
Abstract
Among the various natural disasters that take place around the world, flood is considered to be the most extensive. There have been several floods in Buzău river basin, and as a result of this, the area has been chosen as the study area. For the purpose of this research, we applied deep learning and machine learning benchmarks in order to prepare flood potential maps at the basin scale. In this regard 12 flood predictors, 205 flood and 205 non-flood locations were used as input data into the following 3 complex models: Deep Learning Neural Network-Harris Hawk Optimization-Index of Entropy (DLNN-HHO-IOE), Multilayer Perceptron-Harris Hawk Optimization-Index of Entropy (MLP-HHO-IOE) and Stacking ensemble-Harris Hawk Optimization-Index of Entropy (Stacking-HHO-IOE). The flood sample was divided into training (70%) and validating (30%) sample, meanwhile the prediction ability of flood conditioning factors was tested through the Correlation-based Feature Selection method. ROC Curve and statistical metrics were involved in the results validation. The modeling process through the stated algorithms showed that the most important flood predictors are represented by: slope (importance ≈ 20%), distance from river (importance ≈ 17.5%), land use (importance ≈ 12%) and TPI (importance ≈ 10%). The importance values were used to compute the flood susceptibility, while Natural Breaks method was used to classify the results. The high and very high flood susceptibility is spread on approximately 35–40% of the study zone. The ROC Curve, in terms of Success, Rate shows that the highest performance was achieved FPIDLNN-HHO-IOE (AUC = 0.97), followed by FPIStacking-HHO-IOE (AUC = 0.966) and FPIMLP-HHO-IOE (AUC = 0.953), while the Prediction Rate indicates the FPIStacking-HHO-IOE as being the most performant model with an AUC of 0.977, followed by FPIDLNN-HHO-IOE (AUC = 0.97) and FPIMLP-HHO-IOE (AUC = 0.924).
Similar content being viewed by others


Introduction
The effects of natural disasters such as floods on the environment and human lives are severe, which impedes the growth of the economy in many regions across the world. There has been an increase in major flood events in recent years, which indicates that the frequency of major floods will continue to rise over the next couple of years (Abdo HG 2020; Tarasova et al. 2023). There is a direct correlation between this fact and the changes in the climate around the world (Qazi et al. 2023; Rizwan et al. 2023). Therefore, there will inevitably come a time when flood events will occur more frequently and with greater severity, which will lead to exponential growth in terms of economic damage as well as loss of human life (Endendijk et al. 2023). There are more than 3000 casualties caused by floods across the globe each year, and their economic losses amount to more than $20 billion (Dai et al. 2023; Lan et al. 2022). By the year 2050, flood damage is expected to increase by five times in Europe, and by the year 2080, it is expected to increase by 17 times (Costache et al. 2020c). There are many countries in Europe that are affected by floods, but Romania is one of the worst affected ones. It has been documented those numerous areas across Romania were affected by floods throughout the course of the 20th and early twenty-first centuries. Examples of the floods that occurred during these times include those that occurred in 1912, 1932, 1969, 1970, 2005, 2006 and 2010 (Costache et al. 2022b). Over a hundred-million-euro worth of material losses are caused by floods in Romania every year. Since Romania became a member of the European Union in 2007, Romania was compelled to align its legislative system with the directives of the European Parliament, such as Directive 2007/60/EC. In accordance with this directive, flood risk management activities are included in the list of activities. Generally speaking, floods have a hard time being prevented, and their devastating effects are often amplified by a wide range of human activities and also by climate changes, which make it harder to prevent flooding (Wei et al. 2023; Kanani-Sadat et al. 2019). Although it is possible to greatly reduce the amount of damage caused by floods through the implementation of certain measures by the responsible authorities, it is also possible to reduce the loss of human life as well. Identifying the areas that have a high risk of flooding is the first step to reducing flood vulnerability, and the key to all measures that are meant to reduce flood vulnerability. An element that can increase the flood vulnerability is the groundwater characteristics (Paneerselvam et al. 2023; Sankar et al. 2023). This issue was approached in several studies during the last years (Balamurugan et al. 2020a; Panneerselvam et al. 2023b). The hydraulic modeling method is one of the most effective means of quantifying the extent of floodplains that are at risk from severe flooding. Through hydraulic modeling, the extent of floodplains is directly related to certain discharge values with various probability of exceeding them. While hydraulic modeling is time-consuming, it is also expensive to obtain the necessary data, like high-resolution Digital Elevation Model data, which is required for the hydraulic modeling (Popescu and Bărbulescu 2023). There has been an increasing number of studies in the last few years focusing on flood susceptibility assessment that have been using state-of-the-art methods that are capable of integrating flood predictors into geographical information systems (Xie et al. 2021; Hategekimana et al. 2018). In addition, it has been possible to quantify the influence certain flood predictors have on the amount of water accumulated at the soil surface. As a result, there are a number of different models that are used in the category of bivariate statistics, including the Certainty Factor, the Statistical Index, Index of Entropy, Weights of Evidence and Frequency Ratio (Costache et al. 2022a). Among the machines learning algorithms are: the Artificial Neural Network, the K-Nearest Neighbor, the Logistic Regression, the Adaptive Neuro-Fuzzy Inference System, the Support Vector Machine and the Decision Tree (Zhang 2024; Li et al. 2023; Arora et al. 2021; Shafizadeh-Moghadam et al. 2018). In the last years, there is also an important increase in the use of Deep Learning techniques like: Convolutional Neural Networks, Recurrent Neural Networks or Deep Learning Neural Networks (Guan et al. 2023; Wang et al. 2020; Bui et al. 2020). An ensemble of two or more stand-alone models combines into a hybrid model, which is sometimes considered to be more advanced, providing much more accurate results when compared to two or more stand-alone models (Costache et al. 2020b). A key component of machine learning and statistical models that are utilized in flood prediction is the use of input data from areas where flood phenomena have already occurred. Although there have been numerous hybrid or ensemble methods applied to determine flood susceptibility (Fenglin et al. 2023; Li and Hong 2023), there is no international consensus on a model or combination of models that gives the best results. For this reason, in order to fill the research gaps, the need is felt for the combined application of the most advanced Deep Learning and optimization techniques in order to carry out case studies for flood susceptibility.
Considering the elements exposed above, the present research work proposes a complex and state-of-the-art methodological workflow to derive the flood susceptibility mapping across a highly affected area from Romania. Thus, the Deep Learning, Multilayer Perceptron and a Stacking ensemble, all three models improved through Harris Hawk Optimization (HHO) technique, will be involved in the procedure of deriving the flood susceptibility maps. The stacking ensemble will be derived by the combination of the following machine learning models: Logistic Regression, Classification and Regression Tree, Naïve Bayes and Support Vector Machine. There were five statistical indicators used for the validation of results, including the ROC Curve, as well as several statistical indices.
Study area
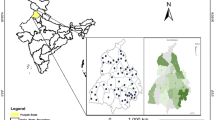
This study area covers 5350 km2 of land in the region of south-east Romania, which is located in the center of the country. A significant relief energy exists in the study area, which is evident at altitudes that range between 1 and 1925 m, reflecting a relatively high range of elevation, which facilitates the propagation of floods from high altitudes to areas at low altitudes (Fig. 1). Moreover, the presence of a slope that exceeds 25° in the upper area of the basin, as well as a flat surface in the lower area of the basin, thereby verifying the possibility of flood propagation and flow accumulation in the upper area of the basin. In accordance with the geological classification of the study area, deposits of internal Cretaceous flysch can be encountered in the mountain region of the area, whereas in the hilly area there is more predominance of Miocene and Sarmato-Pliocene deposits. Clays, gravels, and sands are some of the sedimentary rocks that are common in the plain region. Several geomorphological phenomena, such as gully erosion and landslides, have emerged because of the geological structure of the area and the influence of exogenous factors, which are closely related to flash floods because of the influence of geological factors. There was an average annual precipitation of about 750 mm/year within the study area, but for a 24 h period, the maximum precipitation of 115.4 mm occurred at the meteorological station of Lăcăuți on 12 July 1969 (Minea 2013). From a hydrological perspective, the most important event to remember in 1975 was the increase in discharge of the Buzău river, the main collector in the hydrographic basin, following a heavy rainfall when, at the Măgura hydrometric station, the discharge reached to 2100 m3/s after a heavy rainfall. It should be noted that one of the most important flood events that occurred on all the main tributary rivers occurred in 2005 when the maximum discharge values for the Câlnău and Slănic rivers reached 56.2 m3/s and 54 m3/s, respectively (Costache et al. 2021). Another environmental variable that heavily affects flood potential across the study area is the land use of the area, whether it be forest (40.7%), arable land (30.9%), or built-up areas (4.6%).

