
Abstract
Examining enzyme kinetics is critical for understanding cellular systems and for using enzymes in industry. The Michaelis-Menten equation has been widely used for over a century to estimate the enzyme kinetic parameters from reaction progress curves of substrates, which is known as the progress curve assay. However, this canonical approach works in limited conditions, such as when there is a large excess of substrate over enzyme. Even when this condition is satisfied, the identifiability of parameters is not always guaranteed, and often not verifiable in practice. To overcome such limitations of the canonical approach for the progress curve assay, here we propose a Bayesian approach based on an equation derived with the total quasi-steady-state approximation. In contrast to the canonical approach, estimates obtained with this proposed approach exhibit little bias for any combination of enzyme and substrate concentrations. Importantly, unlike the canonical approach, an optimal experiment to identify parameters with certainty can be easily designed without any prior information. Indeed, with this proposed design, the kinetic parameters of diverse enzymes with disparate catalytic efficiencies, such as chymotrypsin, fumarase, and urease, can be accurately and precisely estimated from a minimal amount of timecourse data. A publicly accessible computational package performing such accurate and efficient Bayesian inference for enzyme kinetics is provided.
Similar content being viewed by others


Introduction
Because enzymes can modulate biochemical reaction rates by selectively catalyzing specific substrates1, they play fundamental roles in metabolism, signal transduction, and cell regulation, and their malfunction can cause serious diseases2,3. Furthermore, enzymes have been used as extremely specific catalysts in diverse industrial fields such as drug development, biofuel production, and food processing4. A canonical approach used to understand enzyme kinetics for a century has been based on the Michaelis-Menten equation (MM equation), which was developed by Michaelis and Menten5 and then was more rigorously derived by Briggs and Haldane6 using the standard quasi-steady-state approximation (sQSSA)7. The equation describes the dependence of enzyme-catalyzed reaction rates on the concentration of substrate by using two parameters, the catalytic constant, k cat and the Michaelis-Menten constant, K M (see below for details). The k cat determines the maximum rate of the reaction at saturating substrate concentrations, V max = k cat E T , where E T is total enzyme concentration, and the K M is the substrate concentration at which the reaction rate is half of V max .
There are two major assays to estimate k cat and K M from a measured accumulation of product over time (i.e. progress curve): the initial velocity assay (initial rate analysis) and the reaction progress curve assay (progress curve analysis)8,9,10,11,12. For the initial velocity assay, initial rates of the reaction are measured for a range of substrate concentrations. Then, by using a linear transform of these data, such as Lineweaver-Burk plots, the two parameters can be easily estimated without use of any computational tools8,9. Recent advances in computational tools have led to an alternative approach: the reaction progress curve assay. In this assay, the entire timecourse (i.e. progress curve) is fitted to the solution of a differential equation or integrated rate equation, and thus the data is used more efficiently than in the initial velocity assay10,11,13. Albeit more technically challenging, the progress curve assay requires less data to estimate parameters than the initial velocity assay does.
Since both assays are based on the MM equation, they should be performed only when the MM equation is valid, that is, when the enzyme concentration is a much lower than the sum of the substrate concentration and the K M 7,14 (see below for more details). Because the value of K M is usually not known a priori, to ensure the validity of the MM equation, in vitro experiments are typically performed with a much lower enzyme concentration than substrate concentration15. However, such conditions cannot be guaranteed in vivo, because endogenous enzyme concentrations are much higher than those used in a typical in vitro assay16,17. It is therefore risky to use the MM equation to analyze in vivo data and to predict in vivo enzyme activity by using parameters estimated from an in vitro assay15,18. Furthermore, even when the MM equation is valid, precise estimation is not guaranteed, because of the highly correlated structure and unidentifiability of the parameters19,20,21,22,23. That is, even though estimated parameters can fit the data accurately, the estimates can differ greatly from the actual values of k cat and K M . Because of the identifiability issue, experimental designs to infer the maximum possible information about the parameters have been investigated12,13,20,21,22,23,24. For instance, to ensure that the parameters can be identified from the initial velocity assay, the initial concentration of substrate needs to be increased from a low level to a higher level until the reaction velocity is saturated. For the saturation, generally the initial substrate concentration needs to be larger than 10 K M , but often such high concentrations cannot be achieved24. For the progress curve assay, the initial substrate concentration is recommended to be at a similar level to K M 23,25. Note that both assays require prior knowledge of K M , which gives rise to the conundrum that, in order to estimate K M , the approximate value of K M needs to be known.
To overcome such limits on the inference using the model based on the MM equation, which is referred to as the sQ (standard QSSA) model, here we propose an alternative approach. In our approach, we use a different approximate model that is derived with the total QSSA and is referred to as the tQ (total QSSA) model26,27,28,29. By applying the Bayesian inference based on either the sQ or the tQ model to the product progress curve, we found that the estimates obtained with the sQ model were considerably biased when the enzyme concentration was not low. On the other hand, the estimates obtained with the tQ model were not biased for any combination of enzyme and substrate concentrations. Thus, with the tQ model, the experimental data from various conditions can be pooled without any restrictions to improve the accuracy and precision of the estimation. For instance, when two sets of timecourse data obtained under low and high enzyme concentrations are used together, the tQ model, but not the sQ model, leads to accurate and precise estimation. Another advantage of our approach is that, by analyzing the scatter plots of current estimates, the next optimal experiment to ensure the parameter identifiability can be easily designed without requiring any prior knowledge of the k cat and K M values. The proposed optimized design yields accurate and precise estimation from a minimal amount of data simulated based on the kinetics of various enzymes: chymotrypsin, fumarase and urease, which have disparate catalytic efficiencies (k cat /K M ). We provide a publicly accessible computational package that performs the Bayesian inference based on the tQ model, thus leading to accurate and efficient estimation of enzyme kinetics.
