
Abstract
In the immediate aftermath of a strong earthquake and in the presence of an ongoing aftershock sequence, scientific advisories in terms of seismicity forecasts play quite a crucial role in emergency decision-making and risk mitigation. Epidemic Type Aftershock Sequence (ETAS) models are frequently used for forecasting the spatio-temporal evolution of seismicity in the short-term. We propose robust forecasting of seismicity based on ETAS model, by exploiting the link between Bayesian inference and Markov Chain Monte Carlo Simulation. The methodology considers the uncertainty not only in the model parameters, conditioned on the available catalogue of events occurred before the forecasting interval, but also the uncertainty in the sequence of events that are going to happen during the forecasting interval. We demonstrate the methodology by retrospective early forecasting of seismicity associated with the 2016 Amatrice seismic sequence activities in central Italy. We provide robust spatio-temporal short-term seismicity forecasts with various time intervals in the first few days elapsed after each of the three main events within the sequence, which can predict the seismicity within plus/minus two standard deviations from the mean estimate within the few hours elapsed after the main event.
Similar content being viewed by others


Introduction
Following a large earthquake and in the presence of a vast number of aftershocks, short-term operational seismicity forecasts (in the order of days to months) are of utmost importance for emergency decision-making and risk mitigation in the disaster area1,2,3,4,5,6. The aftershock activity is forecasted mainly based on the observed data of already registered (and mostly incomplete) recordings within the ongoing sequence7. The Epidemic Type Aftershock Sequence (ETAS) model8, 9 is the stochastic model most frequently used to describe earthquake occurrence within a seismic sequence10. It is an epidemic stochastic point process in which every earthquake within the sequence is a potential triggering event for subsequent earthquakes11, and therefore generates its own well-defined Modified Omori12, 13 (MO) aftershock decay14. Hence, it is capable of accounting for the triggering effect of all the events that have taken place before a desired time. The ETAS model performed quite well in operational seismic forecasting during the L’Aquila 2009 (central Italy) seismic sequence15. The model parameters are usually calibrated a priori based on the maximum likelihood criterion. The first effort on the calibration of temporal model parameters has been carried on by Ogata8, and extended later9, 16,17,18,19 to estimate the spatio-temporal model parameters. In addition, several attempts are made for developing improved algorithms to attain maximum likelihood estimates of ETAS parameters; e.g., the Expected-Maximization algorithm20, an improved maximum likelihood algorithm21, and a new algorithm based on Simulated Annealing optimization technique10, which allows for an automatic maximum likelihood estimation of the model parameters instead of fine-tuning of some algorithm parameters in advance. Adaptive model parameter estimation based on the events in the ongoing sequence (e.g., calibrating the parameters of MO and ETAS models based on the ongoing catalogue by employing Bayesian parameter estimation22,23,24,25) has the advantage of both tuning a sequence-specific model and also capturing possible time variations of the model parameters. As the original purpose of the present paper, we propose a fully simulation-based method to provide a robust estimate 24, 26, 27 for the spatial distribution of the events in a prescribed forecasting time interval after the main event. In the context of this robust estimate, the uncertainty in the ETAS model parameters is taken into account as the posterior joint probability distribution for the model parameters conditioned on the events that have already occurred (i.e., registered events in the ongoing seismic sequence before the beginning of the forecasting interval). The Markov Chain Monte Carlo (MCMC) simulation scheme24, 25, 27 is used to sample directly from the posterior probability distribution for ETAS model parameters (i.e., conditioned on the registered events in the ongoing sequence). Moreover, this robust estimate also considers the sequence of events that is going to occur during the forecasting interval (and hence affect the seismicity in an epidemic type model like ETAS). Although this sequence is unknown at the time of forecasting, we propose a stochastic procedure to generate it. The procedure leads to the stochastic spatio-temporal distribution of the forecasted events and consequently to the uncertainty in the estimated number of events, corresponding to a given forecasting interval. The resulting robust forecasts are directly applicable in adaptive daily aftershock hazard and risk assessment procedures23, 28, 29, 30.
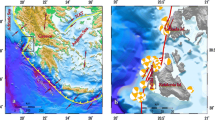
The proposed methodology is applied to provide retrospective forecasting for seismic activities of the 2016 Amatrice sequence by analysing the registered data of quasi real-time catalogues from INGV (Istituto Nazionale di Geofisica E Vulcanologia). The corresponding aftershock zone, as shown in Fig. 1a by the gray-colored area, is located mostly within the seismic zone 923 based on the ZS9 Italian Seismogenetic Zonation31. Fig. 1a shows also the seismogenic zonations surrounding the aftershock zone. It is to note that based on the Italian seismic zonations, the upper-bound magnitude for seismic zone Z923 is M max = 7.06. On the 24th of August 2016 at 01:36 UTC, a Mw 6.0 earthquake struck the Central Italy between towns of Norcia and Amatrice, devastating Amatrice, Accumoli and several surrounding small towns and villages, causing almost 300 fatalities and leaving almost 30,000 homeless. The seismic sequence, including a Mw 5.4 aftershock (occurred almost one hour after the main shock at 02:33 UTC), triggered hundreds of earthquakes per day until the mid-September. Two months after, on the 26th of October, a Mw 5.4 followed within a two-hour delay by a Mw 5.9 earthquake (at 17:10 and 19:18 UTC, respectively) took place in the east of town Visso, and preceded the largest event of the sequence, a Mw 6.5 on October 30 at 06:40 UTC, North of Norcia32. This one is the largest earthquake recorded in Italy since the Mw 6.9 1980 Irpinia event. Fig. 1b and c illustrate the seismic activities within the aftershock zone during the first two months highlighting the key events taken place.

Amatrice 2016 seismic sequence. (a) The aftershock zone indicated by the grey-coloured box in perspective with the surrounding Italian seismogenic zonation. (b) The spatial distribution of aftershock events based on Catalogue 2 from August 24, 2016 (01:36 UTC) up to November 2, 2016 (10:32 UTC) bordering four neighbouring provinces in Italy. The grey-coloured box defines the considered aftershock zone and the most damaged towns are highlighted with green boxes. The main seismic events are illustrated as follows: M6.0 and M6.5 with red stars; M5.4 (24/08/16), M5.4 (26/10/16), M5.9 (26/10/16) with magenta triangles; aftershocks M ≥ 3.0 with grey circles. (c) The number of events (with M ≥ 3.0) in Catalogue 2 occurred within a 24-hour interval starting from 6:00 UTC of the desired day (MATLAB 2016b, http://softwaresso.unina.it/matlab/ is used to create this figure).
In the adaptive procedure presented in Section Method, the spatial maps can provide indications with regards to automatic re-sizing of the aftershock zone (if required) in case the spatial extension of the seismicity is not captured adequately inside a designated aftershock zone. For each forecasting interval, the spatial distribution of aftershock events is estimated based on equation (1) by calculating the (average) number of events N(x, y, m|seq, M l ) in the cell unit centered at Cartesian coordinate (x, y) with magnitude greater than or equal to m. For a prescribed aftershock zone extension, the boundaries of the zone would need to be adjusted if N(x, y, m|seq, M l ) is significantly greater than zero along the border cell units. This is a very important issue especially in case of Amatrice (multiple) seismic sequence 2016, where the seismicity was relocated towards north-west after two months from the main event on August 24. In this study, the aftershock zone is assigned a priori and the adequacy of its extension is monitored for each forecast.
