
Abstract
This paper deals with the estimation of the stress-strength reliability parameter \(R = P(Y < X)\), when X and Y are independent random variables, where X and Y have inverted gamma distribution. The maximum likelihood estimator and the approximate maximum likelihood estimator of R are obtained. The Bayesian estimation of the reliability parameter has been also discussed under the assumption of independent gamma prior, squared error loss and Linex error loss functions. Finally, two real data applications are given for showing the flexibility and potentiality of the inverted gamma distribution.
Similar content being viewed by others
Introduction
In statistical literature the gamma distribution has been the subject of considerable interest, study, and applications for many years in different areas such as medicine, engineering, economics and Bayesian analysis. In Bayesian analysis it is used as the conjugate prior for the variance of a normal distribution. Although ample information about gamma distribution is available, little appears to have been done in the literature to study the distribution of the inverse gamma (IG). For example, Gelen and Leemis [7] studied the inverse gamma as a survival distribution. Gelman [8] studid inverse gamma distribution as a prior distributions for variance parameters in hierarchical models. Llera and Beckmann [14] introduced five different algorithms based on method of moments, maximum likelihood and Baysian to estimate the parameters of inverted gamma distribution. Abid and Al-Hassany [1] studied maximum likelihood estimator, moments estimator, percentile estimator, least square estimator, and weighted least square estimator the parameters of inverted gamma distribution. The inverted gamma distribution is a two-parameter family of continuous probability distributions on the positive real line which belongs to the exponential family and always have a upside-down bathtub shaped hazard function.
A random variable X is said to have a gamma distribution with parameters \(\alpha (>0)\) and \(\beta (>0)\), denoted by \(X \sim Ga(\alpha, \beta )\), if its probability density function (pdf) is given by
where \(\Gamma (.)\) is gamma function. If \(Y=1/X\), then the pdf of Y is given by
A random variable Y with pdf (1) is said to have an Inverted gamma distribution with shape parameter \(\alpha (>0)\) and scale parameter \(\beta (>0)\), denoted by \(Y \sim IG(\alpha, \beta )\). The cumulative distribution function (cdf) of Y are given as:
where \(\gamma (., .)\) and I(., .) are lower incomplete gamma function and regularized incomplete gamma function respectively. If \(\alpha =1\) the distribution of Y is named inverted exponential distribution and denoted by \(Y \sim IED(\beta )\). Thus the pdf and cumulative distribution function (cdf) of Y are given as:
Let X and Y are the independent random variables. Then the stress-strength reliability R is calculated as:
The estimation of stress-strength parameter plays an important role in the reliability analysis. For example, if X is the strength of a system which is subjected to stress Y , then the parameter R measures the system performance which is frequently used in the context of mechanical reliability of a system.
It seems that Birnbaum and McCarty [5] was the first paper with R in its title. They obtained a non-parametric upper confidence bound for R. There are several works on the inference procedures for R based on complete and incomplete data from X and Y samples. We refer the readers to Kotz et al. [11] and references therein for some applications of R. This book collects and digests theoretical and practical results on the theory and applications of the stress–strength relationships in industrial and economic systems up to 2003. Kundu and Raqab [12] considered the estimation of the stress-strength parameter R, when X and Y are independent and both are three parameter Weibull distributions.
Among some works about stress-strength reliability based on records, Baklizi [2, 4] studied point and interval estimation of the stress-strength reliability using record data in the one and two parameter exponential distributions. Baklizi [3] considered the likelihood and Bayesian estimation of stress-strength reliability using lower record values from the generalized exponential distribution.
Also in the literature the estimation of R in the case of Weibull, exponential, Inverted exponential, Generalized Lindley, generalized exponential and many other distributions has been obtained. Some of the recent work on the stress-strength model can be seen in [13, 16,17,18]. Recently Singh et al. [19] consider the estimation of the parameter R when X and Y are independent inverted exponential random variables.