Results
Two types of models describing enzyme kinetics: The sQ and tQ models
A fundamental enzyme reaction consists of a single enzyme and a single substrate, where the free enzyme (E) reversibly binds with the substrate (S) to form the complex (C), and the complex irreversibly dissociates into the product (P) and the free enzyme:
where the total enzyme concentration (E T ≡ C + E) and the total substrate and product concentration (S T ≡ S + C + P) are conserved. A popular model describing the accumulation of the product over time is based on the MM equation, as follows (see Supplementary Method for detailed derivation):
where K M = (k b + k cat )/k f is the Michaelis-Menten constant and k cat is the catalytic constant. This sQ model derived with the standard QSSA has been widely used to estimate the kinetic parameters, K M and k cat from the progress curve of the product8,9,10,11,23,25. Another model describing the accumulation of the product is derived with the total QSSA; it was developed later than the sQ model and thus has received less attention for parameter estimation26,27,28,29:
Although this tQ model is more complicated than the sQ model, it is accurate over wider ranges than the sQ model. Specifically, the sQ model is accurate when
which requires a low enzyme concentration7,14. On the other hand, the tQ model is accurate when
where K = k b /k f is the dissociation constant27,28,29. Importantly, this condition is generally valid and thus the tQ model, unlike the sQ model, is accurate even when the enzyme is in excess. See14,30 for more details.
Next, we investigated the accuracy of the stochastic simulations performed with both models. Specifically, we compared the stochastic simulations using the Gillespie algorithm based on the propensity functions from either the original full model (described in Table S1), the sQ model (Table S2), or the tQ model (Table S3) for 9 different conditions31,32,33,34,35,36: E T is either lower than, similar to, or higher than K M , and S T is also either lower than, similar to, or higher than K M (Fig. 1). The stochastic simulations of the sQ model fail to approximate those of the original full model when E T is not low (i.e., E T is lower than neither S T nor K M ). On the other hand, stochastic simulations using the tQ model are accurate for all conditions (Fig. 1), as is consistent with a recent study showing that stochastic simulations with the sQ and the tQ models are accurate when their deterministic validity conditions hold (Eqs (3) and (4))37,38. Taken together, the tQ model is valid for a wider range of conditions than the sQ model is in both the deterministic and the stochastic sense.

Whereas the sQ model fails to approximate the original full model as E T increases, the tQ model is accurate regardless of E T . Stochastic simulations of the original full model (Table S1), the sQ model (Table S2), and the tQ model (Table S3) were performed with S T = 0.2, 2, or 80 nM, and E T = 0.2, 2, or 40 nM. Note that these concentrations are either lower than, similar to, or higher than K M ≈ 2 nM. Here, the lines and colored ranges represent a mean trajectory and fluctuation range (±2σ from the mean) of 104 stochastic simulations.
Estimation with the tQ model is unbiased for any combination of enzyme and substrate concentrations
Because the tQ model is accurate for a wider range of conditions than the sQ model is (Fig. 1), we hypothesized that the parameter estimation based on the tQ model is also accurate for more general conditions. To investigate this hypothesis, we first generated 102 noisy progress curves of P from the stochastic simulations of the original full model (Fig. S1). Then, we inferred parameters (k cat and K M ) from these simulated data sets by applying the Bayesian inference with the likelihood functions based on either the sQ or the tQ model, under weakly informative gamma priors (Fig. S2) (see Methods for details). Note that throughout this study, we have used the simulated product progress curves (e.g. Fig. S1) because we need to know the true values of parameters for the accurate comparison of the estimations based on the sQ model and the tQ model.
We first focused on the estimation of the k cat under the assumption that the value of K M is known. When E T is low, so that both the sQ and the tQ models are accurate (Fig. 1 left), posterior samples obtained with both models are similar and successfully capture the true value of k cat (Fig. 2a left). The posterior samples obtained with the two models are similar because, when E T is low and thus \({E}_{T}\ll {S}_{T}+{K}_{M}\), both models (Eqs 1 and 2) are approximately equivalent as follows:
where the first approximation comes from the Taylor expansion in terms of \({E}_{T}({S}_{T}-P)/({E}_{T}+{K}_{M}+{S}_{T}-P)\ll 1\) (see27,28,29 for details). Therefore, when \({E}_{T}\ll {S}_{T}+{K}_{M}\) and thus the sQ model is accurate, estimations with the sQ and the tQ models should be similar. On the other hand, when E T is high, they show clear differences (Fig. 2a right): the posterior samples obtained with the sQ model show large errors, while those obtained with the tQ model accurately capture the true value of k cat .

The estimation of a single parameter (k cat or K M ) with either the sQ or the tQ model. For each condition (S T = 0.2, 2, or 80 nM, and E T = 0.2, 2, or 40 nM), 105 posterior samples of either k cat (a) or K M (b) were obtained by applying the Bayesian inference to 102 noisy data sets (Fig. S1) (see Methods for details). When the k cat is sampled, the K M is fixed at its true value (a) and vice versa (b). Here, green triangles indicate the true values of the parameters. Whereas the estimates of k cat and K M obtained with the sQ model are biased as E T increases, those obtained with the tQ model have negligible bias regardless of conditions (See Fig. S3 for box plots of estimates). As E T or S T increases, the posterior variance of K M increases when the tQ model is used.
