
Abstract
In recent years, various computational models have been proposed in neuroscience, but only a few have been utilized in robot visual navigation through engineering approaches. Besides, these engineering methods lack environmental adaptability, especially in the aspect of visual place recognition in weak or uncontrollable light fluctuations. To address this issue and enhance the performance of visual template matching and map loop closure detection in challenging lighting environments, this paper proposed a bionic visual navigation model that combines two neural network architectures, the Pulse Coupled Neural Network (PCNN) and Continuous Attractor Neural Network (CANN). In our navigation model, the visual features of the environments are encoded as temporal information by the spiking model and input into the local view cells for visual template matching. Additionally, we utilize the pose cells network, which incorporates the similarity between current and previous templates, along with odometry data, to encode spatial information and store it as an experience map. To validate the effectiveness of the proposed model, we conducted evaluations on datasets collected within our library, campus, and an open-source office dataset. The experimental results reveal that our algorithm increases the F1-score of template matching by approximately 10.5\( \% \), 35.8\( \% \), 61.7\( \% \), and 1.9\( \% \) in each dataset, compared to the conventional RatSLAM method. Furthermore, our algorithm generates a more accurate map that closely correlates with the real-world trajectory without compromising on computation time. The results suggest that our bionic visual navigation model is reliable for both standard and extreme lighting conditions.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
There is a wide demand for robot SLAM and navigation in challenging lighting conditions including enclosed environments, such as mines and tunnels, as well as service-oriented scenarios like libraries, museums, hotels, and underground parking lots. Additionally, there is potential for nighttime autonomous driving applications as well. In the autonomous navigation of mobile robots, loop closure detection is a critical component for mobile robot navigation because it reduces accumulative error induced by the odometry and avoids building an ambiguous map of the unknown environment. Enhancing the robot’s adaptability to environmental factors, such as light fluctuation, has always been a challenging issue in loop closure detection. The light condition affects the robot’s ability to determine whether it has encountered a previously visited location, resulting in large errors in the robot’s localization and mapping. However, after one hundred million years of evolution, animals have developed the ability to proficiently execute diverse navigation tasks well in natural environments, regardless of fluctuations in lighting conditions. To develop more adaptable and robust robotic navigation systems in challenging lighting environments, it is essential to draw inspiration from visual processing methods and spatial expression calculations of animal navigation mechanisms.
Mammals extract elements from various signals related to the current state in the perceptual space, form spatial cognitive knowledge and experience, analyze the current and historical state, and finally locate themselves in the cognitive space to make decisions. The biological spatial expression mechanism was found in the mammalian brain’s hippocampus and Cornuammonis 3(CA3) areas. O’Keefe et al. [24] found that the place cells would fire when an animal got into a particular spatial position. Moser [22] and colleagues then discovered a group of spatial encoding cells in the hippocampus, CA3, and other brain regions, known as grid cells, head direction cells, speed cells, boundary cells, and so on. Scientists have gained a greater understanding of the spatial cognitive and navigation mechanisms in mammals through various proposed cognitive strategies in the hippocampus and the establishment of the hippocampal neural network [4]. Recent findings have demonstrated that the brain’s navigation systems present in mammals are not limited to internal tracking or integrating path information, also incorporating external cognitive information and episodic memory of the physical world as well [23]. Many spatial cognitive networks have been proposed based on neuroscience research about the mechanics of spatial navigation. CANN is a particular type of recurrent neural network with a unique network connection topology, which has been effectively used to encode some continuous spatial properties in the hippocampus [41]. Milford et al. [1, 21] proposed a visual simultaneous localization and mapping (SLAM) algorithm, called RatSLAM, based on the CANN and neural computation theory, that utilized weak vision information to construct a large-scale topological map. However, a simple vector was used in RatSLAM to represent features of a visual image, the closed-loop detection calculates the difference of feature vectors directly, which ultimately resulted in low robustness and limited adaptability to changes in the environment. Hence, several approaches have been proposed with the aim of enhancing the matching of visual templates. Glover et al. [11] combined Fast Appearance-Based Mapping (FAB-MAP) methods with the RatSLAM to reduce both false positives and false negatives for outdoor mapping, where the changing sun angle can have a significant impact on the appearance of a scene. Tian et al. [36] integrated RGB-D information into RatSLAM, overcoming the issue of fuzzy data generated by featureless surfaces, significantly improving the loop closure, and obtaining an optimized map. Zhou et al. [49] proposed extracting the ORiented Brief (ORB) features to represent the visual template, making an efficient and fast feature matching that would help in map correction. Kazmi et al. [16] utilized Gist features in their research to analyze the perceptual structure of scenes and accurately distinguish between visited and unvisited places, even when the visual inputs were noisy or blurred. While the performance of the template matching and loop closure detection through the above methods can be improved in many scenes, these algorithms still have weak stability under low or fluctuating lighting conditions. Since the preceding methods are not adaptable to the low-light environment, a more robust visual place recognition model is necessitated.
