
Abstract
Evaluating the lifespan distribution of highly reliable commodities under regular use is exceedingly difficult, time consuming, and extremely expensive. As a result of its ability to provide more failure data faster and at a lower experimental cost, accelerated life testing has become increasingly important in life testing studies. In this article, we concentrate on parametric inference for step stress partially life testing utilizing multiple censored data based on the Tampered Random Variable model. Under normal stress circumstances, the lifespan of the experimental units is assumed to follow the Nadarajah–Haghighi distribution, with and being the shape and scale parameters, respectively. Maximum likelihood estimates for model parameters and acceleration factor are developed using multiple censored data. We build asymptotic confidence intervals for the unknown parameters using the observed Fisher information matrix. To demonstrate the applicability of the different methodologies, an actual data set based on the timings of subsequent failures of consecutive air conditioning system failures for each member of a Boeing 720 jet aircraft fleet is investigated. Finally, thorough simulation studies utilizing various censoring strategies are performed to evaluate the estimate procedure performance. Several sample sizes were studied in order to investigate the finite sample features of the considered estimators. According to our numerical findings, the values of mean squared errors and average asymptotic confidence intervals lengths drop as sample size increases. Furthermore, when the censoring level is reduced, the considered estimates of the parameters approach their genuine values.
Similar content being viewed by others
Introduction
Today’s modern goods are incredibly trustworthy and reliable due to recent scientific advances, innovation, and developments based on computers, automation, and simulations. When a product is very reliable, obtaining failure data through an ordinary life test takes a long time; however, accelerated life testing (ALT) may be used to get a product's dependability life in a short amount of time. This type of test entails submitting test objects to stress settings that shorten its lifetime in comparison to what it would be under normal circumstances. Increased stress speeds up the failure time in ALTs. This means that the amount of time it takes for a product to fail is influenced by the stress. Nelson1, Meeker et al.2, Kamal3, Saxena et al.4, El-Din et al.5, Rahman et al.6 and Han and Bai7 provide further information about ALTs.
In general, the acceleration factor in ALT should be well-known, or there should be a well-established model indicating the relationship between life and stress levels. For new things or goods, however, these models do not exist. In such instances, engineers have successfully used partially ALTs to compute the acceleration factor, allowing them to extrapolate accelerated data to normal conditions. Constant-stress and step-stress PALTs (abbreviated as CSPALT and SSPALT) are the two most common categories of PALTs (abbreviated as CSPALT and SSPALT) are depending on how a stress is imposed. In a CSPALT model, each sample of items is subjected to both normal and accelerated levels of constant stress until all units fail or the test is terminated for some reason, such as a censoring method. In SSPALT, a sample of products is first evaluated under regular usage settings for a pre-set amount of time, and then the surviving items are examined under accelerated test conditions until the test is ended for some reason, such as a censoring scheme. Several authors have tackled SSPALT analysis thus far; for example, Goel8 proposed the tampered random variable (TRV) model for SSPALT. DeGroot and Goel9 investigated SSPALT under Bayesian decision framework based on the TRV model. Bai and Chung10, Bai et al.11, and Rahman et al.12 all examine SSPALT when using alternative life distribution and censoring methods.
The exponential distribution is used as a reference model in statistics, reliability, and life testing assessments due to its lack of memory property. The exponential distribution, on the other hand, is limited to describing only the constant hazard rate. To get around these constraints, Nadarajah and Haghighi13 proposed the Nadarajah–Haghighi (NH) distribution, which is an extension of the exponential distribution. In their investigation, they determined that the density function of the NH distribution always has a zero mode. Furthermore, its hazard function can be increasing, decreasing, or constant, and its density function can be monotonically lowering while the hazard rate function is increasing. Because of all of these enticing qualities, the NH distribution may indeed be considered a feasible alternative to the Weibull, Gamma, and exponentiated exponential distributions. In a recent work based on the NH distribution, MirMostafaee et al.14 produced the best unbiased linear estimates of the parameters of the NH distribution using moments of upper record values. Selim15, Sana and Faizan16 offered a brief overview and comparison of frequentist estimating strategies, as well as Bayesian estimates (BE) generated from various loss functions and gamma priors. Kamal et al.17 studied a variety of statistical and mathematical features, as well as the maximum likelihood estimation (MLE) technique for parameter estimation, after expanding the NH distribution to a four-parameter distribution. Minic18 examined many methods for estimating parameters, based on their biases and mean square errors (MSEs). Kamal et al.19 used SSALT to estimate the MLEs of NH distribution parameters.