Similar results are also observed in the box plots of posterior means and posterior coefficient of variations (CVs) (Fig. S3a,b). Whereas posterior means obtained with the sQ model are biased when E T is high, those obtained with the tQ model are accurate for all conditions (Fig. S3a). In particular, narrow distributions of posterior means indicate that the estimation of k cat with the tQ model is robust aginst the noise in the data (Fig. S1). Furthermore, posterior CVs are much smaller than prior CVs (Fig. S3b), indicating precise estimation of k cat with the tQ model.
Next, K M was estimated under the assumption that the value of k cat is known (Fig. 2b). Posterior samples of the K M obtained with the sQ model again show errors that grow with increasing E T . Note that the estimates of the K M are biased upward, which implies that using the posterior estimates of K M to validate the MM equation (\({K}_{M}\gg {E}_{T}\)) can be misleading. On the other hand, the estimates of K M obtained with the tQ model are little biased for all conditions. However, unlike the narrow posterior distributions of k cat (Fig. 2a), those of K M obtained with the tQ model become wider; so precision decreases as E T or S T increases (Fig. 2b). These patterns are also observed in the box plots of posterior means and posterior CVs (Fig. S3c,d). The identifiability problem arises because, when \({E}_{T}\gg {K}_{M}\) or \({S}_{T}\gg {K}_{M}\) and thus \({E}_{T}+{S}_{T}\gg {K}_{M}\), the K M is negligible in the tQ model (Eq. 2), as follows:
Specifically, when K M is too low, the value of K M has little effect on the dynamics of the tQ model and thus the K M is structurally unidentifiable. Taken together, the estimations of K M with both the sQ and the tQ models are not satisfactory, although for different reasons: estimations with the sQ model can be biased and those with the tQ model can be structurally unidentifiable (Fig. 2b). Similar patterns were also observed when a more informative prior was given (Fig. S4). In particular, even with the informative prior, estimates obtained with the sQ model still show considerable error as E T increases.
Simultaneous estimation of k cat and K M suffers from the lack of identifiability
Next, we considered simultaneous estimation of two parameters, k cat and K M , which is the typical goal of enzyme kinetics. For the same gamma priors used in the single-parameter estimation (Fig. 2), the distributions of posterior samples obtained with both models became wider overall (Fig. 3). To find the reason for such imprecise estimation, we analysed the scatter plots of posterior k cat and K M samples (Fig. 4). When \({S}_{T}\ll {K}_{M}\) (Fig. 4a–c), the posterior samples of k cat and K M obtained with the sQ model exhibited a strong correlation, because the dynamics of the sQ model depend only on the ratio k cat /K M , as seen in the following approximation:
where \({K}_{M}\gg {S}_{T}\ge {S}_{T}-P\) is used. On the other hand, when \({S}_{T}\gg {K}_{M}\) (Fig. 4g–i), the scatter plot of the sQ model becomes horizontal, indicating the structure unidentifiability of the K M . Indeed, the value of K M has nearly no effect on the dynamics of the sQ model, as seen in the following approximation:
where K M + S T ≈ S T is used as \({S}_{T}\gg {K}_{M}\). Such lack of parameter identifiability when \({S}_{T}\ll {K}_{M}\) or \({S}_{T}\gg {K}_{M}\) is consistent with previous studies, which recommend using S T ≈ K M for more precise estimation22,23. However, even when S T ≈ K M , estimates are still imprecise (Fig. 3a and b middle). Furthermore, as E T increases, the estimates obtained with the sQ model are biased (Fig. 3) like in the single-parameter estimation (Fig. 2). Based on this analysis it appears that the simultaneous estimation of k cat and K M with the sQ model is challenging because of both identifiability and bias problems.

Simultaneous estimation of two parameters (k cat and K M ) with either the sQ or the tQ model. From the same 102 data sets (Fig. S1) used in the single-parameter estimation (Fig. 2), 105 posterior samples of the k cat (a) and the K M (b) were obtained together. Although the same prior is given, the posterior distributions become wider than the single-parameter estimation (Fig. 2). Here, green triangles indicate the true values of k cat or K M .

The scatter plots of posterior samples obtained with the two-parameter estimation (Fig. 3). The scatter plots imply two types of structure unidentifiability: strong correlation between k cat and K M , and unidentifiability of K M , which is represented as a horizontal plot. Positively correlated scatter plots of the tQ model are changed to horizontal ones when the sampled K M is much lower than S T + E T (dashed gray lines). Here, green triangles represent the true values of parameters.
When \({E}_{T}\gg {K}_{M}\) or \({S}_{T}\gg {K}_{M}\), the K M has a negligible effect on the dynamics of the tQ model (Eq. 6), and thus only k cat was identifiable in the single-parameter estimation (Fig. 2a and b right or bottom). Similarly, when both k cat and K M are inferred simultaneously with the tQ model, estimation of only k cat is accurate and precise (Fig. 3a and b right or bottom), as is shown by the horizontal scatter plots along the true value of k cat (Fig. 4c,f,g–i). In other cases (when neither \({E}_{T}\gg {K}_{M}\) nor \({S}_{T}\gg {K}_{M}\)), posterior variance of both parameters dramatically increases compared to the single-parameter estimation (Figs 2 and 3 left and top). Such imprecise estimation stems from two sources, according to the scatter plots (Fig. 4a,b,d,e). When k cat and K M decrease together, the behavior of the tQ model changes little as the SQ model (Eq. 5), which leads to the strong correlation between posterior samples of k cat and K M . As the estimates of K M keep decreasing together with those of k cat , so that they become much less than E T + S T (dashed vertical line of Fig. 4), the tQ model no longer depends on the value of K M , as shown in Eq. 6, and thus the scatter plots become horizontal.
