
Abstract
Limited research has been conducted in Asian elderly patients (aged 65 years and above) for in-hospital mortality prediction after an ST-segment elevation myocardial infarction (STEMI) using Deep Learning (DL) and Machine Learning (ML). We used DL and ML to predict in-hospital mortality in Asian elderly STEMI patients and compared it to a conventional risk score for myocardial infraction outcomes. Malaysia's National Cardiovascular Disease Registry comprises an ethnically diverse Asian elderly population (3991 patients). 50 variables helped in establishing the in-hospital death prediction model. The TIMI score was used to predict mortality using DL and feature selection methods from ML algorithms. The main performance metric was the area under the receiver operating characteristic curve (AUC). The DL and ML model constructed using ML feature selection outperforms the conventional risk scoring score, TIMI (AUC 0.75). DL built from ML features (AUC ranging from 0.93 to 0.95) outscored DL built from all features (AUC 0.93). The TIMI score underestimates mortality in the elderly. TIMI predicts 18.4% higher mortality than the DL algorithm (44.7%). All ML feature selection algorithms identify age, fasting blood glucose, heart rate, Killip class, oral hypoglycemic agent, systolic blood pressure, and total cholesterol as common predictors of mortality in the elderly. In a multi-ethnic population, DL outperformed the TIMI risk score in classifying elderly STEMI patients. ML improves death prediction by identifying separate characteristics in older Asian populations. Continuous testing and validation will improve future risk classification, management, and results.
Similar content being viewed by others


Introduction
Acute coronary syndrome (ACS) is the world's leading cause of death and the leading cause of morbidity and mortality in the elderly1,2,3. In the majority of developing countries, the elderly are defined as individuals over the age of 654. Age is a significant risk factor for ACS, and the prevalence of elderly patients presenting with ST-elevation myocardial infarction (STEMI) is increasing in developing countries due to an ageing population5,6. Elderly patients have a higher mortality rate, due to more comorbidities and were less likely to get evidence-based treatments7,8,9. With the advancement of general healthcare, elderly are likely to account for a significant proportion of all ACS patients in the future6. However, limited data are available on the delivery of health care and clinical outcomes of elderly patients with cardiovascular disease in the South-East Asia region. Elderly patients with Acute Coronary Syndrome (ACS) are also poorly analyzed and underrepresented in modern-day ACS trials10.
Common scoring systems such as Thrombolysis in Myocardial Infarction (TIMI) and Global Registry of Acute Coronary Events (GRACE) risk scores are often used to predict mortality for elderly patients11,12. TIMI and GRACE scores were developed to predict short-term prognoses based on patients mainly from countries in North America, South America, and Europe, with only Australia and New Zealand providing data from Asian countries to the GRACE registry, despite Asia hosting 60% of the world’s population13.
With the current advances and success of deep learning (DL) and machine learning (ML) algorithms such as random forest (RF), extreme gradient boosting (XGB), logistic regression (LR), and Support Vector Machine (SVM) in ACS mortality prediction over conventional risk scores, these algorithms have been adopted for clinical predictions13,14,15,16,17,18. In comparison to DL, ML algorithms require feature selection to attain higher performance accuracy19,20. DL algorithms allow automatic learning of the feature and relationship from a dataset minus the necessity for feature selection and attained higher accuracy than ML for mortality prediction. However, unlike ML algorithms, the interpretation of the significant factors for determining risk scores in DL models is unknown13.
There has been no research reported on integrating DL with ML feature selection to better understand DL's "black box" feature selection characteristic. Identifying features associated with mortality in the Asian elderly is essential for better patient management in clinical practice. We hypothesize that integrating DL with ML feature selection algorithms will improve in-hospital mortality prediction in Asian elderly STEMI patients. This is an objective, should also clarify that it is a first in world study!
As a result, we propose to integrate ML feature selection with a DL classification algorithm for the prediction and identification of factors associated with in-hospital mortality in multiethnic elderly Asian patients admitted with STEMI. Apart from that, we aim to evaluate the performance of ML with that of DL developed using both complete and selected features from the ML feature selection technique. Additionally, the developed ML and DL prediction models will be compared to the TIMI risk score, which is calculated from multi-ethnic registry data on Asian elderly STEMI patients.
Materials and methods
Study population
We examined data from the Malaysian National Cardiovascular Disease Acute Coronary Syndrome (NCVD-ACS) registry from 2006 to 2017 on 17, 227 in-hospital STEMI patients, 3991 of whom were elderly (65 years and above). The raw data used in this study was approved and granted permission to access study data from the National Heart Association of Malaysia (NHAM).
NCVD informed patient consent was waived where for each patient treated at one of the participating hospitals, the registry collects data on a defined set of clinical, demographic, and procedural information21,22. The UiTM ethics committee (Reference number: 600-TNCPI (5/1/6)) and the National Heart Association of Malaysia (NHAM) also authorized the study. The ethic approval for NCVD ACS have been applied by the principal investigator of each participating institution and have been approved by Malaysian Research Ethic Committee (NMRR: 07-38-164). The data utilised in this study were anonymized prior to usage, as our study data are interested in the values and parameters without accessing patient personal information.
All patients aged 65 years and above from the registry without exclusion were used including patients who received reperfusion (fibrinolysis, primary PCI (PPCI), angiography demonstrating spontaneous reperfusion, or urgent coronary artery bypass grafting (CABG)) for STEMI. STEMI was characterized as persistent ST-segment elevation ≥ 1 mm in two contiguous electrocardiographic leads, or the presence of a new left bundle branch block in the setting of positive cardiac markers. Input variables are features that are used as input in the development of a model to predict the outcome (in-hospital mortality). To develop the initial model in this study, 50 input variables (9 continuous, 41 categorical) representing columns of patient data from the NCVD data registry were used. The fifty variables used in this study are listed in Table 1. Variables used for model development are variables in the emergency department as first contact as well as variables in the hospital. Follow-up variables were excluded from the analysis. Supplementary table 1 shows the missing rates for each variable used in this study.
Categories of variables used are; sociodemographic characteristics, CVD diagnosis and severity, CVD risk factors, CVD comorbidities, non-CVD comorbidities, clinical presentation, baseline investigation, electrocardiography, treatments, and pharmacological therapy. The National Cardiovascular Disease Database (NCVD)—Acute Coronary Syndrome (ACS) registry, which is documented by the National Heart Association of Malaysia, defines the criteria for variables such as hypertension, diabetes, history of heart failure, and chronic renal disease23.
