
Abstract
Chinese is characterized by high syntactic complexity, chaotic annotation granularity, and slow convergence. Joint learning models can effectively improve the accuracy of Chinese Named Entity Recognition (NER), but they focus too much on local feature information and reduce the ability of long sequence feature extraction. To address the limitations of long sequence feature extraction ability, we propose a Chinese NER model called Incorporating Recurrent Cell and Information State Recursion (IRCSR-NER). The model integrates recurrent cells and information state recursion to improve the recognition ability of long entity boundaries. To solve the problem that Chinese and English have different focuses in syntactic analysis. We use the syntactic dependency approach to add lexical relationship information to sentences represented at the word level. The IRCSR-NER is applied to sequence feature extraction to improve the model efficiency and long-text feature extraction ability. The model captures contextual long-distance dependent information while focusing on local feature information. We evaluated our proposed model using four public datasets and compared it with other mainstream models. Experimental results demonstrate that our model outperforms traditional and mainstream models.
Similar content being viewed by others


Introduction
The NER is an essential and critical task in information extraction. Its objective is to extract, locate and classify entities with specific semantics from unstructured text1. This extracted information can be used in various natural language processing downstream tasks, such as information retrieval, knowledge graphs, and question-and-answer systems et al.2,3,4,5,6. Accurately identifying the attributes of named entities is valuable for knowledge representation and information extraction and is widely used.
The given text sequence is often labelled in NER using sequence annotation methods. There are three common annotation methods for entity identification sequences, namely Begin Inside Outside (BIO), Begin Middle End Single (BMES), and Begin Inside Outside Single End (BIOSE) annotation schemes. Reimers et al.7. compared IOB, BIO, and BIOES labelling schemes. Their experiments demonstrate that the BIO and BIOES annotation schemes are superior to the IOB scheme in the NER task. Therefore, our experiment used BIO labelling methods.
Chinese NER techniques have evolved from traditional approaches to deep learning. Early methods based on rules and dictionaries8 required the creation of specific rule templates. As this method depends on creating knowledge bases, it often results in low portability. NER methods based on statistical machine learning relied on selecting and analyzing features, which consumed a lot of manpower. However, deep neural networks with powerful feature learning capabilities have been applied to NER in recent years, achieving excellent results. Hammerton9 was the first to combine Long Short-Term Memory (LSTM) with CRF for NER. To address the problem of not being able to obtain contextual bi-directional sequence information, Lample et al.10. proposed Bi-directional Long Short-Term Memory (Bi-LSTM) combined with the CRF network model. However, the capture of long-distance dependence caused information loss.
To address the limitations in extracting features from long sequences, this study introduces a Chinese named entity recognition (NER) model called Incorporating Recurrent Cell and Information State Recursion (IRCSR-NER). By incorporating recurrent cells and information state recursion, the model enhances its ability to accurately identify long entity boundaries. Additionally, to address the syntactic differences between Chinese and English, we introduce dependency-based syntactic analysis at the input representation layer of Chinese NER. Specifically, we employ a syntactic dependency approach to incorporate lexical relationship information at the word level in sentence representations. This approach is applied in conjunction with IRCSR-NER for sequence feature extraction, resulting in improved efficiency and long-text feature extraction capability. The model effectively captures contextual long-distance dependencies while simultaneously focusing on local feature information. Experimental results demonstrate that the proposed model achieves the best performance in terms of the F1 value on four public datasets when compared to other mainstream models. Overall, this method significantly enhances the model's ability to accurately identify long entities in lengthy texts and exhibits generalization capabilities for Chinese entity recognition tasks.
The main contributions of this paper are as follows: (1) We propose a model that combines recurrent cancer cells and information state recursion (IRCSR) for named entity recognition (NER). By applying IRCSR-NER at the sequence encoding layer, the model captures long-distance contextual dependencies while focusing on local feature information. (2) Our work demonstrates that enhancing the recognition of entity boundaries and improving the performance of Chinese NER can be achieved by incorporating part-of-speech relationship information into Chinese sentences. (3) Through experiments conducted on four public datasets, we demonstrate that our IRCSR-NER model achieves better results in terms of F1 score compared to traditional models and existing state-of-the-art models. We further validate the effectiveness of the syntactic dependency module, the information state recursion module, and the overall IRCSR-NER structure through ablation experiments.
The paper is structured as follows: Section "Related research" provides an overview of related research and background knowledge. In Section "Methods", we present a detailed description of the proposed IRCSR-NER model and its core components. Section "Experimentation and analysis of results" focuses on the experimental design and provides details about the datasets used. In this section, we also present the experimental results with analysis and discussion. Finally, in Section "Conclusions", we summarize the paper and discuss future research directions.
