
Abstract
Quantum machine learning is a rapidly growing field at the intersection of quantum computing and machine learning. In this work, we examine our quantum machine learning models, which are based on quantum support vector classification (QSVC) and quantum support vector regression (QSVR). We investigate these models using a quantum circuit simulator, both with and without noise, as well as the IonQ Harmony quantum processor. For the QSVC tasks, we use a dataset containing fraudulent credit card transactions and image datasets (the MNIST and the Fashion-MNIST datasets); for the QSVR tasks, we use a financial dataset and a materials dataset. For the classification tasks, the performance of our QSVC models using 4 qubits of the trapped-ion quantum computer was comparable to that obtained from noiseless quantum circuit simulations. The result is consistent with the analysis of our device noise simulations with varying qubit gate error rates. For the regression tasks, applying a low-rank approximation to the noisy quantum kernel, in combination with hyperparameter tuning in ε-SVR, improved the performance of the QSVR models on the near-term quantum device. The alignment, as measured by the Frobenius inner product between the noiseless and noisy quantum kernels, can serve as an indicator of the relative prediction performance on noisy quantum devices in comparison with their ideal counterparts. Our results suggest that the quantum kernel, as described by our shallow quantum circuit, can be effectively used for both QSVC and QSVR tasks, indicating its resistance to noise and its adaptability to various datasets.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The field of quantum technologies (Nielsen and Chuang 2010) has seen tremendous progress in recent years, with the potential to transform a wide range of scientific research and industries. One possible application of quantum computing is the field of quantum machine learning (Rebentrost et al. 2014; Biamonte et al. 2017; Cerezo et al. 2022), which could potentially be used for classifying and recognizing complex patterns more efficiently than classical methods (Abbas et al. 2021). The quantum kernel method, a candidate in the field, leverages quantum states as described by quantum circuits to compute inner products between pairwise data points in the high-dimensional quantum feature space (Havlíček et al. 2019; Schuld and Killoran 2019). The classification based on the quantum kernel method is known as quantum support vector machine (QSVM), which is a quantum analog of classical support vector machine (SVM) that has been used for a variety of machine learning tasks (Cortes and Vapnik 1995; Schölkopf and Smola 2002). An advantage of QSVM with certain feature maps for classically hard problems has been mathematically analyzed for the regime of fault-tolerant quantum computing (Liu et al. 2021; Jäger and Krems 2023). On the other hand, current quantum computers are still noisy intermediate-scale quantum (NISQ) devices (Preskill 2018); that is, NISQ processors are error-prone, and error mitigation is sometimes necessary to reduce the impact of errors (Temme et al. 2017; LaRose et al. 2022). Despite the challenges, with the aid of cloud computing technology, there has been growing interest in the quest for early practical applications of near-term devices (Bharti et al. 2022).
In recent years, there has been remarkable progress in quantum hardware (de Leon et al. 2021), opening the path for the implementation of NISQ algorithms. Previous studies on quantum kernels have explored the use of various quantum hardware platforms, such as superconducting qubits (Havlíček et al. 2019; Djehiche and Löfdahl 2021; Heredge et al. 2021; Peters et al. 2021; Wang et al. 2021; Hubregtsen et al. 2022; Krunic et al. 2022), trapped-ion qubits (Moradi et al. 2022), Gaussian boson sampling (Schuld et al. 2020; Giordani et al. 2023), neutral atom qubits (Albrecht et al. 2023), and nuclear-spin qubits (Kusumoto et al. 2021). Owing to quantum decoherence and the noise of quantum gates, one can typically perform a limited number of quantum operations on NISQ devices. In this regard, trapped-ion quantum processors seem to offer some advantages, thanks to long coherence time, all-to-all connectivity, and high-fidelity gate operations (Bruzewicz et al. 2019). Previous studies have demonstrated the implementation of different NISQ algorithms on trapped-ion quantum computers; in particular, researchers have recently used the IonQ Harmony quantum processor and reported interesting results in quantum machine learning (Johri et al. 2021; Ishiyama et al. 2022; Rudolph et al. 2022), finance (Zhu et al. 2022), quantum chemistry (Nam et al. 2020; Zhao et al. 2023), and the generation of pseudo-random quantum state (Cenedese et al. 2023). A recent study has shown the feasibility of implementing QSVM with a simple quantum circuit on a trapped-ion quantum computer (Moradi et al. 2022); nonetheless, further investigation is necessary to understand the full potential of the quantum kernel method on this platform using a different quantum kernel and various datasets.
In the present work, we investigate the performance of quantum support vector classification (QSVC) and quantum support vector regression (QSVR) on a trapped-ion quantum computer, using datasets from different industry domains including finance and materials science, aiming to bridge the gap between potential quantum computing applications and real-world industrial needs. Here, we employ quantum kernels described by a shallow quantum circuit that can be implemented on the IonQ Harmony quantum processor and analyze the performance of the models, in comparison with that of the classical counterpart as well as with that obtained from noiseless quantum circuit simulations.
The remainder of the paper is organized as follows. To estimate the number of quantum measurements necessary for the estimation of quantum kernels for reliable predictions, we first perform noiseless and noisy quantum computing simulations before conducting quantum experiments. Next, we investigate the effect of noise on the performance of the QSVC models using noisy simulations with various values for qubit gate error rates. Then, we report the results of QSVMs on the trapped-ion quantum processor. We train our QSVC models using a dataset containing fraudulent credit card transactions and image datasets such as the MNIST dataset and the Fashion-MNIST (Xiao et al. 2017) dataset. Also, we train our QSVR models using a financial market dataset and a dataset for superconducting materials. In the QSVR tasks, to reduce the effect of noise, we use a low-rank approximation of the noisy quantum kernel and carefully optimize hyperparameters in SVMs. We demonstrate that our quantum kernel can be used for both the QSVC and QSVR tasks for our datasets examined. Finally, we summarize our conclusions.
