
Abstract
Astrocytes, the predominant glial cells in the central nervous system, play essential roles in maintaining brain function. Reprogramming induced pluripotent stem cells (iPSCs) to become astrocytes through overexpression of the transcription factors, NFIB and SOX9, is a rapid and efficient approach for studying human neurological diseases and identifying therapeutic targets. However, the precise differentiation path and molecular signatures of induced astrocytes remain incompletely understood. Accordingly, we performed single-cell RNA sequencing analysis on 64,736 cells to establish a comprehensive atlas of NFIB/SOX9-directed astrocyte differentiation from human iPSCs. Our dataset provides detailed information about the path of astrocyte differentiation, highlighting the stepwise molecular changes that occur throughout the differentiation process. This dataset serves as a valuable reference for dissecting uncharacterized transcriptomic features of NFIB/SOX9-induced astrocytes and investigating lineage progression during astrocyte differentiation. Moreover, these findings pave the way for future studies on neurological diseases using the NFIB/SOX9-induced astrocyte model.
Similar content being viewed by others

Background & Summary
Astrocytes are a crucial component of the central nervous system. As the predominant glial cells, they not only support other cell types, such as neurons, but also play many roles in development, homeostasis, and diseases1. In particular, astrocyte dysfunction is implicated in several neurodegenerative disorders2. However, much of our knowledge about astrocytes comes from studies using mouse models, although mouse and human astrocytes may differ in terms of morphological and functional complexity3,4,5, limiting the generalizability of such findings. Meanwhile, astrocyte models generated from human induced pluripotent stem cells (iPSCs) are an advantageous method for investigating the roles of human astrocytes in neurological diseases and identifying potential therapies6,7.
Current approaches for astrocyte generation from human iPSCs typically involve chemically defined systems, and cells often take weeks or months to acquire glial competency8,9,10. In addition, purification steps are often required to eliminate non-astrocyte cells11,12. Alternatively, astrocytes can be rapidly and efficiently generated within 21 days through the overexpression of the transcription factors, Nfib and Sox9, with high reproducibility13. This method has facilitated the study of astrocytic development and disease modeling14,15,16. However, previous studies on Nfib/Sox9-induced astrocytes primarily focus on functional assays and biomarker expression13. Therefore, the differentiation path and molecular characteristics of Nfib/Sox9-induced astrocytes are incompletely understood, potentially hindering the broad application of this transcription factor-directed astrocyte generation method. While bulk RNA sequencing (RNA-seq) is commonly employed to analyze the transcriptional features of iPSC-derived astrocytes17, it represents an average signal across a cell population and therefore overlooks differences among cells. Therefore, this method is likely incapable of identifying distinct or rare cell subpopulations during astrocyte differentiation.
Accordingly, in this study, we present a single-cell RNA sequencing (scRNA-seq) dataset collected during astrocyte differentiation from iPSCs through Nfib/Sox9 overexpression. This dataset enables the analysis of transcriptional states during astrogenesis. Specifically, we report the scRNA-seq data of cells collected along astrocyte differentiation (i.e., on Day 0, 1, 3, 8, 14, and 21), which can facilitate the delineation of the astrocyte differentiation path (Fig. 1). In addition, we report data on astrocytes derived from multiple iPSC lines, which can help identify previously undescribed cell signatures and cell diversity. Our dataset provides valuable insights into the transcriptomic features and differentiation path of Nfib/Sox9-induced astrocytes. It also serves as a reference for comparative studies of astrogenesis using other in vitro astrocyte generation models as well as the development of primary astrocytes. Thus, our dataset will contribute to further research on astrocyte-associated neurological diseases.

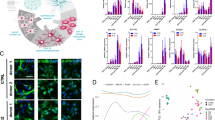
Schematic overview of the experimental design. (a) Generation of astrocytes from induced pluripotent stem cells (iPSCs). Ubiq, ubiquitin; rtTA, reverse tetracycline-controlled transactivator; Dox, doxycycline; Puro, puromycin (for cell selection). Day 0 is the starting time point of Dox induction. (b) Workflow of single-cell RNA sequencing. To establish the astrocyte differentiation path, cells derived from the Monoclonal iPSC1 line were collected on Day 0, 1, 3, 8, 14, and 21. To characterize the molecular signatures of induced astrocytes, astrocytes derived from the iPSC1 and iPSC2 lines on Day 21 were collected. iPSC1: DYR0100 cell line; iPSC2: BIONi037-A cell line; Monoclonal iPSC1: a single colony picked from iPSC1. (c) Bioinformatics pipeline for sequencing data analysis. Raw sequencing data were pre-processed by Cell Ranger and Seurat. Plots were generated using R. This figure was created using BioRender (https://biorender.com/).
