
Abstract
Online reviews contain a great deal of information about consumers' purchasing preferences, which seriously affects potential consumers' purchasing decisions. Using the online review data to help customers make purchasing decisions has become a concern of customers, which has theoretical and practical application value. Therefore, a product selection model is presented based on sentiment analysis combined with an intuitionistic fuzzy TODIM method. Firstly, the product features are extracted by the Apriori algorithm based on online reviews. The sentiment orientation and intensity of the sentiment words for the product features are identified by the lexicon-based sentiment analysis approach. Next, the sentiment orientation of the product features is represented by an intuitionistic fuzzy value. Then the intuitionistic fuzzy TODIM method is used to determine the ranking results of the alternative products. Finally, the case study of mobile phone selection is given to illustrate the proposed approach. The results show that the proposed method considers the online reviews’ sentiment orientation and intensity and the consumers’ gain and loss in the purchasing product process and is more reasonable than the previous research.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The rapid development of the Internet has brought great convenience to people's lives, and online consumer groups are increasing. Online reviews contain a great deal of information about consumers' purchasing preferences, which seriously affects potential consumers' purchasing decisions. It becomes an essential information source for consumers to make purchasing decisions and significantly impacts consumers' decision-making behavior [1,2,3]. However, due to the complexity of online reviews, consumers cannot effectively use online review data. Therefore, fully and effectively using the online review data to make it the basis of purchasing decisions has become a concern of many scholars, merchants, and consumers.
In the existing research [18], the ranking product methods through online reviews include two parts: sentiment analysis and multi-attribute decision-making. The first part is to identify the sentiment orientation of online reviews by analyzing online reviews extracted from online platforms. The second part is to select the best alternative product considering selected criteria based on sentiment analysis. However, some product ranking methods based on online reviews only consider online reviews' positive and negative sentiment tendencies [4,5,6,7,8,9]. The sentiment tendency of each sentence is divided into positive or negative, and ignore the information that the sentiment orientation in online reviews is neutral, resulting in a loss of information in the product purchase decision process.
The sentiment orientations of online reviews are classified into positive, negative, and neutral to avoid the loss of online review information. Intuitionistic fuzzy set (IFS) includes membership, non-membership, and hesitation simultaneously, providing a useful tool to represent the positive, negative, and neutral sentiments in online review data. The IFS is widely used to describe sentiment orientation and sentiment intensity [18]. However, the existing research ignores the customers’ psychological behavior and gain and loss during purchasing. TODIM method is suitable for describing the psychological behavior of the customers in the product ranking process [32,33,34,35]. The main idea of the TODIM method is to compare the product feature value of each alternative product and obtain the gain and loss value, then calculate the dominance degree between every two alternative products and the overall prospect values of each product [36,37,38,39]. According to the overall prospect values, the alternative products are ranked.
Therefore, an online review-based product selection model combined with an intuitionistic fuzzy TODIM (IF-TODIM) method is developed. Firstly, the Apriori algorithm is used to extract the product features that customers focus on based on online reviews. Then the sentiment orientation and intensity of the sentiment words for the product features are identified by the lexicon-based sentiment analysis approach. The proportion of the sentiment orientations of the product features are represented by an intuitionistic fuzzy value (IFV). Finally, the IF-TODIM method is used to determine the final ranking results of the alternative products.
The rest of our work is organized as follows. “Related works” introduces some related works on the ranking selection. Considering the advantages of IFVs and intuitionistic fuzzy sets (IFSs) representing the sentiment orientations of product features, “Preliminaries” provides some concepts of IFVs and IFSs. “The IF-TODIM method for product ranking based on online review” develops a new IF-TODIM method for product selection based on online reviews. A case study is given to illustrate the effectiveness of the developed IF-TODIM method in “Case study”. “Conclusion” takes some conclusions.
Related works
Recently, some scholars have concentrated on ranking products through online reviews [4,5,6,7,8,9, 18]. Zhang et al. [4] identified multiple important product features, then extracted sentences about each feature from online reviews, divided the online reviews into subjective and comparative reviews using a dynamic programming algorithm. The online reviews' sentiment orientation was determined to construct a weighted product graph and rank the products using an improved PageRank algorithm. Later, Zhang et al. [5] improved the algorithm by considering the importance of different reviews. The weight of each review was determined by the review's usefulness and time. Kang et al. [6] proposed a customer satisfaction analysis framework based on customer review mining analysis for product improvement decision making. Najmi et al. [7] calculated each product's score by both review and brand. The review score was derived from sentiment analysis and usefulness analysis, and the brand score was calculated by an improved PageRank algorithm, and the products were ranked based on their combined scores. Li et al. [8] used the value function of prospect theory to determine the perceived value of alternative products based on consumers' expectations of product attributes and the sentiment orientation of product attributes in online reviews. Fan et al. [9] used the stochastic PROMETHEE-II method to determine product ranking based on online ratings.
