
Abstract
This paper aims to enhance the performance of a cascade-forward neural network (CFNN) model to predict the output power of a photovoltaic (PV) module. This improvement is conducted by optimizing the number of hidden neurons using the genetic algorithm (GA). The optimization is carried out to minimize the value of the root mean square error (RMSE) between the actual and predicted PV output power. The performance of the CFNN-based GA is evaluated using five statistical term error terms; namely, RMSE, normalized RMSE (nRMSE), mean bias error (MBE), normalized MBE (nMBE), and mean absolute percentage error (MAPE). The values for these terms are 0.0025 W, 0.0131%, 0.0011 W, 0.0067% and 0.8121%, respectively. The proposed model’s performance is compared with that obtained using the classical CFNN, classical feed-forward neural network (FFNN), and FFNN-based on GA in accuracy training and testing time. The results show that the proposed model performs better than the models mentioned above based on the statistical error terms. The MAPE of the proposed model is 0.8121%, which is lower by 98.63%, 98.77% and 63.93% than that obtained by FFNF, CFNN, and FFNN-GA, respectively. Besides, it is faster than the models mentioned above based on training and testing time. In which, the proposed model is faster than FFNF, CFNN, and FFNN-GA by 89.68%, 59.50% and 53.99% in terms of training time, respectively. Moreover, it is also faster in testing than FFNN, CFNN, and FFNN-GA by 94.92%, 75.57% and 78.95%, respectively. Accordingly, the proposed model can be recommended to predict the output power of the PV modules.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Energy consumption is a critical indicator of the development of any country. Economic growth needs support from electrical energy sources. The conventional sources are the most used sources to meet residential and commercial loads. The increased use of conventional energy sources increases greenhouse emissions, such as carbon dioxide [1]. Buildings are consuming around 51% of global energy generation, which leads to greenhouse gas emissions [2]. The negative impacts of conventional sources, such as global warming, attract governments, investors, engineers, and researchers to implement and integrate renewable energy sources, such as solar energy.
Photovoltaic (PV) systems are among the most used renewable energy technologies worldwide, increasing cities’ energy consumption. Nowadays, the PV systems are widely used as the rooftop solar PV systems, which are called building-integrated photovoltaics (BIPV) systems. The BIPV systems are promoted by most governments worldwide [3]. Therefore, PV systems are considered a secure, clean, and environmentally friendly source. Sizing PV systems’ components can play a significant role in the system’s optimal size, which means the supply’s high availability at minimum cost. PV modules are the main component of any PV system. Therefore, the PV module must be modeled to include the uncertainties coming from the fluctuations of the weather conditions. Such as solar radiation and ambient temperature [4]. The accurate prediction of the PV modules’ performance is very significant in power system applications, especially for energy management applications, to realize the uncertainties from the distributed energy resources and effects on electricity consumers’ behavior. Besides, the PV performance prediction accuracy leads to managing the electricity markets’ prices and avoiding any cost unbalance [5]. Several applications need an accurate model to predict the performance of PV modules. These applications contain the optimal power flow [6], energy storage chagrining, and discharging behaviors [7], demand-side [8], management, and microgrid [9].
Accordingly, the critical role of the applications mentioned above can be represented by characterizing the PV output power or current. The PV module’s performance is mainly a function of solar radiation and ambient temperature. Thus, any modeling or prediction technique for the PV model’s performance is usually developed based on these variables [10]. Several models are used to characterize the performance of PV modules. These models can be classified as linear models [11], regression models [12], and machine learning models [13]. The accuracy of some of these methods, such as linear, regression, and regressive, is questionable as they are suffering to handle the high uncertainty from solar radiation.
