
Abstract
Introduction
The aim of the present analysis was to characterise the absorption, distribution and elimination of semaglutide by means of population pharmacokinetic (PK) models using data from nine clinical pharmacology trials conducted in both healthy subjects and those with type 2 diabetes.
Methods
Data were obtained from trials with subcutaneous and intravenous administration of semaglutide that utilised frequent PK sampling and included a total of 353 subjects with 10,573 concentration values.
Results
Semaglutide PK properties across trials, drug product strengths and populations were well characterised by a two-compartment model with first-order absorption and elimination. For a typical subject with type 2 diabetes, clearance was estimated to be 0.0348 L/h [95% confidence interval (CI) 0.0327–0.0369 L/h], and the central and peripheral volumes were estimated to be 3.59 L (95% CI 3.28–3.90 L) and 4.10 L (95% CI 3.78–4.42 L), respectively (i.e. a total volume of distribution of 7.7 L). Interindividual variation was low (~ 15%) for both clearance and volumes of distribution, with low residual error (< 5%). Clearance and the total volume of distribution were approximately proportional to body weight. Minor differences were identified between healthy subjects and subjects with type 2 diabetes with respect to clearance and absorption rate, and between injection sites with respect to bioavailability.
Conclusions
A novel two-compartment model was developed to provide the general characteristics of semaglutide absorption following subcutaneous administration, and of distribution and elimination across administration routes. Semaglutide PK was shown to be predictable across populations and administration routes and within subjects, and was primarily influenced by body weight.
Funding
Novo Nordisk, Bagsværd, Denmark.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Semaglutide is a receptor agonist of the naturally occurring peptide hormone glucagon-like peptide-1 (GLP-1). As with native GLP-1, semaglutide acts to stimulate insulin secretion and inhibit glucagon release depending on the blood glucose concentration, leading to improved blood glucose levels together with a reduced risk of hypoglycaemia [1, 2]. Semaglutide is approved for the treatment of type 2 diabetes mellitus, using the subcutaneous route of administration. With 94% amino acid sequence homology to native GLP-1, semaglutide has three structural modifications that make it less susceptible to degradation by dipeptidyl peptidase-4 (DPP-4) enzymes and prolong its half-life to approximately 1 week [1, 3]. Semaglutide is thereby appropriate for once-weekly administration.
The prolonged exposure of semaglutide as compared with native GLP-1 is mainly driven by slow systemic elimination and, to a lesser extent, by delayed absorption [4], in line with the observation that more than 99% of the semaglutide is bound to plasma albumin [5]. In a metabolism trial, semaglutide was the primary component circulating in plasma and, prior to excretion, it was metabolised by proteolytic cleavage of the peptide backbone and sequential beta-oxidation of the fatty acid side chain [4]. Semaglutide metabolites are primarily excreted in the urine and faeces [4].
Semaglutide population pharmacokinetics (PK) and exposure in terms of average concentration in the dosing interval have been previously investigated for subcutaneous dosing using phase 3 steady-state data from subjects with type 2 diabetes [6]. Of the covariates investigated, only body weight had a relevant effect on the exposure of semaglutide at either once-weekly maintenance dose of 0.5 or 1.0 mg [6].
In addition to an assessment of semaglutide exposure levels, the aim of the present analysis was to provide additional details of the PK properties of semaglutide in terms of absorption, distribution and elimination and their relationships to covariate factors, in order to develop a novel disposition model that would be generally applicable across different routes of administration. This was achieved by means of population PK models using frequently sampled PK profiles from nine clinical pharmacology trials. Inclusion of data from intravenous administration provided information about the structural two-compartment disposition model, allowing for separate estimation of clearance and bioavailability.
The analysis was applied to identify and validate the use of a one-compartment model previously applied to analyse sparsely sampled phase 3 data [6], and subsequently to investigate the consistency between PK data from phase 1 and phase 3 trials.
Methods
Clinical Data Included in the Analysis
A two-compartment PK model was estimated using data from nine clinical pharmacology trials employing single as well as multiple semaglutide doses and conducted in subjects with type 2 diabetes or obesity, or in healthy volunteers (Table 1). The included trials were those with administration of recombinant semaglutide in which PK samples, assessed via liquid chromatography and tandem mass spectrometry (LC–MS/MS) [3], were available at the time of the analysis. One trial provided data for the intravenous administration of semaglutide and also used different drug product strengths (see further descriptions in the “Methods” section of the Electronic supplementary material, ESM).
