
Abstract
Depression is a prevalent mental disorder with a complex biological mechanism. Following the rapid development of systems biology technology, a growing number of studies have applied proteomics and metabolomics to explore the molecular profiles of depression. However, a standardized resource facilitating the identification and annotation of the available knowledge from these scattered studies associated with depression is currently lacking. This study presents ProMENDA, an upgraded resource that provides a platform for manual annotation of candidate proteins and metabolites linked to depression. Following the establishment of the protein dataset and the update of the metabolite dataset, the ProMENDA database was developed as a major extension of its initial release. A multi-faceted annotation scheme was employed to provide comprehensive knowledge of the molecules and studies. A new web interface was also developed to improve the user experience. The ProMENDA database now contains 43,366 molecular entries, comprising 20,847 protein entries and 22,519 metabolite entries, which were manually curated from 1370 human, rat, mouse, and non-human primate studies. This represents a significant increase (more than 7-fold) in molecular entries compared to the initial release. To demonstrate the usage of ProMENDA, a case study identifying consistently reported proteins and metabolites in the brains of animal models of depression was presented. Overall, ProMENDA is a comprehensive resource that offers a panoramic view of proteomic and metabolomic knowledge in depression. ProMENDA is freely available at https://menda.cqmu.edu.cn.
Similar content being viewed by others


Introduction
Depression is a prevalent mental disorder characterized by low mood and loss of pleasure, with a lifetime prevalence of 11.1%–14.6% [1, 2]. The condition leads to severe functional impairment and was reported as one of the top three leading causes of burden in 2019 [3]. Unlike other somatic diseases, the clinical diagnosis of depression relies entirely on the clinical symptoms of patients, while reliable biomarkers are still lacking [4, 5]. Moreover, the clinical efficacy of antidepressants is limited, with more than one-third of patients demonstrating inadequate treatment responses [6]. Furthermore, the long-term use of antidepressants may lead to various side effects and treatment discontinuation [7]. Therefore, the screening of biomarkers and new drug targets is expected to improve the diagnosis and treatment of depression [8]. Despite substantial research efforts, the precise mechanism underlying the onset of depression remains incompletely defined, and a systematic molecular profile of depression is still lacking.
The rapid development of systems biology technology has led to the emergence of multi-omics approaches as powerful methods enabling the determination of molecular profiles of diseases with complex biological mechanisms [9, 10]. In the field of depression, omics methods, such as metabolomics and proteomics, have been widely applied to study the brain and peripheral samples of patients and animal models. The results have identified numerous differential metabolites and proteins between depressed and normal states [11,12,13]. Recent developments and applications in omics research have highlighted the need for comprehensive resources that integrate the available knowledge from scattered studies and provide a panoramic view of molecular characterization in depression [14]. Therefore, MENDA was developed to present the manually curated metabolic characterization (with 5,600 metabolite entries) in the context of depression [15]. Since its first release in 2019, multiple integrated studies have employed MENDA to generate meaningful biological insights [16,17,18,19]. However, the number of metabolomics studies has doubled since the first release, and the core dataset warrants an update. Moreover, molecular data at the protein level is required to capture the multi-level biochemical dysregulation of depression, which could provide information on specific enzymes in the metabolic pathways and networks [20, 21]. A growing body of proteomics studies have identified alterations in protein abundances in depression [22,23,24], providing an important resource of proteomic information. To date, a platform facilitating the systematic curation of proteomic changes in depression is still lacking. Adding protein information to the MENDA will contribute to a deeper understanding of molecular alterations in depression.
This study aimed to create a standardized resource for all available knowledge in the growing area of proteomic and metabolomic research in depression. Therefore, this study presents Protein and Metabolite Network of Depression Database (ProMENDA), an upgraded resource that provides a platform for the manual annotation of candidate proteins and metabolites linked to depression. The data set now contains 43,366 molecular entries from 1370 studies that investigated differential proteins and metabolites in both patients and animal models of depression. This update represents a significant increase (more than 7-fold) in molecular entries compared to the initial release of MENDA. Additionally, the web interface was redesigned to enhance the ease of use. The design and implementation of these updates and changes are described below. To demonstrate the usage of ProMENDA, a case study analyzing the molecular changes in the brains of animal models is presented. ProMENDA is expected to contribute to the investigation of the molecular profile of depression.
