
Abstract
The coronavirus pandemic identified a clinical need for pediatric tele-neuropsychology (TeleNP) assessment. However, due to limited research, clinicians have had little information to develop, adapt, or select reliable pediatric assessments for TeleNP. This preliminary systematic review aimed to examine the feasibility of pediatric TeleNP assessment alongside (1) patient/family acceptability, (2) reliability, and (3) the quality of the literature. Between May 2021 and November 2022, manual searches of PubMed, PsycINFO, and Google Scholar were conducted using terms related to “pediatric” and “tele-neuropsychology.” After extracting relevant papers with samples aged 0–22 years, predefined exclusion criteria were applied. Quality assessment was completed using the AXIS appraisal tool (91% rater-agreement). Twenty-one studies were included in the review, with reported qualitative and quantitative data on the feasibility, reliability, and acceptability extracted. Across included studies, TeleNP was completed via telephone/video conference with participants either at home, in a local setting accompanied by an assistant, or in a different room but in the same building as the assessor. Pediatric TeleNP was generally reported to be feasible (e.g., minimal behavioral differences) and acceptable (e.g., positive feedback). Nineteen studies conducted some statistical analyses to assess reliability. Most observed no significant difference between in-person and TeleNP for most cognitive domains (i.e., IQ), with a minority finding variable reliability for some tests (e.g., attention, speech, visuo-spatial). Limited reporting of sex-assigned birth, racialized identity, and ethnicity reduced the quality and generalizability of the literature. To aid clinical interpretations, studies should assess underexamined cognitive domains (e.g., processing speed) with larger, more inclusive samples.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Pediatric neuropsychologists assess and support the complex needs of children and young people with brain-related disorders, illnesses, and injuries (e.g., an acquired brain injury, brain tumor, epilepsy, or neurodegenerative disease) (Fisher et al., 2020). Neuropsychological evaluations are targeted cognitive and behavioral assessments aimed at identifying a child’s relative strengths and weaknesses and generating recommendations for strategies and interventions to improve outcomes at home, school, and community engagement (Fisher et al., 2020; Hewitt et al., 2020).
Traditionally, neuropsychologists conduct assessments during in-person sessions, one-on-one in a quiet room, using manual or computerized tests (Tailby et al., 2020). This methodology enables rapport building, adapting test materials as needed, and careful behavioral observation (Barnett et al., 2018; Pritchard et al., 2020). However, more pediatric patients need assessment than the capacity of pediatric neuropsychological services. Additionally, pediatric patients in rural and socioeconomically deprived areas and from racialized communities face numerous structural inequities and barriers to services (Harder et al., 2020; Wright, 2020). The resultant pressure on pediatric neuropsychology services to support a larger and more diverse population has increased interest in remote neuropsychology assessment (Adjorlolo, 2015).
Remote neuropsychology assessment, where the assessor communicates with a patient from a different location using telephone or audio-visual technology, is commonly known as tele-neuropsychology (TeleNP) (Bilder et al., 2020; Stiers & Kewman, 1997). TeleNP has a short history, beginning with verbal working memory and intelligence (IQ) assessments using telephone calls in the late twentieth century (Cardon et al., 1992; Hodge et al., 2019a; Kent & Plomin, 1987). Despite the objective need, recent surveys of neuropsychologists indicate that TeleNP has been used infrequently in pediatric and adult clinical settings with limited data on clinical efficacy (Hammers et al., 2020). Indeed, until recently, there were no practice guidelines for pediatric TeleNP or adaptation of standardized measures for remote administration (Bilder et al., 2020). Restrictions on face-to-face interactions due to the SARS-CoV-2 (coronavirus) pandemic has seen interest in TeleNP accelerate quickly (Hammers et al., 2020), with many pediatric neuropsychology services forced to pivot to remote assessment (Zane et al., 2021). However, the evidence to support these rapid changes is limited.
Among the few research studies on TeleNP, most have recruited adult populations (Parsons et al., 2022). This is partly due to the ethical (e.g., safeguarding) and practical (e.g., knowledge constraints) considerations for pediatric assessments. For a comprehensive overview of ethical considerations for pediatric TeleNP, see Scott et al. (2022), Hewitt et al. (2020), and Bilder et al. (2020). Additionally, the core concerns for adult TeleNP may be compounded in pediatric evaluations, including access to and understanding of technology (Harder et al., 2020; Pritchard et al., 2020), privacy and security (Hewitt et al., 2020; Pritchard et al., 2020), and the importance of rapport building (Koterba et al., 2020). Neuropsychologists also report concerns about cognitive (e.g., ability to follow verbal instructions), behavioral (e.g., hyperactivity), and emotional (e.g., anxiety) difficulties that might prevent engagement and undermine the reliability of assessments (Koterba et al., 2020). Hewitt et al. (2020) reported concerns about school acceptance of pediatric TeleNP assessments and challenges about the role of caregivers who are often needed to guide the patient’s attention during assessments but whose presence may pose additional challenges (e.g., prompting).
Overall, there is strong interest but some hesitancy to implement pediatric TeleNP, with limited research to guide best practices. To date, only one previous review of pediatric tele-assessment has been conducted that only included speech and language assessments (Taylor et al., 2014). From the limited literature base, the authors identified five relevant studies. Of those, all except one had a sample size of less than 30, and there was high variability in participant characteristics and study methodologies.