Study area location
Data
Flood inventory
It is common knowledge that in order to predict accurately what areas will be affected by a phenomenon in the future, factors that have favored the production of that phenomenon in the past need to be considered in determining the characteristics of the factors that will drive that phenomenon in the future. In order to perform this study, the location of the locations affected by floods within the time period 1990–2020 have been surveyed and a list of the floods affected has been generated, taking into account only those events that have caused damage within the socio-economic segment (Fig. 1). The flood locations over the research zone were quantified to a total of 205 locations. The National Administration of Romanian Waters, General Inspectorate for Emergency Situations, as well as the Archives of the General Inspectorate for Emergency Situations were consulted in order to create the flood inventory in the study area. We generated another set of data that represents 205 non-flood locations as a means of improving the performance of the applied models. We divided the two data sets into two groups according to how they would be used for training (70%) and validating (30%).
Flood conditioning factors
During the process of estimating flood susceptibility, the flood locations will be the dependent variable; as explanatory variables, 12 flood predictors will be distributed spatially according to flood exposure values. Based on a very careful review of the literature, the next conditioning factors were involved in the analysis (Ozturk et al. 2018): altitude, slope, TPI, aspect, convergence index, TWI, hydrological soil groups, land use, plan curvature, lithology, distance from rivers and rainfall. The first seven flood predictors from the above, which represents morphometric indices, were found to be obtained from the processing of Digital Elevation Model (DEM). The DEM was achieved from the dataset represented by world Shuttle Radar Topographic Mission (SRTM) 30 m. It has also been shown that by using the DEM extracted from the SRTM 30 m database, previous studies focusing upon the same research topic have been able to achieve a high-quality solution in their results (Zhao et al. 2022).
It is very important to recognize that the gradient of the slope is one of the most important characteristics of the ground surface that contributes significantly to surface runoff and flow accumulation (Senanayake et al. 2022). This slope factor was obtained by the DEM processing, and its values are located between the range 0–55.9° (Fig. 2a). As a matter of fact, the Hydrological Soil Group (HSG) has an important influence on the velocity of water infiltration over the soil profile and thus the accumulation potential (Liu et al. 2023). Within the study area there is a presence of all four HSGs, with HSG B (55%) covering most of the surface area (Fig. 2b). According to the plan curvature measurement, hillslopes are subdivided into concave, convex, and planar regions based on the plan curvature measurement of 0 (Xu et al. 2022). A range of − 4.032 to 4.48 surface curvature values can be found in our study area (Fig. 2c). Using the convergence index, one can determine the perimeters of valleys with negative values and the interfluvial areas with positive values from a morphometric perspective (Fig. 2d). In terms of environmental factors, rainfall is a key factor in determining the genesis of floods (Lu et al. 2024; Yin et al. 2023; Lin et al. 2023). The average rainfall over a multiannual period ranged from 469 to 716 mm in the study area (Fig. 2e). Defining exposure to floods also involves defining the elevation of the land as another very important factor, as it reveals the different levels of water runoff in high and low areas, and thus the differences in exposure to flooding. There are a range of altitudes in the study area, ranging from 1 to 1925 m (Fig. 2f). Aspect is another factor that can have a significant influence on the occurrence of floods. The Eastern and South–Eastern slopes of the study area cover a total area of 30%, and the Eastern slopes cover a total area of 30%, according to (Costache et al. 2020c) (Fig. 3a). Furthermore, along with having a direct effect on the amount of water that is able to infiltrate into valleys, lithology also has a considerable impact on the shape of river valleys (Du & Wang, 2013). Among the twelve lithological categories in the Buzău river basin, the flysch accounts for the largest proportion (25% of the total lithology) (Fig. 3b). There are many flood predictors which use land use information as one of the most important factors because it influences the velocity of surface runoff by changing the Manning roughness coefficients that are used in the model (Singh and Pandey 2021). Nearly seventy-five percent of the study area is covered by arable lands and forests (Fig. 3c). Two other important morphometric factors are TWI (Fig. 3d) and TPI (Fig. 3e). In the Buzau River catchment, the maximum distance between the river and the highest point of the catchment is 10,648 m. As a result, the areas in the catchment are increasingly at risk of flooding due to their proximity to rivers (Fig. 3f).

Flood conditioning factors (a slope; b hydrological soil group; c plan curvature; d convergence index; e Rainfall; f elevation)