2 Results
2.1 Quantum circuit and the quantum kernel method
In the NISQ era, two-qubit gates are typically an order of magnitude lower in fidelity compared to single-qubit gates. This means that one can only perform a limited number of quantum operations to ensure that the results are distinguishable from noise. In the present study, we use the following quantum feature map using a shallow quantum circuit:
and
Note that the connectivity of qubits in Eq. 1 is limited to their neighbors, resulting in \((n-1)\) interactions. This can make quantum computation more amenable for near-term quantum devices. The quantum feature map given in Eq. 1 has been applied to image classification using a specialized quantum kernel simulator, which is highly customized for this particular quantum circuit using field programmable gate arrays (Suzuki et al. 2023). In quantum machine learning, the quantum kernel \(K\left({\varvec{x}},{\varvec{x}}^{\prime}\right)\) described by the quantum feature map can be estimated by the inner product of the quantum states obtained from the two data points \({\varvec{x}}\) and \({\varvec{x}}^{\prime}\):
The kernel represents the similarity between the two data points in the high-dimensional Hilbert space. The quantum kernel entry can be estimated by using a shallow quantum circuit described in Fig. 1a. Once the quantum kernel is estimated by a quantum computer or a quantum circuit simulator, we can use the kernel-based method (Fig. 1b). The goal of SVM is to find the decision function for binary classification. Suppose we are given a set of samples \(\left({{\varvec{x}}}_{i},{y}_{i}\right)\) with \({{\varvec{x}}}_{i}\in {\mathbb{R}}^{d}\) and \({y}_{i}\in \{\pm 1\}\), where \(d\) is the dimension of the input vector and the index \(i\) runs over \(1,\cdots ,m\). To find the decision function, we solve the following problem (Schölkopf and Smola 2002):
subject to

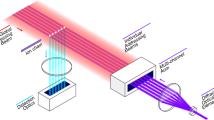
Schematic representation of our QSVC and QSVR workflows. a Shallow quantum circuit for estimating our quantum kernel \({\left|\langle \phi \left({\varvec{x}}\right)|\phi \left({\varvec{x}}{^\prime}\right)\rangle \right|}^{2}\). Our quantum feature map \(\left|\phi\left(\boldsymbol x\right)\rangle=U\left(\boldsymbol x\right)\right|0^{\otimes n}\rangle\) is given in Eq. 1 in the text. b Workflow for our QSVC and QSVR tasks (indicated by orange and green, respectively). For QSVC tasks, a credit card dataset, the MNIST dataset, and the Fashion-MNIST dataset were used. For QSVR tasks, a financial dataset and a materials dataset were used. The estimation of the quantum kernel can be obtained using a quantum circuit simulator (either with or without noise) on a CPU (indicated by the white boxes) or computed using the IonQ Harmony (indicated by the blue box). Low-rank approximation was employed for QSVR tasks to reduce noise in the quantum kernel (for more details, see Sect. 2.3). The optimization of the hyperparameters in the models was also performed
Here, the coefficients \(\left\{{\alpha }_{i}\right\}\) are parameters determined through the optimization process. The patterns \({{\varvec{x}}}_{i}\) for which \({\alpha }_{i}>0\) are called support vectors (SVs). The regularization parameter \(C\) controls the tradeoff between model complexity and its capacity to tolerate errors. The decision function \(f\left({\varvec{x}}\right)\) takes the form:
The bias \(b\) can be determined by the support vectors once the SVs and their Lagrange multipliers are obtained by the dual optimization (Schölkopf and Smola 2002).
2.2 Noiseless and noisy quantum simulations
To understand the effects of noise, we first employed a device noise model provided by Qiskit Aer (Aleksandrowicz et al. 2019). Here, the noise model is based on a depolarizing noise model, in which single-qubit gate errors and two-qubit gate errors are taken into account. Single-qubit errors consist of a single-qubit depolarizing error followed by a single-qubit thermal relaxation error, whereas two-qubit gate errors comprise a two-qubit depolarizing error followed by single-qubit thermal relaxation errors on both qubits in the gate. Hereafter, we denote them as \({p}_{1}\) and \({p}_{2}\), respectively. In the context of the quantum kernel method, it is of particular importance to understand how noise affects the quality of the quantum kernel matrix and the prediction accuracy. To quantify this, we use the alignment between two kernels (Cristianini et al. 2001) defined by
where \({\langle P,Q\rangle }_{F}\) is the Frobenius inner product between the matrices \(P\) and \(Q\):
The alignment \(A\left(K,{K}{^\prime}\right)\) can be viewed as the cosine of the angle between the two matrices viewed as vectors. By using the alignment of the noisy quantum kernel \({K}^{{\text{noise}}}\) with the noiseless quantum kernel \(K\), \(A\left(K,{K}^{{\text{noise}}}\right)\), we can conveniently measure the deviation of a noisy kernel from the noiseless one.
Using device noise model simulations, we investigated the robustness of our quantum kernel matrix in the presence of noise and the prediction performance (Fig. 2). In our noisy simulations, we varied the number of qubits from 4 to 12 in Eq. 1 and considered the following conditions for qubit gate error rates: (i) \({p}_{1} = 0.001\), \({p}_{2}= 0.005\) and (ii) \({p}_{1}= 0.01\), \({p}_{2}=0.05\). In the Appendix, we numerically show that 500 shots per kernel entry were enough to ensure the quality of our quantum kernel and to maintain reliable predictions; thus, 500 shots were conducted for each kernel entry throughout our simulations. To explore the applicability of our quantum kernel, three different datasets were considered: the credit card fraudulent transaction dataset, the MNIST dataset, and the Fashion-MNIST dataset. For the three datasets, the test accuracy obtained from the noisy quantum kernel was on par with that obtained from the noiseless quantum simulations, suggesting that the noise in the quantum kernel had minimal impact on the test accuracy of our QSVM models. This can be confirmed by the fact that the alignment was above 0.996, which may be partly due to the nature of our shallow quantum circuits. On the other hand, we are aware that our simulations based on the device noise model are only an approximation of real errors that occur on actual devices (In Sect. 2.3, we will demonstrate the performance of our QSVC models on the real quantum device using 4 qubits).