Number of reasons including time limits, cost savings, and so on. Type-I and type-II censorship are the two most frequently used censoring strategies. In time censoring, also known as type-I censoring, the exam is cancelled after a specified amount of time. Failure censoring, also known as type-II censoring, allows the testing process to be ended after a certain number of failure observations of items. Type-I and type-II censorings do not permit the removal of testing items from a test at any time other than the test completion time. Other censoring techniques, such as progressive censoring and multiple censoring strategies, can be used to address this problem. In progressive censoring, during the test, numerous surviving units are constantly removed at each pre-determined time or failure point until the greatest pre-determined time or failure point is achieved. Multiply censoring is a generalization of traditional and progressive censoring that allows all units in a life test to be removed at any time throughout the test for any reasons, making it more convenient, Wang20. This scenario is prevalent in situations when many censoring levels are logically present, as is often the case in many applications in life assessment and survival analysis.
So far, numerous researchers have investigated progressive censored data under SSPALT, but there has been relatively little work on multiply censored data. In SSPALT, Wang et al.21 used multiply censored data to produce MLEs of the parameters of the Weibull distribution and the AF. Jia et al.22 estimated the reliability using MLEs and Bayes parameter estimates and investigated how to generate confidence intervals for reliability under a multiple censoring scheme. In the presence of multiple censored data, Hassan and Zaky23 and Bantan et al.24 estimated the Shannon entropy of the inverse Weibull and the inverse Lomax distribution respectively and then used the MLE approach to provide point and confidence interval estimates of parameters. On the basis of multiple censored data and a CSPALT, Alam et al.25 and Nassr and Elharoun26 developed MLEs of unknown parameters of exponentiated exponential and exponentiated Weibull distributions respectively. For an ALT with k increasing stress levels that is terminated by a progressive censoring strategy, Kamal27 produced maximum likelihood estimates of the generalized Pareto distribution parameters. In partially constant-stress accelerated life tests with multiple Type-II censored data, Abushal28 used maximum likelihood and Bayes estimation methods to estimate the exponentiated Weibull life time distribution. Using the MLE approach to estimate the parameters of the NH distribution under SSPALT using AT-II PHCS, Kamal et al.29 proposed two optimum test procedures based on the A and D optimality. Alam and Ahmed30 used AT-II PHCS to explore the MLEs of a Generalized Inverted Exponential distribution under SSPALT. Kamal31 explored a hybrid system and employing the MLE approach to estimate parameters of the power linear hazard rate distribution from progressive hybrid censored masked data. For more details see Abd-Elfattah et al.32, Nassar et al.33, Yousef et al.34 and Hassan et al.35.
Censoring is the termination of a life experiment before all of the units have failed.
Nonetheless, despite its relevance, the estimation of NH distribution and acceleration factor (AF) parameters under SSPALT for multiple censored data remains an unexplored problem, as far as we know. This work addresses that gap by examining the problem of SSPALT in the context of multiple censored data. Rest of the paper is organized as: In “Modeling SSPALT with MCS” section, we describe the TRV model under basic SSLT and establish the NH baseline lifespan CDF, PDF and RF. In “Inferences under SSPALT with MCS” section, using multiple censored data, in our statistical framework, we compute the MLEs of the parameters \(\alpha ,\beta\) and \(\theta\), where, \(\theta > 1\) denotes the AF. Based on the observed Fisher information matrix, the two-sided approximate confidence intervals (ACIs) of the parameters \(\alpha ,\beta\) and \(\theta\) are then addressed. To demonstrate the applicability of the various methodologies, an actual data set based on air conditioning system failure times for each member of a Boeing 720 jet aircraft fleet is evaluated in “Real engineering application” section. A thorough numerical analysis is performed, illustrating the positive behavior of the derived estimates over a wide range of sample sizes in “Simulation study” section.
Modeling SSPALT with MCS
Let \(Y\) is a nonnegative random variable distributed according to NH distribution with scale parameter \(\beta\) and shape parameter \(\alpha\), denoted as NH (\(\alpha ,\beta\)), then its probability density function (PrDF), cumulative distribution function (CDF) and the survival function (SF) are as follows:
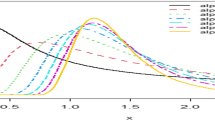
Different shapes of PrDF, CDF, and SF that were created using different input values of parameters are displayed in Fig. 1.

PrDF, CDF, and SF of NH (\(\alpha ,\beta\)).
As a special instance of the NH distribution, when \(\alpha = 1\), an exponential distribution can be produced. It offers closed versions of survival and hazard rate functions, such as that of the Weibull distribution, which makes it an excellent alternative for lifetime data investigators.