Flood conditioning factors (a aspect; b lithology; c land use; d TWI; e TPI; f distance from rivers)
There is a morphometric variable called Topographic Position Index (TPI) that measures the difference in elevation between the cells of a particular raster with those of its neighbors. The maximum value of the TPI as it pertains to the present research area is equivalent to 153.8, whereas the minimum value is equal to − 122.8 (Fig. 3e). It should be noted that TWI values indicate morphometrically that the flow accumulation is favored above the ground surface in these areas. We found a range of TWI values between 0 and 19.89 in the current study (Fig. 3d).
Methods
Correlation-based feature selection (CFS)
In addition to its fast ability to identify redundant, noisy and irrelevant information, Correlation-based Feature Selection (CFS) has many other important properties (Hall 1999). There can be a high degree of redundancy in a variable when it is correlated with other variables, resulting in a high degree of redundancy. This is due to the fact that the predictors with the highest CFS coefficient values are uncorrelated with each other and have a high degree of correlation to flood locations, which is a result of the fact that they are uncorrelated with other predictors. In order to calculate the CFS, we will use the formula below (Ozcift and Gulten 2011):
where CFS represents the Correlation between the conditioning factors and flood points, k represents the amount of conditioning factors, rcf represents the average value of Correlation among the predictors and zones with torrentiality, and rff is the mean intercorrelation among the flood conditioning factors.
In order to derive the CFS, Weka software was used.
Index of entropy
The entropy of a system is a measure of the degree of disorder and instability, the amount of imbalance and uncertainty within it (Pourghasemi et al. 2012). The Boltzmann principle has been used to describe how the thermodynamic status of a system is determined by the quantity of entropy in the system that demonstrates a one-to-one relationship between the degree of disorder and the quantity of entropy. The Boltzmann principle was improved and the entropy model was introduced to the information theory in Shannon's time. It has been widely accepted that the information entropy method can be used to determine hazard weight indices and to assess natural hazards, such as sand storms, droughts, and debris flows, within an integrated environmental assessment. The degree of entropy of a flood can be defined as the extent to which various factors influence how the flood develops over time (Chen et al. 2015). As a result of a number of important factors, the index system provides an additional degree of entropy. As a result, an objective weight can be determined for the index system by using the entropy value as a basis for the calculation. The next equations will be used to derive the index of entropy coefficients that will be involved as input data in the machine learning models:
where FRij is the Frequency Ratio coefficient for each class or category, Sj is the number of classes and (Pij) is the probability density.
where Hj and Hjmax represent the entropy values, Ij is the information coefficient and Pj is the IOE coefficient for each class.
Deep learning neural network (DLNN)
As a machine learning (ML) algorithm, the deep learning neural network (DLNN) has been shown to be efficient at working with large unstructured data sets of all sizes. As part of the studies which are related to the assessment of susceptibility to natural hazards in social communities, the DLNN is a version of the multilayer perceptron neural network. It has a higher number of hidden neurons, which has made it very popular in studies related to the assessment of susceptibility to natural hazards (Yang et al. 2022; Bui et al. 2019a). There are several layers in DLNN when it comes to the input layers which consist of independent variables, and several layers in the hidden layer which transfer the information from the input layer to the output layer (Zhou et al. 2022). It was decided to use the DLNN model to estimate an individual's susceptibility to floods in the current research. It follows that, according to the input layer in the model, the flood conditioning factors simulate the input data, whereas the flood and non-flood data sets simulates the output data in the output layer (Costache et al. 2020b). It was determined that the following sigmoid estimation function E(Y = 1/x) could be used to classify the input data set into torrential pixels (1) and non-torrential pixels (0). In the output layer, there is one neuron per class i. This information provides an approximation of the equation E(Y = i/x) that can be derived from the output layer (Costache et al. 2020b). After summing all the values up, there will be a value equal to one as a result. The following function has been used for the purpose of the present case study:
where ai is softmax function layer.
The next mathematical relationships are associated to a deep learning neural network having multiple hidden layers (h):
For \(h\) = 1, …., H (hidden layers),
where, \(\varnothing\) and is the activation function.
DLNN was applied using a dedicated script in Python language which was written with the help of Keras and Tensorflow packages.
Multilayer perceptron
In the field of artificial neural networks, Multilayer Perceptron (MLP) is one of the most widely used ANNs and it is a multilayer feed-forward network with one-way error propagation. This algorithm is capable of solving a wide range of problems, such as pattern recognition, time series prediction, and so on (Huang 2023; Li et al. 2019). Besides the fact that a flood is a physically complex process, it is also a nonlinear system that is affected by a number of natural factors as well as man-made elements. It thus follows that the MLP model has an excellent nonlinear mapping capability when compared with other techniques for mapping flood susceptibility, such as deterministic models or general linear statistical methods (Kia et al. 2012).
In order for the MLP model to work, it consists of three layers, or input, hidden, and output, which are all composed of the same types of neurons. A weight value is a calculation that determines how the connections are made between the hidden and input layers, as well as between the hidden and output layers. In order to form an orderly and stable structure, neural networks must be trained and tested with these weight values in order for them to be capable of making decisions. In this paper, we mainly examined the MLP model with a single hidden layer, since the MLP with a single hidden layer is able to approximate any nonlinear system with arbitrary accuracy. Specifically, two neurons will be positioned in the output layer representing flood and non-flood points. Input neurons in the input layer will be equal to flood predictor neurons, but output neurons will be equal to flood predictor neurons. The number of hidden neurons will be established according to the lowest RMSE value which will be obtained after the MLP optimization with the help of Harris Hawk Optimization (HHO) algorithm. The RMSE values can be determined using the next equation:
where, n is the number of the flood sample, ci and ĉi are the observed flood data and the computed flood susceptibility values, respectively.
Logistic regression
The logistic regression method is one of the most commonly used methods for forming multidimensional regression relationships involving a dependent variable and a number of independent variables (Bai et al. 2010). There is an advantage to logistic regression that is that it can be applied to both continuous and discrete data, and may be a combination of both. The variables are not required to have normal distributions either, due to the addition of a link function to the usual linear regression model. As a result of taking the logit function of the dependent variable (a natural logarithm of the odds of the dependent occurring or not) into consideration, the algorithm of logistic regression utilizes maximum likelihood estimation of the dependent variable (Ali et al. 2020). Using logistic regression, you can estimate the probability of an event occurring on a given day in this way. In logistic regressions, the dependent variables are binary, with their two classes being defined as the presence (1) or absence (0) of the phenomenon being analyzed. The logistic regression model makes a spatial prediction of the susceptibility to this phenomenon based on the spatial relationship between the phenomenon and the factors classes/categories that are considered. According to this study, areas affected by flood locations have been assigned a value of 1 and non-flood locations have been assigned a value of 0. It is possible to calculate the generalized linear regression model using the following equation, which is based on the logistic regression method:
where p represents the likelihood (probability) of an event. Z represents a ranging from − ∞ to + ∞, which are defined using the next equation:
where b0 is the intercept of the model, the bi (i = 0, 1, 2, …, n) are the slope coefficients of the logistic regression model, and the xi (i = 0, 1, 2, …, n) are the independent variables.
Classification and regression tree (CART)
Using a recursive partitioning method, Classification and Regression Tree (CART) can be used to predict categorical predictor variables (classification) and continuous dependent variables (regression) by creating a classification tree. Using a CART method, you can present information intuitively and easily to yourself in a visual format that helps you understand what the information means. It is possible to use three types of independent variables to analyze the data (number, binary, and categorical), which makes this technique one of the most powerful and versatile tools available today. For the process of creating trees, each predictor must be selected in such a way that the data errors can be reduced in the process. An entropy value is a measure of how much a particular predictor is preferred over another when compared with other predictors. If a particular predictor's value is missing, the optimal ramification of a tree cannot be determined based on the value of that predictor. Using CART to predict new data, missing values will be handled in a way that is similar to substituting (surrogates) for those values (Breiman et al. 1984). There is an average of the response values within a terminal node when we calculate a predicted value for that node. A sampling rule known as modified towing is part of the CART algorithm, and it is based on comparing the target attribute between two child nodes to determine the optimal sampling rule. Following is the equation that describes how this process is carried out (Costache et al. 2020a):
where: k represents the classes that are targeted, PL(k) and PR(k) are equal to the distribution of probability regarding the target in the left and right child nodes, respectively. The power term represented by u means a user-trollable penalty on splits generating unequal-sized child nodes.
Support vector machine
There are several supervised learning methods based on statistical theory that have been developed in conjunction with structural risk minimization theory. Support vector machine (SVM) is one of them (Ashrafzadeh et al. 2020). There is a decision surface that separates the classes based on the margin between the classes, which is maximized by the decision surface. As a result, the data points closest to the optimal hyperplane are called the support vectors, while the closest points to the ideal hyperplane are called the optimal hyperplane. There are several critical elements of a training set which are the support vectors (Wei et al. 2022). As a rule of thumb however, SVMs are usually used for two-class classification purposes, where one aims to maximize the margin between the two classes; however, they may also be used for one-class classification purposes, where one tries to identify one of the classes and reject the rest. After that, in order to derive the optimal hyper plane for the feature space, a maximization of the margins of the class boundaries is performed. A support vector is the representation of the training points closest to the optimal hyperplane that are extracted from the training data. In order to classify new data, it is required that the decision surface is generated (Fig. 4a and b).

