
Abstract
Bipartite networks that characterize complex relationships among data arise in various domains. The existing bipartite network models are mainly based on a type of relationship between objects, and cannot effectively describe multiple relationships in the real world. In this paper, we propose a multi-relationship bipartite network (MBN) model, which can describe multiple relationships between two types of objects, and realizes simple weighted bipartite network reconstruction. Our model contains three major modules, namely multi-relationship bipartite network modeling (MBNM), multi-relationship aggregation module (MAM) and network reconstruction module (NRM). In MBNM, a multi-relationship bipartite network is proposed to describe multiple relationships between two types of objects. In the MAM, considering that different relationships have different information for the model, we introduce a novel relationship-level attention mechanism, and the aggregation of multiple relationships is carried out through the importance of each relationship. Based on the learning framework, the NRM can learn the potential representations of nodes after multi-relationship aggregation, and design a nonlinear fusion mechanism to reconstruct weighted bipartite network. We conducted extensive experiments on three real-world datasets and the results show that multi-relationship aggregation can effectively improve the performance of the model. In addition, experiments also show that our model can outperform existing competitive baseline method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In the era of information overload, the relationships in various domains can be characterized in the form of networks, including item recommendation [1], disease analysis [2], and social network research [3] to name a few. In light of the diversity of complex relationships in the real world, current research attention has been paid to the modeling of two objects on complex networks, giving rise to a novel and also powerful kind of network model, dubbed as bipartite network [4].
A bipartite network is a special network whose vertices are divided into two independent components, and edges only exist between two independent node components, and there are no edges between nodes of the same type [5].This specific type of network needs to be explored in many practical applications to achieve corresponding tasks [6,7,8,9], such as the disease-gene network [10, 11], drug-protein interaction network [12, 13], scientists-papers cooperation network [14], term-document network [15], club members-activities network [16], and investors-company network [17].
Despite a large number of striking research up to now has been published, most studies in the field of bipartite network only focused on a type of relationship, which cannot describe the complex multiple relationships in the real world. In real complex systems, there are multiple relationships between two types of objects. For example, in the recommendation system, there are multiple relationships such as browse, favorite, and purchase between users and items. In social networks, there are multiple relationships such as like, repost, and favorite between users and topics. The traditional bipartite networks can only model a single relationship between two types of nodes. However, each relationship between objects exhibits different semantic information. Modeling based on traditional bipartite networks cannot describe multiple complex relationships between two types of objects.
Based on this, we propose a novel multi-relationship bipartite network (MBN) model to describe the multiple relationships between two types of objects. This model aggregates multiple relationships and reconstructs a weighted bipartite network through a multi-layer neural network, which can not only reflect multiple relationships, but also achieve bipartite network modeling. The performance of the MBN model is proved through experiments. In addition, compared with the seven methods of MF, DMF, DAE, VAE, DeepLTSC, DeepTSQP and DLP, the MBN model has better performance. The main contributions in our paper are as follows:
-
(1)
The definition of multi-relationship bipartite network (MBN) is proposed, which effectively describes the complex multiple relationships between two types of objects in reality.
-
(2)
A novel relationship-level attention mechanism is introduced to focus on the importance of different relationships.
-
(3)
The nonlinear fusion mechanism based on depth features is designed to realize the reconstruction of the weighted bipartite network.
-
(4)
Experiments based on three real datasets demonstrate the effectiveness of our method and show that our method can outperform baseline methods.
Related work
Our work is related to the studies of bipartite network, attention mechanism, and collaborative filtering. Therefore, in this section, we briefly review the relevant literature in these areas.

Examples of related work
Bipartite network
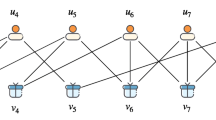
A bipartite network can abstract a complex system into a network composed of two types of nodes, and there are only edges between different types of nodes. It can describe complex systems with two types of objects and a single relationship, such as the purchase relationship between users and items, and the scientific research relationship between authors and papers. As shown in Fig. 1a, the bipartite network modeling of a complex system composed of user-item purchase relationships. The advantage of modeling complex systems as bipartite networks is that complex systems can be analyzed based on complex network theory, such as analyzing the stability of complex systems based on network analysis, predicting unknown relationships based on link prediction, and predicting network development trends based on network evolution. Based on its special structure, related research has received extensive attention. At present, the Bipartite Graph Neural Networks (BGNN) model based on the special structure of the bipartite network has received the greater attention [18]. To it essential characteristics, BGNN recursively updates each node feature through message passing (or aggregation) of its neighbors, by which the patterns of graph topology and node features are both captured, and then performing the corresponding recommendation. Based on the special structure of the bipartite network, this method proposes IDMP as the encoder and IDA by adversarial learning to address the node feature inconsistency issue in bipartite networks, and realize node representation learning. In addition, the GLICR model [19], the HRDR model [20] and the MARank model [21] are based on bipartite network, combined with item features and user comments for recommendation, which not only solves the problem of network sparseness, but also achieves excellent recommendation performance. Based on the bipartite network, this paper proposes a multi-relationship bipartite network (MBN) model, in which there are multiple types of edges between nodes to describe multiple relationships between objects in the real world.
