
Abstract
The malfunction variables of power stations are related to the areas of weather, physical structure, control, and load behavior. To predict temporal power failure is difficult due to their unpredictable characteristics. As high accuracy is normally required, the estimation of failures of short-term temporal prediction is highly difficult. This study presents a method for converting stochastic behavior into a stable pattern, which can subsequently be used in a short-term estimator. For this conversion, K-means clustering is employed, followed by long-short-term memory and gated recurrent unit algorithms are used to perform the short-term estimation. The environment, the operation, and the generated signal factors are all simulated using mathematical models. Weather parameters and load samples have been collected as part of a dataset. Monte-Carlo simulation using MATLAB programming has been used to conduct experimental estimation of failures. The estimated failures of the experiment are then compared with the actual system temporal failures and found to be in good match. Therefore, to address the gap in knowledge for any future power grid estimated failures, the achieved results in this paper form good basis for a testbed to estimate any grid future failures.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
A smart grid is an electricity network enabling a two-way flow of electricity and data with digital communications technology. This gives the ability of monitoring, managing, and automatic decision-making. Besides, smart grid uses a wide range of resources based on information technology techniques to enable new and existing guidelines in minimizing energy costs and reducing electricity wastes. The motivation for proposing the Long Short-Term Memory (LSTM) model are the Power station failures are characterized by unpredictable behavior due to various factors such as weather conditions, physical structure, control systems, and load behavior and achieving high accuracy in predicting power failures is essential for efficient grid management and preventing potential disruptions. However, due to the unpredictable nature of the failures, traditional methods may struggle to provide accurate short-term predictions in addition to LSTM model is integrated into a larger framework that includes K-means clustering for pattern recognition and Monte Carlo simulation for accurate temporal prediction.
According to Ali et al. (2013), the smart grid is one of the most complicated and largest systems considering the design and building processes, although it is one of the easiest to use. It uses all kinds of power plants (including hydro, solar, coal, nuclear, wind turbine, and natural gas, among others), substations, transformers, and high-voltage transmission lines (Hasan et al. 2019), therefore, there is the need for a demand-responsive electrical grid with high efficiency of energy use. The traditional grid uses a one-way limited interaction, in which power flows to the consumers from the power plant. In contrast, the smart grid introduces a two-way interchange which involves the exchange of both information and electricity, in both directions (between consumer and power utilities). The growing network of computers, automation, control, and communications are instrumental in making the grid “greener”, more reliable, more secure, and more efficient (Hasan et al. 2019). The major issues in the existing methods are unpredictable characteristics, complexity of data, temporal dependencies, high accuracy requirement, data preprocessing challenges and model selection and tuning.
This data could be useful when being set to work with different aspects or dimensions of smart grid such as integration with renewable energy sources, management of intermittent power supplies, real-time data responses as well as the energy pricing strategies among others (Jakkula and Cook 2007). As such, it becomes a necessity that we would develop the right tools and methods which could help in conserving the energy by gathering the data from the smart grid using sensors which could then be used to recognize patterns from previous data and forecast or predict to conserve energy in the smart grids.
Some of the algorithms that could be used for prediction are related to deep learning algorithms like Long-short term memory (LSTM), Recurrent Neural Network (RNN), Gated Recurrent Unit (GRU). In this work, the used predictor is the most efficient one of them, in terms of accuracy and delay.
LSTM is an RNN variant that is meant specifically for time series data. The LSTM is used in addressing this problem in addition to empowering RNNs algorithms using internal memory cells (Li et al. 2020; Bui et. al. 2020).
RNNs are a form of neural networks that adopt the feedback connections in various nodes in remembering the previous time steps values. As such, they can capture the time series data’s temporal behaviour (Tealab, Ahmed, 2018).
GRU is a kind of gated RNN which is largely used in mitigating the gradient vanishing problem of RNNs using gating mechanism in addition to making the structure simpler without interfering with the effect of LSTM neural network (Luo et al. 2021).
However, since these prediction methods are based on regression techniques, which tries to find a common pattern for the historical samples to use to predict future values. Considering our application, the historical samples from the energy generators and the load of the smart city may not have a constant pattern. This is due to the stochastic behavior of the environment. Therefore, to convert this dynamicity to a static pattern, in this work, K-Means clustering algorithm is used.
K-means clustering algorithm refers to a simple unsupervised learning algorithm used in solving clustering problems which is useful in clustering analysis. According to (Xu et al. 2020), the algorithm is applied using certain procedures that classify a certain set of data into clusters defined by the letter “K”.
Our methodology in this work is to convert the stochastic behavior of the attributes into an accurate pattern using a clustering algorithm (i.e., K-means). This allows us to be able to identify their fitting curve and use a suitable regression-based algorithm (i.e., LSTM and GRU) for an accurate short-term prediction.
The main objective of this work is to propose a method that allows enhancing the accuracy of the short-term generated power prediction for the smart grid environment.
Although several works have tackled the problem of the prediction in the SmartGrid context, most of these works focus only on the long-term prediction. The advantage of long-term prediction is in bringing long-term strategy and planning, however, the methods that are currently used for this task provide accurate predictions.
The methodology focuses on modelling of the environment.
The main objective of this work is to propose a method that allows enhancing the accuracy of the short-term generated power prediction for the SmartGrid environment.
While the proposed techniques for predicting power station failures in the Smart Grid offer several advantages, they also come with certain limitations are data dependency, computational complexity, overfitting, interpretability and limited explainability.
The main contributions to the existing body of knowledge that this study will make include:
-
1.
Identify the most useful factors that affect the accuracy of the Smart Grid short term prediction process.
-
2.
Implement a model (or a combination of already existing models) for recognizing patterns of failure in the Smart Grid.
-
3.
Identification of the best deep learning algorithm to mine data from a synthetic testbed.
-
4.
Providing a solution that enhances the protection level for smart grid dynamic environment against failures.
