
Abstract
Information overload is a common phenomenon in the advertising dynamics of the twenty-first century, this not only causes inefficiencies in terms of advertising spending, but also, its management affects firms’ potential market power. This article builds a model in which firms compete by sending informative ads to passive consumers with reduced attention. Ads are sent through different transmission technologies, distinguished by their levels of information on consumer preferences. In equilibrium, sender strategies from firms with better-informed transmission technologies dominate sender strategies from firms with worse-informed transmission technologies, generating latent market power as a result of higher efficiency in ad location. This contribution is contrary to pro-competitive effects stated by current literature on strictly informative advertising. For context and simplicity, an iterative simulation of the model in equilibrium is carried out for the case of two transmission technologies, with the best-informed transmission technology belonging to an intermediary monopolist: the segmentation agent. The simulation yields consistent evidence of market power and industrial concentration in favor of firms that resort to intermediation by the segmentation agent. Our findings can be applied to suggest state intervention policies towards segmentation monopolists/oligopolists in information markets, to promote competition and diminish information overload.

Similar content being viewed by others

Data availability
Code and extended simulation outputs are available for request.
Notes
Unidirectional communication means that communication is carried out only from firms (senders) to consumers (receivers), discarding actions such as responses from consumers, information disclosure between firms, or information search processes by receivers. Studies on these actions are related in the literature review section.
In this paper, passive consumers are modeled as a large population represented by a random matching structure, which reflects consumers’ preferences through the evaluation of a probability measure with firms’ offers as its support.
The only possible difference among firms is the transmission technology they use.
Henceforth, the reader may find useful to identify a transmission technology with its probability measure, or Dirichlet distribution form, as will be shown later.
As the reader should suspect, this arrangement is done through a \(kxn\) symmetric matrix, this process is outlined in Appendix 2.
As an example, \(\rho =2\) implies values within \(I\left({T}_{i}\right)\) have probability greater than 75%.
Notice that this analogy is perfectly congruent with real-world examples: as segmentation devices possess richer information on consumer profiles, it is easier for firms to place online ads according to their knowledge about their preferences, augmenting certainty on sales.
A more statistical interpretation is to consider each \({\alpha }_{w}^{k}\) as the result of some parameter estimation process (as a product of a consumer information gathering actions by a transmission technology), and assuming that the estimated parameters are unbiased. As shown by Gelman et. al. (1995, p. 108), this is a plausible assumption for Bayesian models in large samples, in which the Dirichlet distribution is used. Also, this model is conceived for large populations.
For an exploration of First-Order Stochastic Dominance and its uses, see Post (2003).
A non-perceived waste of resources occurs in the sense that, despite being cost-efficient by applying the equilibrium sender strategy for the worse-informed transmission technology, its higher variability, or larger \(I({T}_{i})\), leads firms to send ads to consumer types that are actually less likely, and for which costs may more certainly not be recovered.
See Levin (2006, pág. 17).
Clearly, \({\alpha }_{1}^{k}>\dots >{\alpha }_{\omega }^{k}\) is a component-wise inequality.
Notice that Assumption 1 determines a restriction for the existence of an opportunity cost on transmitting ads towards firms’ equilibrium strategies, but this restriction is given to each firm only with respect to its own surplus coefficient \({S}_{j}\). Consideration of transmission technologies other than the one assigned to the firm is not allowed, as stated in the initial conditions of the game.
A detailed description for the construction of the segmentation agent’s optimal price is deployed in Appendix 2.
This proportion is supported empirically, as shown by Gijsenberg & Nijs (2019). See the parameter calibration section in Appendix 3.
The number of employed types in the simulation will depend on its convenience for calculations.
This is due to the directly proportional relation between the parameter vector and the gamma function. Thus, a reduction of the parameters of both distributions, under the same constant r, provides divergence values for which their mutual inequality occurs in the same direction as for the divergence values with the original parameters, maintaining (22). This also applies to any transformation that does not alter (22).
Referring to Popper’s (1959) falsifiability criteria.
References
Akerlof, G. (1970). The market for “lemons”: Quality uncertainty and the market mechanism. The Quarterly Journal of Economics. https://doi.org/10.2307/1879431
Anderson, S., & De Palma, A. (2009). Information congestion. The RAND Journal of Economics, 40(4), 688–709. https://doi.org/10.1111/j.1756-2171.2009.00085.x
Anderson, S., & De Palma, A. (2012). Competition for attention in the information (overload) age. The RAND Journal of Economics, 43(1), 1–25. https://doi.org/10.1111/j.1756-2171.2011.00155.x
Anderson, S., & Renault, R. (2009). Comparative advertising: Disclosing horizontal match information. The RAND Journal of Economics, 40(3), 558–581. https://doi.org/10.1111/j.1756-2171.2009.00077.x
Bagwell, K. (2007). The economic anaylisis of advertising. Discussion paper series, Department of Economics, Columbia University (pp. 1–178). https://doi.org/10.7916/D8QZ2P6X
Bahri, J., & Elías, M. (2017). El rol de la estadística en los estudios de simulación: Una aproximación al estado del arte. Ingeniería y Sociedad, Universidad De Carabobo, 12(2), 142–149.