Fuzzy set theory has been applied in the product ranking or recommendation to represent the uncertainty in the online review data [10,11,12]. Different forms of fuzzy sets have been used to represent product feature values, such as fuzzy set, hesitant fuzzy set (HFS), Pythagorean fuzzy set (PFS), interval type-2 fuzzy set (IT2 FS), and IFS. Peng et al. [13] calculated the similarity measures of words to cluster each product feature synonyms, then determined the important product features based on the total frequency of each product feature in the reviews. The subjective evaluation of experts was contributed to obtaining a fuzzy decision matrix of important product features, and finally, the products were ranked by the fuzzy PROMETHEE method. Zhang et al. [14] regarded different sentiment scores of product features as different membership values and integrated different sentiment scores by HFS. A product ranking method based on 2-additive fuzzy measures and Choquet integral was developed. Considering IT2 FS was more accurate than the traditional fuzzy set in representing the uncertainty, Bi et al. [15] represented the uncertainty of the product features’ sentiment orientations using IT2 FS. Fu et al. [16] used deep learning models and K-means clustering algorithms to identify sentiment tendencies, considered the credibility of the number of online reviews for different products. Interval-valued PFS sets were used to represent product attribute values, and finally, the Heronian mean operator was used to integrate product attribute information to derive product ranking. To retain both the online review sentiment propensity and its probability, Liu and Teng [17] used probabilistic linguistic term sets (PLTSs). The PL-TODIM method was proposed for alternative products based on the new entropy measures and possibility degrees. The probability multivalued neutrosophic linguistic numbers (PMVNLNs) was developed by Ji et al. [18] to characterize online reviews and reflect the differences in positive (negative) information. Regret theory was combined with outranking methods to construct a review-based decision support model. Liang et al. [19] considered the randomness and ambiguity of online reviews and the interrelationship between product features in the decision support model and developed a linguistic intuitionistic normal cloud (LINC) model. Liang et al. [20] represented tourists’ sentiment preferences by distributed linguistic according to the online reviews, developed a method for determining the ideal and minimum value solutions, and proposed a DL-VIKOR to rank the alternative hotels for tourists.
IFS has been widely used to describe sentiment orientation and sentiment intensity [21]. In the transforming process, the proportions of the positive, negative, and neutral sentiment orientations were transformed into the membership, non-membership, and hesitance values in IFVs, respectively. Therefore, the IFS has strong flexibility and practicality in the product ranking problem. Liu et al. [22] constructed a purchase decision model based on the IF-TOPSIS method, which focuses on product preference through similarity to the ideal solution. Liu et al. [23] ranked the alternative products using the combined intuitionistic fuzzy weighted average (IFWA) operator with the PROMETHEE II method. Çalı and Balaman [24] represented the online ratings of hotel customers by IFSs, and IF-ELECTRE was used to rank alternative hotels with VIKOR integration. Zhang et al. [25] calculated the feature weights considering the customers’ attention and developed a product ranking model combining 2-additive fuzzy measures, non-linear programming, and Choquet integration.
Therefore, the main contributions of the developed IF-TODIM method for ranking products are as follows. Firstly, a new product selection method based on online reviews is proposed to consider the consumers’ online reviews and psychological behavior. Secondly, the product features are exacted by the Apriori algorithm, which is different from the previous research. Thirdly, in the IF-TODIM method, new ranking methods of intuitionistic fuzzy values (IFVs) are developed to compare the gain and loss of each product feature. The objective weight values of product features are calculated by considering entropy measures. Fourthly, compared with the previous method, product ranking with the IF-TODIM method has advantages over the intuitionistic fuzzy TOPSIS (IF-TOPSIS) method.
Preliminaries
The IFVs have the advantage of representing the feature values of products. In the transforming process, the proportions of the positive, negative, and neutral sentiment orientations are transformed into the membership, non-membership, and hesitance values in IFVs, respectively. Therefore, some basic concepts of IFVs and IFSs are introduced.
Definition 1 [26]. Let \(A = \left\{ {\left\langle {x_{i} ,\mu_{A} \left( {x_{i} } \right),\nu_{A} \left( {x_{i} } \right)} \right\rangle \left| {x_{i} \in X} \right.} \right\}\) and \(B = \left\{ {\left\langle {x_{i} ,\mu_{B} \left( {x_{i} } \right),\nu_{B} \left( {x_{i} } \right)} \right\rangle \left| {x_{i} \in X} \right.} \right\}\) be two IFSs representing the feature values of products, where \(\mu_{A} \left( {x_{i} } \right)\), \(\nu_{A} \left( {x_{i} } \right)\) and \(\pi_{A} \left( {x_{i} } \right)\) are the membership value, non-membership value, and hesitance value in IFV, \(\mu_{A} \left( {x_{i} } \right) + \nu_{A} \left( {x_{i} } \right) + \pi_{A} \left( {x_{i} } \right) = 1\). The Hamming, Euclidean, and generalized distances between the two product features \(A\) and \(B\) are defined as follows.
Definition 2 [27, 28]. Let \(A = \left\{ {\left\langle {x_{i} ,\mu_{A} \left( {x_{i} } \right),\nu_{A} \left( {x_{i} } \right)} \right\rangle \left| {x_{i} \in X} \right.} \right\}\) be an IFS, and the entropy measures can be defined as follows.
The score measures of IFVs act as an important role in comparing the magnitude of alternative product feature values. Some new score measures considering the signed distance of IFVs are introduced as follows.
Definition 3. Let \(a = < \mu_{a} ,\nu_{a} >\) and \(b = < \mu_{b} ,\nu_{b} >\) be two IFVs representing the feature values of products, \(\tilde{0} = < 0,1 >\) and \(\tilde{1} = < 1,0 >\) are the worst and best evaluation values of the product features. Then, the new score measures \(R_{h}\), \(R_{e}\) and \(R_{g}\) of IFVs are defined as follows.
Property 1. Let \(a = < \mu_{a} ,\nu_{a} >\) be an IFV, where \(\mu_{a} ,\nu_{a} \in \left[ {0,1} \right]\) and \(0 \le \mu_{a} + \nu_{a} \le 1\), then \(R\left( a \right) \in \left[ {0,1} \right]\).
