
Abstract
In this paper, we present a direct computational method to solve Volterra integral equations. The proposed method is a direct method based on approximate functions with the Bernstein Multiscaling polynomials. In this method, using operational matrices, the integral equation turns into a system of equations. Our approach can solve nonlinear integral equations of the first kind and the second kind with piecewise solution. The computed operational matrices in this article are exact and new. The comparison of obtained solutions with the exact solutions shows that this method is acceptable. We also compared our approach with two direct and expansion–iterative methods based on the block-pulse functions. Our method produces a system, which is more economical, and the solutions are more accurate. Moreover, the stability of the proposed method is studied and analyzed by examining the noise effect on the data function. The appropriateness of noisy solutions with the amount of noise approves that the method is stable.
Similar content being viewed by others


Introduction
Most of integral equations of the first kind are ill-posed problems. Many authors paid attention to solve these equations and presented some methods [1–8]. These problems have application in mathematics, physics, and engineering. Recently, using polynomials have been common to solve these equations, see [9–27].
BMSPs are more general forms of BPs. One of the advantages of BMSPs compared to BPs is that they can approximate piecewise functions. In addition, using BMSP basis, we will have two degrees of freedom which increase accuracy of the method. One of these parameters is m, the degree of polynomials, and the other one k, which corresponds to the number of partitions in the interval \( [a,b) \).
In this paper, we review BP properties and preliminary theorems in Subsect. 1 of Sect. “Review of Bernstein polynomials”. In Subsects. “Tranformation matrices” and “Operational matrices”, transformation matrices and operational matrices for BPs are computed. In Sect. “Bernstein Multiscaling polynomials”, BMSPs are defined. Transformational matrices and operational matrices for BMSPs are obtained in Sects. “Transformation matrices” and “BMSPs operational matrices”, respectively. In Sect. “Solution of Volterra integral equation”, by applying obtained matrices and functions approximation, the integral equations are turned into a system of equations. We present some numerical examples to illustrate the accuracy and ability of this method in Sect. “Numerical examples”. In next section, we compare our approach with two direct and expansion–iterative methods based on block-pulse functions. In Sect. “Stability of method”, stability is shown and we end this paper with a short conclusion in Sect. “Conclusion”.
Review of Bernstein polynomials
Preliminaries
Definition 1. Suppose m is a positive integer number, BPs of degree m on the interval \( [a, b] \) are defined as
In addition, \( B_{i,m} (x) = 0 \) if \( i < 0 \) or \( i > m \).
For convenience, we consider \( \left[ {a, b} \right] = \left[ {0, 1} \right] \), namely
We denote \( \Phi_{m} \), an \( m + 1 - {\text{column}}\,{\text{vector}} \), as follows: \( \Phi_{m} (x) = [\phi_{0} (x), \ldots, \phi_{m} (x)]^{T} \), where \( \phi_{i} (x) = B_{i,m} (x), i = 0, \ldots ,m \).
The BPs have many interesting properties [24–30]. However, here, some of them that are useful in our work are stated:
The following theorems are a fundamental tool that justifies the use of polynomials.
Theorem A [31] Suppose \( H = l^{2} ([a,b]) \) is a Hilbert space with the inner product defined by \({\left\langle {f, g } \right\rangle } = \mathop \int \nolimits_{a}^{b} f(t)g(t){\text{d}}t \) , and in addition, \( Y = {\text{Span}}\{ B_{0,m} (x),B_{1,m} (x), \ldots ,B_{m,m} (x)\} \) is the span space by Bernstein’s polynomials of degree m. Let f be an arbitrary element in H. Since Y is a finite dimensional and closed subspace, it is a complete subset of H. Therefore, f has the unique best approximation out of Y, such that \( y_{0} \)
Therefore, there are the unique coefficients \( \alpha_{j} , j = 0,1, \ldots ,m \) , such that
where \( \alpha = [\alpha_{0} \;\alpha_{0} \ldots \alpha_{m} ]^{T} \) can be obtained by
such that \( {\left\langle {f(t),\Phi_{m} (t)} \right\rangle } = \int \limits_{a}^{b} f(t) \Phi_{m} (t)\;{\text{d}}t \).
In above theorem, we denote \( Q = \langle\Phi_{m} (t),\Phi_{m} (t)\rangle \) as dual matrix. Furthermore, it is easy to see
Next theorem indicates that dual matrix is symmetric and invertible.