Optimally hyper-plane (a linearly separable; b non-linearly separable)
In the present research work, the support vector machine will contribute to the stacking ensemble along with another 3 models.
Naïve Bayes
Naïve Bayes (NB) is the last model that will be involved in the creation of the stacking ensemble algorithm. Naïve Bayes classifiers are regarded as a classifier based on the Bayes' theorem, which is a highly accurate classification system. The conditional independence assumption is made by the NB classifier when determining the output class (Zhou & Liu, 2022). This is called the assumption that all attributes are totally independent of the output class (Dai et al. 2024; Jiang et al. 2016). Among the many advantages associated with this method, the main one is that it is easy to construct, and complicate iterative parameter estimation schemes are not required as a result of the method (Tien Bui et al. 2012). There is also a high degree of robustness with regards to noise and irrelevant attributes in the NB classifier. In addition to the research field of flood susceptibility mapping, this method has also been applied to the areas of other natural hazards. NB simplifies the learning process significantly due to the assumption that features may be applied to any type of class (Jiang et al. 2016). This is done by using the following relation \(P\left(x,c\right)={\prod }_{i=1}^{n}P\left({x}_{i}|c\right)\), where c is the class while x is the feature vector xi = (x1, x2,….xn). The variables xi typically correspond to the predictors of floods, whereas the variables y referred to as the responses to flood points. It is therefore necessary to use Bayes's theorem in order to find the simplest equation which makes the best prediction in order to locate the class with the highest log-posterior probability (Costache et al. 2022c):
in which, P(ti) represents the value of ti prior probability that can be calculated using the proportion of the observed cases with output class.
Stacking ensemble
One of the most popular methods of heterogeneous ensemble learning is the stacking technique, in which metamodels are used that can combine multiple subclassifies in order to produce a prediction that is more accurate based on the combinations of those subclassifies (Fang et al. 2021). It is necessary to point out that in the present case, there are three stages involved in the creation and application of the stacking ensemble (Fig. 5). They are (Costache et al. 2022c): (i) the training of the base classifier models, CART, CART, and SVM; (ii) the collection of the features in the outputs of the base classifiers for generating one new set of training data; (iii) the training of the meta-classifier model, with the help of the Logistic Regression. It is possible to estimate the calculated errors of all the base classifiers simultaneously using stacking ensembles, using the basic learning steps, and then to reduce these residual errors again using the meta-learning steps.

Stacking ensemble structure
Harris Hawk optimization
Among the swarm-based algorithms, Harris Hawk Optimization was one of the algorithms that was discovered by Heidari et al. (2019). In an effort to satisfy its objectives, the HHO algorithm implements strategies to optimize its goals, which can be compared to the predatory behavior of hawks. It includes two main steps: exploration and exploitation. A Harris Hawk explores its prey from a perch at the feet of another hawk at a random place on the ground. They can then apply a soft or a hard besiegement in order to capture the prey (exploitation step). Accordingly, the HHO algorithm is a procedure inspired by the predatory behavior of hawks and is comprised of two main phases: exploration and exploitation. These two phases are important for optimizing the algorithm's objectives. In the exploration phase a mathematical algorithm determines what it is going to wait for, search for, and discover in order to find the desired hunt. Thus, the iter + 1 (representing the Harris Hawk position) can be determined using the next expression (Cao et al. 2021a; Bui et al. 2019b):
where Xrabit is the position of rabbit, iter represent the iteration, Xrand is the hawk which was selected randomly from the entire population, ri, I = 1, 2, 3, 4, q represent the numbers randomly created in the range [0, 1], while Xm revealed the mean position for all hawks and can be generated as following:
where Xi highlights the place where the hawks are located, while N is the size of hawk.
In the phase of transition between exploration and exploitation, T will be considered as maximum size regarding the repetitions, while E0 will belong the interval (− 1, 1) and is the initial energy consumed along with each step. In this case HHO will calculate the energy associated to the escape of rabbit (E) using the next equation:
Then, if |E|≥ 1, the exploration stage will be started. If not, the solution neighborhood will be intended to be exploited.
In the exploitation phase, a certain parameter “r” is considered as being a measure of the chance that the prey to escape. A value of “r” lower than 0.5 is a successful escape situation. However, if |E|≥ 0.5, then then HHO takes soft surround, while is it lower than 0.5 a hard surround is applied (Bui et al. 2019b). In terms of the attack mechanism, the evasion and pursuit strategies of the prey animals, as well as the hawks, play an important role. The Fig. 6 highlights the different stages of HHO.

Different phases of Harris Hawks optimization
Results validation
ROC curve
Two distinct methods were utilized to evaluate the performance of the applied models, namely the ROC Curve in conjunction with the density of flood pixels within each of the flood maps classes. An ROC curve is a graphic that depicts the specificity of a diagnostic test while the sensitivity of the test is represented by the other axis (Cao et al. 2021b). Based on the total number of predicted non-flood locations, specificity refers to the number of flood locations that have been classified incorrectly as flood locations, whereas sensitivity refers to the number of flood locations that have been classified correctly as flood locations as compared to all flood locations. The next equation will be implied for AUC-ROC Curve values calculation:
where TP (true positive) is the flood points number that were correctly classified as being floods, TN (true negative) represents the non-flood locations that were classified as being non-floods in a correct manner, P represents number flood locations within the entire study area, while N represents all non-flood locations within the study zone.
Statistical metrics
To validate the results obtained through the four applied models, the 2nd approach that has been taken is to calculate several statistical measures to provide insight into the results obtained through the 3 models. It was already described in the previous subsection about the Sensitivity and Specificity of the test. As part of the current study, a mathematical inference was made about the overall accuracy of the flood susceptibility analysis, in order to determine its relative effectiveness (Panneerselvam et al. 2023a). The Kappa Index is an indicator of the degree of agreement between two raters who create two exclusive categories for both floods and non-floods based on their categorization of the total number of flood and non-flood locations. Below are represented the equations for the statistical metrics:
where FP (false positive) and FN (false negative) are the floods and non-floods pixels not correctly classified, k is kappa coefficient, po is the observed flood pixels and pe is the estimated flood pixels.
Figure 7 contains the schematically representation of the methodological steps followed in this research.

Flowchart of the methodological workflow
Results
Feature selection
The results of CFS method revealed that the highest average merit was achieved by slope angle (0.667), followed by Land use (0.632), Plan curvature (0.576), TWI (0.521), Hydrological Soil Group (0.452), Distance to rivers (0.421), TPI (0.394), Elevation (0.377), Lithology (0.332), Convergence index (0.314), Rainfall (0.212) and Aspect (0.182) (Fig. 8).

Average merit of flood predictors calculated using CFS method
Taking into account these results, all flood predictors will be considered for the further analysis.
IOE coefficients
In order to encode the classes and categories of flood predictors the Index of Entropy (Pij) coefficients were calculated. The highest IOE coefficient of 0.7, was achieved by TWI class between 10.68 and 19.89, followed by: slope class between 3.1 and 7° ((Pij) = 0.57), TPI class between − 122.8 and − 34.2 ((Pij) = 0.53), distance from river class between 0 and 50 m ((Pij) = 0.53), land use category of water bodies ((Pij) = 0.5) and plan curvature class between − 0.09 and 0.1 ((Pij) = 0.49) (Table 1). The lowest values of this bivariate statistic were equal to 0 and was obtained by 11 flood predictor class/categories in which the flood points are missing. These IOE coefficients were further inserted as input data in the machine learning models in order to derive the flood susceptibility.
DLNN-IOE-HHO
The HHO algorithm was able to optimize the performances of DLNN model determining the loss and accuracy to reach very good values after the application of 100 epochs. Thus, the minimum loss, in terms of training sample was equal to 0.168 and was reached after 82 epochs, while in terms of validating data sample the minimum loss was 0.155 and was obtained after 91 epochs (Fig. 9a). If we discuss about the accuracy, it can be observed that the maximum value in terms of training sample was obtained after 63 epochs, while for validating dataset the optimum accuracy of 0.97 was achieved after 38 epochs (Fig. 9b). The architecture established based on a batch size of 100, a validation rate of 0.3 and a dropout rate of 0.3, is characterized by a number of 3 hidden layers, each of them with 89 hidden neurons. Obviously, the input layer contains 12 neurons and the output layer a number of 2 neurons (Fig. 9c).