Related research
The sequence encoding layer is crucial in deep learning models for named entity recognition (NER). It is responsible for encoding the input sequence into semantic representations, which are then used to annotate the sequence at the output layer. In the past, recurrent neural networks (RNNs) were primarily used for sequence encoding, but they had limited capabilities in modeling long-range dependencies11. Recently, the development of self-attention mechanisms has led to the emergence of fully attention-based networks, such as Transformers, which have replaced RNNs as the mainstream approach. Transformers have shown more effectiveness in capturing global dependencies. Notably, inter-layer self-attention in SPAN-BERT12 and bidirectional transformers in OntoNLP13 have shown significant improvements in feature extraction capabilities. When performing entity extraction tasks on knowledge graphs, the incorporation of different lexical information has been widely applied. For example, the introduction of rule-based lexical information has been extensively utilized14.
For rule-based entity tasks, the part-of-speech (POS) information among words in a sentence is a crucial component. Dependency parsing, also known as dependency analysis, is a commonly used method in relation extraction. It involves analyzing the grammatical structure of a sentence to identify relevant words and their relationship types. Tian et al.15 further improved the predictive accuracy by combining dependency parsing with the bidirectional affine attention mechanism. Fei et al.16 addressed the issue of overlapping entity relation extraction and proposed a method that treats the overlapping relation extraction task as a quintuple prediction problem. This method achieved advanced performance by modeling entity relation graphs using graph attention models. In order to leverage the syntactic knowledge effectively in information extraction tasks, Fei et al.17 proposed a novel structure-aware GLM model. This model greatly addresses the issue of long-range dependencies and boundary recognition, while emphasizing the effectiveness of syntactic structural information in information extraction tasks. Therefore, this paper chooses to incorporate syntactic dependency methods to add POS relationship information to the entity recognition task.
The CNNs are commonly used in the sequence encoding layer of Chinese NER models. Gui et al.18 introduced a parallel sentence matching approach that combines a dictionary with a CNN-based reflection mechanism. Shi et al.19 developed the CNN-Head Transformer Encoder (CHTE) model to handle multi-word expressions, but it comes with increased computational costs. It utilizes CNNs with varying window sizes to capture attention head vectors, thereby enhancing local features while preserving global semantics. In order to simultaneously address flat, overlapping, and disjoint entity recognition, Li et al.20 proposed a model that models the adjacent relationships between entities. This model represents unified NER as a two-dimensional network of word pairs, incorporating multi-granularity 2D convolutions to optimize grid representations.
The RNNs incorporate "recurrence" to retain previous states and impact subsequent outputs, capturing contextual information effectively. However, when dealing with long sequences, RNNs are susceptible to the problems of vanishing or exploding gradients21. Dong et al.22 employed bidirectional LSTM-CRF for Chinese NER, leveraging both character-level and partial-level representations. This study was the first to investigate partial-level performance within this architecture for Chinese NER, achieving state-of-the-art results at the time.
The Transformers are also employed as sequence encoding layers, relying solely on attention mechanisms without the use of recurrence or convolution. They offer reduced training time and demonstrate remarkable performance in addressing natural language problems. Yan et al.11 presented a NER architecture that incorporates a flexible Transformer Encoder for character and word representations. Li et al.23 proposed the plane lattice deformation model, which takes advantage of the robust capabilities of Transformers and meticulously crafted position encodings to fully exploit lattice information, transforming the lattice structure into spans.
Extensive research has been conducted to address the challenges of entity recognition by incorporating different lexical information. Fei et al.24 explored the task of biomedical information extraction (BioIE). To tackle the issue of existing information extraction methods neglecting the fusion of external structured knowledge, they proposed a method that integrates large-scale biomedical knowledge graphs to enrich contextualized language models. To address the problem of overlooked discontinuous and irregular entity recognition, Fei et al.25 introduced a NER model called BIOBERT + MAPtr, which utilizes a pointer network. The model's pointers contain positional information that represents entity labels. Zhang et al.26 proposed the Lattice LSTM model, which incorporates lexical information into LSTM. However, Lattice LSTM is not parallelizable and struggles to handle lexical conflicts effectively. Sui et al.27 presented the Collaborative Graph Network (CGN) model, which combines dictionary and character information at the encoding layer and employs graph attention networks for encoding. This model also resolves the issues of Lattice LSTM by including self-matching word information and closest-word information. Nonetheless, differences still exist between the results obtained from graph structures and sequence structures due to their inherent disparities.