The present study strives to perform robust forecasts for the spatio-temporal evolution of the events in specific time intervals within the very complex sequence described above that is distinguished by three main events (“mainshocks”) of moment magnitudes 6.0, 5.9, and 6.5, respectively (as illustrated in Fig. 1b). We divide the sequence into three parts: (a) from 24-August to 25-October, (b) from 26-October to 29-October, and finally (c) from 30-October to 1-November. We have used two different catalogues herein in order to gather data backwards in time. The two catalogues are distinguished by the date of access to the source database and share the time of origin (01:36 UTC, August 24 2016). The first one (labelled as Catalog 1) lasts until September 9, 2016 (07:23 UTC, date of first access) when the aftershock activities are reduced considerably in the zone. The second one (labelled as Catalog 2 whose registered data are illustrated in Fig. 1b and c) covers until November 2, 2016 (10:32 UTC, date of second access).
Results
Providing daily forecasts of seismicity from August 24 up to October 25
The prediction time window [T start , T end ] indicates a 24-hour interval where T start is 6:00 UTC of the following day. Each forecast uses available information at the time when the forecast is issued, i.e., the sequence (denoted as seq in Section Methods) comprised of events registered in the Catalogue 1 including the main event up to the time T start . To issue the first forecast, the observation history, seq, comprises the main event with Mw 6.0 at 01:36 UTC and the triggered events up to 6:00 UTC of 24 August 2016, where the lower cut-off magnitude, M l , of Catalogue 1 is equal to 3.0 based on the two methods discussed in Ebrahimian et al.23. It is to note that the completeness threshold of the catalog of aftershocks in subsequent forecasting intervals is demonstrated to be even lower than 3.0 (the procedure(s) adopted for evaluating the completeness magnitude M c throughout the various phases of this multiple seismic sequence is described in detail in the Supplementary Information in a Section entitled “Discussion on the Completeness Magnitude M c ”). In any case, M l = 3.0 is considered as the cut-off threshold for the computation of the aftershock rates for the upcoming days.
The first step towards providing seismicity forecasts (with reference to equation 9) is sampling from the distribution of modal parameters θ based on posterior (target) probability distribution p(θ|seq, M l ). The vector θ = [β, K, K t , K R , c, p, d, q] is updated on a daily basis by applying the Bayesian updating routine illustrated in equation (17) and considering that parameters K, K t , K R are derived as function of other parameters within vector θ (see equations 4–7). As prior information, we assigned a normal distribution to the five model parameters [β, c, p, d, q], with a coefficient of variation (COV) equal to 0.30. The prior mean values for [β, c] are assigned equal to those provided by the MO Italian generic model parameters33, while prior mean values assigned to [p, d, q] are equal to the ETAS model parameters calibrated for the L’Aquila aftershock sequence15. The prior COV for each model parameter is set equal to 0.3 –in some cases larger than the reported prior COV’s in the above-mentioned references– to avoid using an over-informative prior distribution (i.e., a prior with a very low COV). Samples for θ are generated as a Markov Chain sequence directly from p(θ|seq, M l ), as noted in Section Methods. It should be noted that sampled p and q values smaller than one are rejected according to equations (4) and (5) with the constraint p > 1 and q > 1. One key restraint on performing operational forecasting during an ongoing sequence is that the procedure should be performed in a reasonably small amount of time. To address this issue, an MCMC procedure for updating the model parameters is carried out adaptively (see the Section Methods).
The evolution in the statistics (mean and COV) of model parameters θ = [β, K, K t , K R , c, p, d, q] are summarized in Table 1. We use Catalogue 1 for constructing seq in order to provide forecasts within the first two weeks after the main event (i.e., from August 24 up to September 06). The first row of Table 1 corresponds to the statistics for the prior marginal PDF’s for θ while the subsequent rows indicate the statistics for the posterior distributions. In addition, Supplementary Fig. S1 illustrates the sampled histograms representing the marginal prior and posterior PDF’s corresponding to the six model parameters [β, K, c, p, d, q]. Moreover, we have illustrated the PDF for K, derived as a function of other model parameters, in Supplementary Fig. S1. The marginal PDF’s for the other two parameters K t and K R are not shown in the figure since they have a very straightforward relationship to other model parameters (see equations 4 and 5). The marginal distributions shown correspond to a 24 hours (1 day) forecasting interval and a magnitude 3.0 lower cut-off.
The sequence of events taking place during the forecasting interval, seqg, is generated (see equation 11 and Section Methods) given that θ and seq are known. Finally, substituting the sampled values for θ and seqg in equation (9), the robust estimate for the number of events with M ≥ m in a spatial cell units centered at (x, y) within the aftershock zone is obtained. This robust estimate is calculated as the expected number of events considering the uncertainties in the spatio-temporal distribution of the sequence of events. Fig. 2 shows the forecasted seismicity maps in terms of the mean plus two logarithmic standard deviation (98% confidence interval) for the number of events with M ≥ 3.0 within each spatial cell unit issued for the 24-hour time forecasting intervals. The earthquakes of interest occurred within the corresponding forecasting interval are illustrated as coloured dots (distinguished by magnitude). The two main events of the sequence with M ≥ 5.0 (see also Fig. 1) are identified with coloured stars (these events are shown for reference only and they did not necessarily take place in the illustrated map’s corresponding forecasting interval). We also report the forecasted daily probabilities of having earthquakes of magnitude equal to or larger than m = 4, 5 and 6 in the whole aftershock zone. These probabilities are calculated from the equation \(1-{e}^{-N(m|{\bf{s}}{\bf{e}}{\bf{q}},{M}_{l})}\) where \(N(m|{\bf{s}}{\bf{e}}{\bf{q}},{M}_{l})\) is the sum over the whole aftershock zone of the expected number of events \(N(x,y,m|{\bf{s}}{\bf{e}}{\bf{q}},{M}_{l})\) from equation (9).

Forecasted vs. observed seismicity distribution in the aftershock zone, the maps report the mean +2 standard deviation confidence interval for the number of events per [km2] (latitude/longitude cells of a 0.01° × 0.01° grid) equal to or greater than magnitude M l = 3 in the indicated 24-hour forecasting time window. In the lower left corner, the daily probabilities of having earthquakes with magnitudes 4, 5, and 6 or larger are reported. Each sub-plot also features the earthquakes (coloured dots) that occurred during the corresponding forecasting time window together with the two main events with M ≥ 5.0 (magenta stars). The sub-figures illustrate the observed (plotted in red star) vs. the error-bar for the forecasted number of events with m ≥ M l corresponding to the forecasting time interval: the median value (the 50th percentile, equivalent of the logarithmic mean in the arithmetic scale) inside a grey-filled square, the (logarithmic) mean plus/minus one (logarithmic) standard deviation indicating the interval between 16th and 84th percentiles (marked with blue horizontal lines), and the (logarithmic) mean plus/minus two (logarithmic) standard deviations indicating the interval between 2nd and 98th percentiles (marked with black horizontal lines). (MATLAB 2016b, http://softwaresso.unina.it/matlab/ is used to create this figure).