The dependence of the prediction performance of our QSVC models on the number of qubits from 4 to 12 (noisy simulations). The error bars indicate the standard deviation obtained from 5 independent seeds. Top panel: test accuracy for a credit card dataset, b MNIST dataset (binary classification of two labels: “0” vs. “1”), and c Fashion-MNIST dataset (binary classification of two image categories: “T-shirt” vs. “trouser”). Bottom panel: alignment of the noisy quantum kernel with the noiseless quantum kernel for d credit card dataset, e MNIST dataset, and f Fashion-MNIST dataset. In our device noise model simulations, we consider the following conditions for single- and two-qubit gate error rates: (i) \({p}_{1} = 0.001\), \({p}_{2}= 0.005\) (indicated by blue); (ii) \({p}_{1}= 0.01\), \({p}_{2}=0.05\) (indicated by red). Five independent seeds for each dataset were used to obtain the statistical results. The number of training data was 40, and the number of test data was 20
Next, we investigated how the device noise level affects the alignment and the test accuracy (Fig. 3). To this end, we performed device noise model simulations using 4 qubits for a range of qubit gate error rates: \(0.001 \le {p}_{1}\le 0.55\) and \(0.001 \le {p}_{2}\le 0.55\). By comparing the alignment and the test accuracy, we found that, for certain regions (\({p}_{1}< \approx 0.05\) and \({p}_{2}< \approx 0.1\)), our QSVC model can predict, even in the presence of noise (Fig. 3a, b). When qubit gate error rates become relatively high, however, the noisy quantum kernel deviates from the ideal quantum kernel, and thus, the prediction performance begins to deteriorate rapidly. Given the fact that \({p}_{1}\approx 0.001\) and \({p}_{2}\approx 0.01\) for state-of-the-art NISQ devices, we can validate the prediction performance of our QSVC model on real quantum computers (which will be demonstrated in the next subsection). Our noise model simulations suggest that the alignment between noiseless and noisy quantum kernels is an indicator of how reliably a QSVC model can predict using a NISQ device in comparison with its noiseless counterpart. In our QSVC model, if the alignment is higher than 0.98, then the QSVC model can make reliable predictions (Fig. 3c). To understand this more intuitively, one can recall that the alignment can be viewed as the cosine of the angle between the two matrices (viewed as vectors); in such a mathematical viewpoint, it means that the angle between noiseless and noisy kernels needs to be less than 11.5° for reliable predictions on a noisy quantum device.

Effects of noise on our QSVM model. a The alignment, b the test accuracy of the QSVC model, and c the correlation between the two. The device noise model simulations were performed using 4 qubits for a range of qubit gate error rates: \(0.005 \le {p}_{1}\le 0.55\) and \(0.005 \le {p}_{2}\le 0.55\). The results suggest that our QSVC model is capable of making reliable predictions, if the alignment is higher than 0.98, which roughly corresponds to the condition that \({p}_{1}< \approx 0.05\) and \({p}_{2}< \approx 0.1\). The shaded area in part c indicates the standard deviation. The Fashion-MNIST dataset was used, and the number of training data was 40 and the number of test data was 20
2.3 QSVC on the IonQ Harmony quantum computer
Having examined the results of the noise model simulations, we now turn to our quantum experiments using the IonQ Harmony. The Gram matrices we obtained using the quantum device (4 qubits) are shown in Fig. 4. To validate the quality of our noisy quantum kernels, we investigated the alignment of the noisy quantum kernel with the noiseless quantum kernel: the values for the alignment \(A\left(K,{K}^{{\text{noise}}}\right)\) were 0.986, 0.984, and 0.993 for the credit card dataset, the MNIST dataset, and the Fashion-MNIST dataset, respectively. Since the three values were higher than 0.98, this suggests that the quantum kernel matrix entries were successfully estimated using the IonQ Harmony and indicates that reliable predictions can be made using our QSVC models on the quantum device (see also Fig. 3c).

Quantum kernel matrices obtained using the IonQ Harmony quantum computer. a Credit card dataset, b MNIST dataset, and c Fashion-MNIST dataset. For all the cases, 4 qubits were used for obtaining the matrices, with the number of training data \(N=20\). The values for the alignment of the noisy quantum kernel with the noiseless quantum kernel, \(A\left(K,{K}{^\prime}\right)\), were 0.986, 0.984, and 0.993 for a, b, and c, respectively. All of the values were higher than 0.98, which suggests that the quantum kernel matrix entries were successfully obtained using the IonQ quantum computer and indicates that reliable predictions can be made using our QSVC models on the quantum device (see also Fig. 3c)
Motivated by the reliable estimation of the quantum kernel on the IonQ Harmony, we trained QSVC models using the three datasets and validated the models using test data (Table 1). For comparison, we used classical Gaussian kernels \(K({\varvec{x}},{\varvec{x}}{^\prime})={\text{exp}}(-{\gamma \Vert {\varvec{x}}-{{\varvec{x}}}{^\prime}\Vert }^{2})\). For the credit card dataset, the classical SVM parameters were the regularization constant \(C=3.2\) and \(\gamma =0.25\), whereas QSVM parameters were \(C=6.2\) for the noiseless simulation and \(C=4.2\) for the IonQ machine. For the MNIST dataset, the classical SVM had \(C=3.5\) and \(\gamma =0.25\), whereas both the noiseless and noisy QSVMs had \(C=1.0\). Finally, for the Fashion-MNIST dataset, the classical SVM parameters were \(C=1.5\) and \(\gamma =0.25\), whereas the QSVM had \(C=0.4\) for the noiseless simulation and \(C=1.0\) for the IonQ machine.
Our results show that the prediction performance of our QSVC models was maintained even in the presence of noise. Test accuracies achieved with the quantum computer for the credit card dataset, the MNIST dataset, and the Fashion-MNIST dataset were 70%, 100%, and 100%, respectively, reflecting equivalent performance to the QSVC models using noiseless quantum kernels. This is consistent with the results of our noise model simulations, in which predictions can be made using noisy quantum kernels with an alignment higher than 0.98. Furthermore, the performance of our QSVC models on the IonQ Harmony was comparable to that of the classical counterparts. In Supplementary Information, we also included the results of the IonQ Aria experiments involving 4 and 8 qubits. Thanks to the improved fidelity of the two-qubit gate operations in the IonQ Aria, we were able to obtain a quantum kernel using an 8-qubit system. Our QSVC model with 8 qubits achieved a 100% test accuracy on the Fashion-MNIST dataset. On a final note, we mention the number of support vectors (note that the decision boundary for the largest margin is determined solely by the position of the support vector): we found that there was a slight difference in the number of support vectors between QSVC models with noiseless kernels and those with noisy kernels on the IonQ Harmony, which might imply a subtle difference in the quantum feature map between noiseless simulations and actual quantum experiments, though both the QSVC models gave the same test accuracies.
2.4 QSVR on the IonQ Harmony quantum computer
2.4.1 Datasets
Two different datasets were used in our QSVR tasks. One is a financial market dataset (given in Tables S2 and S3 in Supplementary Information). Financial data are characterized by high volatility and are often subject to noise caused by random fluctuations. In recent years, pandemics, geopolitical risks, and other microeconomic factors have caused supply chain disruption, which led to price fluctuations of metal commodities such as nickel. In our QSVR model, the target variable \({y}_{i}\) was the UK nickel price, and three attributes \({{\varvec{x}}}_{i}\in {\mathbb{R}}^{3}\) were considered: the Shanghai Stock Exchange Composite (SSE) Index, West Texas Intermediate (WTI) crude oil, and the US Dollar Index. Thus, in our QSVR model, 3 qubits were used for describing the quantum feature map on the Ion Q Harmony. Hereafter, the dataset is referred to as the financial dataset. The other is a superconducting materials dataset (Hamidieh 2018). Here, the target variable \({y}_{i}\) was the critical temperature \({T}_{c}\) for a broad class of superconducting materials. The original dataset contains 81 features (or descriptors); by using dimensionality reduction, four-dimensional vectors \({{\varvec{x}}}_{i}\in {\mathbb{R}}^{4}\) were used as input data in this work (for more details on preprocessing, see Sect. 4.1). Hence, 4 qubits were used to describe the quantum feature map. Hereafter, the dataset is referred to as the materials dataset.