For in-hospital mortality, the time frame was calculated from the first hospital admission. Deaths were confirmed yearly through record linkages with the Malaysian National Registration Department. The registry's data does not include information on short-term complications such as heart failure. The follow-up data points are intended to collect these variables, but due to the high number of missing values, we omitted them from the study. To increase the impact of the study, we focused our algorithm on policy-changing hard endpoints such as death. This was done in other publications as well13,15,24.
Complete cases
We have used a complete set of data for primary analysis to ensure the validity of the findings for model development. The primary analysis was performed on complete cases, and the secondary analysis was performed on the top-performing algorithm using missing cases after data imputation.
A total of 3991 in-hospital elderly STEMI patients aged 65 and above were collected from the registry. The final dataset of complete cases of elderly patients of 1345 datasets was identified as complete cases used for primary analysis (with no missing values on predictors). This rendered patients with a full predictor set of 50 variables (9 continuous, 41 categorical) for the study as shown in Table 1.
Missing cases
Secondary analyses were conducted on the top-performing algorithm after adding 2646 missing cases for a total of 3991 cases. We employed chained equations and predicted mean matching to perform multivariable imputation25.
This method imputes missing values based on real values from other cases where predicted values are closest. We used multiple imputations, which means that missing data is typically imputed five times25.
Our definition of an incomplete dataset includes variables that are missing up to 30%. There is no missing data for electrocardiography, but there is less than 2% to 10% missing data for demographics, pharmacological therapy, invasive therapeutic procedures, smoking status, smoking history, diabetes, hypertension, and clinical representation such as systolic and diastolic blood pressure. Missing variables are reported to be less than 15% for chronic lung and renal disease, as well as a history of myocardial infarction, heart failure, and cerebrovascular disease. There is 20% missing data for baseline invention variables, and up to 30% missing data for Killip class and heart rate.
The referenced missing dataset is for patient characteristics, not outcome data. Due to the prospective nature of our dataset and the retroactive administration of data, the level of missing values across all variables was completely unpredictable and beyond our control. In our dataset, the likelihood of missing values is independent of both the observed values in any variable and the unseen portion of the dataset.
As a result, the dataset is classed as missing completely at random (MCAR), which indicates that the pattern of missing values is random and not dependent on any variable that may or may not is included in the study.
Development of risk models
A stratified random sampling of data was used from Kuhn and Johnson study26. Data were split for model development (70%) and validation (30%) for all models. Multiple admissions are counted as one for each patient; the splits are based on patient identifiers rather than individual examples. The same pool dataset is assigned to patients with the same identifier. This means that if a patient is admitted three times, each of those three admissions will be assigned to the same set of either training or testing. The patient identifier was replaced with a randomly generated patient identifier to ensure the anonymity of the dataset used in this study27.
We accessed the performance of DL and ML algorithms with TIMI using a validation set that accounts for 30% of data that is not used for model development.
Prediction models for the elderly with STEMI were developed using the R package (Version 3.5.2) for DL and conventional ML algorithms such as LR, RF, XGboost, and SVM. These algorithms were selected due to their high performance in previous cardiovascular disease studies. The ML algorithms LR, RF, XGboost, and SVM feature selection methods are used to rank the variables listed in Table 1. Iterative feature selections were performed on the ranked variables in ascending order iteratively to generate the final variables28. Cross-validation was used to avoid overfitting for model development on the training set29. The ML prediction models were trained and tested for each iteration, and the models with the highest performance were selected. Predictive performances of the models were calculated using the validation dataset. DL models were then constructed with features selected from ML feature selection.
Random forest (RF)
RF algorithm implemented in this study was based on Breiman study30. Varying value of entry and number of trees ntree (500–4000) was used in this study to determine the optimum RF model that produced the best results. The RF variable importance method was used to generate ranked variables that were then reduced using sequential backward elimination iteratively. The final model for RF classifier parameters is ntree = 1000, and mtry = 6.
Support vector machine (SVM)
SVM was implemented in this study using the RBF kernel31. SVM in this study uses ROC curve variable importance to select and rank the most important variables. The final parameter after tuning used is sigma = 0.01 and c = 0.25 (cost tuning parameter, which regulates the margin width).
Logistic regression
The LR model was constructed using the generalized linear model function with family binomial. We used the original Akaike IC as the information criterion and backward directions for the LR model feature selection. LR in this study was constructed using default parameters.
XGB
XGB is an implementation of gradient boosting. XGB gives a more accurate result because it used a more regularised form of Gradient Boosting which improves model generalization capabilities that can control overfitting. Besides, it used parallel tree learning which makes the learning process faster. It is more capable of handling missing values compare to gradient boosting32. Default parameters have been used for XGB model development in this study.
Deep learning
We used a multilayer perceptron (MLP) based on deep learning that integrates four hidden layers, 100–200 nodes, batch normalization, and dropout layers33,34,35. Three hidden layers were used as there is no significant increase in performance when more layers were added. We used the R version of the Tensor Flow and Adam optimizer with the default parameters and binary-cross entropy as the loss function36. Rectified linear unit (ReLU) as the activation function37 was used after comparing with other activation functions predictive performance such as SoftMax, linear, Tanh, leaky ReLU, and exponential linear unit. The hyper-parameters used in the development of DL were tuned using grid search and manual tuning. Data for DL model development, categorical variable values were replaced with numeric values, and continuous variable values were normalised using z-scores38. Data preprocessing was performed in the training data and validation data, separately. Table 1 also covered the hyperparameters that were used in all of the deep learning models.
Feature selection
The ML algorithms LR, RF, XGboost, and SVM feature selection methods are used to rank the variables listed in Table 1. Sequential Backward Elimination (SBE) algorithm was then applied to the ranked list of variables in ascending order to generate the final variables.
The sequential Backward elimination algorithm relies only on significance as a sufficient condition to remove insignificant variables from a model39. Dependencies among variables are considered to obtain better performance40. Variables are eliminated in ascending order of importance from RF, XGB, and SVM feature selection methods. The prediction model is retrained and tested each time a variable is eliminated. The variable that causes a decrease in the AUC of the prediction model upon elimination based on the ranked variable list using RF, XGB and SVM feature selection is retained. The retained variables were ranked again using feature importance and the elimination process is repeated until the model with the least number of variables and the highest AUC value is achieved. LR feature selection was done using built feature selection using Akaike IC as the information criterion and backward directions. DL algorithm does not provide built-in feature importance. It has automatic learning of features and relationships from a given data, hence feature importance for the model is unknown. However, we have applied features selected from RF, XGB SVM, and LR to DL model development in this study.
