
Abstract
For mathematical completeness, we propose an error-backpropagation algorithm based on latency code (BPLC) with spiking neurons conforming to the spike–response model but allowed to spike once at most (NOSOs). BPLC is based on gradients derived without approximation unlike previous temporal code-based error-backpropagation algorithms. The latency code uses the spiking latency (period from the first input spike to spiking) as a measure of neuronal activity. To support the latency code, we introduce a minimum-latency pooling layer that passes the spike of the minimum latency only for a given patch. We also introduce a symmetric dual threshold for spiking (i) to avoid the dead neuron issue and (ii) to confine a potential distribution to the range between the symmetric thresholds. Given that the number of spikes (rather than timesteps) is the major cause of inference delay for digital neuromorphic hardware, NOSONets trained using BPLC likely reduce inference delay significantly. To identify the feasibility of BPLC + NOSO, we trained CNN-based NOSONets on Fashion-MNIST and CIFAR-10. The classification accuracy on CIFAR-10 exceeds the state-of-the-art result from an SNN of the same depth and width by approximately 2%. Additionally, the number of spikes for inference is significantly reduced (by approximately one order of magnitude), highlighting a significant reduction in inference delay.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Spiking neural networks (SNNs) of layer-wise feedforward structure can process and convey data forward based on asynchronous spiking events without forward locking unlike feedforward deep neural networks (DNNs) [10, 32]. When implemented in asynchronous neuromorphic hardware, SNNs are believed to leverage their processing efficiency. Nevertheless, asynchronous neuromorphic hardware often suffers from traffic congestion due to a large number of spikes (events) that are routed to their destination neurons through network-on-chip with limited bandwidth [9]. In this regard, the number of synaptic operations per second (SynOPS) is considered as a crucial measure of neuromorphic hardware performance, and attempts have been made to improve this synaptic operation speed to further accelerate the inference process [8, 12, 27, 28]. Algorithm-wise approaches to improve the inference speed include the development of learning algorithms that support the inference process using fewer spikes.
Given the limited accessibility to global data in multicore neuromorphic hardware, learning algorithms of locality are favored as on-chip learning algorithms. However, learning algorithms of locality, e.g., naive Hebb rule [15], spike timing-dependent plasticity [4], and Ca-signaling model [21], fail to achieve high performance. Currently, it appears that the trend is moving toward off-chip learning, allowing the learner to access large global data within the general framework of error-backpropagation (backprop). The advantage is such that enriched optimization techniques for DNNs can readily be applied to SNNs, which significantly improves the performance of SNNs [10]. Nevertheless, the notable inconsistency between DNNs and SNNs lies in the fact that output spikes are non-differentiable unlike activation functions.
As a workaround, the gradients of spikes are often approximated to heuristic functions, which are popularly referred to as surrogate gradients [2, 11, 34, 38, 44]. Using surrogate gradients, the gradient values are available disregarding the presence of events, avoiding the dead neuron issue that hinders the network from learning. To date, various surrogate gradients have been proposed, e.g., boxcar function [38], arctan function [11], exponential function [34]; these methods remove the inconsistency between DNNs and SNNs, yielding the state-of-the-art classification accuracy on various datasets. Despite the technical success, such heuristic surrogate gradient methods lack theoretical completeness given the lack of theoretical foundations of surrogate gradients.
Spike timing-based backprop (temporal backprop) algorithms can avoid such surrogate gradients because the spike timing may be differentiable with the membrane potential using a linear approximation of near-threshold potential evolution [5]. Temporal backprop is generally prone to learning failure because of limited error-backpropagation paths. This is because spike timing gradients are available only for the neurons that spike at a given timestep unlike surrogate gradients. The number of error-backpropagation paths is further limited by dead neurons, i.e., neurons whose current fan-in weights are low so that they no longer fire spikes. STDBP, a temporal backprop algorithm, uses a rectified linear potential kernel to avoid the dead neuron issue [46]. The rectified linear kernel causes a monotonous increase in potential upon receiving an input spike with a positive weight, suggesting that the neurons eventually fire spikes. TSSL-BP considers additional error-backprogation paths via spikes from the same neuron to avoid learning failure due to limited error-backpropagation paths [48]. The timing gradient is calculated using the linear approximation by Bohte et al. [5]. Another temporal backprop algorithm (STiDi-BP) uses a piece-wise linear kernel to approximate the spike timing gradient to a simple function, and thus to reduce the computational cost [25, 26].
Because spike timing gradients are available only for the neurons that spike, generally, the larger the number of spikes, the richer the error-backpropagation paths. Thus, more spikes are desired for a better training. However, this causes a considerable inference delay when implemented in digital neuromorphic hardware because of its limited synaptic operation speed. Concerning the desires for
-
theoretically seamless applications of temporal backprop to SNNs,
-
workaround for the dead neuron issue,
-
fewer spikes for fast inference,
we propose a novel learning algorithm based on the spiking latency code of neurons that only spike once at most (NOSOs). NOSOs are based on the spike–response model (SRM) [13] but with an infinite hard refractory period to avoid additional spikes. The algorithm is based on the backpropagation of errors evaluated using the spiking latency code (BPLC). The key to BPLC + NOSO is such that, when spiking, spiking latency (rather than spike itself) is the measure of the response to a given input, which is differentiable without approximations unlike [5]. Thus, BPLC + NOSO is mathematically rigorous such that all required gradients are derived analytically. Other important features of BPLC + NOSO are as follows.
-
The use of NOSOs for both learning and inference minimizes the workload on the event-routing circuits in neuromorphic hardware.
-
To support the latency code, NOSONet includes minimum-latency pooling (MinPool) layers (instead of MaxPool or AvgPool) that pass the event of the minimum latency only for a given patch.
-
Each NOSO is given two symmetric thresholds (\(-\vartheta \) and \(\vartheta \)) for spiking to confine the potential distribution to the range between the symmetric thresholds.
-
BPLC + NOSO fully supports both folded and unfolded NOSONets, allowing us to use the automatic differentiation framework [31].
The primary contributions of this study include the following:
-
We introduce a novel learning algorithm based on the spiking latency code (BPLC + NOSO) with full derivations of the primary gradients without approximations.
-
We provide novel and essential methods for BPLC + NOSO support, such as MinPool layers and symmetric dual threshold for spiking, which greatly improve accuracy and inference efficiency.
-
We introduce a method to quickly calculate wallclock time for inference on general digital neuromorphic hardware, which allows a quick estimation of the inference delay for a given fully trained SNN.