To overcome the challenges in visual navigation, it’s suggested that a visual model is capable of feature detection, description, and deducing information about the extremely weak light environment. The classical Retinex model and the Log-simplified Retinex model [18] were proposed by eliminating the image illuminance component and retaining the reflection component, resulting in images with good details in low-light conditions. However, traditional models were difficult to obtain stable lighting intensity, which led to unnatural image details. Wang et al. [38] presented a variational Bayesian method for Retinex to obtain more natural image details, which was suitable for images with uneven illumination but always generated noise. Guo et al. [12] utilized an enhancement method that recovered the illumination contrast by choosing the maximum intensity of each channel. However, this method resulted in enhanced images with undesirable noise. To address this problem, Nikola [2] presented a random sprays Retinex model which sought to improve speed while minimizing noise effect. Additionally, Ying et al. [45] introduced a nonlinear camera response model for enhancing image exposure. Wang et al. [40] explained the absorption light imaging process through an absorption light scattering model. Despite the impressive results demonstrated by model-based methods, their great computational complexity can be a drawback, may face certain constraints on their performance. With the rapid development of deep learning, learning-based methods were proposed to mitigate the influence of illumination. Gharbi et al. [10] incorporated bilateral grid processing into a neural network to achieve real-time image enhancement. Zhang et al. [48] developed an effective low-light image enhancer, named Kindling the Darkness, based on Retinex theory, which combined multi-exposure images. In another work, Ren et al. [29] proposed a deep hybrid network that simultaneously learned salient structures and global content for enhancing images. Ye et al. [44] proposed a neural network model with stable bottom feature extraction, lightweight feature extraction, and enhanced adaptive feature fusion. Shen et al. [31] proposed an enhanced YOLOv3-based method to enhance multi-scale road object detection by focusing on valuable regions. Moreover, light condition is also regarded as an external, non-parametric, variable, and characteristic uncertainty. Tutsoy et al. [37] developed a multi-dimensional parametric model with non-pharmacological policies to deal with these large, multi-dimensional, and uncertain data. Despite working well at enhancing images captured under weak illumination, these learning-based techniques need large-scale training datasets and ground truth. Building such training datasets requires a significant amount of time to provide supervised learning. It becomes more difficult to acquire many clear and normal task images, especially under extremely low lighting conditions.

This is a structural diagram of RatSLAM
Despite these methods mentioned above, which can improve the performance of visual scene recognition in low-light or light-changing environments, compared with the mechanism existing in the brain, the speed and accuracy of visual information processing cannot be well balanced. To address these issues, researchers sought to replicate a mammalian visual perception of the external environment, with a primary focus on the visual cortex, an essential component of the cerebral cortex. Eckhorn et al. [8, 37] proposed PCNN based on the synchronous pulse firing phenomenon observed in the primate visual cortex, wherein the visual images received from the eye are converted into a stream of pulses. The proposed PCNN model exhibits the ability to extract significant information from a complex background without discrepancy, rendering it independent from extensive training datasets, ground truth annotations, or excessive time consumption [9]. PCNN can handle geometric changes, tolerate signal distortion, and be insensitive to changes in signal intensity [35], making it effective in coping with noise effects such as light fluctuations. Besides, as a third-generation artificial neural network, where information is processed and communicated through spikes, the PCNN-based system has the potential to achieve a high speed of calculation in neuromorphic chips and finds application in various domains [14, 19]. Johnson et al. [39] applied the time matrix to image enhancement through an improved PCNN factor model based on the biological vision processing mechanism. Schoenauer et al. [15] designed a set of pulse-based integrated circuits to accelerate the PCNN algorithm and applied it to image target segmentation. The heterogeneous PCNN [13, 30] and the non-integer step model [7, 42] have been proposed in recent years, showcasing advancements in neural networks and computational modeling. Notwithstanding these encouraging developments in the bionic visual model, it is still unclear how PCNN integrates with the bionic spatial navigation model and how it achieves such good performance in visual navigation in low-light environments.
In order to address this issue and enable the application of bionic visual navigation models in real-world, GPS-deprived, and challenging lighting environments for robot navigation, it is essential to enhance the capabilities of visual template matching and loop closure detection, while maintaining a balance between speed and accuracy. This paper proposes a hybrid visual navigation model, taking a bionics-based approach, which combines the PCNN-based visual model with the CANN-based spatial model. The input visual information is encoded by spikes and temporal information is extracted as the global descriptor of the scene, the descriptor is stored in a template library. Utilizing template matching to obtain a similarity score, which is then used to correct the map’s loop closure by CANN’s pose calculation. The proposed PCNN-CANN model has been successfully implemented and demonstrated for navigation in low-light or uncontrollable light fluctuation environments. With the help of the PCNN visual model, the robustness of the template matching has increased. Additionally, the rapidity and accuracy of the map generation have been increased. This novel combination opens up new possibilities for enhancing visual navigation performance in complex lighting scenarios and presents a promising avenue for further research in this field.
The remaining content of this paper is organized as follows:
“Related work” section: We adopt RatSLAM as the foundation of the bio-inspired spatial cognition model and presented a brief overview of its structure.
“Bonic visual navigation model” section: We utilized a bionic navigation model with a modified visual perception model that combines PCNN with a CANN-based spatial cognition model. Then, the visual feature extracting, template matching algorithm, and map-generating process were described in detail.
“Experiments and analysis” section: We conducted experiments and analyzed the results after setting up the experiment.
“Conclusion” section: We concluded the main research findings and provided an outlook on future work.
Related work
RatSLAM is a bionic SLAM algorithm based on the brain’s spatial cognitive structure and neural computing process. The method is built from weak visual input data to create large and sophisticated cognitive maps [43]. The encoding of the place cells and grid cells in the hippocampus contributes to spatial representations of the external world in this model, and the encoding represents the position and orientation of the robot [20, 32]. An experience map manages the pose cells network, local view cells, and odometer throughout the navigation process.
As shown in Fig. 1, the RatSLAM algorithm’s fundamental structure is made up of local view cells, pose cells network, path integration, and experience map. The camera’s image is fed into the local view cells where it is stored as a template library for template matching. The matching information is then input into the pose cells network. The odometry data is processed through path integration and then fed into the pose cells network. The input visual and spatial data are processed and corrected by the Pose Cells Network, which then creates precise spatial position data as experience points and outputs the Experience Map. Each part of the method is described in detail below.