The primary aim of this preliminary systematic review was to describe the current pediatric TeleNP research literature and examine the feasibility of pediatric TeleNP assessment. Secondary aims included considering (1) the reliability of pediatric TeleNP by extracting any available statistical comparisons of in-person versus TeleNP scores, (2) the acceptability of TeleNP through patient/family feedback, and (3) the generalizability and quality of the body of literature, including consideration of structural factors (i.e., racialized identity, geographic region).
Methods
This systematic review constituted a narrative synthesis of the extracted data, followed the PRISMA (2020) guidance for systematic reviews (Page et al., 2021) (Online Resource 1) and was pre-registered on PROSPERO (CRD42021248969). Inclusion criteria were intentionally broad due to the limited research base of pediatric TeleNP. Included studies were peer-reviewed empirical articles (including clinical evaluations that were later published for research purposes) assessing TeleNP in clinical (e.g., young people with diagnosed or suspected special educational needs, disorders, or disabilities) and typically developing/non-clinical populations (e.g., no known or suspected special educational needs, disorders or disabilities). Our initial pre-registered age range was 3–18 years; however, to include four relevant studies, we extended the age range to 0–22 years to best capture TeleNP assessments for the pediatric population and account for the maturational period of the brain into early adulthood (Gogtay et al., 2004).
The review defines TeleNP as any neuropsychological assessment completed with the researcher not physically present during the assessment (i.e., video conferencing), including communicating with the participant by telephone. Any standardized neuropsychology assessment adapted for remote use was included, which refers to measures that examined cognitive and behavioral abilities through interviews, questionnaires, and testing (standardized or non-standardized). Studies which reported on non-neuropsychological assessment measures (i.e., audiology, sleep) were not assessed in the narrative synthesis. There were no restrictions on the publication date. Studies were excluded if no neuropsychological data were reported, no full text was available, it was not available in English, or it was conducted with an adult sample (i.e., over 22 years). Furthermore, this review does not contain data from technical reports or white papers available on commercial websites or published test manuals.
Between May 1, 2021, and November 30, 2022, the lead author (EJW) searched Google Scholar, PubMed, and PsycINFO (Online Resource 2). They combined three search strings: terms relating to “tele-assessment” and “video call,” terms relating to “pediatric,” and terms consisting of neuropsychology assessments (for example, “Delis- Kaplan Executive Function System” and “D-KEFS”). They examined the reference lists of each eligible study to identify further relevant work.
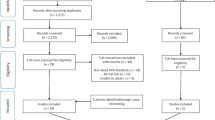
Two authors (EJW and AMH) independently screened each identified paper for inclusion by first reading titles and abstracts, followed by full texts. Firstly, raw data, proportions [%], and means for participant demographic and clinical characteristics were extracted where available. Next, the names of TeleNP assessment measures included qualitative descriptions of TeleNP assessment administration (i.e., TeleNP behavioral observations), and quantitative TeleNP data (i.e., TeleNP raw and standardized scores, proportions [%] and means) were extracted. See our PRISMA flowchart of our search results (Fig. 1) (Page et al., 2021). Four studies were excluded as they did not have a standardized cognitive endpoint (i.e., functional behavioral analysis) (Barretto et al., 2006; Kovas et al., 2007; Machalicek et al., 2009; Wacker et al., 2013). Three studies did not report participant characteristic data (e.g., age, gender) and were contacted by email (Ciccia et al., 2011; Eriks-Brophy et al., 2008; Wright, 2020). Two authors replied, one providing the missing data (Ciccia et al., 2011) and the second unable to do so due to data deletion (Eriks-Brophy et al., 2008).

PRISMA flow diagram. *Articles recommended by author(s) of papers who were contacted for further sample details
Reliability between in-person and TeleNP assessment scores was considered to be good if (a) papers reported no significant differences (p > 0.05) and (b) test–retest reliability (> 0.70) or correlation (> 0.50), or (c) interscorer agreement between in-person and TeleNP assessment (> 0.70). The Appraisal Tool for Cross-Sectional Studies (AXIS) assessed study quality (Downes et al., 2016). Initially, EJW and AMH coded all studies independently using AXIS. Each study was assigned a score from 0 to 19. Studies were considered to be of good quality if the score was greater than 70% (i.e., 14/19). Inter-rater reliability (κ statistic) was calculated by comparing the quality ratings between EJW and AMH.
Results
Twenty-one studies were included in the final review (Fig. 1). Fifteen used a cross-sectional design (all participants completed TeleNP); four used a repeated measures design (participants completed TeleNP and in-person assessment); and two used a matched pairs design (one group completed TeleNP and another completed in-person assessment) (Table 1). All studies were peer-reviewed publications; three were conducted since the beginning of the coronavirus pandemic (i.e., since March 2020), and three recruited samples primarily for clinical evaluation. Three studies included participants aged under 3 years, of which Ransom et al. (2020) was based on a clinical interview, parent report, and play/behavioral observations; Ciccia et al. (2011) generated scores from parent report of emergent language; and Salinas et al. (2020) was based on a clinical practice model and did not report the full assessment measures used. Two studies (Hodge et al., 2019a, 2019b) used the same sample, but each study focused on a separate cognitive domain (i.e., language and IQ).