The rest of the paper is organized as follows— Section “Related work” briefly overviews previous learning algorithms based on temporal codes. Section “Preliminaries” addresses primary techniques employed in BPLC + NOSO. Section “BPLC with spike response model” is dedicated to the theoretical foundations of BPLC + NOSO. Section “Experiments” addresses the performance evaluation of BPLC + NOSO on Fashion-MNIST and CIFAR-10 and effects of MinPool and symmetric dual threshold for spiking on learning efficacy. Section “Discussion” discusses the estimation of inference time for an SNN mapped onto a general digital multicore neuromorphic processor. Finally, Section “Conclusion and outlook” concludes our study.
Related work
Spike timing gradient approximation: Temporal backprop algorithms frequently use linear approximated spike timing gradients proposed by Bohte et al. [5]. The specific form of the gradient depends on the membrane potential kernel used. Bohte et al. [5], Comsa et al. [7], and Kim et al. [19] used an alpha kernel as an approximation of the genuine SRM kernel, and the corresponding gradients were evaluated using the linear approximation. Zhang et al., employed a rectified linear kernel to avoid the dead neuron issue [46] while Mirsadeghi et al., employed a piece-wise linear kernel for simple calculations of the gradient [25, 26]. To apply the linear approximation by Bohte et al. [5], the gradient of membrane potential at the spike timing should be available. Integrate-and-fire (IF) neurons do not allow the gradient value at the spike timing so that Kheradpisheh and Masquelier [17] approximated the gradient to be constant at –1. The same holds for leaky integrate-and-fire (LIF) neurons. Zhang and Li [48] stated that the linear approximated was employed, but the gradient is not clearly derived.
Label-encoding as spike timings: For SNN with temporal code, the correct labels are frequently encoded as particular output spike timings [17, 25, 26] or the temporal order of output spikes such as time-to-first-spike (TTFS) code [30, 45, 46]. In the TTFS code, the neuron index of the first output spike indicates the output label.
Workaround for dead neuron: Comsa et al. proposed temporal backprop with a means to avoid dead neurons (assigning penalties to the presynaptic weights of each dead neuron) [7]. Zhang et al. [46] proposed a rectified linear potential kernel that causes a monotonous increase in potential upon receiving a spike with positive weight. Thus, the neuron eventually fire a spike. Zhang and Li [48] proposed TSSL-BP with additional backprop paths via the spikes emitted from the same neuron (intra-neuron dependency). The additional paths avoid the learning failure due to limited backprop paths by dead neurons. Kim et al. [19] combined temporal backprop paths with rate-based backprop paths to compensate for the loss of temporal backprop paths due to dead neurons.
BPLC + NOSO is clearly distinguished from the previous temporal backprop algorithms in terms of the primary perspectives addressed in this section. First, BPLC + NOSO employs no approximation for gradient evaluation unlike the previous temporal backprop algorithms including those reviewed in this section. Therefore, it barely embodies ambiguity. Second, the proposed spiking latency code is a novel data encoding scheme, distinguishable from the previous temporal code schemes. Third, the symmetric dual threshold for spiking is a novel method to avoid the dead neuron issue, which is computationally efficient since it hardly involves high-cost computations. Additionally, BPLC + NOSO is fully compatible with the original SRM without approximations.
Preliminaries
Latency code
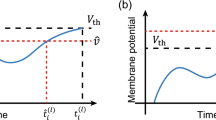
Spiking latency is a period from the first input spike timing \(t_\text {in}\) and consequent spike timing \(\hat{t}\) as illustrated in Fig. 1a. In the latency code, NOSONet encodes input data \(\varvec{x}\) as the spiking latency \(T_\text {lat}^{(L)}\) of the output neurons in the output layer L.
where \(\hat{\varvec{t}}^{(\cdot )}\) and \(\varvec{t}^{(\cdot )}_\text {in}\) denote the spike timings of the neurons in the \((\cdot )\)th layer and their first input spike timings, respectively. The function \(f^{(L)}\) encodes input spikes (from the layer L-1) at \(\hat{\varvec{t}}^{(L-1)}\) as spiking latency values \(\varvec{T}_\text {lat}^{(L)}\). The larger the weight \(\varvec{w}^{(L-1)}\), the shorter the spiking latency \(\varvec{T}_\text {lat}^{(L)}\). This latency code should be distinguished from the TTFS code [30, 45, 46] in which the first input spike timings \(\varvec{t}_\text {in}^{(L)}\) in Eq. (1) are ignored, so that it considers the output spike timings only.
Minimum-latency pooling
The MinPool layers support the latency code. Consider the time elapsed since the first input spike, \(t_\text {elap}=t-t_\text {in}\), for a given neuron. We consider a spiking latency map in a given 2D patch \(\mathcal {D}_\text {pool}\) at timestep t and feature (spike) map in the same patch, \(\varvec{T}_{\text {lat,}\mathcal {D}_\text {pool}}[t]\) and \(\varvec{s}_{\mathcal {D}_\text {pool}}[t]\), respectively. The latency map \(\varvec{T}_{\text {lat},\mathcal {D}_\text {pool}}\) is initialized to infinite values. Each element in the map is replaced by real spiking latency when the neuron spikes. Note that the elements once replaced by real latency values are no longer overwritten because of the use of NOSOs. At time step t, MinPool outputs one if the neuron of the smallest spiking latency in the patch fires a spike, and zero otherwise.
where \(s_{x_\text {min}}[t]\) indicates the spike function value for \(x_\text {min}\) at timestep t. An example of \(\text {MinPool}\left( \mathcal {D}_\text {pool}\right) \left[ t\right] \left( =1\right) \) is illustrated in Fig. 1b.

a Definition of spiking latency, b Schematic of the minimum latency pooling operation
NOSO with dual threshold for spiking
Each NOSO is endowed with a symmetric dual threshold for spiking (\(-\vartheta \) and \(\vartheta \)), and thus a spike is generated if the membrane potential u satisfies \(u\ge \vartheta \) or \(u\le -\vartheta \). Therefore, the subthreshold potential u is confined to the range between \(-\vartheta \) and \(\vartheta \). The restriction on the potential offers the upper limit of potential variance over the samples in a given batch, preventing large potential variance over the samples. The symmetry in the two bounds may offer zero-mean potential over the samples. Additionally, the restriction on the potential is expected to avoid dead neurons given that most dead neurons arise from their potentials largely biased toward the negative side.
BPLC with spike response model
Spike response model mapped onto computational graphs
We consider SRM, which is equivalent to the basic leaky integrate-and-fire (LIF) model with exponentially decaying synaptic current [13]. But our model is allowed to maximally spike only once in response to a single input sample by using an infinite hard refractory period in place of the refractory kernel. The choice of SRM, rather than simpler models, e.g., Stein’s model [35], is to enlarge the mutual information of spike timing and synaptic weight, which is the key to temporal code.