Methods
Cell lines and culture
The DYR0100 cell line (“iPSC1” hereafter) was kindly provided by the Stem Cell Bank of the Chinese Academy of Sciences (cat. no. SCSP-1301, CSTR: 19375.09.3101HUMSCSP1301). The BIONi037-A line (“iPSC2” hereafter) was obtained from Sigma (ECACC cat. no. 66540580, RRID: CVCL_II80). To exclude the effects of the heterogeneity of the starting cell line on the resultant differentiated cells, the Monoclonal iPSC1 line was generated as previously described18. A single cell was obtained from limiting dilution of parental iPSC1 cells and expanded as the Monoclonal iPSC1 line. Briefly, iPSCs were cultured in Essential 8 medium (Thermo Fisher Scientific, A1517001) on 6-well plates coated with Matrigel (Corning, 354277); the medium was changed daily. When the culture reached ~80% confluence, the cells were dissociated using Accutase (Thermo Fisher Scientific, A1110501) or 0.5 mM EDTA and re-plated in Essential 8 medium supplemented with 10 µM ROCK inhibitor (Selleck, S1049) during the first day. All cells described in this study were incubated at 37 °C, 5% CO2, and 90% humidity.
Plasmids and lentivirus production
The full-length cDNA of the mouse Nfib gene was amplified from the tetO-Nfib-Hygro plasmid (Addgene #117271). To generate Nfib-GSG-P2A, a short DNA sequence of GSG-P2A was added to the 3′ end of Nfib by PCR amplification. Similarly, the full-length cDNA of the mouse Sox9 gene followed by the puromycin selection gene was amplified from the tetO-Sox9-Puro plasmid (Addgene #117269) to create Sox9-T2A-Puro. Specific restriction sites were incorporated to allow the cloning of Nfib-GSG-P2A and Sox9-T2A-Puro in tetO-Nfib-Hygro lentiviral vector (Addgene #117271) with EcoRI/PacI restriction enzyme sites, yielding the tetO-Nfib-Sox9-Puro plasmid.
Lentiviruses were produced using a second-generation packaging system in HEK293T cells and titrated by Vigene Biosciences (Shandong, China). The FUdeltaGW-rtTA plasmid (Addgene #19780) and tetO-Nfib-Sox9-Puro plasmid were used to produce lentivirus to overexpress rtTA (reverse tetracycline-controlled transactivator) and Nfib/Sox9, respectively.
Generation of astrocytes from iPSCs
We generated astrocytes from iPSCs as previously described13 with minor modifications (Fig. 1a). First, iPSCs were passaged with Accutase and replated in a Matrigel-coated 6-well plate with Essential 8 medium containing 10 μM ROCK inhibitor. Lentivirus overexpressing rtTA and Nfib/Sox9 was added to each well at a multiplicity of infection of 10 on the same day. The medium was replaced daily with Essential 8 medium. When the iPSCs reached ~80% confluence (i.e., Day 0), the medium was substituted with 2 mL fresh Essential 8 medium containing 1 μg/mL doxycycline (Sigma-Aldrich, D9891). On Day 1 and 2, the medium was exchanged with 2 mL expansion medium. On Day 3, the medium was replaced with 2 mL expansion medium and FGF medium (3:1 v/v). On Day 4, the medium was substituted with 2 mL expansion medium and FGF medium (1:1 v/v). On Day 5, the cells were washed with DPBS (without Ca2+/Mg2+) (Thermo Fisher Scientific, 14190250) and dissociated using 500 μL Accutase for 30 min at 37 °C. The progression of cell detachment was continuously monitored under a microscope. Cell suspensions were collected and centrifuged at 300 × g for 5 min to remove as much supernatant with Accutase as possible without disturbing the cell pellet. Then, cells were evenly replated at 3–4 × 105 cells per well in a 6-well plate pre-coated with Matrigel plus 2 mL expansion medium and FGF medium (1:3 v/v). On Day 6 and 7, the medium was exchanged daily with 2 mL FGF medium. On Day 8, the medium was substituted with 4 mL freshly prepared maturation medium. From Day 10 onward, half of the medium was replaced every other day with 2 mL maturation medium. Day 21 served as the endpoint for one round of astrocyte differentiation. Doxycycline (1 μg/mL) and puromycin at an optimized concentration depending on specific iPSC line (i.e., 2–5 μg/mL, Thermo Fisher Scientific, A1113803) were maintained in the medium throughout the experiments. Puromycin was used to select cells that were transduced with the constructs expressing rtTA and Nfib/Sox9.
