
Abstract
In the realm of behavioral research, significant contributions have greatly advanced reading studies, influencing educational practices. We explored the relationship between the degrees of incidental bidirectional naming (Inc-BiN) capabilities and children's derived relations for literacy responses. Inc-BiN is a repertoire whereby a child acquires listener and speaker responses from observation alone. Incidental unidirectional naming (Inc-UniN) occurs when observation of object-names produces listener, but not speaker behavior. Students who did not demonstrate listener and speaker components were classified as having No Incidental Naming (NiN). Across two studies, we evaluated how component skills involved in Inc-BiN are connected to emergent literacy responses in preschoolers with a disability. In Study 1, participants completed two conditions: (1) directly reinforcing speaker responses and testing for the emergence of listener responses, and (2) directly reinforcing listener responses and testing for the emergence of speaker responses. Results suggested that participants with Inc-BiN readily derived both speaker and listener responses, participants with Inc-UniN readily derived listener, but not speaker responses, and participants with NiN had difficulty acquiring directly reinforced responses and deriving responses. In Study 2, we established Inc-BiN with participants and readministered Study 1 tests. Our results suggest overlap between incidental bidirectional naming and derived responses and point to how one can incorporate derived relations instruction and differentiate instruction for children with varying repertoires.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Becoming a proficient and fluent reader is essential for a child's academic and social success, influencing both their personal development and the broader society. Research underscores the significance of acquiring essential prereading skills by first grade, as it increases the likelihood of reading proficiency in third grade (McNamara et al., 2011). Delving into the social history of reading and the educational policy landscape in the United States, the "separate but equal" fallacy has cast a shadow over the pursuit of equitable literacy opportunities. Although the field of behavior analysis is advancing in reading research, with examples such as Direct Instruction programs and innovative technologies like Headsprout Reading (Carnine et al., 2016; Layng et al., 2003), systemic challenges persist.
Tailored instruction should adapt to the unique learning characteristics of each child, acknowledging the evolution of their behavior, exposure to new contingencies, and diverse learning modalities. To optimize learning efficiency, educators should employ a curriculum that programs for derived relations or emergent responding (Pilgrim, 2020; Stromer & Mackay, 1992). This approach acknowledges the vast practical implications of emergent learning, encompassing the ability to respond to an event in terms of another, even when that correspondence was not directly taught. Extensive research focuses on the emergence of novel or derived responding (Barnes-Holmes et al., 2004; Brodsky & Fienup, 2018; Sidman, 1994; Rehfeldt, 2011).
The potential of engineering derived relations can be seen in early investigations. For example, Sidman and Cresson (1973) used an equivalence framework to teach reading comprehension in adolescents with severe intellectual disabilities. The researchers directly reinforced identity matching with printed words, spoken word to picture relations, and spoken word to printed word relations. This training resulted in the participants learning additional relations between pictures and printed words without direct instruction. This paradigm has been applied to several different academic concepts (see reviews by Brodsky & Fienup, 2018; Fienup & Brodsky, 2020; Raaymakers et al., 2019; Rehfeldt, 2011), even more basic research, and has been elaborated upon to consider different types of relational control between stimuli (Critchfield & Rehfeldt, 2020; Hayes et al., 2001).
This framework has also been evaluated by researchers from a verbal behavior perspective that focuses on speaker and listener behavior and the emergence of additional listener and speaker responses, respectively. Listener trainings are those that target gestural responses (sometimes called receptive responses or auditory-visual conditional discriminations), as is observed when a child matches stimuli or points to a stimulus in a field of exemplars and nonexemplars. Speaker trainings are those that target vocal responses, such as tacting an object. Researchers have examined how the acquisition of one topography of responses produces, without further training, the other topography of responses. For instance, Lee et al. (2015) found that children with autism spectrum disorder (ASD) produced a full range of listener responses following training on corresponding speaker responses (also, see Kobari-Wright & Miguel, 2014; Miguel et al., 2008). Sprinkle and Miguel (2012) conducted a direct comparison of listener and speaker trainings, investigating their respective impacts on emergent responses. Their findings revealed that both types of training led to the formation of stimulus classes. It is notable that speaker trainings generated more robust emergent listener responses compared to listener training's effects on emergent speaker responses, a trend also observed in Frampton et al.’s (2017) study.
The experimental outcomes regarding emergent behavior following listener and speaker trainings exhibit variability (Gibbs & Tullis, 2020). Some studies have shown that speaker trainings more effectively elicit listener responses (Frampton et al., 2017; Sprinkle & Miguel, 2012), whereas others have found that listener trainings produce emergent speaker behavior less consistently (Kobari-Wright & Miguel, 2014). In addition, there are instances where neither speaker nor listener trainings result in emergent behavior (Petursdottir et al., 2008). Despite these mixed findings, researchers have proposed that instructors prioritize teaching speaker responses initially, assessing for the emergence of corresponding listener responses, and only directly instruct listener responses if they fail to emerge without direct reinforcement (Contreras et al., 2020; Petursdottir & Carr, 2011). Although these recommendations are clear, further research is necessary to elucidate the characteristics or repertoires of children that influence the emergence of listener and speaker responses (Gibbs & Tullis, 2020).
One repertoire that has been conceptually linked to derived relations is bidirectional naming (Gibbs & Tullis, 2020; Greer et al., 2017; Horne & Lowe, 1996; Miguel, 2016; Miguel & Petursdottir, 2009). Horne and Lowe (1996) defined naming as “a higher order bidirectional behavioral relation that (a) combines conventional speaker and listener behavior within the individual, (b) does not require reinforcement of both speaker and listener behavior for each new name to be established, and (c) relates to classes of objects and events” (p. 207). This definition linked naming to the emergence of untaught relations, exemplified when a student learns a speaker response (e.g., tact response) and subsequently exhibits the untaught listener response, such as pointing to the stimulus when prompted (Lowe et al., 2002). For instance, a parent might say, "Look, there is an airplane" while driving, and on a later occasion, the child may point to an airplane in the sky when the parent says “airplane” or the child may tact the airplane. Miguel (2016) expanded on this concept by introducing a taxonomical framework that incorporates Common bidirectional naming (C-BiN) and Intraverbal bidirectional naming (I-BiN). C-BiN is concerned with common names establishing relations between stimuli, such as learning “cow” to “cow.” I-BiN is concerned with bidirectional relations established through intraverbals, such as learning to say “milk comes from the cow” that establishes the stimuli milk and cow as intraverbally related.
Moreover, in recent studies researchers have distinguished between emergent behavior when one is reinforced versus the emergence of speaker and listener behavior from observing models of the names of things—or incidental language acquisition. We term the latter incidental bidirectional naming (Inc-BiN) to emphasize that listener and speaker responses are acquired in the absence of direct reinforcement following observing someone tact a stimulus (Sivaraman et al., 2023). Sivaraman and Barnes-Holmes (2023) emphasized the existence of a substantial empirical dataset regarding the diversity in testing and terminology across naming experiments.
Morgan et al. (2020) examined the link between derived relational responding and the degree of Inc-BiN. Participants completed assessments where an instructor modeled the names of objects and later probed for corresponding listener and speaker responses. Participants also learned a small set of stimulus relations and were tested for mutually and combinatorial-entailed relations. Morgan et al. (2020) found strong correlations between children’s Inc-BiN repertoires and derived relations such that the repertoires positively predicted each other—higher degrees of Inc-BiN were associated with higher scores on derived relations tests. That is, as children’s capacity to learn incidentally increases, so too does one’s capacity to derive bidirectional relations when one is directly taught (akin to symmetry or mutual entailment). However, when evaluating derived relations, Morgan et al. (2020) taught all baseline relations using match-to-sample procedures. Thus, the generality of the relationship between Inc-BiN and derived relations from a verbal behavior perspective (teach speaker, test listener, and vice versa), remains unknown.
In the present study, we replicated procedures from Morgan et al. (2020) as well as those reported in the verbal behavior literature dealing with emergent listener/speaker behavior (see Contreras et al., 2020), or bidirectional listener/speaker operants. We implemented procedures and measures used across the areas of verbal behavior and derived relations to examine how they map onto each other with participants with varying degrees of Inc-BiN. Both areas offer insights into early language development and children's incidental learning showcasing similarities that are highlighted in the present study (Sivaraman et al., 2023). The outcomes have educational implications for how to differentiate instruction and capitalize on derived relations curricula as a function of the developmental repertoires, or cusps, that an individual possesses.