Local view cells are used to store global descriptors derived from external visual information of scenes. When the robot encounters a new scenario, a local view cell generates a new template. A view is deemed new if its difference from all previously created ones is greater than a similarity threshold. The comparing computation in the local view cells might match the visual templates to modify the activity of pose cells. Furthermore, each new template is associated with the centroid of the most active package in the pose cells network. Whenever a template such as a cell k gets activated, energy is injected into the pose cells network through an association link, where the overall functioning is updated. This module aids in the relocalization of robots in the environment.

This is a structural diagram of our bonic visual navigation model
Pose cells network is a type of three-dimensional cellular structure that incorporates both excitatory and inhibitory connections with weighted values. This network is implemented by a two-dimensional CANN, which represents the positional information in mobile robots along the X and Y axes. And the Z-axis implemented by one-dimensional CANN represents the robot’s head direction information. The activity of pose cells describes the robot’s possible states. And the maximum activity reflects the robot’s most probable position and orientation.
Path integration is also known as inertial navigation or dead reckoning, which is an essential process that enables robots to determine their spatial location by utilizing idiothetic cues resulting from self-motion by monitoring its trajectory concerning a start location. The process updates the state of the pose cells network by shifting activity based on the odometer’s linear speed and angular velocity, as well as the coordinates of each pose cell. Consequently, path integration produces representations of the robot’s trajectory and imitates mammal navigation standards through complex environments.
Experience map is a comprehensive topological map that combines data from the local view cells, pose cells network, and odometer to identify the robot’s pose on the ground. Essentially, it utilizes map nodes to provide information regarding the activity packet template at the time of generation. A link is formed between two pose cells that contain the distance and relative angle information. As the robot travels, the most active pose cell correlates to an experience of the pose state and subsequently stores environmental information as an experience map. When the activity pack and associated template are engaged concurrently, a loop closure process is triggered, which leads to a path correction procedure. This procedure involves modifying the relative pose of the experiences on the map to ensure its consistency and coherence.
Bonic visual navigation model
Model overview
Based on the research on pulse firing and synaptic transmission in the visual cortex, this section develops a navigation model with PCNN-based visual model for template matching and loop closure detection. As shown in Fig. 2, the image data collected by the camera is pre-processed to enable the evaluation of each sensory neuron corresponding to each pixel of the input image, and the stimulus corresponds to the change of the gray intensity of the image. The pixels that are activated synchronously have approximate grayscale values, while the pixels that are activated asynchronously have different values. Each neuron is not only connected to the corresponding pixel point but also coupled to its adjacent neuron through synaptic weight, and the output of each neuron has only two states, firing or not firing. The LI (Leaky Integrator) model establishes a mathematical model of neurons, which constitutes the neural network model of all sensory neurons and performs the spike encoding and the decoding with the time matrix [33]. Time matrix information is used to compare the similarity of the current template to all previously stored ones to achieve template matching. After template comparison, the CANN-based pose cells network is also used to encode the pose state to build the experience map by combining the template similarity and the path integration of odometry.

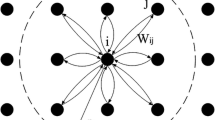
This is a basic structure of PCNN model
PCNN-based visual processing
The PCNN model, as shown in Fig. 3, is composed of three sequential parts and not requiring any training: the receptive field, the modulation field, and the pulse generator. The synapses of adjacent neurons kl in the receptive field generate an electrical impulse that activates neuron ij, mimicking the receiving mechanism of dendrites through synaptic connections represented by \(\textbf{W}\). After gathering electrical impulses, the inputs are segregated into two distinct channels: the feeding and linking inputs. The modulation circuity and pulse generator system are made up of four main constituents, namely the dendritic tree, membrane potential, dynamic threshold, and action potential. The individual neuron receives both feeding and linking inputs from several nearby neurons via the dendritic tree and transmits electrical charges to generate changes in the membrane potential, eventually reaching a dynamic threshold for action potential initiation. Once the dynamic threshold is surpassed, an action potential is triggered. In neuroscience, the Leaky Integrator (LI) model is commonly used to represent either a single neuron or a local population of neurons. Hence, the LI model can represent the fundamental components of PCNN. The dynamics potential v(t) of a single neuron is described by the LI model:
where a is the rate of the leaky, and c is the input. The LI model represents the dynamics of a neuron’s membrane potential, which gradually decays over time \(-a v(t)\) and is influenced by the input c. The dynamics potential can be rewritten in discrete form as:
where \(\beta \) is a positive constant, controlling the decay rate of the previous membrane potential. Each neuron in the PCNN integrates its inputs over time, taking into account the leakage factor to gradually decrease the influence of past inputs.