Three media were used along astrocyte induction: expansion medium, FGF medium, and maturation medium. These media were prepared as follows: (1) expansion medium comprised DMEM/F12 (Thermo Fisher Scientific, 10565018), 10% FBS (Thermo Fisher Scientific, 10091148), 1% N2 (Thermo Fisher Scientific, 17502048), and 1% P/S (Thermo Fisher Scientific, 15140122); (2) FGF medium comprised Neurobasal (Thermo Fisher Scientific, 21103049), 1% FBS, 2% B27 (Thermo Fisher Scientific, 17504044), 1% NEAA (Thermo Fisher Scientific, 11140050), 1% Glutamax (Thermo Fisher Scientific, 35050061), 8 ng/mL bFGF (Peprotech, 100-18B), 5 ng/mL CNTF (Peprotech, 450-13), 10 ng/mL BMP4 (Peprotech, 120-05ET), and 1% P/S; (3) maturation medium comprised DMEM/F12 and Neurobasal (1:1 v/v), 1% N2, 1% Glutamax, 1% sodium pyruvate (Thermo Fisher Scientific, 11360070), 10 ng/mL CNTF, 10 ng/mL BMP4, 5 ng/mL heparin-binding EGF-like growth factor (hbEGF) (Peprotech, 100-47), 5 μg/mL N-acetyl-cysteine (Sigma-Aldrich, A8199), 500 μg/mL dbcAMP (Sigma-Aldrich, D0627), and 1% P/S.
Immunostaining of iPSC-derived astrocytes
On Day 21, the cells were dissociated with Accutase and re-plated on poly-d-lysine (Sigma-Aldrich, P0899) and Matrigel-coated 12-mm-diameter glass coverslips (SPL Life Sciences, 20012). The cells were washed once with DPBS and fixed in 4% paraformaldehyde (Sigma-Aldrich, 158127) for 15 min at room temperature. After washing in DPBS, the cells were permeabilized for 10 min with 0.1% Triton X-100 (Sigma-Aldrich, 93443) diluted in DPBS. The cells were blocked in 5% goat serum (Gibco, 16210064) diluted with 0.1% PBST for 30 min at room temperature. The cells were subsequently immunostained with primary rabbit anti-S100B antibody (Abcam, ab52642) overnight at 4 °C. The cells were then washed 3 times with 0.1% PBST for 20 min each time and treated with goat anti-rabbit AF568 secondary antibody (Life Technologies, A11011) for 1 h at room temperature. The nuclei were simultaneously counterstained with DAPI (Sigma-Aldrich, D9542). The cells were then washed 3 times with 0.1% PBST for 20 min each time. The coverslips were mounted on slides with ProLong Diamond Antifade Mountant (Thermo Fisher Scientific, P36961) and stored at 4 °C before imaging. Images were taken using an LSM900 confocal microscope (Zeiss) and processed with ZEN software (version 3.91.0).
Collection of cells for single-cell RNA sequencing
To establish the astrocyte differentiation path, Monoclonal iPSC1 cells were subjected to time-course profiling. Cells were collected on different differentiation days (i.e., Day 0, 1, 3, 8, 14, or 21) for scRNA-seq. The parental iPSC1 line and iPSC2 line were used to evaluate the consistency of astrocyte generation. Day-21 cells derived from these lines were collected for scRNA-seq. On the collection day, the cultured cells were prewashed with DPBS and dissociated with 200 µL Accutase in a 6-well plate for 10 min at 37 °C. The progression of cell detachment was constantly monitored under a microscope. Cell suspensions were collected and centrifuged for 5 min at 300 × g to remove as much Accutase as possible without disturbing the cell pellet. The cells were resuspended in DPBS with 0.04% filtered BSA and 60 U/mL RNasin Plus Ribonuclease Inhibitor (Promega, N2615). After quantification by a Countess Automated Cell Counter (Invitrogen, C10281), cell suspensions were diluted to 700–1,200 cells per microliter on ice for subsequent scRNA-seq library preparation.
Library preparation and single-cell RNA sequencing
The scRNA-seq workflow is summarized in Fig. 1b. A Chromium Next GEM Single Cell 3′ Reagent Kit v3.1 and Gel Beads Kit (10x Genomics) were used according to the manufacturer’s instructions. Briefly, single-cell suspensions, gel beads, and partitioning oil were added to the 10x Genomic Chromium Chip (Next GEM chip G) and subjected to the 10x Chromium Controller device, which encapsulated single cells within individual gel beads-in-emulsion (GEMs). The targeted number of cells in each sample was 10,000. Captured cells were lysed, and the transcripts inside the individual GEMs were barcoded through reverse transcription. Constructed 10x libraries were quantified by a Qubit 4 Fluorometer (Invitrogen) with a Qubit 1x dsDNA HS Assay Kit (Invitrogen). Quality control for the 10x libraries was performed using a Fragment Analyzer 5200 (Agilent) with a DNF-474 HS NGS Fragment Kit (Agilent). Library sequencing was performed on an Illumina NovaSeq. 6000 Sequencing platform (Novogene), with a paired-end read length of 150 bp and 100 GB raw data per sample.
