
Abstract
In this paper, we contemplate addressing nonlinear problems involving complex symmetric Jacobian matrices. Firstly, we establish a parameter-free method called modified Newton–CAPRESB (MN–CAPRESB) method by harnessing the modified Newton method as the outer iteration and the CAPRESB (Chebyshev accelerated preconditioned square block) method as the inner iteration. Secondly, the local and semilocal convergence theorems of MN–CAPRESB method are proved under some conditions. Eventually, the numerical experiments of two kinds of complex nonlinear equations are presented to validate the feasibility of MN–CAPRESB method compared to other existing iteration methods.
Similar content being viewed by others
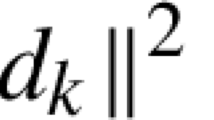
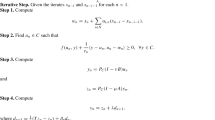

Avoid common mistakes on your manuscript.
1 Introduction
In many fields of physics and engineering, we often encounter nonlinear problems. Examples of such systems can be seen in Ortega and Rheinboldt (2000), Rheinboldt (1998) and references therein.
We contemplate addressing the large and sparse nonlinear system:
Here,
represents a continuously differentiable function.
We assume that the Jacobian matrix \(F'(x)\) has the following form:
where \(i = \sqrt{-1}\) and matrices \(W(x),T(x)\in {\mathbb {R}}^{n\times n}\) are symmetric positive definite (SPD) and symmetric positive semidefinite (SPSD), respectively.
For solving Eq. (1), many researchers have devoted themselves to proposing numerous methods (Ortega and Rheinboldt 2000; Rheinboldt 1998; King 1973). The Newton method is considered as a efficient and widely used iterative method for addressing nonlinear problems. The inexact Newton method (Dembo et al. 1982) outperforms the Newton method. It could be formulated as follows:
Here, \(x_0 \in {\mathbb {D}}\) stands for the provided initial vector, while \(r_k\) denotes a residual acquired during the inner iteration process. The modified Newton method (Darvishi and Barati 2007) was established to reduce the computational load in Newton method, which has the following form:
Among the above methods, we can observe that tackling linear equations is an integral part in these methods. So we review the methods for addressing complex linear equation
where \(A=W+iT\) and the matrices \(W,T\in {\mathbb {R}}^{n\times n}\) are SPD and SPSD, respectively. In 2003, the Hermitian and skew-Hermitian splitting (HSS) method was constructed by Bai et al., which was based on the specific structure of A (Bai et al. 2003). The modified HSS (MHSS) (Bai et al. 2010) and preconditioned MHSS (PMHSS) (Bai et al. 2011) methods have also been established for enhancing the HSS method. Moreover, Hezari et al. established a single-step iterative method known as the SCSP method in Hezari et al. (2016). Subsequently, other researchers have extended and improved upon this method, leading to the development of more effective iteration methods (Zheng et al. 2017; Salkuyeh and Siahkolaei 2018). Furthermore, Wang et al. presented a novel iteration method combining real and imaginary parts (CRI) (Wang et al. 2017). Since then, a number of researchers have devoted their efforts to developing efficient iteration methods (Xiao and Wang 2018; Huang 2021; Shirilord and Dehghan 2022) to solve Eq. (3).
Additionally, it can be confirmed that Eq. (3) is equivalent to the following equation:
Here, \({\tilde{f}} = z^{(1)} + iz^{(2)}\) and \(b = p + iq\). To address Eq. (4), a block PMHSS iteration method (Bai et al. 2013) and the DSS real-valued iteration method (Zhang et al. 2019) were proposed, which can be seen as the variants of PMHSS method (Bai et al. 2011) and DSS method (Zheng et al. 2017). In recent years, several iteration methods akin to the generalized successive overrelaxation (GSOR) approach have also been developed (Salkuyeh et al. 2015; Hezari et al. 2015; Edalatpour et al. 2015; Liang and Zhang 2016). Moreover, Axelsson et al. presented the preconditioned square block (PRESB) preconditioner in Axelsson et al. (2014):
where \(\alpha \) is a real positive parameter.