Therefore, several machine learning techniques are widely used to avoid the limitations of the above methods. These techniques include artificial neural network (ANN), support vector machine (SVM), and random forests (RFs). The ANN model shows promising results to model PV modules’ performance as it can handle the uncertainty. Here, several research works have successfully implemented ANN. In [14], the authors used the ANN model to forecast the PV output power. The feed-forward ANN topology has been utilized. Solar radiation, temperature, and wind velocity are considered as the inputs of the ANN model were. The accuracy of this model was measured based on the absolute error. The error of the predicted values compared with the actual values was between 7.7% and 17.6%. In [15], a hybrid multi-layer feed-forward ANN model has been developed and used to predict the PV output power in a grid-connected PV system. The inputs of this model were the solar radiation and the module’s temperature. In [16], several of ANN’s topologies are optimized based on an adaptive approach to predict the PV output power in a grid-connected PV system. Based on the previous research works, it is clear that the ANN can predict PV modules’ performance with a lower error. The prediction error of predicting PV modules’ performance ranges from 5 to 11% [4]. Besides, solar radiation and temperature are the most used inputs to predict the performance of the PV modules. However, the classical ANN models have several hyperparameters, such as the number of hidden neurons. Till now, there is no direct mathematical formula to select the optimal number of neurons. Most of the researchers are using the trial and error approach to set the number of neurons. Therefore, if the number of neurons is undersized, the results will be underfitting, causing high training and high generalization error. While if the number of neurons is oversized, then the results will be overfitting, and a high variance may occur [17].
Accordingly, optimizing the number of hidden neurons may increase the accuracy of the forecasted results. Several artificial intelligence (AI) methods are used to optimize the number of neurons. The ANN-based AI models’ results show good improvement in the predicted values’ accuracy compared with the classical ANN models. Many AI techniques are proposed in the literature, such as particle swarm optimization (PSO) [18], genetic algorithm (GA) [19], and so on. PSO has several disadvantages, such as stuck in the local optima and requires more iterations to find the solution.
In contrast, GA requires a lower number of iterations to find a solution. GA is successfully used to optimize the parameters of several applications [20]. In addition, the performance analyses of various commercial photovoltaic modules based on local spectral irradiances in Malaysia is carried out using GA [21]. GA is an evolutionary algorithm that can optimize ANN’s weights [22,23,24]. Moreover, GA is used to tune the parameters of ANN towards a comprehensive optimization of engine efficiency and emissions in the work of [21]. GA mimics chromosomes’ generation to produce new DNA strings that merge components from two diverse chromosome strands. GA can be highly adaptable in their application, given that the chromosomes reveal a data array, which can be utilized to express as many characteristics as needed using the base classifier. GA is sensitive to local optima, which may need to be examined iteratively for sounder and dependable results. In [25], GA is utilized to tune SVM’s hyper-parameters for a short-term PV power prediction.
In this paper, an ANN algorithm is developed based on the GA to predict the PV module’s performance, including the voltage, current, and power at the maximum power point. The main idea is to improve the accuracy of the ANN model using GA. Thus, the GA aims to optimize the ANN’s hyperparameters, such as the number of neurons based on minimum root-mean-squared error (RMSE) between the actual data and the predicted one. The main contributions of this paper can be summarized as follows:
-
Improving the cascade-forward neural network (CFNN) model’s accuracy by optimizing the number of hidden neurons using GA.
-
Comparing the accuracy of the CFNN-based GA model with the classical CFNN, classical feed-forward neural network (FFNN), and FFNN-based on GA models to show the superiority of the proposed model.
The remaining paper is organized as follows: Section 2 describes the mathematical modeling of the PV module. In Section 3, the methods used in this paper are briefly discussed. These methods are FFNN, CFNN, and GA. The flowchart and the procedure of the proposed model are described in Section 4. In section 5, the simulation results and discussion are mentioned. Finally, Section 6 summarizes the main findings of this research work.
Mathematical Model of a Photovoltaic Module
The PV module has several PV solar cells. They are connected in parallel and series configurations. The schematic diagram for a PV solar cell is illustrated in Fig. 1. From Fig. 1, it can be noticed that the PV solar cell contains a current source, which represents the solar radiation, connected in parallel with a p-n diode, and a parallel resistance with a series resistance [4].