Preprocessing of raw sequencing data
The workflow for bioinformatics analysis is summarized in Fig. 1c. In the 2 lentiviral constructs overexpressing rtTA and Nfib-Sox9-Puro, an exogenous sequence of WPRE-LTR was included downstream of rtTA and Puro, respectively. First, a Homo sapiens transcriptome (GRch38) reference containing an exogenous WPRE-LTR sequence was constructed using the Cell Ranger mkref pipeline. The exogenous WPRE-LTR sequence in the reference genome was used to identify the lentiviral transduced cells. To obtain transcript count tables, the sequencing data were processed using Cell Ranger software (version 7.0.0, 10x Genomics). The library-specific FASTQ files were aligned to the genome reference by the Cell Ranger count pipeline with the default settings. Cell-free mRNA contamination was removed with SoupX (version 1.6.2) using the output files (i.e., “raw_feature_bc_matrix” and “filtered_feature_bc_matrix”) obtained from Cell Ranger. The contamination fraction (i.e., contFrac) was set to 0.2 according to the recommended guidelines. The SoupX-modified count matrix was used for all downstream analyses.
Bioinformatics analysis of scRNA-seq data
Seurat (version 5.0.3) was used for further quality control. The standards for cell exclusion were individually determined for each sample, guided by the Barcode Rank Plots generated by Cell Ranger. Cells were eliminated based on the following criteria: counts ≤ 2,000–5,500, features ≤ 1,000–2,500, and mitochondrial gene percentage ≥ 10%. These thresholds served as the lower and upper boundaries, respectively. In addition, cells with complexity (i.e., log10-transformed genes per count) less than 0.8–0.85 were filtered out. The lentiviral transduced cells were identified and isolated using the subset function (i.e., based on the expression of WPRE-LTR > 0) for further analysis. Genes were excluded if they were expressed in fewer than 10 cells. The unique molecular identifier (UMI) count matrices were log-normalized, and variable features for each sample were identified using the FindVariableFeatures function (variable.features.n = 3000). Principal component analysis (PCA) was performed using RunPCA with all genes present in the scaled data, excluding immediate early genes (IEGs)19. Clusters within individual samples were then identified using the FindNeighbors and FindClusters functions (resolution = 0.1–0.3). For clearer visualization, the individual samples were subjected to dimensionality reduction techniques, including uniform manifold approximation and projection (UMAP). Doublets were removed by DoubletFinder (version 2.0.3), and the doublet rates were set individually according to the recommendations of 10x Genomics.
To provide an overview of the timepoint samples, the scRNA-seq data of Monoclonal iPSC1 samples at Day 0, 1, 3, 8, 14, and 21 were merged using the Seurat merge function. To identify transcriptionally linked cell clusters, multiple timepoint samples were integrated according to cluster similarity spectrum (CSS). CSS was calculated using the cluster_sim_spectrum function in simspec (version 0.0.0.9000), and all dimensions in the raw cluster similarity spectrum were selected for graph-based clustering (resolution = 0.1). The CSS-integrated data were further visualized using the UMAP dimensional reduction technique. Transcriptionally linked cell clusters between timepoint samples were identified using the FindNeighbors and FindClusters functions (resolution = 0.1). Genes specific to these clusters were identified by the FindAllMarkers function (only.pos = T, min.pct = 0.1, logfc.threshold = 0.25). For pseudotime analysis, we followed the workflow described in Monocle 3 (version 1.3.4). A cell dataset (cds) object was generated using the CSS-integrated Seurat object. The cds object subsequently underwent normalization using the preprocess_cds function (num_dims = 100, norm_method = ‘none’). To visualize the cells, we reduced the dimensionality of the cds object with the reduce_dimension function and projected original Seurat cell embeddings onto the cds object. The cells were then clustered using the cluster_cells function (resolution = 1e−4), and a trajectory graph was generated using the learn_graph function (use_partition = F, close_loop = F, learn_graph_control = list [ncenter = 80]). To order the cells, we specified the root nodes of the trajectory graph of Day-0 cells using the order_cells function. To visualize enriched genes for each timepoint sample, the 10 genes showing the highest expression based on their avg_log2FC (with a cutoff of >1) values were selected, and a heatmap was generated using the pheatmap package (version 1.0.12).
To assess the consistency of astrocyte differentiation, the average expressions of genes among different cell lines were determined using the AggregateExpression function in Seurat (normalization.method = LogNormalize and return.seurat = T). The Pearson correlation test was performed by the cor function. The scRNA-seq data of Monoclonal iPSC1, iPSC1, and iPSC2 samples on Day 21 were integrated by the IntegrateLayers function (method = HarmonyIntegration). The Harmony-integrated data were further visualized using the UMAP dimensional reduction technique. The detailed analytical procedures used to generate all the figures in this study are available on our GitHub repository (https://github.com/ShuaiC-CYLab/iPSC-derived-astrocytes_scRNASeq).
