
Abstract
Signal decomposition and multiscale signal analysis provide many useful tools for time-frequency analysis. We proposed a random feature method for analyzing time-series data by constructing a sparse approximation to the spectrogram. The randomization is both in the time window locations and the frequency sampling, which lowers the overall sampling and computational cost. The sparsification of the spectrogram leads to a sharp separation between time-frequency clusters which makes it easier to identify intrinsic modes, and thus leads to a new data-driven mode decomposition. The applications include signal representation, outlier removal, and mode decomposition. On benchmark tests, we show that our approach outperforms other state-of-the-art decomposition methods.







Similar content being viewed by others


References
Abbott, B.P., et al.: Observation of gravitational waves from a binary black hole merger. Phys. Rev. Lett. 116, 061102 (2016)
Auger, F., Flandrin, P., Lin, Y.-T., McLaughlin, S., Meignen, S., Oberlin, T., Wu, H.-T.: Time-frequency reassignment and synchrosqueezing: an overview. IEEE Sig. Process. Mag. 30(6), 32–41 (2013)
Bach, F.: On the equivalence between kernel quadrature rules and random feature expansions. J. Mach. Learn. Res. 18(21), 1–38 (2017)
Bertsimas, D., Van Parys, B.: Sparse high-dimensional regression: exact scalable algorithms and phase transitions. Ann. Statist. 48(1), 300–323 (2020)
Block, H.-D.: The perceptron: a model for brain functioning. I. Rev. Mod. Phys. 34(1), 123 (1962)
Cai, T.T., Xu, G., Zhang, J.: On recovery of sparse signals via \(\ell ^1\) minimization. IEEE Trans. Inf. Theory 55(7), 3388–3397 (2009)
Candes, E.J., Tao, T.: Near-optimal signal recovery from random projections: universal encoding strategies? IEEE Trans. Inf. Theory 52(12), 5406–5425 (2006)
Carvalho, V.R., Moraes, M.F., Braga, A.P., Mendes, E.M.: Evaluating five different adaptive decomposition methods for EEG signal seizure detection and classification. Biomed. Sig. Process. Control 62, 102073 (2020)
Chen, Z., Schaeffer, H.: Conditioning of random feature matrices: double descent and generalization error. arXiv:2110.11477 (2021)
Daubechies, I., Lu, J., Wu, H.-T.: Synchrosqueezed wavelet transforms: an empirical mode decomposition-like tool. Appl. Comput. Harmon. Anal. 30(2), 243–261 (2011)
Dragomiretskiy, K., Zosso, D.: Variational mode decomposition. IEEE Trans. Sig. Process. 62(3), 531–544 (2013)
E, W., Ma, C., Wojtowytsch, S., Wu, L.: Towards a mathematical understanding of neural network-based machine learning: what we know and what we don’t. arXiv:2009.10713 (2020)
Flandrin, P., Rilling, G., Goncalves, P.: Empirical mode decomposition as a filter bank. IEEE Sig. Process. Lett. 11(2), 112–114 (2004)
Foucart, S., Rauhut, H.: A Mathematical Introduction to Compressive Sensing. Springer, New York (2013)
Frankle, J., Carbin, M.: The lottery ticket hypothesis: finding sparse, trainable neural networks. arXiv:1803.03635 (2018)
Gilles, J.: Empirical wavelet transform. IEEE Trans. Sig. Process. 61(16), 3999–4010 (2013)
Gilles, J., Heal, K.: A parameterless scale-space approach to find meaningful modes in histograms-application to image and spectrum segmentation. Int. J. Wavelets Multiresolution Inf. Process. 12(6), 2456–2464 (2014)
Gilles, J., Tran, G., Osher, S.: 2D empirical transforms, wavelets, ridgelets, and curvelets revisited. SIAM J. Imaging Sci. 7(1), 157–186 (2014)
Goldstein, T., Osher, S.: The split Bregman method for L1-regularized problems. SIAM J. Imaging Sci. 2(2), 323–343 (2009)
Hashemi, A., Schaeffer, H., Shi, R., Topcu, U., Tran, G., Ward, R.: Generalization bounds for sparse random feature expansions. arXiv:2103.03191 (2021)
Hastie, T., Tibshirani, R., Wainwright, M.: Statistical Learning with Sparsity: the Lasso and Generalizations. Chapman and Hall/CRC, USA (2019)
Hazimeh, H., Mazumder, R.: Fast best subset selection: coordinate descent and local combinatorial optimization algorithms. Oper. Res. 68(5), 1517–1537 (2020)
Hou, T.Y., Shi, Z.: Adaptive data analysis via sparse time-frequency representation. Adv. Adapt. Data Anal. 3(1/2), 1–28 (2011)
Huang, N.E., Shen, Z., Long, S.R., Wu, M.C., Shih, H.H., Zheng, Q., Yen, N.C., Tung, C.C., Liu, H.H.: The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. R. Soc. Lond. Proc. Ser. A Math. Phys. Eng. Sci. 454(1971), 903–995 (1998)
Huang, Z., Zhang, J., Zhao, T., Sun, Y.: Synchrosqueezing S-transform and its application in seismic spectral decomposition. IEEE Trans. Geosci. Remote Sens. 54(2), 817–825 (2015)
Li, Z., Ton, J.-F., Oglic, D., Sejdinovic, D.: Towards a unified analysis of random Fourier features. J. Mach. Learn. Res. 22(108), 108 (2021)
Liu, W., Chen, W.: Recent advancements in empirical wavelet transform and its applications. IEEE Access 7, 103770–103780 (2019)
Luedtke, J.: A branch-and-cut decomposition algorithm for solving chance-constrained mathematical programs with finite support. Math. Program. 146(1), 219–244 (2014)
Maass, W., Markram, H.: On the computational power of circuits of spiking neurons. J. Comput. System Sci. 69(4), 593–616 (2004)