In order to compare the current analysis with the analysis conducted using phase 3 data, a one-compartment model was estimated using data from seven of the clinical pharmacology trials (Table 1) which employed multiple doses of the semaglutide drug product used in the phase 3 trials. Data from the two trials with single dose administration were not included in this comparison.
Population Pharmacokinetic Modelling
Datasets containing plasma concentration and covariate data from each trial were converted to a format compatible with the nonlinear mixed-effects modelling (NONMEM) software (ICON Development Solutions, Ellicott City, MD, USA), version 7.1.2. Out of a total of 10,573 concentration values, 43 values (i.e. < 1%) were excluded because the subjects had an inadequate dosing history. Conditional weighted residuals (CWRES) were used as a diagnostic tool to identify outliers, and an additional 24 concentration values (23 in the one-compartment model) were excluded from the final dataset as they were associated with CWRES greater than 6 in order to limit bias from influential data items. The software package R (version 3.2.3, obtained from the R Foundation: http://www.r-project.org/foundation) was used for data file processing, explorative data analysis and to plot figures.
Model Development
Model development was conducted in NONMEM as follows:
-
1.
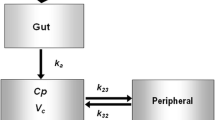
The structural disposition model, which was supported by graphical analysis, in particular of intravenous data, was a two-compartment model with first-order elimination. Different absorption models were investigated, including parallel absorption, but a simpler first-order absorption model for subcutaneous administration was found to adequately describe the data, and no significant improvement was obtained based on other absorption models.
-
2.
An additive residual error model on log-transformed concentration values was assessed to adequately describe the data.
-
3.
Inter-individual variability in the absorption rate (ka), clearance (CL), intercompartmental clearance (Q), central volume (Vc), and peripheral volume (Vp) was explored using a log normal distribution in a model that included covariates with clear effects: drug product strength on the absorption rate constant and body weight as a covariate factor on CL, Vc and Vp. A correlation between the central volume and CL was significant and included in the model. Due to the limited amount of intravenous data, less information was available for individual estimation of Q and for the separation of Vc and Vp. Various implementations for these parameters were investigated and selected based on objective function values; i.e. using individual (eta) values for CL to identify differences across subjects for Q, as well as for Vc and Vp.
-
4.
The covariate effects of sex, race, ethnicity, age, hepatic impairment and glycaemic status were investigated for CL, Vc and ka based on a graphical analysis of individual parameter estimates versus body weight, and glycaemic status was identified as a covariate factor for CL and ka. Similarly, injection site was investigated with respect to F and ka. Covariates with 90% confidence intervals which were within the 80–125% equivalence interval were not considered important.
-
5.
Covariate effects were investigated using a full model approach with inclusion of all investigated covariates in one step (Table 2). The final model included only those covariates that were significant (10% alpha level). To assess the amount of variability explained by covariate factors, a base model was investigated, including only covariates for the effects of drug product strength on the absorption rate constant.
Table 2 Covariates included in the full two-compartment model
Model Description
The full model for subcutaneous administration was a model with first-order absorption, two-compartment disposition and first-order elimination, whereas intravenous data were modelled as a bolus injection into the central compartment. Inter-individual variability was estimated for ka, and CL/Q (with a common factor), and for Vc/Vp (with a common factor).
The covariate models were parameterised as follows for the ith individual:
and the effect of drug product strength on the rate of absorption was described as
Covariate relationships were described as follows:
In the above equations, θ represents an estimated value for a covariate and η represents between-subject variability. The other exponents are indicator variables assigned a value of 1 for the specific covariate values and 0 otherwise. CLref, Qref, Vc,ref, Vp,ref, Fref and ka, ref are parameter values for the reference subject profile, which is a healthy, white, non-Hispanic female aged ≤ 65 years with a body weight of 85 kg, using the abdomen as the injection site and dosed with a 1.34 mg/mL semaglutide drug product. The residual error model was additive for log-transformed observations.
Steady-State Exposure Evaluation for Subcutaneous Semaglutide
A one-compartment model, similar to the one used to evaluate phase 3 data, was investigated using steady-state data from subcutaneous dosing only in clinical pharmacology trials; hence, the fraction absorbed (F) could not be estimated separately in this model. Therefore, the model was parameterised by the apparent clearance (CL/F), volume of distribution (V/F) and the absorption rate constant (ka). The inter-individual variability was estimated for each of these. The residual error model was additive for log-transformed observations.