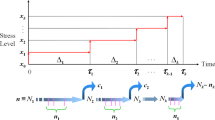
In SSPALT, all testing items are first allocated to be tested under ordinary usage settings until a pre-set stress change time \(\tau\), following which any remaining survivals that have not failed by time \(\tau\) are moved to be tested under accelerated conditions. The effect of stress transition from normal to accelerated condition may be explained by multiplying the remaining lifetime by the inverse of the acceleration factor. The following is a theoretical calculation of the item’s total lifetime \(T\) under accelerated conditions:
where \(Y\) denotes the item’s lifespan under ordinary usage settings and \(\theta > 1\) denotes the AF, which is often depending on applied stress. We can now explain the PDF, CDF, and RF of total life \(T\) of the objects using the model provided in Eq. (4) as follows:
Assume we’re dealing with an SSPALT based on MCS. Assume the test is based on only two stress levels, \(X_{1}\) representing regular working conditions and \(X_{2}\) representing accelerated conditions, where \(X_{2}\) is larger than \(X_{1}\). This life testing consists of \(n\) objects that are both identical and independent in nature. Under each of the stress levels \(X_{1}\) and \(X_{2}\), at least one failure should occur. The failure times of the items at each of the stress levels \(X_{1}\) and \(X_{2}\) are determined by the NH (\(\alpha ,\beta\)) presented by (1). All items in the sample of size \(n\) are now allocated to be tested at stress level \(X_{1}\) with a known number \(r_{1}\) of failures and a corresponding number \(m_{1}\) of multiply censored items till time \(\tau\). The test will now be continued by testing all of the items from \(n\) that have not failed or been censored up to time \(\tau\) at the stress \(X_{2}\) with the pre-requisite \(r_{2}\) number of failures and the associated number of multiply censored items \(m_{2}\) until all of the test items have failed or been censored.
Inferences under SSPALT with MCS
In this section, the MLE method is utilized to estimate the model parameters and the acceleration factor. This method is more consistent and efficient, providing estimates with greater statistical precision and expressing uncertainty using confidence limits.
Assume that \(t_{1,f} ,t_{2,f} , \ldots ,t_{{r_{1} ,f}}\) are the failure timings of \(r_{1}\) units that have failed under normal condition \(X_{1}\), as well as \(m_{1}\) censored units at periods \(t_{1,s} ,t_{2,s} , \ldots ,t_{{m_{1} ,s}}\). We further suppose that \(t_{1,f} ,t_{2,f} , \ldots ,t_{{r_{2} ,f}}\) are the \(r_{2}\) failure times at accelerated condition \(X_{2}\) with \(m_{2}\) censored units with censoring times \(t_{1,s} ,t_{2,s} , \ldots ,t_{{m_{2} ,s}}\). Now, for multiply censored data, the likelihood function under SSALT may be stated as follows Wang et al.21:
The log-likelihood function \(l = L\left( {t,\alpha ,\beta , \theta } \right)\) based on MCS under SSPALT corresponding to Eq. (8) after substituting the values of \(f\left( {t_{i,f} } \right)\), \(f\left( {t_{k,f} } \right)\), \(F\left( {t_{j,s} } \right)\) and \(F\left( {t_{l,s} } \right)\) can be expressed as:
where \(\left( {\tau + \theta \left( { - \tau + t_{k} } \right)} \right) = A_{k}\) and \(\left( {\tau + \theta \left( { - \tau + t_{l} } \right)} \right) = A_{l}\). Now, the likelihood equations may be derived by calculating partial derivatives of Eq. (9) with respect to \(\alpha ,\beta\) and \(\theta\) as:
The ML estimates of the parameters, say \(\hat{\alpha },\hat{\beta }\) and \(\hat{\theta }\), may be derived by solving Eq. (10)–(12) with regard to \(\alpha ,\beta\) and \(\theta\) respectively. These equations are extremely complex, and they cannot be solved analytically. To solve these simultaneous equations, a numerical iteration approach such as a generic method named as Nelder–Mead Method is advised. In this paper, we utilized the Optim() function of R Software.
Because the precise sample distribution of the ML estimates cannot be determined in closed form, the estimated confidence intervals for the parameters \(\alpha ,\beta\) and \(\theta\) are derived by utilizing the approximate distributions of their ML estimates, which is required to compute the Fisher information matrix. Because the predicted information matrix is excessively complex and necessitates numerical integration, the observed information matrix is produced. The asymptotic distribution of ML estimates of \(\alpha ,\beta\) and \(\theta\) is given as \(\left( {\left( {\hat{\alpha } - \alpha } \right),\left( {\hat{\beta } - \beta } \right), \left( {\hat{\theta } - \theta } \right)} \right) \to N\left( {0,I^{ - 1} \left( {\alpha ,\beta , \theta } \right)} \right)\), where I represent 3 × 3 observed information matrix given in the following equation and the elements of I are given in the below.
