
Abstract
This manuscript addresses the critical challenge of fault classification and localization within smart distribution networks, exacerbated by the complex integration of distributed energy resources and the dynamic nature of modern power systems. Traditional methods fall short in accurately and efficiently managing these tasks due to their reliance on linear models and manual inspection, which cannot cope with the data-rich and variable environment of current distribution networks. We introduce a novel data-driven framework utilizing convolutional neural networks to enhance fault classification accuracy and localization precision. Our framework uniquely incorporates an online continual learning algorithm, adapting to system changes and evolving fault patterns without requiring retraining. The method demonstrated significant improvements in fault classification and localization performance. Quantitatively, our CNN-based approach achieved a fault classification accuracy of 98.5% and a fault localization accuracy of 97.9%, outperforming traditional AI models in simulated environments. These results underline the potential of our framework to significantly contribute to the reliability and efficiency of fault management in smart distribution systems, offering a robust solution to the challenges posed by the integration of and the variability of load conditions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The rapid development of smart grids and increased penetration of distributed energy resources (DER) has brought many significant benefits, such as system scalability and effective energy delivery [1]. However, the increased complexity of the power grid also poses fundamental challenges in system operation. Furthermore, the increasing dispersion of advanced metering infrastructure in smart grids leads to massive amounts of available data. Due to these changes, traditional power system protection methods, based on simple linear models and human inspection, have limited performance when faced with increased complexity and enormous amounts of data. Electrical faults that may occur in the distribution system are abnormal conditions caused by human error, equipment failure, or weather conditions. These faults can cause equipment damage and interruptions to the distribution system. As a result, failure to detect and isolate faults can cause catastrophic events and even loss of life [2]. Therefore, effective fault protection systems that address the complexity and dynamics of the system caused by DERs are urgently needed.
In general, four main types of fault can occur in the distribution system: line-to-line fault (LL), line-to-ground fault (LG), double line-to-ground fault (LLG), and three-phase-to-ground fault (LLLG). In recent years, a number of studies have explored techniques for locating faults in a power system. These methods can be divided into two categories: conventional and artificial intelligence (AI) algorithms.
Conventional methods include traveling wave-based and impedance-based methods. Both methods are beneficial for transmission systems. However, when considering the increasing complexity of the distribution system’s topology, these methods are not very effective. Traveling wave-based techniques are based on the principle of reflection and transmission of traveling waves between the line terminal and the fault location. The advantage of the method is that it is independent of system configuration and load variance. However, it can be costly to implement, as it requires high-speed data acquisition devices and sensors to capture the transient waveform for fault location [3,4,5]. Impedance-based algorithms are popular due to their simplicity and cost-effectiveness in comparison with the traveling wave-based techniques. Impedance-based algorithms use measured voltage and current to compute the bus impedance. From the calculated impedance, the fault distance to the measured point can be determined [6, 7]. These algorithms depend on high values of the fault current at the main substation to calculate the fault resistance, which can lead to multiple estimations of the fault location [8]. Additionally, these methods are vulnerable to random noise and changes in system parameters.
Due to the complexity of distribution grids and the availability of massive amounts of data, AI-based algorithms have attracted increasing attention. Since AI methods can automatically extract features and learn from historical information, they are considered a promising tool for application in power systems [9,10,11]. There have been numerous studies exploring AI models for fault classification and location identification in power distribution systems. They include the decision tree (DT) [12, 13], random forest (RF) [14], k-nearest neighbor (KNN) [15], support vector machine (SVM) [16,17,18], artificial neural network (ANN) [19], convolutional neural network (CNN) [20,21,22], ensemble learning-based method [23,24,25], and many others [26, 27]. In [13], a combination of empirical mode decomposition and DT algorithm was proposed to perform fault detection, classification, and localization in the presence of solar photovoltaic (PV) distributed generation (DG). An SVM-based fault detection, which can simultaneously detect islanding and grid faults, was presented in [16]. Lin et al. [28] used the support vector data description method for fault detection and classification with only normal data for its training process. In [21], the authors proposed a faulted line localization method based on a CNN classifier using bus voltages. It is capable of locating the faulted line with high probability under low observability of the buses. In [22], a fault type classification and a possible fire localization algorithm based on independent CNN classifiers were presented with a single observability characteristic. CNN has proven to be effective in handling power distribution data and has achieved state-of-the-art results in fault type classification and faulted line localization. While the previously proposed techniques can successfully classify or locate faults, most of them require large amounts of simulation data on all different types of faults. The fault data, however, can be rare in the distribution system. In addition, their static training mode makes them vulnerable to new data with different distributions that enter the system.
To address these limitations, our work introduces a groundbreaking real-time, data-driven framework for fault classification and localization in partially observable distribution systems, employing CNN models tailored for this purpose. The novelty of our approach lies in the integration of delta information and sequence components, enhancing the model’s ability to accurately classify and localize faults under dynamic system conditions. Moreover, the advancements in remote sensing technologies, including laser-based and vision-based methods, offer complementary solutions for distance measurement and condition assessment in civil engineering, which can further refine the accuracy of fault detection in smart grids [29, 30].
The merits of convolutional neural networks (CNNs) are demonstrated in “Numerical Simulations” section through a comparative analysis with alternative classification models. This paper further explores the preliminary aspects of fault localization, specifically identifying faulted lines or areas. Recognizing the prevalence of data under standard operational conditions and the scarcity of fault data, we introduce a data augmentation strategy to generate synthetic fault data during the preprocessing phase. Moreover, we enhance the model’s performance by incorporating distinctive features that significantly influence fault characterization, beyond traditional voltage or current measurements. Furthermore, our contribution is distinguished by the development of an online continual learning algorithm, leveraging transfer learning and calibration modules to adapt to changes in the distribution system over time. This innovative aspect addresses the critical need for fault detection systems to remain effective as DER integration levels and loading conditions evolve, marking a significant advancement over existing methodologies.
The main contributions of this article can be summarized as follows:
-
1.
Introduction of a novel CNN-based framework for fault classification and location identification in partially observable distribution systems, emphasizing its ability to handle dynamic and complex fault scenarios with high accuracy.
-
2.
Incorporation of delta information and sequence components to the feature set, enabling the model to capture critical changes in pre-fault and fault states, thereby improving the reliability of fault classification and localization.
-
3.
Proposal of an online continual learning algorithm that utilizes transfer learning and calibration techniques to dynamically adjust to system variations, ensuring sustained performance across different operational conditions.
These innovations represent a significant leap forward in the field of smart grid fault management, offering a more adaptable, accurate, and robust solution for fault classification and localization in the face of evolving distribution network challenges.