The objective of the present study was to investigate the association between the degree of incidental bidirectional naming (Inc-BiN) and their derived relations for literacy responses, particularly focusing on preschoolers with disabilities. We aim to shed light on potential overlap and differences, contributing to a deeper understanding of how incidental bidirectional naming might influence the development of derived responses in the context of emergent literacy.
STUDY I
In Study 1, we assessed children’s Inc-BiN repertoires and categorized their repertoires. Next, each participant completed speaker and listener trainings and we tested for the emergence of corresponding listener and speaker responses, respectively. Our analysis focused on the correspondence between Inc-BiN subtypes (Inc-BiN, Inc-UniN, NiN) and derived speaker and listener literacy responses.
Method
Participants
Thirteen preschoolers (10 males), with ages ranging from 3.7 to 4.9 years and a mean age of 4.7 years (SD = 0.54), participated in this study. The participants attended school for a duration ranging from 1.5 to 2.5 years (see Table 1). We selected participants based on the presence and absence of the Inc-BiN capability in their verbal repertoire (Inc-BiN assessment described below). Each participant had been receiving educational services at a private behavior analytic preschool utilizing the Comprehensive Application of Behavior Analysis (CABAS) model (Greer, 2002). At the school, educators determined curricula and assessed the presence of developmental cusps via the Preschool Inventory of Repertoires for Kindergarten (C-PIRK; Greer & McCorkle, 2003). Prior research has demonstrated that the C-PIRK curriculum effectively prepares preschoolers for general education classrooms by developing socialization, communication, and adaptive behaviors (Waddington & Reed, 2009). The current study utilized this curriculum because it outlined the prerequisite repertoires of verbal behavior.
As per the C-PIRK assessment, all 13 participants demonstrated the prerequisite repertoires to Inc-BiN, including reliably attending to instructors’ voices, faces, and instructional stimuli. All participants in the study had an Individualized Education Plan (IEP) and were educationally classified as a “preschooler with a disability” and received related services. Half of the participants attended a behavior analytic Early Intervention (EI) program prior to enrolling in the preschool where the study took place. Table 1 lists basic information about participants.
The performance of three participants met the criterion for Inc-BiN (criterion on listener and speaker responses). These participants had large verbal repertoires and could vocally mand and tact a variety of items. We defined this as participants emitting six or more vocal verbal operants (i.e., echoics, mands, tacts, and intraverbals) during a 5-min probe in a noninstructional setting. Prior to this study, researchers calculated a mean of 134 learning opportunities (i.e., discrete trials) across academic programs before mastering one objective for Inc-BiN participants. Programs included reading instruction and beginning-level math skills (e.g., one-to-one correspondence between 1 and 20 and the concept of more or less).
Seven participants’ performances met the criterion for Inc-UniN (criterion on listener responses, but not speaker responses). Participants emitting three or more vocal verbal operants (i.e., echoics, mands, tacts, and intraverbals) during a 5-min probe in a noninstructional setting, were defined as having a moderate verbal repertoire. At times, these participants gestured to mand, instead of vocalizing mands in novel situations. Inc-UniN participants required a mean of 228.28 learning opportunities before achieving one objective. Academic programming included early reading skills (e.g., textually responding to letter name and sound) and beginning-level math skills (e.g., number identification).
Three participants did not meet the criterion for speaker or listener incidental language acquisition and were thus deemed as having no incidental naming (NiN). Refer to Table 1 for inclusion criteria for participants. All participants could vocally mand and tact 25 or more items in contrived contexts. At times, these participants required teacher vocal prompts to help communicate their needs in natural settings. NiN participants required 330 learning opportunities before meeting the one academic objective. Each completed academic programming that included prereading skills (e.g., textually responding to letter name and sound) and beginning-level math skills (e.g., number identification).
Setting and Materials
All sessions were conducted in the participants’ respective classrooms. During all sessions, the participant sat next to the researcher at a U-shaped table.
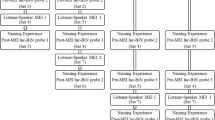
During the derived relations training and testing sessions, participants learned letter-name-sound classes (e.g., A, “A”, “aa”) or sight words that were based on the Fry Sight Word list (e.g., who, pretty, live). Researchers presented the 3.81 by 3.17 cm letters via Microsoft PowerPoint on a 33.2 cm Macintosh laptop. During each trial, one to three letters were presented in a horizontal array, depending on whether the session was measuring speaker (one stimulus at a time) or listener responses (three stimuli simultaneously presented). Sight word instruction was presented in a similar manner, where one to three words appeared on the screen (refer to Fig. 1 for experimental sequence).

Measurement
Bidirectional Naming
During the bidirectional naming assessment, the untaught topography of point, tact and intraverbal responses were measured. For point-to responses, three stimuli were presented in a horizontal array (two nonexemplars and one target exemplar) with the vocal antecedent of “point to (name of stimulus).” For tact and intraverbal responses, stimuli were presented in random order ensuring that target stimuli were not presented consecutively. Correct responses were those that corresponded to the discriminative stimulus and were emitted within 5 s of the discriminative stimulus. Incorrect responses were those that did not correspond to the discriminative stimulus or no response within 5 s. The assessment of each topography included 20 unconsequated trials and we calculated the percentage correct as number of correct responses divided by 20 and multiplied by 100.
All participants observed object-name relations (i.e., seeing and hearing the name) and were assessed for corresponding speaker (tact, intraverbal) and listener (point to) responses 2 hr later. Participants who scored 80% or higher on speaker and listener responses were categorized as having Inc-BiN. Participants who scored 80% or higher on listener responses, but below 80% on speaker responses were categorized as Inc-UniN. Participants who scored 80% or higher on speaker responses, but below 80% on listener responses were also categorized as Inc-UniN, although no participants in the current study demonstrated that form on Inc-UniN. Participants who scored below 80% for both speaker and listener responses we categorized as having no incidental naming (NiN).
Listener/Speaker Trainings and Derived Responses
Teaching data were collected during learn unit instruction, (i.e., interlocking three-term contingencies; at least two for a teacher and one for the student/learner; Albers & Greer, 1991), where correct responses were reinforced and incorrect responses were consequated with a correction procedure. The researcher collected data on learn units to criterion across each training protocol. The mean number of learn units to criterion (i.e., LUC) was calculated by adding the total number of learn units presented to meet mastery criterion and divided by the number of objectives achieved. We calculated learn units to criterion separately for listener and speaker protocols.
During letter name and sound instruction, the researcher administered 30 learn units (LUs; i.e., learning trials) per session. Half of the trials were letter names and half were letter sounds and this included five LUs for each of the three target responses—all presented in a randomized order. Both topographies (letter names and sounds) were plotted as separate data paths (see Figs. 2, 3 and 4). At the end of each session, correct responses were totaled and graphed as a percentage. In order to calculate the correct percentage, the number of correct LU responses were divided by the total number of LU opportunities presented then converted into a percentage (i.e., 5/15 * 100 = 33%).

Training Data for Each Inc-BiN Participant in Study 1

Training Data for Inc-UniN Participants in Study 1

Training Data for Inc- NiN Participants in Study 1
During sight word instruction, the researcher administered 20 LU (i.e., learning trials) per session, that included four operants with five LU opportunities to respond to each operant—also presented in a randomized order. At the end of the session correct responses were recorded in a similar manner as letter name and sound instruction.
We measured the accuracy of derived responses following listener and speaker trainings. We measured derived responses in accordance with which repertoire was reinforced (i.e., measurement of speaker responses following the listener training protocol and measurement of listener responses following the speaker training protocol). A correct response was one that corresponded to the discriminative stimulus and was emitted within 5 s. For example, during the speaker training protocol, if the discriminative stimulus was a picture of the letter A, tacting the stimulus “A” was considered a correct speaker response. An incorrect response was one that did not correspond to the discriminative stimulus or no response within 5 s. Whereas, during the listener training protocol, if the discriminative stimulus was a field of three stimuli (i.e., two nontarget stimuli and one target stimulus) and the vocal antecedent of “point to the letter A” was given, pointing to the target stimulus “A” was considered a correct listener response. An incorrect response was one that did not correspond to the target stimulus or no response within 5 s.