Proof. If the IFV \(a = < 0,1 >\), then
If the IFV \(a = < 1,0 >\), then
\(R_{h} \left( a \right) = d_{h} \left( {a,\tilde{0}} \right) = \frac{1}{2}\left( {\left| {1 - 0} \right| + \left| {0 - 1} \right| + \left| {0 - 0} \right|} \right) = 1\),
Therefore, \(R\left( a \right) \in \left[ {0,1} \right]\).
The corresponding ranking method of IFVs is defined as
(1) If \(R\left( a \right) > R\left( b \right)\), then \(a \succ b\);
(2) If \(R\left( a \right) = R\left( b \right)\), then \(a \sim b\).
The IF-TODIM method for product ranking based on online review
Problem description
The following symbols are used to represent collections and variables in the product selection problem.
\(A = \left\{ {A_{1} ,A_{2} , \ldots ,A_{n} } \right\}\): a collection of \(n\) alternative products, where \(A_{i}\) represents the i-th product, \(i = 1,2, \ldots ,n\) and the consumers select the alternative product set \(A\).
\(F = \left\{ {f_{1} ,f_{2} , \ldots ,f_{m} } \right\}\): a collection of \(m\) features, the products’ features from the online reviews that the consumer focuses on, where \(f_{j}\) represents the j-th feature, \(j = 1,2, \ldots ,m\).
\(W = \left\{ {\omega_{1} ,\omega_{2} , \ldots ,\omega_{m} } \right\}\): the weight vector of the features, where \(\omega_{j}\) represents the weight of the feature \(f_{j}\), \(\omega_{j} > 0\) and \(\sum\nolimits_{j = 1}^{m} {\omega_{j} } = 1\).
\(Q = \left\{ {q_{1} ,q_{2} , \ldots ,q_{n} } \right\}\): the collection of the number of online reviews for the alternative product \(A_{i}\), where \(q_{i}\) means the number of online reviews about the alternative product \(A_{i}\), \(i = 1,2, \ldots ,n\).
\(D_{ik} = \left\{ {d_{ik}^{1} ,d_{ik}^{2} , \ldots ,d_{ik}^{m} } \right\}\): the online review collection of the alternative product \(A_{i}\), where \(d_{ik}^{j}\) represents the \(k\)-th online review on the features \(f_{j}\) in the \(i\)-th alternative product, \(i = 1,2, \ldots ,n\),\(j = 1,2, \ldots ,m\),\(k = 1,2, \ldots ,q_{i}\).
The problem is how to select alternative products \(A_{1} ,A_{2} , \ldots ,A_{n}\) based on online review \(D_{ik}\) and feature weight \(\omega_{j}\), \(i = 1,2, \ldots ,n\), \(j = 1,2, \ldots ,m\), \(k = 1,2, \ldots ,q_{i}\).
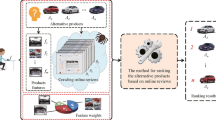
The flowchart of the product selection is shown in Fig. 1. The input information is the crawled online reviews of alternative products. The process includes two parts: sentiment orientation identification and product ranking based on the IF-TODIM method. In the first part, the Apriori algorithm is first used to identify the product features that customers focus on based on online reviews. The sentiment orientation and intensity of the sentiment words for the product features are identified by the lexicon-based sentiment analysis approach. The second part is to convert the sentiment orientation of the product features into an IFV and then use the IF-TODIM method to determine the final ranking results of the alternative products.

The flowchart of the product selection
Sentiment orientation identification of the online reviews
-
(1) Product feature extraction
A product feature extraction method based on online review data mining is introduced to extract the features of the alternative products that the consumers focus on from the online reviews. The process is described as follows.
First, the online review data is segmented, and the online review data after the segmentation is tagged. For the sake of accuracy and rationality, the ICTCLAS (Institute of Computing Technology, Chinese Lexical Analysis System, http://ictclas.nlpir.org/) tool is used for word segmentation of online review data. The lexical marking is for nouns, verbs, adjectives, or verbs with noun functions and proper nouns to improve the accuracy of the search.
Secondly, the association rule transaction file is created using the part-of-speech tagging, and the frequent itemset is searched based on the association rule Apriori algorithm. Here, the minimum support value is 1%, and at the same time, more than three frequent items are not considered.
The frequent itemset is pruned and corrected according to the neighboring rules and independent support and formed into a product feature set \(F^{TF}\).
Then, the common Chinese frequent item noun set \(F^{FF}\) of non-product features (such as some common product brands, colloquial zed nouns, and personal names) and the product feature set \(F^{SF}\) (containing single nouns) are constructed, and \(F^{TF}\) is filtered to form the final product feature set \(F\), i.e. \(F = F^{TF} - F^{FF} - F^{SF}\).
-
(2) Construct the positive and negative sentiment dictionaries of product features
Normally, different features have different positive or negative sentiment dictionaries. A word exhibits different sentiment orientations in the sentiment dictionaries of different features. For example, "high" is the negative sentiment word in the dictionary of the feature "price" and the positive sentiment word of the feature "pixel". Therefore, the positive and negative sentiment dictionary for each product feature should be constructed separately.
Firstly, according to the online review set after the part-of-speech tagging, the association rule object file for the feature \(f_{j}\) in the review is created. The frequent itemset \(F\) is searched based on the association rule Apriori algorithm to form the feature annotation set.
Assume that \(\overline{W}_{i}^{j}\) represents a sentiment word of the feature \(f_{j}\) of the alternative product \(A_{i}\), then \(\overline{W}^{j}\) means all of the sentiment words of the feature \(f_{j}\), \(\overline{W}_{i}^{j}\) and \(\overline{W}^{j}\) are defined as follows.