Membrane potential is the difference in electric potential between the interior and the exterior of a neuron, where the feeding input is feedforward and the linking input is feedback. In our research, it is assumed that the feeding input is independent of the previous feeding value since the pixel values of a static input image are fixed. Additionally, because the effect of a neuron’s output in a neighboring field is considered in the linking field, the feeding input can be simplified to avoid performing additional calculations. Hence, the external stimulus \(\textbf{S}\) is set equal to the feeding input and link it to the synaptic weight. This simplification reduces the time complexity of the PCNN. The membrane potential represented by the LI model can be simplified to a single equation:
where (i, j) denotes the index of the current neuron, and (k, l) refers to the index of the neighboring neuron, \(\textbf{f}\) represents the decay rate of the previous membrane potential, \(\varvec{Y}_{k l}\) is the output action potential of the neighboring neuron, \(\varvec{W}_{k l}\) denotes a linking synaptic weight, \(\varvec{S}_{i j}\) represents the external stimulus corresponding to the change in grayscale intensity at pixel (i, j). The action potential \(\varvec{Y}_{i j}\), also known as nerve impulses or spikes, occurs rapidly in the cell membrane when a neuron transmits information down an axon, given by:
where \(\varvec{H}_{i j}(n)\) represents the threshold of PCNN. The dynamic threshold is a modification of the threshold concept for an analog neuron, where the new threshold for the neuron is calculated as:
where the action potential \(\varvec{Y}_{i j}(n)\) is amplified by the threshold magnitude coefficient q (a larger value) to prevent the generation of a secondary action potential during a given period. The constant g(0 g 1) is a decay factor that controls the rate of threshold value decays. The constant \(\varepsilon \) is responsible for a bias or offset of the threshold. \(\textbf{T}\) is a time matrix that represents the time when the neuron first fired. The neuron (i, j) fires at the time \(\varvec{T}_{i j}\) when the membrane potential \(\varvec{U}_{i j}\) exceeds its threshold \(\varvec{H}_{i j}\). The threshold of the neuron and the membrane potential has a relationship that can be given by:
Therefore, the first firing time \(\varvec{T}_{i j}\) is obtained from (6), and it is defined as the analytical solution to the time matrix, given by:
The time for processing external input information is limited in each processing step of the mammalian visual system. Hence, a quick response to visual stimuli is required and the first firing by the nerve can be considered to contain almost all relevant information. Time-to-first-spike coding is used in our PCNN model to encode the visual input to the firing time of neurons.

Visual processing by PCNN
The brightness perceived by the human eyes has a logarithmic relationship with the objective brightness according to the visual characteristics of human eyes [26]. Therefore, the time matrix extracted by PCNN can describe the images by mapping from the spatial information to time information. In PCNN, there are two stopping conditions that determine when the network has reached a state where all neurons have fired and generated action potentials: the single-pass conditions and the multiple-pass conditions respectively. The single-pass stopping condition is used to acquire the time matrix, whereas the multiple-pass stopping condition is employed to obtain the firing rate [25]. Hence, the single-pass stopping condition has been used in our method to automate the network iterative process. Corresponding to Weber-Fechner’s law, the time matrix has an approximate logarithmic relation with the stimuli matrix [47]. Assuming that the membrane potential of a neuron is equivalent to the stimulus it receives, then the time matrix extracted by PCNN can be rewritten as:
The front-side visual algorithm can be achieved by Algorithm 1, where numfn represents the counting number of the fired neurons and N is the total number of neurons. The time matrix is calculated under the assumption that a high value of the threshold amplification factor q ensures that neurons fire only once. Notably, the firing order of neurons reflects the magnitude of their stimuli, with higher stimulus levels leading to earlier firing times. Therefore, an inverse operation is necessary to obtain the correct output sequence.
The algorithmic complexity is primarily determined by the operations inside the loop, and the complexity of these operations is correlated with the size of the input image and can be approximated as O(N). Overall, the algorithm offers an effective approach of identifying active neurons, based on their timing and stimulus inputs, boosting the visual feature in low-light conditions.
Template comparison
The time information of progressed images is input into the local view cells for visual template matching. We evaluate the similarity between the current template and all previously stored templates. The similarity score calculated by the Sum of Absolute Differences (SAD) algorithm, is given by:
where \( p_n \) is the global description of the current template normalized by time matrix \(\textbf{T}\), \( \mathbf {p_n^k} \) is the global description of a previous template k, n is the current number of learned templates, and w is the width of the template. Lower d(k) indicates higher similarity.
The previously learned visual template with the lowest difference score is the best matching, which is given by:
This equation finds the index b of the previously stored template with the lowest difference score. It identifies the best matching template.
A threshold \( \sigma _{t h} \) determines whether the new template is considered novel \((m=0)\) or familiar \((m=1),\) and the classification is given by:
In brief, A novel template is acquired and then stored in the template sets if the minimum difference in matching between a new template and the existing templates, measured by d(b), is greater than the threshold \( \sigma _{t h} \). Otherwise, the previous template is close enough to the current scene and considered as a match.

This is a experimental setup of each dataset: a the library; b the campus I; c the campus II; d the A* STAR lab. The images on the left column depict the light condition during the collection process, while the ones on the right column describe the approximate trajectory in which the numbers represent the sequence of the motion path
Map generation
After template matching, the local view cells construct a map through associative learning and inject their activities into the pose cells to correct loop closure. The updated link strength \(act^{i}_{x^{\prime } y^{\prime } z^{\prime }}\) is learned through one-shot learning, utilizing the correlation between the local view cells and the centroid of the dominant activity packet in the pose cells. Pose cell activity alterations can manifest themselves by:
where the constant \(\delta \) is included to figure out how visual cues affect the robot’s pose estimation. \(\varvec{L}_i\) is the local view cells activities. The dominant activity packet will occur at the same pose as when the scene was initially viewed. Following visual input and path integration, it is important to normalize the activity of the pose cells.
The constituent elements \(\varvec{E}^{i}_{x^{\prime } y^{\prime } z^{\prime }}\) of an experience level are determined by the present activity of pose cells. The experience \(e_i\) is associated with the location of the experience \(\varvec{E}^{i}_{x^{\prime } y^{\prime } z^{\prime }}\), local view cells activities \(\varvec{L}_i\), and pose cells activities \(\varvec{P}^{i}_{x^{\prime } y^{\prime } z^{\prime }}\), the ith experience can be described by:
In brief, the experience map will be generated as a topological map that combines input from the pose cells and the local view cells to estimate the robot’s pose.