Procedures
The study began with researchers assessing each participant’s degree of incidental bidirectional naming. Then, participants contacted both listener and speaker protocols (see Fig. 1). Below we describe each component in detail.
Inc-BiN assessment
The Inc-BiN assessment was composed of two components: exposure to name-object relations and the assessment of corresponding speaker and listener responses (Greer & Longano, 2010; Morgan et al., 2020). During the exposure, the researcher obtained the participant’s attention, provided identity matching trials, named the stimulus during the trials, and provided consequences contingent on the participant’s match response (not contingent on responses in accordance with the name, such as an echoic).The purpose of the matching trials was to provide an opportunity for the researcher to associate names with stimuli during a task that was in the participant’s repertoire.
At the start of each trial, the researcher laid out three stimuli in front of the participant (two nontarget exemplars and the target stimuli), presented the participant with the target exemplar and the vocal antecedent, “Match ____ to _____” (e.g., “Match Krumm to Krumm”). Contingent upon a correct matching response, the researcher provided social consequences such as vocal praise (i.e., “Great job Susan!”) and tickles (with learner’s consent). If the participant matched the target stimulus to a nonexemplar or did not respond within 3 s, the researcher implemented a correction procedure whereby she modeled the correct matching response and represented the antecedent to allow the participant the opportunity to independently respond. Each session was composed of 20 match responses (five stimuli with four LUs per stimulus). Inc-BiN exposure sessions were continued until a participant responded with 90% matching accuracy during one session (Greer et al., 2005). It is important to note that there were no reinforcement contingencies arranged for responding to the researcher’s modeling of object–name relations (e.g., echoics).
The second component of the Inc-BiN assessment was a test for corresponding listener and speaker responses. After the Inc-BiN exposure, the researcher assessed corresponding listener and speaker responses 2 hr later. Three responses were measured. The researcher assessed listener responses by presenting the participant with three stimuli (two nonexemplars and one target stimulus) and the vocal direction “Point to _____”. For speaker responses, the researcher assessed pure and impure tacts. For pure tacts, the researcher held one stimulus in front of the participant and waited up to 5 s for the participant to provide the corresponding tact (name). For impure tacts, the researcher conducted trials similar to pure tact trials and added the vocal direction, “What is this?” The researcher conducted 20 LUs for each response type (point to, pure tact, impure tact), which was composed of four LUs opportunities to respond to each of five stimuli. During this probe for listener and speaker responses, the researcher provided no accuracy feedback, but intermittently praised academically related behaviors such as sitting and attending.
Listener and Speaker Protocols
During each teaching phase, participants were taught either listener or speaker responses and then tested in the untaught topography (i.e., derived responses). Teaching phases were conducted as learn unit instruction (Albers & Greer, 1991). Upon emitting a correct response, the researcher delivered vocal praise, playful physical contact, or a token—the specifics were tailored to each participant and held constant across training conditions. The researcher engaged in a correction procedure contingent on incorrect responses. During derived response phases, the researcher provided no feedback.
Preassessments
Preassessements were conducted for both listener and speaker responses at the onset of the study to ensure we taught responses not already in each participant’s repertoire. The letter-name-and-sound assessment included the letter names and letter sounds for all 26 letters in the alphabet. During the preassessment, one sample stimulus was presented at a time, where the participant was instructed to respond to “What letter is this?” or “What sound does this make?” During the preassessment and probe sessions no consequences were delivered for correct and incorrect responses. The preassessment consisted of 52 responses for letter names/sounds. The researcher randomized the order of presenting letters for each participant. After completing the preassessment, the researcher chose letters to teach based on those the participant responded to incorrectly during the preassessment and the researcher eliminated letters for which a participant responded accurately.
Preliminary data indicated that five (Inc-BiN- 1, Inc-BiN-2, Inc-BiN-3, Inc-UniN-1, and Inc-UniN-2) of the selected participants had previously mastered all letter names and sounds. For these participants, a preassessment on 100 preprimer Dolch words were conducted in the same manner. During the preassessment, one sample was presented at a time, where the participant was instructed to “read.” During the preassessment and probe sessions no consequences were delivered for correct and incorrect responses. The researcher randomized the order of words for each participant. After completing the preassessment, the researcher chose 16 words to teach based on those the participant responded to incorrectly during the preassessment and the researcher eliminated words to which a participant responded accurately. It is important to note that the researcher selected the same 16 sight words for all participants.
Listener teaching protocol
The listener teaching protocol consisted of teaching the participant to identify target stimuli with a point response, followed by tests of the emergence of corresponding speaker responses. For letter names and sounds instruction, the teaching phase consisted of two experimentally defined responses (i.e., letter names and letter sound). For each session, instruction was presented in a rotated sequence. The participant received 15 LU opportunities to point to the letter name and 15 LU opportunities to point to the letter sound, for a total of 30 LUs. The criterion for each response was 90% accuracy for two consecutive sessions or 100% accuracy in one session. During each session, the researcher presented an array of three stimuli, one target exemplar and two nontarget exemplars. After presenting the stimuli, the researcher presented the vocal antecedent (e.g., “point to M”/ “point to /m/”) and allowed 5 s for the participant to respond. If the participant pointed to the target exemplar, the researcher provided social consequences (i.e., vocal praise, playful physical contact, tokens). If the participants emitted an incorrect response, the researcher implemented a correction procedure. For the correction procedure, the researcher modeled the correct response (i.e., pointed to the target stimulus), and re-presented the antecedent to give the participant an opportunity to emit the response independently. If the participant continued to emit the incorrect response after the correction procedure, the researcher modeled the response up to three times before proceeding to the next learn unit. The researchers provided no consequences for corrected responses.
Researchers taught sight words in the same manner as letter names and sounds, with minor exceptions. The researcher administered 20 LU per sessions, composed of five LU opportunities to point to each of four sight word. During each session, the researcher presented an array of three stimuli, one target exemplar and two nontarget exemplars. After presenting the stimuli, the researcher presented the vocal antecedent (e.g., “point to [word]”) and allowed 5 s for the participant to respond.
Regardless of letter-names-sounds or sight words instruction, after a participant’s responding met mastery criterion during the listener teaching protocol portion, the researcher assessed derived speaker responses. The researcher presented each stimulus on the laptop via Microsoft PowerPoint, said, “What letter is this? / “what sound does this make?” and waited up to 5 s for the participant to respond. For letter names and sounds derived responses, there were 12 LUs in a session, which was composed of three stimuli, two responses (e.g., letter name, letter sound), and two opportunities of each learn unit type. For sight word derived responses there were six unconsequated LUs in a session, which was composed of three stimuli and two opportunities of each learn unit type. Criterion for the demonstration of the derived responding was 80% accuracy in one session.Footnote 1
Speaker teaching protocol
The speaker teaching protocol consisted of teaching the participant to textually respond to target stimuli (e.g., selected sight, followed by tests of the emergence of corresponding listener responses). For letter names and sounds instruction, the training phase consisted of two experimentally defined responses (i.e., letter name and letter sound). For each session, instruction was presented in a rotated sequence. The participant received 15 LU opportunities to answer the intraverbal tact response of letter name (i.e., “What letter is this?”) and 15 LU opportunities to intraverbal tact response of letter sound (i.e., “What sound does this make?”) for a total of 30 LUs. The criterion for each response was 90% accuracy for two consecutive sessions or 100% accuracy across one session. During each session, the researcher presented the target exemplar on a laptop via Microsoft Office PowerPoint with the vocal antecedent and followed 5 s for the participant to respond. If the participant emitted the target response the researcher provided social consequences (i.e., vocal praise, playful physical contact, tokens). If the participants emitted an incorrect response, the researcher implemented a correction procedure. For the correction procedure, the researcher modeled the correct response (e.g., “/m/” or “m”) and re-presented the antecedent to give the participant an opportunity to emit the response independently. If the participant continued to emit the incorrect response after the correction procedure, the researcher modeled the response up to three times before proceeding to the next learn unit. The researchers provided no consequences for corrected responses. Data were collected and recorded in the same manner as stated above. The same procedure was implemented for the participants that were taught sight words.