In addition, let \(\overline{W}_{HowNet}^{ + } = \left\{ {\overline{W}_{1}^{HN + } ,\overline{W}_{2}^{HN + } , \ldots ,\overline{W}_{4566}^{HN + } } \right\}\) and \(\overline{W}_{HowNet}^{ - } = \left\{ {\overline{W}_{1}^{HN - } ,\overline{W}_{2}^{HN - } , \ldots ,\overline{W}_{4370}^{HN - } } \right\}\) represent the positive and negative sentiment word sets in the HowNet sentiment dictionary. \(\overline{W}_{HowNet}^{ + }\) and \(\overline{W}_{HowNet}^{ - }\) include 4566 positive sentiment words and 4370 negative sentiment words, respectively. Assume that \(\overline{W}_{j}^{ + }\) and \(\overline{W}_{j}^{ - }\) are the positive and negative sentiment dictionary of the feature \(f_{j}\), \(\overline{W}_{j}^{ + }\) and \(\overline{W}_{j}^{ - }\) are defined as follows.
To improve their accuracy, \(\overline{W}_{HowNet}^{ + }\) and \(\overline{W}_{HowNet}^{ - }\) need to make adjustments manually.
-
(3) Identify the sentiment orientations of product features
Each feature's positive, neutral or negative sentiment orientations of each review are calculated. The principle of identifying the sentence’s sentiment orientation is as follows [18]. If the number of positive sentiment words in the sentence is greater than that of the negative sentiment, the sentiment is considered positive. If the number of negative sentiment words in a sentence is greater than that of positive sentiment words, the sentence's sentiment orientation is considered negative. If there are equal positive and negative sentiment words or no sentiment words in the sentence, then the sentence is considered neutral in its sentiment orientation. If there is a negative word in the sentence, the sentiment orientation of the sentence is reversed. The rules are shown as follows.
For each sentiment word set \(\overline{W}_{ik}^{j}\) obtained by online reviews, \(\overline{W}_{ik}^{j + }\) and \(\overline{W}_{ik}^{j - }\) are the sets of positive and negative sentiment words, which are the intersections between \(\overline{W}_{ik}^{j}\) and \(\overline{W}_{i}^{j + }\) or \(\overline{W}_{i}^{j - }\). Let \(s_{ik}^{j} = \left( {\alpha_{ik}^{j} ,\beta_{ik}^{j} ,\gamma_{ik}^{j} } \right)\) express the sentiment orientation vector of the sentence \(D_{ik}^{j}\), where \(\alpha_{ik}^{j} ,\beta_{ik}^{j} ,\gamma_{ik}^{j} \in \left\{ {0,1} \right\}\) and \(\alpha_{ik}^{j} + \beta_{ik}^{j} + \gamma_{ik}^{j} = 0\begin{array}{*{20}c} {} \\ \end{array} {\text{or}}\begin{array}{*{20}c} {} \\ \end{array} 1\). If \(\overline{W}_{ik}^{j}\) is an empty set, then \(s_{ik}^{j} = \left( {0,0,0} \right)\). If the number of \(\overline{W}_{ik}^{j + }\) is greater than the number of \(\overline{W}_{ik}^{j - }\), then \(s_{ik}^{j} = \left( {1,0,0} \right)\). If the number of \(\overline{W}_{ik}^{j + }\) is less than the number of \(\overline{W}_{ik}^{j - }\), then \(s_{ik}^{j} = \left( {0,0,1} \right)\). If the number of \(\overline{W}_{ik}^{j + }\) is equal to the number of \(\overline{W}_{ik}^{j - }\) and \(\overline{W}_{ik}^{j}\) is not an empty set, then \(s_{ik}^{j} = \left( {0,1,0} \right)\). The sentiment orientations of the product features are calculated by the above rules.
Product ranking based on IF-TODIM method
-
(1) Transform the sentiment orientations of product features into IFVs
IFVs are a useful tool for representing the ambiguity and hesitation of products’ features. IFVs can simultaneously reflect the like, neutral, and unlike of the online review [29]. Based on the theory of IFSs, online reviews of alternative products' sentiment orientations can be expressed simply and completely by IFVs [30].
In addition, most online reviews now have a click-and-click feature that makes it easy to understand the usefulness of each review. Therefore, more important weights are assigned to more praises, which are more useful reviews. Let \(X_{ik}^{j}\) be the importance of each review, and \(X_{ik}^{j}\) is determined by the number of likes and calculated as follows.
where \(N_{ik}^{j}\) is the number of likes on the k-th review of the product Ai, \(N_{i}\) is the set of the number of likes of the product Ai.
Let \(q_{ij}^{pos}\), \(q_{ij}^{neu}\) and \(q_{ij}^{neg}\) be the frequency of online reviews of positive, neutral, and negative sentiment orientations that characterize the alternative product, and \(q_{ij}^{pos}\), \(q_{ij}^{neu}\) and \(q_{ij}^{neg}\) are defined as follows.
Let \(q_{ij}^{pos}\), \(q_{ij}^{neu}\) and \(q_{ij}^{neg}\) represent the percentage of the alternative product features for positive, neutral, and negative sentiment orientations. The calculation formula is defined as follows
Obviously, \(p_{ij}^{pos} + p_{ij}^{neu} + p_{ij}^{neg} = 1\),\(p_{ij}^{pos} ,p_{ij}^{neu} ,p_{ij}^{neg} \ge 0\).
Thus, based on the interpretation of the IFV [31], an IFV \(a_{ij} = \left( {\mu_{ij} ,v_{ij} ,\pi_{ij} } \right)\) can represent the percentages of positive, neutral, and negative sentiment orientations of product features, where \(\mu_{ij} = p_{ij}^{pos}\), \(\nu_{ij} = p_{ij}^{neg}\) and \(\pi_{ij} = p_{ij}^{neu}\).