Mazumder, R., Radchenko, P., Dedieu, A.: Subset selection with shrinkage: sparse linear modeling when the SNR is low. arXiv:1708.03288 (2017)
Mei, S., Misiakiewicz, T., Montanari, A.: Generalization error of random features and kernel methods: hypercontractivity and kernel matrix concentration. arXiv:2101.10588 (2021)
Moosmann, F., Triggs, B., Jurie, F.: Randomized clustering forests for building fast and discriminative visual vocabularies. In: NIPS. NIPS (2006)
Muradeli, J.: ssqueezepy. GitHub Repository. https://github.com/OverLordGoldDragon/ssqueezepy/ (2020)
Pele, O., Werman, M.: A linear time histogram metric for improved sift matching. In: Forsyth, D., Torr, P., Zisserman, A. (eds) Computer Vision – ECCV 2008, vol. 5304, pp. 495–508. Springer, Berlin, Heidelberg (2008)
Pele, O., Werman, M.: Fast and robust earth mover’s distances. In: 2009 IEEE 12th International Conference on Computer Vision, pp. 460–467. IEEE (2009)
Rahimi, A., Recht, B.: Random features for large-scale kernel machines. In: NIPS, vol. 3, pp. 5. Citeseer (2007)
Rahimi, A., Recht, B.: Uniform approximation of functions with random bases. In: 2008 46th Annual Allerton Conference on Communication, Control, and Computing, pp. 555–561. IEEE (2008)
Rahimi, A., Recht, B.: Weighted sums of random kitchen sinks: replacing minimization with randomization in learning. Adv. Neural Inf. Process. Syst. 21, 1313–1320 (2008)
Rudi, A, Rosasco, L.: Generalization properties of learning with random features. In: NIPS, pp. 3215–3225 (2017)
Saha, E., Schaeffer, H., Tran, G.: HARFE: hard-ridge random feature expansion. arXiv:2202.02877 (2022)
Sriperumbudur, B.K., Szabo, Z.: Optimal rates for random Fourier features. In: NIPS'15: Proceedings of the 28th International Conference on Neural Information Processing Systems, vol. 1, pp. 1144–1152. ACM (2015)
Thakur, G., Brevdo, E., Fučkar, N.S., Wu, H.-T.: The synchrosqueezing algorithm for time-varying spectral analysis: robustness properties and new paleoclimate applications. Sig. Process. 93(5), 1079–1094 (2013)
Thakur, G., Wu, H.-T.: Synchrosqueezing-based recovery of instantaneous frequency from nonuniform samples. SIAM J. Math. Anal. 43(5), 2078–2095 (2011)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. Roy. Statist. Soc. Ser. B 58(1), 267–288 (1996)
Torres, M.E., Colominas, M.A., Schlotthauer, G., Flandrin, P.: A complete ensemble empirical mode decomposition with adaptive noise. In: 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4144–4147. IEEE (2011)
Wu, Z., Huang, N.E.: Ensemble empirical mode decomposition: a noise-assisted data analysis method. Adv. Adapt. Data Anal. 1(1), 1–41 (2009)
Xie, W., Deng, X.: Scalable algorithms for the sparse ridge regression. SIAM J. Optimiz. 30(4), 3359–3386 (2020)
Xie, Y., Shi, B., Schaeffer, H., Ward, R.: SHRIMP: sparser random feature models via iterative magnitude pruning. arXiv:2112.04002 (2021)
Yang, H.: Synchrosqueezed wave packet transforms and diffeomorphism based spectral analysis for 1D general mode decompositions. Appl. Comput. Harmon. Anal. 39(1), 33–66 (2015)
Yen, I.E.-H., Lin, T.-W., Lin, S.-D., Ravikumar, P.K., Dhillon, I.S.: Sparse random feature algorithm as coordinate descent in Hilbert space. Adv. Neural Inf. Process. Syst. 2, 2456-2464 (2014)
Acknowledgements
N.R. and G.T. were supported in part by the NSERC RGPIN 50503-10842. H.S. was supported in part by the AFOSR MURI FA9550-21-1-0084 and the NSF DMS-1752116. The authors would also like to thank Rachel Ward for valuable discussions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Appendixes
Appendixes
As additional examples, we include more comparison results on the intersection time series signal described in Sect. 3.2 as well as the experiments on a noisy signal where the noise level has a larger amplitude than one of the modes (see Sect. 3.3) and on an overlapping and noisy signal (see Sect. 3).
1.1 Appendix A: Comparing Different Methods on the Intersecting Time Series Example
In this section, we present our reconstructed signals as well as our learned modes from the challenging intersecting time series in Sect. 3.2. Specifically, applying the DBSCAN on the extracted time-frequency pairs \(\{(\tau _j,\omega _j)\}_j\) yields three clusters denoted by green triangles, orange circles, and orange squares (see Fig. 3 (right figure in the first row)). The corresponding learned modes are plotted in Fig. 8. To reduce the decomposition to two modes, we keep the mode with the largest \(\ell _2\)-norm and combine the two learned modes with the smallest \(\ell _2\)-norm to construct the second mode, which is shown in Fig. 9. Our proposed algorithm provides a reasonable extraction of modes where the errors between the learned modes and the true ones are almost zero everywhere, except on a time-shift region corresponding to the intersection of instantaneous frequencies. As seen in Fig. 10, the other approaches have difficulty obtaining the two modes, likely due to the intersecting of frequencies in the spectrogram.


