
Abstract
It is imperative to comprehensively evaluate the function, cost, performance and other indices when purchasing a hypertension follow-up (HFU) system for community hospitals. To select the best software product from multiple alternatives, in this paper, we develop a novel integrated group decision-making (GDM) method for the quality evaluation of the system under the interval-valued q-rung orthopair fuzzy sets (IVq-ROFSs). The design of our evaluation indices is based on the characteristics of the HFU system, which in turn represents the evaluation requirements of typical software applications and reflects the particularity of the system. A similarity is extended to measure the IVq-ROFNs, and a new score function is devised for distinguishing IVq-ROFNs to figure out the best IVq-ROFN. The weighted fairly aggregation (WFA) operator is then extended to the interval-valued q-rung orthopair WFA weighted average operator (IVq-ROFWFAWA) for aggregating information. The attribute weights are derived using the LINMAP model based on the similarity of IVq-ROFNs. We design a new expert weight deriving strategy, which makes each alternative have its own expert weight, and use the ARAS method to select the best alternative based on these weights. With these actions, a GDM algorithm that integrates the similarity, score function, IVq-ROFWFAWA operator, attribute weights, expert weights and ARAS is proposed. The applicability of the proposed method is demonstrated through a case study. Its effectiveness and feasibility are verified by comparing it to other state-of-the-art methods and operators.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Hypertension is a chronic disease that requires long-term medication for patients. Some hypertensive patients can cause stroke and other comorbidities and can even lead to disability and death [65]. When about 1.28 billion people suffer from hypertension worldwide, failure to manage this disease effectively poses a heavy economic burden on both patients and the whole society [32, 61, 66]. Research results show that scientific intervention can control and reduce the risk of hypertension, and disease the development of associated cardiovascular and cerebrovascular in some cases prevent [32, 45, 47, 61, 65, 66]. However, a shortage of knowledgeable medical staff and poor patient self-management awareness continues to impede the further improvement of hypertension prevention levels [36]. To this end, researchers proposed the hypertension community management system that can provide better services for patients [27, 37, 54, 58, 82]. This system is safe, reliable and easy-to-use and it enables health facilities to treat hypertension more efficiently. It is no surprise that many community hospitals have purchased and started to use this system, thus raising the question of quality evaluation. Researchers are now calling for hypertension and software experts to come together to evaluate hypertension management systems [7, 8, 74]. For the software evaluation, the Institute of Electrical and Electronics Engineers (IEEE) has published different versions of the ISO/IEC standard [28], even though it is challenging to evaluate the application using these standards [4]. Researchers have proposed other evaluation methods and indices for different application scenarios according to actual requirements [70, 77]. For hospitals, the hypertension management system needs to meet performance, security, and scalability requirements while also meeting functional requirements [7, 8]. Its public-facing nature means it also needs to be easy-to-use [53, 64]. After the system is deployed and implemented, high-quality maintenance services are essential [26]. The evaluation indices of the hypertension community management system can be divided into product quality and post-services according to user aspects. Product quality indices are cost, function, performance, reliability, safety, scalability, integration, ease-of-use, and maintainability [11, 60] and post-service indices are supplier’s stability, follow-up services, and software deployment time [1, 6]. The indices required for the evaluation of the HFU system studied in this paper are described in “Evaluation indices of the HFU system”.
In the process of software evaluation decision-making, the flexibility of the information that experts can express is different depending on the fuzzy environment [46, 51, 56, 63]. As a software evaluation environment, researchers have proposed Fuzzy Sets [26], Intuitionistic Fuzzy Sets (IFSs) [60, 74], Type-2 Fuzzy Sets [7, 8], Pythagorean Fuzzy Sets (PFSs) [11], Interval-valued Intuitionistic Fuzzy Sets (IVIFSs) [7, 8], and Triangular Fuzzy Numbers (TFNs) [1]. A q-rung orthopair fuzzy set (q-ROFS) introduced by Yager [68] is also widely used in GDM [38]. The q-ROFSs are further generalized and applied to the fusion of various operators and decision methods. For example, Liu and Hussain proposed a new aggregation operator based on q-ROFSs [23, 39]. With non-cooperative game method introduced into q-ROFSs, Yang [71] theorized competitive strategy GDM problems based on a hybrid dynamic experts’ weight-determining model. The q-ROFSs were used to solve multi-attribute decision-making (MADM problems [15, 40], and they also have been applied to the group MADM (MAGDM) problem. To express the information of experts more freely, researchers developed IVq-ROFSs [31]. Yang [72] studied the GDM with incomplete interval-valued q-rung orthopair fuzzy (IVq-ROF) preference relations. New exponential operation laws and operators of IVq-ROFSs were developed by Garg [16, 17]. The IVq-ROFS FMEA was applied to improve the risk evaluation process of the tool changing manipulator [29]. Zhang [81] proposed an NA Operator based IVq-ROFSs, and Khan [34] used the combinative distance-based method to evaluate and select the strategy for a green supply chain under IVq-ROF environment. Moreover, the IVq-ROFSs were applied to sustainable smart waste management system evaluation using the multi-criteria decision-making (MCDM) model [57]. IVq-ROFSs have been applied in GDM [14, 16, 17, 72], but have not yet been applied to software management and assessment. In order to make it easier for software experts to evaluate the hypertension management system, IVq-ROFS is applied to the evaluation process in this paper.
Aggregation operators are used for fusing information provided by experts [3, 5, 13], such as weighted averaging (WA) [67], neutral aggregating (NA) [18], and power aggregating (PA) [69] operators. Some researchers have also extended their applications by considering the features of the IVq-ROFSs, for example, IVq-ROFWAMM and IVq-ROFAMM [13, 63]. Saha et al. [55] developed the q-rung orthopair fuzzy weighted fairly aggregation operator (q-ROFWFA) which exhibits neutral characteristics in the aggregating process. To minimize the impact of aggregating information from different software experts and enhance the quality of the evaluation information coming from the hypertension system, we extend the q-ROFWFA operator to interval-valued q-rung orthopair fuzzy weighted fairly aggregation operator (IVq-ROFWFAWA) in this paper.
Although aggregation operators can fuse information, they cannot handle complex problems. Many decision-making methods can be used, for example, the Linear Programming Technique for Multidimensional Analysis of Preference (LINMAP), Technique for Order Preference by Similarity to Ideal Solution (TOPSIS), multi-attributive border approximation area comparison (MABAC), MACBETH, VlseKriterijumska Optimizacija I Kompromisno Resenje (VIKOR), complex proportional assessment (COPRAS) and Interactive and Multicriteria Decision Making (TODIM) [2, 24, 42, 48, 59]. Among them, LINMAP [59] is a typical compromise model which can be used to derive weights [80] and widely applied in practical decision-making problems [9, 12, 35, 80]. Yu [73] integrated the LINMAP with prospect theory to find attribute weights. Mehrabadi and Boyaghchi [44] used the LINMAP for decision-making in geothermal multi-generational energy systems. Fetanat and Tayebi [12] employed LINMAP to design household water systems. However, according to the collected literature, there is no research on the application of the LINMAP model under IVq-ROFS environment. The Additive Ratio Assessment (ARAS), which was presented by Zavadskas and Turskis [79], selects the best alternative by employing a utility degree to reflect the difference between diverse alternatives and the ideal one. ARAS eliminates the influence of unlike measurement units. For this reason, it has received considerable attention from researchers. Heidary et al. [22] used the ARAS to rank high-performance human resource practices. Gül [21] employed ARAS to deal with problems related to the selection of covid-19 experiments. Jovčić et al. [30] used it to make decisions about goods distribution. This paper extends the ARAS method to IVq-ROFS and further devises a new GDM method. However, the result of this integrated GDM method is still IVq-ROFNs. To clarify the aggregated values, it has been necessary to use, like many other researchers have done [20, 38, 62, 67] the score function. These researchers have put forward their own score functions for IVIFNs. Although these score function are effective for solving MADM problems, there still are some deficiencies. To overcome their weaknesses, this article investigates and applies a new score function so that the different software suppliers can be distinguished from each other and allow the best software supplier to be identified.
Community hospitals want an objective means for evaluating their software system and one that is cost-effective. They also want the evaluation results so they can be mapped directly onto the judgment matrix provided by the experts. These desires transform the software evaluation decision into a MAGDM problem with unknown expert weights and attribute weights [52]. In order to derive the attribute weights and expert weights, the LINMAP can be fused by similarity [33]. While the LINMAP is a mature method for solving attribute weights [59], it has not yet been used to determine expert weights. Currently, Yue [75, 76] suggested an expert weight based on similarity and projection. The two methods cannot distinguish the influence of the external environment because experts cannot always maintain their objectivity and fairness. For this reason, we will study the weights of the experts by examining the similarity of the distinct alternatives, and we will derive the experts’ weight matrices that will be used to gather information on the software suppliers from the different experts.
The evaluation method proposed in this article takes the software evaluation information provided by the experts and then integrates the IVq-ROFWFAWA operator, the ARAS method, a novel score function and the similarity under IVq-ROFS to capture the optimal software supplier. This method will improve decision-making efficiency and save evaluation costs. System purchasers will not need to know the expert weights or attribute weights. Our contributions, therefore, are as follows.
-
1.
A novel score function is defined to rank the IVq-ROFNs.
-
2.
The IVq-ROFWFA and IVq-ROFWFAWA operators are extended based on the q-ROFWFA operator.
-
3.
Attribute weights are derived from LINMAP based on the similarity of IVq-ROFNs.
-
4.
Expert weights of different alternatives are proposed. To reduce the decision results affected by experts’ judgments and the external environment, we suggest that different alternatives should have different expert weights.
-
5.
A new integrated MAGDM method has been developed based on the ARAS in this paper. This method combines an IVq-ROFWFAWA operator, LINMAP and ARAS to address decision-making problems.
-
6.
The community HFU management system was evaluated by our MAGDM method. The results confirm that the MAGDM method has strong adaptability and is compatible with existing algorithms. Comparative analysis results confirm that the proposed MAGDM method is effective.
The remainder of this paper is arranged as follows. The next section introduces the preliminaries. “Proposed score function and operators” extends the WFA operator to the IVq-ROFNs. “Integrated group decision method” develops an integrated MAGDM method based on ARAS. “Evaluation and analysis of the HFU system” presents the evaluation process and its analysis of the HFU management system. “Conclusion” offers a conclusion and some suggestions for the direction of future research.
Preliminaries
IVq-ROFS
Definition 1
[63] Let X be the domain of discourse. An IVq-ROFS in X is indicated by
where the membership and non-membership functions are the mapping range of values to meet \({u}_{A}\left(x\right)=\left[{u}_{A}^{-}\left(x\right),{u}_{A}^{+}\left(x\right)\right]\subseteq \left[{0,1}\right]\),\({v}_{A}\left(x\right)=\left[{v}_{A}^{-}\left(x\right),{v}_{A}^{+}\left(x\right)\right]\subseteq \left[{0,1}\right]\),\(0\le ({u}_{A}^{+}\left(x\right){)}^{q}+({v}_{A}^{+}\left(x\right){)}^{q}\le 1,\left(q\ge 1\right)\). The hesitation degree of \(A\) is shown in Eq. (2):
Definition 2
[63]. Let \(a=\left(\left[{u}_{a}^{-},{u}_{a}^{+}\right],\left[{v}_{a}^{-},{v}_{a}^{+}\right]\right)\), \({a}_{1}=\left(\left[{u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+}\right],\left[{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\right]\right)\) and \({a}_{2}=\left(\left[{u}_{{a}_{2}}^{-},{u}_{{a}_{2}}^{+}\right],\left[{v}_{{a}_{2}}^{-},{v}_{{a}_{2}}^{+}\right]\right)\) be the three IVq-ROFNs with \(q\ge 1\), and \(\lambda >0\). Some operations between \(a\), \({a}_{1}\) and \({a}_{2}\) can be defined as follows:
q-ROFWFA operator
The WFA operator can increase the density of the information that experts can obtain by evaluating the neutrality and fairness of the data during the decision-making process.
Definition 3
[55] Given any two q-ROFNs \({a}_{1}\) and \({a}_{2}\), \({a}_{1}{\otimes }_{F}{a}_{2}\) and \({\lambda }_{F}{a}_{1}\) represent, respectively, the multiplication and scalar multiplication operation rules of the q-ROFWFA operator of two q-ROFNs, as shown in Eqs. (6) and (7):
The q-ROFWFA operator can, by evaluating the data, scientifically and comprehensively consider the preferences of different experts and by so doing obtain rich and diversified information. It is used for aggregating information during the process of MAGDM. The q-ROFWFA operator is stated in Definition 4.
Definition 4
[55] Let \({\alpha }_{i}=\left({u}_{{\alpha }_{i}}, {v}_{{\alpha }_{i}}\right),\left(i={1,2},\dots ,n\right)\) be a set of q-ROFNs. The q-ROFWFA operator is
In Eq. (8), \({w}_{i}\) is the weight of \({\alpha }_{i}\left(i={12,3},\dots ,n\right)\), and must satisfy \({w}_{i}\ge 0\), \({\sum }_{i=1}^{n}{w}_{i}=1\).
Interval-valued q-rung orthopair fuzzy similarity
The similarity is used to measure the degree of similarity between two fuzzy subsets. For any two fuzzy numbers in a fuzzy set, similarity can be used to reflect the difference and to distinguish their relationship. Inspired by the similarity suggested in a previous study [52], this paper proposes the similarity of IVq-ROFNs that is as shown in Definition 6.