Model evaluation, validation, and performance measures
The calibration of the models was compared using standardized measures41. The area under the curve (AUC) was used as a predictive performance metric. Additional performance metrics were accuracy, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) for model calibration. Paired resampled t-test was used to compare the ML model’s predictive performances26. The net reclassification index (NRI) was also assessed to evaluate the percentage improvement in identifying both positive and negative cases with the best model compared to the TIMI risk score42.
Comparison with conventional method TIMI score
Calculated TIMI scores were used from the NCVD registry for the validation data performance. TIMI score performance (AUC) was compared with the developed DL and ML—models using the validation set that was not used for model development. A graph was also derived to compare performance with the TIMI score based on cutoff points applicable in clinical practice and literature43. We define the high risk of death as a probability rate of > 8% similar to that reported by43. The ML and DL high-risk population in this study is defined as a mortality probability of > 40% which is equivalent to the TIMI score of > 5.
Additional statistics
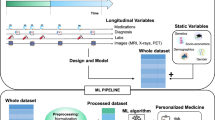
The results are expressed as mean and SD for continuous variables and as frequencies for categorical variables. Correlation analysis was carried out to identify a significant relationship between variables. Univariate analysis was performed using a Chi-Square test to identify significant variables and a two-sided independent student t-test (p < 0.05). The DL and ML performance was compared using a pair-wise corrected resampled t-test29,44. Statistical significance was considered if the p-value was less than 0.0001. Figure 1 summarizes the workflow and methods used in this study.

Research workflow and methodology applied in this study.
Ethical declaration
This study was approved by the UiTM Research Ethics Committee (Reference: 600-TNCPI (5/1/6)), with the approval code REC/673/19. The UiTM Ethics Committee operates in accordance to the ICH Good Clinical Practice Guidelines, Malaysia Good Clinical Practice Guidelines and Declaration of Helsinki.
Results
Patient characteristics
Table 2 depicts the summary statistics for the complete set of cases used in the study. The in-hospital complete feature dataset of elderly STEMI patients has a mean age of 72 years. The majority of patients in the dataset are male (74%), Malay (53.9%), non-smokers (46%), and had a history of chronic diseases such as hypertension (69.1%), diabetes (46%), chronic angina (11.1%), myocardial infarction (9.9%), cardiovascular disease (8%), chronic renal disease (7.4%), peripheral vascular disease (5.3%), heart failure (3.0%), and chronic lung disease (2.9%). Percutaneous coronary intervention (PCI) was used to treat approximately 29% of patients. The overall mortality rate of elderly patients is 37%. There was a significant difference between survival and non-survival in age, ethnicity, diabetes, chronic renal disease, heart rate, systolic blood pressure, diastolic blood pressure, Killip classification, total cholesterol, high-density lipoprotein cholesterol, low-density lipoprotein cholesterol, fasting blood sugar, bundle branch block, cardiac catheterization, aspirin, beta-blockers, ACE inhibitor, diuretics where all variables have p-values < 0.0001.
Table 2 also demonstrates the imputed data’s summary statistics. The dataset was imputed using the predictive mean matching method. The imputed datasets on elderly patients have an average age of 73 years. In the imputed dataset, the overall mortality rate is 44.83%. There was a significant difference between survival and non-survival in age, gender, hypertension, diabetes, history of heart failure, chronic renal disease, heart rate, systolic blood pressure, diastolic blood pressure, Killip classification, fasting blood sugar, t-wave inversion ≥ 1 mm, bundle branch block bundle, ECG abnormal in inferior leads and anterior leads, cardiac catheterization, PCI, aspirin, GPRI, LMWH, beta-blocker, ACE inhibitor, statin, diuretics, oral hypoglycaemic agent, insulin, and Anti-arrhythmic agent (all variables with p-value < 0.0001).
Algorithm performance on complete cases
Table 3 illustrates model performances developed in this study. ML models constructed using reduced sets of features demonstrated higher performance compared to ML models developed using a complete set of features LR (0.91 vs 0.83), RF (0.91 vs 0.89), XGB (0.89 vs 0.89) and SVM (0.91 vs 0.87). XGB automatically selects the most important variable40 in prediction when using a complete set of variables, a similar AUC of (0.89) was reported after using a reduced set of variables. ML models RF (varImp-SBE-RF) (0.91), SVM (varImp-SBE-SVM) (0.91) and LR (varImp-SBE-LR) (0.91) constructed using selected features performed similarly and comparison was non-significant. However as illustrated in Table 2, DL (all features) model (0.93) using a complete set of features performed slightly better than ML models constructed using a reduced set of features RF (varImp-SBE-RF) (vs. 0.91, p < 0.0001), LR (varImp-SBE-LR) (vs. 0.91, p < 0.0001) and SVM (varImp-SBE-SVM) (vs. 0.91, p = 0.309).
Slightly lower AUC value were observed with DL (all features) model using complete set of features (AUC = 0.93) compared to DL models constructed using selected features from DL (RF selected var) (vs. 0.95, p < 0.0001) using 13 predictors, DL (XGB selected var) (vs. 0.94, p < 0.0001) using 6 predictors, DL (SVM selected var) (vs. 0.94, p < 0.0001) with 11 predictors and DL (LR selected var) (vs. 0.94, p < 0.0001) using 15 predictors. There was no statistical significance between all the DL models constructed using selected features from ML (p > 0.05).
Theoretically, by running a model to indicate survival for a new patient aged 65 years and above after STEMI, in the DL (XGB selected var) model with the reduced 6 features selected from XGB, the average mortality risk is reduced to 4% (NPV). While the model is to indicate non-survival, the average risk of a patient being decreased is increased to 37% (PPV). This corresponds to an average 9.25% risk ratio for the outcome in patients classified as non-survival versus survival. Meanwhile, for the DL (RF selected var) model with the reduced features from RF (13 features), the average mortality risk is reduced to 3.2% (NPV). While the model is to indicate non-survival, the average risk of a patient being deceased is increased to 43% (PPV). This corresponds to an average 13% risk ratio for the outcome in patients classified as non-survival versus survival.