This article is organized into six sections. “Data Acquisitionand Feature Extraction” section describes the data acquisition and the feature vectors used by the CNN-based framework to classify and locate faults. “Overview of CNN Algorithmand Training” section presents an overview of the CNN algorithm and its training process. “Proposed Framework” section presents the proposed CNN-based framework and the online learning algorithm. The numerical simulation results in “Numerical Simulations” section validate the proposed framework in the real distribution feeder model. Finally, “Conclusion” section brings the major conclusions and discusses possible directions for future research.
Related Work
The development of fault detection and localization techniques within smart distribution networks marks a pivotal transition from conventional to advanced technological methodologies. Initially, the industry’s reliance on linear models and impedance-based measurements offered a foundational approach to fault analysis. However, the advent of DERs and the increasing complexity of grid configurations necessitated a paradigm shift towards more adaptive and intelligent systems.
This shift saw the introduction of AI algorithms, which brought about a renaissance in fault detection methodologies. Early implementations of decision trees, random forests, and support vector machines laid the groundwork for the exploration of neural network architectures. Among these, CNNs stood out due to their unparalleled efficiency in processing and learning from voluminous datasets. CNNs’ ability to autonomously learn from data patterns without explicit programming made them exceptionally suited for the real-time analysis required by the evolving smart grid ecosystem.
The literature reveals a broad spectrum of approaches aimed at enhancing the accuracy and reliability of fault localization and classification. These range from methodologies that leverage the spatial-temporal data inherent in grid operations to those that incorporate novel signal-processing techniques. For instance, the integration of Big Data analytics, employing techniques such as Principal Component Analysis and Convolutional multi-layer Bi-LSTM algorithms, underscores the importance of sophisticated data preprocessing and feature extraction methods in improving fault detection systems [31]. The integration of machine learning models with traditional grid data, such as voltage and current measurements, has been particularly effective in identifying and categorizing grid anomalies [32].
In response to the limitations of static models and the scarcity of comprehensive fault datasets, recent studies have emphasized the importance of dynamic learning algorithms. Online continual learning mechanisms, which allow for the real-time adaptation of models to new data and changing grid conditions, represent a significant advancement in this domain. These methodologies are complemented by ensemble classifiers and advanced signal processing techniques that enhance the categorization of Power Quality events, offering improved accuracy in fault diagnosis within solar photovoltaic connected Microgrid networks [33]. They address critical challenges in smart grid fault management, including the need for models to evolve alongside the grid they monitor.
The contribution of this paper to the body of knowledge includes the proposal of an innovative CNN-based framework designed to excel in fault classification and localization within smart distribution networks. This framework not only demonstrates superior performance in handling complex fault scenarios but also introduces an online continual learning algorithm. This algorithm enables the model to dynamically adjust to new fault patterns and operational changes, thereby maintaining its efficacy over time. Moreover, the adaptation of Wigner Ville energy-based techniques for fault classification during power swings [34] and the use of fuzzy inference systems for fault detection in the presence of distributed generation [35] is indicative of the growing complexity and the need for more versatile and robust fault management solutions. The proposed model’s integration of delta information and sequence components further distinguishes it from existing approaches, offering a more nuanced analysis of fault dynamics and improving the overall reliability of fault detection systems.
In summary, the evolution from traditional impedance-based fault detection methods to AI-driven approaches underscores a significant technological leap in the management of smart distribution networks. The enhancement of ANN classifiers through optimization techniques like PSO [36], alongside innovations in grid-connected PV system islanding detection [37], further demonstrates the sector’s move towards more efficient and reliable fault management strategies. The proposed CNN-based framework, with its emphasis on online continual learning and the integration of advanced signal processing techniques, represents a cutting-edge solution to the challenges of fault classification and localization. This progression not only reflects the growing complexity of modern electrical grids but also highlights the potential of AI to revolutionize the field of fault management in smart distribution systems. Finally, the exploration of HVDC grid fault detection methods [38] and the assessment of power quality issues in distributed generation [39] illustrate the expansive scope of AI applications, from enhancing system resiliency to optimizing power quality and reliability.
This comprehensive approach, enriched by contributions across various studies [40,41,42,43], not only solidifies the foundation for future advancements in smart grid fault management but also paves the way for innovative solutions that can adapt to and address the dynamically changing needs of modern electrical grids.
Data Acquisition and Feature Extraction
In this section, we briefly describe the test system used in this study and the data acquisition process, including the number of samples generated for each fault scenario. The feature vectors are also introduced for fault classification and faulted line (FL) localization.
Test System and Database
The test system used to evaluate the proposed framework is a real distribution grid located in the Midwest United States. It consists of 240 primary network nodes, 3 feeder lines, and 23 miles of primary feeder conductors involving more than 1,120 customers [44]. To simulate this system, we used the Open Distribution System Simulator (OpenDSS), a commonly used open-source solution. The load information provided in [44] includes hourly active and reactive power consumption calculations for the year from January to December 2017. To ensure that the PV system was modeled as realistically as possible, we obtained hourly irradiance and temperature data for Chicago in 2017 from the NASA Prediction of Worldwide Energy Resources (POWER) project [45]. Each PV source was installed at the existing load location and scaled according to the load size and the desired PV penetration level. In terms of location, the PV sources were randomly distributed on each feeder. For simplicity, the PV sources were assumed to provide only active power, and a penetration of 10% of these sources was considered the baseline.
The simulation steps were performed as follows. First, load information was assigned to each bus on the network. Next, the quasi-static time series power flow over 1 year was solved via the Matlab-OpenDSS interface using the yearly mode in OpenDSS. Finally, the voltage magnitudes and phase angles of the selected buses were extracted for further analysis. According to the study presented in [46], smart meters connected at the end of the line/branches of a radial distribution network give the most relevant information for fault identification applications. Therefore, in this study, buses located at the end of each line or branch of the test system (23% of the total buses) were selected to place the phasor measurement units (PMUs), thus minimizing communication requirements. To evaluate the fault classification and FL identification framework, various fault scenarios were simulated and generated. In each simulation, different types of faults were randomly assigned at different distances between buses. It is assumed that only one fault occurrence at a time. The fault resistance was set to change in the range of 0.01 to 0.05 per unit (p.u.). Table 1 outlines the comprehensive dataset used to train the CNN, differentiating between normal operating states and various fault types, ensuring a balanced and robust model training process.