Data Records
The raw sequencing data (i.e., FASTQ files) are available in the NCBI Sequence Read Archive (SRP463969, BioProject accession ID: PRJNA1022577)20. Cell Ranger-filtered feature barcode matrices (i.e., “features.tsv.gz”, “barcodes.tsv.gz” and “matrix.mtx.gz”) and merged data (i.e., “TimeCourse.h5ad” and “CellLines.h5ad”) have been deposited in the NCBI Gene Expression Omnibus database (accession ID: GSE245169)21.
Technical Validation
Quality control for the single-cell RNA sequencing dataset
The quality indicators obtained from Cell Ranger analysis indicate that the scRNA-seq dataset of induced cells along iPSCs differentiation is of high quality. The report generated by Cell Ranger did not contain any specific warnings or alerts. The key quality indicators were all within acceptable ranges (Table 1). For all samples, the median number of genes per cell was more than 2,400, the mean number of reads per cell was more than 23,000, and the median number of UMI counts per cell was more than 8,000. A sequencing saturation greater than 25% was achieved for all samples. Based on the t-distributed stochastic neighbor embedding (t-SNE) plot of projections of cells colored by UMI counts from Cell Ranger, cells with high and low RNA contents can be separated. The median percentage of mitochondrial genes was less than 4%; this is much lower than the usual threshold of 10%, indicating a low ratio of apoptotic cells. The doublet rates were set individually according to the recommendations of 10x Genomics; the values were acceptable, being less than 13% for all samples. These results collectively demonstrate that the scRNA-seq dataset is of high quality. For further analysis, lentivirus-transduced cells were filtered based on whether the reads mapped to the exogenous WPRE-LTR sequence in the lentiviral vectors for rtTA and Nfib/Sox9 overexpression. Low-quality cells and doublets were removed. Only transduced cells meeting all of these quality control parameters were included in downstream analysis. Genes were excluded if they were expressed by fewer than 10 cells or were not detected in all cells. The final cell quantification statistics (Table 2) show that more than 5,600 cells were input and more than 17,000 genes were detected for each sample. Thus, our scRNA-seq dataset provides a reliable foundation for in-depth analysis of the cells induced during astrocyte differentiation.
Establishment of a comprehensive astrocyte differentiation path
The time-course scRNA-seq data herein can provide valuable insights for establishing the differentiation path of astrocytes from iPSCs. The process of generating astrocytes from iPSCs is dynamic and involves the overexpression of Nfib and Sox9 as well as the supplementation of the culture medium with various factors (Fig. 1a). Cells derived from the Monoclonal iPSC1 line at Day 0, 1, 3, 8, 14, and 21 were selected to analyze critical cell states.
To provide an overview of the timepoint samples, a UMAP plot of CSS-integrated timepoint samples was generated (Fig. 2a). The specific expression of several representative genes reflects the cell state changes along differentiation (Fig. 2b). For example, Day-0 cells (i.e., before induction) show enriched expression of the pluripotent stem cell marker, POLR3G22. Day-1 cells (i.e., immediately after Nfib and Sox9 overexpression) show enriched expression of FABP7—a gene whose expression is largely restricted to astrocytes in the adult central nervous system and is important for the establishment of the radial glial-like cells in the developing brain23,24. Day-3 cells show induction of CRYAB, which is expressed in astrocyte-like cells in gliomas25 and has an anti-apoptotic function in astrocytes26. Day-8 cells show induction of CD44, whose expression indicates astrocyte precursor cells27,28. After Day 8, the differentiating cells show enriched expression of the astrocyte markers, VIM and S100B.

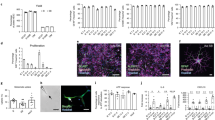
Single-cell RNA sequencing data of timepoint samples of the Monoclonal iPSC1 line. (a) Uniform manifold approximation and projection (UMAP) plot of timepoint samples after integration by cluster similarity spectrum (CSS). (b) Feature plots of representative genes for each time point. (c) Dot plot of the expression and numbers of cells per time point of representative genes. hPSC: human pluripotent stem cell; RGC: radial glia cell; NPC: neural progenitor cell. (d) Violin plot of the expression of astrocyte-relevant genes in timepoint samples. (e) Representative immunostaining image of differentiated astrocytes from the Monoclonal iPSC1 line at Day 21. Scale bar: 50 µm. (f) Pseudotime trajectory analysis of integrated timepoint samples. The number “1” indicates the assigned starting point of the pseudotime trajectory. (g) Transcriptionally linked cell clusters between timepoint samples. (h) Bar plot of cluster number and size in each timepoint sample. (i) Violin plots of gene counts (i.e., nFeature_RNA), unique molecular identifier (UMI) counts (i.e., nCount_RNA), the percentage of mitochondrial genes (i.e., percent.mt), and the percentage of immediate early genes (IEGs, i.e., percent.IEGs) after quality control filtering in all timepoint samples.