IOE-DLNN-HHO properties (a loss; b accuracy; c architecture)
In the last step, before the flood susceptibility computation for each of the flood predictors the importance was determined as following: Slope (19.35), Distance from river (17.63), Land use (12.1), TPI (10.3), Lithology (9.54), Plan curvature (8.32), Rainfall (6.53), Aspect (6.42), Elevation (5.32), Convergence Index (3.98), HSG (3.55) and TWI (1.96) (Fig. 10).

Importance of flood predictors in terms of flood susceptibility
All the importance values were used in Map Algebra from ArcGIS software in order to create the flood susceptibility map through DLNN-HHO-IOE model. The FPIDLNN-HHO-IOE values were classified into 5 classes using Natural Breaks (Fig. 11a). According to the results provided, the very low flood potential values appear on around 17.44% of the study area, while the low flood potential is present on 19.43% of the entire territory. Medium class of flood potential has a percentage equivalent with 27.56%, while, together, the high and very high flood susceptibility is spread on 35.57% Buzău river basin (Fig. 12).

Flood Potential Index (a FPI DLNN-HHO-IOE; b FPI MLP-HHO-IOE; c FPI Stacking-HHO-IOE)

Weights of FPI classes
MLP-IOE-HHO
By the optimization procedure of MLP model, using HHO algorithm, the final results proved to be very performant This situation is highlighted by the metrics like pseudo-probability (Fig. 13a) which confirm the performance of classification the flood and non-flood points. Also, the Lift chart (Fig. 13b), ROC Curve (Fig. 13c) and Gain chart (Fig. 13d) emphasize the very good quality of flood and non-flood pixels classification. Additionally, very low value of RMSE (0.019) is corresponding with an architecture containing 35 hidden neurons (Fig. 13e). The importance assigned to the flood predictors revealed the next situation: Distance from river (18.3), Slope (17.93), Land use (14.32), TPI (13.24), Lithology (11.23), Rainfall (7.72), Convergence Index (6.04), HSG (5.67), Plan curvature (5.21), TWI (4.37), Aspect (4.2) and Elevation (3.21) (Fig. 10).

Multilayer perceptron outputs (a pseudo-probability; b lift chart; c ROC curve; d gain chart; e architecture)
Like in the previous case, the FPIMLP-HHO-IOE was calculated by including the importance of each flood predictor into Map Algebra capabilities. Also, its values were split into 5 classes using the Natural Breaks method. The very low flood potential accounts 22.41% of Buzău river basin, while the low flood potential spans on 21.77% of the same area. Further, it can be seen that medium values of flood potential appears on around 19.72%, while the high and very high flood potential appear on 36.2% (Fig. 11b).
Stacking-HHO-IOE
In a first stage, the Stacking ensemble was created by the combination of of CART, NB and SVM models, having as meta-classifier the Logistic Regression (LR) model. The Stacking ensemble performances were further improved with the help of HHO algorithm. In terms of Stacking-HHO-IOE hybrid combination the highest importance was assigned to Slope angle (18.64), followed by Distance from river (17.965), Land use (13.21), TPI (11.77), Lithology (10.385), Rainfall (7.125), Plan curvature (6.765), Aspect (5.31), Convergence Index (5.01), Hydrological Soil Group (4.61), Elevation (4.265) and TWI (3.165) (Fig. 10).
The obtaining process of FPIStacking-HHO-IOE values assumes the involvement of flood predictors importance into the Map Algebra application (Fig. 11c). Its values, split into 5 class with the Natural Breaks method, revealed that very low potential is spread on 21.47% of Buzău river basin. The same index shows that low flood potential appears on 22.88% of the study zone, while the medium values are located on a percentage of 14.57%. Taken together the high and very high flood potential cover 41.08% of the study area.
Results validation
ROC Curve method implied the construction of both Success and Prediction Rate. According to the Success Rate AUC values, the highest performance was achieved FPIDLNN-HHO-IOE (AUC = 0.97), followed by FPIStacking-HHO-IOE (AUC = 0.966) and FPIMLP-HHO-IOE (AUC = 0.953) (Fig. 14a). Figure 14b highlights the FPIStacking-HHO-IOE as being the most performant model with an AUC of 0.977, followed by FPIDLNN-HHO-IOE (AUC = 0.97) and FPIMLP-HHO-IOE (AUC = 0.924).

