
Abstract
Some features of an image may spoil due to fog or haze, smoke. These images lose their brightness due to air-light scattering. It offers troublesomeness to the people lives in hill and fog regions of the world. This paper proposed two key aspects. One is a modified dark-channel method based on the median for eliminating the refine the transmission map as well as halos and artifacts, another important aspect is a memory-efficient row-based arrangement of the pixels for real-time applications. The advantage of this method is air-light can be predicted directly from the modified dark channel and also accurate transmission map can be estimated. This method is compared with other existing four algorithms. Our proposed method analyzed in terms of Peak Signal to Noise Ratio (PSNR), Average Time cost (ATC), percentage of haze improvement (PHI), average contrast of output image (ACOI), Mean Squared Error (MSE) and Structural Similarity Index (SSIM). The quality of the output de-haze image of our algorithm over existing algorithms is more. It has taken less computation time, equal MSE, with higher SSIM and has more percentage of haze improved over existing methods.
Similar content being viewed by others


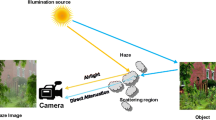
1 Introduction
Environmental conditions such as mist, haze, fog, and smoke lead to degrading the quality of the scenes when captured in the outdoor area. As it changes the colors of the original scene and reduces the contrast becomes an annoying problem to photographers, it declines the visibility of the pictures and acts as a threat to the several applications like object detection, outdoor surveillance; it also declines the clarity of the underwater images and satellite images. Hence, the removal of haze from images is a vital and widely required area in computer vision. The haze transmission depends on transmission depth and, varies in different situations. Hence, noticing and eliminating the fog from the digital images is an ill-posed problem.
Several methods such as histogram-based [1], saturation based and contrast based are proposed day-by-day for adroitly removing haze from images. The above methods consider a single image as input for removing the haze. Depth based and polarization-based methods [2] can effectively eliminate fog by considering many hazy images taken from the dissimilar degree of polarization for finding the transmission-depth. Tan’s [3] used a contrast maximization method; it gives a de-hazed image with better visibility and has more contrast than the hazy input image. The main disadvantage of this method is more assumptions are required to increase the local contrast of the patch of the restored image. He et al. [4] proposed a dark-channel method (DCM) with refined transmission depth using an edge-preserving filter called guided filter [5]. The detailed process of image de-hazing using [4] is explained in Sect. 2. Zhu et al. [6] proposed a de-haze algorithm with the help of a linear image model. They modeled the scene depth of the hazy image under the novel prior and learn the parameters of this model with a supervised learning method. The transmission-depth information is recovered well in this method. The main disadvantage of this method is the scattering coefficient (β) considered constant. The above-mentioned algorithms may not suitable for real-time applications and require more computations as the square patch has been employed. To reduce the number of computations the median channel with row-based pixel structure is proposed in this paper. The row-based pixel arrangement provides an advantage of eliminating the halos and artifacts in the recovered haze-free image. The proposed algorithm involves the following steps: converting image to a row vector model, finding the atmospheric light using the median channel, estimation of transmission depth & scene radiance and lastly, row vector model to image conversion.
The rest of the paper arranged as follows. In Sect. 1, the Dark channel prior is explained. Section 2 discussed the proposed algorithm, Sect. 3, represents the experimental results and discussion, and Sect. 4 conclusion.
2 Dark channel prior method (DCM)
DCM is an effective method for de-hazing. The first step in the de-hazing algorithm is developing a mathematical representation for the hazy image model. The formation of hazy image is depicted in Fig. 1, because of the haze particle’s scattering in the atmosphere; the image captured by the camera sensor looks foggy in nature.