Model prediction using the imputed dataset
The best DL models, DL (RF selected var) and DL (XGB selected var) were also trained on an imputed dataset and tested using a complete case validation dataset. This allows for a valid comparison of models built with imputed and complete case models. Best models trained on imputed datasets performed comparably to models trained on complete dataset on similar validation datasets of complete cases: DL (RF selected var) (AUC = 0.956 (0.944–0.968) vs AUC = 0.954 (0.942–0.966), p = 0.540) and DL (XGB selected var (AUC = 0.948 (0.935–0.960) vs AUC = 0.937 (0.923–0.951) p < 0.0001). There is no statistically significant difference between the DL model (RF selected var) using complete cases with the imputed model.
Feature selection
Table 4 displays the variables chosen by combining SBE and ML algorithm feature selection methods, which resulted in the ML model with the best predictive performance while using the minimum varaibles. Patient age, fasting blood glucose, heart rate, Killip class, oral hypoglycemic agent, systolic blood pressure, and total cholesterol are all common predictors across best ML models. These predictors were also identified as significant predictors in univariate analysis. The XGB model chose the fewest predictors (six): patient age, fasting blood glucose, heart rate, Killip class, and beta-blocker. Age, Killip Class, and Systolic Blood Pressure are similar features selected by ML feature selection with TIMI risk score.
Comparison with TIMI conventional risk score
Using the same validation set, TIMI achieved a lower AUC of 0.750 (95% CI 0.669,0.810) compared to all ML and DL models. Figures 2, 3, and 4 illustrate the graph plotted from the TIMI risk score, DL (RF selected var), and DL (XGB selected variables) in predicting the mortality risk of the elderly STEMI patients respectively. For the elderly patients, the ML score categorized patients as low risk with the probability of < 40% and high-risk stratum as ≥ 40%. This is equivalent to a TIMI low-risk of score ≤ 5 and a high-risk score of > 543.

Mortality rate distribution on the validation set of TIMI risk scores.

Mortality rate distribution on the validation set of DL (using RF variables) model.

Mortality rate distribution on the validation set of DL (using XGBoost variables) model.
Table 5 tabulates the percentage of mortality in the patients with predicted low risk (TIMI score: < 5; ML probabilities < 0.4) and high risk (TIMI score: > 5; ML probabilities: ≥ 0.4). In the high-risk group, ML and DL predicted mortality better in comparison to TIMI for in-hospital death in elderly patients.
NRI analysis
NRI for the in-hospital model, the net reclassification of elderly STEMI patients using the DL (SVM selected var) (Table 6) and DL (XGB selected var) (Table 7) produced a net reclassification improvement of 18.14% with p < 0.00001 over the original TIMI risk score.
Discussion
This study aimed to construct and validate conventional ML and DL models in Asian elderly admitted with STEMI. We also compared the predictive performance of these models against conventional risk score models such as TIMI. This is the first study to include DL and conventional ML models in the risk prediction of in-hospital mortality in Asian elderly with STEMI resulting in a higher predictive ability than the conventional statistical method (TIMI). DL and ML risk stratification models were developed based on the Asian elderly on relatively recent data, which can better predict mortality for STEMI patients in the current practice compared to TIMI.
We observed from the results obtained in this study that (i) DL model (AUC = 0.93) outperform all ML models (AUC ranging from 0.83 to 0.89) on a complete set of features (p < 0.0001) (ii) DL models constructed using ML feature selection (AUC ranging from 0.93 to 0.95) performed better than ML constructed using selected features (AUC ranging from 0.89 to 0.91) (p < 0.0001) (iii) Both DL and ML model constructed using all and selected features (AUC ranging from 0.83 to 0.95) outperformed conventional risk scoring score TIMI (AUC = 0.75) (iv). DL constructed using selected features (AUC ranging from 0.93 to 0.95) were observed to perform better than DL constructed using all features (AUC = 0.93). DL is composed of multiple feature processing layers obtained by composing simple but nonlinear modules, each of which transforms a feature at one level into a feature at a higher, slightly more abstract level13,45. As a result, when compared to ML and the conventional method TIMI score, the higher accuracy obtained with DL in this study is due to the algorithm discrimination power and features used. This is supported by Kwon's findings13, which show that DL outperforms ML and conventional risk scores in predicting mortality in Korean ACS patients.
These risk-scoring models are developed using logistic regression with the limitation of predetermined expectations on data behaviour, and preselected parameters in the development phase13. Further limitations include a lack of bedside convenience and some data only being available following a biochemical test. Since age is a component of risk stratification in-hospital mortality is significantly higher in older adults. As age is incorporated into most conventional risk score algorithms older adults will be scored as higher risk based on their age alone46. Several previous studies on mortality prediction also have reported on the use of feature selection techniques to enhance the performance of machine learning algorithms by reducing the predictor's dimensionality in Asian patients. This study also demonstrated that ML-based models outperformed conventional risk score TIMI18,30,47,48.
Additionally, previous research has also shown that models based on DL perform better in classification tasks than models based on classical ML algorithms and conventional risk scores13. Similar findings were reported in our study as well.
Even though the TIMI risk score has been widely used in the Asian population, this score was developed from the Western Caucasian cohort with limited data from an Asian population. In our study, when DL and ML models were validated against TIMI, we observed a modest AUC value of 0.75 for TIMI score validated on elderly Asian patients which were lower than the TIMI risk score reported on in a fibrinolytic eligible STEMI population AUC of 0.7849. Modest performance AUC of 0.709 (95% CI 0.591–0.827; p < 0.001) have also been reported on TIMI risk score for in-hospital mortality of older women age > 70 who underwent PPCI in a South Asian country50.
We also conducted an accuracy test using data that were not used for the model derivation for comparison with TIMI. We used two DL models as there was no significant difference between DL models constructed using selected variables. Hence, the two DL models used were; the DL (RF selected var) model with the highest performance (AUC = 0.95) with 13 predictors and the DL (XGB selected variable) (AUC = 0.93) with the least number of predictors6. Both algorithms make use of decision trees, while XGB makes use of boosting rather than bagging. This approach reduces variance and bias32. Numerous recent investigations have demonstrated the generalizability and robustness of both methods in clinical practice. Both models managed to identify high-risk patients that reported higher mortality in those classified as high risk in TIMI. The mortality rate, however, was no different suggesting an inherent inaccuracy within the algorithm. The mortality for high-risk patients for TIMI in this study is 18% vs 44% for DL (RF selected variable) model.
