
Abstract
The evolution of learning techniques has led robotics to have a considerable influence in industrial and household applications. With the progress in technology revolution, the demand for service robots is rapidly growing and extends to many applications. However, efficient navigation of service robots in crowded environments, with unpredictable human behaviors, is still challenging. The robot is supposed to recognize surrounding information while navigating, and then act accordingly. To address this issue, the proposed method crowd Aware Memory-based Reinforcement Learning (CAM-RL) uses gated recurrent units to store the relative dependencies among the crowd, and utilizes the human–robot interactions in the reinforcement learning framework for collision-free navigation. The proposed method is compared with the state-of-the-art techniques of multi-agent navigation, such as Collision Avoidance with Deep Reinforcement Learning (CADRL), Long Short-Term Memory Reinforcement Learning (LSTM-RL) and Social Attention Reinforcement Learning (SARL). Experimental results show that the proposed method can identify and learn human–robot interactions more extensively and efficiently than above-mentioned methods while navigating in a crowded environment. The proposed method achieved a success rate of greater than or equal to \(99\%\) and a collision rate of less than or equal to \(1\%\) in all test case scenarios, which is better compared to the previously proposed methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Designing service robots has become one of the most rapidly increasing disciplines of scientific research [1, 2]. Service robots are created to assist humans and perform helpful tasks on their behalf, making significant contributions to industrial automation, manufacturing, agriculture, space, medical science, household utilities, and other social services [3,4,5]. Autonomous navigation is the principle of service robot’s ability to execute a wide range of activities. It enables the robot to maneuver autonomously, perceive their environment, and take actions to complete their tasks in an efficient, effective, and secure manner [6,7,8].
Service robots face various hurdles to achieve autonomous navigation [9, 10]. The robot’s working environment is of primary concern among all difficulties. Sensor configuration and navigation capabilities of the robot differ based on the navigation environment. Therefore, understanding and determining the sort of environment in which a robot must operate becomes crucial. In general, the robot will confront two types of environments, i.e., structured and unstructured [11, 12].
The structured environment is clear, rigid, and static with no variable parameters. The robot can easily navigate in a structured environment, since it is predictable. If the structured environment is supplemented with unexpected variables, such as humans, weather, lighting, hazards, etc., it becomes unstructured. Unstructured environments are cluttered and unpredictable, and thus, it is challenging for the robot to navigate in such environments. Furthermore, the robot is confused by the crowded environment with diverse human behaviors, and unpredictable velocities. These problems increase the collision rate and compromises the safety of robot navigation. Therefore, it is essential to build a robot that can navigate efficiently in the complex unknown crowded environments [6, 13, 14]. The overall performance of the robot, in a crowded environment, can be improved by precise examination of human motion and incorporating insights into the robot navigation algorithms.
The demand and inclusion of mobile robots is increasing in various fields; however, safety of humans, robots, and the surrounding environment is still a concern. In addition, with the increase in crowd density, it is challenging to achieve collision-free navigation. The traditional algorithms like social force [15] and optimal reciprocal collision avoidance (ORCA) [16, 17] tried to solve the issue of multi-agent navigation. However, these algorithms face some drawbacks, since they are unable to generalize unknown environments as they are hand-crafted algorithms based on velocity and force. With the advancement in technology, learning methods have evolved in solving practical problems in various applications. Several researchers incorporated deep neural networks (DNN) and reinforcement learning (RL) techniques to solve collision-free navigation [18,19,20,21,22,23,24]. Some algorithms use end-to-end learning by directly encoding sensor observations to actions, whereas others utilize human–robot interactions to solve collision-free navigation. However, with the increase in crowd density, the collision rate could increase, thus compromising the safety of the surrounding environment. Also, these algorithms considered the concept of homogeneity for human behavior, i.e., all humans behave similarly or follow the same policy for taking actions. However, in reality while navigation, humans follow diverse behaviors and unpredictable velocities. The detailed comparison of existing studies in periodical order is explained in the related work section. Table 1 explains the comparison study of key features of the existing methods with the proposed method. In addition, Table 2 explains the detailed description of the notations used in the following sections.