And \(I^{ - 1} \left( {\alpha ,\beta , \theta } \right)\) represent the variance–covariance matrix and may be approximated by the inverse of the information matrix I, which contains the unknown parameters \(\alpha ,\beta\) and \(\theta\). Due to the consistency of the ML estimators, the parameters are substituted by the necessary MLEs to obtain an estimated \(I^{ - 1} \left( {\alpha ,\beta , \theta } \right)\), which is given by \(\hat{I}^{ - 1} \left( {\hat{\alpha },\hat{\beta }, \hat{\theta }} \right)\) as follows:
Now, the estimated \(100\left( {1 - \psi } \right)\) percent double-sided confidence bounds with \(Z_{\psi /2}\) as an upper \(\left( {\psi /2} \right){\text{th}}\) percentile of standard normal variate for \(\alpha ,\beta\) and \(\theta\) are presented as follows:
Second derivatives
Real engineering application
In this section, we employ real data supplied by Proschon36 to demonstrate the real engineering application of the estimation approaches offered in this paper. The data set provides the times of successive failures of sequential air conditioning system failures for each member of a Boeing 720 jet aircraft fleet. This data is also saved in R’s npsurv package under the name acfail Wang37. The recorded data is given as follows:
1 1 2 3 3 3 3 4 5 5 5 5 5 7 7 7 9 9 10 11 11 11 11 12 12 12 12 13 14 14 14 14 14 14 14 14 15 15 15 16 16 16 18 18 18 18 18 18 20 20 21 21 22 22 22 23 23 23 24 24 25 26 26 27 27 29 29 29 29 30 31 31 32 33 33 34 34 34 35 35 36 36 37 39 39 41 42 43 44 44 44 46 46 47 47 48 49 50 50 51 52 54 54 55 56 56 57 57 57 58 59 59 59 60 61 61 62 62 62 63 65 66 67 67 68 70 70 71 71 72 74 76 77 79 79 80 82 84 85 87 88 90 90 91 95 97 97 98 100 100 101 102 102 104 104 104 106 111 118 118 120 120 130 130 130 134 139 141 142 152 153 156 163 169 176 181 182 184 186 188 191 194 197 201 206 208 208 209 210 216 220 225 230 230 239 246 246 254 261 270 283 310 320 326 359 386 413 438 447 487 493 502 603.
To assess the data’s goodness-of-fit to the NH distribution, we first calculated the NH distribution’s parameters and then the K–S test was utilized. The K-S statistic and their p value are then calculated and reported in Table 1 as follows:
The K-S distance is determined to be 0.04613, with an associated p value of 0.7552. Since the p value is more than 0.05, we cannot reject the null hypothesis, which states that both the theoretical and sample distributions are same. Furthermore, multiple plots are analyzed for the goodness-of-fit test to check further if the data fits the NH distribution. We also illustrate the fitting of the distribution by plotting the estimated cdf, Q–Q and P–P plots of the NH distribution for the supplied real data set. Figure 2 compares the theoretical CDF of the NH distribution to the empirical CDF and histogram. The Q–Q and P–P plots of the supplied actual data set are shown in Fig. 3. The figures and KS test results suggest that the real data set under consideration fits the NH distribution pretty well.

Theoretical CDF of the NH distribution vs the empirical CDF and histogram.

The Q–Q and P–P plots of the supplied actual data set.
Now, under SSPALT, we assume that the test runs under normal operating condition until the high stress is applied, and then the stress is raised to make the test operate at accelerated condition. We assume that the stress change time \(\tau\) is 57 and various censoring levels (CL) are 20%, 30%, and 40%. To reflect multiple censoring strategy, we now delete 20%, 30%, and 40% of data at both stress levels, and the observed data under standard and accelerated stress with the assumed censoring levels are provided in Table 2.
We now estimated the MLEs and loglikelihood function values with stress change time \(\tau = 57\) and various censoring levels using the real data set reported in Table 2. The findings are computed using the R software, and Table 3 summarizes the resulting MLEs and loglikelihood function values. As per the results in Table 3, the estimates perform better at a 20 percent censoring level than at 30 percent and 40 percent filtering levels. This is apparent since larger data sets yield better results with more precision.
We have now raised the stress change duration from 57 to 71 while keeping the same censoring levels of 20%, 30%, and 40% to test the model's flexibility. Table 4 shows the observed data under standard and accelerated stress, as well as the censoring levels after eliminating 20%, 30%, and 40% of the data for both stress levels.