Combined data from different experiments allow accurate and precise estimation with the tQ model
As shown above, the estimation of both k cat and K M using a single progress curve suffers from considerable bias and lack of identifiability (Figs 3 and 4), which is consistent with previous studies reporting that a progress curve obtained from a single experiment is not enough to identify both parameters simultaneously19. Thus, here, we investigate whether using multiple timecourse data sets obtained under different experimental conditions can improve the estimation.
In typical in vitro assays, progress curves are measured with either a fixed S T and varied E T or a fixed E T and varied S T 8,9,10,11,39. We first consider the case when progress curves are measured with a fixed S T and a varied E T . Specifically, progress curves from both low and high E T are used to estimate parameters for a fixed S T at different levels (Fig. S1 top and bottom). In this case, posterior samples obtained with the sQ model show considerable errors as the data from high E T is used (Figs 5a and S5). On the other hand, the posterior samples obtained with the tQ model accurately capture the true values of both k cat and K M with low variance (Figs 5a and S5). Such improvement stems from the fact that data obtained under the low and high E T provide different types of information for parameter estimation. Specifically, from the high E T data, although the K M is not identifiable, the k cat can be accurately estimated with the tQ model (Fig. 4c,f,i). Such accurate estimation of k cat from the high E T data can prevent the correlation between the k cat and the K M when they are estimated from the low E T data (Fig. 4a,d). Indeed, the narrow scatter plots of the tQ model (Fig. 5b left and middle) are the intersection of two scatter plots, a horizontal one obtained with the high E T data (Fig. 4c,f) and a nonhorizontal one obtained with the low E T data (Fig. 4a,d). However, when S T is high, the scatter plot from the low E T also becomes horizontal (Fig. 4c), and thus the synergistic effect of using combined data decreases (Fig. 5a,b right). Taken together, the tQ model can accurately estimate both parameters from the combination of low E T and high E T data when S T is not much larger than K M . Note that such low S T is preferred for in vitro experiments24,39,40,41 and is the case for most physiological conditions24.

When data obtained under low E T and high E T are used together, the accuracy and precision of estimaties obtained with the tQ model, but not with the sQ model, are enhanced. (a) Posterior samples are inferred using data sets from E T = 0.2 nM (Fig. S1 top) and E T = 40 nM (Fig. S1 bottom) together for either S T = 0.2, 2, or 80 nM. The posterior variance of the tQ model dramatically decreases to the level of the single-parameter estimation (Fig. 2). However, the estimates of the sQ model show considerable bias. Here, green triangles represent the true values of k cat or K M . (b) The scatter plots of the posterior samples. Here green triangles, blue circles, and red squares represent true values, posterior means of the sQ model, and those of the tQ model, respectively.
Next, we consider the case when progress curves are measured with a fixed E T and a varied S T . Specifically, the combination of two progress curves from low and high S T is used to infer parameters for a fixed E T at different levels (Fig. S1 left and right). When E T is low, and thus the sQ and the tQ models behave similarly (Eq. 5), posterior samples obtained with both models accurately capture the true values of k cat and K M (Figs 6a left and S6). Again, the narrow scatter plot (Fig. 6b left) is obtained as the intersection of a nonhorizontal scatter plot of low S T (Fig. 4a) and a horizontal scatter plot of high S T (Fig. 4g). However, as E T increases, and thus the sQ model becomes less accurate, those obtained with the sQ model are biased, as expected (Figs 6a right and S6). Whereas such biases are not observed in those obtained with the tQ model, the precision of K M estimates decreases as E T increases, as in the single-parameter estimation (Fig. 2 and Eq. 6).

Estimation using the data obtained under low S T and high S T together. (a) Posterior samples are inferred using data sets from S T = 0.2 nM (Fig. S1 left) and S T = 80 nM (Fig. S1 right) together for either E T = 0.2, 2, or 40 nM. When E T is low, both the sQ and the tQ models allow accurate and precise estimation. As E T increases, the estimates obtained with the sQ model become inaccurate, and the estimates of K M obtained with the tQ model become less precise, similar to the single-parameter estimation (Fig. 2). Here, green triangles represent the true values of k cat or K M . (b) The scatter plots of the posterior samples. Here green triangles, blue circles, and red squares represent true values, posterior means of the sQ model, and those of the tQ model, respectively.