-
(2) IF-TODIM method for ranking products
Step 1: calculate the feature values \(\left( {\mu_{ij} ,\nu_{ij} } \right)\) in each alternative product and construct the decision matrix \(A = \left( {a_{ij} } \right)_{m \times n}\) of product selection.
where \(a_{ij}\) represents the value of the criteria \(f_{j}\) in the alternative product \(A_{i}\), all the values of \(a_{ij}\) are represented by IFVs.
Step 2: compare the feature values of each two alternative products by Eqs. (8)–(10) and construct the advantage-disadvantage matrix, where "A" or "D" means that \(A_{i}\) is larger or smaller than \(A_{k}\).
Step 3: calculate the weight \(w_{j}\) of the feature \(f_{j}\) as follows.
Firstly, calculate the entropy \(E_{ij}\) of each product feature by Eqs. (4)–(7), and normalize the entropy by the following equation:
Then, the entropy weights of each product feature are calculated as follows.
where \(a_{j} = \sum\nolimits_{i = 1}^{m} {h_{ij} }\).
Step 4: the feature with the largest weight value is regarded as the reference feature \(f_{R}\). The relative weight value \(w_{jR}\) of each feature \(f_{j}\) over the reference feature \(f_{R}\) is calculated by Eq. (25).
Step 5: the dominance degree \(\vartheta \left( {A_{i} ,A_{e} } \right)\) of the alternative product \(A_{i}\) over \(A_{e}\) is calculated by Eq. (26).
where
where \(d\left( {a_{ij} ,a_{ej} } \right)\) is calculated by Eqs. (1)–(3).
Step 6: the global prospect value \(\delta \left( {A_{i} } \right)\) of each alternative product \(A_{i}\) is calculated by Eq. (27).
Step 7: rank the alternative products according to the global prospect values \(\delta \left( {A_{i} } \right)\). The larger the value of \(\delta \left( {A_{i} } \right)\) is, the better the alternative product \(A_{i}\) is.
Case study
Decision-making process
Online reviews of five mobile phones from Jingdong Mall (https://www.jd.com/) are crawled. The five alternative mobile phones are iPhone X, Huawei P10, OPPO R11S, Mito T8, and VIVO X9. The crawler software Bazhuayu (http://www.bazhuayu.com/) is used to crawl 5000 reviews (1000 reviews per phone). After processing, 2000 reviews (400 reviews for each phone) are extracted from the review data set obtained. The mobile phone features extracted by the Apriori algorithm that customers focus on are F = {Appearance, Screen, Photo, Battery, Price, System}. The positive sentiment dictionary \(\overline{W}_{j}^{ + }\) and negative sentiment dictionary \(\overline{W}_{j}^{ - }\) of mobile phone feature are constructed by Eqs. (11)–(14) in Table 1. “价格/n 实惠/a” (Price/n is/v affordable/a) is taken as an example to express the process of the sentiment orientation. \(\overline{W}_{5}^{ + } \cap \overline{W}_{51}^{1} \ne \emptyset\) and \(s_{51}^{1} = (1,0,0)\). Thus, the sentiment orientation is positive.
The positive, neutral, and negative sentiment orientation numbers \(q_{ij}^{pos}\), \(q_{ij}^{neu}\) and \(q_{ij}^{neg}\) of alternative mobile phones are calculated by Eqs. (15)–(18) and shown in Table 2.
The steps of ranking mobile phones by the IF-TODIM method are shown as follows.
Step 1: calculate the feature values \(\left( {\mu_{ij} ,\nu_{ij} } \right)\) of each alternative mobile phone by Eqs. (19)–(21) and construct the decision matrix \(A = \left( {a_{ij} } \right)_{m \times n}\). For example, the appearance value of IPONE X (A1) is [0.757, 0.187], where
The intuitionistic fuzzy decision matrix of mobile phone selection is shown in Table 3.
Step 2: compare the feature values of each two alternative products by Eqs. (8)–(10) and construct the advantage-disadvantage matrix. For example, the score measures of IPHONE X (A1) and HUAWEI P10 (A2) under the attribute appearance (f1) are
Therefore, \(R_{h} \left( {a_{11} } \right) \prec R_{h} \left( {a_{21} } \right)\). The score measure of A1 under the attribute appearance (f1) is smaller than A2, represented by “D”. The advantage-disadvantage matrix is shown in Table 4.
Step 3: calculate the weight \(w_{j}\) of the feature \(f_{j}\).
Calculate the entropy \(e_{ij}\) of each mobile phone feature by Eq. (4) in Definition 2. For example, the entropy of \(a_{11}\) is \(e_{11} = 1 - \left( {\mu_{A} \left( {x_{i} } \right) + \nu_{A} \left( {x_{i} } \right)} \right) = 1 - (0.757 + 0.187) = 0.056\). The entropy matrix \(E\) is as follows.
Then, the normalized entropy matrix is obtained by Eq. (23) as follows.
Finally, the entropy weight can be calculated by Eq. (24) as \(W = \left( {w_{j} } \right)_{n \times 1} = \left( {0.076,0.177,0.122,0.325,0.110,0.190} \right)^{T}\).
Step 4: the feature with the largest weight value is regarded as the reference feature \(f_{R}\). The relative weight value \(w_{jR}\) of each feature \(f_{j}\) over the reference feature \(f_{R}\) is calculated by Eq. (25). The relative weight values are shown in Table 5.
Step 5: the dominance \(\vartheta \left( {A_{i} ,A_{e} } \right)\) of the alternative mobile phone \(A_{i}\) over \(A_{e}\) is calculated by Eq. (26).