The schematic diagram for a PV solar cell
The non-linear behavior of the PV cell output current (I) can be mathematically presented as:
where Iph stands for the photogenerated current, V represents the PV cell output voltage, I0 represents the diode saturation current, Rs represents the series resistance, Rsh is the shunt resistance and Vt is the thermal voltage. Here, Vt can be obtained by,
where a stands for the diode ideality factor, kb is Boltzmann constant, q represents the charge of the electron, and Tc is the cell temperature in Kelvin. The value of Tc can be calculated from the ambient temperature as:
where TA is the ambient temperature, NOCT represents the nominal operating temperature of the cell, and G stands for the solar radiation.
The maximum power point of the PV cell (Impp) can be obtained as [26]:
where Vmpp is the PV cell maximum power point voltage.
Accordingly, the PV cell maximum power (Pmpp) can be estimated by,
Methods
In this section, the artificial neural network (ANN) basics as a prediction technique and the genetic algorithm (GA) as an optimization technique are described.
Artificial Neural Network (ANN)
ANN is considered as a machine learning technique that is inspired by the human nervous system to handle the information. The ANN principle aims to identify the data pattern and learn from the characteristics and the interactions on these patterns. The ANN structure has three main layers; the input layer, the hidden layer containing the hidden neurons, and the output layer. The hidden neurons have activation functions, which aim to link the layers by weight links [16]. The ANN model has two main stages; training and testing stages. In the training stage, the hidden neurons receive the information from the input layer by the incoming links and then combine it with a non-linear function with the training stage’s targeted response. The created relationship is utilized to find the current timestep’s proper weight, which predicts the new data. A part of the dataset for the variables considered as inputs is used to test and validate the trained model’s accuracy in the testing stage. The merit of the ANN is the ability to model complex problems accurately [25].
Several topologies of the ANN are utilized to model the performance of the PV modules in the literature [27], such as a feed-forward neural network (FFNN) [15], general regression neural network (GRNN) [27], and cascade-forward neural network (CFFN) [28]. The FFNN is considered the most direct and straightforward ANN topology, allowing it to pass from the input layer to the output layer through the hidden layer. The FFNN updates the weight links by utilizing the back-propagation(BP) algorithm. In contrast, the GRNN is suitable for applications that the availability of the data is limited or relatively small. Finally, the CFNN has also used the BP algorithm as a learning algorithm. However, the weighted link at each neuron depends on the information in the previous neurons. The CFNN has the ability to handle a wide rand of the dataset. Therefore, in this paper the FFNN and CFNN topologies are utilized to forecaste the PV output power with and without optimizing their number of neurons.
Feed-Forward Neural Network (FFNN)
The FFNN is the simplest ANN topology [15]. The structure of the FFNN is illustrated in Fig. 2. The FFNN contains three main layers, such as the input, hidden, and output layers. The hidden layer contains the hidden neuron. The input layer passes the inputs to the hidden layer. Each hidden neuron has an activation function and several links with all the inputs. Accordingly, the weights are calculated for each sample of the dataset and updated at the next sample. The calculation and update of these weights are carried out based on the correlation and estimated error between the actual training data on the output layer with that predicted at each data sample. The update of these weights is conducted based on minimizing the calculated error to improve the model’s accuracy.

The structure of an FFNN topology
Cascade-Forward Neural Network (CFNN)
The CFNN topology structure is similar to that in FFNN. It is started with defining the number of the input and output neurons according to the number of inputs and outputs from the dataset [28]. The data starts feeding to the hidden neurons. The CFNN model aims to maximize the correlation between actual and predicted data by feeding the new data by adjusting the weights. This process is repeated until the minimum error is reached between the actual and predicted data. The structure of the CFNN topology is shown in Fig. 3.

The structure of a CFNN topology
The values of weights are calculated for each neuron. The calculation of these values in FFNN and CFNN topologies is conducted based on the supervising learning algorithm. The BP learning algorithm is utilized for the learning process in FFNN and CFNN topologies as follows:
where ANNurepresents the untrained ANN model, L stands for the number of hidden layers in the network, N is the number of hidden neurons at each L, I stands for the inputs from the training dataset, O is the output from the training dataset and ANNt stands for the trained ANN model.
