reported in the original TIMI study79. The SVM algorithm's robustness in managing high-dimensional and constrained datasets renders it ideal for predicting in-hospital mortality, and its proficiency in modelling non-linear decision boundaries is beneficial for assessing severe AMI prognosis80,81.
NRI was further used for a detailed assessment of model enhancements compared to the TIMI score. The NRI, though less commonly reported in medical research, effectively measures how accurately a new model reclassifies individuals into appropriate risk categories82. In our study we achieved a significant 18.8% improvement in classification accuracy over the TIMI score, indicating that our ML models not only predict more precisely but also better reflect actual patient outcomes. Accuracy tests for NRI were conducted on a separate dataset from that used for model development, providing an unbiased comparison with TIMI and reinforcing the validity of our results.
Our ML models, using feature selection, identified age, Killip class, and systolic blood pressure as key predictors, aligning with univariate analysis and LIME. LIME analysis indicated that factors like older age, increased fasting blood glucose, and absence of percutaneous coronary intervention (PCI) were associated with higher mortality risk, consistent with existing research. However, LIME's identification of influential features should be seen as preliminary and not indicative of causality, necessitating further validation through prospective or randomized controlled trials83,84.
Older female STEMI patients have a higher incidence of coronary artery disease than males2, with Killip class being a key predictor of STEMI patients6,85,86. This finding is consistent with our study and previous ML-based mortality studies40. Women with STEMI face higher mortality due to factors like atypical symptoms, delayed treatment, and less frequent use of cardiac catheterization. Our study found only 34% of Asian STEMI patients received PCI, highlighting a need for improved care. Heart rate is a crucial factor in in-hospital mortality87, and the use of beta-blockers post-STEMI is linked to better outcomes5,7,86,88.
Several limitations exist in this study. Firstly, we could only validate ML models using only the TIMI score. Parameters to calculate the GRACE score were not acquired during patient admission compared to the TIMI score. The TIMI score is adopted during admission due to its simplicity and its development for short-term risk stratification, along with findings that its performance is similar to the GRACE score for predicting in-hospital mortality. Hence collecting information for two risk scores is redundant89.
Future research will aim to utilize high-performance computing and larger datasets for better predictive performance of ensemble techniques. ML models, reliant on data representativeness rather than medical expertise, may exhibit biases and require ongoing validation with real-world data, which can be facilitated by electronic health record systems in hospitals. Integrating these models into hospital systems for physician use and validating them in clinical registries rather than administrative databases, will be key areas of future investigation.
Conclusion
This work demonstrates the effectiveness of both base and ensemble ML models, when combined with feature selection, in predicting in-hospital mortality in Asian women with STEMI. Our findings highlight the potential for combining these advanced ML models with conventional risk-scoring approaches like TIMI to improve mortality risk assessments in this specific group. This opens up the possibility of more nuanced and effective therapeutic decision-making. The improved predictive accuracy achieved by these models not only allows for better patient communication and awareness but also allows healthcare practitioners to optimize their management methods and resource allocation more effectively. In the future, incorporating these ML technologies into clinical practice could greatly enhance care for female STEMI patients. Furthermore, our findings pave the way for future research to test and potentially integrate these models into clinical processes, ultimately leading to more tailored and improved healthcare outcomes for women with STEMI.
Data availability
Data which support the findings of this research are accessible from the National Heart Association of Malaysia (NHAM), but the availability of these data is restricted, therefore they are not publicly available. It belongs to the individual ministry of health universities hospitals and private hospitals that require multiple institutional agreements for data release to third parties therefore ethical approval is required for analysis. Data are however available from NHAM upon request using https://www.malaysianheart.org/?p=contact or email them at secretariat@malaysianheart.org. Any findings from the data need to be reported and permission needs to be obtained from the NHAM committee before publication.
References
Idris, N. et al. Acute coronary syndrome in women of reproductive age. Int. J. Women’s Health 3, 375–380 (2011).
