
Abstract
Distributed scheduling is seldom investigated in hybrid flow shops. In this study, distributed two-stage hybrid flow shop scheduling problem (DTHFSP) with sequence-dependent setup times is considered. A collaborative variable neighborhood search (CVNS) is proposed to simultaneously minimize total tardiness and makespan. DTHFSP is simplified by incorporating factory assignment into machine assignment of a prefixed stage, and its solution is newly represented with a machine assignment string and a scheduling string. CVNS consists of two cooperated variable neighborhood search (VNS) algorithms, and neighborhood structures and global search have collaborated in each VNS. Eight neighborhood structures and two global search operators are defined to produce new solutions. The current solution is periodically replaced with a member of the archive farthest from it. Experiments are conducted , and the computational results validate that CVNS has good advantages over the considered DTHFSP.
Similar content being viewed by others


Introduction
Hybrid flow shop scheduling problems (HFSP) are not uncommon in many real-life manufacturing industries such as electronics, paper, textile and semiconductor1,2. Two-stage HFSP as the particular case of the general HFSP is proved to be NP-hard by Gupta3 decades ago even in the special case that two machines exist in one stage and a single machine is allocated in another stage. Two-stage HFSP also has attracted much attention due to its practical and diverse applications.
Many methods, including heuristic, exact algorithm and meta-heuristic, have been applied to solve two-stage HFSP because of its high complexity. Allaoui and Artiba4 investigated two-stage HFSP with availability constraint by using an exact method and several heuristics to minimize makespan. Wang and Liu5 proposed a genetic algorithm (GA) for two-stage no-wait HFSP. Tan et al.6 presented a hybrid decomposition approach with variable neighborhood search (VNS) for the problem with batch processing machines. Yang7 developed some heuristics for the special cases of the problem with dedicated machines. Wang and Liu8 presented a heuristic-based on branch-and-bound for the problem with dedicated machines. Setup times extensively exist in real-life manufacturing situations9 and are also handled in two-stage HFSP. Lin and Liao10 applied a heuristic method to solve the problem with setup times and dedicated machines. Hekmatfar et al.11 presented some heuristics and a hybrid GA for two-stage reentrant HFSP with setup times. Lee et al.12 provided a hybrid method based on beam search and NEH for the problem with setup times. The previous works also considered batching and scheduling13, interval processing times14, assembly15, renewable resources16 and preventive maintenance17 and applied meta-heuristics such as tabu search16,17, artificial bee colony18 and imperialist competitive algorithm19 to solve two-stage HFSP.
The above works are often implemented in a single factory. To our knowledge, two-stage HFSP is not investigated in multi-factory environments. Production has shifted from a single factory to a multi-factory production network with the development of globalization. In a multi-factory production network, each factory can be considered as an individual entity with different location and efficiency and different constraints such as worker cost, tax, close to suppliers, etc. The distributed scheduling problems in multi-factory networks reveal new features such as many sub-problems and strong coupled relations among sub-problems. In recent years, distributed scheduling in multi-factory networks has attracted some attention. A number of results have been obtained on distributed scheduling in single machine20, parallel machines21,22,23,24,25,26, flow shop27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43 and hybrid flow shop44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65 etc.
Flow shop scheduling is a special case of HFSP. In recent years, distributed flow shop scheduling problems (DFSP) had been considered, and several results have been obtained. Distributed permutation flow shop scheduling problem is often dealt with. For the problem with makespan minimization, Lin et al.27 proposed a modified iterated greedy (IG) algorithm, Naderi and Ruiz28 applied a scatter search algorithm, Xu et al.29 presented a hybrid immune algorithm, Wang et al.30 designed an effective estimation of distribution algorithm and Gao et al.31 developed an efficient tabu search. DFSP with practical constraints such as blocking32, no-wait33,34 and assembly35,36,37 is often addressed. For DFSP with sequence-dependent setup times (SDST), Hatami et al.40 proposed two heuristics, a VNS and an IG. DFSP with multiple objectives is also studied41,42.
Distributed HFSP has also been considered. For this problem with the optimization objective of minimizing maximum completion time, the common methods are iterative greed algorithm44,60, shuffled frog leaping algorithm47, hybrid brain storm optimization algorithm49,54, artificial bee colony algorithm55,56,57, and cooperative memetic algorithm62 etc. For the problem with multi-objective optimization, the methods used are genetic algorithm59, variable neighborhood search48, shuffled frog leaping algorithm45,46,51,64, teaching-learning-based optimization52, cooperative coevolution algorithm63,65, decomposition-based multi-objective optimization50, iterated greedy algorithm61 and other evolutionary algorithms53.
As stated above, the literature on DFSP is mainly about optimizing a single objective such as makespan by using GA and IG, etc. DFSP with multiple objectives and DFSP with SDST is not considered fully; on the other hand, two-stage HFSP is investigated fully in the past decade; however, two-stage HFSP are hardly handled in the multi-factory production network, let alone distributed two-stage hybrid flow shop scheduling problem (DTHFSP) with SDST and objectives such as makespan and total tardiness. Because of the diverse applications of two-stage HFSP in real-life manufacturing situations, it is necessary to address bi-objective DTHFSP with constraints such as SDST.
In general, DTHFSP composes three sub-problems: factory assignment, which assigns jobs to an appropriate factory; machine assignment, which allocates each job to a machine in its assigned factory and scheduling one deciding the sequence of jobs on each machine. When each job is directly allocated to a machine at a predetermined stage s and the results of factory assignment can be obtained directly, that is, factory assignment can be incorporated into machine assignment of a predetermined stage; as a result, the number of sub-problems diminishes and the problem is simplified.
VNS44 is a local-search-based meta-heuristic, which explores increasingly several neighborhoods of the current solution and jumps from this solution to a new one if and only if an improvement has been made. In this way, favorable features of the current solution will be kept and used to obtain promising neighborhood solutions. VNS has been applied to various production scheduling problems6,26,35,66,67,68,69,70; however, VNS is just hybridized with other methods and seldom applied independently35 to solve two-stage HFSP and DFSP.
In this study, DTHFSP with SDST is considered, and a collaborative variable neighborhood search (CVNS) is proposed to simultaneously minimize total tardiness and makespan. The main characteristics of CVNS are as follows. DTHFSP is simplified by incorporating factory assignment into machine assignment of a prefixed stage, and a new coding is adopted by representing a solution with a machine assignment string and a scheduling string. CVNS comprises two cooperated VNS, and neighborhood structures and global search have collaborated in each VNS. Eight neighborhood structures and two global search operators are defined to produce new solutions. The current solution is periodically replaced with a member of the archive farthest from it. Several experiments are conducted on many instances, and CVNS is compared with two famous multi-objective GAs and a multi-objective tabu search algorithm. The computational results demonstrate that CVNS has good advantages over the considered DTHFSP.