Baye, M., & Morgan, J. (2001). Information gatekeepers on the Internet and the competitiveness of homogenoeus product markets. The American Economic Review, 91(3), 454–474. https://doi.org/10.1257/aer.91.3.454
Becker, G., & Murphy, K. (1993). A simple theory of advertising as good or bad. The Quarterly Journal of Economics, 108(4), 941–964. https://doi.org/10.2307/2118455
Bostoen, F. (2018). Neutrality, fairness or freedom? Principles for platform regulation. Internet Policy Review. https://doi.org/10.1476/2018.1.785
Chae, I., Bruno, H. A., & Feinberg, F. M. (2019). Wearout or weariness? Measuring potential negative consequences of online ad volume and placement on website visits. Journal of Marketing Research, 56(1), 57–75. https://doi.org/10.1177/0022243718820587
Esteban, L., Gil, A., & Hernández, J. (2001). Advertising and optimal targeting in a monopoly. The Journal of Industrial Economics., 49(2), 161–180.
Galbraith, J. K. (1967). The new industrial state. Houghton-Mifflin Co.
Gelman, A., et al. (1995). Bayesian data analysis. Chapman and Hall. https://doi.org/10.1201/b16018
Gijsenberg, M., & Nijs, V. (2019). Advertising spending patterns and competitor impact. International Journal Od Research in Marketing. https://doi.org/10.1016/j.ijresmar.2018.11.004
Gordon, B., Jerath, K., Katona, Z., Narayanan, S., Shin, J., & Wilbur, K. (2020). Inefficiencies in digital advertising markets. Journal of Marketing. https://doi.org/10.1177/0022242920913236
Grossman, G., & Shapiro, C. (1984). Informative advertising with differentiated products. Review of Economic Studies, 51(1), 63–81. https://doi.org/10.2307/2297705
Hardin, G. (2009). The tragedy of the commons. Journal of Natural Resources Policy Research, 1(3), 243–253. https://doi.org/10.1080/19390450903037302
Hefti, A. (2018). Limited attention, competition and welfare. Journal of Economic Theory, 178, 318–359. https://doi.org/10.1016/j.jet.2018.09.012
Hefti, A., & Liu, S. (2020). Targeted information and limited attention. RAND Journal of Economics, 51(2), 402–420. https://doi.org/10.1111/1756-2171.12319
Jin, S. (2022). Anti-monopoly regulation of digital platforms. Social Sciences in China, 43(1), 70–87. https://doi.org/10.1080/02529203.2022.2051357
Johnson, J. (2013). Targeted advertising and advertising avoidance. The RAND Journal of Economics, 44(1), 128–144. https://doi.org/10.1111/1756-2171.12014
Kaldor, N. (1950). The economic aspects of advertising. Review of Economic Studies, 18, 1–27. https://doi.org/10.2307/2296103
Lee, D., Hosangar, K., & Nair, H. S. (2018). Advertising content and consumer engagement on social media: evidence from Facebook. Management Science. https://doi.org/10.1287/mnsc.2017.2902
Levin, J. (2006). Choice under uncertainty. Stanford University.
Lin, J. (2016). On the Dirichlet distribution. Queen’s University.
Naylor, T., Finger, J. M., McKenney, J., Schrank, W., & Holt, C. (1967). Verification of computer simulation models. Management Science, 14(2), 92–106. https://doi.org/10.1287/mnsc.14.2.B92
Perri, T. (2019). Signaling and optimal sorting. Journal of Economics, 126(2), 135–151. https://doi.org/10.1007/s00712-018-0618-0
Popper, K. R. (1959). The logic of scientific discovery. Basic Books.
Post, T. (2003). Empirical tests for stochastic dominance efficiency. Journal of Finance., 58(5), 1905–1932. https://doi.org/10.1111/1540-6261.00592
Simbanegavi, W. (2009). Informative advertising: Competition or cooperation? The Journal of Industrial Economics, 51(1), 147–166. https://doi.org/10.1111/j.1467-6451.2009.00367.x
Simon, H. (1971). Designing organizations for an information-rich world. In M. Greenberg (Ed.), Computers, communication and the public interest. The Johns Hopkins Press.
Spence, M. (1973). Job market signaling. The Quarterly Journal of Economics. https://doi.org/10.2307/1882010
Stigler, G. (1961). The economics of information. Journal of Political Economy, 69, 213–225. https://doi.org/10.1086/258464
Tchebishev, P. (1867). Des valeurs moyennes. Journal de mathématiques pures et appliquées, 2(12), 177–184.