Haze formation model
An exact realization for a foggy image according to McCartney [7] is represented in Eq. (1).
where \(J(p)\) is de-hazed image or scene radiance,\(I(p)\) is observed hazy image, \(t(p)\) is transmission depth or transmission map and \(A\) is global air-light. The essential objective is, obtaining a haze-free image \(J(p)\). It is possible by identifying the unknown parameters \(t(p)\) and \(A\).
Generally, the transmission map (t) is a function of two parameters and can be expressed as:
where β scattering coefficient is considered constant when atmospheric condition is homogenous in nature and is highly interrelated with wavelength. The depth of the scene d is ranges from [0, +∞). From Eq. (2) when d tends to infinity, the captured image is very far from the observer and at the same time t tends to zero, which means that there is no transmission map. This case is ambiguous in nature, another observation from Eq. (2) is that if t tends to infinity, no image exists i.e., image dehazing depends on transmission map.
A global air light (A) represent the amount of brightness needed for accurate visualization of output image (J). The atmospheric light for a single channel \(A^{c}\) can be calculated as the 0.1% of brightest pixels in the dark channel, corresponding pixels in a hazy image considered as atmospheric light. Sorting, division and comparison operations are involved in calculations. Therefore, the determination of unknown parameter \(A^{c}\) is a challenging problem. Moreover, refine transmission step is used to enhance the image quality and eliminates the halos, with the help of guided-filter.
Finding the scene radiance according to [4] from the Eq. (1) as
The significance of \(t_{0}\), when \(t(p)\) is close to zero then \(J(p)\) may affect with noise. Therefore, a restricted parameter \(t_{0} = 0.1\) is used and maintained as constant throughout the process.
The Fig. 2 represents DCM [4] based de-hazing system. This method works well for large patch sizes. Hence, the patch size of 16 × 16 is used to find the darkest pixel among three channels, followed by finding the atmospheric light and transmission map. A refine transmission map is obtained with the help of guided-filter, which produces filtered output based on guiding (input) image. It is specially designed to preserve & smoothening the edges and plays a vital role in the performance estimation process. Since it has a high average time cost. Therefore proposed approach is based on eliminating most computational complexity step of refining transmission.

Process of DCM
3 Proposed algorithm
The existing methods [4] employed the minimum channel of the pixels as a dark channel of the image. As a result, it produces halos and artifacts in the de-hazed image. The effect of employing a minimum of pixels is represented in Fig. 3. At the edges, the white region becomes shaded resulting will lead to producing undesired pixel intensity which causes the halo effect.

Halo effect
This problem can be resolved in our proposed method as, in Fig. 4, the points on diagonal line in the RGB cube ranges from (0, 0, 0) to (255, 255, 255). Foggy areas (Brighten pixels) in an image are mostly scattered nearby this diagonal line, indicated with blue points in Fig. 4. Whereas object related pixels are surrounded nearer to the origin which are indicated with pink points. There is less special continuity. By determining variogram (V) [8] for each pixel of the hazy image, we can get the spatial continuity of an original image.

RGB color space of hazy image model
Generally, in sky regions, the value of ‘V’ is very small. However, in non-sky areas, ‘V’ is larger. To measure ‘V’, we used the concept of color fluctuations. According to the depth of field, bright objects will become dimmer as the distance increases. This phenomenon is more observable under the impact of thick haze. The pink points in Fig. 4 shows, an object’s color is unsteady at a distance. To stretch the value of “V” and make it more effective we employed the median of the pixels.
When observing transmission maps with different window sizes, we find a tip to eliminate the refine transmission step as well as halos and artifacts in the recovered image. It can be done by estimating the median channel of the pixels instead of a dark channel. Furthermore, note that in DCM produces a good de-hazed image with a patch size of 16 × 16. Therefore, in the proposed method, the median channel is determined with a 16 × 1 patch size.
Another key aspect with memory management for real-time image processing applications, i.e., memory is the major limiting factor in the field of image processing when wish to implement on FPGAs [9]. Convolution [10] is an important operation on an image and is performed in the spatial domain. Where each pixel and its neighbors are multiplied by kernel or patch, the results are summed up and the result is used to measure the new pixel value. The process is represented in Fig. 5.