The one-compartment model contained three covariate relationships: body weight and glycaemic status (healthy, type 2 diabetes) on CL, and body weight on volume of distribution. These were parameterised as for the two-compartment model.
Compliance with Ethics Guidelines
This article is based on previously conducted studies and does not contain any studies with human participants or animals performed by any of the authors.
Results
Population Characteristics
A total of 353 subjects with 10,573 semaglutide concentrations were included in the population PK model analysis. For the comparison to the phase 3 modelling approach, 267 subjects contributed with 8292 semaglutide concentration values. The demographic characteristics for the subjects included in each of the analyses are summarised in Table 3.
Semaglutide Pharmacokinetics
The final population PK model provided an accurate description of the PK time course across the nine clinical pharmacology trials. Figure 1 shows the consistency between the model and data across the eight trials which employed both single and multiple doses of marketed semaglutide with a drug product strength of 1.34 mg/mL. Figure 2 shows that the biphasic PK profile obtained from the two-compartment model is consistent with intravenous data and, furthermore, that the rate of absorption as well as the maximum concentration following subcutaneous doses of different strengths were well captured by the model.

Observed and model-predicted semaglutide pharmacokinetic profiles from eight clinical pharmacology trials. All trials employed semaglutide doses of up to 1.0 mg, except trial 3, which was a single dose (0.5 mg) trial, and trial 4, which used a supratherapeutic dose of 1.5 mg. Data points with error bars are observed geometric means and 95% CIs. Model predictions (lines) are population predictions from the final two-compartment model of semaglutide PK. CI confidence interval, PK pharmacokinetics, SD single dose, SS steady state

Observed and model-predicted subcutaneous and intravenous semaglutide PK profiles over 7 days (a) and 30 days (b). Data are from trial 7 with semaglutide doses of up to 0.5 mg. Data points with error bars are observed geometric means and 95% CIs. Model predictions (lines) are population predictions from the final two-compartment model of semaglutide PK. In b, two values above the lower limit of quantification obtained at day 35 were not included in the figure. CI confidence interval, i.v. intravenously, PK pharmacokinetic(s), s.c subcutaneously
The model-based analysis suggested that drug product strength influences the rate of absorption but not the bioavailability (Table 4), indicating that the total exposure of semaglutide is not affected by the product strength. These model-based results are consistent with the noncompartmental results for trial 7 (see Table S1 in the ESM), in which equivalence was demonstrated for exposure (AUC0–∞) for all pairwise comparisons between the three strengths of semaglutide. For Cmax, the comparison between 1 mg/mL and 3 mg/mL met the equivalence criterion but equivalence was not shown for 1 mg/mL relative to 10 mg/mL or for 3 mg/mL relative to 10 mg/mL, as Cmax increased with increasing strength.
All parameters were successfully estimated (relative standard error ≤ 11%) in the final model using data from the nine clinical trials (Table 4). In accordance with findings based on phase 3 semaglutide data investigating covariate effects on CL/F [6], body weight was found to be the only important covariate with respect to CL and, hence, average semaglutide concentrations under steady-state conditions with 90% CIs outside the equivalence interval. There were also clear relationships between body weight and the Vc and Vp, whereas the ka was independent of body weight (Table 4 and Fig. S1c in the ESM). Less important though statistically significant effects included an effect on semaglutide CL of glycaemic status, with a 12% higher CL (95% CI 9–16%) observed in subjects with type 2 diabetes compared to healthy subjects (Table 4 and Fig. S1a in the ESM). Moreover, ka was reduced in subjects with type 2 diabetes compared to healthy subjects (Table 4 and Supplementary Fig. S1c in the ESM). For a typical subject with type 2 diabetes and a body weight of 85 kg, clearance was estimated to be 0.0348 L/h (95% CI 0.0327–0.0369 L/h) and the total volume of distribution was estimated to be 7.7 L (Vc + Vp; Table 4). A small effect of injection site was found with respect to the bioavailability, which was 12% lower when using the thigh compared with the abdomen (95% CI 0.84–0.92). The effects of other covariates were not relevant as they were found to lie within the 80–125% equivalence interval. No effects of sex, race, ethnicity, age, or hepatic impairment on CL were found, and these covariates were excluded from the final model.