In SRM, the subthreshold potential of the ith spiking neuron in the lth layer (\(u_{i}^{(l)}\)) is given by
where j denotes the indices of the presynaptic neurons, and \(w_{ij}^{(l)}\) denotes the synaptic weight from the jth neuron in the (l-1)th layer. The spiking-availability function \(sav_i^{(l)}\) is employed to allow each neuron to spike once at most such that \(sav_i^{(l)}=1\) if the neuron has not spiked before, and \(sav_i^{(l)}=0\) otherwise. The kernel \(\epsilon \) is expressed as follows [13].
where \(\Theta \) denotes the Heaviside step function. The potential and synaptic current time constants are denoted by \(\tau _{m}\) and \(\tau _s\), respectively. A spike from the jth neuron in the (l-1)th layer at \(\hat{t}_j^{(l-1)}\) is denoted by \(s_{j}^{(l-1)}\). Because the kernel in Eq. (4) consists of two independent sub-kernels,
Eq. (3) can be expressed as
Here, we introduce a new variable \(v_j^{(l)}\) given by
The variables \(u_{i,m}^{(l)}\) and \(u_{i,s}^{(l)}\) are reset to zero when the neuron fires a spike. The advantage of this method is that the membrane potential can be evaluated by simply convolving input spikes using two independent kernels, which otherwise needs to solve two sequential differential equations [20]. After spiking, the spiking-availability function \(sav_i^{(l)}\) remains constant at zero, hindering additional spike generation.

Unfolded NOSONet on a computational graph
All variables are recursively evaluated using the explicit finite difference method.
Equation (6) can be mapped onto a computational graph as shown in Fig. 2. A layer’s processed data is transmitted along the forward pass through the use of spikes (\(\varvec{s}^{(l)}\)).
Backward pass and gradients
SNNs are typically trained using forward and backward passes aligned in opposing directions, so that it is unavoidable to use surrogate gradients due to non-differentiability of spikes [29, 34, 44]. Instead, BPLC + NOSO uses a backward pass via spike timings \(\hat{\varvec{t}}^{(\cdot )}\) rather than spikes themselves \(\varvec{s}^{(\cdot )}\) (Fig. 2). This backward pass involves differentiable functions only. The output of NOSONet (with M output NOSOs) is the spiking latency values of the output NOSOs, \(\varvec{T}_\text {lat}^{(L)}=\{T^{(L)}_{\text {lat}, i}\}_{i=1}^{M}\), as given in Eq. (1). The prediction is then made by reference to the output neuron of the minimum spiking latency. We use a cross-entropy loss function \(\mathcal {L}(-\varvec{T}_\text {lat}^{(L)}, \varvec{\hat{y}})\), where \(\varvec{\hat{y}}\) denotes a one-hot encoded label vector. The loss is evaluated at the end of the learning phase, and the weights are then updated using the gradients assessed when the neurons spiked.
We calculate the weight’s update \(\Delta w_{ij}^{(l)}\) using the gradient descent method as follows.
The learning rate and loss function are denoted by \(\eta \) and \(\mathcal {L}\), respectively. Equation (7) is equivalent to
with the error \(\varvec{e}^{(l)}\) given by
for N neurons in the lth layer. The symbol \(\odot \) denotes the Hadamard product. The matrix \(\varvec{v}^{(l)}[\varvec{\hat{t}}^{(l)}]\) is given by
for M neurons in the \(\left( l-1\right) \)th layer.
The backward propagation of the error from the lth layer to the \(\left( l-1\right) \)th layer (with M neurons) is given by
Equation (10) is derived in Appendix A. Because NOSO spikes once at most, the elements once written in \(\varvec{v}^{(l)}[\varvec{\hat{t}}^{(l)}]\) and \(\varvec{v}^{(l)'}[\varvec{\hat{t}}^{(l)}]\) are not overwritten. Equation (10) identifies that BPLC involves the gradients of spike timings rather than spikes themselves. Therefore, the backward pass differs from the forward pass.
Two types of gradients are thus required for BPLC + NOSO: (i) \(\partial \hat{t}_i^{(l)}/\partial u_i^{(l)}\) and (ii) \(\partial v_j^{(l)}/\hat{t}_j^{(l-1)}\) at the spike timing \(\hat{t}_i^{(l)}\). Fortunately, SRM allows these gradients to be expressed analytically.
Theorem 1
When an SRM neuron (whose membrane potential is \(u_i^{(l)}\)) spikes at a given time \(t (=\hat{t}_i^{(l)})\), the gradient of spike timing \(\hat{t}_i^{(l)}\) with membrane potential is given by
The proof of Theorem 1 is given in Appendix B. If the neuron does not spike during a learning phase, the gradient in Eq. (11) is zero.
Theorem 2
When an SRM neuron receives an input spike at \(\hat{t}_j^{(l-1)}\), the gradients of \(v_{j,m}^{(l)}\) and \(v_{j,s}^{(l)}\) with respect to \(\hat{t}_j^{(l-1)}\) are given by
The proof of Theorem 2 is also given in Appendix B. Using Theorem 2, the gradient \(\partial v_j^{(l)}/\hat{t}_j^{(l-1)}\) is given by
Likewise, this gradient is also zero if this neuron does not spike. Both gradients in Eqs. (11) and (13) can simply be calculated by reading out the four local variables (\(u_{i,m}^{(l)}\), \(u_{i,s}^{(l)}\), \(v_{j,m}^{(l)}\), \(v_{j,s}^{(l)}\)) when the neuron spikes.
The above derivations are for folded NOSONet, where all tensors for each layer are simply overwritten over time so that the space complexity is independent of the number of timesteps. We used unfolded NOSONet in the temporal domain to apply the the automatic differentiation framework [31]. The equivalence between folded and unfolded NOSONets is proven in Appendix C.
Experiments
Convolutional NOSONet (C-NOSONet) was trained on Fashion-MNIST [40] and CIFAR-10 [22] using BPLC + NOSO. We used the hyperparameters listed in Appendix E unless otherwise stated. The hyperparameters were manually searched. All experiments were conducted in the Pytorch framework [31] on a GPU workstation (CPU: Intel Xeon Processor Gold, GPU: RTX A6000). NOSONet on Fashion-MNIST was trained using one GPU, whereas NOSONet on CIFAR-10 using four GPUs.