Example from Sect. 3.2. Decomposition results of our proposed SRMD method into two modes. First row: noiseless ground truth signal (in black) with the learned signal (in blue) of the full signal (top) and the two learned modes. Last row from left to right: errors between noiseless ground truth and the learned representation, between the true modes and the extracted modes

Example from Sect. 3.2. Comparing different methods on the intersecting time-series example. Top to bottom rows are SRMD, EMD, EEMD, CEEMDAN, EWT, and VMD. The first column displays the noiseless ground truth (in black) and the learned signal representation (in blue). The remaining two columns are the two modes, where the true IMFs are plotted in black and the learned IMFs are in blue
In Fig. 10, we compare the reconstruction and the decomposition results of our method versus those obtained from some of the state-of-the-art intrinsic mode decomposition methods (EMD, EEMD, CEEMDAN, EWT, and VMD) on the intersecting time series signal given in Sect. 3.2.
1.2 Appendix B: Comparison Results on Pure Sinusoidal Signals with Noise
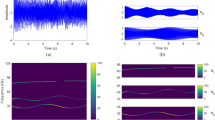
In this section, we present our reconstructed signals as well as our learned modes from the challenging noisy tri-harmonic signal described in Sect. 3.3. In particular, in Fig. 11, we plot the time-frequency pairs associated with non-zero coefficients (top left), the clustering of those non-zero coefficients (top right), the reconstruction signal and the three learned modes (second row), and the corresponding errors (third row). Our method can extract the first two learned modes with high accuracy. Note that both VMD (see [11]) and our method (see Fig. 11) have difficulty in extracting the weak and high-frequency mode \(y_3(t) = \frac{1}{16}\cos (576\uppi t)\). Nevertheless, our method can identify the frequencies of all three modes. More precisely, the median frequencies of the three learned clusters are 1.99, 24.03, and 288.02 Hz, which are very close to the ground truth frequencies 2, 24, and 288 Hz.

Example from Sect. 3.3. First row: the noisy input signal. Second row: magnitude of non-zero learned coefficients (left) and learned clusters (right). Third row from left to right: reconstructed signal (in blue) and the three extracted modes (in blue) versus the corresponding noiseless signal and modes (in black). Last row: error of the reconstruction and the three IMFs compared to the ground truth
1.3 Appendix C: Overlapping Time-Series with Noise
In this experiment, we investigate an example with overlap. The input signal y(t) is the summation of two modes \(y_1(t) = \mathcal{F}^{-1}\{Y_1\}(t)\) and \(y_2(t) = \mathcal{F}^{-1}\{Y_2\}(t)\) with overlapping frequencies and is contaminated by noise:
Here \(\mathcal{F}^{-1}\{Y_i\}\) denotes the inverse Fourier transform of \(Y_i\) for \(i=1,2\), where
for \(k\in \mathbb {Z}\) and \(t\in [0,1].\) Note that the modes \(y_1(t)\) and \(y_2(t)\) produce Gaussians in the Fourier domain centered at \(k=16\) and \(20\text {\,Hz}\), respectively. The leading term, \(m{\rm e}^{-{\rm i}\uppi k}\), centers the wave packets to \(t=0.5\text {\,s}\) where \(m=160\) is the total number of samples. For the SRMD algorithm, the hyperparameters to generate the basis are set to \(\omega _{\max } = 40\), \(N = 20,m = 3\,200\), and \(\Delta =0.2\). The hyperparameter for the DBSCAN algorithm is set to \(\varepsilon = 1.5\).