2.4.2 Low-rank approximation in the noisy quantum kernel
A popular approach to reducing the noise in the quantum kernel is to use a depolarizing model (Hubregtsen et al. 2022; Moradi et al. 2022); however, such a noise model may not necessarily be suited for real quantum devices, because there are various sources of noise. In addition, at the time of conducting our quantum experiment, we were not able to access the full control of native quantum gates of the trapped-ion quantum computer in the cloud service. In this work, we rather employed a postprocessing approach for error mitigation; in particular, we used low-rank approximation to reduce the noise in the quantum kernel. This can maintain the important information of the original matrix while reducing the noise. The low-rank approximation can be performed, for instance, by singular value decomposition (SVD). Recently, a study by Wang et al. (2021) showed that the training performance of noisy quantum kernels is improved when spectral transformation (eigendecomposition) is adopted. Our idea is to reconstruct a quantum kernel \(\widehat{K}\) from a noisy quantum kernel \(K\) by using eigendecomposition:
where \({\mu }_{k}\) is the \(k\) th eigenvalue and \({{\varvec{u}}}_{k}\) is the corresponding \(k\) th eigenvector. The quantum kernel is approximated by summing over \({\mu }_{k}{{\varvec{u}}}_{k}{{\varvec{u}}}_{k}^{{\text{T}}}\), where the index \(k\) runs over \(1,\cdots ,r\). Motivated by the important role of the alignment in QSVC (Fig. 2c), we argue that the optimal value for \(r\) can be determined by maximizing the alignment of the noisy quantum kernel with the noiseless one:
In the case of test data, we calculate a train-test kernel matrix, which is generally a rectangular matrix; hence, SVD was used for low-rank approximation.
We investigated the effects of low-rank approximation in improving the quality of the noisy quantum kernel (Fig. 5). For the financial dataset, the alignment had the maximum value of 0.993 at \({r}^{*}=8\) (Fig. 5a). For the materials dataset, on the other hand, the alignment had the maximum value of 0.984 at \({r}^{*}=10\) (Fig. 5d). The difference in the optimal \({r}^{*}\) appears to be related to the difference in the nature of the datasets. For both cases, after the alignment peaked at the optimal \({r}^{*}\), the value for the alignment was gradually decreased and finally saturated for larger values of \(r\). This can be confirmed by the fact that the contribution of eigenvectors for \(k>{r}^{*}\) became substantially small (Fig. 5b, e), indicating that a large portion of the information is concentrated in eigenvectors up to \({r}^{*}\) th. The results suggest that low-rank approximation can improve the quality of the noisy quantum kernel to some extent.

Use of spectral decomposition in improving the quantum kernel on the quantum processor. Top (financial dataset; 3 qubits): a alignment between the reconstructed quantum kernel and the noiseless quantum kernel with respect to the rank in the low-rank approximation (the alignment has the maximum value of 0.993 at \({r}^{*}=8\), which is indicated by the red circle); b eigenvalues with respect to the Eigenvector Index (the first 8 components are indicated by the red bars); c reconstructed quantum kernel using the low-rank approximation (\({r}^{*}=8\)). Bottom (materials data; 4 qubits): d alignment between the reconstructed quantum kernel and the noiseless quantum kernel with respect to the rank in the low-rank approximation (the alignment has the maximum value of 0.984 at \({r}^{*}=10\), which is indicated by the red circle); e eigenvalues with respect to the Eigenvector Index (the first 10 components are indicated by the red bars); f reconstructed quantum kernel using the low-rank approximation (\({r}^{*}=10\))
2.4.3 Optimization of hyperparameters in \({\varvec{\varepsilon}}\)-support vector regression (SVR)
The goal of \(\varepsilon\)-SVR is to find a regression function \(f({\varvec{x}})\) that has at most \(\varepsilon\) deviation from the obtained targets \(\left\{{y}_{i}\right\}\) for all the training data \(\left\{{{\varvec{x}}}_{i}\right\}\) (Schölkopf and Smola 2002). Here, the hyperparameter \(\varepsilon\) defines a margin of tolerance (orε-insensitive tube) where no penalty is associated with errors. In other words, any data points within this allowable error range are not considered errors, even if they do not fall directly on the regression line. This can be realized by using the \(\varepsilon\)-insensitive loss function introduced by Vapnik, which is an analog of the soft margin in SVC (Schölkopf and Smola 2002). The linear ε-insensitive loss function can be described by
A smaller value of \(\varepsilon\) narrows the “no penalty” region, making the model more sensitive to the training data, whereas a larger value of \(\varepsilon\) creates a wider tube, making the model less sensitive to the training data. An appropriate value of \(\varepsilon\) is related to the noise magnitude of data (Zhang and Han 2013). By using the Lagrangian formalism and introducing a dual set of variables, the primal problem in \(\varepsilon\)-SVR can be transformed into the dual optimization problem (Schölkopf and Smola 2002), which is described as follows:
subject to
Here, the coefficients \(\left\{{\alpha }_{i}\right\}\) and \(\left\{{\alpha }_{i}^{*}\right\}\) are parameters determined through the optimization process. The regularization parameter \(C\) determines the tradeoff between the complexity of the model and its capacity to tolerate errors. A larger value of \(C\) makes the model less tolerant of errors, which potentially leads to a risk of overfitting, whereas a smaller value of \(C\) helps the model be more tolerant of errors, which tends to make the model less complex. By tuning the hyperparameters \(\varepsilon\) and \(C\), one can find a good combination of parameters that makes the model more robust on new data, thus improving its generalization performance. The regression function takes the form (Schölkopf and Smola 2002):
The bias \(b\) can be determined by the SVs, once the Lagrange multipliers are obtained by the dual optimization. To access the performance of the model, we used the root-mean-square error (RMSE):
By performing a grid search for \(\varepsilon\) and \(C\), we optimized the hyperparameters in ε-SVR using the quantum kernel that had been reconstructed by low-rank approximation (Fig. 6). For the financial dataset, the optimal values for the hyperparameters \(\varepsilon\) and \(C\) were 0.21 and 1.4, respectively, indicating that the ε-insensitive loss function was effective in enhancing the generalization of the model and reducing overfitting. The result is partly due to the nature of the financial market data; that is, the data is characterized by high volatility owing to various factors such as geopolitical events and market sentiment and is often subject to noise caused by random fluctuations. For the materials dataset, on the other hand, the optimal values for the hyperparameters \(\varepsilon\) and \(C\) were 0.0 and 0.3, respectively. The optimal value of \(\varepsilon =0\) means that the allowable error range in the training data was unnecessary for this particular case. A possible reason may be that the impact of noise in the quantum kernel was effectively canceled through dimensionality reduction of input data and the use of low-rank approximation of the noisy quantum kernel. At the same time, a slightly smaller value of \(C=0.3\) made the model more robust against overfitting. For both cases, increasing the value for \(C\) (i.e., making the model fit the training data more tightly) did not improve the performance; instead, it had an adverse effect on the results (Fig. 6). Our results suggest that a combined approach that involves both the low-rank approximation to the noisy quantum kernel and the optimization of the hyperparameters in ε-SVR can be a useful strategy for improving the performance and robustness of the QSVR models.