At the right-hand side of each sub-figure, the observed (shown as a red star) vs. forecasted number of events (shown in an error-bar format) is illustrated for events with M l = 3.0 for the entire aftershock zone. The error-bar for the forecasted number of events features: the median value (the 50th percentile, equivalent of the logarithmic mean in the arithmetic scale) inside a grey-filled square, the (logarithmic) mean plus/minus one (logarithmic) standard deviation indicating the interval between 16th and 84th percentiles (marked with blue horizontal lines), and the (logarithmic) mean plus/minus two (logarithmic) standard deviations indicating the interval between 2nd and 98th percentiles (marked with black horizontal lines). This is done to help in locating the observed number of events within plus or minus certain number of standard deviations from the mean estimate. It can be seen that the observed number of events lies within plus/minus one standard deviation of the mean estimate except for 28th of August and 3rd of September (for this one lies within two standard deviations away from the mean estimate).
Providing daily forecasts of seismicity from October 26 up to October 29
As mentioned before, on 26th of October, a Mw 5.4, followed within a two-hour delay by a Mw 5.9 earthquake (at 17:10 and 19:18 UTC, respectively), took place in the east of town Visso (located in the north-western part of the aftershock zone, see Fig. 1b). This triggered a new aftershock sequence within the ongoing one. At this stage, given the time elapsed from the occurrence of the mainshock (i.e., around two months), it seemed quite tedious to consider all the events of interest up to the time of origin (i.e., 24th of August) for each forecasting interval. To achieve this (i.e., avoid considering all the events back to 24th of August), we performed a shift in the time of origin T o from August 24th to 17:10 UTC of October 26th (time of occurrence of the Mw 5.4 earthquake, see Fig. 1). In the following, we describe the details of the forecasting procedure for the period from 26th of October to 29th.
24-hour forecasting from 6:00 UTC of 26/10/2016
We performed the forecasting in this period considering as the sequence seq all the events with magnitude greater than or equal to 3.0 that took place after 01:36 UTC of 24/08/2016 up to T start which is 6:00 UTC of 26/10/2016 (including the main event of August 24th). To facilitate the ETAS model parameter θ estimation, we employed as prior distribution (instead of the priors considered in the previous section) the updated distribution of model parameters on 06-September (see the last row of Table 1); assuming that the model parameters did not undergo significant changes from 6th of September to 26th of October (the sequence activity has decayed significantly in this period). The MCMC procedure is carried out as described in the previous section. The statistics of the updated model parameters (mean and COV) are reported in the first row of Table 2. It can be observed (comparing with the prior distribution in the last row of Table 1) that model parameters remain more-or-less invariant (we could have directly used the ETAS model parameters estimated for 6th of September). Fig. 3a illustrates the forecasted seismicity (mean plus two standard deviations) and the events of interest that occurred during the 24-hour interval of interest. The estimated number of events within the aftershock zone (shown in the error-bar plot reported in the right-hand side of the figure) shows a substantial reduction in the seismicity compared to the first days elapsed after the main event in August 24. The exceedance probabilities are calculated as P(M ≥ 4) = 0.08, P(M ≥ 5) = 0.02, and P(M ≥ 6) = 0.003. It is interesting to note that these probabilities are substantially higher than those provided from the calculation of the long-term seismicity level based on the ZS9 Italian Seismogenic Zonation31 data, estimating a daily probability of around 3.83 × 10−4 for M ≥ 4.76. Hence, the level of (forecasted) seismicity at the desired date is more than 40 times higher than the base seismicity level for M ≥ 5. The distribution of seismicity forecasted for 26th of October (shown in Fig. 3a) is used next as an estimate of the background (base) seismicity denoted as N b (x, y, m|M l ) in Section Methods.

Forecasted vs. observed seismicity distribution in the aftershock zone, the maps report the mean + 2 standard deviation confidence interval for the number of events per [km2] (latitude/longitude cells of a 0.01° × 0.01° grid) equal to or greater than magnitude M l = 3 in the indicated forecasting time window. In the lower left corner, the daily probabilities of having earthquakes with magnitudes 4, 5, and 6 or larger are reported. Each sub-plot also features the earthquakes (colored dots) that occurred during the corresponding forecasting time window together with the two main events with M ≥ 5.0 (magenta stars). The sub-figures illustrate the observed (plotted in red star) vs. the error-bar for the forecasted number of events with m ≥ M l corresponding to the forecasting time interval: the median value (the 50th percentile, equivalent of the logarithmic mean in the arithmetic scale) inside a grey-filled square, the (logarithmic) mean plus/minus one (logarithmic) standard deviation indicating the interval between 16th and 84th percentiles (marked with blue horizontal lines), and the (logarithmic) mean plus/minus two (logarithmic) standard deviations indicating the interval between 2nd and 98th percentiles (marked with black horizontal lines). (MATLAB 2016b, http://softwaresso.unina.it/matlab/ is used to create this figure).
6-hour forecasting from 18:00 UTC of 26/10/2016
After the occurrence of the event with Mw 5.4 at 17:10 UTC of 26/10/2016, we provide a 6-hour prediction of seismicity for the forecasting interval starting from T start set to 18:00 UTC of 26/10/2016 (i.e., 50 minutes after the occurrence of Mw 5.4 event). At this point, we performed a shift in the time of origin by setting T o to 17:10 UTC of 26th of October (see Fig. 4). The sequence seq includes all the triggered events with M ≥ 3 occurred after 17:10 UTC of 26/10/2016 (including the main Mw 5.4 event). It should be noted that the event Mw 5.4 was not preceded by any foreshocks (i.e., no M ≥ 3 events took place between 06:00 UTC and 17:10 UTC of 26 of October). Given the very low seismic activity prior to the major event and given the presence of very few events in seq, we did not perform Bayesian updating on the model parameter θ and used the statistics provided in the first row of Table 2 issued for 26/10/2016 (the parameters updated in the previous step). It is important to note that the forecasted seismicity for the 24-hour interval elapsed after 06:00 UTC of October 26 in the previous step (shown in Fig. 3a) is used herein (after proportioning it to a 6-hour forecasting interval) as the background seismicity N b (x, y, m|M l ). The background seismicity usually considers the long-term seismicity in the calculations and was assumed to be equal to zero in our previous calculations for the first part of the sequence staring from 24th of August. Herein, we use this background seismicity to conservatively approximate the triggering effect of the events occurred in the first part of the sequence (from August 24th to October 26th). The background seismicity is added as a constant term to the contribution of the triggering events (see Section Method). The forecasted seismicity map in terms of the mean plus two standard deviation for the number of events with M ≥ 3.0 is shown in Fig. 3b. Observed events with M ≥ 3.0 (coloured dots) occurred within the corresponding 6-hour forecasting interval are also highlighted on the map. The main two events with Mw 5.4 at 17:10 UTC assigned as the mainshock and the Mw 5.9 event at 19:18 UTC (which lies within the 6-hour forecasting interval) are shown with magenta stars. According to the right-hand side error-bar plot of Fig. 3b, the total number of registered events within the 6-hour forecasting interval (red star) is significantly higher than the forecasted values. This can be attributed to very few number of observed input data in seq for preforming the robust estimation and to the fact that model parameters were not tuned to the newly triggered sequence. Although less successful in predicting the number of events, the model predicts exceedance probabilities P(M ≥ 5) and P(M ≥ 6) to be more than 15 times compared to the initial estimates in Fig. 3a.

Schematic sketch of the shift in the time of origin T o.