The remainder of the paper is organized as follows. The problem under study is described in “Problem descriptions” and followed by the introduction to VNS in “CVNS for DTHFSP with SDST”. CVNS for bi-objective DTHFSP is described in “Computational experiments”. Numerical test experiments on CVNS are reported in “Conclusions”, the conclusions are summarized in the final section, and some topics for future research are provided.
Problem descriptions
Bi-objective DTHFSP is depicted as follows. There are n jobs distributed among F factories at different sites. Each factory \(Fac_f\) has a two-stage hybrid flow shop, where there are \(m_f\) identical parallel machines at stage one and a single machine in stage two. All jobs are available at time zero. Machines \(M_{1,s_f + 1} , \ldots ,M_{1,s_f + m_f }\) are located in the first stage of factory f, where \(s_f = \sum \nolimits _{l = 1}^{f - 1} {m_l } ,f > 1\), \(s_1=0\). There are total \(W = \sum \nolimits _{f = 1}^{F} {m_f }\) parallel machines. \(M_{2,f}\) indicates the single machine in the second stage of factory \(Fac_f\). Each job \(J_i\) has a due date \(d_i\) and a processing time \(p_{isf}\) at stage s of factory \(Fac_f\). SDST is considered. \(u_{jisf}\) indicates the setup time for job \(J_i\) on each machine of stage s in factory \(Fac_f\) when job \(J_j\) is processed directly before it on the same machine. \(u_{0isf}\) represents initial setup time of the first job \(J_i\) processed on machine at stage s of factory \(Fac_f\). In general, \(u_{jisf_1}\ne u_{jisf_2}\) and \(u_{0isf_1} \ne u_{0isf_2}\) for \(f_1 \ne f_2\), and \(u_{jisf}\ne u_{jigf}\) and \(u_{0isf} \ne u_{0igf}\) for \(s\ne g\).
DTHFSP has some constraints on jobs and machines.
Each machine can process at most one operation at a time,
No jobs may be processed on more than one machine at a time,
Operations cannot be interrupted,
All machines are available at all times etc.
In general, DTHFSP can be categorized into three sub-problems, (1) factory assignment used to decide which jobs are allocated to each factory; (2) machine assignment; (3) scheduling. Machines in each factory are fixed in advance. If we allocate each job to a machine at the first stage and then decide the number of jobs on machines at the first stage of each factory, then we can find that jobs are allocated in each factory, in this way, two assignment problems are combined into machine assignment of the first stage, and DTHFSP is simplified, which consists of machine assignment of the first stage and scheduling. Two assignment sub-problems cannot be integrated into machine assignment of the second stage because machine assignment of the first stage must be done and three sub-problems still exist. Figure 1 shows a multi-factory system of the problem.

Multi-factory system of DTHFSP.
The goal of DTHFSP is to allocate jobs to machines from different factories and schedule jobs on each machine to minimize two objectives, the maximum completion time \(C_{max}\) and the total tardiness \(T_{tot}\). Table 1 provides the description of notations. The mathematical model of DTHFSP is as follows:
where Eq. (1) is to minimize maximum completion time; Eq. (2) is to minimize total tardiness; constraint (3) describes that each job can only be processed in one factory; constraints (4–5) show that a job can only be assigned to one machine at each stage in each factory; constraint (6) denotes that each job can be processed after zero time; constraint (7) indicates that jobs can be processed in the second stage only after it is processed in the first stage; constraints (8–9) shows that the process cannot be interrupted; constraints (10–12) demonstrates that each machine can only process one job at one time; constraints (13–15) are binary decision variables.
CVNS for DTHFSP with SDST
DTHFSP is regarded as the problem with machine assignment of the first stage, and scheduling and a two-string representation is adopted. Then eight neighborhood structures and two global search operators are used to produce new solutions; finally, a CVNS is developed based on the cooperation of two VNS algorithms and the collaboration of global search and neighborhood search.
Introduction to VNS
The steps of basic VNS are presented as follows44.
-
Step 1: Initialization. Select the set of neighborhood structures \({{\mathscr {N}}}_k\)(\(k = 1,2, \ldots ,k_{max}\)), produce an initial solution x, choose a stopping condition.
-
Step 2: Repeat the following steps until the stopping condition is met.
-
(1)
\(k=1\).
-
(2)
repeat the following steps until \(k=k_{max}\).
-
a.
Randomly generate a solution \(x^{'} \in {\mathscr {N}}_k \left( x \right) \).
-
b.
Let \(x^{'}\) as the initial solution, apply local search methods to it and obtain local optimum \(x^{''} \).
-
c.
If the local optimum \(x^{''} \) is better than the incumbent, replace x with \(x^{''}\) and continue the search with \({{\mathscr {N}}}_1\); otherwise \(k=k+1\).
-
a.
-
(1)
where \({{\mathscr {N}}}_k\) is the neighborhood structure and \({{\mathscr {N}}}_k \left( x \right) \) indicates the neighborhood of x obtained by using \({{\mathscr {N}}}_k\).
The stopping condition may be the maximum CPU time allowed, the maximum number of iterations, etc.
Two-string representation
In this study, a two-string representation is applied to represent the solution of DTHFSP. For the problem with n jobs and W parallel machines, a solution is denoted by a machine assignment string \([M_{1,h_1},M_{1,h_2},\ldots , M_{1,h_n}]\) and a scheduling string \([q_1,q_2,\ldots , q_n]\). Machine \(M_{1,h_i}\) is allocated for job \(J_i\) on the first stage, \(h_i\in [1,W]\) and \(q_l\) corresponds to \(J_l\). The scheduling string is a random key one, suppose that jobs \(J_i,J_{i+1},\ldots ,J_j\) are processed on the same machine of the first stage, that is, \(M_{1,h_i}=M_{1,h_{i+1}},\ldots , =M_{1,h_j}\), the processing sequence of these jobs on the machine of the first stage is decided by the ascending order of \(q_l, l\in [i,j],i<j\). The processing sequence of all jobs in a factory on the single machine of the second stage is also determined by the ascending order of their \(q_l\).
The decoding procedure is described below. Machine assignment of each job in the first stage is first done according to the first string; then in each factory f, the allocated jobs of each parallel machine are processed sequentially in terms of the ascending order of their \(q_l\), the sequence of the assigned jobs of factory f is decided on machine \(M_{2,f}\) according to the ascending order of their \(q_l\). Each assigned job is processed sequentially after its processing at the first stage is finished.
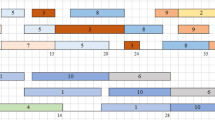
For a example with two factories, 10 jobs, \(M_{1,1}, M_{1,2}, M_{2,1}\) and \(M_{1,3}, M_{1,4}, M_{2,2}\), a possible solution is \([M_{1,2},M_{1,4},M_{1,2},M_{1,3},\) \(M_{1,1},M_{1,2},M_{1,4},M_{1,3},M_{1,1},M_{1,3}]\) and [0.55, 0.32, 0.18, 0.95, 0.44, 0.39, 0.87, 0.56, 0.05, 0.75]. Jobs \(J_1,J_3,J_6\) are assigned on machine \(M_{1,2}\), \(q_1=0.55,q_3=0.18,q_6=0.39\), so the sequence is \(J_3,J_6,J_1\). We also can be found that \(J_1,J_3,J_5,J_6,J_9\) are allocated in factory 1 and other jobs are processed in factory 2. The processing sequence on single machine of factory 1 is \(J_9,J_3,J_6,J_5,J_1\). Figure 2 shows a schedule of the solution.