In this paper we let \(X \sim IG(\alpha _{1}, \beta _1)\) and \(Y\sim IG(\alpha _{2}, \beta _2)\), also X and Y are the independent random variables. Then, the parameter R is calculated as:
From the above, we observed that parameter R is the function of parameters \(\alpha _{1}\), \(\alpha _{2}\), \(\beta _1\) and \(\beta _2\). Therefore, for maximum likelihood estimate (MLE) of R, we need to obtain the MLEs of \(\alpha _{1}\), \(\alpha _{2}\), \(\beta _1\) and \(\beta _2\). In especial case let \(\alpha _{2}=1\) then \(X \sim IG(\alpha _{1}, \beta _1)\) and \(Y\sim IED(\beta _2)\), also X and Y are the independent random variables. So the parameter R (denoted \(R_{1}\)) is calculated as;
Maximum likelihood estimation for \(\alpha\) and \(\beta\)
Let \(x_1, x_2, \cdots , x_n\) are independent observation from \(IG(\alpha , \beta )\). Then, the log-likelihood function of \(\alpha\), \(\beta\) is given by
Differentiating (7) with respect to \(\alpha\) and \(\beta\) and equating the derivative to zero, we get the following normal equations
where \(\psi (\alpha )=\frac{\partial }{\partial \alpha } \ln \Gamma (\alpha )=\frac{\Gamma ^{\prime }(\alpha )}{\Gamma (\alpha )}\) is digamma function which can be approximate by [9]
From Eq. (9) we have \(\beta = \frac{n\alpha }{\sum _{i=1}^n \frac{1}{x_i}}\). By replacing it in (8), we obtain
By approximating \(\psi (\alpha )\approx \ln (\alpha )-\frac{1}{2\alpha }\) from (10), we obtain
From equation (10) if we consider \(\psi (\alpha ) \approx \ln \alpha -\frac{1}{2 \alpha } - \frac{1}{12 \alpha ^2}\) another approximate of \(\alpha\) is obtained, as follows
Maximum likelihood estimation for R
The main aim of this section is to derived the mle of R and \(R_1\) in (5) and (6).
Now let \(x_1, x_2, \ldots , x_n\) and \(y_1, y_2, \ldots , y_m\) are two independent observations from \(IGa(\alpha _1 , \beta _1)\) and \(IGa(\alpha _2 , \beta _2)\), respectively. Then, the log-likelihood function of \(\alpha _{1}\), \(\alpha _{2}\) , \(\beta _1\) and \(\beta _2\) is given by
Differentiating (12) with respect to \(\alpha _1\), \(\alpha _2\), \(\beta _1\) and \(\beta _2\) get the following normal equations
Similar to previous section the MLE of \(\alpha _1\), \(\alpha _2\), \(\beta _1\) and \(\beta _2\) are given by
Hence, using the invariance properties of MLEs, the MLE of the parameters R and \(R_1\) are given by
and
Bayes estimation
In this section, we have developed the Bayesian estimation procedure for the estimation of parameter R from inverted gamma and inverted exponential distributions assuming independent gamma priors for the unknown model parameters. Let \(X_1, ..., X_n \sim IG(\alpha , \beta _1)\) and \(Y_1, ..., Y_m \sim IG(1, \beta _2)= IED(\beta _2)\), where the two samples are independent. Also let \(\alpha\) is known, \(\beta _1 \sim Ga(a,b)\) and \(\beta _2 \sim Ga(c,d)\) where a, b, c and d are known. Since \(\beta _1\) and \(\beta _2\) are independent, then the joint prior distribution of \(\beta _1\) and \(\beta _2\) is given by
Therefore, the joint posterior distribution of \(\beta _1\) and \(\beta _2\) given data is given by
where \(s_1=\sum _{i=1}^{n} \frac{1}{x_i}\) and \(s_2=\sum _{j=1}^{m}\frac{1}{y_j}\). Therefore, the posterior distribution of \(\beta _1\) and \(\beta _2\) are
Lemma 4.1
Let X and Y are independent random variables where\(X \sim Ga(\alpha _1, \beta _2)\) and \(Y \sim Ga (\alpha _2, \beta _2)\). Then the pdf of \(W=\frac{X}{X+Y}\) is given by
where B(., .) is beta function.