Trial 7, which provided data from both subcutaneous and intravenous administration, allowed the absolute bioavailability for subcutaneous administration of semaglutide to be estimated. Using noncompartmental analysis, the absolute bioavailability after the subcutaneous administration of semaglutide was estimated to be 89% (95% CI 0.83–0.94). This was captured well in the final model, which estimated the bioavailability to be 85% (95% CI 0.80–0.90) (Table 4).
Inclusion of covariates in the final two-compartment model explained 58%, 56% and 24% of the interindividual variance of CL, volume of distribution and ka, respectively.
Model Qualification
Parameter estimates (Table 4) were estimated with a low (≤ 11%) relative standard error in the final model; shrinkage values were all below 10%, supporting the accuracy of the individual parameter estimates.
The standard visual predictive checks indicated that the model was able to reproduce the data used for estimation in terms of both median concentrations and variability between subjects (Fig. S2 in the ESM). In addition, an illustration of variability in a dosing interval was included for the dose-normalised steady-state concentrations from the target semaglutide doses 0.5 and 1.0 mg (Fig. 3a). Subjects at other dose levels and those who did not complete the study were excluded from this analysis. Thus, the figure was limited to include data from the last PK profile in each trial to illustrate the variability at steady-state conditions.

Variability of semaglutide PK under steady-state conditions (a) and model fits to dose-normalised semaglutide concentration–time profiles at steady state for different body weight quantiles (b). For a, points with error bars are observed steady-state PK data (geometric mean and 90% range) for 173 completing subjects at selected time points with PK sampling across trials. Overlaid are 58 simulated replicates of data (n = 10,034) in a dosing interval after the latest treatment dose. The light blue line represents the geometric mean of the observed data and the shaded area represents the 90% prediction interval. The figure includes data from six trials with steady-state PK and subjects treated with 0.5 mg and 1.0 mg semaglutide as well as the model from nine clinical pharmacology trials of semaglutide. For b, data points with error bars are observed geometric means and 95% CIs from seven clinical pharmacology trials with semaglutide at steady state concentrations after weekly dosing of 0.5 or 1.0 mg. Model predictions are population predictions from the final two-compartment model of semaglutide PK. CI confidence interval, PK pharmacokinetic(s)
The dose-normalised time profiles across body weight in 10-kg intervals (Fig. 3b) spanned a similar range to the overall 90% range, illustrating that body weight does explain most of the variability. Furthermore, the close fit of the model to data in each of the 10-kg intervals illustrates that the influence of body weight on the different parameters was adequately described by the model.
The above findings indicate that the two-compartment PK model provided an accurate description of the PK of semaglutide across clinical pharmacology trials, including different populations, administration routes and drug product strengths, and was found suitable for predictive purposes, i.e. for the simulation of semaglutide concentration–time profiles in various populations. Moreover, the low interindividual variation of ~ 15% for both CL and Vc as well as the low residual error (< 5%; Table 4) indicate that the PK of semaglutide is highly predictable.
Estimation of a One-Compartment Model for Steady-State Evaluation of Subcutaneous Data
The population PK model was compared to a one-compartment model similar to the one used in the phase 3 analysis. The two models provided almost identical apparent exposure estimates for individual subjects (Fig. S3a in the ESM). In addition, mean simulated PK profiles during subcutaneous administration were almost identical, with similar exposure levels as well as peak-to-trough fluctuations (Fig. S3b in the ESM). The PK parameter estimates in the one-compartment model used for comparison were similar to those obtained with the two-compartment model (Table S2 in the ESM).
Comparison with the Model Estimated with Phase 3 Data
Parameter values obtained in the present analysis for a reference subject profile were compared to the corresponding parameter values obtained with phase 3 data [6] (Table 5). Due to limitations in the phase 3 data, that analysis applied a fixed value of ka. Although the total volume of distribution was lower in the present analysis than in the phase 3 analysis, profiles from these models were similar (Fig. 4), indicating that the higher volume of distribution in the phase 3 model had a relatively small impact on the overall PK profile. High consistency between the simulated profiles indicate that the PK in the phase 3 trials could be predicted using the two-compartment model that was developed using clinical pharmacology data, supporting the overall predictability of semaglutide PK. Furthermore, the estimated inter-individual variability in clearance (15.2%; Table 4) was consistent with phase 3 data (12.9%) [6].