The previously mentioned methods are effective in solving linear systems, but require the selection of a positive parameter or even two parameters, which can be time-consuming during practical implementation. For addressing this issue, a number of researchers provided theoretical optimal parameters in their methods (Bai et al. 2003, 2010, 2011; Hezari et al. 2016; Zheng et al. 2017) while the process of computing optimal parameters often involves the calculation of the eigenvalues of matrices, costing relatively much time. To avoid selecting parameters, Liang and Zhang (2021) proposed a parameter-free method called the Chebyshev accelerated PRESB (CAPRESB) method. They took advantage of the fact that the eigenvalues of \({\mathcal {P}}_{\textrm{PRESB}}^{-1}{\mathcal {A}}\) are located in the interval [0.5, 1] when \(\alpha = 1\), making the PRESB method comparably efficient without the parameter selection.
By incorporating the Newton method with the HSS method, Bai et al. established the Newton–HSS method to address complex nonlinear systems in Bai and Guo (2010) and it was improved by Wu et al. who established the modified Newton–HSS method (Wu and Chen 2013). Examples of such methods can be seen in Zhang et al. (2021, 2022), Yu and Wu (2022), Xiao et al. (2021), Dai et al. (2018), Feng and Wu (2021). In this paper, drawing inspiration from these ideas, we establish a parameter-free method called MN–CAPRESB method by incorporating the modified Newton method with CAPRESB method.
Throughout the full paper, we utilize the notation \(\Vert \cdot \Vert \) to represent the Euclidean norm of a vector or a matrix. If there is no specific explanation, the matrices \(W,T\in {\mathbb {R}}^{n\times n}\) are SPD and SPSD, respectively. Moreover, \(\Re (\cdot )\) and \(\Im (\cdot )\) are used to represent the real and complex components of the corresponding number, respectively.
The structure of the paper is outlined as follows. In Sect. 2, we present the MN–CAPRESB method. In Sects. 3 and 4, the local and semilocal convergence theorems of our approach are demonstrated under proper conditions, respectively. In Sect. 5, we provide numerical results to illustrate the benefits of our approach compared to the MN–MHSS (Yang and Wu 2012), MN–PMHSS (Zhong et al. 2015), MN–SSTS (Yu and Wu 2022) and MN–PSBTS (Zhang et al. 2022) methods. Eventually, we provide a concise conclusion in Sect. 6.
2 MN–CAPRESB method
First of all, we review the CAPRESB method (Liang and Zhang 2021). For simplicity of notation, we denote
\({\mathcal {P}}\) is the special case of \({\mathcal {P}}_{\textrm{PRESB}}\) when \(\alpha = 1\). The details of CAPRESB method can be described as follows:
and
where \(r_k = c-{\mathcal {A}}f_k\), \(\tau _k\) and \(\zeta _k\) are positive acceleration parameters with
and
with \({\tilde{\lambda }}_{\max }=1\) and \({\tilde{\lambda }}_{\min }=0.5\). The iteration formulas (5)-(6) are categorized to the Chebyshev acceleration method (Golub and Varga 1961). Moreover, for the CAPRESB method, we can obtain the Algorithms 1 and 2 in Liang and Zhang (2021).

Liang and Zhang (2021) Computation of u from \({\mathcal {P}}u=r\) with \(u= [u^{{(1)}^T}, u^{{(2)}^T}]^T\) and \(r=[r^{{(1)}^T}, r^{{(2)}^T}]^T\)

From Algorithms 1 and 2, we know that the CAPRESB method involves two linear systems about \(W+T\) at each iteration step, which can be accurately solved through sparse Cholesky factorization or approximately through a preconditioned conjugate gradient (PCG) approach.
Actually, another parameter-free method called CADSS method was also proposed in Liang and Zhang (2021), which accelerates the double-step scale splitting real-valued method (Zhang et al. 2019) with Chebyshev accelerated iteration method. Similarly, we can also establish MN–CADSS method. However, at each step of CADSS method it involves four linear systems to be solved. Based on it, we think that the CAPRESB method outperforms the CADSS method. Hence, we only establish the modified Newton–CAPRESB method.