Definition 6
Let \({a}_{1}=\left(\left[{u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+}\right],\left[{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\right]\right)\) and \({a}_{2}=\left(\left[{u}_{{a}_{2}}^{-},{u}_{{a}_{2}}^{+}\right],\left[{v}_{{a}_{2}}^{-},{v}_{{a}_{2}}^{+}\right]\right)\) be two IVq-ROFNs, if \({u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+},{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\), \({u}_{{a}_{2}}^{-},{u}_{{a}_{2}}^{+},{v}_{{a}_{2}}^{-},{v}_{{a}_{2}}^{+}\) are all 0, the similarity will be 1. When \({u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+},{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\), \({u}_{{a}_{2}}^{-},{u}_{{a}_{2}}^{+},{v}_{{a}_{2}}^{-},{v}_{{a}_{2}}^{+}\) are not 0, the similarity measure between \({a}_{1}\) and \({a}_{2}\) is introduced in Eq. (9):
where the similarity is defined as: the sum of the minimum values of \({u}_{{a}_{1}}^{-}\) and \({u}_{{a}_{2}}^{-},{u}_{{a}_{1}}^{+}\) and \({u}_{{a}_{2}}^{+}\), \({v}_{{a}_{1}}^{-}\) and \({v}_{{a}_{2}}^{-}\), \({v}_{{a}_{1}}^{+}\) and \({v}_{{a}_{2}}^{+}\) divided by the sum of the maximum values between them. The similarity satisfies the four properties:
(S1) \(0\le S\left({a}_{1},{a}_{2}\right)\le 1\);
(S2) \(S\left({a}_{1},{a}_{2}\right)=1\) if and only if \({a}_{1}={a}_{2}\);
(S3) \(S\left({a}_{1},{a}_{2}\right)=S\left({a}_{2},{a}_{1}\right)\);
(S4) if \(\left[{u}_{1}^{-},{u}_{1}^{+}\right]\subseteq \left[{u}_{2}^{-},{u}_{2}^{+}\right]\subseteq \left[{u}_{3}^{-},{u}_{3}^{+}\right]\) and \(\left[{v}_{1}^{-},{v}_{1}^{+}\right]\subseteq \left[{v}_{2}^{-},{v}_{2}^{+}\right]\subseteq \left[{v}_{3}^{-},{v}_{3}^{+}\right]\), then \(S\left({a}_{1},{a}_{3}\right)\le S\left({a}_{1},{a}_{2}\right)\) and \(S\left({a}_{1},{a}_{3}\right)\le S\left({a}_{2},{a}_{3}\right)\).
Equation (9) clearly shows that when the two IVq-ROFNs are farther apart, the similarity is smaller. Otherwise, the similarity is greater. When the two IVq-ROFNs are the same, the similarity is 1.
Score function
When solving MADM and MAGDM problems under the IVIFSs’ and IVq-ROFSs’ environments, target alternatives often need to be sorted and selected. While the results of the aggregating operators and decision-making methods are IVIFNs or IVq-ROFNs, researchers often use score functions to transform the results into crisp numbers. Although the score function proposed by researchers can be used to compare IVIFNs and IVq-ROFNs, there are also deficiencies with these approaches. The following examples are given to illustrate.
Definition 7
[67] Let \(a=(\left[{u}^{-},{u}^{+}\right],\left[{v}^{-},{v}^{+}\right])\) be an IVIFNs, its score function \({S}_{X}\) is
where \({S}_{X}\) represents membership subtracting non-membership and can express the attitude of decision-makers. When \({u}^{-}+{u}^{+}={v}^{-}+{v}^{+}\), Xu [67] proposed the accuracy function \({{H}_{X}\left(\alpha \right)={\frac{1}{2}}(u}^{-}+{u}^{+}+{v}^{-}+{v}^{+})\), which has been widely used in MADM and MAGDM problems under IVIFS environments. If \(q=1\), \({S}_{X}\) can be directly used to compare the IVq-ROFNs. If \(q>1\), it also can be sometimes used to compare the IVq-ROFNs.
Example 1
Given two IVIFNs, \({a}_{1}=\left([0.811, 0.865], [0.692, 0.789]\right)\) and \({a}_{2}=\left([0.676, 1.0], [0.655, 0.826]\right)\), we have \({S}_{X}\left({a}_{1}\right)={S}_{X}\left({a}_{2}\right)=0.0975\). That is to say that \({S}_{X}\) fails to compare \({a}_{1}\) and \({a}_{2}\). In addition, \({H}_{X}\left({a}_{1}\right)={H}_{X}\left({a}_{2}\right)=1.5785\) indicates that \({H}_{X}\) also fails to compare \({a}_{1}\) and \({a}_{2}\).
Based on Xu’s score function, Liu and Wang proposed a new score function for IVq-ROFN which has been also proved useful for some MADM and MAGDM problems, as shown in Definition 8.
Definition 8
[38] Let \(a=(\left[{u}^{-},{u}^{+}\right],\left[{v}^{-},{v}^{+}\right])\) be an IVq-ROFN, \(q\ge 1\), its score function \({S}_{L}\) is
In Eq. (11), \({S}_{L}\) represents membership subtracting non-membership which can express the attitude of decision-makers. When \(({u}^{-}{)}^{q}+({u}^{+}{)}^{q}=({v}^{-}{)}^{q}+({v}^{+}{)}^{q}\), Liu and Wang [38] suggest using the accuracy function \({H}_{L}\left(\alpha \right)={\frac{1}{2}}[({u}^{-}{)}^{q}+({u}^{+}{)}^{q}+({v}^{-}{)}^{q}+({v}^{+}{)}^{q}]\). This approach has been also used in MADM and MAGDM problems under IVq-ROFS environments in recent years.
Example 2
Given two IVq-ROFNs \({a}_{3}=\left([{0.134,0.183}],[{0.172,0.859}]\right)\) and \({a}_{4}=\left([{0.066,0.217}],[{0.584,0.653}]\right)\), when \(q=2\), \({S}_{L}\left({a}_{3}\right)={S}_{L}\left({a}_{4}\right)=-0.35801.\, {\text{It means that }}{S}_{L}\) fails to compare \({a}_{3}\) and \({a}_{4}\). In addition, \({H}_{L}\left({a}_{3}\right)={H}_{L}\left({a}_{4}\right)=0.409455\), it indicates that the \({H}_{L}\left(\alpha \right)\) also fails to compare \({a}_{3}\) and \({a}_{4}\).
Definition 9
[62] Let \(a=\left(\left[{u}^{-},{u}^{+}\left],\right[{v}^{-},{v}^{+}\right]\right)\) be an IVIFN, its score function \({S}_{\text{NWC}}\) is
When \({u}^{-}+{u}^{+}={v}^{-}+{v}^{+}\), Wang and Chen [62] proposed the accuracy function \({H}_{\text{NWC}}\left(\alpha \right)={\frac{1}{2}}(\left(1- {u}^{-}+{u}^{+}\right)\left( 1-{u}^{-}-{v}^{-}\right)+(1-{v}^{-}+{v}^{+})(1-{v}^{+}-{u}^{+}))\), another approach that has been used in MADM and MAGDM problems under IVIFS environments.
Example 3
Given two IVIFNs \({a}_{5}=\left(\left[{0.0,0.0}\right],\left[{0.0,0.0}\right]\right)\) and \({a}_{6}=\left(\left[{0.0,0.1}\right],\left[{0.0,0.0}\right]\right),\) \({S}_{\text{NWC}}\left({a}_{5}\right)={S}_{\text{NWC}}\left({a}_{6}\right)=0\). The \({S}_{\text{NWC}}\) fails to compare \({a}_{5}\) and \({a}_{6}\). \({H}_{\text{NWC}}\left({a}_{5}\right)= {H}_{\text{NWC}}\left({a}_{6}\right)=1\) also indicates a failure of \({H}_{\text{NWC}}\left(\alpha \right)\) in comparing \({a}_{5}\) and \({a}_{6}\).
Definition 10
[20] Let \(a=\left(\left[{u}^{-},{u}^{+}\left],\right[{v}^{-},{v}^{+}\right]\right)\) be an IVIFN. Its score function \({S}_{\text{GM}}\) is
Gong and Ma proposed the accuracy function \({H}_{\text{GM}}=\left({u}_{a}^{+}+{v}_{a}^{+}\right)-0.5({\frac{{{(u}^{+}-{u}^{-})}^{2}}{{u}^{+}}}+{\frac{{{(v}^{+}-{v}^{-})}^{2}}{{v}^{+}}})\). When \({u}^{-}={u}^{+}={v}^{-}={v}^{+}=0, {S}_{\text{GM and}}\) \({H}_{\text{GM}}\) are unreasonable.
Example 4
Given two IVIFNs, \({a}_{7}=\left(\left[0, 0.4\right],\left[0, 0.4\right]\right)\) and \({a}_{8}=\left(\left[{0.2,0.2}\right],\left[{0.2,0.2}\right]\right)\), \({S}_{\text{GM}}\left({a}_{7}\right)\)= \({S}_{\text{GM}}\left({a}_{8}\right)=0.5\) means that the \({S}_{\text{GM}}\) fails to compare \({a}_{7}\) and \({a}_{8}\). The \({H}_{\text{GM}}\) also fails to compare \({a}_{7}\) and \({a}_{8}\) since \({H}_{\text{GM}}\left({a}_{7}\right)\)= \({H}_{\text{GM}}\left({a}_{8}\right)=0.4\).
Proposed score function and operators
In this section, we define a new score function to rank IVq-ROFNs and some operators to aggregate the information.
New score function
From the examples of the score functions outlined in “Score function”, the deficiencies of score functions are described. In order to overcome these deficiencies, we developed a new score function, as shown in Definition 11.
Definition 11
Let \(a=(\left[{{u}_{a}}^{-},{{u}_{a}}^{+}\right],\left[{{v}_{a}}^{-},{{v}_{a}}^{+}\right])\) be an IVq-ROFN, the score function developed as follows:
In Eq. (14), the term \(({u}_{a}^{-}+{u}_{a}^{+}+{v}_{a}^{-}+{v}_{a}^{+})\) expresses the sum of membership and non-membership, which is a certain amount of certainty. \({(u}_{a}^{+}-{u}_{a}^{-})\) represents the uncertainty of membership, and (\({v}_{a}^{+}-{v}_{a}^{-}\)) represents the uncertainty of non-membership. Similarly, ((\({u}_{a}^{-}+{u}_{a}^{+})-{(v}_{a}^{-}+{v}_{a}^{+}))\) is the difference between membership and non-membership, and ((\({u}_{a}^{-}-{u}_{a}^{+})-({v}_{a}^{+}{-v}_{a}^{-}))\) is the difference of uncertainty between membership and non-membership. The Sign function is a signal function. When \({u}_{a}^{-}+{u}_{a}^{+}+{v}_{a}^{-}+{v}_{a}^{+}=0\), the result of Sign is 0 and otherwise 1. It is used to keep the result of \({S}_{c}\) belonging to [− 1, 1].
Theorem 1
Let \(a=\left(\left[{u}_{a}^{-},{u}_{a}^{+}\left],\right[{v}_{a}^{-},{v}_{a}^{+}\right]\right)\) be an IVq-ROFN, the \({S}_{c}\) has the following properties:
-
1.
\(-1\le {S}_{c}(a)\le 1\);
-
2.
\({S}_{c}\left({a}_{\text{min}}\right)=-1\) if \({a}_{\text{min}}=([\text{0,0}],[{1,1}])\);
-
3.
\({S}_{c}({a}_{\text{max}})=1\) if \({a}_{\text{max}}=([{1,1}],[{0,0}])\);
-
4.
\({S}_{c}({a}_{\text{mid}})=0\) if \({a}_{\text{mid}}=([{0,0}],[{0,0}])\).
Proof
Substituting \({a}_{\text{min}}=([{0,0}],[{1,1}])\), \({a}_{\text{max}}=([{1,1}],[{0,0}])\) and \({a}_{\text{mid}}=([{0,0}],[{0,0}])\) into Eq. (14), we know that \({S}_{c}\left({a}_{\text{min}}\right)=-1\), \({S}_{c}({a}_{\text{max}})=1\) and \({S}_{c}({a}_{\text{mid}})=0\). Consequently, the properties (2), (3) and (4) hold.
The partial derivatives of \({u}_{a}^{-}\), \({u}_{a}^{+}\), \({v}_{a}^{-}\) and \({v}_{a}^{+}\) are
It can be seen that \({u}_{a}^{-}\), \({u}_{a}^{+}\), \({v}_{a}^{-}\) and \({v}_{a}^{+}\) are monotonic. Specifically, \({u}_{a}^{-}\) and \({u}_{a}^{+}\) are monotonically increasing and \({v}_{a}^{-}\) and \({v}_{a}^{+}\) are monotonically decreasing. For any IVq-ROFN \(a\), \({{S}_{c}({a}_{\text{min}})\le {S}}_{c}\left(a\right)\le {{S}}_{c}({a}_{\text{max}})\) and \(-1\le {S}_{c}(a)\le 1\), Property (1) holds.
According to Theorem 1, for any two IVq-ROFNs, membership is monotonically increasing and non-membership is monotonically decreasing. Thus, IVq-ROFNs can be compared using Definition 12.
Definition 12
Given the two IVq-ROFNs \({a}_{1}=(\left[{u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+}\right],\left[{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\right])\) and \({a}_{2}=(\left[{u}_{{a}_{2}}^{-},{u}_{{a}_{2}}^{+}\right],\) \(\left[{v}_{{a}_{2}}^{-},{v}_{{a}_{2}}^{+}\right])\), their comparison laws are
-
1.
If \({S}_{c}\left({a}_{1}\right)>{S}_{c}\left({a}_{2}\right)\), then \({a}_{1}>{a}_{2}\);
-
2.
If \({S}_{c}\left({a}_{1}\right)<{S}_{c}\left({a}_{2}\right)\), then \({a}_{1}<{a}_{2}\);
-
3.
If \({S}_{c}\left({a}_{1}\right)={S}_{c}\left({a}_{2}\right)\), then \({a}_{1}={a}_{2}\).
Example 5
\({S}_{c}\) is used to calculate the four groups of data in Examples 1–4. The results are shown in Table 1.
As can be seen from Table 1, the proposed score function overcomes the deficiency and can better distinguish IVq-ROFNs. However, \({S}_{X}\) cannot compare \({a}_{1}\) and \({a}_{2}\), \({a}_{7}\) and \({a}_{8}\), \({S}_{L}\) cannot compare \({a}_{3}\) and \({a}_{4}\), \({a}_{7}\) and \({a}_{8}\), \({S}_{\text{NWC}}\) cannot compare \({a}_{5}\) and \({a}_{6}\), and \({S}_{\text{GM}}\) cannot compare \({a}_{5}\) and \({a}_{6}\), \({a}_{7}\) and \({a}_{8}\). In order to illustrate its advantages and show better adaptability to various environments, we designed four cases to test the \({S}_{c}\) function.
Example 6.
We design four cases to test \({{S}}_{c}\). Let \({a}_{1}\) and \({a}_{2}\) be two IVq-ROFNs and \({a}_{1}\) be a fixed point. \({a}_{2}\) changes from ([1,1], [0,0]) to ([0,0], [1,1]) by a 0.05 step (move point, MP). The scores of \({a}_{1}\) and \({a}_{2}\) are presented by RP and MP in Fig. 1: (1) Case 1. The interval length of \({a}_{1}\) and \({a}_{2}\) is 0, and \({a}_{1}=([{0.5,0.5}],[{0.5,0.5}])\). (2) Case 2. The interval length of \({a}_{1}\) and \({a}_{2}\) is 0, and \({a}_{1}\) is randomly generated. (3) Case 3. The interval length of \({a}_{1}\) and \({a}_{2}\) is the same but not equal to 0. (4) Case 4. The interval length of \({a}_{1}\) is larger than that of \({a}_{2}\) and neither of them equals 0.

