
Abstract
Rectangular concrete-filled steel tubular (RCFST) columns are widely used in structural engineering due to their excellent load-carrying capacity and ductility. However, existing design equations often yield different design results for the same column properties, leading to uncertainty for engineering designers. Furthermore, basic regression analysis fails to precisely forecast the complicated relation between the column properties and its compressive strength. To overcome these challenges, this study suggests two machine learning (ML) models, including the Gaussian process (GPR) and the extreme gradient boosting model (XGBoost). These models employ a range of input variables, such as the geometric and material properties of RCFST columns, to estimate their strength. The models are trained and evaluated based on two datasets consisting of 958 axially loaded RCFST columns and 405 eccentrically loaded RCFST columns. In addition, a unitless output variable, termed the strength index, is introduced to enhance model performance. From evolution metrics, the GPR model emerged as the most accurate and reliable model, with nearly 99% of specimens with less than 20% error. In addition, the prediction results of ML models were compared with the predictions of two existing standard codes and different ML studies. The results indicated that the developed ML models achieved notable enhancement in prediction accuracy. In addition, the Shapley additive interpretation (SHAP) technique is employed for feature analysis. The feature analysis results reveal that the column length and load end-eccentricity parameters negatively impact compressive strength.
Similar content being viewed by others

Introduction
A concrete-filled steel tube (CFST) is a composite structural element composed of a steel tube and an inner concrete infill to optimize the usage of the two materials, resulting in favorable mechanical behavior over conventional reinforced concrete or pure steel elements. The confinement provided by the steel tube enhances the concrete capacity and ductility, while the infill concrete restrains the inner local buckling of the steel tube1,2. Therefore, CFST columns are highly employed for their exceptional strength and excellent performance, making them the most suitable choice in many construction applications, such as buildings and bridges.
Many experimental studies have been conducted to understand the axial behavior of CFST columns3,4,5. In the early loading stage of CFST columns, no significant interaction stress is created between the outer tube and the concrete infill6 as the lateral strain of steel material is higher than that of concrete at the beginning of loading. However, as the loading progresses, concrete volume rapidly increases at the elastic–plastic stage, reducing the separation and activating confining stresses. These confining stresses increase gradually until the peak load is reached and a large contacting pressure is formed6. The post-peak behavior mainly depends on the confinement provided by the outer tube7. It was noticed that increasing the thickness of the steel tube and using relatively low-strength concrete can enhance the ductility and post-peak performance of CFST columns6.
Compressive resistance stands as the primary mechanical characteristic of CFST columns. Due to the complex behavior of CFST columns, exploring various techniques to extract their compressive resistance can facilitate the comprehension of their behavior. The most commonly used techniques for predicting the compressive strength of CFST columns are experimental investigation and finite element analysis8,9. While experimental analysis yields valuable findings, it is both labor-intensive and costly. Furthermore, finite element analysis requires high computational resources, a comprehensive understanding of the complex behavior of concrete material under confinement, and appropriate modeling of the concrete-steel interface. Many design codes are available for predicting compressive strength CFST columns, including Eurocode 410 and AISC 360-2211. However, it should be noted that they have specific application scopes and produce different results due to the restricted nonlinear mapping between the inputs and outputs, raising concerns about their prediction accuracy.
The machine learning (ML) technique can be employed as an alternative to predict the axial capacity of RCFST columns. ML has emerged as a promising tool to tackle complicated problems by conserving resources using existing experimental tests and lessening the necessity for additional testing12,13,14,15,16,17. Recently, many studies have employed various ML algorithms, including artificial neural networks (ANNs), support vector regression (SVR)18, and Gaussian process (GPR)19, to develop empirical formulas and statistical models for predicting the compressive strength of RCFST columns based on experimental tests collected from the literature and have provided positive satisfactory outcomes20,21,22,23,24,25,26.