Convolution operation on Sub-window of the frame (X) [18]
For several reasons, among many image/video restoration algorithms we focused on this iterative algorithm. This exhibits a pattern of local computations due to the dependence of a restored pixel value on its 1-neighbors. These computations make it possible to implement spatially. The same process is repeated on a significant amount of data for a number of iterations. There have also been some difficulties related to this algorithm. The process is expected to be sequential, i.e. until the next iteration step can begin, all pixels of the image will move through the current restoration stage. This requires a fast and wider bandwidth.
Another key aspect proposed in this paper is about memory. To address this issue, assume that the ‘ X ‘ image or frame will be stored as an array (A) of 8-bit elements. The ‘A’ array has columns and rows and is usually stored in BRAM [11] like a row by row or a column by column manner (ixj). Generally, the computer or processor does not keep track of each element of an array’s address. Relatively, it keeps track of address of the first pixel \(A(0,0)\) and is called the base address. It can use measure the specific pixel’s address \(A(i,j)\).
The moment of mask or patch in the image is varying from top to bottom as well as left to right end. In a particular row, when elements are finished, the mask moves one position right and down. Therefore, nine-pixel numbers (if patch size-3 × 3) are involved during the convolution process at each step. Sequentially, it extracts nine pixels in each step. Because a single pixel’s data is replicated, therefore this strategy is costly in terms of memory storage. Hence, a sequential pattern of pixels employed like a row vector manner. Most exceptional de-hazed output can be obtained by combing the above light of ideas. The process of proposed method as:
Initially, an image is converted to a row vector model. As a result, the square patch will be changed as rectangular. Figure 6 indicates the patch moment in existing and proposed algorithm respectively.

Patch moment a square, b rectangular
In the next step, the median [12] of the pixels is employed as a dark channel. Since the information of any image will hide in the middle of the image so, instead of finding the minimum of pixels in [4] we proposed the median. Median is nothing but middle value or average of the central values within the list. It is a non-linear signal processing technique based on statistics. The noisy value of any digital image or the sequence is replaced with its median value of the neighborhood (mask). Generally, noise elimination is employed at a pre-processing step to improve the outcomes in post-processing (ex: Edge detection). The pixels within the mask are ranked in the order of their gray levels, and the median value of the group is stored to replace the noisy value. The median of the pixels can be obtained as
where \(M(x,y),I(x,y)\) are output de-noise image and the original noisy image respectively, \(W\) is a single-dimensional mask. Sometimes the mask shape may be linear, circular, cross and square. In our method, we considered linear mask with size W = 16 × 1. Then, Eq. (1) can be modified as
Step 1 Taking the median in the local patch in the hazy input image individually on each R, G&B channels from Eq. (1)
Step 2 Applying normalization with air-light then Eq. (8) can be re-written as
Step 3 Obtaining the minimum value of pixel from three RGB color channels as
We considered an assumption according to the DCM, minimum value of median of three color channels approximated to zero. This can be represented as
Step 4 The patch transmission obtained as
The existence of haze is a basic indication for a human to identify depth. Even, if the pictures are captured in good weather conditions, the image will appear to be abnormal if the entire haze is removed and it seems to depth may be lost.
It can be defeated by adding a small quantity of fog (\(\omega\) = 0.25), with the constant parameter (0 ˂ \(\omega\) ≤ 1) in the above equation.
Here the combining patch’s transmission is equal to transmission depth of the entire image. Once, the transmission and air-light is known the scene radiance J(p) can be determined as
Step 5
The above whole process is done in the row vector model. At last, after finding the scene radiance for a row vector, it is reshaped into the matrix (image) form. The architecture of the proposed algorithm with array-based pixel arrangement and corresponding rectangular patch moment is represented in Fig. 7. To understand the variation of the image at each succeeding step, we demonstrated the architecture with images.

Architecture of proposed algorithm (input hazy image, array based arrangement, median of the pixels in each channel, Transmission map, atmospheric light estimation and de-hazed image from left to right)
Figure 8, represents the block diagram and pseudo code of the proposed method is represented in algorithm 1. Initially, matrix-based pixel arrangement converted to the vector-based manner and then with a patch size of 16 × 1 the median of pixels is obtained. Later, atmospheric light, transmission map, and scene radiance are predicted according to Sect. 2. Finally, vector-based arrangement converted to a matrix-based manner for visualization purposes.


