
Abstract
CoViD19 is a novel disease which has created panic worldwide by infecting millions of people around the world. The last significant variant of this virus, called as omicron, contributed to majority of cases in the third wave across globe. Though lesser in severity as compared to its predecessor, the delta variant, this mutation has shown higher communicable rate. This novel virus with symptoms of pneumonia is dangerous as it is communicable and hence, has engulfed entire world in a very short span of time. With the help of machine learning techniques, entire process of detection can be automated so that direct contacts can be avoided. Therefore, in this paper, experimentation is performed on CoViD19 chest X-ray images using higher order statistics with iterative and non-iterative models. Higher order statistics provide a way of analyzing the disturbances in the chest X-ray images. The results obtained are quite good with 96.64% accuracy using a non-iterative model. For fast testing of the patients, non-iterative model is preferred because it has advantage over iterative model in terms of speed. Comparison with some of the available state-of-the-art methods and some iterative methods proves efficacy of the work.
Similar content being viewed by others


Introduction
Since December 2019, a novel disease named corona virus disease 2019 (or CoViD19), which originated from Wuhan, China, has been spreading all over the world. According to the World Health Organization (WHO), the disease is named after its causing virus i.e. severe accurate respiratory syndrome coronavirus 2 (SARS-CoV-2)1. Till date, more than 529.17 million number of cases have been already reported worldwide with 6,304,145 deaths. Maximum cases have been reported in the countries like USA, India, Brazil, and France. With a brief pause in spread, this virus has again become active in countries like China, Japan, Australia and South Korea. Saudi Arabia recently cancelled flights to 15 countries in order to prevent spread of virus in the country. Thus, the statistics are increasing day-by-day2. The pandemic, which has affected the whole world, has no strange symptoms but rather common ones like tiredness, dry cough, fever and difficulty in breathing. Some other symptoms have also been experienced by a few infected persons like swelling in toes, running nose, sore throat, diarrhoea, ache and pain and nasal congestion3. The first wave showed severe effect on population above 50 whereas the second wave majorly impacted middle age groups. The third wave was comparatively mild, but spread massively. The ever-mutating nature of virus has left researchers baffled. Further, it has been reported that patients with hypertension and diabetes mellitus are at increased risk for CoViD194.
In India and many other countries, reports have shown that patients have recovered from CoViD19 with the help of plasma therapy5,6. During this therapy, patients are treated using plasma donated by those patients who have already recovered from this virus. Some vaccines have also been produced by various countries. In India, Covaxin, Covishield and Sputnik V are being used to vaccinate its population7. USA is using vaccines like Pfizer, Moderna and Johnson & Johnson out of which Johnson & Johnson was previously banned for 11 days as recipients suffered from a dangerous blood clot8. Still a few countries are under lockdown across the world. A nasal spray called SaNOtize founded in 20179 has won an approval as an option for early treatment of CoViD19 in February, 2022. India was praised by WHO, for taking the decision of lockdown, as “tough and timely”10. But, in the second wave, India also faced serious problems with almost four lacs cases being reported each day during the peak. Despite a successful and massive vaccination drive in the year 2021, the latter part of the year showed rising cases of virus owing to Omicron variant of CoViD19. 43.14 million cases have been observed in India till date, with 524,507 number of deaths. Due to the continued spread of virus, researchers from around the globe have realized the importance of carrying out active research in the field and have relentlessly focused their attention towards it11,12,13. Everyone understands that the need of the hour is to come up with solutions to contain and control this globe-spread virus.
The remaining paper is organized in the following manner: Section II gives a brief idea about the literature survey of this pandemic as well as research carried out to tackle the problem. Section III gives the details about the role of machine learning in classification of Chest X-ray images and briefly describes different models. Section IV details the proposed technique explaining feature extraction method with various classifiers and the database utilized to prove the efficacy of machine learning in CoViD19 with various tested methods. Section V discusses the experimental results followed by comparison of proposed method with other existing state-of-the-art methods in Section VI. At last, Section VII concludes the paper and discusses briefly about the future work that can be possible in machine learning to cater situations like this pandemic.
Related work
In the past two years, a lot of research has been conducted on this novel virus. In some studies, it has been stated that CoViD19 is associated with pneumonia and can be cured using a drug related to malaria. This drug, called as chloroquine or hydroxychloroquine has been recommended by National Health Commission of the People’s Republic of China. But, it is able to cure patients who are at low risk14. As a side-effect of CoViD19, a fungal infection called as mucormycosis or black fungus has also been observed in a few patients in India post CoViD19 recovery15,16. Since the virus spreads through contact, an obvious solution to this problem has seemed to be the development of learned machines that can minimize human contact and ease out diagnostic procedures for doctors. The novel virus impacts lungs and causes heaviness in breathing. So, CT scans are being used by medical community to monitor the condition of patients from time to time. Automatic detection and classification of CT scans17 can lift off the burden from the diagnosticians and speed up the process of identifying potential patients. Apostolopoulous and Mpesiana18 have evaluated the performance of CNN architectures, which are a popular choice for medical image classification, pertaining to automatic detection of Coronavirus disease through X-rays19. The dataset for their research included 1427 X-ray images including normal conditions, confirmed Corona cases as well as common bacterial pneumonia cases. They have applied Transfer Learning strategy and CNN for classification. Based on the results, it has been suggested that X-ray imaging with deep-learning can be used for diagnosis of Coronavirus. Singh and Bansal20 have proposed the use of a deep learning model namely truncated Visual Geometry Group from Oxford (truncated VVG16) for screening of CT scans. After extraction of features, they have implemented principal