For example, Ahmadi et al.12,13 employed ANN to predict the compressive resistance of short CFST columns and derived a design expression for axially loaded CFST columns. Du et al.14 utilized ANNs to forecast the ultimate capacity of stub rectangular concrete-filled steel tube (RCFST) columns using 305 specimens collected from the literature. Le et al.15 used ANNs to predict the axial load strength of square and rectangular CFST columns using a dataset of 880 specimens. Tran et al.16 used a database of 300 axially loaded experimental tests to compute the axial capacity of the squared CFT column using ANNs. Furthermore, Zarringol et al.17 utilized four separate databases for predicting the compressive resistance of circular and rectangular CFST columns under axial and eccentric loading and proposed empirical equations and strength reduction factors to facilitate practical design applications. Le20 proposed a GPR-based ML model for the ultimate strength of square CFST columns. In addition, Naser et al.21 employed a genetic algorithm (GA) and gene expression programming (GEP) for extracting the strength of rectangular and circular CFST columns using 3103 test results. Nguyen et al.23,24 proposed two ANN models trained with 99 concentrically loaded and 662 eccentrically loaded rectangular CFST specimens. Memarzadeh et al.25 predicted the axial capacity of square CFST specimens by training GEP and ANN models using 347 axially loaded rectangular CFST specimens. Wang et al.26 trained three models, including SVR, ANN, and random forest (RFR) models, to predict the strength of eccentrically loaded rectangular CFST specimens. Table 1 summarizes the recent machine learning models in predicting square and rectangular CFST column strength.
The ML techniques mentioned earlier can be effectively combined with metaheuristic optimization methods27, such as particle swarm optimization (PSO)28 and grey wolf optimization (GWO)29. Metaheuristic optimization methods are specifically designed to mitigate the issue of getting trapped in local minima during optimization, unlike traditional optimization methods, such as gradient-based approaches. Several models have been employed in the literature for hybrid computational intelligence methods22,23,30,31. Ren et al.22 used a hybrid model based on an SVR, with parameters optimized using PSO to investigate the axial capacity of short square CFST columns.
Generally, ML can offer an innovative approach to predicting the capacity of CFST columns. Although various ML models have been introduced for CFST column predictions, as shown in Table 1, further work is necessary, primarily for the following reasons. First, most studies focused on predicting the loading capacity of RCFST columns under axial loads, with less exploration of their behavior under diverse loading conditions. Second, most studies focus on using ANN and SVR to predict the compression strength of CFST columns, and other ML algorithms, such as the Gaussian process (GPR) and the extreme gradient boosting (XGBoost) model32, are less commonly employed and require further exploration. Third, many researchers directly used axial strength as the output parameter despite its skewed and biased statistical distribution. In addition, the axial strength fails to capture the physical properties of CFST columns, such as the confinement efficiency of the CFST column and the effect of the local and global slenderness ratios. This paper introduces a dimensionless strength index as an alternative output parameter to address these limitations.
The primary objective of this research is to introduce several ML models, including the Gaussian process (GPR)19, extreme gradient boosting model (XGBoost)32,33, support vector regression18 optimized by the particle swarm optimization method (PSVR), and artificial neural network (ANN), for predicting the compressive resistance of RCFST columns under axial and eccentric loadings.
Gaussian process model
Gaussian processes (GPR)19 are an ML method based on Bayesian and statistical learning theories. GPR defines a distribution over functions, as defined in Eq. (1), reasoning about functions based on observed data points. This technique can effectively handle uncertainty and adapt to noise and complexity levels.
where f(x) is the function value at input \(x\), \(m\left(x\right)\) is the prior mean function, and \(K\left(x,{x}^{\mathrm{^{\prime}}}\right)\) is the covariance (kernel) function determining the covariance between any inputs x and \({x}^{\mathrm{^{\prime}}}\). A combination of kernels, including the Gaussian kernel, Matern kernel, and periodic kernel, are used together to capture different aspects of the data, such as the overall level, smoothness, noise, and variations. The kernel parameters are optimized by maximizing the log-marginal-likelihood19. The mean procedures of the GPR are introduced in Fig. 1(a). Given observed input‒output pairs, GPR allows predictions for new inputs by inferring a Gaussian distribution over functions as follows:
where the posterior distribution \(p\left(f\left(x\right)|X,y\right)\) is also a Gaussian distribution with a posterior mean function \({\mu }_{p}\left(X\right)\) and a posterior covariance function \({\Sigma }_{p}\left(X\right)\) defined, respectively, as follows:
where \({\mu }_{p}\left(x\right)\) and \({\Sigma }_{p}\left(x\right)\) define the mean prediction of the new input point x and the uncertainty (variance) associated with each prediction. The mean procedures of the GPR are introduced in Fig. 1a.