Van Zandt, T. (2004). Information overload in a network of targeted communication. The RAND Journal of Economics, 35(3), 542–560. https://doi.org/10.2307/1593707
Funding
The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No potential conflict of interest was reported by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendices
Appendix 1: Proofs for theoretical constructions
Proof of Proposition 1
Fix \(\rho\), then consider Tchebishev’s inequality for any probability measure \(\gamma\), for any type \({T}_{i}\):
Since \(\gamma\) is non-decreasing, this implies,
The highest probability consumer segments are those for which \({\bar{\bar{I}}}_{ij}\) is completely contained in \(I\left({T}_{i}\right)\). Since profits increase strictly on expected sales, and the latter increase strictly on \(\psi \left(.\right)\), define a strategy profile \(X\), such that:
And define a strategy profile \(Y\), such that:
Strategy profile \(Y\) can be given under two possible cases, in the first one, firm \(j\) neglects at least one \(T_{i}\) where \(\bar{\bar{I}}_{ij} \subseteq I\left( {T_{i} } \right)\), and, instead, selects a \(T_{i}\) where \(\bar{\bar{I}}_{ij} {\not \subseteq }I\left( {T_{i} } \right)\). Given (17) and considering profits increase strictly on expected sales \(\sigma_{j}\), it follows:
In the second case, firm \(j\) selects all \(T_{i}\)’s where \(\bar{\bar{I}}_{ij} \subseteq I\left( {T_{i} } \right)\), and, additionally, selects at least one \(T_{i}\) where \(\bar{\bar{I}}_{ij} {\not \subseteq }I\left( {T_{i} } \right)\), then, firm \(j\)’s expected sales are expressed as:
where \(V\) is a strategy profile such that \(V_{j} \equiv \left\{ {T_{i} \in T{ }|{ }\forall T_{i} { },{ }\bar{\bar{I}}_{ij} {\not \subseteq }I\left( {T_{i} } \right)} \right\}\), then:
Following the above expression, profits under profile \(Y\) are stated as:
Which leads to:
Consider that, since communication in this game implies a random process, transmission technologies charge their fees, prior to an uncertain result for firms, with respect to the expected value of \({T}_{i}\) as a central tendency measure of consumer type behavior, then:
Since \(E\left({T}_{i}\right)\in I({T}_{i})\) for any \({T}_{i}\), (17) implies:
\(\gamma \left(V\right)=\gamma \left(E\left({T}_{i}\in V\right)\right)>\psi \left({\bar{\bar{I}}}_{ij}\right)\) for any \({T}_{i}\in V\)
Then, under Assumption 1, the following holds:
Implying:
Hence,
\(\square\)
Proof of Lemma 1
Consider two Dirichlet distributions, such that,
Recall Assumption 2, then, concentration parameter values can be stated as:
Since concentration parameters depend on a total amount weighted by the fixed expected value of \({T}_{i}\), from (18) there is:
Now, take the expression for the variance of \({T}_{i}^{g}\) from (14):
Replacing with the obtained values for \({\beta }_{i}\), there is:
This leads to:
Applying the same process to \({T}_{i}^{u}\), it is obtained:
Then, from (19), the pursued inequality is quite straightforward:
\(\square\)
Proof of Lemma 2
The inequality in Lemma 1 implies the same for standard deviations: \(\delta ({T}_{i}^{g})<\delta ({T}_{i}^{u})\). This affects Tchebishev’s intervals for each distribution in the following way.
Let the difference between \(\rho \delta ({T}_{i}^{u})\) and \(\rho \delta ({T}_{i}^{g})\) be defined as:
With \(b>0\) a constant. Then, consider Tchebishev’s inequality for g:
Since all values on the support of \({T}_{i}\) within the interval of size b do not belong to \({I}^{g}\), the following inequality is deducted:
In terms of cumulative distribution functions, the latter is equivalent to:
With strict inequality at:
This is equivalent to the definition of First-order Stochastic Dominance.
\(\square\)
Proof of Proposition 2
This proof follows easily by applying induction on \({\alpha }_{1}^{k}>\dots >{\alpha }_{\omega }^{k}\) using Lemma 2.
\(\square\)
Appendix 2: Technical specifications
1.1 Dirichlet distribution’s compliance with the model and symmetric partition matrix
As a multivariate probability distribution, the joint integral of the Dirichlet’s density function equals 1, so compliance with \(\gamma \left(T\right)=1\) is achieved. The last requirement for the admission of its use in this model, is the definition of types \({T}_{i}\subseteq \left[\mathrm{0,1}\right]\) where \({T}_{i}\equiv \langle {\bar{\bar{I}}}_{i1}, {\bar{\bar{I}}}_{i2}, \dots , {\bar{\bar{I}}}_{in}\rangle\) and the set of all types is expressed as \(T\subseteq {[\mathrm{0,1}]}^{k}\). This is possible defining a partition for the support of a measure of each component \({T}_{i}\), such partition can be obtained using \(T\)’s marginal distribution under Dirichlet: Beta distribution with parameters \(({\alpha }_{i}, {\alpha }_{0}-{\alpha }_{i})\).
The expected value and variance of the Beta distribution equal the expression of these measures for each component of the Dirichlet, (13) and (14). For a proof of Beta distribution as the marginal distribution of the components of a Dirichlet distributed random vector, see Lin (2016, p. 12).
Thus, compliance for condition \({t}_{ij}\in {[\mathrm{0,1}]}^{n}\) can be achieved by operating the following matrix, which contains the assigned partition limit values for every firm within each consumer type:
For \(i=1, \dots , k\) and \(j=1, \dots , n\). With the purpose of establishing a partition on the support of \(\gamma \left({T}_{i}\right)\), these values most be re arranged from lowest to highest, yielding intervals corresponding to each firm within the support of the marginal distribution as a measure. To guarantee an initial state of perfect competition, the arrangement is done by permuting symmetrically the assignation of firms’ ordered values, providing each firm with a segment in distinct positions across the \([\mathrm{0,1}]\) whole population, such that all of the \(n\) firms possess the same number of segments within the smallest \(I\left({T}_{i}\right)\)’s. In this way, all firms will have the same overall possibilities of achieving sales.