While sequence encoding methods have shown promising results in NER, they still have some limitations in modeling tasks. The CNN can only capture local features and falls short in modeling long-distance dependencies. The RNN encounters issues of vanishing and exploding gradients when dealing with lengthy sequential text, and it has slower training speed. Although Transformers theoretically have the ability to model dependencies across any distance, the practical application of dependency modeling is still limited. To address these challenges, we propose a novel structure called Integrated Recurrent Cell and Information State Recursion (IRCSR-NER) as a sequence encoding layer. In the input representation layer of Chinese NER, dependency syntactic analysis is introduced. The model combines recurrent cells with information state recursion. We integrate this structure with pre-trained language models and Conditional Random Fields (CRF) to form a joint learning model. By utilizing recurrent units and information state recursion, the model enhances the recognition capability of long entity boundaries. Applying IRCSR-NER to sequence feature extraction improves the efficiency and effectiveness of extracting features from lengthy texts. The model's input layer incorporates lexical relation information into the sentence representation at the word level, thus enhancing the entity boundary recognition capability. The model captures both long-distance contextual dependencies and local feature information. Experimental results demonstrate that this approach enhances the model's ability to accurately identify long entities in long texts.
Methods
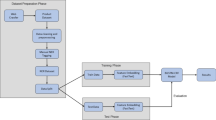
Our proposed IRCSR-NER structure serves as a sequence coding framework within a joint learning model. Our proposed NER model comprises three layers: an input representation layer, a sequence encoding layer, and an output decoding layer, as shown in Fig. 1. We introduce dependent syntactic analysis to the input representation layer specifically for Chinese NER. Dependent syntactic analysis is a technique that aims to uncover the semantic structure of a sentence by examining the dependencies between its components. In contrast to English, where syntactic analysis relies on spatial relationships between sentence components, Chinese syntactic analysis focuses on the dependency relationships between these components. Our model is inspired by Hutchins et al.28 who applied recurrent units to classification tasks. In our approach, the input representation layer gathers block-level information from syntactic dependency chunking. This information, which reflects rich semantic knowledge, is leveraged for downstream sequential coding tasks through pre-training language models with BERT. The sequence encoding layer incorporates multiple IRCSR structures. The input sequence is horizontally extracted using the Transformer with Attention mechanism to extract features. The state information from the previous moment is interactively updated with semantic vectors, while the new semantic vector is passed to the subsequent moment. Vertically, the Transformer with attention mechanism efficiently computes Self-Attention and Cross-Attention for feature extraction. Finally, the sequence encoding information is outputted to the decoding layer, which predicts the corresponding out sequence text.

Application of IRCSR-NER's entity recognition model.
Syntactic dependency chunking
In this paper, we introduce dependent syntactic analysis to the input representation layer of Chinese NER. The goal of dependent syntactic analysis in Chinese is to reveal the semantic structure of a sentence through the dependencies between its components. Unlike English syntactic analysis, which is based on the concept of space, Chinese syntactic analysis is based on the dependency relationship between sentence components. We use the HanLP Chinese natural language processing tool to implement neural network-based Chinese dependency syntactic analysis. Based on lexical relations, we perform syntactically dependent chunking of the input sequence text. The chunking information is then assembled into the original sequence text.
Based on the Dependency Syntax Tree, a sentence can be divided into several semantically meaningful chunks. Each of the chunks contains a central word and its closely related constituents. We break down sentences into separate components (such as subject-verb and verb-object blocks, as well as modifier blocks) based on their respective subtrees in the tree structure. These blocks are then assembled into a vector representation of the input sequence, as shown in Fig. 2. This facilitates the downstream sequence annotation task to focus on semantic information.

Example results of syntactic dependency blocking information.
In Fig. 2, we can see that the subject "张三" and the predicate "工作" are part of the Subject-Verb-Block. The predicate "工作" and the object "微软公司" are part of the Verb-Object-Block. The remaining modifying relations, adverbs, prepositions, auxiliaries, and other lexical words are also part of the Verb-Object-Block. The predicate "工作" and the object "微软公司" are also part of the Verb-Object-Block. The rest of the modifier relations, prepositions, and other lexical words such as "在" are part of the individual Modifier-Block. We add the information of the constituent block containing each word in the input vector information. This distinguishes the core constituents, reduces the interference between them and helps downstream models focus on the entity itself. Words in the constituent block have a close local dependency and carry rich local semantic information, which is useful for knowledge expression.
Incorporating recurrent cell and information state recursion (IRCSR-NER)
The IRCSR units receive two inputs: a set of semantic vectors from the input representation layer and a set of current state information vectors. The IRCSR operation consists of three components: the vertical direction, the horizontal direction, and the state information recursion. The process of transforming input semantic vectors into output semantic vectors in the decoding layer is referred to as the vertical direction. The process of transitioning from the current state vector to the next state vector is referred to as the horizontal direction. The recursive operation of propagating information in the horizontal direction is known as state information recursion. Figure 3 and Fig. 4 illustrates this process.