Our knowledge gap contribution in this work is to convert the stochastic behavior of the attributes into an accurate pattern using a clustering algorithm (i.e., K-means). This allows us to be able to identify their fitting curve and use a suitable regression-based algorithm (i.e., LSTM and GRU) for an accurate short-term prediction.
The paper is organized as follows: First, we provide an introduction to the topic and its significance. Next, we review the relevant literature to establish the context and background for our study. We then outline the methodology used in our research, followed by a description of the experiments conducted. The results of these experiments are presented and analyzed. Finally, we discuss our conclusions and suggest potential directions for further research. The paper concludes with a list of references.
2 Related works
Efficient delivery of energy resources to the smart grid requires a balanced energy demand and supply by developing energy resource management strategies. However, the significant fluctuations in energy demand and supply enhance the challenges in the development of these energy resource management schemes. This problem has been tackled using different approaches in follows:
For instance, this work (Yu et. al. 2015) developed several approaches to predict energy supply and demand effectively. The study then develops machine learning-based methods for accurate energy consumption and generation forecasts. Lastly, the study used the prediction results to establish energy consumption upper and lower bounds realizing optimal demand and anomaly detections.
The problem is the smart meters acquire large amounts of data through sophisticated signal processing algorithms. The methodology will be applied in the study for it will the first develops a new classification scheme that categorizes users based on their consumption patterns. The study will then test the proposed and benchmarked models. Additionally, this research uses semi-Markov models to generate more extensive and more realistic test data due to insufficient power consumption data (Tornai et. al. 2016).
The problem in electrical load prediction is a fundamental factor in the planning, operations, and resource management within the grid system. The numerous restructurings of the grid and the integration of new devices to the grid heighten the need for forecasting to better plan for energy supply and demand. The study assesses the prediction model’s performance and effectiveness against several metrics (Chemetova et. al.2017).
The problem in harvesting various renewable energy forms led to the use of the smart grids integrated with photovoltaic (PV) power. However, various atmospheric conditions, for instance, rain, affect solar irradiance occurrence. This solution proposes the adoption of wavelet transform and Elman Neural Network (WT- ENN) for short-term solar energy production and irradiance forecasting. Also, the study reconstructed solar irradiance using the prediction model and the new coefficients. The prediction model’s performance was then assessed using two real-world data solar irradiance datasets (Huang et. al. 2019).
The problem of Smart grid systems allowing consumers to use more energy from the grid or vend it back to the grid for other consumers. Smart homes with photovoltaic systems can establish the daily energy yield. This solution recommends the use of multi-layer perceptron based on photovoltaic forecasting on rooftop PV systems. The study then trains its historical data, conducts cross-validation, and tests the model using real-world PV data (Parvez et. al. 2020).
Smart grids offer better integration of power systems between energy producers and consumers. The bidirectional nature of these smart grids calls energy consumption optimization measures to maintain the grid’s reliability and supply-demand balance. The solution evaluates the available short-term energy consumption prediction models to determine next-day energy consumption forecasts at one-hour intervals, realizing a 24-point forecast. This methodology conducted a thorough assessment of various high-level machine algorithms adopted to forecast and evaluate the various model instances (Petrican et. al. 2018).
The problem is Efficient energy delivery in the smart grid requires adopting energy resource management strategies that balance energy supply and demand. This solution proposes several techniques that accurately model and predict energy production and demand over time. Similarly, the study recommends modeling analyses that statistical output models of energy consumption and machine learning approaches improve prediction accuracy (Yu et. al. 2014).
Several countries continue to record an increase in their solar power capacity connections to the distribution grids. Adopting the smart grid concept has since contributed to this increase. The solution study suggests a new forecasting model that uses autoregressive models and gradient boosting algorithms. The researchers propose a model that overcomes the information and communication technology (ICT) limitations to promote solar energy forecasts at secondary substation levels. It then combined the values obtained from various distributed sensors (Bessa 2014, November).
Various new technology appliances that consumers currently use in their households overwhelm the existing smart grid infrastructure as they were initially not developed to support these devices. This solution proposes the implementation of various methods energy providers can improve their energy consumption forecasts for households despite their variability in electrical appliance usage. The authors assess the existing prediction models and their significance. Then describes various modeling techniques that assess the existing statistical approaches and machine learning algorithms (Lauer et. al. 2019).
Internationally, photovoltaic systems already are amongst the most extensively employed kinds of renewable energy. Still, photovoltaic energy is exceedingly unpredictable as it is subject to the elements. This presents challenges for network operators in terms of integrating, controlling, and operating this form of energy. Hence, the significance of renewable energy forecasting is growing in importance as a strategy for effectively managing the integration of renewable energy into the electrical grid. The focus of this research is a comparison of available algorithms for analyzing energy data. The following algorithms and a solar production database for smart houses have been proposed for this purpose: The Three Neural Networks: LSTM, FFNN, and GRU.This study utilized working on Data from 300 randomly chosen solar customers in the Ausgrid electricity grid area were used. From July 1, 2010, through June 30, 2013, we collected data on consumption. Both normal electricity usage for always-supplied electricity and load-controlled electricity consumption are stored here (Souabi et al., 2023).
Eco-friendly generators, and in particular wind generators, have emerged as a solution to the electric demand problem in light of projections of fossil fuels depletion in the coming years and the detrimental impact they have due to the exhaust gases they emit. Since the output power of wind turbines is reliant upon the variable as well as intermittent behavior of wind speed, it is problematic to maximize the employment of this renewable energy source. Most studies have basically focused on the development of novel algorithms, but none of these investigations have encompassed a pre-processing phase of the data in an effort to get as much beneficial information as possible from prevailing datasets. The aim of this research endeavor entails exploring the potential for boosting the precision of existing wind speed forecasts for a 10-minute time frame by integrating time-frequency decomposition techniques with varied machine learning approaches. The error metrics obtained indicate that the newly developed wind speed forecasting model achieved a level of accuracy within 0.1% of the validation database approximately 62% of the time. In this study, the average wind speed, monthly, and hourly numbers from the database were used as input to simple models, and the findings were then used. After the forecasters have been trained, their true accuracy can be measured against a validation dataset (Rodríguez et al. 2023).