Here, assume that \(\theta = 1\) [36], then the gain and losses \(\phi_{j} \left( {A_{i} ,A_{e} } \right)\) are calculated and shown in Table 6. For example, \(\phi_{1} \left( {A_{1} ,A_{2} } \right) = - \frac{1}{\theta }\sqrt {{{\left( {\sum\nolimits_{j = 1}^{n} {w_{jR} } } \right)d\left( {a_{ij} - a_{ej} } \right)} \mathord{\left/ {\vphantom {{\left( {\sum\nolimits_{j = 1}^{n} {w_{jR} } } \right)d\left( {a_{ij} - a_{ej} } \right)} {w_{jR} }}} \right. \kern-\nulldelimiterspace} {w_{jR} }}} = - \frac{1}{1}\sqrt {{{3.077 \times 0.1255} \mathord{\left/ {\vphantom {{3.077 \times 0.1255} {0.233}}} \right. \kern-\nulldelimiterspace} {0.233}}} = - 1.340\).
Then, the dominance degree of mobile phone Ai over mobile phone Ae is calculated by Eq. (26). For example, the dominance degree of mobile phone A1 over A2 is \(\vartheta \left( {A_{1} ,A_{2} } \right) = \sum\limits_{j = 1}^{6} {\phi_{j} \left( {A_{1} ,A_{2} } \right)} = - 1.340 - 0.499 - 0.857 - 0.480 - 1.691 - 0.590 = - 5.457\). The dominance degree matrix is shown in Table 7.
Step 6: the global prospect value \(\delta \left( {A_{i} } \right)\) of each alternative mobile phone \(A_{i}\) is calculated by Eq. (27). The global prospect values are \(\delta \left( {A_{1} } \right) = \frac{{\sum\nolimits_{e = 1}^{m} {\vartheta \left( {A_{1} ,A_{e} } \right)} - \min \left\{ {\sum\nolimits_{e = 1}^{m} {\vartheta \left( {A_{1} ,A_{e} } \right)} } \right\}}}{{\max \left\{ {\sum\nolimits_{e = 1}^{m} {\vartheta \left( {A_{1} ,A_{e} } \right)} } \right\} - \min \left\{ {\sum\nolimits_{e = 1}^{m} {\vartheta \left( {A_{1} ,A_{e} } \right)} } \right\}}} = \frac{ - 21.059 - ( - 21.059)}{{1.408 - ( - 21.059)}} = 0\), \(\delta \left( {A_{2} } \right) = 0.785\), \(\delta \left( {A_{3} } \right) = 0.913\), \(\delta \left( {A_{4} } \right) = 0.220\) and \(\delta \left( {A_{5} } \right) = 1\).
Step 7: rank the alternative mobile phones according to the global prospect values \(\delta \left( {A_{i} } \right)\), the ranking result is \(\delta \left( {A_{5} } \right) > \delta \left( {A_{3} } \right) > \delta \left( {A_{2} } \right) > \delta \left( {A_{4} } \right) > \delta \left( {A_{1} } \right)\).
The alternative mobile phones are sorted as VIVO X9 > OPPO R11S > Huawei P10 > Mito T8 > IPHONE X. In the case of priority price, system performance, and appearance, the optimal choice is VIVO X9. According to the online reviews of VIVO X9, most of the online reviews indicate that the system is fluent and the mobile phone is cost-effective. Most of the online reviews of IPHONE X are too expensive, resulting in a lower ranking.
Analysis of the effect of the parameter
The product selection based on online reviews involves the attenuation coefficient \(\theta\). The attenuation coefficient \(\theta\) affecting the ranking result is analyzed by taking different values. When the attenuation coefficient \(\theta = 1,2,3,4\), the product ranking result calculated by the IF-TODIM method under different attenuation coefficients are shown in Table 8. From the result, the A5 is always the best choice under different attenuation coefficients. Therefore, different attenuation coefficient values have no effect on the product ranking results.
Comparison analysis
The developed IF-TODIM method is compared with the IF-TOPSIS [22], IF-VIKOR [40], and IF-PROMETHEE [9] methods to illustrate the effectiveness.
-
(1) Comparison with IF-TOPSIS method
The main idea of the IF-TOPSIS method for ranking products is to normalize the original data matrix and determine the distance between the alternative products and the optimal or worst solution based on each attribute index's weight [20]. The relative closeness of each alternative product to the optimal solution is used as the evaluating basis. The steps of the IF-TOPSIS method are as follows.
Step 1: the mobile phone’s positive ideal solution (PIS) A+ and negative ideal solution (NIS) A− are defined as follows.
Then, the PIS and NIS of each mobile phone feature are shown in Table 9.
Step 2: Calculate the weighted distance from each alternative mobile phone Ai to the PIS A+ and the NIS A−.
Step 3: Calculate the relative closeness (CIi) of each alternative mobile phone Ai as follows.
Here, the weighted Hamming distance between the alternative mobile phone Ai and the PIS A+ or the NIS A− represented by the IFSs is calculated. The ranking result calculated by the IF-TOPSIS method is shown in Table 10. The product ranking result is \(A_{3} > A_{5} > A_{2} > A_{1} > A_{4}\). Namely, the best choice to buy the alternative mobile phone based on online reviews is OPPO R11S (A3).
-
(2) Comparison with IF-VIKOR method
The IF-VIKOR method is developed by Yang et al. [40] to select the best compromise hotels.
Step 1: the PISs and NISs of mobile phones are shown in Table 9.
Step 2: calculate the \(S_{i}\) and \(R_{i}\) of alternative mobile phone Ai.
Step 3: assume that \(v = 0.5\), and calculate the \(Q_{i}\) of alternative mobile phone Ai.