Researchers taught sight words in the same manner as letter names and sounds, with minor exceptions. The researcher administered 20 LUs per session, composed of five LU opportunities to textually respond/tact each of the four sight words. During each session, the researcher presented one target exemplar on the laptop screen via Microsoft Office PowerPoint. After presenting the stimuli, the researcher presented the vocal antecedent “read” and allowed 5 s for the participant to respond.
After a participant’s responding met mastery criterion during the speaker training portion of the protocol, the researcher assessed derived listener responses. The researcher presented each stimulus on the laptop via Microsoft Office PowerPoint and said, “point to the letter m / “point to the letter that makes the /mm/ sound?” or “point to here” and waited up to 5 s for the participant to respond. For letter names and sounds derived responses, there were 12 LUs in a session, which was composed of three stimuli, two responses (e.g., letter name, letter sound), and two opportunities of each learn unit type. For sight word derived relations, there were six unconsequated LUs in a session, which was composed of three stimuli and two opportunities of each learn unit type. Criterion for the demonstration of the derived responding was 80% accuracy in one session. See Table 2 for acquisition probes and intervention rotation per participant.
Decisions to Stop a Protocol
The researcher ended teaching portions of protocols contingent on a participant mastering the respective protocol. In addition, we implemented a decision protocol (Keohane & Greer, 2005) to make decisions about whether to stop instruction if learning was not occurring. We implemented the decision protocol as an ethical guard against keeping participants in a training phase when additional instructional supports were needed beyond the purview of this experiment. We analyzed data paths, or the line connecting two consecutive data points. “Stop” decisions in the decision protocol included 0% accuracy in one session, three consecutive descending data paths, or five variable and overall descending data paths. We terminated a training phases contingent on the data meeting two stop decisions. This rule only affected NiN participants.
Experimental Design
In the present study, repeated acquisition design was utilized (Kirby et al., 2021). Each participant underwent both listener and speaker protocols, along with corresponding derived responses tests. The order of the training protocols (listener or speaker) was counterbalanced across participants, ensuring variability, and controlling for potential order effects. For instance, Participant Inc-BiN-1 commenced with the listener training phase, whereas Participant Inc-BiN-2 started the study with the speaker training phase. In addition, the assignment of specific stimuli to protocols was counterbalanced across participants to minimize potential bias. For example, the set of stimuli assigned to Participant Inc-UniN-1’s listener protocol was systematically assigned to Participant Inc-UniN-2’s speaker protocol. Participants progressed through the designated conditions (listener training protocol or speaker training protocol) at their individual pace, continuing until their performance met the predefined teaching criterion within a given condition. Each participant rotated through both conditions (listener and speaker) twice, resulting in a total of four conditions for each participant.
Throughout the study, we assessed the association between the degree of Inc-BiN (including participants with varying degrees such as Inc-BiN, Inc-UniN, and NiN) and derived responses. We categorized participants based on their respective degrees and examined differences in derived listener and speaker responses among these groups. This analysis allowed us to explore potential patterns or distinctions in the relationship between the participants' degree of Inc-BiN and their performance on derived responses tasks for both listener and speaker protocols. The inclusion of participants with different degrees adds depth to our exploration, providing an understanding of the interplay between the degree of Inc-BiN and the acquisition of derived responses.
Interobserver Agreement and Procedural Fidelity
A second independent observer collected data for the purposes of calculating interobserver agreement (IOA) and treatment fidelity using the Teacher Performance Accuracy Rate Observation form (TPRA; Hranchuk & Williams, 2021; Ingham & Greer, 1992; Ross et al., 2005). The researchers calculated trial-by-trial IOA by counting the number of learn units on which researcher and independent observer agreed, divided that number by the total number of opportunities presented, and multiplied the resulting number by 100. IOA was collected for 56% of the Inc-BiN probe (i.e., untaught response topographies after Inc-BiN exposure) sessions with 100% agreement. We recorded IOA for 32% of the training protocol sessions (i.e., listener and speaker training phases) with 100% agreement and 100% of the derived responses sessions with 98% agreement (range, 95% to 100%).
The independent observer also collected procedural fidelity data using the TPRA form. Per observation, the independent observer rated the accuracy of researcher-delivered antecedents and consequences. Fidelity was calculated by dividing the number of correct components divided by the total number of components multiplied by 100. Treatment fidelity was conducted for 21% of all session with a mean fidelity of 98% (range, 95% to 100%).
Results and Discussion
Listener and Speaker Protocol Performances
Each participant completed speaker and listener trainings and were tested for untaught derived responses. Below we categorize outcomes by level of Inc-BiN at the start of the study. Figures 2, 3, and 4 display the training and derived responses data for participants with Inc-BiN, Inc-UniN, and NiN, respectively. In each graph, all listener responses are grey, such that grey data points represent listener trainings and grey bars represent derived listener responses. All speaker responses are black, such that black data points represent speaker training and black bars represent derived speaker responses.
Participants with Inc-BiN
Figure 2 displays the training and derived responses data for three Inc-BiN participants. All Inc-BiN participants steadily achieved the acquisition criterion during the respective trainings and met criterion levels during all derived responses probes. Inc-BiN-1, Inc-BiN-2, and Inc-BiN-3 exhibited a rapid learning pattern, regardless of the specific training approach. On average, it took these participants 63 LUs to master speaker responses across two to four sessions, achieving derived listener responses with high accuracy between 98% to 100%. Likewise, the acquisition of listener responses was consistent, with participants requiring an average of 50 LUs across one to seven sessions. They also achieved derived speaker responses with an accuracy ranging from 94% to 100%. Overall, Inc-BiN participants readily acquired speaker and listener responses under direct reinforcement contingencies and derived corresponding listener and speaker responses.
Participants with Inc-UniN
Figure 3 displays the training and derived responses data for seven Inc-UniN participants. All Inc-UniN participants steadily achieved acquisition criterion during the respective trainings and met criterion levels during derived listener relation probes. On average, it took participants approximately 120–255 LUs to master speaker responses, with the number of sessions ranging from 3.5 to 8.5. However, accuracy rates in deriving listener responses after learning speaker responses ranged from 83.33% to 100%. Learning listener responses also varied, taking an average of about 30–180 LUs, over two to six sessions. After mastering listener responses, accuracy rates in deriving speaker responses ranged from 25% to 100%.
Participants with NiN
Figure 4 displays the training and derived responding data for three NiN participants. NiN participants completed each condition only one time due to the lack of prerequisite skills needed in order to complete the academic task, such as attending to letter stimuli. All NiN participant’s performances met the decision protocol rules to stop a training phase and no NiN participant met criterion levels during derived responses probes. Overall, NiN participants did not acquire derived listener or speaker responses under direct reinforcement contingencies for both training conditions.
Summary
Overall, participants categorized as Inc-BiN derived both listener and speaker responses, independent of the training protocol. In addition, they also had a faster rate of acquisition during both trainings; approximately half of their Inc-UniN counterparts. Inc-UniN participants derived listener responses after completing speaker trainings, but not vice versa. These results are consistent with verbal behavior development theory (VBDT), which states that listener behavior precedes speaker behavior (Greer & Speckman, 2009). That is, participants can readily acquire listener responses (i.e., matching and pointing) before emitting speaker behavior (i.e., tacting/labeling). Furthermore, all NiN participants had variable responding across trainings, and demonstrated a lack of derived responding for both listener and speaker responses. The outcomes are in alignment with Morgan et al. (2020), who showed similar relations. These outcomes extended previous work by quantifying outcomes in terms of meeting criterion for demonstrating reliable derived responses or not. This study also extends Morgan et al.’s findings on the emergence of speaker and listener responses following match-to-sample responses by examining both listener–speaker and speaker–listener derived responses.
Outcomes According to Degrees of Bidirectional Naming
In the following analysis, we compare outcomes based on each participant’s degree of bidirectional naming at the start of the study, categorized as Inc-BiN, Inc-UniN, or NiN. Descriptive statistics were conducted for three measures: (1) the mean number of LUC across all academic programs; (2) LUC across the listener training protocol; and (3) LUC across the speaker training protocol. These measures are depicted in Tables 1 and 3.
Learn Units to Criterion (LUC)
We compared the number of learn units required to master listener and speaker responses. We omitted data from NiN participants because these participants’ responding often met the stop decision protocol rule. Thus, below we report data on Inc-BiN and Inc-UniN participants (refer to Table 3). Overall, Inc-UniN participants had a higher average of overall LUC (M = 228.29, SD = 57.43) than Inc-BiN participants (M = 134, SD = 10.15) – meaning Inc-UniN participants required more learning opportunities to respond at criterion.