In order to increase customer satisfaction with bike sharing programs, it is important for managers to accurately predict trip demand in order to better manage the distribution and relocation of bikes. In recent years, a plethora of deep learning techniques have been put forth with the aim of improving the accuracy of bicycle utilization prediction. To capture spatial-temporal dependency in past trip demand, it is common to combine convolutional CNN-RNN. The convolution process in a regular CNN is often carried out by a kernel that “walks” over a “matrix-format” city in order to extract features over geographically close neighborhoods. In this study, Singapore has implemented a single dockless bike sharing system alongside four station-based system in London, New York, and Washington D.C. are used to compare and contrast the concept with a set of benchmark models. It compares IrConv+LSTM to other benchmark models and finds that it performs better across all five cities (Li et al. 2023).
Control centers make extensive use of short-term load forecasting to investigate shifting consumer load patterns and anticipate the load value at a future time. It is a crucial piece of equipment for building a smart grid. There are a wide variety of influences on the load parameters. To begin, in this research we reconstruct data using several feature parameters and feed it into a ResNeT network to extract features. Second, LSTM is fed the recovered feature vector to make near-term load predictions. Finally, the proposed combination technique is compared to other models using a real-world example, demonstrating its superiority through the verification of the examination of the viability and superiority of input parameter feature extraction. This study employed the application of short-term load forecasting, wherein the model was compared against various methods inclusive of MLR, CNN, LSTM, CNN-LSTM, as well as ResNet for the aim of short-term load forecasting. Each of the models essentially makes predictions for three time periods: December 1, 2010; December 1 to December 2, 2010; as well as December 1 to December 7, 2010 (Chen et al. 2023).
The precise and effective prediction of load is highly important for ensuring the stable operation and scheduling of contemporary power systems. Nevertheless, the nature of load data typically exhibits nonlinearity and non-stationarity, posing challenges for achieving precise forecasting. While certain serial hybrid models have demonstrated effectiveness in extracting spatiotemporal features from load data, the sequential extraction of features is found to be inefficient as it results in the loss of significant features. The primary objective of this study is to investigate a novel ensemble framework that can be utilized for short-term load forecasting. The proposed framework utilizes parallel CNN and GRU, incorporating an enhanced variant of the iResNet. Primarily, the raw data is subjected to preprocessing techniques purposed for reconstructing the electrical characteristics. Besides, (CNN) is responsible for extracting spatial features, whereas the (GRU) is employed for extracting temporal features. Subsequently, the integration of the two features extracted is achieved through the utilization of an attention mechanism that operates dynamically. The iResNet model is utilized to accurately forecast power consumption. This research employed the use of working. This paper introduces an innovative ensemble framework for predicting short-term load. The framework combines parallel CNN and LSTM models, while integrating the iResNet architecture (Hua et al. 2023).
3 Materials and methods
To realize our proposed solution, we need first to identify the environment model, which in this case includes a photovoltaic grid. Then the process of generating the energy depending on the physical structure and the weather conditions in addition to the generated signal needs to be modelled and then simulated. After this, the generated data are clustered using the K-means clustering algorithm. Finally, (Long-Short-Term Memory) LSTM and (Gated Recurrent Unit) GRU are used to provide the short-term predictions.
3.1 Environment and PV Model
The earth rotates around the sun approximately 8766 h about 365.242 days. Earth is closest to the Sun (147million km) on January 2, and this point is called perihelion.
Specific points on earth aligned with sun position. It’s determined by two angels; they are altitude angle (α) and azimuth angle \(\theta_{s}\)
The altitude angle is the angular height of the sun is measured from the horizontal. The altitude angle can be given by: (Duffie et al. 2013).
where, \(L\) : attitude of the location, ξ: Angle of declination, ω: Hour angle.
The declination angle is between Earth sun vector and equatorial plane its calculated degree, arguments to trig function noted in radian mode (Duffie et al. 2013).

(Iqbal 1983), noted hour angel ω is the angular displacement of the sun local point is given by:
AST the true daily motion of solar time is given by a daily apparent solar motion of true observed sun. AST is constructed on the actual solar day. The two intervals fall between two consecutive returns of local meridian and the sun. Solar time is illustrious as, (Duffie et al. 2013).
\(LMT\): Local meridian time, \(LOD\): Longitude, \(LSMT\): Local standard meridian time, \(E_{0} T\): Equation of time, \(AST\): Apparent solar time, h: Hour.
(Iqbal 1983), the \(LSMT\) is a reference meridian used for a particular time zone, used for Greenwich Mean Time.
\({\text{LSMT}}\) is given by:
(Duffie et al. 2013), The \(E_{0} T\) is the difference between apparent and mean solar times, both taken at a given longitude at the same real instant of time.
\(E_{0} T\) is given by:
where, \(B\) can be given by;
where, N: Day number defined as the number of days elapsed each year up to a particular date (Iqbal 1983).
Angular displacement of the Sun reference line from the source axis, (Duffie et al. 2013). The azimuth angle can be given by:
The solar source model is to estimate the emitted radiation from the Sun. The function of the temperature is described as radiant energy of emitting objects.
We associate radiating energy with the blackbody. A blackbody is defined as a perfect absorber and emitter. A perfect absorber can absorb all the received energy with any reflections, (Planck 1914).
Planck’s law describes the wavelengths emitted by a blackbody at a specific temperature as follows:
\(E_{\lambda }\): Total emissive per unit area of blackbody emission rate (W/m2 µm), T: Absolute temperature of the blackbody (K), λ: Wavelength (µm).