Attention mechanism
The attention mechanism originates from human vision. Humans scan the global image to obtain the target area that needs to be focused on, and pay more attention to the area, while ignoring other irrelevant information. At present, in the field of deep learning, the attention mechanism mainly focuses on important features and ignores unimportant features, which are generally reflected in the form of weights. As shown in Fig. 1b, the process of paying attention to features. First, the feature is concerned, and the importance of the feature is expressed in the form of weights. Then, the weight and the feature are multiplied to obtain the attention-based feature, which amplifies the main feature and realizes the purpose of the model identifying the main feature information. Based on the attention mechanism, the importance of each latent features or factors can be distinguished to enhance the accuracy of the model. The attention mechanism is widely used in deep learning, among which the Heterogeneous Graph Attention Network (HAN) has received widespread attention [22]. Specifically, HAN is based on hierarchical attention, where the purpose of node-level attention is to learn the significance between a node and its meta-path based neighbors, and semantic-level attention can learn the importance of different meta-paths. In addition, in the recommendation system, HACN models users and items based on review text [23]. The model evaluates the contribution of each review text based on two layers of attention, and realizes the matching degree between the review texts and the target user (item). Based on this model, the feature representation of users and items can be adaptively enhanced, and effective information can be fully utilized to reduce the interference of irrelevant information. In addition, the DANet model [24] and the CBAM model [25] are based on the attention mechanism, which can enhance the discriminative ability of feature representations. In this paper, we introduce a novel relationship-level attention mechanism to focus on the importance of different relationships, and the aggregation of multiple relationships is carried out through the importance of each relationship.
Collaborative filtering
Collaborative filtering (CF) is the main technology based on interaction recommendation [26], which aims to represent users and items through latent feature vectors. Matrix Factorization (MF) is one of the most popular techniques. Matrix factorization splits a matrix into a product of smaller matrices. An example of matrix factorization is shown in Fig. 1c. There are unknown ratings in the rating matrix. Based on the known rating, the matrix is factorized to obtain two implicit matrices, and the unknown rating in the matrix is complemented by the implicit matrix. The MF model tries to learn the potential features of users and items by matching the user-item interaction matrix with the dot product (DP) operation [27]. Then, the rating prediction is made through the DP operation of the potential features for a given user-item pair. With the development of artificial intelligence, it has been naturally applied to the research of recommender systems [28]. The NeuMF model realizes the combination of neural network and matrix factorization [29]. The model inputs user and item feature vectors, and replaces the DP operation with a neural architecture to achieve deep collaborative filtering with implicit feedback. Based on the deep neural network architecture, NeuMF can model the potential feature interaction between users and items, and shows superior performance than existing latent factor learning techniques. In this paper, a multi-layer neural network is used to learn the latent features in the interaction matrix, and a nonlinear fusion mechanism is designed to realize the prediction of new interactions.

The network and the corresponding adjacency matrix
Definition of MBN
Definition 1
(Bipartite network) The bipartite network is defined as \(G = (U, V, E)\), where \(U = \left\{ u_1, u_2,..., u_m\right\} \) represents a type of node, and \(V = \left\{ v_1, v_2,..., v_n\right\} \) represents another type of node, and \(E = \left\{ e_1, e_2,..., e_k\right\} \) represents the interaction of the nodes in the set U and the set V. The bipartite network can be represented by the adjacency matrix \(A_\textrm{BN}\), Where i and j represent nodes in set U and set V, respectively.
Definition 2
(Weighted bipartite network) The weighted bipartite network is defined as \(G = (U, V, E, W)\). \(U = \left\{ u_1, u_2,..., u_m\right\} \), \(V = \left\{ v_1, v_2,..., v_n\right\} \), \(E = \left\{ e_1, e_2,..., e_k\right\} \), \(W = \left\{ w(e_1), w(e_2),..., w(e_k)\right\} \), \(w(e_i)\) is the weight of an edge \(e_i\). The weighted bipartite network can be represented by the adjacency matrix \(A_\textrm{WBN}\), where w represents the weight of the edge.
Definition 3
(Multi-relationship bipartite network) The multi-relationship bipartite network is defined as \(MG = (U, V, E^T)\). \(U = \left\{ u_1, u_2,..., u_m\right\} \), \(V = \left\{ v_1, v_2,..., v_n\right\} \), \(E = \left\{ e_1, e_2,..., e_k\right\} \), where \(T \in \left\{ t_1, t_2,..., t_l\right\} \) is the interaction type of different nodes. The Multi-relationship bipartite network can be represented by the adjacency matrix \(A_{MBN}\), where l represents the type of relationship.