component analysis (PCA) for feature selection. Once the useful features are available, they have used four learning models namely extreme learning machine (ELM), online sequential ELM, deep CNN and bagging ensemble along with SVM as classification models. On a dataset of 208 images, the last classifier has achieved an accuracy of 95.7% and performs better than other classifiers. Use of multi-objective differential evolution (MODE) and CNN has been advocated by Singh et al. in21. Instead of using random valued parameters for CNN, the researchers have proposed fine tuning of the initial parameters with the help of MODE. They have compared the results with CNN, adaptive neuro-fuzzy inference systems, and artificial neural networks and shown that their technique performs with a good accuracy rate. Sethy and Behera22 have also suggested deep learning based methodology for classification of X-ray images as Corona positive or negative. They have obtained validated data images from Kaggle, Github and Open-i. The Resnet 50 plus SVM model proposed by them achieves accuracy of 95.38%. A deep CNN model DeTraC (decompose, transfer and compose) has been validated and adapted by Abbas et al.23 for classification of chest X-rays for identifying COVID19 positive cases. They have also discussed the importance of transfer learning in situations where availability of annotated medical images in limited. Their deep CNN model achieves accuracy, sensitivity and specificity of 95.12%, 97.91% and 91.87% respectively. Detection of this infected virus based on the comprehensive dataset of CT scan and X-ray images collected from different sources that needs deep learning and transfer learning algorithms24. Wu et al. has developed novel idea to diagnose CoViD19 with the help of joint classification and segmentation (JCS) system in which they were able to detect CoViD19 chest CT scan. To develop the JCS system, they have built a high scale CoViD19 classification and segmentation dataset, with 350 uninfected cases and 144,167 chest CT images of 400 CoViD19 patients. Fine-grained pixel-level marks of opacifications, which are enhanced attenuation of the lung parenchyma, are annotated on 3,855 chest CT images of 200 patients25. Ahuja et al. detected CoViD19 using transfer learning from CT scan images decomposed to three levels using stationary wavelet in the proposed study. To improve detection accuracy, a three-phase detection model is proposed, with the following procedures: Phase 1: data augmentation using stationary wavelets, Phase 2: COVID-19 detection using a pre-trained CNN model, and Phase 3: abnormality localization in CT scan images. For the experimental evaluation, this work used well-known pre-trained architectures such as ResNet18, ResNet50, ResNet101, and SqueezeNet26. Umar et al. also used the transfer learning method for the virus detection in lungs. Authors have utilized the pre-trained Alexnet model for the proposed method and achieved satisfactory results27. Zhu et al. introduced a joint classification and regression approach to assess if the patients will experience CoViD19 symptoms in the future or not28. Hussain et al. proposed a technique named as Corona Detection (CoroDet) in which 2-, 3- and 4-class classifications were performed, where author claimed 99.1%, 94.2% and 91.2% of accuracy respectively29. Some more deep learning models are also introduced by the researchers which also includes pre-trained networks of deep learning28,30,31,32.
Motivation
In the past year, various transfer learning models have been implemented for CoViD19 prediction33. These include ResNet 32 based model34, VGG19 model35, ResNet50 based model36, AlexNet based and Bidirectional Long Short-Term Memories (BiLSTM) layer based model37, DenseNet201 based model38, Deep-COVID (ResNet18, SqueezeNet and DenseNet121)26,39,five deep convolutional neural networks (AlexNet, VGGNet16, VGGNet19, GoogleNet, and ResNet50)40. All these studies have utilized the pre-trained convolutional neural network models for classification of CoViD19 chest X-ray images. All these transfer learning models achieved very good results in terms of accuracy. But, while taking the computational time into consideration, these models take a large amount of time.
Contribution
At the moment, even after so many efforts, the virus is not completely contained. So, there is a need to detect CoViD19 virus in patients with great accuracy and in lesser time. Deep learning techniques are efficient but take more time in execution because of their iterative nature. Currently, with new cases being reported in some countries, leading to lockdown in some cities, there must be a faster solution for the prediction of CoViD19+ve patients. To deal with the situation at hand, some methods need to be developed which can help in detecting this virus without coming in contact with the patient with higher accuracy and lesser time. This is possible by using non-iterative approach in detecting the CoViD19.
Machine learning in CoViD19
Machine learning helps in making a system, which is trained with the help of some data, detect and identify the patterns and make decisions with minimum level of human intervention41,42. As an effective vaccine has not yet been invented for the virus, it is a must to detect this virus in patients at an early stage. Since the virus is transmitted by touching and breathing close to another individual, it is imperative that a person should not come in contact with the patients. Under given circumstances, machine learning is one of the best solutions for the detection of CoViD19. Preliminaries used during this experimentation have been briefly discussed below.
Support vector machine
Any non-linear problem can be converted into linearly separable problem in a higher dimensional space. This is the key point on which Support vector machines work. It maps the given input training data to a higher dimension feature space and then finds a hyperplane which maximizes the margin between two classes as shown in Fig. 1. As a result, the decision boundary in the input space is of non-linear nature. By using kernels, the separating hyperplane can be computed without explicitly transforming the input space to a higher dimensional feature space43.

Basic idea of SVM.
What makes SVM a favourable choice is that it works well even when the training data available is small in size. Further, they are tolerant to imbalance in the number of training samples of two classes, which usually is the case44.
Convolutional neural network
Problem with simple feedforward neural network is the use of huge number of neurons for their operation which results in large amount of execution time requirement. This problem is resolved with the help of convolutional neural network (CNN). It is also a type of deep neural network but what it performs is that it extracts the image features by reducing the dimensions of the image without even losing their characteristics45. A single layer CNN consists of three main sub-layers i.e. convolutional layer, ReLU layer and max pooling layer. Architecture for Nth-layer CNN is shown in Fig. 2.