Derived Responses
Figure 5 displays the percentage of derived speaker and listener responses grouped by degrees of bidirectional naming. Overall, participants who demonstrated Inc-BiN derived the untaught topography, regardless of protocol, whereas participants who demonstrated Inc-UniN derived 95.92% of the listener responses (following speaker training) and 52.92% of the speaker listener (following listener training). Participants who demonstrated NiN, were unable to derive the untaught relation at criteria levels, which was not surprising given that these participants did not meet mastery criterion during trainings.

Percentage of Derived Responses for Participants with Various Degrees of the Bidirectional Naming Capability in Study 1. Note. BiN (n = 3), UniN (n = 7), and NiN (n = 3)
Summary
The findings from Study 1 demonstrate associations between a participant’s degree of Inc-BiN and derived responses, similar to Morgan et al. (2020). However, Morgan et al. taught baseline relations using match-to-sample procedures. Thus, our findings expand the generality of the relation between Inc-BiN and derived responses to traditional verbal behavior research on the emergence of listener and speaker responses. In particular, participants who demonstrated NiN struggled to acquire both listener and speaker responses and subsequently failed to derive corresponding speaker and listener responses. Participants who demonstrated Inc-UniN acquired both listener and speaker responses under direct reinforcement conditions and derived listener, but not speaker responses. Last, participants who demonstrated Inc-BiN acquired both listener and speaker responses under direct reinforcement conditions and derived both speaker and listener responses. The current findings suggest a relation between bidirectional naming and derived responses and pinpoint how different subcategories of bidirectional naming are associated with different types of derived responses. Our findings replicate those of Morgan et al. (2020) and add a level of detail by parsing out differential effects on listener and speaker derived responses, in particular.
Eikeseth and Smith (1992) was one of the first studies to highlight the impact of naming on derived relations. Once naming was established, discrimination training such as match-to-sample procedure (i.e., listener training) produced emergent performance as a speaker, and vice versa. This effect was replicated by Howarth et al. (2015). Research focused on listener and speaker trainings demonstrate mixed findings, suggesting that these trainings may not be universally applicable, but should be tailored to individual learners based on their preexperimental repertoires and learning histories. These discrepancies prompt questions about the learner—for whom do these outcomes apply?
The results of Study 1 demonstrated an association between a learner’s degree of bidirectional naming and the acquisition of both listener and speaker responses, as well as derived speaker and listener responses (Morgan et al., 2020). However, we observed this association based on the degree of bidirectional naming that a participant possessed at the outset of the experiment. Thus, it remains to be seen how altering a participant’s Inc-BiN repertoire leads to corresponding changes in derived responses.
STUDY 2
We examined this phenomenon within-subjects and established Inc-BiN repertoires for participants who entered Study 1 with Inc-UniN repertoires. Participants categorized as having Inc-UniN in Study 1 served as participants in Study 2. First, we established Inc-BiN using multiple-exemplar instruction (MEI; Greer et al., 2007; Hawkins et al., 2009; LaFrance & Tarbox, 2019) or repeated probes (Kleinert-Ventresca et al., 2023). MEI involved teaching new responses and rotating between multiple exemplars and multiple topographies (match, point to, tact, intraverbal) during sessions until participants mastered all responses. Once a participant mastered MEI and passed the Inc-BiN assessment, we replicated the derived responses assessments from Study 1 in order to observe whether each participant’s responses to derived responses changed as a function of improving Inc-BiN repertoires. Our analysis focused on the learn-units-to-criterion before and after the induction of bidirectional naming and the percentage of derived speaker and listener responses.
Method
Participants
Six of the seven Inc-UniN participants from Study 1 met criterion to continue in Study 2. Participant Inc-UniN 7 from Study 1 was not included in Study 2 because the participant did not demonstrate an adequate self-management repertoire to continue onto the MEI phase. In the case of MEI, the participants are required to sit and attend to the stimuli for longer than 5 min; this participant was easily distracted and required dense schedules of reinforcement. Participants Inc-UniN-1 through 6 from Study 1 participated in Study 2.
Settings and Materials
Study 2 was conducted in the same setting as Study 1. Table 4 lists the stimuli used during MEI. The stimuli were printed on index cards measuring 3 cm x 4 cm. We used the similar materials as described in Study 1 for the Inc-BiN assessment and derived responses protocols.
Measurement
We measured Inc-BiN and derived responses the same as in Study 1. During MEI, we measured the accuracy of four response topographies: (1) match; (2) point to; (3) tact; and (4) intraverbal. MEI data were collected using learn unit instruction (Albers & Greer, 1991), where correct responses were reinforced and recorded as a plus (+), and incorrect responses were recorded as a minus (-), and a correction procedure was utilized. For match responses, three stimuli were presented in a horizontal array (two nonexemplars and one target exemplar), the participants were then handed the target stimulus and given the vocal antecedent of “Match___ to ______”. For point to responses, three stimuli were presented in a horizontal array (two nonexemplars and one target exemplar) with the vocal antecedent of “point to.” For tact and intraverbal responses, stimuli were presented in random order ensuring that target stimuli were not presented consecutively. Correct responses were those that corresponded to the discriminative stimulus and were emitted within 5 s of the discriminative stimulus. Incorrect responses were those that did not correspond to the discriminative stimulus or no response within 5 s. All learn units were rotated across topographies and operants (see Table 5).
Independent Variable
The independent variable was multiple exemplar instruction (MEI). MEI was implemented, and probes were conducted until participants met the criterion for incidental bidirectional naming (Inc-BiN). The investigation aimed to analyze the resulting changes in derived responses, comparing them to those observed in Study 1.
Procedure
Inc-BiN assessments
The same Inc-BiN assessments described in Study 1 were implemented in Study 2. Inc-BiN assessments were conducted each time a participant met criterion during MEI. If a participant’s behavior met criterion for Inc-BiN (80% accuracy or higher for listener and speaker responses), the researcher moved the participant on to the derived responses protocols. If a participant’s behavior did not meet criterion another round of MEI was conducted.
Multiple Exemplar Instruction
This procedure involved the rotation of listener and speaker topographies during instructional sessions and the incorporation of multiple exemplars of stimuli (Greer et al., 2005; LaFrance & Tarbox, 2019). For example, if teaching animals (e.g., dog, cat, mouse), the researcher first produces four pictures of each animal that vary in form. Next, during instruction the researcher rotates between listener (match, point to responses) and speaker (tact, intraverbal) responses across the animal stimuli. A single complete MEI session consisted of 80 LUs, composed of five stimuli (and corresponding multiple exemplars), four topographies, and four opportunities to respond to each topography. The criterion for terminating a phase of MEI was 90% accuracy across two consecutive sessions or 100% accuracy in one session. The researcher selected novel cartoon characters to assist in motivating the participant to attend to the stimuli.
After criterion was met for each set of MEI, researchers conducted an Inc-BiN assessment. If a participant demonstrated Inc-BiN (i.e., achieving 80% accuracy across listener and speaker responses) another Inc-BiN assessment was conducted using a novel set to confirm the establishment of Inc-BiN. If the participant did not demonstrate Inc-BiN, another phase of MEI was implemented with new stimuli. It is important to note that this sequence continued until the participant achieved criterion or completed three sets of novel MEI sets.
Repeated Probe Procedure
After completing three sets of MEI, without changes in Inc-BiN, we implemented a repeated probe (i.e., stimulus–stimulus pairing) procedure (see Kleinert-Ventresca et al., 2023). Previous research has shown that after the presence of Inc-UniN for participants with certain existing cusps or stimulus control accrue reinforcement stimulus control for the speaker component as a result of pairings that are the same as repetition of probes, as were done in the pre- and postassessments (Kleinert-Ventresca et al., 2023). The repeated probe procedure consisted of repeated Inc-BiN assessment with the same set until criterion levels of 80% accuracy across topographies. It is important to note that the Inc-BiN exposure was only conducted once and the subsequent sessions consisted of the Inc-BiN assessment (i.e., point to, tact, and intraverbal responses)—untaught topographies, refer to Study 1. The Inc-BiN assessment probe repetitions were unconsequated and participants repeated the Inc-BiN assessment until they demonstrated criterion of 80% accuracy. All phases consisted of tests for listener or speaker responses without repeating the Inc-BiN experience. The predetermined criterion for mastery of the intervention was 80% accuracy across all response topographies (i.e., point, tact, and intraverbal) in a single Inc-BiN assessment.
