
Abstract
In an attempt to reduce the errors and uncertainties associated with predicting reservoir properties for static modeling, seismic inversion was integrated with artificial neural network for improved porosity and water saturation prediction in the undrilled prospective area of the study field, where hydrocarbon presence had been confirmed. Two supervised neural network techniques (MLFN and PNN) were adopted in the feasibility study performed to predict reservoir properties, using P-impedance volumes generated from model-based inversion process as the major secondary constraint parameter. Results of the feasibility study for predicted porosity with PNN gave a better result than MLFN, when correlated with well porosity, with a correlation coefficient of 0.96 and 0.69, respectively. Validation of the prediction revealed a cross-validation correlation of 0.88 and 0.26, respectively, for both techniques, when a random transfer function derived from a given well is applied on other well locations. Prediction of water saturation using PNN also gave a better result than MLFN with correlation coefficient of 0.97 and 0.57 and cross-validation correlation coefficient of 0.89 and 0.3, respectively. Hence, PNN technique was adopted to predict both reservoir properties in the field. The porosity and water saturation predicted from seismic in the prospective area were 24–30% and 20–30%, respectively. This indicates the presence of good quality hydrocarbon bearing sand within the prospective region of the studied reservoir. As such, the results from the integrated techniques can be relied upon to predict and populate static models with very good representative subsurface reservoir properties for reserves estimation before and after drilling wells in the prospective zone of reservoirs.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Porosity and water saturation are some reservoir properties vital for reservoir static and dynamic modeling during hydrocarbon field development. To build a robust 3D geological reservoir model, precise knowledge of these reservoir properties is essential. The best-known technique to achieve accurate reservoir properties value is to measure them from core plugs in the laboratory (Kareem et al. 2017; Goral et al. 2020), but this technique however has some drawbacks: time consuming, exorbitant cost, and most times, incomplete coverage of the total well depth. Hence, geologists frequently core only a small portion of few wells. To obtain spatial distribution of these properties, statistical approach is being deployed to correlate the reservoir properties mostly obtained from petrophysical evaluation and core measurements at scanty well locations across field (Jensen et al. 2000; Ringrose and Bentley 2016).
These techniques have been demonstrated to be poor in handling some subsurface challenges like complex reservoirs, especially without a reliable control data. According to Moline and Bahr 1995, statistical techniques introduce a lot of uncertainties and errors into our subsurface model as they attempt to interpolate information between well control points and extrapolate away from wells to the undrilled area of a field, without a secondary data to serve as constrain (Grana 2018). These errors and uncertainties are introduced into models in most cases, as geologist depends mainly on Facies Models to constrain such predictions. These models are non-unique and are subjective to the modeler’s experience, non-availability of vital data due to cost and data density. Hence, these models are unreliable.
The introduction of artificial intelligence in Quantitative Seismic Interpretation (QI) studies provides a new dimension in predicting these sparsely distributed data, provided input secondary information with keen relationship to the targeted reservoir properties is available across the field of study. Seismic data are vital for providing information across field, not just fault, fracture and geologic horizons, but also the lateral distribution of reservoir properties across field (Chatterjee et al. 2016; Alvarez et al. 2017). Inversion of seismic data yields rock attributes (P-impedance, S-impedance, etc.) which have strong relationship with these reservoir properties, that has been demonstrated using rock physics models (Avseth et al. 2008). Seismic inversion generally is the process of recovering the subsurface layered rock properties (such as acoustic impedance and reservoir properties) that produced the seismic (Lines and Levin, 1992; Sukmono 2002). Several authors have demonstrated the effectiveness of adopting seismic inversion results for reservoir properties prediction using artificial neural network (Chatterjee et al. 2016; Maurya and Sarkar 2016; Abiodun et al. 2018; Abdulaziz 2019).
The very strong relationship between well logs-derived reservoir properties and elastic rock properties (especially acoustic impedance) presents the motivation of extracting reservoir properties from seismic inverted elastic volumes using the predictive power of artificial neural network (ANN). The ANN is an application of artificial intelligence that emulates the biological neural system information processing patterns during learning and problem-solving process (Chakraborty 2010). Neural network is generally classified into supervised, unsupervised and reinforcement learning methods. The supervised neural networks (NN) are the most preferable NN technique employed by geoscientists for both prediction and correlation problems during field development (Li 1994; Leite and Vidal 2011; Mokhtari et al. 2011; Aliouane et al. 2012; Horváth 2014; Odesanya et al. 2016; Said et al. 2018; Alabi and Enikanselu 2019; Zahmatkesh et al. 2018).