N-layer convolutional neural network architecture.
Convolutional layer
In this layer of CNN, features are extracted from the image by convolving a filter with the part of image (having size same as that of filter). This process is repeated over whole image by sliding the filter using a Stride and features are obtained.
ReLU layer
ReLU is rectifying linear unit. It is an activation function that makes all negative values of the resultant obtained from convolutional layer to zero. Its function is shown below:
Max pooling layer
Max pooling is the most common non-linear down sampling process of CNN. It is a necessary step before applying next convolutional layer in CNN as it reduces the dimensions of the image and hence, computational cost can be reduced. In this layer also, a filter ‘f’ is chosen which is slide over the image with Stride ‘s’. Filter size image field is selected and maximum value of that portion is obtained by non-overlapping sliding of the filter over the image. It is shown in an example in Fig. 3.

Max pooling layer with f = 2 × 2 and s = 2.
Therefore, CNN is also helpful in dimension reduction as well, keeping the important information within the resultant image. It is utilized here for binary classification of chest X-ray images.
Kernel extreme learning machine
Extreme learning machines have gained attention widely because of their simplicity. They have a single hidden layer, which does not need to be tuned. Since their proposal in 200646, they have been extended to adopt a more generalized form, where the neurons in a single layer feed-forward network (SLFFN) need not be alike47,48,49.
For a SLFFN, let there be a dataset of H samples {si, oi} i = 1,2,…,M, where si is the ith training input vector of dimension D and oi is the corresponding class label belonging to either one of the classes {1, 2, …, L}. Hence the dimension of input space for SLFFN is D and the dimension of output layer is L. The input space is first mapped to a higher dimensional space that has the dimension equal to number of neurons in the hidden layer (here, say \({\ddot{\text{H}}}\)). The important features are preserved during this mapping. Next phase is the projection of high-dimension feature space to a low-dimension feature space so as to map the output from H neurons to L output classes50.
Thus, the system can be modelled using Eq. (2) as given below:
where A(s) is the activation function of the hidden layer, \({\mathrm{\varpi }}_{\mathrm{i}}={[{\mathrm{\varpi }}_{\mathrm{i}1}, {\mathrm{\varpi }}_{\mathrm{i}2}, \dots , {\mathrm{\varpi }}_{\mathrm{iD}}]}^{\mathrm{T}}\) is the weight vector connecting the inputs to the ith hidden neuron, \({\mathcal{B}}_{\mathrm{i}}={[{\mathcal{B}}_{\mathrm{i}1}, {\mathcal{B}}_{\mathrm{i}2}, \dots , {\mathcal{B}}_{\mathrm{iL}}]}^{\mathrm{T}}\) is the weights connecting hidden layer neurons to output layer nodes, and bi is the bias. The output layer is assumed to have a linear activation function.
According to Huang et al.46, a SLFFN with Ḧ nodes in the hidden layer and an activation function A(s) can achieve zero error for H sample by approximation such that,
For H samples, Eq. (2) can thus be written as,
where,
The minimum norm least square solution of SLFFN can be given by:
where M′ is the generalized inverse (Moore–Penrose) of M.
Unlike other machine learning algorithms, what makes extreme learning machines stand out is their non-iterative behaviour. They are highly scalable and have comparatively less computational complexity51.
Kernel extreme learning machines are an extension of ELM. Here, the hidden layer outputs are calculated once and stored permanently in the kernel matrix. It is not calculated on the output layer of dimensionality L, but rather on the input data dimension and samples52,53. It is shown is Fig. 4.

KELM architecture.
KELM has the capability of approximation as well as classification. Single model can be thus used for variety of applications. In the propose scheme, KELM is used as a binary classifier as only CoViD19+ve and CoViD19−ve are the two classes which are classified using this classifier.
Proposed technique
This section begins with a detailed discussion on the database used for checking the efficacy of proposed technique. Next, pre-processing as well as feature extraction is elaborated as it is an important step before formation of dataset for KELM. Also, the steps of implementing the proposed technique are also discussed in this section.
Database used
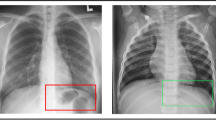
As CoViD19 is nothing but associated pneumonia, therefore, chest X-ray of an individual can be helpful in detecting whether the person is CoViD19 positive or not. The database consists of 5,856 images of chest X-ray having 4,273 CoViD19 positive images and 1,583 normal images. The X-ray images are gray scale in nature and have different dimensions. Hence, all the images have been resized to dimension 50 × 50. In terms of pixel values, images are normalized between − 1 and + 1. Sample images are shown in Fig. 5 in which the chest X-ray of the normal (CoViD19−ve) and CoViD19 associated pneumonia (CoViD19+ve) are shown. It is a publicly available database54. Normal chest X-ray is a clear image of lungs without any areas of opacification. CoViD19 associated pneumonia is detected by interstitial pattern as depicted with red arrows. But, this difference may seem insignificant to an untrained person. A scatter plot of all the images is also shown in Fig. 6 showing the distribution of the database. Red dots are representing the normal chest X-ray images and blue dots are denoting the CoViD19 associated pneumonia images of the patients. The x-axis and y-axis in Fig. 6 are particular pixel values of all the samples of the database. As all images (samples) have been resized to 50 × 50, hence, there are 2500 pixel values for each image in the database which are converted into a vector from its matrix representation. Thus, from all the images, a dataset is formed consisting of 5856 rows and 2500 columns. Figure 6 only represents correlation among column 1 (x-axis) and column 2 (y-axis) of all the samples. Some X-ray images have been added in Fig. 6 along with red and blue dots to showcase that the images are indistinguishable for untrained people and may seem similar to them.

Chest X-ray of normal (CoViD19−ve) and CoViD19+ve.