Theorem B [31] Elements \( y_{1} ,y_{2} , \ldots ,y_{n} \) of a Hilbert space \( H \) constitute a linearly independent set in \( H \) if and only if \( G(y_{1} ,y_{2} , \ldots ,y_{n} ) \ne 0. \)
where \( G(y_{1} ,y_{2} , \ldots ,y_{n} ) \) is the Gram determinant of \( y_{1} ,y_{2} , \ldots ,y_{n} \) defined by
For a two-dimensional function \( k(x,t) \in l^{2} ([0,1] \times [0,1]) \) , it can be similarly expanded with respect to BPs, such as
and \( K \) is the \( (m + 1) \times (m + 1) \) BP coefficient matrix with
Transformation matrices
Transformation matrix is used to change the dimension of the problem. In other words, this matrix can convert \( \Phi_{m} \) to \( \Phi_{n} \) and vice versa.
Suppose m is less than n, \( T_{m}^{n} \) is an \( (m + 1) \times (n + 1) \) matrix, called increasing transformation matrix, that converts \( \Phi_{m} \) to \( \Phi_{n} \). In other words, \( \Phi_{m} = T_{m}^{n} .\Phi_{n} . \)
The increasing transformation matrix can be computed as follows:
It is sufficient to use \( p3 \), k times, where \( k = n - m \).
In addition, decreasing transformation matrix is an \( (n + 1) \times (m + 1) \) matrix, which is shown by \( T_{n}^{m} \), and converts \( \Phi_{n} \) to \( \Phi_{m} \), where n is greater than m. In other words, \( \Phi_{n} = T_{n}^{m} \Phi_{m} . \)
The ith row of decreasing transformation matrix can be calculated as follows:
Operational matrices
Operational matrix is a matrix that works on basis, such as an operator; in other words, if \( \varLambda \) is an operator, an operational matrix is a matrix, such as P, such that \( \varLambda (\Phi )\simeq P \Phi \).
Operational matrix of integration
Lemma 3 Suppose \( \Phi_{m} (x) = [\phi_{0} (x), \ldots ,\phi_{m} (x)]^{T} , \) , then
where M is called operational matrix of integration.
Proof With a simple calculation can be seen
Assume \( 0 \le k \le m, \)
Therefore,
where
It is obvious, \( im = \left[ {\begin{array}{*{20}c} {\begin{array}{*{20}c} {M_{0}^{T} } \\ {M_{1}^{T} } \\ \end{array} } \\ {\begin{array}{*{20}c} \vdots \\ {M_{m}^{T} } \\ \end{array} } \\ \end{array} } \right] \) is an \( (m + 2) \times (m + 1) \) matrix. Accordingly, \( M = im\,T_{m + 1}^{m} \).
Operational matrix of product
Lemma 4 Let \( C \) be an \( (m + 1) \times m + 1 \) matrix, then
where
Proof. Let \( \phi_{i}^{*} (x) = B_{i,2m} (x), {\text{for}} \quad i = 0, \ldots ,2m \).
Using \( p1 \) gives:
Lemma 5 Let \( u \) be an arbitrary \( (m + 1) \) vector, then
where \( \tilde{u} \) is an \( (m + 1) \times (2m + 1) \) matrix with elements
Proof. Property \( p1 \) implies
Now, the ith entry of the above matrix can be rewritten as follows:
Bernstein Multiscaling polynomials
Definition 3. Suppose \( B_{i,m} (x) \) is the ith BPs of degree m on interval \( [0, 1], \) Bernstein Multiscaling polynomials on \( [0, 1) \) define as follows:
where \( k \ge 1 \) is the number of partitions on \( [0,1] \) and \( i = 0, \ldots ,m \), and in addition, \( j = 0, \ldots ,k - 1. \)
Now, every function \( f \in {\mathcal{L}}^{2} (\left[ {0,1} \right)) \) has the unique best approximation with respect to span space by BMSPs as follows:
where \( C^{T} = \left[ {c_{0,0} ,c_{1,0} , \ldots ,c_{m - 1,0} ,c_{m,0} , \ldots ,c_{0,k - 1} ,c_{1,k - 1} , \ldots ,c_{m - 1,k - 1} ,c_{m,k - 1} } \right]. \)
We denote
Equation (4) implies that \( \psi_{i}^{'}{\rm s}\) are disjoint. In other words when
In addition, Eq. (4) and \( p3 \) imply
Lemma 6. Suppose \( \bar{Q} \) is the dual operational matrix of BMSPs, then
where \( \bar{0} \) is an \( (m + 1) \times (m + 1) \) zero matrix, and \( Q \) is the dual operational matrix of BPs.