According to Fig. 3, the equations are formed from the CFNN model can be written as follows [29]:
where y represents the output from CFNN, fi is the activation function from the input layer to the output layer, \( {w}_i^i \) is weight from the input layer to the output layer, xi stands for the input vector, fo is the activation function on the output layer, \( {w}_j^o \) stands for the weight of the output layer, \( {f}_j^h \)is an activation function on the hidden layer, \( {w}_{ji}^h \) represents the weight of the hidden layer.
If a bias is added to the input layer and the activation function of each neuron in the hidden layer, then the output from CFNN in (7) can be rewritten as:
where wb stands for the weight from bias to output and \( {w}_j^b \) is the weight from bias to hidden layer.
The number of hidden neurons is considered one of the essential hyper-parameters in the ANN, which significantly affects the ANN models’ accuracy. According to the literature, no mathematical formula can be used to find the optimal number of hidden neurons directly [30]. The number of hidden neurons is dependent on the data characterization and the number of inputs, outputs, and hidden layers. The number of hidden neurons is mostly calculated based on a trial and error method. Here, if the number is high, then over-fitting and high variance may happen. While if it is low, high training and generalization errors may happen. Therefore, the number of hidden neurons should be selected optimally. In this research, the genetic algorithm (GA) is proposed to optimize the FFNN and CFNN models’ neurons. The objective function aims to minimize the value of root mean square error (RMSE).
Genetic Algorithm (GA)
The genetic algorithm (GA) was introduced in the 1960s and 1970s by John Holland and his collaborators [31, 32]. GA mimics an abstraction of biological evolution based on Charles Darwin’s theory of natural evolution by modifying a population of individual solutions [25]. Therefore, GA is considered as a class of heuristic optimization methods. GA has several advantages over traditional optimization algorithms, such as the ability of dealing with complex problems and parallelism. Accordingly, GA can handle several objective functions, including (i) linear or nonlinear; (ii) stationary or non-stationary;(iii) continuous or discontinuous; or (iv) with random noise [33]. As GA has multiple offsprings in a population; therefore, the population can explore the search space in many directions simultaneously. This fact supports the parallization of the GA [34]. A GA flowchart is shown in Fig. 4. Therefore, the main characteristics of a GA are as follows:
-
1.
GA works with a coding of the parameter set, not the parameters themselves.
-
2.
GA initiates its search from a population of points, not a single point.
-
3.
GA uses payoff information, not derivatives.
-
4.
GA uses probabilistic transition rules, not deterministic ones.

GA working principle flowchart
GAs are being used to solve a wide variety of problems in energy applications, such as MPPT controllers introduced in [35] and overviewed in [36, 37], and PV performance analysis in [21].
The Proposed Model
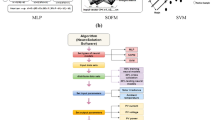
The proposed model is a combination between the CFNN and the GA. The GA is utilized to tune the number of hidden neurons in the CFNN. The main procedure for optimizing the number of hidden neurons using GA is lustrated in Fig. 5. Here, the main steps of the proposed model structure can be summarized as follows:
-
1.
In the first stage, the variables and inputs are imported to be used in the proposed model. In this paper, the proposed model’s inputs are solar radiation, ambient temperature, day number of the year, and hours. At the same time, the output of the proposed model is the output PV power.
-
2.
The maximum number of iterations, size of the population, which equals to the dimension of the optimization problem multiply by 10, and the dimension of the optimization problem, which is one in this work as the GA aims to optimally tune one hyper-parameter of the CFNN model based on minimum RMSE are set. Finally, set the upper and lower limits of the dimension of the optimization problem.
-
3.
The objective function is defined in this stage. In this paper, the RMSE is considered to be the objective function. RMSE is calculated as a relation between the predicted and the actual values.
-
4.
The GA is utilized to optimize the number of hidden neurons in the CFNN model based on minimum RMSE. This stage is started by randomizing the hidden neuron’s number as an initial value for the first iteration.