ROC curves (a success rate; b prediction rate)
The second stage of results validation procedure was accomplished with the help of several statistical metrics. Thus, in terms of training sample, the highest accuracy of 0.941 was achieved by DLNN-HHO-IOE, followed by Stacking-HHO-IOE (0.934) and MLP-HHO-IOE (0.927). The use of the same sample revealed a K-index equal to 0.882 for DLNN-HHO-IOE model, 0.868 for Stacking-HHO-IOE and 0.854 for MLP-HHO-IOE. In terms of validating data set, the best value of accuracy was attributed to DLNN-HHO-IOE (0.926), followed by Stacking-HHO-IOE (0.918) and MLP-HHO-IOE (0.91). The highest K-index was assigned to DLNN-HHO-IOE (0.852), followed by Stacking-HHO-IOE (0.836) and MLP-HHO-IOE (0.82) (Table 2).
Discussions
In today's society, floods are considered to be one of the most dangerous and complex natural disasters due to their short occurrence time, high-speed water runoff, as well as great sediment transportation, which can lead to severe damage to property and the loss of human life in a matter of seconds (Ruidas et al. 2022). Also, if there are some specific characteristics like groundwater level very close to the terrain altitude, the damages will be higher due to the fact that the amount of water will last more time at the ground surface (Balamurugan et al. 2020b; Panneerselvam et al. 2020). There is, however, no method that can completely prevent its occurrence. Due to this need, the development of flood prediction and mitigation strategies is crucial to reducing the risk of human deaths from floods and reducing the socioeconomic impacts of these events, which present several challenges for local authorities. Researchers have attempted to develop a proper mitigation strategy for floods in several different ways (Huang et al. 2022); among them is the Flood Susceptibility Mapping, which is one of the most crucial flood mitigation strategies available to help identify flood prone areas and to implement appropriate structural and nonstructural procedures that will minimize the impact of flooding in these areas (Mehryar and Surminski 2022). It has been discovered that there are several methods and modeling approaches that can be utilized to determine flood areas (Zhang et al. 2022). However, it is also very important to identify those methods that have more predictability and liability so that flooding can be prevented in the future. In the recent era, the field of Artificial Intelligence and Machine Learning algorithms has attracted considerable attention, particularly for the purpose of predicting environmental hazards (Pande et al. 2021); this is due to the accuracy of their predictions and the ability to work with very large datasets which are less costly. The results produced by each of these methods have been optimal on the basis of appropriate flood affecting factors in the region concerned. The Flood Susceptibility Mapping (FSM) has undergone substantial improvements over the last decade; however, improvements are still needed to improve the capability of the system to map flash floods. Machine Learning algorithms have been found to achieve similar accuracy compared to a number of existing methods of modeling flood probability, as well as differentiating the relationship between the environment effect and flooding incidence (Zhao et al. 2022). In a flood, geological conditions, hydrological conditions, morphological conditions, and topographical features play an important part in the entire phenomenon. Although, it is widely accepted that only a small number of factors contribute significantly to causing flood events in a particular area, thus choosing the right factors is an essential step in the Flood Susceptibility Mapping. In this study a number of 12 flood predictors were selected to be involved in the modeling procedure. From them, the most important factors revealed to be the Slope angle, Distance from river, Land use and Lithology (Chowdhuri et al. 2020). These factors achieved the highest importance values in terms of all the three complex models that were applied in this research work. The results is in a partially agreement with those achieved by Costache et al. (2020b). In the aforementioned research work, the application of Support Vector Machine (SVM)—IOE ensemble showed that distance from river obtained the highest importance, followed by slope angle, land use and lithology. The use of Harris Hawk Optimization algorithm in the present study played a crucial role in the improvement of model’s prediction accuracy. The same optimization algorithm was also successfully used by Paryani et al. (2021) that estimated the landslide susceptibility in Middle Zagros Mountain Range. The results of flood potential estimated over the Buzău river basin from Romania, shows that the most prone regions to flood occurence are located along the main river valleys and also within the main hilly and mountain depressions from the study zone.
There is always a possibility of uncertainty in any scientific model, which may induce some limitations to the results of a specific analysis. Input data or model parameters may be the source of limitation. The spatial representation of flood conditioning factors can lead to inherent errors in the present study, as well as in similar studies. Although the models used for flood susceptibility prediction performed very well, these results make it clear that any errors in input data or model parameters are minimal.
Conclusions
The present research aimed to propose three new optimized ensembles to evaluate the flood susceptibility within Buzău river basin from Romania. The study area represents a complex region that equally covers the mountain hilly and plain zones. In a first phase of the study, a number of 205 locations were collected where floods occurred in the past within the study area. At the same time, 12 flood predictors were selected as input data in the artificial intelligence models, whose ability to predict floods was tested by the Correlation-based Feature Selection method. By applying the prediction capacity evaluation method, all factors proposed were found to be important to some extent for the occurrence of flooding. Following the calculation of the index of entropy coefficients, the flood potential calculation models were developed based on their values. The highest performances, in terms of modeling procedure, was achieved by DLNN-HHO-IOE and Stacking-HHO-IOE models with values of AUC equal to 0.97 and 0.977, respectively. It should be noted also the coverage of high and very high flood potential that range from 35.57%, in the case of DLNN-HHO-IOE, to 41.09% in the case of Stacking-HHO-IOE.
The main novelty of the present research is represented by the combination of artificial intelligence models like DLNN, MLP and Stacking ensemble with Harris Hawk Optimization algorithm. The very high quality of the results makes this research a benchmark for the future studies related to the natural hazards susceptibility. Moreover, the results of this study can be very useful to the local and central authorities which are in charge with the flood mitigation measures.
Data availability
The data that support the findings of this study are available on request from the corresponding author.
References
Abdo HG (2020) Evolving a total-evaluation map of flash flood hazard for hydro-prioritization based on geohydromorphometric parameters and GIS–RS manner in Al-Hussain river basin Tartous Syria. Nat Hazards 104(1):681–703. https://doi.org/10.1007/s11069-020-04186-3
Ali SA, Parvin F, Pham QB, Vojtek M, Vojteková J, Costache R, Linh NTT, Nguyen HQ, Ahmad A, Ghorbani MA (2020) GIS-based comparative assessment of flood susceptibility mapping using hybrid multi-criteria decision-making approach, naïve Bayes tree, bivariate statistics and logistic regression: a case of Topľa basin. Slovakia Ecol Indic 117:106620. https://doi.org/10.1016/j.ecolind.2020.106620
Arora A, Arabameri A, Pandey M, Siddiqui MA, Shukla U, Bui DT, Mishra VN, Bhardwaj A (2021) Optimization of state-of-the-art fuzzy-metaheuristic ANFIS-based machine learning models for flood susceptibility prediction mapping in the middle Ganga Plain, India. Sci Total Environ 750:141565
Ashrafzadeh A, Kişi O, Aghelpour P, Biazar SM, Masouleh MA (2020) Comparative study of time series models, support vector machines, and GMDH in forecasting long-term evapotranspiration rates in northern Iran. J Irrig Drain Eng 146:04020010
Bai S-B, Wang J, Lü G-N, Zhou P-G, Hou S-S, Xu S-N (2010) GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area, China. Geomorphology 115:23–31