Optimal design of experiments for accurate and efficient estimation with the tQ model
When a progress curve obtained from a single experiment is used, the posterior scatter plots of the tQ model can be categorized as a correlated type (Fig. 4a,b,d,e) and a horizontal type (Fig. 4c,f,g–i). The intersections of these two different types of scatter plots tend to be narrowly distributed near the true value (Figs 5b and 6b). Thus, combining two such data sets allows accurate estimation of both k cat and K M (Figs 5a and 6a). Specifically, a progress curve measured under \({E}_{T}\ll {K}_{M}\) and \({S}_{T}\ll {K}_{M}\) (Fig. 4a,b,d,e) and one measured under \({E}_{T}\gg {K}_{M}\) or \({S}_{T}\gg {K}_{M}\) (Fig. 4c,f,g–i) provide different types of information for parameter estimation; so using both data sets leads to successful estimation. However, it is hard to compare the values of S T , E T , and K M in practice, because the value of K M is usually unknown a priori. This problem can be easily resolved by using the scatter plot. That is, if the posterior scatter plot obtained from the first experiment is horizontal, then both E T and S T should be decreased for the next experiment, so that the nonhorizontal scatter plot can be obtained (Fig. 7a). On the other hand, if the scatter plot from the first experiment shows a strong correlation between K M and k cat , then either S T or E T should be increased in the next experiment (Fig. 7b). Basically, without any prior information of the value of K M and k cat , the shape of the scatter plots of the current estimates determines the next optimal experimental design, which ensures accurate and precise estimation. However, this approach cannot be used with the sQ model, because estimation with the sQ model can be biased, depending on the relationship between E T or S T and K M , which is unknown a priori. That is, unlike the tQ model, precise estimation does not always guarantee accurate estimation with the sQ model, as seen above (e.g. Fig. 5a right).

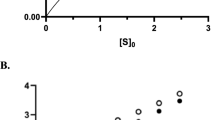
The optimal experimental design for accurate and precise estimation with the tQ model. (a) When the scatter plot of posterior samples from the first experiment is horizontal, E T and S T need to be decreased to obtain the nonhorizontal scatter plot in the next experiment. Then, using the combination of the two experiments leads to accurate and precise estimation (red scatter plots). (b) When the scatter plot from the first experiment is nonhorizontal, E T or S T need to be increased in the next experiment to obtain a horizontal scatter plot. (c) Inference with a single progress curve from the low E T (0.1 K M ) and the high E T (10 K M ) leads to nonhorizontal and horizontal scatter plots, respectively, for chymotrypsin, urease, and fumarase (gray scatter plots). When both data sets were used together, accurate estimates were obtained for all enzymes (red scatter plots). Here, low S T (0.1 K M ) is used. Here, green triangles represent the true values of the parameters.
We test whether the proposed approach with the tQ model can accurately estimate k cat and K M for catalysis of the N-acetylglycine ethyl ester, fumarate, and urea by the enzymes the chymotrypsin, urease, and fumarase, respectively (Fig. 7c). These three enzymes were chosen because they have disparate catalytic efficiencies (k cat /K M )1: 0.12, 4 · 105, and 1.6 · 108 s −1 M −1, respectively. For each enzyme, 102 noisy timecourse data sets were generated using stochastic simulations based on known enzyme kinetic parameters1. When progress curves obtained with low E T and low S T are used, as expected, nonhorizontal scatter plots of posterior samples were obtained for all three enzymes (Fig. 7c). This indicates that either E T or S T should be increased in the next experiment to obtain a horizontal scatter plot. Indeed, when a progress curve with a 100-fold increase of E T was used, horizontal scatter plots were obtained for all enzymes (Fig. 7c). Therefore, when these two progress curves are used together, both k cat and K M can be accurately estimated (Fig. 7c red dots). These results support that such two-step optimized experimental design (Fig. 7a,b) to get two different types of scatter plots allows accurate and efficient estimation of enzyme kinetics with the tQ model. The computational package performing such estimation is provided (see Method for the details).
Discussion
The standard approach for estimating enzyme kinetic parameters even today continues to be based on the 100-year old MM equation (Eq. 1)5,6. However, when enzyme concentration is high, this approach can lead to biased estimation (Fig. 2). Even when enzyme concentration is relatively low, it may not be possible to identify kinetic parameters (Figs 3 and 4). To overcome the limitations of the canonical approach, we proposed an estimation method based on an alternative to the MM equation: the tQ model (Eq. 2), which is derived with the total QSSA26,27,28,29. Because the estimation procedure with the tQ model is not biased regardless of enzyme or substrate concentrations (Fig. 2), more accurate and precise estimations can be made when pooled data from different experimental conditions are used, unlike the canonical approach (Figs 5 and 6). It appears thus that the tQ model is especially appropriate for creating a consistent Bayesian inferential framework, which becomes more accurate as more data is used.
The canonical enzyme kinetic assay based on the MM equation generally requires a large excess of substrate over enzyme42. However, such conditions impose experimental limitations and cannot be always guaranteed and verified15. For instance, it is hard to generate a high concentration of barely soluble substrate24, and a low concentration of substrate is required for sensitive kinetic analysis, e.g., in the case of QD-FRET-based probes39,40,41. Importantly, to analyze in vivo enzyme kinetics, where enzyme concentration is often high16,17,18, our approach, but not the canonical approach, can be used. For example, one needs to estimate the kinetic parameters underlying drug metabolism by CYP enzymes in the liver in order to predict the effects of drugs, as is essential for drug development43. Because of dosing requirements for potent drugs, the amount of CYP enzyme can greatly exceed the drug amount in the liver44,45. Another large area where our estimation method can be applied is in the development of nanobiosensors, which measure in vivo activity of a specific enzyme for precise diagnostics, because such enzymes are often in large excess over biosensors46,47.
KinTek Explorer has been widely used to estimate enzyme kinetic parameters from the progress curves48,49,50. This software provides the confidence contours, which reveal the relationships between the estimated parameters. This approach recommends using multiple data sets to narrow down the confidence contours and thus improve precision of estimates and resolve the unidentifiability issue. Our finding (Fig. 7a,b) can provide the specific type of data sets required for the identifiability of k cat and K M , so that the KinTek Explore could perform parameter estimation more efficiently for the Michales-Menten type of enzyme reactions.