Example from Appendix C. Ground truth (left) and noisy input with \(r=25\%\) (right)
The noiseless and noisy time series with \(r=25\%\) are shown in Fig. 12. All reconstruction and decomposition results will be compared against the true signal (or modes) \(y_{\rm true}(t), y_1(t),\) and \(y_2(t)\). We compare our results with other methods applied to noisy signals with different noise ratios \(r = 5\%, 15\%,\) and \(25\%\). From the results in Fig. 13, we see that only VMD and our method properly reconstruct and decompose the noisy signal. Moreover, when the noise level r is small (5%), the VMD approach produces comparable results with our method. When r increases, our method is still able to capture the intrinsic modes and denoise the input signal. On the other hand, the VMD is able to identify some aspects of the two intrinsic modes but is polluted by noise, see Figs. 14 and 15.
The clusters of the non-zero coefficients obtained by SRMD applied to the noisy signal with the noise levels \(r= 5\%, 15\%\), and \(25\%\) are shown in Fig. 16. Note that the clusters surround the two Gaussian peaks (\(16 \text {\,Hz}\) and \(20 \text {\,Hz}\)) that define the true input signal. The other features obtained by the SRMD provide slightly corrects to the overall shape to ensure the reconstruction error is below the specified upper bound. This implies one has the flexibility in choosing the width and number of random features since additional features can be used to ensure the reconstruction is reasonable.

Example from Appendix C. Decomposition results with \(r= 5\%\) noise using six different methods. Top to bottom rows: SRMD, EMD, EEMD, CEEMDAN, EWT, and VMD. First column: the noiseless ground truth (black) and the learned signal (blue). Middle and last columns: the first and second ground truth IMFs (black) with the learned IMFs (blue)

Example from Appendix C. Decomposition results with \(r= 15\%\) noise using SRMD (first row) and VMD (second row). First column: the noiseless ground truth (black) and the learned signal (blue). Middle and last columns: the first and second ground truth IMFs (black) with the learned IMFs (blue)

Example from Appendix C. Decomposition results with \(r= 25\%\) noise using SRMD (first row) and VMD (second row). First column: the noiseless ground truth (black) and the learned signal (blue). Middle and last columns: the first and second ground truth IMFs (black) with the learned IMFs (blue)

Example from Appendix C. First column: magnitude of non-zero learned coefficients for noisy signals with \(r=5\%, 15\%\) , and \(25\%\). Second column: two learned clusters (green and orange)
1.4 Appendix D: Example on Parameter Tuning and Limitations
As we discuss in Sect. 3.6, the window size \(\Delta\) and the clustering neighborhood scale \(\varepsilon\) are sensitive tunable parameters. For example, in the discontinuous time-series example (see Sect. 3.1), if \(\varepsilon = 0.06\) (instead of 0.1), the non-zero learned coefficients align with the true instantaneous frequencies. However, the learned modes are not reasonable due to wrong clusters (see Fig. 17). On the other hand, if \(\varepsilon = 0.15\), although the non-zero learned coefficients still align with the true instantaneous frequencies, Algorithm 2 can not extract the mode since the clustering part is not able to cluster the set \({\widehat{S}}\).

Example from Sect. 3.1with DBSCAN hyperparameter \(\varepsilon = 0.05 \). First row from left to right: magnitude of non-zero learned coefficients used for DBSCAN and clustering of non-zero coefficients into three modes. Second row from left to right: three extracted modes
Finally, if we choose the window size \(\Delta\) too big or too small, the non-zero learned coefficients may not align well with the instantaneous frequencies or make it difficult to cluster (see Fig. 18).

Example from Sect. 3.1with various window sizes \(\Delta \). From left to right: clustering of non-zero coefficients (the true instantaneous frequencies are in black) for \(\Delta = 0.02\) (left) and \(\Delta = 0.2\)
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Richardson, N., Schaeffer, H. & Tran, G. SRMD: Sparse Random Mode Decomposition. Commun. Appl. Math. Comput. (2023). https://doi.org/10.1007/s42967-023-00273-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42967-023-00273-x