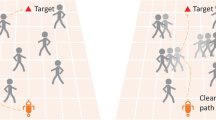
The main contribution of this manuscript is to achieve collision-free efficient navigation for service robots in highly dense crowd characterized by diverse human behavior and unpredictable velocities. In the proposed method, gated recurrent units (GRU) are used to store the relative importance and dependencies among humans. In addition, to understand the human–robot relationship, interactions between them are extracted with the help of multilayer perceptron. Furthermore, attention scores are assigned for humans to explain the significance of each human interplay with a robot. To achieve collision-free navigation, the robot is trained in the proposed network architecture in the reinforcement framework. Figure 1 illustrates the robot’s navigation in a crowded environment by integrating human navigation technique that stores the other human’s relative dependencies.

Robot navigation in crowded environment using memory units for storing the relative importance and dependencies among humans
The remainder of this paper is organized as follows. The section “Related work” discusses the related work and motivation for the proposed method. The section “Problem formulation” explains the problem formulation and proposed network architecture for collision-free navigation in a crowded environment. The experimental setup and results are thoroughly discussed to evaluate the performance of the proposed method in the section “Experimental setup”. The manuscript is concluded in the section “Results and discussion” by discussing the proposed method’s importance and future goals.
Related work
Service robots have become prominent with a wide range of applications due to the rapidly evolving technology. Navigation is a remarkable feature that has brought about the development of service robots over time. In addition, service robots have more significant interactions with humans because of their human-oriented applications; however, concerns about the physical safety are still an issue. Therefore, robot navigation in a crowded environment has become a challenging field of interest [25, 26].
The modeling of crowd dynamics in the simulated environment is an essential research aspect of crowd-aware robot navigation. Previous works in the literature employed hand-crafted techniques to solve crowd navigation or multi-agent navigation. Social force model (SFM) [15] is the well-known method that uses force as an interaction component among agents to navigate a crowd. Optimal reciprocal collision avoidance (ORCA) considers the agent’s velocity factor as an interaction tool [16, 17]. This technique selects the optimal velocity that satisfies the collision-free condition by observing the velocity of other agents. Interacting Gaussian Process is another technique considering each agent’s trajectory as an individual Gaussian process and modeling the potential terms of interaction as an interaction component [27, 28]. All these techniques are based on hand-crafted rules and cannot capture strong interactions in complex unknown environments.
Because of the advances in learning techniques and their successful applications in various fields, several researchers have incorporated these techniques into crowd-aware robot navigation. Previous literature on robot navigation studies using learning techniques has followed the traditional pipeline of mapping, path planning, and motion planning [29, 30]. The problem of multi-agent navigation is solved by training value-based policies to encode the agent behaviors [18]. The reinforcement learning framework helps to map raw sensor data directly to the desired actions by learning sensor-level policies [19]. The RL framework with the modified reward function was used in the preceding work to capture the social norm behaviors of humans [31]. Later, long short-term memory was applied to handle the variable density of humans by embedding them into fixed-length vectors [20]. As mentioned previously, the studies successfully achieved multi-agent navigation but failed to take into account the complex interactions among the crowd. Attention mechanisms [32, 33] were used to carry out the importance of individual humans in the crowd by considering human–human and human–robot interactions [21, 22]. Their application improved the robot navigation in a crowded environment; however, the safety of humans remained a challenging task. A safety framework was introduced to clear the path for safe and efficient robot navigation in [23]. Another solution uses danger zones around humans defined on the basis of real-time human behavior, and the robot was trained to avoid them while navigating [24]. Despite the improved safety and time efficiency of robot navigation by these algorithms, concerns about increased crowd density with unpredictable behaviors remain a challenge. The concept of recurrent units to solve the problem of path planning and autonomous robot navigation was applied and described in [34, 35]. Inspired by mentioned works, this study uses the concept of storing the relative dependencies among humans using memory-based neural networks, and thereby encoding the complex interactions that help the robot navigate in a high-density crowd.
Problem formulation
The purpose of this research is to enhance robot navigation in a crowd of n humans, so that it can reach its goal without colliding. This navigation problem is formalized as a sequential decision-making problem in a reinforcement learning framework. The major elements of reinforcement learning framework as states, actions, rewards, and policy can explain the problem formulation of the proposed model.