Optimization of the hyperparameters \(C\) and \(\varepsilon\) in \(\varepsilon\)-SVR using the quantum kernel reconstructed by low-rank approximation (see also Fig. 5). RMSE with respect to \(\varepsilon\) for a financial dataset and b materials dataset. The optimal values for \((\varepsilon , C)\) were (0.21, 1.4) and (0.0, 0.3) for a and b, respectively
2.4.4 Performance
Herein, we report the results of our QSVR models on the IonQ trapped-ion quantum computer and compare the performance with that obtained by the classical SVR tasks (Table 2 and Fig. 7). For the classical SVR, we used Gaussian kernels \(K({\varvec{x}},{\varvec{x}}{^\prime})={\text{exp}}(-\gamma {\Vert {\varvec{x}}-{{\varvec{x}}}{^\prime}\Vert }^{2})\). The optimized hyperparameters \(\left(\gamma , \varepsilon , C\right)\) were (0.6, 0.1, 5.7) and (0.3, 0.18, 3.4) for the financial dataset and the materials dataset, respectively. For the financial dataset, the performance of our QSVR model using the noiseless simulation was comparable to that of our classical SVR model: the coefficient of determination (\({R}^{2}\)) for the classical SVR model was 0.930, whereas that for the QSVR model was 0.932. On the other hand, \({R}^{2}\) for the QSVR model using the IonQ Harmony was 0.868, which was 6.9% lower than that obtained by the noiseless simulation (Table 2). The QSVR model worked well in predicting the financial price for this particular period (note that the model may not guarantee a similar performance for another time window). For the materials dataset, \({R}^{2}\) for the classical SVR model was 0.728, whereas that for the QSVR with the noiseless quantum kernel was 0.703. The coefficient of determination \({R}^{2}\) for the QSVR model using the real quantum device was 0.628, which was 10.7% lower than that obtained from the noiseless simulation (Table 2). Since the alignment of the reconstructed quantum kernel for the materials dataset (0.984) was slightly lower than that for the financial dataset (0.993), the decrease in \({R}^{2}\) observed in the real device appeared to be more significant in the case of the former dataset. Overall, the presence of noise negatively affected the performance of tasks (Fig. 7). In QSVC models, the performance appears to be less impacted by noise, as data points can be effectively separated in the high-dimensional space. However, regression models, which predict real values, were more acutely affected by noise. Similar to the case with the QSVC models, the results suggest that the alignment of the quantum kernel is a reliable measure for accessing the performance of the quantum kernel method on the real quantum device.

Parity plot between the predicted and observed values. Top panel (financial dataset): a classical SVR (\({R}^{2}=0.930\)); b QSVR using the noiseless simulation (\({R}^{2}=0.932\)); c QSVR using the IonQ Harmony with 3 qubits (\({R}^{2}=0.868\)). Bottom panel (materials dataset): d classical SVR (\({R}^{2}=0.728\)); e QSVR using the noiseless simulation (\({R}^{2}=0.703\)); f QSVR using the IonQ Harmony with 4 qubits (\({R}^{2}=0.628\)). For all cases, the number of test data was 40
3 Discussion
In the present work, we have investigated our QSVC and QSVR models, by performing quantum circuit simulations and using the IonQ Harmony quantum processor. For the classification tasks, we used the credit card dataset, the MNIST dataset, and the Fashion-MNIST dataset. The performance of our QSVC models obtained using 4 qubits of the trapped-ion quantum computer was comparable to that of the classical counterparts and that of the QSVC models obtained from the noiseless quantum kernels. This suggests that the presence of noise in the quantum kernel had a minimal impact on the test accuracy of the QSVM models. Our quantum experiments with 4 qubits were consistent with the analysis of our device noise simulations, in which the prediction performance can be maintained so long as the device noise level is lower than a certain threshold. The robustness of our quantum kernel in the presence of noise can be explained by the fact that the alignment between the noiseless and the noisy quantum kernels was close to one (the alignment was higher than 0.98). Hence, our results suggest that the alignment is a reliable measure for evaluating the performance of a QSVM model on a NISQ device in comparison with a noiseless counterpart.
In the case of our QSVR models, we used the financial dataset and the dataset for superconducting materials. In particular, we investigated the role of the low-rank approximation and the effects of the hyperparameter tuning in ε-SVR in improving the performance and robustness of the QSVR models. We found that the low-rank approximation was effective in reducing the effects of noise in the quantum kernel. The optimization of the hyperparameters in ε-SVR was also beneficial for mitigating the effect of noise. Therefore, a combined approach using the low-rank approximation to the noisy quantum kernel and the hyperparameter tuning in ε-SVR can be a useful method for enhancing the performance of the QSVR models. We have demonstrated that the quantum kernel described by our shallow circuit was versatile for both the QSVM and QSVR tasks for the different datasets we examined. While our quantum feature map did not necessarily exemplify a so-called quantum advantage because of its shallow quantum circuit and the limited number of qubits, our findings could provide valuable insights for designing quantum feature maps.