4-hour forecasting from 20:00 UTC of 26/10/2016
After the occurrence of the event with Mw 5.9 at 19:18 UTC, the seismicity forecast is provided again for the interval starting from 20:00 UTC (42 minutes after the Mw 5.9 event) up to 24:00 UTC of 26/10/2016 (i.e., a 4-hour time interval). The corresponding seq includes all the events with M ≥ 3.0 which occurred (including the main event of Mw 5.4 at 17:10 UTC and Mw 5.9 at 19:18 UTC) after 17:10 UTC up to the starting time (20:00 UTC) of October 26. The model parameters θ are updated based on the information provided by the sequence seq with M l set to 2.5 and reported in the second row of Table 2. Note that the cut-off magnitude lower than 3.0 is assigned only for model updating purposes to gain more data and the seismicity rate is later calculated with M l = 3.0. Fig. 3c illustrates the forecasted seismicity map in terms of the mean plus two standard deviation for the number of events with M ≥ 3.0 within the 4-hour forecasting interval. Note that for the 4-hour time interval, the exceedance probabilities P(M ≥ 5) and P(M ≥ 6) increase considerably in Fig. 3c after the occurrence of the event with Mw 5.9 at 19:18 UTC (compared to Fig. 3a). In addition, the observed number of events within the 4-hour time interval (sub-figure) lies within the plus/minus one standard deviation confidence interval.
6-hour forecasting from 24:00 UTC of October 26, and 24-hour forecasting from 6:00 UTC of 27th and 29th of October
At this stage, seismicity forecasts are provided first for the 6-hour time interval starting from 24:00 UTC of 26/10/2016, and later extended for issuing 24-hour forecasts with T start = 6:00UTC corresponding to the two consecutive days of October 27 and October 29. These predictions are issued based on the sequence of events seq including the mainshock of Mw 5.4 (considering 17:10 UTC 26th of October as time of origin T o ) and the triggered events with M ≥ 3.0 up to the associated T start . The last three rows of Table 2 illustrate the statistics of updated model parameters. The predicted seismicity distribution maps and the corresponding error-bar plots for the number of events (in sub-plots) are presented in Fig. 3(d–f), which manage to properly forecast the distribution/number of observed events.
Providing daily forecasts of seismicity from October 30 up to November 1
As mentioned before, on 30th of October, a Mw 6.5 event occurred in the North of Norcia at 6:40 UTC (located in the north-western part of the aftershock zone, see Fig. 1b).
24-hour forecasting from 6:00 UTC of 30th of October (starting time 40 minutes before the main event)
The forecasted seismicity is issued for a 24-hour time interval starting at 6:00UTC of 30/10/2016 based on the sequence of events seq comprising of events occurring after the time of origin T o set to 17:10 UTC of 26th of October (time of occurrence of the Mw5.4 event). The statistics of the updated model parameters are shown in the first row of Table 3. The forecasted seismicity distribution for the next 24 hours for M ≥ 3 is mapped in Fig. 5a. The background seismicity is set to the time-invariant distributed seismicity equal to N b (x, y, m|M l ) as defined in the previous section (shown in Fig. 3a). According to Fig. 5a, our blind prediction of the exceedance probability P(M ≥ 6) is a value around 10% which is quite high as compared to the daily probability equal to 3.83 × 10−4 for M ≥ 4.76 calculated based on long-term seismicity in the previous section. It is also interesting to note that the forecasted value for P(M ≥ 6) is equal to the forecast provided for October 29; this can be viewed as somewhat alarming (does not represent the expected decay with time). Nevertheless, the forecasted error-bar for the number of events (see right-hand side of Fig. 5a) is not able to properly predict the huge number of events triggered due to Mw 6.5 at 06:40UTC.

Forecasted vs. observed seismicity distribution in the aftershock zone, the maps report the mean + 2 standard deviation confidence interval for the number of events per [km2] (latitude/longitude cells of a 0.01° × 0.01° grid) equal to or greater than magnitude M l = 3 in the indicated forecasting time window. In the lower left corner, the daily probabilities of having earthquakes with magnitudes 4, 5, and 6 or larger are reported. Each sub-plot also features the earthquakes (colored dots) that occurred during the corresponding forecasting time window together with the main events with M ≥ 5.0 (magenta stars). The sub-figures illustrate the observed (plotted in red star) vs. the error-bar for the forecasted number of events with m ≥ M l corresponding to the forecasting time interval: the median value (the 50th percentile, equivalent of the logarithmic mean in the arithmetic scale) inside a grey-filled square, the (logarithmic) mean plus/minus one (logarithmic) standard deviation indicating the interval between 16th and 84th percentiles (marked with blue horizontal lines), and the (logarithmic) mean plus/minus two (logarithmic) standard deviations indicating the interval between 2nd and 98th percentiles (marked with black horizontal lines). (MATLAB 2016b, http://softwaresso.unina.it/matlab/ is used to create this figure).
5-hour forecasting from 7:00 UTC of 30th of October (starting time 20 minutes after the main event of Mw 6.5)
In order to test the forecasting ability of the model right after the main event, we provided a forecast with starting time T start set to 7:00UTC (only 20 minutes after the main event). The same as the previous forecast, the time of origin is set to 17.10 UTC of 26th of October and the same invariant background seismicity N b (x, y, m|M l ) is being adopted. The second row of Table 3 shows the statistics of the updated model parameters. The forecasted (5-hour) seismicity distribution is mapped in Fig. 5b. Moreover, the error-bar plot for the forecasted number of events is reported against the observed number of events. Comparing Fig. 5b with Fig. 5a, we can appreciate the improvement in the forecasted seismicity distribution and number of events based on the few events that occurred in the one hour that separates the two starting times (i.e., 6:00 UTC and 7:00 UTC, respectively).
18-hour forecasting from 12:00 UTC of 30th of October (starting time 5 hours and 20 minutes after the main event of Mw 6.5, T o = 6:40 UTC of 30th of October)
The next forecasting is performed for the same day of 30/10/2016 with T start set to 12:00UTC and T end set to 06:00 UTC of 31/10/2016 (i.e., 18-hour interval). At this stage, we performed a shift in the time of origin T o from 17:10 UTC of 26th of October to 6:40 UTC of 30th of October. The background seismicity N b (x, y, m|M l ) is set (and proportioned to an 18-hour interval) to that of 30th of October for a 24-hour interval with starting time set to 6:00 UTC (shown in Fig. 5a). The prior distributions for the model parameters are taken equal to those of the original priors reported in the first row of Table 1. The fourth row of Table 3 shows the statistics of the updated model parameters. Fig. 5d shows the map of forecasted seismicity with the back-drop of events occurred in this interval. The error-bar plot for the forecasted number of events manages to capture the observed number of events within one standard deviation confidence interval.
18-hour forecasting from 12:00 UTC of 30th of October (starting time 5 hours and 20 minutes after the main event of Mw 6.5, T o = 17:10 UTC of 26th of October)
To measure the effect of the shift in the time of origin, the same forecasting presented in the previous step is performed with time of origin set to 17:40 UTC of 26th of October. The third row of Table 3 illustrates the statistics of updated model parameters. Fig. 5c shows the forecasted map of seismicity and the error-bar for the predicted number of events. The forecasted number of events are slightly lower than those predicted in the previous step in Fig. 5c (after shifting the time of origin). This is to be expected since the latter forecast employs a time-invariant background seismicity to consider the events of interest occurred in the time interval between 17:10 UTC of 26th of October and 6.40 UTC of 30th of October. This is while the former forecast explicitly considers the triggering contribution of these events and the associated time-decay. Overall, it is reassuring to note that the two forecasts provide essentially the same information.