States
In reinforcement learning, states are the observations that an agent receives from the environment. In the other words, states represent the environment or current world of the task. Let \(\varvec{\delta }_t\) and \(\varvec{\theta }_t\) stand for the state and action of the robot at time t. The state of the agents (human and robot) is divided into observable and hidden states. The observable state is represented by \(\varvec{\delta }^{O}_t\), and can be observed by all other agents. The observable state of the agents comprises position, velocity, and radius, that is given by
The hidden state is represented by \(\varvec{\delta }^{H}_t\), and is known only to the agent itself, but hidden from the other agents. The hidden state of the agents comprises the intended goal position, preferred speed, and heading angle, which is given by
The observable and hidden states are integrated to create the full state of the agent. These states are further used to establish the joint state of the system, by combining human and robot states
where \(\varvec{\delta }^{h}_t = [\varvec{\delta }^{h_1}_{t}, \varvec{\delta }^{h_2}_{t} ,\ldots , \varvec{\delta }^{h_m}_{t}]\). The agent-centric frame is defined in a similar way as given in [18, 21] to reduce the uncertainty of joint state parametrization. The x-axis of the agent-centric frame points towards the goal of the agent, whereas the origin indicates the position of the agent. The transformed states of the robot and human are given by
where \(d_g\) = \({||p-p_g||}_2\) is the distance of the robot to the goal, and \(d_m\) = \({||p-p_m||}_2\) is the distance of the robot to its neighbor m.
Actions
The robot used in the studies is holonomic, which means that it can move freely in any direction. There are 80 different actions in the robot’s action space, including 16 equally spaced orientations ranging from 0 to \(2\) \(\pi \) and five exponentially dispersed speeds ranging from 0 to \(v_{\text {pref}}\).
Rewards
The reward function in Reinforcement Learning (RL) is an incentive mechanism that tells the agent what is correct and what is wrong using reward and punishment, respectively. The goal of agents in RL is to maximize the total reward. The total reward can be both positive and negative based on the behavior of the robot. The negative reward penalizes the robot for collisions and uncomfortable distances, which encourages collision-free navigation. At the same time, the positive reward encourages the robot to achieve the task. We follow the same reward formulation as given in previous literature [18, 21]. The rewards encourage collision-free navigation by penalizing the robot for collisions and uncomfortable distances. Besides the negative rewards, a positive reward for achieving the task is also given to the robot. The total reward (\(\phi _t\)) is given by
where \(d_c\) is the distance between human and robot in the consecutive time period. \(p_t\) is the position of the robot at time t and \(p_g\) is the goal position.
Agent/policy
Reinforcement learning teaches an agent to execute a task in an unpredictable, continuously changing environment. The environment provides the agent with observations and a reward, and the agent responds by sending actions to the environment. The reward is an effectiveness indicator of the action aimed at achieving the goal. The agent response is mainly handled by two modules, i.e., policy and learning algorithm.

A policy is typically a function approximator that maps states into actions, such as deep neural network. The learning algorithm continuously updates the policy based on the observations and rewards. The ultimate target of the learning algorithm is to find the optimal policy \(\pi ^*\) as in (6) which selects the action \(\varvec{\theta }_t\), considering joint state \(\varvec{\delta }^{j}_t\), to navigate the robot in a crowd of n humans towards the goal without any collisions
where \(\phi ( \varvec{\delta }^{j}_t, \varvec{\theta }_t)\) is the reward received at time t, \(\gamma \) is the discount factor in the range 0 to 1, \(\nu ^*\) is the optimal value function, and \(\rho = \rho ( \varvec{\delta }^{j}_t\), \(\varvec{\theta }_t\), \(\varvec{\delta }^{j}_{t+\Delta {t}}\)) is the transition probability from time t to \({t+{\Delta {t}}}\). The preferred velocity is used in the discount factor as the normalization factor, similar to that given in [18, 21]. The optimal value function is used to recover the optimal policy by choosing the action with the highest value, as shown in (7). The value function is trained with temporal difference (TD) learning, as shown in Algorithm 1. The model is initially trained using demonstrator knowledge with imitation learning (line 1–3), and is subsequently updated with experience of interactions line (4–14). The process is repeated until the terminal state (line 12) is achieved. TD learning updates the value function towards the expected return in the direction of TD error, which is the difference between the estimated return before (line 10) and after executing the step as shown in (8)
where (\(\phi _{t+{\Delta {t}}} + \gamma \nu ( \varvec{\delta }_{t+{\Delta {t}}}))\) is the TD target, and (\(\phi _{t+{\Delta {t}}} + \gamma \nu ( \varvec{\delta }_{t+{\Delta {t}}} ) - \nu ( \varvec{\delta }_{t}))\) denotes the TD error.