Simulated PK profiles under steady-state conditions for a reference subject profile based on the final two-compartment model developed from clinical pharmacology data and the one-compartment model developed from phase 3 data
Discussion
The PK of semaglutide were well characterised by a two-compartment model with first-order absorption and elimination, and were shown to be predictable across clinical pharmacology and phase 3 trials and across subjects with low interindividual variation and low residual error. This model provided a joint description of semaglutide PK across clinical pharmacology trials in both healthy subjects and those with type 2 diabetes with frequently sampled PK profiles following subcutaneous and intravenous administration in well-controlled settings.
The total volume of distribution (Vc + Vp) was approximately 8 L, similar to the volume of extracellular water in the body and supporting the idea that semaglutide distributes into plasma and peripheral tissues to the same extent as albumin [7, 8]. The terminal half-life was driven by the disposition parameters rather than the rate of absorption. The population PK model for semaglutide was similar overall to that developed for dulaglutide [9], whereas liraglutide had much faster elimination [10], and exenatide extended-release had nonlinear disposition and a substantially slower absorption [11]. Compared to semaglutide, dulaglutide has approximately 50% greater CL and a 20% lower volume of distribution, as well as approximately threefold slower absorption [9]. The interindividual variability was, however, greater for dulaglutide (40.5% coefficient of variation (CV) for CL) compared to semaglutide (CV for CL was 15.2% in the present analysis and 12.9% in the phase 3 analysis [6]). Similarly, both exenatide extended-release and liraglutide had large variabilities between subjects compared to semaglutide [10, 11].
Based on the present steady-state data, we compared the developed population PK model to a one-compartment PK model similar to the one estimated in the phase 3 analysis [6] with almost identical results. Moreover, we verified that the typical steady-state profiles obtained from phase 3 data [6] were consistent with those predicted based on clinical pharmacology data, and similar estimates for clearance CV% also verified that variability was consistent compared to phase 3 trial results.
In the phase 3 population PK analysis, only body weight had a relevant effect on the exposure of semaglutide, a finding which did not warrant dose adjustment [12]. No effects of sex, age, race, ethnicity, renal function or injection site used on semaglutide exposure were observed [6]. The present analysis confirmed the finding that only body weight was a relevant covariate for exposure. Compared to the phase 3 evaluation, the current analysis provides a more general description of semaglutide PK that is applicable across different administration routes, and informs on covariate relationships not only for exposure, but also for absorption, distribution and elimination. Additional covariate effects were identified for body weight on the Vc and Vp and glycaemic status on CL and the ka. Other investigated covariates (sex, race, ethnicity, age group, hepatic impairment) were not found to be influential and were not included in the final model. The impact of covariates on the PK of semaglutide support previous findings [6, 12] that no adjustment of the dose is needed across population subgroups.
With once-daily liraglutide, another GLP-1 receptor agonist approved for the treatment of type 2 diabetes at doses of up to 1.8 mg, body weight and sex were found to be the most important covariates for exposure which, however, did not influence liraglutide PK to any clinically relevant degree [13]. Similarly, neither age, body weight, sex, race, ethnicity nor injection site influenced once-weekly semaglutide or dulaglutide PK to any clinically relevant extent [6, 9]. For twice-daily exenatide and once-weekly exenatide extended-release, body weight was also found to have a significant relationship with the volume of distribution, and a significant relationship between renal function and elimination was found [11, 14].
The slightly higher CL of semaglutide in subjects with type 2 diabetes compared to healthy subjects has also been seen previously with liraglutide 1.8 mg [10] and with liraglutide for weight management at a higher 3.0 mg dose [15]. The mechanism behind this difference is not known.
The present analysis showed that injection site had a small effect on the bioavailability of semaglutide, which was lower following injection in the thigh compared to abdominal injection. This observation was in accordance with previous findings that the injection site has a minor and not clinically relevant effect on the CL/F of semaglutide [6]. Similarly, the bioavailability of liraglutide was found to be slightly lower after administration in the thigh versus the abdomen [16]. Differences between injection sites are generally considered to be of no clinical relevance across GLP-1 receptor agonists [9, 17]. A limitation of the present analysis is that we cannot exclude the possibility that other demographic factors that we did not evaluate were influential in the target patient population.