Let us now discuss open questions and challenges. A recent theoretical study by Thanasilp et al. (2022) shows that under certain conditions, quantum kernel entries can exponentially concentrate around a certain value (with an increasing number of qubits). On the other hand, such exponential concentration was not observed in the quantum experiments conducted for our tasks. This discrepancy can be attributed partly to our choice of shallow quantum circuits, which circumvent high expressibility, and partly to the nature of the datasets we used. In general, quantum kernels with high expressibility can lead to training difficulties. For instance, quantum kernels with \(L\) layers of hardware-efficient circuit unit reach the exponential decay regime when \(L\) is sufficiently large (\(L \ge 75\)); in contrast, for a small number of layers (\(L \le 8\)), quantum kernels do not enter the exponential concentration regime (see Fig. 4 in the paper by Thanasilp et al. (2022)). Our quantum kernels consisting of low-depth circuits correspond to the latter scenario, which is in line with our successful results in training and prediction. Furthermore, noise can significantly impose limitations on the potential of quantum computing in the NISQ era. The presence of noise results in the loss of information during gate operations before extracting information through measurements. Although our quantum experiments have shown that training and prediction were feasible for systems with 4 and 8 qubits, an increase in the number of qubits (which in turn leads to an increase in two-qubit gate operations) may result in a substantial decrease in the values of quantum kernels, thereby making the training process more difficult. Lastly, the scalability of quantum kernels remains an open question (Thanasilp et al. 2022; Jerbi et al. 2023), and further advancements are necessary for the practical application of quantum kernel methods. In this context, a new field of geometric quantum machine learning (Meyer et al. 2023; Ragone et al. 2023; West et al. 2023), given its broad theoretical scope, could facilitate the development of carefully designed quantum kernels.
4 Computational details
4.1 Quantum-computing experiments
All the quantum calculations were carried out using the IonQ Harmony quantum processor provided by the Amazon Braket cloud service. To conduct our quantum computing experiments, we have developed our quantum software development kit (SDK) called PhiQonnect, which is especially intended for quantum kernel–based methods, including QSVC and QSVR. The quantum SDK utilizes open-source libraries such as IBM Qiskit (Aleksandrowicz et al. 2019) (ver. 0.39.5); pytket (ver. 1.11.1), which is a language-agnostic optimizing compiler provided by Quantinuum (Sivarajah et al. 2020); amazon-braket-sdk (ver. 1.35.3) developed by Amazon Braket (Amazon Braket SDK Python 2022); and scikit-learn (Pedregosa et al. 2011) (ver. 1.2.1), in which LIBSVM library (Chang and Lin 2011) is included. All the quantum computations on the NISQ device were obtained using our SDK, which is available as open-source software (see Code Availability).
The computational details of our quantum experiments using the IonQ Harmony are summarized in Table 3. To obtain the quantum kernel estimation, the number of quantum measurements per kernel entry was set to 500 (we measured the quantum state on \(Z\) basis). This is supported by our noise model simulations, in which 500 shots were shown to be enough to ensure the quality of the quantum kernel for the objective of this study (see Appendix). To obtain the quantum kernel matrix for the training data, only the upper triangular entries were computed considering the symmetric nature of the quantum kernel, reducing the computational cost of using the quantum device. In training and testing our QSVC model, we used 20 data points for training and 10 data points (which are separate from the training data) for testing. A total of \(\mathrm{105,000} (=20\times \frac{21}{2}\times 500)\) quantum measurements were conducted to obtain the quantum kernel, and a total of \(\mathrm{100,000} \left(20\times 10\times 500\right)\) shots were conducted to obtain the train-test kernel matrix. In training and testing our QSVR model, we used 40 data points for training and 40 out-of-sample data points for testing. A total of \(\mathrm{410,000} (=40\times \frac{41}{2}\times 500)\) quantum measurements were conducted to obtain the quantum kernel, and a total of \(\mathrm{800,000} (40\times 40\times 500)\) shots were conducted to obtain the train-test kernel matrix.
To improve the performance of the machine learning models using the quantum kernels, we introduced a scaling hyperparameter \(\uplambda\) in the quantum feature map (i.e., \({{\varvec{x}}}^{(i)}\leftarrow\uplambda {{\varvec{x}}}^{(i)}\) in the quantum circuit). Such a hyperparameter can calibrate the angles of the rotation gates and affect the quantum feature map in the Hilbert space. The hyperparameter can help improve the performance of the QSVM model (Canatar et al. 2022; Shaydulin and Wild 2022; Suzuki et al. 2023). In the present work, for the classification tasks, the hyperparameter \(\uplambda\) was set to 1.0, whereas for the regression tasks, \(\uplambda\) was set to 1.3.
4.2 Preprocessing the materials dataset
We used a dataset for superconducting materials provided by Hamidieh (2018), which was originally compiled by the National Institute of Materials Science in Japan. In this particular dataset, there are 81 features for the critical temperature \({T}_{c}\). To reduce the number of features that can be encoded into the NISQ device, the original 81-dimensional vector was reduced into the 4-dimensional vector using principal component analysis (Subasi and Gursoy 2010).
The distribution of critical temperature is concentrated in the low-temperature region. Such a non-normal distribution is not suited for building regression models. To overcome this, we used the Box–Cox transformation (Sakia 1992), which is a statistical technique used to transform a non-normal distribution into a normal distribution. It is often used in regression analysis to improve the performance of the model when the data does not follow a normal distribution. The Box–Cox transformation is defined by the following equation:
Here, \(y\) is the original data, \({y}^{(\xi )}\) is the transformed data, and \(\xi\) is the Box–Cox transformation parameter. In this study, we used \(\xi =0.15084028\).