Examining human motion
The exact understanding of human motion is essential to develop effective robot navigation in a crowded environment. Humans use specific kinematic patterns to navigate with ease among crowds. In addition, when navigating, humans observe other human’s behavior and store them in the subconscious memory. It helps humans to navigate safely in a crowd with no collisions. The robot can improve the navigation in a crowd using the similar concept. The robot could use memory units to store the human-level dependencies, and use them further to encode human–robot interactions. The following section describes and explains the memory units and the detailed implementation of the proposed model.
Network architecture

Architecture of gated recurrent unit
To extract the human-level dependencies among the crowd as mentioned earlier, the proposed method utilizes gated recurrent units (GRU) [36]. GRU is an improved version of standard recurrent neural networks (RNN). Long short-term memory (LSTM) followed RNN to overcome the vanishing/exploding gradient problem [37]. The GRU is the newest representative in the sequential modeling approaches, and it outperforms its two predecessors—RNN and LSTM [38]. GRU is quite similar to LSTM, which uses gates to control the flow of information. These gates can determine whether a certain information in a sequence should be retained or discarded. The described process helps storing and conveying crucial information through long sequences and making predictions. LSTM has three gates, including input, output, and reset gate, whereas GRU has only two of them, reset and update gate. GRU is simpler in structure with fewer parameters than LSTM, that makes it train faster. Figure 2 shows the architecture of GRU with reset gate and update gate. The complete functions of GRU can be explained by the following equations:

Schematic diagram of bi-directional gated recurrent unit

Network architecture of the proposed model
Initially, the update gate vector (\(u_t\)) is calculated, as shown in (9a), by plugging in the input state (\(\delta _t\)) and previous hidden state (\(h_{t-1}\)). The output of the update gate is squeezed between 0 and 1 using sigmoid activation function (\(\sigma _{g}\)). The update gate enables the model to determine how much of previous information should be passed on to the next step. Later, the reset gate which helps to decide how much of the past information to forget is computed, as shown in (9b). Subsequently, element wise multiplication is performed between the output of the reset gate and the hidden state determining what information to remove from the previous time steps. Adding input of the current time step to the above result and passing through tanh function (\(\tau _{h}\)), as shown in (9c), results in the current memory unit also called candidate-hidden state \((\hat{h}_t)\). Finally, the network calculates the hidden state vector (\(h_{t}\)) that holds the current unit information and passes it to the next time step. This step utilizes the update gate output to determine what to collect from the candidate-hidden state and the previous hidden state, as shown in (9d). The current hidden state proceeds further to calculate the hidden state of the next time step. This process continues until the last input in the sequence to get the final output or prediction. In (9a)–(9c), W and V refer to the weights of the corresponding vector, while b represents bias in the network.
The proposed method adapts the merits of bi-directional gated recurrent unit (Bi-GRU) to handle the variable size of input vector and store the relative information of crowd. The Bi-GRU is the combination bi-directional RNN and the GRU. The schematic architecture of Bi-GRU is shown in Fig. 3. In bi-directional networks, the information is processed simultaneously in both forward and backward directions. The forward layer feeds the input normally, but backward layer feeds in the reverse order. The output of Bi-GRU is obtained by concatenating the individual outputs from forward and backward layers. The complete network architecture of the proposed method is shown in Fig. 4. The input states of the human \({\varvec{\delta }_h}_{t}\) and robot \({\varvec{\delta }_r}_t\) are fed into corresponding GRU to get respective outputs as human state \(h_o\) and robot state \(r_o\). The output from the GRU helps to understand the relative importance of the crowd. Element-wise multiplication of the both outputs is performed to get the initial human–robot interactions \(\kappa \), which is further fed to multilayer perceptron to get the final human robot interactions \(\beta \) as given below
where \(\psi \)(.) is multilayer perceptron with RELU activation function, and \(W_{hr}\) are the network weights. On the other hand softmax is performed over the initial human–robot interactions to get attention scores of individual humans (\(\alpha \)) as shown in (11). The weighted linear combination of all the pairs between attention scores and final human robot interactions is obtained to get the state representation (\(\lambda \)), and is given by
The state representation is concatenated with the robot state, and fed as input to another multilayer perceptron to estimate the state value. The state representation is given by
where \(\chi \)(.) is multilayer perceptron with RELU activation function and the network weights are denoted by \(W_{v}\).