24-hour forecasting from 6:00 UTC of October 31st and November 1st
The seismicity forecasts are provided next for the 24-hour time intervals starting from 6:00UTC of October 31 and November 1. These predictions are issued based on time of origin T o set to 6:40 UTC of 30 October and the sequence of records seq including all the events of interest M ≥ 3.0 that occurred between the time of origin T o (including the 6.5 Mw “mainshock”) and the time of start T start of each forecasting interval (6:00 UTC of each of these two days). The prior probability distributions are set to the original priors (whose statistics are reported in the first row of Table 1). The last two rows of Table 3 illustrate the statistics of updated model parameters. The seismicity forecasts (i.e, mean estimate plus two standard deviations) are shown in Fig. 5(e,f). The observed number of events lies within two standard deviation from the forecasted mean estimate.
Discussion
We have proposed a fully simulation-based procedure for both Bayesian model updating of an epidemiological-type aftershock spatio-temporal clustering model and robust operational forecasting of the number of events of interest expected to happen in each time frame. The adopted epidemiological model parameters are defined so that the model converges asymptotically (spatio-temporally speaking) to the long-term seismicity of the zone of interest. The forecasting is “robust” because it considers the uncertainty (i.e., the joint probability distribution) in the model parameters. Apart from being quite efficient (the most challenging forecasting we performed took 45 minutes on a normal PC), the model updating and forecasting procedure is carried on without human interference and use of expert judgement. The model is simply “tuning-in” automatically into the sequence of observed events. The choice of the recent Central Italy sequence of events as a demonstration of this procedure, albeit quite a natural choice, proved to be very challenging. This is because the sequence embedded three “sub-sequences” with different productive and decaying properties. We used the peculiarities of this sequence to test several different strategies for forecasting. For example, we performed a shift in the time of origin of the sequence by conservatively introducing a constant background seismicity (calculated by the procedure). This shift proved to be quite useful as it relieved us from the burden of summing up the triggering properties of all the events that took place in the previous “sub-sequence” (or the previous part of the sequence as we may wish to call it) at the small price of neglecting the time-decay in their triggering contribution. We observe that after an initial transition time (in the order of few hours, enough to accumulate sufficient events for updating the model parameters), the model quickly tunes into the sequence and provides forecasting that is reliable in most cases up to plus/minus one standard deviations. As expected, the procedure falls short of predicting the “mainshock” of 26th of October (17:10 UTC) as it happened when the sequence had decayed. The procedure, however, did a better job for forecasting the events occurred at 19:18 UTC of 26th of October and on 6.40 UTC of 30th October. This relative success can be attributed to the fact that these events took place at the initial stages of the newly triggered sequence of 26th of October when the seismic activity was still very high. The estimated model parameters present some time-dependent fluctuations but after a certain number of days elapsed after the main event, they seem to stabilize. In general, the first sub-sequence (Mw 6 “mainshock” occurred at 1:36 UTC 24th of August) seems to be the mildest one in terms of the time decay in seismicity and is the least active in terms of sequence’s productivity. The second sub-sequence (Mw 5.4 “mainshock” occurred at 17:10 UTC 26th of October) is intermediate both in terms of the rate of time-decay and the productivity. The third sub-sequence (Mw 6.5 “mainshock” occurred at 6:40 UTC 30th of October) has the steepest time-decay of seismicity and is the most active in terms of the productivity of the sequence. Last but not least, it is important to mention that the proposed procedure for robust forecasting is conditioned on the available catalogue of events and the epidemiological model adopted for capturing the spatio-temporal aftershock clustering.
Methods
Let the aftershock occurrence be described by a non-homogenous Poisson point process over the two-dimensional space and time. Hence, the aftershock zone can be described as the set A in the Cartesian space discretized into mutually exclusive and collectively exhaustive (MECE) subsets or spatial cell units centered at (x, y) ∈ A. In this manner, λ(t, x, y, m|seq, M l ) represents the rate of occurrence of events in the forecasting interval [T start , T end ] at time t elapsed after the main event (a.k.a. mainshock) occurred at time of origin T o with magnitude greater than or equal to m and in the cell unit centered at (x, y) ∈ A, given (a) the observation history seq which is the sequence of N o events (including mainshock and the sequence of aftershocks) taken place before the forecasting interval (i.e. in the interval [T o, T start )), and (b) the lower cut-off magnitude M l . Hence, seq can be expressed as seq = {(t i , x i , y i , m i ), t i < T start , m i ≥ M l , i = 1: N o}, where t i is the arrival time for the ith event with magnitude M i and location (x i , y i ) ∈ A. The average number of events in the spatial cell unit centered at (x, y) with magnitude greater than or equal to m in the forecasting interval [T start , T end ] can then be calculated as:
where N b (x, y, m|M l ) is a constant representing the background seismicity of the area. Let θ denote the vector of model parameters for λ(t, x, y, m|seq, M l ). Given a particular space-time model and a realization of the vector of model parameters θ, one can calculate a plausible value for the rate of occurrence denoted as λ(t, x, y, m|θ, seq, M l ). Note that we have not included the conditioning on the model assumptions34 for the sake of brevity. A robust estimate24, 26, 27, 35, 36 of the average number of events in the spatial cell unit centered at (x, y) with magnitude greater than or equal to m in the forecasting interval [T start , T end ], and over the domain of the model parameters Ω θ can be calculated as:
where p(θ|seq, M l ) is the conditional probability distribution function (PDF) for θ given the seq and the lower cut-off magnitude M l .
An epidemiological model for space-time clustering of aftershocks
The ETAS model is an epidemiological stochastic point process in which every earthquake is a potential triggering event for subsequent earthquakes8, 9, 16,17,18,19. According to the general ETAS model, we adopt the spatio-temporal triggering effect of a given sequence on the seismicity rate, denoted as λ ETAS, as:
where seq t = {(t j , x j , y j , M j ), t j < t, M j ≥ M l } is the observation history up to the time t; parameter β is related to Gutenberg-Richter seismicity; parameters c and p are similar to those of the Modified Omori’s Law12, 13 defining the decay in time of short-term triggering effect; d and q characterize the spatial distribution of the triggered events; r j is the distance between the location (x, y) ∈ A and the epicenter of the jth event (x j , y j ); parameters K, K t and K R satisfy the achievement of asymptotic compatibility between ETAS predictions and the long-term seismicity. Thus, the vector of model parameters λ can be defined as θ = [β, K, K t , K R , c, p, d, q]. The integral of λETAS over infinite space and time needs to converge in limit to the number of events predicted by the Gutenberg and Richter model with magnitude greater than m, denoted generally as K o e − β m; note that K o is different from K. Herein, such compatibility is achieved by making sure that the following three conditions are satisfied:
-
1)
The normalizing coefficient K t is obtained such that integrating the time-dependent term over infinite time will in limit be equal to unity (see also Lippiello et al.21, 37):
$${K}_{t}{\int }_{{t}_{j}}^{+\infty }\frac{{\rm{d}}t}{{(t-{t}_{j}+c)}^{p}}=1\therefore p > 1,{K}_{t}=(p-1){c}^{p-1}$$(4) -
2)
The coefficient KR is normalized such that integrating the spatial term over infinite space will in limit be equal to unity (see also Lippiello et al.21, 37):
$${\int }_{{x}_{j}}^{+\infty }{\int }_{{y}_{j}}^{+\infty }\frac{{K}_{R}{\rm{d}}x{\rm{d}}y}{{({(x-{x}_{j})}^{2}+{(y-{y}_{j})}^{2}+{d}^{2})}^{q}}\triangleq {K}_{R}{\int }_{0}^{+\infty }\frac{2\pi r{\rm{d}}r}{{[{r}^{2}+{d}^{2}]}^{q}}=1\therefore q > 1,{K}_{R}=\frac{(q-1)}{\pi }{d}^{2(q-1)}$$(5) -
3)
The coefficient K is calibrated such that the number of events with magnitude greater than or equal to M l taking place in time interval t ∈ [T o, T start ] over the whole aftershock zone A is equal to N o :
where T o defines the mainshock occurrence time; the term λ ETAS(t, x, y, M l |θ, seq t , M l ) is obtained by substituting m = M l in equation (3), and denotes the rate of events with magnitude greater than or equal to M l . Since N o denotes the events occurred within the aftershock zone A, the integration over the whole aftershock zone can be approximated with that over infinite space. Thus, according to equation (5), K can be derived as follows:
Since the integral with respect to time in equation (7) cannot be calculated analytically over the interval [T o, T start ], we approximated it by summing over the sub-intervals [t i −1, t i ] (where i = 2:N o) and the last interval [t N o, T start ] (where t N o is the arrival time of the N o th event).