Flow charts of the introduced ML models.
Extreme gradient boosting model
The extreme gradient boosting (XGBoost)32 model builds upon the foundation of gradient boosting trees (GBDTs) by introducing algorithmic enhancements, including robustness, effectiveness, and scalability for large-scale datasets. XGBoost uses an ensemble of decision trees as its base learners. These decision trees are often shallow typically called weak learners. Combining multiple simple trees helps reduce overfitting and improves model generalization. XGBoost aims to reduce the sum of two key components: the training error and regularization, as illustrated in Eq. (5).
where L represents the loss function, quantifying the difference between the predicted and the actual value, and Ω denotes the regularization term, controlling the model complexity to prevent overfitting. The second-order Taylor approximation of the loss function can be written in Eqs. (6–8).
The fundamental tree employed in this study is a simple regression tree, defined by Eq. (9).
where γ represents the penalty factor, T defines the count of leaf nodes, and ωj defines the weighting assigned to the leaf j. Disregarding the constant term, the objective function reduces to the form in Eq. (10).
The superiority of XGBoost over other ensemble techniques can be attributed to its mechanism of integrating several weaker base learners to form a stronger model through a process known as boosting. Boosting is an iterative training process such that training a new decision tree requires reducing the errors made by the preceding trees in prior iterations. The flow chart of the XGBoost model is illustrated in Fig. 1b.
Database description
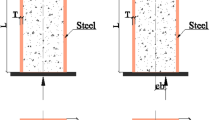
To construct a precise model for predicting the strength of RCFST columns, a comprehensive experimental database was compiled, consisting of 958 tests conducted on RCFST columns subjected to axial loading (Database 1) and 405 tests on RCFST columns subjected to eccentric loading (Database 2)3,4,5. While these experimental tests may not be identical in terms of their testing conditions, they are substantial in volume and diverse in sources, simulating different real-world manufacturing scenarios. RCFST columns subjected to monotonic axial loading are selected, where the entire cross-sections, i.e., concrete and steel tube, are fully loaded. Only CFST columns with normal and high-strength concrete and low-carbon steel tubes are collected. Specimens with stainless steel tubes, aluminum tubes, recycled aggregate concrete, steel fiber concrete, etc., are excluded.
As illustrated in Fig. 2, the input variables include geometric variables, including the column width (B), column height (H), steel tube thickness (t), column length (L), load top eccentricity (et), and load bottom eccentricity (eb), as well as material properties, including steel yield strength (fy) and concrete compressive strength (fc’). Naser et al.21 suggested that the remaining material properties of concrete and steel, i.e., Young’s modulus of steel (Es) and concrete (Ec) and the ultimate strength of steel (fu), have no significant influence on the training of data-driven models. The statistical distributions of these databases are presented in Fig. 3 and Table 2.

RCFST column configurations under axial and eccentric loading conditions.


Distribution of the two databases.
Generally, ML models perform better when working with data that follow a roughly normal distribution. However, the axial capacity distribution for the RCFST columns shown in Fig. 4a exhibits significant skewness, which can negatively impact model performance. A dimensionless strength index, denoted as psi, is introduced as the main output parameter to address this issue. It is defined by dividing the column axial load by the sum of the individual strengths of its components, as given in Eq. (11).
where As and Ac are the outer steel tube and concrete areas, respectively. This introduced index can reflect the confinement efficiency of the CFST column, i.e., a relatively high value of the strength index indicates high confinement exerted by the outer tube. Furthermore, the statistical distribution of the strength index resembles a normal distribution, as shown in Fig. 4b and Table 2, enhancing predictability performance.