If \(\beta _1=\beta _2=\beta\) then \(W \sim Beta(\alpha _1, \alpha _2)\). Now let W has the pdf in (16), it is easy to prove that the distribution of \(U=W^{\alpha }\) is
According to (15) and (17) the posterior density of R is given by
To obtain the Bayes estimator of R, we consider the squared error loss function (SELF) and Linex loss function (LLF) as follows
where \(\delta\) is loss parameter. Under SELF, the Bayes estimator of R is mean of the posterior distribution of R, which is given in following equation.
Under LLF the Bayes estimator of R is
The analytical solution of the above equations is not possible. Therefore, we may propose the use of any approximation technique to solve such integrals. Here, we suggest the use of Gauss quadrature method of approximation or Lindley approximation.
Applications
In this section we use two real data set to show that the IGa distribution can be a better model than other ones. The first data set shows active repair times (hours) For an airborne communication transceiver (n = 40) which are initially proposed by Jorgensen [10].
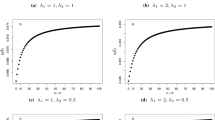
we use this real data set to show that the inverse gamma distribution (IGa) can be a better model than the inverted exponential distribution (IED), generalized inverted exponential distribution (GIED), inverse Rayleigh distribution (IRD) and log-normal distribution (LN) distributions. To compare the models, we used Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC). Table 1 lists the MLEs of the parameters from the fitted models and the values of the AIC and BIC. Based on the values of these statistics, we conclude that the IGa distribution is better than others models. The plots of the empirical and theoretical cumulative distribution function for the five distributions and P–P plot for IGa distribution are given in Fig. 1. This figure again shows that the IGa distribution gives a good fit for these data.

Empirical and theoretical CDFs and P–P plot for example 1
In second example we consider data sets, from two groups of patients suffering from head and neck cancer disease which are initially proposed by [6]. The data are corresponded to the survival times of 51 patients in one group were treated using radiotherapy (X), whereas the 45 patients belonging to other group were treated using a combined radiotherapy and chemotherapy (Y). The data sets given as follows
Recently Singh et al. [19] is modelled this data using inverted exponential distribution(IED), inverse Rayleigh distribution (IRD) and generalized inverted exponential distribution (GIED). Also Makkar et al. [15] is modelled the data using log-normal distribution (LN) and considered Bayesian survival analysis.
In this paper we consider IED, GIED and IGa distributions for above data. Table 2 shows the MLEs of the parameters from the fitted models and the values of the AIC and BIC. Based on the values of these statistics, we conclude that the IGa distribution, sometimes is better than and sometimes is as good as others models. In Fig. 2 the plots of the empirical and theoretical cumulative distribution function for the three distributions and P–P plot for IGa distribution are given. These figures illustrate again that the IGa distribution has a good fit for data. We obtain the MLE estimates of \((\alpha _{i}, \beta _{i}), ~~i=1, 2\) as, (0.761, 44.997) and (1.1373, 85.7317) for data X and Y, respectively. Therefore, the MLE of R and \(R_1\) using (13) and (14) become \(\widehat{R}=0.482\) and \(\widehat{R}_1=0.444\).

Emprical and theoretical CDFs for example 2

P–P plots for data set X (left) and data set Y (right)
According to Table 2 let \(X_1, ..., X_n \sim IG(\alpha , \beta _1)\) and \(Y_1, ..., Y_m \sim IG(1, \beta _2)= IED(\beta _2)\), where the two samples are independent and \(\alpha\) is known. Also let \(\beta _1 \sim Ga(2, 2)\) and \(\beta _2 \sim Ga(2, 2)\), then the Bayes estimates of R using (19) and (20 )become \(\widehat{R}_{B}=0.5544\), \(\widehat{R}_{BL}=0.5550(\delta =0.5)\) and \(\widehat{R}_{BL}=0.5539(\delta =-0.5)\).