Scatter plot of the chest X-ray data showing normal (CoViD19−ve) and CoViD19+ve patients.
Similarly, some more scatter plots have been shown in Fig. 7. These scatter plots have been plotted by taking various random combinations of pixel values of all the images. The column numbers are written on x-axis and y-axis of respective images1. The scatter plots depict normalized pixel values between (− 1.0) to (+ 1.0). The basis of showing these scatter plots is only that X-ray images of normal people and CoViD19+ve patients are so similar that it is difficult for an untrained person to differentiate between the two.

Scatter plots of chest X-ray data with different combinations of pixel value columns. 1The x and y-axis of scatter plots are the column numbers out of 2500 columns in the dataset namely column 341 and column 968, column 358 and column 1542, column 392 and column 2236, column 362 and column 324, column 939 and column 326, column 946 and column 1514, column 979 and column 2182, column 972 and column 948, column 1234 and column 361, column 1272 and column 925, column 1548 and column 2198, column 1576 and column 1535, column 2123 and column 493, column 2144 and column 970, column 2167 and column 1522, column 2243 and column 2152 respectively.
This database is split sequentially into train and test data on the basis of train-test ratio of 10–90, 30–70, 50–50 and 70–30. Therefore, train data will have 158, 475, 791 and 1108 images from normal chest X-ray or CoViD19−ve images and 427, 1282, 2136 and 2991 images from CoViD19 positive patients (CoViD19+ve) respectively. This makes 585, 1757, 2215 and 4099 images (for 10–90, 30–70, 50–50 and 70–30) in total for train data. Therefore, remaining 5271, 4099, 2929 and 1757 images are utilized as test data (1425, 1108, 792 and 475 images of normal chest X-ray and 3846, 2991, 2137 and 1282 of CoViD19 positive patients) for 10–90, 30–70, 50–50 and 70–30 respectively.
Preprocessing and feature extraction
The images of chest X-ray are pre-processed by enhancing the image as shown in Fig. 8 (second column). Four sample images are represented (two samples of CoViD19+ve in first two rows) and (two images of CoViD19−ve in last two rows). The last column of the figure shows the extraction of features from images. This extraction of features, from chest X-ray enhanced images, is performed with the help of a higher order statistics parameter like Bispectrum.

CoViD19+ve (first two rows) and CoViD19−ve (last two rows).
Higher order statistics can be defined in terms of moments and cumulants. Cumulants are non-linear combinations of various moments. The motivation behind using higher order statistics is to analyze the disturbances in chest X-ray images of the patients due to the attack of CoViD19. Bispectrum is the Fourier transform of third order cumulant55,56.
The third-order cumulant \({K}_{3}\left({\epsilon }_{1},{\epsilon }_{2}\right)\) is represented as
In this, \({n}_{3}\left({\epsilon }_{1},{\epsilon }_{2}\right)\) depicts the third-order moment. \({K}_{3}\left({\epsilon }_{1},{\epsilon }_{2}\right)\) is the third-order cumulant that explains the skewness of the data and is equal to \({n}_{3}\left({\epsilon }_{1},{\epsilon }_{2}\right)\) for zero-mean. Skewness is a measure of asymmetry of any distribution about its mean. Positive value of skew indicates that the tail on the left side of the data, is shorter and thicker than the right side. In cases where one tail is short but the other tail is thick, skewness does not obey a simple rule. A zero value shows that the tails on both sides of the mean is balanced, which is the case for a symmetric distribution. It is also true for an asymmetric distribution where the asymmetries, such as one tail being short but thin, and the other being long but thick.
If these cumulants are considered in frequency domain, then it can be obtained by taking the Fourier transform of these cumulants. Fourier transform of third-order cumulant is given as:
where \(S\left({\varphi }_{1},{\varphi }_{2}\right)\) is the Bispectrum of z(m), \({K}_{3}\left({\epsilon }_{1},{\epsilon }_{2}\right)\) is the third-order cumulant and \(Z\left(\varphi \right)\) is the Fourier transform of x(n).
We demonstrate that bispectral analysis has great potential in this new application where bicoherence magnitude responses of the image are used to identify chest X-ray images. Bispectrum is often used for detecting the existence of quadratic correlation within a signal, as being applied in oceanography, EEG signal analysis, manufacturing, non-destructive structural fatigue detection and plasma physics applications57. We compute the bispectrum magnitude response for the chest X-ray images for different class of images and observe that the distributions for the CoViD19+ve images are greater than that of CoViD19−ve images as shown in Fig. 8.
Steps of implementation
A basic block diagram of workflow for non-iterative approach using KELM is shown in Fig. 9. The steps for implementing proposed technique are as follows:
-
1.
Select CoViD19 chest X-ray images and resize them to size 50 × 50. The images in dataset are of variable size, and hence need to be made coherent to a uniform size and dimension.
-
2.
Enhance the images using adaptive histogram equalization58. Pre-processing techniques lead to data enhancement and refinement by identifying the affected part in the chest X-ray images59.
-
3.
Perform feature extraction using third-order cumulants.
-
4.
Apply fast Fourier transform on third-order cumulants to obtain bispectrum of the images. It helps in taking out features that includes color, texture information in the images60.
-
5.
Normalize data between values − 1.0 and + 1.0.
-
6.
Divide these normalized features into train and test data. Train data helps in training of the classifier and thereafter, a trained model is obtained. There are multiple available classifiers in machine learning like kNN61, SVM62,63, artificial neural network (ANN)64, etc. We have implemented SVM, CNN and KELM.
-
7.
Provide test data features to the trained model for testing and hence, derive the classification results.