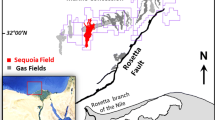
The present study applies the model-based inversion and supervised neural network techniques for porosity and water saturation prediction from seismic, to evaluate an already validated prospect in the undrilled area of a major producing reservoir in the Alose field. (yellow ellipse in Fig. 1b). The studied field is situated in the Central Swamp Depo-belt, Onshore Niger Delta Basin within the Gulf of Guinea (Fig. 1). The field was discovered in 1960 and production commenced in 1965. A total of eighty-four reservoirs have been discovered to date. The estimated reserve in the field is approximately 1602.2 MMstb with an estimated ultimate recovery of 520.9 MMstb. Presently, a total net production of 340.4 MMstb has been recovered from the field. The prospective reservoir is one of the major producing reservoirs in the field, and a good understanding of the reservoir would further help improve upon the field reserved already recorded, at a reduced cost devoid of drilling several appraisal wells.

Map showing the location of Niger Delta Basin (a) The 3D seismic survey geometry with well distributions in the studied field (b) An amplitude map showing prospective area of the field with validated hydrocarbon presence (yellow ellipse)
Material and methods
The data set used for the research include; a 3D SEG normal, full post-stack depth migrated (PSDM) seismic reflectivity data approximately 226 sqkm and eight spatially distributed wells as shown on the field survey base map(Fig. 1). The basic well logs required for this study were available in only six wells; caliper, gamma ray, resistivity, density and velocity logs. The logs were initially processed and conditioned for spurious readings. Two major observations were made on the quality of the logs available; mild to severe wash out and caving were registered on the caliper logs across the well interval, very low range of resistivity values observed across the wells, with the maximum value been less than 300 Ω.m for hydrocarbon bearing sands. These greatly imparted the values of porosity (density porosity) and water saturation estimated from well logs. Hence, the porosity values are unusually high, resulting in very low water saturation values in some cases especially for hydrocarbon bearing sands. These ultimately affected the estimated result from seismic since the prediction process depends on the well-derived reservoir properties. Since the effectiveness of the process is largely dependent on the quality of correlation coefficient obtained between well porosity and the porosity predicted from seismic, the well logs were passed ok to achieve the research objectives. The washout was observed to be extremely severe in two wells (Well 1 and 61) across the entire depth interval. Due to the limited number of wells available for this study, these wells were still included in the pre-inversion feasibility analysis to determine if they would be excluded in the inversion and neural network training process. However, further quality check was conducted to improve upon the quality of all available well logs. These include; median filtering, depth matching and de-spiking.
Model-based inversion and supervised neural network techniques were integrated to predict porosity and water saturation, in the prospective undrilled area of the Alose field using information from the available wells in the adjacent structure; the exploited zone with well penetrations. The choice of model-based inversion was because aside generating acoustic impedance (AI) model, which is the main secondary constrained parameter employed in this work, it also outputs a low velocity model derived from well data and several other seismic attribute that are vital for effective neural network training process. The low velocity model accounts for the low frequency band between 0 and 15 Hz, which are absent from the seismic data due to energy loss during acquisition (Fig. 2b). Thus, the model serves as an additional secondary data that helps to further constrain and improve upon the quality of inversion process and the neural network training and prediction results.

(a) Synthetic correlation, relative error and P-impedance error for the six wells available for the inversion process (b) Comparison of amplitude spectrum of wavelet extracted from the seismic data (light blue shade) and that extracted from the low frequency model (dark blue shade) for model-based inversion process
Inversion analysis was performed to compare the AI results from seismic at well location with the well-derived AI log for the six selected wells with the required acoustic logs. This was necessary to establish the suitability of the wells logs for both the model-based inversion and neural network training process. (Fig. 2a).
Very low correlation coefficient and high AI prediction error were recorded in well 61 and 1. These observed errors are the result of the poor quality of some well logs earlier reported, which would introduce a lot of errors and uncertainties in both the inversion and neural network training process. Hence, they were both excluded from the inversion and training processes. The observed errors in both wells were specifically as a result of the spurious readings associated with the very poor quality of the density logs. This was observed from the erratic behavior of the caliper logs at several depths intervals. This could be an indication of the possible presence of severe wash out zones all through the wells that altered the measured density of the formations.