Proof. With respect to (5) and (6), it is obvious.For any arbitrary function \( f\left( x \right) \in {\mathcal{L} }^{2} \left( {\left[ {0,1} \right)} \right) , \) there is an expansion with respect to BMSPs, such that
where F is a \( k(m + 1) - {\text{vector}} \)
Theorem A indicates
Let \( k(x,t) \in {\mathcal{L}}^{2} (\left[ {0,1} \right) \times \left[ {0,1} \right)) \) be a two-dimensional function. With respect to BMSPs, \( k \) has the following expansion:
where
Transformation matrices
Let \( \Psi_{m} \) and \( \Psi_{n} \) be two different BMSPs and \( m \le n \). There are two matrices, \( \tau_{m }^{n}\,{\text{and }}\tau_{n }^{m}, \) such that \( \Psi_{m} = \tau_{m}^{n} .\Psi_{n }\; {\text{and}}\; \Psi_{n} = \tau_{n}^{m} .\Psi_{m } \). These transformation matrices have dimensions \( k (m + 1) \times k (n + 1) \) and \( k (n + 1) \times k (m + 1) \), respectively:
where \( T_{m}^{n} \) and \( T_{n}^{m} \) are increasing transformation matrix and decreasing transformation matrix, respectively.
BMSP operational matrices
Operational matrices for BMSPs are obtained by BPs operational matrices and results are similar.
Operational matrices of product
Lemma 7. Assume \( A \) is a \( k (m + 1) \times k (m + 1) \) matrix, then
where \( \hat{A} \) is a \( k(2m + 1) - {\text{vector}}. \)
Proof. Let \( C \) is a \( (m + 1) \times (m + 1) \) matrix, Eq. (5) implies
where \( i \ne j. \)
Furthermore, Lemma 4 gives:
where \( \hat{C} \) is a \( (2m + 1) - {\text{vector}}. \)
Now, consider \( A \) as follows:
where \( A_{i,j} (i,j = 0, \ldots ,k - 1) \) is an \( (m + 1) \times (m + 1) \) matrix.
Equation (10) implies:
Equation (11) gives
Therefore,
where \( \hat{A}_{i,i} \) is a \( 2m + 1 \) vector.
Lemma 8. Suppose \( C \) is an arbitrary \( k(m + 1) \) vector, then,
where \( \tilde{C} \) is a \( k(m + 1) \times k(2m + 1) \) matrix.
Proof. Suppose
where \( C_{i} (i = 0, \ldots ,k - 1) \) is an \( m + 1 - {\text{vector}}. \)
Equation (3) implies:
where \( \tilde{C}_{i} \) is an \( (m + 1) \times (2m + 1) \) matrix.
Now
Equation (12) gives:
Operational matrix of integration
Lemma 7. Assume \( {\mathcal{M} } \) be the operational matrix of integration, then
Proof Lemma 1 implies:
For \( i = 1, \ldots ,k - 2 \), Eq. (1) gives:
and
Consequently,
where \( \bar{1} \) is an \( (m + 1) \times (m + 1) \) matrix that all entries are one.
Solution of Volterra integral equation
In this section, we are going to convert an integral equation to a system.
Linear Volterra integral equation of the first kind
Consider the following Volterra integral equation of the first kind:
where f and k are known, but \( u \) is not. Moreover, \( k(x, t) \in l^{2} ([0, 1) \times [0, 1)) \) and \( f (t) \in l^{2} ([0, 1)). \)
Approximating functions \( f, \,u, \) and k with respect to BMSPs gives:
where the vectors \( F, U \), and matrix K are BMSP coefficients of \( f (x), u(t), \) and \( k(x, t) \), respectively.
Now, replacing (15) into (14) gives:
Using (12) follows:
Using operational matrix of integration \( { \mathcal{M}} ,\) in Eq. (16) gives
Let \( U^{*} = K\tilde{U}M\tau_{2m}^{m}, \) where \( U^{*} \) is a \( k(m + 1) \times k(m + 1). \)
Equation (17) changes to:
Using decreasing transformation matrix \( \tau_{2m}^{m} \), gives the final system:
where \( \overline{U}^{T} = \hat{{U^{*} }}^{T} \tau_{2m}^{m} . \)
Nonlinear Volterra integral equation of the first kind
Consider the following nonlinear Volterra integral equation:
where W is an unknown \( k(m + 1) \) vector. Following the same procedure, the final system is as follows:
Finally, \( u(x) = g^{ - 1} (w(x)) \) is the desire solution.
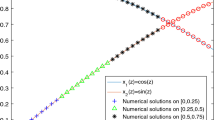
One advantage of this method is solving linear or nonlinear Volterra integral equation of the second kind with piecewise functions. In these equations, solution, kernel, or data function can be piecewise. It is essential k, the number of partitions, be chosen, such that discontinuity points lie on boundary point of partitions.