Experiments and analysis
This section presents the detailed implementation of the proposed method and compares the performance with traditional RatSLAM. To evaluate the proposed PCNN-based template matching algorithm, the experiments are carried out on four datasets: three datasets are collected by a handheld camera, and the remaining one is an open-source dataset.

Raw odometry of each dataset is depicted: a the library; b the campus I; c the campus II; d the A* STAR lab
Experimental setup
Four datasets from indoor and outdoor environments with varying light conditions are used in experimental validation. The dataset (a) was obtained in the library, whereas the datasets (b) and (c) were acquired on campus with a DJI Osmo Pocket camera set to a field of view (FOV) of \(80{^\circ }\) and a resolution of 1920\( \times \)1080. The dataset (d) was collected by a mobile robot in A* STAR lab, Singapore. The details of the four scenarios are described as follows:
First scene: The place is in the library hall of Soochow University, as shown in Fig. 4a. With the ambient light intensity alternating, we move around in the shape of an ’8’ and finally back to the starting point. We still walked a short distance (about 10 m) along the original route after arriving at the end location.
Second scene: The scene is on the campus of Soochow University, as shown in Fig. 4b. We walked down the road where the lamp shimmered at night. The pathway was starting at the beginning of the circle several times before returning to the beginning. After coming back to the start point, we also traveled a little distance (less than 10 m) through the previous path to check the loop was closed.
Third scene: The light is dim and the scene is also located on the campus of Soochow University. We walked down the road from the start and back to the beginning and then walked on a short distance to the end.
Fourth scene: The location is in the A* STAR lab of Singapore, as shown in Fig. 4d. The dataset was obtained in a typical lab office with an unnaturally lit indoor environment. The robot traveled from the beginning to the end along the corridors of the office a few times until it reaches loop closures.
The odometer data differ greatly from the actual route in each dataset, as shown in Fig. 5. The number of frames in each dataset is approximately 1900, 8200, 1900, and 2100 respectively. The visual image input frequency is 10 frames per second (fps). All datasets lack GPS data because they are either indoors or shaded by huge trees and construction, but the path is relatively neat and traceable. All trials are carried out on a computer configured with Intel Xeon Gold 6134 3.2 GHz CPU and 128 GB RAM.
With reference to the experience of the literature [5], we can debug the parameters suitable for our task navigation in the low-light environment. The main parameters are listed: the constant \(g=0.9811\), \(q=2\)e10, the decay rate \(\textbf{f}=0.75e^{-\textbf{S}^{2}/0.16}+0.05\), the synaptic weight \(\textbf{W}=\left[ \begin{array}{ccc} 0.7 &{} 1 &{} 0.7\\ 1 &{} 0 &{} 1 \\ 0.7 &{} 1 &{} 0.7 \end{array} \right] \), and the threshold of similarity score \(\sigma _{t h}=0.07\). Due to the incorporation of template matching calculation and CANN’s map generation calculation, even when the parameters are adjusted within a narrow range surrounding the given parameters, the closed-loop map results obtained from our method remain consistently effective.

Results of local view cells activity and the experience maps over the duration of the library dataset: a and c are the results of using traditional RatSLAM; b and d are the results of our method

Results of local view cells activity and the experience maps over the duration of the campus I dataset: a and c are the results of using traditional RatSLAM; b and d are the results of using our method

Results of local view cells activity and the experience maps over the duration of the campus II dataset: a and c are the results of using traditional RatSLAM; b and d are the results of using our method

Results of local view cells activity and the experience maps over the duration of the A* STAR lab dataset: a and c are the results of using traditional RatSLAM; b and d are the results of using our method

TP, FP, and F1-score are used to evaluate traditional RatSLAM (blue) and our method (red) in four datasets. The x-axis is marked with the labels of the four scenes
Experimental results
In this section, the experimental results are presented in detail. We analyze the experimental results obtained from traditional RatSLAM and our optimized algorithm regarding local view cells and experience map generation respectively.
Local view cell activity is assessed first to identify loop closures affecting experience map generation because every cell contains a feature of the visual template. The current visual scenes are compared with all visual templates stored in local view cells. A visual template is considered a successful match if the similarity score is greater than the threshold. If not, a new visual template is built. The experience map is analyzed because the performance of template matching is relevant to the map’s quality. The focus of the discussion is on the topology and connectivity of the map, assessing the effects of the template matching on the changes of the map, rather than the map’s metric accuracy. All critical parameters are set to the same in the original and proposed algorithm. The results of the four scenarios are described as follows:
First scene: Fig. 6a, b depicts the active experiences and visual templates over the duration of the experiment. They show the continuous monotonically creation of new experiences and visual templates as the upper ’bounding line’ before reaching the closed-loop point. The short segments under the bounding line represent previously learned experiences and visual templates. As shown in the green dotted box, traditional RatSLAM has only one red short segment and our method has two. It means that the proposed method generates more matches than traditional RatSLAM, and it’s consistent with the actual situation. The blue line is higher than the red line, indicating that experiences are learned faster than templates, and the greater the slope, the faster. Hence, the rate of experience learning of our method is shown to be faster than that of traditional RatSLAM. Indeed, our method has showcased its capability to compactly represent the environment using fewer created visual templates compared to RatSLAM while achieving comparable or improved performance. This highlights the efficiency and effectiveness of our approach in representing complex environments with reduced memory requirements. Figure 6c, d show the evolution of the experience map for the college’s library dataset. As shown, using our method to achieve the loop closure for repeated traverses is more successful. The final cognition map generated by traditional RastSLAM fails to finish a closed-loop correction at the end. However, the map created by our method is almost the same as the real walk path, except for a bit of twist at the top of the map.