Let \({t}_{ij}\left(1\right)<{t}_{ij}\left(2\right)<\dots <{t}_{ij}(\Theta )\) for\(h=1, \dots ,\Theta\), and, considering a fixed type, it is obtained the final matrix of symmetric partitions for each domain of measures\(\gamma \left({T}_{i}\right)\):
Thus, the matrix of partitions on the support of \(\gamma \left({T}_{i}\right)\) is derived from the determination of values in \([\mathrm{0,1}]\) assigned to each firm, within the domain of the marginal distribution of each component of random vector \(T\).
It is important to mention that the degree of generality of this method increases with the amount of fixed consumer types, in this way, firm partition values are known for each type with increasing certainty, that is, as more types are defined, each firm takes more certain values from [0,1], expanding its information to fix sending strategies.Footnote 17
By these means, the behavior of population regarding its preferences becomes traceable under the parameters of Dirichlet distributions, and the determination of optimal sending strategies is given according to the information they provide.
1.2 Example of equilibrium solution for a firm under the Dirichlet Distribution
Consider the following example. There exist \(k=5\) consumer types in the market, the transmission technology for firm \(j\) follows a symmetrical Dirichlet distribution, such that all parameters \({\alpha }_{i}=50\), consequently, the parameter sum \({\alpha }_{0}=250\), and fixed \(\rho =2\). Then, with an average behavior of each consumer type as approximately 20% of the population, and consumer segments for firm \(j\), the following table deploys its optimal sender strategy under the equilibrium imposed by Proposition 1.
\(E({T}_{i})\) | \(Var({T}_{i})\) | \(\delta ({T}_{i})\) | \(\mathrm{min}\left(I\left({T}_{i}\right)\right)\) | \(\mathrm{max}\left(I\left({T}_{i}\right)\right)\) | \({t}_{i(j-1)}\) | \({t}_{ij}\) | Optimal strategy | |
|---|---|---|---|---|---|---|---|---|
\({T}_{1}\) | 0.2 | 0.00063745 | 0.0252 | 0.1495 | 0.2505 | 0.14 | 0.16 | Not send |
\({T}_{2}\) | 0.2 0.2 | 0.00063745 | 0.0252 | 0.1495 | 0.2505 | 0.20 | 0.22 | Send ad |
\({T}_{3}\) | 0.00063745 | 0.0252 | 0.1495 | 0.2505 | 0.10 | 0.12 | Not send | |
\({T}_{4}\) | 0.2 | 0.00063745 | 0.0252 | 0.1495 | 0.2505 | 0.15 | 0.17 | Send ad |
\({T}_{5}\) | 0.2 | 0.00063745 | 0.0252 | 0.1495 | 0.2505 | 0.24 | 0.26 | Not send |
Limit values for consumer types \({\bar{\bar{I}}}_{ij}\) are set deliberately in order to outline different cases for decision making under the equilibrium selection rule. Computation of values is provided by the expressions for the Tchebishev interval in (11), and Dirichlet’s expected value and variance in (13) and (14), respectively.
1.3 Kullback–Liebler divergence as a measure of the information quality of transmission technologies
Divergence measures the distance between two distributions \(f\) and \(g\). If there exists a random variable X with the true distribution \(f\), then divergence is a measure of the inefficiency when assuming the distribution of X is \(g\) (Lin, 2016).
Noted as \(D\left(f\left({y}^{k}\right) \right|g({y}^{k}))\), Kullback-Liebler divergence between two Dirichlet distributions is expressed as:
where \(f\left({y}^{k}\right)\sim Dir({\alpha }_{1}, \dots , {\alpha }_{k})\), \(g\left({y}^{k}\right)\sim Dir({\beta }_{1}, \dots , {\beta }_{k})\), and \(\xi \left(.\right)=\frac{d}{dx}\mathrm{ln}\left(\Gamma \left(.\right)\right)\) Is the digamma function. It is important to highlight that \(D\left(f\left({y}^{k}\right) \right|g({y}^{k}))\ge 0\), Kullback-Liebler divergence equals zero only when the two compared distributions are identical, and approaches infinity as the difference between both parametric vectors increases.
The introduction of this concept for the simulation proceeds as follows. Suppose that for the random vector of Dirichlet distributed consumer types \({T}_{i}\), there is a true distribution \(f=\gamma \left({\alpha }^{k}\right)\), which reflects the real behavior of consumers’ population preferences with respect to the participating firms. Furthermore, suppose that public information for all firms about population’s preferences is given through a transmission technology that operates under another distribution \(u=\gamma \left({\phi }^{k}\right)\). Finally, suppose a transmission technology operated by a segmentation agent is given under a third distribution \(g=\gamma \left({\beta }^{k}\right)\).