As shown in Fig. 2, the schematic diagram of the network and the corresponding adjacency matrix, where \(U = \left\{ u_1, u_2, u_3\right\} \), \(V = \left\{ v_1, v_2, v_3\right\} \), w represents weight, and different edges represent different relationships.
The MBN model
The overview of MBN model is shown in Fig. 3. There are three modules in the MBN model: multi-relationship bipartite network modeling (MBNM), multi-relationship aggregation module (MAM) and network reconstruction module (NRM). The MBNM model multiple relationships between two types of objects, and describes complex multiple relationships in reality. Bipartite networks can only model one relationship between two types of nodes, and cannot effectively model complex systems with multiple relationships between users and items. Therefore, this paper proposes a multi-relationship bipartite network, which contains two types of nodes (users and items), and can describe various relationships between users and items. The MAM introduces a relationship-level attention mechanism to focus on the importance of different relationships, and realizes the aggregation of multiple relationships through the importance of each relationship. The attention mechanism is designed to analyze the influence of various relationships on purchase relationship, and predict the user purchasing relationship based on the importance of different relationships. The NRM designs a nonlinear fusion mechanism based on features to realize the reconstruction of the weighted bipartite network. This module learns representations of users and items through neural networks, and designs a fusion mechanism to predict user purchases of items.

The overview of MBN
Algorithm process
The workflow of MBN is depicted in Algorithm 1. First, the importance of each relationship to the target relationship (purchase) is calculated in a multi-relationship bipartite network. Next, the adjacency matrix of each relationship and its importance are weighted to obtain an adjacency matrix A, which contains all types of relationships. Then, the representation \(\varvec{X_u}\) of the users and the representation \(\varvec{X_v}\) of the items are learned based on neural networks. Finally, based on the product of \(\varvec{X_u}\) and \(\varvec{X_v}\), the fusion score \(\varvec{{\hat{R}}}\) of the user to purchase the item is obtained.

Multi-relationship bipartite network modeling (MBNM)
A type of relationship is often used by the existing works for bipartite network modeling. For example, nodes represent users and items, and edges represent purchase relationships. However, there are multiple relationships between objects in the real world, and modeling based on a type of relationship cannot describe the complex relationships between objects [30, 31]. Therefore, this paper proposes a multi-relationship bipartite network (MBN), in which vertices are divided into two independent components, multiple types of edges only exist between two independent node components, and there are no edges between nodes of the same type.
The structure of MBN is complex, and it is more difficult to analyze than a type of relationship network. Therefore, we consider transforming the MBN into bipartite networks, where each bipartite network represents a type of relationship. Assuming that there are l types of relationships, MBN is represented as l bipartite networks, each bipartite network represents a type of relationship, and these bipartite networks are independent of each other. These l bipartite networks can be represented by adjacency matrices \(A_\textrm{BN}^1\), \(A_\textrm{BN}^2\),...,\(A_\textrm{BN}^l\), respectively.
Multi-relationship aggregation module (MAM)
In Multi-relationship Aggregation Module (MAM), we will explore how to aggregate multiple relationships between two types of objects. One popular aggregation function is the mean operation, where we can simply average the contribution of each relationship. However, different relationships are of different usefulness, and contribute differently for modeling. Hence, we propose to design a novel relationship-level attention mechanism to focus on the importance of relationships, and realize the aggregation of multiple relationships through the attention mechanism. The aggregation of multiple relationships is computed by the following formula:
Among them, A represents the adjacency matrix after the aggregation of multiple relationships; \(w_1\), \(w_2\),..., \(w_l\) represent the attention parameter, which reflects the importance of relationships.
Network Reconstruction module (NRM)
In Network Reconstruction Module (NRM), we will learn the representations of nodes via multi-layer neural network from adjacency matrix A. There are two multi-layer neural networks in NRM, User Network and Item Network. In the case of users and items in the recommendation system, the User Network learns the representation of users, and the Item Network learns the representation of items. Since the User Network and the Item Network have similar structures, we will focus on illustrating the User Network in detail. The same process is applied for Item Network. We utilize the multi-layer neural network, which can learn the feature of the user from the adjacency matrix A as follows:
Where the input \({\varvec{x}}\) of the User Network is a row in the adjacency matrix A (i.e., the feature of the user), h is the number of hidden layers in the neural network, \(\varvec{\sigma }\) is a sigmoid function, \({\varvec{w}}\) represents the parameter weight, \({\varvec{b}}\) represents the bias. Based on the learning of the neural network, the representation \(\varvec{x^h}\) of user is obtained. The features of m users are represented as \(X_u\) = [\(x^h_1\), \(x_2^h\),...\(x_m^h\)]. Similarly, we can also get the representation of item in a similar way.