-
5.
According to the hidden neurons’ initial value, the CFNN model is trained to predict the response. The predicted response is used as an input to the objective function. Here, the RMSE is calculated.
-
6.
If the calculated RMSE is lower than the calculated using the random number of neurons, then the new number is updated. Otherwise, the previous number of neurons is still dominating, and it is used for the next iteration.
-
7.
The above steps will be returned until the maximum number of iterations reached the maximum number of iterations.
-
8.
The number of the hidden neurons at a minimum RMSE value is considered the optimal number of the hidden neurons.
-
9.
The optimal number of the hidden neurons is used to train the CFNN using 70% of the dataset. Besides, the remaining dataset (30%) is used to test the CFNN model. The predicted response is used to evaluate the performance of the CFNN-based GA model.

The flowchart of the proposed CFNN-based GA model
To evaluate the performance of the proposed model, five statistical error terms are utilized. These terms are RMSE, nRMSE, MBE, nMBE, and MAPE, which they can be mathematically formulated as:
where Ip represents the predicted PV power value, Ia represents the real PV power value, and N represents the length of the dataset.
Results and Discussion
The Four models, FFNN, CFNN, and FFNN-GA and the proposed model (CFNN-GA) are developed using MATLAB 2020a operated by a standard PC under Windows 10. Actual hourly data for a PV module and meteorological data are utilized to show the proposed model’s effectiveness. Here, the PV data are measured at 30° tilt angle and 0° azimuth using four wire connection to a bipolar power supply. Accordingly, the global tilt irradiance is measured using a ventilated pyranometer mounted in 30° plane, while the module temperature is measured using three wire connections to Pt100 resistance temperature detectors. The electrical specifications of the used PV module can be summarized as listed in Table 1.
A sample of each of the utilized meteorological data is shown in the following figures. Here, a sample for 500 h of the solar radiation and ambient temperature is shown in Figs. 6 and 7, respectively. Figure 8 shows a sample of the training PV power output. Here, 70% of the dataset is utilized for training the proposed model and the other models. At the same time, the remaining dataset is utilized to test and validate the models.

A sample of the training solar radiation data

A sample of the training ambient temperature data

A sample of the training output power data
The GA is utilized to optimally tune the number of hidden neurons for the CFNN and FFNN models. The maximum number of iterations in GA is set to be 500 iterations. Also, the dimension of the optimization problem is set to be 1. Therefore, the population is set to be 10. Finally, the search space limits for the hidden neurons are set as [1, 100] neurons. Accordingly, the convergence curves for the GA for optimizing the number of hidden neurons in CFNN and FFNN are shown in Figs. 9 and 10, respectively.

Convergence curve for the FFNN-based on GA model

Convergence curve for the proposed model
Based on Fig. 9, it can be noticed that the optimal number of the hidden neurons in the CFNN model is nine neurons with an RMSE value of 0.06 W. The optimal solution is reached after 200 iterations. In comparison, the optimal number of the hidden neurons for the FFNN model is seven neurons with an RMSE value of 0.0025 W, as shown in Fig. 10, which is obtained after 100 iterations. To show the proposed model’s effectiveness, 30% of the data set is used to test it and validate it by utilizing the hidden neurons’ optimized number. Accordingly, Fig. 11 shows the forecasted output power utilizing the proposed model and the PV module’s actual values.

A sample of 100 h of the predicted PV output power using the proposed model
Based on Fig. 11, it is clear that the forecasted values are very close to the actual values visually. Statistically, the RMSE, nRMSE, MBE, nMBE, and MAPE values compared to the predicted and actual values are 0.0025 W, 0.0131%, and 0.0011 W 0.0067% and 0.8121%, respectively.
To show the CFNN-based GA model’s superiority, its performance is compared with that obtained by the classical CFNN, classical FFNN, FFNN-based on GA models. Here, the predicted output power of the PV module using the model mentioned above with the actual data are shown in Fig. 12.