Subsequently, we estimated the MLEs and loglikelihood function values with stress change time \(\tau = 71\) and various censoring levels using the real data set reported in Table 4. The findings are again computed using the R software, Team38 and Table 5 summarizes the resulting MLEs and loglikelihood function values. As per the results in Table 5, we again observed that the estimates perform better at a 20% censoring level than at 30%, and 40% filtering levels.
Simulation study
This section provides a simulation study to investigate the performance of MLEs of parameters for NH distribution under SSPALT based on multiply censored data. The mean squared error (MSE) is used to compare the performance of point estimates, whereas the CPs are used to compare the performance of ACIs. The data were derived from Eq. (2) using the inverse CDF approach. The quantile function that has been utilized for this task is defined as \(t = \left( {\left( {1 - \log (1 - u)} \right)^{1/\alpha } - 1} \right)/\beta\), where u is generated from uniform distribution, i.e., \(u \sim U\left( {0,1} \right)\). We selected five different sample sizes \(n\) = 80, 90, 100, 110, and 120 in order to analyse the nature of the estimates as the sample size increased. We also considered the NH distribution in order to produce data with starting values of the shape parameter \(\alpha = 0.2\) and the scale parameter \(\beta = 1.6\). The value of acceleration factor is set to \(\theta = 2.5\), with two distinct values of stress change time \(\tau = 5, 8\) and three different censoring levels (CL) of 20%, 30%, and 40%. The simulation study is developed based on 8,000 multiply censored samples under SSPALT to observe changes in parameter values. The complete steps of the algorithm are detailed below:
-
i.
Using the pre-specified parameter values, generate \(n\) random samples from the NH distribution. To do so, first generate u from a uniform distribution with the command \(u = runif\left( {n, 0, 1} \right)\), and then use the quantile function \(t = \left( {\left( {1 - \log (1 - u} \right))^{1/\alpha } - 1} \right)/\beta\) to generate the values of \(t = \left( {t_{1} ,t_{2} , \ldots ,t_{n} } \right)\) from an NH distribution.
-
ii.
Now select the number of failures before the stress change time \(\tau\) and denote it as \(n_{1}\). The generated sample up to time \(\tau\) is \(t_{1s} = \left( {t_{1} ,t_{2} , \ldots ,t_{{n_{1} }} } \right)\). Also select the number of failed items at accelerated condition and denote it as \(n_{2}\), where \(n_{1} + n_{2} = n\) and the generated sample is given as \(t_{2s} = \left( {t_{{n_{1} + 1}} ,t_{{n_{1} + 2}} \ldots ,t_{{n_{1} + n_{2} }} } \right)\)
-
iii.
Choose the CL at 20%, 30% and 40% respectively at both normal and accelerated condition. At 20% CL, we have 80% failed items and 20% censored items. So, we have number of failures at normal and accelerated stress level \(r_{1} = n_{1} \left( {1 - CL} \right)\) and \(r_{2} = n_{2} \left( {1 - CL} \right)\) respectively.
-
iv.
Let \(\delta_{1s,i} = \left\{ {\begin{array}{*{20}l} {1,} \hfill & {i = 1,2, \ldots ,r_{1} } \hfill \\ {0,} \hfill & {i = r_{1} + 1,r_{1} + 2, \ldots ,n_{1} } \hfill \\ \end{array} } \right.\) and \(\delta_{2s,j} = \left\{ {\begin{array}{*{20}l} {1,} \hfill & {j = 1,2, \ldots ,r_{2} } \hfill \\ {0,} \hfill & {i = r_{2} + 1,r_{2} + 2, \ldots ,n_{2} } \hfill \\ \end{array} } \right.\)
-
v.
Now set \(y_{1,i} = \delta_{1s,i} \times t_{1s}\) and \(y_{2,j} = \delta_{2s,j} \times \left( {\frac{{\left( {t_{2s} - \tau } \right)}}{\alpha } + \tau } \right)\), thus the generated multiply censored data set is given as: \(Y = \left\{ {y_{1,i} ,y_{2,j} ,i = 1,2,...,n_{1} ,j = 1,2,...,n_{2} } \right\}\)
-
vi.
Estimate the parameters using the \(Optim\left( \right)\) function and the data obtained in steps (i–v).
-
vii.
Repeat the process N times.
-
viii.