Now, we summarize the convergence characteristics of the CAPRESB method in Liang and Zhang (2021). From Axelsson (1996), the iterative error \(e_k = f_k - f_*\) satisfies
where \(f_*\) represents the exact solution of (4) and
which conforms to the subsequent recurrence equations:
Consequently, we have
where \(\lambda _{\max }\) and \(\lambda _{\min }\) represent the largest and smallest eigenvalues of the matrix \({\mathcal {P}}^{-1}{\mathcal {A}}\), respectively, satisfying
If \({\mathcal {P}}^{-1}{\mathcal {A}}\) is symmetric, it is straightforward to derive the convergence characteristics according to Eqs. (7) and (8). Moreover, the authors in Liang and Zhang (2021) have proved that \({\mathcal {P}}^{-1}{\mathcal {A}}\) can be diagonalized, which contributes to the convergence characteristics of the CAPRESB method. Now, we summarize the convergence characteristics of the CAPRESB method in Liang and Zhang (2021).
Theorem 2.1
We denote \(e_k = f_k - f_*\) and \({\tilde{e}}_k = {\tilde{f}}_k-{\tilde{f}}_*\), \(k=0,1,\ldots \). Here, \(f_k = \begin{bmatrix} z^{(1)}_k \\ z^{(2)}_k \end{bmatrix}\), \(f_* = \begin{bmatrix} z^{(1)}_* \\ z^{(2)}_* \end{bmatrix}\), \({\tilde{f}}_k = z^{(1)}_k + iz^{(2)}_k\), \({\tilde{f}}_* = z^{(1)}_* + iz^{(2)}_*\), and \(f_*\) and \({\tilde{f}}_*\) are the exact solutions of (4) and (3), respectively. Then we have
and
\(k=0,1,\ldots \), where \(H=W+T\), \(\kappa _2(H) = \Vert H\Vert \Vert H^{-1}\Vert \), \(\kappa _{\mu } = 2+\mu _{\max }^2+\mu _{\max }\sqrt{4+\mu _{\max }^{2}}\), \(\theta =\frac{\sqrt{2}-1}{\sqrt{2}+1}\), and \(\mu _{\max }\) represents the largest eigenvalue of the matrix \(W^{-1}T\).
Proof
From Theorem 3.1 in Liang and Zhang (2021), we know that there exist inverse matrix \({\tilde{X}}\) and diagonal matrix D such that
where \(\kappa _2({\tilde{X}}) \le \frac{\sqrt{\kappa _2(H)}\kappa _{\mu }}{2}\). According to the Eqs. (7) and (8), we can obtain
\(k=0,1,\ldots \). It is trivial to see \(\Vert {\tilde{e}}_k\Vert = \Vert e_k\Vert \) and \(\Vert {\tilde{e}}_*\Vert = \Vert e_*\Vert \). Hence, the other formula holds. \(\square \)
Moreover, we propose the following theorem to further describe the convergence characteristics.
Theorem 2.2
In accordance with the conditions stated in Theorem 2.1, we can hold
and
\(k=0,1,\ldots \), where \(M = \Vert W^{-1}\Vert (\Vert W\Vert +\Vert T\Vert )\) and \(\theta =\frac{\sqrt{2}-1}{\sqrt{2}+1}\).
Proof
Actually, we can obtain
and
Hence, from Theorem 2.1, it holds that
\(k=0,1,\ldots \). Moreover, it is straightforward to know the other formula holds. \(\square \)
The CAPRESB method is converged when \(W,T\in {\mathbb {R}}^{n\times n}\) are both SPSD and null(W) \(\cap \) null(T) = 0, where null(A) denotes the null space of A (Liang and Zhang 2021). We restrict W to be SPD to better estimate \(\kappa _2(H)\) and \(\mu _{\max }\) as Theorem 2.2 shows.
Then, we propose the MN–CAPRESB method, which implies that we utilize CAPRESB method for the following equations:
Actually, the MN–CAPRESB method for addressing Eq. (1) can be derived as demonstrated in Algorithm 3. We make the following markings to better illustrate the algorithm. \({\mathcal {P}}(x)\) and \({\mathcal {A}}(x)\) denote the special case of \({\mathcal {P}}\) and \({\mathcal {A}}\) when \(W = W(x)\) and \(T = T(x)\), respectively. Moreover, \(c(x) \equiv \begin{bmatrix} \Re {(-F(x))}\\ \Im {(-F(x))} \end{bmatrix}\).