Four different methodologies were used in included studies, with two using more than one methodology in the same study: (1) the participant at home without an on-site facilitator and the off-site researcher (depending on the age of the participant) conducting the assessment via video or telephone call (n = 4); (2) the participant at home or local setting accompanied by an on-site facilitator (e.g., parent or university student) and the off-site researcher conducting testing via video or telephone call (n = 6); (3) the participant in a local setting accompanied by an on-site researcher, with the off-site researcher conducting testing via video or telephone call (both researchers simultaneously scoring) (n = 5); or (4) the participant in a different room but the same location as the researcher (e.g., hospital setting) either accompanied by a second researcher (both researchers simultaneously scoring n = 6) or a facilitator (e.g., university student; n = 2), with the primary researcher conducting testing via video or telephone call.
The 21 included studies reported 54 different assessment measures (Table 2). Most studies assessed multiple cognitive domains. All assessment measures were adapted from existing standardized measures. The most commonly researched measures for remote assessment were the Wechsler Intelligence Scale for Children–Fifth Edition (WISC-V) (Wechsler, 2014) (n = 5) to measure IQ and the Clinical Evaluation of Language Fundamentals–Fourth Edition (CELF-4) (Semel et al., 2006) (n = 4) to assess language. Only Ransom et al. (2020) included free-standing performance or symptom validity tests (PVT or SVT), and they did not report PVT or SVT results. Demographic characteristics extracted from included studies are reported in Table 3. After contacting authors for missing data, sex assigned at birth was missing for two studies. Ten studies did not report the primary language of participants, fifteen studies did not report the racialized identity of participants, and sixteen did not report the ethnic identity of participants (Table 3).
Quality
Two studies were excluded due to poor quality scores (i.e., limited reporting of participant characteristics and TeleNP methods (Cardon et al., 1992; Kent & Plomin, 1987). EW and AMH compared results at the data extraction stage with substantial agreement between the two raters (91.30%; Cohen’s κ = 0.62). Raters then obtained consensus on the two remaining studies. Of note, most studies (> 85%) did not provide justification for their sample size. See Online Resources 3, 4, and 5 for full results from the AXIS appraisal.
Feasibility
See Table 4 for an overview of the characteristics of the included studies. Seven studies provided attrition rates (Dale et al., 2005; Harder et al., 2020; Ransom et al., 2020; Salinas et al., 2020; Sutherland et al., 2017, 2019; Worhach et al., 2021). Three studies reported that 2.86–27.37% of recruited participants were lost to follow-up or did not book a TeleNP appointment (Harder et al., 2020; Ransom et al., 2020; Salinas et al., 2020). Salinas et al. (2020) reported one participant did not attend their TeleNP appointment. Two studies had participants complete only partial TeleNP testing (Harder et al., 2020). Dale et al. (2005) reported missing/invalid TeleNP data of unspecified cause. Three studies reported that all participants completed all TeleNP testing (Salinas et al., 2020; Sutherland et al., 2017; Worhach et al., 2021).
Environmental and technical difficulties most commonly occurred within individual sessions than across sessions (Table 5). Harder et al. (2020) reported that 23% of individuals needed to borrow a study device. Ransom et al. (2020) found a significant correlation between device type (i.e., no laptop access) and TeleNP assessment attendance. Most studies that reported feasibility discussed technological difficulties or poor sound quality. For example, Hodge et al. (2019a) found that slow bandwidth and poor audio quality disrupted 6.06% sessions. However, according to assessor feedback, environmental distractions and technological difficulties were most often brief and did not appear to invalidate test performance or stop the assessment (Harder et al., 2020; Hodge et al., 2019b).
Acceptability
Acceptability was recorded via parent/carer/assessor/participant feedback using questionnaires (n = 8) (Ciccia et al., 2011; Harder et al., 2020; Hodge et al., 2019a, 2019b; Kronenberger et al., 2021; Reese et al., 2013) and the assessor’s behavioral observations of participants (n = 4) (Eriks-Brophy et al., 2008; Hodge et al., 2019a; Sutherland et al., 2017, 2019). All studies that used questionnaires found overall positive feedback. For example, Hodge et al. (2019a) reported that children found touchscreens “intuitive” during TeleNP, and caregivers observed positive behavioral responses. Sutherland et al. (2017) reported no assessor-observed behavioral differences between TeleNP and in-person assessment. When negative feedback was reported, it was generally related to audio or visual quality (Hodge et al., 2019a; Sutherland et al., 2019). Particularly, Kronenberger et al. (2021) found less acceptability for participants with cochlear implants, who reported more challenges from poor video-quality.
Reliability
Nineteen of the included studies reported reliability statistics, of which six studies (assessing IQ, memory, and language) found good overall reliability per our predetermined criteria (i.e., no significant differences and good test–retest reliability, correlations, or interscorer agreement) (Kronenberger et al., 2021; Sutherland et al., 2017, 2019; Waite et al., 2010b; Worhach et al., 2021).