Block diagram of proposed algorithm
4 Experimental results and discussion
The simulations are performed in MATLAB 17a running on Intel i5 CPU 3 GHz and 8 GB memory with OS window 8.1. To verify the validity of our proposed algorithm, we choose a well-known standard database Middlebury [13]. This database covers all the challenging factors. Our proposed algorithm compared for an image size of 640 × 480 with a patch size 16 × 16. They are Zhu et al. [6], Tarel et al. [14], He et al. [4] and Tripathi et al. [15] in terms of MSE, PSNR, Average Time cost, Average Contrast of the output image and visibility analysis (percentage of haze improvement). From the comparison Table 1, the proposed approach taking minimum average time cost; produces output with high contrast and equal mean square error (MSE) i.e., for canon image the MSE is 2.07 similar for other methods and haze improvement of the proposed algorithm gives a significant result. In the motorcycle database, He et al. and Tripathi et al. produces halos and artifacts. Whereas, in the proposed method we employed the median of the pixels along with row-based patch moment, which performs well on removing artifacts and halos around the depth discontinuities. Zhu et al. produces contrast-enhanced output and they look unnatural. Tarel et al. produces natural de-hazed as an output but recovered image has noticeable haze. Proposed method has highest SSIM value among other state-of-the-art methods. These evaluations parameters are more trustworthy for analysis and the bold value in the Table 1 indicates the better evaluation metric value produced by the corresponding method.

De-haze result of proposed method. a Hazy input image, b median channel of hazy image, c Transmission depth map, d De-haze output image

Qualitative comparison of different Dehazing algorithms on Middlebury standard challenging database
An example of a bi-cycle image from a standard database chosen for illustration, Fig. 9a denotes a bi-cycle hazy image with a resolution of 800 × 600 and it’s median, transmission depth and de-hazed output image represented in Fig. 9b–d respectively. Figure 10 shows the qualitative comparison of five state-of-the-art algorithms on different real-world images. The Figs. 11, 12, 13, 14 15, and 16 shows the results comparison with help of bar charts in terms of PSNR, ATC, ACOI, MSE, PHI and SSIM of different De-hazing algorithms respectively. Our algorithm gives less computational time for all standard databases. The percentage of haze improvement as well as SSIM is significantly high for all the databases.

