
Abstract
In this paper, inferential procedures based on classical and Bayesian framework for the Kumaraswamy distribution under random censoring model are studied. We first propose estimators for the distribution parameters, reliability function, failure rate function, and Mean time to system failure based on the maximum likelihood estimation method. Then, we calculate asymptotic confidence intervals for the parameters based on the observed Fisher’s information matrix. Also, for the parameters and reliability characteristics, Bayesian estimates are derived using the importance sampling and Gibbs sampling procedures. Highest posterior density credible intervals for the parameters are constructed using Markov Chain Monte Carlo method. Expected time on test of experiment with random censoring is also calculated. A simulation study is conducted to compare the efficiency of the derived estimates. Finally, the analysis of a real data set is presented for the illustration purpose.
Similar content being viewed by others


1 Introduction
Censoring occurs in life-testing trials when only a subset of the test items have known exact lifetimes, and the remaining test items’ lifetimes are merely known to exceed predetermined values. There are several censoring techniques that can be utilized for life-testing. Among them, the most popular and basic methods are Type I and Type II censorings. However, periodic removals of items from the life-testing trials are not permitted by these censoring techniques.
When the object of investigation is lost or arbitrarily taken out of the experiment before it fails, this is referred to as random censoring. Alternatively, to put it another way, at the end of the experiment, some of the subjects under consideration did not experience the particular incident. For instance, some subjects in a medical study or clinical trial might not receive treatment at all and end the course of treatment before it is completed. Some participants in a sociological study become disoriented during the follow-up. In these situations, the accurate survival time also called as time to the event of interest is unknown to the experimenter. Gilbert [20] was the pioneer of the random censoring model. Afterwards, Breslow and Crowley [6] and Koziol and Green [26] have done some preliminary research on the random censoring scheme. Ghitany and Al-Awadhi [19] used randomly right censored data to generate the ML estimators of the Burr XII distribution’s parameters. Using randomly censored data, Liang [34, 35] investigated empirical Bayesian estimation for the uniform and the exponential distributions. Under random censoring, Danish and Aslam [11, 12] introduced Bayesian estimates for Weibull and generalised exponential distributions. For some recent and notable advancements, one may refer to Krishna et al. [27], Kumar and Garg [30], Garg et al. [18], Krishna and Goel [28], Kumar [29], Kumar and Kumar [31], Ajmal et al. [2] and the references therein. Besides these references, one may also refer to Chaturvedi et al. [9], Shrivastava et al. [44], Jaiswal et al. [22], where the authors have studied Bayesian analysis techniques and dynamic models. These Bayesian analysis techniques can be utilized to tackle uncertainties and variations in the data, making it suitable for situations like random censoring in reliability analysis. Also, the dynamic models can be utilized to understand how the reliability of a system changes over a certain period of time.
Kumaraswamy [33] suggested a distribution for double-bounded random processes, which have applications in hydrology. Sundar and Subbiah [48], Fletcher and Ponnambalam [16], Seifi et al. [43], Ponnambalam et al. [41], and Ganji et al. [17] conducted in-depth studies on the other applications of this distribution in related fields. Jones [23] described some of the similarities and differences between the beta and Kum distributions as well as the origins, evolution, and characteristics of the Kum distribution. He continued by enumerating the Kum distribution’s several advantages over the beta distribution. Using type II censored data, Sindhu et al. [45] derived both classical and Bayesian estimates of the shape parameter of the Kum distribution. The Kum Burr XII distribution, which is an extension of the Burr XII distribution and comprises numerous lifetime distributions as special instances, was proposed by Paranaíba et al. [40]. They have researched a range of statistical characteristics, reliability metrics, and estimation techniques for this broader class of distributions. Eldin et al. [15], Kizilaslan and Nadar [25], Dey et al. [13, 14] and Wang et al. [50] are a few additional noteworthy contributors. Recently, Mahto et al. [36] have studied statistical inference for a competing risks model when latent failure times belong to Kum distribution. Sultana et al. [47] came up with the statistical inference based on the Kum distribution under type I progressive hybrid censoring model. Chaturvedi and Kumar [8] have developed estimation procedures for the reliability functions of Kum-G Distributions based on Type I and Type II censoring schemes. Modhesh and Basheer [39] used progressively first-failure censored (PFFC) data to examine the behaviour of the entropy of random variables that follow a Kumaraswamy distribution. Abo-Kasem et al. [1] have discussed optimal sampling and statistical inferences for the Kum distribution under progressive Type-II censoring schemes. One may also refer to Kumar and Chaturvedi [32], Chaturvedi and Kumar [7], Aslam et al. [4], Younis et al. [49] and Kiani et al. [24] for a quick review of inferential procedures based on different distributions.
In this paper, inferential procedures based on classical and Bayesian framework for Kum distribution under random censoring model are considered. The rest of the paper is organized as follows: the Kum distribution is discussed in Sect. 2. Also, mathematical formulation is given for random censoring with failure and censoring time distributions. Section 3 deals with the ML estimation and ACIs of the parameters. Section 4 deals with the ETT of items. The essence of Sect. 5 is to formulate the Bayesian inferential procedure using two techniques, namely (1) importance sampling procedure under SELF using non-informative and gamma informative priors, and (2) Gibbs sampling. HPD credible intervals for the parameters are derived using MCMC method. In Sect. 6 the features of the various estimates established in this research are explored through a rigorous simulation analysis. A real data set is analyzed in support of the practical utility of the proposed methodologies in Sect. 7. Finally, some concluding thoughts and future research directions are provided in Sect. 8 Note that the statistical software R is used for computation purposes throughout the paper.