Experimental setup
To evaluate the proposed model a simulated environment is modeled and executed in Python using the PyTorch module. The proposed algorithm is compared with collision avoidance with deep reinforcement learning (CADRL) [18], long short-term memory with reinforcement learning (LSTM-RL) [20], and social attention with reinforcement learning (SARL) [21]. All models, including the proposed method, were initially trained for 3k episodes by imitation learning utilizing ORCA demonstrations [17]. For imitation learning and subsequent training of all the models, a simulated environment with one robot was used.
The reinforcement learning parameters are arbitrarily chosen based on the performance of all the models. The training was started initially with a learning rate of 0.01; however, the model began to learn fast and failed to find the optimal solution. Consequently, the learning rate was adjusted as 0.001 to balance the rate of convergence and overshooting. After analyzing the importance of future rewards, a discount factor (\(\gamma \)) of 0.9 was assumed. The epsilon greedy policy is used to balance exploration and exploitation. The exploration rate (\(\epsilon \)) ranges from 0 to 1, is the factor used to manipulate both. The exploration rate of the greedy policy is linearly reduced from 0.5 to 0.1 for the first 5k episodes and remains 0.1 for the subsequent 5k episodes. The preferred speed of robot ranges from 0 to 1 m/s, whereas for human, it ranges from 0.5 to 3 m/s. The training of the robot in the simulated environment is performed for 10k episodes, while testing is conducted for 500 different scenarios.
The literature includes many studies describing the usage of crossing scenarios to examine the robot navigation in crowded environment [39]. The proposed method also applies circular and square crossing scenarios for training and testing. The crossing scenarios set the starting position and the final goal of humans; however, the actions of the human are governed by the policy they follow. Humans are initially placed in a circle of radius 8 m in the circular crossing scenario, and on the sides of a square of 16 m in the square crossing scenario. In both scenarios, the goals of the human are assigned precisely opposite to their initial location. The robot trained and tested in these simulated environments can be easily transferred and adapted to real-time environments with slight modifications. The performance of the robot navigation is evaluated by considering five and ten humans in the simulated environment. In general, every human behaves differently when navigating in a crowded environment. Social Force Model [15] and ORCA [16] are used in the same ratio to navigate the humans in the simulated environment to incorporate the diverse human behavior. The performance metrics include the following:
-
Success rate (SR): The rate at which the robot reaches the goal safely without any collisions.
-
Collision rate (CR): The rate at which robot collides the humans.
-
Timeout rate (TO): The rate at which the robot exceeds the time limit before reaching the goal.
-
Time (\(\upmu \)T): The average time taken by the robot to reach the goal.
-
Distance (\(\upmu \)D): The average distance taken by the robot to reach the goal.
Results and discussion
This manuscript focuses on collision-free robot navigation in a crowded environment. To assess the significance of the proposed method, it is compared with state-of-the-art techniques in multi-agent navigation like CADRL, LSTM-RL, and SARL. The experimental results of robot navigation in circular and square crossing scenarios with ten and five humans are shown in Tables 3 and 4, respectively. The robot is initially trained and tested in a circular crossing scenario with ten humans, as shown in Table 3. Later, the trained algorithm is used for testing different scenarios as given in Tables 3 and 4 to analyze the generalized ability of the models.
CADRL trained in a circular crossing scenario with ten humans achieved a success rate of 0.94 and a collision rate of 0.03. In addition, it was tested against its training scenario, as shown in Tables 3 and 4. CADRL succeeded with the highest success rate of 0.97 with 0.01 collision rate and 0.01 time-out cases when tested with five humans in a circular crossing scenario. On the other hand, LSTM reached a success rate of 0.92 with a 0.08 collision rate in the training environment. Furthermore, LSTM has performed well in different testing scenarios, and attained a maximum success rate of 0.97 with a 0.02 collision rate, as shown in Table 4. CADRL and LSTM-RL showed high collision rates with increased human density. The low success rate of both methods is due to the neglect of human–robot interactions.