Since the initial velocity estimation with the MM equation is not accurate when enzyme concentration is high (Fig. 1), the standard initial velocity based on the MM equation would also be inaccurate15. On the other hand, the tQ model accurately captures the initial velocity for all conditions, and thus the modified initial velocity assay based on the tQ model is likely to be accurate over a wider range of conditions. To simplify such estimation procedures, an interesting future study could derive an analogous Lineweaver-Burk plot or the Hanes-Woolf plot8,9,15,42 for the tQ model.
Even with relatively large noise in the data (Fig. S1), our proposed method leads to accurate estimation (Figs 5, 6 and 7), indicating its robustness against experimental noise and some minor inaccuracy of the tQ model in certain ranges of parameter observed in14,30. Furthermore, if there are departures from simple non-inhibitory enzyme kinetics (e.g. inhibition of enzyme by product)51,52, our method can be easily adjusted by modifying the tQ model (see53,54 for the tQ model for other enzyme kinetics). Our work can also be used to improve the estimation of the kinetics underlying diverse biological functions, such as gene regulation55,56, cellular rhythms57,58,59, quorum sensing60,61, signal cascade62,63 and membrane transport64,65, where the MM equation has been widely used.
Methods
Simulated Data
To obtain timecourse data (Fig. S1) for Bayesian inference, stochastic simulations of the original full model (Table S1) were performed with the Gillespie algorithm66. E(0) = E T , S(0) = S T , C(0) = 0, and P(0) = 0 are used as initial conditions following the typical in vitro enzyme kinetics protocol.
Description of the Bayesian inference approach
The Bayesian inference approach is used to estimate the catalytic constant k cat and the Michaelis-Menten constant K M , based on the hazard function, with respective rates described in Eq. 1 for the sQ model and in Eq. 2 for the tQ model (Fig. S2). The likelihood functions are constructed based on an approximation to the underlying Markov model66 as follows.
where λ i is given by
or
where P i is the scaled number of product molecules observed at time point t i over [0, T] = [t 0, t m ] and n i = P i − P i−1 is an observed increment of P i . With these likelihood functions, the usual independent gamma priors67 are assigned to k cat and K M in order to get their posterior distributions with the help of the Markov Chain Monte Carlo (MCMC) method. Weakly informative gamma priors are used for both k cat and K M : their prior means are the same as their true values, and their prior variance is 10 times larger than the prior mean, which covers orders of magnitude (e.g. Fig. 2). The estimation of a single parameter, i.e., either k cat or K M is done conditionally on the other parameter. For estimating the two parameters simultaneously, the Gibbs sampler method is used. In order to draw the sample for K M , we also use the Metropolis-Hastings algorithm within the Gibbs sampler step. See Supplementary material for further details.
Computational code
The R package that performs the Bayesian inference based on the tQ model is available on the CRAN repository (https://cran.r-project.org/web/packages/EKMCMC).
References
Chang, R. Physical chemistry for the chemical and biological sciences (University Science Books, 2000).
Cooper, G. The Cell: A Molecular approach (USA: Sinauer Associates, 2000).
Griffiths, A. J. Modern genetic analysis: integrating genes and genomes (Macmillan, 2002).
Kirk, O., Borchert, T. V. & Fuglsang, C. C. Industrial enzyme applications. Curr. Opin. Biotechnol. 13, 345–351 (2002).
Michaelis, L. & Menten, M. L. Die kinetik der invertinwirkung. Biochem. z 49, 352 (1913).
Briggs, G. E. & Haldane, J. B. S. A note on the kinetics of enzyme action. Biochem. J. 19, 338 (1925).
Segel, L. A. & Slemrod, M. The quasi-steady-state assumption - a case-study in perturbation. SIAM Rev. 31, 446–477 (1989).
Tummler, K., Lubitz, T., Schelker, M. & Klipp, E. New types of experimental data shape the use of enzyme kinetics for dynamic network modeling. FEBS J. 281, 549–571 (2014).
Johnson, K. A. A century of enzyme kinetic analysis, 1913 to 2013. FEBS Lett 587, 2753–2766 (2013).
Duggleby, R. G. Analysis of enzyme progress curves by nonlinear regression. Methods Enzymol 249, 61–90 (1995).
Duggleby, R. G. & Wood, C. Analysis of progress curves for enzyme-catalysed reactions. automatic construction of computer programs for fitting integrated rate equations. Biochem. J. 258, 397–402 (1989).
Chen, W. W., Niepel, M. & Sorger, P. K. Classic and contemporary approaches to modeling biochemical reactions. Genes & Dev 24, 1861–1875 (2010).
Varón, R. et al. An alternative analysis of enzyme systems based on the whole reaction time: evaluation of the kinetic parameters and initial enzyme concentration. J. Math. Chem. 42, 789–813 (2007).
Schnell, S. & Maini, P. K. A century of enzyme kinetics. should we believe in the km and vmax estimates? Comments Theor. Biol. 8, 169–187 (2003).
Pinto, M. F. et al. Enzyme kinetics: the whole picture reveals hidden meanings. The FEBS J. 282, 2309–2316 (2015).
Albe, K. R., Butler, M. H. & Wright, B. E. Cellular concentrations of enzymes and their substrates. J. Theor. Biol. 143, 163–195 (1990).
Srere, P. A. Enzyme concentrations in tissues. Science. 158, 936–937 (1967).
Eunen, K. V. & Bakker, B. M. The importance and challenges of in vivo-like enzyme kinetics. Perspectives Sci. 1, 126–130 (2014).