Score function value analysis
As shown in Fig. 1, random IVq-ROFNs are generated to simulate the four cases. The scores of \({a}_{1}\) and \({a}_{2}\) have just one coincidence point where \({a}_{1}={a}_{2}\). Therefore, the proposed score function can be used to distinguish different IVq-ROFNs.
Evaluation indices of the HFU system
The high cost of adopting ISO/IEC standards in the application of software quality assessment [28] means they cannot be used to meet the needs of small and medium-sized enterprises. Even large organizations like healthcare agencies are often not able to afford to adopt such standards, especially if they are only required by an individual unit. HFU systems have been developed primarily to help hospitals manage hypertension among diagnosed outpatients. The management systems that many hospitals currently use struggle to control and manage the manifestations of this condition within a mobile and scattered population. Hypertension software systems, however, can improve the detection of blood pressure changes and can help to control them. More importantly, they can do this for a scattered and mobile outpatient population. To justify the expense associated with purchasing such a system, community hospitals need to resolve two contradictions. First, patients have limited ability to prevent their symptoms. They often cannot effectively manage their blood pressure or timely get hospital treatment. Second, primary healthcare facilities do not have the resources to track and monitor all their outpatients and have no way to escalate the treatment of those patients in need. Any remote management system, therefore, needs to (1) allow outpatients to access follow-up medical services from any location at any time and (2) enable medical staff to provide hypertension management services to outpatients in any location at any time.
Any HFU system should, first, be able to meet the requirements of function, performance, safety, and reliability. It should be an acceptable cost and easy-to-use, both for outpatients and medical staff. Second, for the intercommunication of other software, the purchased system needs to meet the needs of community hospitals in terms of scalability [70], integration [43], reliability [6, 78] and compatibility [19], and reduces the hospital's future cost expenditures. Third, a management system should meet a number of post-purchase criteria: the stability of the supplier [6, 49], the supplier's follow-up service [6], and the likely extent of daily maintenance [4, 50]. Inspired by the existing literature on hypertension management systems [4, 6, 10, 11, 28, 70, 77], an evaluation of the effectiveness of a community HFU system evaluation should encompass 13 indices: (1) Cost (C1), (2) Performance (C2), (3) Reliability (C3), (4) Security (C4), (5) Function (C5), (6) Easy-to-use (C6), (7) Extensibility (C7), (8) Compatibility (C8), (9) Deployment time (C9), (10) Integration (C10), (11) Supplier stability (C11), (12) Follow-up service (C12), and (13) Maintainability (C13). A detailed explanation of each index is shown in Table 2.
Table 2 outlines the full range of indices required for any viable and usable management system. Some of these indices reflect the possible cost to a hospital and others reflect the potential benefit that the adoption of a management system might involve.
IVq-ROFWFA operations
Inspired by operations of q-ROFWFA [55], the multiplication and scalar multiplication of IVq-ROFNs are developed. Definition 13 proposes the properties of the IVq-ROFWFA operation.
Definition 13
Let \({a}_{1}=\left(\left[{u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+}\left],\right[{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\right]\right)\) and \({a}_{2}=\left(\left[{u}_{{a}_{2}}^{-},{u}_{{a}_{2}}^{+}\left],\right[{v}_{{a}_{2}}^{-},{v}_{{a}_{2}}^{+}\right]\right)\) be two IVq-ROFNs, and \(q\ge 1\), \({\lambda }_{F}>0\). The multiplication and scalar multiplication of IVq-ROFN are defined as follows:
According to Eqs. (15) and (16), the result obtained by \({a}_{1}{\otimes }_{F}{a}_{2}\) and \({\lambda }_{F}{a}_{1}\) is still an IVq-ROFN.
Proposition 1
Let \({a}_{1}=\left(\left[{u}_{{a}_{1}}^{-},{u}_{{a}_{1}}^{+}\right],\left[{v}_{{a}_{1}}^{-},{v}_{{a}_{1}}^{+}\right]\right)\) and \(a_{2} = \left( {\left[ {u_{{a_{2} }}^{ - } ,u_{{a_{2} }}^{ + } } \right],\left[ {v_{{a_{2} }}^{ - } ,v_{{a_{2} }}^{ + } } \right]} \right)\) be two IVq-ROFNs. If \({u}_{{a}_{1}}={v}_{{a}_{1}}\) and \({u}_{{a}_{2}}={v}_{{a}_{2}}\) , then
-
1.
\({u}_{{a}_{1}{\otimes }_{F}{a}_{2}}= {v}_{{a}_{1}{\otimes }_{F}{a}_{2}},\)
-
2.
\({u}_{{\lambda }_{F}{a}_{1}}= {v}_{{\lambda }_{F}{a}_{1}}.\)
The above proposition shows that when the membership and non-membership are initially equal, operations \({a}_{1}{\otimes }_{F}{a}_{2}\) and \({\lambda }_{F}{a}_{1}\) reflect a neutral or fair situation for experts. We are, therefore, calling the \({a}_{1}{\otimes }_{F}{a}_{2}\) and \({\lambda }_{F}{a}_{1}\) neutral operations. Equations (15) and (16) make it easy to deduce that the multiplication and scalar multiplication of IVq-ROFWFA satisfy the commutative law.
The IVq-ROFWFAWA operator
In this subsection, the definition of the IVq-ROFWFAWA operator is introduced. In addition, its properties are described.
Definition 14
Let \({a}_{i}=\left(\left[{u}_{{a}_{i}}^{-},{u}_{{a}_{i}}^{+}\right],\left[{v}_{{a}_{i}}^{-},{v}_{{a}_{i}}^{+}\right]\right)(i={1,2},\dots ,n)\) be a group of IVq-ROFNs and \(\omega =({\omega }_{1},{\omega }_{2},\ldots,{\omega }_{n}{)}^{T}\) be a weight vector with \(\sum_{i=1}^{n}{w}_{i}=1,{w}_{i}\ge 0,(i={1,2},\dots ,n)\). The definition of the IVq-ROFWFAWA operator is
Theorem 3
Let \({a}_{i}=\left(\left[{u}_{{a}_{i}}^{-},{u}_{{a}_{i}}^{+}\right], \left[{v}_{{a}_{i}}^{-},{v}_{{a}_{i}}^{+}\right]\right)\left(i={1,2},\right.\break \left.\dots ,n\right)\) be a group of IVq-ROFNs. The result of \({\text{IVq-ROFWFAWA}}\left({\alpha }_{1},{\alpha }_{2},\dots ,{\alpha }_{n}\right)\) is still an IVq-ROFN, which is shown in Eq. (18):
Using Eqs. (15) and (16), Theorem 3 can be easily deduced and the proof omitted. The IVq-ROFWFAWA operator satisfies idempotency, boundedness, monotonicity and commutativity which are described by Theorems 4, 5, 6 and 7. Using Eqs. (15), (16) and (18), the proof processes can be easily deduced and, therefore, omitted.
Theorem 4
(Idempotency) Let \({\alpha }_{0}=\left(\left[{u}_{{\alpha }_{0}}^{-},{u}_{{\alpha }_{0}}^{+}\right],\left[{v}_{{\alpha }_{0}}^{-},{v}_{{\alpha }_{0}}^{+}\right]\right)\) be an IVq-ROFN and \({\alpha }_{i}=\left(\left[{u}_{{\alpha }_{i}}^{-},{u}_{{\alpha }_{i}}^{+}\right],\left[{v}_{{\alpha }_{i}}^{-},{v}_{{\alpha }_{i}}^{+}\right]\right)\left(i={1,2},\dots ,n\right)\) be a group of IVq-ROFNs. When \({\alpha }_{i}={\alpha }_{0}\), Eq. (19) holds:
Theorem 5
(Boundedness) Let \(A=\left\{{a}_{1},{a}_{2},\ldots ,{a}_{n}\right\}\) be a group of IVq-ROFNs. If \({a}_{\text{max}}={\text{max}}_{i=1}^{n}\left\{{a}_{i}\right\}\) and \({a}_{\text{min}}={\text{min}}_{i=1}^{n}\left\{{a}_{i}\right\}\), it is easy to obtain:
Theorem 6
(Monotonicity) Let \({\alpha }_{i}=\left(\left[{u}_{{\alpha }_{i}}^{-},{u}_{{\alpha }_{i}}^{+}\right],\right.\break \left.\left[{v}_{{\alpha }_{i}}^{-},{v}_{{\alpha }_{i}}^{+}\right]\right)\) and \({{\alpha }_{i}}^{{^{\prime}}}=\left(\left[{u}_{{{\alpha }_{i}}^{{^{\prime}}}}^{-},{u}_{{{\alpha }_{i}}^{{^{\prime}}}}^{+}\right],\left[{v}_{{{\alpha }_{i}}^{{^{\prime}}}}^{-},{v}_{{{\alpha }_{i}}^{{^{\prime}}}}^{+}\right]\right)\left(i={1,2},\right.\break\left.\ldots,n\right)\) be two groups of IVq-ROFNs. For any \(i:{\alpha }_{i}\le {{\alpha }_{i}}^{{^{\prime}}}\), Eq. (21) holds:
Theorem 7
(Commutativity) Let \({\alpha }_{i}=\left(\left[{u}_{{\alpha }_{i}}^{-},{u}_{{\alpha }_{i}}^{+}\right],\left[{v}_{{\alpha }_{i}}^{-},{v}_{{\alpha }_{i}}^{+}\right]\right)\) be a group of IVq-ROFNs and \({{\alpha }_{i}}^{\prime}=\left(\left[{u}_{{{\alpha }_{i}}^{\prime}}^{-},{u}_{{{\alpha }_{i}}^{\prime}}^{+}\right],\left[{v}_{{{\alpha }_{i}}^{\prime}}^{-},{v}_{{{\alpha }_{i}}^{\prime}}^{+}\right]\right)\) is then the permutation of \({\alpha }_{i}\), Eq. (22) holds:
The purpose of the IVq-ROFWFAWA operator is used to aggregate the information of multiple experts and is used to aggregate the alternative information of multiple attributes.
Integrated group decision method
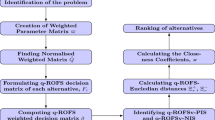
To make the decision-making process more scientific and reduce the influence of human subjectivity on the results, an integrated group decision-making method is presented. “Group decision environment description” describes the GDM environment. The attribute weights are derived in “Deriving attribute weights”. “Deriving expert weights” describes a strategy for determining the expert weights. “MAGDM method based on ARAS” clarifies the MAGDM method based on the ARAS.
Group decision environment description
To make selecting the best HFU system more reliable for the hospital, experts who have rich experiences and knowledge are invited to evaluate the supplier's products and have a making-decision. In order to reduce the influence of subjective factors and improve the efficiency of MAGDM, expert or attribute weights are unknown in advance. For this reason, the MAGDM environment should satisfy (1) there are k experts and m alternatives, (2) each alternative has the same n attributes, (3) the expert and attribute weights are incomplete, and (4) the elements of the decision matrix are IVq-ROFNs. The mathematical description of the MAGDM environment is as follows.
Suppose there are \(k\) experts, and the expert set is \(D=\left\{{D}^{\left(1\right)},{D}^{\left(2\right)},\dots ,{D}^{\left(k\right)}\right\}\). The expert weights are unknown and satisfy \({\lambda }^{\left(t\right)}\ge 0,{\sum }_{t=1}^{k}{\lambda }^{\left(t\right)}=1\). The \(m\) alternatives are \(X=\left\{{x}_{1},{x}_{2},\dots ,{x}_{m}\right\}\), each of which contains the same \(n\) attributes: \(C=\left\{{C}_{1},{\text{C}}_{2}, \ldots,{{\text{C}}}_{n}\right\}\). The attribute weights are unknown and satisfy \({\sum }_{j=1}^{n}{w}_{j}=1,{w}_{j}\ge 0\). The decision matrix is \({A}^{{{\prime}}\left(t\right)}=({a}_{ij}^{{{\prime}}\left(t\right)}{)}_{m\times n},\left(i={1,2},\dots ,m; j=1,2,\dots ,n; t={1,2},\ldots,k\right)\). \({a}_{ij}^{{{\prime}}\left(t\right)}=\left([{u}_{{a}_{ij}^{{{\prime}}\left(t\right)}}^{-},{u}_{{a}_{ij}^{{{\prime}}\left(t\right)}}^{+}],[{v}_{{a}_{ij}^{{{\prime}}\left(t\right)}}^{-},{v}_{{a}_{ij}^{{{\prime}}\left(t\right)}}^{+}]\right)\) is an IVq-ROFN. There exists an integer \(q(q\ge 1)\) satisfying \({\left({u}_{{a}_{ij}^{{{\prime}}\left(t\right)}}^{+}\right)}^{q}+{\left({v}_{{a}_{ij}^{{{\prime}}\left(t\right)}}^{+}\right)}^{q}\le 1\). \({a}_{ij}^{{{\prime}}\left(t\right)}\) that represents the judgment value of the t-th expert on the j-th attribute in alternative i-th. \({A}^{{{\prime}}\left(t\right)}\) is defined in Eq. (23):
Before decision-making, experts are allowed to carry out a pre-judgment on the priority of the alternatives. If experts give preference \(\left(g,l\right)\) for any pair (\({x}_{g}\), \({x}_{l}\)) of alternatives, which means that the expert prefers the alternative \({x}_{g}\). The set of all preference pairs, \(P=\left\{\left(g,l\right)\right\}\), \(1\le g\le m\), \(1\le l\le m,g\ne l\), is given by experts in advance.
The indices of different performances need to be standardized. The \({\Omega }_{1}\) presents a set of benefit indices, and the \({\Omega }_{2}\) presents a set of cost indices. Equations (24) and (25) normalize the decision matrix \({A}^{{{\prime}}\left(t\right)}\) to the standard matrix \({A}^{\left(t\right)}\), where Eq. (25) is the complement operation of IVq-ROFN:
Deriving attribute weights
The LINMAP model has advantages in obtaining attribute weight. First, the LINMAP is simple, clear, and easy to implement. Second, LINMAP does not need attribute weights which can be solved by the linear programming model, and LINMAP can reflect the preferences and experience of the experts. Third, the linear programming model reflects the overall characteristics of the results. Therefore, we select LINMAP to derive attribute weights.