Block diagram of workflow in non-iterative approach of KELM.
Experimental results and discussion
For all the experiments, the images of the Chest X-ray database have been resized to 50 × 50 and converted to gray scale. All the images gone through the image enhancement process and bispectrum features are obtained from all the enhanced images. The feature vector set size remains same as the size of the resized image (50 × 50 matrix – 1 × 2500 vector). The features computed from the enhanced chest X-ray image database is experimented over three classifiers viz. SVM, Convolutional Neural Network and kernel extreme learning machine (KELM), which is a non-iterative learning machine model. SVM and Convolutional Neural Network are the iterative learning approaches which are utilized here to compare the execution time of the iterative learning approaches with non-iterative learning approach. The performance of these classifiers is measured mainly on three parameters based on confusion matrix. They are briefly explained here.
Confusion matrix is defined as the matrix using which correctness of a classifier can be measured. It is represented below and its parameters are defined as:
tp | fn |
|---|---|
fp | tn |
tn (true negatives)—number of correctly identified instances that do not belong to the class.
tp (true positives)—number of correctly identified instances that belong to the class.
fp (false positives)—number of instances that were incorrectly assigned to the class.
fn (false negatives)—number of instances that not identified as a class instance.
As we know the output is either CoViD (+ ve) or Normal (−ve). The three parameters for identifying the output are briefly explained below:.
-
a)
Accuracy: It is defined as ratio of the total number of accurate predictions and total number of predictions.
$$\mathrm{Accuracy}=\frac{tp+tn}{tp+tn+fp+fn}$$(8) -
b)
Sensitivity: It is also known as recall and defined as the ratio of correctly identified (tp) cases and summation of tp & fn.
$$\mathrm{Sensitivity}=\frac{tp}{tp+fn}$$(9) -
c)
Specificity: It is the ratio of number of correctly identified cases that do not belong to the class (tn) and the summation of tn & fp.
$$\mathrm{Specificity}=\frac{tn}{tn+fp}$$(10)
Results computed on the fore-mentioned classifiers based on these performance metrics are here as follows.
Results with SVM classifier
SVM is utilized with train-test ratio of 10–90, 30–70, 50–50 and 70–30 as shown in Table 1. Quite good percentage accuracy of 95.85% is achieved on 70–30 train-test ratio. SVM gives such good results with quadratic kernel, penalty parameter taken as 1, 0.001 of tolerance, and value of degree as 3 during experimentation. SVM performs very well but have very high execution time because of iterative learning approach. It can be seen in Table 1.
Results with CNN classifier
Table 2 shows the performance of 2-Layer CNN on the bispectrum features of CoViD19 chest X-ray images. In both the layers of CNN, 3 × 3 size of filter is utilized in convolutional layer and 2 × 2 size of mask in max pooling layer. The results achieved are excellent in terms of accuracy as 96.81% accuracy is achieved with 70–30 train-test ratio. The execution time for this set is 215 s which is better than the previous classifiers used in the experimentation.
Table 3 is representing the results for 3-Layer CNN. Results achieved with this classifier are almost same as that achieved using 2-Layer CNN. A small disadvantage of using this classifier is increase in execution time which is due to the increase in one layer of CNN. Specifications of filter and stride are same as that used in 2-Layer CNN. Maximum percentage accuracy achieved with 3-layer CNN is 95.90% with 363 s of execution time.
All these classifiers utilized are iterative and hence, execution time is quite large. In CNN, only two and three layers are used and execution time is comparatively large. If transfer learning approaches are utilized, in which there are so many layers, results in very large execution time.
Results with KELM classifier
KELM is a faster classifier that is non-iterative in nature. There are various kernel functions which can be used in the kernel-based ELM. They are linear, polynomial kernel, sigmoid kernel, wavelet kernel, and RBF kernel65. Any of these kernel functions can be utilized with KELM depending upon the requirement and hence, the kernel-based ELM model is defined as the kernel extreme learning machine.
Table 4 represents the variation in accuracy observed with various kernel functions. For this, regularization coefficient and kernel parameters are computed as 1 and 345 respectively. These parameters’ values were obtained experimentally by optimizing the accuracy using optimization algorithm. The table is shown below:
It can be seen from the table that best accuracy is achieved with RBF kernel function and hence, RBF kernel function is utilized here for the results and comparing them with other state-of-the-art methods.
Table 5 shows the classification results for KELM classifier with RBF kernel function on CoViD19 database.
For KELM also, train-test ratio is selected as 10–90, 30–70, 50–50 and 70–30 and an accuracy of 90.86%, 95.32%, 96.52% and 96.64% has been obtained respectively. It can be seen through the execution time (Table 5) that non-iterative nature of KELM gives an advantage of much faster speed.
Comparison and discussion
All the classifiers with bispectral magnitude analysis of the chest X-ray images of CoViD19 patients utilized during experimentation provide very good results and it has already been seen in the previous sections. Now, in this section, results obtained from these classifiers are compared with each other and with the existing state-of-art methods on the chest X-ray database of CoViD19 (Table 6). Comparison of these classifiers is shown in Figs. 10, 11, 12 and 13 on the basis of their ROC curves.

Comparison of the classifiers based on ROC curves (10–90 train-test ratio) of CoViD19+ve and CoViD19−ve.

Comparison of the classifiers based on ROC curves (30–70 train-test ratio) of CoViD19+ve and CoViD19−ve.

Comparison of the classifiers based on ROC curves (50–50 train-test ratio) of CoViD19+ve and CoViD19−ve.

Comparison of the classifiers based on ROC curves (70–30 train-test ratio) of CoViD19+ve and CoViD19−ve.
Tables 1, 2, 3 and 5 also show the values of performance measures, sensitivity and specificity. Sensitivity tells about the images of chest X-ray which are not affected with corona virus signifying CoViD19−ve images while specificity represents the chest X-ray images having the presence of corona virus. It can be seen from the tables that KELM performs best among all these classifiers in identifying CoViD19+ve and CoViD19−ve cases based on chest X-ray images. The same is also clearly visible in Figs. 10, 11, 12 and 13 which are plotted using the values of sensitivity and specificity of these classifiers. These figures are plotted for 10–90, 30–70, 50–50 and 70–30 train-test ratio respectively. Figure 14 represents the plots of classifiers used during experimentation based on their accuracies in classifying CoViD19+ve and CoViD19−ve images. It can be clearly seen that KELM performs best and Decision tree performs worst among these classifiers. 2-Layer CNN also performs equally as KELM but only when the train data is large.