The schedule of the possible solution.
Neighborhood structures
Eight neighborhood structures are defined for the current solution x, four for machine assignment of the first stage and four for scheduling.
Neighborhood structure \({{\mathscr {N}}}_1\) is executed in a factory and described below. A factory f is randomly chosen, and then a parallel machine \(M_{1,l}\) with maximum workload and \(M_{1,g}\) with minimum workload are decided at the first stage of factory f, a job on \(M_{1,l}\) is finally moved to machine \(M_{1,g}\), where the workload of a machine is the sum of setup time and processing time of all jobs processed on this machine. For the solution in Fig. 2, factory 1 is chosen, \(M_{1,2}\) and \(M_{1,1}\) have the maximum workload and minimum workload,respectively, finally, job 1 is moved from \(M_{1,2}\) to \(M_{1,1}\).
Neighborhood structure \({{\mathscr {N}}}_2\) is performed between two factories and shown as follows. Two factories \(f_1,f_2,f_1 \ne f_2\) are stochastically selected; then in each factory, a parallel machine \(M_{1,l_i}\) with maximum workload and a machine \(M_{1,g_i}\) with minimum workload are respectively decided, \(i=1,2\); finally, if the workload of \(M_{1,l_1}\) is greater than that of \(M_{1,l_2}\), then move a job from \(M_{1,l_1}\) to \(M_{1,g_2}\), otherwise allocate a job from \(M_{1,l_2}\) to \(M_{1,g_1}\). For factories 1 and 2 in Fig. 2, \(M_{1,2}\) and \(M_{1,1}\) have the maximum and minimum workload, respectively. \(M_{1,4}\) and \(M_{1,3}\) are machines in factory 2 with the maximum workload and minimum workload. Workload of \(M_{1,2}\) is greater than that of \(M_{1,4}\), job 3 is moved from \(M_{1,2}\) to \(M_{1,3}\).
Neighborhood structure \({{\mathscr {N}}}_3\) is also done between two factories. Two factories \(f_1,f_2, f_1 \ne f_2\) are stochastically selected; then in each factory, a parallel machine \(M_{1,l_i}\) with maximum workload and a parallel machine \(M_{1,g_i}\) with minimum workload are respectively decided, \(i=1,2\); finally, if the workload of \(M_{1,l_1}\) is greater than that of \(M_{1,l_2}\), then move a job from \(M_{1,l_1}\) to \(M_{1,g_2}\) and assign a job from \(M_{1,g_2}\) to \(M_{1,l_1}\), otherwise a job is moved from \(M_{1,l_2}\) to \(M_{1,g_1}\) and another job is from \(M_{1,g_1}\) to \(M_{1,l_2}\).
\({{\mathscr {N}}}_4\) is applied to lead to a new machine assignment for the chosen jobs described below. Randomly choose a job \(J_i\) from a factory f with the maximum completion time, that is, this maximum completion time is makespan, then a parallel machine \(M_{1,w}\) of the first stage is stochastically chosen from the factory g with the minimum completion time and the job \(J_i\) is assigned on the machine \(M_{1,w}\). In Fig. 2, the maximum completion times of two factories are 279 and 250, job 4 is moved from \(M_{1,3}\) to \(M_{1,1}\).
\({{\mathscr {N}}}_1,{{\mathscr {N}}}_2,{{\mathscr {N}}}_3,{{\mathscr {N}}}_4\) directly act on the schedule of a solution, and the machine assignment string can be obtained after they are done. These neighborhood structures are used to produce new assignments for some jobs at the first stage.
The scheduling string is used to decide the sequences of jobs on each parallel machine and single machine in each factory. Neighborhood structures \({{\mathscr {N}}}_5,{{\mathscr {N}}}_6\) are applied to result in some changes to the second string. \({{\mathscr {N}}}_5\) generates new solutions by swapping two pairs of randomly chosen genes \(q_l\) and \(q_g\), \(l\ne g\). \({{\mathscr {N}}}_6\) produces new solutions by inserting a randomly selected gene \(q_l\) into a new position \(g,l\ne g\).
\({{\mathscr {N}}}_7\) is depicted for each factory f: sort all jobs in factory f in the ascending order of due dates and then let the sequence of their \(q_l\) of these jobs be identical with the order of due dates. In Fig. 2, for jobs \(J_9,J_3,J_6,J_5,J_1\) in factory 2, suppose that their due dates are 35, 45, 65, 23, 78, jobs are sorted as \(J_5,J_9,J_3,J_6,J_1\) and the sequence of their \(q_l\) is \(q_5,q_9,q_3,q_6,q_1\).
The steps of \({{\mathscr {N}}}_8\) are identical with \({{\mathscr {N}}}_7\) except that the ascending order of processing times on single machine substitutes for that of the due date. For the factory 2 in Fig. 2, suppose that processing times jobs of \(J_9,J_3,J_6,J_5,J_1\) on single machine are 10, 13, 8, 5, 23, 9, these jobs are sorted as \(J_6,J_3,J_1,J_9,J_5\) and the sequence of their \(q_l\) is \(q_6,q_3,q_1,q_9,q_5\), then the scheduling string becomes [0.39, 0.32, 0.18, 0.95, 0.55, 0.05, 0.87, 0.56, 0.44, 0.75].
Figure 3 explains 8 neighborhood structures.

The explanation of 8 neighborhood structures.
Global search
In general VNS, only neighborhood search is used to produce new solutions. To intensify the global search ability of VNS, two two-point global searches are adopted between the current solution x and a member y of archive \(\Omega \), which is utilized to store non-dominated solutions. The first global search \(GS_1\) acts on the machine assignment string of x and y. A member y is randomly chosen from \(\Omega \), two positions \(k_1,k_2\) are randomly selected and machines between \(k_1\) and \(k_2\) on the first string of x are directly replaced with those on the first string of y. The second global search \(GS_2\) is executed in the same way on the scheduling string; genes of x between two positions are displaced by those of y on the same positions.
Descriptions on CVNS
The detailed procedure of CVNS is described as follows.
-
Step1:
Initialization. Randomly produce an initial solution x and build an initial archive \(\Omega \), \(t=1,\theta _1=\theta _2=1\).