References
Abid, S.H., Al-Hassany, S.A.: On the inverted gamma distribution. Int. J. Syst. Sci. Appl. Math. 1(3), 16–22 (2016)
Baklizi, A.: Estimation of \(Pr(Y < X)\) using record values in the one and two parameter exponential distributions. Commun. Stat. Theory Methods 37, 692–698 (2008a)
Baklizi, A.: Likelihood and Bayesian estimation of \(R = P(Y < X)\) using lower record values from the generalized exponential distribution. Comput. Stat. Data Anal. 52, 3468–3473 (2008b)
Baklizi, A.: Interval estimation of the stress-strength reliability in the two-parameter exponential distribution based on records. J. Stat. Comput. Simul. 84, 2670–2679 (2014)
Birnbaum, Z.W., McCarty, B.C.: A distribution-free upper confidence bounds for \(Pr(Y <X)\) based on independent samples of X and Y. Ann. Math. Stat. 29, 558–562 (1958)
Efron, B.: Logistic regression, survival analysis, and the Kaplan–Meier curve. J. Am. Stat. Assoc. 83, 414–425 (1988)
Gelen, A.G., Leemis, L.M.: Computational Probability Applications. Springer International Publishing, Switzerland (2017)
Gelman, A.: Prior distributions for variance parameters in hierarchical models. Bayesian Anal. 1(3), 515–533 (2006)
Gradshteyn, I.S., Ryzhik, I.M.: Table of Integrals, Series and Products. Academic Press, San Diego (2000)
Jorgensen, B.: Statistical Properties of the Generalized Inverse Gaussian Distribution. Springer, New York (1982)
Kotz, S., Lumelskii, Y., Pensky, M.: The Stress–Strength Model and its Generalizations. World Scientic Press, Singapore (2003)
Kundu, D., Raqab, M.Z.: Estimation of \(R = P(Y < X)\) for three-parameter Weibull distribution. Stat Probab Lett 79, 1839–1846 (2009)
Kundu, D., Gupta, R.D.: Estimation of \(R = P[Y < X]\) for Weibull distributions. IEEE Trans Reliab 55, 270–280 (2006)
Llera, A. Beckmann, C. F. (2016). Estimating an Inverse Gamma distribution. Technical report, Radboud University Nijmegen, Donders Institute for Brain Cognition and Behaviour. , arXiv:1605.01019v2
Makkar, P., Srivastava, P.K., Singh, R.S., Upadhyay, S.K.: Bayesian survival analysis of head and neck cancer data using log normal model. Commun. Stat. Theory Methods 43, 392–407 (2014)
Pundir, P.S., Singh, B.P., Maheshwari, S.: On hybrid censored inverted exponential distribution. Int. J. Curr. Res. 6(1), 4539–4544 (2014)
Salehi, M., Ahmadi, J.: Estimation of stress–strength reliability using record ranked set sampling scheme from the exponential distribution. Filomat 29, 1149–1162 (2015)
Singh, S.K., Singh, U., Vishwakarma, P.K., Yadav, A.S.: Bayesian reliability estimation of inverted exponential distribution under progressive type-II censored data. J. Stat. Appl. Prob. 3(3), 1–17 (2014)
Singh, S.K., Singh, U., Singh Yadav, A., Vishwkarma, P.K.: On the estimation of stress strength reliability parameter of inverted exponential distribution. Int. J. Sci. World 3(1), 98–112 (2015). https://doi.org/10.14419/ijsw.v3i1.4329
Acknowledgements
The authors would like to thank the anonymous referees for careful reading and many helpful suggestions.
Author information
Authors and Affiliations
Contributions
AI, KFV and MH contributed to the design and implementation of the research, to the analysis of the result and to the writing of the manuscript.
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Iranmanesh, A., Fathi Vajargah, K. & Hasanzadeh, M. On the estimation of stress strength reliability parameter of inverted gamma distribution. Math Sci 12, 71–77 (2018). https://doi.org/10.1007/s40096-018-0246-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-018-0246-4
Keywords
- Bayes estimator
- Maximum likelihood estimator
- Inverted exponential distribution
- Inverted gamma distribution
- Stress-strength reliability parameter