The very robust relationship that exists between well logs-derived reservoir properties and AI lead to the justification of estimating reservoir properties from inversion result using artificial neural network (ANN). Artificial neural network (ANN) is a subdivision of artificial intelligence that wholly mimics the way human biological nervous systems solves problems. It is designed in such a way that it is composed of a large number of interconnected elements (neurons) working in parallel to resolve specific problems (Chakraborty 2010). Feed-forward networks are one of the frequently used neural network technique for prediction and correlation of properties in geological processes. In feed-forward networks, the neurons are structured in different layers. Each of the neurons in one layer can receive one input only from units in the preceding layers. The presence of one or more hidden layers enables the network to extract higher order statistics. Two supervised neural network techniques adopted in this research; multilayer feed-forward network (MLFN) and probability neural network (PNN) are among the most dependable and commonly used feed-forward neural network technique for reservoir properties prediction (Maurya and Sakar 2016).
Multilayer feed-forward network (MLFN) is also known as multilayer perceptron (MLP). The general architecture of a MLFN consists of neurons, which are ordered into layers. The first layer is the input layer. The second layer is defined by one or more hidden layers with an ideal number of nodes and an output layer. In the typical configuration, every input is linked to each neuron in the hidden layer, and every neuron in the hidden layer is connected to each neuron in the output layer. Each layer contains nodes that are connected and referred to as weights (Maurya et. al. 2020). A weight is associated with every connection and biased with every neuron. The major aim of MLFN training is to fine-tune the connection weights and biases for an effective mapping of the input data to the output or targeted values. The weights are adjusted using nonlinear error minimization over a number of iterations. Hence, the network possesses the ability to solve nonlinear problems but with a final answer that is dependent on the initial guess of the weights (Gholami et al. 2014).
The network weight was derived by adopting the error back-propagation algorithm in which errors are back-propagated through the network, to improve the correlation between the actual output and the training value. The back-propagation uses the expression in Eq. 1, for the desired output computation.
where; Y and X are the output and input variable, α and β are the connecting weights, n1 is the input vector size, and n2 is the amount of hidden neurons. α0 and β0j are the bias weights. The sigmoidal transfer function was adopted in this research and is defined in Eq. 2
In this research, to obtain appropriate weights with the MLFN, two equations were employed; the feed-forward and feedback equations. The former is used to compute the error function. In order to minimize the computed error function, the latter is then used next to calculate and define the search directions using the conjugate gradient method (Singha et al. 2014).
The second neural network technique employed; probabilistic neural network (PNN) is an interpolation system which mathematically uses neural network structure for its application. It is also a type of feed-forward neural network technique that calculates weights based on the principle of distance in attribute space. The distance is computed from defined points in space to unknown points. PNN uses one or more independent variables to predict the value of a single-dependent variable (Maurya and Singh 2019). PNN is made up of several subclasses or sub-networks. In general, a parent probability distribution function (PDF) of each class is designed to take into consideration statistical parameters such as mean and variance for its approximation. Using PDF of each class, the PDF of a new set of input data is estimated and Bayes’ rule is then applied to allocate the class with the highest posterior probability to new input data.
With the PNN approach, a new log value can be estimated as using the expression in Eq. 3,4 and 5 (Mahmood et al. 2017; Maurya and Singh 2018).
where; D(x, xi) is the distance between the input point and each of the training points x, σj is the smoothing parameter.
The predicted log value at the mth sample point is given by ym (Eq. 4). As the original value ym from the well log is known at mth sample point, the total validation error can be computed at the mth sample point using following formula.
Although, Liu and Liu, 1998 highlighted the uniqueness of both MLFN and PNN in their application on geological and seismic inversion data. To select the more effective of the two techniques that best suites the complex geology of the study field for prospect evaluation of the undrilled area, both techniques were employed in a feasibility study that employs similar inputs, parameters and structures in the training process.
Both techniques were designed with one hidden layer of sigmoid function containing 30 attributes (neurons) that were derived from the model-based inversion conducted and an output layer comprising only one neuron with pureline function. Multiple layers of neurons with nonlinear transfer functions allow the networks to learn nonlinear relationships between the inputs (well logs and seismic attributes) and output vector (porosity and water saturation logs). An automated selection of weighting function for the attributes was done by assigning an initial guess of 0.5. The weight was further modified through inversion process to reach a minimum error.