-
Step2:
If \(\theta _1=1\), \(x^{'} \in {{\mathscr {N}}}_1(x)\); if \(\theta _1=2\), \(x^{'} \in {{\mathscr {N}}}_5(x)\); if \(\theta _1=3\), \(x^{'} \in {\mathscr {N}}_3(x)\); if \(\theta _1=4\) and a member \(y\in \Omega \) and \(y\ne x\) exists, \(GS_1\) is executed between x and y and \(x^{'}\) is gotten.
-
Step3:
If solution \(x^{'}\) is not dominated by x, then replace x with \(x^{'}\), update \(\Omega \) and \(\theta _1=1\); otherwise \(\theta _1=\theta _1+1\) and let \(\theta _1=1\) if \(\theta _1=5\).
-
Step4:
\(x^{'}\in {{\mathscr {N}}}_4(x)\) is generated, compare \(x^{'}\) with x and update \(\Omega \) as done in Step3.
-
Step5:
If \(\theta _2=1\), \(x^{'} \in {{\mathscr {N}}}_5(x)\); if \(\theta _2=2\), \(x^{'} \in {{\mathscr {N}}}_6(x)\); if \(\theta _2=3\), \(x^{'} \in {mathscr{N}}_2(x)\); if \(\theta _2=4\) and a member \(y\in \Omega \) with \(y\ne x\) exists, \(GS_2\) is done between x and y, and \(x^{'}\) is produced.
-
Step6:
If solution \(x^{'}\) is not dominated by x, then replace x with \(x^{'}\),update \(\Omega \) and \(\theta _2=1\); otherwise \(\theta _2=\theta _2+1\) and let \(\theta _2=1\) if \(\theta _2=5\).
-
Step7:
\({{\mathscr {N}}}_7\) and \({{\mathscr {N}}}_8\) are sequentially performed on x, \(x^{'}\) is generated, compare \(x^{'}\) with x and update \(\Omega \) as done in Step3.
-
Step8:
\(t=t+5\). If t is exactly divided by \(\beta \), then a solution \(y\in \Omega \) being farthest to x substitutes for x.
-
Step9:
If algorithm running time exceeds \(max\_it\), then go to step 2.
-
Step10:
Output the archive \(\Omega \).
where \(max \_it\) indicates the maximum algorithm running time, \(\beta \) is an integer, if \(C_{max}(x^{'})\le C_{max}(x)\) and \(T_{tot}(x^{'})\le T_{tot}(x)\), and \(C_{max}(x^{'})< C_{max}(x)\) or \(T_{tot}(x^{'})< T_{tot}(x)\), then \(x^{'}\) dominates x or x is dominated by \(x^{'}\). If there is no dominating relation between x and \(x^{'}\), they are non-dominated by each other. That \(x^{'}\) dominates x or is non-dominated with x means that \(x^{'}\) is not dominated by x.
The archive \(\Omega \) is used to store the non-dominated solutions obtained by CVNS. The set \(\Omega \) is updated using the new solution \(x^{'}\) in the following way: the new solution \(x^{'}\) is added into \(\Omega \), and all solutions of \(\Omega \) are compared according to Pareto dominance and the dominated ones are removed from \(\Omega \).
In CVNS, global search and neighborhood search have collaborated, two VNS algorithms have cooperated, some neighborhood structures are applied to improve solution quality, and the current solution is periodically replaced, these strategies can make a good balance between exploration and exploitation and keep high diversity, so CVNS can have promising performances.
Computational experiments
Extensive experiments are conducted on a set of problems to test the performance of CVNS for bi-objective DTHFSP. All experiments are implemented by using Microsoft Visual C++ 2015 and run on a 4.0G RAM 2.00GHz CPU PC.
Test instances, comparative algorithms and metrics
188 instances are randomly produced, and Table 2 describes the basic information for these instances. \(u_{0isf},u_{jisf} \in [5,10]\) and \(p_{isf}\in [1,100]\) in instances 1-94. \(u_{0isf},u_{jisf} \in [5,10]\) and \(p_{isf}\in [10,80]\) in instances 95-188. Cai et al.45 provided the method to generate due data \(d_i\), which is defined by
As shown in Table 2, instance 60 includes 4 factories, 150 jobs, and the first processing stage of the 4 factories contains 2, 2, 3 and 3 parallel machines, respectively. The processing time of each job is a uniformly distributed random number. An example for generating due dates is provided as follows. The processing time and setup time related to job \(J_3\) are \(p_{3sf}\) and \(u_{j3fs} \). Assuming that \(\mathop {\min }\nolimits _{i,s,f} {p_{isf}}=20\), \(\mathop {\min }\nolimits _{j,i,s,f} {u_{jisf}}=5\), \(\mathop {\max }\nolimits _{i,s,f} {p_{isf}}=80\) and \(\mathop {\max }\nolimits _{j,i,s,f} {u_{jisf}}=10\), then \({d_i} \in [50,900]\) according to Eqs. (16–18), so the value of \(d_3\) could be 100.
As stated above, bi-objective DTHFSP is not considered, so there are no existing methods as comparative algorithms. To test the performance of CVNS, we choose three famous multi-objective evolutionary algorithms called non-dominated sorting genetic algorithm-II (NSGA-II71), strength Pareto evolutionary algorithm2 (SPEA272) and multi-objective tabu search (MOTS73).
NSGA-II has a very competitive performance in solving the multi-objective problem. In NSGA-II, a non-dominated sorting approach is used for each individual to create a Pareto rank, and a crowding distance assignment method is applied to implement density estimation. NSGA-II prefers the point with a lower rank value or the point located in a region with fewer points if both of the points belong to the same front. By combining a fast non-dominated sorting method, an elitism scheme and a parameter-less sharing method with its origin, NSGA-II is claimed to produce a better spread of solutions in some testing problems. The intense search ability on multi-objective problems motivated us to choose NSGA-II as the comparative algorithm.
In SPEA2, a fitness assignment scheme is used, which takes each individual into account how many individuals it dominates and it is dominated by; a nearest neighbor density estimation technique is incorporated, which allows more precise guidance of the search process; a new archive truncation method guarantees the preservation of boundary solutions. SPEA2 has been proved to perform well in convergence and diversity, so we use SPEA2 as a comparative algorithm.
MOTS is presented to solve a two-stage hybrid flow shop scheduling problem with SDST and preventive maintenance. Some parallel tabu lists and the Pareto dominance concept are used to generate non-nominated solutions in MOTS. MOTS can solve DTHFSP by deleting a code string corresponding to preventive maintenance and adding a code string corresponding to the factory. So, MOTS is used as another comparative algorithm.
Metric \(\rho \) is the proportion of solutions that an algorithm can provide for the reference solution set. \(\rho \) is calculated as
where \(\Omega _A\) is the non-dominated solutions obtained by algorithm A and \(\Omega ^*\) represents the reference solution set.
Metric \({{\mathscr {C}}}\)74 is applied to compare the approximate Pareto optimal set obtained by algorithms. \({{\mathscr {C}}}\left( {L,B} \right) \) measures the fraction of members of B that are dominated by members of L.
where \(x \succ y\) indicates that x dominates y, which is defined in Sect. 4.4.