Solar radiation value outside the atmosphere varies as the Earth orbits the Sun. Therefore, the distance between the Sun and the Earth must be considered in modeling extraterrestrial solar radiation. (Duffie et al. 2013). Thus, the (\(G_{{{\text{ex}}}}\)) is given by:
where, \(G_{{{\text{ex}}}}\): Extraterrestrial solar radiation. \(G_{0}\): Solar constant. \(R_{av}\) : Mean distance between the Sun and the Earth. \(R\) : Instantaneous distance between the Sun and the Earth depends on the day of the year or day number.
There are different approximations for the factor (\(R_{av} /R)\) in the literature (Iqbal 1983). A recommended approximation can be given by:
By substituting Equations (11, 10)
The extraterrestrial solar radiation unit of time falling at a right on square meter of a surface can be given by:
Once the surface faces the Sun (normal to a central ray), the solar irradiance falling on, is \(G_{ex}\), utilizes maximum solar radiation at that distance. If the surface is not normal to the Sun, the solar radiation drops on it will be decreased by cosine of the angle between the surface normal and a central ray from the Sun (Duffie et al. 2013).
Thus, the extraterrestrial solar radiation on a horizontal surface located in a specific location (\(G_{exH}\)) can be calculated by: (Iqbal 1983).
where, φ: Solar zenith angle.
(Duffie et al. 2013). The solar zenith angle value is equal to the altitude value, and thus Equation (13) can be rewritten as follows:
Finally, the total extraterrestrial solar energy \(E_{{{\text{ex}}}}\) (Wh/m2) is calculated as follows: (Duffie et al. 2013).
There are several components of a solar radiation on a tilted surface are in addition to the direct \((G_{B,\beta } )\) and diffuse \((G_{D,\beta } )\) solar radiation, reflected solar radiation (\(G_{R}\)\()\) is added to form the global solar radiation incident on a tilted surface (Duffie et al. 2013).
(Iqbal 1983). The solar energy components on a horizontal surface as follows:
where, \(R_{B}\), \(R_{D}\), and \(R_{R}\):are coefficients. \(\rho\) : Ground Aledo. \(R_{B}\): Ratio between global solar energy on a horizontal surface and global solar energy on a tilted surface. \(R_{D}\): Ratio between diffuse solar energy on a horizontal surface and diffuse solar energy on a tilted surface, \(R_{R}\) : Factor of reflected solar energy on a tilted surface.
The finding of solar energy components on a tilted surface is to estimate the coefficients \(R_{B}\), \(R_{D}\), and \(R_{R}\). Used model for calculating \(R_{B}\) is the Liu and Jordan model (Liu and Jordan 1963).
The surfaces in the southern hemisphere, the slope toward the equator \({R}_{B}\) is given as:
The most recommended formula \({R}_{R}\) is:
\(R_{D}\) Have been classified into isotropic and anisotropic models.
Four statistic errors are used, which are:
-
1.
(\(MAPE\) ): Mean absolute percentage error.
-
2.
(\(MBE\) ): Mean bias error.
-
3.
(\(MAE\) ): Mean absolute error.
-
4.
(\(RMSE\) ): Root mean square error.
(Hyndman et al. 2006), The general accuracy of a neural network can be highlighted by \(MAPE\). \(MAPE\) can be defined as follows:
where, \(M\) : Measured data. \(P\) : Predicted data.
(Willmott et al. 2005), The information of long‐term performance of the neural network model can also be evaluated by \(MBE\). \(MBE\) can be calculated as follows:
(Willmott et al. 2005), The mean absolute error \(MAE\): is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. \(MAE\) is calculated as:
where, \(y_{i}\) : Prediction, \(x_{i}\) : True value, n: Total number of data points.
The final statistic error is \(RMSE\); it represents the measurement of the variation of the predicted data around the measured data. (Chai et al. 2014).
The short‐term performance information of the model can be evaluated by \(RMSE\):
3.2 Problem definition and proposed Model
Having identified the models for the environment, the operation, and the generated signals, now the problem of the accurate generated power prediction can be formulated as below.
The above definition is a min-max-optimization problem,
where, \(P\) : PV power output, \({\upeta }\) : Is conversion efficiency of PV module. \(Q_{S}\) : Respects the thermal energy losses through radiation and convection heat transfer from modules.
While the optimization variables can be defined as:

However, a problem with all these variables can be defined as an NP-Hard problem. And cannot be solved using traditional optimization techniques. Therefore, to solve this problem we will follow the below methodology.
After having modelled the environment, the operation, and the signals to generate the patterns that are like the real patterns of the physical instruments, this pattern is clustered using k-mean clustering algorithm.
After that, we implement a Monte-Carlo simulation with the identification of all the bounds of the remained stochastic variables, and the optimization outputs, as mentioned in the above table. Inside the iterations of this simulation, Particle Swarm Optimization (PSO) algorithm, which is a metaheuristic stochastic-based algorithm, is applied to identify the optimal values of the selected optimization variables.
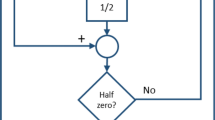
After finding the optimal values of the parameters, these parameters as well as the output values, will be used in addition to the current and previous loads to produce the short-term prediction, for example, LSTM or GRU algorithms will be used in this phase. The below Fig. 1 shows the block diagram of our proposed solution. The below figure summarizes this proposed method.

Methodology block diagram
The main parameters which are tried to improve by the author are achieving high accuracy in predicting power failures is a primary objective. The author seeks to improve the accuracy of short-term predictions by addressing the challenges posed by the unpredictable nature of power failures and the complex interaction of various factors such as weather conditions and load behavior, Exact optimal values for the future predicted of the P, \({Q}_{S}\), and efficiency for using LSTM, GRU algorithms. And statistic errors. In the prediction phase, initially LSTM, see Fig. 2a, has been selected with training input is the output of the clustering phase with size of 1400 × 34and then this and 300 hidden layers with three output signals, representing the next or the future temporal values of \(n, p\) and the \(Qs\) in the LSTM we have used look up in order to use only the most useful or the most related samples in building that pattern. Moreover, GRU, see Fig. 2b, followed the same structure to compare both algorithms using the same benchmark to be able to figure out which one provides us with the most accurate future temporal value, and which one provides us with a most with the fastest processing time.