To show the representative gene expression changes along differentiation, the expression patterns of genes related to human pluripotent stem cells (i.e., POU5F1, POLR3G, and SOX2), radial glial cells (i.e., FABP7), neural progenitor cells (i.e., PAX6 and NES), astrocytes (i.e., VIM, CLU, ITGA6, S100B, CD44, NFIA, CRYAB, and ID4), neurons (i.e., STMN2, DCX, and PCP4), and oligodendrocytes (i.e., OLIG2, SOX10, PLP1, and MOG) in these timepoint samples are presented in a dot plot (Fig. 2c). The expression patterns of more astrocyte-relevant genes (e.g., VIM, S100B, CD44, CLU, ITGA6, ID3, GFAP, GJA1, AQP4, ALDH1L1, SLC1A3, and HEPACAM) are presented in a violin plot along these differentiation time points (Fig. 2d). The expression of S100B in Day-21 cells was validated by immunostaining (Fig. 2e), which is consistent with a previous report of S100B expression in most astrocytes derived from Nfib/Sox9 overexpression13.
To provide an overview of the astrocyte differentiation path, a continuous differentiation trajectory was apparent from Day 0 to 21 (Fig. 2f). To further demonstrate the potential of the dataset to capture cell states along differentiation, eight transcriptionally linked cell clusters were identified, including cluster size and number per time point (Fig. 2g–h). To visualize data quality for all the timepoint samples, gene counts (i.e., nFeature_RNA), UMI counts (i.e., nCount_RNA), the percentages of mitochondrial genes (i.e., percent.mt), and the percentages of IEGs (i.e., percent.IEGs) are shown in violin plots (Fig. 2i). Enriched genes for each timepoint sample were also identified (Fig. 3). Overall, these time-course scRNA-seq data offer a valuable perspective of the progressive differentiation of astrocytes from iPSCs, highlighting the transcriptional dynamics and critical states of the differentiation process.

Heatmap showing timepoint-specific gene expression along astrocyte differentiation.
Validity assessment of astrocyte differentiation from multiple iPSC lines
To ensure the reproducibility of astrocyte generation, three different iPSC lines—Monoclonal iPSC1, iPSC1, and iPSC2—were used to assess the validity of the astrocyte differentiation process. The UMAP plots (Fig. 4a) show the Day-21 cells derived from the three iPSC lines after Harmony integration. Pearson correlation analysis using multiple line samples without Harmony integration confirmed the reproducibility of astrocyte differentiation (Fig. 4b). In addition, the consistent expression pattern of some representative genes in astrocytes, neurons, and oligodendrocytes (Fig. 4c) also suggests the reproduction of highly efficient astrocyte induction from different iPSC lines. To visualize data quality for all Day-21 samples derived from multiple iPSC lines, gene counts, UMI counts, the percentages of mitochondrial genes, and the percentages of immediately early genes are shown in violin plots (Fig. 4d).

Single-cell RNA sequencing data of astrocytes differentiated from multiple iPSC lines. (a) Uniform manifold approximation and projection (UMAP) plots showing Harmony-integrated Day-21 astrocyte samples differentiated from multiple induced pluripotent stem cell (iPSC) lines plotted overlayed and individually. (b) Pearson correlation coefficients of a normalized transcriptome between samples without Harmony integration. The color intensity of the heatmap represents the correlation coefficients. (c) Violin plot of the expressions of astrocyte-, neuron-, and oligodendrocyte-relevant genes in Day-21 cells differentiated from multiple iPSC lines. (d) Violin plots of gene counts (i.e., nFeature_RNA), unique molecular identifier (UMI) counts (i.e., nCount_RNA), the percentage of mitochondrial genes (i.e., percent.mt), and the percentage of immediate early genes (IEGs, i.e., percent.IEGs) after quality control filtering in Day-21 samples from multiple iPSC lines.
Usage Notes
Our dataset provides a comprehensive picture of Nfib/Sox9-induced astrocyte differentiation, offering valuable insights for further research in neuroscience, stem cell biology, and systems biology. Furthermore, our dataset may facilitate further discoveries with the application of existing methodologies, approaches, and/or datasets. First, the dataset may help identify potential surface marker genes of heterogeneous astrocyte populations for the segregation of specific cell populations by cell sorting29,30. Second, it may aid the identification of transcription factors expressed in astrocyte subpopulations to predict astrocytic heterogeneity and guide astrocyte differentiation31,32. Third, the dataset could help decipher the epigenetic and transcriptional programs involved in NFIB/SOX9-induced astrocyte differentiation via integration of scRNA-seq and scATAC-seq data33,34. Fourth, it may help dissect the mechanisms of astrocyte differentiation in this induction model through detailed analysis of differentiation trajectory35. Finally, the dataset can facilitate comparison of the differences between astrocytes derived from different in vitro differentiation protocols and their similarity to in vivo cells through the integration of relevant datasets11,34,36,37,38. Overall, our dataset will advance our understanding of the features of the astrocytic transcriptome as well as the in vitro astrocyte differentiation path. In turn, this will pave the way for targeted investigations into astrocyte function, disease modeling, and the development of therapeutic interventions.