2 Random Censoring Model
Suppose the failure times \(X_{1},X_{2},\ldots ,X_{n}\) are iid random variables with pdf \(f_{X}(x),\) \(x>0\) and cdf \(F_{X}(x),\) \(x>0\) respectively. Let \(T_{1},T_{2},\ldots ,T_{n}\) are iid censoring times associated with these failure times with pdf \(f_{T}(t),\) \(t>0\) and cdf \(F_{T}(t),\) \(t>0\) respectively. Further, let \(X_{i}'s\) and \(T_{i}'s\) be mutually independent. We observe failure or censored time \(Y_{i}=min(X_{i},T_{i});\) \(i=1,2,\ldots ,n\) and the corresponding censor indicators \(D_{i}=1 (0)\) if failure (censoring) occurs. Since, \(X_{i}\) and \(T_{i}\) are independent, so will be \(Y_{i}\) and \(D_{i},\) \(i=1,2,\ldots ,n.\) As a special case, the proposed censoring model includes complete sample scenario when \(T_{i}=\infty\) for all \(i=1,2,\ldots ,n\) and Type I censoring scenario when \(T_{i}=t_{\circ }\) for all \(i=1,2,\ldots ,n\) where, \(t_{\circ }\) is the pre-fixed study period. Thus, the joint pdf of Y and D is given by
The marginal distributions of Y and D are obtained as
and
respectively, where, p stands for the probability of observing a failure and is given by
The Kum distribution is characterized by the pdf and cdf:
and
respectively. Then, the corresponding reliability function, R(t), failure rate function, h(t) and MTSF are given, respectively, by
and
where, \(\Gamma (a)\) stands for the gamma function and \(B(a,b)=\frac{\Gamma (a)\Gamma (b)}{\Gamma (a+b)}\) is the beta function.The present study considers that the failure time X and the censoring time T follow Kum distribution with common shape parameter \(\beta .\) Let X follow \(Kum(\alpha _{1},\beta )\) and T follow \(Kum(\alpha _{2},\beta ),\) then, their pdfs are given by,
and
respectively. Using (1), (7) and (8), the joint density of Y and D is given by
Thus, from (9), the marginal distribution of \(Y_{i}\) is
Hence, Y follows \(Kum(\alpha _{1}+\alpha _{2},\beta ).\) The marginal distribution of \(D_{i}\) is given by
where, \(p=P[X_{i}\le T_{i}]=\frac{\alpha _{1}}{\alpha _{1}+\alpha _{2}}.\)
3 ML Estimation
In this section, we obtain MLEs of the unknown parameters of the Kum distribution using random censoring technique. Let \(({\underline{y}},{\underline{d}})=(y_{1},d_{1}),(y_{2},d_{2}),\ldots , (y_{n},d_{n})\) be the randomly censored sample of size n generated from (9). Then, the likelihood function for this randomly censored sample \(({\underline{y}},{\underline{d}})\) is given by
Taking logarithm on both the sides, we have
Differentiating Eq. (13) with respect to unknown model parameters \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta\) and equating them to zero, we have the normal equations as
Substituting (14) and (15) in (16), we obtain
Since, it is not easy to solve Eq. (17), we need an iterative method to solve it. Let \({\widehat{\beta }}\) be the ML estimator of \(\beta\) then the ML estimator of \(\alpha _{1}\) and \(\alpha _{2}\) are given by
and
Then, by the invariance property of ML estimators, the ML estimator of R(t), h(t) and MTSF are given by
and
3.1 The ACIs
In this subsection, in order to obtain ACI, we first obtain Fisher’s Information Matrix. The observed Fisher information matrix is given to evaluate the estimated variance of the \({\widehat{\alpha }}_{1}, {\widehat{\alpha }}_{2}, {\widehat{\beta }}\) respectively, and given by
The second order partial derivatives are
The estimated variance of \({\widehat{\alpha }}_{1},\) \({\widehat{\alpha }}_{2}\) and \({\widehat{\beta }}\) are the diagonal terms of \(I^{-1}({\widehat{\alpha }}_{1},{\widehat{\alpha }}_{2}, {\widehat{\beta }}),\) where \(I^{-1}({\widehat{\alpha }}_{1},{\widehat{\alpha }}_{2}, {\widehat{\beta }})\) is the inverse of the observed Fisher’s Information Matrix. The \((1-\alpha )100\%\) ACI for \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta\) are given by
and
respectively.