Frequency histogram of compressive strength and strength index for database 1.
Additionally, the correlations between all input and output variables in the databases are investigated through the Pearson correlation coefficient and are displayed in Fig. 5. There is a relatively strong correlation between the input variables and the axial capacity (P) across different datasets, negatively impacting the predictivity performance. However, the correlations between the input variables and the strength index (psi) are less significant. In addition, as shown in Figs. 3 and 5, increasing the load eccentricity, global slenderness λg, or local slenderness λl, defined in Eq. (12), reduces the column strength index. These observations align well with the experimental behavior of CFST columns. These findings indicate the benefits of using the strength index as an output variable instead of the axial capacity.

Correlation matrix for the RCFST columns databases under axial and eccentric loading conditions.
where EsIs and EcIc are the flexural stiffness of steel and concrete materials.
It is important to acknowledge that the parameter ranges of CFST samples in the databases fall outside the scope of existing design codes10,11, as illustrated in Table 2 and Fig. 3. This aspect can be advantageous in training machine learning models with broader applicable ranges. In addition, the axial database covers a wide range of steel section slenderness, including both compact, noncompact, and slender sections (λl coefficient ranges from 0.25 up to 10.17)11. In addition, a wide range of global slenderness is covered, ranging from 0.0243 to 2.64, covering short (λg < 0.5 as recommended by Eurocode 410) and long columns. Furthermore, the database encompasses a wide range of concrete and steel strengths. The introduced databases include both traditional materials (with fc’ values below 70 MPa and fy values below 460 MPa, as suggested by AISC 360-2211) and higher strength classes (with fc’ up to 175.9 MPa and fy up to 1031 MPa). While a wide range of material strengths is considered, their distributions are not uniform. Specifically, steel strength tends to cluster in the 200–800 MPa range, with only a limited number of samples exceeding 800 MPa. In the case of concrete strength, most specimens fall within the 20–100 MPa range, with a smaller subset exceeding 100 MPa. ML models rely on the information contained in the input data. However, the scarcity of training data within a specific range of an input feature can lead to insufficient learning for that range. Consequently, the application of the trained machine learning model might encounter challenges when applied to data falling within a range for which the model lacks sufficient training.
Performance and results of ML models
Data normalization is performed using the min–max scaling technique to mitigate the impact of multidimensionality and ensure numerical stability. During the training phase, the grid searching technique was employed for tuning the model hyperparameters, and fivefold cross-validation was utilized to reduce overfitting issues. As recommended by Nguyen 202023 and other studies24,26, eighty percent of the original dataset was chosen randomly for training, leaving the remaining 20% to test the models. To compare and evaluate the effectiveness and reliability of the introduced models, two different ML models, including the support vector machine integrated with particle swarm optimized (PSVR)22 and ANN models, were introduced. Figure 6 illustrates the relation between the predictions generated by the four ML models and the experimental results. It is evident from Fig. 6 that the scatter between the predicted and experimental results for the four ML models closely follows the diagonal line, falling mostly within the ± 20% margins for the training and test subsets. Table 3 presents the evaluation metrics to assess the prediction accuracy for these ML models: the mean (μ), coefficient of variation (CoV), coefficient of determination (R2), root mean squared error (RMSE), mean absolute percentage error (MAPE), a20-index, Nash–Sutcliffe efficiency (NSE), Willmott index of agreement (d), and confidence index (CI)34. These measures are defined as:

Comparison between ML models for training and testing datasets.
where \({y}_{i}\) defines the actual output value of the i-th sample, \({\widehat{y}}_{i}\) is the output value of the i-th sample, \(\overline{y }\) is the mean value of experimental observations, and n is the number of specimens in the database. The a20-index15,35 is a percentile-based metric that measures the partition of samples for which the absolute differences between predicted and observed results exceed 20%.