The efforts of the segmentation agent to develop a transmission technology, based on constructing data bases with more accurate information on consumers’ preferences, with a view to exploiting this resource in a sense of intermediation towards firms, are then quantified in the following inequality:
As described in Sect. 4, (22) implies an inequality regarding the transmission costs of both technologies, transmission cost will be the price charged by the segmentation agent for the use of its transmission technology. Let \({c}_{pub}\) be the transmission cost under the public information technology and let \({c}_{as}\) be the transmission cost, or price of the segmentation monopoly services, both subject to Assumption 1. Then, there must be:
Thus, the simulation conceives two transmission technologies, the one based on public information, with low cost, and the one based on more precise private information, due to the least divergence compared to the real distribution of consumer types, and which price is subject to a monopoly pricing rule contrived by the segmentation agent. Optimal sender strategies are obtained on the basis of both approximations \(g\) and \(u\) under Proposition 1; however, random samples follow the true distribution of types \(f\).
1.4 Technical specifications and arrangements of KL Divergence for simulation
In order to fulfill computational requirements for the calculations of the resulting model, an adjustment is necessary. Due to the non-symmetrical nature of the Kullback–Liebler divergence and the possibility that its equation’s output takes too high and non-computable values, particularly from the usage of the gamma function, it is necessary to apply a reduction constant to this expression, this constant will multiply the parametric values of the implied distributions to obtain a comfortable value, generating a measure that here will be called reduced divergence:
where r is the reduction constant that multiplies the parameters of the distributions to be considered (\(0<r<1\)). This constant reduces the original divergence value, nevertheless, reduced divergence values maintain the inequality in (22).Footnote 18
1.5 The role of the segmentation agent and efficiency in ad location for its firms
Transmission cost for firms, given the segmentation agent’s transmission technology, is the key variable for the operation of the segmentation agent in the market as a network of targeted communication, since it is the price to be set for its more accurate information about consumers’ preferences.
In the simulation, the mechanism to contrast the hypothesis of emergence of industrial concentration, will start from the ability of the segmentation agent’s transmission technology to locate more efficiently the messages of its subscribing firms, matching its predictions to consumers’ preferences with a higher frequency than firms under public technology, as stated by Proposition 2. This is because the distribution it uses is closer to the true distribution \(f\), implying less KL divergence than for the case of the public transmission technology. In this sense, a monopoly optimization rule for the segmentation agent must be contrived.
An optimization process subject to the properties of KL divergence of Dirichlet distributions can be obtained by several approaches, this exceeds the purposes of this article. Hence, for simplicity and intuitiveness, the following assumptions are taken to contrive an optimal monopoly price for the segmentation agent, which is congruent with its expected relation to subscribing firms, and comfortable numerical conditions for simulation:
-
(a)
Firms are split into two groups before the market simulation: those that access the segmentation monopoly—group A—and those that opt for public transmission technology—group B—. It can be stated that the set of firms that access the segmentation agent show less elasticity with respect to their advertising expenditure, which is why they access the private transmission technology in each time period as long as they can finance it. (b) The transmission cost of the segmentation agent will be fixed per period, as a function of a single value for the divergence of g, this assumption protects the model against problems corresponding to KL divergence as a non-symmetrical measure, however, it allows to take the properties of its limits to construct a consistent cost function (zero and infinity). (c) The segmentation agent contrives its price based on a previously fixed benefit–cost ratio, as follows:
$$MG=\frac{{\pi }_{as}}{CT}$$(24)
where \({\pi }_{as}\) is the expression for the segmentation agent’s benefits, and \(CT\) its total operation costs.
In order to construct an objective function that yields an optimal price for the segmentation agent’s transmission technology, an expression must be given for the gross revenue of the segmentation agent:
where \(n*\) is the latest firm to opt for the segmentation agent’s platform services. 1 is added to the sum of the population measure of strategies of each firm that accesses the segmentation agent, this can be interpreted as the autonomous value of this expression, it is used as a control variable when developing the cost expression for the segmentation agent, due to the volatility of this element at the optimal value.
As stated in (22), the development of a more accurate information transmission technology implies, in terms of this model, the minimization of the divergence of \(g({y}^{k})\) with respect to \(f({y}^{k})\). In this sense, as a consequence of (22), the divergence is inversely related to the cost of the private transmission technology. Under this premise, its cost function and the consequent net profit are derived:
Providing a functional form according to (23), there is:
where \(a\) is a scale constant. The following expression is obtained for the segmentation agent’s net profit:
The orientation of the segmentation agent will be based on providing its services for an optimal price, \({c}_{as}\), obtained from:
Hence, with the above assumptions taken for simplicity, and benefit–cost ratio, (24), used as a central optimization criterion for the segmentation agent, the optimization problem is reduced to a linear relation between the optimal monopoly price and a fixed expected return of investment for the private transmission technology:
Given the previous elaboration, the segmentation agent’s optimal price is obtained as a function of the monopoly benefit–cost ratio:
where \(n*\) is the last one of group A firms for a time period.
Appendix 3 Simulation specifications
1.1 Technical specifications of the simulation algorithm by stages
Stage 1: Sending prices and strategies
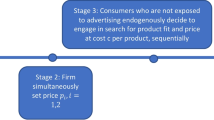
Initially, partition matrix \(P\left(M\right)\), (21), is defined, and its correspondence with each firm, coming from matrix \(M\) at (20). This is given in order to establish symmetry between firms, considering that the only difference between them must be the transmission technology they utilize.