Balamurugan P, Kumar PS, Shankar K (2020a) Dataset on the suitability of groundwater for drinking and irrigation purposes in the Sarabanga river region, Tamil Nadu. India Data in Brief 29:105255. https://doi.org/10.1016/j.dib.2020.105255
Balamurugan P, Kumar PS, Shankar K, Nagavinothini R, Vijayasurya K, Balamurugan P, Kumar PS, Shankar K, Nagavinothini R, Vijayasurya K (2020b) Non-carcinogenic risk assessment of groundwater in southern part of Salem district in Tamilnadu, India. J Chil Chem Soc 65:4697–4707. https://doi.org/10.4067/S0717-97072020000104697
Breiman L, Friedman JH, Olshen RA, Stone CJ (1984) Classification and regression trees. Wadsworth International Group, Belmont, CA, pp 151–166
Bui DT, Hoang N-D, Martínez-Álvarez F, Ngo P-TT, Hoa PV, Pham TD, Samui P, Costache R (2019) A novel deep learning neural network approach for predicting flash flood susceptibility: a case study at a high frequency tropical storm area. Sci Total Environ 701:134413
Bui DT, Moayedi H, Kalantar B, Osouli A, Pradhan B, Nguyen H, Rashid ASA (2019b) A novel swarm intelligence—Harris hawks optimization for spatial assessment of landslide susceptibility. Sensors 19:3590
Bui Q-T, Nguyen Q-H, Nguyen XL, Pham VD, Nguyen HD, Pham V-M (2020) Verification of novel integrations of swarm intelligence algorithms into deep learning neural network for flood susceptibility mapping. J Hydrol 581:124379. https://doi.org/10.1016/j.jhydrol.2019.124379
Cao B, Zhao J, Lv Z, Yang P (2021a) Diversified personalized recommendation optimization based on mobile data. IEEE Trans Intell Transp Syst 22(4):2133–2139. https://doi.org/10.1109/TITS.2020.3040909
Cao B, Gu Y, Lv Z, Yang S, Zhao J, Li Y (2021b) RFID reader anticollision based on distributed parallel particle swarm optimization. IEEE Internet Things J 8(5):3099–3107. https://doi.org/10.1109/JIOT.2020.3033473
Chen W, Li W, Hou E, Bai H, Chai H, Wang D, Cui X, Wang Q (2015) Application of frequency ratio, statistical index, and index of entropy models and their comparison in landslide susceptibility mapping for the Baozhong region of Baoji, China. Arab J Geosci 8:1829–1841
Chowdhuri I, Pal SC, Chakrabortty R (2020) Flood susceptibility mapping by ensemble evidential belief function and binomial logistic regression model on river basin of eastern India. Adv Space Res 65:1466–1489
Costache R, Hong H, Pham QB (2020a) Comparative assessment of the flash-flood potential within small mountain catchments using bivariate statistics and their novel hybrid integration with machine learning models. Sci Total Environ 711:134514. https://doi.org/10.1016/j.scitotenv.2019.134514
Costache R, Ngo PTT, Bui DT (2020b) Novel ensembles of deep learning neural network and statistical learning for flash-flood susceptibility mapping. Water 12:1549
Costache R, Popa MC, Bui DT, Diaconu DC, Ciubotaru N, Minea G, Pham QB (2020) Spatial predicting of flood potential areas using novel hybridizations of fuzzy decision-making, bivariate statistics, and machine learning. J Hydrol 585:124808
Costache R, Arabameri A, Elkhrachy I, Ghorbanzadeh O, Pham QB (2021) Detection of areas prone to flood risk using state-of-the-art machine learning models. Geomat Nat Haz Risk 12:1488–1507
Costache R, Pham QB, Arabameri A, Diaconu DC, Costache I, Crăciun A, Ciobotaru N, Pandey M, Arora A, Ali SA (2022a) Flash-flood propagation susceptibility estimation using weights of evidence and their novel ensembles with multicriteria decision making and machine learning. Geocarto Int 37:8361–8393
Costache R, Tin TT, Arabameri A, Crăciun A, Ajin R, Costache I, Islam ARMT, Abba S, Sahana M, Avand M (2022b) Flash-flood hazard using deep learning based on H2O R package and fuzzy-multicriteria decision-making analysis. J Hydrol 609:127747
Costache R, Tin TT, Arabameri A, Crăciun A, Costache I, Islam ARMT, Sahana M, Pham BT (2022) Stacking state-of-the-art ensemble for flash-flood potential assessment. Geocarto Int 37:1–24
Dai Z, Li X, Lan B (2023) Three-dimensional modeling of Tsunami waves triggered by submarine landslides based on the smoothed particle hydrodynamics method. J Mar Sci Eng 11(10):2015. https://doi.org/10.3390/jmse11102015
Dai H, Liu Y, Guadagnini A, Yuan S, Yang J, Ye M (2024) Comparative assessment of two global sensitivity approaches considering model and parameter uncertainty abstract key points. Water Resour Res 60(2):e2023WR036096. https://doi.org/10.1029/2023WR036096
Du W, Wang G (2013) Intra-event spatial correlations for cumulative absolute velocity arias intensity and spectral accelerations based on regional site conditions. Bull Seismol Soc Am 103(2A): 1117–1129. https://doi.org/10.1785/0120120185
Endendijk T, Botzen WW, de Moel H, Aerts JC, Slager K, Kok M (2023) Flood vulnerability models and household flood damage mitigation measures: An econometric analysis of survey data. Water Resour Res 59:e2022WR034192
Fang Z, Wang Y, Peng L, Hong H (2021) A comparative study of heterogeneous ensemble-learning techniques for landslide susceptibility mapping. Int J Geogr Inf Sci 35:321–347
Fenglin W, Ahmad I, Zelenakova M, Fenta A, Dar MA, Teka AH, Belew AZ, Damtie M, Berhan M, Shafi SN (2023) Exploratory regression modeling for flood susceptibility mapping in the GIS environment. Sci Rep 13:247
Guan H, Huang J, Li L, Li X, Miao S, Su W, Ma Y, Niu Q, Huang H (2023) Improved Gaussian mixture model to map the flooded crops of VV and VH polarization data. Remote Sens Environ 295:113714. https://doi.org/10.1016/j.rse.2023.113714
Hall MA (1999) Correlation-based feature selection for machine learning (PhD Thesis). University of Waikato Hamilton
Hategekimana Y, Yu L, Nie Y, Zhu J, Liu F, Guo F (2018) Integration of multi-parametric fuzzy analytic hierarchy process and GIS along the UNESCO world heritage: a flood hazard index, Mombasa County, Kenya. Nat Hazards 92:1137–1153
Heidari AA, Mirjalili S, Faris H, Aljarah I, Mafarja M, Chen H (2019) Harris hawks optimization: algorithm and applications. Futur Gener Comput Syst 97:849–872
Huang Y, Chen X, Zou Y-A, Zhang P, Li F, Hou Z, Li X, Zeng J, Deng Z, Zhong J (2022) Exploring the relative contribution of flood regimes and climatic factors to Carex phenology in a Yangtze River-connected floodplain wetland. Sci Total Environ 847:157568
Huang H, Huang J, Wu Y, Zhuo W, Song J, Li X, Li L, Su W, Ma H, Liang S (2023) The improved winter wheat yield estimation by assimilating GLASS LAI into a crop growth model with the proposed bayesian posterior-based ensemble kalman filter. IEEE Trans Geosci Remote Sens 611:1–18. https://doi.org/10.1109/TGRS.2023.3259742
Jiang L, Li C, Wang S, Zhang L (2016) Deep feature weighting for naive Bayes and its application to text classification. Eng Appl Artif Intell 52:26–39
Kanani-Sadat Y, Arabsheibani R, Karimipour F, Nasseri M (2019) A new approach to flood susceptibility assessment in data-scarce and ungauged regions based on GIS-based hybrid multi criteria decision-making method. J Hydrol 572:17–31
Kia MB, Pirasteh S, Pradhan B, Mahmud AR, Sulaiman WNA, Moradi A (2012) An artificial neural network model for flood simulation using GIS: Johor River Basin, Malaysia. Environmental Earth Sciences 67:251–264
Lan T, Hu Y, Cheng L, Chen L, Guan X, Yang Y, Guo Y, Pan, J (2022) Floods and diarrheal morbidity: evidence on the relationship effect modifiers and attributable risk from Sichuan Province China. J Global Health 12:1100712. https://doi.org/10.7189/jogh.12.11007
Li B, Guan T, Dai L, Duan G (2023) Distributionally robust model predictive control with output feedback. IEEE Trans Autom Control 1:8. https://doi.org/10.1109/TAC.2023.3321375
Li Y, Hong H (2023) modeling flood susceptibility based on deep learning coupling with ensemble learning models. J Environ Manage 325:116450
Li D, Huang F, Yan L, Cao Z, Chen J, Ye Z (2019) Landslide susceptibility prediction using particle-swarm-optimized multilayer perceptron: comparisons with multilayer-perceptron-only, bp neural network, and information value models. Appl Sci 9:3664
Lin X, Zhu G, Qiu D, Ye L, Liu Y, Chen L, Liu J, Lu S, Wang L, Zhao K, Zhang W, Li R, Sun N (2023) Stable precipitation isotope records of cold wave events in Eurasia. Atmos Res 296:107070. https://doi.org/10.1016/j.atmosres.2023.107070
Liu J, Wang Y, Li Y, Peñuelas J, Zhao Y, Sadans J, Tetzlaff D, Liu J, Liu X, Yuan H, Li Y, Chen J, Wu J (2023) Soil ecological stoichiometry synchronously regulates stream nitrogen and phosphorus concentrations and ratios. CATENA 231:107357. https://doi.org/10.1016/j.catena.2023.107357