Feature Extraction
A power distribution network consisting of 240 buses with 55 observable nodes is considered in this study. A single-line fault may be one of the following four types: LG, LL, LLG, and LLLG. We are interested in real-time fault classification and FL localization using PMU measurements collected before and during the fault occurrence. Specifically, voltage magnitudes and phase angles will be collected to extract feature vectors to be fed into the proposed framework. Suppose that a fault occurs on the line between an upstream bus \(p\) and a downstream bus \(s\). Prior to the fault occurrence, its admittance model can be described as
where \(I^{pre-F}_{ps}\) and \(I^{pre-F}_{sp}\) are, respectively, the vectors of phase currents flowing from bus \(p\) to bus \(s\), and bus \(s\) to bus \(p\) on the line. \(V^{pre-F}_{p}\) and \(V^{pre-F}_{s}\) are the vectors of phase voltages at bus \(p\) and bus \(s\) respectively. \(Y^{pp}_{ps}\) and \(Y^{ss}_{ps}\) are the self-admittance at bus \(p\) and bus \(s\), and \(Y^{ps}_{ps}\) and \(Y^{sp}_{ps}\) are the mutual admittance matrices between bus \(p\) and bus \(s\), and bus \(s\) and bus \(p\), respectively.
When a fault occurs on the line segment between bus \(p\) and bus \(s\), the during-fault admittance model can be represented as follows
The during-fault current can then be derived as
Therefore, the difference between the pre-fault and during-fault voltage, \(\Delta V = V^{pre-F}_{p/s} - V^{F}_{p/s}\), can be constructed as
From Eq. 4, it is clear that the difference between the pre-fault and during-fault voltages contributes to the fault type classification and FL localization based on the admittance differences in each phase. Therefore, both its real and imaginary parts, \(|\Delta V|\) and \(\Delta \theta _v\), are added to the feature vectors to classify and locate faults.
In addition, symmetrical components are also incorporated during the feature vector extraction. The symmetrical component method has been widely used in fault analysis [47] by converting a three-phase unbalanced system into two sets of balanced phasors and a set of single-phase phasors, or symmetrical components. These sets of positive, negative, and zero-sequence components may contain valuable information about the fault. Therefore, these three sequence components are added to the feature vectors, to improve the accuracy of fault type classification. To convert a set of phase quantities into symmetrical components, the following calculation can be performed
where \(\alpha \) is defined as \(1\angle 120\), \(V_0, V_1\), and \(V_2\) are the zero, positive, and negative sequence components, respectively, and \(V_A, V_B\), and \(V_C\) are the voltages for phase A, B, and C, respectively.

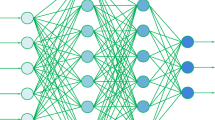
Representation of the one-dimensional convolutional neural network (CNN) architecture with data input connected to the convolution, pooling, flattening, fully connected, and the output layer
This results in the following equations
Consequently, the feature vectors for fault type classification (C) and faulted line localization (L) are defined as:
Overview of CNN Algorithm and Training
In this section, we briefly review the CNN algorithm and its training process.
Convolutional Neural Network (CNN)
Deep learning has gained much popularity and many successful applications have been described in the literature [48, 49]. As a type of deep network, CNN has shown excellent performance in many machine-learning problems. Examples include image recognition, financial time series analysis, medical image analysis, and natural language processing [50,51,52]. CNN can automatically extract local features and identify complex patterns in input data. It is robust to distortions or shifts of the input, owing to the three important concepts different from traditional feed-forward neural networks: local receptive field, weight sharing, and pooling [53].
To design the CNN structure for application in fault classification and location identification, we follow the common practice of adopting a model that has already shown competitive performance in other fields. Specifically, the CNN is based on the AlexNet model [54], which uses one-dimensional CNNs with hyperparameters designed to fit the input. There are five main layers in this type of CNN: input layer, convolutional layer(s), pooling layer(s), fully connected layer(s), and output layer, as shown in Fig. 1. These layers can be described as follows.
(i) The input layer accepts multidimensional raw data for processing in the network. It is usually specified by its width, height, and several channels. When input data are images, the number of channels is often set to three to account for the color channels (red, green, and blue). In this study, the input layer has 1xN neurons, where N denotes a variable number of features.
(ii) The primary purpose of convolutional layers is to extract features from the input data. Convolution preserves the spatial relationship between the data by learning features using a small part of the input data. Essentially, a filter or kernel is used during convolution, and the feature map is formed by sliding the filter over the entire input and computing the dot product. The size of the feature map is controlled by three parameters: depth, stride, and padding. The depth corresponds to the number of filters used in the convolutional layers. The stride denotes the number of steps by which the window moves after each operation. A larger stride produces smaller feature maps. Sometimes, it is convenient to pad the input matrix with zeros around the border to obtain a feature map of the same size as the input matrix. The convolutional layer is followed by the non-linear rectified linear unit (ReLU) activation function, which discards the negative values of feature maps without changing the size.
(iii) The pooling layer is used to reduce the dimensionality of the feature map while retaining information from the input feature map. It reduces the computational cost by decreasing the number of parameters and prevents overfitting, therefore increasing the overall performance and accuracy of the network. In this study, max-pooling is applied, where the largest elements are taken from the rectified feature map within a specific window.
(iv) After several convolution and pooling operations, the original data is represented by a series of feature maps. The feature maps are then flattened into a one-dimensional vector which can be fed into the fully connected layer network. The fully connected layer contains numerous neurons that are connected to all nodes in the preceding layers.
(v) The output layer has n neurons, corresponding to n classes of input data. It is fully connected to the feature layer. Depending on the type of output, the output layer uses a different type of activation function.

Calibration modules containing spatial and channel-wise calibration modules applied sequentially to the activation maps. Here \(\oplus \) and \(\otimes \) represent element-wise addition and channel-wise multiplication operations, respectively
CNN Training Process
The CNN is trained in a supervised manner using a sequence of training examples \([(x_1,y_1),(x_2,y_2),...,(x_K,y_K)]\), where \(x_t \in \textbf{R}^{1xN}\), \(y_t \in \textbf{R}^{n}\) for \(1\le t \le K\). Data \(x_t\) is given as input to the network, while vector \(y_t\) denotes the target output. Let \(\Theta \) denote the set of CNN parameters. The CNN training process can be represented as an optimization problem with the objective of minimizing the expected loss on the training set [55]. The cross-entropy loss function is utilized for multiclass classification with a regularization term \(\lambda \parallel \Theta \parallel ^2_f\) to avoid overfitting, as shown below
where \(f(x; \Theta )\) is the output probability of the CNN parameterized by \(\Theta \) when the input is x, m is the number of training examples, and \(\lambda \) denotes the regularization coefficient.
To solve this optimization problem and find the optimal set of \(\Theta \) that minimizes the above loss, the stochastic gradient descent algorithm and some of its variants (such as RMSProp [56] and Adam [57]) performed fairly robustly in various tasks. Adam is the most often used optimization algorithm since it is fairly robust to the choice of hyperparameters. In addition, batch normalization and dropout layers are often introduced into the network to prevent overfitting. The batch normalization layer is used to prevent internal covariate shift by standardizing each element in the layer to zero mean and unit variance [58].
Proposed Framework
In this section, we introduce the calibration incremental learning algorithm for online updating. Next, the overall proposed framework used for fault classification and FL localization is presented.