4 The ETT
In this section, we discuss ETT. In lifetime experiments and reliability experiments, since time is directly related to cost, it is therefore beneficial to have an idea about the expected time of the experiment. First time in literature, the ETT for randomly censored data was introduced by Krishna et al. [27]. Let \(Y_{i}=min(X_{i},T_{i});\) \(i=1,2,\ldots ,n\) be the random sample of size n generated from \(Kum(\alpha _{1}+\alpha _{2},\beta ).\) Let \(Y_{n}=max(Y_{1},Y_{2},\ldots ,Y_{n})\) be the \(n\)th order statistic. Then, the cdf of \(Y_{n}\) is given by
Thus, for randomly censored Kum data, the ETT is given by
Then, the ML estimator of \(ETT_{RC}\) is given by
Further, the OBTT is the maximum ordered statistic in \(Y_{1},Y_{2},\ldots ,Y_{n},\) i.e.,
Similarly, let \(X_{(n)}\) denote the nth order statistic in the case of complete sample. Then, ETT in case of complete sample is given by
Equations (23) and (25) can now be solved for different combinations of \(\alpha _{1},\) \(\alpha _{2},\) \(\beta\) and n with the help of integral function in R software.
5 Bayesian Estimation
Here, we develop the Bayes estimates of the unknown model parameters of the randomly censored Kum distribution. In order to compute the Bayes estimates, let \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta\) independently follow the gamma priors with hyper-parameters \((a_{1},b_{1}),\) \((a_{2},b_{2}),\) and \((a_{3},b_{3}),\) respectively, with their respective pdf’s
Following there pdf’s, we can obtain the joint prior distribution of \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta\) as
Now using the likelihood function given in Eq. (12) and the joint prior given in Eq. (26), the joint posterior distribution of the parameters \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta\) is given by
Now, we compute the Bayes estimates under SELF. Let \(\phi (\alpha _{1},\alpha _{2},\beta )\) be any function of the parameters \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta ,\) then the Bayes estimate of \(\phi (\alpha _{1},\alpha _{2},\beta )\) under SELF is given by
One can clearly observe that it is not possible to obtain the closed form solution of Eq. (28). Hence, we tend to exploit two approximation methodologies, namely (i) Importance Sampling, and (ii) Gibbs Sampling, to derive the Bayes’ estimates.
5.1 Importance Sampling Technique
In this subsection, we discuss the importance sampling method to derive the Bayes estimates of the parameters and the reliability characteristics. Note that the posterior distribution given in (27) can be rewritten as
where, \(A_{1}=a_{1}-\sum _{i=1}^{n}log(1-y_{i}^{\beta }),\) \(B_{1}=b_{1}+\sum _{i=1}^{n}d_{1},\) \(A_{2}=a_{2}-\sum _{i=1}^{n}log(1-y_{i}^{\beta }),\) \(B_{2}=b_{2}+n-\sum _{i=1}^{n}d_{1},\) \(A_{3}=a_{3}-\sum _{i=1}^{n}log(y_{i}),\) \(B_{3}=n+b_{3},\) and \(W(\alpha _{1},\alpha _{2},\beta )=\frac{e^{-\sum _{i=1}^{n} log(1-y_{i}^{\beta })}}{A_{1}^{B_{1}}A_{2}^{B_{2}}}.\) Now, for the computation of Bayes estimates using the importance sampling technique, following steps are used:
-
Step 1.
Generate \(\beta ^{(1)}\) from gamma\((A_{3},B_{3}).\)
-
Step 2.
Generate \(\alpha _{1}^{(1)}\) from gamma\((A_{1},B_{1})\) using \(\beta ^{(1)}\) generated in Step 1.
-
Step 3.
Generate \(\alpha _{2}^{(1)}\) from gamma\((A_{2},B_{2})\) using \(\beta ^{(1)}\) generated in Step 1.
-
Step 4.
Compute \(W\left( \alpha ^{(1)}_{1},\alpha ^{(1)}_{2},\beta ^{(1)}\right) .\)
-
Step 5.
Repeat steps 1 to 4, \((M-1)\) times to obtain importance samples.
Now, the approximate Bayes estimates of the parameters and reliability characteristics under SELF are given by
and
5.2 MCMC Method
Here, we consider MCMC technique to compute Bayes estimates and the corresponding HPD credible intervals. The Gibbs sampling is a particular type of MCMC method (see [46]). The full posterior conditional distributions for the parameters \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta ,\) respectively, are given by
and
From Eqs. (29) and (30), it can be seen that the posterior samples of \(\alpha _{1}\) and \(\alpha _{2}\) can be easily generated using gamma distributions, but the posterior sample of \(\beta\) cannot be generated directly. For the generation of the sample of \(\beta ,\) we shall use the MH algorithm, see Metropolis et al. [38] and Hastings [21]. Thus, we use the following steps to generate samples from the full conditional posterior densities given in Eqs. (29), (30) and (31), respectively:
-
Step 1.
Start with an initial guess of \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta ,\) say \(\alpha _{1}^{(0)},\) \(\alpha _{2}^{(0)}\) and \(\beta ^{(0)}.\)
-
Step 2.
Set \(j=1.\)
-
Step 3.
Generate \(\beta ^{(j)}\) from \(\pi _{3}(\beta |\alpha _{1}^{(j-1)},\alpha _{2}^{(j-1)},data)\) using MH algorithm with normal proposal distribution as
-
(i)
Generate a candidate point \(\beta _{c}^{j}\) from the proposal distribution \(N(\beta ^{(j-1)},1).\)
-
(ii)
Generate u from Uniform(0, 1).