Juhan, N. et al. Gender differences in mortality among ST elevation myocardial infarction patients in Malaysia from 2006 to 2013. Ann. Saudi Med. 38(1), 1–7 (2018).
Venkatason, P. et al. Characteristics and short-term outcomes of young women with acute myocardial infarction in Malaysia: A retrospective analysis from the Malaysian National Cardiovascular Database registry. BMJ Open 9(11), e030159 (2019).
Lawesson, S. S. et al. A gender perspective on short-and long term mortality in ST-elevation myocardial infarction–A report from the SWEDEHEART register. Int. J. Cardiol. 168(2), 1041–1047 (2013).
Shehab, A. et al. Clinical presentation, quality of care, risk factors and outcomes in women with acute ST-elevation myocardial infarction (STEMI): An observational report from six middle Eastern countries. Curr. Vasc. Pharmacol. 17(4), 388–395 (2019).
van der Meer, M. G. et al. Worse outcome in women with STEMI: A systematic review of prognostic studies. Eur. J. Clin. Invest. 45(2), 226–235 (2015).
Zachura, M. et al. Gender-related differences in men and women with ST-segment elevation myocardial infarction and incomplete infarct-related artery flow restoration: A multicenter national registry. Adv. Intervent. Cardiol./Postępy Kardiol. Interwencyjnej 14(4), 356–362 (2018).
Eagle, K. A. et al. A validated prediction model for all forms of acute coronary syndrome: Estimating the risk of 6-month postdischarge death in an international registry. Jama 291(22), 2727–2733 (2004).
Kwon, J.-M. et al. Deep-learning-based risk stratification for mortality of patients with acute myocardial infarction. PloS one 14(10), e0224502 (2019).
Morrow, D. A. et al. TIMI risk score for ST-elevation myocardial infarction: A convenient, bedside, clinical score for risk assessment at presentation: An intravenous nPA for treatment of infarcting myocardium early II trial substudy. Circulation 102(17), 2031–2037 (2000).
Shaw, L. J., Bugiardini, R. & Merz, C. N. B. Women and ischemic heart disease: Evolving knowledge. J. Am. Coll. Cardiol. 54(17), 1561–1575 (2009).
Bagley, S. C., White, H. & Golomb, B. A. Logistic regression in the medical literature: Standards for use and reporting, with particular attention to one medical domain. J. Clin. Epidemiol. 54(10), 979–985 (2001).
Hand, D. J. Data mining: Statistics and more?. Am. Stat. 52(2), 112–118 (1998).
Sun, G.-W., Shook, T. L. & Kay, G. L. Inappropriate use of bivariable analysis to screen risk factors for use in multivariable analysis. J. Clin. Epidemiol. 49(8), 907–916 (1996).
Grote, T. & Keeling, G. Enabling fairness in healthcare through machine learning. Ethics Inf. Technol. 24(3), 39 (2022).
Brownlee, J. Ensemble Learning Algorithms with Python: Make Better Predictions with Bagging, Boosting, and Stacking. (Machine Learning Mastery, 2021).
Sarker, I. H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2(3), 160 (2021).
Davenport, T. & Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 6(2), 94 (2019).
Chang, W. et al. A machine-learning-based prediction method for hypertension outcomes based on medical data. Diagnostics 9(4), 178 (2019).
Davagdorj, K. et al. A comparative analysis of machine learning methods for class imbalance in a smoking cessation intervention. Appl. Sci. 10(9), 3307 (2020).
Saqlain, M., Jargalsaikhan, B. & Lee, J. Y. A voting ensemble classifier for wafer map defect patterns identification in semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 32(2), 171–182 (2019).
Sherazi, S. W. A. et al. A machine learning-based 1-year mortality prediction model after hospital discharge for clinical patients with acute coronary syndrome. Health Inform. J. 26(2), 1289–1304 (2020).
Jargalsaikhan, B. et al. The early prediction acute myocardial infarction in real-time data using an ensemble machine learning model. In Advances in Intelligent Information Hiding and Multimedia Signal Processing 259–264 (Springer, 2020).