PSNR: Peak Signal to Noise Ratio

ATC: Average Time Cost

ACOI: Average Contrast of Output Image

MSE: Mean Square Error

PHI: Percentage of Haze Improvement

SSIM: Structural Similarity index
4.1 Performance evaluation metrics
Evaluation metrics basically gives information about which scheme of method can be preferable. In this paper five performance metrics are used for evaluating the efficiency of proposed algorithm.
4.1.1 PSNR and MSE
PSNR [16] and MSE are well-identified performance metric for measuring the degree of error because these represent overall error content in the entire output image.
PSNR is defined as the “logarithmic ratio of peak signal energy (P) to the mean squared error (MSE) between output \(N_{j}\) and input \(M_{i}\) images”. It can be expressed as
where, \(P\) is maximum value of the pixel in an image (typical value of \(P\) = 255), \(MSE\) is Mean Squared Error, \(k,n\) are the no. of rows, no. of columns of the image respectively and \(M_{i} ,N_{j}\) are the input image, output image respectively. Generally, the value of PSNR would be desirably high.
4.1.2 Computation time or average time cost
It represents the amount time needed to complete an algorithm in MATLAB. Using commands ‘tic’ &‘toc’, the computational time is calculated. The unit are in seconds.
The average time cost of our proposed algorithm is estimated with other four existing algorithms in 21 number of iteration.
4.1.3 Average contrast of de-hazed image
Here \(L_{\hbox{min} }\), \(L_{\hbox{max} }\) is the minimum, maximum luminance of an output image correspondingly. \(M,N\) row and column of an output image respectively. Generally, the maximum value of it directs that an image is more quality.
4.1.4 Structural Similarity Index (SSIM) [17]
It is a method for quantifying the similarity between two images. The SSIM can be observed as a quality measure of one of the images being compared with the other image is regarded as of perfect quality.
5 Conclusion
Based on qualitative and quantitative metrics we concluded that the proposed approach took minimum computation time; produces output with high contrast and has almost equal mean squared error (MSE). The haze improvement of the proposed algorithm gives a better result than state-of-the-art methods.
Our method has a common limitation like all de-hazed algorithms: the haze imaging model is valid only for non-sky regions and it has another drawback of dealing with hazy images which are obtained at long distance, e.g. aerial images. In the future, we will focus on the above aspects.
References
Xu Z, Liu X, Ji N (2009) Fog removal from color images using contrast limited adaptive histogram equalization. In: Proceedings 2nd international congress image signal process (CISP), pp 1–5
Schechner YY, Narasimhan SG, Nayar SK (2001) Instant dehazing of images using polarization. In: Proceedings IEEE conference on computer vision and pattern recognition (CVPR), vol 1, pp I-325–I-332
Tan R (2008) Visibility in bad weather from a single image. In: CVPR
He K, Sun J, Tang X (2009) Single image haze removal using dark channel prior In: IEEE international conference on computer vision and pattern recognition, pp 1956–1963
He K, Sun J, Tang X (2010) Guided image filtering. In: Proceedings European conference on computer vision, Heraklion, Greece, pp 1–14
Zhu QS, Mai JM, Shao L (2015) A fast single image haze removal algorithm using color attenuation prior. IEEE Trans Image Process 24(11):3522–3533
McCartney EJ (1976) Optics of atmosphere: scattering by molecules and particles. John Wiley and Sons, New York, pp 23–32
Gui F, Wei L (2004) Application of variogram function in image analysis. In: Proceedings 7th IEEE international conference on signal processing, vol 2, pp 1099–1102
Torres-Huitzil C, Nuno-Maganda MA (2014) A realtime efficient implementation of local adaptive image thresholding in reconfigurable hardware. ACM SIGARCH Comput Arch News 42:33–38
Ludwig J (2013) Image convolution. Portland State University
Garcia P, Bhowmik D, Stewart R, Michaelson G, Wallace A (2019) Optimized memory allocation and power minimization for FPGA based image processing. J Imaging 5:7
Devarajan G, Aatre VK, Sridhar CS (1990) Analysis of median filter. In: ACE’90. Proceedings of XVI annual convention and exhibition of the IEEE in India, pp 274–276
Ancuti C, Ancuti CO, De Vleeschouwer C (2016) D-Hazy: a dataset to evaluate quantitatively dehazing algorithms. In: IEEE international conference on image processing (ICIP) ICIP’16 2016 Pheonix, USA
Tarel J-P, Hautiere N (2009) Fast visibility restoration from a single color or gray level image. In: Proceedings of IEEE international conference on computer vision (ICCV’09), Kyoto, Japan
Tripathi AK, Mukhopadhyay S (2012) Efficient fog removal from video. Signal Image Video Process 8(8):1431–1439
Zhang K, Wang S, Zhang X (2002) New metric for quality assessment of digital images based on weighted mean square error. In: International Society for Optics and Photonics, City
Wang Z (2003) The SSIM index for image quality assessment. https://ece.uwaterloo.ca/z70wang/research/ssim. Accessed 10 Dec 2019
Soma P, Jatoth RK (2018) Hardware implementation issues on image processing algorithms. In: 2018 4th international conference on computing communication and automation (ICCCA), IEEE
Acknowledgements
This work is supported by the Science and Engineering Research Board (SERB) India, under the Grant of EEQ/2016/000556.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Soma, P., Jatoth, R.K. & Nenavath, H. Fast and memory efficient de-hazing technique for real-time computer vision applications. SN Appl. Sci. 2, 454 (2020). https://doi.org/10.1007/s42452-020-2254-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-020-2254-x