Linear Volterra integral equation of the second kind
Consider linear Volterra integral equations as the following form:
Substituting (15) into (22) and a process similar to the previous state final linear system is
Nonlinear Volterra integral equation of the second kind
Consider the following nonlinear Volterra equation of the second kind:
where g(x) is one to one on \( [0,1] \).
Let \( w(t) = g(u(t)) \), substituting (23) gives
Now, substituting (15) and (20) into (24) implies:
Numerical examples
Now, we test our method on some numerical examples; in every example, we use a table to show approximations, exact solution, and absolute errors in some points.
Example 1
Suppose \( u(x) = e^{ - x} \) be the exact solution of the following Volterra integral equation of the first kind:
Table 1 shows results of Example 1.
Example 2
Consider the following integral equation:
with the exact solution \( u(x) = 2{ \sin }x \).
Table 2 shows approximated solutions, absolute errors, and exact solution in some points.
Example 3
\( x = \mathop \int \limits_{0}^{x} (x - t + 1)e^{ - u(t)} {\text{d}}t \)
Table 3 shows results of Example 3.
Example 4
Consider the following linear integral equation \( u(x) = f(x) + \mathop \int \limits_{0}^{x} (t - x)u(t){\text{d}}t, \) with exact solution:
and the nonsmooth data function:
Results of Example 4 are presented in Table 4.
Example 5
Assume \( u(x) = \left\{ \begin{array}{ll} 1 - x,&\quad 0 < x < 0.5, \\ \sqrt {x}, &\quad 0.5 < x < 1, \end{array} \right. \) be the exact solution of the following nonlinear Volterra integral equation of the second kind:
where
Table 5 shows results of Example 5.
Comparison
Block-pulse functions are a special case of BMSPs. However, our method is different from the methods, as presented in [32] and [33]. Consider Example 1, in Table 6, the expansion–iterative method and direct method are compared with our method. In Table 6, we presented mean-absolute errors for the expansion–iterative method and direct method and absolute error of BMSPs for two different values of m and k. With respect to dimensions of the final system, our method is more accurate than the expansion–iterative method and direct method.
Consider Example 2, Table 7 shows a comparison between BMSPs method and the expansion–iterative method and direct method with block-pulse functions. Mean-absolute errors for methods are presented in Table 7.
Stability of method
To demonstrate the stability of the method, we review effect of noise on data function. In other words, we replace \( f(x) \) by \( \left( {1 + \varepsilon p} \right)f(x) \) into integral equation. Where p is a real random number between −1 and 1, and \( \varepsilon \) is percent of noise. Now, we want to show that our method is stable and noise is proportional to the variations of solutions.
Example 6
Consider the following Volterra integral equation of first kind:
with exact solution \( u(x) = x^{2} . \)
Table 8 shows approximated solution, noisy solutions, and exact solution.
Conclusion
BMSPs that we use to solve Volterra integral equations have acceptable accuracy. Operational matrices, which we have computed, are exact. These exact matrices lead to fewer errors in our computations. In addition, BMSPs can solve piecewise Volterra integral equations of the second kind. Effect of noise on data function shows that our method is reliable and ill-posedness does not occur. This method with respect to complexity of computations and desirable accuracy is recommended. Furthermore, this method can be used to solve optimal control equations, differential equations, and systems of integral or differential equations.