IQ was the most frequently researched domain. Seven studies provided reliability data for remote IQ assessments (Harder et al., 2020; Hodge et al., 2019a; Kronenberger et al., 2021; Petril et al., 2002; Ragbeer et al., 2016; Worhach et al., 2021; Wright, 2020). Four studies found no significant differences between most TeleNP and in-person IQ subtests and index scores, three reported good test–retest reliability, and one reported good inter-scorer agreement. However, four subtests from IQ batteries demonstrated either a significant difference (i.e., a processing speed subtest) (Wright, 2020), poor test–retest reliability (attention, short-term and verbal working memory subtests) assessed 1.6 years apart (Kronenberger et al., 2021), a poor correlation (i.e., perceptual reasoning subtest) (Worhach et al., 2021), or poor inter-scorer agreement (i.e., verbal fluency subtest) (Ragbeer et al., 2016) between TeleNP and in-person assessments.
Visuo-spatial abilities were assessed across five studies (including subtests within IQ assessments) (Harder et al., 2020; Hodge et al., 2019a; Ransom et al., 2020; Worhach et al., 2021; Wright, 2020), with four reporting reliability statistics. Of these, three studies reported no significant differences, and two reported some good correlations between TeleNP and in-person visuo-spatial assessment. In an interim analysis, Worhach et al. (2021) found poor reliability between in-person and TeleNP visuo-spatial assessment (one camera visible on the assessor’s screen), so switched WASI subtests (Matrix Reasoning used instead of Block Design), which increased reliability. Comparatively, Hodge et al. (2019a) successfully used the WISC-V Block Design subtest with two cameras split on the assessor’s screen. Wright (2020) used Q-Global’s adapted digital administration to reliably assess visuo-spatial abilities.
Five studies reported good interscorer agreement for language assessment, of which three also found good correlations, and two found no significant differences between in-person and TeleNP assessment (Ciccia et al., 2011; Eriks-Brophy et al., 2008; Sutherland et al., 2017, 2019; Waite et al., 2010b). Four studies reported on speech assessment reliability, all of which reported good interscorer agreement between in-person and TeleNP assessment—although there was variability in agreement for some individual oromotor variables (which requires interpretation of speech sounds) (Ciccia et al., 2011; Eriks-Brophy et al., 2008; Waite et al., 2006, 2012). Reading and literacy reliability were reported across four studies (Dale et al., 2005; Hodge et al., 2019b; Waite et al., 2010a; Wright, 2016, 2018), with good inter-rater agreement in two of these studies, no significant differences found by Wright (2018) and good correlations found in three of these studies) between TeleNP and in-person reading assessment.
Processing speed was assessed in five studies (three as part of IQ assessment) (Harder et al., 2020; Hodge et al., 2019a; Petril et al., 2002; Ransom et al., 2020; Wright, 2020), four of which reported reliability statistics. Two studies found good reliability; however, Wright, 2020 found a significant difference between in-person and TeleNP. Three studies reported on executive function assessments (Harder et al., 2020; Ransom et al., 2020; Salinas et al., 2020). Only Harder et al. (2020) reported reliability statistics, with no significant difference between in-person and TeleNP. Three studies reported on the reliability of memory assessment (Harder et al., 2020; Kronenberger et al., 2021; Ragbeer et al., 2016), of which Ragbeer et al. (2016) reported good interscorer agreement, Harder et al. (2020) and Kronenberger et al. (2021) reported no significant differences with some good test–retest reliability between in-person and TeleNP.
Diagnostic assessments for autism spectrum disorder were included in three studies (Ransom et al., 2020; Reese et al., 2013; Salinas et al., 2020). Only Reese et al. (2013) provided reliability statistics, finding no significant differences and high interscorer agreement overall. However, inter-rater agreement varied between items (15 items did not reach > 0.70 agreement), and one pointing subtest demonstrated a significant difference.
Discussion
This preliminary systematic review examined the feasibility, acceptability, reliability, and quality of 21 published/peer-reviewed pediatric TeleNP studies. Some studies demonstrated significant differences or poorer correlations between TeleNP and in-person assessment subtests, but feasibility, reliability, and acceptability were most robust across IQ, memory, and language assessments. Across the included studies, feedback was generally positive, assessment completion rates were high, and there were mostly strong relationships between in-person and TeleNP assessment scores, particularly for studies including children three years and older. Barriers to TeleNP for assessors and participants (i.e., inadequate internet access) were not reported to have affected assessment completion. These findings align with research in adult populations (Parsons et al., 2022; Tailby et al., 2020). However, due to the small number of studies, evidence for the feasibility and acceptability of TeleNP for participants younger than 3 years old was limited.
The reliability of TeleNP varied most for speech, language, and reading comprehension assessments, which may have been due to audio and visual challenges. Differences in design (i.e., repeated measures versus simultaneous scoring), TeleNP setup (i.e., number of video-cameras), statistical analyses (i.e., intraclass correlations versus inter-rater reliability), and study periods (e.g., 1 week vs 1 year) made reliability across studies harder to interpret. Additionally, although recent work has shown that TeleNP assessing executive function and processing speed is reliable with adults (Parks et al., 2021), more studies are needed to determine reliability in the pediatric population.