Metric IGD75,76 is a comprehensive performance indicator to evaluate algorithms. The smaller the value of IGS, the better algorithm’s overall performance of A. IGD is calculated as
where d(x, y) is the Euclidean distance between solution x and y by normalized objectives.
Parameter settings
There are two parameters \(max \_it\) and \(\beta \) for CVNS. We used three settings of \(0.05 \times n \times s\), \(0.10 \times n \times s\) and \(0.15 \times n \times s\) for \(max\_it\) and 8000, 9000, 10,000 for \(\beta \). There are 9 combinations for parameters. Based on the results measured using the above metrics, the best results are achieved using the following setting: \(max\_it=0.10 \times n \times s\), \(\beta =10{,}000\).
To apply NSGA-II, the above coding method and decoding procedure are adopted, eight neighborhood structures can be chosen as mutation, we applied five mutation operators using five neighborhood structures \({{\mathscr {N}}}_1,{{\mathscr {N}}}_2,{{\mathscr {N}}}_3,{{\mathscr {N}}}_5,{{\mathscr {N}}}_6\), because NSGA-II with these mutations can have the best performance. Two-point crossovers act on machine assignment string and scheduling string, respectively. SPEA2 is also implemented using the same way as NSGA-II. In these algorithms, five mutations are done sequentially, and so do two crossovers. In MOTS, only the operations for the factory string need to add. All parameters of NSGA-II, SPEA2 and MOTS are directly selected from Deb et al.71, Zitzler et al.72 and Wang and Liu73 except the stopping condition. For a fair comparison, the termination condition of all algorithms is \(0.10 \times n \times s\). Experiments showed that parameter settings of three comparative algorithms could result in the best results in most instances, so these settings are used.
Results and analyses
Four algorithms randomly run 20 times for each instance. The computational results of four algorithms are reported in Tables 3, 4 and 5. The reference set \(\Omega ^*\) is composed of non-dominated solutions obtained by four algorithms. Symbol ‘Ins’ indicates instance. Symbols ‘N’, ‘C’, ‘S’ and ‘M’ represent NSGA-II, CVNS, SPEA2 and MOTS. Figure 4 describes the distribution of non-dominated solutions on objective space of four algorithms. To make the results statistically convincing, the p-value results of paired-sample t-test are provided in Table 6. To show the overall distribution of all algorithms on all metrics, the box plot are provided in Figs. 5, 6, 7, 8 and 9.

Distribution of non-dominated solutions of three algorithms.

The box plots of three metrics for instances with 2 factories.

The box plots of three metrics for instances with 3 factories.

The box plots of three metrics for instances with 4 factories.

The box plots of three metrics for instances with 5 factories.

The box plots of three metrics for all instances.
Results analyses
As shown in Table 3, CVNS provides a larger proportion of solutions to the reference solution set than the three comparison algorithms in most instances. In 71 instances, the \(\rho \) of CVNS equals 1, which means that all solutions of the reference set are provided by CVNS. As can be seen from Figs. 5, 6, 7, 8 and 9, only when \(F=2\), the performance of NSGA-II is comparable to that of CVNS; when \(F=3,4,5\), CVNS is significantly better than that of NSGA-II. It is noted that when \(F=2,3,4,5\), CNVS performed better than SPEA2 and MOTS. So CNVS can provide more non-dominated solutions than comparison algorithms.
As stated in Table 4, CVNS performed better than its comparison algorithms regarding dominance ratio. In most instances, \(\mathscr {C}\) of CVNS equals 1, and \(\mathscr {C}\) of its comparison algorithms equals 0, that is, solutions of CVNS dominate all solutions obtained by the comparison algorithm. CVNS can get higher quality calculation results under different factories, especially when the number of factories increases. Therefore, CNVS is superior in the dominance relationship compared with comparison algorithms.
As exhibited in Table 5, CVNS converges better than NSGA-II, SPEA2 and MOTS in most instances. IGD of CVNS is less than that of three comparison algorithms on 176 instances and equal to 0 on 163 instances; that is, all members of the reference set \(\Omega ^*\) are generated by CVNS. So CVNS has better convergence.
Robustness analysis
In all 188 instances, the relevant variables are the range of processing time, the range of due date, the number of jobs and the number of parallel machines. As can be seen from the computational results of the three metrics in Tables 3, 4 and 5, CVNS is better than the comparison algorithms in most instances as these variables change, so CVNS has good robustness.
Sensitivity analysis
Instances 1–94 have a different range of processing time with instances 95–188. After the range of processing time is changed, CVNS can still obtain better results than the three comparison algorithms, as shown in Table 3, 4 and 5. In addition, as the number of factories changes, CVNS still outperforms comparison algorithms. As shown in the box plots of Figs. 5, 6, 7, 8 and 9, with the different factories, the metric \(\rho \) tends to 1, the metric \(\mathscr {C}\) tends to 1, and the metric IGD tends to 0; that is, CVNS performs better in different instances with the different number of factories.
The paired-sample t-test is a simple statistical test to testify to the performance of algorithms. The term t-test (A, B) means that paired t-test is conducted to judge whether algorithm A gives a better sample mean than B. We assume a significance level of 0.05. There is a significant difference between A and B in the statistical sense if the p-value is less than 0.05. As stated in the statistical results of Table 6, p-value(\(\rho \)), p-value(\(\mathscr {C}\)) and p-value(IGD) are all equal to 0, thus, CVNS has promising advantages on solving DTHFSP statistically. The same conclusion also can be drawn from Fig. 4.
The excellent performance of CVNS mainly results from its two cooperation mechanisms: the collaboration of global search and neighborhood search and the cooperation of two VNS algorithms; on the contrary, two GAs have strong global search ability and often low efficiency in local search, based on the above discussions, it can be concluded that CVNS is a promising method for solving bi-objective DTHFSP with SDST.
Conclusions
Two-stage HFSP has been extensively investigated in the past decade; however, this problem is not studied in the multi-factory production network. This paper aims to solve DTHFSP with SDST by using a new algorithm called CVNS to minimize simultaneously total tardiness and makespan. DTHFSP is simplified by incorporating factory assignment into machine assignment of the first stage, and its solution is newly represented with a machine assignment string and a scheduling string. CVNS consists of two cooperated VNS algorithms, and in each VNS, neighborhood structures and global search have collaborated. Some neighborhood structures and global search operators are applied to produce new solutions. The current solution is periodically replaced with a member of the archive farthest from it. The performance of CVNS is tested by using 94 instances. The computational results show that CVNS is a promising method to solve the considered DTHFSP.
In the near future, we will continue to pay attention to distributed scheduling problems in the two-stage hybrid flow shop or the hybrid flow shop and try to solve the problem using meta-heuristics such as the imperialist competitive algorithm. We also deal with the above problems with energy-related objectives. Energy-efficient HFSP is also our future topic.
Data availibility
All data generated or analysed during this study are included in this published article.