Step 4: obtain the ranking result of alternative mobile phones.
The ranking result of alternative mobile phones is obtained as \(A_{5} > A_{2} > A_{3} > A_{1} > A_{4}\).
-
(3) Comparison with IF-PROMETHEE method
The IF-PROMETHEE method [23] is developed to support the consumers’ purchase decisions.
Step 1: the priority index of Ai over Aj is shown in Table 7.
Step 2: the entering flow \(\varphi^{ + } \left( {A_{i} } \right)\) and exiting flow \(\varphi^{ - } \left( {A_{i} } \right)\) are calculated as
Step 3: the comprehensive outranking indices \(\varphi \left( {A_{i} } \right)\) are
Step 4: the ranking result of the alternative mobile phones is \(A_{5} > A_{3} > A_{2} > A_{4} > A_{1}\).
-
(4) Discussion
To illustrate the effectiveness of ranking products based on the IF-TODIM method and online reviews, the product ranking results of the IF-TODIM method and the three other methods are shown in Fig. 2. The results show that the product ranking result by the IF-TODIM method is the same as the IF-PROMETHEE method and different from those of the two other methods. The best choice to buy the mobile phone obtained by the IF-TODIM, IF-VIKOR, and IF-PROMETHEE methods is A5 (VIVO X9), while that of the IF-TOPSIS method is A3 (OPPO R11S). A1 (IPHONE X) and A4 (Mito T8) are always the worst two choices. The main reason for the different results is that the IF-TODIM method considers the gain and loss of each mobile phone feature and prospect value in the product ranking process. VIVO X9 has some advantages in the attribute of price, and other features reappraise from all the features. The ranking result by the IF-TODIM method is closer to the actual situation. The customers are fully rational in purchasing mobile phones under the IF-TOPSIS and IF-VOKOR method. Customers are non-fully rational in the purchase decision process. The IF-TOPSIS and IF-VOKOR method is not reasonable for the ranking product. Therefore, the IF-TODIM method based on online reviews is more reasonable than the IF-TOPSIS and IF-VIKOR method.

Product ranking results by the developed IF-TODIM method and other methods
Conclusion
In this paper, a new analytical method for ranking products is presented. The main idea of ranking product method through online reviews and IF-TODIM is as follows. Firstly, the Apriori algorithm is used to identify the product features based on online reviews. Then the sentiment orientation and intensity of the sentiment words for the product features are identified by the lexicon-based sentiment analysis approach. Next, the sentiment orientation of the product features is converted into an IFV, and then the IF-TODIM method is used to determine the ranking results of the alternative products.
The proposed method fully considers consumers' subjective needs and different sentiment orientations (positive, neutral, and negative) for each product feature. The IFVs are used to fully reflect the different sentiment orientations of online reviews, which is more elaborate than previous studies and makes up for the lack of consideration of the neural sentiment orientation. In addition, the gain and loss of each mobile phone feature in the product ranking process are also considered. The obtained result is closer to the actual purchase needs of consumers. In general, the degree of membership, non-membership, and hesitation in IFV provides an effective way to solve the problem of product ranking. The proposed method has operability and practical application value and provides a new decision-making technology to solve the problem of product purchase decision-making using online review data in the current era of big data.
The developed method provides a convenient tool to give recommendations for purchasing products, and the decision support system needs to improve. In addition, the emojis and photos in the online review data are neglected during the data pre-processing process. In future work, it is necessary to study the product ranking method combing with emojis and photos.
Data availability
The data used to support the findings of this study are included within the article.
References
Naragund GH, Santhosh Kumar KL, Majumdar J (2015) Development of decision making and analysis on customer reviews using sentiment dictionary for human-robot interaction. Int J Adv Res Comput Commun Eng (IJARCCE) 4(8):387–391
Zhang Z, Zhang H, Zhou L, Li Y (2021) Analyzing the coevolution of mobile application diffusion and social network: a multi-agent model. Entropy 23(5):521
Zhou L, Lin J, Li Y, Zhang Z (2020) Innovation diffusion of mobile applications in social networks: a multi-agent system. Sustainability 12(7):2884
Zhang K, Narayanan R, Choudhary AN (2010) Voice of the customers: mining online customer reviews for product feature-based ranking. WOSN 10:11–11
Zhang K, Cheng Y, Liao WK, Choudhary A (2011, August) Mining millions of reviews: a technique to rank products based on importance of reviews. In: Proceedings of the 13th international conference on electronic commerce, pp 1–8
Kang D, Park Y (2014) Review-based measurement of customer satisfaction in mobile service: sentiment analysis and VIKOR approach. Expert Syst Appl 41(4):1041–1050
Najmi E, Hashmi K, Malik Z, Rezgui A, Khan HU (2015) CAPRA: a comprehensive approach to product ranking using customer reviews. Computing 97(8):843–867
Li MY, Zhao XJ, Zhang L, Ye X, Li B (2020) Method for product selection considering consumer’s expectations and online reviews. Kybernetes 50(9):2488–2520
Fan ZP, Xi Y, Liu Y (2018) Supporting consumer’s purchase decision: a method for ranking products based on online multi-attribute product ratings. Soft Comput 22(16):5247–5261