Listener and Speaker Protocols
For Study 2, speaker and listener protocol conditions were presented in the same manner as described in Study 1, including the preassessment of targets taught during these phases. The only difference between Study 1 and Study 2 was the type of target operants taught. In this experiment, all participant learned sight words.
Decision to Stop a Protocol
We used the same decision protocol to stop as described in Study 1; however, no performances met the decision protocol rules and thus no training was stopped (Keohane & Greer, 2005).
Experimental Design
The current study used a pre- and postassessment design to evaluate the impact of MEI on derived responses. In Study 2, participants underwent both listener and speaker protocols. Once participants established Inc-BiN, we replicated the rotation of listener and speaker protocols.
Interobserver Agreement and Treatment Fidelity
Interobserver agreement (IOA) and treatment fidelity were collected in the same manner as Study 1. During Inc-BiN assessments, we collected IOA for 93% of sessions and fidelity for 78% of sessions, resulting in 100% agreement and 100% fidelity. During the MEI (i.e., intervention) we collected IOA for 37.5 % of sessions with a mean agreement of 98%. During the DRR probes, we collected IOA for 63% of sessions, resulting in 100% agreement and 95% fidelity. Across trainings sessions, we collected IOA for 14% of listener sessions, and 4% of speaker sessions, resulting in a 100% agreements and 100% fidelity.
Results and Discussion
Establishment of Inc-BiN
Table 6 displays the MEI performance data. Participants mastered MEI in an average of 382 LUs (range, 240 to 560). Participants required between one and four sets of MEI before demonstrating the Inc-BiN repertoire. Following the initial probe, researchers conducted a second pre-MEI probe with all participants. The number of correct responses to the point topography remained similar for five out of six participants, demonstrating they all had Inc-UniN prior to the onset of the MEI intervention. The number of speaker responses varied across participants during the initial probe. Overall, all participants were able to acquire the capability of Inc-BiN, through MEI or a repeated probe (i.e., stimulus–stimulus) procedure.
Listener and Speaker Protocol Performances
Each participant completed speaker and listener trainings, as well as tests for untaught, derived responses. Figure 6 displays the training and derived response data for six Inc-UniN participants. This occurred following the establishment of Inc-BiN. All Inc-UniN participants steadily achieved mastery criteria during their respective trainings. During the derived listener probe, all Inc-UniN participants met the criterion levels, whereas four out of six participants met the criterion levels during the derived speaker relation probes. Prior to the acquisition of Inc-BiN, Inc-UniN participants displayed varying levels of proficiency in both speaker and listener responses. On average, it took participants 100 LUs to master speaker responses across 7 to 14 sessions, achieving derived listener responses with high accuracy between 95% to 100%. This accounts for a 25.42-point difference in learn units to criterion, pre- and postacquisition of Inc-BiN. Likewise, the acquisition of listener responses was consistent, with participants requiring an average of 60 LUs across 6 to 13 sessions. They also achieved derived speaker responses with an accuracy ranging from 56% to 95%. This accounts for a 50.04-point difference in learn units to criterion, pre- and postacquisition of Inc-BiN. After the acquisition, participants generally showed improvement in their speaker and listener responses. For instance, UniN-1 increased their speaker responses from 31.25 to 56.25 and listener responses from 87.5 to 94.

Training Data for Inc-UniN Participants in Study 2
Overall, four out of the six Inc-UniN participants readily acquired both listener and speaker responses under direct reinforcement contingencies and derived corresponding responses
Outcomes Comparing Pre- and Postestablishment of Inc-BiN
We compared participant’s performance from before the induction of Inc-BiN (Inc-UniN participant performances in Study 1) to those following the induction of Inc-BiN (Inc-UniN performances during Study 2).
Learn Units to Criterion for Learning Listener and Speaker Responses
We compared the number of learn units required to master listener and speaker responses before and after the acquisition of Inc-BiN. Participants reported a higher learn units to criterion pre-Inc-BiN (M = 117.93, SD = 39.95) than post-Inc-BiN (M = 80.21, SD = 22.86). A dependent-samples t-test was performed to assess the disparities between pre-Inc-BiN and post-Inc-BiN learn units, resulting in a p-value of less than 0.05, indicating statistical significance. Findings correspond to previous research that show participants with Inc-BiN learn at a faster rate and require fewer learn units to meet criterion (Greer et al., 2011; Greer & Longano, 2010; Hranchuk et al., 2019). In addition, these results also revealed that learn units to criterion across listener and speaker trainings decreased at a substantial rate after the acquisition of Inc-BiN, approximately a 50 and 25 mean difference, respectively.
Derived Responding after the Induction of Inc-BiN
Figure 7 shows the percentage of derived relation across untaught topographies for participants, before (grey bars) and after (black bars) Inc-UniN participants acquired bidirectional naming. Results were similar to Study 1 when comparing Inc-UniN and Inc-BiN participants, with participants emitting a higher percentage of speaker responses following the induction of Inc-BiN. Participant Inc-UniN-4 demonstrated high levels of derived responding before and after the acquisition, suggesting that another subtype of Inc-BiN was present at the onset of the study (Hawkins et al., 2018). Participants Inc-UniN-1, 2, 3, 5, and 6 remained stable in emitting listener responses and increase by 25, 31, 62, 67, and 16.5 percentage points for speaker responses, respectively. Overall, all participants increased in correct responding but not consistently to mastery levels (Inc-UniN-1, Inc-UniN-6).

General Discussion
Across two studies, we observed an association between degrees of Inc-BiN and specific derived responses. In Study 1, participants with the Inc-BiN capability, who learned listener and speaker responses from antecedents alone, derived both listener and speaker responses with high levels of accuracy. Participants with the Inc-UniN capability, who learned listener but not speaker responses from antecedents, derived listener but not speaker responses. Participants who did not demonstrate listener or speaker responses from antecedents (no incidental naming, or NiN) struggled to acquire listener and speaker responses and did not derive corresponding responses. In Study 2, we further supported a correspondence between bidirectional naming and derived responses by establishing bidirectional naming with participants and observing corresponding changes in those participants accuracy of derived responses. In particular, Inc-UniN participants from Study 1 developed the stimulus control for Inc-BiN and then were able to derive speaker responses as they had been able to derive listener responses during Study 1. These participants’ performances at the end of Study 2 mimicked those of Inc-BiN participants in Study 1.
The outcomes of this study replicate and potentially clarify previous research. Similar to Eikeseth and Smith (1992) and Howarth et al. (2015), we observed participants derive a full range of responses when the child demonstrated the Inc-BiN capability (Inc-BiN participants, Study 1) or when we induced this capability (Study 2). The current study potentially clarifies the outcomes of previous research (e.g., Petursdottir et al., 2008; Sprinkle & Miguel, 2012) suggesting that degrees of Inc-BiN predict the ability to derive speaker and listener responses following the direct reinforcement of the other. That is, in previous research where children did or did not derive speaker or listener responses, the results of this study suggest that those behaviors can be predicted by one’s ability for incidental language acquisition (Inc-BiN) and learning from antecedent stimuli. We found that participants with the Inc-BiN capability can learn tacts from antecedents (i.e., they learn the tact from pairings of name–object during listener training and then this shows up in tests of derived speaker responses). Whereas, participants with Inc-UniN do not learn tacts from antecedents, which is why they do not meet criterion for the tests of derived speaker responses. Thus, it is not the case that speaker or listener trainings produce (e.g., Sprinkle & Miguel, 2012) or do not produce (Petursdottir et al., 2008) emergent verbal behavior; rather, the effects of these trainings are potentially mediated by the Inc-BiN capability (Miguel, 2018; Morgan et al., 2020). Although more data and research are needed to clarify the aforementioned concerns, the data thus far demonstrate a connection between the degrees of bidirectional naming (specifically Inc-UniN and Inc-BiN) and derived listener and speaker responses.