Lu S, Zhu G, Meng G, Lin X, Liu Y, Qiu D, Xu Y, Wang Q, Chen L, Li R, Jiao Y (2024) Influence of atmospheric circulation on the stable isotope of precipitation in the monsoon margin region. Atmos Res 298:107131. https://doi.org/10.1016/j.atmosres.2023.107131
Mehryar S, Surminski S (2022) Investigating flood resilience perceptions and supporting collective decision-making through fuzzy cognitive mapping. Sci Total Environ 837:155854
Minea G (2013) Assessment of the flash flood potential of Bâsca river catchment (Romania) based on physiographic factors. Open Geosci 5:344–353
Ozcift A, Gulten A (2011) Classifier ensemble construction with rotation forest to improve medical diagnosis performance of machine learning algorithms. Comput Methods Programs Biomed 104:443–451
Ozturk U, Wendi D, Crisologo I, Riemer A, Agarwal A, Vogel K, López-Tarazón JA, Korup O (2018) Rare flash floods and debris flows in southern Germany. Sci Total Environ 626:941–952
Pande CB, Moharir KN, Panneerselvam B, Singh SK, Elbeltagi A, Pham QB, Varade AM, Rajesh J (2021) Delineation of groundwater potential zones for sustainable development and planning using analytical hierarchy process (AHP), and MIF techniques. Appl Water Sci 11:186. https://doi.org/10.1007/s13201-021-01522-1
Paneerselvam B, Ravichandran N, Li P, Thomas M, Charoenlerkthawin W, Bidorn B (2023) Machine learning approach to evaluate the groundwater quality and human health risk for sustainable drinking and irrigation purposes in south India. Chemosphere 336:139228. https://doi.org/10.1016/j.chemosphere.2023.139228
Panneerselvam B, Karuppannan S, Muniraj K (2020) Evaluation of drinking and irrigation suitability of groundwater with special emphasizing the health risk posed by nitrate contamination using nitrate pollution index (NPI) and human health risk assessment (HHRA). Hum Ecol Risk Assess Int J 27:1324–1348. https://doi.org/10.1080/10807039.2020.1833300
Panneerselvam B, Muniraj K, Duraisamy K, Pande C, Karuppannan S, Thomas M (2023a) An integrated approach to explore the suitability of nitrate-contaminated groundwater for drinking purposes in a semiarid region of India. Environ Geochem Health 45:647–663. https://doi.org/10.1007/s10653-022-01237-5
Panneerselvam B, Muniraj K, Pande C, Ravichandran N (2023b) Prediction and evaluation of groundwater characteristics using the radial basic model in semi-arid region, India. Int J Environ Anal Chem 103:1377–1393. https://doi.org/10.1080/03067319.2021.1873316
Paryani S, Neshat A, Pradhan B (2021) Improvement of landslide spatial modeling using machine learning methods and two Harris hawks and bat algorithms. Egypt J Remote Sens Space Sci 24:845–855
Popescu C, Bărbulescu A (2023) Floods simulation on the Vedea river (Romania) using hydraulic modeling and GIS software: a case study. Water 15:483
Pourghasemi HR, Mohammady M, Pradhan B (2012) Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: Safarood basin. Iran Catena 97:71–84
Qazi A, Singh K, Vishwakarma DK, Abdo HG (2023) GIS based landslide susceptibility zonation mapping using frequency ratio information value and weight of evidence: a case study in Kinnaur District HP India. Bull Eng Geol Environ 82(8):332. https://doi.org/10.1007/s10064-023-03344-8
Rizwan M, Li X, Chen Y, Anjum L, Hamid S, Yamin M, Chauhdary JN, Shahid MA, Mehmood Q (2023) Simulating future flood risks under climate change in the source region of the Indus River. J Flood Risk Manag 16:e12857
Ruidas D, Chakrabortty R, Islam ARM, Saha A, Pal SC (2022) A novel hybrid of meta-optimization approach for flash flood-susceptibility assessment in a monsoon-dominated watershed, eastern India. Environ Earth Sci 81:1–22
Sankar K, Karunanidhi D, Kalaivanan K, Subramani T, Shanthi D, Balamurugan P (2023) Integrated hydrogeophysical and GIS based demarcation of groundwater potential and vulnerability zones in a hard rock and sedimentary terrain of southern India. Chemosphere 316:137305. https://doi.org/10.1016/j.chemosphere.2022.137305
Senanayake S, Pradhan B, Alamri A, Park H-J (2022) A new application of deep neural network (LSTM) and RUSLE models in soil erosion prediction. Sci Total Environ 845:157220
Shafizadeh-Moghadam H, Valavi R, Shahabi H, Chapi K, Shirzadi A (2018) Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J Environ Manag 217:1–11
Singh G, Pandey A (2021) Flash flood vulnerability assessment and zonation through an integrated approach in the Upper Ganga Basin of the northwest Himalayan region in Uttarakhand. Int Journal Disaster Risk Reduct 66:102573
Tarasova L, Lun D, Merz R, Blöschl G, Basso S, Bertola M, Miniussi A, Rakovec O, Samaniego L, Thober S (2023) Shifts in flood generation processes exacerbate regional flood anomalies in Europe. Commun Earth Environ 4:49
Tien Bui D, Pradhan B, Lofman O, Revhaug I (2012) Landslide susceptibility assessment in Vietnam using support vector machines, decision tree, and Naive Bayes models. Math Probl Eng. https://doi.org/10.1155/2012/974638
Wang X, Huang J, Feng Q, Yin D (2020) Winter wheat yield prediction at county level and uncertainty analysis in main wheat-producing regions of China with deep learning approaches. Remote Sens 12(11):1744. https://doi.org/10.3390/rs12111744
Wei W, Gong J, Deng J, Xu W (2023) Effects of air vent size and location design on air supply efficiency in flood discharge tunnel operations. J Hydraul Eng 149(12). https://doi.org/10.1061/JHEND8.HYENG-13305
Wei W, Xu W, Deng J, Guo Y (2022) Self-aeration development and fully cross-sectional air diffusion in high-speed open channel flows. J Hydraul Res 60(3):445–459. https://doi.org/10.1080/00221686.2021.2004250
Xie X, Xie B, Cheng J, Chu Q, Dooling, T (2021) A simple Monte Carlo method for estimating the chance of a cyclone impact. Nat Hazards 107(3):2573–2582. https://doi.org/10.1007/s11069-021-04505-2
Xu J, Zhou G, Su S, Cao Q, Tian Z (2022) The development of a rigorous model for bathymetric mapping from multispectral satellite-images. Remote Sens 14(10):2495. https://doi.org/10.3390/rs14102495
Yang M, Wang H, Hu K, Yin G, Wei Z (2022) IA-Net an inception–attention-module-based network for classifying underwater images from others. IEEE J Oceanic Eng 47(3):704–717. https://doi.org/10.1109/JOE.2021.3126090
Yin L, Wang L, Keim BD, Konsoer K, Yin Z, Liu M, Zheng W (2023) Spatial and wavelet analysis of precipitation and river discharge during operation of the three Gorges Dam China. Ecol Indic 154:110837. https://doi.org/10.1016/j.ecolind.2023.110837
Zhang Y, Li Z, Wang J, Ge W, Chen X (2022) Environmental impact assessment of dam-break floods considering multiple influencing factors. Sci Total Environ 837:155853
Zhang J, Ren J, Cui Y, Fu D, Cong, J. (2024) Multi-USV task planning method based on improved deep reinforcement learning. IEEE Internet Things J 1–1. https://doi.org/10.1109/JIOT.2024.3363044
Zhao M, Liu Y, Wang Y, Chen Y, Ding W (2022) Effectiveness assessment of reservoir projects for flash flood control, water supply and irrigation in Wangmo Basin, China. Sci Total Environ 851:157918
Zhou G, Liu W, Zhu Q, Lu Y, Liu Y (2022) ECA-MobileNetV3(Large)+SegNet model for binary sugarcane classification of remotely sensed images. IEEE Trans Geosci Remote Sens 60:1–15. https://doi.org/10.1109/TGRS.2022.3215802
Zhou G, Liu X (2022) Orthorectification model for extra-length linear array imagery. IEEE Trans Geosci Remote Sens 60:1–10. https://doi.org/10.1109/TGRS.2022.3223911
Acknowledgements
The authors extend their appreciation to Abdullah Alrushaid Chair for Earth Science Remote Sensing Research for funding.
Funding
This research was funded by Abdullah Alrushaid Chair for Earth Science Remote Sensing Research at King Saud University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Contributions
RC contributed to Methodology, RC, SCP, CBP, ARMTI, FA and HGA contributed to Formal analysis and investigation, RC, SCP, CBP, ARMTI, FA and HGA contributed to Writing—original draft preparation, RC, SCP, CBP, ARMTI, FA and HGA contributed to Writing—review and editing, RC, ARMTI, FA and HGA contributed to Supervision. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare.
Research involving Human Participants and/or Animals
Not applicable.
Informed consent
Not applicable.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Costache, R., Pal, S.C., Pande, C.B. et al. Flood mapping based on novel ensemble modeling involving the deep learning, Harris Hawk optimization algorithm and stacking based machine learning. Appl Water Sci 14, 78 (2024). https://doi.org/10.1007/s13201-024-02131-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-024-02131-4