Materials and methods
Overview of ProMENDA framework
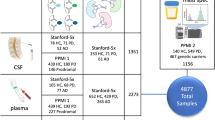
The schematic overview of ProMENDA is illustrated in Fig. 1. In brief, information on study design and candidate molecules from proteomics and metabolomics studies of depression was manually collected using standardized data extraction tables. These tables were then integrated into annotated datasets based on a multi-faceted annotation scheme. In addition, a brand-new web interface was developed in this update to enhance user experience.

The flowchart of the construction process for the ProMENDA.
Creation of the proteomic dataset
Data from proteomic studies of depression were incorporated to expand the scope of MENDA. Relevant proteomic studies were searched from PubMed, Embase, Web of Science, and PsychInfo (Table S1), resulting in a cumulative total of 13,742 literature records retrieved as of May 18, 2023 (Table S2). Studies that investigated proteomic changes associated with depression and its treatment in both human and animal models were screened based on titles and abstracts, yielding 436 potential studies. After checking the full text of these studies, 227 studies were finally included. The exclusion reasons are summarized in Table S3.
Subsequently, a proteomic dataset was created by manually selecting the study information and differentially expressed proteins from the full texts and supplementary materials of these studies using a standardized data abstraction spreadsheet (Table S4). To present experimental information on each protein, the proteomic data were annotated based on a multi-faceted annotation scheme as described in MENDA [15], with minor modifications. The annotation scheme involved manual annotation of information of interest at both the study and protein levels, including experimental design, types of organisms, categories of depression, categories of tissues, experimental techniques, citations, etc.
Moreover, protein information was annotated to ensure standardization, including UniProt accessions, UniProt entry names, protein names, and gene symbols based on the UniProtKB database (version 2023_03) [25]. This step was necessary as proteins were presented in different formats in the original reports, such as protein names, Uniprot accession, or gene symbols. A total of 20,847 protein entries were finally curated.
Update for metabolomic dataset
In this update, MENDA was expanded to include more comprehensive and up-to-date metabolite entries. The initial release of MENDA included 5675 metabolite entries from 464 metabolomics and magnetic resonance spectroscopy studies as of March 20, 2018. To ensure that the ProMENDA remains current, literature databases were re-screened as of May 18, 2023, resulting in a cumulative total of 22,678 records. After screening the full text of 3195 studies, a total of 1143 eligible studies were included in ProMENDA. The reasons for the exclusion of the ineligible studies are summarized in Table S3. Using a similar data extraction and annotation process to the proteomic dataset, a total of 22,519 differential metabolite entries were curated in this update. The expansion of the metabolite dataset will provide researchers with a more comprehensive overview of metabolic changes associated with depression.
Web interface implementation
The front end of the ProMENDA website has been implemented using HTML, JavaScript, and CSS. The web interface was designed using Bootstrap (https://getbootstrap.com/) and jQuery (https://jquery.com/) libraries, and the interactive tables were constructed using the DataTables library (https://datatables.net/). In addition, the website is hosted on an Apache server (https://httpd.apache.org).
Case study for applications of ProMENDA
In addition to data browsing, users can download data from ProMENDA to conduct data mining studies. To illustrate the potential applications of ProMENDA, a case study involving an integrated analysis was conducted based on protein and metabolite entries in the brains of animal models of depression. Metabolite and protein entries were selected based on the following criteria: (1) differential molecules between depressed vs. healthy states; (2) all types of animal models; (3) all brain tissues; and (4) all analytical platforms. Semi-quantitative analyses were performed based on selected data. Considering the possibility of inconsistencies in the up- and down-regulation of certain molecules (with unique gene symbols or metabolite names) across different studies, a vote-counting method was utilized for semi-quantitative analysis. This approach effectively identifies the molecules exhibiting consistent up- or down-regulation under specific conditions, indicating their high reproducibility and potential as biomarkers [26]. Furthermore, the binom.test function in R (version 4.3.0, https://www.rproject.org/) was used based on the downloaded data of interest to identify consistently differentially expressed molecules [27]. Candidate molecules with one-tailed P < 0.05 across different studies were considered as consistently altered. ImageGP was used to create plots [28].