As observed in Table 3, the prediction accuracy of the introduced ML models exhibits little difference with R2 and mean values approaching 1.0 and CoV values less than 0.113. The predictions of all proposed models have error values lower than 20% for 95.5% of axially loaded specimens and 91.1% of the eccentrically loaded specimens. Similar performance can be found for the remaining metrics. Table 3 reveals that the GPR model introduces the best evaluation metrics for the training and testing subsets, with MAPE% values equal to 3.78% and 3.41% for the axially and eccentrically loaded column datasets, respectively, followed in accuracy by the XGBoost model for the axially loaded column dataset and the ANN model for the eccentrically loaded column dataset. The ANN and XGBoost models are the least accurate for axially and eccentrically loaded column datasets, respectively, while the PSVR model introduces moderate prediction accuracy. In addition, the evolution metrics of the testing sets exhibit similar results to the training sets, indicating minimizing the overfitting issues.
The predictions by the introduced models were compared with the existing codes in Table 3, including Eurocode 4 (EC4)10 and AISC36011. The mean values of code methods are all above 1.0, representing conservative predictions. This result is reasonable as design codes are inclined to be conservative to yield safer designs. In addition, the accuracy of the introduced ML models is significantly higher than that of the two design standards, particularly noticed when evaluating a20-index. For instance, 99%, 97.8%, 96.1%, and 95.5% of the concentrically loaded CFST database obtained, respectively, from GPR, XGBoost, PSVR, and ANN models exhibit error rates within 20%, much higher than the 74% and 64% proportions reported by EC410 and AISC 360-2211, respectively. Furthermore, the RMSE and MAPE of EC4 and AISC36011 predictions are approximately two to four times those of ML models, indicating the better performance of ML models compared to available standards. These findings can be attributed to the fact that AISC 360-22 neglects the confinement interaction between steel and concrete materials, and EC4 disregards the local buckling effect and imposes a limitation for the slenderness ratio λl.
Compared with some ML models introduced in the literature, as summarized in Table 1, the developed models achieved notable improvement in prediction accuracy. The introduced GPR model exhibits an a20-index of 98.8%, surpassing the models introduced by Wang et al.26 (a20-index = 96%) and the GPR model proposed by Le et al.15 (a20-index = 92.5%). The enhanced performance of the introduced GPR model compared to the GPR model of Le et al.15 can be attributed to using a combination of kernels, which can capture various aspects of the data, including smoothness, noise, and variations. Furthermore, the MAPE of the proposed GPR model stands at 3.41, which is considerably lower than that of the SVR models proposed by Ren et al.22 and Nguyen et al.24.
In addition to the relatively high accuracy of the GPR model, it can provide the confidence intervals for the prediction results, as shown in Fig. 7 for the axially loaded column database. This quantification of uncertainty enhances its applicability in guiding practical design considerations. The even distribution of the predicted column strength around the measured strength, as depicted in Fig. 7, further confirms the accurate predictive capabilities of the GPR model for RCFST column strength.

Gaussian process regression on a semilog scale on the y-axis for axially loaded column database.
Feature importance analysis
Analyzing the impact of input parameters on compressive strength is a crucial guiding factor in designing RCFST columns. In this study, the Shapley Additive Explanation (SHAP) method is utilized to assess the impact of input parameters on the strength index33,36. As depicted in Fig. 8, a feature value larger than zero signifies a positive correlation between the variable and the strength index. In contrast, a feature value less than zero indicates a negative impact on the strength index. For RCFST columns under eccentric loading, the top-end eccentricity (et) and column length (L) emerge as the most influential design parameters within the collected database. The feature importance of the remaining variables is ranked from highest to lowest. Furthermore, it can be deduced that, except for column width (B), height (H), and steel tube thickness (t), all remaining input variables have a negative influence on the strength index, indicating that an increase in these parameters reduces the strength index. Increasing column height and steel thickness enhance the flexural strength and confinement behavior of RCFST columns while increasing column length and load eccentricity reduce the column capacity strength. These findings agree well with the experimental results.

Summary plot and SHAP feature importance for the eccentrically loaded RCFST column database.