References
Ruiz, R. & Vazquez-Rodriguez, J. A. The hybrid flow shop scheduling problem. Eur. J. Oper. Res. 205, 1–18. https://doi.org/10.1016/j.ejor.2009.09.024 (2010).
Qin, H.-X. et al. An improved iterated greedy algorithm for the energy-efficient blocking hybrid flow shop scheduling problem. Swarm Evolut. Comput. 69. https://doi.org/10.1016/j.swevo.2021.100992 (2022).
Gupta, J. N. D. Two-stage, hybrid flowshop scheduling problem. J. Oper. Res. Soc. 39, 359–364. https://doi.org/10.1057/jors.1988.63 (2017).
Allaoui, H. & Artiba, A. Scheduling two-stage hybrid flow shop with availability constraints. Comput. Oper. Res. 33, 1399–1419. https://doi.org/10.1016/j.cor.2004.09.034 (2006).
Wang, S. J. & Liu, M. A genetic algorithm for two-stage no-wait hybrid flow shop scheduling problem. Comput. Oper. Res. 40, 1064–1075. https://doi.org/10.1016/j.cor.2012.10.015 (2013).
Tan, Y., Monch, L. & Fowler, J. W. A hybrid scheduling approach for a two-stage flexible flow shop with batch processing machines. J. Sched. 21, 209–226. https://doi.org/10.1007/s10951-017-0530-4 (2018).
Yang, J. Minimizing total completion time in two-stage hybrid flow shop with dedicated machines. Comput. Oper. Res. 38, 1045–1053. https://doi.org/10.1016/j.cor.2010.10.009 (2011).
Wang, S. J. & Liu, M. A heuristic method for two-stage hybrid flow shop with dedicated machines. Comput. Oper. Res. 40, 438–450. https://doi.org/10.1016/j.cor.2012.07.015 (2013).
Allahverdi, A., Gupta, J. N. D. & Aldowaisan, T. A review of scheduling research involving setup considerations. Omega 27, 219–239. https://doi.org/10.1016/s0305-0483(98)00042-5 (1999).
Lin, H. T. & Liao, C. J. A case study in a two-stage hybrid flow shop with setup time and dedicated machines. Int. J. Prod. Econ. 86, 133–143. https://doi.org/10.1016/S0925-5273(03)00011-2 (2003).
Hekmatfar, M., Ghomi, S. M. T. F. & Karimi, B. Two stage reentrant hybrid flow shop with setup times and the criterion of minimizing makespan. Appl. Soft Comput. 11, 4530–4539. https://doi.org/10.1016/j.asoc.2011.08.013 (2011).
Lee, G. C., Hong, J. M. & Choi, S. H. Efficient heuristic algorithm for scheduling two-stage hybrid flowshop with sequence-dependent setup times. Math. Probl. Eng. 2015, https://doi.org/10.1155/2015/420308 (2015).
Yu, J. M., Huang, R. & Lee, D. H. Iterative algorithms for batching and scheduling to minimise the total job tardiness in two-stage hybrid flow shops. Int. J. Prod. Res. 55, 3266–3282. https://doi.org/10.1080/00207543.2017.1304661 (2017).
Feng, X., Zheng, F. F. & Xu, Y. F. Robust scheduling of a two-stage hybrid flow shop with uncertain interval processing times. Int. J. Prod. Res. 54, 3706–3717. https://doi.org/10.1080/00207543.2016.1162341 (2016).
Komaki, G. M., Teymourian, E. & Kayvanfar, V. Minimising makespan in the two-stage assembly hybrid flow shop scheduling problem using artificial immune systems. Int. J. Prod. Res. 54, 963–983. https://doi.org/10.1080/00207543.2015.1035815 (2016).
Figielska, E. A heuristic for scheduling in a two-stage hybrid flowshop with renewable resources shared among the stages. Eur. J. Oper. Res. 236, 433–444. https://doi.org/10.1016/j.ejor.2013.12.003 (2014).
Wang, S. J. & Liu, M. Two-stage hybrid flow shop scheduling with preventive maintenance using multi-objective tabu search method. Int. J. Prod. Res. 52, 1495–1508. https://doi.org/10.1080/00207543.2013.847983 (2014).
Kheirandish, O., Tavakkoli-Moghaddam, R. & Karimi-Nasab, M. An artificial bee colony algorithm for a two-stage hybrid flowshop scheduling problem with multilevel product structures and requirement operations. Int. J. Comput. Integr. Manuf. 28, 437–450. https://doi.org/10.1080/0951192x.2014.880805 (2015).
Rabiee, M., Rad, R. S., Mazinani, M. & Shafaei, R. An intelligent hybrid meta-heuristic for solving a case of no-wait two-stage flexible flow shop scheduling problem with unrelated parallel machines. Int. J. Adv. Manuf. Technol. 71, 1229–1245. https://doi.org/10.1007/s00170-013-5375-1 (2014).
Thoney, K. A., Hodgson, T. J., King, R. E., Taner, M. R. & Wilson, A. D. Satisfying due-dates in large multi-factory supply chains. IIE Trans. 34, 803–811. https://doi.org/10.1080/07408170208928913 (2002).
Hooker, J. A hybrid method for the planning and scheduling. Constraints 10, 385–401. https://doi.org/10.1007/s10601-005-2812-2 (2005).
Chen, Z. L. & Pundoor, G. Order assignment and scheduling in a supply chain. Oper. Res. 54, 555–572. https://doi.org/10.1287/opre.1060.0280 (2006).
Terrazas-Moreno, S. & Grossmann, I. E. A multiscale decomposition method for the optimal planning and scheduling of multi-site continuous multiproduct plants. Chem. Eng. Sci. 66, 4307–4318. https://doi.org/10.1016/j.ces.2011.03.017 (2011).
Behnamian, J. & Ghomi, S. M. T. F. The heterogeneous multi-factory production network scheduling with adaptive communication policy and parallel machine. Inf. Sci. 219, 181–196. https://doi.org/10.1016/j.ins.2012.07.020 (2013).
Behnamian, J. Decomposition based hybrid vns-ts algorithm for distributed parallel factories scheduling with virtual corporation. Comput. Oper. Res. 52, 181–191. https://doi.org/10.1016/j.cor.2013.11.017 (2014).
Behnamian, J. & Ghomi, S. M. T. F. Minimizing cost-related objective in synchronous scheduling of parallel factories in the virtual production network. Appl. Soft Comput. 29, 221–232. https://doi.org/10.1016/j.asoc.2015.01.003 (2015).
Lin, S. W., Ying, K. C. & Huang, C. Y. Minimising makespan in distributed permutation flowshops using a modified iterated greedy algorithm. Int. J. Prod. Res. 51, 5029–5038. https://doi.org/10.1080/00207543.2013.790571 (2013).
Naderi, B. & Ruiz, R. A scatter search algorithm for the distributed permutation flowshop scheduling problem. Eur. J. Oper. Res. 239, 323–334. https://doi.org/10.1016/j.ejor.2014.05.024 (2014).