Of note, several considerations must be taken into account when utilizing this dataset. The UMAP plot indicates a high degree of homogeneity of induced astrocytes as well as a few small subclusters that are separate from the main cluster (Fig. 4a). To enhance the resolution to resolve more cell clusters, deeper sequencing is required. Furthermore, additional analysis is required to understand the differences in gene expression across these clusters. In addition, as non-transduced cells were not included in the present analysis, further investigation is required to identify these cells. Nevertheless, this dataset is a useful resource for elucidating glial biology.
Code availability
All analytical code for data analysis is available on GitHub (https://github.com/ShuaiC-CYLab/iPSC-derived-astrocytes_scRNASeq) and run in R 4.3.1.
References
de Majo, M., Koontz, M., Rowitch, D. & Ullian, E. M. An update on human astrocytes and their role in development and disease. Glia 68, 685–704 (2020).
Brandebura, A. N., Paumier, A., Onur, T. S. & Allen, N. J. Astrocyte contribution to dysfunction, risk and progression in neurodegenerative disorders. Nat Rev Neurosci 24, 23–39 (2023).
Oberheim, N. A., Wang, X., Goldman, S. & Nedergaard, M. Astrocytic complexity distinguishes the human brain. Trends Neurosci 29, 547–553 (2006).
Oberheim, N. A. et al. Uniquely hominid features of adult human astrocytes. J Neurosci 29, 3276–3287 (2009).
Zhang, Y. et al. Purification and Characterization of Progenitor and Mature Human Astrocytes Reveals Transcriptional and Functional Differences with Mouse. Neuron 89, 37–53 (2016).
Albert, K., Niskanen, J., Kälvälä, S. & Lehtonen, Š. Utilising Induced Pluripotent Stem Cells in Neurodegenerative Disease Research: Focus on Glia. Int J Mol Sci 22, 4334 (2021).
Ren, B. & Dunaevsky, A. Modeling Neurodevelopmental and Neuropsychiatric Diseases with Astrocytes Derived from Human-Induced Pluripotent Stem Cells. International Journal of Molecular Sciences 22, 1692 (2021).
Krencik, R. & Zhang, S.-C. Directed differentiation of functional astroglial subtypes from human pluripotent stem cells. Nat Protoc 6, 1710–1717 (2011).
Shaltouki, A., Peng, J., Liu, Q., Rao, M. S. & Zeng, X. Efficient generation of astrocytes from human pluripotent stem cells in defined conditions. Stem Cells 31, 941–952 (2013).
Tcw, J. et al. An Efficient Platform for Astrocyte Differentiation from Human Induced Pluripotent Stem Cells. Stem Cell Reports 9, 600–614 (2017).
Barbar, L. et al. CD49f Is a Novel Marker of Functional and Reactive Human iPSC-Derived Astrocytes. Neuron 107, 436–453.e12 (2020).
Sloan, S. A. et al. Human Astrocyte Maturation Captured in 3D Cerebral Cortical Spheroids Derived from Pluripotent Stem Cells. Neuron 95, 779–790.e6 (2017).
Canals, I. et al. Rapid and efficient induction of functional astrocytes from human pluripotent stem cells. Nat Methods 15, 693–696 (2018).
Canals, I. et al. Astrocyte dysfunction and neuronal network hyperactivity in a CRISPR engineered pluripotent stem cell model of frontotemporal dementia. Brain Commun 5, fcad158 (2023).
Huang, S., Zhang, Z., Cao, J., Yu, Y. & Pei, G. Chimeric cerebral organoids reveal the essentials of neuronal and astrocytic APOE4 for Alzheimer’s tau pathology. Signal Transduct Target Ther 7, 176 (2022).
Lee, H. et al. Cell-type-specific regulation of APOE and CLU levels in human neurons by the Alzheimer’s disease risk gene SORL1. Cell Rep 42, 112994 (2023).
Hedegaard, A. et al. Pro-maturational Effects of Human iPSC-Derived Cortical Astrocytes upon iPSC-Derived Cortical Neurons. Stem Cell Reports 15, 38–51 (2020).
Guan, M. et al. Generation of a homozygous ABCA7-knockout human iPSC line using the CRISPR/Cas9 system. Stem Cell Research 66, 103000 (2023).
Okuno, H. Regulation and function of immediate-early genes in the brain: Beyond neuronal activity markers. Neuroscience Research 69, 175–186 (2011).