The operator length of the network is 3, the pre-whitening adopted during training is 0.15%. The neural network parameters used are; number of iterations is 20, number of nodes in the hidden layer is 30, and number of conjugate iteration is 100. The number of nodes was a function of the number of attributes employed, the selected attributes from the well data and seismic inversion output were those with the closest correlation with the targeted porosity and water saturation. Some of the major inversion results aside the seismic data that served as input into the training process include; the low frequency model, the generated synthetic volume, inverted P-impedance volume, inverted P-wave volume, inverted density volume, etc.
To determine the validity of the training process, test wells were withheld from the training set at intervals. The training process is then repeated as many times as the number of available wells with a different test well withheld each time the result of test conducted at each well location. A validation correlation coefficient is calculated for each well based on its testing results. This technique is referred to as cross-validation. The validation correlation coefficients for each well are a measure of the generalization ability of the feed-forward networks at each well to make prediction with very high accuracy when compared with well data.
Results and discussion
Results of feasibility analysis performed for porosity prediction using both neural network techniques (MLFN and PNN) employed the porosity estimated from the well as the targeted property, and the results of model based inversion as input data. In the feasibility study, the results of cross-correlation included the training data of the wells where reservoir property is to be predicted. The predicted properties from seismic were correlated with the well-derived reservoir properties to test the accuracy of the process, whereas blind testing was done during cross-validation by using weighted transfer function developed form well data of all the wells, excluding data from the specific well location to be blind tested. The blind testing was to demonstrate and validate the applicability of the technique to predict reservoir properties at the undrilled area of the field. From the obtained results, it was observed that the predicted porosity from seismic, when cross-correlated with the well-derived porosity, gave good correlations for both MLFN and PNN for each well (Fig. 3, 6), with an average correlation coefficient of 0.69 and 0.96, respectively (Fig. 4). These predictions from seismic were achieved when the transfer function generated at a specific well was used to predict porosity at the same well location by converting the trace closest to the well path on seismic to porosity log. To demonstrate if the established transfer functions at these well locations can be relied upon to predict same property in other points in the field where there no wells, blind test were conducted by employing transfer functions developed at each well to randomly predict porosity at other well locations. The weighted effect of each transfer function on a given well was relied upon to predict porosity randomly on other wells, which were cross-correlated with the well porosity to test for accuracy and validation.

(a) Well porosity (black curve) and predicted porosity (red curve) from MLFN (b) Well porosity (black curve) and predicted porosity (red curve) from PNN

(a) Correlation between predicted and actual porosity from MLFN (b) Correlation between predicted and actual porosity from PNN
The cross-validation performed with both neural network techniques are demonstration of blind test in locations where the available well logs with estimated reservoir properties were not included in the training process that generated the transfer function used for the predictions in these blind spots. The result represents the level of accuracy expected where predictions are done blindly in areas where there are no well controls; the prospective zone of the reservoir of interest. Cross-validation of porosity prediction performed is presented in Fig. 5. The result reveals the superiority of the PNN technique with a cross-validation correlation coefficient of 0.88 when compared with 0.26 of the MLFN technique. This cross-validation result gave an idea of the quality of result to be expected when both techniques are employed to predict porosity at the undrilled prospective area of the reservoir by converting any AI trace on seismic to porosity log using the weighted established transfer functions.

(a) Random transfer function cross-validation showing well porosity (black curve) and predicted porosity (red curve) from MLFN (b) Random transfer function cross-validation showing well porosity (black curve) and predicted porosity (red curve) from PNN
The summary of each well’s correlation coefficient and cross-validation correlation coefficient is presented in Fig. 6. Well 34 was selected as the reference well since it is the deepest of the available wells, it is closest to the prospective zone and has the best correlation and cross-validation results as observed in the figure.

(a) Summary of correlation coefficient for well predicted versus MLFN predicted porosity (black curve) and cross-validation correlation coefficient across the four wells (red curve) (b) Summary of correlation coefficient for well predicted versus PNN predicted porosity (black curve) and cross-validation correlation coefficient across the four wells (red curve)
Prediction of water saturation was also done from seismic employing both techniques at each well location. The results show that the predicted water saturation using MLFN method gave an average result when the logs estimated from seismic are compared with the predicted logs from each well (Fig. 7a), with low correlation coefficient value as low as 0.45 (Fig. 10a). The average correlation coefficient of all the wells was very low at 0.57 (Fig. 8a). This is unreliably low, considering the fact that the prediction was done using the transfer function generated at the individual well locations. The water saturation prediction obtained employing the PNN technique from seismic produced porosity logs that compare favorably with the well porosity (Fig. 7b), with very high correlation coefficient (Fig. 10b). The average well correlation for the PNN prediction across the well as seen in the cross-plot of Fig. 8b is as high as 0.97. This result is a further indication of the superiority of PNN technique over MFLN method for reservoir properties prediction from seismic as earlier demonstrated during porosity predicting.