The structure of IRCSR-NER vertical and horizontal.

The structure of IRCSR-NER status update.
According to Fig. 3, the purpose of the vertically oriented Transformer unit is to obtain the feature representation. It performs self-attention computation on word sequences and cross-attention computation on word sequences and state vectors. The self-attention and cross-attention mechanisms compute the vector values of the query (query vector), value (information vector), and key (key vector). The inputs of Linear(Ks,Vs) and Linear(Qs) are the word sequence vector Mt and the state vector Cl incorporating the learning state, respectively. Additionally, The input of Linear(Ke,Qe,Ve) is the word sequence vector Mt, and the state vector Cl is denoted as:
Equation (1) introduces the input state vector at the previous time step, denoted as η−1 s, and the learned state ID, Lid, which is employed to label the IRCSR structural unit.
To compute the self-attention representation sa and the cross-attention representation ca, distinct vector values are employed. Specifically, for the self-attention representation, the vector values Qe,p, Ve,p, and Ke,p are obtained from the query vector, value vector, and key vector, respectively, using the Linear(Ke,Qe,Ve) operation. These values are utilized to determine the self-attention weights. On the other hand, for the cross-attention representation, the vector values Qs,p, Vs,p and Ks,p are obtained from the query vector, value vector, and key vector, respectively, by applying the Linear(Ks,Vs) and Linear(Qs) operations. These values are employed to calculate the cross-attention weight. The computation process is illustrated in Eqs. (2) and (3).
To derive the vertical word sequence feature vector, a series of computations is employed. Initially, the self-attention and cross-attention operations are linearly projected, yielding a linear projection vector, lp. Subsequently, the word sequence vector, Mt, and the linear projection vector, lp, are processed through a vertical feedforward fully connected network junction output, denoted as FFV(Mt + lp). Finally, the word sequence vector, Mt, the linear projection vector, lp, and the feedforward fully connected network junction output, FFV(Mt + lp), are fused to generate the vertical word sequence feature vector, Mt,n. The computation process is illustrated in Eqs. (4) and (5).
In the equation, W_1 and W_2 represent two linear transformation matrices. The variables sa and ca correspond to the self-attention representation and the cross-attention representation, respectively, computed in Eqs. (2) and (3).As illustrated in the horizontal structure depicted in Fig. 3, the loop unit performs self-attention computations on the input word sequence. Additionally, the loop unit conducts cross-attention computations on the word sequence vectors and state vectors. The gating unit is utilized to implement the forgetting mechanism, which controls the flow of information computed by the attention mechanism. The structure also generates a new state vector through interaction with the state vector to update the sequence vector from the previous time step. This new state vector is then propagated to the next time step. The query vector, value vector, and key vector values are computed using both the self-attention mechanism and the cross-attention mechanism. The inputs for Linear(Ks,Vs) are the word sequence vectors, Mt. The inputs for Linear(Ks,Qhs,Vs) and Linear(Qhe) are the state vectors of the fused learning state. The state vector, Cl, is defined in Eq. (1).
During the calculation of the self-attention representation, the vector values Qhs,t, Vs,t and Ks,t derived from the query vector, value vector, and key vector using Linear(Ks,Qhs,Vs) are employed to compute the self-attention weights. In the computation of the cross-attention representation, the cross-attention weights are computed using the vector values Qhe,t, Ve,t and Ke,t obtained from the query, value, and key vectors through Linear(Ke,Ve) and Linear(Qhe). The calculation process is illustrated in Eqs. (6) and (7).
Linear projection is applied to the self-attention and cross-attention to obtain the linear projection vector, lhp, as calculated in Eq. (8):
In the equation, W_3 and W_4 represent two linear transformation matrices. The variables sha and cha correspond to the self-attention representation and the cross-attention representation, respectively, computed in Eqs. (6) and (7).
The output f1 of the word sequence vector, Mt, and the linear projection vector, lhp, after undergoing the gating unit is calculated as demonstrated in Eq. (9).
In the equation, W_5 and W_6 represent two linear transformation matrices and σ is the sigmoid activation function.
To compute the horizontal state vector, ηf, which represents the output of gated unit 2, the output f1 of gated unit 1 is combined with the output of the feedforward fully connected network junction. This fusion is accomplished using gating unit 2, yielding the desired horizontal state vector.