Conclusions
In summary, semaglutide PK was shown to be predictable across clinical pharmacology and phase 3 trials, with limited interindividual variability that was primarily influenced by body weight. A novel two-compartment model provided a general characterisation of semaglutide absorption following subcutaneous administration and of distribution and elimination across administration routes. A one-compartment model structure was found to be suitable for conducting covariate analyses of exposure levels based on sparse PK sampling in late-stage trials for subcutaneous semaglutide.
References
Lau J, Bloch P, Schaffer L, Pettersson I, Spetzler J, Kofoed J, et al. Discovery of the once-weekly glucagon-like peptide-1 (GLP-1) analogue semaglutide. J Med Chem. 2015;58:7370–80.
Meloni AR, DeYoung MB, Lowe C, Parkes DG. GLP-1 receptor activated insulin secretion from pancreatic beta-cells: mechanism and glucose dependence. Diabetes Obes Metab. 2013;15:15–27.
Kapitza C, Nosek L, Jensen L, Hartvig H, Jensen CB, Flint A. Semaglutide, a once-weekly human GLP-1 analog, does not reduce the bioavailability of the combined oral contraceptive, ethinylestradiol/levonorgestrel. J Clin Pharmacol. 2015;55:497–504.
Jensen L, Helleberg H, Roffel A, Jaap van Lier J, Bjornsdottir I, Pedersen PJ, et al. Absorption, metabolism and excretion of the GLP-1 analogue semaglutide in humans and nonclinical species. Eur J Pharm Sci. 2017;104:31–41.
Jensen L, Kupcova V, Arold G, Pettersson J, Hjerpsted JB. Pharmacokinetics and tolerability of semaglutide in people with hepatic impairment. Diabetes Obes Metab. 2018;20:998–1005.
Petri KCC, Ingwersen SH, Flint A, Zacho J, Overgaard RV. Semaglutide s.c. once-weekly in type 2 diabetes: a population pharmacokinetic analysis. Diabetes Ther. 2018;9:1533–47.
Peters TJ. All about albumin: biochemistry, genetics, and medical applications. New York: Academic; 1995.
Diao L, Meibohm B. Pharmacokinetics and pharmacokinetic-pharmacodynamic correlations of therapeutic peptides. Clin Pharmacokinet. 2013;52:855–68.
Geiser JS, Heathman MA, Cui X, Martin J, Loghin C, Chien JY, et al. Clinical pharmacokinetics of dulaglutide in patients with type 2 diabetes: analyses of data from clinical trials. Clin Pharmacokinet. 2016;55:625–34.
Watson E, Jonker DM, Jacobsen LV, Ingwersen SH. Population pharmacokinetics of liraglutide, a once-daily human glucagon-like peptide-1 analog, in healthy volunteers and subjects with type 2 diabetes, and comparison to twice-daily exenatide. J Clin Pharmacol. 2010;50:886–94.
Cirincione B, Edwards J, Mager DE. Population pharmacokinetics of an extended-release formulation of exenatide following single- and multiple-dose administration. AAPS J. 2017;19:487–96.
Petri KCC, Ingwersen SH, Flint A, Zacho J, Overgaard RV. Exposure-response analysis for evaluation of semaglutide dose levels in type 2 diabetes. Diabetes Obes Metab. 2018;20:2238–45.
Ingwersen SH, Khurana M, Madabushi R, Watson E, Jonker DM, Le Thi TD, et al. Dosing rationale for liraglutide in type 2 diabetes mellitus: a pharmacometric assessment. J Clin Pharmacol. 2012;52:1815–23.
Cirincione B, Mager DE. Population pharmacokinetics of exenatide. Br J Clin Pharmacol. 2017;83:517–26.
Overgaard RV, Petri KC, Jacobsen LV, Jensen CB. Liraglutide 3.0 mg for weight management: a population pharmacokinetic analysis. Clin Pharmacokinet. 2016;55:1413–22.
Kapitza C, Zdravkovic M, Zijlstra E, Segel S, Heise T, Flint A. Effect of three different injection sites on the pharmacokinetics of the once-daily human GLP-1 analogue liraglutide. J Clin Pharmacol. 2011;51:951–5.
Calara F, Taylor K, Han J, Zabala E, Carr EM, Wintle M, et al. A randomized, open-label, crossover study examining the effect of injection site on bioavailability of exenatide (synthetic exendin-4). Clin Ther. 2005;27:210–5.