Based on the multi-layer neural network, the User Network outputs the depth feature \(\varvec{X_u}\) of the user, and the Item Network outputs the depth feature \(\varvec{X_v}\) of the item, and designs a nonlinear fusion mechanism to calculate the fusion score between user and item, and then the weighted bipartite network is reconstructed based on the fusion score. The formula of this nonlinear fusion mechanism is as follows:
where \({\hat{R}}\) represents the fusion score, \(\varvec{X_u}\) and \(\varvec{X_v}\) represent the depth features of users and items, respectively, \(\varvec{\sigma }\) is an activation function. Since the nonlinear fusion mechanism obtains continuous values, this paper employs the square loss function to train MBN model. In addition, the L2 regularization term is introduced into the loss function to improve the generalization ability of the model and avoid over-fitting. Assuming that the model is over-fitting, the value of the parameter w will generally be relatively large. w can be constrained based on the size of the parameter \(\alpha \). Therefore, our final loss function is expressed as:
where u denotes the set of users, v denotes the set of items, \(R_{ij}\) denotes the real purchase relationship, \(\alpha \) is the regularization parameter, w represents the parameter weight in the model, and Q represents the number of w.
Experiment
Experiments were performed on a workstation equipped with Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz, NVIDIA Geforce GTX 1080Ti GPU and 192 GB RAM. The time complexity of this method is O(\(l \times m \times n \times \mid w \mid \))+O(\(m \times n \times \) (\(\mid w 1\mid \)+\(\mid w 2\mid \)))+O(\(m \times n \times d\)). l represents the number of relationships, \(\mid w \mid \) is the number of attention parameters, m is the number of users, n is the number of items, \(\mid w 1\mid \) and \(\mid w 2\mid \) are the number of parameters in the neural networks, and d is the output dimension of the neural network. In the experiments, the running times on the real datasets are used to verify the time complexity of the algorithm. The running times of the experiments on the three datasets are 145.4 s, 178.0 s, and 243.4 s, respectively. The modules of MBN in the experiments are implemented by Python 3.8.3 with Pytorch 1.11.0. The MBN model adopts the Adam optimizer with parameters lr = 0.1, weight_decay = 5e–4.
Dataset investigation
To evaluate the performance of MBN, we used the User Behavior dataset, which is a dataset of user behaviors from TaoBao [32,33,34]. At the same time, we also evaluate our MBN on two datasets collected from MovieLens [35] and Ciao [36]. These datasets contain user ratings for items 1–5. In this paper, the ratings are divided into five behaviors for analysis, \(r = 1\): very dislike behavior; \(r = 2\): dislike behavior; \(r = 3\): neutral behavior; \(r = 4\): like behavior; \(r = 5\): very like behavior. This paper regards very like behavior (\(r = 5\)) as the main relationship, and other behaviors (\(r = 1-4\)) as auxiliary relationships. In this paper, the User Behavior dataset is introduced in detail and used as the main research object to analyze the impact of user relationship on purchases. This dataset randomly selected users who have behaviors including click, purchase, adding item to shopping cart and item favoring during November 25 to December 03, 2017. The dataset contains 4 different types of behaviors, they are Pv: page view of an item’s detail page, equivalent to an item click, Fav: favor an item, Cart: add an item to shopping cart, Buy: purchase an item. In this paper, we take the item category as the item, where Buy is the label, and Pv, Fav and Cart are the multiple relationships between users and items. In addition, we select three small datasets as experimental dataset, as shown in Table 1. Based on the same data processing for datasets MovieLens and Ciao.
In this paper, the three relationships of Pv, Fav, and Cart are used as auxiliary relationships, and purchase relationships are used as targets. Distinguish which types of auxiliary relationships are more important in the forecasting task on the target relationship. In the MB-GMN model, the purchase behavior is regarded as the target behavior, and other behaviors (page view, add-to-cart) are regarded as auxiliary behaviors [40]. In the CML model, the purchase behaviors are set as the target behaviors and other types of interactions are considered as the auxiliary behaviors [41]. In the KHGT model, page view, add-to-cart, and add-to-favorite are used as auxiliary behavioral signals to predict the impact on target behaviors (purchases) [42]. These research show that it is feasible to predict purchase relationship based on auxiliary relationships. Therefore, this paper predicts the target relationship (purchase) based on the auxiliary relationship (Pv, Fav, Cart).
In this paper, BR is based on statistical knowledge. The BR idea is the ratio of purchases in Pv relationships, the ratio of purchases in Fav relationships, and the ratio of purchases in Cart relationships. BR counts which relationship has a greater impact on the purchase relationship. The meaning of the formula is the proportion of the target relationships under certain auxiliary relationships, which reflects the importance of the auxiliary relationship. As shown in Fig. 4, an example of BR calculation, the Cart relationship is carried out for three items, and only two of them are purchased. Therefore, BR is calculated to be equal to 2/3, which reflects the importance of the Cart relationship to the purchase.