GRU and LSTM Structures
3.3 Datasets
Regarding the load, we have acquired it from a with short-term slots of a frequency of 5min which is very useful for our application in short-term prediction. This dataset (Dataset employed by this research can be retrieved from UK Smart Grid Industry 2021-2024) contains 371 samples each sample is 5min separated from the other sample from the period of the first of January to the second of January in the year in the previous year 2020.This dataset was generated from a real site located in London city in the UK. The exact coordinates are 51.5074°N, 0.1278°W.
3.4 Results
Modelling the sun’s position for a specific location like London involves predicting where the sun will be in the sky at different times of the day and year. This process considers factors like the latitude and longitude of London, the date and time, and the Earth’s tilt and orbit. By understanding the sun's position, we can better analyze how sunlight interacts with the area, impacting variables such as temperature and solar radiation. This modelling helps in various applications, from urban planning to renewable energy development.
In Fig. 3, two plots depict aspects of the sun’s position in London throughout the year. The first plot illustrates the alpha angle, which represents the sun’s position from day 0 to day 350. This angle helps visualize how the sun’s position changes over the course of the year relative to London’s coordinates. The second plot shows Theta, another angle that describes the sun’s position over time at the same location. Both plots provide valuable insights into the sun’s movements and can aid in understanding factors like daylight duration and solar energy availability in London throughout the year.

The alpha angle of the sun position
Figure 4, below chooses the hourly extraterrestrial solar radiation profile for 16 days of January, each plots of this 16 plots for a specific date is shown that the plots almost similar to each other but the related plot for corresponding days increase with the increase of that day which means the peak value of each day as increasing according to the day number for example day 1 we have the value around 350 for day 2 its around 360 and so on the big value .the x-axis here is \(\left(LMT\right)\) and y -axis the \(\left(GextH\right)\).While Fig. 5 shows five minutes step for only one day.

The hourly extraterrestrial solar radiation

Five minutes step for only one day solar radiation
Figure 6a displays the solar radiation data recorded at five-minute intervals for a single day in January. This data provides insights into the intensity of sunlight received at the specified location in London during that time period. On the other hand, Fig. 6b showcases the diffuse solar radiation specifically for the same day in January and at the same five-minute intervals. Diffuse solar radiation refers to sunlight scattered by the atmosphere before reaching the Earth’s surface, and its measurement aids in understanding the distribution of sunlight in the area. These plots offer detailed information on solar radiation patterns, crucial for various applications such as solar energy planning and building design.

The solar radiation for one day and diffuse solar radiation showing time from sunrise to sunset and from sunset to sunrise
Figure 7 presents samples of global solar radiation and diffuse solar radiation for specific days, including the first day, day 50, day 100, day 180, day 250, and day 360. Each sample day provides insight into the variation of solar radiation throughout that particular day. The data is based on 60-minute intervals of solar radiation measurements for each day. By observing these variations, we can gain a better understanding of how solar radiation fluctuates over the course of a day and how it may change from one day to another. This information is valuable for predicting future solar radiation patterns and can aid in various applications such as energy production forecasting and solar panel efficiency optimization.

Global solar radiation and diffused solar radiation at different days in the year based on one day and 7h
The analysis of Figs. 1, 2, 3, 4, 5, 6, 7 reveals a notable observation: the position of the sun for the same day varies across different years. This variability is a fundamental characteristic of natural phenomena, including wind patterns, dust levels, shading effects, and more. As depicted in the figures, these natural factors exhibit stochastic behavior, meaning they follow random and unpredictable patterns. Since electricity generation from renewable resources is heavily influenced by these factors, predicting the amount of energy generated becomes a complex challenge. Recognizing this challenge, this study contributes by developing a methodology aimed at addressing the issue of short-term prediction for energy generation reliant on renewable resources and their associated factors. By devising techniques to forecast the short-term future energy output under the influence of these stochastic natural elements, this research aims to enhance our ability to effectively utilize renewable energy sources despite their inherent unpredictability. This contribution is crucial for improving energy planning and management in the context of renewable energy systems.
4 Discussion
Figure 8 displays the generated signals comprising 1000 normal and 1000 faulty signals, with each signal characterized by 34 features. These signals have been produced utilizing the stochastic features of Monte Carlo simulation, adding a layer of randomness and variability to the dataset. This dataset serves as a testing ground for evaluating the performance of the prediction model. By incorporating stochastic elements into the signal generation process, the dataset reflects real-world scenarios where various factors contribute to signal behavior unpredictability. Testing the prediction model with such a diverse and realistic dataset enables researchers to assess its robustness and effectiveness in accurately predicting outcomes despite inherent stochasticity.

Sample traffic from the generated big-data signals
In Fig. 9, we need to know the status of the pattern. Whether this signal is normal or a fault signal. The behavior of the normal traffic and that the behavior faulty traffic in the real life is a little bit of stochastic that does not follow a stable pattern. Therefore, we will not be able to identify the exact features of the input pattern and the target for them. Therefore, our problem can be defined as a clustering problem, to solve this clustering problem, we have used k-mean clustering algorithm. The previously generated sample traffic has been sent to k-mean clustering algorithm then trained on it after that the clustering algorithm showed as a very clear recognition for the statues of traffic as shown in Fig. 9. The given pattern is found in the first column of the table and therefore the predicted pattern has been produced by the k-mean clustering algorithm and as we see here both are identical with no missing values. Therefore, when we calculated the loss, we found the loss low close to 0 which means that the accuracy is almost 100%.