Existing studies yield diverse results regarding the optimal training methodologies, with some suggesting that listener and speaker trainings yield equivalent outcomes (Delfs et al., 2014; Frampton et al., 2017). The current research broadens its scope by assessing the extent of incidental bidirectional naming and categorizing students' verbal behavior repertoires.
These findings suggest that special education educators cannot apply the “one size fits all” methodology to instruction, rather they should differentiate instruction based on a student’s verbal behavior repertoire. As Greer and Ross (2008) point out, the capability of Inc-BiN is fundamental for students’ success across educational setting. After acquiring both repertoires of observational learning and Inc-BiN, students will have mastered the critical tools for incidental learning that allow them to learn independently from experiences (Greer & Speckman, 2009).
The intersection of bidirectional naming and derived listener–speaker responses in this study begs a molecular analysis of what are derived relations (Sivaraman et al., 2023). Researchers have suggested verbal repertoires mediate derived relations. Miguel (2016, 2018) has suggested both common bidirectional naming (C-BiN), and intraverbal bidirectional naming (I-BiN). Both types of BiN involve the integration of speaker with listener relations—the specific manner in which stimuli are related will differ between common (all one name, "cow with cow") or intraverbal ("milk goes with cow") BiN. In this study, the structure of listener and speaker trials may account for the “emergence” of additional behavior. During speaker trials, participant’s naming of stimuli is associated with pictures. For children who can learn listener object–name relations from models alone (Inc-BiN and Inc-UniN), this structure is sufficient for participants to learn listener responses from speaker teaching trials, although stronger empirical work is needed to fully grasp the causal mechanisms.
This study acknowledges certain limitations that temper the outcomes and pave the way for important considerations in future research. It should be noted that although Study 2 demonstrated changes in derived responses for six participants, it introduced a shift in stimuli (from letter names and sounds to sight words), potentially confounding the observed changes in derived responses. This divergence in stimuli raises concerns about the consistent application of findings across different learning contexts and stimuli, affecting the study's external validity. The absence of a discussion on scalability poses a limitation, particularly in the context of broader educational implementation. Future research endeavors should delve into the scalability of the present strategies, considering the practical aspects of implementing such interventions on a larger scale within diverse educational settings. Addressing these limitations will not only enhance the robustness of the study's findings but also contribute to the broader goal of scalable and powerful interventions in the realm of behavioral research.
As a result, future research may further investigate the association between the degree of Inc-BiN and derived responding in more participants across subsamples. Future research may also study the relation between other capabilities, such as observational learning and gross motor imitation and derived responses. Although more data and research are needed to clarify the aforementioned concerns, these data clearly demonstrate that the degree of Inc-BiN is correlated with derived responding in preschoolers with a disability. The next stage of research should evaluate different curricula. This speaks directly to engineering for emergence across various educational content (i.e., reading, math, and science). Curricula should be designed with the students’ level of verbal behavior in mind, this promotes the efficiency and effectiveness of instruction. For example, if a student has Inc-BiN it is not warranted to teach them all the relations directly, rather we should determine what training method would be the most efficient because the data in the current study suggest that they will derive responses.
Implications
The science of behavior has important applications in reading research for educationally marginalized children and adults, including those from diverse racial and ethnic groups, individuals with disabilities, those who are economically disadvantaged, and English Language Learners. Unfortunately, only a small percentage of these students gain proficient reading skills as children (National Center for Education Statistics, 2022). As the literacy gap increases with this population, it is essential to consider the repertoires that guide how we teach, particularly in the context of literacy and comprehension. One important repertoire that has been shown to mediate derived listener–speaker responses is incidental bidirectional naming (Inc-BiN; Morgan et al., 2020). Therefore, it is crucial to explore how we can promote the development of this repertoire in children.
It is important to note that comprehension is inherently a derived responses repertoire, meaning that it is developed through exposure to multiple examples and contexts (Hayes et al., 2001). Therefore, promoting the development of Inc-BiN through MEI and repeated-naming exposures can not only support the development of this specific repertoire but can also contribute to the overall language and literacy development, especially for those who are from diverse racial and ethnic groups. By implementing these strategies in the classroom, teachers can help bridge the literacy gap for educationally marginalized students, giving them the tools they need to succeed academically and beyond.
Data Availability
Data and materials can be obtained by contacting the corresponding author.
Notes
It is common practice to select 90% as criterion to demonstrate mastery of derived relations (Brodsky & Fienup, 2018), but in this case 80% was selected due to the number of opportunities presented (i.e., totaling six). The participant could emit one error (83%) and is still said to have derived responding.
References
Albers, A. E., & Greer, R. D. (1991). Is the three-term contingency trial a predictor of effective instruction? Journal of Behavioral Education, 1, 337–354.
Barnes-Holmes, D., Barnes-Holmes, Y., Smeets, P. M., Cullinan, V., & Leader, G. (2004). Relational frame theory and stimulus equivalence: Conceptual and procedural issues. International Journal of Psychology & Psychological Therapy, 4, 181–214.
Brodsky, J., & Fienup, D. M. (2018). Sidman goes to college: A meta-analysis of equivalence-based instruction in higher education. Perspectives on Behavior Science, 41, 94–119.
Carnine, D., Silbert, J., Kame’enui, E., Slocum, T., & Travers, P. (2016). Direct instruction reading (6th ed.). Pearson.
Contreras, B., Cooper, A., & Kahng, S. (2020). Recent research on the relative efficiency of speaker and listener instruction for children with autism spectrum disorder. Journal of Applied Behavior Analysis, 53, 584–589.
Critchfield, T. S., & Rehfeldt, R. A. (2020). Engineering emergent learning with nonequivalence relations. In J. O. Cooper, T. E. Heron, & W. L. Heward (Eds.), Applied behavior analysis (3rd ed.). Pearson.
Delfs, C. H., Conine, D. E., Frampton, S. E., Shillingsburd, M. A., & Robinson, H. C. (2014). Evaluation of the efficiency of listener and tact instruction for children with autism. Journal of Applied Behavior Analysis, 47, 793–809.
Eikeseth, S., & Smith, T. (1992). The development of functional and equivalence classes in high functioning autistic children: The role of naming. Journal of the Experimental Analysis of Behavior, 58, 123–133.
Fienup, D. M., & Brodsky, J. (2020). Equivalence-based instruction: Designing instruction using stimulus equivalence. In M. Fryling, R. A. Rehfeldt, J. Tarbox, & L. J. Hayes (Eds.), Applied behavior analysis of language and cognition: Core concepts and principles for practitioners (pp. 157–173). New Harbinger.
Frampton, S. E., Robinson, H. C., Conine, D., & Delfs, C. H. (2017). An abbreviated evaluation of the efficiency of listener and tact instruction for children with autism. Behavior Analysis in Practice, 10, 131–144.
Gibbs, A. R., & Tullis, C. A. (2020). The emergence of untrained relations in individuals with autism and other intellectual and developmental disabilities: A systematic review of recent literature. Review Journal of Autism & Developmental Disorders, 8, 213–238. https://doi.org/10.1007/s40489-020-00211-0
Greer, R. D. (2002). Designing teaching strategies: An applied behavior analysis systems approach. Academic Press.
Greer, R. D., & Longano, J. (2010). A rose by Naming: How we may learn to do it. The Analysis of Verbal Behavior, 26, 73–106.
Greer, R. D., & McCorkle, N. P. (2003). CABAS® curriculum and inventory of repertoires for children from pre-school through kindergarten (3rd ed.). CABAS®/Fred S. Keller School.
Greer, R. D., & Ross, D. (2008). Verbal behavior analysis: Inducing and expanding new verbal capabilities in children with language delays. Pearson Education.
Greer, R. D., & Speckman, J. M. (2009). The integration of speaker and listener responses: A theory of verbal development. The Psychological Record, 59, 449–488.
Greer, R. D., Stolfi, L., Chavez-Brown, M., & Rivera-Vales, C. (2005). The emergence of the listener to speaker component of naming in children as a function of multiple exemplar instruction. The Analysis of Verbal Behavior, 21(1), 123–134.
Greer, R. D., Stolfi, L., & Pistoljevic, N. (2007). Emergence of naming in preschoolers: A comparison of multiple and single exemplar instruction. European Journal of Behavior Analysis., 8, 119–131.