Among them, \(\textrm{behavior}\) represents the number of interactions between user and the item based on a type of relationship, and \(\textrm{buy}\) represents the number of purchases based on this relationship.

An example of BR calculation
As shown in Table 2, based on the Cart relationship between user and item, BR is the highest, which indicates that the Cart relationship is the most important when purchasing item, and this relationship can better guide users to purchase item. Based on the PV relationship between user and item, BR is the lowest, which shows that this type of relationship has a weaker impact on the purchase of item. In addition, the number of PV relationships is the most, and the bipartite network based on this type of relationship is dense; the number of Fav relationships is the least, and the bipartite network is the sparsest.
Baseline method
We evaluate our method with the following baseline methods:
MF [37]: Based on matrix factorization, sparse matrix can be factored into low-dimensional latent vectors, and potential relationships can be mined based on latent vectors. At the same time, the program is simple and easy to implement.
DMF [38]: Based on the latent vectors obtained by MF and the characteristics of machine learning, the deep latent features between users and items can be mined.
DAE [39]:Based on the characteristics of high dimension and sparsity of the data, it is necessary to reduce the dimension of the data. This paper selects DAE for processing to ensure the robustness of the output data. The method introduces noise into the input data, compresses the data into a low-dimensional feature space based on encoding, and restores noise-free data based on decoding, and represents nodes by low-dimensional features.
VAE [43]: VAE can learn the smooth hidden state of input data, and the encoded data can not only be effectively distinguished, but also have intersection in distribution. This method is based on AE (Auto-Encoder), in which the encoder represents the potential features based on probability distribution, and then reconstructs the input based on the decoder.
DeepLTSC [44]: This method is a novel implicit service feature extraction and service feature augmentation model, which can extract implicit features and enhance them, which can comprehensively improve the prediction accuracy on all of service categories.
DeepTSQP [45]: This method proposes a new feature representation method, and the hidden features are mined in the context content of nodes to realize QoS prediction.
DLP [46]: The method extracts the latent features between target nodes based on the local structure of the bipartite network, and completes the link prediction based on the deep learning framework.
Evaluation metrics
The performance of the model is evaluated based on 5-fold cross validation. The 5-fold cross validation divides the dataset into 5 independent equal parts, and then one part (20%) is used as the test dataset, and the remaining 4 parts (80%) are used as the training dataset. This process is repeated 5 times, and the trained model is obtained on average.
The well-known Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) are adopted for performance evaluation [47, 48]. MAE reflects the error of the measurement, and RMSE reflects the precision of the measurement. The main difference between MAE and RMSE is that the measurement methods are different, and the performance of the model is evaluated based on the error. In this paper, there is a purchase relationship between user and item, the target value is 1, and no purchase relationship is regarded as 0. Three relationships, Pv, Fav, and Cart, are input into our model to predict purchase relationship values. At the same time, the MovieLens and Ciao datasets are used as experimental subjects. These datasets contain user ratings for items 1–5. In this paper, a score of 5 is considered the target relationships, and 1–4 are considered auxiliary relationships. The model is evaluated based on the MAE and RMSE between the target value and the predicted value obtained by the model. RMSE and MAE can be calculated by the following formulas:
Where \(r_{ij}\) is the true value, if there is a relationship between i and j, \(r_{ij}\) = 1, otherwise \(r_{ij}\) = 0, \({{\hat{r}}}_{ij}\) is the predicted value of the MBN model, and L is the number of observation samples.
Results
Performance comparison
We compared our method with the above baselines in terms of MAE and RMSE, and the results are shown in Table 3. We have the following observations:
-
(1)
MBN achieves the best performance on all the datasets, which consistently and significantly outperforms all the baselines. It indicates that MBN is beneficial to describe the purchase relationship between users and items.
-
(2)
On the five datasets, in terms of MAE, MBN has achieved an overall reduction of 0.391, 0.412, 0.421, 0.218 and 0.329, which shows that the aggregation of multiple relationships can reduce the error between the predicted value and the actual value.
-
(3)
As we can see, in terms of RMSE, the overall reduction of the MBN model on the five datasets is 0.804, 0.948, 0.857, 0.462 and 0.819. The RMSE of the DLP model is the largest, indicating that the model has a huge fluctuation between the predicted value and the true value. At the same time, the RMSE of the MBN on all datasets is stable, indicating that the prediction result of the model is stable.
-
(4)
The MBN method obtains the smallest variance, indicating that the fluctuation of the prediction results is small, and the performance is stable.