Classification accuracy and the number of spikes for inference

Active NOSO ratio \(\overline{n}_{sp}^{(i)}\) for each layer on a Fashion-MNIST and b CIFAR-10 over all timesteps
We evaluated the classification accuracy on Fashion-MNIST and CIFAR-10 and the total number of spikes used for inference \(N_{\text {sp}} (=\sum _{i,t}n_{\text {sp}}^{(i,t)})\), where \(n_{\text {sp}}^{(i,t)}\) denotes the number of spikes generated from the layer i at timestep t.
Fashion-MNIST: Fashion-MNIST consists of 70,000 gray-scale images (each of which \(28\times 28\) in size) of clothing categorized as 10 classes [40]. We rescaled each gray-scale pixel value of an image to the range \(0-0.3\) and applied an additive white Gaussian noise (zero mean and 0.05 standard deviation). These values were then used as input currents into input LIF neurons. We trained a C-NOSONet (32C5-MP2-64C5-MP2-600, where MP denotes MinPool). The classification accuracy of the C-NOSONet is shown in Table 2 in comparison with previous works. We also evaluated the total number of spikes \(N_{\text {sp}}\) over all hidden+output NOSOs in the network for each test sample (Table 2). The results highlight large sparsity of active NOSOs, which likely reduces the inference latency when implemented in neuromorphic hardware. This will be discussed in Section “Discussion”. Figure 3a shows the ratio of active NOSOs to all NOSOs, \(\overline{n}_{\text {sp}}^{(i)} (=\sum _tn_{\text {sp}}^{(i,t)}/C^{(i)}H^{(i)}W^{(i)})\), for layer i over the entire timesteps.
CIFAR-10: CIFAR-10 consists of 60,000 real-world color images (each of which \(3\times 32\times 32\) in size) of objects labeled as 10 classes [22]. All training images were pre-processed such that each image with zero-padding of size 4 was randomly cropped to \(32\times 32\), which was followed by random horizontal flipping. The RGB values of each pixel were rescaled to the range \(0-0.3\) and then used as input currents. For learning stability, we linearly increased the initial learning rate (1E-2) to the plateau learning rate (5E-2) for the first five epochs (ramp rate: 8E-3/epoch). The fully trained C-NOSONet (64C5-128C5-MP2-256C5-MP2-512C5-256C5-1024-512) yields the classification accuracy and the number of spikes for inference in Table 2. Notably, our classification accuracy exceeds the result from an SNN of the same depth and width (CNN2-half-ch) [39] by approximately 2.0%. Additionally, our NOSONet uses much fewer spikes (only 10.9% of CNN2-half-ch), supporting high-throughput inference. The layer-wise active NOSO ratio \(\overline{n}_{\text {sp}}^{(i)}\) over the entire timesteps is plotted in Fig. 3b, highlighting the high sparsity of spikes.

Comparison between MinPool and MaxPool in terms of a validation accuracy, b training loss, and c layer-wise active NOSO ratio on Fashion-MNIST

Comparison between MinPool and MaxPool in terms of a validation accuracy, b training loss, and c layer-wise active NOSO ratio on CIFAR-10

Mean potential and standard deviation for neurons in each layer of NOSONet a on Fashion-MNIST, b on CIFAR-10. They were evaluated from potential distribution over samples in a random batch (size: 300 on Fashion-MNIST and 100 on CIFAR-10)
Minimum-latency pooling versus MaxPool
MinPool supports the latency code by passing the event of the minimum spiking latency in a given 2D patch. To identify its effects on learning, we compared NOSONets with MinPool layers and conventional MaxPool layers. Figures 4 and 5 show the comparisons on Fashion-MNIST and CIFAR-10, respectively. Compared with MaxPool, MinPool yields (i) the higher classification accuracy as shown in Figs. 4a and 5a and (ii) higher spike sparsity as shown in Figs. 4c and 5c. The accuracy increase despite the decrease in spike number may imply that MinPool removes unimportant spikes in classification unlike dropout that randomly removes spikes.
Effect of symmetric dual threshold on potential distribution
We identified the effect of the dual threshold on potential distribution over samples in a given batch by training NOSONet (32C5-MP2-64C5-MP2-600) on Fashion-MNIST and CIFAR-10 with four different threshold conditions: single threshold 0.05 and 0.1, and dual threshold ±0.1 and ±0.15. The results are shown in Fig. 6. The usage of dual threshold greatly lowers the standard deviation and results in a mean that is almost zero because it limits the potential to the range between \(-\vartheta \) and \(\vartheta \). Additionally, the highest accuracy was attained with the dual threshold ±0.15. The potential distributions for a single threshold case (0.1) and dual threshold case (±0.15) on Fashion-MNIST are detailed in Appendix F.
Discussion
We estimate the inference time for an SNN mapped onto a general digital multicore neuromorphic processor using the following assumptions.
Assumption 1: Total \(N_\text {n}\) neurons in a given SNN are distributed uniformly over \(N_\text {c}\) cores of a neuromorphic processor, i.e., \(N_{\text {n}}/N_{\text {c}}\) neurons per core.
Assumption 2: All \(N_{\text {n}}/N_{\text {c}}\) neurons in each core share a multiplier by time-division multiplexing, so that the current potential is multiplied by a potential decay factor (\(e^{-1/\tau _\text {m}}\)) for one neuron at each cycle.
Assumption 3: Synaptic operations are also executed serially.
Assumption 4: Neurons in different cores are updated parallel.
Each timestep for an SNN with LIF neurons includes two primary processes: (i) the process of multiplying the current potential by a decay factor and (ii) synaptic operation (spike routing to the destination neurons plus the consequent potential update). Process (i) in a digital neuromorphic processor is commonly pipelined within a core but executed in parallel over the \(N_{\text {c}}\) cores [20]. Thus, at each timestep, the time for process (i) for all \(N_{\text {n}}\) neurons (\(T_{\text {up}}\)) is given by
where a and \(f_{\text {clk}}\) denote the initialization cycle number and clock speed, respectively. Although the number of initialization cycles a differs for different processor designs, it is commonly a few clock cycles. Given the total number of spikes generated at timestep t (\(n_{\text {sp}}[t]\)), the time for synaptic operations at each timestep is given by
Given Assumptions, the total time for processes (i) and (ii) at each timestep is given by \(T_{\text {step}}=T_{\text {up}}+T_{\text {sop}}\). Therefore, we have the total time for inference during total \(N_{\text {step}}\) timesteps, \(T_{\text {inf}}=\sum _tT_{\text {step}}[t]\), as follows.
where \(N_{\text {sp}}=\sum _tn_{\text {sp}}[t]\). The number of neurons in a core \((N_{\text {n}}/N_{\text {c}})\) differs for different designs. We assume 1k neurons in each core [8], a few tens MSynOPS as for [3, 12, 27], and 100 MHz clock speed. For inference involving \(N_{sp}\) spikes (\(\sim 10^6\) as in Table 2) and a \(N_{\text {step}}\) of \(\sim 100\), Eq. (14) identifies that \(T_{\text {sop}}\) is dominant over \(T_{\text {up}}\) so that \(T_{\text {inf}}\) is dictated by \(T_{\text {sop}}\). Therefore, it is desired to concern \(N_{\text {sp}}\) when developing learning algorithms.