Zhang Z, Li J, Sun Y, Lin J (2019) Novel distance and similarity measures on hesitant fuzzy linguistic term sets and their application in clustering analysis. IEEE Access 7:100231–100242
Wu S, Lin J, Zhang Z (2020) New distance measures of hesitant fuzzy linguistic term sets. Phys Scr 96(1):015002
Zhang Z, Lin J, Miao R, Zhou L (2019) Novel distance and similarity measures on hesitant fuzzy linguistic term sets with application to pattern recognition. J Intell Fuzzy Syst 37(2):2981–2990
Peng Y, Kou G, Li J (2014) A fuzzy PROMETHEE approach for mining customer reviews in Chinese. Arab J Sci Eng 39(6):5245–5252
Zhang D, Wu C, Liu J (2020) Ranking products with online reviews: a novel method based on hesitant fuzzy set and sentiment word framework. J Operat Res Soc 71(3):528–542
Bi JW, Liu Y, Fan ZP (2019) Representing sentiment analysis results of online reviews using interval type-2 fuzzy numbers and its application to product ranking. Inf Sci 504:293–307
Fu X, Ouyang T, Yang Z, Liu S (2020) A product ranking method combining the features–opinion pairs mining and interval-valued Pythagorean fuzzy sets. Appl Soft Comput 97:106803
Liu P, Teng F (2019) Probabilistic linguistic TODIM method for selecting products through online product reviews. Inf Sci 485:441–455
Ji P, Zhang HY, Wang JQ (2018) A fuzzy decision support model with sentiment analysis for items comparison in e-commerce: The case study of http://PConline.com. IEEE Trans Syst Man Cybern Syst 49(10):1993–2004
Liang R, Wang JQ (2019) A linguistic intuitionistic cloud decision support model with sentiment analysis for product selection in E-commerce. Int J Fuzzy Syst 21(3):963–977
Liang X, Liu P, Wang Z (2019) Hotel selection utilizing online reviews: a novel decision support model based on sentiment analysis and DL-VIKOR method. Technol Econ Dev Econ 25(6):1139–1161
Fan ZP, Li GM, Liu Y (2020) Processes and methods of information fusion for ranking products based on online reviews: an overview. Information Fusion 60:87–97
Liu Y, Bi JW, Fan ZP (2017) A method for ranking products through online reviews based on sentiment classification and interval-valued intuitionistic fuzzy TOPSIS. Int J Inf Technol Decis Mak 16(06):1497–1522
Liu Y, Bi JW, Fan ZP (2017) Ranking products through online reviews: a method based on sentiment analysis technique and intuitionistic fuzzy set theory. Information Fusion 36:149–161
Çalı S, Balaman ŞY (2019) Improved decisions for marketing, supply and purchasing: mining big data through an integration of sentiment analysis and intuitionistic fuzzy multi criteria assessment. Comput Ind Eng 129:315–332
Zhang D, Li Y, Wu C (2020) An extended TODIM method to rank products with online reviews under intuitionistic fuzzy environment. J Operat Res Soc 71(2):322–334
Szmidt E, Kacprzyk J (2000) Distances between intuitionistic fuzzy sets. Fuzzy Sets Syst 114(3):505–518
Szmidt E, Kacprzyk J (2001) Entropy for intuitionistic fuzzy sets. Fuzzy Sets Syst 118(3):467–477
Chen TY, Li CH (2010) Determining objective weights with intuitionistic fuzzy entropy measures: a comparative analysis. Inf Sci 180(21):4207–4222
Xu Z, Zhao N (2016) Information fusion for intuitionistic fuzzy decision making: an overview. Inf Fusion 28:10–23
Atanassov KT (1989) More on intuitionistic fuzzy sets. Fuzzy Sets Syst 33(1):37–45
Xu Z (2007) Intuitionistic fuzzy aggregation operators. IEEE Trans Fuzzy Syst 15(6):1179–1187
Liu P, Zhang P (2020) Normal wiggly hesitant fuzzy TODIM approach for multiple attribute decision making. J Intell Fuzzy Syst 39(1):627–644
Lu J, Wei C (2019) TODIM method for performance appraisal on social-integration-based rural reconstruction with interval-valued intuitionistic fuzzy information. J Intell Fuzzy Syst 37(2):1731–1740
Deng X, Gao H (2019) TODIM method for multiple attribute decision making with 2-tuple linguistic Pythagorean fuzzy information. J Intell Fuzzy Syst 37(2):1769–1780
Huang YH, Wei GW (2018) TODIM method for Pythagorean 2-tuple linguistic multiple attribute decision making. J Intell Fuzzy Syst 35(1):901–915
Zhang Z, Lin J, Zhang H, Wu S, Jiang D (2020) Hybrid TODIM method for law enforcement possibility evaluation of judgment debtor. Mathematics 8(10):1806
Gomes L, Lima M (1992) TODIM: Basics and application to multicriteria ranking of projects with environmental impacts. Found Comput Decis Sci 16(4):113–127
Zhang Z, Zhao X, Qin Y, Si H, Zhou L (2021) Interval type-2 fuzzy TOPSIS approach with utility theory for subway station operational risk evaluation. J Ambient Intell Hum Comput. https://doi.org/10.1007/s12652-021-03182-0
Gomes L, Lima M (1992) From modeling individual preferences to multicriteria ranking of discrete alternatives: a look at prospect theory and the additive difference model. Found Comput Decis Sci 17(3):171–184
Yang Z, Gao Y, Fu X (2021) A decision-making algorithm combining the aspect-based sentiment analysis and intuitionistic fuzzy-VIKOR for online hotel reservation. Ann Operat Res. https://doi.org/10.1007/s10479-021-04339-y
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We declare that we do have no commercial or associative interests that represent a conflict of interests in connection with this manuscript. There are no professional or other personal interests that can inappropriately influence our submitted work.
Research involving human participants and/or animals
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Z., Guo, J., Zhang, H. et al. Product selection based on sentiment analysis of online reviews: an intuitionistic fuzzy TODIM method. Complex Intell. Syst. 8, 3349–3362 (2022). https://doi.org/10.1007/s40747-022-00678-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00678-w