Pattern clustering with K-mean
4.1 Prediction final results (for LSTM)
Figure 10 depicts the plots of input training and target training, as well as input testing and target testing for the prediction process, specifically using LSTM (Long Short-Term Memory) models. Additionally, it showcases the output of the prediction process. Remarkably, the output closely resembles the target testing data, indicating the effectiveness of the LSTM model in accurately predicting outcomes based on the input data. This alignment underscores the model's capability to capture and learn from patterns in the training data, allowing it to make accurate predictions for unseen testing data. Such performance validates the utility of LSTM models in forecasting tasks, particularly in scenarios where temporal dependencies and long-range dependencies are prevalent Table 1.

The input training and target training input testing and targeted testing for the prediction process (LSTM)
Figure 11 illustrates the prediction process for forecasting future traffic based on recognized patterns. To achieve this, the identified parameters are fed into a prediction algorithm, specifically utilizing Long Short-Term Memory (LSTM), which has been determined to be the most effective recognition technique through trial and error, as indicated in the accompanying table. The training, validation, and testing phases of the prediction process are visualized in Fig. 11. This process involves training the LSTM model on historical traffic data, validating its performance, and testing its predictive capabilities on unseen data. LSTM models are well-suited for this task due to their ability to capture long-term dependencies in sequential data, making them a valuable tool for traffic prediction and forecasting applications.

Prediction (LSTM model and parameters)
In Fig. 12, the prediction task is performed using a different approach: Gated Recurrent Unit (GRU), while utilizing the same input data. This comparison phase is conducted to evaluate the performance of GRU against LSTM. It’s evident from the results that GRU exhibits slightly faster computation compared to LSTM. However, this efficiency comes at the cost of a slightly higher error rate, approximately 1%. Despite the faster processing speed, the GRU model sacrifices a small degree of accuracy compared to LSTM. This trade-off highlights the importance of considering both speed and accuracy requirements when selecting the appropriate model for a given prediction task. Overall, the comparison between LSTM and GRU offers valuable insights into their respective strengths and weaknesses, aiding in the selection of the most suitable model for specific predictive analytics applications.

Prediction (GRU model and parameters)
In Table 2 conducting short-term predictions, the most efficient algorithm between Gated Recurrent Unit (GRU) and Long-Short Term Memory (LSTM) was utilized. The evaluation was based on several metrics including Root Mean Square Error (RMSE), Mean Absolute Percentage Error (MAPE), Mean Absolute Error (MAE), Mean Bias Error (MBE), and Accuracy. By employing these metrics, the goal was to identify the algorithm that provided predictions closest to the actual values. The comparison aimed to determine the algorithm that offers the most accurate and reliable predictions for the given dataset. Evaluating the performance of both GRU and LSTM models across these metrics allowed for a comprehensive assessment of their predictive capabilities. Ultimately, selecting the algorithm that minimizes errors while maximizing accuracy is crucial for achieving reliable short-term predictions.
After implementing the optimization algorithm, we have obtained the optimal below values for using LSTM and GRU algorithms. The below tables Illustrate the exact optimal values for the future predicted values of the P, \({Q}_{S}\), and the efficiency Table 3.
5 Conclusions
Accurately estimating faults in the electric supply, which is based on data exhibiting stochastic behavior, poses a significant challenge. Two crucial factors in this estimation are weather conditions and load behavior. These factors require a thorough analysis of active generated power (QS, which indicates the quality of the solar resource) and the active efficiency of the photovoltaic (PV) grid. Our proposed solution leverages K-means clustering to convert this stochastic data into a recognizable pattern of faults, which can then be used for short-term predictions using Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) algorithms. These algorithms provide quick and accurate results due to their capability to handle sequential data and remember important information over long periods.
To further enhance the application of fault estimation, we used the results from K-means clustering as inputs for Monte Carlo simulations. Monte Carlo simulations are statistical techniques that utilize repeated random sampling to compute the results, enabling accurate temporal predictions. This method validates our initial assumption regarding the stochastic nature of the data. The outcomes demonstrate the high accuracy of short-term predictions based on this stochastic approach. The dataset used for our research, obtained from the UK Smart Grid Industry (covering the period from 2021 to 2024), comprised 371 samples with short-term slots at 5-minute intervals. This dataset proved to be highly effective for our short-term prediction application.
6 Future work
Future work will need to consider dynamic environmental changes imposed by emerging non-zero carbon policies. These changes will introduce new parameters in weather conditions and sunlight availability, which are critical for solar power generation. As a result, new factors such as temperature, wind speed, and humidity will need to be incorporated into the predictive models. Although the mathematical models presented in this paper have proven to be accurate, these new environmental factors will necessitate updates to the LSTM and GRU models to ensure continued accuracy in predictions. Specifically, future research should focus on refining these models to account for the varying impacts of these additional environmental parameters on solar power generation and fault estimation.
Data availability
Dataset employed by this research can be retrieved from UK Smart Grid Industry 2021–2024. reportlinker.com/report-summary/Electric-Power/88256/UK-Smart-Grid-Industry html.