The classical LINMAP is based on pairwise comparisons of alternatives that are given by the DMs [59, 80]. The linear programming model is constructed to get attribute weights by minimizing the deviation of the total inconsistency index and the total consistency index. The LINMAP model includes primarily the following steps: (1) the alternative preference pairs are given by experts in advance, (2) the linear programming model is constructed according to the minimization of deviation of the total inconsistency index and the total consistency index, and (3) the attribute weights are obtained by solving linear programming model. Inspired by Zhang [80], we designed a method to derive attribute weights using the LINMAP model based on the similarity of IVq-ROFNs. First, the similarity between the alternatives and the positive ideal point is calculated, and the weighted similarity of alternatives is constructed according to the preference pair of alternatives given by experts in advance. Second, the linear programming model is constructed by minimizing the deviation of the inconsistent and consistent weighted similarity according to the preference pair of alternatives. The attribute weights of different experts are obtained by solving the linear programming model. Finally, the attribute weight matrix of all decision matrices is obtained. The LINMAP model solves the attribute weights as in the following steps.
-
1.
Determining the preference set of alternatives \({\varvec{P}}=\left\{\left({\varvec{g}},{\varvec{l}}\right)\right\}\).
-
2.
Calculating the positive ideal point.
Get the positive ideal point \({{a}_{j}^{*}}^{(t)}\) of j-th column in the matrix \({A}^{\left(t\right)}\) as shown Eq. (26):
$${a}_{j}^{*(t)}=\left(\left[\underset{1\le i\le m}{\text{max}}\left({u}_{{a}_{ij}^{(t)}}^{-}\right), \underset{1\le i\le m}{\text{max}}\left({u}_{{a}_{ij}^{(t)}}^{+}\right)\right], \qquad \left[\underset{1\le i\le m}{\text{min}}\left({v}_{{a}_{ij}^{(t)}}^{-}\right),\underset{1\le i\le m}{\text{min}}\left({v}_{{a}_{ij}^{(t)}}^{+}\right)\right]\right)$$(26) -
3.
Calculate the similarity of the alternatives to the ideal point.
Use Eq. (9) to calculate the similarity \({S}_{g}({a}_{gj}^{(t)},{{a}_{j}^{*}}^{(t)})\), \({S}_{l}({a}_{lj}^{(t)},{{a}_{j}^{*}}^{(t)})\), for \(j=1, 2, \dots , n\):
$${S}_{g}({a}_{gj}^{(t)},{{a}_{j}^{*}}^{(t)})=\frac{\left({\left({u}_{{a}_{gj}^{(t)}}^{-}\right)}^{q}\wedge {\left({u}_{{{a}_{j}^{*}}^{(t)}}^{-}\right)}^{q}\right)+\left({\left({v}_{{a}_{gj}^{(t)}}^{-}\right)}^{q}\wedge {\left({v}_{{{a}_{j}^{*}}^{(t)}}^{-}\right)}^{q}\right)+\left({\left({u}_{{a}_{gj}^{(t)}}^{+}\right)}^{q}\wedge {\left({u}_{{{a}_{j}^{*}}^{(t)}}^{+}\right)}^{q}\right)+\left({\left({v}_{{a}_{gj}^{(t)}}^{+}\right)}^{q}\wedge {\left({v}_{{{a}_{j}^{*}}^{(t)}}^{+}\right)}^{q}\right)}{\left({\left({u}_{{a}_{gj}^{(t)}}^{-}\right)}^{q}\vee {\left({u}_{{{a}_{j}^{*}}^{(t)}}^{-}\right)}^{q}\right)+\left({\left({v}_{{a}_{gj}^{(t)}}^{-}\right)}^{q}\vee {\left({v}_{{{a}_{j}^{*}}^{(t)}}^{-}\right)}^{q}\right)+\left({\left({u}_{{a}_{gj}^{(t)}}^{+}\right)}^{q}\vee {\left({u}_{{{a}_{j}^{*}}^{(t)}}^{+}\right)}^{q}\right)+\left({\left({v}_{{a}_{gj}^{(t)}}^{+}\right)}^{q}\vee {\left({v}_{{{a}_{j}^{*}}^{(t)}}^{+}\right)}^{q}\right)}$$(27)$${S}_{l}\left({a}_{lj}^{\left(t\right)},{{a}_{j}^{*}}^{\left(t\right)}\right)=\frac{\left({\left({u}_{{a}_{lj}^{\left(t\right)}}^{-}\right)}^{q}\wedge {\left({u}_{{{a}_{j}^{*}}^{\left(t\right)}}^{-}\right)}^{q}\right)+\left({\left({v}_{{a}_{lj}^{\left(t\right)}}^{-}\right)}^{q}\wedge {\left({v}_{{{a}_{j}^{*}}^{\left(t\right)}}^{-}\right)}^{q}\right)+\left({\left({u}_{{a}_{lj}^{\left(t\right)}}^{+}\right)}^{q}\wedge {\left({u}_{{{a}_{j}^{*}}^{\left(t\right)}}^{+}\right)}^{q}\right)+\left({\left({v}_{{a}_{lj}^{\left(t\right)}}^{+}\right)}^{q}\wedge {\left({v}_{{{a}_{j}^{*}}^{\left(t\right)}}^{+}\right)}^{q}\right)}{\left({\left({u}_{{a}_{lj}^{\left(t\right)}}^{-}\right)}^{q}\vee {\left({u}_{{{a}_{j}^{*}}^{\left(t\right)}}^{-}\right)}^{q}\right)+\left({\left({v}_{{a}_{lj}^{\left(t\right)}}^{-}\right)}^{q}\vee {\left({v}_{{{a}_{j}^{*}}^{\left(t\right)}}^{-}\right)}^{q}\right)+\left({\left({u}_{{a}_{lj}^{\left(t\right)}}^{+}\right)}^{q}\vee {\left({u}_{{{a}_{j}^{*}}^{\left(t\right)}}^{+}\right)}^{q}\right)+\left({\left({v}_{{a}_{lj}^{\left(t\right)}}^{+}\right)}^{q}\vee {\left({v}_{{{a}_{j}^{*}}^{\left(t\right)}}^{+}\right)}^{q}\right)}.$$(28) -
4.
Calculate the weighted similarity of alternatives.
Suppose the attribute weights are \({w}^{(t)}=({w}_{1}^{(t)},{w}_{2}^{(t)},\dots ,{w}_{n}^{(t)})\). According to the preference pair set \(P=\left\{\left(g,l\right)\right\}\), the weighted average \(Eq_{g}^{(t)}\) and \(Eq_{l}^{(t)}\) of \({w}_{j}^{(t)}\) are calculated, which are as shown in Eqs. (29) and (30):
$$ Eq_{g}^{(t)} = \sum \limits_{j = 1}^{n} w_{j}^{(t)} \times S_{g} (a_{gj}^{(t)} ,a_{j}^{* (t)} ),\;j = 1,2, \ldots ,n $$(29)$$ Eq_{l}^{(t)} = \sum \limits_{j = 1}^{n} w_{j}^{(t)} \times S_{l} (a_{lj}^{(t)} ,a_{j}^{* (t)} ),\;j = 1,2, \ldots ,n $$(30) -
5.
Construct a linear programming model.
For a pair of preference \((g,l)\) in the set \(P\), if \(Eq_{g}^{(t)}\le Eq_{l}^{(t)}\), it means that the alternative \({x}_{g}\) is closer to the ideal point than \({x}_{l}\), and the weighted similarity is consistent with the preference of the expert. On the contrary, if \(Eq_{g}^{(t)}>Eq_{l}^{(t)}\), it means that the weighted similarity is inconsistent with the preference of the experts. The actual alternative goal is to require the weighted similarity to be consistent with the preference of the experts. For this reason, the goal can be transformed into a linear programming problem as shown in Eq. (31):
$$ \begin{gathered} {\text{min}} \sum \limits_{{\left( {g,l} \right) \in P}} \theta_{gl}^{(t)} \hfill \\ {\text{S.T.}}\left\{ {\begin{array}{*{20}l} {Eq_{l}^{(t)} - Eq_{g}^{(t)} + \theta_{gl}^{(t)} \ge 0} \hfill \\ { \sum \limits_{{\left( {g,l} \right) \in P}} \left( {Eq_{l}^{(t)} - Eq_{g}^{(t)} } \right) = B^{(t)} } \hfill \\ {\sum\limits_{j = 1}^{n} {w_{j}^{(t)} = 1} } \hfill \\ {w_{j}^{(t)} \ge 0} \hfill \\ {\theta_{gl}^{(t)} \ge 0} \hfill \\ \end{array} } \right. \hfill \\ \end{gathered} $$(31)In Eq. (31), \({\theta }_{gl}^{(t)}\) represents the deviation between alternatives and the weighted similarity of \(\left(g,l\right)\) and \({\theta }_{gl}^{(t)}\ge 0\). The \({\theta }_{gl}^{(t)}\) of different alternative pairs does not affect each other. The sum of \({\theta }_{gl}^{(t)}\) is \({B}^{(t)}\) corresponding to all pairs of the alternatives in the order set \(P\) of the preferred alternative.
-
6.
Solve the attribute weights of the decision matrix.
From Eq. (31), the attribute weight \({w}^{(t)}\) of the decision matrix of the t-th expert can be obtained as
$${w}^{\left(t\right)}=\left({w}_{1}^{\left(t\right)},{w}_{2}^{\left(t\right)},\ldots,{w}_{n}^{\left(t\right)}\right).$$(32) -
7.
Get the attribute weight matrix of all decision matrices.
According to Eq. (32), the attribute weights of all decision matrices are expressed as a matrix with \(k\) rows and \(n\) columns in Eq. (33):
$$W=\left[\begin{array}{l}{w}^{(1)}\\ {w}^{(2)}\\ \vdots \\ {w}^{\left(k\right)}\end{array}\right]=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}{w}_{1}^{\left(1\right)}& {w}_{2}^{\left(1\right)}& \cdots & {w}_{n}^{\left(1\right)}\\ {w}_{1}^{\left(2\right)}& {w}_{2}^{\left(2\right)}& \cdots & {w}_{n}^{\left(2\right)}\\ \vdots & \vdots & \ddots & \vdots \\ {w}_{1}^{\left(k\right)}& {w}_{2}^{\left(k\right)}& \cdots & {w}_{n}^{\left(k\right)}\end{array}\right].$$(33)Using the LINMAP model, the attribute weight \({w}^{\left(t\right)}\) of a single expert decision matrix \({A}^{\left(t\right)}\) can be calculated separately. Elements at corresponding positions in different matrices can be aggregated by expert weights, which better reflect the way that the sum is calculated.
Deriving expert weights
The decision matrices \({A}^{\left(1\right)}\) and \({A}^{\left(2\right)}\) produced by the two experts are shown in Tables 3 and 4. It can be seen from Tables 3 and 4 that alternatives \({x}_{1}\) and \({x}_{2}\) given by the experts \({D}^{\left(1\right)}\) and \({D}^{\left(2\right)}\) have obvious differences. The weights of \({D}^{\left(1\right)}\) and \({D}^{\left(2\right)}\) have been set at 0.5 as suggested by Yue [75, 76] which cannot be distinguished. It is obviously inconsistent with the difference of the alternative judgment value given by experts \({D}^{\left(1\right)}\) and \({D}^{\left(2\right)}\), so it cannot reflect the objective actual situation. In real life, experts’ judgments on different system options will be affected by the external environment, such as their psychological state, alternative expression, and surrounding environment. Thus, the experts are given different weights.
Inspired by [75], the LINMAP model is used to derive expert weights that each alternative has itself expert weights. First, the IVq-ROFWFAWA operator is adopted to aggregate expert decision matrices according to different alternatives, and the fusion matrix is obtained. Second, the similarity, which is calculated each element of the fusion matrix between ideal point, is used to derive expert weights for each alternative. In this way, the expert weight matrix of different alternatives is obtained. For \(k\) experts and \(m\) alternatives, an \(m\times k\) expert weight matrix can be obtained by the following steps.
-
1.
Aggregate different expert decision matrices according to different alternatives.
According to the attribute weights of the decision matrix, the IVq-ROFWFAWA operator is used to aggregate the rows of each decision matrix as shown Eq. (34). For t-th expert, the aggregation result of \({{\overline{D}}}^{(t)}\) has m IVq-ROFNs which can be obtained as Eq. (35). For all experts, the aggregation result is a fusion matrix \({\overline{D}}\) with k rows and m columns defined as Eq. (36):
$$ d_{i}^{{\left( t \right)}} = {\text{IVq - ROFWFAWA}}\left( {a_{{ij}}^{{\left( t \right)}} ,a_{{ij}}^{{\left( t \right)}} , \ldots ,a_{{ij}}^{{\left( t \right)}} } \right) = \mathop { \otimes _{F} }\limits_{{j = 1}}^{n} w_{j}^{{\left( t \right)}} a_{{ij}}^{{\left( t \right)}} , $$(34)$${{\overline{D}}}^{\left(t\right)}=\left[{d}_{1}^{\left(t\right)},{d}_{2}^{\left(t\right)},\ldots,{d}_{m}^{\left(t\right)}\right],$$(35)$${\overline{D}}=\left(\begin{array}{l}{{\overline{D}}}^{\left(1\right)}\\ {{\overline{D}}}^{\left(2\right)}\\ \vdots \\ {{\overline{D}}}^{\left(k\right)}\end{array}\right)=\left(\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}{d}_{1}^{\left(1\right)}& {d}_{2}^{\left(1\right)}& \cdots & {d}_{m}^{\left(1\right)}\\ {d}_{1}^{\left(2\right)}& {d}_{2}^{\left(2\right)}& \cdots & {d}_{m}^{\left(2\right)}\\ \vdots & \vdots & \ddots & \vdots \\ {d}_{1}^{\left(k\right)}& {d}_{2}^{\left(k\right)}& \cdots & {d}_{m}^{\left(k\right)}\end{array}\right).$$(36) -
2.
Obtain the ideal point of the fusion matrix \({\overline{D}}\).
The positive ideal point \({d}_{j}^{+*}\) and the negative ideal point \({d}_{j}^{-*}\) of j-th column in the matrix \({\overline{D}}\) are calculated in Eqs. (37) and (38):
$${d}_{j}^{+*}=\left(\left[\underset{1\le t\le k}{\text{max}}\left({u}_{{d}_{j}^{\left(t\right)}}^{-}\right),\underset{1\le t\le k}{\text{max}}\left({u}_{{d}_{j}^{\left(t\right)}}^{+}\right)\right],\left[\underset{1\le t\le k}{\text{min}}\left({v}_{{d}_{j}^{\left(t\right)}}^{-}\right),\underset{1\le t\le k}{\text{min}}\left({v}_{{d}_{j}^{\left(t\right)}}^{+}\right)\right]\right),$$(37)$${d}_{j}^{-*}=\left(\left[\underset{1\le t\le k}{\text{min}}\left({u}_{{d}_{j}^{\left(t\right)}}^{-}\right),\underset{1\le t\le k}{\text{min}}\left({u}_{{d}_{j}^{\left(t\right)}}^{+}\right)\right],\left[\underset{1\le t\le k}{\text{max}}\left({v}_{{d}_{j}^{\left(t\right)}}^{-}\right),\underset{1\le t\le k}{\text{max}}\left({v}_{{d}_{j}^{\left(t\right)}}^{+}\right)\right]\right).$$(38) -
3.