Kasim, S. et al. In-hospital risk stratification algorithm of Asian elderly patients. Sci. Rep. 12(1), 17592 (2022).
Li, X. et al. Using machine learning models to predict in-hospital mortality for ST-elevation myocardial infarction patients. In MEDINFO 2017: Precision Healthcare through Informatics 476–480 (IOS Press, 2017).
Patel, B. & Sengupta, P. Machine learning for predicting cardiac events: What does the future hold?. Exp. Rev. Cardiovasc. Ther. 18(2), 77–84 (2020).
Zheng, H., Sherazi, S. W. A. & Lee, J. Y. A stacking ensemble prediction model for the occurrences of major adverse cardiovascular events in patients with acute coronary syndrome on imbalanced data. IEEE Access 9, 113692–113704 (2021).
Aziz, F. et al. Short-and long-term mortality prediction after an acute ST-elevation myocardial infarction (STEMI) in Asians: A machine learning approach. PloS one 16(8), e0254894 (2021).
Yang, L. et al. Study of cardiovascular disease prediction model based on random forest in eastern China. Sci. Rep. 10(1), 5245 (2020).
Alqahtani, A. et al. Cardiovascular disease detection using ensemble learning. Comput. Intell. Neurosci. 2022, 5267498 (2022).
Almulihi, A. et al. Ensemble learning based on hybrid deep learning model for heart disease early prediction. Diagnostics 12(12), 3215 (2022).
Mahajan, P. et al. Ensemble learning for disease prediction: A review. Healthcare 11(12), 1808 (2023).
Sherazi, S. W. A., Bae, J.-W. & Lee, J. Y. A soft voting ensemble classifier for early prediction and diagnosis of occurrences of major adverse cardiovascular events for STEMI and NSTEMI during 2-year follow-up in patients with acute coronary syndrome. PloS one 16(6), e0249338 (2021).
Chen, X. & Ishwaran, H. Random forests for genomic data analysis. Genomics 99(6), 323–329 (2012).
Wallert, J. et al. Predicting two-year survival versus non-survival after first myocardial infarction using machine learning and Swedish national register data. BMC Med. Inform. Decis. Mak. 17(1), 1–11 (2017).
Ahmad, W. A. et al. The journey of Malaysian NCVD-PCI (National Cardiovascular Disease Database-Percutaneous Coronary Intervention) Registry: A summary of three years report. Int. J. Cardiol. 165(1), 161–164 (2013).
Ahmad, W. A. W. et al. The journey of Malaysian NCVD–PCI (National Cardiovascular Disease Database–Percutaneous Coronary Intervention) Registry: A summary of three years report. Int. J. Cardiol. 165(1), 161–164 (2013).
Ahmad, W. A. W. et al. Malaysian national cardiovascular disease database (NCVD)–acute coronary syndrome (ACS) registry: How are we different?. CVD Prevention and Control 6(3), 81–89 (2011).
Venkatason, P. et al. Trends in evidence-based treatment and mortality for ST elevation myocardial infarction in Malaysia from 2006 to 2013: time for real change. Ann. Saudi Med. 36(3), 184–189 (2016).
Shouval, R. et al. Machine learning for prediction of 30-day mortality after ST elevation myocardial infraction: An Acute Coronary Syndrome Israeli Survey data mining study. Int. J. Cardiol. 246, 7–13 (2017).
Yang, J. et al. Machine learning models to predict in-hospital mortality for ST-elevation myocardial infarction: From china acute myocardial infarction (cami) registry. J. Am. Coll. Cardiol. 71(11S), A236–A236 (2018).
Kuhn, M. & Johnson, K. Applied Predictive Modeling. Vol. 26. (Springer, 2013).
Kapoor, S. & Narayanan, A. Leakage and the Reproducibility Crisis in ML-Based Science. arXiv preprint arXiv:2207.07048 (2022).
Draelos, R. Best Use of Train/Val/Test Splits, with Tips for Medical Data. (Glass Box: Artificial Intelligence+ Medicine, 2019).