MN–CAPRESB method
3 Local convergence theorem of the MN–CAPRESB method
Suppose that \(x_* \in {\mathbb {N}}_0 \subseteq {\mathbb {D}}\) with \(F(x_*) = 0\), and \({\mathbb {N}}(x_*, r)\) represents an open ball centered at \(x_*\) with radius r.
Assumption 3.1
For any \(x \in {\mathbb {N}}(x_*, r) \subset {\mathbb {N}}_0\), we assume that the formulas below are satisfied.
(THE BOUNDED CONDITION) There exist numbers \(\beta , \gamma > 0\) such that
(THE LIPSCHITZ CONDITION) There exist numbers \(L_w, L_t \ge 0\) such that
Lemma 3.1
Under the condition that \(r \in (0, \frac{1}{\gamma L})\) and subject to Assumption 3.1, \(W(x)^{-1}\) and \(F'(x)^{-1}\) exist for all \(x \in {\mathbb {N}}(x_*, r) \subset {\mathbb {N}}_0\). Additionally, the formulas below are satisfied for any \(x, z \in {\mathbb {N}}(x_*, r)\) with \(L:= L_w + L_t\):
Proof
The proof closely resembles that of Lemma 3.3 in Xie et al. (2020), so we omit it here. \(\square \)
Lemma 3.2
In accordance with the conditions stated in Lemma 3.1, let \(r \in (0, r_0)\), \(r_0:= \min \{r_1, r_2\}\) and \(u:= \min \{l_*, m_*\}\), where
\(l_* = \liminf _{k \rightarrow \infty } l_k\) and \(m_* = \liminf _{k \rightarrow \infty } m_k\). Moreover, the number u is subjected to
where the notation \(\lfloor \cdot \rfloor \) represents the smallest integer at least as much as the corresponding real number. Additionally, we set
Subsequently, for all \(x_k \in {\mathbb {N}}(x_*,r) \subset {\mathbb {N}}_0\), we have
and
Here, \(d_{k,l_k}\) and \(h_{k,m_k}\) are obtained by Algorithm 3, \(d_k = -F'(x_k)^{-1}F(x_k)\) and \(h_k = -F'(x_k)^{-1}F(y_k)\). Moreover, \(\theta =\frac{\sqrt{2}-1}{\sqrt{2}+1}\) and \(\tau =\sqrt{{\tilde{M}}}\left( 2+{\tilde{M}}^2+{\tilde{M}}\sqrt{4+{\tilde{M}}^{2}}\right) \) with \({\tilde{M}}=3\gamma \beta \). When \(t \in (0, r)\) and \(v>u\), we can obtain that
Proof
Firstly, since \(r<\frac{1}{\gamma L}\), for all \(x_k \in {\mathbb {N}}(x_*,r)\), it holds that
and
Moreover, in accordance with Lemma 3.1, since \(r<r_1\),
According to the formula (10) in Theorem 2.2, we have
and
where \(M_k = \Vert W(x_k)^{-1}\Vert (\Vert W(x_k)\Vert +\Vert T(x_k)\Vert )\). Furthermore, since \(0< t < r\), \(r<r_2\) and \(v>u\), we have
\(\square \)
Theorem 3.1
In accordance with the conditions stated in Lemmas 3.1 and 3.2, for all \(x_0 \in {\mathbb {N}}(x_*, r)\) and any positive integers sequences \(\{l_k\}_{k=0}^\infty , \{m_k\}_{k=0}^\infty \), the sequence \(\{x_k\}_{k=0}^\infty \) generated by the Algorithm 3 converges to \(x_*\). Furthermore, it holds that
Proof
Firstly, according to Lemmas 3.1, 3.2 and formula (11), if \(x_k \in {\mathbb {N}}(x_*,r) \subset {\mathbb {N}}_0\), we can obviously obtain
and
Based on the above formulas, we can use mathematical induction to prove that \(\{x_k\}_{k=0}^\infty \subset {\mathbb {N}}(x_*, r)\) converges to \(x_*\). Actually, we have \(\Vert x_0 - x_*\Vert < r\). Moreover, it holds
Therefore, we have \(\Vert x_1 - x_*\Vert < r\). Furthermore, assume that \(x_n \in {\mathbb {N}}(x_*,r)\), then it holds that
which implies that \(x_{n+1} \in {\mathbb {N}}(x_*,r)\) and
Additionally, when \(n \rightarrow \infty \), we get \(x_{n+1} \rightarrow x_*\). \(\square \)
4 Semilocal convergence theorem of MN–CAPRESB method
Assumption 4.1
Let \(x_0\in {\mathbb {C}}^n\) and assume that the formulas below are satisfied.