Calculate the similarity of each element of \({\overline{D}}\) to the ideal point.
In matrix \({\overline{D}}\), the positive ideal similarity \({s}_{j}^{(+t)}\) and the negative ideal similarity \({s}_{j}^{(-t)}\) between each element \({d}_{j}^{\left(t\right)}\) and \({d}_{j}^{*}\) are calculated in Eqs. (39) and (40). The similarity matrices \({\text{SIM}}^{+}\) and \({{\text{SIM}}}^{-}\) of all ideal points are given in Eqs. (41) and (42):
$${{s}_{j}}^{\left(+t\right)}=S\left({d}_{j}^{\left(t\right)},{d}_{j}^{+*}\right)=\frac{\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\wedge {\left({u}_{{d}_{j}^{+*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\wedge {\left({v}_{{d}_{j}^{+*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\wedge {\left({u}_{{d}_{j}^{+*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\wedge {\left({v}_{{d}_{j}^{+*}}^{+}\right)}^{q}\right)}{\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\vee {\left({u}_{{d}_{j}^{+*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\vee {\left({v}_{{d}_{j}^{+*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\vee {\left({u}_{{d}_{j}^{+*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\vee {\left({v}_{{d}_{j}^{+*}}^{+}\right)}^{q}\right)},$$(39)$${{s}_{j}}^{\left(-t\right)}=S\left({d}_{j}^{\left(t\right)},{d}_{j}^{-*}\right)=\frac{\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\wedge {\left({u}_{{d}_{j}^{-*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\wedge {\left({v}_{{d}_{j}^{-*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\wedge {\left({u}_{{d}_{j}^{-*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\wedge {\left({v}_{{d}_{j}^{-*}}^{+}\right)}^{q}\right)}{\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\vee {\left({u}_{{d}_{j}^{-*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{-}\right)}^{q}\vee {\left({v}_{{d}_{j}^{-*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\vee {\left({u}_{{d}_{j}^{-*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{d}_{j}^{\left(t\right)}}^{+}\right)}^{q}\vee {\left({v}_{{d}_{j}^{-*}}^{+}\right)}^{q}\right)},$$(40)$${\text{SIM}}^{+}=\left[\begin{array}{l}{{\text{SIM}}}^{(+1)}\\ {{\text{SIM}}}^{(+2)}\\ \vdots \\ {{\text{SIM}}}^{(+{k})}\end{array}\right]=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}{s}_{1}^{\left(+1\right)}& {s}_{2}^{\left(+1\right)}& \cdots & {s}_{m}^{\left(+1\right)}\\ {s}_{1}^{\left(+2\right)}& {s}_{2}^{\left(+2\right)}& \cdots & {s}_{m}^{\left(+2\right)}\\ \vdots & \vdots & \ddots & \vdots \\ {s}_{1}^{\left(+k\right)}& {s}_{2}^{\left(+k\right)}& \cdots & {s}_{m}^{\left(+k\right)}\end{array}\right],$$(41)$${{\text{SIM}}}^{-}=\left[\begin{array}{l}{{\text{SIM}}}^{(-1)}\\ {{\text{SIM}}}^{(-2)}\\ \vdots \\ {{\text{SIM}}}^{(-k)}\end{array}\right]=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}{s}_{1}^{\left(-1\right)}& {s}_{2}^{\left(-1\right)}& \cdots & {s}_{m}^{\left(-1\right)}\\ {s}_{1}^{\left(-2\right)}& {s}_{2}^{\left(-2\right)}& \cdots & {s}_{m}^{\left(-2\right)}\\ \vdots & \vdots & \ddots & \vdots \\ {s}_{1}^{\left(-k\right)}& {s}_{2}^{\left(-k\right)}& \cdots & {s}_{m}^{\left(-k\right)}\end{array}\right].$$(42) -
4.
Get expert weight matrix.
For the i-th alternative of the t-th expert, the expert weight of \({\lambda }_{i}^{\left(t\right)}\) is calculated in Eq. (43). The expert weight matrix can be determined by Eq. (44):
$$ \lambda_{i}^{\left( t \right)} = \frac{{\frac{{s_{i}^{{^{{\left( { - t} \right)}} }} }}{{s_{i}^{{^{{\left( { - t} \right)}} }} + s_{i}^{{^{{\left( { + t} \right)}} }} }}}}{{ \sum \nolimits_{t = 1}^{k} \frac{{s_{i}^{{^{{\left( { - t} \right)}} }} }}{{s_{i}^{{^{{\left( { - t} \right)}} }} + s_{i}^{{^{{\left( { + t} \right)}} }} }}}}, $$(43)$$\lambda =\left[\begin{array}{l}{\lambda }^{(1)}\\ {\lambda }^{(2)}\\ \vdots \\ {\lambda }^{(k)}\end{array}\right]=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}{\lambda }_{1}^{\left(1\right)}& {\lambda }_{2}^{\left(1\right)}& \cdots & {\lambda }_{m}^{\left(1\right)}\\ {\lambda }_{1}^{\left(2\right)}& {\lambda }_{2}^{\left(2\right)}& \cdots & {\lambda }_{m}^{\left(2\right)}\\ \vdots & \vdots & \ddots & \vdots \\ {\lambda }_{1}^{\left(k\right)}& {\lambda }_{2}^{\left(k\right)}& \cdots & {\lambda }_{m}^{\left(k\right)}\end{array}\right].$$(44)According to the decision matrices \({A}^{\left(1\right)}\) and \({A}^{\left(2\right)}\) given by the experts \({D}^{\left(1\right)}\) and \({D}^{\left(2\right)}\), the expert weights which are presented by a matrix are derived by our proposed method, the results are shown in Table 5.
Table 5 Expert weights results of the proposed method
It can be seen from Table 5 that expert weights are different, compared with Yue [75, 76], the proposed method is more adaptable. Our method, thus, reflects the real situation of the experts more objectively.
MAGDM method based on ARAS
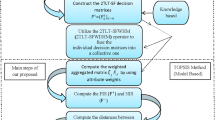
In this subsection, the proposed MAGDM method includes two information aggregating processes. First, the proposed IVq-ROFWFAFWA operator is used to aggregate the decision matrix of each expert that obtains the aggregation matrix R. Second, the ARAS method is used to select the optimal alternative from matrix R. Figure 2 shows the process for developing the MAGDM method. In addition, its steps of implementation are following.

MAGDM flow based on the ARAS method
-
1.
Determine the appropriate q value.
According to the decision matrix provided by the experts, the traversal method is used to compute the smallest positive integer q which makes all elements satisfy \({\left({u}_{{a}_{ij}^{\left(t\right)}}^{+}\right)}^{q}+{\left({v}_{{a}_{ij}^{\left(t\right)}}^{+}\right)}^{q}\le 1, q\ge 1\).
-
2.
Standardize.
In the application scenario, if both cost-type and benefit-type attributes are included, cost-type attributes will be uniformly transformed into benefit-type attributes. The standardizing process is given by Eqs. (24) and (25).
-
3.
Determine the preference pairs set \(P=\left\{\left(g,l\right)\right\}\).
The pre-evaluation, which the experts have carried out in advance, determines the alternative preference pairs set P.
-
4.
Derive expert weight matrix \(\lambda \).
First, the LINMAP model is used to solve the attribute weight vector \({w}^{(t)}\) of each decision matrix and to obtain the attribute weight matrix W. The solving steps are shown in Eqs. (26)–(33). The W and the IVq-ROFWFAWA operator are used to aggregate the different alternatives and obtain the aggregation vector \({{\overline{D}}}^{(t)}\) of each expert. \({{\overline{D}}}^{(t)}\) is fused to a matrix \({\overline{D}}\). The solving processes are given in Eqs. (34)–(36). The similarity is then used to compute the weights of the different alternatives. For each alternative, the weights of each expert are obtained. After combination, an expert weight matrix \(\lambda \) is obtained. The solving processes are conducted in Eqs. (37)–(44).
-
5.
Get the aggregation matrix \(R\).
According to the expert weight matrix λ solved in step (4), the IVq-ROFWFAWA operator is used to aggregate elements at the same position of \({A}^{\left(t\right)}\) (t = 1, 2, …, k). The aggregation matrix \(R={\left({r}_{ij}\right)}_{m\times n}\) is obtained by Eq. (45) for \(i={1,2},\dots ,m;j={1,2},\dots ,n\):
$$ r_{{ij}} = {\text{IVq-ROFWFAWA}}\left( {a_{{ij}}^{{\left( 1 \right)}} ,a_{{ij}}^{{\left( 2 \right)}} , \ldots ,a_{{ij}}^{{\left( k \right)}} } \right) = \mathop { \otimes _{F} }\limits_{{t = 1}}^{k} \lambda _{j}^{{\left( t \right)}} a_{{ij}}^{{\left( t \right)}} . $$(45) -
6.
Calculate the similarity of the matrix R to the ideal point.
The positive ideal point \({r}_{j}^{*}\) of each column of the matrix R can be found by Eq. (46). The similarity \({SR}_{g}({r}_{gj},{r}_{j}^{*})\) and \({SR}_{l}({r}_{lj},{r}_{j}^{*})\) are then calculated by Eqs. (47) and Eq. (48):
$$\begin{aligned}{r}_{j}^{*}&=\left(\left[\underset{1\le i\le m}{\text{max}}\left({u}_{{r}_{ij}}^{-}\right),\underset{1\le i\le m}{\text{max}}\left({u}_{{r}_{ij}}^{+}\right)\right],\right.\\ &\left.\left[\underset{1\le i\le m}{\text{min}}\left({v}_{{r}_{ij}}^{-}\right),\underset{1\le i\le m}{\text{min}}\left({v}_{{r}_{ij}}^{+}\right)\right]\right),\end{aligned}$$(46)$$S{R}_{g}\left({r}_{gj},{r}_{j}^{*}\right)=\frac{\left({\left({u}_{{r}_{gj}}^{-}\right)}^{q}\wedge {\left({u}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{r}_{gj}}^{-}\right)}^{q}\wedge {\left({v}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{r}_{gj}}^{+}\right)}^{q}\wedge {\left({u}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{r}_{gj}}^{+}\right)}^{q}\wedge {\left({v}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)}{\left({\left({u}_{{r}_{gj}}^{-}\right)}^{q}\vee {\left({u}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{r}_{gj}}^{-}\right)}^{q}\vee {\left({v}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{r}_{gj}}^{+}\right)}^{q}\vee {\left({u}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{r}_{gj}}^{+}\right)}^{q}\vee {\left({v}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)},$$(47)$$S{R}_{l}\left({r}_{lj},{r}_{j}^{*}\right)=\frac{\left({\left({u}_{{r}_{lj}}^{-}\right)}^{q}\wedge {\left({u}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{r}_{lj}}^{-}\right)}^{q}\wedge {\left({v}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{r}_{lj}}^{+}\right)}^{q}\wedge {\left({u}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{r}_{lj}}^{+}\right)}^{q}\wedge {\left({v}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)}{\left({\left({u}_{{r}_{lj}}^{-}\right)}^{q}\vee {\left({u}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({v}_{{r}_{lj}}^{-}\right)}^{q}\vee {\left({v}_{{r}_{j}^{*}}^{-}\right)}^{q}\right)+\left({\left({u}_{{r}_{lj}}^{+}\right)}^{q}\vee {\left({u}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)+\left({\left({v}_{{r}_{lj}}^{+}\right)}^{q}\vee {\left({v}_{{r}_{j}^{*}}^{+}\right)}^{q}\right)}.$$(48) -
7.
Calculate the weighted similarity of the matrix \(R\).
Let attribute weights of \(R\) be \(w=({w}_{1},{w}_{2},\dots ,{w}_{n})\). The weighted average values \({Eqr}_{g}\,{ {and}\, Eqr}_{l}\) of \({SR}_{g}({r}_{gj},{r}_{j}^{*})\) and \({SR}_{l}({r}_{lj},{r}_{j}^{*})\) are calculated by Eqs. (49) and (50).
$$ Eqr_{g} = \sum \limits_{j = 1}^{n} w_{j} \times SR_{g} (r_{gj} ,r_{j}^{*} ),\;j = 1,2, \ldots ,n $$(49)$$ Eqr_{l} = \sum \limits_{j = 1}^{n} w_{j} \times SR_{l} (r_{lj} ,r_{j}^{*} ),\;j = 1,2, \ldots ,n $$(50) -
8.
Construct a linear programming model.
For a pair of alternatives \((g,l)\) in the set of preference pair \(P\), if \(E{qr}_{g}\le E{qr}_{l}\), it means that the alternative \({x}_{g}\) is closer to the ideal point than \({x}_{l}\), and the weighted similarity is consistent with the expert’s preference. On the contrary, if \(E{qr}_{g}>E{qr}_{l}\), the weighted similarity will be inconsistent with the expert preference. The goal of the actual alternative should be that the weighted similarity and the preference of the expert are usually consistent. According to the idea of the LINMAP model, this goal can be transformed into the linear programming model:
$$ \begin{gathered} {\text{min}} \sum \limits_{{\left( {g,l} \right) \in P}} \theta r_{gl} , \hfill \\ {\text{S.T.}}\left\{ {\begin{array}{*{20}l} {Eqr_{l} - Eqr_{g} + \theta r_{gl} \ge 0} \hfill \\ { \sum \limits_{{\left( {g,l} \right) \in P}} \left( {Eqr_{l} - Eqr_{g} } \right) = B} \hfill \\ {\sum\limits_{j = 1}^{n} {w_{j} = 1} } \hfill \\ {w_{j} \ge 0} \hfill \\ {\theta r_{gl} \ge 0} \hfill \\ \end{array} } \right.. \hfill \\ \end{gathered} $$(51) -
9.
Get the attribute weights of R.
The linear programming model of Eq. (51) will be solved. The attribute weight w of R can be obtained:
$$w=\left({w}_{1},{w}_{2},\ldots,{w}_{n}\right).$$(52)The ARAS method is used to select the best alternative. The main idea of the ARAS method is to select the best alternative based on multiple attributes and determine the final ranking of the alternatives by determining the utility of each one. The following steps use the ARAS idea to obtain the optimal alternative.
-
10.
Obtain the optimal alternative \({\overline{R}}\).