Xu, Y., Wang, L., Wang, S. Y. & Liu, M. An effective hybrid immune algorithm for solving the distributed permutation flow-shop scheduling problem. Eng. Optim. 46, 1269–1283. https://doi.org/10.1080/0305215x.2013.827673 (2014).
Wang, S. Y., Wang, L., Liu, M. & Xu, Y. An effective estimation of distribution algorithm for solving the distributed permutation flow-shop scheduling problem. Int. J. Prod. Econ. 145, 387–396. https://doi.org/10.1016/j.ijpe.2013.05.004 (2013).
Gao, J., Chen, R. & Deng, W. An efficient tabu search algorithm for the distributed permutation flowshop scheduling problem. Int. J. Prod. Res. 51, 641–651. https://doi.org/10.1080/00207543.2011.644819 (2013).
Ying, K. C. & Lin, S. W. Minimizing makespan in distributed blocking flowshops using hybrid iterated greedy algorithms. IEEE Access 5, 15694–15705. https://doi.org/10.1109/Access.2017.2732738 (2017).
Shao, W., Pi, D. & Shao, Z. Optimization of makespan for the distributed no-wait flow shop scheduling problem with iterated greedy algorithms. Knowl.-Based Syst. 137, 163–181 (2017).
Lin, S. W. & Ying, K. C. Minimizing makespan for solving the distributed no-wait flowshop scheduling problem. Comput. Ind. Eng. 99, 202–209. https://doi.org/10.1016/j.cie.2016.07.027 (2016).
Komaki, M. & Malakooti, B. General variable neighborhood search algorithm to minimize makespan of the distributed no-wait flow shop scheduling problem. Prod. Eng. Res. Devel. 11, 315–329. https://doi.org/10.1007/s11740-017-0716-9 (2017).
Zhang, G. H., Xing, K. Y. & Cao, F. Scheduling distributed flowshops with flexible assembly and set-up time to minimise makespan. Int. J. Prod. Res. 56, 3226–3244. https://doi.org/10.1080/00207543.2017.1401241 (2018).
Deng, J., Wang, L., Wang, S. Y. & Zheng, X. L. A competitive memetic algorithm for the distributed two-stage assembly flow-shop scheduling problem. Int. J. Prod. Res. 54, 3561–3577. https://doi.org/10.1080/00207543.2015.1084063 (2016).
Lin, J., Wang, Z.-J. & Li, X. A backtracking search hyper-heuristic for the distributed assembly flow-shop scheduling problem. Swarm Evol. Comput. 36, 124–135 (2017).
Lin, J. & Zhang, S. An effective hybrid biogeography-based optimization algorithm for the distributed assembly permutation flow-shop scheduling problem. Comput. Ind. Eng. 97, 128–136. https://doi.org/10.1016/j.cie.2016.05.005 (2016).
Hatami, S., Ruiz, R. & Andres-Romano, C. Heuristics and metaheuristics for the distributed assembly permutation flowshop scheduling problem with sequence dependent setup times. Int. J. Prod. Econ. 169, 76–88. https://doi.org/10.1016/j.ijpe.2015.07.027 (2015).
Rifai, A. P., Nguyen, H.-T. & Dawal, S. Z. M. Multi-objective adaptive large neighborhood search for distributed reentrant permutation flow shop scheduling. Appl. Soft Comput. 40, 42–57. https://doi.org/10.1016/j.asoc.2015.11.034 (2016).
Xiong, F. L. & Xing, K. Y. Meta-heuristics for the distributed two-stage assembly scheduling problem with bi-criteria of makespan and mean completion time. Int. J. Prod. Res. 52, 2743–2766. https://doi.org/10.1080/00207543.2014.884290 (2014).
Rifai, A. P., Mara, S. T. W. & Sudiarso, A. Multi-objective distributed reentrant permutation flow shop scheduling with sequence-dependent setup time. Expert Syst. Appl. 183. https://doi.org/10.1016/j.eswa.2021.115339 (2021).
Ying, K. C. & Lin, S. W. Minimizing makespan for the distributed hybrid flowshop scheduling problem with multiprocessor tasks. Expert Syst. Appl. 92, 132–141. https://doi.org/10.1016/j.eswa.2017.09.032 (2018).
Cai, J., Lei, D. & Li, M. A shuffled frog-leaping algorithm with memeplex quality for bi-objective distributed scheduling in hybrid flow shop. Int. J. Prod. Res. 59, 5404–5421. https://doi.org/10.1080/00207543.2020.1780333 (2020).
Cai, J. C. & Lei, D. M. A cooperated shuffled frog-leaping algorithm for distributed energy-efficient hybrid flow shop scheduling with fuzzy processing time. Complex Intell. Syst. 7, 2235–2253. https://doi.org/10.1007/s40747-021-00400-2 (2021).
Cai, J. C., Zhou, R. & Lei, D. M. Dynamic shuffled frog-leaping algorithm for distributed hybrid flow shop scheduling with multiprocessor tasks. Eng. Appl. Artif. Intell. 90, 103540. https://doi.org/10.1016/j.engappai.2020.103540 (2020).
Cai, J. C., Zhou, R. & Lei, D. M. Fuzzy distributed two-stage hybrid flow shop scheduling problem with setup time: collaborative variable search. J. Intell. Fuzzy Syst. 38, 3189–3199. https://doi.org/10.3233/Jifs-191175 (2020).
Hao, J. H. et al. Solving distributed hybrid flowshop scheduling problems by a hybrid brain storm optimization algorithm. IEEE Access 7, 66879–66894. https://doi.org/10.1109/Access.2019.2917273 (2019).
Jiang, E. D., Wang, L. & Wang, J. J. Decomposition-based multi-objective optimization for energy-aware distributed hybrid flow shop scheduling with multiprocessor tasks. Tsinghua Sci. Technol. 26, 646–663. https://doi.org/10.26599/tst.2021.9010007 (2021).
Lei, D. & Wang, T. Solving distributed two-stage hybrid flowshop scheduling using a shuffled frog-leaping algorithm with memeplex grouping. Eng. Optim. 52, 1461–1474. https://doi.org/10.1080/0305215x.2019.1674295 (2019).
Lei, D. M. & Xi, B. J. Diversified teaching-learning-based optimization for fuzzy two-stage hybrid flow shop scheduling with setup time. J. Intell. Fuzzy Syst. 41, 4159–4173. https://doi.org/10.3233/JIFS-210764 (2021).
Li, J., Chen, X.-l., Duan, P. & Mou, J.-h. Kmoea: A knowledge-based multi-objective algorithm for distributed hybrid flow shop in a prefabricated system. IEEE Trans. Ind. Inf. (2021).
Li, J. Q. et al. Solving type-2 fuzzy distributed hybrid flowshop scheduling using an improved brain storm optimization algorithm. Int. J. Fuzzy Syst. 23, 1194–1212. https://doi.org/10.1007/s40815-021-01050-9 (2021).