Now calculate the mean MLEs, mean MSEs, 95% ACIs and its CPs by using the following formulae.
$$\begin{aligned} \hat{\alpha } & = \frac{1}{N}\mathop \sum \limits_{i = 1}^{N} \alpha_{i} ; \hat{\beta } = \frac{1}{N}\mathop \sum \limits_{i = 1}^{N} \beta_{i} ; \hat{\theta } = \frac{1}{N}\mathop \sum \limits_{i = 1}^{N} \theta_{i} ; CP\left( {\hat{\alpha }, \hat{\beta }, \hat{\theta }} \right) \\ & = No.\;of\;ACI\;includes\;\left( {\hat{\alpha }, \hat{\beta }, \hat{\theta }} \right)/N \\ \end{aligned}$$$$\begin{aligned} & MSE\left( {\hat{\alpha }} \right) = \frac{1}{N}\mathop \sum \limits_{i = 1}^{N} (\hat{\alpha }_{i} - \alpha )^{2} ;\;MSE\left( {\hat{\beta }} \right) = \frac{1}{N}\mathop \sum \limits_{i = 1}^{N} (\hat{\beta }_{i} - \beta )^{2} ; \\ & MSE\left( {\hat{\theta }} \right) = \frac{1}{N}\mathop \sum \limits_{i = 1}^{N} (\hat{\theta }_{i} - \theta )^{2} \\ \end{aligned}$$
In Tables 6, 7, 8, 9, 10 and 11 summarizes MLEs, MSEs, Lower 95% ACI Limit (L95%CL), Upper 95% ACI Limit (U95%CL), 95% ACI length (95%ACIL) and 95% ACI Coverage Probability (95%ACICP) under multiply censored data based on MLE method are presented with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5} \right)\), \(\tau = \left( {5, 8} \right)\) and different CL of 20%, 30%, and 40% based on N = 10,000 simulations respectively. Figures 3, 4, 5 and 6 provides the plots for simulated samples and the histogram of the parameters based on N = 10,000 simulations respectively based on different initial values of parameters and distinct values of stress change time.

The plots for simulated samples and the histogram of the parameters for \(\left( {\alpha ,\beta , \theta } \right)\) with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5,CL = 0.20} \right)\) for (a) \(\tau = 5\) and (b) \(\tau = 8\).

The plots for simulated samples and the histogram of the parameters for \(\left( {\alpha ,\beta , \theta } \right)\) with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5,CL = 0.30} \right)\) for (a) \(\tau = 5\) and (b) \(\tau = 8\).

The plots for simulated samples and the histogram of the parameters for \(\left( {\alpha ,\beta , \theta } \right)\) with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5,CL = 0.40} \right)\) for (a) \(\tau = 5\) and (b) \(\tau = 8\).
Based on the results in Tables 6, 7, 8, 9, 10 and 11 and Figs. 7, 8 and 9, we can observe that:
-
i.
The MLEs of the parameters \(\alpha , \beta\) and \(\theta\) based on multiply censored data are moving closer to their true values with decreasing MSEs in all cases as n grows.
-
ii.
The values of MSEs and the average length of 95%ACIs fall as n grows for fixed values of \(\alpha , \beta , \theta\) and \(\tau\) while the related 95%ACI coverage probabilities approach 95%.
-
iii.
For fixed values of \(\alpha , \beta\) and \(\theta\), the average values of MSEs and the average length of 95%ACIs increase as \(\tau\) grows.
-
iv.
For fixed values of \(\alpha , \beta\) and \(\theta\), the average values of MSEs and the average length of 95%ACIs increase as CL increases.
-
v.
The average value of estimates for \(\beta\) and \(\theta\) increases as the value of CL increases for fixed values of \(\alpha , \beta\) and \(\theta\), whereas the average value of estimates for \(\alpha\) decrease.
-
vi.
For fixed values of \(\alpha , \beta\) and \(\theta\), the mean result of estimates for \(\beta\) and \(\theta\) increase as the value of t rises, but the mean values of estimates for \(\alpha\) decrease.

The plots of MSEs of the estimates for \(\left( {\alpha ,\beta , \theta } \right)\) with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5} \right)\) for (a) \(\tau = 5\) and (b) \(\tau = 8\).

The plots of 95%ACICP of the estimate for \(\left( {\alpha ,\beta , \theta } \right)\) with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5} \right)\) for (a) \(\tau = 5\) and (b) \(\tau = 8\).

The plots of 95%ACIL of the estimate for \(\left( {\alpha ,\beta , \theta } \right)\) with \(\left( {\alpha = 0.2,\beta = 1.6,\theta = 2.5} \right)\) for (a) \(\tau = 5\) and (b) \(\tau = 8\).