Each firm has a segment for each type of consumer. Based on the positions of these segments and the transmission technology they select, their sending strategies will be contrived, that is, the consumer types they choose to send their ads to.
The model starts by randomly assigning a group for each firm at the first period: group A opts for the transmission technology with highest accuracy, the segmentation agent, group B opts for public transmission technology, with lower accuracy. This random selection occurs under a fixed proportion PropA.
Once groups A and B have been defined, both technologies determine their sending strategy rule for firms, according to Proposition 1. It is important to remind that, despite using the same optimal sender strategies, firms’ Tchebishev intervals are different for each group, since they operate according to the approximate distribution of different transmission technologies. Group A selects its receiver types according to an interval corresponding to \(g\) distribution, with a smaller distance with respect to \(f\), the true distribution, indicating more accurate the information from segmentation agent’s technology, whose price is set by (16).
On the other hand, group B selects its types according to an interval corresponding to \(u\) distribution, with greater distance to f and, therefore, less precision. The price of this technology must be a constant that complies with (23). Thus, the global strategy profile is constructed:
where \({X}^{{\prime}}\) is the subset of strategies based on public transmission technology, and \({X}^{\prime\prime}\) is the subset of strategies based on the segmentation agent’s technology.
Stage 2: Sent messages and attention filter
Since it has already been determined to which types firms send their messages, coming from both groups, the attention filter selection mechanism is deployed. In this step, and given the previous setting of an attention span \(m\), the software randomly selects \(m\) messages from all those received, this under the equal probability rule:
Stage 3: Selected messages
With \(m\) randomly selected messages from those received by each type, that is, they passed the attention filter for this period, the way to make their offers visible to consumer types is to locate their partition values, this prior to the next step: consumer preferences filter. Then, for \(m\) offers received, their \({t}_{ij}\left(h\right)\) are located in the domain of the marginal distribution (Beta) of each \({T}_{i}\). Thus, correspondent intervals \({\bar{\bar{I}}}_{ij}\) are delimited for the determination of a sale, and to which firm \(j\) it belongs.
Stage 4: Consumer preferences filter
Dirichlet distribution, depending on the parameters it takes, contains a set of random vector samples that evaluate the behavior of a population. Applying this concept to the model, it is stated that the behavior of consumer types, \({T}_{i}\) components of random vector \(T\sim Dir(\alpha )\), is traceable from a random sample \(T\sim Dir(\alpha )\) generated for each period.
In this sense, to determine the preferences of consumer types in a period, a sample is drawn from a random vector \(T\sim Dir(\alpha )\), it is important to highlight that these random draws are extracted under the “real” distribution of types \(f\left({y}^{k}\right)\), different than \(u\left({y}^{k}\right)\) and \(g\left({y}^{k}\right)\), which correspond to the approximations of public and private technologies, respectively, with which the strategy profile \(X\) is elaborated.
Stage 5: Sales per period
Given the extraction of a sample of \(T\sim Dir(\alpha )\) in the previous stage, a sale is defined from the approximation of each component of this sample to the partition values of the firms whose messages passed the attention filter and were revealed in Stage 3. Thus, a sale is made and attributed to the firm whose partition value is closest to the sample component, according to:
where \({T}_{i}^{*}\) is the value of the component associated with type \(i\) of the random vector sample, according to true distribution \(f\) for the current period. \({t}_{i(j-1)}\left(h\right)\) is the immediately preceding value to \({t}_{ij}\left(h\right)\) in the partition matrix, corresponding to a firm other than \(j\). This is done for each type, up to \(k\).
Stage 6: Defining income and profits per period
Given the sale made in each type \({T}_{i}\), according to (30) in the previous stage, income must be assigned to each firm for the current period. From inequality (30) and the execution of the sales criterion, it is possible to define an actual sales function per period for each firm.
Let the indicator function of successful types, for each firm, be:
The sum of this function will be the total sales for each firm in the current period, and it is possible to define the income function:
where \(p=1, \dots , P\) is the current time period, and \(k*\) is the last type selected by firm \(j\), according to its strategy. The expression for total communication costs per period is quite straightforward:
where \({c}^{*}\) is the price paid by firm j for a transmission technology corresponding to its group, if this group is A, it will be \({c}_{as}\), if it is B, it will be \({c}_{pub}\). \(\gamma ({X}_{j})\) will be the measure of the set of types to which firm \(j\) sends its ads, depending on the sending strategy corresponding to its transmission technology. Thus, it is possible to obtain a function for the profits of firm \(j\) in period \(p\):
Stage 7: Exit condition contrast
Since the model evaluates the capacity of firms to make a sale under the conditions of both filters and in competition for attention, the exit condition is defined from a limit number of periods under which benefits are negative. That is, a streak with not a single sale been made. Let \(PS\) be the limit number of periods with negative profits, then, the exit condition is:
This simulation will take one year of sales and 3 sales opportunities each day, so the number of periods to run for all scenarios will be \(P=1095\). It is considered that a firm leaves the market if it fails to obtain at least zero profits for a whole month, so, for each scenario \(PS=90\).