Despite the primarily robust findings from the 21 TeleNP studies, generalizability is more challenging. There were very few large-scale TeleNP studies, with small samples (ns < 30) across large age ranges. Furthermore, most were pilot or feasibility studies, many were missing sample characteristics, the majority were conducted in the USA (n = 11; 52%) (Hammers et al., 2020), and there was little overlap in TeleNP assessments across studies. In addition, the most common type of TeleNP had two researchers (one in-person and one remote) simultaneous scoring. However, this research methodology does not best reflect how TeleNP would be used in clinical practice and may circumvent potential ethical challenges. Given that the majority of pediatric neuropsychologists do not embed free-standing PVT or SVT (Kirk et al., 2020) during in-person evaluations, it is perhaps unsurprising that they were utilized in only one of the TeleNP studies included in this review—the results of which were not reported (Ransom et al., 2020). Therefore, the failure or base rates of PVTs, which can be as high as 19% for in-person administrations, are unknown for pediatric TeleNP and must be incorporated in future research to inform formulation, interpretation, and recommendations (Kirk et al., 2020).
Our review indicates that the forced but often necessary shift to TeleNP since the beginning of the coronavirus pandemic in 2020 requires much more research to support this change. Significantly, the evidence base is not supported for specific pediatric assessment settings (e.g., adolescent forensic settings) where there are additional ethical (e.g., safeguarding) and practical (e.g., supervision) considerations. Privacy and informed consent would also need to be adapted for the specific risks (e.g., explaining to families the increased risk with electronic information transfer) for modified, remotely administered assessments (Scott et al., 2022).
Our review did not include any technical reports for remote assessment available on test publisher websites (e.g., PAR®) or in test manuals. This meant that some assessments with equivalency studies were missed. However, although these technical reports and white papers describe how remote administration should be completed, they do not yet include test scores that were normed specifically for TeleNP. Critically, tested developed specifically for TeleNP assessment (e.g., Reynolds Intellectual Assessment Scales–Second Edition; Wright, 2018) often cite equivalency studies based on smaller samples (e.g., ~ 100) compared to the larger normative samples (e.g., ~ 3000) used with in-person administrations, potentially reducing validity and reliability of modified assessment tools.
Children from under-resourced and marginalized communities were underrepresented in the included studies. This makes it difficult to conclude whether TeleNP is feasible or reliable for these populations, even though children from these communities are less likely to be able to attend in-person appointments (Lundine et al., 2020). Only one small study focused on a First Nation Indigenous population (Eriks-Brophy et al., 2008), and some studies excluded participants based on accessibility issues (e.g., hearing loss) (Waite et al., 2006). Future research should look to improve the inclusivity of samples to strengthen the evidence for TeleNP in clinical practice, which is particularly needed for families with limited or restricted transportation and those who live in rural communities (Adjorlolo, 2015).
This systematic review is preliminary as it includes a limited literature base of research primarily conducted before the coronavirus pandemic. We expect that there will be a larger number of studies in the next few years that can expand our knowledge of TeleNP. In our current study, having only one reviewer complete the initial screening may have reduced the number of eligible studies identified by up to 9% (Edwards et al., 2002). A meta-analysis was also beyond the scope of this research, as it would have been challenging to complete given most included studies used different cognitive assessments in TeleNP.
Conclusion
Evidence from research studies indicates that pediatric TeleNP in clinical and non-clinical populations is feasible and acceptable. There is preliminary evidence for the reliability of some assessment measures. However, performance validity was not tested, and most studies included small, homogenous, mostly white samples with children over 3 years of age, limiting generalizability. Much more research with inclusive samples is needed before TeleNP can be used as an established and reliable option for clinical practice—particularly in specific complex populations such as pediatric forensic settings and for children with significant support needs. Tests used currently in TeleNP, even those modified for remote assessment, most often include normative samples tested during in-person evaluations. Thus, there is a critical need for tests specifically designed, tested, and normed for TeleNP. From such practice, appropriate guidance may be developed and further clinical pediatric TeleNP service models to be piloted.