Results
Data summary
The initial release of MENDA comprised 5675 metabolite entries. In ProMENDA, significant efforts have been made to expand the molecular entries. A cumulative total of 36,420 records were screened from electronic databases, and after checking the full texts of 3631 studies, 1370 studies that investigated the levels of proteins and metabolites in depression and its treatment were included. A standardized data extraction and annotation process was adopted, and 43,366 molecular entries were curated, including 20,847 protein entries (Supplementary Data 1) and 22,519 metabolite entries (Supplementary Data 2). This has resulted in a significant increase (more than 7-fold) in molecular entries compared to the previous version of MENDA (Fig. 1). Moreover, our laboratory provided 3173 metabolites entries and 3927 protein entries in ProMENDA, accounting for 16.4% of all molecular entries.
The number of studies that explored molecular alterations in each organism and each tissue is shown in Fig. S1. In ProMENDA, 7490 molecular entries were curated from human tissues, 1487 from non-human primate tissues, 19,925 from rat tissues, and 14,464 from mice (Fig. 2A). The numbers of unique proteins and metabolites in humans, non-human primates, rats, and mice are shown in Fig. 2B. Specifically, in humans, 3161 protein entries (from 1877 unique proteins) and 4329 metabolite entries (from 2991 unique metabolites) were curated from 8 types of tissues (Fig. 2C). In non-human primates, 143 protein entries (from 131 unique proteins) and 1344 metabolite entries (from 1100 unique metabolites) were curated from 8 types of tissues (Fig. 2D). In rats, 10,302 protein entries (from 4563 unique proteins) and 9623 metabolite entries (from 2180 unique metabolites) were collected from 14 types of tissues (Fig. 2E). In mice, 7241 protein entries (from 4165 unique proteins) and 7223 metabolite entries (from 3046 unique metabolites) were obtained from 11 types of tissues (Fig. 2F). The most frequently reported proteins and metabolites in each organism are displayed in Fig. S2. Among these molecular entries, 72.7% of protein entries and 63.8% of metabolite entries were collected from studies that compared molecular levels between depressed and healthy states; the remaining entries were collected from studies that investigated molecular changes resulting from antidepressant treatments.

A The number of molecular entries from each organism. B The number of unique proteins and metabolites from each organism. C The number of molecular entries and unique molecules in 8 human tissues. D The number of molecular entries and unique molecules in 8 non-human primate tissues. E The number of molecular entries and unique molecules in 14 rat tissues. F The numbers of molecular entries and unique molecules in 11 mouse tissues.
Web interface of ProMENDA
To facilitate the storage and access of study-level and molecular-level datasets, a new web interface was developed for ProMENDA. This interface comprises three main web pages, including Browse, Search, and Download.
-
(i)
Browse page: The Browse page features interactive tables that present molecular and study information, providing web links for each study and molecule (Fig. 3). Users can easily search these tables by using search columns and applying filters based on study type, organism, categories of depression, tissue, platform, and up/down-regulation. Users are also allowed to select and download data of interest. Basic information about the molecule is provided on the web page of each molecule and the related data entries are summarized. On the web page of each study, its experimental design and candidate molecules are listed.
Fig. 3: The user-friendly web interface of ProMENDA. 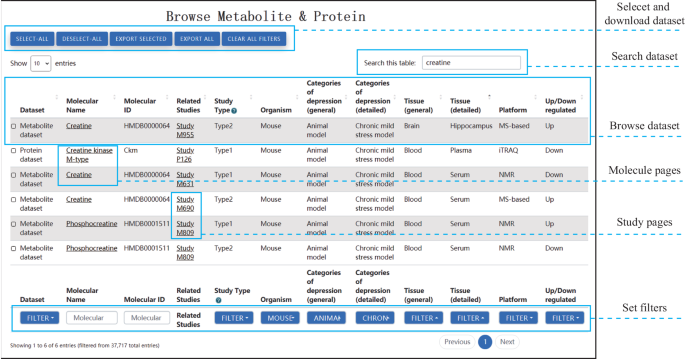
The web interface allows users to easily browse, search, filter, and download molecular entries of interest. The browse page displays molecular entries in an interactive table format, enabling users to quickly access relevant information.
-
(ii)
(ii) Search page: On the Search page, users can search for protein or metabolite entries using molecular names or IDs. Each query generates hyperlinks for relevant molecules and their links to other databases, including UniProt, HMDB, KEGG, and PubChem [25, 29,30,31].
-
(iii)
(iii) Download page: The Download page provides free access to the core datasets of ProMENDA, with additional information available in the Excel documents.