Stage 8: Market readjustment and loop restart
The abandonment of the market by a firm generates two kinds of effects, according to the group to which it belongs: (i) If the firm belongs to group A, the sum of measures of strategies managed the segmentation agent \(\sum_{j=1}^{n*}\gamma \left({X}_{j}\right)\) decreases, increasing the price charged by the monopolist due to its fixed benefit–cost ratio. (ii) If the firm belongs to group A or B, total messages received by each type will decrease for the next period, re-adjusting each firm’s chances of success: the probability of crossing the first filter of the model (attention) increases. An interesting annotation is that the exit of B firms will enhance the capabilities of A firms, since B firms send messages to more types due to the less accurate information of their transmission technology, generating congestion at the attention filter. Thus, at the end of each period, the sales loop is restarted with the remaining firms and a consequent market readjustment for stage 1.
1.2 Parameter calibration
Proposition 1, establishing optimal sender strategies for firms through a segmentation criterion, and Proposition 2, stating First-order Stochastic Dominance as the theoretical frame to prove the advantage for firms subscribing to a more accurate transmission technology, define the orientation of the constructed advertising information transmission game. These statements hold statically, hence, the purpose of the simulation is to extend their conclusions in dynamical terms, leading to the development of a contrast for the main hypothesis of industrial concentration.
Nevertheless, a dynamical approach to industrial concentration does not seem practical through standard indices such as Lerner index or Herfindahl–Hirschman index. Thus, the chosen mechanism to elaborate a contrast to the hypothesis of industrial concentration from ad location efficiency, in dynamical terms, is firm elimination through time, in this way, analyzing the number of surviving firms per group, as explained in Sect. 4, is the target of this exercise. To accomplish this purpose, the presented simulation was designed in order to accelerate firm elimination due to high information overload conditions, rather than emulating empirical conditions for the market.
First of all, the total number of periods \(P=1095\), and its approximate division into 12 ‘months’, each one of 90 periods, obey to the intention of generating a large sized sample, seeking stability for simulation results, while, at the same time, offer few sale opportunities to each firm. The latter makes each firm prone to elimination given the exit condition \(PS=90\).
The next parameter to discuss is the amount of consumer types, k. Since all types are parameterized through a symmetric partition, implying equal conditions for all firms, the two initial scenarios, with \(k=10\), assign one successful consumer segment for each firm \(\left({\bar{\bar{I}}}_{ij}\subseteq I({T}_{i})\right)\), this implies high difficulty to achieve a sale for each firm. Flexibilization for this condition is presented in the next 2 scenarios, with \(k=20\). Doubling the successful consumer segments for each firm improves firms’ performance in the simulated market, however, elimination remains as central criteria for this parameterization, as seen in the results. The latter explains the motives behind values for k in positive scenarios, these criteria also hold for the case of normative scenarios.
Attention span, m, as shown in the main conclusions, is the key variable for accelerated elimination in all scenarios, since it is the main driver of information overload. Consider that, being 100 firms, \(m=10\) and \(m=15\), imply consumer types process 10% and 15% of messages if they receive ads from all firms, this is a limit case for a market scenario with high propensity to information overload. Setting m under a low amount not only imposes accelerated elimination as the orientation of simulation scenarios, but also leads to a dynamical analysis of information (de)congestion, as shown in Sect. 4.
Finally, the asymmetry for PropA, the ratio of group A firms, being 30% in positive scenarios, responds to imposing disadvantages for group A firms as a minority. This is supported not only on the notion that less firms opt for more expensive transmission technologies, but also on empirical evidence by Gijsenberg and Nijs (2019) on their analysis of american advertising expenditure per types of media for consumer-packaged goods, showing a proportion of a third corresponding to digital segmentation platforms. Hence, accelarated elimination mechanisms from PropA are focused on group A, despite this, industrial concentration hypothesis holds in all positive scenarios, and is reinforced as scenarios with higher PropA appear.
All other parameters were chosen in order to impose firm symmetry, since the only difference between firms is their randomly assigned transmission technology, as seen in the theoretical setting of the model. Values for the parametric vectors of f, g, and u, shown in the table below, were fixed such that (22) holds, also applying Lemmas 1 and 2 (Table 3).
1.3 Validity tests
Statistical validity of simulations has critical importance for most investigations of this type, as stated by Bahri and Elías (2017). Thus, these authors suggest the Kolmogorov–Smirnov and Chi-2 tests as the most plausible methodologies for this exercise. This in so far as these methods offer a convergence test of the output data considering specific distributions. However, the model developed in this work lacks favorable conditions for carrying out such tests, due to the fact that, despite this simulation emulates real industrial dynamics, there is no robust information available to provide a series of data or an approximate distribution that serves as a contrast for carrying out this kind of tests.
Thus, while the absence of data for a statistical validity test may represent a problem regarding the value of the conclusions drawn here compared to the central hypothesis of the research, it is necessary to justify the validity of this study from its logical conditions. Naylor et al. (1967) show that, particularly for cases under which it is not possible to determine stable statistical verification criteria, either due to empirical or theoretical conditions, it is possible to appeal to falsifiability criteriaFootnote 19 in sequential experiments, determining gradual confirmation of the hypothesis as a function of the number of experiments with a positive result, compared to those with a negative result.