Lunardon, N., Menardi, G. & Torelli, N. ROSE: A Package for Binary Imbalanced Learning. R J. 6(1), 33 (2014).
Van Buuren, S. & Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 45, 1–67 (2011).
Dunkler, D. et al. Augmented backward elimination: A pragmatic and purposeful way to develop statistical models. PloS one 9(11), e113677 (2014).
Genuer, R., Poggi, J.-M. & Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 31(14), 2225–2236 (2010).
Schaffer, C. Selecting a classification method by cross-validation. Mach. Learn. 13(1), 135–143 (1993).
Zhang, Z. et al. Predictive analytics with ensemble modeling in laparoscopic surgery: A technical note. Laparosc. Endosc. Robot. Surg. 5(1), 25–34 (2022).
Ribeiro, M.T., Singh, S. & Guestrin, C. "Why should i trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016).
Vapnik, V., Guyon, I. & Hastie, T. Support vector machines. Mach. Learn. 20(3), 273–297 (1995).
Cover, T. & Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 13(1), 21–27 (1967).
Breiman, L. et al. Classification and Regression Trees. (Routledge, 2017).
Chen, T. & Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016).
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55(1), 119–139 (1997).
Aziida, N. et al. Predicting 30-day mortality after an acute coronary syndrome (ACS) using machine learning methods for feature selection, classification and visualisation. Sains Malays. 50(3), 753–768 (2021).
Cho, S.-Y. et al. Pre-existing and machine learning-based models for cardiovascular risk prediction. Sci. Rep. 11(1), 8886 (2021).
Nath, A. & Sahu, G. K. Exploiting ensemble learning to improve prediction of phospholipidosis inducing potential. J. Theor. Biol. 479, 37–47 (2019).
Tama, B. A., Im, S. & Lee, S. Improving an intelligent detection system for coronary heart disease using a two-tier classifier ensemble. BioMed. Res. Int. 2020, 9816142 (2020).
Zaman, S.M.M. et al. Survival Prediction of Heart Failure Patients using Stacked Ensemble Machine Learning Algorithm. In 2021 IEEE International Women in Engineering (WIE) Conference on Electrical and Computer Engineering (WIECON-ECE) (2021).
Steyerberg, E. W. et al. Assessing the performance of prediction models: A framework for some traditional and novel measures. Epidemiology (Cambridge, Mass.) 21(1), 128 (2010).
Yang, T. & Ying, Y. AUC maximization in the era of big data and AI: A survey. ACM Comput. Surv. 55(8), 1–37 (2022).
Halimu, C., Kasem, A. & Newaz, S.H.S. Empirical comparison of area under ROC curve (AUC) and mathew correlation coefficient (MCC) for evaluating machine learning algorithms on imbalanced datasets for binary classification. In Proceedings of the 3rd International Conference on Machine Learning and Soft Computing. 1–6. (Association for Computing Machinery, 2019).
Kuhn, M. et al. Classification trees and rule-based models. Appl. Predict. Model. 4, 369–413 (2013).
Benjamin, E. J. et al. Heart disease and stroke statistics–2017 update: A report from the American Heart Association. Circulation 135(10), 146–603 (2017).
Breiman, L. Random forests. Mach. Learn. 45(1), 5–32 (2001).
Correia, L. C. et al. Prognostic value of TIMI score versus GRACE score in ST-segment elevation myocardial infarction. Arq. Bras. Cardiol. 103, 98–106 (2014).
Perez-Riverol, Y. et al. Accurate and fast feature selection workflow for high-dimensional omics data. PloS one 12(12), e0189875 (2017).
Dioşan, L., Rogozan, A. & Pecuchet, J.-P. Improving classification performance of support vector machine by genetically optimising kernel shape and hyper-parameters. Appl. Intell. 36(2), 280–294 (2012).
Vomlel, J. et al. Machine learning methods for mortality prediction in patients with st elevation myocardial infarction. Proc. WUPES 2012, 204–213 (2012).