-
(iv)
(iv) Others: In addition to the pages mentioned above, ProMENDA also offers other pages in its web interface, including Home, Introduction, News, Tutorial, and Contact pages. These pages enhance the user experience and provide users with a complete understanding of ProMENDA and its features.

Use case: investigating molecular changes in the brains of animal models of depression
To illustrate the usage of ProMENDA, a case study was conducted to investigate the molecular changes of candidate proteins and metabolites in the brains of animal models of depression (Fig. 4A). Based on the inclusion criteria, 9458 protein entries and 4132 metabolite entries were initially included from the ProMENDA database. From these molecular entries, 317 candidate proteins and 127 candidate metabolites (or metabolite ratios) were identified from more than four studies. The results of the vote-counting strategy showed that the levels of 28 proteins and 32 metabolites were consistently dysregulated in the brain (P < 0.05; Fig. 4B and Table S5).

A Overview of the study design for the case study. B Volcano plot showing consistently dysregulated molecules in the vote-counting procedure.
Discussion
Depression is a prevalent disease with complex molecular alterations, and exploring potential molecular changes presents an opportunity to unravel the neurobiology and treatment targets of depression [32]. In recent years, numerous clinical and preclinical studies with various designs have employed high-throughput assays to study the molecular changes associated with depression. However, collecting and integrating this massive amount of data from a systems biology perspective remains challenging. Therefore, MENDA was previously developed, containing over 5000 metabolite entries associated with depression. Building on this foundation, ProMENDA was created, presenting a significant extension of the initial release of MENDA, which includes both a new protein dataset and an updated metabolite dataset.
The prime objective of this study was to create a comprehensive knowledge base for proteomic and metabolomic characterization in depression, which may serve as a valuable resource for researchers in the field of depression. To complement the initial release of MENDA, the molecular entries were expanded in ProMENDA by adding a proteomic dataset. While metabolic disturbance only covers a small portion of all biological processes in depression, a platform facilitating the systematic curation of molecules other than metabolites is required. Proteins are major macromolecules that are involved in complex biological functions and regulate metabolic processes; hence, proteomics is a powerful technology enabling a comprehensive understanding of human biology [33,34,35]. To provide a deeper understanding of candidate protein alterations in depression, 20,847 protein entries were manually curated from 227 studies, which significantly expanded our knowledge base of proteomic alterations in depression. ProMENDA demonstrates the molecular landscape of depression at both the protein and metabolite levels. Compared to Pharos, which contains about 1318 candidate proteins associated with depression based on evidence from proteins, genes, or transcriptions [36], ProMENDA provides a significantly wider selection of protein entries and rich annotation information.
In addition to expanding the proteomic dataset, the metabolite dataset was also updated in ProMENDA. Currently, 22,519 metabolite entries are provided, which is more than three times the number of entries since the initial release of MENDA. The metabolite entries in ProMENDA were compared with other knowledge bases such as MetSigDis, which provides a comprehensive resource of metabolite alterations in 129 diseases [37]. Compared to MetSigDis, ProMENDA provided a 3.2-fold higher number of metabolite entries for pan-diseases and a 600-fold higher number of metabolite entries for depression. This significantly higher number of metabolite entries in ProMENDA will provide researchers with a more comprehensive understanding of the metabolomic landscape of depression. Additionally, a new web interface was implemented in this update, integrating data browsing, searching, selecting, filtering, and downloading functions, improving user access to data analysis.
The efficient usage of ProMENDA was demonstrated in a case study investigating molecular alterations in the brains of animal models of depression. Compared to the initial release of MENDA, which only contained metabolite data, the integrated analysis based on changes in both protein expression and metabolite concentrations provided a more comprehensive insight due to the chemical and functional diversities between proteins and metabolites, as well as their interactions [38]. The results of the vote-counting strategy in the case study revealed that 60 molecules were consistently up-regulated or down-regulated across animal studies. Expectedly, this case study found significantly decreased levels of several neurotransmitters, including serotonin, dopamine, gamma-aminobutyric acid, and norepinephrine, which further support the role of monoamines and gamma-aminobutyric acid in depression [39, 40]. In addition to the analysis methods mentioned in the case study, users are also encouraged to perform further analysis using other analytical strategies and analysis tools. In a previous study, Fu et al. constructed a comprehensive knowledge graph focusing on food, gut microbiota, and mental diseases, which incorporated metabolite-disease associations from our database [41]. Moreover, Gao et al. performed a comprehensive analysis of metabolites in the hippocampus of depression models based on our database. They employed pathway analysis and experiment validation and found that disturbances in the neurotransmitter pathways of the hippocampus were associated with depression [42]. However, users should take data heterogeneity into account during study design, such as differences between human and animal studies, the subtypes of depression, and the type of tissues.