(a) Well water saturation (black curve) and predicted water saturation (red curve) from MLFN (b) Well water saturation (black curve) and predicted water saturation (red curve) from PNN

(a) Correlation between predicted and well water saturation from MLFN (b) Correlation between predicted and well water saturation from PNN
Cross-validation was also carried out to further verify the reliability of the water saturation prediction results done with both techniques, which is typical of what is expected for predictions at the prospective area of the studied reservoir (locations away from well control points). From the result in Fig. 9, the PNN gave an excellent result with an average cross-validation correlation coefficient of 0.89 for all wells, compared with the 0.30 (Fig. 9a) obtained from the MLFN technique.

(a) Random transfer function cross-validation showing well water saturation (black curve) and predicted water saturation (red curve) from MLFN (b) Random transfer function cross-validation showing well water saturation (black curve) and predicted water saturation (red curve) from PNN
The summary of each well’s correlation coefficient and cross-validation correlation coefficient is presented in Fig. 10.

(a) Summary of correlation coefficient for well predicted versus MLFN predicted water saturation (black curve) and cross-validation correlation coefficient across the four wells (red curve) (b) Summary of correlation coefficient for well predicted versus PNN predicted water saturation (black curve) and cross-validation correlation coefficient across the four wells (red curve)
The superiority and reliability of PNN techniques over the MLFN method for reservoir properties prediction have been demonstrated in the neural network feasibility analysis for both porosity and water saturation prediction with its higher average well correlation coefficient and the cross-validation correlation coefficient especially. Hence, the PNN technique was adopted for the seismic base prediction of both reservoir properties.
The result for porosity prediction from seismic using the preferred PNN algorithm is presented in Fig. 11b. A cross section line (dip line 11,563) was extracted from the generated porosity volume, with the corresponding well-derived porosity and gamma ray log of the reference well 34 superimposed along the well path on the cross section. From the legend, it was observed that the well-derived porosity matches the predicted porosity from seismic excellently across the well. The high porosity values as observed from the legend coincide with intervals with low gamma ray reading indicating reservoir presence (Agbasi et al. 2018; Das and Chatterjee 2018), at the exploited zone where wells have been drilled and production is ongoing. The high cross-validation correlation coefficient observed within the exploited zone gave confidence to rely on the porosity values recorded and was interpreted away from the well locations toward the prospective zone. The region where the prospective reservoir is situated (enclosed in the black ellipse) revealed porosity value greater than 24%, which suggest the presence of good quality reservoir at that zone.

(a) Map of MLFN predicted porosity on the prospective D2 reservoir (b) Inline 11,563 that shows the fit between predicted and well-derived porosity along the reference well
As we go deeper, it was observed that the porosity value within the sands reduces gradually. This is as a result of the compaction effect on lithology with depth in the Niger Delta Basin due to the weight of the overburden on rocks at a given depth. (Adewole et al. 2016; Austine et al. 2018; Okocha et al. 2020).
Porosity map was extracted from the porosity cube on the interpreted surface of the prospective reservoir (Fig. 11a). It was observed that the porosity value was highest within the vicinity of the drilled well in the exploited zone, which is an indication of the presence of very low acoustic impedance synonymous with the presence of hydrocarbon (Ogbamikhumi et al. 2018; Mavko et al. 2020). Since the implemented transfer function transforms AI into porosity, an observed increase in porosity is interpreted as a subsequent drop in acoustic impedance; very high negative amplitude (Das and Chatterjee 2016) due to the presence of hydrocarbon as observed in the exploited zone on the amplitude map (Fig. 1b). An extension of this observation to the prospective zone of the reservoir shows similar porosity values, with the very high values restricted to a zone close to the bounding fault defined as a region with the highest elevation in the zone, where hydrocarbon is expected to accumulate due to buoyancy effect (Richards et al. 2015), typically for a rollover anticline structure (Fig. 1b). The high porosity value observed within this zone agrees with the presence of a good quality hydrocarbon bearing sand with low AI values and very high negative amplitude (Kumar et al. 2016).