The TIMI risk score lacks risk factors relevant to older adults and fails to account for the overall complexity of the older adult with ACS13,51. The Asian cohort was found to be carrying an overall higher disease burden and risk compared to the TIMI cohort. The lack of weighting for the risk factors, while improving usability, decreased TIMI risk score discriminatory performance52,53. Not only that, TIMI is known to underestimate mortality risk in the high-risk group as seen in this study. This may delay proper treatment and sufficient resource allocation to high-risk elderly patients incurring excess avoidable deaths.
It is essential that the risk prediction model be interpretable. To this end, it is true that one of the significant advantages of a deep learning algorithm is its intrinsic hierarchical feature selection along with successive levels of increasing abstraction for pattern detection. While the newly extracted features are largely meaningless from the perspective of the deep learning method, their extraction can be beneficial for driving the learning process in certain circumstances. This was likewise the case in our instance where the DL model with selected features performed similarly or better than DL constructed using all features. Not only that, but a new genre of literature is forming that recounts similar circumstances, such as those found in54,55.
Exploring the feasibility of DL and ML on the predictors of mortality among Asian elderly provides clinicians with a tool that allows the identification of higher-risk populations in the emergency department that could influence effective management based on their prognostic characteristics as described by their risk scores. ML methods discussed in this study are needed to rank and select significant risk factors associated with in-hospital mortality of the elderly. Feature selection allows better interpretation of the models by restricting the scope of predictors used, selecting only those clinically relevant, and ease of implementation of the model for bedside risk assessment usage.
Hence, our data-driven model for risk prediction and identification of factors associated with in-hospital mortality was developed using a nationwide registry of a multiethnic Asian elderly population. We identified age, fasting blood glucose, heart rate, Killip class, oral hypoglycemic medication, systolic blood pressure, and total cholesterol to be common predictors of in-hospital mortality in Asian elderly patients following STEMI. Additionally, invasive procedures such as heart catheterization were also selected in our study. These factors are consistent with the findings of this study's univariate analysis. These factors have also been chosen by machine learning and deep learning studies aimed at predicting mortality post STEMI in the Asian population13,30. We discovered that STEMI-related treatments have no effect on outcomes in different groups. In the main dataset of STEMI in-hospital patients, 97.3% (16,829) received ASA, while 6176 (35.7%) underwent PCI18. In the elderly patient dataset, 3482 patients were given ASA, accounting for 85.9%, and 1197 patients were given PCI, accounting for 29.5%. In terms of significant analysis performed on raw datasets in both studies, both datasets exhibit similar characteristics and yield similar results.
Additionally, we identified common predictive variables between the conventional risk score TIMI and feature-selected by ml algorithms. These variables include age, Killip class, systolic blood pressure, and fasting blood sugar, which is an indicator of diabetes. These factors also corroborate the findings of the univariate analysis in this study.
Older age and higher Killip class were significant predictors of mortality in Asian patients12,56. The elderly, especially those aged equal or greater than 65 years old represents a subgroup of high-risk ACS patients due to the fact that they commonly have other comorbidities57. Killip class is also noted to be among the factors that are associated with increased mortality in the elderly. Generally, older patients have a higher incidence of heart-related complications (Killip class II-IV) than younger patients58. Killip class selected by ML and univariate analysis conforms with the study by15 where Killip class is selected as main predictors by ML algorithm. As the most significant determinant of myocardial oxygen and cardiac workload, heart rate plays a vital role in in-hospital mortality and was also selected59.
Diabetes in individuals aged ≥ 65 years has globally become a growing public health burden. The prevalence of diabetes and diabetes-related complications, such as myocardial infarction (MI) and ischemic stroke, is increasing in the older age group. Fasting glucose level is a fundamental element in managing diabetes and both high and low fasting glucose levels are associated with a higher risk of mortality60,61. Fasting blood glucose has been selected in our study by all ML features selection methods and our previous published study18. Pharmacological treatments such as beta-blockers post-STEMI are also often associated with improved outcomes and significant predictors of STEMI patients3,62,63,64. Oral hypoglycemic agent indicates the presence of diabetes and its use by patients during an ACS event may reflect pre-existing diabetes. Knowing the duration of illness with diabetes may have helped risk prediction better as it has been associated with a higher risk of death in other studies65. Nonetheless, oral hypoglycaemic agents were selected as the main predictors of mortality of the elderly in our study66,67.
Older age has been found to be predictive of lower use of cardiac catheterization, with significant variation internationally68. We have noted a significant difference in survival vs non-survival (p < 0.0001) in our study between older patients that underwent cardiac catheterization procedures. However, we identified only 29% of Asian elderly STEMI patients who have undergone PCI and 44% cardiac catheterization. This is despite the data showing that in‐hospital mortality after percutaneous coronary intervention (PCI) has fallen for all age groups over the past several years. Elderly patients with ACS tend to be undertreated, both invasively and pharmacologically. Invasive treatment seems to yield better outcomes for this group of patients57. This is an area that needs improvement to raise the level of care.
Data imputation was performed to ensure the validity of the findings. We tested the results of data imputation on model with the highest AUC in this study DL (RF selected var) and model high AUC and least number of predictors DL (XGB selected var). We used multivariable imputation using chained equations and the predictive mean matching method for data imputation. The multivariable imputation using chained equations and predictive mean matching method used in this study was selected as recommended in a similar study conducted on the Swedish heart registry dataset that resulted in high model performance20. Additionally, Solaro69 studies observed that miss forests a machine learning data imputation method relative performance varied according to the MCAR data patterns and did not provide a clear advantage. In general, miss forests imputation accuracy and applicability remain unknown.
Data imputation techniques produced models with comparable prediction performance to those developed using complete cases. We first excluded patients with more than 50% missing data because this would necessitate data imputation, which could alter our conclusion. We do not believe this is a constraint on the population, given the dataset is still quite large. Due to the fact that the dataset contained complete data for all follow-up time points, risk calculators for both the DL and TIMI calculators could be generated. However, identifying characteristics associated with the use of complete cases for in-hospital elderly mortality prediction would result in more reliable conclusions. We repeated the experiment using an incomplete dataset and imputed data and obtained comparable findings. However, the imputed model for DL (XGB chosen var) performed slightly better, as the DL technique performs better when datasets with lower feature dimensions and a larger number of datasets are utilized.