References
Agarap AFM 2018 February. A neural network architecture combining gated recurrent unit (GRU) and support vector machine (SVM) for intrusion detection in network traffic data. In: Proceedings of the 2018 10th international conference on machine learning and computing, pp 26–30
Al-Housani M, Bicer Y, Koç M (2019) Assessment of various dry photovoltaic cleaning techniques and frequencies on the power output of CdTe-type modules in dusty environments. Sustainability 11(10):2850
Ali AS and Azad S 2013 Demand forecasting in smart grid. In: Smart grids. Springer, London, pp 135–150
Alyoubi KH, Sharma A (2023) Deep recurrent neural model for multi domain sentiment analysis with attention mechanism. Wireless Pers Commun 130(1):43–60
Bessa RJ 2014 Solar power forecasting for smart grids considering ICT constraints. In: Proceedings of the 4th solar integration workshop. Berlin-Germany
Bui V, Kim J, and Jang YM, 2020 February. Power demand forecasting using long short-term memory neural network based smart grid. In: 2020 International conference on artificial intelligence in information and communication (ICAIIC) IEEE. PP388-391
Butt A, Narejo S, Anjum MR, Yonus MU, Memon M, Samejo AA (2022) Fall detection using LSTM and transfer learning. Wireless Pers Commun 126(2):1733–1750
Cao E (2010) Heat transfer in process engineering. McGraw-Hill, New York
Chai T, Draxler RR (2014) Root mean square error (RMSE) or mean absolute error (MAE)?–arguments against avoiding RMSE in the literature. Geosci Model Dev 7(3):1247–1250
Chemetova S, Santos P, and Ventim-Neves M, 2017 Load forecasting as a computational tool to support smart grids. In: 2017 12th Iberian conference on information systems and technologies (CISTI) IEEE. pp 1–6
Chen X, Chen W, Dinavahi V, Liu Y, Feng J (2023) Short-term load forecasting and associated weather variables prediction using ResNet-LSTM based deep learning. IEEE Access 11:5393–5405
Das R, Christopher AF (2023) Prediction of failed sensor data using deep learning techniques for space applications. Wireless Pers Commun 128(3):1941–1962
Din AFU, Mir I, Gul F, Akhtar S (2023) Development of reinforced learning based non-linear controller for unmanned aerial vehicle. J Ambient Intell Humaniz Comput 14(4):4005–4022
Duffie JA, Beckman WA (2013) Solar engineering of thermal processes, 4th edn. Wiley, New York
Emin T, Akram Q, Nezihe Y (2013) Shunt active power filters based on diode clamped multilevel inverter and hysteresis band current controller. Innov Syst Des Eng, ISSN 4(14):2222
Hasan M, Toma RN, Nahid AA, Islam M, Kim JM (2019) Electricity theft detection in smart grid systems: a CNN-LSTM based approach. Energies 12(17):3310
F Hazzaa, S Yousef, E Sanchez and M Cirstea 2018 Lightweight and Low-Energy Encryption Scheme for Voice over Wireless Devices. In: IECON 2018 - 44th Annual conference of the IEEE industrial electronics society. Washington, DC
Hua H, Liu M, Li Y, Deng S, Wang Q (2023) An ensemble framework for short-term load forecasting based on parallel CNN and GRU with improved ResNet. Electr Power Syst Res 216:109057
Huang X, Shi J, Gao B, Tai Y, Chen Z, Zhang J (2019) Forecasting hourly solar irradiance using hybrid wavelet transformation and Elman model in smart grid. IEEE Access 7:139909–139923
Hyndman RJ, Koehler AB (2006) Another look at measures of forecast accuracy. Int J Forecast 22(4):679–688
Iqbal M (1983).an introduction to solar radiation. Academic Press
Jakkula V, Cook DJ (2007) Mining sensor data in smart environment for temporal activity prediction. Poster session at the ACM SIGKDD, CA
Katiyar H (2013) Outage performance of two multi-antenna relay cooperation in Rayleigh fading channel. IETE J Res 59(1):4–8
Katiyar H, Bhattacharjee R (2009) Power allocation strategies for non-regenerative relay network in Nakagami-m fading channel. IETE J Res 55(5):205–211
Kieu TN, Tran DD, Ha DB, Voznak M (2022) Secrecy performance analysis of cooperative MISO NOMA networks over Nakagami-m fading. IETE J Res 68(2):1183–1194
Koushik CP, Vetrivelan P (2020) Heuristic relay-node selection in opportunistic network using RNN-LSTM based mobility prediction. Wireless Pers Commun 114(3):2363–2388
Koushik CP, Vetrivelan P, Chang E (2023) Markov chain-based mobility prediction and relay-node selection for QoS provisioned routing in opportunistic wireless network. IETE J Res 70:1–13
Kumari N, Anwar S, Bhattacharjee V (2023) A comparative analysis of machine and deep learning techniques for EEG evoked emotion classification. Wireless Pers Commun 128(4):2869–2890
Lamnatou C, Chemisana D, Mateus R, Almeida MGD, Silva SM (2015) Review and perspectives on life cycle analysis of solar technologies with emphasis on building-integrated solar thermal systems. Renew Energy 75:833–846
Lauer M, Jaddivada R, and Ilic M, 2019 Household energy prediction: methods and applications for smarter grid design. In: 2019 8th Mediterranean conference on embedded computing (MECO) IEEE. pp 1–4
Lee EK, Shi W, Gadh R, Kim W (2016) Design and implementation of a microgrid energy management system. Sustainability 8(11):1143
Li J, Deng D, Zhao J, Cai D, Hu W, Zhang M, Huang Q (2020) A novel hybrid short-term load forecasting method of smart grid using MLR and LSTM neural network. IEEE Trans Industr Inf 17(4):2443–2452
Li X, Xu Y, Zhang X, Shi W, Yue Y, Li Q (2023) Improving short-term bike sharing demand forecast through an irregular convolutional neural network. Transp Res Part C Emerg Technol 147:103984
Liu W (2021) Slam algorithm for multi-robot communication in unknown environment based on particle filter. J Ambient Intell Humaniz Comput. https://doi.org/10.1007/s12652-021-03020-3
Liu BY, Jordan RC (1963) The long-term average performance of flat-plate solar-energy collectors: with design data for the US, its outlying possessions and Canada. Sol Energy 7(2):53–74
Liu Y et al (2023) Retracted article: fault identification and relay protection of hybrid microgrid using blockchain and machine learning. IETE J Res. https://doi.org/10.1080/03772063.2022.2050307
Luo H, Wang M, Wong PKY, Tang J, Cheng JC (2021) Construction machine pose prediction considering historical motions and activity attributes using gated recurrent unit (GRU). Autom Constr 121:103444