-
(iii)
Calculate \(\eta =min\left( 1,\frac{\pi _{3}(\beta _{c}^{(j)} |\alpha _{1}^{(j-1)},\alpha _{2}^{(j-1)},data)}{\pi _{3}(\beta ^{(j-1)} |\alpha _{1}^{(j-1)},\alpha _{2}^{(j-1)},data)} \right) .\)
-
(iv)
If \(u\le \eta ,\) set \(\beta ^{(j)}=\beta _{c}^{(j)}\) with acceptance probability \(\eta ,\) otherwise \(\beta ^{(j)}=\beta ^{(j-1)}.\)
-
(i)
-
Step 4.
Generate \(\alpha _{1}^{(j)}\) from \(gamma(A_{1},B_{1})\) using \(\beta ^{(j)}\) generated in Step 3.
-
Step 5.
Generate \(\alpha _{2}^{(j)}\) from \(gamma(A_{2},B_{2})\) using \(\beta ^{(j)}\) generated in Step 3.
-
Step 6.
Set j = j + 1.
-
Step 7.
Repeat step 3 to step 6, N times, to obtain the sequence of the parameters as \(\alpha _{1}^{(1)},\alpha _{2}^{(1)},\ldots ,\beta ^{(1)},\) \(\alpha _{1}^{(2)},\alpha _{2}^{(2)},\ldots ,\beta ^{(2)}, \ldots ,\) \(\alpha _{1}^{(N)},\alpha _{2}^{(N)}\ldots ,\beta ^{(N)}.\)
We discard first \(N_{\circ }=20\%\) of the N of the generated values of the parameters as the burn-in-period to obtain independent samples from the stationary distribution of the Markov chain which are typically the posterior distributions. Thus, the Bayes estimates of the parameters \(\alpha _{1},\) \(\alpha _{2},\) \(\beta\) and reliability characteristics R(t), h(t) and MTSF under SELF, respectively, are given by
and
5.3 HPD Credible Interval
In this subsection, we construct HPD credible intervals of the unknown parameters \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta ,\) respectively, by using the algorithm proposed by Chen and Shao [10]. Let \(\alpha _{1(1)}<\alpha _{1(2)}<\cdots <\alpha _{1(N-N_{\circ })}\) denote the ordered form of the MCMC sample of \(\alpha _{1}\) generated in the previous subsection. Thus, the \(100(1-\delta )\%,\) where \(0<\delta <1,\) HPD credible interval for \(\alpha _{1}\) is given by
where j is chosen such that
here, [x] is the largest integer less than or equal to x. Similarly, we can construct the \(100(1-\delta )\%\) HPD credible intervals for \(\alpha _{2}\) and \(\beta ,\) respectively.
6 Simulation Study
A Monte Carlo simulation study is conducted in this section to evaluate the effectiveness and performance of the various estimation techniques. We generate a randomly censored sample from the Kum distribution an algorithm. The steps of the algorithm are provided below:
Step 1. Generate a random sample \(u_{1},u_{2},\ldots ,u_{n}\) from standard Uniform distribution, i.e., U(0, 1).
Step 2. Make a transformation to obtain failure observations \(x_{i},\) \(i=1,2,\ldots ,n,\)
Step 3. Generate another random sample \(v_{1},v_{2},\ldots ,v_{n}\) from U(0, 1).
Step 4. Make another transformation to obtain censoring observations \(t_{i},\) \(i=1,2,\ldots ,n,\)
Step 5. Now obtain \(y_{i}\) and \(d_{i}\) by using the condition that if \(x_{i}<t_{i},\) then \(y_{i}=x_{i}\) and \(d_{i}=1,\) else \(y_{i}=t_{i}\) and \(d_{i}=0.\) Hence, we obtain a randomly censored sample \((y_{i},d_{i})\) of n observations from Kum distribution.
We have generated 10,000 randomly censored samples using the aforementioned approach for various sample sizes \(n=30(5)100\) and parameter values \(\alpha _{1},\) \(\alpha _{2},\) and \(\beta\) in order to examine the behaviour of various estimates. We have used the procedure covered in Sect. 3 to calculate the average values of the ML estimators. Additionally, we have calculated the average length of the relevant CPs and the \(95\%\) asymptotic confidence intervals. By taking \(M=10{,}000\) as mentioned in Sect. 5, we were able to acquire the Bayes estimates using the Gibbs Sampling and importance sampling methodologies, as well as \(95\%\) HPD credible intervals of the parameters. Hyperparameters are selected so that the true value of the parameter equals the mean of the prior distribution.