Result on a type of relationship

The performance of the MBN model is based on the aggregation of the two types of relationships. A MAE and RMSE based on the aggregation of Pv and Fav, where the abscissa represents the Attention of Pv, and the Attention of Fav is 1-Attention. B MAE and RMSE based on the aggregation of Pv and Cart, where the abscissa represents the Attention of Pv, and the Attention of Cart is 1-Attention. C MAE and RMSE based on the aggregation of Fav and Cart, where the abscissa represents the Attention of Fav, and the Attention of Cart is 1-Attention
In this section, modeling is based on a type of relationship, that is, only one relationship is used for modeling in the MBN model. As shown in Table 4, based on the Cart relationship, this model has the smallest MAE and RMSE, which shows that the Cart relationship has the most significant impact on purchases, and the results are consistent with the dataset investigation.
Result on two types of relationship
In this section, modeling is based on two types of relationships. As shown in Fig. 5, the performance of the MBN model is based on the aggregation of the two types of relationships. In terms of Pv and Fav aggregation, when the Attention of Pv and Fav are 0.2 and 0.8, respectively, MAE and RMSE are the smallest. As far as the aggregation of Pv and Cart is concerned, when the Attention of Pv and Cart is 0.2 and 0.8, MAE and RMSE are the smallest. In terms of Fav and Cart aggregation, when the Attention of Fav and Cart are 0.1 and 0.9, respectively, MAE and RMSE are the smallest.

The aggregation performance of three types of relationships, where the coordinates represent the Attention of the corresponding relationships and MAE values
As shown in Table 5, the best performance based on two types of relationship. When aggregation is based on Pv and Cart, MBN has the smallest MAE and RMSE on the three datasets. This shows that compared to the aggregation of other relationships, the aggregation of Pv and Cart can reflect the relationship characteristics of users when buying items.

The comparison of cross-network computing and our method
Result on multi-relationships
This section will verify the performance of multi-relationship aggregation. Modeling is based on three types of relationships to analyze the performance of the MBN model. As shown in Fig. 6, when the Attention of Pv, Fav and Cart are 0.2, 0.1 and 0.7 respectively, MBN has the best performance in terms of MAE on the three datasets.
As shown in Table 6, compared to the above work, the aggregation of the three types of relationships can improve the performance of the model, and the average MAE is reduced by 0.045, 0.043, and 0.040, respectively. This shows that the aggregation of multiple relationships can truly describe real purchase relationships.
Discussion
The MBN adds complexity to represent a group of independent bipartite networks. It is thus simpler to have those independent bipartite networks and perform any necessary cross-network computations when needed. However, cross-network computation requires a large number of edge relationships, such as cross-network computation between drug-target, drug-disease, and disease-RNA networks. These cross-network computations require a large number of edge relationships, not only drug-target relationships, but also drug–drug, disease-disease relationships [49,50,51]. The datasets in the paper are very sparse, with sparseness of 0.101%, 0.091%, and 0.088%, respectively, which shows that cross-network computation is not advantageous. As shown in Fig. 7a, a cross-network example of multi-relationship sparse network, there is disconnection between the networks, and cross-network computation cannot be performed. Based on cross-network computation, additional edge relationship information is required, such as adding edge relationship information between \(u_2\) and \(u_3\) or between \(v_1\) and \(v_3\) to connect each network. However, user-user and item-item relationships do not exist in the dataset. At the same time, users and items are represented by ids, and the ids are independent of each other. Moreover, the user’s information involves privacy, and more additional information cannot be obtained to establish the edge relationship. Therefore, we do not perform cross-network computations.
Our method is represented based on a group of independent bipartite networks, whose purpose is to obtain the importance of each relationship based on the attention mechanism, and to obtain the adjacency matrix containing various relationship information based on the attention weight. Then the latent features \(X_u\) and \(X_v\) of users and items are mined based on the adjacency matrix. Finally, the adjacency matrix R is completed based on the idea of matrix factorization. Specifically, as shown in Fig. 7b. The essence of our method is to learn the latent features of users and items based on a group of independent bipartite networks and predict the purchase relationship between users and items based on the features. This method can effectively deal with sparse networks and make up for the shortcomings of cross-network computation.
Conclusion
In this paper, based on the multiple relationships between two types of objects in the real world, a multi-relationship bipartite network (MBN) model is proposed. This model introduces a relationship-level attention mechanism that aggregates various relationships based on the importance of the relationship. At the same time, a nonlinear fusion mechanism is designed to reconstruct the weighted bipartite network based on the depth features. Extensive experiments have shown that MBN can better describe the multiple relationships between users and items in e-commerce. The relationship between two types of objects in the real world is generally multiple, and modeling based on only one type of relationship cannot describe complex relationships. This model belongs to a more general framework, which can model bipartite networks based on multiple relationships, such as multiple relationships between users and items, drugs and diseases, and researchers and papers, etc. There are still some problems to be studied in the future. For example, there are relationships between objects of the same type in the real world, and these relationships are also of great significance for depicting complex systems in reality. In the future, we will establish edges between nodes of the same type in MBN, aiming to describe complex relationships in reality more truly and effectively.