Mahadik SS, Pawar PM, Muthalagu R, Prasad NR, Mantri D (2023) Intelligent LSTM (iLSTM)-security model for HetIoT. Wireless Pers Commun 133(1):323–350
Mahani K, Nazemi S, Ghofrani A, Köse B, and Jafari M (2019) Techno-economic analysis and optimization of a microgrid considering demand-side management. In: IIE Annual conference. proceedings. pp 1743-1748
Mills B, Schleich J (2012) Residential energy-efficient technology adoption, energy conservation, knowledge, and attitudes: an analysis of European countries. Energy Policy 49:616–628
Mostafavi M, Niya JM (2016) A novel subchannel and power allocation in IEEE 80.216 OFDMA systems. IETE J Res 62(2):228–238
Parvez I, Sarwat A, Debnath A, Olowu T, Dastgir MG, and Riggs H, 2020 Multi-layer perceptron based photovoltaic forecasting for rooftop PV applications in smart grid. In: 2020 Southeast con IEEE. pp 1–6
Patil SV, Babu PV (2012) Experimental studies on mixed convection heat transfer in laminar flow through a plain square duct. Heat Mass Transf 48(12):2013–2021
Petrican T, Vesa AV, Antal M, Pop C, Cioara T, Anghel I, and Salomie I 2018 September. Evaluating forecasting techniques for integrating household energy prosumers into smart grids. In: 2018 IEEE 14th International conference on intelligent computer communication and processing (ICCP) IEEE. pp 79–85
Planck M (1914) The theory of heat radiation. Blakiston’s Son, France
Qashou A, Yousef S, Smadi AA, AlOmari AA (2021) Distribution system power quality compensation using a HSeAPF based on SRF and SMC features. Int J Syst Assur Eng Manag 12(5):976–989
Qashou A, Yousef S, Sanchez-Velazquez E (2022) Mining sensor data in a smart environment: a study of control algorithms and microgrid testbed for temporal forecasting and patterns of failure. Int J Syst Assur Eng Manag 13(5):2371–2390
Qashou A, Hazzaa F, Yousef S (2024) Wireless IoT networks security and lightweight encryption schemes-survey. Int J Emerg Technol 14:28
Ramya R, Srinivasan K (2022) Classification of amniotic fluid level using Bi-LSTM with homomorphic filter and contrast enhancement techniques. Wireless Pers Commun 124(2):1123–1150
Rodríguez F, Alonso-Pérez S, Sánchez-Guardamino I, Galarza A (2023) Ensemble forecaster based on the combination of time-frequency analysis and machine learning strategies for very short-term wind speed prediction. Electr Power Syst Res 214:108863
Rostami M, Farajollahi A, Parvin H (2024) Deep learning-based face detection and recognition on drones. J Ambient Intell Humaniz Comput 15(1):373–387
Saloux E, Teyssedou A, Sorin M (2011) Explicit model of photovoltaic panels to determine voltages and currents at the maximum power point. Sol Energy 85(5):713–722
Samiayya D, Radhika S, Chandrasekar A (2023) An efficient hybrid ensemble svm for optimal channel and power allocation using chaotic quantum bat optimization. IETE J Res 69(10):7041–7050
Sarvi M, Ahmadi S, Abdi S (2015) A PSO-based maximum power point tracking for photovoltaic systems under environmental and partially shaded conditions. Prog Photovoltaics Res Appl 23(2):201–214
Sharma S, Singh S (2023) A spatio-temporal framework for dynamic indian sign language recognition. Wireless Pers Commun 132(4):2527–2541
Souabi S, Chakir A, Tabaa M (2023) Data-driven prediction models of photovoltaic energy for smart grid applications. Energy Rep 9:90–105
Sun Y, Wang F, Wang B, Chen Q, Engerer NA, Mi Z (2017) Correlation feature selection and mutual information theory based quantitative research on meteorological impact factors of module temperature for solar photovoltaic systems. Energies 10(1):7
Taneja A, Saluja N (2023) A transmit antenna selection based energy-harvesting mimo cooperative communication system. IETE J Res 69(1):368–377
Tealab A (2018) Time series forecasting using artificial neural networks methodologies: a systematic review. Future Comput Inform J 3(2):334–340
Tornai K, Kovács L, Oláh A, Drenyovszki R, Pintér I, Tisza D, Levendovszky J (2016) Classification for consumption data in a smart grid based on the forecasting time series. Electr Power Syst Res 141:191–201
Wechsler H (2023) Immunity and security using holism, ambient intelligence, triangulation, and stigmergy: sensitivity analysis confronts fake news and COVID-19 using open set transduction. J Ambient Intell Humaniz Comput 14(4):3057–3074
Willmott CJ, Matsuura K (2005) Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Climate Res 30(1):79–82
Xu L, Zhang H, Gulliver TA (2016) op performance and power allocation for DF relaying M2M cooperative system. IETE J Res 62(5):627–633
Xu H, Yao S, Li Q, and Ye Z 2020 An improved k-means clustering algorithm. In: 2020 IEEE 5th International symposium on smart and wireless systems within the conferences on intelligent data acquisition and advanced computing systems (IDAACS-SWS) IEEE. pp 1–5
Yu W, An D, Griffith D, Yang Q, Xu G (2015) Towards statistical modeling and machine learning-based energy usage forecasting in the smart grid. ACM SIGAPP Appl Comput Rev 15(1):6–16
Yu W, An D, Griffith D, Yang Q, and Xu G 2014 On statistical modeling and forecasting of energy usage in smart grid. In: Proceedings of the 2014 conference on research in adaptive and convergent systems. pp 12–17
Zhang K, Qu T, Zhou D, Thürer M, Liu Y, Nie D, Li C, Huang GQ (2019) IoT-enabled dynamic lean control mechanism for typical production systems. J Ambient Intell Humaniz Comput 10:1009–1023
Acknowledgments
The authors thank the anonymous reviewers forgiving their valuable comments and helping us to improve the quality of the paper.
Funding
Funding for the publication fees from Anglia Ruskin University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. All applicable international, national, and/or institutional guidelines for the care and use of animals were followed.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Qashou, A., Yousef, S., Hazzaa, F. et al. Temporal forecasting by converting stochastic behaviour into a stable pattern in electric grid. Int J Syst Assur Eng Manag (2024). https://doi.org/10.1007/s13198-024-02454-0
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13198-024-02454-0