The average ML estimates and the average Bayes estimates of \(\alpha _{1}\) with hyperparameters \(a_{1}=2,\) \(a_{2}=2,\) \(a_{3}=3,\) \(b_{1}=1,\) \(b_{2}=3,\) \(b_{3}=6\) and their corresponding MSE for true values of parameters \(\alpha _{1} =0.5,\) \(\alpha _{2}=1.5\) and \(\beta =2\) are computed and the results are reported in Table 1. Comparing the estimates on the basis of MSE, from Table 1 we observe that the Bayes estimate based on Importance Sampling performs the best and ML estimate performs the least. Bayes estimate based on Gibbs sampling method lies between the two. Further, as n increases, the performance of all the estimators improve and the three estimators come close to each other. Similarly, the average ML estimate and the average Bayes estimates for \(\alpha _{2}\) and their corresponding MSE are computed and the results are reported in Table 2. From Table 2 we can observe that the Bayes estimate of \(\alpha _{2}\) based on the Importance Sampling performs better than the Bayes estimate based on Gibbs Sampling Method and ML estimate. However, as n increases, their MSE decreases and all the estimates become almost equally efficient. In case of \(\beta ,\) for \(n<60,\) Bayes estimate based on Importance sampling performs the best, ML estimate performs the least and Bayes estimate based on Gibbs sampling lies in between the two. However, for \(n\ge 60,\) Bayes estimate based on Gibbs sampling performs the best, ML estimate performs the least and the Bayes estimate based on Importance sampling lies between the two. Further, for \(n\ge 85,\) Bayes estimate based on Gibbs sampling performs the best, Bayes estimate based on Importance sampling performs the least and ML estimate lies between the two. Also, as sample size increases, all the estimates become almost equally efficient. The results for \(\beta\) are reported in Table 3. The average length and CPs of the \(95\%\) ACIs and HPD credible intervals of the three parameters are obtained for different values of n and the results are presented in Table 4. From Table 4 we observe that the length of both the intervals for \(\alpha _{1},\) \(\alpha _{2}\) and \(\beta\) decreases as n increases, which shows the improvement in precision of the estimates as sample size increases. We also observe that the CPs of the interval estimates are much close to nominal values even for small values of n. The average length of ACI of \(\alpha _{1}\) is smaller than average length of HPD credible interval, while, CP of HPD is higher than ACI. However, for \(\alpha _{2}\) and \(\beta ,\) the average length of HPD is smaller than the average length of ACI while, CP of ACI is higher than HPD.
For comparing the performance of ML estimate and Bayes estimate of reliability function R(t), we obtain the average ML and Bayes estimates and their respective MSEs for \(\alpha _{1} =0.5,\) \(\alpha _{2}=1.5\) and \(\beta =2\) and different values of n and \(t=0.5\) and the results are reported in Table 5. Comparing the estimates on the basis of MSE, we observe that the Bayes estimate of R(t) based on Gibbs sampling method performs better than the ML estimate and Bayes estimate based on Importance sampling method. Also, as n increases, MSE of the three estimates decreases and the estimates become almost equally efficient. Along the similar lines, we obtain the average value of ML estimate and Bayes estimate and their MSE of the failure rate function h(t) and the results are reported in Table 6. From Table 6, on the basis of MSE, we can conclude that the Bayes estimate of h(t) based on Gibbs sampling performs better than the ML estimate and the Bayes estimate based on Importance sampling method and the estimates improve and come close to each other as n increases. Similarly, for investigating the performance of MTSF, we have obtained average ML and Bayes estimates and their respective MSEs and the results are presented in Table 7. From Table 7 we conclude that Bayes estimate of MTSF based on Gibbs sampling performs better than the Bayes estimate based on Importance sampling technique and ML estimate. Also, as n increases, MSE of the three estimates decreases and the estimates become almost equally efficient.
We have also calculated ETT based on complete sample and randomly generated sample and OBTT based on randomly generated sample as discussed in Sect. 4 for different sample sizes and the results are presented in Table 8. From Table 8, we observe that the random censoring reduces ETT and as n increases, ETT increases.
7 Real Data Analysis
We perform a real data analysis in this section. Here, we look at the data set that includes the monthly survival times (in months) of 24 patients who had Dukes’C colorectal cancer disease. This dataset was originally investigated by McIllmurray and Turkie [37]. Danish and Aslam [11] also examined this data set with a randomly censored Weibull distribution. The dataset is provided below: 3 + 6, 6, 6, 8, 12, 12, 12 +, 15 + 16 + 18 + 20 + 22 + 24, 28 + 28 + 28 + 30 + 33 + 42. The censoring times are indicated by the ‘+’ sign. To make computation easier, we first divide all observations by 50 without loss of generality. The resulting modified data are provided below: 0.06 +, 0.12, 0.12, 0.12, 0.12, 0.16, 0.16, 0.24, 0.24, 0.24 +, 0.30 +, 0.32 +, 0.36 +, 0.36 +, 0.40, 0.44 +, 0.48, 0.56 +, 0.56 +, 0.56 +, 0.60, 0.60 +, 0.66 +, 0.84.