References
Zhao Z, Zhang X, Zhou H, Li C, Gong M (2020) HetNERec: heterogeneous network embedding based recommendation. Knowl Based Syst 204:106218
Zhao T, Yang H, Valsdottir LR, Zang T, Peng J (2021) Identifying drug-target interactions based on graph convolutional network and deep neural network. Brief Bioinform 22:2141–2150
Ren L, Zhu B, Zeshui X (2021) Robust consumer preference analysis with a social network. Inform Sci 566:379–400
Guillaume J, Latapy M (2006) Bipartite graphs as models of complex networks. Physica A Stat Mech Appl 371:795–813
Gao M, Chen L, Li B, Li Y, Liu W, Yongcheng Xu (2017) Projection-based link prediction in a bipartite network. Inform Sci 376:158–171
Calderer G, Kuijjer ML (2021) Community detection in large-scale bipartite biological networks. Front Gen 12:649440
Gao M, Chen L, He X, Zhou A (2018) BiNE: bipartite network embedding. In: The 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, pp 715-724
Jiao P, Tang M, Liu H, Wang Y, Chunyu L, Huaming Wu (2020) Variational autoencoder based bipartite network embedding by integrating local and global structure. Inform Sci 519:9–21
Chang F, Zhang B, Zhao Y, Songxian W, Yoshigoe K (2019) Overlapping community detecting based on complete bipartite graphs in micro-bipartite network bi-egonet. IEEE Access 7:91488–91498
He M, Huang C, Liu B, Wang Y, Li J (2021) Factor graph-aggregated heterogeneous network embedding for disease-gene association prediction. BMC Bioinform 22:165
Wang X, Gong Y, Yi J, Zhang W (2019) Predicting gene-disease associations from the heterogeneous network using graph embedding. In: IEEE International Conference on Bioinformatics and Biomedicine, pp 504-511
Wang W, Lv H, Yuan Z, Liu D, Wang Y, Zhang Y (2020) DLS: a link prediction method based on network local structure for predicting drug-protein interactions. Front Bioeng Biotechnol 8:330
Wang W, Lv H, Zhao Y (2020) Predicting DNA binding protein-drug interactions based on network similarity. BMC Bioinform 21:322
Li Y, Wen A, Lin Q, Li R, Zhengding L (2014) Name disambiguation in scientific cooperation network by exploiting user feedback. Artif Intell Rev 41:563–578
Klimek P, Jovanovic AS, Egloff R, Schneider R (2016) Successful fish go with the flow: citation impact prediction based on centrality measures for term-document networks. Scientometrics 107:1265–1282
Coates D, Naidenova I, Parshakov P (2020) Transfer policy and football club performance: evidence from network analysis. Int J Sport Fin 15:95–109
Villiers C (2014) The role of investor networks in transnational corporate governance, networked governance, 285–313. Springer, Berlin
He C, Xie T, Rong Y, Huang W, Li Y, Huang J, Ren X, Shahabi C (2020) Bipartite graph neural networks for efficient node representation learning. In: The Thirty-Fourth AAAI Conference on Artificial Intelligence
Liu H, Liu H, Ji Q, Zhao P, Xindong W (2020) Collaborative deep recommendation with global and local item correlations. Neurocomputing 385:278–291
Liu H, Wang Y, Peng Q, Fangzhao W, Gan L, Pan L, Jiao P (2020) Hybrid neural recommendation with joint deep representation learning of ratings and reviews. Neurocomputing 374:77–85
Yu L, Zhang C, Liang S, Zhang X (2019) Multi-order attentive ranking model for sequential recommendation. In: The Thirty-Third AAAI Conference on Artificial Intelligence, pp 5709-5716
Wang X, Ji H, Shi C, Wang B, Cui P, Yu P, Ye Y (2019) Heterogeneous graph attention network. In: The 2019 World Wide Web Conference, pp 11
Yongping D, Wang L, Peng Z, Guo W (2021) Review-based hierarchical attention cooperative neural networks for recommendation. Neurocomputing 447:38–47
Fu J, Liu J, Tian H, Li Y, Bao Y, Fang Z, Lu H (2020) Dual attention network for scene segmentation. In: the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 3146-3154
Woo S, Park J, Lee J (2018) In So Kweon, CBAM: convolutional block attention module. In: the European Conference on Computer Vision, pp 3-19
Xiaoyuan S, Khoshgoftaar TM (2009) A survey of collaborative filtering techniques. Adv Artif Intell 2009:1–19
Salakhutdinov R, Mnih A (2007) Probabilistic matrix factorization. In: the Advances in Neural Information Processing Systems 20, pp 1257-1264
Zhang Q, Jie L, Jin Y (2021) Artificial intelligence in recommender systems. Complex Intell Syst 7:439–457