The cross-validation and hyperparameter tuning approach used in this study increases the efficacy of the DL and ML algorithms during model construction as it reduces the risk of model over-fitting. Also, the classification performance is highly influenced by data pre-processing and tuning of algorithms70.
To ensure the study's reliability, all models were validated using untouched validation data. The DL model performed similarly to models with feature selection when using complete sets of variables collected. This refutes the claim that feature selection leads to the loss of important prognostic information as claimed by Kwon13.
Study limitations
Despite the excluded patient, the number of elderly people over the age of 65 (3991 patients) was large enough to allow for analysis; however, we regard this as a limitation of the study. Several other limitations also exist in this study. Firstly, we could only validate DL and ML models for in-hospital, with a clinical prognostic model TIMI score that was designed for 30 days’ mortality. TIMI score was adopted due to its simplicity and it was developed for short term risk stratification. Parameters to calculate GRACE score were not acquired during patient admission compared to TIMI score. Furthermore, studies by Aragam and Correia43,71 reported that both scores show similar discriminatory capacity for STEMI in-hospital death, and the TIMI score had better calibration than GRACE. Hence comparing performance for two risk scores appears redundant. In-hospital bleeding was not captured in the NCVD registry, which is a limitation of the study despite the fact that it is an important factor affecting in-hospital mortality, particularly in the elderly. Both GP receptor inhibitors and ASA are relevant in-hospital antiplatelet drug therapy72 that were present in the initial complete variable set used for model development but were not selected by the ML feature selection algorithm. The ML feature selection algorithm selects variables that are significant to the outcome73. In this study, we discovered that GP receptor inhibitor is not a significant factor using both the univariate and machine learning methods. The majority of elderly patients are given ASA, but it is not chosen as a significant variable affecting mortality by the all ML feature selection method used in this study. As shown in Table 2, smoking is significantly associated with mortality in elderly patients, and similar findings in STEMI patients indicated that smoking affects mortality18,74. However, smoking and gender predominance have no effect on mortality in this cohort. In this cohort, which includes 50% of patients aged 65 and above, former and current smokers are men. Meanwhile, female smokers account for only about 0.022% of current and former smokers of all patients.
Future studies using interpretable DL will be our next area of study. Both DL and ML models rely on representability as opposed to medical knowledge which can lead to bias due to the representativeness of training data. It is still unclear whether DL and ML will consistently perform on real live data sets. Hence, the model needs to be continuously evaluated with real-time patient data which can be easily acquired due to the implementation of the Electronic Health Record System in hospitals. These risk scores could be implemented into the hospital electronic systems for physicians’ use. This might be the scope for future studies, as well as validating this risk score in a registry rather than an administrative database. The study's generalizability is relevant to Asians in general, given the NCVD registry's ethnic make-up of Malay, Chinese, and Indian descendants. It is particularly relevant for Malaysia, Brunei, and Singapore, as well as other Asian countries such as China and India75.
Conclusion
We demonstrated that DL with ML feature selection can be applied in conjunction with conventional risk score methods to improve mortality prediction in Asian elderly patients presenting with STEMI. This knowledge could be used to improve communication and awareness among elderly patients, allowing physicians to make management changes and better manage limited resources.
Data availability
The data that support the findings of this study are available from the National Heart Association of Malaysia (NHAM) but restrictions apply to the availability of these data, and so are not publicly available. The data belongs to the individual ministry of health universities hospitals and private hospitals that require multiple institutional agreements for data release to third parties hence ethical approval is needed for analysis. Data are however available from NHAM upon request using https://www.malaysianheart.org/?p=contact or email them at secretariat@malaysianheart.org. Any findings from the data need to be reported and permission needs to be obtained from the NHAM committee before publication.
References
World Health Organization. Media centre: the top 10 causes of death. (2020) (Accessed 20 Nov 2020) https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death.
Alexander, K. P., CRUSADE investigators. Evolution in cardiovascular care for elderly patients with non-ST-segment elevation acute coronary syndromes: Results from the CRUSADE national quality improvement initiative. J. Am. Coll. Cardiol. 46(8), 1479–1487 (2005).
Mehta, R. H. et al. Acute myocardial infarction in the elderly: Differences by age. J. Am. Coll. Cardiol. 38(3), 736–741 (2001).
Su, P. H. et al. Comparison of clinical presentations and outcomes between adult and elderly acute myocardial infarction patients in emergency department. Heal Technol. 3(7), 10–21037 (2019).
Alexander, K. et al. Acute coronary care in the elderly, part II: ST-segment–elevation myocardial infarction: A scientific statement for healthcare professionals from the American Heart Association Council on Clinical Cardiology: In collaboration with the Society of Geriatric. Circulation 115(19), 2570–2589 (2007).
Cai, J. X. et al. Elderly Asian patients have lower revascularisation rates and poorer outcomes for ST-elevation myocardial infarction compared to younger patients. Ann. Acad. Med. Singapore. 49, 3–14 (2020).
Ahmed, E. et al. Effect of age on clinical presentation and outcome of patients hospitalized with acute coronary syndrome: A 20-year registry in a Middle Eastern Country. Open Cardiovasc. Med. J. 6, 60–67 (2012).
Zaman, M. et al. The association between older age and receipt of care and outcomes in patients with acute coronary syndromes: A cohort study of the Myocardial Ischaemia National Audit Project (MINAP). Eur. Heart J. 35, 1551–1558 (2014).
Avezum, A. et al. Impact of age on management and outcome of acute coronary syndrome: Observations from the Global Registry of Acute Coronary Events (GRACE). Am. Heart J. 149(1), 67–73 (2005).
Tahhan, A. S. et al. Enrollment of older patients, women, and racial/ethnic minority groups in contemporary acute coronary syndrome clinical trials: A systematic review. JAMA Cardiol. 5(6), 714–722 (2020).
Morrow, D. A. et al. TIMI risk score for ST-elevation myocardial infarction: A convenient, bedside, clinical score for risk assessment at presentation: An intravenous nPA for treatment of infarcting myocardium early II trial substudy. Circulation 102(17), 2031–2037 (2000).
Granger, C. et al. Predictors of hospital mortality in the global registry of acute coronary events. Arch. Intern. Med. 163(19), 2345–2353 (2003).
Kwon, J. M. et al. Deep-learning-based risk stratification for mortality of patients with acute myocardial infarction. PLoS ONE 14(10), e0224502 (2019).