A test case scenario of robot navigation in circular crossing scenario with ten humans

Comparison of state-of-art methods of multi-agent navigation in the context of avoiding human cluster while robot navigating
SARL has performed better than CADRL and LSTM-RL because of its collective importance to the crowd. The test results of SARL trained in a circular crossing scenario have yielded a success rate of 0.98 with a 0.02 collision rate. It has also operated well with the trained model in various testing scenarios. In contrast to CADRL and LSTM-RL, SARL has performed slightly better with ten humans. It has achieved the maximum success rate of 0.99 and collision rate of 0.01 with five humans in circular and square crossing scenarios, as shown in Table 4.
Conversely, the CAM-RL has performed better with ten humans, exhibiting its good performance in the crowd. It outperformed CADRL, LSTM-RL, and SARL in all testing scenarios with the highest success rate of 1.00, as shown in Table 4. The better performance of proposed method in crowded environment was the result of understanding human-level dependencies and computing double layered human–robot interactions. The proposed method with ten humans accomplished a success rate of 0.99 and a collision rate of 0.01 in the circular crossing scenario, as shown in Table 3. The average time and distance traveled by the robot to reach the goal are also of great significance in the proposed method.
The qualitative analysis of a some test case scenarios is also demonstrated in this section to understand the significance of experimental results. The same test case scenario is selected for all the methods to achieve an objective comparison. All the humans in the test case scenario are numbered to distinguish them from each other. The numbers are positioned in the southwest direction at an offset of 0.3 m from the center of the human. Figure 5 illustrates the sample test case scenario of robot navigation in a circular crossing scenario with ten humans. It is crucial for the robot to avoid human clusters and to quickly reach the goal. In LSTM-RL and SARL, the robot entered the group immediately, increasing the risk factor, and finally collided with the human 1 and human 0, respectively, as shown in Fig. 5b, c. As seen in Fig. 5a, CADRL initially made the robot move sideways, but finally entered the cluster. Nevertheless, the robot did not collide with humans, and it was very close to Human 3 and Human 9. Contrary to the previously described situations, the proposed method made the robot take more deviations and wait for the humans to pass by and avoid collisions. The robot cleverly escaped from Human 7 and Human 1 by changing direction and maintaining a safe distance, as shown in Fig. 5d.
Figure 6 demonstrates the another test case scenario that shows the relevance of avoiding clusters during robot navigation. CADRL and LSTM-RL have failed to prevent human clusters in the illustrated test case scenarios, as shown in Fig. 6a, b, since they have not taken into account human–robot interactions and the collective importance of the crowd. In CADRL and LSTM-RL, the robot collided with Human 0 and Human 6 respectively, as shown in Fig. 6a, b. In contrast, SARL and the proposed method functioned properly in these situations to avoid human clusters and reach the goal safely, as shown in Fig. 6c, d. The proposed method has further improved the performance of the robot by storing human-level dependencies along with the human–robot interactions.
Statistical analysis
To evaluate the significance of the proposed method over the previous methods, Wilcoxon signed-rank-test is performed. Wilcoxon signed-rank test is used to compare matched samples, two related samples, or to conduct a paired test of repeated measurements on a single model to assess if their population mean ranks differ. The Wilcoxon signed-rank test results in z score, which is converted into \(\rho \) values. The lower \(\rho \) value indicates the significant difference across the populations. In this article, one-sided alternative hypothesis with less than option is considered for the testing of paired data. If the \(\rho \) value is less than 0.05, the null hypothesis is rejected accepting the alternative hypothesis, i.e., pair 1 is less than pair 2. The statistical analysis of experimental results is shown in Table 5. The results of the proposed method are compared with previous methods individually, and their significance can be seen in the table. The statistical analysis shows that the success rate rejects the null hypothesis, demonstrating that the proposed method has greater significance than other methods. In contrast, collision rate, time, and distance accept the null hypothesis indicating previous methods have higher collision rate, time, and distance when compared to the proposed method (Table 5).