Second scene: As shown in Fig. 7 since there are more red short segments in (b) than in (a), the templates are matched several more times before back to square one, which will affect the generation of the experience map. As explained above, observing the slope between the blue line and the red line, the rate of experience learning of our method is shown to be faster than that of traditional RatSLAM According to (c) and (d), it seems that the experience map generated by our method is largely similar to the actual route, despite some failure matching on the two-way path.
Third scene: Referring to Fig. 8, it can be observed that in (b), there are more red short segments in the cyan dotted box compared to (a), resulting in several additional template matches before returning to the initial scene. As mentioned earlier, by examining the slope between the blue line and the red line, it is evident that our method exhibits a faster rate of experience learning compared to traditional RatSLAM. Based on (c) and (d), it appears that the experience map generated by our method closely resembles the actual route and has a more effective loop closure detection.
Fourth scene: As seen in Fig. 9, since (b) contains more red short segments than (a), the templates are matched more times before going back to the beginning. The rate of experience learning of our method is also shown to be faster than that of traditional RatSLAM. The experience map created by each algorithm is shown in (c) and (d), indicating that the accuracy of the experience map is improved by utilizing PCNN. Due to passing from two directions in the middle aisle, the two algorithms both have relatively mismatches, but the PCNN-based method has a more accurate map than the traditional method.
As a result, our method has more template matching points, a faster experience learning rate, and a more accurate map generation. Even though moving from two directions has less matching in the middle part, our method has more matching points on either side of the aisle, resulting in a high overlap ratio in the formed two-way path. Moreover, our method appears to impose lower memory demands compared to the front-end of RatSLAM, based on the observation of local view cells activity. Consequently, our method appears greater adaptability in challenging low-light environments, resulting in the generation of highly accurate maps that closely resemble the actual path.
Evaluation
The precision rate and the recall rate are commonly used to evaluate the quality and effectiveness of the algorithm [3]. The precision rate is based on prediction results. It is the ratio of the samples whose predictions are true positive in all positive instances:
In our approach, it can be used to assess how much of the current scenario matches the historical template correctly. The recall rate is based on original samples, and it indicates how many positive samples in all samples are predicted correctly:
Precision and Recall are commonly challenging to maintain high at the same time. The F1-score combines Precision and Recall, which is defined as the harmonic mean of Precision and Recall:
We calculate the Precision, Recall, and F1-score for four datasets using the above-mentioned evaluation criteria. The result of a comparison with assessment criteria of TP, FP, and F1-score between traditional RatSLAM and our method is provided in Fig. 10 and then summarized in Table 1. With the PCNN model processing, the counting number of TP in each dataset increases significantly, especially in the second scene and third scene. While the number of FP counted in each dataset decreases notably, from 8 to 0 in the first scene, from 6 to 0 in the second scene, and from 73 to 29 in the fourth scene especially. FP refers to the generation of false template matching that will result in error loop closure during the mapping process. Thus, the accuracy of the experience map is significantly improved by the reduction of FP. In addition to the third dataset, the Precision of others rises by roughly 4.4\( \% \), 1.7\( \% \), and 4.6\( \% \) respectively in sequence. The Recall increases by nearly 6.5\( \% \), 8.8\( \% \) and 29.6\( \% \) respectively in the first three scenes, while the one in the fourth scene is nearly the same. As can be seen in each dataset, Precision and Recall cannot keep increasing at a similar rate. The F1-score is used to evaluate synthetically and increases by nearly 10.5\( \% \), 35.8\( \% \), 61.7\( \% \) and 1.9\( \% \) respectively in four scenes. Due to the improvement in Precision, Recall, and F1-score of the template matching, the trajectory effect of experience maps produced by our method in Figs. 6d, 7d, 8d, and 9d is much closer to the real route (referring to the movement locus of data collecting in Fig. 4) than the above mapping results without PCNN in Figs. 6c, 7c, 8c, and 9c.
To assess the trade-off between the speed and accuracy of our algorithm and to provide a comprehensive evaluation of its applicability and effectiveness in real-world scenarios, we compare the mapping performance and visual processing time of our algorithm with RatSLAM. Additionally, we include Gist + SLAM in the comparison, conducting tests for three methods both using our first dataset comprising 1900 frames. All experiments are conducted under identical computing resources and system conditions. The comparison result of mapping performance is shown in Fig. 11, while the visual processing time is summarized in Table 2. Based on our observations and evaluations, our proposed method has demonstrated superior performance in mapping compared to the RatSLAM and Gist + RatSLAM algorithms in low-light conditions. The Gist + RatSLAM algorithm has shown limitations in accurately matching templates and correcting the map effectively under such lighting conditions. The visual processing speed of Gist + RatSLAM has always been slower than the other two. The RatSLAM was faster than the others in the initial frames, but as the number of frames increased steadily, the RatSLAM became slower than our method. It indicates that our model has successfully maintained a balance between accuracy and computation time, without compromising on either.