Nikolova, N., Tenekedjiev, K. & Kolev, K. Uses and misuses of progress curve analysis in enzyme kinetics. Cent. Eur. J. Biol 3, 345–350 (2008).
Cornish-Bowden, A. One hundred years of michaelis–menten kinetics. Perspectives Sci. 4, 3–9 (2015).
Yang, X., Long, G., Jiang, H., Liao, P. & Liao, F. Integration of kinetic analysis of reaction curve with a proper classical approach for enzymatic analysis. The Sci. World J. 2012 (2012).
Duggleby, R. G. Experimental designs for estimating the kinetic parameters for enzyme-catalysed reactions. J. Theor. Biol. 81, 671–684 (1979).
Stroberg, W. & Schnell, S. On the estimation errors of k m and v from time-course experiments using the michaelis–menten equation. Biophys. Chem. 219, 17–27 (2016).
Bisswanger, H. Enzyme assays. Perspectives Sci. 1, 41–55 (2014).
Duggleby, R. G. & Clarke, R. B. Experimental designs for estimating the parameters of the michaelis-menten equation from progress curves of enzyme-catalyzed reactions. Biochimica et Biophys. Acta (BBA)-Protein Struct. Mol. Enzymol. 1080, 231–236 (1991).
Cha, S. Kinetic behavior at high enzyme concentrations magnitude of errors of michaelis-menten and other approximations. J. Biol. Chem. 245, 4814–4818 (1970).
Tzafriri, A. R. Michaelis-menten kinetics at high enzyme concentrations. Bull. Math. Biol. 65, 1111–1129 (2003).
Bersani, A. M., Bersani, E., DellAcqua, G. & Pedersen, M. G. New trends and perspectives in nonlinear intracellular dynamics: one century from michaelis–menten paper. Continuum Mech. Thermodyn. 27, 659–684 (2015).
Borghans, J. M., De Boer, R. J. & Segel, L. A. Extending the quasi-steady state approximation by changing variables. Bull. Math. Biol. 58, 43–63 (1996).
Schnell, S. & Maini, P. Enzyme kinetics far from the standard quasi-steady-state and equilibrium approximations. Math. Comput. Model. 35, 137–144 (2002).
Rao, C. V. & Arkin, A. P. Stochastic chemical kinetics and the quasi-steady-state assumption: Application to the Gillespie algorithm. J. Chem. Phys. 118, 4999–5010 (2003).
Barik, D., Paul, M. R., Baumann, W. T., Cao, Y. & Tyson, J. J. Stochastic simulation of enzyme-catalyzed reactions with disparate timescales. Biophys. J. 95, 3563–3574 (2008).
Thomas, P., Straube, A. V. & Grima, R. The slow-scale linear noise approximation: an accurate, reduced stochastic description of biochemical networks under timescale separation conditions. BMC Syst. Biol. 6 (2012).
Kim, J. K., Josić, K. & Bennett, M. R. The validity of quasi-steady-state approximations in discrete stochastic simulations. Biophys. J. 107, 783–793 (2014).
Kim, J. K. & Sontag, E. D. Reduction of multiscale stochastic biochemical reaction networks using exact moment derivation. PLoS Comput. Biol. 13, e1005571 (2017).
Kim, J. K., Rempala, G. A. & Kang, H.-W. Reduction for stochastic biochemical reaction networks with multiscale conservations. Multiscale Modeling & Simulation, 15(4), 1376–1403 (2017).
Sanft, K. R., Gillespie, D. T. & Petzold, L. R. Legitimacy of the stochastic michaelis-menten approximation. IET Syst. Biol. 5, 58–69 (2011).
Kim, J. K., Josić, K. & Bennett, M. R. The relationship between stochastic and deterministic quasi-steady state approximations. BMC Syst. Biol. 9, 87 (2015).
Sapsford, K. E. et al. Monitoring of enzymatic proteolysis on a electroluminescent-ccd microchip platform using quantum dot-peptide substrates. Sensors Actuators B: Chem. 139, 13–21 (2009).
Algar, W. R. et al. Proteolytic activity at quantum dot-conjugates: Kinetic analysis reveals enhanced enzyme activity and localized interfacial hopping. Nano Lett. 12, 3793–3802 (2012).
Algar, W. R. et al. Multiplexed tracking of protease activity using a single color of quantum dot vector and a time-gated forster resonance energy transfer relay. Anal. Chem. 84, 10136–10146 (2012).
Singh, N. et al. A safe lithium mimetic for bipolar disorder. Nat. Commun. 4, 1332 (2013).
Obach, R. S. & Reed-Hagen, A. E. Measurement of michaelis constants for cytochrome p450-mediated biotransformation reactions using a substrate depletion approach. Drug Metab. Dispos. 30, 831–837 (2002).
Wienkers, L. C. & Heath, T. G. Predicting in vivo drug interactions from in vitro drug discovery data. Nat. Rev. Drug Discov. 4, 825–833 (2005).
Houston, J. B. & Kenworthy, K. E. In vitro-in vivo scaling of cyp kinetic data not consistent with the classical michaelis-menten model. Drug Metab. Dispos. 28, 246–254 (2000).
Turk, B. E., Huang, L. L., Piro, E. T. & Cantley, L. C. Determination of protease cleavage site motifs using mixture-based oriented peptide libraries. Nat. Biotechnol. 19, 661–667 (2001).