Using the score function in Eq. (14), the element with the largest matrix R score for each column can be identified. The element with the largest score in the j-th column can be solved by Eq. (53), where \(S({r}_{ij})\) represents the score of the element \({r}_{ij}\). The elements with the highest scores in all columns then form a new alternative \({x}_{0}\). This is then added to the 0th row of R, so that a new decision matrix \(\overline{R }={({\overline{r} }_{ij})}_{m\times n}\) can be obtained by Eq. (54) for \(i={0,1},2,\dots ,m;j={1,2},\dots ,n\):
$${{\overline{r}}}_{0j}=\left(\left[{u}_{{r}_{ij}}^{-},{u}_{{r}_{ij}}^{+}\right],\left[{v}_{{r}_{ij}}^{-},{v}_{{r}_{ij}}^{+}\right]\right)\underset{i}{={\text{max}}}\left\{S\left({r}_{ij}\right)\right\},$$(53)$${\overline{R}}=({\overline{r}}{)}_{m\times n}=\left(\begin{array}{ccc}\left(\left[{u}_{{{\overline{r}}}_{01}}^{-},{u}_{{{\overline{r}}}_{01}}^{+}\right],\left[{v}_{{{\overline{r}}}_{01}}^{-},{v}_{{{\overline{r}}}_{01}}^{+}\right]\right)& \cdots & \left(\left[{u}_{{{\overline{r}}}_{0n}}^{-},{u}_{{{\overline{r}}}_{0n}}^{+}\right],\left[{v}_{{{\overline{r}}}_{0n}}^{-},{v}_{{{\overline{r}}}_{0n}}^{+}\right]\right)\\ \vdots & \ddots & \vdots \\ \left(\left[{u}_{{{\overline{r}}}_{m1}}^{-},{u}_{{{\overline{r}}}_{m1}}^{+}\right],\left[{v}_{{{\overline{r}}}_{m1}}^{-},{v}_{{{\overline{r}}}_{m1}}^{+}\right]\right)& \cdots & \left(\left[{u}_{{{\overline{r}}}_{mn}}^{-},{u}_{{{\overline{r}}}_{mn}}^{+}\right],\left[{v}_{{{\overline{r}}}_{mn}}^{-},{v}_{{{\overline{r}}}_{mn}}^{+}\right]\right)\end{array}\right).$$(54) -
11.
Aggregate the elements in \(\overline{R }\).
The IVq-ROFWFAWA operator is used to aggregate the elements \({\overline{r} }_{ij}\) of each row of \(\overline{R }\) by Eq. (55), and the aggregation value \(b{{\overline{r}}}_{i}\) can be obtained:
$$ b{\overline{r}}_{i} = {\text{IVq-ROFWFAWA}}\left( {{\overline{r}}_{{i1}} ,{\overline{r}}_{{i2}} ,\ldots,{\overline{r}}_{{in}} } \right) = \mathop { \otimes _{F} }\limits_{{j = 1}}^{n} w_{j} {\overline{r}}_{{ij}} . $$(55) -
12.
Calculate alternative score.
With the \(b{{\overline{r}}}_{i}\) of each alternative solved in step (11), each alternative score \(s{{\overline{r}}}_{i}\) is calculated by Eq. (56):
$$s{{\overline{r}}}_{i}=\frac{1}{4}\left(\begin{array}{l}ln\left({u}_{b{{\overline{r}}}_{i}}^{-}+{u}_{b{{\overline{r}}}_{i}}^{+}+{v}_{b{{\overline{r}}}_{i}}^{-}+{v}_{b{{\overline{r}}}_{i}}^{+}+1\right)+2\times \left(\left({u}_{b{{\overline{r}}}_{i}}^{-}+{u}_{b{{\overline{r}}}_{i}}^{+}\right)-\left({v}_{b{{\overline{r}}}_{i}}^{-}+{v}_{b{{\overline{r}}}_{i}}^{+}\right)\right)\\ +\left(({u}_{b{{\overline{r}}}_{i}}^{+}-{u}_{b{{\overline{r}}}_{i}}^{-})+({v}_{b{{\overline{r}}}_{i}}^{+}-{v}_{b{{\overline{r}}}_{i}}^{-})\right)+\left(({u}_{b{{\overline{r}}}_{i}}^{+}-{u}_{b{{\overline{r}}}_{i}}^{-})-({v}_{b{{\overline{r}}}_{i}}^{+}-{v}_{b{{\overline{r}}}_{i}}^{-})\right)\\ -{Sign}\left({u}_{b{{\overline{r}}}_{i}}^{-}+{u}_{b{{\overline{r}}}_{i}}^{+}+{v}_{b{{\overline{r}}}_{i}}^{-}+{v}_{b{{\overline{r}}}_{i}}^{+}\right)\times ln3\end{array}\right).$$(56) -
13.
Calculate the utility value of the alternative.
Because the 0-th alternative is best, the utility of the alternative is equal to the score of the alternative divided by the score of the 0-th alternative:
$${e}_{i}=\frac{s{{\overline{r}}}_{i}}{s{{\overline{r}}}_{0}}, i=1,\dots ,m.$$(57) -
14.
Rank alternatives and select the optimal alternative.
According to the utility \({e}_{i}\) for each alternative obtained in step (13), the greater the effect is, the better the alternative is. The alternative with the largest utility, therefore, is the optimal alternative.
Evaluation and analysis of the HFU system
The process for evaluating an HFU system is described in “Evaluating an HFU system”. A sensitivity analysis of the evaluation methods is conducted in “Sensitivity analysis of evaluation parameters”, and a comparison and more general analysis are carried out in “Comparative analysis”.
Evaluating an HFU system
Expert evaluation
After a public bidding procedure, the optimal HFU system will be selected from the five HFU systems. Each HFU system was subjected to expert review, and was preliminarily evaluated by the hospital. The preference pairs set is obtained: \(P=\left\{(\text{5,4}),(\text{5,1}),(\text{3,2}),(\text{1,2})\right\}\). Five experts were then invited to evaluate each system. In order to facilitate expert evaluation, a linguistic-graded evaluation scale was adopted. Inspired by Ilbahar et al. [25], the linguistic-graded scale included ten grades, with each of the linguistic terms corresponding to the ten IVq-ROFNs listed in Table 6. Five experts evaluated the five HFU systems according to their expertise and the indices given in Table 1. The evaluation matrices \({L}^{\left(1\right)},{L}^{\left(2\right)},{L}^{\left(3\right)},{L}^{\left(4\right)},{L}^{\left(5\right)}\) are listed in Tables 7, 8, 9, 10, and 11.
Alternatives selection
As can be seen from Tables 7, 8, 9, 10, and 11, it is difficult to determine the best HFU system based on the decision matrix provided by the five experts. For some attributes, there seems to be little difference among the respective experts. However, determining expert weights and attribute weights are not straightforward. That is why, as described in “Integrated Group Decision method”, the proposed MAGDM method should be used to select the best alternative. The HFU system evaluation process includes the following 15 steps.
-
1.
Transform \({L}^{\left(t\right)}\) into \({A}^{{{\prime}}\left(t\right)}\).
The evaluation matrices \({L}^{\left(1\right)},{L}^{\left(2\right)},{L}^{\left(3\right)},{L}^{\left(4\right)},{L}^{\left(5\right)}\) are transformed into IVq-ROFN decision matrices \({A}^{{{\prime}}\left(1\right)},{A^{\prime}}^{\left(2\right)},{A}^{{{\prime}}\left(3\right)},{A}^{{{\prime}}\left(4\right)},{A}^{{{\prime}}\left(5\right)}\) using Table 1.
-
2.
Determine the q value.
It is found that when \(q\) is greater than or equal to 2, all elements of \({A}^{{{\prime}}\left(1\right)},{A^{\prime}}^{\left(2\right)},{A}^{{{\prime}}\left(3\right)},{A}^{{{\prime}}\left(4\right)},{A}^{{{\prime}}\left(5\right)}\) satisfy the definition of IVq-ROFS. \(q\) is set to 3 in this case.
-
3.
Standardize \({A}^{{{\prime}}\left(t\right)}\).
The cost-type attributes (C1, C9) are then converted into benefit-type attributes by Eqs. (24) and (25). \({A}^{{{\prime}}\left(1\right)},{A^{\prime}}^{\left(2\right)},{A}^{{{\prime}}\left(3\right)},{A}^{{{\prime}}\left(4\right)},{A}^{{{\prime}}\left(5\right)}\) are transformed into \({A}^{\left(1\right)},{A}^{\left(2\right)},{A}^{\left(3\right)},{A}^{\left(4\right)},{A}^{\left(5\right)}\) as shown in Tables 12, 13, 14, 15, and 16.
-
4.
Determine the preference pairs set \(P\).
Table 12 Evaluation value \({A}^{\left(1\right)}\) Table 13 Evaluation value \({A}^{\left(2\right)}\) Table 14 Evaluation value A(3) Table 15 Evaluation value A(4) Table 16 Evaluation value A(5) The preference pairs’ set \(P=\left\{\left({5,4}\right),\left({5,1}\right),\left({3,2}\right),\left({1,2}\right)\right\}\) was determined in advance.
-
5.
Derive expert weight matrix \(\lambda \).
According to the decision matrix \({A}^{\left(t\right)}\), the attribute weight \({w}^{(t)}\) is solved using the LINMAP model. The steps of the solution are given in Eqs. (26)–(33). The IVq-ROFWFAWA operator is used to aggregate row elements of the matrices in Tables 12, 13, 14, 15, and 16. The matrix \({\overline{D}}\) is obtained using Eqs. (34)–(36). The expert weight matrix can be obtained using Eqs. (37)–(44). The result of the expert weight matrix \(\lambda \) (keeping four decimal places) is as follows:
$$\begin{aligned} \lambda = &\left( {\begin{array}{*{20}l} {\lambda ^{{\left( 1 \right)}} } \\ {\lambda ^{{\left( 2 \right)}} } \\ {\lambda ^{{\left( 3 \right)}} } \\ {\lambda ^{{\left( 4 \right)}} } \\ {\lambda ^{{\left( 5 \right)}} } \\ \end{array} } \right)\\ &= \left( {\begin{array}{c@{\quad}c@{\quad}c@{\quad}c@{\quad}c} {{{0.1714}}} & {{{0.2360}}} & {{{0.2012}}} & {{{0.2069}}} & {{{0.1828}}} \\ {{{0.2231}}} & {{{0.1798}}} & {{{0.2303}}} & {{{0.2153}}} & {{{0.1942}}} \\ {{{0.2192}}} & {{{0.1946}}} & {{{0.2086}}} & {{{0.2197}}} & {{{0.1953}}} \\ {{{0.2039}}} & {{{0.2119}}} & {{{0.2164}}} & {{{0.2017}}} & {{{0.1973}}} \\ {{{0.1824}}} & {{{0.1777}}} & {{{0.1435}}} & {{{0.1564}}} & {{{0.2304}}} \\ \end{array} } \right).\end{aligned} $$ -
6.
Aggregating expert decision matrix.
Using Eq. (45) to aggregate five experts' matrices of \({A}^{(t)}\)(t = 1, 2, 3, 4, 5), the collective matrix \(R={({r}_{ij})}_{5\times 13}\) is calculated as shown in Table 17.
-
7.
Calculate each point’s similarity of R to the ideal point.
Table 17 Aggregate matrix \(R\) After obtaining the ideal points of each attribute of the matrix \(R\) by Eq. (46), as shown as follows:
$$\begin{aligned}{r}_{1}^{*}&=\left(\left[{0.55,0.65}\right],\left[{0.35,0.45}\right]\right),\\ {r}_{2}^{*}&=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),\\ {r}_{3}^{*}&=\left(\left[{0.78,0.88}\right],\left[{0.12,0.23}\right]\right),\\ {r}_{4}^{*}&=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),\\ {r}_{5}^{*}&=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),\\ {r}_{6}^{*}&=\left(\left[{0.78,0.89}\right],\left[{0.12,0.22}\right]\right),\\ {r}_{7}^{*}&=\left(\left[{0.77,0.87}\right],\left[{0.14,0.25}\right]\right),\\ {r}_{8}^{*}&=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),\\ {r}_{9}^{*}&=\left(\left[{0.52,0.62}\right],\left[{0.42,0.53}\right]\right),\\ {r}_{10}^{*}&=\left(\left[{0.78,0.88}\right],\left[{0.12,0.23}\right]\right),\\ {r}_{11}^{*}&=\left(\left[{0.78,0.88}\right],\left[{0.12,0.23}\right]\right),\\ {r}_{12}^{*}&=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),\\ {r}_{13}^{*}&=\left(\left[{0.75,0.87}\right],\left[{0.14,0.26}\right]\right). \end{aligned}$$We calculate the similarity for each point of \(R\) by Eqs. (47) and (48), which are shown in Table 18.
-
8.
Calculate the weighted similarity of R.
Table 18 The similarity of aggregate matrix R Let the attribute weight of \(R\) be \(w=({w}_{1},{w}_{2},\dots ,{w}_{n})\), the weighted average \({Eqr}_{g}\) and \({Eqr}_{l}\) are shown in Eqs. (49) and (50), and the results are
$$\begin{aligned}Eq{r}_{1}&={0.085}{w}_{1}+{w}_{2}+{w}_{3}+{w}_{4}+{w}_{5}+0.992{w}_{6}+{0.017}{w}_{7}+0.005{w}_{8}+{w}_{9}+{0.01}{w}_{10}+{w}_{11}+{w}_{12}+{0.046}{w}_{13},\\ Eq{r}_{2}&={0.151}{w}_{1}+{0.512}{w}_{2}+{0.278}{w}_{3}+{w}_{4}+{0.371}{w}_{5}+{0.44}{w}_{6}+{0.014}{w}_{7}+{0.015}{w}_{8}+{0.793}{w}_{9}+{0.02}{w}_{10}\\ &+{0.554}{w}_{11}+{w}_{12}+{0.112}{w}_{13},\\ Eq{r}_{3}&={w}_{1}+0.02{w}_{2}+0.044{w}_{3}+{0.176}{w}_{4}+{0.381}{w}_{5}+{0.188}{w}_{6}+0.611{w}_{7}+{w}_{8}+0.139{w}_{9}+{0.455}{w}_{10} \\ &+{0.224}{w}_{11}+{0.71}{w}_{12}+{0.517}{w}_{13},\\ Eq{r}_{4}&={w}_{1}+{0.021}{w}_{2}+{0.045}{w}_{3}+{0.178}{w}_{4}+{0.382}{w}_{5}+{0.189}{w}_{6}+{0.622}{w}_{7}+0.933{w}_{8}+{0.14}{w}_{9}+{0.455}{w}_{10} \\& +{0.092}{w}_{11}+{0.085}{w}_{12}+{0.669}{w}_{13},\\ Eq{r}_{5}&={0.56}{w}_{1}+0.268{w}_{2}+0.88{w}_{3}+0.569{w}_{4}+0.403{w}_{5}+{w}_{6}+{w}_{7}+{0.311}{w}_{8}+0.746{w}_{9}+{w}_{10} \\ &+0.429{w}_{11}+{w}_{12}+{w}_{13}.\end{aligned}$$ -
8.