Ikushima I, Jensen L, Flint A, Nishida T, Zacho J, Irie S. A randomized trial investigating the pharmacokinetics, pharmacodynamics, and safety of subcutaneous semaglutide once-weekly in healthy male Japanese and Caucasian subjects. Adv Ther. 2018;35:531–44.
Kapitza C, Dahl K, Jacobsen JB, Axelsen MB, Flint A. Effects of semaglutide on beta cell function and glycaemic control in participants with type 2 diabetes: a randomised, double-blind, placebo-controlled trial. Diabetologia. 2017;60:1390–9.
Demmel V, Sandberg-Schaal A, Jacobsen JB, Golor G, Pettersson J, Flint A. No QTc prolongation with semaglutide: a thorough QT study in healthy subjects. Diabetes Ther. 2018;9:1441–56.
Korsatko S, Jensen L, Brunner M, Sach-Friedl S, Tarp MD, Holst AG, et al. Effect of once-weekly semaglutide on the counterregulatory response to hypoglycaemia in subjects with type 2 diabetes: a randomised, placebo-controlled, double-blind, crossover trial. Diabetes Obes Metab. 2018;20:2565–73.
Blundell J, Finlayson G, Axelsen M, Flint A, Gibbons C, Kvist T, et al. Effects of once-weekly semaglutide on appetite, energy intake, control of eating, food preference and body weight in subjects with obesity. Diabetes Obes Metab. 2017;19:1242–51.
Hausner H, Karsbøl JD, Holst AG, Jacobsen JB, Wagner F, Golor G, et al. Effect of semaglutide on the pharmacokinetics of metformin, warfarin, atorvastatin and digoxin in healthy subjects. Clin Pharmacokinet. 2017;56:1391–401.
Acknowledgements
We thank the participants whose data contributed to this study, as well as Niels Rode Kristensen, PhD (Novo Nordisk A/S, Søborg, Denmark) for taking part in the planning of the analysis.
Funding
Funding for the trials included in the analysis, the journal’s article processing charges as well as the trial products was provided by Novo Nordisk, Bagsværd, Denmark. All authors had full access to all of the data in this study and take complete responsibility for the integrity of the data and accuracy of the data analysis.
Medical Writing and Editorial Assistance
Editorial and medical writing services in the preparation of this manuscript were provided by Angela Stocks, PhD, of Larix A/S, Copenhagen, Denmark. Support for these services was funded by Novo Nordisk.
Authorship
All named authors meet the International Committee of Medical Journal Editors (ICMJE) criteria for authorship for this article, take responsibility for the integrity of the work as a whole, and have given their approval for this version to be published.
Authorship Contributions
Philip H. Delff and Rune V. Overgaard planned the analysis with contributions from Kristin C.C. Petri and Steen H. Ingwersen. Philip H. Delff and Rune V. Overgaard were responsible for the data collection and statistical analysis. All authors contributed to the interpretation of the data. All authors were involved in the writing, reviewing and editing of the manuscript, gave final approval and agreed to be accountable for all aspects of the work.
Disclosures
Rune V. Overgaard is employed by and holds stock in Novo Nordisk. Philip H. Delff holds stock in Novo Nordisk. He was employed by Novo Nordisk when the work was carried out. His current affiliation is: Quantitative Clinical Pharmacology, Early Clinical Development, IMED Biotech Unit, AstraZeneca, Boston, USA. Kristin C.C. Petri is employed by and holds stock in Novo Nordisk. Thomas W. Anderson is employed by and holds stock in Novo Nordisk. Anne Flint is employed by and holds stock in Novo Nordisk. Steen H. Ingwersen is employed by and holds stock in Novo Nordisk.
Compliance with Ethics Guidelines
This article is based on previously conducted studies and does not contain any studies with human participants or animals performed by any of the authors.
Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Open Access
This article is distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/), which permits any noncommercial use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Author information
Authors and Affiliations
Corresponding author
Additional information
Enhanced Digital Features
To view enhanced digital features for this article go to https://doi.org/10.6084/m9.figshare.7667777.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Overgaard, R.V., Delff, P.H., Petri, K.C.C. et al. Population Pharmacokinetics of Semaglutide for Type 2 Diabetes. Diabetes Ther 10, 649–662 (2019). https://doi.org/10.1007/s13300-019-0581-y
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13300-019-0581-y