Limitations
Despite the significant improvements made in ProMENDA compared to MENDA, the platform still has some limitations. Only data from omics studies was included, so molecular entries from traditional experimental methods such as Western blotting have not been included. The slow manual curation process poses a major challenge for researchers who wish to collect and annotate molecular entries from all relevant publications [43]. However, the continuous progress of biomedical text mining techniques might facilitate the curation of large-scale molecular data from scattered literature [44, 45]. Another limitation of ProMENDA is the need for additional omics data, such as genomic and transcriptomic data, reflecting the multifactorial molecular changes that occur in depression. Data curation for the ProMENDA database will be an ongoing process. ProMENDA provides a more comprehensive understanding of the molecular landscape of depression; subsequent updates will facilitate the development of new therapeutic strategies.
Conclusions
In summary, ProMENDA is a valuable resource for depression research, offering a significant expansion of the core dataset compared to the initial release of MENDA. The current version of ProMENDA includes 43,366 molecular entries, comprising 20,847 protein entries and 22,519 metabolite entries, which were manually curated from 1370 human, rat, mouse, and non-human primate studies. This represents a more than seven-fold increase in molecular entries compared to the previous version of MENDA. ProMENDA is freely accessible to the public at https://menda.cqmu.edu.cn and provides a new user-friendly web interface that allows users to browse, search, select, filter, and download data.
Data availability
The datasets generated in the current study are available in Supplementary Data 1 and Supplementary Data 2, or on the ProMENDA website (https://menda.cqmu.edu.cn).
References
Kessler RC, Bromet EJ. The epidemiology of depression across cultures. Annu Rev Public Health. 2013;34:119–38.
Lu J, Xu X, Huang Y, Li T, Ma C, Xu G, et al. Prevalence of depressive disorders and treatment in China: a cross-sectional epidemiological study. Lancet Psychiatry. 2021;8:981–90.
GBD 2019 Mental Disorders Collaborators. Global, regional, and national burden of 12 mental disorders in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet Psychiatry. 2022;9:137–50.
Kim YK, Park SC. An alternative approach to future diagnostic standards for major depressive disorder. Prog Neuropsychopharmacol Biol Psychiatry. 2021;105:110133.
Gadad BS, Jha MK, Czysz A, Furman JL, Mayes TL, Emslie MP, et al. Peripheral biomarkers of major depression and antidepressant treatment response: current knowledge and future outlooks. J Affect Disord. 2018;233:3–14.
Fava M, Rush AJ, Alpert JE, Balasubramani GK, Wisniewski SR, Carmin CN, et al. Difference in treatment outcome in outpatients with anxious versus nonanxious depression: a STAR*D report. Am J Psychiatry. 2008;165:342–51.
Carvalho AF, Sharma MS, Brunoni AR, Vieta E, Fava GA. The safety, tolerability and risks associated with the use of newer generation antidepressant drugs: a critical review of the literature. Psychother Psychosom. 2016;85:270–88.
Abi-Dargham A, Moeller SJ, Ali F, DeLorenzo C, Domschke K, Horga G, et al. Candidate biomarkers in psychiatric disorders: state of the field. World Psychiatry. 2023;22:236–62.
Wörheide MA, Krumsiek J, Kastenmüller G, Arnold M. Multi-omics integration in biomedical research - a metabolomics-centric review. Anal Chim Acta. 2021;1141:144–62.
Hu C, Jia W. Multi-omics profiling: the way towards precision medicine in metabolic diseases. J Mol Cell Biol. 2021;13:576–93.
Bot M, Milaneschi Y, Al-Shehri T, Amin N, Garmaeva S, Onderwater GLJ, et al. Metabolomics profile in depression: a pooled analysis of 230 metabolic markers in 5283 cases with depression and 10,145 controls. Biol Psychiatry. 2020;87:409–18.
Pu J, Liu Y, Zhang H, Tian L, Gui S, Yu Y, et al. An integrated meta-analysis of peripheral blood metabolites and biological functions in major depressive disorder. Mol Psychiatry. 2021;26:4265–76.