Given this notion of validity, the central hypothesis of this study was confirmed by the final results of the simulations in 7 out of 8 cases, and by convergence behavior across the simulations in all of them (appearance of informational decongestion through time). In addition to this, the variation in the input variables of the simulation of each scenario was introduced to maintain the contrast of the hypothesis despite the difficulty in the market conditions modeled for firms (propensity to information overload). Therefore, the Popperian perspective of validation fully applies to this exercise.
In addition, the model has its greatest strengths coming from two compelling reasons: First, the model’s conclusions are based on proven logical premises, stated in propositions 1 and 2. Second, conclusions are also based on the use of the Dirichlet distribution as the conjugate prior to the Categorical Distribution for arrangements on continuous intervals, emphasizing that initial conditions denote symmetry in all firms’ properties, except in the randomly assigned transmission technologies. Under this theoretical frame, results confirm the central industrial concentration hypothesis through time, despite the variation of the key parameters in each scenario, by showing the effects of the implicated First-order Stochastic Dominance in the simulated market.
1.4 Firm departure per period
Periods were grouped in intervals under an approximation to the months of a year of sales. It begins in period 90, since from this period the exit of firms is possible.
Scenario 1
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 17 | 41 |
180–269 | 6 | 12 |
270–359 | 1 | 6 |
360–449 | 3 | 5 |
450–539 | 3 | 0 |
540–629 | 0 | 2 |
630–719 | 0 | 1 |
720–809 | 0 | 0 |
810–899 | 0 | 1 |
900–989 | 0 | 0 |
990–1095 | 0 | 0 |
Total | 30 | 68 |
Scenario 2
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 4 | 21 |
180–269 | 5 | 4 |
270–359 | 2 | 1 |
360–449 | 1 | 5 |
450–539 | 2 | 4 |
540–629 | 3 | 1 |
630–719 | 0 | 1 |
720–809 | 1 | 0 |
810–899 | 1 | 0 |
900–989 | 0 | 0 |
990–1095 | 0 | 2 |
Total | 19 | 39 |
Scenario 3
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 11 | 18 |
180–269 | 3 | 11 |
270–359 | 1 | 2 |
360–449 | 0 | 6 |
450–539 | 2 | 1 |
540–629 | 1 | 2 |
630–719 | 0 | 3 |
720–809 | 1 | 5 |
810–899 | 1 | 0 |
900–989 | 1 | 1 |
990–1095 | 0 | 0 |
Total | 21 | 49 |
Scenario 4
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 3 | 8 |
180–269 | 1 | 7 |
270–359 | 0 | 2 |
360–449 | 0 | 3 |
450–539 | 2 | 0 |
540–629 | 0 | 1 |
630–719 | 0 | 1 |
720–809 | 3 | 0 |
810–899 | 1 | 1 |
900–989 | 0 | 0 |
990–1095 | 0 | 0 |
Total | 10 | 23 |
Scenario 5
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 13 | 12 |
180–269 | 5 | 7 |
270–359 | 1 | 4 |
360–449 | 1 | 1 |
450–539 | 1 | 1 |
540–629 | 0 | 1 |
630–719 | 2 | 1 |
720–809 | 2 | 1 |
810–899 | 0 | 2 |
900–989 | 0 | 1 |
990–1095 | 0 | 0 |
Total | 25 | 31 |
Scenario 6
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 6 | 2 |
180–269 | 1 | 0 |
270–359 | 0 | 1 |
360–449 | 0 | 1 |
450–539 | 1 | 0 |
540–629 | 0 | 2 |
630–719 | 0 | 1 |
720–809 | 0 | 0 |
810–899 | 0 | 0 |
900–989 | 0 | 3 |
990–1095 | 0 | 1 |
Total | 8 | 11 |
Scenario 7
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 8 | 0 |
180–269 | 3 | 0 |
270–359 | 2 | 0 |
360–449 | 3 | 0 |
450–539 | 2 | 0 |
540–629 | 2 | 0 |
630–719 | 1 | 0 |
720–809 | 1 | 0 |
810–899 | 0 | 0 |
900–989 | 2 | 0 |
990–1095 | 6 | 0 |
Total | 30 | 0 |
Scenario 8
Periods | Outgoing firms (A) | Outgoing firms (B) |
|---|---|---|
90–179 | 1 | 0 |
180–269 | 0 | 0 |
270–359 | 0 | 0 |
360–449 | 0 | 0 |
450–539 | 0 | 0 |
540–629 | 0 | 0 |
630–719 | 0 | 0 |
720–809 | 0 | 0 |
810–899 | 0 | 0 |
900–989 | 1 | 0 |
990–1095 | 1 | 0 |
Total | 3 | 0 |
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Burbano-Gómez, J.A., Sinisterra-Rodríguez, M.M. Effects of informative advertising on the formation of market structures. J. Ind. Bus. Econ. 50, 445–486 (2023). https://doi.org/10.1007/s40812-022-00254-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40812-022-00254-w
Keywords
- Market power
- Informative advertising
- Information overload
- Networks of targeted communication
- Transmission technologies