This is an experience map comparison generated by three methods
Conclusion
In this paper, a hybrid PCNN-CANN bionic visual navigation system was proposed to improve the environmental adaptability of template matching, as well as the accuracy of experience map generation under conditions of weak light or uncontrollable light fluctuations. The visual template processed by PCNN moderately enhances brightness and contrasts at the layers, and more comprehensively retains the features regarding the objects in the scene graph. The experiments demonstrate quantitatively that the PCNN model improves the robustness of template matching. This improvement is evidenced by an increase in the number of correct matches, a decrease in mismatches, and evaluation based on Precision, Recall, and F1-score. Additionally, the template matching approach reduces the time cost, effectively balancing speed and accuracy. The experiments also qualitatively show that our navigation model generates more accurate maps that closely resemble the actual trajectory and have. Currently, our model is utilizing CPU for computations. However, if we leverage GPU to accelerate the visual template similarity calculations on heterogeneous CPU-GPU platforms, we anticipate a reduction of approximately 10% in processing time [17]. Moreover, we expect a substantial increase in processing speed along with a significant reduction in energy consumption by deploying the PCNN model on heterogeneous neuromorphic chips [6]. In future work, we will concern the following aspects to develop:
Incorporating factor analysis and regression methods [28] for handling non-linear mechanisms in the context of visual navigation.
Combining parameter optimization and feature metric learning [34] for handling sparse and diverse visual data in the real world.
Handling constraints and ensuring monotonic convergence [50] for our bionic visual navigation model used in scenarios where environmental constraints and irregular visual data may be encountered.
Enhancing transparency and reducing computation time by referring to the work presented in [27].
And we will transplant the algorithm to the neuromorphic hardware.
Data availability
The data are available from the corresponding authors on reasonable request.
References
Ball D, Heath S, Wiles J et al (2013) Openratslam: an open source brain-based slam system. Auton Robot 34:149–176
Banić N, Lončarić S (2013) Light random sprays retinex: exploiting the noisy illumination estimation. IEEE Signal Process Lett 20(12):1240–1243
Chakraborty B, Chaterjee A, Malakar S et al (2022) An iterative approach to unsupervised outlier detection using ensemble method and distance-based data filtering. Complex Intell Syst 8(4):3215–3230
Craig MT, McBain CJ (2015) Navigating the circuitry of the brain’s GPS system: future challenges for neurophysiologists. Hippocampus 25(6):736–743
Deng X, Yan C, Ma Y (2019) PCNN mechanism and its parameter settings. IEEE Trans Neural Netw Learn Syst 31(2):488–501
Dong Z, Lai CS, Qi D et al (2018) A general memristor-based pulse coupled neural network with variable linking coefficient for multi-focus image fusion. Neurocomputing 308:172–183
Duan P, Kang X, Li S et al (2019) Multichannel pulse-coupled neural network-based hyperspectral image visualization. IEEE Trans Geosci Remote Sens 58(4):2444–2456
Eckhorn R, Bauer R, Jordan W et al (1988) Coherent oscillations: a mechanism of feature linking in the visual cortex? multiple electrode and correlation analyses in the cat. Biol Cybern 60:121–130
Eckhorn R, Reitboeck HJ, Arndt M et al (1990) Feature linking via synchronization among distributed assemblies: simulations of results from cat visual cortex. Neural Comput 2(3):293–307
Gharbi M, Chen J, Barron JT et al (2017) Deep bilateral learning for real-time image enhancement. ACM Trans Graph (TOG) 36(4):1–12
Glover AJ, Maddern WP, Milford MJ et al (2010) Fab-map + ratslam: appearance-based slam for multiple times of day. In: 2010 IEEE international conference on robotics and automation. IEEE, pp 3507–3512
Guo X (2016) Lime: a method for low-light image enhancement. In: Proceedings of the 24th ACM international conference on multimedia, pp 87–91
Huang Y, Ma Y, Li S et al (2016) Application of heterogeneous pulse coupled neural network in image quantization. J Electron Imaging 25(6):061603–061603
Jin SM, Kim D, Yoo DH et al (2023) BPLC + NOSO: backpropagation of errors based on latency code with neurons that only spike once at most. Complex Intell Syst. https://doi.org/10.1007/s40747-023-00983-y
Johnson JL, Padgett ML (1999) PCNN models and applications. IEEE Trans Neural Netw 10(3):480–498
Kazmi SAM, Mertsching B (2016) Gist+ ratslam: an incremental bio-inspired place recognition front-end for ratslam. EAI Endors Trans Creative Technol 3(8):e3
Latif R, Dahmane K, Amraoui M et al (2021) Evaluation of bio-inspired slam algorithm based on a heterogeneous system cpu-gpu. In: E3S web of conferences. EDP Sciences, p 01023
Li M, Liu J, Yang W et al (2018) Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans Image Process 27(6):2828–2841
Liu X, Zeng Z (2022) Memristor crossbar architectures for implementing deep neural networks. Complex Intell Syst 8(2):787–802. https://doi.org/10.1007/s40747-021-00282-4
Milford M, Wyeth G (2010) Improving recall in appearance-based visual slam using visual expectation. In: Proceedings of the 2010 Australasian conference on robotics and automation. Australian Robotics & Automation Association, pp 1–9
Milford M, Jacobson A, Chen Z et al (2016) Ratslam: using models of rodent hippocampus for robot navigation and beyond. In: Robotics research: the 16th international symposium ISRR. Springer, pp 467–485