Kwong, G. A. et al. Mathematical framework for activity-based cancer biomarkers. Proc. Natl. Acad. Sci. 112, 12627–12632 (2015).
Johnson, K. A. Fitting enzyme kinetic data with kintek global kinetic explorer. Methods Enzymol. 467, 601–626 (2009).
Johnson, K. A., Simpson, Z. B. & Blom, T. Global kinetic explorer: a new computer program for dynamic simulation and fitting of kinetic data. Anal. Biochem. 387, 20–29 (2009).
Johnson, K. A., Simpson, Z. B. & Blom, T. Fitspace explorer: an algorithm to evaluate multidimensional parameter space in fitting kinetic data. Anal. Biochem. 387, 30–41 (2009).
Cao, W. & Enrique, M. Quantitative full time course analysis of nonlinear enzyme cycling kinetics. Sci. Reports 3, 2658 (2013).
Duggleby, R. G. Quantitative analysis of the time courses of enzyme-catalyzed reactions. Methods 24, 168–174 (2001).
Pedersen, M. G., Bersani, A. M., Bersani, E. & Cortese, G. The total quasi-steady-state approximation for complex enzyme reactions. Math. Comput. Simul. 79, 1010–1019 (2008).
Ciliberto, A., Capuani, F. & Tyson, J. J. Modeling networks of coupled enzymatic reactions using the total quasi-steady state approximation. PLoS Comput. Biol 3, e45 (2007).
Ronen, M., Rosenberg, R., Shraiman, B. I. & Alon, U. Assigning numbers to the arrows: parameterizing a gene regulation network by using accurate expression kinetics. Proc. Natl. Acad. Sci. 99, 10555–10560 (2002).
Del Vecchio, D., Abdallah, H., Qian, Y. & Collins, J. J. A blueprint for a synthetic genetic feedback controller to reprogram cell fate. Cell Syst. (2017).
Pigolotti, S., Krishna, S. & Jensen, M. H. Oscillation patterns in negative feedback loops. Proc. Natl. Acad. Sci. 104, 6533–6537 (2007).
Kim, J. K. Protein sequestration versus hill-type repression in circadian clock models. IET Syst. Biol. 10, 125–135(10) (2016).
Gotoh, T. et al. Model-driven experimental approach reveals the complex regulatory distribution of p53 by the circadian factor period 2. Proc. Natl. Acad. Sci. 113, 13516–13521 (2016).
Dockery, J. D. & Keener, J. P. A mathematical model for quorum sensing in pseudomonas aeruginosa. Bull. Math. Biol. 63, 95–116 (2001).
Chen, Y., Kim, J. K., Hirning, A. J., Josić, K. & Bennett, M. R. Emergent genetic oscillations in a synthetic microbial consortium. Sci. 349, 986–989 (2015).
Ossareh, H. R., Ventura, A. C., Merajver, S. D. & Del Vecchio, D. Long signaling cascades tend to attenuate retroactivity. Biophys. J. 100, 1617–1626 (2011).
Chen, M., Wang, L., Liu, C. C. & Nie, Q. Noise attenuation in the on and off states of biological switches. ACS Synth. Biol. 2, 587–593 (2013).
Knight, M. J., Senior, L., Nancolas, B., Ratcliffe, S. & Curnow, P. Direct evidence of the molecular basis for biological silicon transport. Nat. Commun. 7 (2016).
Lawson, M. J., Drawert, B., Khammash, M., Petzold, L. & Yi, T.-M. Spatial stochastic dynamics enable robust cell polarization. PLoS Comput. Biol 9, e1003139 (2013).
Gillespie, D. T. Exact stochastic simulation of coupled chemical reactions. The J. Phys. Chem. 2340–2361 (1977).
Choi, B. & Rempala, G. A. Inference for discretely observed stochastic kinetic networks with applications to epidemic modeling. Biostat. 13, 153–165 (2012).
Acknowledgements
The research was initiated when all authors were visiting The Mathematical Biosciences Institute at the Ohio State University. This work was supported by the National Research Foundation of Korea grant NRF-2017R1D1A3B03031008 (B.C.), US National Science Foundation (NSF) Grant DMS-1440386 (G.A.R.) and DMS-1318886 (G.A.R.), the National Research Foundation of Korea grant N01160447 (J.K.K.), and the TJ Park Science Fellowship of POSCO TJ Park Foundation (J.K.K.).
Author information
Authors and Affiliations
Contributions
J.K.K. designed the research. B.C. and J.K.K. performed simulations and analysis. All authors discussed the results and wrote the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Choi, B., Rempala, G.A. & Kim, J.K. Beyond the Michaelis-Menten equation: Accurate and efficient estimation of enzyme kinetic parameters. Sci Rep 7, 17018 (2017). https://doi.org/10.1038/s41598-017-17072-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-17072-z
- Springer Nature Limited
This article is cited by
-
Optimizing the standardized assays for determining the catalytic activity and kinetics of peroxidase-like nanozymes
Nature Protocols (2024)
-
Construction and optimization of a biocatalytic route for the synthesis of neomenthylamine from menthone
Bioresources and Bioprocessing (2023)
-
Impact of the Error Structure on the Design and Analysis of Enzyme Kinetic Models
Statistics in Biosciences (2023)
-
Natural Parameter Conditions for Singular Perturbations of Chemical and Biochemical Reaction Networks
Bulletin of Mathematical Biology (2023)
-
Comparison of in vitro Antifungal Activity Methods Using Extract of Chitinase-producing Aeromonas sp. BHC02
The Protein Journal (2023)