The cross section line (dip line 11,563) extracted from the predicted water saturated cube using the preferred PNN technique is presented in Fig. 12b. The superimposed well-derived water saturation log shows a good match with the predicted result from seismic along the referenced well path. As seen from the superimposed gamma ray log, the intervals with low gamma ray response define the reservoir intervals and are characterized by low water saturation values typical of hydrocarbon presence (Kulyk and Bondarenko 2016). The field is characterized by numerous vertically stacked hydrocarbon bearing reservoirs as observed along the well, with the prospective reservoir being one of the shallowest. The good match observed within the exploited zone along the reference well and the very good correlation and cross-validation coefficient recorded during the feasibility analysis is the justification to depend on the predicted water saturation volume for the characterization of the prospective area of the field. Within the prospective reservoir zone (black ellipse), water saturation values less than 40% were recorded, which is an indication of the possible presence of hydrocarbon. Water situation has a direct relationship with acoustic impedance (Latimer et al. 2000). Hence, any increase in water saturation can be interpreted as the replacement of hydrocarbon with brine in the pore spaces of reservoirs either partially or completely, which will result in a corresponding increase in acoustic impedance (Farfour et al. 2015). That would be expressed as a decrease in negative amplitude on seismic due to the reduction in the volume of hydrocarbon in the reservoir. The water saturation map extracted from the generated volume (Fig. 12a) shows value less than 20% (hydrocarbon saturation greater than 80%) within the exploited structure. Across the bounding fault to the prospective zone, the hydrocarbon saturation observed ranges between 20 and 30% (hydrocarbon saturation between 80 and 70%).

(a) Map of MLFN predicted water saturation on the prospective D2 reservoir (b) Inline 11,563 that shows the fit between predicted and well-derived water saturation along the reference well
Hence, it can be concluded that the prospective zone of the reservoir is marked with the presence of good quality hydrocarbon bearing reservoir. Thus, the reservoir properties predicted using this integrated techniques can be relied upon to populate reservoir static models for a more accurate first pass reserve calculation, which captures the spatial variation in reservoir properties even before wells are drilled, rather than depending on reserves estimated from volumetric method that employs just a single average porosity and water saturation values for its computation. Upon drilling of appraisal wells in the prospective area of a field, an integration of the PNN and model-based inversion techniques is expected to give a better result for the estimated reservoir properties when the transfer functions are developed with wells within the concerned structure. Since the throw across the fault automatically alters the velocity profile in this zone compared with the footwall due to the variation in the thickness of formations across fault (Ogbamikhumi and Aderibigbe 2019). As such, the quality of the result may be affected. Such scenario is expected since the transfer functions developed in the exploited footwall are been employed to predict reservoir properties in the down thrown hanging wall with different velocity profile.
Conclusion
The study presented the application of artificial neural network to predict porosity and water saturation from seismic for the evaluation of an identified prospect in the undrilled area of the Alose field in the onshore Niger Delta Basin. A feasibility analysis was conducted with two supervised feed-forward neural network techniques (multilayer feed-forward and probability neural network techniques) to select the better technique for the prediction process proper. The PNN was selected for the final prediction process since it was demonstrated to be the more superior algorithm, with cross-validation correlation coefficient of 0.88 and 0.89 for porosity and water saturation prediction, compared with results of the MLFN technique, with cross-validation correlation coefficient of 0.26 and 0.30 for porosity and water saturation prediction, respectively.
The predicted result from seismic gave porosity value of 24–30% and water saturation values of 20–30%, respectively, which reveals the presence of good quality hydrocarbon bearing reservoir at the prospective zone of the reservoir. Hence, the integrated technique can be reliably adopted to predict reservoir properties to populate reservoir models for reserve estimation.