Limitations and future works
This section outlines the limitations of the established data-driven models and highlights potential areas for future research. The validity of the proposed model is constrained within the range of minimum and maximum values for each input parameter, as outlined in Table 2. These values not only define the applicability of the computational model but also set the boundaries within which accurate predictions can be made. In addition, considering the uneven distribution of certain parameters, as explained in Fig. 3, applying the ML models needs caution where the input features fall within ranges lacking sufficient training data, and experimental studies are needed to enrich the database within these less-represented ranges.
An innovative methodology that can be considered involves integrating finite element modeling with the GPR model within the Design of Experiments (DOEs) framework. This approach is designed to identify and select the optimal training points that can effectively reduce errors through adaptive learning and use the predictive capabilities of finite element modeling to model these critical points. The accuracy of predictive models can be substantially enhanced, yielding more efficient and reliable ML models for CFST columns.
Conclusions
This study introduces two ML models, including the Gaussian process (GPR) and extreme gradient boosting (XGBoost) models, for predicting the compressive resistance of rectangular concrete-filled steel tubular (CCFST) columns subjected to axial and eccentric loading conditions. These models are compared with other ML models, including support vector regression optimized by particle swarm optimization (PSVR), an artificial neural network (ANN), and previous ML studies. The key findings are summarized as follows:
-
1.
The provided ML models can effectively capture the complicated relationship between geometric and material parameters and compressive resistance for RCFST columns subjected to different loading conditions.
-
2.
The proposed normalization approach of the axial load by introducing the strength index yields a nearly normal distribution, which improves model performance and robustness. In addition, using the strength index as an output parameter reflects insights into the level of strength in terms of local and global buckling.
-
3.
The GPR model is the most accurate and reliable model, with MAPE% less than 4%. In addition, the remaining ML models offer acceptable accuracy with MAPE% less than 8%. This high prediction accuracy promotes using the ML techniques as valuable tools alongside design code standards for estimating the compressive strength of RCFST columns.
-
4.
Compared with existing standards and ML studies, the developed models achieved better performance in prediction accuracy. The predictions of all proposed models have error values lower than 20% for 95.5% of axially loaded specimens and 91.1% of the eccentrically loaded specimens, much higher than the proportions reported by EC 4. and AISC 360-22.
-
5.
From feature importance analysis, top-end eccentricity and column length have the most negative influence on the strength index of RCFST columns. Therefore, designers should consider these parameters in optimizing and designing RCFST columns.
In summary, the proposed data-driven models can extract the axial compression capacity of RCFST columns with reliable and accurate results, making them valuable tools for structural engineers. While this paper illustrates the capability and precision of the introduced ML models for RCFST compressive strength prediction, future studies are needed to address the existing gaps in databases and to integrate the predictive capabilities of finite element modeling with ML models.
Research significance
This study introduces two machine learning (ML) algorithms for predicting the compressive strength of rectangular concrete-filled steel tubular (RCFST) columns under different loading conditions. It employs two powerful ML models, the Gaussian process (GPR) and the extreme gradient boosting (XGBoost) model. The employed techniques can be considered valuable tools alongside the design code standards and finite element analysis.
Data availability
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Xiong, M. X., Xiong, D. X. & Liew, J. Y. R. Axial performance of short concrete filled steel tubes with high- and ultra-high- strength materials. Eng. Struct. 136, 494–510. https://doi.org/10.1016/j.engstruct.2017.01.037 (2017).
Han, L. H., Li, W. & Bjorhovde, R. Developments and advanced applications of concrete-filled steel tubular (CFST) structures: Members. J. Constr. Steel Res. 100, 211–228. https://doi.org/10.1016/j.jcsr.2014.04.016 (2014).
Thai, S. J. et al. Concrete-filled steel tubular (CFST) columns database with 3,208 tests. Mendeley Data https://doi.org/10.17632/j3f5cx9yjh.1 (2020).
Goode, C. D. Composite columns-1819 tests on concrete-filled steel tube columns compared with Eurocode 4. Struct. Eng. 86(16), 33–38 (2008).