He X, Liao L, Zhang H, Nie L, Hu X, Chua T (2017) Neural collaborative filtering. In: the 26th International Conference on World Wide Web, pp 173-182
Li X, Wang J, Zhao B, Fangxiang W, Pan Y (2016) Identification of protein complexes from multi-relationship protein interaction networks. Hum Genom 10:61–70
Nian F, Yao S (2018) The epidemic spreading on the multi-relationships network. Appl Math Comput 339:866–873
Zhuo J, Xu Z, Dai W, Zhu H, Li H, Xu J, Gai K (2020) Learning optimal tree models under beam search. In: the 37th International Conference on Machine Learning, pp 11650-11659
Zhu H, Li X, Zhang P, Li G, He J, Li H, Gai K (2018) Learning tree-based deep model for recommender systems. In: The 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 1079-1088
Zhu H, Chang D, Xu Z, Zhang P, Li X, He J, Li H, Xu J, Gai K (2019) Joint optimization of tree-based index and deep model for recommender systems. In: The 33rd Conference on Neural Information Processing Systems, pp 3973-3982
Xia L, Huang C, Xu Y, Dai P, Lu M, Bo L (2021) Multi-behavior enhanced recommendation with cross-interaction collaborative relation modeling. In: 37th IEEE International Conference on Data Engineering, pp 1931-1936
Lin J, Chen S, Wang J (2022) Graph neural networks with dynamic and static representations for social recommendation. In: Database Systems for Advanced Applications - 27th International Conference, pp 264-271
Koren Y, Bell R, Volinsky C (2009) Matrix factorization techniques for recommender systems. Computer 42:30–37
Xue H, Dai X, Zhang J, Huang S, Chen J (2017) Deep matrix factorization models for recommender systems. In: The Twenty-Sixth International Joint Conference on Artificial Intelligence, pp 3203-3209
Geoffrey E, Hinton, Osindero S, Teh YW (2006) A fast learning algorithm for deep belief nets. Neural Comput 18:1527–1554
Xia L, Xu Y, Huang C, Dai P, Bo L (2021) Graph meta network for multi-behavior recommendation. In: the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp 757-766
Wei W, Huang C, Xia L, Xu Y, Zhao J, Yin D (2022) Contrastive meta learning with behavior multiplicity for recommendation. In: the Fifteenth ACM International Conference on Web Search and Data Mining, pp 1120-1128
Xia L, Huang C, Xu Y, Dai P, Zhang X, Yang H, Pei J, Bo L (2021) Knowledge-enhanced hierarchical graph transformer network for multi-behavior recommendation. In: Thirty-Fifth AAAI Conference on Artificial Intelligence, pp 4486-4493
Kingma DP, Max W (2014) Auto-encoding variational bayes. In: 2nd International Conference on Learning Representations
Zou G, Yang S, Duan S, Zhang B, Gan Y, Chen Yixin (2022) DeepLTSC: long-tail service classification via integrating category attentive deep neural network and feature augmentation. IEEE Trans Netw Serv Manag 19:922–935
Zou Gu, Li T, Jiang M, Hu S, Cao C, Zhang B, Gan Y, Chen Y (2022) DeepTSQP: temporal-aware service qos prediction via deep neural network and feature integration. Knowl Syst 241: 108062
Lv H, Zhang B, Shengxiang H, Zhikang X (2022) Deep link-prediction based on the local structure of bipartite networks. Entropy 24:610
Fan W, Ma Y, Li Q, He Y, Zhao E, Tang J, Yin D (2019) Graph neural networks for social recommendation. In: The 2019 World Wide Web Conference, pp 417-426
Mingsheng F, Hong Q, Moges D, Li L (2018) Attention based collaborative filtering. Neurocomputing 311:88–98
Wang W, Yang S, Zhang X, Li J (2014) Drug repositioning by integrating target information through a heterogeneous network model. Bioinformatics 30:2923–2930
Chen X, Jia Q, Yin J (2018) TLHNMDA: triple layer heterogeneous network based inference for MiRNA-disease association prediction. Front Gen 9:234
Wang W, Yang S, Li J (2013) Drug target predictions based on heterogeneous graph inference. In: Proceedings of the Pacific Symposium, pp 53-64
Acknowledgements
This work was supported by National Key R &D Program of China (No. 2017YFC0907505)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lv, H., Zhang, B., Li, T. et al. Construction and analysis of multi-relationship bipartite network model. Complex Intell. Syst. 9, 5851–5863 (2023). https://doi.org/10.1007/s40747-023-01038-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01038-y