The calculation process for deriving the horizontal state vector through gating unit 2, as illustrated in Eq. (10), is as:
In the equation, W_5 and W_6 represent two linear transformation matrices, η−1 s is the input state vector at the previous moment, and σ is the sigmoid activation function.
In the IRCSR model illustrated in Fig. 3, the keys and values (K, V) are shared between the vertical and horizontal segments. We calculate one set of keys and values (Ke, Ve) from the input semantic vectors, and another set (Ks, Vs) from the state vectors. Each segment has its own unique query vector (Q), leading to four different sets: Qe and Qs for the vertical segment, and Qhe and Qhs for the horizontal segment. The query vectors Qe, Qs, Qhe, and Qhs are four distinct and non-overlapping vectors. This approach is designed to enhance the model's versatility and separability. By incorporating multiple relevant features within the sequence, it enables the model to improve its expressive power and generalization ability.
As shown in Fig. 4, we input the acquired state vector and the word sequence vector from the previous moment into the recursive update module. This module determines the number of rounds to operate on the horizontally propagated state vectors by judging whether it's an odd or even number of rounds. For odd rounds, we use Eq. (11), and for even rounds, we use Eq. (12). Finally, the state vector ηf is obtained after an odd number of rounds into the next loop cell.
where σ is the sigmoid activation function, Qi is the random initialisation matrix, Mt−1 is the block of semantic vectors input at the previous moment, and ηprev denotes the state vector computed at even numbers.
CRF-conditional random field
Conditional Random Field (CRF) is used to globally predict the labelled sequence of any given sequence. Given an input sequence X = {x1,x2,…,xn} and a labelled sequence Y = {y1,y2,…,yn} can be computed s(X,Y) as:
where A is the transfer matrix. Pn*k is the label score of the encoder and k is the number of label types. Ai,j represents the score from label i to label j.
The probability of optimizing the label sequence:
where YX represents the set of all possible labelled sequences.
In the training phase, the maximum logarithmic probability of correct prediction is considered. For decoding, the labelled sequence that has the highest score for the input sequence is filtered as the final output:
Experimentation and analysis of results
Datasets
The MSRA dataset is a Chinese named entity recognition dataset provided by Microsoft Research Asia, specifically in the news domain. It consists of over 50,000 Chinese sentences with entity annotations. The entities are categorized into three types: Person, Location, and Organization.The Resume dataset is generated by filtering and manually annotating the summary data of senior executives' resumes from listed companies on the Sina Finance website. It includes 1027 resume summaries, and the entities are classified into eight categories: Person, Country, Location, Race, Profession, Education, Organization, and Title. The OneNote dataset is derived from a large manually annotated corpus. It includes 18 entity types, including Person, Location, and Organization.The Weibo dataset is generated by filtering historical data from Sina Weibo between November 2013 and December 2014. It contains 1890 Weibo messages, and the entities are classified into four categories: Person, Location, Organization, and GPE (Geopolitical Entity).
Experiments configuration
All our experiments were conducted on an NVIDIA Quadro RTX4000 GPU for training purposes. The model parameters are presented in Table 1. During the training process, we utilized a Chinese pre-trained language model, BERT, for pre-training. The model employed the Adam optimization function, with the numerical stability parameter epsilon set to 1e−8. The learning rate was set to 3e−5, and the hidden layers had a dimensionality of 768. We employed the IRCSR-NER architecture for sequence encoding tasks, where the number of multi-head attention heads was set to 8, and each head had a dimensionality of 64. The model utilized hidden layers with a dimensionality of 768, an encoding depth of 6, a feed-forward layer expansion ratio of 4, and 4 recursive iterations. During the information state recursion, we employed 5 rounds of information interaction. We applied dropout with a probability of 0.5 at all layers. The maximum sentence length in this study was set to 256 tokens, and the batch size was set to 16. We present the most optimal outcomes for all metrics obtained in the experiment.
Evaluation indicators
The following three mainstream evaluation metrics are mainly used in Chinese NER experiments: Precision (P), Recall (R), and F1-Score (F1). The specific calculations of these three evaluation metrics are shown in Eqs. (16–18):
The TP represents the number of positive classes that are correctly predicted to be positive. FN represents the number of positive classes that are predicted to be negative. The FP represents the number of negative classes that are predicted to be positive. The TN represents the number of negative classes that are correctly predicted to be negative.
Analysis of results
In this paper, we propose a Chinese named entity recognition model called IRCSR-NER, which incorporates syntactic dependency information in the input representation and combines recurrent units with information state recursion in the sequence encoding process. In this section, we analyze and discuss the performance of different models on four public datasets. We compare the performance of three different types of entity recognition models: adaptive base framework, graph structure, and adaptive embedding. We present the optimal results for all metrics in the experiments.