-
9.
Construct a linear programming model.
According to Eq. (51) and the results of step (8), the linear programming model is constructed as Eq. (58):
$$\begin{array}{l}\begin{array}{l}{\text{min}}\theta ={\theta }_{54}+{\theta }_{51}+{\theta }_{32}+{\theta }_{12} \\ \end{array}\\ {\text{S.T.}}\left\{\begin{array}{l}\begin{array}{l}{0.44}{w}_{1}-{0.247}{w}_{2}-{0.835}{w}_{3}-{0.391}{w}_{4}-{0.021}{w}_{5}-{0.811}{w}_{6}-{0.378}{w}_{7}+{0.622}{w}_{8}\\ -{0.606}{w}_{9}-{0.545}{w}_{10}-{0.337}{w}_{11}-{0.915}{w}_{12}-{0.331}{w}_{13}\ge -{\theta }_{54}\end{array}\\ \begin{array}{l}-{0.475}{w}_{1}+{0.732}{w}_{2}+{0.12}{w}_{3}+{0.431}{w}_{4}+{0.597}{w}_{5}-{0.008}{w}_{6}-{0.983}{w}_{7}-{0.306}{w}_{8}\\ \text{ +0.254}{w}_{9}-{0.99}{w}_{10}+{0.571}{w}_{11}+ 0 {w}_{12}-{0.954}{w}_{13}\ge -{\theta }_{51}\end{array}\\ \begin{array}{l}\begin{array}{l}-{0.849}{w}_{1}+{0.492}{w}_{2}+{0.235}{w}_{3}+{0.824}{w}_{4}-{0.01}{w}_{5}+{0.252}{w}_{6}-{0.597}{w}_{7}-{0.985}{w}_{8}\\ \text{ +0.653}{w}_{9}-{0.436}{w}_{10}+{0.329}{w}_{11}+{0.2}{9}_{12}-{0.405}{w}_{13}\ge -{\theta }_{32}\end{array}\\ \begin{array}{l}{0.066}{w}_{1}-{0.488}{w}_{2}-{0.722}{w}_{3}+ 0 {w}_{4}-{0.629}{w}_{5}-{0.552}{w}_{6}-{0.003}{w}_{7}+{0.01}{w}_{8}-{0.207}{w}_{9}\\ \text{ +0.01}{w}_{10}-{0.446}{w}_{11}+ 0 {w}_{12}+{0.067}{w}_{13}\ge -{\theta }_{12}\end{array}\\ \begin{array}{l}{w}_{1}+{w}_{2}+{w}_{3}+{w}_{4}+{w}_{5}+{w}_{6}+{w}_{7}+{w}_{8}+{w}_{9}+{w}_{10}+{w}_{11}+{w}_{12}+{w}_{13}=1\\ {w}_{1},{w}_{2},{w}_{3},{w}_{4},{w}_{5},{w}_{6},{w}_{7},{w}_{8},{w}_{9},{w}_{10},{w}_{11},{w}_{12},{w}_{13}\ge 0\\ {\theta }_{54},{\theta }_{51},{\theta }_{32},{\theta }_{12}\ge 0\end{array}\end{array}\end{array}\right.\end{array}.$$(58) -
10.
Derive the attribute weights of R.
By solving Eq. (58), the attribute weight \(w\) of R is shown as follows:
$$ w = \left( {\begin{array}{*{20}l} {0.0876,0.0411,{ }0.0964,{ }0.0008,{ }0.0721,{ }0.0937,0.1259,} \hfill \\ {0.0862,{ }0.0429,{ }0.1205,{ }0.0557,{ }0.0689,{ }0.1082} \hfill \\ \end{array} } \right). $$ -
11.
Obtain the optimal alternative \({\overline{R}}\).
The element with the highest score in each column of the decision matrix R can be found using Eq. (53). All elements with the highest score are
$$\begin{array}{ccc}{{\overline{r}}}_{01}=\left(\left[{0.55,0.65}\right],\left[{0.35,0.45}\right]\right),& {{\overline{r}}}_{02}=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),& {{\overline{r}}}_{03}=\left(\left[{0.78,0.88}\right],\left[{0.12,0.23}\right]\right),\\ {{\overline{r}}}_{04}=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),& {{\overline{r}}}_{05}=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right), & {{\overline{r}}}_{06}=\left(\left[{0.78,0.89}\right],\left[{0.12,0.22}\right]\right),\\ {{\overline{r}}}_{07}=\left(\left[{0.77,0.87}\right],\left[{0.14,0.25}\right]\right),& {{\overline{r}}}_{08}=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),& {{\overline{r}}}_{09}=\left(\left[{0.52,0.62}\right],\left[{0.42,0.53}\right]\right),\\ {{\overline{r}}}_{010}=\left(\left[{0.78,0.88}\right],\left[{0.12,0.23}\right]\right),& {{\overline{r}}}_{011}=\left(\left[{0.78,0.88}\right],\left[{0.12,0.23}\right]\right),& {{\overline{r}}}_{012}=\left(\left[{0.80,0.90}\right],\left[{0.10,0.20}\right]\right),\\ {{\overline{r}}}_{013}=\left(\left[{0.75,0.87}\right],\left[{0.14,0.26}\right]\right).& & \end{array}$$By adding these elements to row 0 of the matrix R, we can get an optimal matrix \(\overline{R }={({\overline{r} }_{ij})}_{6\times 13}\) as shown in Table 19.
-
12.
Aggregate the attribute of \(\overline{R }\).
Table 19 Decision matrix \({\overline{R}}\) of the optimal alternative Equation (55) is used to aggregate the elements \({\overline{r} }_{ij}\) of each row of \(\overline{R }\). The results of each alternative of \(b{{\overline{r}}}_{i}\) are
$$ \begin{array}{*{20}l} {b\overline{r}_{0} = \left( {\left[ {0.76,0.87} \right],\left[ {0.14,0.26} \right]} \right)} & {b\overline{r}_{1} = \left( {\left[ {0.58,0.66} \right],\left[ {0.65,0.74} \right]} \right)} & {b\overline{r}_{2} = \left( {\left[ {0.43,0.56} \right],\left[ {0.62,0.73} \right]} \right)} \\ {b\overline{r}_{3} = \left( {\left[ {0.61,0.71} \right],\left[ {0.42,0.54} \right]} \right)} & {b\overline{r}_{4} = \left( {\left[ {0.58,0.68} \right],\left[ {0.46,0.57} \right]} \right)} & {b\overline{r}_{5} = \left( {\left[ {0.71,0.82} \right],\left[ {0.21,0.34} \right]} \right)} \\ \end{array} . $$ -
13.
Obtain the score of alternatives.
The score \(s{{\overline{r}}}_{i}\) of \(b{{\overline{r}}}_{i}\) is calculated by Eq. (56). They are
$$\begin{aligned} s{\overline{r}}_{0} &= 0.6758, \quad s{\overline{r}}_{1} = 0.0194, \quad s{\overline{r}}_{2} = - 0.0872, \\ s{\overline{r}}_{3} &= 0.2494 \quad s{\overline{r}}_{4} = 0.1857,~s{\overline{r}}_{5} = 0.5520 .\end{aligned} $$ -
14.
Calculate the utility degrees of the alternatives.
The utility degrees of the alternatives are calculated by Eq. (57):
$$ \begin{aligned} e_{1} &= 0.0288, \quad e_{2} = - 0.1290, \\ e_{3} &= 0.3690, \quad e_{4} = 0.2748, \quad e_{5} = 0.8168 .\end{aligned} $$-
15.
Rank alternatives and select the best alternative.
-
15.
The utility degree ranking of the alternatives is \({e}_{5}>{e}_{3}>{e}_{4}>{e}_{1}>{e}_{2}\). Thus, the ranking of alternatives is \({x}_{5}>{x}_{3}>{x}_{4}>{x}_{1}>{x}_{2}\), and the \({x}_{5}\) represents the best alternative, it means that the 5th software product is an ideal HFU system for purchasing. In addition, the result is consistent with the preference pairs preset by experts. It can be concluded that the proposed MAGDM is effective and objective.
Sensitivity analysis of evaluation parameters
In order to further verify the influence of the value of q, we varied q without changing the expert decision matrix. The analysis is taken from the perspective of alternative attribute weights and utility degrees. When q value changes from 3 to 10, the changes of alternative attribute weights and utility degrees are shown in Figs. 3 and 4.

The attribute weight influence of q value

The influence of q value changes on decision-making methods

Comparative analysis of decision-making methods

Comparison chart of different aggregation matrix operators
Figure 3 shows that with the increase of q, the changing trend of the attribute weights remains in the same direction. If attribute weights increase with the increase of q, the changing trend of the attribute weights also increases.
Figure 4 shows that when q changes from 3 to 10, each alternative fluctuates within a certain range and that the ranking of each alternative is basically unchanged.
Comparative analysis
Comparative analysis of decision-making methods
To analyze the influence of different decision-making methods, the ARAS method is compared to MACBETH [2], MABAC [48] and TOPSIS [24]. The results are shown in Table 20.
It can be seen from Fig. 5 that the optimal alternative is \({x}_{5}\) obtained by the ARAS, MACBETH, MABAC and TOPSIS methods under the environment of IVq-ROFS. It can be proved that they can obtain the same optimal alternative. At the same time, it can be seen from Fig. 5 that the alternative ranking results obtained by ARAS, MACBETH and TOPSIS are completely consistent: \({x}_{5}>{x}_{3}>{x}_{4}>{x}_{1}>{x}_{2}\), which proves that the ARAS is effective and feasible. The ranking result of MABAC is \({x}_{5}>{x}_{1}>{x}_{3}>{x}_{4}>{x}_{2}\), implying that \({x}_{1}\) is superior to alternative \({x}_{3}\) and alternative \({x}_{4}\). However, since the alternatives \({x}_{3}\) and \({x}_{4}\) are preferable to \({x}_{1}\) for ARAS, MACBETH and TOPSIS, ARAS is more stable than MABAC. At the same time, it can be seen from Fig. 5 that the deviation of alternatives score obtained by ARAS is easier to distinguish than MACBETH, MABAC and TOPSIS, allowing decision-makers to easily obtain the ranking results.
Comparative analysis of aggregate operators
To analyze the influence of different aggregating operators, the IVq-ROFWFAWA (WFAWA) operator is compared with the WA [67], NA [18] and PA [69] aggregate operators in the decision-making process under an IVq-ROFS environment. The comparison results are presented in Table 21 and Fig. 6.
As can be seen from Fig. 6, for IVq-ROFWFAWA, WA, NA and PA aggregate operators, the results of the ranking of each alternative are generally consistent across all four operators. At the same time, the IVq-ROFWFAWA operator is still the most concise and efficient and outperforms the other operators when choosing the best alternative.
Based on the implementation and comparative analysis of the case in this paper, the optimal HFU system can be selected from the five HFU systems by our developed GDM method. In addition, our research work has advantages. (1) Compared with q-ROFSs, the proposed GDM method can expand the freedom of DMs under IVq-ROFS. (2) The new score function can better distinguish IVq-ROFNs which further improves the processing ability of the proposed GDM method. (3) Our developed GDM method does not need attribute weights and expert weights, which can save evaluating time and reduce decision-making costs. (4) The proposed method for deriving expert weights makes each alternative have its own expert weights, which can more objectively reflect the expert’s real situation, and which makes the proposed GDM method more suitable for evaluating a small number of alternatives in a dynamic environment. (5) The neutral IVq-ROFWFAWA operator can improve the information carry capacity of the developed GDM method, which can more accurately preserve the attitude characteristics of DMs. Therefore, our proposed GDM method can be more conveniently, objectively, and cost-effectively used for evaluating a small number of alternatives.
Conclusion
To evaluate the differences among HFU management systems, this paper develops a MAGDM method that integrates an IVq-ROFWFAWA operator, the LINMAP method and the ARAS method under IVq-ROFNs. We designed our indices according to the features of medical software that are measured in quality reviews and evaluations. Then, we propose a novel score function that overcomes the deficiency of existing score functions for measuring IVq-ROFNs, and extend WFA operator to IVq-ROFWFAWA operator under IVq-ROFSs for aggregating information neutrally. Afterward, the attribute weights are solved through a linear programming model constructed by LINMAP, and expert weights of different alternatives are obtained based on the similarity of IVq-ROFNs. Finally, the integrated GDM method is developed to evaluate the quality of the HFU system under IVq-ROFSs. The results of the evaluation are consistent with the results provided by the experts in advance. The sensitivity analysis and comparative analysis further verify the effectiveness and feasibility of the proposed MAGDM method.
Nevertheless, our developed method is only applicable to the case of a small number of experts and a small number of alternatives, with the rapid growth of complexity and uncertainty of the system, it is necessary to combine big data and artificial intelligence to deal with complex problems in the decision-making process. For future research, we will concentrate on the study of big data decision problems. On the other hand, experts often give preference information between alternatives and provide a judgment matrix according to their own experience and knowledge. Therefore, decision-making methods based on preference relations will also be our research focus.
Data Availability
All data used to support the findings of the study are included within the article.