Comparison of the classifiers based on accuracy of recognizing CoViD19+ve and CoViD19−ve.
As CNN is an iterative algorithm, therefore, increasing the training data results in the increase in their execution time as well. Similar case can be observed with transfer learning approaches used in the existing approaches where there are so many layers compared to 2-Layer CNN and 3-Layer CNN. KELM is non-iterative, hence, performs faster. It can be observed from Fig. 15. KELM is fastest among all the classifiers utilized during the experimentation followed by 2-Layer CNN and kNN is slowest. The results of these classifiers are compared with other state-of-art approaches and are shown in Table 6. In21 and34, classification was performed on Corona virus database based on differential evolution based CNN and deep transfer learning respectively. Both these papers have utilized comparatively lesser number of images in their experimentation. Narin et al.66 have achieved 98% accuracy in detecting the patients correctly but they have trained the model with 95% of the total data which might result in overtraining of the model leading to good results. One advantage that can be observed in our models is that they maintain high accuracy even with large number of test images, especially for KELM with very less computational complexity.

Comparison of the classifiers based on execution time of recognizing CoViD19+ve and CoViD19−ve.
On the contrary, CNN based state-of-art approaches like ResNet, Inception, etc. also produce comparable results to KELM. A comparison table in which accuracy of KELM is compared with ResNet and Inception CNNs is shown in the Table 7. KELM performs classification with high accuracy even if less amount of data is used to train the classifier while CNNs require large amount of training data for good classification results as seen from Tables 2, 3 and 5. Also, all these CNN based approaches are iterative in nature and take large amount of time compared to KELM. Hence, KELM being a non-iterative algorithm comes out as very helpful, fast and efficient algorithm in this pandemic (CoViD19).
Conclusion and future scope
The results obtained in this experiment depicts that machine learning can be very helpful in dealing with this worldwide pandemic. Higher order statistics has provided a clear view in differentiating the CoViD+ve patients from the normal ones. As various classifiers are applied, they give very good results on the chest X-ray images of CoViD19 database. 2-Layer CNN performs the best with 96.81% of accuracy in classifying the CoViD19−ve chest X-ray images from CoViD19+ve images. But the execution time for 2-Layer CNN for this accuracy is 215 s. And when speed is the concern, as it is the peer requirement in current situation, KELM comes out to be best. KELM gives 96.64% accuracy with only 1.599 s of execution time. The techniques performed better as compared to the existing techniques introduced in21,23,34. Thus, the researchers and scientists working in the labs can focus on machine learning techniques for CoViD19 detection so that proper treatment can be given to the patients at an early-stage only with faster speed. And in the situation of third wave approaching, this non-iterative machine learning methods can replace the kits utilized these days for the testing.
Also, as various countries are under lockdown during this pandemic, daily life activities are at halt as everything is closed included shopping malls, cinema halls etc. This is resulting in an increase in anxiety level among people, mainly young ones, which further can lead to anger, isolation, mood swings, panic attacks, fear, depression etc. This behavior change is evident on social networking sites like twitter71 where the usage of words like bored, frustrated, want to get out etc. has increased after lockdown72. Such words depict the mental status of an individual and reports state that such mental status leads to suicidal tendencies. Hence, emotion detection can also be possible with the help of machine learning. By detecting such words of emotions on the social networking sites, it can be made possible to give any individual appropriate counseling at the right time in this serious pandemic.
Ethics approval
All methods were carried out in accordance with relevant guidelines and regulations.
References
COVID-19. World Health Organisation. https://www.who.int/emergencies/diseases/novel-coronavirus-2019/technical-guidance/naming-the-coronavirus-disease-(covid-2019)-and-the-virus-that-causes-it.
Coronavirus Stats. https://www.worldometers.info/coronavirus/.
Lu, S. et al. Alert for non-respiratory symptoms of Coronavirus Disease 2019 (COVID-19) patients in epidemic period: A case report of familial cluster with three asymptomatic COVID-19 patients. J. Med. Virol. 93, 518–521. https://doi.org/10.1002/jmv.25776 (2021).
Fang, L., Karakiulakis, G. & Roth, M. Are patients with hypertension and diabetes mellitus at increased risk for COVID-19 infection? Lancet. Respir. Med. 8(4), e21 (2020).
Yoo, J.-H. Convalescent plasma therapy for corona virus disease 2019: A long way to go but worth trying. J. Korean Med. Sci. 35, e150 (2020).
Plasma Therapy. Science https://www.indiatoday.in/science/story/what-is-convalescent-plasma-therapy-possible-treatment-coronavirus-covid-19-1669050-2020-04-20.
Wani, R., Manihar, P. H. & Wani, V. J. Covid-19 vaccination: Part played in pregnancy. Indian Pract. 74, 7–10 (2021).