Li S, Luo H, Lou R, Tian C, Miao C, Xia L, et al. Multiregional profiling of the brain transmembrane proteome uncovers novel regulators of depression. Sci Adv. 2021;7:eabf0634.
Brookes AJ, Robinson PN. Human genotype-phenotype databases: aims, challenges and opportunities. Nat Rev Genet. 2015;16:702–15.
Pu J, Yu Y, Liu Y, Tian L, Gui S, Zhong X, et al. MENDA: a comprehensive curated resource of metabolic characterization in depression. Brief Bioinform. 2020;21:1455–64.
Gao Y, Li X, Zhao HL, Ling-Hu T, Zhou YZ, Tian JS, et al. Comprehensive analysis strategy of nervous-endocrine-immune-related metabolites to evaluate arachidonic acid as a novel diagnostic biomarker in depression. J Proteome Res. 2021;20:2477–86.
Lei X, Tie J, Pan Y. Inferring metabolite-disease association using graph convolutional networks. IEEE/ACM Trans Comput Biol Bioinform. 2022;19:688–98.
Pu J, Liu Y, Gui S, Tian L, Yu Y, Song X, et al. Metabolomic changes in animal models of depression: a systematic analysis. Mol Psychiatry. 2021;26:7328–36.
Tian L, Pu J, Liu Y, Gui S, Zhong X, Song X, et al. Metabolomic analysis of animal models of depression. Metab Brain Dis. 2020;35:979–90.
Karczewski KJ, Snyder MP. Integrative omics for health and disease. Nat Rev Genet. 2018;19:299–310.
Tolani P, Gupta S, Yadav K, Aggarwal S, Yadav AK. Big data, integrative omics and network biology. Adv Protein Chem Struct Biol. 2021;127:127–60.
Choi JE, Lee JJ, Kang W, Kim HJ, Cho JH, Han PL, et al. Proteomic analysis of hippocampus in a mouse model of depression reveals neuroprotective function of ubiquitin C-terminal hydrolase L1 (UCH-L1) via stress-induced cysteine oxidative modifications. Mol Cell Proteomics. 2018;17:1803–23.
Qi YJ, Lu YR, Shi LG, Demmers JAA, Bezstarosti K, Rijkers E, et al. Distinct proteomic profiles in prefrontal subareas of elderly major depressive disorder and bipolar disorder patients. Transl Psychiatry. 2022;12:275.
Liu Y, Wang H, Gui S, Zeng B, Pu J, Zheng P, et al. Proteomics analysis of the gut-brain axis in a gut microbiota-dysbiosis model of depression. Transl Psychiatry. 2021;11:568.
UniProt Consortium. UniProt: the universal protein knowledgebase in 2021. Nucleic Acids Res. 2021;49:D480–9.
Rikke BA, Wynes MW, Rozeboom LM, Barón AE, Hirsch FR. Independent validation test of the vote-counting strategy used to rank biomarkers from published studies. Biomark Med. 2015;9:751–61.
Pu J, Liu Y, Gui S, Tian L, Yu Y, Wang D, et al. Effects of pharmacological treatment on metabolomic alterations in animal models of depression. Transl Psychiatry. 2022;12:175.
Chen T, Liu Y, Huang L. ImageGP: an easy-to-use data visualization web server for scientific researchers. iMeta. 2022;1:e5.
Wishart DS, Guo A, Oler E, Wang F, Anjum A, Peters H, et al. HMDB 5.0: the Human Metabolome Database for 2022. Nucleic Acids Res. 2022;50:D622–31.
Kanehisa M, Furumichi M, Sato Y, Ishiguro-Watanabe M, Tanabe M. KEGG: integrating viruses and cellular organisms. Nucleic Acids Res. 2021;49:D545–51.
Kim S, Chen J, Cheng T, Gindulyte A, He J, He S, et al. PubChem in 2021: new data content and improved web interfaces. Nucleic Acids Res. 2021;49:D1388–95.
Cui L, Li S, Wang S, Wu X, Liu Y, Yu W, et al. Major depressive disorder: hypothesis, mechanism, prevention and treatment. Signal Transduct Target Ther. 2024;9:30.
Müller JB, Geyer PE, Colaço AR, Treit PV, Strauss MT, Oroshi M, et al. The proteome landscape of the kingdoms of life. Nature. 2020;582:592–6.