It is to note that parameters K, K t , and K R are derived as a function of other model parameters in θ; therefore, the main parameters of the ETAS model include [β, c, p, d, q]. The rate of events in the ETAS model with magnitude (exactly) equal to m, denoted herein as μ ETAS herein, is calculated by taking the derivative of equation (3) with respect to magnitude m:
Robust estimation for the number of aftershock events
As mentioned above, seq denotes the sequence of events taking place before the beginning of the forecasting interval (i.e., in the interval [T o, T start )). However, the triggering effect of the events taking place during the forecasting interval [T start , T end ] is expected to play a major role. The sequence of events taking place during the forecasting interval denoted as seqg, which is unknown at the time of forecasts, is simulated/generated herein. Let us assume that a plausible seqg is defined as the events within the forecasting interval defined as seqg = {(IAT i , x i , y i , m i ), T start ≤ t i ≤ T end , m i ≥ M l }, where IAT i = t i − t i−1 stands for the inter-arrival time. The robust estimate for the number of aftershock events in equation (2) should also consider all the plausible sequences of events seqg (i.e., the domain Ω seqg ) that can happen during the forecasting time interval:
where p(seqg|θ, seq, M l ) is the PDF for the generated sequence seqg given that θ and seq are known and λ(t, x, y, m|seqg, θ, seq, M l ) is the space-time clustering ETAS model considering also the sequence of events taking place within the forecasting interval. The integral with respect to time in equation (9) cannot be calculated analytically over the entire interval [T start , T end ], and is approximated by summing over the sub-intervals [t i−1, t i ] within seqg:
where λ ETAS has the functional form presented in equation (3), and seqg i−1 is the previous (i − 1) events within the generated sequence. In the following sections, it is described first how sequence of events seqg for the forecasting interval is sampled based on p(seqg|θ, seq, M l ). Later on, the method for sampling θ from the distribution p(θ|seq, M l ) is discussed.
Generating sequences according to p(seqg|θ, seq, M l )
The probability distribution p(seqg|θ, seq, M l ) can be written as follows (based on the probability product rule, see e.g. Jaynes38):
where seqg i is the generated sequence up to the ith event, where seqg i = {seqg i−1, (IAT i , x i , y i , m i )}, and the sequence of events that precede the ith generated event is {seq, seqg i−1}. The probability distribution p(IAT i , x i , y i , m i |seqg i−1, θ, seq, M l ) can be further expanded (again using the probability product rule) as follows:
where p(m i |seqg i−1, θ, seq, M l ) is the marginal PDF for the magnitude m i given the sequence of events that precede it, θ, and M l ; p(IAT i |m i , seqg i−1, θ, seq, M l ) is the (conditional) marginal PDF for inter-arrival time IAT i given that the value of magnitude is equal to m i ; finally, the term p(x i , y i |IAT i , m i , seqg i−1, θ, seq, M l ) is the conditional joint PDF for the spatial position (x i , y i ) ∈ A given that IAT i and m i are known. It should be noted that the break-down into the product of several conditional PDFs is necessary during the sequence generation process.
To generate a plausible sequence of events during the forecasting interval, the procedure, illustrated by the flowchart in Supplementary Fig. S4, is adopted. The ith event within the sequence seqg is generated through the following steps:
-
1)
Generate the magnitude of the ith event, m i , within seqg according to the following truncated Exponential PDF with rate β 23 (see Phase 1 in Supplementary Fig. S4).
$$p(m|{\bf{s}}{\bf{e}}{\bf{q}}{{\bf{g}}}_{i-1},{\boldsymbol{\theta }},{\bf{s}}{\bf{e}}{\bf{q}},{M}_{l})\cong p(m|{\boldsymbol{\theta }},{\bf{s}}{\bf{e}}{\bf{q}},{M}_{l})=\frac{\beta {e}^{-\beta m}}{{e}^{-\beta {M}_{l}}-{e}^{-\beta {M}_{\max }}}$$(13)where M max is the upper-bound magnitude of the site. This truncated Exponential PDF has a cumulative density function equal to \(\frac{1-\exp (-\beta (m-{M}_{l}))}{{F}_{{M}_{{\rm{\max }}}}}\triangleq \frac{1-\exp (-\beta (m-{M}_{l}))}{1-\exp (-\beta ({M}_{{\rm{\max }}}-{M}_{l}))}\); hence, a generated/sampled m i can analytically be drawn as \({m}_{i}=\frac{-\mathrm{log}(1-{F}_{{M}_{{\rm{\max }}}}\cdot {r}_{{\rm{rand}}})}{\beta }+{M}_{l}\) where r rand (as shown also in the flowchart of Supplementary Fig. S4) is a random number generated from a Uniform distribution in the interval (0, 1).
-
2)
Generate the inter-arrival time of the ith event within seqg (given that its magnitude mi is already known from previous step) by using the Thinning algorithm39, 40. The algorithm, as shown in Phase 2 in Supplementary Fig. S4, consists of a two-stage process. First, the temporal Poisson rate over the entire aftershock zone is calculated for an event with magnitude equal to m i at time t = t i − 1, and denoted by μ max using equation (8) as follows:
$${\mu }_{\max }={\iint }_{x,y\in A}{\mu }_{{\rm{ETAS}}}({t}_{i-1},x,y,{m}_{i}|{\bf{s}}{\bf{e}}{\bf{q}}{{\bf{g}}}_{i-1},{\boldsymbol{\theta }},{\bf{s}}{\bf{e}}{\bf{q}},{M}_{l}){\rm{d}}x{\rm{d}}y$$(14)Note that for generating the first event within the forecasting interval [T start , T end ], t i−1 is set to T start . In the next stage of Thinning algorithm, the inter-arrival time IAT gen is sampled/generated from a homogeneous Exponential PDF with the form \({\mu }_{{\rm{\max }}}\exp (-{\mu }_{{\rm{\max }}}IAT)\) which is equivalent to generating it as \(IA{T}_{{\rm{gen}}}=\frac{-\,\mathrm{log}(1-{r}_{{\rm{rand}}})}{{\mu }_{{\rm{\max }}}}\). The Poisson rate at time t gen = t i−1 + IAT gen and denoted by μ gen can then be calculated from equation (14) by substituting t i−1 with t gen. The generated inter-arrival time can then be (1) either accepted with probability p \(\,=\frac{{\mu }_{{\rm{gen}}}}{{\mu }_{{\rm{\max }}}}\) and thus t i = t gen and the procedures continues by generating the next interarrival time until t i > T end ; (2) or rejected with probability 1-p. Let us denote the rejected t gen as t gen (−) (in order to keep track of it for the next simulation). Also in the case of rejection, the procedure continues by sampling a new inter-arrival time IAT gen from the homogeneous Exponential PDF with rate μ max. The new generated arrival time is calculated as t gen = t gen (−) + IAT gen, t gen < T end . The quantities μ gen and p are calculated again to test whether the newly generated interarrival time is accepted or rejected.