Greer, R. D., Pohl, P., Du, L., & Moschella, J. L. (2017). The separate development of children’s listener and speaker behavior and the intercept as behavioral metamorphosis. Journal of Behavioral & Brain Science, 7, 674–704.
Greer, R. D., Corwin, A., & Buttigieg, S. (2011). The effects of the verbal developmental capability of naming on how children can be taught. Acta de Investigación Psicológica, 1(1), 23–54. https://doi.org/10.22201/fpsi.20074719e.2011.1.214
Hawkins, E., Kingsdorf, S., Charnock, J., Szabo, M., & Gautreaux, G. (2009). Effects of multiple exemplar instruction on naming. European Journal of Behavior Analysis, 10(2), 265–273.
Hawkins, E., Gautreaux, G., & Chiesa, M. (2018). Deconstructing common bidirectional naming: A proposed classification framework. The Analysis of Verbal Behavior, 34, 44–61.
Hayes, S., Barnes-Homes, D., & Roche, B. (2001). Relational frame theory: A post-Skinnerian of human language and cognition. Kluwer/Academic Plenum.
Horne, P. J., & Lowe, C. F. (1996). On the origins of naming and other symbolic behavior. Journal of Experimental Analysis of Behavior, 65, 185–241.
Howarth, M., Dudek, J., & Greer, R. D. (2015). Establishing derived relations for stimulus equivalence in children with severe cognitive and language delays. European Journal of Behavior Analysis, 16, 49–81.
Hranchuk, K. S., & Williams, M. J. (2021). Addressing the feasibility of the teacher performance rate and accuracy scale as a treatment integrity tool. Behavioral Interventions, 36(2), 355–368. https://doi.org/10.1002/bin.1774
Hranchuk, K., Greer, R. D., & Longano, J. (2019). Instructional demonstrations are more efficient than consequences alone for children with naming. The Analysis of Verbal Behavior, 35, 1–20.
Ingham, P., & Greer, R. D. (1992). Changes in student and teacher responses in observed and generalized settings as a function of supervisor observations. Journal of Applied Behavior Analysis, 25, 153–164.
Keohane, D. D., & Greer, R. D. (2005). Teacher’s use of verbally governed algorithm and student learning. International Journal of Behavior Consultation & Therapy, 1, 252–271.
Kirby, M., Spencer, T., & Ferron, J. (2021). How to be RAD: repeated acquisition design features that enhance internal and external validity. Perspectives on Behavior Science, 44, 389–416.
Kleinert-Ventresca, K., Greer, R. D., & Baldonado, L. (2023). The incidental naming cusp expands the symbolic properties of name learning from exposure alone. Journal of the Experimental Analysis of Behavior, 119, 461–475.
Kobari-Wright, V. V., & Miguel, C. F. (2014). The effects of tact training on the emergence of categorization and listener behavior in children with autism. Journal of Applied Behavior Analysis, 46, 669–773.
LaFrance, D., & Tarbox, J. (2019). The importance of multiple exemplar instruction in the establishment of novel verbal behavior. Journal of Applied Behavior Analysis, 53, 10–24.
Layng, T. V. J., Twyman, J. S., & Stikeleather, G. (2003). Headsprout Early Reading: Reliably teaching children to read. Behavioral Technology Today, 3, 7–20. http://www.behavior.org/resources/191.pdf
Lee, G. P., Miguel, C. F., Darcey, E. K., & Jennings, A. M. (2015). A further investigation of the effects of listener training on the emergence of speaker behavior and categorization in children with autism. Research in Autism Spectrum Disorders, 19, 72–81.
Lowe, F., Horne, P. J., Harris, F. D., & Randle, V. R. (2002). Naming and categorization: Vocal tact training. Journal of the Experimental Analysis of Behavior, 78, 527–549.
McNamara, J., Scissons, M., & Gutknecth, N. (2011). A longitudinal study of kindergarten children at risk for reading disabilities: the poor are getting poorer. Journal of Learning Disabilities, 44, 421–430.
Miguel, C. F. (2016). Common and intraverbal bidirectional naming. The Analysis of Verbal Behavior, 32, 125–138.
Miguel, C. F. (2018). Problem-solving, bidirectional naming, and the development of verbal repertoires. Behavior Analysis: Research & Practice, 18, 340–353.
Miguel, C. F., & Petursdottir, A. I. (2009). Naming and frames of coordination. In R. A. Rehfeldt & Y. Barnes-Holmes (Eds.), Derived relational responding: Applications for learners with autism and other developmental disabilities (pp. 129–148). New Harbinger.
Miguel, C. F., Petursdottir, A. I., Carr, J. E., & Michael, J. (2008). The role of naming in stimulus categorization by preschool children. Journal of the Experimental Analysis of Behavior, 89, 383–405.
Morgan, G. A., Greer, R. D., & Fienup, D. M. (2020). Descriptive analyses of relations between bidirectional naming, arbitrary, and non-arbitrary relations. The Psychological Record, 71, 367–387. https://doi.org/10.1007/s40732-020-00408-z
National Center for Education Statistics. (2022). Nation’s report card. National Assessment of Educational Progress.
Petursdottir, A., & Carr, J. E. (2011). A review of recommendation for sequencing receptive and expressive language instruction. Journal of Applied Behavior Analysis, 44, 859–876.
Petursdottir, A., Carr, J. E., Lechago, S. A., & Almason, S. M. (2008). An evaluation of intraverbal training and listener training for teaching categorization skills. Journal of Applied Behavior Analysis, 41, 53–68.
Pilgrim, C. (2020). Equivalence-based instruction. In J. O. Cooper, T. E. Heron, & W. L. Heward (Eds.), Applied behavior analysis (3rd ed.) pages 452-496. Pearson.
Raaymakers, C., Garcia, Y., Cunningham, K., Krank, L., & Nemer-Kaiser, L. (2019). A systematic review of derived verbal behavior research. Journal of Contextual Behavioral Science, 12, 128–148.
Rehfeldt, R. A. (2011). Toward a technology of derived stimulus: An analysis of articles published in the Journal of Applied Behavior Analysis, 1992–2009. Journal of Applied Behavior Analysis, 44, 109–119.
Ross, D., Singer-Dudek, J., & Greer, R. (2005). The teacher performance rate and accuracy scale (TPRA): Training as evaluation. Education & Training in Developmental Disabilities, 40, 411–423.
Sidman, M. (1994). Equivalence relations and behavior: A research story. Authors Cooperative.
Sidman, M., & Cresson, O. (1973). Reading and cross-modal transfer of stimulus equivalences in severe retardation. American Journal of Mental Deficiency, 77, 515–523.
Sivaraman, M., & Barnes-Holmes, D. (2023). Naming: What do we know so far? A systematic review. Perspectives on Behavior Science, 46, 585–615. https://doi.org/10.1007/s40614-023-00374-1
Sivaraman, M., Barnes-Holmes, D., Greer, R. D., Fienup, D. M., & Roeyers, H. (2023). Verbal behavior development theory and relational frame theory: Reflecting on similarities and differences. Journal of the Experimental Analysis of Behavior, 119(3), 539–553.
Sprinkle, E. C., & Miguel, C. F. (2012). The effects of listener and speaker training on emergent relations in children with autism. The Analysis of Verbal Behavior, 28, 111–117.
Stromer, R., & Mackay, H. A. (1992). Spelling and emergent picture-printed word relations established with delayed identity matching to complex samples. Journal of Applied Behavior Analysis, 25, 893–904.
Waddington, E., & Reed, P. (2009). The impact of using the “Preschool Inventory of Repertoires for Kindergarten” (PIRK (R)) on school outcomes of children with autism spectrum disorders. Research in Autism Spectrum Disorders, 3, 809–827.
Funding
Open access funding provided by SCELC, Statewide California Electronic Library Consortium.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of Interest
Both authors declare that s/he has no conflict of interests.
Ethical Approval
This study was approved by the Institutional Review Board (IRB) of the respective school where the study was conducted, as well the respective university IRB, as exempt educational research.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abdool-Ghany, F., Fienup, D. A Preliminary Analysis of Incidental Bidirectional Naming and Derived Listener and Speaker Relations for Literacy Responses. Behav. Soc. Iss. (2024). https://doi.org/10.1007/s42822-024-00163-8
Accepted:
Published:
DOI: https://doi.org/10.1007/s42822-024-00163-8