Bludau I, Aebersold R. Proteomic and interactomic insights into the molecular basis of cell functional diversity. Nat Rev Mol Cell Biol. 2020;21:327–40.
Noor Z, Ahn SB, Baker MS, Ranganathan S, Mohamedali A. Mass spectrometry-based protein identification in proteomics-a review. Brief Bioinform. 2021;22:1620–38.
Kelleher KJ, Sheils TK, Mathias SL, Yang JJ, Metzger VT, Siramshetty VB, et al. Pharos 2023: an integrated resource for the understudied human proteome. Nucleic Acids Res. 2023;51:D1405–16.
Cheng L, Yang H, Zhao H, Pei X, Shi H, Sun J, et al. MetSigDis: a manually curated resource for the metabolic signatures of diseases. Brief Bioinform. 2019;20:203–9.
Piazza I, Kochanowski K, Cappelletti V, Fuhrer T, Noor E, Sauer U, et al. A map of protein-metabolite interactions reveals principles of chemical communication. Cell. 2018;172:358–72.e323.
Krishnan V, Nestler EJ. The molecular neurobiology of depression. Nature. 2008;455:894–902.
Duman RS, Sanacora G, Krystal JH. Altered connectivity in depression: GABA and glutamate neurotransmitter deficits and reversal by novel treatments. Neuron. 2019;102:75–90.
Fu C, Huang Z, van Harmelen F, He T, Jiang X. Food4healthKG: Knowledge graphs for food recommendations based on gut microbiota and mental health. Artif Intell Med. 2023;145:102677.
Gao Y, Mu J, Xu T, Linghu T, Zhao H, Tian J, et al. Metabolomic analysis of the hippocampus in a rat model of chronic mild unpredictable stress-induced depression based on a pathway crosstalk and network module approach. J Pharm Biomed Anal. 2021;193:113755.
Saqi M, Lysenko A, Guo YK, Tsunoda T, Auffray C. Navigating the disease landscape: knowledge representations for contextualizing molecular signatures. Brief Bioinform. 2019;20:609–23.
Karatzas E, Baltoumas FA, Kasionis I, Sanoudou D, Eliopoulos AG, Theodosiou T, et al. Darling: a web application for detecting disease-related biomedical entity associations with literature mining. Biomolecules. 2022;12:520.
Singhal A, Leaman R, Catlett N, Lemberger T, McEntyre J, Polson S, et al. Pressing needs of biomedical text mining in biocuration and beyond: opportunities and challenges. Database. 2016;2016:baw161.
Acknowledgements
This work was supported by the Natural Science Foundation Project of China (Grant no. 82101596, 82371526, and 81820108015), the Joint project of Chongqing Municipal Science and Technology Bureau and Chongqing Health Commission (Grant no. 2023CCXM003), the National Key Research and Development Program of China (Grant no. 2017YFA0505700), the Young Elite Scientists Sponsorship Program by CAST (Grant no. 2021QNRC001), the China Postdoctoral Science Foundation (Grant no. 2022MD723735), the Natural Science Foundation of Chongqing (Grant no. cstc2022ycjh-bgzxm0033), and the Chongqing Postdoctoral Science Foundation (Grant no. 2022NSCQ-BHX1283). We thank Home for Researchers editorial team (www.home-for-researchers.com) for language editing service.
Author information
Authors and Affiliations
Contributions
Concept, design, and supervision of the study: Juncai Pu, Yue Yu and Peng Xie. Data collection: Juncai Pu, Yiyun Liu, Dongfang Wang, Siwen Gui, Xiaogang Zhong, Weiyi Chen, Xiaopeng Chen, Yue Chen, Xiang Chen, Renjie Qiao, Yanyi Jiang, Hanping Zhang, Li Fan, Yi Ren, Xiangyu Chen and Haiyang Wang. Drafting display items: Juncai Pu, Yue Yu and Siwen Gui. Drafting manuscript: Juncai Pu and Peng Xie. All authors read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
The study was approved by The Ethics Committee of Chongqing Medical University (2017013). The datasets generated in the current study were collected from publicly available literature or reports, therefore informed consent forms are not applicable.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pu, J., Yu, Y., Liu, Y. et al. ProMENDA: an updated resource for proteomic and metabolomic characterization in depression. Transl Psychiatry 14, 229 (2024). https://doi.org/10.1038/s41398-024-02948-2
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41398-024-02948-2
- Springer Nature Limited