Table 2 shows the experimental results on the Resume dataset and MSRA dataset. On the Resume dataset, the BERT-IRCSR-CRF model achieves the highest precision, recall, and F1 score. Compared to the BERT-PLTE-BIGRU-CRF29 model that incorporates positional information and a porous mechanism, our model improves precision, recall, and F1 score by 0.26%, 1.01%, and 0.63%, respectively. This demonstrates the effectiveness of our model in identifying multiple labels and capturing long-distance dependency information. On the MSRA dataset, our model achieves the highest recall result. The precision and F1 score obtain the second-highest results, surpassing the adaptive embedding model MECT30 and the graph structure model FGN31. This indicates that our model exhibits comprehensiveness in the task of entity capturing with standardized data.
Table 3 presents the experimental results on the Weibo dataset and OneNotes dataset. On the Weibo dataset, due to the nature of short text messages in Weibo, our model achieves the second-highest accuracy and recall. However, our model obtains the highest F1 score, surpassing the Visphone32 model, which ranks second in terms of effectiveness, by 0.06%. This demonstrates that our model has the ability to capture both long entity boundaries and focus on short entity boundaries. On the OneNotes dataset, our model achieves the best results in terms of accuracy and F1 score. This indicates that our model is applicable to handling complex contextual relationships and complex entity boundaries.
To validate the effectiveness of the IRCSR structure, ablation experiments were conducted. We primarily employed three ablation conditions: -Syntactic Dependency Information (SDI), -Information State Recursion Module (SR), and -IRCSR structure. -SDI denotes the removal of syntactic dependency information from the input representation layer. -SR signifies the elimination of the information State recursion module within the IRCSR structure. -IRCSR indicates the removal of the entire IRCSR structure.
According to the statistical analysis, when using models without the SDI module for entity recognition, the F1 scores decreased by 0.49%, 0.52%, and 1.19% on the Resume dataset, MSRA dataset, and OneNote dataset, respectively. On the Weibo dataset, the accuracy and F1 scores decreased by 0.27% and 0.03%, while interestingly, the recall rate increased by 0.21%. This can be attributed to the interference of syntactic dependency methods in handling unstructured texts, such as the Weibo dataset, leading to mislabeling some entities as negative examples. When the SR module was removed for entity recognition, the F1 score on the Weibo dataset showed the largest decrease of 2.57% among all datasets. This is because the State Representation module has a more comprehensive ability to capture crucial contextual information. For texts with high importance on contextual information, the SR module can better capture long-distance dependencies within the sequence. When the IRCSR module was removed from the model for entity recognition, the F1 scores decreased by 1.4% and 2.58% on the Resume dataset and MSRA dataset, respectively. On the Weibo dataset and OneNote dataset, the F1 scores decreased by 7.05% and 4.9%, respectively.
Table 4 presents the varying degrees of F1 score reduction across the four datasets when removing the SDI module, SR module, or IRCSR module. Analyzing the changes in accuracy, recall, and F1 score during the ablation experiments leads to the following conclusions:(1) The syntactic dependency method incorporates the grammatical relationships between words into the model, enabling better handling of data sparsity and improved contextual support. However, challenges still exist when dealing with informal and unstructured texts. (2) The utilization of horizontal recursive information propagation in the IRCSR model enhances the model's ability to handle complex sentences. This model improves the limitations of information propagation, particularly in long sequences. (3) By employing the IRCSR-NER structure as the entity recognition sequence encoding layer, the model effectively focuses on local feature information while capturing long-distance contextual dependencies. This demonstrates the effectiveness and robustness of the IRCSR-NER structure.
The Chinese NER is a complex process where one character can correspond to multiple words. To observe the performance of the BERT-CRF model and the BERT-IRCSR-CRF model, we recorded their character weights for the sentence "汉中城固县许家村" and drew a heat map (Fig. 5). By comparing the results, we noticed that the BERT-CRF model pays more attention to the characters "城", "县", and "庙" when identifying the address entity "汉中城固县许家村". However, this model incorrectly identifies the sentence as three address entities—"汉中城", "固县", and "许家村". After consulting our entity thesaurus, we discovered that most entities have secondary and tertiary structures. In such cases, the entity boundary recognition ability plays a vital role in identifying named entities.

Example of character weight heat map: (a) BERT-CRF, (b) BERT-IRCSR-CRF.
Our IRCSR-NER model can reduce the recognition ability of first-level and second-level endings while strengthening the recognition ability of lower-level endings. The heat map shows that "汉" and "村" carry the highest weight. The result indicates that the IRCSR structure can effectively improve entity boundary recognition for medium and long entities while reducing the interference of irrelevant endings.