References
Abdulaziz AM, Mahdi HA, Sayyouh MH (2019) Prediction of reservoir quality using well logs and seismic attributes analysis with an artificial neural network: a case study from Farrud Reservoir, Al-Ghani Field, Libya. J Appl Geophys 161:239–254
Abiodun OI, Jantan A, Omolara AE, Dada KV, Mohamed NA, Arshad H (2018) State-of-the-art in artificial neural network applications: a survey. Heliyon 4(11):e00938
Adewole EO, Macdonald DIM, Healy D (2016) Estimating density and vertical stress magnitudes using hydrocarbon exploration data in the onshore Northern Niger Delta Basin, Nigeria: implication for overpressure prediction. J Afr Earth Sc 123:294–308
Agbasi OE, Chukwu GU, Igboekwe MU, Etuk EE (2018) Pore fluid and lithology discrimination of a well in the niger delta region using elastic parameters. World News of Nat Sci 17:75–88
Alabi A, Enikanselu PA (2019) Integrating seismic acoustic impedance inversion and attributes for reservoir analysis over ‘DJ’Field, Niger Delta. J Pet Explor Product Technol 9(4):2487–2496
Aliouane L, Ouadfeul S, Boudella A (2012) Well logs data processing using the fractal analysis and neural networks fractal analysis and chaos in geosciences. Intech, IAP, Algeria
Austin OE, Onyekuru SI, Ebuka AO, Abdulrazzaq ZT (2018) Application of model-based inversion technique in a field in the coastal swamp depobelt, Niger delta. Int J Adv Geosci 6(1):122–126
Avseth P, Mukerji T, Mavko G (2008) Quantitative seismic interpretation: applying rock physics tool to reduce interpretation risk. Cambridge University Press, Cambridge
Alvarez P, Alvarez A, MacGregor L, Bolivar F, Keirstead R, Martin T (2017) Reservoir properties prediction integrating controlled-source electromagnetic, prestack seismic, and well-log data using a rock-physics framework: case study in the Hoop Area, Barents Sea, Norway. Interpretation 5(2):SE43–SE60
Bosch M, Campos C, Fernandez E (2009) Seismic inversion using a geostatistical, petrophysical, and acoustic model. Lead Edge 28(6):690–696
Chakraborty RC (2010) Fundamentals of neural networks: ai course lecture notes, -38. Arindam, California
Chatterjee S, Burreson M, Six B, Michel J (2016) Seismically derived porosity prediction for field development- an onshore abu dhabi jurassic carbonate reservoir case study. Society of petroleum engineers conference and exhibition 183116-MS, pp. 1–9
Das B, Chatterjee R (2016) Porosity mapping from inversion of post-stack seismic data. Georesursy 18(4):306–313
Das B, Chatterjee R (2018) Well log data analysis for lithology and fluid identification in Krishna-Godavari Basin India. Arab J Geosci 11(10):231
Farfour M, Yoon WJ, Kim J (2015) Seismic attributes and acoustic impedance inversion in interpretation of complex hydrocarbon reservoirs. J Appl Geophys 114:68–80
Gholami R, Moradzadeh A, Rasouli V, Hanachi J (2014) Shear wave velocity prediction using seismic attributes and well log data. Acta Geophys 62(4):818–848
Grana D (2018) Joint facies and reservoir properties inversion. Geophysics 83(3):M15–M24
Goral J, Andrew M, Olson T, Deo M (2020) Correlative core-to pore-scale imaging of shales. Mar Pet Geol 111:886–904
Horváth J (2014) Depositional facies analysis in clastic sedimentary environments based on neural network clustering and probabilistic extension. Dissertation, University of Szeged
Jensen J, Lake L, Corbett P, Goggin D (2000) Statistics for petroleum engineers and geoscientists Gulf professional publishing, 2nd edn. Elsevier, Amsterdam
Kareem R, Cubillas P, Gluyas J, Bowen L, Hillier S, Greenwell HC (2017) Multi-technique approach to the petrophysical characterization of Berea sandstone core plugs (Cleveland Quarries, USA). J Petrol Sci Eng 149:436–455
Kulyk VV, Bondarenko MS (2016) Identification of gas reservoirs and determination of their parameters by the combination of radioactive logging methods. Geofizicheskiy Zhurnal 38(2):106–119
Kumar R, Das B, Chatterjee R, Sain K (2016) A methodology of porosity estimation from inversion of post-stack seismic data. J Nat Gas Sci Eng 28:356–364
Latimer RB, Davidson R, Van Riel P (2000) An interpreter’s guide to understanding and working with seismic-derived acoustic impedance data. Lead Edge 19(3):242–256
Leite EM, Vidal AC (2011) 3D porosity prediction from seismic inversion and neural networks. Comput Geosci 37:1174–1180
Li EY (1994) Artificial neural networks and their business applications. Inf Manag 27(5):303–313
Li Y (2004) Lithology and partial gas saturation. CSEG National Convention,S054.