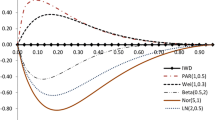
Now we compare the fitted Kum distribution with some other well-known survival models, like, exponential, Rayleigh, and Weibull distributions for Dukes’C colorectal cancer data. The ML estimates of the parameters of these distributions under random censorship model are obtained. These estimates, along with the data, are used to calculate the negative log likelihood function \(-ln\,L,\) the AIC \((AIC=2\times k-2ln\,L),\) proposed by Akaike [3] and BIC \((BIC=k\times kln\,(n)-2ln\,L)\) proposed by Schwarz [42], where k is the number of parameters in the reliability model, n is the number of observations in the given data set, L is the maximized value of the likelihood function for the estimated model and KS statistic with its p-value. The lowest \(-ln\,L,\) AIC, BIC and KS statistic values and the highest p values indicate the best distribution fit. These values are listed in Table 9. It is clearly reflected from Table 9 that the Kum distribution is the best choice among other counterparts. We have also demonstrated the empirical cdf to fit the randomly censored data through the graphs. The graph of the empirical cdf along with the estimates of cdfs for randomly censored exponential, Rayleigh, Weibull and Kum distributions are represented by Fig. 1. One can observe from Fig. 1 that the estimate of cdf for Kum distribution is quite close to that proposed by empirical cdf estimator, which clearly indicates that the empirical cdf also supports the choice of Kum distribution to represent the Dukes’ C colorectal cancer data.
We now examine how to estimate the randomly censored Kum distribution’s parameters for this set of data. Here, we have \(n=24\) and the effective sample size is \(m=12.\) We also use the median mission time of the data, \(t=0.34.\) We consequently use non-informative priors under SELF to derive the Bayes estimates of the parameters since we lack any prior knowledge. The hyperparameters for the non-informative priors are \(a_{1}=b_{1}=a_{2}=b_{2}=a_{3}=b_{3}=0.\) The Gibbs sampling method and importance sampling approach are used to produce the Bayes estimates. We use \(M=10{,}000\) for the importance sampling approach and \(N=50{,}000\) with a burn-in-period of \(N_{\circ }=10{,}000\) for the Gibbs sampling method. Furthermore, the 95% ACI and HPD credible intervals of the parameters are calculated. All results of the real data set are reported in Tables 10 and 11 respectively.
8 Concluding Remarks
In this study, we have developed estimation methods based on random censoring for the Kum distribution. Both point and interval estimations of the parameters are discussed. Extensive Monte Carlo experiments are conducted to examine the finite sample performances of the ML and the Bayes estimates based on the Importance sampling and Gibbs sampling methods. The MSE criterion is used to compare different estimates. Based on simulation experiments, we find that the ML estimator performs the least and the Bayes estimator based on importance sampling performs the best for \(\alpha _{1}.\) On the other hand, the Bayes estimate based on the importance sampling approach outperforms the one based on the Gibbs sampling method and ML estimator for \(\alpha _{2}.\) When \(n<60,\) the Bayes estimate based on importance sampling outperforms the Bayes estimate based on Gibbs sampling and ML estimator in case of \(\beta .\) Nevertheless, the Gibbs sampling based Bayes estimate outperforms the importance sampling and ML estimates for \(n\ge 60.\) Furthermore, all the three estimators perform better and approach each other as n increases. Additionally, the length of CI and HPD reduces as n increases, demonstrating how the estimates’ precision improves with increasing sample size. We further find that when n increases, the estimates improve and approach each other, and that the Bayes estimates of R(t), h(t), and MTSF based on the Gibbs sampling perform better than the Bayes estimates based on Importance sampling and the ML estimator. Furthermore, we note that the ETT reduces with the random censoring and increases with n. Additionally, a real data set is examined to illustrate the proposed estimation techniques. The main focus of the paper is on drawing conclusions about the parameters under random censoring. An extension of the work for the cases when one encounters with random non-responses may be interesting and considered in future research, see Basit and Bhatti [5].

The empirical and fitted cdfs of different competing models for Dukes’C colorectal cancer data
Data Availability Statement
All data sets analyzed during this study are included in this article.
Abbreviations
- ACI:
-
Asymptotic confidence interval
- AIC:
-
Akaike information criterion
- AL:
-
Average length
- BIC:
-
Bayesian information criterion
- CI:
-
Confidence interval
- CP:
-
Coverage probability
- ETT:
-
Expected time on test
- KS:
-
Kolmogorov–Smirnov
- MH:
-
Metropolis–Hastings
- ML:
-
Maximum likelihood
- MSE:
-
Mean square error
- Kum:
-
Kumaraswamy
- OBTT:
-
Observed time on test