NCBI Sequence Read Archive https://identifiers.org/ncbi/insdc.sra:SRP463969 (2023).
Yi, R. et al. A single-cell transcriptomic dataset of pluripotent stem cell-derived astrocytes via NFIB/SOX9 overexpression. Gene Expression Omnibus. https://identifiers.org/geo/GSE245169 (2023).
Lund, R. J. et al. RNA Polymerase III Subunit POLR3G Regulates Specific Subsets of PolyA+ and SmallRNA Transcriptomes and Splicing in Human Pluripotent Stem Cells. Stem Cell Reports 8, 1442–1454 (2017).
Hamilton, H. L. et al. FABP7 drives an inflammatory response in human astrocytes and is upregulated in Alzheimer’s disease. Geroscience https://doi.org/10.1007/s11357-023-00916-0 (2023).
Kurtz, A. et al. The expression pattern of a novel gene encoding brain-fatty acid binding protein correlates with neuronal and glial cell development. Development 120, 2637–2649 (1994).
Augustus, M. et al. Identification of CRYAB+ KCNN3+ SOX9+ Astrocyte-Like and EGFR+ PDGFRA+ OLIG1+ Oligodendrocyte-Like Tumoral Cells in Diffuse IDH1-Mutant Gliomas and Implication of NOTCH1 Signalling in Their Genesis. Cancers (Basel) 13, 2107 (2021).
Ousman, S. S. et al. Protective and therapeutic role for αB-crystallin in autoimmune demyelination. Nature 448, 474–479 (2007).
Liu, Y. et al. CD44 expression identifies astrocyte-restricted precursor cells. Dev Biol 276, 31–46 (2004).
Cai, N., Kurachi, M., Shibasaki, K., Okano-Uchida, T. & Ishizaki, Y. CD44-positive cells are candidates for astrocyte precursor cells in developing mouse cerebellum. Cerebellum 11, 181–193 (2012).
Li, R., Banjanin, B., Schneider, R. K. & Costa, I. G. Detection of cell markers from single cell RNA-seq with sc2marker. BMC Bioinformatics 23, 276 (2022).
Zhou, Z., Ye, C., Wang, J. & Zhang, N. R. Surface protein imputation from single cell transcriptomes by deep neural networks. Nat Commun 11, 651 (2020).
Camp, J. G., Wollny, D. & Treutlein, B. Single-cell genomics to guide human stem cell and tissue engineering. Nat Methods 15, 661–667 (2018).
Aibar, S. et al. SCENIC: single-cell regulatory network inference and clustering. Nat Methods 14, 1083–1086 (2017).
Alaterre, E. et al. Integrative single-cell chromatin and transcriptome analysis of human plasma cell differentiation. Blood https://doi.org/10.1182/blood.2023023237 (2024).
Jovanovic, V. M. et al. A defined roadmap of radial glia and astrocyte differentiation from human pluripotent stem cells. Stem Cell Reports 18, 1701–1720 (2023).
Van den Berge, K. et al. Trajectory-based differential expression analysis for single-cell sequencing data. Nat Commun 11, 1201 (2020).
Berryer, M. H. et al. Robust induction of functional astrocytes using NGN2 expression in human pluripotent stem cells. iScience 26, 106995 (2023).
Rapino, F. et al. Small-molecule screen reveals pathways that regulate C4 secretion in stem cell-derived astrocytes. Stem Cell Reports 18, 237–253 (2023).
Tchieu, J. et al. NFIA is a gliogenic switch enabling rapid derivation of functional human astrocytes from pluripotent stem cells. Nat Biotechnol 37, 267–275 (2019).
Acknowledgements
This study was supported in part by the National Key R&D Program of China (2021YFE0203000), the National Natural Science Foundation of China (32100778), the National Natural Science Foundation of China (NSFC)/RGC Joint Research Scheme (32061160472), the Guangdong Provincial Fund for Basic and Applied Basic Research (2022A1515011639, 2019B1515130004, and 2021A1515111079), the Guangdong Provincial Key S&T Program (2018B030336001), and the Technology Innovation Commission of Shenzhen (JCYJ20220818100800001, JCYJ20200109115631248, JCYJ20220531100217038 and ZDSYS20200828154800001).
Author information
Authors and Affiliations
Contributions
R.Y. and T.Y. conceived of the project; R.Y., M.G., C.L. and Y.Z. performed the experiments; R.Y., S.C., T.Y. and Y.C. analyzed the data and wrote the manuscript; T.Y., J.P.K.I. and Y.C. supervised the project.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yi, R., Chen, S., Guan, M. et al. A single-cell transcriptomic dataset of pluripotent stem cell-derived astrocytes via NFIB/SOX9 overexpression. Sci Data 11, 987 (2024). https://doi.org/10.1038/s41597-024-03823-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-024-03823-x
- Springer Nature Limited