Data availability
The datasets used in the present study are available at the following:
Credit card fraud transaction: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
MNIST: http://yann.lecun.com/exdb/mnist/index.html
Fashion-MNIST: https://github.com/zalandoresearch/fashion-mnist
A financial market dataset used for our QSVR task is tabulated in Supplementary Information (Tables S2 and S3)
Superconductor materials: https://archive.ics.uci.edu/ml/datasets/Superconductivty+Data
Code availability
A quantum software development kit for reproducing our quantum experiments is available at https://github.com/scsk-quantum/phiqonnect
References
Abbas A, Sutter D, Zoufal C, Lucchi A, Figalli A, Woerner S (2021) The power of quantum neural networks. Nat Comput Sci 1:403–409. https://doi.org/10.1038/s43588-021-00084-1
Albrecht B, Dalyac C, Leclerc L et al (2023) Quantum feature maps for graph machine learning on a neutral atom quantum processor. Phys Rev A 107:042615. https://doi.org/10.1103/PhysRevA.107.042615
Aleksandrowicz G, Alexander T, Barkoutsos P et al (2019) Qiskit: an open-source framework for quantum computing. https://github.com/qiskit
Amazon Web Services (2022) Amazon Braket SDK Python. https://github.com/aws/amazon-braket-sdk-python
Bharti K, Cervera-Lierta A, Kyaw TH et al (2022) Noisy intermediate scale quantum algorithms. Rev Mod Phys 94:015004. https://doi.org/10.1103/RevModPhys.94.015004
Biamonte J, Wittek P, Pancotti N, Rebentrost P, Wiebe N, Lloyd S (2017) Quantum machine learning. Nature 549:195–202. https://doi.org/10.1038/nature23474
Bruzewicz CD, Chiaverini J, McConnell R, Sagex JM (2019) Trapped-ion quantum computing: progress and challenges. Appl Phys Rev 6:021314. https://doi.org/10.1063/1.5088164
Canatar A, Peters E, Pehlevan C, Wild SM, Shaydulin R (2022) Bandwidth enables generalization in quantum kernel models. https://arxiv.org/abs/2206.06686
Cenedese G, Bondani M, Rosa D, Benenti G (2023) Generation of pseudo-random quantum states on actual quantum processors. Entropy 25:607. https://doi.org/10.3390/e25040607
Cerezo M, Verdon G, Huang HY, Cincio L, Coles PJ (2022) Challenges and opportunities in quantum machine learning. Nat Comput Sci 2:567–576. https://doi.org/10.1038/s43588-022-00311-3
Chang CC, Lin CJ (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2:1–27. https://doi.org/10.1145/1961189.1961199
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/BF00994018
Cristianini N, Shawe-Taylor J, Elisseeff A, Kandola J (2001) On kernel target alignment. In: Dietterich T, Becker S, Ghahramani Z (eds) Advances in Neural Information Processing Systems, vol 14. https://proceedings.neurips.cc/paper_files/paper/2001/file/1f71e393b3809197ed66df836fe833e5-Paper.pdf. Accessed 9 May 2024
de Leon NP, Itoh KM, Kim D, Mehta KK, Northup TE, Paik H, Palmer BS, Samarth N, Sangtawesin S, Steuerman DW (2021) Materials challenges and opportunities for quantum computing hardware. Science 372:eabb2823. https://doi.org/10.1126/science.abb2823
Djehiche B, Löfdahl B (2021) Quantum support vector regression for disability insurance. Risks 9:216. https://doi.org/10.3390/risks9120216
Giordani T, Mannucci V, Spagnolo N, Fumero M, Rampini A, Rodolà E, Sciarrino F (2023) Certification of Gaussian boson sampling via graphs feature vectors and kernels. Quantum Sci Technol 8:015005. https://doi.org/10.1088/2058-9565/ac969b
Hamidieh K (2018) A data-driven statistical model for predicting the critical temperature of a superconductor. Comput Mat Sci 154:346–354. https://doi.org/10.1016/j.commatsci.2018.07.052
Havlíček V, Córcoles AD, Temme K, Harrow AW, Kandala A, Chow JM, Gambetta JM (2019) Supervised learning with quantum-enhanced feature spaces. Nature 567:209–212. https://doi.org/10.1038/s41586-019-0980-2
Heredge J, Hill C, Hollenberg L, Sevior M (2021) Quantum support vector machines for continuum suppression in B meson decays. Comput Softw Big Sci 5:27. https://doi.org/10.1007/s41781-021-00075-x
Hubregtsen T, Wierichs D, Gil-Fuster E, Derks PJH, Faehrmann PK, Meyer JJ (2022) Training quantum embedding kernels on near-term quantum computers. Phys Rev A 106:042431. https://doi.org/10.1103/PhysRevA.106.042431
Ishiyama Y, Nagai R, Mieda S, Takei Y, Minato Y, Natsume Y (2022) Noise-robust optimization of quantum machine learning models for polymer properties using a simulator and validated on the IonQ quantum computer. Sci Rep 12:19003. https://doi.org/10.1038/s41598-022-22940-4
Jäger J, Krems RV (2023) Universal expressiveness of variational quantum classifiers and quantum kernels for support vector machines. Nat Commun 14:576. https://doi.org/10.1038/s41467-023-36144-5
Jerbi S, Fiderer LJ, Nautrup HP, Kübler JM, Briegel HJ, Dunjko V (2023) Quantum machine learning beyond kernel methods. Nat Commun 14:517. https://doi.org/10.1038/s41467-023-36159-y
Johri S, Debnath S, Mocherla A, Singk A, Prakash A, Kim J, Kerenidis I (2021) Nearest centroid classification on a trapped ion quantum computer. Npj Quantum Inf 7:122. https://doi.org/10.1038/s41534-021-00456-5
Krunic Z, Flöther FF, Seegan G, Earnest-Noble ND, Shehab O (2022) Quantum kernels for real-world predictions based on electronic health records. IEEE Trans Quantum Eng 3:1–11. https://doi.org/10.1109/TQE.2022.3176806
Kusumoto T, Mitarai K, Fujii K, Kitagawa M, Negoro M (2021) Experimental quantum kernel trick with nuclear spins in a solid. Npj Quantum Inf 7:94. https://doi.org/10.1038/s41534-021-00423-0
LaRose R, Mari A, Kaiser S et al (2022) Mitiq: a software package for error mitigation on noisy quantum computers. Quantum 6:774. https://doi.org/10.22331/q-2022-08-11-774
Liu Y, Arunachalam S, Temme K (2021) A rigorous and robust quantum speed-up in supervised machine learning. Nat Phys 17:1013–1017. https://doi.org/10.1038/s41567-021-01287-z
Meyer JJ, Mularski J, Gil-Fuster E, Mele AA, Arzani F, Wilms A, Eisert J (2023) Exploiting symmetry in variational quantum machine learning. PRX Quantum 4:010328. https://doi.org/10.1103/PRXQuantum.4.010328
Moradi S, Brandner C, Coggins M, Wille R, Drexler W, Papp L (2022) Error mitigation for quantum kernel based machine learning methods on IonQ and IBM quantum computers. https://arxiv.org/abs/2206.01573
Nam Y, Chen JS, Pisenti NC et al (2020) Ground-state energy estimation of the water molecule on a trapped-ion quantum computer. Npj Quantum Inf 6:33. https://doi.org/10.1038/s41534-020-0259-3
Nielsen MA, Chuang IL (2010) Quantum computing and quantum information, 10th, anniversary. Cambridge University Press, Cambridge, UK
Pedregosa F, Varoquaux G, Gramfort A et al (2011) Scikit-learn: machine learning in Python. J Mach Learn Res 12:2825–2830. https://scikit-learn.org/stable