A sample of the predicted output PV power using several models
Based on Fig. 12, it can be noticed that the predicted output power of the PV module using the proposed model is more accurate as it is closer to the actual data curve. To prove that, the statistical error terms are used as listed in Table 2.
According to Table 2, it can be noticed that the values of RMSE, nRMSE, MABE, nMBE and MAPE for the proposed model is less than that for the other models. Besides, the training and testing time for the proposed model is faster. Thus, the proposed model can be recommended to model the PV modules’ performance accurately and faster than other models. This will lead to more accurate sizing results or/and control response for PV systems.
To validate the effectiveness of the proposed model, its performance in terms of MAPE compared with some of the research works in the same area. Here, the proposed model compared with perturb and observe (P&O) method with incremental conductance method (ICM) [38], random forests (RFs) model [4], generalized regression artificial neural network (GRNN) [30] and CFNN [30] as listed in Table 3.
Based on Table 3, it can be noticed that the proposed model outperforms the above-mentioned models in terms of MAPE. In which, the MAPE of the proposed model is lower by 61.89%, 90.68%, 83.68% and 88.53% than P&O method with ICM, RFs model, GRNN model and CFNN model, respectively. Therefore, the proposed model can perform better than the above-mentioned models in predicting the PV output current in terms of MAPE. Accordingly, the proposed model can recommend for future research works that required the modeling the current of the PV modules. Here, the optimal parameters of GA that used in this paper are listed in Table 4.
Conclusions
This paper proposed a new prediction model to predict the output power of a PV module. This model was a combination of machine learning and artificial intelligence technique. The CFNN model represents the machine learning technique, and the GA stands for the artificial intelligence algorithm. This combination aimed to improve the accuracy and performance of the CFNN model by optimizing the number of its hidden neurons by the genetic algorithm. The main idea was to secure a minimum RMSE between the predicted and actual data. The proposed model’s performance was evaluated and compared with that obtained by a classical CFNN, classical FFNN, and FFN-based on GA models. This compression was carried out in terms of RMSE, nRMSE, MBE, nMBE, and MAPE and the training and testing time. The results show the proposed model’s superiority as the values of RMSE, nRMSE, MBE, nMBE, and MAPE were 0.0025 W, 0.0131%, 0.0011 W, and 0.0067% and 0.8121%, respectively. Also, its training and testing time was 0.0098 s. and 0.0032 s., which were less than the other models. Accordingly, the proposed model can be recommended to characterize the PV modules’ performance faster and more accurately than the other mentioned models.
References
Ibrahim IA, Hossain MJ (2018) The Technical, Operational and Energy Policy Issues for Developing Photovoltaic Systems: A Review. 2018 IEEE Reg. Ten Symp 100–105. https://doi.org/10.1109/TENCONSpring.2018.8691971
Zhu L, Xu Y, Pan Y (2019) Enabled comparative advantage strategy in China’s solar PV development. Energy Policy 133:110880. https://doi.org/10.1016/j.enpol.2019.110880
Ameur A, Berrada A, Loudiyi K, Aggour M (2020) Forecast modeling and performance assessment of solar PV systems. J Clean Prod 267:122167. https://doi.org/10.1016/j.jclepro.2020.122167
Ibrahim IA, Khatib T, Mohamed A, Elmenreich W (2018) Modeling of the output current of a photovoltaic grid-connected system using random forests technique. Energy Explor Exploit 36:132–148. https://doi.org/10.1177/0144598717723648