Incremental CNN with Calibration Modules
A static CNN model learned from past data may not fully capture the characteristics of future data. To solve this problem, incremental learning is proposed to update the CNN model and satisfy the need for online learning. Traditional incremental learning can be costly and time-consuming, as it often requires retraining the model to adapt to changes in the system or data distribution over time. Moreover, it may not preserve previously acquired knowledge and can lead to catastrophic forgetting. An effective incrementally trained model must be able to learn from new data that arrive sequentially and still retain the knowledge gained from previous data sets without retraining on all previously seen data. To address the above challenges, we adopted transfer learning and calibration modules, aimed at accommodating variations of the integration level of DERs and loading in distribution systems over time.
Transfer learning is a technique for transferring knowledge from one domain/data set to another using a specific weight adjustment strategy [59]. It selects partial knowledge gained from training the network on the source data set as supplements to the training set in the target domain by assigning appropriate weight values to these selected instances. Based on the above idea and inspired by [60], we use spatial and channel-wise calibration modules within the intermediate activation maps of the CNN, as shown in Fig. 2. Specifically, the spatial calibration modules (SCM) learn weights to calibrate each point in the feature map while the channel-wise calibration modules (CCM) learn weights to calibrate each channel in the feature map. The calibration module (CM) was added after each layer of the base CNN.
Suppose that the output activation map of the \(i^{th}\) CNN layer is \(M_i\). Let \(\alpha _i\) be the SCM operator added after the \(i^{th}\) layer of the base module. The SCM uses 1D-convolution with \(3\times 3\) kernel size and the output of \(\alpha _i\) representing the spatial calibration weights. The calibration weights will be added element-wise to \(M_i\) to give the spatially calibrated activation maps, \(M_i^*\), which are then fed as input to the channel-wise calibration module. Let \(\beta _i\) be the CCM operator added after the SCM operator for the \(i^{th}\) layer of the base module. The CCM operator first performs global average pooling (GAP) on \(M_i^*\) and then applies a 1D convolution with kernel size \(1\times 1\). This is followed by a batch normalization operation that produces an output of \(\beta _i\) that represents the channel-wise calibrated activation maps. Each of the calibration weights is multiplied by the corresponding channel of \(M_i^*\) to produce the final calibrated activation maps \(M_i^{**}\) for the \(i^{th}\) layer. Algorithm 1 shows the workflow of \(\textrm{CM}_i\), and the overall calibration process can be described as:

Calibration modules workflow.
For the first task, a base CNN model with a classification layer and calibration module is trained using historical data, as shown in Fig. 3. For the subsequent task, where part of the historical data and all new data are fed to the system, the parameters of the base CNN module \(\Theta \) are kept frozen and only the data-adaptive calibration module and the classification module are trained. This way, the model adapts features relevant to new data from the base model using calibration modules.

Proposed architecture for incremental learning. The top architecture is used for the first task, where the model is trained from historical data. The bottom architecture is for all subsequent tasks where the model is trained from part of historical data and all new data. \(L_1 - L_n\) represents layers of the base CNN module. The calibration modules calibrate the output activation map \(M_i\) to produce \(M_i^{**}\) at layer i. \(C_1\) is the classification module. To adapt to new input data, the base CNN modules are frozen and not trainable. They are marked in grey color with hatched pattern

Overall fault type classification and fault location identification framework
Fault Type and Fault Location Identification Process
The overall proposed framework for fault type and FL identification is presented in Fig. 4. There are two major components in the framework, namely the offline learning and the online continual learning. For offline learning, a CNN-based model is proposed for identifying the 10 different types of faults that can occur in a distribution network. These faults are presented in Table 1. Identifying the type of fault that occurs in a distribution network is an essential operation for further determining the FL in the system. The historical voltage magnitudes and phase angles collected at the end of the line/branches were input into the system. Next, features \(\phi _C\) shown in “Feature Extraction” section were extracted and fed into the fault type identification model, CNN\(_C\). The number of features fed into the model was determined by the number of buses where the PMU was located. Using these features, the CNN\(_C\) was capable of determining the type of fault by recognizing the pattern in the bus voltage magnitude and phase angle values, the delta voltage information, and the calculated symmetrical components. The output of the CNN\(_C\) was a one-hot encoded vector of size 11, where each index denoted one of the 10 fault types and the normal type.
After the fault type was determined, the next step was to identify the FL. The fault type, along with the features \(\phi _L\), were fed into the fault location identification model, CNN\(_L\). Note that if the fault type is normal, the framework will not proceed to the CNN\(_L\). Since the features \(\phi _L\) were all numerical values, the one-hot encoded fault type vector was converted to dummy encoding columns to ensure consistency within the input. In total, 11 additional columns were added and a value of 1 was placed in a specific column and 0 for all other columns, to indicate a particular fault type. CNN\(_L\) learned the correlations between the input features and the provided labels and was capable of identifying the FL. CNN\(_L\) was designed to produce a vector of size m, which represents the likelihood that the fault is located on a particular line in the set of all lines M in the distribution network. For example, using the test system described in “Test Systemand Database” section, if a single line to ground fault occurs between node 2028 and node 2029, the output vector would indicate a value of 1 at the 2027\(^{th}\) index and a value of 0 for all other lines. Similarly, if a double line to ground fault occurs at node 2028, the output vector would indicate a value of 1 at the 2027\(^{th}\) index or the 2028\(^{th}\) index and a value of 0 for all other lines.
However, as mentioned in “Incremental CNN with Calibration Modules” section, a static CNN model may not fully capture the characteristics of the future data and is not suitable for online applications. For example, consider historical data collected from a system with DER penetration levels of 0-20% and loading between 70-100%. When the system undergoes further increase in DER penetration levels or loading, the offline model cannot capture the pattern learned in the new data and its performance is likely to degrade. To address this problem, an incremental CNN model with transfer learning is used to provide online continual learning. Note that this model requires labeled data for training. Essentially, the model training process is similar to the offline learning model. The feature vectors \(\phi _C\) and \(\phi _L\) were extracted from part of the historical data that contained all different types of faults and all new data. The convolutional layers \(L_1\) to \(L_n\) were frozen while the calibration module CM\(_i\) and the fully connected classifier C\(_1\) were trained and fine-tuned using the newly extracted feature vectors. The online model can adapt to changes when new data enter the system continuously within a short training time period. This is possible by using parameters transferred from the offline model. When needed, all subsequent new data and historical data can be further used together to train the offline model to enhance the model in recognizing patterns within a more complex data distribution.
Numerical Simulations
In this section, the performance of the proposed framework for the classification of fault types and identification of FL in the distribution system is evaluated using the test system introduced in “Test System and Database” section. First, we compare the proposed framework with other frequently used models from the literature. This verifies the feasibility and effectiveness of the proposed model under a specific DER penetration level and loading condition, i.e., during the offline learning mode. The robustness to noise and fault resistance are also analyzed. Finally, the online fault type and FL identification system are verified by the data collected under different DER penetration levels and loading conditions.