Peters E, Caldeira J, Ho A, Leichenauer S, Mohseni M, Neven H, Spentzouris P, Strain D, Perdue GN (2021) Machine learning of high dimensional data on a noisy quantum processor. Npj Quantum Inf 7:1–61. https://doi.org/10.1038/s41534-021-00498-9
Preskill J (2018) Quantum computing in the NISQ era and beyond. Quantum 2:79. https://doi.org/10.22331/q-2018-08-06-79
Ragone M, Braccia P, Nguyen QT, Schatzki L, Coles PJ, Sauvage F, Larocca M, Cerezo M (2023) Representation theory for geometric quantum machine learning. https://arxiv.org/abs/2210.07980
Rebentrost P, Mohseni M, Lloyd S (2014) Quantum support vector machine for big data classification. Phys Rev Lett 113:130503. https://doi.org/10.1103/PhysRevLett.113.130503
Rudolph MS, Toussaint NB, Katabarwa A, Johri S, Peropadre B, Perdomo-Ortiz A (2022) Generation of high-resolution handwritten digits with an ion-trap quantum computer. Phys Rev X 12:031010. https://doi.org/10.1103/PhysRevX.12.031010
Sakia RM (1992) The Box-Cox transformation technique: a review. J R Stat Soc Ser D Stat 41:169–178. https://doi.org/10.2307/2348250
Schölkopf B, Smola AJ (2002) Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT Press, Cambridge, MA
Schuld M, Killoran N (2019) Quantum machine learning in feature Hilbert spaces. Phys Rev Lett 122:040504. https://doi.org/10.1103/PhysRevLett.122.040504
Schuld M, Brádler K, Israel R, Su D, Gupt B (2020) Measuring the similarity of graphs with a Gaussian boson sampler. Phys Rev A 101:032314. https://doi.org/10.1103/PhysRevA.101.032314
Shaydulin R, Wild SM (2022) Importance of kernel bandwidth in quantum machine learning. Phys Rev A 106:042407. https://doi.org/10.1103/PhysRevA.106.042407
Sivarajah S, Dilkes S, Cowtan A, Simmons W, Edgington A, Duncan R (2020) t|ket⟩: a retargetable compiler for NISQ devices. Quantum Sci Technol 6:014003. https://doi.org/10.1088/2058-9565/ab8e92
Subasi A, Gursoy MI (2010) EEG signal classification using PCA, ICA, LDA and support vector machines. Expert Syst Appl 37:8659–8666. https://doi.org/10.1016/j.eswa.2010.06.065
Suzuki T, Miyazaki T, Inaritai T, Otsuka T (2023) Quantum AI simulator using a hybrid CPU–FPGA approach. Sci Rep 13:7735. https://doi.org/10.1038/s41598-023-34600-2
Temme K, Bravyi S, Gambetta JM (2017) Error mitigation for short-depth quantum circuits. Phys Rev Lett 119:180509. https://doi.org/10.1103/PhysRevLett.119.180509
Thanasilp S, Wang S, Cerezo M, Holmes Z (2022) Exponential concentration and untrainability in quantum kernel methods. https://arxiv.org/abs/2208.11060
Wang X, Du Y, Luo Y, Tao D (2021) Towards understanding the power of quantum kernels in the NISQ era. Quantum 5:531. https://doi.org/10.22331/q-2021-08-30-531
West MT, Heredge J, Sevior M, Usman M (2023) Provably trainable rotationally equivariant quantum machine learning. https://arxiv.org/abs/2311.05873
Xiao H, Rasul K, Vollgraf R (2017) Fashion-MNIST: a novel image dataset for benchmarking machine learning algorithms. https://arxiv.org/abs/1708.07747
Zhang K, Han Z (2013) Support vector regression-based multidisciplinary design optimization in aircraft conceptual design. In: 51st AIAA Aerospace Sciences Meeting including the New Horizons Forum and Aerospace Exposition, pp 1160. https://doi.org/10.2514/6.2013-1160
Zhao L, Goings J, Wright K, Nguyen J et al (2023) Orbital-optimized pair-correlated electron simulations on trapped-ion quantum computers. Npj Quantum Inf 9:60. https://doi.org/10.1038/s41534-023-00730-8
Zhu EY, Johri S, Bacon D et al (2022) Generative quantum learning of joint probability distribution functions. Phys Rev Res 4:043092. https://doi.org/10.1103/PhysRevResearch.4.043092
Author information
Authors and Affiliations
Contributions
TS conceived the original idea of the work. TM developed the software for the work and conducted the quantum circuit simulations as well as the quantum experiments. TH conducted the machine learning tasks including the hyperparameter tuning. All the authors analyzed the result data. TS wrote the manuscript. All the authors reviewed the manuscript and commented on it.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix. The number of quantum measurements per kernel entry
Appendix. The number of quantum measurements per kernel entry
In Appendix A, we investigate how the number of measurements affects the kernel matrix and the prediction performance (Fig.

The effects of shots on the accuracy of QSVM. The error bars indicate the standard deviation obtained from 5 independent seeds. Top panel: test accuracy for a credit card dataset, b MNIST dataset, and c Fashion-MNIST dataset. Bottom panel: alignment of the noisy quantum kernel with the noiseless quantum kernel for d credit card dataset, e MNIST dataset, and f Fashion-MNIST dataset. In our device noise model simulations, we consider the following conditions for single- and two-qubit gate error rates: (i) \({p}_{1} = 0.001\), \({p}_{2}= 0.005\) (indicated by blue); (ii) \({p}_{1}= 0.01\), \({p}_{2}=0.05\) (indicated by red). Five independent seeds for each dataset were used to obtain the statistical results. The number of training data was 80, and the number of test data was 40
8). Three different datasets (the credit card fraudulent transaction dataset, the MNIST dataset, and the Fashion-MNIST dataset) were examined. We considered the following conditions for qubit gate error rates: (i) \({p}_{1} = 0.001\), \({p}_{2}= 0.005\) and (ii) \({p}_{1}= 0.01\), \({p}_{2}=0.05\). In the case of the lower qubit gate error rates, the alignment \(A\left(K,{K}^{{\text{noise}}}\right)\) remained high and almost unchanged. In the case of the higher qubit gate error rates, the alignment was slightly improved by increasing the number of measurements. On the other hand, the test accuracy of QSVC models with the higher qubit gate error rates was very similar to that in the case of the lower error rates. The results suggest that at least 500 shots per kernel entry are enough to ensure the prediction performance of our QSVC models. This is consistent with a recent work by Wang et al. (2021), in which the accuracy is saturated at 500 shots per kernel entry. In the present work, the number of shots per kernel entry was set to 500 for our noisy numerical simulations as well as for quantum experiments using the real quantum device.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Suzuki, T., Hasebe, T. & Miyazaki, T. Quantum support vector machines for classification and regression on a trapped-ion quantum computer. Quantum Mach. Intell. 6, 31 (2024). https://doi.org/10.1007/s42484-024-00165-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42484-024-00165-0