Wang F, Xu H, Xu T, Li K, Shafie-khah M, Catalão JPS (2017b) The values of market-based demand response on improving power system reliability under extreme circumstances. Appl Energy 193:220–231. https://doi.org/10.1016/j.apenergy.2017.01.103
Biswas PP, Suganthan PN, Amaratunga GAJ (2017) Optimal power flow solutions incorporating stochastic wind and solar power. Energy Convers Manag 148:1194–1207. https://doi.org/10.1016/j.enconman.2017.06.071
Wang F, Zhou L, Ren H, Liu X, Talari S, Shafie-khah M, Catalao JPS (2018)Multi-objective optimization model of source–load–storage synergetic dispatch for a building energy management system based on TOU Price demand response. IEEE Trans Ind Appl 54:1017–1028. https://doi.org/10.1109/TIA.2017.2781639
Chen Q, Wang F, Hodge B-M, Zhang J, Li Z, Shafie-Khah M, Catalao JPS (2017) Dynamic price vector formation model-based automatic demand response strategy for PV-assisted EV charging stations. IEEE Trans Smart Grid 8:2903–2915. https://doi.org/10.1109/TSG.2017.2693121
Wang F, Zhou L, Wang B, Wang Z, Shafie-khah M, Catalão J (2017a) Modified Chaos particle swarm optimization-based optimized operation model for stand-alone CCHP microgrid. Appl Sci 7:754. https://doi.org/10.3390/app7080754
Ibrahim IA, Hossain MJ, Duck BC, Badar AQH (2019) Parameters extraction of a photovoltaic cell model using a co-evolutionary heterogeneous hybrid algorithm. In: 2019 20th international conference on intelligent system application to power systems (ISAP). IEEE, pp 1–6. https://doi.org/10.1109/ISAP48318.2019.9065989
Bacher P, Madsen H, Nielsen HA (2009) Online short-term solar power forecasting. Sol Energy 83:1772–1783. https://doi.org/10.1016/j.solener.2009.05.016
Chowdhury BH, Rahman S (1988) Is central station photovoltaic power dispatchable? IEEE Trans Energy Convers. 3:747–754. https://doi.org/10.1109/60.9348
Wang F, Xuan Z, Zhen Z, Li K, Wang T, Shi M (2020) A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers Manag 212:112766. https://doi.org/10.1016/j.enconman.2020.112766
Hiyama T, Kitabayashi K (1997) Neural network based estimation of maximum power generation from PV module using environmental information. IEEE Trans Energy Convers 12:241–247. https://doi.org/10.1109/60.629709
Sulaiman SI, Rahman TKA, Musirin I, Shaari S (2012) An artificial immune-based hybrid multi-layer feedforward neural network for predicting grid-connected photovoltaic system output. Energy Procedia 14:260–264. https://doi.org/10.1016/j.egypro.2011.12.927
Lo Brano V, Ciulla G, Di Falco M (2014) Artificial neural networks to predict the power output of a PV panel. Int J Photoenergy 2014:1–12. https://doi.org/10.1155/2014/193083
Ameen AM, Pasupuleti J, Khatib T (2015a) Modeling of photovoltaic array output current based on actual performance using artificial neural networks. J Renew Sustain Energy 7:053107. https://doi.org/10.1063/1.4931464
Fernandez-Martinez JL, Garcia-Gonzalo E (2011) Stochastic stability analysis of the linear continuous and discrete PSO models. IEEE Trans Evol Comput 15:405–423. https://doi.org/10.1109/TEVC.2010.2053935
Cheng Y-F, Shao W, Zhang S-J, Li Y-P(2016) An improved multi-objective genetic algorithm for large planar array thinning. IEEE Trans Magn 52:1–4. https://doi.org/10.1109/TMAG.2015.2481883
Ostadmohammadi Arani B, Mirzabeygi P, Shariat Panahi M (2013) An improved PSO algorithm with a territorial diversity-preserving scheme and enhanced exploration-exploitation balance. Swarm Evol Comput 11:1–15. https://doi.org/10.1016/j.swevo.2012.12.004
Seera M, Tan CJ, Chong K-K, Lim CP (2021) Performance analyses of various commercial photovoltaic modules based on local spectral irradiances in Malaysia using genetic algorithm. Energy 223:120009. https://doi.org/10.1016/j.energy.2021.120009