Conclusion
This manuscript presents the solution to the problem of collision-free navigation in a crowded environment with diverse human behaviors. The proposed model examines real-time human behavior while navigating and tries to incorporate it into the robot. The robot is trained to understand and store the human-level dependencies using gated recurrent units. In addition, human–robot interactions are encoded employing a multi-layered perceptron and later used to calculate the relative importance of the crowd. The proposed network architecture is trained in a reinforcement learning framework for collision-free navigation. The experimental results prove that the proposed method has outperformed the existing state-of-the-art methods in multi-agent navigation. In the future, we aim to include safety factors and human–human interactions in the existing framework for efficient collision-free navigation [24, 40].
References
Wirtz J, Patterson PG, Kunz WH, et al (2018) Brave new world: service robots in the frontline. J Serv Manag 29(5):907–931
Gonzalez-Aguirre JA, Osorio-Oliveros R, Rodríguez-Hernández KL et al (2021) Service robots: trends and technology. Appl Sci 11(22):10,702
Zielinska TT (2019) History of service robots and new trends. In: Dan Z, Bin W (eds) Novel design and applications of robotics technologies. IGI Global, pp 158–187
Das S, Das I, Shaw RN et al (2021) Advance machine learning and artificial intelligence applications in service robot. In: Rabindra S, Ankush G, Valentina B, Monica B (eds) Artificial intelligence for future generation robotics. Elsevier, pp 83–91
Sun Y, Wang R (2022) The research framework and evolution of service robots. J Comput Inf Syst 62(3):598–608
Lin J, Yang X, Zheng P et al (2019) End-to-end decentralized multi-robot navigation in unknown complex environments via deep reinforcement learning. In: 2019 IEEE international conference on mechatronics and automation (ICMA). IEEE, pp 2493–2500
Kakoty NM, Mazumdar M, Sonowal D (2019) Mobile robot navigation in unknown dynamic environment inspired by human pedestrian behavior. In: Chhabi Rani P, Bibudhendu P, Prasant M, Rajkumar B, Kuan-Ching L (eds) Progress in advanced computing and intelligent engineering. Springer, pp 441–451
Pico N, Jung Hr, Medrano J et al (2022) Climbing control of autonomous mobile robot with estimation of wheel slip and wheel-ground contact angle. J Mech Sci Technol 36(2):959–968
Veloso M, Biswas J, Coltin B et al (2015) Cobots: robust symbiotic autonomous mobile service robots. In: Twenty-fourth international joint conference on artificial intelligence
Kästner L, Fatloun B, Shen Z et al (2022) Human-following and-guiding in crowded environments using semantic deep-reinforcement-learning for mobile service robots. arXiv preprint arXiv:2206.05771
Kolski S, Ferguson D, Bellino M et al (2006) Autonomous driving in structured and unstructured environments. In: 2006 IEEE intelligent vehicles symposium. IEEE, pp 558–563
Visca M, Kuutti S, Powell R, et al (2021) Deep learning traversability estimator for mobile robots in unstructured environments. In: Annual conference towards autonomous robotic systems. Springer, pp 203–213
Savkin AV, Wang C (2014) Seeking a path through the crowd: robot navigation in unknown dynamic environments with moving obstacles based on an integrated environment representation. Robot Auton Syst 62(10):1568–1580
Mavrogiannis C, Hutchinson AM, Macdonald J et al (2019) Effects of distinct robot navigation strategies on human behavior in a crowded environment. In: 2019 14th ACM/IEEE international conference on human–robot interaction (HRI). IEEE, pp 421–430
Helbing D, Molnar P (1995) Social force model for pedestrian dynamics. Phys Rev E 51(5):4282
Van den Berg J, Lin M, Manocha D (2008) Reciprocal velocity obstacles for real-time multi-agent navigation. In: 2008 IEEE international conference on robotics and automation. IEEE, pp 1928–1935
Van Den Berg J, Guy SJ, Lin M et al (2011) Reciprocal n-body collision avoidance. In: Cédric P, Roland S, Gerhard H (eds) Robotics research. Springer, pp 3–19
Chen YF, Liu M, Everett M et al (2017) Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In: 2017 IEEE international conference on robotics and automation (ICRA). IEEE, pp 285–292