-
3)
Generate/sample the Cartesian coordinates (x i , y i ) for the ith event, given that the magnitude m i , the time of occurrence t i , and the previous (i − 1) events within the generated sequence seqg i-1 are known (see Supplementary Fig. S4, Phase 3), according the following joint PDF using the probability product rule:
The nominator p(IAT i , x, y, m i |seqg i−1, θ, seq, M l ) in equation (15) can be calculated as:
where μ ETAS is calculated from equation (8), and the integral in the sub-interval [t i−1, t i ] has the similar analytical expression shown in equation (10) being multiplied by β in order to account for μ ETAS.
Sampling θ from the distribution p(θ|seq, M l )
The probability distribution p(θ|seq, M l ) can be calculated using Bayesian parameter estimation:
where p(seq|θ, M l ) denotes the likelihood of the observed sequence given the vector of model parameters θ and lower cut-off magnitude M l , p(θ|M l ) is the prior distribution for the vector θ, and C −1 is a normalizing constant. In lieu of additional information (e.g., statistics of regional model parameters), the prior joint distribution p(θ|M l ) can be estimated as the product of marginal uniform probability distributions for each model parameter. In order to sample from p(θ|seq, M l ), Markov Chain Monte Carlo (MCMC) simulation routine is employed which is particularly useful for cases where the sampling needs to be done from a probability distribution that is known up to a constant value27 (herein, C −1). The MCMC routine uses the Metropolis-Hastings (MH) algorithm41, 42 in order to generate samples as a Markov Chain sequence used first to sample from the target probability distribution p(θ|seq, M l ), and later to estimate the robust reliability in equation (9). The MH routine, as shown in Supplementary Fig. S5, functions by generating a Markov chain that produces a sequence of samples [θ 1→θ 2→…→θ n →…], where θ n represents the state of Markov chain at nth iteration (the first few samples are often discarded to reduce the initial transient effect). This procedure continues until the ns Markov chain samples were simulated. It can be shown that the samples from the chain after the initial transient ones reflect samples from the target distribution p(θ|seq, M l ). Given the Markovian nature of this simulation scheme, we limit ourselves to describe how the (n + 1)th sample θ n+1 is generated given that the nth sample θ n is already known:
-
Generate a candidate sample θ * from a proposal (candidate) distribution ζ(θ|θ n ). It is important to note that there are no specific restrictions about the choice of ζ (·) apart from the fact that it should be possible to calculate both ζ (θ i + 1|θ i ) and ζ (θ i |θ i + 1).
-
Accept the candidate sample with the probability p accept = min(1, r) (where r is defined in equation (18) as follows) and set θ n+1 = θ *; otherwise, θ n+1 = θ n :
It can be shown27 using the Total probability theorem that, if the current sample θ n is distributed as p(·|seq, M l ), also the (n + 1)th sample θ n+1 is distributed as p(·|seq, M l ):
Equation (19) is derived using the arithmetic property that for any positive numbers A and B, the identity min(1, A/B)∙B = min(1, B/A)∙A holds. Having the proposal PDF ζ centered around the current sample renders the MH algorithm similar to a local random walk that adaptively leads to the generation of the target PDF. In order to improve the rate of convergence of the simulation process, we have used an adaptive MH algorithm (as proposed by Beck and Au27) that introduces a sequence of intermediate evolutionary candidate PDF’s that resemble more and more the target PDF.
Calculating the likelihood of the observed sequence p(seq|θ, M l )
The likelihood for the observed sequence, seq = {(t i , x i , y i , m i ), t i < T start , m i ≥ M l , i = 1: N o}, with N o events, including the mainshock (with i = 1) and the sequence of aftershocks, can be calculated as:
where λ(∙) and μ(∙) are ETAS rates calculated from equations (3) and (8), respectively. The first term of the likelihood function in equation (20) is calculated by multiplying the probabilities that the ith arrival time (i = 2:N o) is equal to the observed value, t i = t i−1 + IAT i , occurred at spatial position (x i , y i ) ∈ A with magnitude m i assuming a non-homogenous Poisson process (i.e., the inter-arrival times are independent) with a rate equal to μ ETAS (equation 8). Accordingly
where the term I0 is previously defined in equation (7) and r ji indicates the distance of the ith event to the previously occurred jth event. The last probability term in equation (20) is the probability that no event with magnitude greater than the cut-off level M l takes place over the entire aftershock zone A in the time interval between the N o th event at t No and T start .
References
Gerstenberger, M. C., Wiemer, S., Jones, L. M. & Reasenberg, P. A. Real-time forecasts of tomorrow’s earthquakes in California. Nature 435, 328–331 (2005).
Jordan, T. H. & Jones, L. M. Operational earthquake forecasting: Some thoughts on why and how. Seism. Res. Lett. 81(4), 571–574 (2010).
Jordan, T. H. et al. Operational earthquake forecasting: State of knowledge and guidelines for implementation. Annals of Geophysics 54(4), 315–391, doi:10.4401/ag-5350 (2011).
Jordan, T. H., Marzocchi, W., Michael, A. J. & Gerstenberger, M. C. Operational earthquake forecasting can enhance earthquake preparedness. Seism. Res. Lett. 85(5), 955–959 (2014).
Marzocchi, W., Lombardi, A. M. & Casarotti, E. The establishment of an operational earthquake forecasting system in Italy. Seism. Res. Lett. 85(5), 961–969 (2014).
Zechar, J. D., Marzocchi, W. & Wiemer, S. Operational earthquake forecasting in Europe: progress, despite challenges. Bull. Earthq. Eng. 14, 2459–2469 (2016).
Omi, T., Ogata, Y., Hirata, Y. & Aihara, K. Forecasting large aftershocks within one day after the main shock. Sci. Rep. 3, 2218, doi:10.1038/srep02218 (2013).
Ogata, Y. Statistical models for earthquake occurrences and residual analysis for point processes. J. Am. Stat. Assoc. 83, 9–27 (1988).
Ogata, Y. Space-time point-process models for earthquake occurrences. Ann. Inst. Statist. Math. 50(2), 379–402 (1998).
Lombardi, A. M. Estimation of the parameters of ETAS models by Simulated Annealing. Sci. Rep. 5, 8417, doi:10.1038/srep08417 (2015).
Lombardi, A. M. & Marzocchi, W. The ETAS model for daily forecasting of Italian seismicity in the CSEP experiment. Annals of Geophysics 53, 155–164 (2010).