For SNNs with IF neurons (without leakage), process (i) is unnecessary so that \(T_{\text {up}}\) vanishes. Therefore, \(T_{\text {inf}}\) is solely determined by \(N_{\text {sp}}\).
Conclusion and outlook
We proposed a mathematically rigorous learning algorithm (BPLC) based on spiking latency code in conjunction with minimum-latency pooling (MinPool) operations. We overcome the dead neuron issue using a symmetric dual threshold for spiking, which additionally improves the potential distribution over samples in a given batch (and thus the classification accuracy). BPLC-trained NOSONet on CIFAR-10 highlights its high accuracy outperforming the SNN of the same depth and width by approximately 2\(\%\) with much fewer spikes (only 10.9%). This large reduction in the number of spikes largely reduces the inference latency of SNNs implemented in digital neuromorphic processors.
Currently, we conceive the following future work to boost the impact of BPLC + NOSO.
-
Scalability confirmation: Although the viability of BPLC + NOSO was identified, its applicability to deeper SNNs on more complex datasets should be confirmed. Such datasets include not only static image datasets like ImageNet [33] but also event datasets like CIFAR10-DVS [24] and DVS128 Gesture [1]. Given that the number of spikes is severely capped, BPLC + NOSO on event datasets in particular might be challenging.
-
Hyperparameter fine-tuning: To further increase the classification accuracy, the hyperparameters should be fine-tuned using optimization techniques.
-
Weight quantization: BPLC + NOSO is based on full-precision (32b FP) weights. However, the viability of BPLC + NOSO with reduced precision weights should be confirmed to improve the efficiency in memory use. This may need an additional weight-quantization algorithm in conjunction with BPLC + NOSO like CBP [18].
-
Search for new application domains: We need to search for new applications domains in which BPLC + NOSO can leverage its low process latency and power when implemented in neuromorphic hardware. The examples potentially include intelligent control systems like constrained nonlinear systems [41,42,43].
Availability of data and materials
The datasets generated during and/or analyzed during the current study are available in the GitHub repository, https://github.com/dooseokjeong/BPLC-NOSO.
References
Amir A, Taba B, Berg D, et al (2017) A low power, fully event-based gesture recognition system. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 7243–7252. https://doi.org/10.1109/CVPR.2017.781
Bellec G, Salaj D, Subramoney A, et al (2018) Long short-term memory and learning-to-learn in networks of spiking neurons. In: Advances in Neural Information Processing Systems, vol 31. Curran Associates, Inc
Benjamin BV, Gao P, McQuinn E et al (2014) Neurogrid: a mixed-analog-digital multichip system for large-scale neural simulations. Proc IEEE 102(5):699–716. https://doi.org/10.1109/JPROC.2014.2313565
Bi GQ, Poo MM (1998) Synaptic modifications in cultured hippocampal neurons: Dependence on spike timing, synaptic strength, and postsynaptic cell type. J Neurosci 18(24):10,464–10,472. https://doi.org/10.1523/JNEUROSCI.18-24-10464.1998
Bohte SM, Kok JN, La Poutre H (2002) Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 48(1–4):17–37. https://doi.org/10.1016/S0925-2312(01)00658-0
Cheng X, Hao Y, Xu J, et al (2020) Lisnn: Improving spiking neural networks with lateral interactions for robust object recognition. In: IJCAI, pp 1519–1525. https://doi.org/10.24963/ijcai.2020/211
Comsa IM, Potempa K, Versari L, et al (2020) Temporal coding in spiking neural networks with alpha synaptic function. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp 8529–8533, https://doi.org/10.1109/icassp40776.2020.9053856
Davies M, Srinivasa N, Lin TH et al (2018) Loihi: a neuromorphic manycore processor with on-chip learning. IEEE Micro 38(1):82–99. https://doi.org/10.1109/MM.2018.112130359
Davies M, Wild A, Orchard G et al (2021) Advancing neuromorphic computing with loihi: a survey of results and outlook. Proc IEEE 109(5):911–934. https://doi.org/10.1109/JPROC.2021.3067593
Eshraghian JK, Ward M, Neftci E et al (2021) Training spiking neural networks using lessons from deep learning. https://doi.org/10.48550/ARXIV.2109.12894
Fang W, Yu Z, Chen Y et al (2021) Incorporating learnable membrane time constant to enhance learning of spiking neural networks. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 2661–2671. https://doi.org/10.1109/ICCV48922.2021.00266
Frenkel C, Lefebvre M, Legat JD et al (2018) A 0.086-mm \(^{2}\) 1.27-pj/sop 64k-synapse 256-neuron online-learning digital spiking neuromorphic processor in 28-nm cmos. IEEE Trans Biomed Circ Syst 13(1):145–158. https://doi.org/10.1109/TBCAS.2018.2880425
Gerstner W, Kistler WM (2002) Spiking neuron models: single neurons, populations, plasticity. Cambridge University Press, Cambridge
Glorot X, Bengio Y (2010) Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics, pp 249–256
Hebb DO (1949) The organization of behavior. Wiley, New York
Si I, Saiin R, Sawada Y et al (2022) Rethinking the role of normalization and residual blocks for spiking neural networks. Sensors 22(8):2876. https://doi.org/10.3390/s22082876
Kheradpisheh SR, Masquelier T (2020) Temporal backpropagation for spiking neural networks with one spike per neuron. Int J Neural Syst 30(6):2050,027. https://doi.org/10.1142/S0129065720500276
Kim G, Jeong DS (2021) Cbp: backpropagation with constraint on weight precision using a pseudo-lagrange multiplier method. In: Advances in Neural Information Processing Systems, vol 34. Curran Associates, Inc
Kim J, Kim K, Kim JJ (2020a) Unifying activation-and timing-based learning rules for spiking neural networks. In: Advances in Neural Information Processing Systems, vol 33. Curran Associates, Inc