Mahmood MF, Shakir U, Abuzar MK, Khan MA, Khattak N, Hussain HS, Tahir AR (2017) Probabilistic neural network approach for porosity prediction in balkassar area: a case study. J Himal Earth Sci 50(1):111–120
Maurya SP, Sakar P (2016) Comparism of post stack seismic inversion method: a case study from blackfoot field, Canada. Int J Sci Eng Res 7(8):43–52
Maurya SP, Singh KH (2019) Predicting porosity by multivariate regression and probabilistic neural network using model-based and coloured inversion as external attributes: a quantitative comparison. J Geol Soc India 93(2):207–212
Maurya SP, Singh NP (2018) Application of LP and ML sparse spike inversion with probabilistic neural network to classify reservoir facies distribution: a case study from the Blackfoot field, Canada. J Appl Geophys 159:511–521
Maurya SP, Singh NP (2020) Singh K H (2020) Seismic inversion methods: a practical approach. Springer Science and Business Media LLC, Springer Nature Switzerland AG
Mavko G, Mukerji T, Dvorkin J (2020) The rock physics handbook. Cambridge University Press, London
Moline GR, Bahr JM (1995) Estimating spatial distributions of heterogeneous subsurface characteristics by regionalized classification of electrofacies. Math Geol 27:3–22
Mokhtari M, Jalalifar H, Alinejad-Rokny H, Afshary P (2011) Prediction of permeability from reservoir main properties using neural network. Sci Res Essays 6(32):6626–6635
Odesanya I, Ogbamikhumi A, Azi OS (2016) Well log analysis for identification using self-organising map(SOM). Int J Res Appl Phys 2(3):21–28
Ogbamikhumi A, Aderibigbe OT (2019) Velocity modelling and depth conversion uncertainty analysis of onshore reservoirs in the Niger Delta basin. J Cameroon Acad Sci 14(3):239–247
Ogbamikhumi A, Imasuen OI, Omoregbe OI (2018) Inversion feasibility study for reservoir characterization of Osi field onshore Niger Delta basin. FUW Trends Sci Technol J 3(2B):972–976
Okocha IA, Mamah LI, Okeugo CG (2020) Abnormal pore pressure prediction using modified eaton model. a case of zeta field, onshore-shelf Niger Delta Basin. Pet Coal 62(1):244–254
Richards FL, Richardson NJ, Bond CE, Cowgill M (2015) Interpretational variability of structural traps: implications for exploration risk and volume uncertainty. Geol Soc Lond Spec Publ 421(1):7–27
Ringrose P, Bentley M (2016) Reservoir model design. Springer, Berlin, Germany
Said W, Mohamed I A, Ali A (2018) Enhancing pre-stack seismic inversion using neural networks for clastic reservoir characterization–simian field, offshore Nile delta, Egypt. AAPG international conference and exhibition, London, England. Article #20413
Singha DK, Chatterjee R, Sen MK, Sain K (2014) Pore pressure prediction in gas-hydrate bearing sediments of Krishna-Godavari basin, India. Mar Geol 357:1–11
Sukmono S (2002) Seismic inversion & AVO analysis for reservoir characterization. Lab. of Reservoir Geophysics, Department of Geophysics Engineering, FIKTM, Institut Teknologi Bandung
Zahmatkesh I, Kadkhodaie A, Soleimani B, Golalzadeh A, Azarpour M (2018) Estimating Vsand and reservoir properties from seismic attributes and acoustic impedance inversion: A case study from the Mansuri oilfield, SW Iran. J Petrol Sci Eng 161:259–274
Acknowledgements
Our sincere gratitude goes to Petroleum Trust Development Fund Nigeria, for awarding us the scholarship to sponsor this research work. We also appreciate Shell Petroleum Development Company Nigeria, for releasing the data set used for this research. Special thanks go to the Center of Excellence in Geosciences and Petroleum Engineering for making their workstations and software available to complete this work.
Funding
This research was funded by Petroleum Trust Development Fund (PTDF), Nigeria.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all the co-authors, the corresponding author states that there is no conflict of interest.
Ethical statement
On behalf of all the co-authors, the corresponding author states that there are no ethical statements contained in the manuscripts.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ogbamikhumi, A., Ebeniro, J.O. Reservoir properties estimation from 3D seismic data in the Alose field using artificial intelligence. J Petrol Explor Prod Technol 11, 1275–1287 (2021). https://doi.org/10.1007/s13202-021-01105-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-021-01105-5