Denavit, M. D. Characterization of behavior of steel-concrete composite members and frames with applications for design. (University of Illinois at Urbana-Champaign, 2012).
Tao, Z., Han, L. H. & Zhao, X. L. Behaviour of concrete-filled double skin (CHS inner and CHS outer) steel tubular stub columns and beam-columns. J. Constr. Steel Res. 60(8), 1129–1158. https://doi.org/10.1016/j.jcsr.2003.11.008 (2004).
Ho, J. C. M., Lam, J. Y. K. & Kwan, A. K. H. Effectiveness of adding confinement for ductility improvement of high-strength concrete columns. Eng. Struct. 32(3), 714–725 (2010).
Du, Y., Chen, Z., Richard Liew, J. Y. & Xiong, M.-X. Rectangular concrete-filled steel tubular beam-columns using high-strength steel: Experiments and design. J. Constr. Steel Res. 131, 1–18. https://doi.org/10.1016/j.jcsr.2016.12.016 (2017).
Tao, Z., Bin Wang, Z. & Yu, Q. Finite element modelling of concrete-filled steel stub columns under axial compression. J. Constr. Steel Res. 89, 121–131. https://doi.org/10.1016/j.jcsr.2013.07.001 (2013).
BEng, S. H. & Park, S. EN 1994-eurocode 4: Design of composite steel and concrete structures. Retrieved May, vol. 10, p. 2022 (1994).
AISC. AISC 360-22 specification for structural steel buildings. Am. Inst. Steel Constr., p. 780. (2022).
Ahmadi, M., Naderpour, H. & Kheyroddin, A. Utilization of artificial neural networks to prediction of the capacity of CCFT short columns subject to short term axial load. Arch. Civ. Mech. Eng. 14(3), 510–517. https://doi.org/10.1016/j.acme.2014.01.006 (2014).
Ahmadi, M., Naderpour, H. & Kheyroddin, A. ANN model for predicting the compressive strength of circular steel-confined concrete. Int. J. Civ. Eng. 15(2), 213–221. https://doi.org/10.1007/s40999-016-0096-0 (2017).
Du, Y., Chen, Z., Zhang, C. & Cao, X. Research on axial bearing capacity of rectangular concrete-filled steel tubular columns based on artificial neural networks. Front. Comput. Sci. 11(5), 863–873. https://doi.org/10.1007/s11704-016-5113-6 (2017).
Le, T.-T., Asteris, P. G. & Lemonis, M. E. Prediction of axial load capacity of rectangular concrete-filled steel tube columns using machine learning techniques. Eng. Comput. 38(4), 3283–3316. https://doi.org/10.1007/s00366-021-01461-0 (2022).
Tran, V.-L., Thai, D.-K. & Kim, S.-E. Application of ANN in predicting ACC of SCFST column. Compos. Struct. 228, 111332. https://doi.org/10.1016/j.compstruct.2019.111332 (2019).
Zarringol, M., Thai, H.-T., Thai, S. & Patel, V. Application of ANN to the design of CFST columns. Structures 28, 2203–2220. https://doi.org/10.1016/j.istruc.2020.10.048 (2020).
Suykens, J. A. K. & Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 9(3), 293–300. https://doi.org/10.1023/A:1018628609742 (1999).
Rasmussen, C. E. Williams, C. K. I. & others. in Gaussian Processes for Machine Learning, vol. 1. (Springer, 2006).
Le, T.-T. Practical machine learning-based prediction model for axial capacity of square CFST columns. Mech. Adv. Mater. Struct. 29(12), 1782–1797. https://doi.org/10.1080/15376494.2020.1839608 (2022).
Naser, M. Z., Thai, S. & Thai, H.-T. Evaluating structural response of concrete-filled steel tubular columns through machine learning. J. Build. Eng. 34, 101888. https://doi.org/10.1016/j.jobe.2020.101888 (2021).
Ren, Q., Li, M., Zhang, M., Shen, Y. & Si, W. Prediction of ultimate axial capacity of square concrete-filled steel tubular short columns using a hybrid intelligent algorithm. Appl. Sci. 9(14), 2802. https://doi.org/10.3390/app9142802 (2019).