Moser EI, Moser MB, McNaughton BL (2017) Spatial representation in the hippocampal formation: a history. Nat Neurosci 20(11):1448–1464
Naigong Y, Lin W, Xiaojun J et al (2020) An improved bioinspired cognitive map-building system based on episodic memory recognition. Int J Adv Rob Syst 17(3):1729881420930948
O’Keefe J, Dostrovsky J (1971) The hippocampus as a spatial map: preliminary evidence from unit activity in the freely-moving rat. Brain Res 34:171–175
Panetta KA, Wharton EJ, Agaian SS (2008) Human visual system-based image enhancement and logarithmic contrast measure. IEEE Trans Syst Man Cybern B (Cybern) 38(1):174–188
Paugam-Moisy H, Bohte SM (2012) Computing with spiking neuron networks. Handbook of natural computing, vol 1. Springer, New York, pp 1–47
Pozna C, Precup RE, Tar JK et al (2010) New results in modelling derived from Bayesian filtering. Knowl-Based Syst 23(2):182–194
Precup RE, Duca G, Travin S et al (2022) Processing, neural network-based modeling of biomonitoring studies data and validation on republic of Moldova data. Proc Roman Acad Ser A Math Phys Techn Sci Inf Sci 23(4):403–410
Ren W, Liu S, Ma L et al (2019) Low-light image enhancement via a deep hybrid network. IEEE Trans Image Process 28(9):4364–4375
Schoenauer T, Atasoy S, Mehrtash N et al (2002) Neuropipe-chip: a digital neuro-processor for spiking neural networks. IEEE Trans Neural Netw 13(1):205–213
Shen L, Tao H, Ni Y et al (2023) Improved yolov3 model with feature map cropping for multi-scale road object detection. Meas Sci Technol 34(4):045406
Shim VA, Tian B, Yuan M et al (2014) Direction-driven navigation using cognitive map for mobile robots. In: 2014 IEEE/RSJ international conference on intelligent robots and systems. IEEE, pp 2639–2646
Shipston-Sharman O, Solanka L, Nolan MF (2016) Continuous attractor network models of grid cell firing based on excitatory–inhibitory interactions. J Physiol 594(22):6547–6557
Tao H, Cheng L, Qiu J et al (2022) Few shot cross equipment fault diagnosis method based on parameter optimization and feature mertic. Meas Sci Technol 33(11):115005
Thyagharajan KK, Kalaiarasi G (2018) Pulse coupled neural network based near-duplicate detection of images (PCNN-NDD). Adv Electr Comput Eng 18(3):87–96
Tian B, Shim VA, Yuan M et al (2013) RGB-d based cognitive map building and navigation. In: 2013 IEEE/RSJ International conference on intelligent robots and systems. IEEE, pp 1562–1567
Tutsoy O, Polat A, Çolak Ş et al (2020) Development of a multi-dimensional parametric model with non-pharmacological policies for predicting the covid-19 pandemic casualties. IEEE Access 8:225272–225283
Wang L, Xiao L, Liu H et al (2014) Variational Bayesian method for retinex. IEEE Trans Image Process 23(8):3381–3396
Wang Q, Lei Y, Ren C et al (2019) Spiking cortical model: a new member in the third generation of artificial neural network. In: 2019 3rd International conference on electronic information technology and computer engineering (EITCE). IEEE, pp 1883–1887
Wang YF, Liu HM, Fu ZW (2019) Low-light image enhancement via the absorption light scattering model. IEEE Trans Image Process 28(11):5679–5690
Wu S, Wong KM, Fung CA et al (2016) Continuous attractor neural networks: candidate of a canonical model for neural information representation. F1000Res 5:F1000 Faculty Rev-156. https://doi.org/10.12688/f1000research.7387.1
Yang Z, Dong M, Guo Y et al (2016) A new method of micro-calcifications detection in digitized mammograms based on improved simplified PCNN. Neurocomputing 218:79–90
Yang Z, Guo Y, Gong X et al (2017) A non-integer step index PCNN model and its applications. In: Medical image understanding and analysis: 21st annual conference, MIUA 2017, Edinburgh, UK, July 11–13, 2017, Proceedings 21. Springer, pp 780–791
Ye T, Zhao Z, Wang S et al (2022) A stable lightweight and adaptive feature enhanced convolution neural network for efficient railway transit object detection. IEEE Trans Intell Transp Syst 23(10):17952–17965
Ying Z, Li G, Ren Y et al (2017) A new low-light image enhancement algorithm using camera response model. In: Proceedings of the IEEE international conference on computer vision workshops, pp 3015–3022
Zhan K, Teng J, Shi J et al (2016) Feature-linking model for image enhancement. Neural Comput 28(6):1072–1100
Zhan K, Shi J, Wang H et al (2017) Computational mechanisms of pulse-coupled neural networks: a comprehensive review. Archiv Comput Methods Eng 24:573–588
Zhang Y, Zhang J, Guo X (2019) Kindling the darkness: a practical low-light image enhancer. In: Proceedings of the 27th ACM international conference on multimedia, pp 1632–1640
Zhou SC, Yan R, Li JX et al (2017) A brain-inspired slam system based on ORB features. Int J Autom Comput 14(5):564–575
Zhuang Z, Tao H, Chen Y et al (2022) An optimal iterative learning control approach for linear systems with nonuniform trial lengths under input constraints. IEEE Trans Syst Man Cybern Syst 53(6):3461–3473
Acknowledgements
We would like to express our gratitude to Bo. Tian from Tianbot, China for generously providing the open dataset of the A *STAR lab, Singapore. We appreciate his contribution to our research and believe that this dataset will greatly benefit our project.
Funding
Research supported by the National Natural Science Foundation of China (Number:61773273).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors have no conflict of interest or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, H., Yu, S., Sun, R. et al. Bionic visual navigation model for enhanced template matching and loop closing in challenging lighting environments. Complex Intell. Syst. 10, 1265–1281 (2024). https://doi.org/10.1007/s40747-023-01207-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01207-z