Li, X. et al. Using machine learning models to predict in-hospital mortality for ST-elevation myocardial infarction patients. Stud. Health Technol. Inform. 245, 476–480 (2017).
Shouval, R. et al. Machine learning for prediction of 30-day mortality after ST elevation myocardial infraction: An Acute Coronary Syndrome Israeli Survey data mining study. Int. J. Cardiol. 246, 7–13 (2017).
Yang, L. Artificial intelligence: A survey on evolution, models, applications and future trends. J. Manag. Anal. 6(1), 1–29 (2019).
Li, Y. M. et al. Machine learning to predict the 1-year mortality rate after acute anterior myocardial infarction in Chinese patients. Ther. Clin. Risk Manag. 16, 1 (2020).
Aziz, F. et al. Short-and long-term mortality prediction after an acute ST-elevation myocardial infarction (STEMI) in Asians: A machine learning approach. PLoS ONE 16(8), e0254894 (2021).
Chen, X. & Ishwaran, H. Random forests for genomic data analysis. Genomics 99(6), 323–329 (2012).
Wallert, J., Tomasoni, M., Madison, G. & Held, C. Predicting two-year survival versus non-survival after first myocardial infarction using machine learning and Swedish national register data. BMC Med. Inform. Decis. Making. 17(1), 1–11 (2017).
Ahmad, W. A. W. et al. Malaysian national cardiovascular disease database (NCVD)–acute coronary syndrome (ACS) registry: How are we different?. CVD Prev. Control 6(3), 81–89 (2011).
Ahmad, W. A. W. et al. The Journey of Malaysian NCVD—PCI (National Cardiovascular Disease Database—Percutaneous Coronary Intervention) Registry: A summary of three years report. Int. J. Cardiol. 165(1), 161–164 (2013).
Wan Ahmad, W. Annual Report of the NCVD-ACS Registry, 2016–2017. (National Cardiovascular Disease Database, 2019).
Peng, Y. et al. Predicting in-hospital mortality in patients with acute coronary syndrome in China. Am. J. Cardiol. 120(7), 1077–1083 (2017).
Van Buuren, S. & Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 45, 1–68 (2010).
Kuhn, M. & Johnson, K. Classification trees and rule-based models. In Applied Predictive Modeling, 369–413 (Springer, 2013).
Draelos R. Best Use of Train/Val/Test Splits, with Tips for Medical Data. [Online] (2022) https://glassboxmedicine.com/2019/09/15/best-use-of-train-val-test-splits-with-tips-for-medical-data.
Genuer, R., Poggi, J. M. & Tuleau-Malot, C. Variable selection using random forests. Pattern Recogn. Lett. 31(14), 2225–2236 (2010).
Schaffer, C. Selecting a classification method by cross-validation. Mach. Learn. 13(1), 135–143 (1993).
Aziz, F., Malek, S., Ibrahim, K. K. S. & Kasim, S. A novel local machine learning algorithm to predict death in ACS patients. Int. J. Cardiol. 297, 18 (2019).
Vapnik, V., Guyon, I. & Hastie, T. Support vector machines. Mach. Learn. 20(3), 273–297 (1995).
Chen, T. & Guestrin, C. Xgboost: a scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 785–794 (2016).
Schalkoff, R. Pattern Recognition: Statistical, Structural and Neural Approaches (Wiley, 1992).
Ioffe, S. & Szegedy, C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning 448–456 (2015).
Tang, C., Srivastava, N. & Salakhutdinov, R. R. Learning generative models with visual attention. Adv. Neural Inf. Process. Syst. 27, 1–9 (2014).
Kingma, D. P. & Ba, J. Adam: A Method for Stochastic Optimization. arXiv preprint arXiv:1412.6980 (2014).
Nair, V. & Hinton, G. E. Rectified Linear Units Improve Restricted Boltzmann Machines (Icml, 2010).
Jayalakshmi, T. & Santhakumaran, A. Statistical normalization and backpropagation for classification. Int. J. Comput. Theory Eng. 3, 89–93 (2011).
Dunkler, D., Plischke, M., Leffondré, K. & Heinze, G. Augmented backward elimination: A pragmatic and purposeful way to develop statistical models. PLoS ONE 9(11), e113677 (2014).
Jain, D. & Singh, V. Feature selection and classification systems for chronic disease prediction: A review. Egypt. Inform. J. 19(3), 179–189 (2018).
Steyerberg, E. et al. Assessing the performance of prediction models: A framework for traditional and novel measures. Epidemiology 21(1), 128–138 (2010).
Benjamin, E. J. et al. Heart disease and stroke statistics—2017 update: A report from the American Heart Association. Circulation 135(10), e146–e603 (2017).
Correia, L. C. et al. Prognostic value of TIMI score versus GRACE score in ST-segment elevation myocardial infarction. Arq. Bras. Cardiol. 103, 98–106 (2014).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Hall, M. A. & Holmes, G. Benchmarking attribute selection techniques for discrete class data mining. IEEE Trans. Knowl. Data Eng. 15(6), 1437–1447 (2003).
Labos, C. et al. Traditional risk factors and a Genetic Risk Score are associated with age of first acute coronary syndrome. Heart 100(20), 1620–1624 (2014).
Aziida, N., Malek, S., Aziz, F., Ibrahim, K. S. & Kasim, S. Predicting 30-day mortality after an acute coronary syndrome (ACS) using machine learning methods for feature selection, classification and visualisation. Sains Malaysiana. 50(3), 753–768 (2021).
Kasim, S. S., Malek, S., Ibrahim, K. K. & Aziz, M. F. Risk stratification of Asian patients after ST-elevation myocardial infarction using machine learning methods. Eur. Heart J. 41(Supplement_2), ehaa946-3494 (2020).
Selvarajah, S. et al. Impact of cardiac care variation on ST-elevation myocardial infarction outcomes in Malaysia. Am. J. Cardiol. 111(9), 1270–1276 (2013).
Furnaz, S. et al. Performance of the TIMI risk score in predicting mortality after primary percutaneous coronary intervention in elderly women: Results from a developing country. PLoS ONE 14(7), e0220289 (2019).
Chen, Y. H., Huang, S. S. & Lin, S. J. TIMI and GRACE risk scores predict both short-term and long-term outcomes in Chinese patients with acute myocardial infarction. Acta Cardiol. Sin. 34(1), 4–12 (2018).