To evaluate the effectiveness of the IRCSR structure in enhancing the performance of the Chinese NER model. We conducted an analysis of the difference in entity detection results based on several examples.
Figure 6 clearly illustrates that the general network structure IRCSR(-er) model, which doesn't use the IRCSR structure in the first sentence, can accurately detect the place names (LOC) "汉中" and "中国". However, it incorrectly identifies "汉中城", "固县" and "许家庙" in "汉中城固县许家庙" as three separate LOCs. In contrast, the IRCSR model can correctly identify "汉中城固县许家庙" as a single place name (LOC). Similarly, in the second sentence, the IRCSR(-er) model correctly detects the name (NAME) "万毅", occupation (TITLE) "高级会计师", and education (EDU) "大学学历". However, it incorrectly identifies "武汉钢铁股份有限公司董事会秘书." as an organization name (ORG) and occupation (TITLE). On the other hand, the IRCSR model can correctly identify "武汉钢铁股份有限公司董事会秘书" as an occupation (TITLE). The above experimental results fully demonstrate the effectiveness of the IRCSR-NER model. It can improve the problems of incorrect detection of long entity nouns and insufficient ability to capture long-distance dependent information.

Example analysis and comparison.
Conclusions
In this work, we propose a Chinese NER model named IRCSR-NER. To enhance the identification of entity boundaries, we incorporate word information into the word-level representation of sentences via a syntactic dependency approach at the input layer of the model. We employ the IRCSR structure to sequence feature extraction, which improves its efficiency and ability to extract features from long texts. The model is designed to capture contextual long-range dependent information, while also focusing on local feature information. Compared to the five mainstream models, it achieved the highest accuracy, recall, and F1 values on the Resume dataset and the highest recall on the MASR dataset. There are many directions for our future work. One of the promising directions is to introduce multimodal network architecture in our model. Using correlated images to better recognize named entities with polysemous words contained in the text.
Data availability
The datasets used and analysed in the current study are available from the corresponding author upon reasonable request.
References
Wang, Y., Zhang, C., Bai, F., Wang, Z. & Ji, C. A survey on Chinese named entity recognition. J. Comput. Sci. Explor. 17(2), 18 (2023).
Khalid, M. A., Jijkoun, V. & Rijke, M. D. The Impact of Named Entity Normalization on Information Retrieval for Question Answering. In Advances in Information Retrieval Vol. 4956 (eds Macdonald, C. et al.) (Springer, 2008).
Riedel, S., Yao, L., Mccallum, A., & Marlin, B. M. Relation extraction with matrix factorization and universal schemas. NAACL-HLT (2023).
Diefenbach, D., Lopez, V., Singh, K. & Maret, P. Core techniques of question answering systems over knowledge bases: A survey. J. Knowl. Inf. Syst. 55, 529–569 (2018).
Wang, Z. et al. A hybrid model of sentimental entity recognition on mobile social media. EURASIP J. Wirel. Commun. Netw. 2016, 1–12 (2016).
Karatay, D. & Karagoz, P. User interest modeling in twitter with named entity recognition. In Proc. 5th Workshop on Making Sense of Microposts. Florence, Italy, May 19, 2015. Aachen, Germany: CEUR Workshop Proceedings, 2015, 35–38 (2015).
Yamada, I., Asai, A., Shindo, H., Takeda, H. & Matsumoto, Y. Luke: deep contextualized entity representations with entity-aware self-attention. In Proc. Conference on Empirical Methods in Natural Language Processing (2020).
Chen, X., Ouyang, C., Liu, Y. & Bu, Y. Improving the named entity recognition of Chinese electronic medical records by combining domain dictionarie and rules. Int. J. Environ. Res. Public Health 17(8), 2687 (2020).
Khalifa, M. & Shaalan, K. Character convolutions for Arabic named entity recognition with long short-term memory networks. Comput. Speech Lang. 58, 335–346 (2019).
Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K. & Dyer, C. Neural architectures for named entity recognition. In Proc. Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. https://doi.org/10.18653/v1/N16-1030 (2016).
Yan, H., Deng, B., Li, X. & Qiu, X. TENER: Adapting transformer encoder for named entity recognition. https://arxi.org/abs/1911.04474 (2019).
Joshi, M. et al. SpanBERT: Improving pre-training by representing and predicting spans. In Proc. Transactions of the Association for Computational Linguistics 8, 64–77. https://doi.org/10.48550/arXiv.1907.10529 (2019).
Lin et al. OntoNLP: Joint ontological and linguistic knowledge bases for natural language processing. In Proc Conferenceon Empirical Methods in Natural Language Processing (2021).