- HPD:
-
Highest posterior density
- MCMC:
-
Markov chain Monte Carlo
- iid:
-
Independent and identically distributed
- pdf:
-
Probability density function
- cdf:
-
Cumulative distribution function
- min:
-
Minimum
- MTSF:
-
Mean time to system failure
- SELF:
-
Squared-error loss function
References
Abo-Kasem, O.E., El Saeed, A.R., El Sayed, A.I.: Optimal sampling and statistical inferences for Kumaraswamy distribution under progressive Type-II censoring schemes. Sci. Rep. 13(1), 12063 (2023)
Ajmal, M., Danish, M.Y., Arshad, I.A.: Objective Bayesian analysis for Weibull distribution with application to random censorship model. J. Stat. Comput. Simul. 22(1), 43–59 (2022)
Akaike, H.: A new look at the statistical models identification. IEEE Trans. Autom. Control 19(6), 716–723 (1974)
Aslam, M., Afzaal, M., Bhatti, M.I.: A study on exponentiated Gompertz distribution under Bayesian discipline using informative priors. Stat. Transit. New Ser. 22(4), 101–119 (2021)
Basit, Z., Bhatti, M.I.: Efficient classes of estimators of population variance in two-phase successive sampling under random non-response. Statistica 82(2), 177–198 (2022)
Breslow, N., Crowley, J.: A large sample study of the life table and product limit estimates under random censorship. Ann. Stat. 2(3), 437–453 (1974)
Chaturvedi, A., Kumar, S.: Estimation and testing procedures for the reliability characteristics of Chen distribution based on type II censoring and the sampling scheme of Bartholomew. Stat. Optim. Inf. Comput. 9(1), 99–122 (2021)
Chaturvedi, A., Kumar, S.: Estimation procedures for reliability functions of Kumaraswamy-G distributions based on Type II censoring and the sampling scheme of Bartholomew. Stat. Transit. New Ser. 23(1), 129–152 (2022)
Chaturvedi, A., Bhatti, M.I., Kumar, K.: Bayesian analysis of disturbances variance in the linear regression model under asymmetric loss functions. Appl. Math. Comput. 114(2–3), 149–153 (2000)
Chen, M., Shao, Q.: Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 8(1), 69–92 (1999)
Danish, M.Y., Aslam, M.: Bayesian estimation for randomly censored generalized exponential distribution under asymmetric loss functions. J. Appl. Stat. 40(5), 1106–1119 (2013). https://doi.org/10.1080/02664763.2013.780159
Danish, M.Y., Aslam, M.: Bayesian inference for the randomly censored Weibull distribution. J. Stat. Comput. Simul. 84(1), 215–230 (2014)
Dey, S., Mazucheli, J., Anis, M.S.: Estimation of reliability of multicomponent stress–strength for a Kumaraswamy distribution. Commun. Stat. Theory Methods 46(4), 1560–1572 (2017). https://doi.org/10.1080/03610926.2015.1022457
Dey, S., Mazucheli, J., Nadarajah, S.: Kumaraswamy distribution: different methods of estimation. Comput. Appl. Math. 37(2), 2094–2111 (2018). https://doi.org/10.1007/s40314-017-0441-1
Eldin, M.M., Khalil, N., Amein, M.: Estimation of parameters of the Kumaraswamy distribution based on general progressive type II censoring. Am. J. Theor. Appl. Stat. 3(6), 217–222 (2014). https://doi.org/10.11648/j.ajtas.20140306.17
Fletcher, S.G., Ponnambalam, K.: Estimation of reservoir yield and storage distribution using moments analysis. J. Hydrol. 182, 259–275 (1996). https://doi.org/10.1016/0022-1694(95)02946-X
Ganji, A., Ponnambalam, K., Khalili, D., Karamouz, M.: Grain yield reliability analysis with crop water demand uncertainty. Stoch. Environ. Res. Risk Assess. 20, 259–277 (2006). https://doi.org/10.1007/s00477-005-0020-7
Garg, R., Dube, M., Kumar, K., Krishna, H.: On randomly censored generalized inverted exponential distribution. Am. J. Math. Manag. Sci. 35(4), 361–379 (2016). https://doi.org/10.1080/01966324.2016.1236711
Ghitany, M.E., Al-Awadhi, S.: Maximum likelihood estimation of Burr XII distribution parameters under random censoring. J. Appl. Stat. 29(7), 955–965 (2002). https://doi.org/10.1080/0266476022000006667
Gilbert, J.P.: Random censorship. PhD thesis, University of Chicago (1962)
Hastings, W.K.: Monte Carlo sampling methods using Markov chains and their applications. Biometrika S7, 97–109 (1970)
Jaiswal, S., Chaturvedi, A., Bhatti, M.I.: Bayesian inference for unit root in smooth transition autoregressive models and its application to OECD countries. Stud. Nonlinear Dyn. Econom. 26(1), 25–34 (2020)
Jones, M.C.: Kumaraswamy’s distribution: a beta-type distribution with some tractability advantages. Stat. Methodol. 6(1), 70–81 (2009)
Kiani, S.K., Aslam, M., Bhatti, M.I.: Investigation of half-normal model using informative priors under Bayesian structure. Stat. Transit. New Ser. 24(4), 19–36 (2023)
Kizilaslan, F., Nadar, M.: Estimation and prediction of the Kumaraswamy distribution based on record values and inter-record times. J. Stat. Comput. Simul. 86(12), 2471–2493 (2016). https://doi.org/10.1080/00949655.2015.1119832
Koziol, J., Green, S.: A Cramer–von Mises statistic for randomly censored data. Biometrika 63(3), 465–474 (1976). https://doi.org/10.2307/2335723
Krishna, H., Vivekanand, Kumar, K.: Estimation in Maxwell distribution with randomly censored data. J. Stat. Comput. Simul. 85(17), 3560–3578 (2015). https://doi.org/10.1080/00949655.2014.986483