Conclusions and suggestions for further studies
In this article, we used TRV modeling for SSPALT to estimate the unknown model parameters of the NH distribution using the MLE technique. It has been discovered that the MLEs for all unknown parameters cannot be derived explicitly. As a result, we utilized R software to compute MLEs numerically using the Optim() function. Using the observed Fisher information matrix, ACIs for the unknown parameters were also computed. An actual data set based on the timings of subsequent failures of sequential air conditioning system failures for each member of a Boeing 720 jet aircraft fleet was analyzed to illustrate the applicability of the different techniques. Finally, extensive simulation tests with various censoring mechanisms were carried out to evaluate the performance of the estimate procedure. In particular, MSEs, ACIs, and corresponding average interval lengths were used as benchmarks. According to our numerical findings, the values of MSEs and average lengths drop as sample size increases. Furthermore, when the censoring level is reduced, the considered estimates of \(\alpha ,\beta\) and \(\theta\) approach to their real values. As a future research, researchers may use rank set sampling to examine the NH distribution for hybrid censored data under SSPALT. A Bayesian analysis may be performed and compared with present study for the multiple censoring technique. Same has been added in the “Conclusion” section.
Data availability
All data available in the paper with references.
References
Nelson, W. Accelerated Testing: Statistical Models, Test Plans and Data Analysis (Wiley, 1990).
Meeker, W. Q., Escobar, L. A. & Lu, C. J. Accelerated degradation tests: Modeling and analysis. Technometrics 40(2), 89–99 (1998).
Kamal, M. Application of geometric process in accelerated life testing analysis with type-I censored Weibull failure data. Reliab. Theory Appl. 8(3), 87–96 (2013).
Saxena, S., Zarrin, S., Kamal, M. & Islam, A. U. Optimum step stress accelerated life testing for Rayleigh distribution. Int. J. Stat. Appl. 2(6), 120–125 (2012).
El-Din, M. M., Abu-Youssef, S. E., Ali, N. S. & Abd El-Raheem, A. M. Estimation in constant-stress accelerated life tests for extension of the exponential distribution under progressive censoring. Metron 74(2), 253–273 (2016).
Rahman, A., Sindhu, T. N., Lone, S. A. & Kamal, M. Statistical inference for Burr Type X distribution using geometric process in accelerated life testing design for time censored data. Pak. J. Stat. Oper. Res. 16(3), 577–586 (2020).
Han, D. & Bai, T. Design optimization of a simple step-stress accelerated life test–Contrast between continuous and interval inspections with non-uniform step durations. Reliab. Eng. Syst. Saf. 199, 106875 (2020).
Goel, P. K. (1971). Some estimation problems in the study of tampered random variables. (Ph.D. Thesis), Department of Statistics, Cranegie-Mellon University, Pittsburgh, Pennsylvania.
DeGroot, M. H. & Goel, P. K. Bayesian estimation and optimal designs in partially accelerated life testing. Nav. Res. Logist. 26(2), 223–235 (1979).
Bai, D. S. & Chung, S. W. Optimal design of partially accelerated life tests for the exponential distribution under type-I censoring. IEEE Trans. Reliab. 41(3), 400–406 (1992).
Bai, D. S., Chung, S. W. & Chun, Y. R. Optimal design of partially accelerated life tests for the lognormal distribution under type I censoring. Reliab. Eng. Syst. Saf. 40(1), 85–92 (1993).
Rahman, A., Lone, S. A. & Islam, A. Analysis of exponentiated exponential model under step stress partially accelerated life testing plan using progressive type-II censored data. Investigación Oper. 39(4), 551–559 (2019).
Nadarajah, S. & Haghighi, F. An extension of the exponential distribution. Statistics 45(6), 543–558 (2011).
Mir Mostafaee, S. K., Asgharzadeh, A. & Fallah, A. Record values from NH distribution and associated inference. Metron 74(1), 37–59 (2016).
Selim, M. A. Estimation and prediction for Nadarajah–Haghighi distribution based on record values. Pak. J. Stat. 34(1), 77–90 (2018).
Sana, M. S. & Faizan, M. Bayesian estimation for Nadarajah–Haghighi distribution based on upper record values. Pak. J. Stat. Oper. Res. 15(1), 217–230 (2019).
Kamal, M., Alamri, O. A. & Ansari, S. I. A new extension of the Nadarajah Haghighi model: Mathematical properties and applications. J. Math. Comput. Sci. 10(6), 2891–2906 (2020).
Minic, M. Estimation of parameters of Nadarajah–Haghighi extension of the exponential distribution using perfect and imperfect ranked set sample. Yugoslav J. Oper. Res. 30(2), 177–198 (2020).