Livingston, E. H., Malani, P. N. & Creech, C. B. The Johnson \& Johnson vaccine for COVID-19. JAMA 325, 1575 (2021).
Kutschera, U. RE: Nasal spray: No chemical war to combat COVID-19. (2021).
India under COVID-19 lockdown. The Lancet 395(10233), 1315 (2020).
Huang, L. et al. Initial CT imaging characters of an imported family cluster of COVID-19. Clin. Imaging 65, 78–81 (2020).
Zhifeng, J., Feng, A. & Li, T. Consistency analysis of COVID-19 nucleic acid tests and the changes of lung CT. J. Clin. Virol. 127, 104359 (2020).
Yang, P. et al. Clinical characteristics and risk assessment of newborns born to mothers with COVID-19. J. Clin. Virol. 127, 104356 (2020).
Gao, J., Tian, Z. & Yang, X. Breakthrough: Chloroquine phosphate has shown apparent efficacy in treatment of COVID-19 associated pneumonia in clinical studies. Biosci. Trends 14, 72–73 (2020).
Werthman-Ehrenreich, A. Mucormycosis with orbital compartment syndrome in a patient with COVID-19. Am. J. Emerg. Med. 42, 264-e5 (2021).
Garg, D. et al. Coronavirus disease (Covid-19) associated mucormycosis (CAM): Case report and systematic review of literature. Mycopathologia 186, 289–298 (2021).
Shi, F. et al. Review of artificial intelligence techniques in imaging data acquisition, segmentation and diagnosis for COVID-19. IEEE Rev. Biomed. Eng. 3333, 1–13 (2020).
Apostolopoulos, I. D. & Mpesiana, T. A. Covid-19: Automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. https://doi.org/10.1007/s13246-020-00865-4 (2020).
Tabik, S. et al. COVIDGR dataset and COVID-SDNet methodology for predicting COVID-19 based on chest X-ray images. IEEE J. Biomed. Health Inform. 24, 3595–3605 (2020).
Singh, M. et al. Transfer learning based ensemble support vector machine model for automated COVID-19 detection using lung computerized tomography scan data. 59(4), 825–839 (2021).
Singh, D., Kumar, V. & Kaur, M. Classification of COVID-19 patients from chest CT images using multi-objective differential evolution–based convolutional neural networks. Eur. J. Clin. Microbiol. Infect. Dis. 39, 1379–1389 (2020).
Kumar, P. & Kumari, S. Detection of coronavirus disease (COVID-19) based on deep features. (2020). https://doi.org/10.20944/preprints202003.0300.v1.
Abbas, A., Abdelsamea, M. M. & Gaber, M. M. Classification of COVID-19 in chest X-ray images using DeTraC deep convolutional neural network. Appl. Intell. 51(2), 854–864 (2021).
Maghdid, H. S., Asaad, A. T., Ghafoor, K. Z., Sadiq, A. S. & Khan, M. K. Diagnosing COVID-19 pneumonia from X-ray and CT images using deep learning and transfer learning algorithms. arXiv Prepr. arXiv:2004.00038 (2020).
Wu, Y.-H. et al. Jcs: An explainable covid-19 diagnosis system by joint classification and segmentation. IEEE Trans. Image Process. 30, 3113–3126 (2021).
Ahuja, S., Panigrahi, B. K., Dey, N., Rajinikanth, V. & Gandhi, T. K. Deep transfer learning-based automated detection of COVID-19 from lung CT scan slices. Appl. Intell. 51, 571–585 (2021).
Ibrahim, A. U., Ozsoz, M., Serte, S., Al-Turjman, F. & Yakoi, P. S. Pneumonia classification using deep learning from chest X-ray images during COVID-19. Cognit. Comput. https://doi.org/10.1007/s12559-020-09787-5 (2021).
Zhu, X. et al. Joint prediction and time estimation of COVID-19 developing severe symptoms using chest CT scan. Med. Image Anal. 67, 101824 (2021).
Hussain, E. et al. CoroDet: A deep learning based classification for COVID-19 detection using chest X-ray images. Chaos Solitons Fractals 142, 110495 (2021).
Shah, V. et al. Diagnosis of COVID-19 using CT scan images and deep learning techniques. Emerg. Radiol. 28, 497–505 (2021).
Rahimzadeh, M., Attar, A. & Sakhaei, S. M. A fully automated deep learning-based network for detecting covid-19 from a new and large lung CT scan dataset. Biomed. Signal Process. Control 68, 102588 (2021).
Khan, M. A. et al. Prediction of COVID-19-pneumonia based on selected deep features and one class kernel extreme learning machine. Comput. Electr. Eng. 90, 106960 (2021).
Sufian, A., Ghosh, A., Sadiq, A. S. & Smarandache, F. A survey on deep transfer learning to edge computing for mitigating the COVID-19 pandemic. J. Syst. Archit. 108, 101830 (2020).
Pathak, Y. et al. Deep transfer learning based classification model for COVID-19 disease. IRBM. 43(2), 87–92 (2022).
Horry, M. J. et al. COVID-19 detection through transfer learning using multimodal imaging data. IEEE Access 8, 149808–149824 (2020).
Loey, M., Manogaran, G., Taha, M. H. N. & Khalifa, N. E. M. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Measurement 167, 108288 (2021).
Aslan, M. F., Unlersen, M. F., Sabanci, K. & Durdu, A. CNN-based transfer learning—BiLSTM network: A novel approach for COVID-19 infection detection. Appl. Soft Comput. 98, 106912 (2021).
Jaiswal, A., Gianchandani, N., Singh, D., Kumar, V. & Kaur, M. Classification of the COVID-19 infected patients using DenseNet201 based deep transfer learning. J. Biomol. Struct. Dyn. 39, 5682–5689 (2020).
Minaee, S., Kafieh, R., Sonka, M., Yazdani, S. & Soufi, G. J. Deep-covid: Predicting covid-19 from chest x-ray images using deep transfer learning. Med. Image Anal. 65, 101794 (2020).
Loey, M., Manogaran, G. & Khalifa, N. E. M. A deep transfer learning model with classical data augmentation and cgan to detect covid-19 from chest ct radiography digital images. Neural Comput. Appl. https://doi.org/10.1007/s00521-020-05437-x (2020).