Data Preprocessing and Model Setting
The test distribution system under normal conditions and with four types of line fault of “Introduction” section, was simulated and data were collected. As shown in Table 1, only a small amount of fault data was simulated compared to the normal data. This corresponds to the scarcity of fault data in real distribution systems. The preprocessing of collected data started by converting the categorical labels to one-hot encoding to ensure the labels and the target outputs from the proposed model were in the same format. Next, to address the class-imbalance problem (normal vs. fault cases), we utilized the synthetic minority over-sampling technique (SMOTE) [61]. It over-sampled the fault classes so that the number of samples for each minority class was the same as the majority class. Then, the over-sampled data was partitioned as follows: 70% of the data were used for training, 20% for validation, and the remaining 10% for model testing. Finally, a min-max scalar was applied and the data set was normalized to the interval [0, 1] to improve its uniformity and speed up learning.
Fault Type Classification Model
The fault type is classified using the CNN-based model. The structure of the CNN\(_C\) classifier is summarized in Table 2. There are a total of four major layers in this model: the input size of the model is \([-1, 1, 344]\), and there are two main convolutional layers (layer 1 and layer 4), one fully connected layer (layer 7), and one output layer. The last dimension of 344 corresponds to the total number of features. The “-1” in the output shapes are placeholders for batch size. In each convolutional layer, the convolution-1d operation has a kernel size of 1 while stride and padding are set to 1. The convolution-1d operation is followed by a maxpool-1d operation that has a stride of 1. To prevent the model from overfitting, a 20% dropout is added after the maxpool-1d operation. Furthermore, after each convolutional layer, the spatial calibration module (layer 2 and layer 5) and the channel-wise calibration module (layer 3 and layer 6) are added to calibrate the output activation map from the previous convolutional layer. The output of this model is \([-1, 11]\), which represents the 11 types of faults.
The CNN\(_C\) model was trained using Adam optimizer with decay factor parameter \(\alpha = 0.9\) and the learning rate or iteration step size was set to 0.001. The cross entropy loss was selected as the loss function and the network was trained for 50 epochs. The effectiveness of the CNN\(_C\) was evaluated by the fault type classification accuracy, \(\eta _C\). The F1-score was also used to evaluate the performance of CNN; it is the harmonic mean of precision and recall that gives a better measure of the incorrectly classified cases than the accuracy metric. Both metrics are shown below
where precision and recall are calculated as
Faulted Line Localization Model
Another CNN-based model, CNN\(_L\), was developed to localize the faulted line for the ten fault types. The structure of the model is shown in Table 3. There are two major convolutional layers in which the convolution-1d, maxpool-1d and dropout have the same property as CNN\(_C\). The spatial calibration module and channel-wise calibration module are also added after each convolutional layer. The input feature has a shape of [-1, 1, 260] while the output of the CNN\(_L\) model has a shape of [-1, 239] which indicates the 239 lines in the test system.
The Adam optimizer with the same properties as for CNN\(_C\) was used during the training process of CNN\(_L\). The cross entropy loss was selected as the loss function and the CNN\(_L\) was trained for 45 epochs. The effectiveness of CNN\(_L\) was evaluated using the faulted line localization accuracy, \(\eta _L\), as well as the F1-score
Offline Performance
We first compare the proposed framework with the classifiers described in the previous literature to assess the performance of the proposed offline model. Next, we evaluate the effectiveness of the SMOTE approach. Finally, we investigate the robustness to noise. The offline model was trained and tested on the data set under 10% PV penetration level and 80% of the rated load condition. The fault resistance was set to change in the range of 0.01 to 0.05 p.u.

Comparison of fault type classification performance (proposed CNN, ANN, M-SVM, and KNN) for 11 types of faults using F1 score

Comparison of faulted line localization performance (proposed CNN, ANN, M-SVM, and KNN) for 10 types of faults using F1 score

Comparison of performance of models with and without SMOTE using F1 score
Model Comparison
A total of 96,360 data points (70% for training, 20% for validation, and 10% for testing) including 86,000 SMOTE-generated data points were used to train and test CNN\(_C\). Meanwhile, a total of 2000 data points (70% for training, 20% for validation, and 10% for testing) including 580 points generated by SMOTE were employed to train and test the CNN\(_L\). We compare the proposed CNN with that of three other machine learning classifiers, including multiclass support vector machine (MSVM) [62], fully connected artificial neural network (ANN), and k-nearest neighbor (KNN).
The MSVM used the coupled pairwise strategy and radial basis function kernel to find the globally optimal solution. ANN of two layers was implemented with 64 neurons in the first layer and 32 neurons in the second layer, 20% dropout, and a 1D-batch normalization layer was applied before the output layer. RELU was selected as the activation function, while the learning rate was set at 0.001. The k parameter in the KNN was set to 11 for the fault type classification case and 50 for the faulted line localization case. The simulation results of the different models and fault types are presented in Figs. 5 and 6 for the fault type classification and FL localization, respectively. Figure 5 Illustrates the superior performance of the proposed CNN in fault type classification, outperforming traditional machine learning models (ANN, M-SVM, KNN) in terms of F1 score across 11 fault types, underscoring the effectiveness of deep learning in complex classification tasks. Figure 6 Showcases the CNN’s adeptness in faulted line localization, again surpassing other models, highlighting our CNN’s robust feature extraction capabilities that contribute to its precise fault localization. The results demonstrate that the proposed CNN\(_C\) and CNN\(_L\) can detect, classify, and localize distribution system faults accurately and reliably. A high F1 score also indicates that there are fewer misclassified samples as there are fewer FN and FP. Moreover, both models perform much better for all types of faults compared to the other three classifiers. In particular, the CNN\(_C\) model achieved an F1 score of more than 98.5% for the LG, LLLG, and normal types, while its performance for the LLG and LL fault types is only slightly worse. Table 4 shows the weighted averages of accuracy over all types of faults for different classifiers. The results further confirm the feasibility of the proposed method.
Effectiveness of SMOTE
Two types of data sets were used to evaluate the effectiveness of SMOTE for fault type classification: the unbalanced simulated data set described in Table 1 (10,360 samples in total), and its version augmented using SMOTE (96,360 samples in total). Similarly, the unbalanced data set in Table 1 except the normal case (1,420 samples in total) was employed with its augmented version using SMOTE (2,000 samples in total) to evaluate the effectiveness of SMOTE in fault line localization. The results shown in Fig. 7a and b demonstrate how SMOTE improves model performance in both fault type classification and faulted line localization, effectively addressing class imbalance and enhancing the model’s generalization capability. In particular, We can observe that there is a significant performance drop for the fault type LLLG compared to the other types of faults since this class has the lowest amount of samples in the unbalanced data set. With SMOTE, the above problem is eliminated as we can observe that both CNN models achieved high F1 scores of about 97% for all types of faults. However, note that there is a trade-off between time and accuracy: as more data samples are generated, the model requires more time for training.