References
Al-Zahrani FA (2020) Evaluating the usable-security of healthcare software through unified technique of fuzzy logic, ANP and TOPSIS. IEEE Access 8:109905–109916
Bana e Costa C, Ensslin L, Corrêa E, Vansnick J (1999) Decision support systems in action: integrated application in a multicriteria decision aid process. Eur J Oper Res 113(2):315–335
Beliakov G, Pradera A, Calvo T (2007) Aggregation functions: a guide for practitioners, vol 221. Springer, Heidelberg
Bertoa MF, Troya JM, Vallecillo A (2006) Measuring the usability of software components. J Syst Softw 79(3):427–439
Bonferroni C (1950) Sulle medie multiple di potenze. Boll dell’Unione Mat Ital 5(3–4):267–270
Büyüközkan G, Göçer F (2021) Evaluation of software development projects based on integrated Pythagorean fuzzy methodology. Expert Syst Appl 183:115355
Chen TY (2015) An interval type-2 fuzzy LINMAP method with approximate ideal solutions for multiple criteria decision analysis. Inf Sci 297:50–79
Chen TY (2015) The inclusion-based TOPSIS method with interval-valued intuitionistic fuzzy sets for multiple criteria group decision making. Appl Soft Comput 26:57–73
Chen TY (2021) Pythagorean fuzzy linear programming technique for multidimensional analysis of preference using a squared-distance-based approach for multiple criteria decision analysis. Expert Syst Appl 164:113908
Dayanandan U, Kalimuthu V (2018) A fuzzy analytical hierarchy process (FAHP) based software quality assessment model: maintainability analysis. Int J Intell Eng Syst 11(4):88–96
Deb R, Roy S (2021) A Software Defined Network information security risk assessment based on Pythagorean fuzzy sets. Expert Syst Appl 183:115383
Fetanat A, Tayebi M (2021) Sustainable design of the household water treatment systems using a novel integrated fuzzy QFD and LINMAP approach: a case study of Iran. Environ Dev Sustain 23(10):15031–15061
Gao H, Ju Y, Zhang W, Ju D (2019) Multi-attribute decision-making method based on interval-valued q-rung orthopair fuzzy Archimedean muirhead mean operators. IEEE Access 7:74300–74315
Gao H, Ran L, Wei G, Wei C, Wu J (2020) VIKOR method for MAGDM based on q-rung interval-valued orthopair fuzzy information and its application to supplier selection of medical consumption products. Int J Environ Res Public Health 17(2):525
Garg H, Atef M (2022) Cq-ROFRS: Covering q-rung orthopair fuzzy rough sets and its application to multi-attribute decision-making process. Complex Intell Syst 8(3):2349–2370
Garg H (2021) A new possibility degree measure for interval-valued q-rung orthopair fuzzy sets in decision-making. Int J Intell Syst 36(1):526–557
Garg H (2021) New exponential operation laws and operators for interval-valued q-rung orthopair fuzzy sets in group decision making process. Neural Comput Appl 33(20):13937–13963
Garg H, Chen SM (2020) Multiattribute group decision making based on neutrality aggregation operators of q-rung orthopair fuzzy sets. Inf Sci 517:427–447
Geng S, Ma J, Wang C, Liu F (2020) Multihoming vs. single-homing software: compatibility or competition? IEEE Access 9:24119–24132
Gong R, Ma LY (2019) A new score function and accuracy function of interval-valued intuitionistic fuzzy number and its application. Syst Eng Theor Pract 39(2):463–475
Gül S (2021) Fermatean fuzzy set extensions of SAW, ARAS, and VIKOR with applications in COVID-19 testing laboratory selection problem. Expert Syst 38(8):e12769
Heidary Dahooie J, Estiri M, Zavadskas EK, Xu Z (2021) A novel hybrid fuzzy DEA-Fuzzy ARAS method for prioritizing high-performance innovation-oriented human resource practices in high tech SME’s. Int J Fuzzy Syst 24:1–26
Hussain A, Ali MI, Mahmood T, Munir M (2021) Group-based generalized q-rung orthopair average aggregation operators and their applications in multi-criteria decision making. Complex Intell Syst 7(1):123–144
Hwang CL, Yoon K (1981) Multiple attribute decision-making, methods and applications. Lecture notes in economics and mathematical systems[M], vol 186. Springer, New York
Ilbahar E, Karaşan A, Cebi S, Kahraman C (2018) A novel approach to risk assessment for occupational health and safety using Pythagorean fuzzy AHP and fuzzy inference system. Saf Sci 103:124–136
Ilieva G, Yankova T, Radeva I, Popchev I (2021) Blockchain software selection as a fuzzy multi-criteria problem. Computers 10(10):120
Irizarry T, Allen M, Suffoletto BP, Einhorn J, Burke LE, Kamarck TW, Muldoon MF (2018) Development and preliminary feasibility of an automated hypertension self-management system. Am J Med 131(9):1125-e1
ISO/IEC 25001:2014: ISO/IEC 25001:2007 (2014) Software engineering—software product quality requirements and evaluation (SQuaRE)—planning and management. ISO Geneva. http://www.iso.org/iso/home/store/catalogue_ics/catalogue_detail_ics.htm?csnumber=64787
Jin C, Ran Y, Zhang G (2021) Interval-valued q-rung orthopair fuzzy FMEA application to improve risk evaluation process of tool changing manipulator. Appl Soft Comput 104:107192
Jovčić S, Simić V, Průša P, Dobrodolac M (2020) Picture fuzzy ARAS method for freight distribution concept selection. Symmetry 12(7):1062
Ju Y, Luo C, Ma J, Gao H, Santibanez Gonzalez ED, Wang A (2019) Some interval-valued q-rung orthopair weighted averaging operators and their applications to multiple-attribute decision making. Int J Intell Syst 34(10):2584–2606
Kario K (2020) Management of hypertension in the digital era: small wearable monitoring devices for remote blood pressure monitoring. Hypertension 76(3):640–650
Khan MJ, Kumam P, Alreshidi NA, Kumam W (2021) Improved cosine and cotangent function-based similarity measures for q-rung orthopair fuzzy sets and TOPSIS method. Complex Intell Syst 7(5):2679–2696
Khan SAR, Mathew M, Dominic PDD, Umar M (2022) Evaluation and selection strategy for green supply chain using interval-valued q-rung orthopair fuzzy combinative distance-based assessment. Environ Dev Sustain 24(9):10633–10665
Khanmohammadi S, Musharavati F (2021) Multi-generation energy system based on geothermal source to produce power, cooling, heating, and fresh water: exergoeconomic analysis and optimum selection by LINMAP method. Appl Therm Eng 195:117127
Li C, Lumey LH (2019) Impact of disease screening on awareness and management of hypertension and diabetes between 2011 and 2015: results from the China health and retirement longitudinal study. BMC Public Health 19(1):1–8
Li H, Ma Y, Liang Z, Wang Z, Cao Y, Xu Y, Feng X (2020) Wearable skin-like optoelectronic systems with suppression of motion artifacts for cuff-less continuous blood pressure monitor. Natl Sci Rev 7(5):849–862
Liu P, Wang Y (2020) Multiple attribute decision making based on q-rung orthopair fuzzy generalized Maclaurin symmetic mean operators. Inf Sci 518:181–210
Liu P, Ali Z, Mahmood T (2021) Generalized complex q-rung orthopair fuzzy Einstein averaging aggregation operators and their application in multi-attribute decision making. Complex Intell Syst 7(1):511–538
Liu P, Mahmood T, Ali Z (2022) The cross-entropy and improved distance measures for complex q-rung orthopair hesitant fuzzy sets and their applications in multi-criteria decision-making. Complex Intell Syst 8(2):1167–1186
Mahmudova S, Jabrailova Z (2020) Development of an algorithm using the AHP method for selecting software according to its functionality. Soft Comput 24(11):8495–8502
Malamiri MO, Alinezhad A (2015) Provides a combination method from Gray ANP and Six Sigma and TRIZ to prioritize projects[J]. Cumhuriyet Sci J 36(4):1437–1448
Mehlawat MK, Gupta P, Mahajan D (2020) A multi-period multi-objective optimization framework for software enhancement and component evaluation, selection and integration. Inf Sci 523:91–110
Mehrabadi ZK, Boyaghchi FA (2019) Thermodynamic, economic and environmental impact studies on various distillation units integrated with gasification-based multi-generation system: comparative study and optimization. J Clean Prod 241:118333
Mills KT, Bundy JD, Kelly TN, Reed JE, Kearney PM, Reynolds K, He J (2016) Global disparities of hypertension prevalence and control: a systematic analysis of population-based studies from 90 countries. Circulation 134(6):441–450
Mougouei D, Mougouei E, Powers DM (2021) Partial selection of software requirements: a fuzzy method. Int J Fuzzy Syst 23(7):2067–2079
Nerenberg KA, Zarnke KB, Leung AA, Dasgupta K, Butalia S, McBrien K, Daskalopoulou SS (2018) Hypertension Canada. Hypertension Canada’s 2018 guidelines for diagnosis, risk assessment. Prevention, and treatment of hypertension in adults and children. Can J Cardiol 34(5):506–525
Pamucar D, Cirovic G (2015) The selection of transport and handling resources in logistics centers using Multi-Attributive Border Approximation area Comparison (MABAC). Expert Syst Appl 42(6):3016–3028
Pan W, Chai C (2019) Measuring software stability based on complex networks in software. Clust Comput 22(2):2589–2598
Peercy DE (1981) A software maintainability evaluation methodology. IEEE Trans Software Eng 4:343–351
Peng X, Huang H (2020) Fuzzy decision making method based on CoCoSo with critic for financial risk evaluation. Technol Econ Dev Econ 26(4):695–724
Peng X, Liu L (2019) Information measures for q-rung orthopair fuzzy sets. Int J Intell Syst 34(8):1795–1834
Perera M, de Silva CK, Tavajoh S, Kasturiratne A, Luke NV, Ediriweera DS, Jafar TH (2019) Patient perspectives on hypertension management in health system of Sri Lanka: a qualitative study. BMJ Open 9(10):e031773
Rong M, Li K (2021) A blood pressure prediction method based on imaging photoplethysmography in combination with machine learning. Biomed Signal Process Control 64:102328
Saha A, Majumder P, Dutta D, Debnath BK (2021) Multi-attribute decision making using q-rung orthopair fuzzy weighted fairly aggregation operators. J Ambient Intell Humaniz Comput 12(7):8149–8171
Segev DL, Haukoos JS, Pawlik TM (2020) Practical guide to decision analysis. JAMA Surg 155(5):436–437
Seker S (2022) IoT based sustainable smart waste management system evaluation using MCDM model under interval-valued q-rung orthopair fuzzy environment. Technol Soc 71:102100
Shahaj O, Denneny D, Schwappach A, Pearce G, Epiphaniou E, Parke HL et al (2019) Supporting self-management for people with hypertension: a meta-review of quantitative and qualitative systematic reviews. J Hypertens 37(2):264–279
Srinivasan V, Shocker AD (1973) Linear programming techniques for multidimensional analysis of preferences. Psychometrika 38(3):337–369
Suresh K, Dillibabu R (2021) An integrated approach using IF-TOPSIS, fuzzy DEMATEL, and enhanced CSA optimized ANFIS for software risk prediction. Knowl Inf Syst 63(7):1909–1934
Unger T, Borghi C, Charchar F, Khan NA, Poulter NR, Prabhakaran D, Schutte AE (2020) 2020 International Society of Hypertension global hypertension practice guidelines. Hypertension 75(6):1334–1357
Wang CY, Chen SM (2018) A new multiple attribute decision making method based on linear programming methodology and novel score function and novel accuracy function of interval-valued intuitionistic fuzzy values. Inf Sci 438:145–155
Wang J, Gao H, Wei G, Wei Y (2019) Methods for multiple-attribute group decision making with q-rung interval-valued orthopair fuzzy information and their applications to the selection of green suppliers. Symmetry 11(1):56
Wang Z, An J, Lin H, Zhou J, Liu F, Chen J, Deng N (2021) Pathway-driven coordinated telehealth system for management of patients with single or multiple chronic diseases in China: system development and retrospective study. JMIR Med Inform 9(5):e27228
Whelton PK, Carey RM, Aronow WS, Casey DE, Wright JT (2017) acc/aha/aapa/abc/acpm/ags/apha/ash/aspc/nma/pcna guideline for the prevention, detection, evaluation, and management of high blood pressure in adults. a report of the American College of Cardiology/American Heart Association Task Force on clinical practice guidelines. Hypertension 19(19):213–221
Williams B, Mancia G, Spiering W, Agabiti Rosei E, Azizi M, Burnier M, Desormais I (2018) 2018 ESC/ESH Guidelines for the management of arterial hypertension: the Task Force for the management of arterial hypertension of the European Society of Cardiology (ESC) and the European Society of Hypertension (ESH). Eur Heart J 39(33):3021–3104
Xu Z (2007) Methods for aggregating interval-valued intuitionistic fuzzy information and their application to decision making. Control Decis 22(2):215–219
Yager RR, Alajlan N (2017) Approximate reasoning with generalized orthopair fuzzy sets. Inf Fusion 38:65–73
Yager RR (2001) The power average operator. IEEE Trans Syst Man Cybern Part A Syst Hum 31(6):724–731
Yan M, Xia X, Zhang X, Xu L, Yang D, Li S (2019) Software quality assessment model: a systematic mapping study. Sci China Inf Sci 62(9):1–18
Yang YD, Ding XF (2021) A q-rung orthopair fuzzy non-cooperative game method for competitive strategy group decision-making problems based on a hybrid dynamic experts’ weight determining model. Complex Intell Syst 7(6):3077–3092
Yang Z, Zhang L, Li T (2021) Group decision making with incomplete interval-valued q-rung orthopair fuzzy preference relations. Int J Intell Syst 36(12):7274–7308
Yu G, Wang Q, Yu Z, Zhang N, Ming P (2022) A Four-Hierarchy method for the design of organic Rankine cycle (ORC) power plants. Energy Convers Manage 251:114996. https://doi.org/10.1016/j.enconman.2021.114996
Yue C (2020) An intuitionistic fuzzy projection-based approach and application to software quality evaluation. Soft Comput 24(1):429–443
Yue Z (2011) Deriving decision maker’s weights based on distance measure for interval-valued intuitionistic fuzzy group decision making. Expert Syst Appl 38(9):11665–11670
Yue Z (2012) Approach to group decision making based on determining the weights of experts by using projection method. Appl Math Model 36(7):2900–2910
Yuen KKF, Lau HC (2011) A fuzzy group analytical hierarchy process approach for software quality assurance management: Fuzzy logarithmic least squares method. Expert Syst Appl 38(8):10292–10302
Zarzour N, Rekab K (2021) Sequential procedure for Software Reliability estimation. Appl Math Comput 402:126116
Zavadskas EK, Turskis Z, Vilutiene T (2010) Multiple criteria analysis of foundation instalment alternatives by applying Additive Ratio Assessment (ARAS) method. Arch Civ Mech Eng 10(3):123–141
Zhang S, Zhu J, Liu X, Chen Y (2016) Regret theory-based group decision-making with multidimensional preference and incomplete weight information. Inf Fusion 31:1–13
Zhang, X., Dai, L. & Wan, B (2022) NA operator-based interval-valued q-rung orthopair fuzzy PSI-COPRAS group decision-making method. Int J Fuzzy Syst. https://doi.org/10.1007/s40815-022-01375-z
Zhou R, Cao Y, Zhao R, Zhou Q, Shen J, Zhou Q, Zhang H (2019) A novel cloud based auxiliary medical system for hypertension management. Appl Comput Informat 15(2):114–119
Acknowledgements
This work is supported in part by the Department of Shenzhen Local Science and Technology Development under Grant 2021Szvup052.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All the authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wan, B., Hu, Z., Garg, H. et al. An integrated group decision-making method for the evaluation of hypertension follow-up systems using interval-valued q-rung orthopair fuzzy sets. Complex Intell. Syst. 9, 4521–4554 (2023). https://doi.org/10.1007/s40747-022-00953-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00953-w