Data availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
References
Adjorlolo, S. (2015). Can teleneuropsychology help meet the neuropsychological needs of Western Africans? The case of Ghana. Applied Neuropsychology: Adult, 22(5), 388–398. https://doi.org/10.1080/23279095.2014.949718
Barnett, M. D., Parsons, T. D., Reynolds, B. L., & Bedford, L. A. (2018). Impact of rapport on neuropsychological test performance. Applied Neuropsychology: Adult, 25(3), 258–265. https://doi.org/10.1080/23279095.2017.1293671
Barretto, A., Wacker, D. P., Harding, J., Lee, J., & Berg, W. K. (2006). Using telemedicine to conduct behavioral assessments. Journal of Applied Behavior Analysis, 39(3), 333–340. https://doi.org/10.1901/jaba.2006.173-04
Bilder, R. M., Postal, K. S., Barisa, M., Aase, D. M., Cullum, C. M., Gillaspy, S. R., Harder, L., Kanter, G., Lanca, M., & Lechuga, D. M. (2020). Inter organizational practice committee recommendations/guidance for teleneuropsychology in response to the COVID-19 pandemic. The Clinical Neuropsychologist, 34(7–8), 1314–1334. https://doi.org/10.1080/13854046.2020.1767214
Cardon, L. R., Corley, R. P., DeFries, J. C., Plomin, R., & Fulker, D. W. (1992). Factorial validation of a telephone test battery of specific cognitive abilities. Personality and Individual Differences, 13(9), 1047–1050. https://doi.org/10.1016/0191-8869(92)90137-E
Ciccia, A. H., Whitford, B., Krumm, M., McNeal, K., Hein, C. A., Bridgid, W., Krumm, M., McNeal, K., Ciccia, A. H., Whitford, B., Krumm, M., McNeal, K., Hein, C. A., Bridgid, W., Krumm, M., McNeal, K., Ciccia, A. H., Whitford, B., Krumm, M., & McNeal, K. (2011). Improving the access of young urban children to speech, language and hearing screening via telehealth. Journal of Telemedicine and Telecare, 17(5), 240–244. https://doi.org/10.1258/jtt.2011.100810
Dale, P. S., Harlaar, N., & Plomin, R. (2005). Telephone testing and teacher assessment of reading skills in 7-year-olds: I. Substantial correspondence for a sample of 5544 children and for extremes. Reading and Writing, 18(5), 385–400. https://doi.org/10.1007/s11145-004-8130-z
Downes, M. J., Brennan, M. L., Williams, H. C., & Dean, R. S. (2016). Development of a critical appraisal tool to assess the quality of cross-sectional studies (AXIS). BMJ Open, 6(12), e011458. https://doi.org/10.1136/bmjopen-2016-011458
Edwards, P., Clarke, M., DiGuiseppi, C., Pratap, S., Roberts, I., & Wentz, R. (2002). Identification of randomized controlled trials in systematic reviews: Accuracy and reliability of screening records. Statistics in Medicine, 21(11), 1635–1640. https://doi.org/10.1002/sim.1190
Eriks‐Brophy, A., Quittenbaum, J., Anderson, D., Nelson, T., Eriks-Brophy, A., Quittenbaum, J., Anderson, D., Nelson, T., Eriks‐Brophy, A., Quittenbaum, J., Anderson, D., Nelson, T. (2008). Part of the problem or part of the solution? Communication assessments of Aboriginal children residing in remote communities using videoconferencing. Clinical Linguistics & Phonetics, 22(8), 589–609. https://doi.org/10.1080/02699200802221737
Fisher, E. L., Zimak, E., Sherwood, A. R., & Elias, J. (2020). Outcomes of pediatric neuropsychological services: A systematic review. The Clinical Neuropsychologist, 36(6), 1265–1289. https://doi.org/10.1080/13854046.2020.1853812
Gogtay, N., Giedd, J. N., Lusk, L., Hayashi, K. M., Greenstein, D., Vaituzis, A. C., Nugent, T. F., III., Herman, D. H., Clasen, L. S., & Toga, A. W. (2004). Dynamic mapping of human cortical development during childhood through early adulthood. Proceedings of the National Academy of Sciences, 101(21), 8174–8179. https://doi.org/10.1073/pnas.0402680101
Hammers, D. B., Stolwyk, R., Harder, L., & Cullum, C. M. (2020). A survey of international clinical teleneuropsychology service provision prior to and in the context of COVID-19. The Clinical Neuropsychologist, 34(7–8), 1267–1283. https://doi.org/10.1080/13854046.2020.1810323
Harder, L., Hernandez, A., Hague, C., Neumann, J., McCreary, M., Cullum, C. M., & Greenberg, B. (2020). Home-based pediatric teleneuropsychology: A validation study. Archives of Clinical Neuropsychology, 35(8), 1266–1275. https://doi.org/10.1093/arclin/acaa070
Hewitt, K. C., Rodgin, S., Loring, D. W., Pritchard, A. E., & Jacobson, L. A. (2020). Transitioning to telehealth neuropsychology service: Considerations across adult and pediatric care settings. The Clinical Neuropsychologist, 34(7–8), 1335–1351. https://doi.org/10.1080/13854046.2020.1811891
Hodge, M. A., Sutherland, R., Jeng, K., Bale, G., Batta, P., Cambridge, A., Detheridge, J., Drevensek, S., Edwards, L., & Everett, M. (2019a). Agreement between telehealth and face-to-face assessment of intellectual ability in children with specific learning disorder. Journal of Telemedicine and Telecare, 25(7), 431–437. https://doi.org/10.1177/1357633x18776095
Hodge, M. A., Sutherland, R., Jeng, K., Bale, G., Batta, P., Cambridge, A., Detheridge, J., Drevensek, S., Edwards, L., Everett, M., Ganesalingam, C., Geier, P., Kass, C., Mathieson, S., McCabe, M., Micallef, K., Molomby, K., Pfeiffer, S., Pope, S., …, Silove, N. (2019b). Literacy assessment via telepractice is comparable to face-to-face assessment in children with reading difficulties living in Rural Australia. Telemedicine and E-Health, 25(4), 279–287. https://doi.org/10.1089/tmj.2018.0049
Kent, J., & Plomin, R. (1987). Testing specific cognitive abilities by telephone and mail. Intelligence, 11(4), 391–400. https://doi.org/10.1016/0160-2896(87)90019-5
Kirk, J. W., Baker, D. A., Kirk, J. J., & MacAllister, W. S. (2020). A review of performance and symptom validity testing with pediatric populations. Applied Neuropsychology: Child, 9(4), 292–306.