Li, Y., Li, F., Pan, Q.-K., Gao, L. & Tasgetiren, M. F. An artificial bee colony algorithm for the distributed hybrid flowshop scheduling problem. Proc. Manuf. 39, 1158–1166 (2019).
Li, Y. et al. A discrete artificial bee colony algorithm for distributed hybrid flowshop scheduling problem with sequence-dependent setup times. Int. J. Prod. Res. 59, 3880–3899. https://doi.org/10.1080/00207543.2020.1753897 (2021).
Li, Y. L., Li, X. Y., Gao, L. & Meng, L. L. An improved artificial bee colony algorithm for distributed heterogeneous hybrid flowshop scheduling problem with sequence-dependent setup times. Comput. Ind. Eng. 147. https://doi.org/10.1016/j.cie.2020.106638 (2020).
Meng, L. et al. Novel milp and cp models for distributed hybrid flowshop scheduling problem with sequence-dependent setup times. Swarm Evol. Comput. 71, 101058. https://doi.org/10.1016/j.swevo.2022.101058 (2022).
Qin, H., Li, T., Teng, Y. & Wang, K. Integrated production and distribution scheduling in distributed hybrid flow shops. Mem. Comput. 13, 185–202. https://doi.org/10.1007/s12293-021-00329-6 (2021).
Shao, W. S., Shao, Z. S. & Pi, D. C. Modeling and multi-neighborhood iterated greedy algorithm for distributed hybrid flow shop scheduling problem. Knowl. Based Syst. 194, 105527. https://doi.org/10.1016/j.knosys.2020.105527 (2020).
Shao, W. S., Shao, Z. S. & Pi, D. C. Multi-objective evolutionary algorithm based on multiple neighborhoods local search for multi-objective distributed hybrid flow shop scheduling problem. Expert Syst. Appli. 183. https://doi.org/10.1016/j.eswa.2021.115453 (2021).
Wang, J. J. & Wang, L. A bi-population cooperative memetic algorithm for distributed hybrid flow-shop scheduling. IEEE Trans. Emerging Top. Comput. Intell. 5, 947–961 (2020).
Wang, J.-j. & Wang, L. A cooperative memetic algorithm with learning-based agent for energy-aware distributed hybrid flow-shop scheduling. IEEE Trans. Evol. Comput. (2021).
Wang, L. & Li, D. D. Fuzzy distributed hybrid flow shop scheduling problem with heterogeneous factory and unrelated parallel machine: a shuffled frog leaping algorithm with collaboration of multiple search strategies. IEEE Access 8, 214209–214223. https://doi.org/10.1109/Access.2020.3041369 (2020).
Zheng, J., Wang, L. & Wang, J. J. A cooperative coevolution algorithm for multi-objective fuzzy distributed hybrid flow shop. Knowl. Based Syst. 194, 105536. https://doi.org/10.1016/j.knosys.2020.105536 (2020).
Lei, D. M. & Guo, X. P. Variable neighbourhood search for dual-resource constrained flexible job shop scheduling. Int. J. Prod. Res. 52, 2519–2529. https://doi.org/10.1080/00207543.2013.849822 (2014).
Moslehi, G. & Khorasanian, D. A hybrid variable neighborhood search algorithm for solving the limited-buffer permutation flow shop scheduling problem with the makespan criterion. Comput. Oper. Res. 52, 260–268. https://doi.org/10.1016/j.cor.2013.09.014 (2014).
Türkyılmaz, A. & Bulkan, S. A hybrid algorithm for total tardiness minimisation in flexible job shop: genetic algorithm with parallel vns execution. Int. J. Prod. Res. 53, 1832–1848. https://doi.org/10.1080/00207543.2014.962113 (2014).
Zhang, G., Zhang, L., Song, X., Wang, Y. & Zhou, C. A variable neighborhood search based genetic algorithm for flexible job shop scheduling problem. Cluster Comput. in press (2018).
Pacheco, J., Porras, S., Casado, S. & Baruque, B. Variable neighborhood search with memory for a single-machine scheduling problem with periodic maintenance and sequence-dependent set-up times. Knowl.-Based Syst. 145, 236–249. https://doi.org/10.1016/j.knosys.2018.01.018 (2018).
Deb, K., Pratap, A., Agarwal, S. & Meyarivan, T. A fast and elitist multiobjective genetic algorithm: Nsga-ii. IEEE Trans. Evolut. Comput. 6, 182–197. https://doi.org/10.1109/4235.996017 (2002).
Zitzler, E., Laumanns, M. & Thiele, L. Spea2: Improving the strength pareto evolutionary algorithm for multiobjective optimization. Technical Report Gloriastrasse, Swiss Federal Institute of Technology, Lausanne, Switzerl, Tech. Rep. 103, TIK-Rep 1–20 (2001).
Wang, S. J. & Liu, M. Two-stage hybrid flow shop scheduling with preventive maintenance using multi-objective tabu search method. Int. J. Prod. Res. 52, 1495–1508. https://doi.org/10.1080/00207543.2013.847983 (2014).
Zitzler, E. & Thiele, L. Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE Trans. Evol. Comput. 3, 257–271. https://doi.org/10.1109/4235.797969 (1999).
Luong, N. H., La Poutré, H. & Bosman, P. A. N. Multi-objective gene-pool optimal mixing evolutionary algorithm with the interleaved multi-start scheme. Swarm Evol. Comput. 40, 238–254. https://doi.org/10.1016/j.swevo.2018.02.005 (2018).
Laszczyk, M. & Myszkowski, P. B. Survey of quality measures for multi-objective optimization: Construction of complementary set of multi-objective quality measures. Swarm Evol. Comput. 48, 109–133. https://doi.org/10.1016/j.swevo.2019.04.001 (2019).
Acknowledgements
This work was supported by the Open Research Fund of AnHui Province Key Laboratory of Detection Technology and Energy Saving Devices of Anhui Polytechnic University (JCKJ2021A06), Joint Project of NFSC and Guangdong Big Data Science Center(U1611262), the Research Initiation Foundation of Anhui Polytechnic University (2022YQQ002), Anhui Polytechnic University Research Project (Xjky2022002) and Anhui Polytechnic University - Jiujiang District Industrial Collaborative Innovation Special Fund Project(2022cyxtb6).
Author information
Authors and Affiliations
Contributions
J.C.: Writing-Original draft preparation, Conceptualization. S.L.: Data curation, Validation. J.C.: Software, Supervision. L.W.: Writing- Reviewing and Editing. Y.G.: Methodology. T.T.: Software. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cai, J., Lu, S., Cheng, J. et al. Collaborative variable neighborhood search for multi-objective distributed scheduling in two-stage hybrid flow shop with sequence-dependent setup times. Sci Rep 12, 15724 (2022). https://doi.org/10.1038/s41598-022-19215-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-19215-3
- Springer Nature Limited