Comparison of model performance with different SNR using F1 score

Performance of the proposed online learning model on fault type classification over varying PV penetration level and loading condition
Robustness to Noise
The signal-noise-ratio (SNR) is a commonly used measure that compares the level of desired signal to the background noise, including in PMU data [63]. The experimental range of SNR from 40 dB to 100 dB was selected to test the robustness of the proposed model to noise. Gaussian noise of the same SNR was added to both the training and testing data set. Other preprocessing of the data set was the same as described in “Model Comparison” section, including the use of SMOTE. The model setting also remained the same for both CNN\(_C\) and CNN\(_L\).
Figure 8 Depicts the resilience of our CNN models to varying levels of noise (SNR), with minimal performance degradation, indicating the models’ reliability in noisy environments typical of real-world grid conditions. Figure 8a shows the F1 score for fault type classification with different SNR levels ranging from 40 to 100 dB, and Fig. 8b shows the F1 score for FL localization under the same SNR level. The results indicate that the sensitivities of CNN\(_C\) and CNN\(_L\) to different types of faults differ. For example, the normal class shows a decreasing trend when SNR is 70 and 80 dB, while the LLGAB fault indicates a continuously increasing trend. Moreover, the LGA and LGC faults are less robust to noise compared to other fault types, while the LLLG and normal cases are more robust to noise. A relatively steady trend can be observed when the SNR is higher than 50 dB in both Fig. 8a and b where the F1 score can reach 95% or more. Table 5 shows the performance of CNN\(_C\) and CNN\(_L\) with different SNR using weighted average accuracy. When the SNR is 40 dB, a degradation of around 5% can be observed for both models. The influence of noise is contained when the SNR is greater than 60 dB, where the performance does not degrade noticeably.
Online Performance
“Offline Performance” section confirmed the feasibility of the CNN-based framework under a distribution system with a fixed PV penetration level and fixed rated load. However, in practice, the PV penetration levels and loading conditions may vary over time during the operation. Considering the situation where new data are continuously collected from systems with varying levels of PV penetration and loading, we conducted simulations to test the proposed online continual learning algorithm. As shown in “Offline Performance” section, the data with 10% PV penetration level and 80% rated load condition were used to initialize the offline model.
PV Penetration Level Variation
With the recent rapid deployment of DERs, it is crucial that fault detection and localization systems can adapt to various PV penetration levels. To test the ability of the proposed online learning algorithm to handle data involving different levels of PV penetration, additional cases were simulated and data was collected from the test distribution system. Specifically, 50 data samples of random fault type were simulated under PV penetration levels of 20%, 30%, and 40%. File data samples for each fault type in the original data along with the new collected data were fed as a data stream to update the trained offline model. Both CNN\(_C^C\) and CNN\(_L^C\) were trained for 15 epochs while other model settings were identical to the offline models CNN\(_C\) and CNN\(_L\).
The results for CNN\(_C^C\) and CNN\(_L^C\) are presented in Fig. 9a and b which highlights the adaptability of our online learning models (CNNCC and CNNCL) to different PV penetration levels, maintaining high F1 scores across fault types, showcasing the models’ capability to adjust to dynamic grid conditions effectively. Both figures show the performance comparison between data sets with different PV penetration levels for all types of faults. Note that the line labeled PV-mix represents the data set containing 50 data samples of mixed PV penetration levels (20%, 30%, 40%). Overall, the F1-score for CNN\(_C^C\) and CNN\(_L^C\) is higher than 96%; it can be concluded that the proposed online learning model can quickly adapt to data with different distributions, in this case with different PV penetration levels. A similar trend in performance over different types of faults can also be captured, e.g., the LG, LLLG, and normal types performed relatively better than the LL and LLG fault type. Table 6 presents the weighted accuracy \(\eta _C\) and \(\eta _L\) for different levels of PV penetration. It could be seen that the results of the proposed online updating algorithm is quite promising. In the worst case, the accuracy of locating the faulted line decreased only by 1.2% (for PV penetration level of 40%). Furthermore, with the input of different new data, the model update times remain within 1.6 seconds. Therefore, the training process is suitable for practical implementation.
Load Variation
As the load in distribution systems can vary during normal operation over time, it is essential to evaluate the online accuracy of the model when the load is different than its rated value. In this scenario, the data set used for training the model involved 50%, 80%, and 125% of the rated load. In total, 50 data samples were simulated and collected for each case above. Note that other parameters, such as the level of PV penetration, remained the same as for the offline model. Both CNN\(_C^C\) and CNN\(_L^C\) were trained for 15 epochs while other model settings were identical to the offline models CNN\(_C\) and CNN\(_L\). To demonstrate that the online model can effectively adapt to variation of loading, the F1-score was computed for different types of fault in Fig. 9c and d. The results demonstrate that the online model can capture the patterns in the data set with varying loading conditions within a short amount of time. Furthermore, the data set with different loading conditions was fed to the trained offline model and the weighted average accuracy were calculated. The results were compared with the online model as illustrated in Table 7. The performance of the offline model varies with differing loading conditions. In particular, when the dataset is at 50% of the rated load, both offline model CNN\(_C\) and CNN\(_L\) resulted in a significant performance degradation. Due to the large difference between this new dataset compared to the original dataset (100% of the rated load), the offline model was not capable of accurately classifying and locating the faults. On the other hand, the online model achieved an average accuracy of above 97% in locating the fault lines. Moreover, the performance of the online model does not degrade or vary significantly over different loading conditions.
Conclusion
This article introduces a novel, real-time, data-driven framework for fault classification and localization in partially observable distribution systems, utilizing CNNs. Our proposed framework innovatively applies special feature vectors extracted from voltage magnitude and phase angles, which are highly correlated with faults and crucially aid the CNN in pattern recognition. Furthermore, the use of SMOTE in the data preprocessing stage significantly augments the limited simulated fault data, enhancing fault classification and localization performance. Incorporating an online continual learning algorithm, based on transfer learning and calibration modules, our approach dynamically adapts to variations in DER integration levels and loading conditions within distribution systems. A real distribution grid in the Midwestern United States served to validate the feasibility and effectiveness of our method. Our findings demonstrate that the proposed offline CNN-based models achieve fault classification and localization with F1 scores exceeding 97%, highlighting the model’s robustness against varying noise levels. Significantly, the online model has proven its capability to swiftly adjust to changes in PV penetration and load conditions, showcasing a substantial improvement over traditional methods. Specifically, our CNN-based model attained a fault classification accuracy of 98.5% and a fault localization precision of 97.9%, emphasizing the efficacy of our data-driven approach in complex distribution network scenarios. These results underscore the potential of our framework to revolutionize fault management in smart grids, setting a new benchmark for reliability and efficiency in modern electrical systems.