Long P, Fan T, Liao X et al (2018) Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning. In: 2018 IEEE international conference on robotics and automation (ICRA). IEEE, pp 6252–6259
Everett M, Chen YF, How JP (2018) Motion planning among dynamic, decision-making agents with deep reinforcement learning. In: 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 3052–3059
Chen C, Liu Y, Kreiss S et al (2019) Crowd–robot interaction: crowd-aware robot navigation with attention-based deep reinforcement learning. In: 2019 international conference on robotics and automation (ICRA). IEEE, pp 6015–6022
Chen Y, Liu C, Shi BE et al (2020) Robot navigation in crowds by graph convolutional networks with attention learned from human gaze. IEEE Robot Autom Lett 5(2):2754–2761
Nishimura M, Yonetani R (2020) L2b: learning to balance the safety-efficiency trade-off in interactive crowd-aware robot navigation. In: 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 11004–11010
Samsani SS, Muhammad MS (2021) Socially compliant robot navigation in crowded environment by human behavior resemblance using deep reinforcement learning. IEEE Robot Autom Lett 6(3):5223–5230
Kato Y, Nagano Y, Yokoyama H (2017) A pedestrian model in human–robot coexisting environment for mobile robot navigation. In: 2017 IEEE/SICE international symposium on system integration (SII). IEEE, pp 992–997
Rojas RA, Garcia MAR, Gualtieri L et al (2021) Combining safety and speed in collaborative assembly systems-an approach to time optimal trajectories for collaborative robots. Procedia CIRP 97:308–312
Trautman P, Krause A (2010) Unfreezing the robot: navigation in dense, interacting crowds. In: 2010 IEEE/RSJ international conference on intelligent robots and systems. IEEE, pp 797–803
Trautman P (2017) Sparse interacting gaussian processes: efficiency and optimality theorems of autonomous crowd navigation. In: 2017 IEEE 56th annual conference on decision and control (CDC). IEEE, pp 327–334
Fethi D, Nemra A, Louadj K et al (2018) Simultaneous localization, mapping, and path planning for unmanned vehicle using optimal control. Adv Mech Eng 10(1):1687814017736653
Chaplot DS, Gandhi D, Gupta S et al (2020) Learning to explore using active neural slam. arXiv preprint arXiv:2004.05155
Chen YF, Everett M, Liu M et al (2017) Socially aware motion planning with deep reinforcement learning. In: 2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, pp 1343–1350
Vaswani A, Shazeer N, Parmar N et al (2017) Attention is all you need. Adv Neur Inf Process Syst 30
Vemula A, Muelling K, Oh J (2018) Social attention: modeling attention in human crowds. In: 2018 IEEE international conference on robotics and automation (ICRA). IEEE, pp 4601–4607
Yuan J, Wang H, Lin C et al (2019) A novel gru-rnn network model for dynamic path planning of mobile robot. IEEE Access 7:15,140-15,151
Quan H, Li Y, Zhang Y (2020) A novel mobile robot navigation method based on deep reinforcement learning. Int J Adv Robot Syst 17(3):1729881420921672
Cho K, Van Merriënboer B, Bahdanau D et al (2014) On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Chung J, Gulcehre C, Cho K et al (2014) Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555
Gao Y, Huang CM (2021) Evaluation of socially-aware robot navigation. Front Robot AI 8:721317. https://doi.org/10.3389/frobt.2021.721317
Kobayashi Y, Sugimoto T, Tanaka K et al (2022) Robot navigation based on predicting of human interaction and its reproducible evaluation in a densely crowded environment. Int J Soc Robot 14(2):373–387
Funding
This work was supported in part by National Research foundation of Korea (NRF), Government of Korea (MSIT) (No. NRF- 2022R1G1A1012746) and Institute of Information and Communications Technology Planning and Evaluation (IITP), Government of Korea (MSIT) (No. 2019-0-00421), and Artificial Intelligence Graduate School Program, Sungkyunkwan university.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix A: Additional tables
Appendix A: Additional tables
See Table 6.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Samsani, S.S., Mutahira, H. & Muhammad, M.S. Memory-based crowd-aware robot navigation using deep reinforcement learning. Complex Intell. Syst. 9, 2147–2158 (2023). https://doi.org/10.1007/s40747-022-00906-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00906-3