Chen P, Yuan L, He Y, Luo S (2016) An improved SVM classifier based on double chains quantum genetic algorithm and its application in analogue circuit diagnosis. Neurocomputing 211:202–211. https://doi.org/10.1016/j.neucom.2015.12.131
Li Y, He Y, Su Y, Shu L (2016) Forecasting the daily power output of a grid-connected photovoltaic system based on multivariate adaptive regression splines. Appl Energy 180:392–401. https://doi.org/10.1016/j.apenergy.2016.07.052
Mojumder JC, Ong HC, Chong WT, Shamshirband S, Abdullah-Al-Mamoon(2016) Application of support vector machine for prediction of electrical and thermal performance in PV/T system. Energy Build 111:267–277. https://doi.org/10.1016/j.enbuild.2015.11.043
VanDeventer W, Jamei E, Thirunavukkarasu GS, Seyedmahmoudian M, Soon TK, Horan B, Mekhilef S, Stojcevski A (2019)Short-term PV power forecasting using hybrid GASVM technique. Renew Energy 140:367–379. https://doi.org/10.1016/j.renene.2019.02.087
Ibrahim IA, Hossain MJ, Duck BC, Fell CJ (2020) An adaptive wind-driven optimization algorithm for extracting the parameters of a single-diode PV cell model. IEEE Trans Sustain Energy 11:1054–1066. https://doi.org/10.1109/TSTE.2019.2917513
Mellit A, Kalogirou S a (2008) Artificial intelligence techniques for photovoltaic applications: a review. Prog Energy Combust Sci 34:574–632. https://doi.org/10.1016/j.pecs.2008.01.001
Shaban K, El-Hag A, Matveev A (2009) A cascade of artificial neural networks to predict transformers oil parameters. IEEE Trans Dielectr Electr Insul 16:516–523. https://doi.org/10.1109/TDEI.2009.4815187
Warsito B, Santoso R, Suparti YH (2018) Cascade forward neural network for time series prediction. J Phys Conf Ser 1025:012097. https://doi.org/10.1088/1742-6596/1025/1/012097
Ameen AM, Pasupuleti J, Khatib T, Elmenreich W, Kazem HA (2015) Modeling and characterization of a photovoltaic array based on actual performance using cascade-forward back propagation artificial neural network. J Sol Energy Eng 137:1–5. https://doi.org/10.1115/1.4030693
De Jong KA (1975) An analysis of the behavior of a class of genetic adaptive systems. University of Michigan
Holland JH (1975) Adaptation in natural and artificial systems. University of Michigan
Yang X-S(2021)Nature-inspired optimization algorithms, 2nd ed. Elsevier. https://doi.org/10.1016/C2019-0-03762-4
Roetzel W, Luo X, Chen D (2020) Design and operation of heat exchangers and their networks. Elsevier. https://doi.org/10.1016/C2017-0-03210-X
Messai A, Mellit A, Guessoum A, Kalogirou SA (2011) Maximum power point tracking using a GA optimized fuzzy logic controller and its FPGA implementation. Sol Energy 85:265–277. https://doi.org/10.1016/j.solener.2010.12.004
Ahmad FF, Ghenai C, Hamid AK, Bettayeb M (2020) Application of sliding mode control for maximum power point tracking of solar photovoltaic systems: a comprehensive review. Annu Rev Control 49:173–196. https://doi.org/10.1016/j.arcontrol.2020.04.011
Kamarzaman NA, Tan CW (2014) A comprehensive review of maximum power point tracking algorithms for photovoltaic systems. Renew Sust Energ Rev 37:585–598. https://doi.org/10.1016/j.rser.2014.05.045
Halim AAEBA El, Saad NH, Sattar AA El (2019) Application of a combined system between perturb and observe method and incremental conductance technique for MPPT in PV systems. In: 2019 21st international Middle East power systems conference (MEPCON). IEEE, pp 103–110. https://doi.org/10.1109/MEPCON47431.2019.9008079
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Al Turki, F.A., Al Shammari, M.M. Predicting the Output Power of a Photovoltaic Module Using an Optimized Offline Cascade-Forward Neural Network-Based on Genetic Algorithm Model. Technol Econ Smart Grids Sustain Energy 6, 20 (2021). https://doi.org/10.1007/s40866-021-00113-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40866-021-00113-y