Future Work
Future work will focus on extending the model’s applicability to larger and more diverse grid architectures, exploring the integration of additional data sources for even greater accuracy, and further refining the online learning algorithm to accommodate real-time changes more efficiently. Acknowledging the limitations discussed, such as the need for large labeled datasets, adaptability challenges, computational demands, and the effectiveness of the online learning algorithm in rapidly changing environments, this research lays a solid foundation for advancements in smart grid fault management, contributing to the reliability and safety of power distribution systems worldwide. Efforts will also be made to enhance the model’s robustness against overfitting and to optimize it for shorter updating times, ensuring accuracy and adaptability to various power distribution network topologies.
Availability of data and material
The OpenDSS model of the real distribution grid analyzed in this study can be downloaded from Dr. Zhaoyu Wang’s homepage at Iowa State University http://wzy.ece.iastate.edu/Testsystem.html.
Code Availability
Not applicable.
References
Jiang H, Wang K, Wang Y, Gao M, Zhang Y (2016) Energy big data: A survey. IEEE Access 4:3844–3861
Moloi K, Ntombela M, Mosetlhe TC, Ayodele TR, Yusuff AA (2021) Feature extraction based technique for fault classification in power distribution system. In: 2021 IEEE PES/IAS PowerAfrica, pp 1–5. IEEE
Ding J, Wang X, Zheng Y, Li L (2018) Distributed traveling-wave-based fault-location algorithm embedded in multiterminal transmission lines. IEEE Trans Power Delivery 33(6):3045–3054
Lopes FV, Silva KM, Costa FB, Neves WLA, Fernandes D (2015) Real-time traveling-wave-based fault location using two-terminal unsynchronized data. IEEE Trans Power Delivery 30(3):1067–1076
Sanseverino ER, Vigni VL, Di Stefano A, Candela R (2018) A two-end traveling wave fault location system for mv cables. IEEE Trans Ind App 55(2):1180–1188
Dzafic I, Mohapatra P (2011) Impedance based fault location for weakly meshed distribution networks. In: ISGT 2011, pp 1–6. IEEE
Lee S-J, Choi M-S, Kang S-H, Jin B-G, Lee D-S, Ahn B-S, Yoon N-S, Kim H-Y, Wee S-B (2004) An intelligent and efficient fault location and diagnosis scheme for radial distribution systems. IEEE Trans Power Delivery 19(2):524–532
Aboshady F, Thomas D, Sumner M (2019) A new single end wideband impedance based fault location scheme for distribution systems. Electric Power Syst Res 173:263–270
Esmalifalak M, Liu L, Nguyen N, Zheng R, Han Z (2014) Detecting stealthy false data injection using machine learning in smart grid. IEEE Syst J 11(3):1644–1652
Ozay M, Esnaola I, Vural FTY, Kulkarni SR, Poor HV (2015) Machine learning methods for attack detection in the smart grid. IEEE Trans Neural Netw Learn Syst 27(8):1773–1786
Schofield K, Kazemi N, Musilek P (2021) Vrf battery characterization using microwave planar complementary split ring resonators. In: 2021 IEEE Canadian conference on electrical and computer engineering (CCECE), pp 1–6. IEEE
Malhotra A, Mahela OP, Doraya H (2018) Detection and classification of power system faults using discrete wavelet transform and rule based decision tree. In: 2018 International conference on computing, power and communication technologies (GUCON), pp 142–147
Shaik M, Yadav SK, Shaik AG (2021) An emd and decision tree-based protection algorithm for the solar pv integrated radial distribution system. IEEE Trans Ind App 57(3):2168–2177
Zainab A, Refaat SS, Syed D, Ghrayeb A, Abu-Rub H (2019) Faulted line identification and localization in power system using machine learning techniques. In: 2019 IEEE International conference on big data (big data), pp 2975–2981. https://doi.org/10.1109/BigData47090.2019.9006377
Liang Y, Li K-J, Ma Z, Lee W-J (2020) A multi-label classification model for type recognition of single-phase-to-ground fault based on knn-bayesian method. In: 2020 IEEE/IAS Industrial and commercial power system asia (I CPS Asia), pp 929–936
Baghaee HR, Mlakić D, Nikolovski S, Dragicević T (2019) Support vector machine-based islanding and grid fault detection in active distribution networks. IEEE J Emerg Select Topics Power Elect 8(3):2385–2403
Perez R, Vásquez C, Viloria A (2019) An intelligent strategy for faults location in distribution networks with distributed generation. J Intell Fuzzy Syst 36(2):1627–1637
Zheng X, Geng X, Xie L, Duan D, Yang L, Cui S (2018) A svm-based setting of protection relays in distribution systems. In: 2018 IEEE Texas power and energy conference (TPEC), pp 1–6. IEEE
Usman MU, Ospina J, Faruque MO (2020) Fault classification and location identification in a smart dn using ann and ami with real-time data. J Eng 1:19–28
Guo M, Zeng X, Chen D, Yang N (2017) Deep-learning-based earth fault detection using continuous wavelet transform and convolutional neural network in resonant grounding distribution systems. IEEE Sensors J 18(3):1291–1300
Li W, Deka D, Chertkov M, Wang M (2020) Real-time faulted line localization and pmu placement in power systems through convolutional neural networks. In: 2020 IEEE Power energy society general meeting (PESGM), pp 1–1
Zhao M, Barati M (2021) A real-time fault localization in power distribution grid for wildfire detection through deep convolutional neural networks. IEEE Trans Ind App 57(4):4316–4326
Ghaemi A, Safari A, Afsharirad H, Shayeghi H (2022) Accuracy enhance of fault classification and location in a smart distribution network based on stacked ensemble learning. Elect Power Syst Res 205:107766
Kazemi N, Abdolrazzaghi M, Musilek P (2021) Comparative analysis of machine learning techniques for temperature compensation in microwave sensors. IEEE Trans Microwave Theory Tech 69(9):4223–4236
Gholizadeh N, Kazemi N, Musilek P (2023) A comparative study of reinforcement learning algorithms for distribution network reconfiguration with deep q-learning-based action sampling. IEEE Access 11:13714–13723
Stefanidou-Voziki P, Sapountzoglou N, Raison B, Dominguez-Garcia J (2022) A review of fault location and classification methods in distribution grids. Elect Power Syst Res 209:108031
Wilches-Bernal F, Jiménez-Aparicio M, Reno MJ (2022) A machine learning-based method using the dynamic mode decomposition for fault location and classification. In: 2022 IEEE Power & energy society innovative smart grid technologies conference (ISGT), pp 1–5. IEEE