Koterba, C. H., Baum, K. T., Hamner, T., Busch, T. A., Davis, K. C., Tlustos-Carter, S., Howarth, R., Fournier-Goodnight, A., Kramer, M., & Landry, A. (2020). COVID-19 issues related to pediatric neuropsychology and inpatient rehabilitation–challenges to usual care and solutions during the pandemic. The Clinical Neuropsychologist, 34(7–8), 1380–1394. https://doi.org/10.1080/13854046.2020.1811892
Kovas, Y., Haworth, C. M. A., Dale, P. S., & Plomin, R. (2007). The genetic and environmental origins of learning abilities and disabilities in the early school years. Monographs of the Society for Research in Child Development, 72(3), 1–144. https://doi.org/10.1111/j.1540-5834.2007.00439.x
Kronenberger, W. G., Montgomery, C. J., Henning, S. C., Ditmars, A., Johnson, C. A., Herbert, C. J., & Pisoni, D. B. (2021). Remote assessment of verbal memory in youth with cochlear implants during the COVID-19 pandemic. American Journal of Speech-Language Pathology, 30(2), 740–747. https://doi.org/10.1044/2021_ajslp-20-00276
Lundine, J. P., Peng, J., Chen, D., Lever, K., Wheeler, K., Groner, J. I., Shen, J., Lu, B., & Xiang, H. (2020). The impact of driving time on pediatric TBI follow-up visit attendance. Brain Injury, 34(2), 262–268. https://doi.org/10.1080/02699052.2019.1690679
Machalicek, W., O’Reilly, M., Chan, J. M., Lang, R., Rispoli, M., Davis, T., Shogren, K., Sigafoos, J., Lancioni, G., & Antonucci, M. (2009). Using videoconferencing to conduct functional analysis of challenging behavior and develop classroom behavioral support plans for students with autism. Education and Training in Developmental Disabilities, 207–217. https://www.jstor.org/stable/24233495
Page, M. J., McKenzie, J. E., Bossuyt, P. M., Boutron, I., Hoffmann, T. C., Mulrow, C. D., Shamseer, L., Tetzlaff, J. M., Akl, E. A., & Brennan, S. E. (2021). The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Systematic Reviews, 10(1), 1–11. https://doi.org/10.1136/bmj.n71
Parks, A. C., Davis, J., Spresser, C. D., Stroescu, I., & Ecklund-Johnson, E. (2021). Validity of in-home teleneuropsychological testing in the wake of COVID-19. Archives of Clinical Neuropsychology, 36(6), 887–896. https://doi.org/10.1093/arclin/acab002
Parsons, M. W., Gardner, M. M., Sherman, J. C., Pasquariello, K., Grieco, J. A., Kay, C. D., Pollak, L. E., Morgan, A. K., Carlson-Emerton, B., & Seligsohn, K. (2022). Feasibility and acceptance of direct-to-home tele-neuropsychology services during the COVID-19 pandemic. Journal of the International Neuropsychological Society, 28(2), 210–215. https://doi.org/10.1017/s1355617721000436
Petrill, S. A., Rempell, J., Oliver, B., & Plomin, R. (2002). Testing cognitive abilities by telephone in a sample of 6-to 8-year-olds. Intelligence, 30(4), 353–360. https://doi.org/10.1016/S0160-2896(02)00087-9
Pritchard, A. E., Sweeney, K., Salorio, C. F., & Jacobson, L. A. (2020). Pediatric neuropsychological evaluation via telehealth: Novel models of care. The Clinical Neuropsychologist, 34(7–8), 1367–1379. https://doi.org/10.1080/13854046.2020.1806359
Ragbeer, S. N., Augustine, E. F., Mink, J. W., Thatcher, A. R., Vierhile, A. E., & Adams, H. R. (2016). Remote assessment of cognitive function in juvenile neuronal ceroid lipofuscinosis (Batten disease). Journal of Child Neurology, 31(4), 481–487. https://doi.org/10.1177/0883073815600863
Ransom, D. M., Butt, S. M., DiVirgilio, E. K., Cederberg, C. D., Srnka, K. D., Hess, C. T., Sy, M. C., & Katzenstein, J. M. (2020). Pediatric teleneuropsychology: Feasibility and recommendations. Archives of Clinical Neuropsychology, 35(8), 1204–1214. https://doi.org/10.1093/arclin/acaa103
Reese, R. M., Jamison, R., Wendland, M., Fleming, K., Braun, M. J., Schuttler, J. O., & Turek, J. (2013). Evaluating interactive videoconferencing for assessing symptoms of Autism. Telemedicine and E-Health, 19(9), 671–677. https://doi.org/10.1089/tmj.2012.0312
Salinas, C. M., Bordes Edgar, V., Berrios Siervo, G., & Bender, H. A. (2020). Transforming pediatric neuropsychology through video-based teleneuropsychology: An innovative private practice model pre-COVID-19. Archives of Clinical Neuropsychology, 35(8), 1189–1195. https://doi.org/10.1093/arclin/acaa101
Scott, T. M., Marton, K. M., & Madore, M. R. (2022). A detailed analysis of ethical considerations for three specific models of teleneuropsychology during and beyond the COVID-19 pandemic. The Clinical Neuropsychologist, 36(1), 24–44. https://doi.org/10.1080/13854046.2021.1889678
Semel, E., Wiig, E. H., & Secord, W. A. (2006). CELF 4. Clinical Evaluation of Language Fundamentals Fourth (UK). Pearson Assessment.