Syarif, I., Prugel-Bennett, A. & Wills, G. SVM parameter optimization using grid search and genetic algorithm to improve classification performance. TELKOMNIKA (Telecommun. Comput. Electron. Control) 14(4), 1502–1509 (2016).
Cho, M.-Y. & Hoang, T.T. Feature selection and parameters optimization of SVM using particle swarm optimization for fault classification in power distribution systems. Comput. Intell. Neurosci. (2017).
Manurung, J., Mawengkang, H. & Zamzami, E. Optimizing support vector machine parameters with genetic algorithm for credit risk assessment. J. Phys. Conf. Ser. (IOP Publishing, 2017).
Mohammed, L.B. & Raahemifar, K. Improving support vector machine classification accuracy based on kernel parameters optimization. In Proceedings of the Communications and Networking Symposium (2018).
Motwani, M. et al. Machine learning for prediction of all-cause mortality in patients with suspected coronary artery disease: A 5-year multicentre prospective registry analysis. Eur. Heart J. 38(7), 500–507 (2017).
H2O Tutorials. https://github.com/h2oai/h2o-tutorials/blob/master/tutorials/ensembles-stacking/README.md. Accessed 6 May 2020 (2020).
Alahmar, A., Mohammed, E. & Benlamri, R.. Application of data mining techniques to predict the length of stay of hospitalized patients with diabetes. In 2018 4th International Conference on Big Data Innovations and Applications (Innovate-Data). (IEEE, 2018).
Selvarajah, S. et al. An Asian validation of the TIMI risk score for ST-segment elevation myocardial infarction. PLoS One 7(7), e40249 (2012).
Uddin, S. et al. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 19(1), 281 (2019).
Zhou, X. et al. Support vector machine deep mining of electronic medical records to predict the prognosis of severe acute myocardial infarction. Front. Physiol. 13, 991990 (2022).
Kerr, K. F. et al. Net reclassification indices for evaluating risk prediction instruments: A critical review. Epidemiology 25(1), 114–121 (2014).
Cynthia, R. et al. Interpretable machine learning: Fundamental principles and 10 grand challenges. Stat. Surv. 16, 1–85 (2022).
Xu, G. et al. Causality Learning: A New Perspective for Interpretable Machine Learning. arXiv: abs/2006.16789 (2020).
Gevaert, S. A. et al. Gender, TIMI risk score and in-hospital mortality in STEMI patients undergoing primary PCI: Results from the Belgian STEMI registry. EuroIntervention 9(9), 1095–1101 (2014).
Wei, J. et al. Sex-based differences in quality of care and outcomes in a health system using a standardized STEMI protocol. Am. Heart J. 191, 30–36 (2017).
Davidovic, G., Iric-Cupic, V. & Milanov, S. Associated influence of hypertension and heart rate greater than 80 beats per minute on mortality rate in patients with anterior wall STEMI. Int. J. Clin. Exp. Med. 6(5), 358 (2013).
Mehta, L. S. et al. Acute myocardial infarction in women: A scientific statement from the American Heart Association. Circulation 133(9), 916–947 (2016).
Aragam, K. G. et al. Does simplicity compromise accuracy in ACS risk prediction? A retrospective analysis of the TIMI and GRACE risk scores. PloS one 4(11), e7947 (2009).
Funding
This work was supported by Kementerian Sains, Teknologi dan Inovasi, Malaysia (Grant No: TDF03211036). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
S.M., S.K., and P.N.F.A.R contributed equally to formal analysis, resources, supervision, review, and editing. W.A.W.A. assisted in data curation, resources, review & editing. As for K.S. assisted in investigation, validation, and writing editing. A.F. supported in data curation, formal analysis, validation, and feedback on data related to cardiology. L.W.Y. and F.A. worked on data validation. N.I. worked on writing and editing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kasim, S., Amir Rudin, P.N.F., Malek, S. et al. Ensemble machine learning for predicting in-hospital mortality in Asian women with ST-elevation myocardial infarction (STEMI). Sci Rep 14, 12378 (2024). https://doi.org/10.1038/s41598-024-61151-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-61151-x
- Springer Nature Limited