Lin Z, Duan D, Yang Q, Hong X, Cheng X, Yang L, Cui S (2020) One-class classifier based fault detection in distribution systems with varying penetration levels of distributed energy resources. IEEE Access 8:130023–130035
Liu Y, Bao Y (2023) Automatic interpretation of strain distributions measured from distributed fiber optic sensors for crack monitoring. Measurement 211:112629
Liu Y, Bao Y (2021) Review of electromagnetic waves-based distance measurement technologies for remote monitoring of civil engineering structures. Measurement 176:109193
Kotikam G, Lokesh S (2023) Big data classification using enhanced dynamic kpca and convolutional multi-layer bi-lstm network. IETE J Res 1–19
Kazemi N, Abdolrazzaghi M, Light PE, Musilek P (2023) In–human testing of a non-invasive continuous low–energy microwave glucose sensor with advanced machine learning capabilities. Biosensors Bioelectron 241:115668
Thirusenthil Kumaran P, Vinayagam A, Suganthi S, Veerasamy V, Inbamani A, Chandran J, Farade RA (2023) A voting approach of ensemble classifier for detection of power quality in islanded pv microgrid. IETE J Res 69(10):7408–7424
Sai Kumar M, Kumar J, Mahanty R (2023) Fault classification in a tcsc compensated transmission line during power swing using wigner ville transform. IETE J Res 69(9):6483–6504
Paul M, Debnath S (2023) Fault detection and classification scheme for transmission lines connecting windfarm using single end impedance. IETE J Res 69(4):2057–2069
Raval PD, Pandya AS (2022) A hybrid pso-ann-based fault classification system for ehv transmission lines. IETE J Res 68(4):3086–3099
Bai K, Sindhu V, Haque A (2023) Grid integration issues of photovoltaic systems and islanding detection. IETE J Res 1–16
Mishra GK, Singh Y (2022) Rapid fault detection with periodic update feature for transmission line parameters in hvdc grids. IETE J Res 1–11
Singh N, Ansari M, Tripathy M, Singh VP (2023) Feature extraction and classification techniques for power quality disturbances in distributed generation: A review. IETE J Res 69(6):3836–3851
Hamid B, Hussain I, Iqbal SJ (2022) Optimal control of bess for improved grid integration of the hybrid dfig/pv system using dual-layer adaptive control. IETE J Res 1–15
Van Dai L (2023) A novel protection method to enhance the grid-connected capability of dfig based on wind turbines. IETE J Res 1–17
Nguyen NA, Le TN, Quyen HA, Phan TTB (2019) Data reduction for dynamic stability classification in power system. IETE J Res 65(2):148–156
Venkatesh A, Nalinakshan S, Jayasankar V, Aneesh V, Kiran S, Sivasubramanian V (2023) Stability testing and restoration of a deig-based wind power plant with indirect grid control strategies. IETE J Res 69(6):3928–3942
Bu F, Yuan Y, Wang Z, Dehghanpour K, Kimber A (2019) A time-series distribution test system based on real utility data. In: 2019 North American power symposium (NAPS), pp 1–6. IEEE
Sparks AH (2018) nasapower: A nasa power global meteorology, surface solar energy and climatology data client for r. J Open Source Softw 3(30):1035. https://doi.org/10.21105/joss.01035
Trindade FC, Freitas W (2016) Low voltage zones to support fault location in distribution systems with smart meters. IEEE Trans Smart Grid 8(6):2765–2774
Abdel-Akher M, Nor KM (2010) Fault analysis of multiphase distribution systems using symmetrical components. IEEE Trans Power Delivery 25(4):2931–2939
Bhattacharya S, Maddikunta PKR, Pham Q-V, Gadekallu TR, Chowdhary CL, Alazab M, Piran MJ et al (2021) Deep learning and medical image processing for coronavirus (covid-19) pandemic: A survey. Sustain Cities Soc 65:102589
Deng L, Yu D (2014) Deep learning: methods and applications. Foundations Trends Signal Process 7(3–4):197–387
Frid-Adar M, Diamant I, Klang E, Amitai M, Goldberger J, Greenspan H (2018) Gan-based synthetic medical image augmentation for increased cnn performance in liver lesion classification. Neurocomputing 321:321–331
Mehtab S, Sen J (2022) Analysis and forecasting of financial time series using cnn and lstm-based deep learning models. In: Advances in distributed computing and machine learning, pp 405–423. Springer
Qassim H, Verma A, Feinzimer D (2018) Compressed residual-vgg16 cnn model for big data places image recognition. In: 2018 IEEE 8th Annual computing and communication workshop and conference (CCWC), pp 169–175. IEEE
Swietojanski P, Ghoshal A, Renals S (2014) Convolutional neural networks for distant speech recognition. IEEE Signal Process Lett 21(9):1120–1124
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst 25
Goodfellow I, Bengio Y, Courville A (2016) Deep Learning. MIT press
Tieleman T, Hinton G et al (2012) Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Netw Mach Learn 4(2):26–31
Kingma DP, Ba J (2014) Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
Ioffe S, Szegedy C (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: International conference on machine learning, pp 448–456. PMLR
Tan C, Sun F, Kong T, Zhang W, Yang C, Liu C (2018) A survey on deep transfer learning. In: International conference on artificial neural networks, pp 270–279. Springer
Singh P, Verma VK, Mazumder P, Carin L, Rai P (2020) Calibrating cnns for lifelong learning. Adv Neural Inf Process Syst 33:15579–15590
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP (2002) Smote: synthetic minority over-sampling technique. J Artif Intell Res 16:321–357
Pöyhönen S, Arkkio A, Jover P, Hyötyniemi H (2005) Coupling pairwise support vector machines for fault classification. Control Eng Pract 13(6):759–769
Brown M, Biswal M, Brahma S, Ranade SJ, Cao H (2016) Characterizing and quantifying noise in pmu data. In: 2016 IEEE Power and Energy Society General Meeting (PESGM), pp 1–5. https://doi.org/10.1109/PESGM.2016.7741972
Funding
This research was funded by the Natural Sciences and Engineering Research Council (NSERC) of Canada grant number ALLRP 549804-19, and by the Alberta Electric System Operator, AltaLink, ATCO Electric, ENMAX, EPCOR Inc., and FortisAlberta.
Author information
Authors and Affiliations
Contributions
M.Z. - Conceptualization, Methodology, Software, Evaluation, Drafting, P.M. - Conceptualization, Funding acquision, supervision, Editing
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflicts of interest/Competing interests
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhou, M., Kazemi, N. & Musilek, P. Distribution Grid Fault Classification and Localization using Convolutional Neural Networks. Smart Grids and Energy 9, 24 (2024). https://doi.org/10.1007/s40866-024-00205-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40866-024-00205-5