(THE BOUNDED CONDITION) There exist positive numbers \(\beta , \gamma \) and \(\delta \) such that
(THE LIPSCHITZ CONDITION) There exist numbers \(L_w, L_t \ge 0\) such that for any \(x,z\in {\mathbb {N}}(x_0,r)\subset {\mathbb {N}}_0\),
Lemma 4.1
Subject to Assumption 4.1, for all \(x, z \in {\mathbb {N}}(x_0, r)\), if \(r \in (0, \frac{1}{\gamma L})\), we have \(W(x)^{-1}\) and \(F'(x)^{-1}\) exist. Additionally, we can obtain the following inequalities with \(L:= L_w+L_t:\)
Proof
The proof resembles the Lemma 3 of Zhang et al. (2021); therefore, we omit it here. \(\square \)
Let we denote
The sequences of iteration \(\{t_k\}\) and \(\{s_k\}\) are subject to the formulas below:
Here,
We have the following property about the two sequences.
Lemma 4.2
Suppose that the numbers are subject to
Then the sequences \(\{t_k\}\) and \(\{s_k\}\) of (14) converge to \(t_*\) with \(t_* =\frac{b-\sqrt{b^2-2ac}}{a}\). Furthermore,
Proof
The proof can be seen in Lemma 4.2 and Lemma 4.3 of Wu and Chen (2013). \(\square \)
Theorem 4.1
In accordance with the conditions stated in Lemmas 4.1 and 4.2, define \(r:= \min \{r_1, r_2\}\) and \(u:= \min \{l_*, m_*\}\), where
\(l_* = \liminf _{k\rightarrow \infty } l_k\) and \(m_* = \liminf _{k\rightarrow \infty } m_k\). Moreover, the number u is subject to
where \(\tau \) and \(\theta \) are same in Lemma 3.2. Then the sequence \(\{x_k\}_{k=0}^\infty \) generated by the Algorithm 3 converges to \(x_*\).
Proof
In fact, for any \(x_k \in {\mathbb {N}}(x_*,r)\), analysis resembling that of Lemma 3.2 indicates
and
We use mathematical induction to prove the following formulas:
According to Lemmas 4.1, 4.2 and formula (12), we can obtain
Hence, when \(k=0\), the inequalities (15) are true. Now, assume that when \(n \le k-1\), the inequalities (15) hold. We consider the case \(n=k\). For the first inequality in (15), we can obtain
Since \(x_{k-1},y_{k-1}\in {\mathbb {N}}(x_0,r)\) and due to the inequalities(13) as well as formulas in Lemma 4.1, it holds that
Therefore, it holds that
and then
Also, by the inequality (12), we can obtain
It follows that
and then
Consequently, for any k, the formulas (15) are true. Since \(\{t_k\}\) and \(\{s_k\}\) converge to \(t_*\), \(\{x_k\}\) and \(\{y_k\}\) also converge, to say \(x_*\). Additionally, according to Eq. (7) and
we have
In addition, since the eigenvalues of \(Q_{l_*}({\mathcal {P}}(x_*)^{-1}{\mathcal {A}}(x_*))\) are located in \((-1,1)\) according to Eq. (8), we have \(F(x_*)=0\). \(\square \)
5 Numerical examples
In this part, we display two nonlinear problems to show the robustness of the MN–CAPRESB method. We compare our method to the MN–MHSS (Yang and Wu 2012), MN–PMHSS (Zhong et al. 2015), MN–SSTS (Yu and Wu 2022) and MN–PSBTS (Zhang et al. 2022) methods. In practical implementation, selecting parameters can be a complex headache. When conducting the experiments, for MN–MHSS and MN–PMHSS methods, to avoid this repetitive and tedious process, we adopt the same experimental ideas as Xie et al. (2020) to directly use the selected parameters, which are determined experimentally by minimizing the respective iteration steps and errors in relation to the precise solution. We use the following termination condition in the outer iteration:
Moreover, we use Outer IT and Inner IT to represent the number of outer and inner iterations, respectively, and we denote the elapsed CPU time in seconds as “CPU time”. The experimental results draw a conclusion that MN–CAPRESB method achieves better results than both MN–MHSS and MN–PMHSS methods without the process of selecting a parameter and exhibits strong competitiveness by virtue of its inherent lack of dependence on parameter selection compared to the MN–SSTS and MN–PSBTS methods.