Utsu, T. A statistical study of the occurrence of aftershocks. Geophys. Mag. 30, 521–605 (1961).
Utsu, T., Ogata, Y. & Matsu’ura, R. S. The centenary of the Omori formula for a decay law of aftershock activity. J. Phys. Earth. 43, 1–33 (1995).
Zhang, X. & Shcherbakov, R. Power-law rheology controls aftershock triggering and decay. Sci. Rep. 6, 36668, doi:10.1038/srep36668 (2016).
Marzocchi, W. & Lombardi, A. M. Real-time forecasting following a damaging earthquake. Geophys. Res. Lett. 36, L21302, doi:10.1029/2009GL040233 (2009).
Zhuang, J., Ogata, Y. & Vere-Jones, D. Stochastic declustering of space-time earthquake occurrences. J. Am. Stat. Assoc. 97(458), 369–380 (2002).
Zhuang, J., Ogata, Y. & Vere-Jones, D. Analyzing earthquake clustering features by using stochastic reconstruction. J. Geophys. Res. 109, B05301, doi:10.1029/2003JB002879 (2004).
Ogata, Y. & Zhuang, J. Space–time ETAS models and an improved extension. Tectonophysics 413(1), 13–23 (2006).
Zhuang, J. Next-day earthquake forecasts for the Japan region generated by the ETAS model. Earth planets space 63(3), 207–216 (2011).
Veen, A. & Schoenberg, F. P. Estimation of space-time branching process models in seismology using an EM-type algorithm. J. Am. Stat. Assoc. 103, 614–624 (2008).
Lippiello, E., Giacco, F., de Arcangelis, L., Marzocchi, W. & Godano, C. Parameter Estimation in the ETAS Model: Approximations and Novel Methods. Bull. Seism. Soc. Am. 104(2), 985–994 (2014).
Jalayer, F., Asprone, D., Prota, A. & Manfredi, G. A decision support system for post-earthquake reliability assessment of structures subjected to aftershocks: an application to L’Aquila earthquake, 2009. Bull. Earthq. Eng. 9(4), 997–1014 (2011).
Ebrahimian, H. et al. Adaptive daily forecasting of seismic aftershock hazard. Bull. Seism. Soc. Am. 104(1), 145–161 (2014).
Jalayer, F. & Ebrahimian, H. MCMC-based Updating of an Epidemiological Temporal Aftershock Forecasting Model. Vulnerability, Uncertainty, and Risk, 2093–2103, doi: 10.1061/9780784413609.210 (2014).
Omi, T., Ogata, Y., Hirata, Y. & Aihara, K. Intermediate‐term forecasting of aftershocks from an early aftershock sequence: Bayesian and ensemble forecasting approaches. J. Geophysical Res: Solid Earth 120(4), 2561–2578, doi:10.1002/2014JB011456 (2015).
Papadimitriou, C., Beck, J. L. & Katafygiotis, L. S. Updating robust reliability using structural test data. Probabilist. Eng. Mech. 16(2), 103–113 (2001).
Beck, J. L. & Au, S. K. Bayesian updating of structural models and reliability using Markov Chain Monte Carlo simulation. J. Eng. Mech. ASCE 128(4), 380–391 (2002).
Ebrahimian, H. et al. A performance-based framework for adaptive seismic aftershock risk assessment. Earthq. Eng. Struct. Dyn. 43(14), 2179–2197 (2014).
Jalayer, F. & Ebrahimian, H. Seismic risk assessment considering cumulative damage due to aftershocks. Earthq. Eng. Struct. Dyn. 46(3), 369–389 (2016).
Ebrahimian, H. et al. An outlook into time-dependent aftershock vulnerability assessment. ECCOMAS Thematic Conference (COMPDYN2013): 4th International Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, M. Papadrakakis, V. Papadopoulos, V. Plevris (eds.), Kos Island, Greece, pp 54–76 12–14 June (2013).
Gruppo di Lavoro. Redazione della mappa di pericolosità sismica prevista dall’Ordinanza PCM 3274 del 20 marzo 2003. Rapporto Conclusivo per il Dipartimento della Protezione Civile, INGV, Milano-Roma, April 2004: 65 pp. +5 appendixes (in Italian).
Michele, M. et al. The Amatrice 2016 seismic sequence: a preliminary look at the mainshock and aftershocks distribution. Annals of Geophysics 59, 5, doi:10.4401/ag-7227 (2016).
Lolli, B. & Gasperini, P. Aftershocks hazard in Italy part I: Estimation of time-magnitude distribution model parameters and computation of probabilities of occurrence. J. Seism. 7(2), 235–257 (2003).
Muto, M. & Beck, J. L. Bayesian updating and model class selection for hysteretic structural models using stochastic simulation. J. Vib. Control 14(1–2), 7–34 (2008).
Jalayer, F. & Beck, J. L. Effects of two alternative representations of ground-motion uncertainty on probabilistic seismic demand assessment of structures. Earthq. Eng. Struct. Dyn. 37(1), 61–79 (2008).
Jalayer, F., Iervolino, I. & Manfredi, G. Structural modeling uncertainties and their influence on seismic assessment of existing RC structures. Struct. Saf. 32(3), 220–228 (2010).
Lippiello, E., Marzocchi, W., de Arcangelis, L. & Godano, C. Spatial organization of foreshocks as a tool to forecast large earthquakes. Sci. Rep. 2, 846, doi:10.1038/srep00846 (2012).
Jaynes, E. T. Probability theory: The logic of science (Cambridge University Press, London, 2003).
Lewis, P. A. W. & Shedler, G. S. Simulation methods for Poisson processes in nonstationary systems. Proceedings of the 10 th conference on Winter simulation 155–163 (IEEE Press, 1978).
Ogata, Y. On Lewis’ simulation method for point processes. IEEE Trans. Inform. Theory 27(1), 23–31 (1981).
Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H. & Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 21(6), 1087–1092 (1953).
Hastings, W. K. Monte-Carlo sampling methods using Markov chains and their applications. Biometrika 57(1), 97–109 (1970).
Acknowledgements
This work was supported in part by Project METROPOLIS (Metodologie e Tecnologie Integrate e Sostenibili Per L’adattamento e La Sicurezza di Sistemi Urbani, “Methodologies and sustainable innovative technologies to assess and manage natural and man-caused hazards in urban environment”). This support is gratefully acknowledged.
Author information
Authors and Affiliations
Contributions
F.J. developed the framework and H.E. implemented the framework and performed the analyses. H.E. and F.J. both contributed to the writing of the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ebrahimian, H., Jalayer, F. Robust seismicity forecasting based on Bayesian parameter estimation for epidemiological spatio-temporal aftershock clustering models. Sci Rep 7, 9803 (2017). https://doi.org/10.1038/s41598-017-09962-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-09962-z
- Springer Nature Limited
This article is cited by
-
Bayesian earthquake forecasting approach based on the epidemic type aftershock sequence model
Earth, Planets and Space (2024)
-
Variations in uniform hazard spectra and disaggregated scenarios during earthquake sequences
Bulletin of Earthquake Engineering (2023)
-
Seismicity characteristics of secondary faults in the Zhangjiakou-Bohai tectonic zone
Applied Geophysics (2023)
-
Improvements to seismicity forecasting based on a Bayesian spatio-temporal ETAS model
Scientific Reports (2022)
-
Modeling and Prediction of Aftershock Activity
Surveys in Geophysics (2022)