Ye, H., Zhang, N. & Chen, H. Generative knowledge graph construction: A Review. In Proc. The 2022 Conference on Empirical Methods in Natural Language Processing, pp 1–17. https://doi.org/10.48550/arXiv.2210.12714 (2022).
Tian, Y. et al. Enhancing structure-aware encoder with extremely limited data for graph-based dependency parsing. In Proc. Proceedings of the 29th International Conference on Computational Linguistics. 5438–5449 (2022).
Fei, H., Ren, Y. & Ji, D. Boundaries and edges rethinking: An end-to-end neural model for overlap entity relation extraction. Inf. Proc. Manag. 57(6), 102311 (2020).
Fei, H. et al. Lasuie: Unifying information extraction with latent adaptive structure-aware generative language model. Adv. Neural Inf. Proc. Syst. 35, 15460–15475 (2022).
Gui, T., Ma, R., Zhang, Q., Zhao, L. & Huang, X. CNN-based Chinese NER with Lexicon Rethinking. In Proc. Twenty-Eighth International Joint Conference on Artificial Intelligence IJCAI-19 (2019).
Shi, Z. et al. Chinese named entity recognition based on CNN-head transformer encoder. Comput. Eng. 48(10), 73–80 (2022).
Li, J. et al. Unified named entity recognition as word-word relation classification. In Proc. The AAAI Conference on Artificial Intelligence, 36(10), 10965–10973 (2022).
Ouyang, E., Li, Y., Jin, L., Li, Z. & Zhang, X. Exploring n-gram character presentation in bidirectional RNN-CRF for Chinese clinical named entity recognition. In Proc. CCKS: China Conference on Knowledge Graph and Semantic Computing, 1976, 37–42 (2017).
Dong, C., Zhang, J., Zong, C., Hattori, M. & Di, H. Character-based LSTM-CRF with radical-level features for chinese named entity recognition. In Proc. International Conference on Computer Processing of Oriental Languages National CCF Conference on Natural Language Processing and Chinese Computing. https://doi.org/10.1007/978-3-319-50496-4_20 (2016).
Li, X., Yan, H., Qiu, X. & Huang, X. Flat: Chinese NER using a flat-lattice transformer. http://arxi.org/abs/2004.11795 (2020).
Fei, H., Ren, Y., Zhang, Y., Ji, D. & Liang, X. Enriching contextualized language model from knowledge graph for biomedical information extraction. Brief. Bioinf. 22(3), 110 (2021).
Fei, H. et al. Rethinking boundaries: End-to-end recognition of discontinuous mentions with pointer networks. In Proc. The AAAI conference on artificial intelligence, 35(14), 12785–12793 (2021).
Zhang, Y. & Yang, J. Chinese NER using lattice LSTM. In Proc. 56th Annual Meeting of the Association for Computational Linguistics, Volume 1: Long Papers, 1554–1564 (2018).
Sui, D., Chen, Y., Liu, K., Zhao, J. & Liu, S. Leverage lexical knowledge for Chinese named entity recognition via collaborative graph network. In Proc. 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) 3830–3840 (2019).
Hutchins, D. L., Schlag, I., Wu, Y., Dyer, E. & Neyshabur, B. Block-recurrent transformers. https://arxiv.org/abs/2203.07852 (2022).
Mengge, X. et al. Porous lattice transformer encoder for Chinese NER. In Proc. The 28th international conference on computational linguistics, pp 3831–3841. (2020).
Wu, S., Song, X. & Feng, Z. MECT: Multi-metadata embedding based cross-transformer for Chinese named entity recognition. https://doi.org/10.48550/arXiv.2107.05418 (2021).
Xuan, Z., Bao, R., Ma, C. & Jiang, S. FGN: Fusion Glyph network for Chinese named entity recognition. In Proc. China Conference on Knowledge Graph and Semantic Computing. https://doi.org/10.48550/arXiv.2001.05272 (2020)
Zhang, B., Cai, J., Zhang, H. & Shang, J. VisPhone: Chinese named entity recognition model enhanced by visual and phonetic features. Inf. Proc. Manag. 60(3), 103314 (2023).
Author information
Authors and Affiliations
Contributions
Q.H.: Conceptualization, Writing-Review & Editing, Data Curation, Formal analysis, Methodology, Sofware, Validation, Writing-Original Draf. J.M.: Supervision, Project administration, Funding acquisition, Writing-Review & Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Han, Q., Ma, J. A Chinese named entity recognition model incorporating recurrent cell and information state recursion. Sci Rep 14, 5564 (2024). https://doi.org/10.1038/s41598-024-56166-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-56166-3
- Springer Nature Limited