Example 1
(Yang and Wu 2012) We examine the subsequent nonlinear equations:
where \(\Omega =[0,1]\times [0,1]\), the coefficients \(\alpha _1=\beta _1=1\), \(\alpha _2=\beta _2=1\) and \(\rho > 0\).
For discretizing this system, we can utilize a similar methodology in Yang and Wu (2012) and get the following equation:
with
where \(B_N = \text {tridiag}(-1,2,-1)\) and \(n = N^2\).
During the experiments, the initial vector \(x_0=[1,1,\ldots ,1]^T\) and the inner tolerance \(\eta _k\) and \(\tilde{\eta _k}\) of linear systems have the same value \(\eta \).
Tables 1 and 2 present the parameters \(\alpha \) used in experiments for the MN–MHSS and MN–PMHSS methods, respectively. These optimal parameters are determined based on extensive experiments in Xie et al. (2020). Moreover, Tables 3 and 4 show the two parameters used in the experiments for the MN–SSTS and MN–PSBTS methods. It is worth emphasizing that the main advantage of the MN–CAPRESB method is its parameter-free nature, contributing to the effectiveness and convenience of the MN–CAPRESB method in practical implementation.
In Tables 5, 6, 7, 8 and 9, we display the experimental results regarding these five approaches associated with the problem size \(N = 2^5\) with inner tolerance \(\eta = 0.1, 0.2, 0.4\), as well as for \(N = 2^6\) and \(N = 2^7\) with the same inner tolerance value \(\eta = 0.4\), respectively. Additionally, the parameter \(\rho = 1, 10, 200\), respectively. From these tables, we know that the MN–CAPRESB method almost obtains extraordinary results regarding errors, CPU time, and inner and outer iterations compared to the MN–MHSS and MN–PMHSS methods. By comparing the results of different parameter values, we can observe that the MN–CAPRESB method consistently performs well across different values of \(\rho \), \(\eta \) and N, demonstrating lower errors and fewer iterations compared to the MN–MHSS and MN–PMHSS methods. Additionally, MN–CAPRESB demonstrates heightened competitiveness due to its inherent parameter-free nature in comparison with the MN–SSTS and MN–PSBTS methods. Therefore, the MN–CAPRESB method can be considered as an effective method.
Indeed, from Tables 5, 6 and 7, it is evident that the residuals of the MN–CAPRESB method exhibit identical values despite having the same scales N and parameters \(\rho \), but varying inner tolerances \(\eta \). As the inner tolerance increases, the numbers of outer iterations steps for MN–MHSS and MN–PMHSS methods significantly increase, which leads to longer runtime, while the MN–CAPRESB method remains constant. Thus, the MN–CAPRESB method is robust and efficient. On the other hand, as the scale of the problem increases, the MN–CAPRESB method has become increasingly advantageous in terms of time compared to the MN–MHSS and MN–PMHSS methods, which has more obvious advantages when dealing with large-scale problems. From Table 9, when \(N=2^7\), the MN–CAPRESB method almost takes half and one-third of the time compared to the MN–PMHSS and MN–MHSS methods, respectively. While the MN–CAPRESB method may not yield as strong results as the MN–SSTS and MN–PSBTS methods, its inherent lack of parameter selection confers a competitive edge.