Stiers, W. M., & Kewman, D. G. (1997). Psychology and medical rehabilitation: Moving toward a consumer-driven health care system. Journal of Clinical Psychology in Medical Settings, 4(2), 167–179. https://doi.org/10.1023/A:1026252624965
Sutherland, R., Trembath, D., Hodge, A., Drevensek, S., Lee, S., Silove, N., & Roberts, J. (2017). Telehealth language assessments using consumer grade equipment in rural and urban settings: Feasible, reliable and well tolerated. Journal of Telemedicine and Telecare, 23(1), 106–115. https://doi.org/10.1177/1357633x15623921
Sutherland, R., Trembath, D., Hodge, M. A., Rose, V., & Roberts, J. (2019). Telehealth and autism: Are telehealth language assessments reliable and feasible for children with autism? International Journal of Language & Communication Disorders, 54(2), 281–291. https://doi.org/10.1111/1460-6984.12440
Tailby, C., Collins, A. J., Vaughan, D. N., Abbott, D. F., O’Shea, M., Helmstaedter, C., & Jackson, G. D. (2020). Teleneuropsychology in the time of COVID-19: The experience of The Australian Epilepsy Project. Seizure, 83, 89–97. https://doi.org/10.1016/j.seizure.2020.10.005
Taylor, O. D., Armfield, N. R., Dodrill, P., & Smith, A. C. (2014). A review of the efficacy and effectiveness of using telehealth for paediatric speech and language assessment. Journal of Telemedicine and Telecare, 20(7), 405–412. https://doi.org/10.1177/1357633x14552388
Wacker, D. P., Lee, J. F., Dalmau, Y. C. P., Kopelman, T. G., Lindgren, S. D., Kuhle, J., Pelzel, K. E., & Waldron, D. B. (2013). Conducting functional analyses of problem behavior via telehealth. Journal of Applied Behavior Analysis, 46(1), 31–46. https://doi.org/10.1002/jaba.29
Waite, M. C., Cahill, L. M., Theodoros, D. G., Busuttin, S., & Russell, T. G. (2006). A pilot study of online assessment of childhood speech disorders. Journal of Telemedicine and Telecare, 12(SUPPL. 3), 92–94. https://doi.org/10.1258/135763306779380048
Waite, M. C., Theodoros, D. G., Russell, T. G., & Cahill, L. M. (2010a). Assessment of children’s literacy via an Internet-based telehealth system. Telemedicine Journal and E-Health : The Official Journal of the American Telemedicine Association, 16(5), 564–575. https://doi.org/10.1089/tmj.2009.0161
Waite, M. C., Theodoros, D. G., Russell, T. G., & Cahill, L. M. (2010b). Internet-based telehealth assessment of language using the CELF–4. Language, Speech, and Hearing Services in Schools. https://doi.org/10.1044/0161-1461(2009/08-0131)
Waite, M. C., Theodoros, D. G., Russell, T. G., & Cahill, L. M. (2012). Assessing children’s speech intelligibility and oral structures, and functions via an internet-based telehealth system. Journal of Telemedicine and Telecare, 18(4), 198–203. https://doi.org/10.1258/jtt.2012.111116
Wechsler, D. (2014). Wechsler intelligence scale for children–Fifth Edition (WISC-V). Bloomington, MN: Pearson.
Worhach, J., Boduch, M., Zhang, B., & Maski, K. (2021). Remote assessment of pediatric patients with daytime sleepiness and healthy controls: A pilot study of feasibility and reliability. Child Neurology Open, 8, 2329048X211048064. https://doi.org/10.1177/2329048X211048064
Wright, A. J. (2016). Equivalence of remote, online administration and traditional, face-to-face administration of the Woodcock-Johnson IV cognitive and achievement tests (Online white paper). Presence Learning. https://nyuscholars.nyu.edu/en/publications/equivalence-of-remote-online-administration-and-traditional-face--3
Wright, A. J. (2018). Equivalence of remote, online administration and traditional, face-to-face administration of the Reynolds intellectual assessment scales-second edition (Online white paper). Presence Learning. https://nyuscholars.nyu.edu/en/publications/equivalence-of-remote-online-administration-and-traditional-face--2
Wright, A. J. (2020). Equivalence of remote, digital administration and traditional, in-person administration of the wechsler intelligence scale for children, fifth edition (WISC-V). Psychological Assessment, 32(9), 809–817. https://doi.org/10.1037/pas0000939
Zane, K. L., Thaler, N. S., Reilly, S. E., Mahoney, J. J., III., & Scarisbrick, D. M. (2021). Neuropsychologists’ practice adjustments: The impact of COVID-19. The Clinical Neuropsychologist, 35(3), 490–517. https://doi.org/10.1080/13854046.2020.1863473
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Walker, E.J., Kirkham, F.J., Stotesbury, H. et al. Tele-neuropsychological Assessment of Children and Young People: A Systematic Review. J Pediatr Neuropsychol 9, 113–126 (2023). https://doi.org/10.1007/s40817-023-00144-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40817-023-00144-6