Bishop, C. M. Pattern Recognition and Machine Learning (Springer, 2006).
Malviya, A. Machine learning: An overview of classification techniques. In Computing Algorithms with Applications in Engineering (eds Giri, V. K. et al.) 389–401 (Springer, 2020).
Hearst, M. A., Scholkopf, B., Dumais, S., Osuna, E. & Platt, J. Support vector machines. IEEE Intell. Syst. Appl. 13, 18–28 (1998).
Ghaddar, B. & Naoum-Sawaya, J. High dimensional data classification and feature selection using support vector machines. Eur. J. Oper. Res. 265, 993–1004 (2018).
Kim, Y.-H., Kim, H., Kim, S.-W., Kim, H.-Y. & Ko, S.-J. Illumination normalisation using convolutional neural network with application to face recognition. Electron. Lett. 53, 399–401 (2017).
Huang, G. B., Zhu, Q. Y. & Siew, C. K. Extreme learning machine: Theory and applications. Neurocomputing 70, 489–501 (2006).
Huang, G. B. & Chen, L. Convex incremental extreme learning machine. Neurocomputing 70, 3056–3062 (2007).
Huang, G. B. & Chen, L. Enhanced random search based incremental extreme learning machine. Neurocomputing 71, 3460–3468 (2008).
Vishwakarma, V. P. & Dalal, S. An adaptive illumination normalization using non-linear regression for robust person identification under varying illuminations. J. Stat. Manag. Syst. 23, 77–90 (2020).
Iosifidis, A., Tefas, A. & Pitas, I. Minimum variance extreme learning machine for human action recognition. In ICASSP IEEE International Conference on Acoustics, Speech, and Signal Processing Proceedings 5427–5431 (2014). https://doi.org/10.1109/ICASSP.2014.6854640
Huang, G.-B., Zhou, H., Ding, X. & Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. B 42, 513–529 (2012).
Dalal, S. & Vishwakarma, V. P. A novel approach of face recognition using optimized adaptive illumination—Normalization and KELM. Arab. J. Sci. Eng. 45, 9977–9996 (2020).
Vishwakarma, V. P. & Dalal, S. Neuro-fuzzy hybridization using modified S membership function and kernel extreme learning machine for robust face recognition under varying illuminations. EAI Endorsed Trans. Scalable Inf. Syst. https://doi.org/10.4108/eai.13-7-2018.163575 (2020).
Chest X-ray pneumonia. https://www.kaggle.com/nabeelsajid917/covid-19-x-ray-10000-images#IM-0214-0001.jpeg.
Papoulis, A. & Pillai, S. U. Probability, Random Variables, and Stochastic Processes (Tata McGraw-Hill Education, 2002).
Martis, R. J., Acharya, U. R., Ray, A. K. & Chakraborty, C. Application of higher order cumulants to ECG signals for the cardiac health diagnosis. In 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society 1697–1700 (2011).
Ng, T. T. Statistical and Geometric Methods for Passive-Blind Image Forensics (Citeseer, 2007).
Vishwakarma, V. P., Dalal, S. & Sisaudia, V. Efficient feature extraction using DWT-DCT for robust face recognition under varying illuminations. In 2018 2nd IEEE International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES) 982–987 (2018).
Vishwakarma, V. P. & Dalal, S. A novel non-linear modifier for adaptive illumination normalization for robust face recognition. Multimed. Tools Appl. 79, 11503–11529 (2020).
Vishwakarma, V. P. & Dalal, S. Generalized DCT and DWT hybridization based robust feature extraction for face recognition. J. Inf. Optim. Sci. 41, 61–72 (2020).
Zuo, W. M., Lu, W. G., Wang, K. Q. & Zhang, H. Diagnosis of cardiac arrhythmia using kernel difference weighted KNN classifier. Comput. Cardiol. 2008, 253–256 (2008).
Dalal, S. & Birok, R. Analysis of ECG signals using hybrid classifier. Int. Adv. Res. J. Sci. Eng. Technol. 3, 89–95 (2016).
Dalal, S. A Comparative Study and Analysis on the Classification of ECG Signals (Delhi Technological University, 2016).
Dalal, S., Vishwakarma, V. P. & Sisaudia, V. ECG classification using kernel extreme learning machine. In 2nd IEEE International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES-2018) 988–992 (2018). https://doi.org/10.1109/ICPEICES.2018.8897416.
Dalal, S. & Vishwakarma, V. P. Classification of ECG signals using multi-cumulants based evolutionary hybrid classifier. Sci. Rep. 11, 1–25 (2021).
Narin, A., Kaya, C. & Pamuk, Z. Automatic detection of coronavirus disease (covid-19) using x-ray images and deep convolutional neural networks. arXiv Prepr. arXiv:2003.10849 (2020).
Xu, X. et al. A deep learning system to screen novel coronavirus disease 2019 pneumonia. Engineering 6, 1122–1129 (2020).
Pham, T. D. A comprehensive study on classification of COVID-19 on computed tomography with pretrained convolutional neural networks. Sci. Rep. 10, 1–8 (2020).
Li, L. et al. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology 296(2), E65–E71 (2020).
Ghoshal, B. & Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv Prepr. arXiv:2003.10769 (2020).
Lamsal, R. Corona Virus (COVID-19) Tweets Dataset. (2020). https://doi.org/10.21227/781w-ef42.
Coronavirus and children’s mental health. https://www.childrenscommissioner.gov.uk/2020/04/03/angry-fed-up-isolated-coronavirus-and-childrens-mental-health/.
Author information
Authors and Affiliations
Contributions
All authors contributed equally for the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
Cite this article
Dalal, S., Vishwakarma, V.P., Sisaudia, V. et al. Non-iterative learning machine for identifying CoViD19 using chest X-ray images. Sci Rep 12, 11880 (2022). https://doi.org/10.1038/s41598-022-15268-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-15268-6
- Springer Nature Limited