Example 2
(Xie et al. 2020) Considering the complex nonlinear Helmholtz system:
with \(\sigma _1\) and \(\sigma _2\) being both real coefficient functions. We can wield finite differences to discretize the problem, which contributes to the following nonlinear equation:
where
and
with
During our experiments, we take values of parameters \(\sigma _1=100\) and \(\sigma _2=1000\). Tables 10 and 11 show the parameters used in experiments. In addition, the initial guess \(x_0 = [0,0,\ldots ,0]^T\), the inner tolerance \( \eta = 0.1, 0.2, 0.4\) as well as the problem size \(N=30, 60, 90\), respectively. Also, we use above five iteration methods to solve this nonlinear problem. We can know that MN–PMHSS method is almost as efficient as MN–MHSS method while MN–CAPRESB method outperforms them upon Tables 12, 13 and 14. Actually, MN–CAPRESB method almost takes half of the time and one-third of inner iteration steps compared to MN–MHSS and MN–PMHSS methods. Moreover, MN–CAPRESB method is competitive with MN–SSTS and MN–PSBTS methods from cpu, outer and inner iterations. Consequently, we yield the conclusion that MN–CAPRESB method outperforms MN–MHSS and MN–PMHSS methods and stands as a viable competitor to MN–SSTS and MN–PSBTS methods.
6 Conclusion
In this paper, we establish a parameter-free method called the MN–CAPRESB method for addressing nonlinear complex equations by harnessing the modified Newton method as the outer iteration and the CAPRESB (Chebyshev accelerated preconditioned square block) method as the inner iteration. The local and semilocal convergence theorems of our approach are proved. Moreover, to validate the superiority and robustness of the MN–CAPRESB method, we conduct some experiments on two kinds of nonlinear examples compared to other existing iteration methods. Unlike some existing methods, the MN–CAPRESB method can avoid selecting one parameter or even two parameters. However, our research is not exhaustive. We may harness other efficient outer iteration method to accelerate our method, which may be a interesting topic to further explore.
Data Availability
Data available on request from the authors
References
Axelsson O (1996) Iterative solution methods. Cambridge University Press, Cambridge
Axelsson O, Neytcheva M, Ahmad B (2014) A comparison of iterative methods to solve complex valued linear algebraic systems. Numer Algorithms 66:811–841
Bai ZZ, Guo XP (2010) On Newton-HSS methods for systems of nonlinear equations with positive-definite Jacobian matrices. J Comput Math 28:235–260
Bai ZZ, Golub GH, Ng MK (2003) Hermitian and skew-Hermitian splitting methods for non-Hermitian positive definite linear systems. SIAM J Matrix Anal Appl 24(3):603–626
Bai ZZ, Benzi M, Chen F (2010) Modified HSS iteration methods for a class of complex symmetric linear systems. Computing 87(3–4):93–111
Bai ZZ, Benzi M, Chen F (2011) On preconditioned MHSS iteration methods for complex symmetric linear systems. Numer Algorithms 56(2):297–317
Bai ZZ, Benzi M, Chen F et al (2013) Preconditioned MHSS iteration methods for a class of block two-by-two linear systems with applications to distributed control problems. IMA J Numer Anal 33(1):343–369
Dai PF, Wu QB, Chen MH (2018) Modified Newton-NSS method for solving systems of nonlinear equations. Numer Algorithms 77:1–21
Darvishi MT, Barati A (2007) A third-order Newton-type method to solve systems of nonlinear equations. Appl Math Comput 187(2):630–635
Dembo RS, Eisenstat SC, Steihaug T (1982) Inexact newton methods. SIAM J Numer Anal 19(2):400–408
Edalatpour V, Hezari D, Khojasteh Salkuyeh D (2015) Accelerated generalized SOR method for a class of complex systems of linear equations. Math Commun 20(1):37–52
Feng YY, Wu QB (2021) MN-PGSOR method for solving nonlinear systems with block two-by-two complex symmetric Jacobian matrices. J Math 2021:1–18
Golub GH, Varga RS (1961) Chebyshev semi-iterative methods, successive overrelaxation iterative methods, and second order Richardson iterative methods. Numer Math 3(1):157–168