Feder, S. L. et al. Physicians’ perceptions of the thrombolysis in myocardial infarction (TIMI) risk score in older adults with acute myocardial infarction. Heart Lung 44(5), 371–381 (2015).
Bawamia, B., Mehran, R., Qiu, W. L. & Vijay, K. Risk scores in acute coronary syndrome and percutaneous coronary intervention: A review. Am. Heart J. 165(4), 441–450 (2013).
Ntakaris, A., Mirone, G., Kanniainen, J. & Iosifidis, A. Feature engineering for mid-price prediction with deep learning. IEEE Access 7, 82390–82412 (2019).
Yu, L., Sun, X., Tian, S. & Shi, X. Drug and nondrug classification based on deep learning with various feature selection strategies. Curr. Bioinform. 13(3), 2539 (2018).
Cheng, J. M. et al. A simple risk chart for initial risk assessment of 30-day mortality in patients with cardiogenic shock from ST-elevation myocardial infarction. Eur. Heart J. Acute Cardiovasc. Care. 5(2), 101–107 (2016).
Zuhdi, A. S. M. et al. Acute coronary syndrome in the elderly: The Malaysian National Cardiovascular Disease Database-Acute Coronary Syndrome registry. Singap. Med. J. 57(4), 191 (2016).
DeGeare, V., Boura, J., Grines, L., O’Neill, W. & Grines, C. Predictive value of the Killip classification in patients undergoing primary percutaneous coronary intervention for acute myocardial infarction. Am. J. Cardiol. 87(9), 1035–1038 (2001).
Erceg, P. et al. Health-related quality of life in elderly patients hospitalized with chronic heart failure. Clin. Interv. Aging 8, 1539 (2013).
Lee, J. H., Han, K. & Huh, J. H. The sweet spot: fasting glucose, cardiovascular disease, and mortality in older adults with diabetes: A nationwide population-based study. Cardiovasc. Diabetol. 19(1), 1–10 (2020).
Lee, G. et al. The effect of change in fasting glucose on the risk of myocardial infarction, stroke, and all-cause mortality: A nationwide cohort study. Cardiovasc. Diabetol. 17(1), 1–10 (2018).
Wei, J. et al. Sex-based differences in quality of care and outcomes in a health system using a standardized STEMI protocol. Am. Heart J. 191, 30–36 (2017).
Shehab, A. et al. Clinical presentation, quality of care, risk factors and outcomes in women with acute ST-elevation myocardial infarction (STEMI): An observational report from six middle Eastern countries. Curr. Vasc. Pharmacol. 17(4), 388–395 (2019).
Zachura, M. et al. Gender-related differences in men and women with ST-segment elevation myocardial infarction and incomplete infarct-related artery flow restoration: A multicenter national registry. Adv. Interv. Cardiol. 14(4), 356 (2018).
Sarwar, N. et al. Emerging Risk Factors Collaboration Diabetes mellitus, fasting blood glucose concentration, and risk of vascular disease: A collaborative meta-analysis of 102 prospective studies. Lancet 375, 2215–2222 (2010).
Cui, J., Liu, Y., Li, Y., Xu, F. & Liu, Y. Type 2 diabetes and myocardial infarction: Recent clinical evidence and perspective. Front. Cardiovasc. Med. 8, 64 (2021).
Mooradian, A. D. Evidence-based management of diabetes in older adults. Drugs Aging 35(12), 1065–1078 (2018).
Kumar, S., McDaniel, M., Samady, H. & Forouzandeh, F. Contemporary revascularization dilemmas in older adults. J. Am. Heart Assoc. 9(3), e014477 (2020).
Solaro, N., Barbiero, A., Manzi, G. & Ferrari, P. A simulation comparison of imputation methods for quantitative data in the presence of multiple data patterns. J. Stat. Comput. Simul. 88(18), 3588–35619 (2018).
Mao, K. Orthogonal forward selection and backward elimination algorithms for feature subset selection. IEEE Trans. Syst. Man Cybern. Part B 34(1), 629–634 (2004).
Aragam, K. G. et al. Does simplicity compromise accuracy in ACS risk prediction? A retrospective analysis of the TIMI and GRACE risk scores. PLoS ONE 4(11), e7947 (2009).
Zhao, G. et al.. In‐Hospital Outcomes of Dual Loading Antiplatelet Therapy in Patients 75 Years and Older With Acute Coronary Syndrome Undergoing Percutaneous Coronary Intervention: Findings From the CCC‐ACS (Improving Care for Cardiovascular Disease in China‐Acute Coronary Syndrome) Project. J. Am. Heart Assoc. 7(7), e008100 (2018).
Khaire, U. M. & Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ.-Comput. Inf. Sci. (2019).
Hu, G. et al. Smoking and provision of smoking cessation interventions among inpatients with acute coronary syndrome in China: Findings from the Improving Care for Cardiovascular Disease in China-Acute Coronary Syndrome Project. Glob. Heart 15(1) (2020).
Irawati, S. et al. Long-term incidence and risk factors of cardiovascular events in Asian populations: Systematic review and meta-analysis of population-based cohort studies. Curr. Med. Res. Opin. 35(2), 291–299 (2019).
Funding
This work was supported by Kementerian Sains, Teknologi dan Inovasi, Malaysia (Grant No: TDF03211036). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
Contributed equally to this work with Dr S.M., Prof S.K. and C.S. Dr M.S. and Prof W.A.W. contributed in formal analysis, resources, supervision, review and editing. As for Dr K.S. assist in investigation, validation, and writing editing. F.A. worked on data validation. Prof K.N. assisted in review and provides feedback on data related to cardiology. N.I. worked on writing and editing of the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kasim, S., Malek, S., Cheen, S. et al. In-hospital risk stratification algorithm of Asian elderly patients. Sci Rep 12, 17592 (2022). https://doi.org/10.1038/s41598-022-18839-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-18839-9
- Springer Nature Limited
This article is cited by
-
Ensemble machine learning for predicting in-hospital mortality in Asian women with ST-elevation myocardial infarction (STEMI)
Scientific Reports (2024)
-
Machine learning prediction of mortality in Acute Myocardial Infarction
BMC Medical Informatics and Decision Making (2023)
-
A comprehensive review of machine learning algorithms and their application in geriatric medicine: present and future
Aging Clinical and Experimental Research (2023)