Krishna, H., Goel, N.: Classical and Bayesian inference in two parameter exponential distribution with randomly censored data. Comput. Stat. 33, 249–275 (2018). https://doi.org/10.1007/s00180-017-0725-3
Kumar, K.: Classical and Bayesian estimation in log-logistic distribution under random censoring. Int. J. Syst. Assur. Eng. Manag. 9(2), 440–451 (2018)
Kumar, K., Garg, R.: Estimation of the parameters of randomly censored generalized inverted Rayleigh distribution. Int. J. Agric. Stat. Sci. 10(1), 147–155 (2014)
Kumar, K., Kumar, I.: Parameter estimation for inverse Pareto distribution with randomly censored life time data. Int. J. Agric. Stat. Sci. 16(1), 419–430 (2020)
Kumar, S., Chaturvedi, A.: On a generalization of the positive exponential family of distributions and the estimation of reliability characteristics. Statistica 80(1), 57–77 (2020)
Kumaraswamy, P.: A generalized probability density function for double-bounded random process. J. Hydrol. 46, 79–88 (1980)
Liang, T.: Empirical Bayes testing for uniform distributions with random censoring. J. Stat. Theory Pract. 2, 633–649 (2008). https://doi.org/10.1080/15598608.2008.10411899
Liang, T.: Empirical Bayes estimation with random censoring. J. Stat. Theory Pract. 4, 71–83 (2010). https://doi.org/10.1080/15598608.2010.10411974
Mahto, A.K., Lodhi, C., Tripathi, Y.M., Wang, L.: Inference for partially observed competing risks model for Kumaraswamy distribution under generalized progressive hybrid censoring. J. Appl. Stat. (2021). https://doi.org/10.1080/02664763.2021.1889999
McIllmurray, M.B., Turkie, W.: Controlled trial of gamma linolenic acid in Duke’s C colorectal cancer. Br. Med. J. (Clin. Res. Ed.) 294(6582), 1260 (1987). https://doi.org/10.1136/bmj.294.6582.1260
Metropolis, N., Rosenbluth, A.W., Rosenbluth, M.N., Teller, A.H., Teller, E.: Equations of state calculations by fast computing machines. J. Chem. Phys. 21, 1087–1092 (1953)
Modhesh, A.A., Basheer, A.M.: Bayesian estimation of entropy for Kumaraswamy distribution and its application to progressively first-failure censored data. Asian J. Probab. Stat. 21(4), 22–33 (2023)
Paranaíba, P.F., Ortega, E.M., Cordeiro, G.M., Pascoa, M.A.D.: The Kumaraswamy Burr XII distribution: theory and practice. J. Stat. Comput. Simul. 83(11), 2117–2143 (2013)
Ponnambalam, K., Seifi, A., Vlach, J.: Probabilistic design of systems with general distributions of parameters. Int. J. Circuit Theory Appl. 29, 527–536 (2001). https://doi.org/10.1002/cta.173
Schwarz, G.: Estimating the dimension of a model. Ann. Stat. 6(2), 421–464 (1978)
Seifi, A., Ponnambalam, K., Vlach, J.: Maximization of manufacturing yield of systems with arbitrary distributions of component values. Ann. Oper. Res. 99, 373–383 (2000). https://doi.org/10.1023/A:1019288220413
Shrivastava, A., Chaturvedi, A., Bhatti, M.I.: Robust Bayesian analysis of a multivariate dynamic model. Physica A 528, 121451 (2019)
Sindhu, T.N., Feroze, N., Aslam, M.: Bayesian analysis of the Kumaraswamy distribution under failure censoring sampling scheme. Int. J. Adv. Sci. Technol. 51, 39–58 (2013)
Smith, A.F.M., Roberts, G.O.: Bayesian computation via the Gibbs sampler and related Markov chain Monte Carlo methods. J. R. Stat. Soc.: Ser. B (Methodol.) 55(1), 3–23 (1993). https://doi.org/10.1111/j.2517-6161.1993.tb01466.x
Sultana, F., Tripathi, Y.M., Wu, S.J., Sen, T.: Inference for Kumaraswamy distribution based on type I progressive hybrid censoring. Ann. Data Sci. 9, 1283–1307 (2022)
Sundar, V., Subbiah, K.: Application of double bounded probability density function for analysis of ocean waves. Ocean Eng. 16(2), 193–200 (1989). https://doi.org/10.1016/0029-8018(89)90005-X
Younis, F., Aslam, M., Bhatti, M.I.: Preference of prior for two-component mixture of Lomax distribution. J. Stat. Theory Appl. 20(2), 407–424 (2021)
Wang, L., Dey, S., Tripathi, Y.M., Wu, S.J.: Reliability inference for a multicomponent stress–strength model based on Kumaraswamy distribution. J. Comput. Appl. Math. (2020). https://doi.org/10.1016/j.cam.2020.112823
Acknowledgements
I am grateful to the Editor-in-Chief, Professor M. Ishaq Bhatti, and the anonymous reviewer(s) for carefully reading the original manuscript and providing valuable comments and suggestions. Their suggestions led me to come up with this revised and substantially improved version.
Funding
The author received no funding for this research.
Author information
Authors and Affiliations
Contributions
This paper was written by a single author who also created the figures and tables and reviewed and approved it.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethics Approval
Not applicable.
Consent to Participate
Not applicable.
Consent for Publication
The author hereby consents to publication of her work upon its acceptance.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chaturvedi, A. Randomly Censored Kumaraswamy Distribution. J Stat Theory Appl (2024). https://doi.org/10.1007/s44199-023-00068-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44199-023-00068-2