Hezari D, Edalatpour V, Salkuyeh DK (2015) Preconditioned GSOR iterative method for a class of complex symmetric system of linear equations. Numer Linear Algebra Appl 22(4):761–776
Hezari D, Salkuyeh DK, Edalatpour V (2016) A new iterative method for solving a class of complex symmetric system of linear equations. Numer Algorithms 73:927–955
Huang ZG (2021) Modified two-step scale-splitting iteration method for solving complex symmetric linear systems. Comput Appl Math 40(4):122
King RF (1973) A family of fourth order methods for nonlinear equations. SIAM J Numer Anal 10(5):876–879
Liang ZZ, Zhang GF (2016) On SSOR iteration method for a class of block two-by-two linear systems. Numer Algorithms 71:655–671
Liang ZZ, Zhang GF (2021) On Chebyshev accelerated iteration methods for two-by-two block linear systems. J Comput Appl Math 391:113449
Ortega JM, Rheinboldt WC (2000) Iterative solution of nonlinear equations in several variables. SIAM, Philadelphia
Rheinboldt WC (1998) Methods for solving systems of nonlinear equations. SIAM, Philadelphia
Salkuyeh DK, Siahkolaei TS (2018) Two-parameter TSCSP method for solving complex symmetric system of linear equations. Calcolo 55:1–22
Salkuyeh DK, Hezari D, Edalatpour V (2015) Generalized successive overrelaxation iterative method for a class of complex symmetric linear system of equations. Int J Comput Math 92(4):802–815
Shirilord A, Dehghan M (2022) Single step iterative method for linear system of equations with complex symmetric positive semi-definite coefficient matrices. Appl Math Comput 426:127111
Wang T, Zheng Q, Lu L (2017) A new iteration method for a class of complex symmetric linear systems. J Comput Appl Math 325:188–197
Wu Q, Chen M (2013) Convergence analysis of modified Newton-HSS method for solving systems of nonlinear equations. Numer Algorithms 64:659–683
Xiao XY, Wang X (2018) A new single-step iteration method for solving complex symmetric linear systems. Numer Algorithms 78:643–660
Xiao Y, Wu Q, Zhang Y (2021) Newton-PGSS and its improvement method for solving nonlinear systems with saddle point Jacobian matrices. J Math 2021:1–18
Xie F, Lin RF, Wu QB (2020) Modified Newton-DSS method for solving a class of systems of nonlinear equations with complex symmetric Jacobian matrices. Numer Algorithms 85:951–975
Yang AL, Wu YJ (2012) Newton-MHSS methods for solving systems of nonlinear equations with complex symmetric Jacobian matrices. Numer Algebra Control Optim 2(4):839–853
Yu X, Wu Q (2022) Modified Newton-SSTS method for solving a class of nonlinear systems with complex symmetric Jacobian matrices. Comput Appl Math 41(6):258
Zhang J, Wang Z, Zhao J (2019) Double-step scale splitting real-valued iteration method for a class of complex symmetric linear systems. Appl Math Comput 353:338–346
Zhang L, Wu QB, Chen MH et al (2021) Two new effective iteration methods for nonlinear systems with complex symmetric Jacobian matrices. Comput Appl Math 40:1–27
Zhang Y, Wu Q, Feng Y et al (2022) Modified Newton-PSBTS method for solving complex nonlinear systems with symmetric Jacobian matrices. Appl Numer Math 182:308–329
Zheng Z, Huang FL, Peng YC (2017) Double-step scale splitting iteration method for a class of complex symmetric linear systems. Appl Math Lett 73:91–97
Zhong HX, Chen GL, Guo XP (2015) On preconditioned modified Newton-MHSS method for systems of nonlinear equations with complex symmetric Jacobian matrices. Numer Algorithms 69(3):553–567
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. 12271479).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest to this work
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, J., Yu, X. & Wu, Q. Modified Newton–CAPRESB method for solving a class of systems of nonlinear equations with complex symmetric Jacobian matrices. Comp. Appl. Math. 43, 219 (2024). https://doi.org/10.1007/s40314-024-02691-w
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40314-024-02691-w
Keywords
- Complex nonlinear system
- Preconditioned square block (PRESB) method
- Chebyshev acceleration
- Modified Newton method
- Convergence analysis