Kim J, Kornijcuk V, Ye C et al (2020) Hardware-efficient emulation of leaky integrate-and-fire model using template-scaling-based exponential function approximation. IEEE Trans Circ Syst I Regul Pap 68(1):350–362. https://doi.org/10.1109/TCSI.2020.3027583
Kornijcuk V, Kim D, Kim G et al (2020) Simplified calcium signaling cascade for synaptic plasticity. Neural Netw 123:38–51. https://doi.org/10.1016/j.neunet.2019.11.022
Krizhevsky A (2009) Learning multiple layers of features from tiny images https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
Lee C, Sarwar SS, Panda P et al (2020) Enabling spike-based backpropagation for training deep neural network architectures. Front Neurosci 14:119. https://doi.org/10.3389/fnins.2020.00119
Li H, Liu H, Ji X et al (2017) Cifar10-dvs: an event-stream dataset for object classification. Front Neurosci 11:309. https://doi.org/10.3389/fnins.2017.00309
Mirsadeghi M, Shalchian M, Kheradpisheh SR, et al (2021a) Spike time displacement based error backpropagation in convolutional spiking neural networks. arXiv preprint . https://doi.org/10.48550/arXiv.2108.13621
Mirsadeghi M, Shalchian M, Kheradpisheh SR et al (2021) Stidi-bp: spike time displacement based error backpropagation in multilayer spiking neural networks. Neurocomputing 427:131–140. https://doi.org/10.1016/j.neucom.2020.11.052
Moradi S, Qiao N, Stefanini F et al (2018) A scalable multicore architecture with heterogeneous memory structures for dynamic neuromorphic asynchronous processors (dynaps). IEEE Trans Biomed Circuits Syst 12(1):106–122. https://doi.org/10.1109/TBCAS.2017.2759700
Neckar A, Fok S, Benjamin BV et al (2019) Braindrop: a mixed-signal neuromorphic architecture with a dynamical systems-based programming model. Proc IEEE 107(1):144–164. https://doi.org/10.1109/JPROC.2018.2881432
Neftci EO, Mostafa H, Zenke F (2019) Surrogate gradient learning in spiking neural networks: bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process Mag 36(6):51–63. https://doi.org/10.1109/MSP.2019.2931595
Park S, Kim S, Na B et al (2020) T2fsnn: Deep spiking neural networks with time-to-first-spike coding. In: 2020 57th ACM/IEEE Design Automation Conference (DAC), pp 1–6. https://doi.org/10.1109/DAC18072.2020.9218689
Paszke A, Gross S, Massa F et al (2019) Pytorch: An imperative style, high-performance deep learning library. In: Advances in neural information processing systems, vol 32. Curran Associates, Inc
Pfeiffer M, Pfeil T (2018) Deep learning with spiking neurons: opportunities and challenges. Front Neurosci 12:774. https://doi.org/10.3389/fnins.2018.00774
Russakovsky O, Deng J, Su H et al (2015) Imagenet large scale visual recognition challenge. Int J Comput Vision 115(3):211–252. https://doi.org/10.1007/s11263-015-0816-y
Shrestha SB, Orchard G (2018) Slayer: Spike layer error reassignment in time. In: Advances in Neural Information Processing Systems, vol 31. Curran Associates, Inc
Stein RB (1965) A theoretical analysis of neuronal variability. Biophys J 5(2):173–194. https://doi.org/10.1016/S0006-3495(65)86709-1
Sun C, Chen Q, Fu Y, et al (2022) Deep spiking neural network with ternary spikes. In: 2022 IEEE Biomedical Circuits and Systems Conference (BioCAS), pp 251–254. https://doi.org/10.1109/BioCAS54905.2022.9948581
Tan PY, Wu CW, Lu JM (2021) An improved stbp for training high-accuracy and low-spike-count spiking neural networks. In: 2021 Design, Automation & Test in Europe Conference & Exhibition (DATE), pp 575–580. https://doi.org/10.23919/DATE51398.2021.9474151
Wu Y, Deng L, Li G et al (2018) Spatio-temporal backpropagation for training high-performance spiking neural networks. Front Neurosci 12:331. https://doi.org/10.3389/fnins.2018.00331
Wu Y, Deng L, Li G, et al (2019) Direct training for spiking neural networks: Faster, larger, better. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp 1311–1318, https://doi.org/10.1609/aaai.v33i01.33011311
Xiao H, Rasul K, Vollgraf R (2017) Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. https://doi.org/10.48550/arXiv.1708.07747
Yang G (2022) Asymptotic tracking with novel integral robust schemes for mismatched uncertain nonlinear systems. Int J Robust Nonlinear Control. https://doi.org/10.1002/rnc.6499
Yang G, Yao J (2022) Multilayer neuroadaptive force control of electro-hydraulic load simulators with uncertainty rejection. Appl Soft Comput 130(109):672. https://doi.org/10.1016/j.asoc.2022.109672
Yang G, Yao J, Dong Z (2022) Neuroadaptive learning algorithm for constrained nonlinear systems with disturbance rejection. Int J Robust Nonlinear Control 32(10):6127–6147. https://doi.org/10.1002/rnc.6143
Zenke F, Ganguli S (2018) Superspike: Supervised learning in multilayer spiking neural networks. Neural Comput 30(6):1514–1541. https://doi.org/10.1162/neco_a_01086
Zhang L, Zhou S, Zhi T et al (2019) Tdsnn: From deep neural networks to deep spike neural networks with temporal-coding. Proceedings of the AAAI Conference on Artificial Intelligence 33(1):1319–1326. https://doi.org/10.1609/aaai.v33i01.33011319
Zhang M, Wang J, Wu J et al (2021) Rectified linear postsynaptic potential function for backpropagation in deep spiking neural networks. IEEE Transactions on Neural Networks and Learning Systems 33(5):1947–1958. https://doi.org/10.1109/TNNLS.2021.3110991
Zhang W, Li P (2019) Spike-train level backpropagation for training deep recurrent spiking neural networks. In: Advances in Neural Information Processing Systems, vol 32. Curran Associates, Inc
Zhang W, Li P (2020) Temporal spike sequence learning via backpropagation for deep spiking neural networks. In: Advances in Neural Information Processing Systems, vol 33. Curran Associates, Inc
Zhao D, Zeng Y, Li Y (2022) Backeisnn: A deep spiking neural network with adaptive self-feedback and balanced excitatory-inhibitory neurons. Neural Netw 154:68–77. https://doi.org/10.1016/j.neunet.2022.06.036
Funding
This research was supported by National R &D Program through the National Research Foundation of Korea (NRF) funded by Ministry of Science and ICT (2021M3F3A2A01037632 and 2019R1C1C1009810).