References
Delves, L.M., Walsh, J.: Numerical solution of integral equations. Clarendon Press, Oxford (1974)
Delves, L.M., Mohamed, J.L.: Computational methods for integral equations. Cambridge University Press, Cambridge (1985)
Golberg, M.A.: Numerical solution of integral equations. Plenum Press, Berlin (1990)
Atkinson, K.E.: The numerical solution of integral equations of the second kind. Cambridge University Press, Cambridge (1997)
Collins, P.J.: Differential and integral equations. Oxford University Press, Oxford (2006)
Rahman, M.: Integral equations and their applications. WIT Press, Southampton (2007)
Wazwaz, A.: Linear and nonlinear integral equations methods and applications. Higher Education Press, Beijing (2011)
Chakrabarti, A., Martha, S.C.: Methods of solution of singular integral equations. Math. Sci. 6, 15 (2012)
Rashidinia, J., Najafi, E., Arzhang, A.: An iterative scheme for numerical solution of Volterra integral equations using collocation method and Chebyshev polynomials. Math. Sci. 6, 60 (2012)
Maleknejad, K., Hashemizadeh, E., Ezzati, R.: A new approach to the numerical solution of Volterra integral equations by using Bernstein’s approximation, Commun. Nonlinear Sci. Numer. Simul. 16, 647–655 (2011)
Mandal, B.N., Bhattacharya, S.: Numerical solutions of some classes of integral equations using Bernstein polynomials. Appl. Math. Comput. 190, 1707–1716 (2007)
Shahsavaran, A.: Numerical approach to solve second kind Volterra integral equations of Abel type using Block-Pulse functions and Taylor expansion by collocation method. Appl. Math. Sci. 5, 685–696 (2011)
Bellour, A., Rawashdeh, A.E.: Numerical solution of first kind integral equations by using Taylor polynomials. J. Inequal. Spec. Func. 1, 23–29 (2011)
Wang, W.: A mechanical algorithm for solving the Volterra integral equation. Appl. Math. Comput. 172, 1323–1341 (2006)
Shirin, A., Islam, M.S.: Numerical solutions of Fredholm integral equations using Bernstein polynomials. J. Sci. Res. 2(2), 264–272 (2010)
Sannuti, P.: Analysis and synthesis of dynamic systems via block pulse functions. Proc. Inst. Electr. Eng. 124, 569–571 (1977)
Hwang, C., Shih, Y.P.: Solution of integral equations via Laguerre polynomials. J. Optim. Theory Appl. 45, 101–112 (1985)
Paraskevopoulos, P.N., Sparis, P.D., Mouroutsos, S.G.: The Fourier series operational matrix of integration. Int. J. Syst. Sci. 16, 171–176 (1985)
Tsay, S.C., Lee, T.T.: Solution of the integral equations via Taylor series. Int. J. Control 32, 701–709 (1986)
Paraskevopoulos, P. N.: The operational matrices of integration and differentiation for Fourier sine-cosine and exponential series. IEEE Trans. Autom. Control. 32, 648–651 (1987)
Paraskevopoulos, P.N., Sklavounos, P., Georgiou, G.C.: The operation matrix of integration for Bessel functions. J. Franklin Inst. 327, 329–341 (1990)
Babolian, E., Mokhtari, R., Salmani, M.: Using direct method for solving variational problems via triangular orthogonal functions. Appl. Math. Comput. 191, 206–217 (2007)
Babolian, E., Marzban, H.R., Salmani, M.: Using triangular orthogonal functions for solving Fredholm integral equations of the second kind. Appl. Math. Comput. 201, 452–464 (2008)
Yousefi, S.A., Behroozifar, M.: Operational matrices of Bernstein polynomials and their applications. Int. J. Syst. Sci. 41(6), 709–716 (2010)
Yousefi, S.A., Behroozifar, M., Dehghan, M.: The operational matrices of Bernstein polynomials for solving the parabolic equation subject to specification of the mass. J. Comput. Appl. Math. 235, 5272–5283 (2011)
Maleknejad, K., Basirat, B., Hashemizadeh, E.: A Bernstein operational matrix approach for solving a system of high order linear Volterra-Fredholm integro-differential equations. Math. Comput. Model. 55, 1363–1372 (2012)
Yousefi, S.A., Behroozifar, M., Dehghan, M.: Numerical solution of the nonlinear age-structured population models by using the operational matrices of Bernstein polynomials. Appl. Math. Model. 36, 945–963 (2012)
Joy, K. I.: Bernstein polynomials. On-line Geom. Model. Notes. (2000). http://www.idav.ucdavis.edu/education/CAGDNotes/Bernstein-Polynomials/Bernstein-Polynomials.html. Accessed 28 Nov 2000
Phillips, G.M.: Interpolations and approximation by polynomials. Springer, New York (2003)
Parand, K., Kaviani, S.A.: Application of the exact operational matrices based on the Bernstein polynomials. J. Math. Comput. Sci. 6, 36–59 (2013)
Kreyszig, E.: Introduction functional analysis with applications. Wiley, New Jersey (1978)
Babolian, E., Masouri, Z.: Direct method to solve Volterra integral equation of the first kind using operational matrix with block-pulse functions. J. Comput. Appl. Math. 220, 51–57 (2008)
Masouri, Z., Babolian, E., Varmazyar, S.H.: An expansion iterative method for numerically solving Volterra integral equation of the first kind. Comput. Math Appl. 59, 1491–1499 (2010)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Mohamadi, M., Babolian, E. & Yousefi, S.A. Bernstein Multiscaling polynomials and application by solving Volterra integral equations. Math Sci 11, 27–37 (2017). https://doi.org/10.1007/s40096-016-0201-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40096-016-0201-1