Nguyen, H. Q., Ly, H., Tran, V. Q. & Nguyen, T. Optimization of Artificial Intelligence System by Evolutionary Algorithm for Prediction of Axial Capacity of Rectangular Concrete Filled Steel Tubes under Compression. (2020).
Nguyen, M. S. T. & Kim, S. E. A hybrid machine learning approach in prediction and uncertainty quantification of ultimate compressive strength of RCFST columns. Constr. Build. Mater. 302, 124208. https://doi.org/10.1016/j.conbuildmat.2021.124208 (2021).
Memarzadeh, A., Sabetifar, H. & Nematzadeh, M. A comprehensive and reliable investigation of axial capacity of Sy-CFST columns using machine learning-based models. Eng. Struct. 284, 115956. https://doi.org/10.1016/j.engstruct.2023.115956 (2023).
Wang, C. & Chan, T. M. Machine learning (ML) based models for predicting the ultimate strength of rectangular concrete-filled steel tube (CFST) columns under eccentric loading. Eng. Struct. 276, 115392. https://doi.org/10.1016/j.engstruct.2022.115392 (2023).
Bianchi, L., Dorigo, M., Gambardella, L. M. & Gutjahr, W. J. A survey on metaheuristics for stochastic combinatorial optimization. Nat. Comput. An Int. J. 8(2), 239–287. https://doi.org/10.1007/s11047-008-9098-4 (2009).
Kennedy, J. & Eberhart, R. Particle swarm optimization. In Proceedings of ICNN’95—International Conference on Neural Networks, vol. 4, pp. 1942–1948 (1995). https://doi.org/10.1109/ICNN.1995.488968
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Yaseen, Z. M., Tran, M. T., Kim, S., Bakhshpoori, T. & Deo, R. C. Shear strength prediction of steel fiber reinforced concrete beam using hybrid intelligence models: A new approach. Eng. Struct. 177, 244–255. https://doi.org/10.1016/j.engstruct.2018.09.074 (2018).
Ngo, N.-T., Le, H. A. & Pham, T.-P.-T. Integration of support vector regression and grey wolf optimization for estimating the ultimate bearing capacity in concrete-filled steel tube columns. Neural Comput. Appl. 33(14), 8525–8542. https://doi.org/10.1007/s00521-020-05605-z (2021).
Chen, T. & Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794. (2016) https://doi.org/10.1145/2939672.2939785
Wang, J., Lu, R. & Cheng, M. Application of ensemble model in capacity prediction of the CCFST columns under axial and eccentric loading. Sci. Rep. 13(1), 9488. https://doi.org/10.1038/s41598-023-36576-5 (2023).
El, M. et al. Modeling the nonlinear behavior of ACC for SCFST columns using experimental-data and a novel evolutionary-algorithm. Structures 30, 692–709. https://doi.org/10.1016/j.istruc.2021.01.036 (2021).
Asteris, P. G. & Mokos, V. G. Concrete compressive strength using artificial neural networks. Neural Comput. Appl. 32(15), 11807–11826. https://doi.org/10.1007/s00521-019-04663-2 (2020).
Abdallah, M. H. et al. The machine-learning-based prediction of the punching shear capacity of reinforced concrete flat slabs: An advanced M5P model tree approach. Appl. Sci. 13(14), 8324. https://doi.org/10.3390/app13148325 (2023).
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
K.M. is responsible for analysis and preparing the figures. N.M. is responsible for material preparation and data collection. S.A. wrote the first draft of the manuscript. All authors contributed to the study conception and design, reviewed all previous versions of the manuscript, and read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Megahed, K., Mahmoud, N.S. & Abd-Rabou, S.E.M. Application of machine learning models in the capacity prediction of RCFST columns. Sci Rep 13, 20878 (2023). https://doi.org/10.1038/s41598-023-48044-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-48044-1
- Springer Nature Limited
This article is cited by
-
Prediction of the axial compression capacity of stub CFST columns using machine learning techniques
Scientific Reports (2024)