Author information
Authors and Affiliations
Contributions
Conceptualization: Doo Seok Jeong, Dohun Kim, SeongMin Jin; Methodology: Dohun Kim, SeongMin Jin; Software: Doo Seok Jeong, Dohun Kim, SeongMin Jin, DongHyung Yoo; Investigation: Dohun Kim, SeongMin Jin, Jason Eshraghian; Writing-original draft: Doo Seok Jeong.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Code availability
The code is available in the GitHub repository, https://github.com/dooseokjeong/BPLC-NOSO.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A Derivation of backward propagation of errors
We define
The subthreshold membrane potential of NOSO is
Thus, the following equation holds when spiking with a spiking threshold \(\vartheta \).
For simplicity, we omit the spiking-availability function \(sav_i^{(l)}\) hereafter. The derivative \(\partial \hat{t}_{i}^{(l)}/\partial \hat{t}_{j}^{(l-1)}\) is acquired by differentiating Eq. (A3) with respect to \(\hat{t}_{j}^{(l-1)}\).
According to Theorem 1, the denominator of the right-hand side of Eq. (A4) equals \(\left( \partial \hat{t}_i^{(l)}/\partial u_i^{(l)}\right) ^{-1}\), and thus we have
Applying a chain rule on the left-hand side of Eq. (A5) yields the following equation—
Given that
Eq. (A6) is re-expressed as
According to Theorem 2,
Using Eq. (A7) at \(t=\hat{t}_i^{(l)}\), the following equation holds: \(\tau _{(\cdot )}^{-1}v_{j,(\cdot )}^{(l)}\left[ \hat{t}_i^{(l)}\right] =\partial v_{j,(\cdot )}^{(l)}/\partial \hat{t}_{j}^{(l)}\left[ \hat{t}_i^{(l)}\right] \), where \(\left( \cdot \right) \in \left\{ m, s\right\} \). Therefore, Eq. (A8) is re-arranged as
The error for the jth neuron in the \((l-1)\)th layer \(e_j^{(l-1)}\) is given by
Plugging Eq. (A9) into Eq. (A10) therefore leads to
Equation (A11) is expressed as the following matrix formula.
where
Appendix B Proofs of Theorems
Theorem 1
When an SRM neuron (whose membrane potential is \(u_i^{(l)}\)) spikes at a given time \(t (=\hat{t}_i^{(l)})\), the gradient of spike timing \(\hat{t}_i^{(l)}\) with membrane potential is given by
Proof
The update of weight \(w_{ij}^{(l)}\) is calculated using the gradient descent method as follows—
Regarding that \(u_i^{(l)}\left[ t\right] =w_{ij}^{(l)}v_j^{(l)}\left[ t\right] \), the gradient \(\partial u_i^{(l)}/\partial w_{ij}^{(l)}\left[ t\right] \) equals \(v_j^{(l)}\left[ t\right] \). Consequently, we have
Differentiating Eq. (A3) with \(w_{ij}^{(l)}\) yields
The left-hand side of Eq. (B14) is zero because the threshold \(\vartheta \) is constant. Thus, the following equation holds—
Plugging Eq. (B15) into Eq. (B12) yields
A comparison between Eqs. (B13) and (B16) indicates that the following equation holds.
The right-hand side of Eq. (B17) is obtained by differentiating Eq. (A2) with t and evaluating the derivative at the spike timing \(\hat{t}_i^{(l)}\), which finally leads to
where
\(\square \)
Theorem 2
When an SRM neuron receives an input spike at \(\hat{t}_j^{(l-1)}\), the gradients of \(v_{j,m}^{(l)}\) and \(v_{j,s}^{(l)}\) with respect to \(\hat{t}_j^{(l-1)}\) are given by
Proof
The variables \(v_{j,m}^{(l)}\) and \(v_{j,s}^{(l)}\) are given by
To be precise, the Heaviside step function in Eq. (B18) should be \(\Theta \left[ t-\hat{t}_{j}^{(l-1)}-\varepsilon \right] \) with \(\varepsilon \rightarrow 0^+\) because \(v_{j,\left( \cdot \right) }^{(l)}\) at \(\hat{t}_j^{(l-1)}\) is \(\tau _m/\left( \tau _m-\tau _s\right) \) rather than \(\tau _m/\left[ 2\left( \tau _m-\tau _s\right) \right] \). Given this substitution, differentiating Eq. (B18) with respect to \(\hat{t}_j^{(l-1)}\) yields
\(\square \)
Theorem 3
Spike-stamp vectors for NOSOs satisfy the following equation:
Proof
Because NOSOs spike once maximally, for all i, \(s_i^{(l)}\left[ t_1\right] s_i^{(l)}\left[ t_2\right] =0\) if \(t_1\ne t_2\), and \(s_i^{(l)}\left[ t_1\right] s_i^{(l)}\left[ t_2\right] =s_i^{(l)}\left[ t_1\right] \) if \(t_1 = t_2\). Therefore, Eq. (B19) is true. \(\square \)
Theorem 4
The weight update for the folded SNN,
is equivalent to the following equation—
where \(\varvec{v}^{(l)}[t]\) is given by \(\varvec{v}^{(l)}[t]=\left[ v_1^{(l)}[t],\cdots , v_m^{(l)}[t]\right] ^\textrm{T}\).
Proof
The error \(\varvec{e}^{(l)}\) is known to be
Using Eq. (B22) and a basic property of the Hamadard product, the matrix \(diag\left( \varvec{e}^{(l)\mathrm T}\right) \) on the right-hand side of Eq. (B20) is unfolded as
The matrix \(\varvec{v}^{(l)}\left[ \varvec{\hat{t}}^{(l)}\right] \) in Eq. (B20), given by
is unfolded as
Entering Eqs. (B23) and (B24) into Eq. (B20) yields
Note that \(diag\left( \varvec{s}^{(l)}\left[ t\right] \right) \varvec{s}^{(l)}\left[ t'\right] =\varvec{s}^{(l)}\left[ t\right] \odot \varvec{s}^{(l)}\left[ t'\right] \), which is always zero if \(t\ne t'\) according to Theorem 3. Therefore, we have
\(\square \)
Theorem 5
The backward propagation of errors
is unfolded over the timesteps as follows—
The all-one vector is denoted by \(\varvec{1}=\left[ 1,\cdots , 1\right] ^\textrm{T}\).