Kamal, M., Rahman, A., Ansari, S. I. & Zarrin, S. Statistical analysis and optimum step stress accelerated life test design for Nadarajah Haghighi distribution. Reliab. Theory Appl. 15(4), 1–9 (2020).
Wang, F. K. Using BBPSO algorithm to estimate the Weibull parameters with censored data. Commun. Stat. Simul. Comput. 43(10), 2614–2627 (2014).
Wang, F. K., Cheng, Y. F. & Lu, W. L. Partially accelerated life tests for the Weibull distribution under multiply censored data. Commun. Stat. Simul. Comput. 41(9), 1667–1678 (2012).
Jia, X., Wang, D., Jiang, P. & Guo, B. Inference on the reliability of Weibull distribution with multiply Type-I censored data. Reliab. Eng. Syst. Saf. 150, 171–181 (2016).
Hassan, A. S. & Zaky, A. N. Estimation of entropy for inverse Weibull distribution under multiple censored data. J. Taibah Univ. Sci. 13(1), 331–337 (2019).
Bantan, R. A., Elgarhy, M., Chesneau, C. & Jamal, F. Estimation of entropy for inverse Lomax distribution under multiple censored data. Entropy 22(6), 601 (2020).
Alam, I., Islam, A. U. & Ahmed, A. Parametric estimation on constant stress partially accelerated life tests for the exponentiated exponential distribution using multiple censoring. Reliab. Theory Appl. 14(4), 20–31 (2019).
Nassr, S. G. & Elharoun, N. M. Inference for exponentiated Weibull distribution under constant stress partially accelerated life tests with multiple censored. Commun. Stat. Appl. Methods 26(2), 131–148 (2019).
Kamal, M. Parameter estimation for progressive censored data under accelerated life test with k levels of constant stress. Reliab. Theory Appl. 16(3), 149–159 (2021).
Abushal, T. A. Estimation for exponentiated Weibull distribution under accelerated multiple type-II censored samples. J. Inf. Sci. Eng. 36(6), 1191–1210 (2020).
Kamal, M., Rahman, A., Zarrin, S. & Kausar, H. Statistical inference under step stress partially accelerated life testing for adaptive type-II progressive hybrid censored data. J. Reliab. Stat. Stud. 14(2), 1–17 (2021).
Alam, I. & Ahmed, A. Inference on maintenance service policy under step-stress partially accelerated life tests using progressive censoring. J. Stat. Comput. Simul. 92(4), 813–829 (2022).
Kamal, M. Parameter estimation based on censored data under partially accelerated life testing for hybrid systems due to unknown failure causes. CMES-Comput. Model. Eng. Sci. 130(3), 1239–1269 (2022).
Abd-Elfattah, A. M., Hassan, A. S. & Nassr, S. G. Estimation in step-stress partially accelerated life tests for the burr type XII distribution using type I censoring. Stat. Methodol. 5(6), 502–514 (2008).
Nassar, M., Nassr, S. G. & Dey, S. Analysis of burr type XII distribution under step stress partially accelerated life tests with type I and adaptive type II progressively hybrid censoring schemes. Ann. Data Sci. 4(2), 227–248 (2017).
Yousef, M. M., Alsultan, R. & Nassr, S. G. Parameter inference on partially accelerated life testing for the inversed Kumaraswamy distribution based on type-II progressive censoring data. Math. Biosci. Eng. 20(2), 1674–1694 (2022).
Hassan, A. S., Nassr, S. G., Pramanik, S. & Maiti, S. S. Estimation in constant stress partially accelerated life tests distribution based on censored competing risks data. Ann. Data Sci. 7(1), 45–62 (2020).
Proschan, F. Theoretical explanation of observed decreasing failure rate. Technometrics 5(3), 375–383 (1963).
Wang, Y. Package-npsurv: Nonparametric Survival Analysis. R package version 0.5-0. https://CRAN.R-project.org/package=npsurv (2020).
Team, R. C. (2013). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/.
Acknowledgements
Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2023R368), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
All authors reviewed the manuscript and contributed equally to this paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rahman, A., Kamal, M., Khan, S. et al. Statistical inferences under step stress partially accelerated life testing based on multiple censoring approaches using simulated and real-life engineering data. Sci Rep 13, 12452 (2023). https://doi.org/10.1038/s41598-023-39170-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-023-39170-x
- Springer Nature Limited
This article is cited by
-
Statistical analysis using multiple censoring scheme under partially accelerated life tests for the power Lindley distribution
International Journal of System Assurance Engineering and Management (2024)
-
Topp-Leone Cauchy Family of Distributions with Applications in Industrial Engineering
Journal of Statistical Theory and Applications (2023)