Proof
The matrix \(\varvec{v}^{(l)'}\left[ \varvec{\hat{t}}^{(l)}\right] \) in Eq. (B26),
is unfolded as
Its elements are given by
Note that the element \(\partial v_j^{(l)}/\partial \hat{t}_j^{(l-1)}\left[ t\right] \) is a continuous function of \(t \left( \ge \hat{t}_j^{(l-1)}\right) \), and \(\varvec{v}^{(l)'}\left[ \varvec{\hat{t}}^{(l)}\right] \) is the read of \(\varvec{A}^{(l)}\left[ t\right] \) at \(\varvec{\hat{t}}^{(l)}\) using \(\varvec{s}^{(l)}\). Plugging Eqs. (B22) and (B27) into Eq. (B26) yields
We use a general property of the Hadamard product,
where \(\varvec{w}\in \mathbb {R}^{n\times m}\), \(\varvec{a}\in \mathbb {R}^{n}\), \(\varvec{b}\in \mathbb {R}^{m}\), and \(\varvec{c}\in \mathbb {R}^{m}\). Equation (B30) is consequently arranged as
Using Theorem 3, we have
Considering the following equations—
The gradient \(\hat{\varvec{t}}^{(l-1)'}\) on the right-hand side of Eq. (B32) is unfolded as
From Eqs. (B32) and (B33), we have
Note that the lower limit of the summation over \(t'\) is set to t because \(\varvec{C}^{(l)}\left[ t'\right] \) in this equation becomes zero for any \(t'<t\) according to Theorem 2 (see the Heaviside step function). As such, \(\varvec{C}^{(l)}\left[ t'\right] =\left[ \partial v^{(l)}_1/\partial \hat{t}_1^{(l-1)}\left[ t'\right] ,\cdots \partial v^{(l)}_m/\partial \hat{t}_m^{(l-1)}\left[ t'\right] \right] ^\textrm{T}\). If we leave the presynaptic spike timing \(\hat{t}_j^{(l-1)}\) as a variable t, the element becomes
As shown in Eq. (B34), the variable t is the time argument of the presynaptic spike-stamp vector \(s^{(l-1)}\), so that t such that \(s_j^{(l-1)}\left[ t\right] =1\) is \(t_j^{(l-1)}\), rendering Eq. (B35) equal to Eq. (B29). For clearity, we introduce a new vector \(\varvec{B}^{(l)}\left[ t,t'\right] \) whose element is given by Eq. (B35). The product \(\varvec{\overline{e}}^{(l)}\left[ t'\right] \odot \varvec{s}^{(l)}\left[ t'\right] \) in Eq. (B33) is the error at the timestep \(t'\), i.e., \(\varvec{\tilde{e}}^{(l-1)}\left[ t'\right] \). Therefore, we eventually have
where
\(\square \)
Appendix C Proof of equivalence between folded and unfolded NOSONets
NOSONet can be unfolded on a computational graph to use the the automatic differentiation framework [31]. To begin with, we define a spike-stamp vector at timestep t (\(s^{(l)}\left[ t\right] \)) such that its element is ‘1’ if the corresponding NOSO spikes at the timestep, and ‘0’ otherwise.
Given that the variables \(u_{i,m}^{(l)}\) and \(u_{i,s}^{(l)}\) are continuous functions of time t, the gradient \(\partial \hat{t}_i^{(l)}/\partial u_i^{(l)}\) in Eq. (11) is the read-out of \(\left( u_{i,m}^{(l)}\left[ t\right] /\tau _m - u_{i,s}^{(l)}\left[ t\right] /\tau _s\right) ^{-1}\) at \(\hat{t}_i\). In this regard, Eq. (11) can be re-expressed as
Therefore, the error \(\varvec{e}^{(l)}\) in Eq. (9) is re-expressed as the read-out of the variable \(\varvec{\overline{e}}^{(l)}\left[ t\right] \) (calculated at every timestep) upon spiking:
Theorem 4
The weight update for the folded SNN,
is equivalent to the following equation.
Theorem 5
The backward propagation of errors in aggregate
is decomposed into timestep-wise errors \(\varvec{\tilde{e}}^{(l-1)}[t]\), each of which is calculated at every timestep, as follows:
The all-one vector is denoted by \(\varvec{1}=\left[ 1,\dots , 1\right] ^\textrm{T}\).
Theorems 4 and 5 are proven in Appendix B. Theorem 4 identifies the backward propagation of errors at timestep \(t'\) toward timestep t through time. Thus, BPLC + NOSO can be unfolded on a computational graph as shown in Fig. 2, allowing the automatic differentiation framework to be used to learn the weights. Note that we rule out the backward pass from \(sav^{(l)}\left[ t+1\right] \) to \(\varvec{s}^{(l)}\left[ t\right] \) because it can be ignored if the learning uses spike function gradients (rather than surrogate gradients) and refractory periods. This is proven in Appendix D.
Appendix D Gradient of the spike-availability function with respect to a spike from the previous timestep
Spike-function gradients are non-zero only when the neurons spike unlike surrogate gradients. The same neuron cannot spike at the consecutive timesteps in a row because of the refractory period. Consider the computational graph in Fig. 2. When the ith neuron in the lth layer is quiet at timestep \(t+1\), the gradient \(\partial \hat{t}_i^{(l)}/\partial u_i^{(l)}\left[ t+1\right] \) is zero, so that no gradient flows to \(s_i^{(l)}\left[ t\right] \) regardless of the presence of the backward pass. When the neuron is active at timestep \(t+1\) (i.e., quiet at timestep t), the gradient \(\partial \hat{t}_i^{(l)}/\partial u_i^{(l)}\left[ t+1\right] \) is non-zero. However, the gradient at timestep t is zero, so that the presence or absence of the backward pass does not affect any gradient flow.
Appendix E Hyperparameters
We used the hyperparameters in Table 3. The input scaling factor is an upper limit of the scaled pixel value of input image. We initialized the kernels and weight matrices using the Xavier uniform initialization method given by
where a is set to 6. The parameters in NOSONet (32C5-MP2-64C5-MP2-600) on Fashion-MNIST were initialized using the Xavier uniform method. We also initialized NOSONet (64C5-128C5-MP2-256C5-MP2-512C5-256C5-1024-512) on CIFAR-10 using the Xavier uniform method, but the weight matrices for the fully connected layers were initialized using a modified Xavier uniform method with \(a=3\) rather than 6.
Appendix F Potential distribution over samples in a batch
Figures 7 and 8 show potential distributions over samples in a random batch (batch size: 300) for single threshold and dual threshold cases, respectively. Note that the distributions exclude zero potential.

Potential distribution over samples in a random batch (size: 300) for single threshold NOSOs (\(\vartheta =0.1\))

Potential distribution over samples in a random batch (size: 300) for dual threshold NOSOs (\(\vartheta =\pm 0.15\))
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jin, S.M., Kim, D., Yoo, D.H. et al. BPLC + NOSO: backpropagation of errors based on latency code with neurons that only spike once at most. Complex Intell. Syst. 9, 4959–4976 (2023). https://doi.org/10.1007/s40747-023-00983-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-00983-y